Spaces:
Runtime error

Runtime error
Harry_FBK
commited on
Commit
·
60094bd
1
Parent(s):
277d7e6
Clone original THA3
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +134 -0
- LICENSE +21 -0
- README.md +239 -13
- colab.ipynb +542 -0
- docs/ifacialmocap_ip.jpg +0 -0
- docs/ifacialmocap_puppeteer_click_start_capture.png +0 -0
- docs/ifacialmocap_puppeteer_ip_address_box.png +0 -0
- docs/ifacialmocap_puppeteer_numbers.png +0 -0
- docs/input_spec.png +0 -0
- docs/pytorch-install-command.png +0 -0
- environment.yml +141 -0
- manual_poser.ipynb +460 -0
- tha3/__init__.py +0 -0
- tha3/app/__init__.py +0 -0
- tha3/app/ifacialmocap_puppeteer.py +439 -0
- tha3/app/manual_poser.py +464 -0
- tha3/compute/__init__.py +0 -0
- tha3/compute/cached_computation_func.py +9 -0
- tha3/compute/cached_computation_protocol.py +43 -0
- tha3/mocap/__init__.py +0 -0
- tha3/mocap/ifacialmocap_constants.py +239 -0
- tha3/mocap/ifacialmocap_pose.py +27 -0
- tha3/mocap/ifacialmocap_pose_converter.py +12 -0
- tha3/mocap/ifacialmocap_poser_converter_25.py +463 -0
- tha3/mocap/ifacialmocap_v2.py +89 -0
- tha3/module/__init__.py +0 -0
- tha3/module/module_factory.py +9 -0
- tha3/nn/__init__.py +0 -0
- tha3/nn/common/__init__.py +0 -0
- tha3/nn/common/conv_block_factory.py +55 -0
- tha3/nn/common/poser_args.py +68 -0
- tha3/nn/common/poser_encoder_decoder_00.py +121 -0
- tha3/nn/common/poser_encoder_decoder_00_separable.py +92 -0
- tha3/nn/common/resize_conv_encoder_decoder.py +125 -0
- tha3/nn/common/resize_conv_unet.py +155 -0
- tha3/nn/conv.py +189 -0
- tha3/nn/editor/__init__.py +0 -0
- tha3/nn/editor/editor_07.py +180 -0
- tha3/nn/eyebrow_decomposer/__init__.py +0 -0
- tha3/nn/eyebrow_decomposer/eyebrow_decomposer_00.py +102 -0
- tha3/nn/eyebrow_decomposer/eyebrow_decomposer_03.py +109 -0
- tha3/nn/eyebrow_morphing_combiner/__init__.py +0 -0
- tha3/nn/eyebrow_morphing_combiner/eyebrow_morphing_combiner_00.py +115 -0
- tha3/nn/eyebrow_morphing_combiner/eyebrow_morphing_combiner_03.py +117 -0
- tha3/nn/face_morpher/__init__.py +0 -0
- tha3/nn/face_morpher/face_morpher_08.py +241 -0
- tha3/nn/face_morpher/face_morpher_09.py +187 -0
- tha3/nn/image_processing_util.py +58 -0
- tha3/nn/init_function.py +76 -0
- tha3/nn/nonlinearity_factory.py +72 -0
.gitignore
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
pip-wheel-metadata/
|
| 24 |
+
share/python-wheels/
|
| 25 |
+
*.egg-info/
|
| 26 |
+
.installed.cfg
|
| 27 |
+
*.egg
|
| 28 |
+
MANIFEST
|
| 29 |
+
|
| 30 |
+
# PyInstaller
|
| 31 |
+
# Usually these files are written by a python script from a template
|
| 32 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 33 |
+
*.manifest
|
| 34 |
+
*.spec
|
| 35 |
+
|
| 36 |
+
# Installer logs
|
| 37 |
+
pip-log.txt
|
| 38 |
+
pip-delete-this-directory.txt
|
| 39 |
+
|
| 40 |
+
# Unit test / coverage reports
|
| 41 |
+
htmlcov/
|
| 42 |
+
.tox/
|
| 43 |
+
.nox/
|
| 44 |
+
.coverage
|
| 45 |
+
.coverage.*
|
| 46 |
+
.cache
|
| 47 |
+
nosetests.xml
|
| 48 |
+
coverage.xml
|
| 49 |
+
*.cover
|
| 50 |
+
*.py,cover
|
| 51 |
+
.hypothesis/
|
| 52 |
+
.pytest_cache/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
target/
|
| 76 |
+
|
| 77 |
+
# Jupyter Notebook
|
| 78 |
+
.ipynb_checkpoints
|
| 79 |
+
|
| 80 |
+
# IPython
|
| 81 |
+
profile_default/
|
| 82 |
+
ipython_config.py
|
| 83 |
+
|
| 84 |
+
# pyenv
|
| 85 |
+
.python-version
|
| 86 |
+
|
| 87 |
+
# pipenv
|
| 88 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 89 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 90 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 91 |
+
# install all needed dependencies.
|
| 92 |
+
#Pipfile.lock
|
| 93 |
+
|
| 94 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 95 |
+
__pypackages__/
|
| 96 |
+
|
| 97 |
+
# Celery stuff
|
| 98 |
+
celerybeat-schedule
|
| 99 |
+
celerybeat.pid
|
| 100 |
+
|
| 101 |
+
# SageMath parsed files
|
| 102 |
+
*.sage.py
|
| 103 |
+
|
| 104 |
+
# Environments
|
| 105 |
+
.env
|
| 106 |
+
.venv
|
| 107 |
+
env/
|
| 108 |
+
venv/
|
| 109 |
+
ENV/
|
| 110 |
+
env.bak/
|
| 111 |
+
venv.bak/
|
| 112 |
+
|
| 113 |
+
# Spyder project settings
|
| 114 |
+
.spyderproject
|
| 115 |
+
.spyproject
|
| 116 |
+
|
| 117 |
+
# Rope project settings
|
| 118 |
+
.ropeproject
|
| 119 |
+
|
| 120 |
+
# mkdocs documentation
|
| 121 |
+
/site
|
| 122 |
+
|
| 123 |
+
# mypy
|
| 124 |
+
.mypy_cache/
|
| 125 |
+
.dmypy.json
|
| 126 |
+
dmypy.json
|
| 127 |
+
|
| 128 |
+
# Pyre type checker
|
| 129 |
+
.pyre/
|
| 130 |
+
|
| 131 |
+
data/
|
| 132 |
+
*.iml
|
| 133 |
+
.idea/
|
| 134 |
+
*.pt
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Pramook Khungurn
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,239 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Demo Code for "Talking Head(?) Anime from A Single Image 3: Now the Body Too"
|
| 2 |
+
|
| 3 |
+
This repository contains demo programs for the [Talking Head(?) Anime from a Single Image 3: Now the Body Too](https://pkhungurn.github.io/talking-head-anime-3/index.html) project. As the name implies, the project allows you to animate anime characters, and you only need a single image of that character to do so. There are two demo programs:
|
| 4 |
+
|
| 5 |
+
* The ``manual_poser`` lets you manipulate a character's facial expression, head rotation, body rotation, and chest expansion due to breathing through a graphical user interface.
|
| 6 |
+
* ``ifacialmocap_puppeteer`` lets you transfer your facial motion to an anime character.
|
| 7 |
+
|
| 8 |
+
## Try the Manual Poser on Google Colab
|
| 9 |
+
|
| 10 |
+
If you do not have the required hardware (discussed below) or do not want to download the code and set up an environment to run it, click [](https://colab.research.google.com/github/pkhungurn/talking-head-anime-3-demo/blob/master/colab.ipynb) to try running the manual poser on [Google Colab](https://research.google.com/colaboratory/faq.html).
|
| 11 |
+
|
| 12 |
+
## Hardware Requirements
|
| 13 |
+
|
| 14 |
+
Both programs require a recent and powerful Nvidia GPU to run. I could personally ran them at good speed with the Nvidia Titan RTX. However, I think recent high-end gaming GPUs such as the RTX 2080, the RTX 3080, or better would do just as well.
|
| 15 |
+
|
| 16 |
+
The `ifacialmocap_puppeteer` requires an iOS device that is capable of computing [blend shape parameters](https://developer.apple.com/documentation/arkit/arfaceanchor/2928251-blendshapes) from a video feed. This means that the device must be able to run iOS 11.0 or higher and must have a TrueDepth front-facing camera. (See [this page](https://developer.apple.com/documentation/arkit/content_anchors/tracking_and_visualizing_faces) for more info.) In other words, if you have the iPhone X or something better, you should be all set. Personally, I have used an iPhone 12 mini.
|
| 17 |
+
|
| 18 |
+
## Software Requirements
|
| 19 |
+
|
| 20 |
+
### GPU Related Software
|
| 21 |
+
|
| 22 |
+
Please update your GPU's device driver and install the [CUDA Toolkit](https://developer.nvidia.com/cuda-toolkit) that is compatible with your GPU and is newer than the version you will be installing in the next subsection.
|
| 23 |
+
|
| 24 |
+
### Python Environment
|
| 25 |
+
|
| 26 |
+
Both ``manual_poser`` and ``ifacialmocap_puppeteer`` are available as desktop applications. To run them, you need to set up an environment for running programs written in the [Python](http://www.python.org) language. The environment needs to have the following software packages:
|
| 27 |
+
|
| 28 |
+
* Python >= 3.8
|
| 29 |
+
* PyTorch >= 1.11.0 with CUDA support
|
| 30 |
+
* SciPY >= 1.7.3
|
| 31 |
+
* wxPython >= 4.1.1
|
| 32 |
+
* Matplotlib >= 3.5.1
|
| 33 |
+
|
| 34 |
+
One way to do so is to install [Anaconda](https://www.anaconda.com/) and run the following commands in your shell:
|
| 35 |
+
|
| 36 |
+
```
|
| 37 |
+
> conda create -n talking-head-anime-3-demo python=3.8
|
| 38 |
+
> conda activate talking-head-anime-3-demo
|
| 39 |
+
> conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
|
| 40 |
+
> conda install scipy
|
| 41 |
+
> pip install wxpython
|
| 42 |
+
> conda install matplotlib
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
#### Caveat 1: Do not use Python 3.10 on Windows
|
| 46 |
+
|
| 47 |
+
As of June 2006, you cannot use [wxPython](https://www.wxpython.org/) with Python 3.10 on Windows. As a result, do not use Python 3.10 until [this bug](https://github.com/wxWidgets/Phoenix/issues/2024) is fixed. This means you should not set ``python=3.10`` in the first ``conda`` command in the listing above.
|
| 48 |
+
|
| 49 |
+
#### Caveat 2: Adjust versions of Python and CUDA Toolkit as needed
|
| 50 |
+
|
| 51 |
+
The environment created by the commands above gives you Python version 3.8 and an installation of [PyTorch](http://pytorch.org) that was compiled with CUDA Toolkit version 11.3. This particular setup might not work in the future because you may find that this particular PyTorch package does not work with your new computer. The solution is to:
|
| 52 |
+
|
| 53 |
+
1. Change the Python version in the first command to a recent one that works for your OS. (That is, do not use 3.10 if you are using Windows.)
|
| 54 |
+
2. Change the version of CUDA toolkit in the third command to one that the PyTorch's website says is available. In particular, scroll to the "Install PyTorch" section and use the chooser there to pick the right command for your computer. Use that command to install PyTorch instead of the third command above.
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
### Jupyter Environment
|
| 59 |
+
|
| 60 |
+
The ``manual_poser`` is also available as a [Jupyter Nootbook](http://jupyter.org). To run it on your local machines, you also need to install:
|
| 61 |
+
|
| 62 |
+
* Jupyter Notebook >= 7.3.4
|
| 63 |
+
* IPywidgets >= 7.7.0
|
| 64 |
+
|
| 65 |
+
In some case, you will also need to enable the ``widgetsnbextension`` as well. So, run
|
| 66 |
+
|
| 67 |
+
```
|
| 68 |
+
> jupyter nbextension enable --py widgetsnbextension
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
After installing the above two packages. Using Anaconda, I managed to do the above with the following commands:
|
| 72 |
+
|
| 73 |
+
```
|
| 74 |
+
> conda install -c conda-forge notebook
|
| 75 |
+
> conda install -c conda-forge ipywidgets
|
| 76 |
+
> jupyter nbextension enable --py widgetsnbextension
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
### Automatic Environment Construction with Anaconda
|
| 80 |
+
|
| 81 |
+
You can also use Anaconda to download and install all Python packages in one command. Open your shell, change the directory to where you clone the repository, and run:
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
> conda env create -f environment.yml
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
This will create an environment called ``talking-head-anime-3-demo`` containing all the required Python packages.
|
| 88 |
+
|
| 89 |
+
### iFacialMocap
|
| 90 |
+
|
| 91 |
+
If you want to use ``ifacialmocap_puppeteer``, you will also need to an iOS software called [iFacialMocap](https://www.ifacialmocap.com/) (a 980 yen purchase in the App Store). You do not need to download the paired application this time. Your iOS and your computer must use the same network. For example, you may connect them to the same wireless router.
|
| 92 |
+
|
| 93 |
+
## Download the Models
|
| 94 |
+
|
| 95 |
+
Before running the programs, you need to download the model files from this [Dropbox link](https://www.dropbox.com/s/y7b8jl4n2euv8xe/talking-head-anime-3-models.zip?dl=0) and unzip it to the ``data/models`` folder under the repository's root directory. In the end, the data folder should look like:
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
+ data
|
| 99 |
+
+ images
|
| 100 |
+
- crypko_00.png
|
| 101 |
+
- crypko_01.png
|
| 102 |
+
:
|
| 103 |
+
- crypko_07.png
|
| 104 |
+
- lambda_00.png
|
| 105 |
+
- lambda_01.png
|
| 106 |
+
+ models
|
| 107 |
+
+ separable_float
|
| 108 |
+
- editor.pt
|
| 109 |
+
- eyebrow_decomposer.pt
|
| 110 |
+
- eyebrow_morphing_combiner.pt
|
| 111 |
+
- face_morpher.pt
|
| 112 |
+
- two_algo_face_body_rotator.pt
|
| 113 |
+
+ separable_half
|
| 114 |
+
- editor.pt
|
| 115 |
+
:
|
| 116 |
+
- two_algo_face_body_rotator.pt
|
| 117 |
+
+ standard_float
|
| 118 |
+
- editor.pt
|
| 119 |
+
:
|
| 120 |
+
- two_algo_face_body_rotator.pt
|
| 121 |
+
+ standard_half
|
| 122 |
+
- editor.pt
|
| 123 |
+
:
|
| 124 |
+
- two_algo_face_body_rotator.pt
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
The model files are distributed with the
|
| 128 |
+
[Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/legalcode), which
|
| 129 |
+
means that you can use them for commercial purposes. However, if you distribute them, you must, among other things, say
|
| 130 |
+
that I am the creator.
|
| 131 |
+
|
| 132 |
+
## Running the `manual_poser` Desktop Application
|
| 133 |
+
|
| 134 |
+
Open a shell. Change your working directory to the repository's root directory. Then, run:
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
> python tha3/app/manual_poser.py
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
Note that before running the command above, you might have to activate the Python environment that contains the required
|
| 141 |
+
packages. If you created an environment using Anaconda as was discussed above, you need to run
|
| 142 |
+
|
| 143 |
+
```
|
| 144 |
+
> conda activate talking-head-anime-3-demo
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
if you have not already activated the environment.
|
| 148 |
+
|
| 149 |
+
### Choosing System Variant to Use
|
| 150 |
+
|
| 151 |
+
As noted in the [project's write-up](http://pkhungurn.github.io/talking-head-anime-3/index.html), I created 4 variants of the neural network system. They are called ``standard_float``, ``separable_float``, ``standard_half``, and ``separable_half``. All of them have the same functionalities, but they differ in their sizes, RAM usage, speed, and accuracy. You can specify which variant that the ``manual_poser`` program uses through the ``--model`` command line option.
|
| 152 |
+
|
| 153 |
+
```
|
| 154 |
+
> python tha3/app/manual_poser --model <variant_name>
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
where ``<variant_name>`` must be one of the 4 names above. If no variant is specified, the ``standard_float`` variant (which is the largest, slowest, and most accurate) will be used.
|
| 158 |
+
|
| 159 |
+
## Running the `manual_poser` Jupyter Notebook
|
| 160 |
+
|
| 161 |
+
Open a shell. Activate the environment. Change your working directory to the repository's root directory. Then, run:
|
| 162 |
+
|
| 163 |
+
```
|
| 164 |
+
> jupyter notebook
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
A browser window should open. In it, open `manual_poser.ipynb`. Once you have done so, you should see that it has two cells. Run the two cells in order. Then, scroll down to the end of the document, and you'll see the GUI there.
|
| 168 |
+
|
| 169 |
+
You can choose the system variant to use by changing the ``MODEL_NAME`` variable in the first cell. If you do, you will need to rerun both cells in order for the variant to be loaded and the GUI to be properly updated to use it.
|
| 170 |
+
|
| 171 |
+
## Running the `ifacialmocap_poser`
|
| 172 |
+
|
| 173 |
+
First, run iFacialMocap on your iOS device. It should show you the device's IP address. Jot it down. Keep the app open.
|
| 174 |
+
|
| 175 |
+

|
| 176 |
+
|
| 177 |
+
Open a shell. Activate the Python environment. Change your working directory to the repository's root directory. Then, run:
|
| 178 |
+
|
| 179 |
+
```
|
| 180 |
+
> python tha3/app/ifacialmocap_puppeteer.py
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
You will see a text box with label "Capture Device IP." Write the iOS device's IP address that you jotted down there.
|
| 184 |
+
|
| 185 |
+

|
| 186 |
+
|
| 187 |
+
Click the "START CAPTURE!" button to the right.
|
| 188 |
+
|
| 189 |
+

|
| 190 |
+
|
| 191 |
+
If the programs are connected properly, you should see the numbers in the bottom part of the window change when you move your head.
|
| 192 |
+
|
| 193 |
+

|
| 194 |
+
|
| 195 |
+
Now, you can load an image of a character, and it should follow your facial movement.
|
| 196 |
+
|
| 197 |
+
## Contraints on Input Images
|
| 198 |
+
|
| 199 |
+
In order for the system to work well, the input image must obey the following constraints:
|
| 200 |
+
|
| 201 |
+
* It should be of resolution 512 x 512. (If the demo programs receives an input image of any other size, they will resize the image to this resolution and also output at this resolution.)
|
| 202 |
+
* It must have an alpha channel.
|
| 203 |
+
* It must contain only one humanoid character.
|
| 204 |
+
* The character should be standing upright and facing forward.
|
| 205 |
+
* The character's hands should be below and far from the head.
|
| 206 |
+
* The head of the character should roughly be contained in the 128 x 128 box in the middle of the top half of the image.
|
| 207 |
+
* The alpha channels of all pixels that do not belong to the character (i.e., background pixels) must be 0.
|
| 208 |
+
|
| 209 |
+

|
| 210 |
+
|
| 211 |
+
See the project's [write-up](http://pkhungurn.github.io/talking-head-anime-3/full.html#sec:problem-spec) for more details on the input image.
|
| 212 |
+
|
| 213 |
+
## Citation
|
| 214 |
+
|
| 215 |
+
If your academic work benefits from the code in this repository, please cite the project's web page as follows:
|
| 216 |
+
|
| 217 |
+
> Pramook Khungurn. **Talking Head(?) Anime from a Single Image 3: Now the Body Too.** http://pkhungurn.github.io/talking-head-anime-3/, 2022. Accessed: YYYY-MM-DD.
|
| 218 |
+
|
| 219 |
+
You can also used the following BibTex entry:
|
| 220 |
+
|
| 221 |
+
```
|
| 222 |
+
@misc{Khungurn:2022,
|
| 223 |
+
author = {Pramook Khungurn},
|
| 224 |
+
title = {Talking Head(?) Anime from a Single Image 3: Now the Body Too},
|
| 225 |
+
howpublished = {\url{http://pkhungurn.github.io/talking-head-anime-3/}},
|
| 226 |
+
year = 2022,
|
| 227 |
+
note = {Accessed: YYYY-MM-DD},
|
| 228 |
+
}
|
| 229 |
+
```
|
| 230 |
+
|
| 231 |
+
## Disclaimer
|
| 232 |
+
|
| 233 |
+
While the author is an employee of [Google Japan](https://careers.google.com/locations/tokyo/), this software is not Google's product and is not supported by Google.
|
| 234 |
+
|
| 235 |
+
The copyright of this software belongs to me as I have requested it using the [IARC process](https://opensource.google/documentation/reference/releasing#iarc). However, Google might claim the rights to the intellectual
|
| 236 |
+
property of this invention.
|
| 237 |
+
|
| 238 |
+
The code is released under the [MIT license](https://github.com/pkhungurn/talking-head-anime-2-demo/blob/master/LICENSE).
|
| 239 |
+
The model is released under the [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/legalcode). Please see the README.md file in the ``data/images`` directory for the licenses for the images there.
|
colab.ipynb
ADDED
|
@@ -0,0 +1,542 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "1027b46a",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# Talking Head(?) Anime from a Single Image 3: Now the Body Too (Manual Poser Tool)\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"**Instruction**\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"1. Run the four cells below, one by one, in order by clicking the \"Play\" button to the left of it. Wait for each cell to finish before going to the next one.\n",
|
| 13 |
+
"2. Scroll down to the end of the last cell, and play with the GUI.\n",
|
| 14 |
+
"\n",
|
| 15 |
+
"**Links**\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"* Github repository: http://github.com/pkhungurn/talking-head-anime-3-demo\n",
|
| 18 |
+
"* Project writeup: http://pkhungurn.github.io/talking-head-anime-3/"
|
| 19 |
+
]
|
| 20 |
+
},
|
| 21 |
+
{
|
| 22 |
+
"cell_type": "code",
|
| 23 |
+
"execution_count": null,
|
| 24 |
+
"id": "54cc96d7",
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": [
|
| 28 |
+
"# Clone the repository\n",
|
| 29 |
+
"%cd /content\n",
|
| 30 |
+
"!git clone https://github.com/pkhungurn/talking-head-anime-3-demo.git"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"cell_type": "code",
|
| 35 |
+
"execution_count": null,
|
| 36 |
+
"id": "77f2016c",
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": [
|
| 40 |
+
"# CD into the repository directory.\n",
|
| 41 |
+
"%cd /content/talking-head-anime-3-demo"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": null,
|
| 47 |
+
"id": "1771c927",
|
| 48 |
+
"metadata": {},
|
| 49 |
+
"outputs": [],
|
| 50 |
+
"source": [
|
| 51 |
+
"# Download model files\n",
|
| 52 |
+
"!mkdir -p data/models/standard_float\n",
|
| 53 |
+
"!wget -O data/models/standard_float/editor.pt https://www.dropbox.com/s/zp3e5ox57sdws3y/editor.pt?dl=0\n",
|
| 54 |
+
"!wget -O data/models/standard_float/eyebrow_decomposer.pt https://www.dropbox.com/s/bcp42knbrk7egk8/eyebrow_decomposer.pt?dl=0\n",
|
| 55 |
+
"!wget -O data/models/standard_float/eyebrow_morphing_combiner.pt https://www.dropbox.com/s/oywaiio2s53lc57/eyebrow_morphing_combiner.pt?dl=0\n",
|
| 56 |
+
"!wget -O data/models/standard_float/face_morpher.pt https://www.dropbox.com/s/8qvo0u5lw7hqvtq/face_morpher.pt?dl=0\n",
|
| 57 |
+
"!wget -O data/models/standard_float/two_algo_face_body_rotator.pt https://www.dropbox.com/s/qmq1dnxrmzsxb4h/two_algo_face_body_rotator.pt?dl=0\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"!mkdir -p data/models/standard_half\n",
|
| 60 |
+
"!wget -O data/models/standard_half/editor.pt https://www.dropbox.com/s/g21ps8gfuvz4kbo/editor.pt?dl=0\n",
|
| 61 |
+
"!wget -O data/models/standard_half/eyebrow_decomposer.pt https://www.dropbox.com/s/nwwwevzpmxiilgn/eyebrow_decomposer.pt?dl=0\n",
|
| 62 |
+
"!wget -O data/models/standard_half/eyebrow_morphing_combiner.pt https://www.dropbox.com/s/z5v0amgqif7yup1/eyebrow_morphing_combiner.pt?dl=0\n",
|
| 63 |
+
"!wget -O data/models/standard_half/face_morpher.pt https://www.dropbox.com/s/g03sfnd5yfs0m65/face_morpher.pt?dl=0\n",
|
| 64 |
+
"!wget -O data/models/standard_half/two_algo_face_body_rotator.pt https://www.dropbox.com/s/c5lrn7z34x12317/two_algo_face_body_rotator.pt?dl=0\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"!mkdir -p data/models/separable_float \n",
|
| 67 |
+
"!wget -O data/models/separable_float/editor.pt https://www.dropbox.com/s/nwdxhrpa9fy19r4/editor.pt?dl=0\n",
|
| 68 |
+
"!wget -O data/models/separable_float/eyebrow_decomposer.pt https://www.dropbox.com/s/hfzjcu9cqr9wm3i/eyebrow_decomposer.pt?dl=0\n",
|
| 69 |
+
"!wget -O data/models/separable_float/eyebrow_morphing_combiner.pt https://www.dropbox.com/s/g04dyyyavh5o1e2/eyebrow_morphing_combiner.pt?dl=0\n",
|
| 70 |
+
"!wget -O data/models/separable_float/face_morpher.pt https://www.dropbox.com/s/vgi9dsj95y0rrwv/face_morpher.pt?dl=0\n",
|
| 71 |
+
"!wget -O data/models/separable_float/two_algo_face_body_rotator.pt https://www.dropbox.com/s/8u0qond8po34l24/two_algo_face_body_rotator.pt?dl=0\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"!mkdir -p data/models/separable_half\n",
|
| 74 |
+
"!wget -O data/models/separable_half/editor.pt https://www.dropbox.com/s/on8kn6z9fj95j0h/editor.pt?dl=0\n",
|
| 75 |
+
"!wget -O data/models/separable_half/eyebrow_decomposer.pt https://www.dropbox.com/s/0hxu8opu1hmghqe/eyebrow_decomposer.pt?dl=0\n",
|
| 76 |
+
"!wget -O data/models/separable_half/eyebrow_morphing_combiner.pt https://www.dropbox.com/s/bgz02afp0xojqfs/eyebrow_morphing_combiner.pt?dl=0\n",
|
| 77 |
+
"!wget -O data/models/separable_half/face_morpher.pt https://www.dropbox.com/s/bgz02afp0xojqfs/eyebrow_morphing_combiner.pt?dl=0\n",
|
| 78 |
+
"!wget -O data/models/separable_half/two_algo_face_body_rotator.pt https://www.dropbox.com/s/vr8h2xxltszhw7w/two_algo_face_body_rotator.pt?dl=0"
|
| 79 |
+
]
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"cell_type": "code",
|
| 83 |
+
"execution_count": null,
|
| 84 |
+
"id": "062014f7",
|
| 85 |
+
"metadata": {
|
| 86 |
+
"id": "breeding-extra"
|
| 87 |
+
},
|
| 88 |
+
"outputs": [],
|
| 89 |
+
"source": [
|
| 90 |
+
"# Set this constant to specify which system variant to use.\n",
|
| 91 |
+
"MODEL_NAME = \"standard_float\" \n",
|
| 92 |
+
"\n",
|
| 93 |
+
"# Load the models.\n",
|
| 94 |
+
"import torch\n",
|
| 95 |
+
"DEVICE_NAME = 'cuda'\n",
|
| 96 |
+
"device = torch.device(DEVICE_NAME)\n",
|
| 97 |
+
"\n",
|
| 98 |
+
"def load_poser(model: str, device: torch.device):\n",
|
| 99 |
+
" print(\"Using the %s model.\" % model)\n",
|
| 100 |
+
" if model == \"standard_float\":\n",
|
| 101 |
+
" from tha3.poser.modes.standard_float import create_poser\n",
|
| 102 |
+
" return create_poser(device)\n",
|
| 103 |
+
" elif model == \"standard_half\":\n",
|
| 104 |
+
" from tha3.poser.modes.standard_half import create_poser\n",
|
| 105 |
+
" return create_poser(device)\n",
|
| 106 |
+
" elif model == \"separable_float\":\n",
|
| 107 |
+
" from tha3.poser.modes.separable_float import create_poser\n",
|
| 108 |
+
" return create_poser(device)\n",
|
| 109 |
+
" elif model == \"separable_half\":\n",
|
| 110 |
+
" from tha3.poser.modes.separable_half import create_poser\n",
|
| 111 |
+
" return create_poser(device)\n",
|
| 112 |
+
" else:\n",
|
| 113 |
+
" raise RuntimeError(\"Invalid model: '%s'\" % model)\n",
|
| 114 |
+
" \n",
|
| 115 |
+
"poser = load_poser(MODEL_NAME, DEVICE_NAME)\n",
|
| 116 |
+
"poser.get_modules();"
|
| 117 |
+
]
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"cell_type": "code",
|
| 121 |
+
"execution_count": null,
|
| 122 |
+
"id": "breeding-extra",
|
| 123 |
+
"metadata": {
|
| 124 |
+
"id": "breeding-extra"
|
| 125 |
+
},
|
| 126 |
+
"outputs": [],
|
| 127 |
+
"source": [
|
| 128 |
+
"# Create the GUI for manipulating character images.\n",
|
| 129 |
+
"import PIL.Image\n",
|
| 130 |
+
"import io\n",
|
| 131 |
+
"from io import StringIO, BytesIO\n",
|
| 132 |
+
"import IPython.display\n",
|
| 133 |
+
"import numpy\n",
|
| 134 |
+
"import ipywidgets\n",
|
| 135 |
+
"import time\n",
|
| 136 |
+
"import threading\n",
|
| 137 |
+
"import torch\n",
|
| 138 |
+
"from tha3.util import resize_PIL_image, extract_PIL_image_from_filelike, \\\n",
|
| 139 |
+
" extract_pytorch_image_from_PIL_image, convert_output_image_from_torch_to_numpy\n",
|
| 140 |
+
"\n",
|
| 141 |
+
"FRAME_RATE = 30.0\n",
|
| 142 |
+
"\n",
|
| 143 |
+
"last_torch_input_image = None\n",
|
| 144 |
+
"torch_input_image = None\n",
|
| 145 |
+
"\n",
|
| 146 |
+
"def show_pytorch_image(pytorch_image):\n",
|
| 147 |
+
" output_image = pytorch_image.detach().cpu()\n",
|
| 148 |
+
" numpy_image = numpy.uint8(numpy.rint(convert_output_image_from_torch_to_numpy(output_image) * 255.0))\n",
|
| 149 |
+
" pil_image = PIL.Image.fromarray(numpy_image, mode='RGBA')\n",
|
| 150 |
+
" IPython.display.display(pil_image)\n",
|
| 151 |
+
"\n",
|
| 152 |
+
"upload_input_image_button = ipywidgets.FileUpload(\n",
|
| 153 |
+
" accept='.png',\n",
|
| 154 |
+
" multiple=False,\n",
|
| 155 |
+
" layout={\n",
|
| 156 |
+
" 'width': '512px'\n",
|
| 157 |
+
" }\n",
|
| 158 |
+
")\n",
|
| 159 |
+
"\n",
|
| 160 |
+
"output_image_widget = ipywidgets.Output(\n",
|
| 161 |
+
" layout={\n",
|
| 162 |
+
" 'border': '1px solid black',\n",
|
| 163 |
+
" 'width': '512px',\n",
|
| 164 |
+
" 'height': '512px'\n",
|
| 165 |
+
" }\n",
|
| 166 |
+
")\n",
|
| 167 |
+
"\n",
|
| 168 |
+
"eyebrow_dropdown = ipywidgets.Dropdown(\n",
|
| 169 |
+
" options=[\"troubled\", \"angry\", \"lowered\", \"raised\", \"happy\", \"serious\"],\n",
|
| 170 |
+
" value=\"troubled\",\n",
|
| 171 |
+
" description=\"Eyebrow:\", \n",
|
| 172 |
+
")\n",
|
| 173 |
+
"eyebrow_left_slider = ipywidgets.FloatSlider(\n",
|
| 174 |
+
" value=0.0,\n",
|
| 175 |
+
" min=0.0,\n",
|
| 176 |
+
" max=1.0,\n",
|
| 177 |
+
" step=0.01,\n",
|
| 178 |
+
" description=\"Left:\",\n",
|
| 179 |
+
" readout=True,\n",
|
| 180 |
+
" readout_format=\".2f\"\n",
|
| 181 |
+
")\n",
|
| 182 |
+
"eyebrow_right_slider = ipywidgets.FloatSlider(\n",
|
| 183 |
+
" value=0.0,\n",
|
| 184 |
+
" min=0.0,\n",
|
| 185 |
+
" max=1.0,\n",
|
| 186 |
+
" step=0.01,\n",
|
| 187 |
+
" description=\"Right:\",\n",
|
| 188 |
+
" readout=True,\n",
|
| 189 |
+
" readout_format=\".2f\"\n",
|
| 190 |
+
")\n",
|
| 191 |
+
"\n",
|
| 192 |
+
"eye_dropdown = ipywidgets.Dropdown(\n",
|
| 193 |
+
" options=[\"wink\", \"happy_wink\", \"surprised\", \"relaxed\", \"unimpressed\", \"raised_lower_eyelid\"],\n",
|
| 194 |
+
" value=\"wink\",\n",
|
| 195 |
+
" description=\"Eye:\", \n",
|
| 196 |
+
")\n",
|
| 197 |
+
"eye_left_slider = ipywidgets.FloatSlider(\n",
|
| 198 |
+
" value=0.0,\n",
|
| 199 |
+
" min=0.0,\n",
|
| 200 |
+
" max=1.0,\n",
|
| 201 |
+
" step=0.01,\n",
|
| 202 |
+
" description=\"Left:\",\n",
|
| 203 |
+
" readout=True,\n",
|
| 204 |
+
" readout_format=\".2f\"\n",
|
| 205 |
+
")\n",
|
| 206 |
+
"eye_right_slider = ipywidgets.FloatSlider(\n",
|
| 207 |
+
" value=0.0,\n",
|
| 208 |
+
" min=0.0,\n",
|
| 209 |
+
" max=1.0,\n",
|
| 210 |
+
" step=0.01,\n",
|
| 211 |
+
" description=\"Right:\",\n",
|
| 212 |
+
" readout=True,\n",
|
| 213 |
+
" readout_format=\".2f\"\n",
|
| 214 |
+
")\n",
|
| 215 |
+
"\n",
|
| 216 |
+
"mouth_dropdown = ipywidgets.Dropdown(\n",
|
| 217 |
+
" options=[\"aaa\", \"iii\", \"uuu\", \"eee\", \"ooo\", \"delta\", \"lowered_corner\", \"raised_corner\", \"smirk\"],\n",
|
| 218 |
+
" value=\"aaa\",\n",
|
| 219 |
+
" description=\"Mouth:\", \n",
|
| 220 |
+
")\n",
|
| 221 |
+
"mouth_left_slider = ipywidgets.FloatSlider(\n",
|
| 222 |
+
" value=0.0,\n",
|
| 223 |
+
" min=0.0,\n",
|
| 224 |
+
" max=1.0,\n",
|
| 225 |
+
" step=0.01,\n",
|
| 226 |
+
" description=\"Value:\",\n",
|
| 227 |
+
" readout=True,\n",
|
| 228 |
+
" readout_format=\".2f\"\n",
|
| 229 |
+
")\n",
|
| 230 |
+
"mouth_right_slider = ipywidgets.FloatSlider(\n",
|
| 231 |
+
" value=0.0,\n",
|
| 232 |
+
" min=0.0,\n",
|
| 233 |
+
" max=1.0,\n",
|
| 234 |
+
" step=0.01,\n",
|
| 235 |
+
" description=\" \",\n",
|
| 236 |
+
" readout=True,\n",
|
| 237 |
+
" readout_format=\".2f\",\n",
|
| 238 |
+
" disabled=True,\n",
|
| 239 |
+
")\n",
|
| 240 |
+
"\n",
|
| 241 |
+
"def update_mouth_sliders(change):\n",
|
| 242 |
+
" if mouth_dropdown.value == \"lowered_corner\" or mouth_dropdown.value == \"raised_corner\":\n",
|
| 243 |
+
" mouth_left_slider.description = \"Left:\"\n",
|
| 244 |
+
" mouth_right_slider.description = \"Right:\"\n",
|
| 245 |
+
" mouth_right_slider.disabled = False\n",
|
| 246 |
+
" else:\n",
|
| 247 |
+
" mouth_left_slider.description = \"Value:\"\n",
|
| 248 |
+
" mouth_right_slider.description = \" \"\n",
|
| 249 |
+
" mouth_right_slider.disabled = True\n",
|
| 250 |
+
"\n",
|
| 251 |
+
"mouth_dropdown.observe(update_mouth_sliders, names='value')\n",
|
| 252 |
+
"\n",
|
| 253 |
+
"iris_small_left_slider = ipywidgets.FloatSlider(\n",
|
| 254 |
+
" value=0.0,\n",
|
| 255 |
+
" min=0.0,\n",
|
| 256 |
+
" max=1.0,\n",
|
| 257 |
+
" step=0.01,\n",
|
| 258 |
+
" description=\"Left:\",\n",
|
| 259 |
+
" readout=True,\n",
|
| 260 |
+
" readout_format=\".2f\"\n",
|
| 261 |
+
")\n",
|
| 262 |
+
"iris_small_right_slider = ipywidgets.FloatSlider(\n",
|
| 263 |
+
" value=0.0,\n",
|
| 264 |
+
" min=0.0,\n",
|
| 265 |
+
" max=1.0,\n",
|
| 266 |
+
" step=0.01,\n",
|
| 267 |
+
" description=\"Right:\",\n",
|
| 268 |
+
" readout=True,\n",
|
| 269 |
+
" readout_format=\".2f\", \n",
|
| 270 |
+
")\n",
|
| 271 |
+
"iris_rotation_x_slider = ipywidgets.FloatSlider(\n",
|
| 272 |
+
" value=0.0,\n",
|
| 273 |
+
" min=-1.0,\n",
|
| 274 |
+
" max=1.0,\n",
|
| 275 |
+
" step=0.01,\n",
|
| 276 |
+
" description=\"X-axis:\",\n",
|
| 277 |
+
" readout=True,\n",
|
| 278 |
+
" readout_format=\".2f\"\n",
|
| 279 |
+
")\n",
|
| 280 |
+
"iris_rotation_y_slider = ipywidgets.FloatSlider(\n",
|
| 281 |
+
" value=0.0,\n",
|
| 282 |
+
" min=-1.0,\n",
|
| 283 |
+
" max=1.0,\n",
|
| 284 |
+
" step=0.01,\n",
|
| 285 |
+
" description=\"Y-axis:\",\n",
|
| 286 |
+
" readout=True,\n",
|
| 287 |
+
" readout_format=\".2f\", \n",
|
| 288 |
+
")\n",
|
| 289 |
+
"\n",
|
| 290 |
+
"head_x_slider = ipywidgets.FloatSlider(\n",
|
| 291 |
+
" value=0.0,\n",
|
| 292 |
+
" min=-1.0,\n",
|
| 293 |
+
" max=1.0,\n",
|
| 294 |
+
" step=0.01,\n",
|
| 295 |
+
" description=\"X-axis:\",\n",
|
| 296 |
+
" readout=True,\n",
|
| 297 |
+
" readout_format=\".2f\"\n",
|
| 298 |
+
")\n",
|
| 299 |
+
"head_y_slider = ipywidgets.FloatSlider(\n",
|
| 300 |
+
" value=0.0,\n",
|
| 301 |
+
" min=-1.0,\n",
|
| 302 |
+
" max=1.0,\n",
|
| 303 |
+
" step=0.01,\n",
|
| 304 |
+
" description=\"Y-axis:\",\n",
|
| 305 |
+
" readout=True,\n",
|
| 306 |
+
" readout_format=\".2f\", \n",
|
| 307 |
+
")\n",
|
| 308 |
+
"neck_z_slider = ipywidgets.FloatSlider(\n",
|
| 309 |
+
" value=0.0,\n",
|
| 310 |
+
" min=-1.0,\n",
|
| 311 |
+
" max=1.0,\n",
|
| 312 |
+
" step=0.01,\n",
|
| 313 |
+
" description=\"Z-axis:\",\n",
|
| 314 |
+
" readout=True,\n",
|
| 315 |
+
" readout_format=\".2f\", \n",
|
| 316 |
+
")\n",
|
| 317 |
+
"body_y_slider = ipywidgets.FloatSlider(\n",
|
| 318 |
+
" value=0.0,\n",
|
| 319 |
+
" min=-1.0,\n",
|
| 320 |
+
" max=1.0,\n",
|
| 321 |
+
" step=0.01,\n",
|
| 322 |
+
" description=\"Y-axis rotation:\",\n",
|
| 323 |
+
" readout=True,\n",
|
| 324 |
+
" readout_format=\".2f\", \n",
|
| 325 |
+
")\n",
|
| 326 |
+
"body_z_slider = ipywidgets.FloatSlider(\n",
|
| 327 |
+
" value=0.0,\n",
|
| 328 |
+
" min=-1.0,\n",
|
| 329 |
+
" max=1.0,\n",
|
| 330 |
+
" step=0.01,\n",
|
| 331 |
+
" description=\"Z-axis rotation:\",\n",
|
| 332 |
+
" readout=True,\n",
|
| 333 |
+
" readout_format=\".2f\", \n",
|
| 334 |
+
")\n",
|
| 335 |
+
"breathing_slider = ipywidgets.FloatSlider(\n",
|
| 336 |
+
" value=0.0,\n",
|
| 337 |
+
" min=0.0,\n",
|
| 338 |
+
" max=1.0,\n",
|
| 339 |
+
" step=0.01,\n",
|
| 340 |
+
" description=\"Breathing:\",\n",
|
| 341 |
+
" readout=True,\n",
|
| 342 |
+
" readout_format=\".2f\", \n",
|
| 343 |
+
")\n",
|
| 344 |
+
"\n",
|
| 345 |
+
"\n",
|
| 346 |
+
"control_panel = ipywidgets.VBox([\n",
|
| 347 |
+
" eyebrow_dropdown,\n",
|
| 348 |
+
" eyebrow_left_slider,\n",
|
| 349 |
+
" eyebrow_right_slider,\n",
|
| 350 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 351 |
+
" eye_dropdown,\n",
|
| 352 |
+
" eye_left_slider,\n",
|
| 353 |
+
" eye_right_slider,\n",
|
| 354 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 355 |
+
" mouth_dropdown,\n",
|
| 356 |
+
" mouth_left_slider,\n",
|
| 357 |
+
" mouth_right_slider,\n",
|
| 358 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 359 |
+
" ipywidgets.HTML(value=\"<center><b>Iris Shrinkage</b></center>\"),\n",
|
| 360 |
+
" iris_small_left_slider,\n",
|
| 361 |
+
" iris_small_right_slider,\n",
|
| 362 |
+
" ipywidgets.HTML(value=\"<center><b>Iris Rotation</b></center>\"),\n",
|
| 363 |
+
" iris_rotation_x_slider,\n",
|
| 364 |
+
" iris_rotation_y_slider,\n",
|
| 365 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 366 |
+
" ipywidgets.HTML(value=\"<center><b>Head Rotation</b></center>\"),\n",
|
| 367 |
+
" head_x_slider,\n",
|
| 368 |
+
" head_y_slider,\n",
|
| 369 |
+
" neck_z_slider,\n",
|
| 370 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 371 |
+
" ipywidgets.HTML(value=\"<center><b>Body Rotation</b></center>\"),\n",
|
| 372 |
+
" body_y_slider,\n",
|
| 373 |
+
" body_z_slider,\n",
|
| 374 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 375 |
+
" ipywidgets.HTML(value=\"<center><b>Breathing</b></center>\"),\n",
|
| 376 |
+
" breathing_slider,\n",
|
| 377 |
+
"])\n",
|
| 378 |
+
"\n",
|
| 379 |
+
"controls = ipywidgets.HBox([\n",
|
| 380 |
+
" ipywidgets.VBox([\n",
|
| 381 |
+
" output_image_widget, \n",
|
| 382 |
+
" upload_input_image_button\n",
|
| 383 |
+
" ]),\n",
|
| 384 |
+
" control_panel,\n",
|
| 385 |
+
"])\n",
|
| 386 |
+
"\n",
|
| 387 |
+
"from tha3.poser.modes.pose_parameters import get_pose_parameters\n",
|
| 388 |
+
"pose_parameters = get_pose_parameters()\n",
|
| 389 |
+
"pose_size = poser.get_num_parameters()\n",
|
| 390 |
+
"last_pose = torch.zeros(1, pose_size, dtype=poser.get_dtype()).to(device)\n",
|
| 391 |
+
"\n",
|
| 392 |
+
"iris_small_left_index = pose_parameters.get_parameter_index(\"iris_small_left\")\n",
|
| 393 |
+
"iris_small_right_index = pose_parameters.get_parameter_index(\"iris_small_right\")\n",
|
| 394 |
+
"iris_rotation_x_index = pose_parameters.get_parameter_index(\"iris_rotation_x\")\n",
|
| 395 |
+
"iris_rotation_y_index = pose_parameters.get_parameter_index(\"iris_rotation_y\")\n",
|
| 396 |
+
"head_x_index = pose_parameters.get_parameter_index(\"head_x\")\n",
|
| 397 |
+
"head_y_index = pose_parameters.get_parameter_index(\"head_y\")\n",
|
| 398 |
+
"neck_z_index = pose_parameters.get_parameter_index(\"neck_z\")\n",
|
| 399 |
+
"body_y_index = pose_parameters.get_parameter_index(\"body_y\")\n",
|
| 400 |
+
"body_z_index = pose_parameters.get_parameter_index(\"body_z\")\n",
|
| 401 |
+
"breathing_index = pose_parameters.get_parameter_index(\"breathing\")\n",
|
| 402 |
+
"\n",
|
| 403 |
+
"def get_pose():\n",
|
| 404 |
+
" pose = torch.zeros(1, pose_size, dtype=poser.get_dtype())\n",
|
| 405 |
+
"\n",
|
| 406 |
+
" eyebrow_name = f\"eyebrow_{eyebrow_dropdown.value}\"\n",
|
| 407 |
+
" eyebrow_left_index = pose_parameters.get_parameter_index(f\"{eyebrow_name}_left\")\n",
|
| 408 |
+
" eyebrow_right_index = pose_parameters.get_parameter_index(f\"{eyebrow_name}_right\")\n",
|
| 409 |
+
" pose[0, eyebrow_left_index] = eyebrow_left_slider.value\n",
|
| 410 |
+
" pose[0, eyebrow_right_index] = eyebrow_right_slider.value\n",
|
| 411 |
+
"\n",
|
| 412 |
+
" eye_name = f\"eye_{eye_dropdown.value}\"\n",
|
| 413 |
+
" eye_left_index = pose_parameters.get_parameter_index(f\"{eye_name}_left\")\n",
|
| 414 |
+
" eye_right_index = pose_parameters.get_parameter_index(f\"{eye_name}_right\")\n",
|
| 415 |
+
" pose[0, eye_left_index] = eye_left_slider.value\n",
|
| 416 |
+
" pose[0, eye_right_index] = eye_right_slider.value\n",
|
| 417 |
+
"\n",
|
| 418 |
+
" mouth_name = f\"mouth_{mouth_dropdown.value}\"\n",
|
| 419 |
+
" if mouth_name == \"mouth_lowered_corner\" or mouth_name == \"mouth_raised_corner\":\n",
|
| 420 |
+
" mouth_left_index = pose_parameters.get_parameter_index(f\"{mouth_name}_left\")\n",
|
| 421 |
+
" mouth_right_index = pose_parameters.get_parameter_index(f\"{mouth_name}_right\")\n",
|
| 422 |
+
" pose[0, mouth_left_index] = mouth_left_slider.value\n",
|
| 423 |
+
" pose[0, mouth_right_index] = mouth_right_slider.value\n",
|
| 424 |
+
" else:\n",
|
| 425 |
+
" mouth_index = pose_parameters.get_parameter_index(mouth_name)\n",
|
| 426 |
+
" pose[0, mouth_index] = mouth_left_slider.value\n",
|
| 427 |
+
"\n",
|
| 428 |
+
" pose[0, iris_small_left_index] = iris_small_left_slider.value\n",
|
| 429 |
+
" pose[0, iris_small_right_index] = iris_small_right_slider.value\n",
|
| 430 |
+
" pose[0, iris_rotation_x_index] = iris_rotation_x_slider.value\n",
|
| 431 |
+
" pose[0, iris_rotation_y_index] = iris_rotation_y_slider.value\n",
|
| 432 |
+
" pose[0, head_x_index] = head_x_slider.value\n",
|
| 433 |
+
" pose[0, head_y_index] = head_y_slider.value\n",
|
| 434 |
+
" pose[0, neck_z_index] = neck_z_slider.value\n",
|
| 435 |
+
" pose[0, body_y_index] = body_y_slider.value\n",
|
| 436 |
+
" pose[0, body_z_index] = body_z_slider.value\n",
|
| 437 |
+
" pose[0, breathing_index] = breathing_slider.value\n",
|
| 438 |
+
"\n",
|
| 439 |
+
" return pose.to(device)\n",
|
| 440 |
+
"\n",
|
| 441 |
+
"display(controls)\n",
|
| 442 |
+
"\n",
|
| 443 |
+
"def update(change):\n",
|
| 444 |
+
" global last_pose\n",
|
| 445 |
+
" global last_torch_input_image\n",
|
| 446 |
+
"\n",
|
| 447 |
+
" if torch_input_image is None:\n",
|
| 448 |
+
" return\n",
|
| 449 |
+
"\n",
|
| 450 |
+
" needs_update = False\n",
|
| 451 |
+
" if last_torch_input_image is None:\n",
|
| 452 |
+
" needs_update = True \n",
|
| 453 |
+
" else:\n",
|
| 454 |
+
" if (torch_input_image - last_torch_input_image).abs().max().item() > 0:\n",
|
| 455 |
+
" needs_update = True \n",
|
| 456 |
+
"\n",
|
| 457 |
+
" pose = get_pose()\n",
|
| 458 |
+
" if (pose - last_pose).abs().max().item() > 0:\n",
|
| 459 |
+
" needs_update = True\n",
|
| 460 |
+
"\n",
|
| 461 |
+
" if not needs_update:\n",
|
| 462 |
+
" return\n",
|
| 463 |
+
"\n",
|
| 464 |
+
" output_image = poser.pose(torch_input_image, pose)[0]\n",
|
| 465 |
+
" with output_image_widget:\n",
|
| 466 |
+
" output_image_widget.clear_output(wait=True)\n",
|
| 467 |
+
" show_pytorch_image(output_image) \n",
|
| 468 |
+
"\n",
|
| 469 |
+
" last_torch_input_image = torch_input_image\n",
|
| 470 |
+
" last_pose = pose\n",
|
| 471 |
+
"\n",
|
| 472 |
+
"def upload_image(change):\n",
|
| 473 |
+
" global torch_input_image\n",
|
| 474 |
+
" for name, file_info in upload_input_image_button.value.items():\n",
|
| 475 |
+
" content = io.BytesIO(file_info['content'])\n",
|
| 476 |
+
" if content is not None:\n",
|
| 477 |
+
" pil_image = resize_PIL_image(extract_PIL_image_from_filelike(content), size=(512,512))\n",
|
| 478 |
+
" w, h = pil_image.size\n",
|
| 479 |
+
" if pil_image.mode != 'RGBA':\n",
|
| 480 |
+
" with output_image_widget:\n",
|
| 481 |
+
" torch_input_image = None\n",
|
| 482 |
+
" output_image_widget.clear_output(wait=True)\n",
|
| 483 |
+
" display(ipywidgets.HTML(\"Image must have an alpha channel!!!\"))\n",
|
| 484 |
+
" else:\n",
|
| 485 |
+
" torch_input_image = extract_pytorch_image_from_PIL_image(pil_image).to(device)\n",
|
| 486 |
+
" if poser.get_dtype() == torch.half:\n",
|
| 487 |
+
" torch_input_image = torch_input_image.half()\n",
|
| 488 |
+
" update(None)\n",
|
| 489 |
+
"\n",
|
| 490 |
+
"upload_input_image_button.observe(upload_image, names='value')\n",
|
| 491 |
+
"eyebrow_dropdown.observe(update, 'value')\n",
|
| 492 |
+
"eyebrow_left_slider.observe(update, 'value')\n",
|
| 493 |
+
"eyebrow_right_slider.observe(update, 'value')\n",
|
| 494 |
+
"eye_dropdown.observe(update, 'value')\n",
|
| 495 |
+
"eye_left_slider.observe(update, 'value')\n",
|
| 496 |
+
"eye_right_slider.observe(update, 'value')\n",
|
| 497 |
+
"mouth_dropdown.observe(update, 'value')\n",
|
| 498 |
+
"mouth_left_slider.observe(update, 'value')\n",
|
| 499 |
+
"mouth_right_slider.observe(update, 'value')\n",
|
| 500 |
+
"iris_small_left_slider.observe(update, 'value')\n",
|
| 501 |
+
"iris_small_right_slider.observe(update, 'value')\n",
|
| 502 |
+
"iris_rotation_x_slider.observe(update, 'value')\n",
|
| 503 |
+
"iris_rotation_y_slider.observe(update, 'value')\n",
|
| 504 |
+
"head_x_slider.observe(update, 'value')\n",
|
| 505 |
+
"head_y_slider.observe(update, 'value')\n",
|
| 506 |
+
"neck_z_slider.observe(update, 'value')\n",
|
| 507 |
+
"body_y_slider.observe(update, 'value')\n",
|
| 508 |
+
"body_z_slider.observe(update, 'value')\n",
|
| 509 |
+
"breathing_slider.observe(update, 'value')"
|
| 510 |
+
]
|
| 511 |
+
}
|
| 512 |
+
],
|
| 513 |
+
"metadata": {
|
| 514 |
+
"accelerator": "GPU",
|
| 515 |
+
"colab": {
|
| 516 |
+
"name": "tha3.ipynb",
|
| 517 |
+
"provenance": []
|
| 518 |
+
},
|
| 519 |
+
"interpreter": {
|
| 520 |
+
"hash": "684906ad716c90e6f3397644b72c2a23821e93080f6b0264e4cd74aee22032ce"
|
| 521 |
+
},
|
| 522 |
+
"kernelspec": {
|
| 523 |
+
"display_name": "Python 3 (ipykernel)",
|
| 524 |
+
"language": "python",
|
| 525 |
+
"name": "python3"
|
| 526 |
+
},
|
| 527 |
+
"language_info": {
|
| 528 |
+
"codemirror_mode": {
|
| 529 |
+
"name": "ipython",
|
| 530 |
+
"version": 3
|
| 531 |
+
},
|
| 532 |
+
"file_extension": ".py",
|
| 533 |
+
"mimetype": "text/x-python",
|
| 534 |
+
"name": "python",
|
| 535 |
+
"nbconvert_exporter": "python",
|
| 536 |
+
"pygments_lexer": "ipython3",
|
| 537 |
+
"version": "3.8.13"
|
| 538 |
+
}
|
| 539 |
+
},
|
| 540 |
+
"nbformat": 4,
|
| 541 |
+
"nbformat_minor": 5
|
| 542 |
+
}
|
docs/ifacialmocap_ip.jpg
ADDED
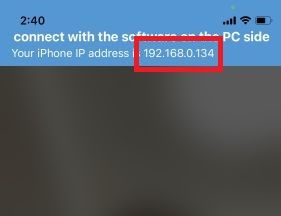
|
docs/ifacialmocap_puppeteer_click_start_capture.png
ADDED

|
docs/ifacialmocap_puppeteer_ip_address_box.png
ADDED

|
docs/ifacialmocap_puppeteer_numbers.png
ADDED

|
docs/input_spec.png
ADDED

|
docs/pytorch-install-command.png
ADDED
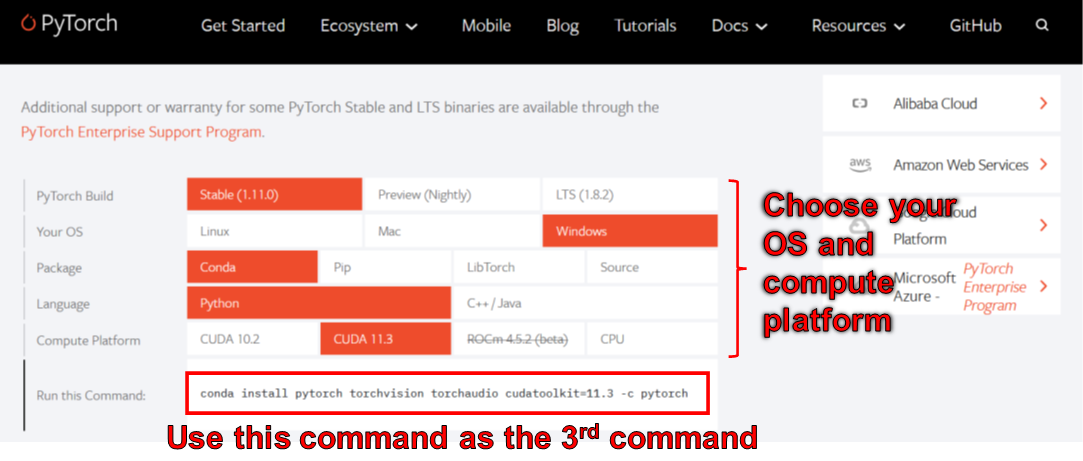
|
environment.yml
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: talking-head-anime-3-demo
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- conda-forge
|
| 5 |
+
- defaults
|
| 6 |
+
dependencies:
|
| 7 |
+
- argon2-cffi=21.3.0=pyhd8ed1ab_0
|
| 8 |
+
- argon2-cffi-bindings=21.2.0=py38h294d835_2
|
| 9 |
+
- asttokens=2.0.5=pyhd8ed1ab_0
|
| 10 |
+
- attrs=21.4.0=pyhd8ed1ab_0
|
| 11 |
+
- backcall=0.2.0=pyh9f0ad1d_0
|
| 12 |
+
- backports=1.0=py_2
|
| 13 |
+
- backports.functools_lru_cache=1.6.4=pyhd8ed1ab_0
|
| 14 |
+
- beautifulsoup4=4.11.1=pyha770c72_0
|
| 15 |
+
- blas=1.0=mkl
|
| 16 |
+
- bleach=5.0.0=pyhd8ed1ab_0
|
| 17 |
+
- brotli=1.0.9=ha925a31_2
|
| 18 |
+
- brotlipy=0.7.0=py38h2bbff1b_1003
|
| 19 |
+
- ca-certificates=2022.5.18.1=h5b45459_0
|
| 20 |
+
- certifi=2022.5.18.1=py38haa244fe_0
|
| 21 |
+
- cffi=1.15.0=py38h2bbff1b_1
|
| 22 |
+
- charset-normalizer=2.0.4=pyhd3eb1b0_0
|
| 23 |
+
- colorama=0.4.4=pyh9f0ad1d_0
|
| 24 |
+
- cryptography=37.0.1=py38h21b164f_0
|
| 25 |
+
- cudatoolkit=11.3.1=h59b6b97_2
|
| 26 |
+
- cycler=0.11.0=pyhd3eb1b0_0
|
| 27 |
+
- debugpy=1.6.0=py38h885f38d_0
|
| 28 |
+
- decorator=5.1.1=pyhd8ed1ab_0
|
| 29 |
+
- defusedxml=0.7.1=pyhd8ed1ab_0
|
| 30 |
+
- entrypoints=0.4=pyhd8ed1ab_0
|
| 31 |
+
- executing=0.8.3=pyhd8ed1ab_0
|
| 32 |
+
- flit-core=3.7.1=pyhd8ed1ab_0
|
| 33 |
+
- fonttools=4.25.0=pyhd3eb1b0_0
|
| 34 |
+
- freetype=2.10.4=hd328e21_0
|
| 35 |
+
- icc_rt=2019.0.0=h0cc432a_1
|
| 36 |
+
- icu=58.2=ha925a31_3
|
| 37 |
+
- idna=3.3=pyhd3eb1b0_0
|
| 38 |
+
- importlib-metadata=4.11.4=py38haa244fe_0
|
| 39 |
+
- importlib_resources=5.7.1=pyhd8ed1ab_1
|
| 40 |
+
- intel-openmp=2021.4.0=haa95532_3556
|
| 41 |
+
- ipykernel=6.13.1=py38h4317176_0
|
| 42 |
+
- ipython=8.4.0=py38haa244fe_0
|
| 43 |
+
- ipython_genutils=0.2.0=py_1
|
| 44 |
+
- ipywidgets=7.7.0=pyhd8ed1ab_0
|
| 45 |
+
- jedi=0.18.1=py38haa244fe_1
|
| 46 |
+
- jinja2=3.1.2=pyhd8ed1ab_1
|
| 47 |
+
- jpeg=9e=h2bbff1b_0
|
| 48 |
+
- jsonschema=4.6.0=pyhd8ed1ab_0
|
| 49 |
+
- jupyter_client=7.3.4=pyhd8ed1ab_0
|
| 50 |
+
- jupyter_core=4.10.0=py38haa244fe_0
|
| 51 |
+
- jupyterlab_pygments=0.2.2=pyhd8ed1ab_0
|
| 52 |
+
- jupyterlab_widgets=1.1.0=pyhd8ed1ab_0
|
| 53 |
+
- kiwisolver=1.4.2=py38hd77b12b_0
|
| 54 |
+
- libpng=1.6.37=h2a8f88b_0
|
| 55 |
+
- libsodium=1.0.18=h8d14728_1
|
| 56 |
+
- libtiff=4.2.0=he0120a3_1
|
| 57 |
+
- libuv=1.40.0=he774522_0
|
| 58 |
+
- libwebp=1.2.2=h2bbff1b_0
|
| 59 |
+
- lz4-c=1.9.3=h2bbff1b_1
|
| 60 |
+
- markupsafe=2.1.1=py38h294d835_1
|
| 61 |
+
- matplotlib=3.5.1=py38haa95532_1
|
| 62 |
+
- matplotlib-base=3.5.1=py38hd77b12b_1
|
| 63 |
+
- matplotlib-inline=0.1.3=pyhd8ed1ab_0
|
| 64 |
+
- mistune=0.8.4=py38h294d835_1005
|
| 65 |
+
- mkl=2021.4.0=haa95532_640
|
| 66 |
+
- mkl-service=2.4.0=py38h2bbff1b_0
|
| 67 |
+
- mkl_fft=1.3.1=py38h277e83a_0
|
| 68 |
+
- mkl_random=1.2.2=py38hf11a4ad_0
|
| 69 |
+
- munkres=1.1.4=py_0
|
| 70 |
+
- nbclient=0.6.4=pyhd8ed1ab_1
|
| 71 |
+
- nbconvert=6.5.0=pyhd8ed1ab_0
|
| 72 |
+
- nbconvert-core=6.5.0=pyhd8ed1ab_0
|
| 73 |
+
- nbconvert-pandoc=6.5.0=pyhd8ed1ab_0
|
| 74 |
+
- nbformat=5.4.0=pyhd8ed1ab_0
|
| 75 |
+
- nest-asyncio=1.5.5=pyhd8ed1ab_0
|
| 76 |
+
- notebook=6.4.12=pyha770c72_0
|
| 77 |
+
- numpy=1.22.3=py38h7a0a035_0
|
| 78 |
+
- numpy-base=1.22.3=py38hca35cd5_0
|
| 79 |
+
- openssl=1.1.1o=h8ffe710_0
|
| 80 |
+
- packaging=21.3=pyhd3eb1b0_0
|
| 81 |
+
- pandoc=2.18=h57928b3_0
|
| 82 |
+
- pandocfilters=1.5.0=pyhd8ed1ab_0
|
| 83 |
+
- parso=0.8.3=pyhd8ed1ab_0
|
| 84 |
+
- pickleshare=0.7.5=py_1003
|
| 85 |
+
- pillow=9.0.1=py38hdc2b20a_0
|
| 86 |
+
- pip=21.2.2=py38haa95532_0
|
| 87 |
+
- prometheus_client=0.14.1=pyhd8ed1ab_0
|
| 88 |
+
- prompt-toolkit=3.0.29=pyha770c72_0
|
| 89 |
+
- psutil=5.9.1=py38h294d835_0
|
| 90 |
+
- pure_eval=0.2.2=pyhd8ed1ab_0
|
| 91 |
+
- pycparser=2.21=pyhd3eb1b0_0
|
| 92 |
+
- pygments=2.12.0=pyhd8ed1ab_0
|
| 93 |
+
- pyopenssl=22.0.0=pyhd3eb1b0_0
|
| 94 |
+
- pyparsing=3.0.4=pyhd3eb1b0_0
|
| 95 |
+
- pyqt=5.9.2=py38hd77b12b_6
|
| 96 |
+
- pyrsistent=0.18.1=py38h294d835_1
|
| 97 |
+
- pysocks=1.7.1=py38haa95532_0
|
| 98 |
+
- python=3.8.13=h6244533_0
|
| 99 |
+
- python-dateutil=2.8.2=pyhd3eb1b0_0
|
| 100 |
+
- python-fastjsonschema=2.15.3=pyhd8ed1ab_0
|
| 101 |
+
- python_abi=3.8=2_cp38
|
| 102 |
+
- pytorch=1.11.0=py3.8_cuda11.3_cudnn8_0
|
| 103 |
+
- pytorch-mutex=1.0=cuda
|
| 104 |
+
- pywin32=303=py38h294d835_0
|
| 105 |
+
- pywinpty=2.0.2=py38h5da7b33_0
|
| 106 |
+
- pyzmq=23.1.0=py38h09162b1_0
|
| 107 |
+
- qt=5.9.7=vc14h73c81de_0
|
| 108 |
+
- requests=2.27.1=pyhd3eb1b0_0
|
| 109 |
+
- scipy=1.7.3=py38h0a974cb_0
|
| 110 |
+
- send2trash=1.8.0=pyhd8ed1ab_0
|
| 111 |
+
- setuptools=61.2.0=py38haa95532_0
|
| 112 |
+
- sip=4.19.13=py38hd77b12b_0
|
| 113 |
+
- six=1.16.0=pyhd3eb1b0_1
|
| 114 |
+
- soupsieve=2.3.1=pyhd8ed1ab_0
|
| 115 |
+
- sqlite=3.38.3=h2bbff1b_0
|
| 116 |
+
- stack_data=0.2.0=pyhd8ed1ab_0
|
| 117 |
+
- terminado=0.15.0=py38haa244fe_0
|
| 118 |
+
- tinycss2=1.1.1=pyhd8ed1ab_0
|
| 119 |
+
- tk=8.6.12=h2bbff1b_0
|
| 120 |
+
- torchaudio=0.11.0=py38_cu113
|
| 121 |
+
- torchvision=0.12.0=py38_cu113
|
| 122 |
+
- tornado=6.1=py38h2bbff1b_0
|
| 123 |
+
- traitlets=5.2.2.post1=pyhd8ed1ab_0
|
| 124 |
+
- typing_extensions=4.1.1=pyh06a4308_0
|
| 125 |
+
- urllib3=1.26.9=py38haa95532_0
|
| 126 |
+
- vc=14.2=h21ff451_1
|
| 127 |
+
- vs2015_runtime=14.27.29016=h5e58377_2
|
| 128 |
+
- wcwidth=0.2.5=pyh9f0ad1d_2
|
| 129 |
+
- webencodings=0.5.1=py_1
|
| 130 |
+
- wheel=0.37.1=pyhd3eb1b0_0
|
| 131 |
+
- widgetsnbextension=3.6.0=py38haa244fe_0
|
| 132 |
+
- win_inet_pton=1.1.0=py38haa95532_0
|
| 133 |
+
- wincertstore=0.2=py38haa95532_2
|
| 134 |
+
- winpty=0.4.3=4
|
| 135 |
+
- xz=5.2.5=h8cc25b3_1
|
| 136 |
+
- zeromq=4.3.4=h0e60522_1
|
| 137 |
+
- zipp=3.8.0=pyhd8ed1ab_0
|
| 138 |
+
- zlib=1.2.12=h8cc25b3_2
|
| 139 |
+
- zstd=1.5.2=h19a0ad4_0
|
| 140 |
+
- pip:
|
| 141 |
+
- wxpython==4.1.1
|
manual_poser.ipynb
ADDED
|
@@ -0,0 +1,460 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"id": "062014f7",
|
| 7 |
+
"metadata": {
|
| 8 |
+
"id": "breeding-extra"
|
| 9 |
+
},
|
| 10 |
+
"outputs": [],
|
| 11 |
+
"source": [
|
| 12 |
+
"import torch\n",
|
| 13 |
+
"MODEL_NAME = \"standard_float\"\n",
|
| 14 |
+
"DEVICE_NAME = 'cuda'\n",
|
| 15 |
+
"device = torch.device(DEVICE_NAME)\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"def load_poser(model: str, device: torch.device):\n",
|
| 18 |
+
" print(\"Using the %s model.\" % model)\n",
|
| 19 |
+
" if model == \"standard_float\":\n",
|
| 20 |
+
" from tha3.poser.modes.standard_float import create_poser\n",
|
| 21 |
+
" return create_poser(device)\n",
|
| 22 |
+
" elif model == \"standard_half\":\n",
|
| 23 |
+
" from tha3.poser.modes.standard_half import create_poser\n",
|
| 24 |
+
" return create_poser(device)\n",
|
| 25 |
+
" elif model == \"separable_float\":\n",
|
| 26 |
+
" from tha3.poser.modes.separable_float import create_poser\n",
|
| 27 |
+
" return create_poser(device)\n",
|
| 28 |
+
" elif model == \"separable_half\":\n",
|
| 29 |
+
" from tha3.poser.modes.separable_half import create_poser\n",
|
| 30 |
+
" return create_poser(device)\n",
|
| 31 |
+
" else:\n",
|
| 32 |
+
" raise RuntimeError(\"Invalid model: '%s'\" % model)\n",
|
| 33 |
+
" \n",
|
| 34 |
+
"poser = load_poser(MODEL_NAME, DEVICE_NAME)\n",
|
| 35 |
+
"poser.get_modules();"
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "code",
|
| 40 |
+
"execution_count": null,
|
| 41 |
+
"id": "breeding-extra",
|
| 42 |
+
"metadata": {
|
| 43 |
+
"id": "breeding-extra"
|
| 44 |
+
},
|
| 45 |
+
"outputs": [],
|
| 46 |
+
"source": [
|
| 47 |
+
"import PIL.Image\n",
|
| 48 |
+
"import io\n",
|
| 49 |
+
"from io import StringIO, BytesIO\n",
|
| 50 |
+
"import IPython.display\n",
|
| 51 |
+
"import numpy\n",
|
| 52 |
+
"import ipywidgets\n",
|
| 53 |
+
"import time\n",
|
| 54 |
+
"import threading\n",
|
| 55 |
+
"import torch\n",
|
| 56 |
+
"from tha3.util import resize_PIL_image, extract_PIL_image_from_filelike, \\\n",
|
| 57 |
+
" extract_pytorch_image_from_PIL_image, convert_output_image_from_torch_to_numpy\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"FRAME_RATE = 30.0\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"last_torch_input_image = None\n",
|
| 62 |
+
"torch_input_image = None\n",
|
| 63 |
+
"\n",
|
| 64 |
+
"def show_pytorch_image(pytorch_image):\n",
|
| 65 |
+
" output_image = pytorch_image.detach().cpu()\n",
|
| 66 |
+
" numpy_image = numpy.uint8(numpy.rint(convert_output_image_from_torch_to_numpy(output_image) * 255.0))\n",
|
| 67 |
+
" pil_image = PIL.Image.fromarray(numpy_image, mode='RGBA')\n",
|
| 68 |
+
" IPython.display.display(pil_image)\n",
|
| 69 |
+
"\n",
|
| 70 |
+
"upload_input_image_button = ipywidgets.FileUpload(\n",
|
| 71 |
+
" accept='.png',\n",
|
| 72 |
+
" multiple=False,\n",
|
| 73 |
+
" layout={\n",
|
| 74 |
+
" 'width': '512px'\n",
|
| 75 |
+
" }\n",
|
| 76 |
+
")\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"output_image_widget = ipywidgets.Output(\n",
|
| 79 |
+
" layout={\n",
|
| 80 |
+
" 'border': '1px solid black',\n",
|
| 81 |
+
" 'width': '512px',\n",
|
| 82 |
+
" 'height': '512px'\n",
|
| 83 |
+
" }\n",
|
| 84 |
+
")\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"eyebrow_dropdown = ipywidgets.Dropdown(\n",
|
| 87 |
+
" options=[\"troubled\", \"angry\", \"lowered\", \"raised\", \"happy\", \"serious\"],\n",
|
| 88 |
+
" value=\"troubled\",\n",
|
| 89 |
+
" description=\"Eyebrow:\", \n",
|
| 90 |
+
")\n",
|
| 91 |
+
"eyebrow_left_slider = ipywidgets.FloatSlider(\n",
|
| 92 |
+
" value=0.0,\n",
|
| 93 |
+
" min=0.0,\n",
|
| 94 |
+
" max=1.0,\n",
|
| 95 |
+
" step=0.01,\n",
|
| 96 |
+
" description=\"Left:\",\n",
|
| 97 |
+
" readout=True,\n",
|
| 98 |
+
" readout_format=\".2f\"\n",
|
| 99 |
+
")\n",
|
| 100 |
+
"eyebrow_right_slider = ipywidgets.FloatSlider(\n",
|
| 101 |
+
" value=0.0,\n",
|
| 102 |
+
" min=0.0,\n",
|
| 103 |
+
" max=1.0,\n",
|
| 104 |
+
" step=0.01,\n",
|
| 105 |
+
" description=\"Right:\",\n",
|
| 106 |
+
" readout=True,\n",
|
| 107 |
+
" readout_format=\".2f\"\n",
|
| 108 |
+
")\n",
|
| 109 |
+
"\n",
|
| 110 |
+
"eye_dropdown = ipywidgets.Dropdown(\n",
|
| 111 |
+
" options=[\"wink\", \"happy_wink\", \"surprised\", \"relaxed\", \"unimpressed\", \"raised_lower_eyelid\"],\n",
|
| 112 |
+
" value=\"wink\",\n",
|
| 113 |
+
" description=\"Eye:\", \n",
|
| 114 |
+
")\n",
|
| 115 |
+
"eye_left_slider = ipywidgets.FloatSlider(\n",
|
| 116 |
+
" value=0.0,\n",
|
| 117 |
+
" min=0.0,\n",
|
| 118 |
+
" max=1.0,\n",
|
| 119 |
+
" step=0.01,\n",
|
| 120 |
+
" description=\"Left:\",\n",
|
| 121 |
+
" readout=True,\n",
|
| 122 |
+
" readout_format=\".2f\"\n",
|
| 123 |
+
")\n",
|
| 124 |
+
"eye_right_slider = ipywidgets.FloatSlider(\n",
|
| 125 |
+
" value=0.0,\n",
|
| 126 |
+
" min=0.0,\n",
|
| 127 |
+
" max=1.0,\n",
|
| 128 |
+
" step=0.01,\n",
|
| 129 |
+
" description=\"Right:\",\n",
|
| 130 |
+
" readout=True,\n",
|
| 131 |
+
" readout_format=\".2f\"\n",
|
| 132 |
+
")\n",
|
| 133 |
+
"\n",
|
| 134 |
+
"mouth_dropdown = ipywidgets.Dropdown(\n",
|
| 135 |
+
" options=[\"aaa\", \"iii\", \"uuu\", \"eee\", \"ooo\", \"delta\", \"lowered_corner\", \"raised_corner\", \"smirk\"],\n",
|
| 136 |
+
" value=\"aaa\",\n",
|
| 137 |
+
" description=\"Mouth:\", \n",
|
| 138 |
+
")\n",
|
| 139 |
+
"mouth_left_slider = ipywidgets.FloatSlider(\n",
|
| 140 |
+
" value=0.0,\n",
|
| 141 |
+
" min=0.0,\n",
|
| 142 |
+
" max=1.0,\n",
|
| 143 |
+
" step=0.01,\n",
|
| 144 |
+
" description=\"Value:\",\n",
|
| 145 |
+
" readout=True,\n",
|
| 146 |
+
" readout_format=\".2f\"\n",
|
| 147 |
+
")\n",
|
| 148 |
+
"mouth_right_slider = ipywidgets.FloatSlider(\n",
|
| 149 |
+
" value=0.0,\n",
|
| 150 |
+
" min=0.0,\n",
|
| 151 |
+
" max=1.0,\n",
|
| 152 |
+
" step=0.01,\n",
|
| 153 |
+
" description=\" \",\n",
|
| 154 |
+
" readout=True,\n",
|
| 155 |
+
" readout_format=\".2f\",\n",
|
| 156 |
+
" disabled=True,\n",
|
| 157 |
+
")\n",
|
| 158 |
+
"\n",
|
| 159 |
+
"def update_mouth_sliders(change):\n",
|
| 160 |
+
" if mouth_dropdown.value == \"lowered_corner\" or mouth_dropdown.value == \"raised_corner\":\n",
|
| 161 |
+
" mouth_left_slider.description = \"Left:\"\n",
|
| 162 |
+
" mouth_right_slider.description = \"Right:\"\n",
|
| 163 |
+
" mouth_right_slider.disabled = False\n",
|
| 164 |
+
" else:\n",
|
| 165 |
+
" mouth_left_slider.description = \"Value:\"\n",
|
| 166 |
+
" mouth_right_slider.description = \" \"\n",
|
| 167 |
+
" mouth_right_slider.disabled = True\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"mouth_dropdown.observe(update_mouth_sliders, names='value')\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"iris_small_left_slider = ipywidgets.FloatSlider(\n",
|
| 172 |
+
" value=0.0,\n",
|
| 173 |
+
" min=0.0,\n",
|
| 174 |
+
" max=1.0,\n",
|
| 175 |
+
" step=0.01,\n",
|
| 176 |
+
" description=\"Left:\",\n",
|
| 177 |
+
" readout=True,\n",
|
| 178 |
+
" readout_format=\".2f\"\n",
|
| 179 |
+
")\n",
|
| 180 |
+
"iris_small_right_slider = ipywidgets.FloatSlider(\n",
|
| 181 |
+
" value=0.0,\n",
|
| 182 |
+
" min=0.0,\n",
|
| 183 |
+
" max=1.0,\n",
|
| 184 |
+
" step=0.01,\n",
|
| 185 |
+
" description=\"Right:\",\n",
|
| 186 |
+
" readout=True,\n",
|
| 187 |
+
" readout_format=\".2f\", \n",
|
| 188 |
+
")\n",
|
| 189 |
+
"iris_rotation_x_slider = ipywidgets.FloatSlider(\n",
|
| 190 |
+
" value=0.0,\n",
|
| 191 |
+
" min=-1.0,\n",
|
| 192 |
+
" max=1.0,\n",
|
| 193 |
+
" step=0.01,\n",
|
| 194 |
+
" description=\"X-axis:\",\n",
|
| 195 |
+
" readout=True,\n",
|
| 196 |
+
" readout_format=\".2f\"\n",
|
| 197 |
+
")\n",
|
| 198 |
+
"iris_rotation_y_slider = ipywidgets.FloatSlider(\n",
|
| 199 |
+
" value=0.0,\n",
|
| 200 |
+
" min=-1.0,\n",
|
| 201 |
+
" max=1.0,\n",
|
| 202 |
+
" step=0.01,\n",
|
| 203 |
+
" description=\"Y-axis:\",\n",
|
| 204 |
+
" readout=True,\n",
|
| 205 |
+
" readout_format=\".2f\", \n",
|
| 206 |
+
")\n",
|
| 207 |
+
"\n",
|
| 208 |
+
"head_x_slider = ipywidgets.FloatSlider(\n",
|
| 209 |
+
" value=0.0,\n",
|
| 210 |
+
" min=-1.0,\n",
|
| 211 |
+
" max=1.0,\n",
|
| 212 |
+
" step=0.01,\n",
|
| 213 |
+
" description=\"X-axis:\",\n",
|
| 214 |
+
" readout=True,\n",
|
| 215 |
+
" readout_format=\".2f\"\n",
|
| 216 |
+
")\n",
|
| 217 |
+
"head_y_slider = ipywidgets.FloatSlider(\n",
|
| 218 |
+
" value=0.0,\n",
|
| 219 |
+
" min=-1.0,\n",
|
| 220 |
+
" max=1.0,\n",
|
| 221 |
+
" step=0.01,\n",
|
| 222 |
+
" description=\"Y-axis:\",\n",
|
| 223 |
+
" readout=True,\n",
|
| 224 |
+
" readout_format=\".2f\", \n",
|
| 225 |
+
")\n",
|
| 226 |
+
"neck_z_slider = ipywidgets.FloatSlider(\n",
|
| 227 |
+
" value=0.0,\n",
|
| 228 |
+
" min=-1.0,\n",
|
| 229 |
+
" max=1.0,\n",
|
| 230 |
+
" step=0.01,\n",
|
| 231 |
+
" description=\"Z-axis:\",\n",
|
| 232 |
+
" readout=True,\n",
|
| 233 |
+
" readout_format=\".2f\", \n",
|
| 234 |
+
")\n",
|
| 235 |
+
"body_y_slider = ipywidgets.FloatSlider(\n",
|
| 236 |
+
" value=0.0,\n",
|
| 237 |
+
" min=-1.0,\n",
|
| 238 |
+
" max=1.0,\n",
|
| 239 |
+
" step=0.01,\n",
|
| 240 |
+
" description=\"Y-axis rotation:\",\n",
|
| 241 |
+
" readout=True,\n",
|
| 242 |
+
" readout_format=\".2f\", \n",
|
| 243 |
+
")\n",
|
| 244 |
+
"body_z_slider = ipywidgets.FloatSlider(\n",
|
| 245 |
+
" value=0.0,\n",
|
| 246 |
+
" min=-1.0,\n",
|
| 247 |
+
" max=1.0,\n",
|
| 248 |
+
" step=0.01,\n",
|
| 249 |
+
" description=\"Z-axis rotation:\",\n",
|
| 250 |
+
" readout=True,\n",
|
| 251 |
+
" readout_format=\".2f\", \n",
|
| 252 |
+
")\n",
|
| 253 |
+
"breathing_slider = ipywidgets.FloatSlider(\n",
|
| 254 |
+
" value=0.0,\n",
|
| 255 |
+
" min=0.0,\n",
|
| 256 |
+
" max=1.0,\n",
|
| 257 |
+
" step=0.01,\n",
|
| 258 |
+
" description=\"Breathing:\",\n",
|
| 259 |
+
" readout=True,\n",
|
| 260 |
+
" readout_format=\".2f\", \n",
|
| 261 |
+
")\n",
|
| 262 |
+
"\n",
|
| 263 |
+
"\n",
|
| 264 |
+
"control_panel = ipywidgets.VBox([\n",
|
| 265 |
+
" eyebrow_dropdown,\n",
|
| 266 |
+
" eyebrow_left_slider,\n",
|
| 267 |
+
" eyebrow_right_slider,\n",
|
| 268 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 269 |
+
" eye_dropdown,\n",
|
| 270 |
+
" eye_left_slider,\n",
|
| 271 |
+
" eye_right_slider,\n",
|
| 272 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 273 |
+
" mouth_dropdown,\n",
|
| 274 |
+
" mouth_left_slider,\n",
|
| 275 |
+
" mouth_right_slider,\n",
|
| 276 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 277 |
+
" ipywidgets.HTML(value=\"<center><b>Iris Shrinkage</b></center>\"),\n",
|
| 278 |
+
" iris_small_left_slider,\n",
|
| 279 |
+
" iris_small_right_slider,\n",
|
| 280 |
+
" ipywidgets.HTML(value=\"<center><b>Iris Rotation</b></center>\"),\n",
|
| 281 |
+
" iris_rotation_x_slider,\n",
|
| 282 |
+
" iris_rotation_y_slider,\n",
|
| 283 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 284 |
+
" ipywidgets.HTML(value=\"<center><b>Head Rotation</b></center>\"),\n",
|
| 285 |
+
" head_x_slider,\n",
|
| 286 |
+
" head_y_slider,\n",
|
| 287 |
+
" neck_z_slider,\n",
|
| 288 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 289 |
+
" ipywidgets.HTML(value=\"<center><b>Body Rotation</b></center>\"),\n",
|
| 290 |
+
" body_y_slider,\n",
|
| 291 |
+
" body_z_slider,\n",
|
| 292 |
+
" ipywidgets.HTML(value=\"<hr>\"),\n",
|
| 293 |
+
" ipywidgets.HTML(value=\"<center><b>Breathing</b></center>\"),\n",
|
| 294 |
+
" breathing_slider,\n",
|
| 295 |
+
"])\n",
|
| 296 |
+
"\n",
|
| 297 |
+
"controls = ipywidgets.HBox([\n",
|
| 298 |
+
" ipywidgets.VBox([\n",
|
| 299 |
+
" output_image_widget, \n",
|
| 300 |
+
" upload_input_image_button\n",
|
| 301 |
+
" ]),\n",
|
| 302 |
+
" control_panel,\n",
|
| 303 |
+
"])\n",
|
| 304 |
+
"\n",
|
| 305 |
+
"from tha3.poser.modes.pose_parameters import get_pose_parameters\n",
|
| 306 |
+
"pose_parameters = get_pose_parameters()\n",
|
| 307 |
+
"pose_size = poser.get_num_parameters()\n",
|
| 308 |
+
"last_pose = torch.zeros(1, pose_size, dtype=poser.get_dtype()).to(device)\n",
|
| 309 |
+
"\n",
|
| 310 |
+
"iris_small_left_index = pose_parameters.get_parameter_index(\"iris_small_left\")\n",
|
| 311 |
+
"iris_small_right_index = pose_parameters.get_parameter_index(\"iris_small_right\")\n",
|
| 312 |
+
"iris_rotation_x_index = pose_parameters.get_parameter_index(\"iris_rotation_x\")\n",
|
| 313 |
+
"iris_rotation_y_index = pose_parameters.get_parameter_index(\"iris_rotation_y\")\n",
|
| 314 |
+
"head_x_index = pose_parameters.get_parameter_index(\"head_x\")\n",
|
| 315 |
+
"head_y_index = pose_parameters.get_parameter_index(\"head_y\")\n",
|
| 316 |
+
"neck_z_index = pose_parameters.get_parameter_index(\"neck_z\")\n",
|
| 317 |
+
"body_y_index = pose_parameters.get_parameter_index(\"body_y\")\n",
|
| 318 |
+
"body_z_index = pose_parameters.get_parameter_index(\"body_z\")\n",
|
| 319 |
+
"breathing_index = pose_parameters.get_parameter_index(\"breathing\")\n",
|
| 320 |
+
"\n",
|
| 321 |
+
"def get_pose():\n",
|
| 322 |
+
" pose = torch.zeros(1, pose_size, dtype=poser.get_dtype())\n",
|
| 323 |
+
"\n",
|
| 324 |
+
" eyebrow_name = f\"eyebrow_{eyebrow_dropdown.value}\"\n",
|
| 325 |
+
" eyebrow_left_index = pose_parameters.get_parameter_index(f\"{eyebrow_name}_left\")\n",
|
| 326 |
+
" eyebrow_right_index = pose_parameters.get_parameter_index(f\"{eyebrow_name}_right\")\n",
|
| 327 |
+
" pose[0, eyebrow_left_index] = eyebrow_left_slider.value\n",
|
| 328 |
+
" pose[0, eyebrow_right_index] = eyebrow_right_slider.value\n",
|
| 329 |
+
"\n",
|
| 330 |
+
" eye_name = f\"eye_{eye_dropdown.value}\"\n",
|
| 331 |
+
" eye_left_index = pose_parameters.get_parameter_index(f\"{eye_name}_left\")\n",
|
| 332 |
+
" eye_right_index = pose_parameters.get_parameter_index(f\"{eye_name}_right\")\n",
|
| 333 |
+
" pose[0, eye_left_index] = eye_left_slider.value\n",
|
| 334 |
+
" pose[0, eye_right_index] = eye_right_slider.value\n",
|
| 335 |
+
"\n",
|
| 336 |
+
" mouth_name = f\"mouth_{mouth_dropdown.value}\"\n",
|
| 337 |
+
" if mouth_name == \"mouth_lowered_corner\" or mouth_name == \"mouth_raised_corner\":\n",
|
| 338 |
+
" mouth_left_index = pose_parameters.get_parameter_index(f\"{mouth_name}_left\")\n",
|
| 339 |
+
" mouth_right_index = pose_parameters.get_parameter_index(f\"{mouth_name}_right\")\n",
|
| 340 |
+
" pose[0, mouth_left_index] = mouth_left_slider.value\n",
|
| 341 |
+
" pose[0, mouth_right_index] = mouth_right_slider.value\n",
|
| 342 |
+
" else:\n",
|
| 343 |
+
" mouth_index = pose_parameters.get_parameter_index(mouth_name)\n",
|
| 344 |
+
" pose[0, mouth_index] = mouth_left_slider.value\n",
|
| 345 |
+
"\n",
|
| 346 |
+
" pose[0, iris_small_left_index] = iris_small_left_slider.value\n",
|
| 347 |
+
" pose[0, iris_small_right_index] = iris_small_right_slider.value\n",
|
| 348 |
+
" pose[0, iris_rotation_x_index] = iris_rotation_x_slider.value\n",
|
| 349 |
+
" pose[0, iris_rotation_y_index] = iris_rotation_y_slider.value\n",
|
| 350 |
+
" pose[0, head_x_index] = head_x_slider.value\n",
|
| 351 |
+
" pose[0, head_y_index] = head_y_slider.value\n",
|
| 352 |
+
" pose[0, neck_z_index] = neck_z_slider.value\n",
|
| 353 |
+
" pose[0, body_y_index] = body_y_slider.value\n",
|
| 354 |
+
" pose[0, body_z_index] = body_z_slider.value\n",
|
| 355 |
+
" pose[0, breathing_index] = breathing_slider.value\n",
|
| 356 |
+
"\n",
|
| 357 |
+
" return pose.to(device)\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"display(controls)\n",
|
| 360 |
+
"\n",
|
| 361 |
+
"def update(change):\n",
|
| 362 |
+
" global last_pose\n",
|
| 363 |
+
" global last_torch_input_image\n",
|
| 364 |
+
"\n",
|
| 365 |
+
" if torch_input_image is None:\n",
|
| 366 |
+
" return\n",
|
| 367 |
+
"\n",
|
| 368 |
+
" needs_update = False\n",
|
| 369 |
+
" if last_torch_input_image is None:\n",
|
| 370 |
+
" needs_update = True \n",
|
| 371 |
+
" else:\n",
|
| 372 |
+
" if (torch_input_image - last_torch_input_image).abs().max().item() > 0:\n",
|
| 373 |
+
" needs_update = True \n",
|
| 374 |
+
"\n",
|
| 375 |
+
" pose = get_pose()\n",
|
| 376 |
+
" if (pose - last_pose).abs().max().item() > 0:\n",
|
| 377 |
+
" needs_update = True\n",
|
| 378 |
+
"\n",
|
| 379 |
+
" if not needs_update:\n",
|
| 380 |
+
" return\n",
|
| 381 |
+
"\n",
|
| 382 |
+
" output_image = poser.pose(torch_input_image, pose)[0]\n",
|
| 383 |
+
" with output_image_widget:\n",
|
| 384 |
+
" output_image_widget.clear_output(wait=True)\n",
|
| 385 |
+
" show_pytorch_image(output_image) \n",
|
| 386 |
+
"\n",
|
| 387 |
+
" last_torch_input_image = torch_input_image\n",
|
| 388 |
+
" last_pose = pose\n",
|
| 389 |
+
"\n",
|
| 390 |
+
"def upload_image(change):\n",
|
| 391 |
+
" global torch_input_image\n",
|
| 392 |
+
" for name, file_info in upload_input_image_button.value.items():\n",
|
| 393 |
+
" content = io.BytesIO(file_info['content'])\n",
|
| 394 |
+
" if content is not None:\n",
|
| 395 |
+
" pil_image = resize_PIL_image(extract_PIL_image_from_filelike(content), size=(512,512))\n",
|
| 396 |
+
" w, h = pil_image.size\n",
|
| 397 |
+
" if pil_image.mode != 'RGBA':\n",
|
| 398 |
+
" with output_image_widget:\n",
|
| 399 |
+
" torch_input_image = None\n",
|
| 400 |
+
" output_image_widget.clear_output(wait=True)\n",
|
| 401 |
+
" display(ipywidgets.HTML(\"Image must have an alpha channel!!!\"))\n",
|
| 402 |
+
" else:\n",
|
| 403 |
+
" torch_input_image = extract_pytorch_image_from_PIL_image(pil_image).to(device)\n",
|
| 404 |
+
" if poser.get_dtype() == torch.half:\n",
|
| 405 |
+
" torch_input_image = torch_input_image.half()\n",
|
| 406 |
+
" update(None)\n",
|
| 407 |
+
"\n",
|
| 408 |
+
"upload_input_image_button.observe(upload_image, names='value')\n",
|
| 409 |
+
"eyebrow_dropdown.observe(update, 'value')\n",
|
| 410 |
+
"eyebrow_left_slider.observe(update, 'value')\n",
|
| 411 |
+
"eyebrow_right_slider.observe(update, 'value')\n",
|
| 412 |
+
"eye_dropdown.observe(update, 'value')\n",
|
| 413 |
+
"eye_left_slider.observe(update, 'value')\n",
|
| 414 |
+
"eye_right_slider.observe(update, 'value')\n",
|
| 415 |
+
"mouth_dropdown.observe(update, 'value')\n",
|
| 416 |
+
"mouth_left_slider.observe(update, 'value')\n",
|
| 417 |
+
"mouth_right_slider.observe(update, 'value')\n",
|
| 418 |
+
"iris_small_left_slider.observe(update, 'value')\n",
|
| 419 |
+
"iris_small_right_slider.observe(update, 'value')\n",
|
| 420 |
+
"iris_rotation_x_slider.observe(update, 'value')\n",
|
| 421 |
+
"iris_rotation_y_slider.observe(update, 'value')\n",
|
| 422 |
+
"head_x_slider.observe(update, 'value')\n",
|
| 423 |
+
"head_y_slider.observe(update, 'value')\n",
|
| 424 |
+
"neck_z_slider.observe(update, 'value')\n",
|
| 425 |
+
"body_y_slider.observe(update, 'value')\n",
|
| 426 |
+
"body_z_slider.observe(update, 'value')\n",
|
| 427 |
+
"breathing_slider.observe(update, 'value')"
|
| 428 |
+
]
|
| 429 |
+
}
|
| 430 |
+
],
|
| 431 |
+
"metadata": {
|
| 432 |
+
"accelerator": "GPU",
|
| 433 |
+
"colab": {
|
| 434 |
+
"name": "tha3.ipynb",
|
| 435 |
+
"provenance": []
|
| 436 |
+
},
|
| 437 |
+
"interpreter": {
|
| 438 |
+
"hash": "684906ad716c90e6f3397644b72c2a23821e93080f6b0264e4cd74aee22032ce"
|
| 439 |
+
},
|
| 440 |
+
"kernelspec": {
|
| 441 |
+
"display_name": "Python 3 (ipykernel)",
|
| 442 |
+
"language": "python",
|
| 443 |
+
"name": "python3"
|
| 444 |
+
},
|
| 445 |
+
"language_info": {
|
| 446 |
+
"codemirror_mode": {
|
| 447 |
+
"name": "ipython",
|
| 448 |
+
"version": 3
|
| 449 |
+
},
|
| 450 |
+
"file_extension": ".py",
|
| 451 |
+
"mimetype": "text/x-python",
|
| 452 |
+
"name": "python",
|
| 453 |
+
"nbconvert_exporter": "python",
|
| 454 |
+
"pygments_lexer": "ipython3",
|
| 455 |
+
"version": "3.8.13"
|
| 456 |
+
}
|
| 457 |
+
},
|
| 458 |
+
"nbformat": 4,
|
| 459 |
+
"nbformat_minor": 5
|
| 460 |
+
}
|
tha3/__init__.py
ADDED
|
File without changes
|
tha3/app/__init__.py
ADDED
|
File without changes
|
tha3/app/ifacialmocap_puppeteer.py
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import socket
|
| 4 |
+
import sys
|
| 5 |
+
import threading
|
| 6 |
+
import time
|
| 7 |
+
from typing import Optional
|
| 8 |
+
|
| 9 |
+
sys.path.append(os.getcwd())
|
| 10 |
+
|
| 11 |
+
from tha3.mocap.ifacialmocap_pose import create_default_ifacialmocap_pose
|
| 12 |
+
from tha3.mocap.ifacialmocap_v2 import IFACIALMOCAP_PORT, IFACIALMOCAP_START_STRING, parse_ifacialmocap_v2_pose, \
|
| 13 |
+
parse_ifacialmocap_v1_pose
|
| 14 |
+
from tha3.poser.modes.load_poser import load_poser
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import wx
|
| 18 |
+
|
| 19 |
+
from tha3.poser.poser import Poser
|
| 20 |
+
from tha3.mocap.ifacialmocap_constants import *
|
| 21 |
+
from tha3.mocap.ifacialmocap_pose_converter import IFacialMocapPoseConverter
|
| 22 |
+
from tha3.util import torch_linear_to_srgb, resize_PIL_image, extract_PIL_image_from_filelike, \
|
| 23 |
+
extract_pytorch_image_from_PIL_image
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def convert_linear_to_srgb(image: torch.Tensor) -> torch.Tensor:
|
| 27 |
+
rgb_image = torch_linear_to_srgb(image[0:3, :, :])
|
| 28 |
+
return torch.cat([rgb_image, image[3:4, :, :]], dim=0)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class FpsStatistics:
|
| 32 |
+
def __init__(self):
|
| 33 |
+
self.count = 100
|
| 34 |
+
self.fps = []
|
| 35 |
+
|
| 36 |
+
def add_fps(self, fps):
|
| 37 |
+
self.fps.append(fps)
|
| 38 |
+
while len(self.fps) > self.count:
|
| 39 |
+
del self.fps[0]
|
| 40 |
+
|
| 41 |
+
def get_average_fps(self):
|
| 42 |
+
if len(self.fps) == 0:
|
| 43 |
+
return 0.0
|
| 44 |
+
else:
|
| 45 |
+
return sum(self.fps) / len(self.fps)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class MainFrame(wx.Frame):
|
| 49 |
+
def __init__(self, poser: Poser, pose_converter: IFacialMocapPoseConverter, device: torch.device):
|
| 50 |
+
super().__init__(None, wx.ID_ANY, "iFacialMocap Puppeteer (Marigold)")
|
| 51 |
+
self.pose_converter = pose_converter
|
| 52 |
+
self.poser = poser
|
| 53 |
+
self.device = device
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
self.ifacialmocap_pose = create_default_ifacialmocap_pose()
|
| 57 |
+
self.source_image_bitmap = wx.Bitmap(self.poser.get_image_size(), self.poser.get_image_size())
|
| 58 |
+
self.result_image_bitmap = wx.Bitmap(self.poser.get_image_size(), self.poser.get_image_size())
|
| 59 |
+
self.wx_source_image = None
|
| 60 |
+
self.torch_source_image = None
|
| 61 |
+
self.last_pose = None
|
| 62 |
+
self.fps_statistics = FpsStatistics()
|
| 63 |
+
self.last_update_time = None
|
| 64 |
+
|
| 65 |
+
self.create_receiving_socket()
|
| 66 |
+
self.create_ui()
|
| 67 |
+
self.create_timers()
|
| 68 |
+
self.Bind(wx.EVT_CLOSE, self.on_close)
|
| 69 |
+
|
| 70 |
+
self.update_source_image_bitmap()
|
| 71 |
+
self.update_result_image_bitmap()
|
| 72 |
+
|
| 73 |
+
def create_receiving_socket(self):
|
| 74 |
+
self.receiving_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
|
| 75 |
+
self.receiving_socket.bind(("", IFACIALMOCAP_PORT))
|
| 76 |
+
self.receiving_socket.setblocking(False)
|
| 77 |
+
|
| 78 |
+
def create_timers(self):
|
| 79 |
+
self.capture_timer = wx.Timer(self, wx.ID_ANY)
|
| 80 |
+
self.Bind(wx.EVT_TIMER, self.update_capture_panel, id=self.capture_timer.GetId())
|
| 81 |
+
self.animation_timer = wx.Timer(self, wx.ID_ANY)
|
| 82 |
+
self.Bind(wx.EVT_TIMER, self.update_result_image_bitmap, id=self.animation_timer.GetId())
|
| 83 |
+
|
| 84 |
+
def on_close(self, event: wx.Event):
|
| 85 |
+
# Stop the timers
|
| 86 |
+
self.animation_timer.Stop()
|
| 87 |
+
self.capture_timer.Stop()
|
| 88 |
+
|
| 89 |
+
# Close receiving socket
|
| 90 |
+
self.receiving_socket.close()
|
| 91 |
+
|
| 92 |
+
# Destroy the windows
|
| 93 |
+
self.Destroy()
|
| 94 |
+
event.Skip()
|
| 95 |
+
|
| 96 |
+
def on_start_capture(self, event: wx.Event):
|
| 97 |
+
capture_device_ip_address = self.capture_device_ip_text_ctrl.GetValue()
|
| 98 |
+
out_socket = None
|
| 99 |
+
try:
|
| 100 |
+
address = (capture_device_ip_address, IFACIALMOCAP_PORT)
|
| 101 |
+
out_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
|
| 102 |
+
out_socket.sendto(IFACIALMOCAP_START_STRING, address)
|
| 103 |
+
except Exception as e:
|
| 104 |
+
message_dialog = wx.MessageDialog(self, str(e), "Error!", wx.OK)
|
| 105 |
+
message_dialog.ShowModal()
|
| 106 |
+
message_dialog.Destroy()
|
| 107 |
+
finally:
|
| 108 |
+
if out_socket is not None:
|
| 109 |
+
out_socket.close()
|
| 110 |
+
|
| 111 |
+
def read_ifacialmocap_pose(self):
|
| 112 |
+
if not self.animation_timer.IsRunning():
|
| 113 |
+
return self.ifacialmocap_pose
|
| 114 |
+
socket_bytes = None
|
| 115 |
+
while True:
|
| 116 |
+
try:
|
| 117 |
+
socket_bytes = self.receiving_socket.recv(8192)
|
| 118 |
+
except socket.error as e:
|
| 119 |
+
break
|
| 120 |
+
if socket_bytes is not None:
|
| 121 |
+
socket_string = socket_bytes.decode("utf-8")
|
| 122 |
+
self.ifacialmocap_pose = parse_ifacialmocap_v2_pose(socket_string)
|
| 123 |
+
return self.ifacialmocap_pose
|
| 124 |
+
|
| 125 |
+
def on_erase_background(self, event: wx.Event):
|
| 126 |
+
pass
|
| 127 |
+
|
| 128 |
+
def create_animation_panel(self, parent):
|
| 129 |
+
self.animation_panel = wx.Panel(parent, style=wx.RAISED_BORDER)
|
| 130 |
+
self.animation_panel_sizer = wx.BoxSizer(wx.HORIZONTAL)
|
| 131 |
+
self.animation_panel.SetSizer(self.animation_panel_sizer)
|
| 132 |
+
self.animation_panel.SetAutoLayout(1)
|
| 133 |
+
|
| 134 |
+
image_size = self.poser.get_image_size()
|
| 135 |
+
|
| 136 |
+
if True:
|
| 137 |
+
self.input_panel = wx.Panel(self.animation_panel, size=(image_size, image_size + 128),
|
| 138 |
+
style=wx.SIMPLE_BORDER)
|
| 139 |
+
self.input_panel_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 140 |
+
self.input_panel.SetSizer(self.input_panel_sizer)
|
| 141 |
+
self.input_panel.SetAutoLayout(1)
|
| 142 |
+
self.animation_panel_sizer.Add(self.input_panel, 0, wx.FIXED_MINSIZE)
|
| 143 |
+
|
| 144 |
+
self.source_image_panel = wx.Panel(self.input_panel, size=(image_size, image_size), style=wx.SIMPLE_BORDER)
|
| 145 |
+
self.source_image_panel.Bind(wx.EVT_PAINT, self.paint_source_image_panel)
|
| 146 |
+
self.source_image_panel.Bind(wx.EVT_ERASE_BACKGROUND, self.on_erase_background)
|
| 147 |
+
self.input_panel_sizer.Add(self.source_image_panel, 0, wx.FIXED_MINSIZE)
|
| 148 |
+
|
| 149 |
+
self.load_image_button = wx.Button(self.input_panel, wx.ID_ANY, "Load Image")
|
| 150 |
+
self.input_panel_sizer.Add(self.load_image_button, 1, wx.EXPAND)
|
| 151 |
+
self.load_image_button.Bind(wx.EVT_BUTTON, self.load_image)
|
| 152 |
+
|
| 153 |
+
self.input_panel_sizer.Fit(self.input_panel)
|
| 154 |
+
|
| 155 |
+
if True:
|
| 156 |
+
self.pose_converter.init_pose_converter_panel(self.animation_panel)
|
| 157 |
+
|
| 158 |
+
if True:
|
| 159 |
+
self.animation_left_panel = wx.Panel(self.animation_panel, style=wx.SIMPLE_BORDER)
|
| 160 |
+
self.animation_left_panel_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 161 |
+
self.animation_left_panel.SetSizer(self.animation_left_panel_sizer)
|
| 162 |
+
self.animation_left_panel.SetAutoLayout(1)
|
| 163 |
+
self.animation_panel_sizer.Add(self.animation_left_panel, 0, wx.EXPAND)
|
| 164 |
+
|
| 165 |
+
self.result_image_panel = wx.Panel(self.animation_left_panel, size=(image_size, image_size),
|
| 166 |
+
style=wx.SIMPLE_BORDER)
|
| 167 |
+
self.result_image_panel.Bind(wx.EVT_PAINT, self.paint_result_image_panel)
|
| 168 |
+
self.result_image_panel.Bind(wx.EVT_ERASE_BACKGROUND, self.on_erase_background)
|
| 169 |
+
self.animation_left_panel_sizer.Add(self.result_image_panel, 0, wx.FIXED_MINSIZE)
|
| 170 |
+
|
| 171 |
+
separator = wx.StaticLine(self.animation_left_panel, -1, size=(256, 5))
|
| 172 |
+
self.animation_left_panel_sizer.Add(separator, 0, wx.EXPAND)
|
| 173 |
+
|
| 174 |
+
background_text = wx.StaticText(self.animation_left_panel, label="--- Background ---",
|
| 175 |
+
style=wx.ALIGN_CENTER)
|
| 176 |
+
self.animation_left_panel_sizer.Add(background_text, 0, wx.EXPAND)
|
| 177 |
+
|
| 178 |
+
self.output_background_choice = wx.Choice(
|
| 179 |
+
self.animation_left_panel,
|
| 180 |
+
choices=[
|
| 181 |
+
"TRANSPARENT",
|
| 182 |
+
"GREEN",
|
| 183 |
+
"BLUE",
|
| 184 |
+
"BLACK",
|
| 185 |
+
"WHITE"
|
| 186 |
+
])
|
| 187 |
+
self.output_background_choice.SetSelection(0)
|
| 188 |
+
self.animation_left_panel_sizer.Add(self.output_background_choice, 0, wx.EXPAND)
|
| 189 |
+
|
| 190 |
+
separator = wx.StaticLine(self.animation_left_panel, -1, size=(256, 5))
|
| 191 |
+
self.animation_left_panel_sizer.Add(separator, 0, wx.EXPAND)
|
| 192 |
+
|
| 193 |
+
self.fps_text = wx.StaticText(self.animation_left_panel, label="")
|
| 194 |
+
self.animation_left_panel_sizer.Add(self.fps_text, wx.SizerFlags().Border())
|
| 195 |
+
|
| 196 |
+
self.animation_left_panel_sizer.Fit(self.animation_left_panel)
|
| 197 |
+
|
| 198 |
+
self.animation_panel_sizer.Fit(self.animation_panel)
|
| 199 |
+
|
| 200 |
+
def create_ui(self):
|
| 201 |
+
self.main_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 202 |
+
self.SetSizer(self.main_sizer)
|
| 203 |
+
self.SetAutoLayout(1)
|
| 204 |
+
|
| 205 |
+
self.capture_pose_lock = threading.Lock()
|
| 206 |
+
|
| 207 |
+
self.create_connection_panel(self)
|
| 208 |
+
self.main_sizer.Add(self.connection_panel, wx.SizerFlags(0).Expand().Border(wx.ALL, 5))
|
| 209 |
+
|
| 210 |
+
self.create_animation_panel(self)
|
| 211 |
+
self.main_sizer.Add(self.animation_panel, wx.SizerFlags(0).Expand().Border(wx.ALL, 5))
|
| 212 |
+
|
| 213 |
+
self.create_capture_panel(self)
|
| 214 |
+
self.main_sizer.Add(self.capture_panel, wx.SizerFlags(0).Expand().Border(wx.ALL, 5))
|
| 215 |
+
|
| 216 |
+
self.main_sizer.Fit(self)
|
| 217 |
+
|
| 218 |
+
def create_connection_panel(self, parent):
|
| 219 |
+
self.connection_panel = wx.Panel(parent, style=wx.RAISED_BORDER)
|
| 220 |
+
self.connection_panel_sizer = wx.BoxSizer(wx.HORIZONTAL)
|
| 221 |
+
self.connection_panel.SetSizer(self.connection_panel_sizer)
|
| 222 |
+
self.connection_panel.SetAutoLayout(1)
|
| 223 |
+
|
| 224 |
+
capture_device_ip_text = wx.StaticText(self.connection_panel, label="Capture Device IP:", style=wx.ALIGN_RIGHT)
|
| 225 |
+
self.connection_panel_sizer.Add(capture_device_ip_text, wx.SizerFlags(0).FixedMinSize().Border(wx.ALL, 3))
|
| 226 |
+
|
| 227 |
+
self.capture_device_ip_text_ctrl = wx.TextCtrl(self.connection_panel, value="192.168.0.1")
|
| 228 |
+
self.connection_panel_sizer.Add(self.capture_device_ip_text_ctrl, wx.SizerFlags(1).Expand().Border(wx.ALL, 3))
|
| 229 |
+
|
| 230 |
+
self.start_capture_button = wx.Button(self.connection_panel, label="START CAPTURE!")
|
| 231 |
+
self.connection_panel_sizer.Add(self.start_capture_button, wx.SizerFlags(0).FixedMinSize().Border(wx.ALL, 3))
|
| 232 |
+
self.start_capture_button.Bind(wx.EVT_BUTTON, self.on_start_capture)
|
| 233 |
+
|
| 234 |
+
def create_capture_panel(self, parent):
|
| 235 |
+
self.capture_panel = wx.Panel(parent, style=wx.RAISED_BORDER)
|
| 236 |
+
self.capture_panel_sizer = wx.FlexGridSizer(cols=5)
|
| 237 |
+
for i in range(5):
|
| 238 |
+
self.capture_panel_sizer.AddGrowableCol(i)
|
| 239 |
+
self.capture_panel.SetSizer(self.capture_panel_sizer)
|
| 240 |
+
self.capture_panel.SetAutoLayout(1)
|
| 241 |
+
|
| 242 |
+
self.rotation_labels = {}
|
| 243 |
+
self.rotation_value_labels = {}
|
| 244 |
+
rotation_column_0 = self.create_rotation_column(self.capture_panel, RIGHT_EYE_BONE_ROTATIONS)
|
| 245 |
+
self.capture_panel_sizer.Add(rotation_column_0, wx.SizerFlags(0).Expand().Border(wx.ALL, 3))
|
| 246 |
+
rotation_column_1 = self.create_rotation_column(self.capture_panel, LEFT_EYE_BONE_ROTATIONS)
|
| 247 |
+
self.capture_panel_sizer.Add(rotation_column_1, wx.SizerFlags(0).Expand().Border(wx.ALL, 3))
|
| 248 |
+
rotation_column_2 = self.create_rotation_column(self.capture_panel, HEAD_BONE_ROTATIONS)
|
| 249 |
+
self.capture_panel_sizer.Add(rotation_column_2, wx.SizerFlags(0).Expand().Border(wx.ALL, 3))
|
| 250 |
+
|
| 251 |
+
def create_rotation_column(self, parent, rotation_names):
|
| 252 |
+
column_panel = wx.Panel(parent, style=wx.SIMPLE_BORDER)
|
| 253 |
+
column_panel_sizer = wx.FlexGridSizer(cols=2)
|
| 254 |
+
column_panel_sizer.AddGrowableCol(1)
|
| 255 |
+
column_panel.SetSizer(column_panel_sizer)
|
| 256 |
+
column_panel.SetAutoLayout(1)
|
| 257 |
+
|
| 258 |
+
for rotation_name in rotation_names:
|
| 259 |
+
self.rotation_labels[rotation_name] = wx.StaticText(
|
| 260 |
+
column_panel, label=rotation_name, style=wx.ALIGN_RIGHT)
|
| 261 |
+
column_panel_sizer.Add(self.rotation_labels[rotation_name],
|
| 262 |
+
wx.SizerFlags(1).Expand().Border(wx.ALL, 3))
|
| 263 |
+
|
| 264 |
+
self.rotation_value_labels[rotation_name] = wx.TextCtrl(
|
| 265 |
+
column_panel, style=wx.TE_RIGHT)
|
| 266 |
+
self.rotation_value_labels[rotation_name].SetValue("0.00")
|
| 267 |
+
self.rotation_value_labels[rotation_name].Disable()
|
| 268 |
+
column_panel_sizer.Add(self.rotation_value_labels[rotation_name],
|
| 269 |
+
wx.SizerFlags(1).Expand().Border(wx.ALL, 3))
|
| 270 |
+
|
| 271 |
+
column_panel.GetSizer().Fit(column_panel)
|
| 272 |
+
return column_panel
|
| 273 |
+
|
| 274 |
+
def paint_capture_panel(self, event: wx.Event):
|
| 275 |
+
self.update_capture_panel(event)
|
| 276 |
+
|
| 277 |
+
def update_capture_panel(self, event: wx.Event):
|
| 278 |
+
data = self.ifacialmocap_pose
|
| 279 |
+
for rotation_name in ROTATION_NAMES:
|
| 280 |
+
value = data[rotation_name]
|
| 281 |
+
self.rotation_value_labels[rotation_name].SetValue("%0.2f" % value)
|
| 282 |
+
|
| 283 |
+
@staticmethod
|
| 284 |
+
def convert_to_100(x):
|
| 285 |
+
return int(max(0.0, min(1.0, x)) * 100)
|
| 286 |
+
|
| 287 |
+
def paint_source_image_panel(self, event: wx.Event):
|
| 288 |
+
wx.BufferedPaintDC(self.source_image_panel, self.source_image_bitmap)
|
| 289 |
+
|
| 290 |
+
def update_source_image_bitmap(self):
|
| 291 |
+
dc = wx.MemoryDC()
|
| 292 |
+
dc.SelectObject(self.source_image_bitmap)
|
| 293 |
+
if self.wx_source_image is None:
|
| 294 |
+
self.draw_nothing_yet_string(dc)
|
| 295 |
+
else:
|
| 296 |
+
dc.Clear()
|
| 297 |
+
dc.DrawBitmap(self.wx_source_image, 0, 0, True)
|
| 298 |
+
del dc
|
| 299 |
+
|
| 300 |
+
def draw_nothing_yet_string(self, dc):
|
| 301 |
+
dc.Clear()
|
| 302 |
+
font = wx.Font(wx.FontInfo(14).Family(wx.FONTFAMILY_SWISS))
|
| 303 |
+
dc.SetFont(font)
|
| 304 |
+
w, h = dc.GetTextExtent("Nothing yet!")
|
| 305 |
+
dc.DrawText("Nothing yet!", (self.poser.get_image_size() - w) // 2, (self.poser.get_image_size() - h) // 2)
|
| 306 |
+
|
| 307 |
+
def paint_result_image_panel(self, event: wx.Event):
|
| 308 |
+
wx.BufferedPaintDC(self.result_image_panel, self.result_image_bitmap)
|
| 309 |
+
|
| 310 |
+
def update_result_image_bitmap(self, event: Optional[wx.Event] = None):
|
| 311 |
+
ifacialmocap_pose = self.read_ifacialmocap_pose()
|
| 312 |
+
current_pose = self.pose_converter.convert(ifacialmocap_pose)
|
| 313 |
+
if self.last_pose is not None and self.last_pose == current_pose:
|
| 314 |
+
return
|
| 315 |
+
self.last_pose = current_pose
|
| 316 |
+
|
| 317 |
+
if self.torch_source_image is None:
|
| 318 |
+
dc = wx.MemoryDC()
|
| 319 |
+
dc.SelectObject(self.result_image_bitmap)
|
| 320 |
+
self.draw_nothing_yet_string(dc)
|
| 321 |
+
del dc
|
| 322 |
+
return
|
| 323 |
+
|
| 324 |
+
pose = torch.tensor(current_pose, device=self.device, dtype=self.poser.get_dtype())
|
| 325 |
+
|
| 326 |
+
with torch.no_grad():
|
| 327 |
+
output_image = self.poser.pose(self.torch_source_image, pose)[0].float()
|
| 328 |
+
output_image = convert_linear_to_srgb((output_image + 1.0) / 2.0)
|
| 329 |
+
|
| 330 |
+
background_choice = self.output_background_choice.GetSelection()
|
| 331 |
+
if background_choice == 0:
|
| 332 |
+
pass
|
| 333 |
+
else:
|
| 334 |
+
background = torch.zeros(4, output_image.shape[1], output_image.shape[2], device=self.device)
|
| 335 |
+
background[3, :, :] = 1.0
|
| 336 |
+
if background_choice == 1:
|
| 337 |
+
background[1, :, :] = 1.0
|
| 338 |
+
output_image = self.blend_with_background(output_image, background)
|
| 339 |
+
elif background_choice == 2:
|
| 340 |
+
background[2, :, :] = 1.0
|
| 341 |
+
output_image = self.blend_with_background(output_image, background)
|
| 342 |
+
elif background_choice == 3:
|
| 343 |
+
output_image = self.blend_with_background(output_image, background)
|
| 344 |
+
else:
|
| 345 |
+
background[0:3, :, :] = 1.0
|
| 346 |
+
output_image = self.blend_with_background(output_image, background)
|
| 347 |
+
|
| 348 |
+
c, h, w = output_image.shape
|
| 349 |
+
output_image = 255.0 * torch.transpose(output_image.reshape(c, h * w), 0, 1).reshape(h, w, c)
|
| 350 |
+
output_image = output_image.byte()
|
| 351 |
+
|
| 352 |
+
numpy_image = output_image.detach().cpu().numpy()
|
| 353 |
+
wx_image = wx.ImageFromBuffer(numpy_image.shape[0],
|
| 354 |
+
numpy_image.shape[1],
|
| 355 |
+
numpy_image[:, :, 0:3].tobytes(),
|
| 356 |
+
numpy_image[:, :, 3].tobytes())
|
| 357 |
+
wx_bitmap = wx_image.ConvertToBitmap()
|
| 358 |
+
|
| 359 |
+
dc = wx.MemoryDC()
|
| 360 |
+
dc.SelectObject(self.result_image_bitmap)
|
| 361 |
+
dc.Clear()
|
| 362 |
+
dc.DrawBitmap(wx_bitmap,
|
| 363 |
+
(self.poser.get_image_size() - numpy_image.shape[0]) // 2,
|
| 364 |
+
(self.poser.get_image_size() - numpy_image.shape[1]) // 2, True)
|
| 365 |
+
del dc
|
| 366 |
+
|
| 367 |
+
time_now = time.time_ns()
|
| 368 |
+
if self.last_update_time is not None:
|
| 369 |
+
elapsed_time = time_now - self.last_update_time
|
| 370 |
+
fps = 1.0 / (elapsed_time / 10**9)
|
| 371 |
+
if self.torch_source_image is not None:
|
| 372 |
+
self.fps_statistics.add_fps(fps)
|
| 373 |
+
self.fps_text.SetLabelText("FPS = %0.2f" % self.fps_statistics.get_average_fps())
|
| 374 |
+
self.last_update_time = time_now
|
| 375 |
+
|
| 376 |
+
self.Refresh()
|
| 377 |
+
|
| 378 |
+
def blend_with_background(self, numpy_image, background):
|
| 379 |
+
alpha = numpy_image[3:4, :, :]
|
| 380 |
+
color = numpy_image[0:3, :, :]
|
| 381 |
+
new_color = color * alpha + (1.0 - alpha) * background[0:3, :, :]
|
| 382 |
+
return torch.cat([new_color, background[3:4, :, :]], dim=0)
|
| 383 |
+
|
| 384 |
+
def load_image(self, event: wx.Event):
|
| 385 |
+
dir_name = "data/images"
|
| 386 |
+
file_dialog = wx.FileDialog(self, "Choose an image", dir_name, "", "*.png", wx.FD_OPEN)
|
| 387 |
+
if file_dialog.ShowModal() == wx.ID_OK:
|
| 388 |
+
image_file_name = os.path.join(file_dialog.GetDirectory(), file_dialog.GetFilename())
|
| 389 |
+
try:
|
| 390 |
+
pil_image = resize_PIL_image(
|
| 391 |
+
extract_PIL_image_from_filelike(image_file_name),
|
| 392 |
+
(self.poser.get_image_size(), self.poser.get_image_size()))
|
| 393 |
+
w, h = pil_image.size
|
| 394 |
+
if pil_image.mode != 'RGBA':
|
| 395 |
+
self.source_image_string = "Image must have alpha channel!"
|
| 396 |
+
self.wx_source_image = None
|
| 397 |
+
self.torch_source_image = None
|
| 398 |
+
else:
|
| 399 |
+
self.wx_source_image = wx.Bitmap.FromBufferRGBA(w, h, pil_image.convert("RGBA").tobytes())
|
| 400 |
+
self.torch_source_image = extract_pytorch_image_from_PIL_image(pil_image) \
|
| 401 |
+
.to(self.device).to(self.poser.get_dtype())
|
| 402 |
+
self.update_source_image_bitmap()
|
| 403 |
+
except:
|
| 404 |
+
message_dialog = wx.MessageDialog(self, "Could not load image " + image_file_name, "Poser", wx.OK)
|
| 405 |
+
message_dialog.ShowModal()
|
| 406 |
+
message_dialog.Destroy()
|
| 407 |
+
file_dialog.Destroy()
|
| 408 |
+
self.Refresh()
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
if __name__ == "__main__":
|
| 413 |
+
parser = argparse.ArgumentParser(description='Control characters with movement captured by iFacialMocap.')
|
| 414 |
+
parser.add_argument(
|
| 415 |
+
'--model',
|
| 416 |
+
type=str,
|
| 417 |
+
required=False,
|
| 418 |
+
default='standard_float',
|
| 419 |
+
choices=['standard_float', 'separable_float', 'standard_half', 'separable_half'],
|
| 420 |
+
help='The model to use.')
|
| 421 |
+
args = parser.parse_args()
|
| 422 |
+
|
| 423 |
+
device = torch.device('cuda')
|
| 424 |
+
try:
|
| 425 |
+
poser = load_poser(args.model, device)
|
| 426 |
+
except RuntimeError as e:
|
| 427 |
+
print(e)
|
| 428 |
+
sys.exit()
|
| 429 |
+
|
| 430 |
+
from tha3.mocap.ifacialmocap_poser_converter_25 import create_ifacialmocap_pose_converter
|
| 431 |
+
|
| 432 |
+
pose_converter = create_ifacialmocap_pose_converter()
|
| 433 |
+
|
| 434 |
+
app = wx.App()
|
| 435 |
+
main_frame = MainFrame(poser, pose_converter, device)
|
| 436 |
+
main_frame.Show(True)
|
| 437 |
+
main_frame.capture_timer.Start(10)
|
| 438 |
+
main_frame.animation_timer.Start(10)
|
| 439 |
+
app.MainLoop()
|
tha3/app/manual_poser.py
ADDED
|
@@ -0,0 +1,464 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
from typing import List
|
| 6 |
+
|
| 7 |
+
sys.path.append(os.getcwd())
|
| 8 |
+
|
| 9 |
+
import PIL.Image
|
| 10 |
+
import numpy
|
| 11 |
+
import torch
|
| 12 |
+
import wx
|
| 13 |
+
|
| 14 |
+
from tha3.poser.modes.load_poser import load_poser
|
| 15 |
+
from tha3.poser.poser import Poser, PoseParameterCategory, PoseParameterGroup
|
| 16 |
+
from tha3.util import extract_pytorch_image_from_filelike, rgba_to_numpy_image, grid_change_to_numpy_image, \
|
| 17 |
+
rgb_to_numpy_image, resize_PIL_image, extract_PIL_image_from_filelike, extract_pytorch_image_from_PIL_image
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class MorphCategoryControlPanel(wx.Panel):
|
| 21 |
+
def __init__(self,
|
| 22 |
+
parent,
|
| 23 |
+
title: str,
|
| 24 |
+
pose_param_category: PoseParameterCategory,
|
| 25 |
+
param_groups: List[PoseParameterGroup]):
|
| 26 |
+
super().__init__(parent, style=wx.SIMPLE_BORDER)
|
| 27 |
+
self.pose_param_category = pose_param_category
|
| 28 |
+
self.sizer = wx.BoxSizer(wx.VERTICAL)
|
| 29 |
+
self.SetSizer(self.sizer)
|
| 30 |
+
self.SetAutoLayout(1)
|
| 31 |
+
|
| 32 |
+
title_text = wx.StaticText(self, label=title, style=wx.ALIGN_CENTER)
|
| 33 |
+
self.sizer.Add(title_text, 0, wx.EXPAND)
|
| 34 |
+
|
| 35 |
+
self.param_groups = [group for group in param_groups if group.get_category() == pose_param_category]
|
| 36 |
+
self.choice = wx.Choice(self, choices=[group.get_group_name() for group in self.param_groups])
|
| 37 |
+
if len(self.param_groups) > 0:
|
| 38 |
+
self.choice.SetSelection(0)
|
| 39 |
+
self.choice.Bind(wx.EVT_CHOICE, self.on_choice_updated)
|
| 40 |
+
self.sizer.Add(self.choice, 0, wx.EXPAND)
|
| 41 |
+
|
| 42 |
+
self.left_slider = wx.Slider(self, minValue=-1000, maxValue=1000, value=-1000, style=wx.HORIZONTAL)
|
| 43 |
+
self.sizer.Add(self.left_slider, 0, wx.EXPAND)
|
| 44 |
+
|
| 45 |
+
self.right_slider = wx.Slider(self, minValue=-1000, maxValue=1000, value=-1000, style=wx.HORIZONTAL)
|
| 46 |
+
self.sizer.Add(self.right_slider, 0, wx.EXPAND)
|
| 47 |
+
|
| 48 |
+
self.checkbox = wx.CheckBox(self, label="Show")
|
| 49 |
+
self.checkbox.SetValue(True)
|
| 50 |
+
self.sizer.Add(self.checkbox, 0, wx.SHAPED | wx.ALIGN_CENTER)
|
| 51 |
+
|
| 52 |
+
self.update_ui()
|
| 53 |
+
|
| 54 |
+
self.sizer.Fit(self)
|
| 55 |
+
|
| 56 |
+
def update_ui(self):
|
| 57 |
+
param_group = self.param_groups[self.choice.GetSelection()]
|
| 58 |
+
if param_group.is_discrete():
|
| 59 |
+
self.left_slider.Enable(False)
|
| 60 |
+
self.right_slider.Enable(False)
|
| 61 |
+
self.checkbox.Enable(True)
|
| 62 |
+
elif param_group.get_arity() == 1:
|
| 63 |
+
self.left_slider.Enable(True)
|
| 64 |
+
self.right_slider.Enable(False)
|
| 65 |
+
self.checkbox.Enable(False)
|
| 66 |
+
else:
|
| 67 |
+
self.left_slider.Enable(True)
|
| 68 |
+
self.right_slider.Enable(True)
|
| 69 |
+
self.checkbox.Enable(False)
|
| 70 |
+
|
| 71 |
+
def on_choice_updated(self, event: wx.Event):
|
| 72 |
+
param_group = self.param_groups[self.choice.GetSelection()]
|
| 73 |
+
if param_group.is_discrete():
|
| 74 |
+
self.checkbox.SetValue(True)
|
| 75 |
+
self.update_ui()
|
| 76 |
+
|
| 77 |
+
def set_param_value(self, pose: List[float]):
|
| 78 |
+
if len(self.param_groups) == 0:
|
| 79 |
+
return
|
| 80 |
+
selected_morph_index = self.choice.GetSelection()
|
| 81 |
+
param_group = self.param_groups[selected_morph_index]
|
| 82 |
+
param_index = param_group.get_parameter_index()
|
| 83 |
+
if param_group.is_discrete():
|
| 84 |
+
if self.checkbox.GetValue():
|
| 85 |
+
for i in range(param_group.get_arity()):
|
| 86 |
+
pose[param_index + i] = 1.0
|
| 87 |
+
else:
|
| 88 |
+
param_range = param_group.get_range()
|
| 89 |
+
alpha = (self.left_slider.GetValue() + 1000) / 2000.0
|
| 90 |
+
pose[param_index] = param_range[0] + (param_range[1] - param_range[0]) * alpha
|
| 91 |
+
if param_group.get_arity() == 2:
|
| 92 |
+
alpha = (self.right_slider.GetValue() + 1000) / 2000.0
|
| 93 |
+
pose[param_index + 1] = param_range[0] + (param_range[1] - param_range[0]) * alpha
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class SimpleParamGroupsControlPanel(wx.Panel):
|
| 97 |
+
def __init__(self, parent,
|
| 98 |
+
pose_param_category: PoseParameterCategory,
|
| 99 |
+
param_groups: List[PoseParameterGroup]):
|
| 100 |
+
super().__init__(parent, style=wx.SIMPLE_BORDER)
|
| 101 |
+
self.sizer = wx.BoxSizer(wx.VERTICAL)
|
| 102 |
+
self.SetSizer(self.sizer)
|
| 103 |
+
self.SetAutoLayout(1)
|
| 104 |
+
|
| 105 |
+
self.param_groups = [group for group in param_groups if group.get_category() == pose_param_category]
|
| 106 |
+
for param_group in self.param_groups:
|
| 107 |
+
assert not param_group.is_discrete()
|
| 108 |
+
assert param_group.get_arity() == 1
|
| 109 |
+
|
| 110 |
+
self.sliders = []
|
| 111 |
+
for param_group in self.param_groups:
|
| 112 |
+
static_text = wx.StaticText(
|
| 113 |
+
self,
|
| 114 |
+
label=" ------------ %s ------------ " % param_group.get_group_name(), style=wx.ALIGN_CENTER)
|
| 115 |
+
self.sizer.Add(static_text, 0, wx.EXPAND)
|
| 116 |
+
range = param_group.get_range()
|
| 117 |
+
min_value = int(range[0] * 1000)
|
| 118 |
+
max_value = int(range[1] * 1000)
|
| 119 |
+
slider = wx.Slider(self, minValue=min_value, maxValue=max_value, value=0, style=wx.HORIZONTAL)
|
| 120 |
+
self.sizer.Add(slider, 0, wx.EXPAND)
|
| 121 |
+
self.sliders.append(slider)
|
| 122 |
+
|
| 123 |
+
self.sizer.Fit(self)
|
| 124 |
+
|
| 125 |
+
def set_param_value(self, pose: List[float]):
|
| 126 |
+
if len(self.param_groups) == 0:
|
| 127 |
+
return
|
| 128 |
+
for param_group_index in range(len(self.param_groups)):
|
| 129 |
+
param_group = self.param_groups[param_group_index]
|
| 130 |
+
slider = self.sliders[param_group_index]
|
| 131 |
+
param_range = param_group.get_range()
|
| 132 |
+
param_index = param_group.get_parameter_index()
|
| 133 |
+
alpha = (slider.GetValue() - slider.GetMin()) * 1.0 / (slider.GetMax() - slider.GetMin())
|
| 134 |
+
pose[param_index] = param_range[0] + (param_range[1] - param_range[0]) * alpha
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def convert_output_image_from_torch_to_numpy(output_image):
|
| 138 |
+
if output_image.shape[2] == 2:
|
| 139 |
+
h, w, c = output_image.shape
|
| 140 |
+
numpy_image = torch.transpose(output_image.reshape(h * w, c), 0, 1).reshape(c, h, w)
|
| 141 |
+
elif output_image.shape[0] == 4:
|
| 142 |
+
numpy_image = rgba_to_numpy_image(output_image)
|
| 143 |
+
elif output_image.shape[0] == 3:
|
| 144 |
+
numpy_image = rgb_to_numpy_image(output_image)
|
| 145 |
+
elif output_image.shape[0] == 1:
|
| 146 |
+
c, h, w = output_image.shape
|
| 147 |
+
alpha_image = torch.cat([output_image.repeat(3, 1, 1) * 2.0 - 1.0, torch.ones(1, h, w)], dim=0)
|
| 148 |
+
numpy_image = rgba_to_numpy_image(alpha_image)
|
| 149 |
+
elif output_image.shape[0] == 2:
|
| 150 |
+
numpy_image = grid_change_to_numpy_image(output_image, num_channels=4)
|
| 151 |
+
else:
|
| 152 |
+
raise RuntimeError("Unsupported # image channels: %d" % output_image.shape[0])
|
| 153 |
+
numpy_image = numpy.uint8(numpy.rint(numpy_image * 255.0))
|
| 154 |
+
return numpy_image
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
class MainFrame(wx.Frame):
|
| 158 |
+
def __init__(self, poser: Poser, device: torch.device):
|
| 159 |
+
super().__init__(None, wx.ID_ANY, "Poser")
|
| 160 |
+
self.poser = poser
|
| 161 |
+
self.dtype = self.poser.get_dtype()
|
| 162 |
+
self.device = device
|
| 163 |
+
self.image_size = self.poser.get_image_size()
|
| 164 |
+
|
| 165 |
+
self.wx_source_image = None
|
| 166 |
+
self.torch_source_image = None
|
| 167 |
+
|
| 168 |
+
self.main_sizer = wx.BoxSizer(wx.HORIZONTAL)
|
| 169 |
+
self.SetSizer(self.main_sizer)
|
| 170 |
+
self.SetAutoLayout(1)
|
| 171 |
+
self.init_left_panel()
|
| 172 |
+
self.init_control_panel()
|
| 173 |
+
self.init_right_panel()
|
| 174 |
+
self.main_sizer.Fit(self)
|
| 175 |
+
|
| 176 |
+
self.timer = wx.Timer(self, wx.ID_ANY)
|
| 177 |
+
self.Bind(wx.EVT_TIMER, self.update_images, self.timer)
|
| 178 |
+
|
| 179 |
+
save_image_id = wx.NewIdRef()
|
| 180 |
+
self.Bind(wx.EVT_MENU, self.on_save_image, id=save_image_id)
|
| 181 |
+
accelerator_table = wx.AcceleratorTable([
|
| 182 |
+
(wx.ACCEL_CTRL, ord('S'), save_image_id)
|
| 183 |
+
])
|
| 184 |
+
self.SetAcceleratorTable(accelerator_table)
|
| 185 |
+
|
| 186 |
+
self.last_pose = None
|
| 187 |
+
self.last_output_index = self.output_index_choice.GetSelection()
|
| 188 |
+
self.last_output_numpy_image = None
|
| 189 |
+
|
| 190 |
+
self.wx_source_image = None
|
| 191 |
+
self.torch_source_image = None
|
| 192 |
+
self.source_image_bitmap = wx.Bitmap(self.image_size, self.image_size)
|
| 193 |
+
self.result_image_bitmap = wx.Bitmap(self.image_size, self.image_size)
|
| 194 |
+
self.source_image_dirty = True
|
| 195 |
+
|
| 196 |
+
def init_left_panel(self):
|
| 197 |
+
self.control_panel = wx.Panel(self, style=wx.SIMPLE_BORDER, size=(self.image_size, -1))
|
| 198 |
+
self.left_panel = wx.Panel(self, style=wx.SIMPLE_BORDER)
|
| 199 |
+
left_panel_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 200 |
+
self.left_panel.SetSizer(left_panel_sizer)
|
| 201 |
+
self.left_panel.SetAutoLayout(1)
|
| 202 |
+
|
| 203 |
+
self.source_image_panel = wx.Panel(self.left_panel, size=(self.image_size, self.image_size),
|
| 204 |
+
style=wx.SIMPLE_BORDER)
|
| 205 |
+
self.source_image_panel.Bind(wx.EVT_PAINT, self.paint_source_image_panel)
|
| 206 |
+
self.source_image_panel.Bind(wx.EVT_ERASE_BACKGROUND, self.on_erase_background)
|
| 207 |
+
left_panel_sizer.Add(self.source_image_panel, 0, wx.FIXED_MINSIZE)
|
| 208 |
+
|
| 209 |
+
self.load_image_button = wx.Button(self.left_panel, wx.ID_ANY, "\nLoad Image\n\n")
|
| 210 |
+
left_panel_sizer.Add(self.load_image_button, 1, wx.EXPAND)
|
| 211 |
+
self.load_image_button.Bind(wx.EVT_BUTTON, self.load_image)
|
| 212 |
+
|
| 213 |
+
left_panel_sizer.Fit(self.left_panel)
|
| 214 |
+
self.main_sizer.Add(self.left_panel, 0, wx.FIXED_MINSIZE)
|
| 215 |
+
|
| 216 |
+
def on_erase_background(self, event: wx.Event):
|
| 217 |
+
pass
|
| 218 |
+
|
| 219 |
+
def init_control_panel(self):
|
| 220 |
+
self.control_panel_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 221 |
+
self.control_panel.SetSizer(self.control_panel_sizer)
|
| 222 |
+
self.control_panel.SetMinSize(wx.Size(256, 1))
|
| 223 |
+
|
| 224 |
+
morph_categories = [
|
| 225 |
+
PoseParameterCategory.EYEBROW,
|
| 226 |
+
PoseParameterCategory.EYE,
|
| 227 |
+
PoseParameterCategory.MOUTH,
|
| 228 |
+
PoseParameterCategory.IRIS_MORPH
|
| 229 |
+
]
|
| 230 |
+
morph_category_titles = {
|
| 231 |
+
PoseParameterCategory.EYEBROW: " ------------ Eyebrow ------------ ",
|
| 232 |
+
PoseParameterCategory.EYE: " ------------ Eye ------------ ",
|
| 233 |
+
PoseParameterCategory.MOUTH: " ------------ Mouth ------------ ",
|
| 234 |
+
PoseParameterCategory.IRIS_MORPH: " ------------ Iris morphs ------------ ",
|
| 235 |
+
}
|
| 236 |
+
self.morph_control_panels = {}
|
| 237 |
+
for category in morph_categories:
|
| 238 |
+
param_groups = self.poser.get_pose_parameter_groups()
|
| 239 |
+
filtered_param_groups = [group for group in param_groups if group.get_category() == category]
|
| 240 |
+
if len(filtered_param_groups) == 0:
|
| 241 |
+
continue
|
| 242 |
+
control_panel = MorphCategoryControlPanel(
|
| 243 |
+
self.control_panel,
|
| 244 |
+
morph_category_titles[category],
|
| 245 |
+
category,
|
| 246 |
+
self.poser.get_pose_parameter_groups())
|
| 247 |
+
self.morph_control_panels[category] = control_panel
|
| 248 |
+
self.control_panel_sizer.Add(control_panel, 0, wx.EXPAND)
|
| 249 |
+
|
| 250 |
+
self.non_morph_control_panels = {}
|
| 251 |
+
non_morph_categories = [
|
| 252 |
+
PoseParameterCategory.IRIS_ROTATION,
|
| 253 |
+
PoseParameterCategory.FACE_ROTATION,
|
| 254 |
+
PoseParameterCategory.BODY_ROTATION,
|
| 255 |
+
PoseParameterCategory.BREATHING
|
| 256 |
+
]
|
| 257 |
+
for category in non_morph_categories:
|
| 258 |
+
param_groups = self.poser.get_pose_parameter_groups()
|
| 259 |
+
filtered_param_groups = [group for group in param_groups if group.get_category() == category]
|
| 260 |
+
if len(filtered_param_groups) == 0:
|
| 261 |
+
continue
|
| 262 |
+
control_panel = SimpleParamGroupsControlPanel(
|
| 263 |
+
self.control_panel,
|
| 264 |
+
category,
|
| 265 |
+
self.poser.get_pose_parameter_groups())
|
| 266 |
+
self.non_morph_control_panels[category] = control_panel
|
| 267 |
+
self.control_panel_sizer.Add(control_panel, 0, wx.EXPAND)
|
| 268 |
+
|
| 269 |
+
self.control_panel_sizer.Fit(self.control_panel)
|
| 270 |
+
self.main_sizer.Add(self.control_panel, 1, wx.FIXED_MINSIZE)
|
| 271 |
+
|
| 272 |
+
def init_right_panel(self):
|
| 273 |
+
self.right_panel = wx.Panel(self, style=wx.SIMPLE_BORDER)
|
| 274 |
+
right_panel_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 275 |
+
self.right_panel.SetSizer(right_panel_sizer)
|
| 276 |
+
self.right_panel.SetAutoLayout(1)
|
| 277 |
+
|
| 278 |
+
self.result_image_panel = wx.Panel(self.right_panel,
|
| 279 |
+
size=(self.image_size, self.image_size),
|
| 280 |
+
style=wx.SIMPLE_BORDER)
|
| 281 |
+
self.result_image_panel.Bind(wx.EVT_PAINT, self.paint_result_image_panel)
|
| 282 |
+
self.result_image_panel.Bind(wx.EVT_ERASE_BACKGROUND, self.on_erase_background)
|
| 283 |
+
self.output_index_choice = wx.Choice(
|
| 284 |
+
self.right_panel,
|
| 285 |
+
choices=[str(i) for i in range(self.poser.get_output_length())])
|
| 286 |
+
self.output_index_choice.SetSelection(0)
|
| 287 |
+
right_panel_sizer.Add(self.result_image_panel, 0, wx.FIXED_MINSIZE)
|
| 288 |
+
right_panel_sizer.Add(self.output_index_choice, 0, wx.EXPAND)
|
| 289 |
+
|
| 290 |
+
self.save_image_button = wx.Button(self.right_panel, wx.ID_ANY, "\nSave Image\n\n")
|
| 291 |
+
right_panel_sizer.Add(self.save_image_button, 1, wx.EXPAND)
|
| 292 |
+
self.save_image_button.Bind(wx.EVT_BUTTON, self.on_save_image)
|
| 293 |
+
|
| 294 |
+
right_panel_sizer.Fit(self.right_panel)
|
| 295 |
+
self.main_sizer.Add(self.right_panel, 0, wx.FIXED_MINSIZE)
|
| 296 |
+
|
| 297 |
+
def create_param_category_choice(self, param_category: PoseParameterCategory):
|
| 298 |
+
params = []
|
| 299 |
+
for param_group in self.poser.get_pose_parameter_groups():
|
| 300 |
+
if param_group.get_category() == param_category:
|
| 301 |
+
params.append(param_group.get_group_name())
|
| 302 |
+
choice = wx.Choice(self.control_panel, choices=params)
|
| 303 |
+
if len(params) > 0:
|
| 304 |
+
choice.SetSelection(0)
|
| 305 |
+
return choice
|
| 306 |
+
|
| 307 |
+
def load_image(self, event: wx.Event):
|
| 308 |
+
dir_name = "data/images"
|
| 309 |
+
file_dialog = wx.FileDialog(self, "Choose an image", dir_name, "", "*.png", wx.FD_OPEN)
|
| 310 |
+
if file_dialog.ShowModal() == wx.ID_OK:
|
| 311 |
+
image_file_name = os.path.join(file_dialog.GetDirectory(), file_dialog.GetFilename())
|
| 312 |
+
try:
|
| 313 |
+
pil_image = resize_PIL_image(extract_PIL_image_from_filelike(image_file_name),
|
| 314 |
+
(self.poser.get_image_size(), self.poser.get_image_size()))
|
| 315 |
+
w, h = pil_image.size
|
| 316 |
+
if pil_image.mode != 'RGBA':
|
| 317 |
+
self.source_image_string = "Image must have alpha channel!"
|
| 318 |
+
self.wx_source_image = None
|
| 319 |
+
self.torch_source_image = None
|
| 320 |
+
else:
|
| 321 |
+
self.wx_source_image = wx.Bitmap.FromBufferRGBA(w, h, pil_image.convert("RGBA").tobytes())
|
| 322 |
+
self.torch_source_image = extract_pytorch_image_from_PIL_image(pil_image)\
|
| 323 |
+
.to(self.device).to(self.dtype)
|
| 324 |
+
self.source_image_dirty = True
|
| 325 |
+
self.Refresh()
|
| 326 |
+
self.Update()
|
| 327 |
+
except:
|
| 328 |
+
message_dialog = wx.MessageDialog(self, "Could not load image " + image_file_name, "Poser", wx.OK)
|
| 329 |
+
message_dialog.ShowModal()
|
| 330 |
+
message_dialog.Destroy()
|
| 331 |
+
file_dialog.Destroy()
|
| 332 |
+
|
| 333 |
+
def paint_source_image_panel(self, event: wx.Event):
|
| 334 |
+
wx.BufferedPaintDC(self.source_image_panel, self.source_image_bitmap)
|
| 335 |
+
|
| 336 |
+
def paint_result_image_panel(self, event: wx.Event):
|
| 337 |
+
wx.BufferedPaintDC(self.result_image_panel, self.result_image_bitmap)
|
| 338 |
+
|
| 339 |
+
def draw_nothing_yet_string_to_bitmap(self, bitmap):
|
| 340 |
+
dc = wx.MemoryDC()
|
| 341 |
+
dc.SelectObject(bitmap)
|
| 342 |
+
|
| 343 |
+
dc.Clear()
|
| 344 |
+
font = wx.Font(wx.FontInfo(14).Family(wx.FONTFAMILY_SWISS))
|
| 345 |
+
dc.SetFont(font)
|
| 346 |
+
w, h = dc.GetTextExtent("Nothing yet!")
|
| 347 |
+
dc.DrawText("Nothing yet!", (self.image_size - w) // 2, (self.image_size - - h) // 2)
|
| 348 |
+
|
| 349 |
+
del dc
|
| 350 |
+
|
| 351 |
+
def get_current_pose(self):
|
| 352 |
+
current_pose = [0.0 for i in range(self.poser.get_num_parameters())]
|
| 353 |
+
for morph_control_panel in self.morph_control_panels.values():
|
| 354 |
+
morph_control_panel.set_param_value(current_pose)
|
| 355 |
+
for rotation_control_panel in self.non_morph_control_panels.values():
|
| 356 |
+
rotation_control_panel.set_param_value(current_pose)
|
| 357 |
+
return current_pose
|
| 358 |
+
|
| 359 |
+
def update_images(self, event: wx.Event):
|
| 360 |
+
current_pose = self.get_current_pose()
|
| 361 |
+
if not self.source_image_dirty \
|
| 362 |
+
and self.last_pose is not None \
|
| 363 |
+
and self.last_pose == current_pose \
|
| 364 |
+
and self.last_output_index == self.output_index_choice.GetSelection():
|
| 365 |
+
return
|
| 366 |
+
self.last_pose = current_pose
|
| 367 |
+
self.last_output_index = self.output_index_choice.GetSelection()
|
| 368 |
+
|
| 369 |
+
if self.torch_source_image is None:
|
| 370 |
+
self.draw_nothing_yet_string_to_bitmap(self.source_image_bitmap)
|
| 371 |
+
self.draw_nothing_yet_string_to_bitmap(self.result_image_bitmap)
|
| 372 |
+
self.source_image_dirty = False
|
| 373 |
+
self.Refresh()
|
| 374 |
+
self.Update()
|
| 375 |
+
return
|
| 376 |
+
|
| 377 |
+
if self.source_image_dirty:
|
| 378 |
+
dc = wx.MemoryDC()
|
| 379 |
+
dc.SelectObject(self.source_image_bitmap)
|
| 380 |
+
dc.Clear()
|
| 381 |
+
dc.DrawBitmap(self.wx_source_image, 0, 0)
|
| 382 |
+
self.source_image_dirty = False
|
| 383 |
+
|
| 384 |
+
pose = torch.tensor(current_pose, device=self.device, dtype=self.dtype)
|
| 385 |
+
output_index = self.output_index_choice.GetSelection()
|
| 386 |
+
with torch.no_grad():
|
| 387 |
+
output_image = self.poser.pose(self.torch_source_image, pose, output_index)[0].detach().cpu()
|
| 388 |
+
|
| 389 |
+
numpy_image = convert_output_image_from_torch_to_numpy(output_image)
|
| 390 |
+
self.last_output_numpy_image = numpy_image
|
| 391 |
+
wx_image = wx.ImageFromBuffer(
|
| 392 |
+
numpy_image.shape[0],
|
| 393 |
+
numpy_image.shape[1],
|
| 394 |
+
numpy_image[:, :, 0:3].tobytes(),
|
| 395 |
+
numpy_image[:, :, 3].tobytes())
|
| 396 |
+
wx_bitmap = wx_image.ConvertToBitmap()
|
| 397 |
+
|
| 398 |
+
dc = wx.MemoryDC()
|
| 399 |
+
dc.SelectObject(self.result_image_bitmap)
|
| 400 |
+
dc.Clear()
|
| 401 |
+
dc.DrawBitmap(wx_bitmap,
|
| 402 |
+
(self.image_size - numpy_image.shape[0]) // 2,
|
| 403 |
+
(self.image_size - numpy_image.shape[1]) // 2,
|
| 404 |
+
True)
|
| 405 |
+
del dc
|
| 406 |
+
|
| 407 |
+
self.Refresh()
|
| 408 |
+
self.Update()
|
| 409 |
+
|
| 410 |
+
def on_save_image(self, event: wx.Event):
|
| 411 |
+
if self.last_output_numpy_image is None:
|
| 412 |
+
logging.info("There is no output image to save!!!")
|
| 413 |
+
return
|
| 414 |
+
|
| 415 |
+
dir_name = "data/images"
|
| 416 |
+
file_dialog = wx.FileDialog(self, "Choose an image", dir_name, "", "*.png", wx.FD_SAVE)
|
| 417 |
+
if file_dialog.ShowModal() == wx.ID_OK:
|
| 418 |
+
image_file_name = os.path.join(file_dialog.GetDirectory(), file_dialog.GetFilename())
|
| 419 |
+
try:
|
| 420 |
+
if os.path.exists(image_file_name):
|
| 421 |
+
message_dialog = wx.MessageDialog(self, f"Override {image_file_name}", "Manual Poser",
|
| 422 |
+
wx.YES_NO | wx.ICON_QUESTION)
|
| 423 |
+
result = message_dialog.ShowModal()
|
| 424 |
+
if result == wx.ID_YES:
|
| 425 |
+
self.save_last_numpy_image(image_file_name)
|
| 426 |
+
message_dialog.Destroy()
|
| 427 |
+
else:
|
| 428 |
+
self.save_last_numpy_image(image_file_name)
|
| 429 |
+
except:
|
| 430 |
+
message_dialog = wx.MessageDialog(self, f"Could not save {image_file_name}", "Manual Poser", wx.OK)
|
| 431 |
+
message_dialog.ShowModal()
|
| 432 |
+
message_dialog.Destroy()
|
| 433 |
+
file_dialog.Destroy()
|
| 434 |
+
|
| 435 |
+
def save_last_numpy_image(self, image_file_name):
|
| 436 |
+
numpy_image = self.last_output_numpy_image
|
| 437 |
+
pil_image = PIL.Image.fromarray(numpy_image, mode='RGBA')
|
| 438 |
+
os.makedirs(os.path.dirname(image_file_name), exist_ok=True)
|
| 439 |
+
pil_image.save(image_file_name)
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
if __name__ == "__main__":
|
| 443 |
+
parser = argparse.ArgumentParser(description='Manually pose a character image.')
|
| 444 |
+
parser.add_argument(
|
| 445 |
+
'--model',
|
| 446 |
+
type=str,
|
| 447 |
+
required=False,
|
| 448 |
+
default='standard_float',
|
| 449 |
+
choices=['standard_float', 'separable_float', 'standard_half', 'separable_half'],
|
| 450 |
+
help='The model to use.')
|
| 451 |
+
args = parser.parse_args()
|
| 452 |
+
|
| 453 |
+
device = torch.device('cuda')
|
| 454 |
+
try:
|
| 455 |
+
poser = load_poser(args.model, device)
|
| 456 |
+
except RuntimeError as e:
|
| 457 |
+
print(e)
|
| 458 |
+
sys.exit()
|
| 459 |
+
|
| 460 |
+
app = wx.App()
|
| 461 |
+
main_frame = MainFrame(poser, device)
|
| 462 |
+
main_frame.Show(True)
|
| 463 |
+
main_frame.timer.Start(30)
|
| 464 |
+
app.MainLoop()
|
tha3/compute/__init__.py
ADDED
|
File without changes
|
tha3/compute/cached_computation_func.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Callable, Dict, List
|
| 2 |
+
|
| 3 |
+
from torch import Tensor
|
| 4 |
+
from torch.nn import Module
|
| 5 |
+
|
| 6 |
+
TensorCachedComputationFunc = Callable[
|
| 7 |
+
[Dict[str, Module], List[Tensor], Dict[str, List[Tensor]]], Tensor]
|
| 8 |
+
TensorListCachedComputationFunc = Callable[
|
| 9 |
+
[Dict[str, Module], List[Tensor], Dict[str, List[Tensor]]], List[Tensor]]
|
tha3/compute/cached_computation_protocol.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Dict, List
|
| 3 |
+
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Module
|
| 6 |
+
|
| 7 |
+
from tha3.compute.cached_computation_func import TensorCachedComputationFunc, TensorListCachedComputationFunc
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class CachedComputationProtocol(ABC):
|
| 11 |
+
def get_output(self,
|
| 12 |
+
key: str,
|
| 13 |
+
modules: Dict[str, Module],
|
| 14 |
+
batch: List[Tensor],
|
| 15 |
+
outputs: Dict[str, List[Tensor]]):
|
| 16 |
+
if key in outputs:
|
| 17 |
+
return outputs[key]
|
| 18 |
+
else:
|
| 19 |
+
output = self.compute_output(key, modules, batch, outputs)
|
| 20 |
+
outputs[key] = output
|
| 21 |
+
return outputs[key]
|
| 22 |
+
|
| 23 |
+
@abstractmethod
|
| 24 |
+
def compute_output(self,
|
| 25 |
+
key: str,
|
| 26 |
+
modules: Dict[str, Module],
|
| 27 |
+
batch: List[Tensor],
|
| 28 |
+
outputs: Dict[str, List[Tensor]]) -> List[Tensor]:
|
| 29 |
+
pass
|
| 30 |
+
|
| 31 |
+
def get_output_tensor_func(self, key: str, index: int) -> TensorCachedComputationFunc:
|
| 32 |
+
def func(modules: Dict[str, Module],
|
| 33 |
+
batch: List[Tensor],
|
| 34 |
+
outputs: Dict[str, List[Tensor]]):
|
| 35 |
+
return self.get_output(key, modules, batch, outputs)[index]
|
| 36 |
+
return func
|
| 37 |
+
|
| 38 |
+
def get_output_tensor_list_func(self, key: str) -> TensorListCachedComputationFunc:
|
| 39 |
+
def func(modules: Dict[str, Module],
|
| 40 |
+
batch: List[Tensor],
|
| 41 |
+
outputs: Dict[str, List[Tensor]]):
|
| 42 |
+
return self.get_output(key, modules, batch, outputs)
|
| 43 |
+
return func
|
tha3/mocap/__init__.py
ADDED
|
File without changes
|
tha3/mocap/ifacialmocap_constants.py
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
EYE_LOOK_IN_LEFT = "eyeLookInLeft"
|
| 2 |
+
EYE_LOOK_OUT_LEFT = "eyeLookOutLeft"
|
| 3 |
+
EYE_LOOK_DOWN_LEFT = "eyeLookDownLeft"
|
| 4 |
+
EYE_LOOK_UP_LEFT = "eyeLookUpLeft"
|
| 5 |
+
EYE_BLINK_LEFT = "eyeBlinkLeft"
|
| 6 |
+
EYE_SQUINT_LEFT = "eyeSquintLeft"
|
| 7 |
+
EYE_WIDE_LEFT = "eyeWideLeft"
|
| 8 |
+
EYE_LOOK_IN_RIGHT = "eyeLookInRight"
|
| 9 |
+
EYE_LOOK_OUT_RIGHT = "eyeLookOutRight"
|
| 10 |
+
EYE_LOOK_DOWN_RIGHT = "eyeLookDownRight"
|
| 11 |
+
EYE_LOOK_UP_RIGHT = "eyeLookUpRight"
|
| 12 |
+
EYE_BLINK_RIGHT = "eyeBlinkRight"
|
| 13 |
+
EYE_SQUINT_RIGHT = "eyeSquintRight"
|
| 14 |
+
EYE_WIDE_RIGHT = "eyeWideRight"
|
| 15 |
+
BROW_DOWN_LEFT = "browDownLeft"
|
| 16 |
+
BROW_OUTER_UP_LEFT = "browOuterUpLeft"
|
| 17 |
+
BROW_DOWN_RIGHT = "browDownRight"
|
| 18 |
+
BROW_OUTER_UP_RIGHT = "browOuterUpRight"
|
| 19 |
+
BROW_INNER_UP = "browInnerUp"
|
| 20 |
+
NOSE_SNEER_LEFT = "noseSneerLeft"
|
| 21 |
+
NOSE_SNEER_RIGHT = "noseSneerRight"
|
| 22 |
+
CHEEK_SQUINT_LEFT = "cheekSquintLeft"
|
| 23 |
+
CHEEK_SQUINT_RIGHT = "cheekSquintRight"
|
| 24 |
+
CHEEK_PUFF = "cheekPuff"
|
| 25 |
+
MOUTH_LEFT = "mouthLeft"
|
| 26 |
+
MOUTH_DIMPLE_LEFT = "mouthDimpleLeft"
|
| 27 |
+
MOUTH_FROWN_LEFT = "mouthFrownLeft"
|
| 28 |
+
MOUTH_LOWER_DOWN_LEFT = "mouthLowerDownLeft"
|
| 29 |
+
MOUTH_PRESS_LEFT = "mouthPressLeft"
|
| 30 |
+
MOUTH_SMILE_LEFT = "mouthSmileLeft"
|
| 31 |
+
MOUTH_STRETCH_LEFT = "mouthStretchLeft"
|
| 32 |
+
MOUTH_UPPER_UP_LEFT = "mouthUpperUpLeft"
|
| 33 |
+
MOUTH_RIGHT = "mouthRight"
|
| 34 |
+
MOUTH_DIMPLE_RIGHT = "mouthDimpleRight"
|
| 35 |
+
MOUTH_FROWN_RIGHT = "mouthFrownRight"
|
| 36 |
+
MOUTH_LOWER_DOWN_RIGHT = "mouthLowerDownRight"
|
| 37 |
+
MOUTH_PRESS_RIGHT = "mouthPressRight"
|
| 38 |
+
MOUTH_SMILE_RIGHT = "mouthSmileRight"
|
| 39 |
+
MOUTH_STRETCH_RIGHT = "mouthStretchRight"
|
| 40 |
+
MOUTH_UPPER_UP_RIGHT = "mouthUpperUpRight"
|
| 41 |
+
MOUTH_CLOSE = "mouthClose"
|
| 42 |
+
MOUTH_FUNNEL = "mouthFunnel"
|
| 43 |
+
MOUTH_PUCKER = "mouthPucker"
|
| 44 |
+
MOUTH_ROLL_LOWER = "mouthRollLower"
|
| 45 |
+
MOUTH_ROLL_UPPER = "mouthRollUpper"
|
| 46 |
+
MOUTH_SHRUG_LOWER = "mouthShrugLower"
|
| 47 |
+
MOUTH_SHRUG_UPPER = "mouthShrugUpper"
|
| 48 |
+
JAW_LEFT = "jawLeft"
|
| 49 |
+
JAW_RIGHT = "jawRight"
|
| 50 |
+
JAW_FORWARD = "jawForward"
|
| 51 |
+
JAW_OPEN = "jawOpen"
|
| 52 |
+
TONGUE_OUT = "tongueOut"
|
| 53 |
+
|
| 54 |
+
BLENDSHAPE_NAMES = [
|
| 55 |
+
EYE_LOOK_IN_LEFT, # 0
|
| 56 |
+
EYE_LOOK_OUT_LEFT, # 1
|
| 57 |
+
EYE_LOOK_DOWN_LEFT, # 2
|
| 58 |
+
EYE_LOOK_UP_LEFT, # 3
|
| 59 |
+
EYE_BLINK_LEFT, # 4
|
| 60 |
+
EYE_SQUINT_LEFT, # 5
|
| 61 |
+
EYE_WIDE_LEFT, # 6
|
| 62 |
+
EYE_LOOK_IN_RIGHT, # 7
|
| 63 |
+
EYE_LOOK_OUT_RIGHT, # 8
|
| 64 |
+
EYE_LOOK_DOWN_RIGHT, # 9
|
| 65 |
+
EYE_LOOK_UP_RIGHT, # 10
|
| 66 |
+
EYE_BLINK_RIGHT, # 11
|
| 67 |
+
EYE_SQUINT_RIGHT, # 12
|
| 68 |
+
EYE_WIDE_RIGHT, # 13
|
| 69 |
+
BROW_DOWN_LEFT, # 14
|
| 70 |
+
BROW_OUTER_UP_LEFT, # 15
|
| 71 |
+
BROW_DOWN_RIGHT, # 16
|
| 72 |
+
BROW_OUTER_UP_RIGHT, # 17
|
| 73 |
+
BROW_INNER_UP, # 18
|
| 74 |
+
NOSE_SNEER_LEFT, # 19
|
| 75 |
+
NOSE_SNEER_RIGHT, # 20
|
| 76 |
+
CHEEK_SQUINT_LEFT, # 21
|
| 77 |
+
CHEEK_SQUINT_RIGHT, # 22
|
| 78 |
+
CHEEK_PUFF, # 23
|
| 79 |
+
MOUTH_LEFT, # 24
|
| 80 |
+
MOUTH_DIMPLE_LEFT, # 25
|
| 81 |
+
MOUTH_FROWN_LEFT, # 26
|
| 82 |
+
MOUTH_LOWER_DOWN_LEFT, # 27
|
| 83 |
+
MOUTH_PRESS_LEFT, # 28
|
| 84 |
+
MOUTH_SMILE_LEFT, # 29
|
| 85 |
+
MOUTH_STRETCH_LEFT, # 30
|
| 86 |
+
MOUTH_UPPER_UP_LEFT, # 31
|
| 87 |
+
MOUTH_RIGHT, # 32
|
| 88 |
+
MOUTH_DIMPLE_RIGHT, # 33
|
| 89 |
+
MOUTH_FROWN_RIGHT, # 34
|
| 90 |
+
MOUTH_LOWER_DOWN_RIGHT, # 35
|
| 91 |
+
MOUTH_PRESS_RIGHT, # 36
|
| 92 |
+
MOUTH_SMILE_RIGHT, # 37
|
| 93 |
+
MOUTH_STRETCH_RIGHT, # 38
|
| 94 |
+
MOUTH_UPPER_UP_RIGHT, # 39
|
| 95 |
+
MOUTH_CLOSE, # 40
|
| 96 |
+
MOUTH_FUNNEL, # 41
|
| 97 |
+
MOUTH_PUCKER, # 42
|
| 98 |
+
MOUTH_ROLL_LOWER, # 43
|
| 99 |
+
MOUTH_ROLL_UPPER, # 44
|
| 100 |
+
MOUTH_SHRUG_LOWER, # 45
|
| 101 |
+
MOUTH_SHRUG_UPPER, # 46
|
| 102 |
+
JAW_LEFT, # 47
|
| 103 |
+
JAW_RIGHT, # 48
|
| 104 |
+
JAW_FORWARD, # 49
|
| 105 |
+
JAW_OPEN, # 50
|
| 106 |
+
TONGUE_OUT, # 51
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
EYE_LEFT_BLENDSHAPES = [
|
| 110 |
+
EYE_LOOK_IN_LEFT, # 0
|
| 111 |
+
EYE_LOOK_OUT_LEFT, # 1
|
| 112 |
+
EYE_LOOK_DOWN_LEFT, # 2
|
| 113 |
+
EYE_LOOK_UP_LEFT, # 3
|
| 114 |
+
EYE_BLINK_LEFT, # 4
|
| 115 |
+
EYE_SQUINT_LEFT, # 5
|
| 116 |
+
EYE_WIDE_LEFT, # 6
|
| 117 |
+
]
|
| 118 |
+
|
| 119 |
+
EYE_RIGHT_BLENDSHAPES = [
|
| 120 |
+
EYE_LOOK_IN_RIGHT, # 7
|
| 121 |
+
EYE_LOOK_OUT_RIGHT, # 8
|
| 122 |
+
EYE_LOOK_DOWN_RIGHT, # 9
|
| 123 |
+
EYE_LOOK_UP_RIGHT, # 10
|
| 124 |
+
EYE_BLINK_RIGHT, # 11
|
| 125 |
+
EYE_SQUINT_RIGHT, # 12
|
| 126 |
+
EYE_WIDE_RIGHT, # 13
|
| 127 |
+
]
|
| 128 |
+
|
| 129 |
+
BROW_LEFT_BLENDSHAPES = [
|
| 130 |
+
BROW_DOWN_LEFT, # 14
|
| 131 |
+
BROW_OUTER_UP_LEFT, # 15
|
| 132 |
+
|
| 133 |
+
]
|
| 134 |
+
|
| 135 |
+
BROW_RIGHT_BLENDSHAPES = [
|
| 136 |
+
BROW_DOWN_RIGHT, # 16
|
| 137 |
+
BROW_OUTER_UP_RIGHT, # 17
|
| 138 |
+
|
| 139 |
+
]
|
| 140 |
+
|
| 141 |
+
BROW_BOTH_BLENDSHAPES = [
|
| 142 |
+
BROW_INNER_UP, # 18
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
NOSE_BLENDSHAPES = [
|
| 146 |
+
NOSE_SNEER_LEFT, # 19
|
| 147 |
+
NOSE_SNEER_RIGHT, # 20
|
| 148 |
+
]
|
| 149 |
+
|
| 150 |
+
CHECK_BLENDSHAPES = [
|
| 151 |
+
CHEEK_SQUINT_LEFT, # 21
|
| 152 |
+
CHEEK_SQUINT_RIGHT, # 22
|
| 153 |
+
CHEEK_PUFF, # 23
|
| 154 |
+
]
|
| 155 |
+
|
| 156 |
+
MOUTH_LEFT_BLENDSHAPES = [
|
| 157 |
+
MOUTH_LEFT, # 24
|
| 158 |
+
MOUTH_DIMPLE_LEFT, # 25
|
| 159 |
+
MOUTH_FROWN_LEFT, # 26
|
| 160 |
+
MOUTH_LOWER_DOWN_LEFT, # 27
|
| 161 |
+
MOUTH_PRESS_LEFT, # 28
|
| 162 |
+
MOUTH_SMILE_LEFT, # 29
|
| 163 |
+
MOUTH_STRETCH_LEFT, # 30
|
| 164 |
+
MOUTH_UPPER_UP_LEFT, # 31
|
| 165 |
+
]
|
| 166 |
+
|
| 167 |
+
MOUTH_RIGHT_BLENDSHAPES = [
|
| 168 |
+
MOUTH_RIGHT, # 32
|
| 169 |
+
MOUTH_DIMPLE_RIGHT, # 33
|
| 170 |
+
MOUTH_FROWN_RIGHT, # 34
|
| 171 |
+
MOUTH_LOWER_DOWN_RIGHT, # 35
|
| 172 |
+
MOUTH_PRESS_RIGHT, # 36
|
| 173 |
+
MOUTH_SMILE_RIGHT, # 37
|
| 174 |
+
MOUTH_STRETCH_RIGHT, # 38
|
| 175 |
+
MOUTH_UPPER_UP_RIGHT, # 39
|
| 176 |
+
]
|
| 177 |
+
|
| 178 |
+
MOUTH_BOTH_BLENDSHAPES = [
|
| 179 |
+
MOUTH_CLOSE, # 40
|
| 180 |
+
MOUTH_FUNNEL, # 41
|
| 181 |
+
MOUTH_PUCKER, # 42
|
| 182 |
+
MOUTH_ROLL_LOWER, # 43
|
| 183 |
+
MOUTH_ROLL_UPPER, # 44
|
| 184 |
+
MOUTH_SHRUG_LOWER, # 45
|
| 185 |
+
MOUTH_SHRUG_UPPER, # 46
|
| 186 |
+
]
|
| 187 |
+
|
| 188 |
+
JAW_BLENDSHAPES = [
|
| 189 |
+
JAW_LEFT, # 47
|
| 190 |
+
JAW_RIGHT, # 48
|
| 191 |
+
JAW_FORWARD, # 49
|
| 192 |
+
JAW_OPEN, # 50
|
| 193 |
+
]
|
| 194 |
+
|
| 195 |
+
TONGUE_BLENDSHAPES = [
|
| 196 |
+
TONGUE_OUT, # 51
|
| 197 |
+
]
|
| 198 |
+
|
| 199 |
+
COLUMN_0_BLENDSHAPES = EYE_RIGHT_BLENDSHAPES + BROW_RIGHT_BLENDSHAPES + [NOSE_SNEER_RIGHT, CHEEK_SQUINT_RIGHT]
|
| 200 |
+
COLUMN_1_BLENDSHAPES = EYE_LEFT_BLENDSHAPES + BROW_LEFT_BLENDSHAPES + [NOSE_SNEER_LEFT, CHEEK_SQUINT_LEFT]
|
| 201 |
+
COLUMN_2_BLENDSHAPES = MOUTH_RIGHT_BLENDSHAPES + [JAW_RIGHT]
|
| 202 |
+
COLUMN_3_BLENDSHAPES = MOUTH_LEFT_BLENDSHAPES + [JAW_LEFT]
|
| 203 |
+
COLUMN_4_BLENDSHAPES = [BROW_INNER_UP, CHEEK_PUFF] + MOUTH_BOTH_BLENDSHAPES + [JAW_FORWARD, JAW_OPEN, TONGUE_OUT]
|
| 204 |
+
|
| 205 |
+
BLENDSHAPE_COLUMNS = [
|
| 206 |
+
COLUMN_0_BLENDSHAPES,
|
| 207 |
+
COLUMN_1_BLENDSHAPES,
|
| 208 |
+
COLUMN_2_BLENDSHAPES,
|
| 209 |
+
COLUMN_3_BLENDSHAPES,
|
| 210 |
+
COLUMN_4_BLENDSHAPES,
|
| 211 |
+
]
|
| 212 |
+
|
| 213 |
+
RIGHT_EYE_BONE_X = "rightEyeBoneX"
|
| 214 |
+
RIGHT_EYE_BONE_Y = "rightEyeBoneY"
|
| 215 |
+
RIGHT_EYE_BONE_Z = "rightEyeBoneZ"
|
| 216 |
+
RIGHT_EYE_BONE_ROTATIONS = [RIGHT_EYE_BONE_X, RIGHT_EYE_BONE_Y, RIGHT_EYE_BONE_Z]
|
| 217 |
+
|
| 218 |
+
LEFT_EYE_BONE_X = "leftEyeBoneX"
|
| 219 |
+
LEFT_EYE_BONE_Y = "leftEyeBoneY"
|
| 220 |
+
LEFT_EYE_BONE_Z = "leftEyeBoneZ"
|
| 221 |
+
LEFT_EYE_BONE_ROTATIONS = [LEFT_EYE_BONE_X, LEFT_EYE_BONE_Y, LEFT_EYE_BONE_Z]
|
| 222 |
+
|
| 223 |
+
HEAD_BONE_X = "headBoneX"
|
| 224 |
+
HEAD_BONE_Y = "headBoneY"
|
| 225 |
+
HEAD_BONE_Z = "headBoneZ"
|
| 226 |
+
HEAD_BONE_ROTATIONS = [HEAD_BONE_X, HEAD_BONE_Y, HEAD_BONE_Z]
|
| 227 |
+
|
| 228 |
+
ROTATION_NAMES = RIGHT_EYE_BONE_ROTATIONS + LEFT_EYE_BONE_ROTATIONS + HEAD_BONE_ROTATIONS
|
| 229 |
+
|
| 230 |
+
RIGHT_EYE_BONE_QUAT = "rightEyeBoneQuat"
|
| 231 |
+
LEFT_EYE_BONE_QUAT = "leftEyeBoneQuat"
|
| 232 |
+
HEAD_BONE_QUAT = "headBoneQuat"
|
| 233 |
+
QUATERNION_NAMES = [
|
| 234 |
+
RIGHT_EYE_BONE_QUAT,
|
| 235 |
+
LEFT_EYE_BONE_QUAT,
|
| 236 |
+
HEAD_BONE_QUAT
|
| 237 |
+
]
|
| 238 |
+
|
| 239 |
+
IFACIALMOCAP_DATETIME_FORMAT = "%Y/%m/%d-%H:%M:%S.%f"
|
tha3/mocap/ifacialmocap_pose.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tha3.mocap.ifacialmocap_constants import BLENDSHAPE_NAMES, HEAD_BONE_X, HEAD_BONE_Y, HEAD_BONE_Z, \
|
| 2 |
+
HEAD_BONE_QUAT, LEFT_EYE_BONE_X, LEFT_EYE_BONE_Y, LEFT_EYE_BONE_Z, LEFT_EYE_BONE_QUAT, RIGHT_EYE_BONE_X, \
|
| 3 |
+
RIGHT_EYE_BONE_Y, RIGHT_EYE_BONE_Z, RIGHT_EYE_BONE_QUAT
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def create_default_ifacialmocap_pose():
|
| 7 |
+
data = {}
|
| 8 |
+
|
| 9 |
+
for blendshape_name in BLENDSHAPE_NAMES:
|
| 10 |
+
data[blendshape_name] = 0.0
|
| 11 |
+
|
| 12 |
+
data[HEAD_BONE_X] = 0.0
|
| 13 |
+
data[HEAD_BONE_Y] = 0.0
|
| 14 |
+
data[HEAD_BONE_Z] = 0.0
|
| 15 |
+
data[HEAD_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 16 |
+
|
| 17 |
+
data[LEFT_EYE_BONE_X] = 0.0
|
| 18 |
+
data[LEFT_EYE_BONE_Y] = 0.0
|
| 19 |
+
data[LEFT_EYE_BONE_Z] = 0.0
|
| 20 |
+
data[LEFT_EYE_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 21 |
+
|
| 22 |
+
data[RIGHT_EYE_BONE_X] = 0.0
|
| 23 |
+
data[RIGHT_EYE_BONE_Y] = 0.0
|
| 24 |
+
data[RIGHT_EYE_BONE_Z] = 0.0
|
| 25 |
+
data[RIGHT_EYE_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 26 |
+
|
| 27 |
+
return data
|
tha3/mocap/ifacialmocap_pose_converter.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Dict, List
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class IFacialMocapPoseConverter(ABC):
|
| 6 |
+
@abstractmethod
|
| 7 |
+
def convert(self, ifacialmocap_pose: Dict[str, float]) -> List[float]:
|
| 8 |
+
pass
|
| 9 |
+
|
| 10 |
+
@abstractmethod
|
| 11 |
+
def init_pose_converter_panel(self, parent):
|
| 12 |
+
pass
|
tha3/mocap/ifacialmocap_poser_converter_25.py
ADDED
|
@@ -0,0 +1,463 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import time
|
| 3 |
+
from enum import Enum
|
| 4 |
+
from typing import Optional, Dict, List
|
| 5 |
+
|
| 6 |
+
import numpy
|
| 7 |
+
import scipy.optimize
|
| 8 |
+
import wx
|
| 9 |
+
|
| 10 |
+
from tha3.mocap.ifacialmocap_constants import MOUTH_SMILE_LEFT, MOUTH_SHRUG_UPPER, MOUTH_SMILE_RIGHT, \
|
| 11 |
+
BROW_INNER_UP, BROW_OUTER_UP_RIGHT, BROW_OUTER_UP_LEFT, BROW_DOWN_LEFT, BROW_DOWN_RIGHT, EYE_WIDE_LEFT, \
|
| 12 |
+
EYE_WIDE_RIGHT, EYE_BLINK_LEFT, EYE_BLINK_RIGHT, CHEEK_SQUINT_LEFT, CHEEK_SQUINT_RIGHT, EYE_LOOK_IN_LEFT, \
|
| 13 |
+
EYE_LOOK_OUT_LEFT, EYE_LOOK_IN_RIGHT, EYE_LOOK_OUT_RIGHT, EYE_LOOK_UP_LEFT, EYE_LOOK_UP_RIGHT, EYE_LOOK_DOWN_RIGHT, \
|
| 14 |
+
EYE_LOOK_DOWN_LEFT, HEAD_BONE_X, HEAD_BONE_Y, HEAD_BONE_Z, JAW_OPEN, MOUTH_FROWN_LEFT, MOUTH_FROWN_RIGHT, \
|
| 15 |
+
MOUTH_LOWER_DOWN_LEFT, MOUTH_LOWER_DOWN_RIGHT, MOUTH_FUNNEL, MOUTH_PUCKER
|
| 16 |
+
from tha3.mocap.ifacialmocap_pose_converter import IFacialMocapPoseConverter
|
| 17 |
+
from tha3.poser.modes.pose_parameters import get_pose_parameters
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class EyebrowDownMode(Enum):
|
| 21 |
+
TROUBLED = 1
|
| 22 |
+
ANGRY = 2
|
| 23 |
+
LOWERED = 3
|
| 24 |
+
SERIOUS = 4
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class WinkMode(Enum):
|
| 28 |
+
NORMAL = 1
|
| 29 |
+
RELAXED = 2
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def rad_to_deg(rad):
|
| 33 |
+
return rad * 180.0 / math.pi
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def deg_to_rad(deg):
|
| 37 |
+
return deg * math.pi / 180.0
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def clamp(x, min_value, max_value):
|
| 41 |
+
return max(min_value, min(max_value, x))
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class IFacialMocapPoseConverter25Args:
|
| 45 |
+
def __init__(self,
|
| 46 |
+
lower_smile_threshold: float = 0.4,
|
| 47 |
+
upper_smile_threshold: float = 0.6,
|
| 48 |
+
eyebrow_down_mode: EyebrowDownMode = EyebrowDownMode.ANGRY,
|
| 49 |
+
wink_mode: WinkMode = WinkMode.NORMAL,
|
| 50 |
+
eye_surprised_max_value: float = 0.5,
|
| 51 |
+
eye_wink_max_value: float = 0.8,
|
| 52 |
+
eyebrow_down_max_value: float = 0.4,
|
| 53 |
+
cheek_squint_min_value: float = 0.1,
|
| 54 |
+
cheek_squint_max_value: float = 0.7,
|
| 55 |
+
eye_rotation_factor: float = 1.0 / 0.75,
|
| 56 |
+
jaw_open_min_value: float = 0.1,
|
| 57 |
+
jaw_open_max_value: float = 0.4,
|
| 58 |
+
mouth_frown_max_value: float = 0.6,
|
| 59 |
+
mouth_funnel_min_value: float = 0.25,
|
| 60 |
+
mouth_funnel_max_value: float = 0.5,
|
| 61 |
+
iris_small_left=0.0,
|
| 62 |
+
iris_small_right=0.0):
|
| 63 |
+
self.iris_small_right = iris_small_left
|
| 64 |
+
self.iris_small_left = iris_small_right
|
| 65 |
+
self.wink_mode = wink_mode
|
| 66 |
+
self.mouth_funnel_max_value = mouth_funnel_max_value
|
| 67 |
+
self.mouth_funnel_min_value = mouth_funnel_min_value
|
| 68 |
+
self.mouth_frown_max_value = mouth_frown_max_value
|
| 69 |
+
self.jaw_open_max_value = jaw_open_max_value
|
| 70 |
+
self.jaw_open_min_value = jaw_open_min_value
|
| 71 |
+
self.eye_rotation_factor = eye_rotation_factor
|
| 72 |
+
self.cheek_squint_max_value = cheek_squint_max_value
|
| 73 |
+
self.cheek_squint_min_value = cheek_squint_min_value
|
| 74 |
+
self.eyebrow_down_max_value = eyebrow_down_max_value
|
| 75 |
+
self.eye_blink_max_value = eye_wink_max_value
|
| 76 |
+
self.eye_wide_max_value = eye_surprised_max_value
|
| 77 |
+
self.eyebrow_down_mode = eyebrow_down_mode
|
| 78 |
+
self.lower_smile_threshold = lower_smile_threshold
|
| 79 |
+
self.upper_smile_threshold = upper_smile_threshold
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class IFacialMocapPoseConverter25(IFacialMocapPoseConverter):
|
| 83 |
+
def __init__(self, args: Optional[IFacialMocapPoseConverter25Args] = None):
|
| 84 |
+
super().__init__()
|
| 85 |
+
if args is None:
|
| 86 |
+
args = IFacialMocapPoseConverter25Args()
|
| 87 |
+
self.args = args
|
| 88 |
+
pose_parameters = get_pose_parameters()
|
| 89 |
+
self.pose_size = 45
|
| 90 |
+
|
| 91 |
+
self.eyebrow_troubled_left_index = pose_parameters.get_parameter_index("eyebrow_troubled_left")
|
| 92 |
+
self.eyebrow_troubled_right_index = pose_parameters.get_parameter_index("eyebrow_troubled_right")
|
| 93 |
+
self.eyebrow_angry_left_index = pose_parameters.get_parameter_index("eyebrow_angry_left")
|
| 94 |
+
self.eyebrow_angry_right_index = pose_parameters.get_parameter_index("eyebrow_angry_right")
|
| 95 |
+
self.eyebrow_happy_left_index = pose_parameters.get_parameter_index("eyebrow_happy_left")
|
| 96 |
+
self.eyebrow_happy_right_index = pose_parameters.get_parameter_index("eyebrow_happy_right")
|
| 97 |
+
self.eyebrow_raised_left_index = pose_parameters.get_parameter_index("eyebrow_raised_left")
|
| 98 |
+
self.eyebrow_raised_right_index = pose_parameters.get_parameter_index("eyebrow_raised_right")
|
| 99 |
+
self.eyebrow_lowered_left_index = pose_parameters.get_parameter_index("eyebrow_lowered_left")
|
| 100 |
+
self.eyebrow_lowered_right_index = pose_parameters.get_parameter_index("eyebrow_lowered_right")
|
| 101 |
+
self.eyebrow_serious_left_index = pose_parameters.get_parameter_index("eyebrow_serious_left")
|
| 102 |
+
self.eyebrow_serious_right_index = pose_parameters.get_parameter_index("eyebrow_serious_right")
|
| 103 |
+
|
| 104 |
+
self.eye_surprised_left_index = pose_parameters.get_parameter_index("eye_surprised_left")
|
| 105 |
+
self.eye_surprised_right_index = pose_parameters.get_parameter_index("eye_surprised_right")
|
| 106 |
+
self.eye_wink_left_index = pose_parameters.get_parameter_index("eye_wink_left")
|
| 107 |
+
self.eye_wink_right_index = pose_parameters.get_parameter_index("eye_wink_right")
|
| 108 |
+
self.eye_happy_wink_left_index = pose_parameters.get_parameter_index("eye_happy_wink_left")
|
| 109 |
+
self.eye_happy_wink_right_index = pose_parameters.get_parameter_index("eye_happy_wink_right")
|
| 110 |
+
self.eye_relaxed_left_index = pose_parameters.get_parameter_index("eye_relaxed_left")
|
| 111 |
+
self.eye_relaxed_right_index = pose_parameters.get_parameter_index("eye_relaxed_right")
|
| 112 |
+
self.eye_raised_lower_eyelid_left_index = pose_parameters.get_parameter_index("eye_raised_lower_eyelid_left")
|
| 113 |
+
self.eye_raised_lower_eyelid_right_index = pose_parameters.get_parameter_index("eye_raised_lower_eyelid_right")
|
| 114 |
+
|
| 115 |
+
self.iris_small_left_index = pose_parameters.get_parameter_index("iris_small_left")
|
| 116 |
+
self.iris_small_right_index = pose_parameters.get_parameter_index("iris_small_right")
|
| 117 |
+
|
| 118 |
+
self.iris_rotation_x_index = pose_parameters.get_parameter_index("iris_rotation_x")
|
| 119 |
+
self.iris_rotation_y_index = pose_parameters.get_parameter_index("iris_rotation_y")
|
| 120 |
+
|
| 121 |
+
self.head_x_index = pose_parameters.get_parameter_index("head_x")
|
| 122 |
+
self.head_y_index = pose_parameters.get_parameter_index("head_y")
|
| 123 |
+
self.neck_z_index = pose_parameters.get_parameter_index("neck_z")
|
| 124 |
+
|
| 125 |
+
self.mouth_aaa_index = pose_parameters.get_parameter_index("mouth_aaa")
|
| 126 |
+
self.mouth_iii_index = pose_parameters.get_parameter_index("mouth_iii")
|
| 127 |
+
self.mouth_uuu_index = pose_parameters.get_parameter_index("mouth_uuu")
|
| 128 |
+
self.mouth_eee_index = pose_parameters.get_parameter_index("mouth_eee")
|
| 129 |
+
self.mouth_ooo_index = pose_parameters.get_parameter_index("mouth_ooo")
|
| 130 |
+
|
| 131 |
+
self.mouth_lowered_corner_left_index = pose_parameters.get_parameter_index("mouth_lowered_corner_left")
|
| 132 |
+
self.mouth_lowered_corner_right_index = pose_parameters.get_parameter_index("mouth_lowered_corner_right")
|
| 133 |
+
self.mouth_raised_corner_left_index = pose_parameters.get_parameter_index("mouth_raised_corner_left")
|
| 134 |
+
self.mouth_raised_corner_right_index = pose_parameters.get_parameter_index("mouth_raised_corner_right")
|
| 135 |
+
|
| 136 |
+
self.body_y_index = pose_parameters.get_parameter_index("body_y")
|
| 137 |
+
self.body_z_index = pose_parameters.get_parameter_index("body_z")
|
| 138 |
+
self.breathing_index = pose_parameters.get_parameter_index("breathing")
|
| 139 |
+
|
| 140 |
+
self.breathing_start_time = time.time()
|
| 141 |
+
|
| 142 |
+
self.panel = None
|
| 143 |
+
|
| 144 |
+
def init_pose_converter_panel(self, parent):
|
| 145 |
+
self.panel = wx.Panel(parent, style=wx.SIMPLE_BORDER)
|
| 146 |
+
self.panel_sizer = wx.BoxSizer(wx.VERTICAL)
|
| 147 |
+
self.panel.SetSizer(self.panel_sizer)
|
| 148 |
+
self.panel.SetAutoLayout(1)
|
| 149 |
+
parent.GetSizer().Add(self.panel, 0, wx.EXPAND)
|
| 150 |
+
|
| 151 |
+
if True:
|
| 152 |
+
eyebrow_down_mode_text = wx.StaticText(self.panel, label=" --- Eyebrow Down Mode --- ",
|
| 153 |
+
style=wx.ALIGN_CENTER)
|
| 154 |
+
self.panel_sizer.Add(eyebrow_down_mode_text, 0, wx.EXPAND)
|
| 155 |
+
|
| 156 |
+
self.eyebrow_down_mode_choice = wx.Choice(
|
| 157 |
+
self.panel,
|
| 158 |
+
choices=[
|
| 159 |
+
"ANGRY",
|
| 160 |
+
"TROUBLED",
|
| 161 |
+
"SERIOUS",
|
| 162 |
+
"LOWERED",
|
| 163 |
+
])
|
| 164 |
+
self.eyebrow_down_mode_choice.SetSelection(0)
|
| 165 |
+
self.panel_sizer.Add(self.eyebrow_down_mode_choice, 0, wx.EXPAND)
|
| 166 |
+
self.eyebrow_down_mode_choice.Bind(wx.EVT_CHOICE, self.change_eyebrow_down_mode)
|
| 167 |
+
|
| 168 |
+
separator = wx.StaticLine(self.panel, -1, size=(256, 5))
|
| 169 |
+
self.panel_sizer.Add(separator, 0, wx.EXPAND)
|
| 170 |
+
|
| 171 |
+
if True:
|
| 172 |
+
wink_mode_text = wx.StaticText(self.panel, label=" --- Wink Mode --- ", style=wx.ALIGN_CENTER)
|
| 173 |
+
self.panel_sizer.Add(wink_mode_text, 0, wx.EXPAND)
|
| 174 |
+
|
| 175 |
+
self.wink_mode_choice = wx.Choice(
|
| 176 |
+
self.panel,
|
| 177 |
+
choices=[
|
| 178 |
+
"NORMAL",
|
| 179 |
+
"RELAXED",
|
| 180 |
+
])
|
| 181 |
+
self.wink_mode_choice.SetSelection(0)
|
| 182 |
+
self.panel_sizer.Add(self.wink_mode_choice, 0, wx.EXPAND)
|
| 183 |
+
self.wink_mode_choice.Bind(wx.EVT_CHOICE, self.change_wink_mode)
|
| 184 |
+
|
| 185 |
+
separator = wx.StaticLine(self.panel, -1, size=(256, 5))
|
| 186 |
+
self.panel_sizer.Add(separator, 0, wx.EXPAND)
|
| 187 |
+
|
| 188 |
+
if True:
|
| 189 |
+
iris_size_text = wx.StaticText(self.panel, label=" --- Iris Size --- ", style=wx.ALIGN_CENTER)
|
| 190 |
+
self.panel_sizer.Add(iris_size_text, 0, wx.EXPAND)
|
| 191 |
+
|
| 192 |
+
self.iris_left_slider = wx.Slider(self.panel, minValue=0, maxValue=1000, value=0, style=wx.HORIZONTAL)
|
| 193 |
+
self.panel_sizer.Add(self.iris_left_slider, 0, wx.EXPAND)
|
| 194 |
+
self.iris_left_slider.Bind(wx.EVT_SLIDER, self.change_iris_size)
|
| 195 |
+
|
| 196 |
+
self.iris_right_slider = wx.Slider(self.panel, minValue=0, maxValue=1000, value=0, style=wx.HORIZONTAL)
|
| 197 |
+
self.panel_sizer.Add(self.iris_right_slider, 0, wx.EXPAND)
|
| 198 |
+
self.iris_right_slider.Bind(wx.EVT_SLIDER, self.change_iris_size)
|
| 199 |
+
self.iris_right_slider.Enable(False)
|
| 200 |
+
|
| 201 |
+
self.link_left_right_irises = wx.CheckBox(
|
| 202 |
+
self.panel, label="Use same value for both sides")
|
| 203 |
+
self.link_left_right_irises.SetValue(True)
|
| 204 |
+
self.panel_sizer.Add(self.link_left_right_irises, wx.SizerFlags().CenterHorizontal().Border())
|
| 205 |
+
self.link_left_right_irises.Bind(wx.EVT_CHECKBOX, self.link_left_right_irises_clicked)
|
| 206 |
+
|
| 207 |
+
separator = wx.StaticLine(self.panel, -1, size=(256, 5))
|
| 208 |
+
self.panel_sizer.Add(separator, 0, wx.EXPAND)
|
| 209 |
+
|
| 210 |
+
if True:
|
| 211 |
+
breathing_frequency_text = wx.StaticText(
|
| 212 |
+
self.panel, label=" --- Breathing --- ", style=wx.ALIGN_CENTER)
|
| 213 |
+
self.panel_sizer.Add(breathing_frequency_text, 0, wx.EXPAND)
|
| 214 |
+
|
| 215 |
+
self.restart_breathing_cycle_button = wx.Button(self.panel, label="Restart Breathing Cycle")
|
| 216 |
+
self.restart_breathing_cycle_button.Bind(wx.EVT_BUTTON, self.restart_breathing_cycle_clicked)
|
| 217 |
+
self.panel_sizer.Add(self.restart_breathing_cycle_button, 0, wx.EXPAND)
|
| 218 |
+
|
| 219 |
+
self.breathing_frequency_slider = wx.Slider(
|
| 220 |
+
self.panel, minValue=0, maxValue=60, value=20, style=wx.HORIZONTAL)
|
| 221 |
+
self.panel_sizer.Add(self.breathing_frequency_slider, 0, wx.EXPAND)
|
| 222 |
+
|
| 223 |
+
self.breathing_gauge = wx.Gauge(self.panel, style=wx.GA_HORIZONTAL, range=1000)
|
| 224 |
+
self.panel_sizer.Add(self.breathing_gauge, 0, wx.EXPAND)
|
| 225 |
+
|
| 226 |
+
self.panel_sizer.Fit(self.panel)
|
| 227 |
+
|
| 228 |
+
def restart_breathing_cycle_clicked(self, event: wx.Event):
|
| 229 |
+
self.breathing_start_time = time.time()
|
| 230 |
+
|
| 231 |
+
def change_eyebrow_down_mode(self, event: wx.Event):
|
| 232 |
+
selected_index = self.eyebrow_down_mode_choice.GetSelection()
|
| 233 |
+
if selected_index == 0:
|
| 234 |
+
self.args.eyebrow_down_mode = EyebrowDownMode.ANGRY
|
| 235 |
+
elif selected_index == 1:
|
| 236 |
+
self.args.eyebrow_down_mode = EyebrowDownMode.TROUBLED
|
| 237 |
+
elif selected_index == 2:
|
| 238 |
+
self.args.eyebrow_down_mode = EyebrowDownMode.SERIOUS
|
| 239 |
+
else:
|
| 240 |
+
self.args.eyebrow_down_mode = EyebrowDownMode.LOWERED
|
| 241 |
+
|
| 242 |
+
def change_wink_mode(self, event: wx.Event):
|
| 243 |
+
selected_index = self.wink_mode_choice.GetSelection()
|
| 244 |
+
if selected_index == 0:
|
| 245 |
+
self.args.wink_mode = WinkMode.NORMAL
|
| 246 |
+
else:
|
| 247 |
+
self.args.wink_mode = WinkMode.RELAXED
|
| 248 |
+
|
| 249 |
+
def change_iris_size(self, event: wx.Event):
|
| 250 |
+
if self.link_left_right_irises.GetValue():
|
| 251 |
+
left_value = self.iris_left_slider.GetValue()
|
| 252 |
+
right_value = self.iris_right_slider.GetValue()
|
| 253 |
+
if left_value != right_value:
|
| 254 |
+
self.iris_right_slider.SetValue(left_value)
|
| 255 |
+
self.args.iris_small_left = left_value / 1000.0
|
| 256 |
+
self.args.iris_small_right = left_value / 1000.0
|
| 257 |
+
else:
|
| 258 |
+
self.args.iris_small_left = self.iris_left_slider.GetValue() / 1000.0
|
| 259 |
+
self.args.iris_small_right = self.iris_right_slider.GetValue() / 1000.0
|
| 260 |
+
|
| 261 |
+
def link_left_right_irises_clicked(self, event: wx.Event):
|
| 262 |
+
if self.link_left_right_irises.GetValue():
|
| 263 |
+
self.iris_right_slider.Enable(False)
|
| 264 |
+
else:
|
| 265 |
+
self.iris_right_slider.Enable(True)
|
| 266 |
+
self.change_iris_size(event)
|
| 267 |
+
|
| 268 |
+
def decompose_head_body_param(self, param, threshold=2.0 / 3):
|
| 269 |
+
if abs(param) < threshold:
|
| 270 |
+
return (param, 0.0)
|
| 271 |
+
else:
|
| 272 |
+
if param < 0:
|
| 273 |
+
sign = -1.0
|
| 274 |
+
else:
|
| 275 |
+
sign = 1.0
|
| 276 |
+
return (threshold * sign, (abs(param) - threshold) * sign)
|
| 277 |
+
|
| 278 |
+
def convert(self, ifacialmocap_pose: Dict[str, float]) -> List[float]:
|
| 279 |
+
pose = [0.0 for i in range(self.pose_size)]
|
| 280 |
+
|
| 281 |
+
smile_value = \
|
| 282 |
+
(ifacialmocap_pose[MOUTH_SMILE_LEFT] + ifacialmocap_pose[MOUTH_SMILE_RIGHT]) / 2.0 \
|
| 283 |
+
+ ifacialmocap_pose[MOUTH_SHRUG_UPPER]
|
| 284 |
+
if smile_value < self.args.lower_smile_threshold:
|
| 285 |
+
smile_degree = 0.0
|
| 286 |
+
elif smile_value > self.args.upper_smile_threshold:
|
| 287 |
+
smile_degree = 1.0
|
| 288 |
+
else:
|
| 289 |
+
smile_degree = (smile_value - self.args.lower_smile_threshold) / (
|
| 290 |
+
self.args.upper_smile_threshold - self.args.lower_smile_threshold)
|
| 291 |
+
|
| 292 |
+
# Eyebrow
|
| 293 |
+
if True:
|
| 294 |
+
brow_inner_up = ifacialmocap_pose[BROW_INNER_UP]
|
| 295 |
+
brow_outer_up_right = ifacialmocap_pose[BROW_OUTER_UP_RIGHT]
|
| 296 |
+
brow_outer_up_left = ifacialmocap_pose[BROW_OUTER_UP_LEFT]
|
| 297 |
+
|
| 298 |
+
brow_up_left = clamp(brow_inner_up + brow_outer_up_left, 0.0, 1.0)
|
| 299 |
+
brow_up_right = clamp(brow_inner_up + brow_outer_up_right, 0.0, 1.0)
|
| 300 |
+
pose[self.eyebrow_raised_left_index] = brow_up_left
|
| 301 |
+
pose[self.eyebrow_raised_right_index] = brow_up_right
|
| 302 |
+
|
| 303 |
+
brow_down_left = (1.0 - smile_degree) \
|
| 304 |
+
* clamp(ifacialmocap_pose[BROW_DOWN_LEFT] / self.args.eyebrow_down_max_value, 0.0, 1.0)
|
| 305 |
+
brow_down_right = (1.0 - smile_degree) \
|
| 306 |
+
* clamp(ifacialmocap_pose[BROW_DOWN_RIGHT] / self.args.eyebrow_down_max_value, 0.0, 1.0)
|
| 307 |
+
if self.args.eyebrow_down_mode == EyebrowDownMode.TROUBLED:
|
| 308 |
+
pose[self.eyebrow_troubled_left_index] = brow_down_left
|
| 309 |
+
pose[self.eyebrow_troubled_right_index] = brow_down_right
|
| 310 |
+
elif self.args.eyebrow_down_mode == EyebrowDownMode.ANGRY:
|
| 311 |
+
pose[self.eyebrow_angry_left_index] = brow_down_left
|
| 312 |
+
pose[self.eyebrow_angry_right_index] = brow_down_right
|
| 313 |
+
elif self.args.eyebrow_down_mode == EyebrowDownMode.LOWERED:
|
| 314 |
+
pose[self.eyebrow_lowered_left_index] = brow_down_left
|
| 315 |
+
pose[self.eyebrow_lowered_right_index] = brow_down_right
|
| 316 |
+
elif self.args.eyebrow_down_mode == EyebrowDownMode.SERIOUS:
|
| 317 |
+
pose[self.eyebrow_serious_left_index] = brow_down_left
|
| 318 |
+
pose[self.eyebrow_serious_right_index] = brow_down_right
|
| 319 |
+
|
| 320 |
+
brow_happy_value = clamp(smile_value, 0.0, 1.0) * smile_degree
|
| 321 |
+
pose[self.eyebrow_happy_left_index] = brow_happy_value
|
| 322 |
+
pose[self.eyebrow_happy_right_index] = brow_happy_value
|
| 323 |
+
|
| 324 |
+
# Eye
|
| 325 |
+
if True:
|
| 326 |
+
# Surprised
|
| 327 |
+
pose[self.eye_surprised_left_index] = clamp(
|
| 328 |
+
ifacialmocap_pose[EYE_WIDE_LEFT] / self.args.eye_wide_max_value, 0.0, 1.0)
|
| 329 |
+
pose[self.eye_surprised_right_index] = clamp(
|
| 330 |
+
ifacialmocap_pose[EYE_WIDE_RIGHT] / self.args.eye_wide_max_value, 0.0, 1.0)
|
| 331 |
+
|
| 332 |
+
# Wink
|
| 333 |
+
if self.args.wink_mode == WinkMode.NORMAL:
|
| 334 |
+
wink_left_index = self.eye_wink_left_index
|
| 335 |
+
wink_right_index = self.eye_wink_right_index
|
| 336 |
+
else:
|
| 337 |
+
wink_left_index = self.eye_relaxed_left_index
|
| 338 |
+
wink_right_index = self.eye_relaxed_right_index
|
| 339 |
+
pose[wink_left_index] = (1.0 - smile_degree) * clamp(
|
| 340 |
+
ifacialmocap_pose[EYE_BLINK_LEFT] / self.args.eye_blink_max_value, 0.0, 1.0)
|
| 341 |
+
pose[wink_right_index] = (1.0 - smile_degree) * clamp(
|
| 342 |
+
ifacialmocap_pose[EYE_BLINK_RIGHT] / self.args.eye_blink_max_value, 0.0, 1.0)
|
| 343 |
+
pose[self.eye_happy_wink_left_index] = smile_degree * clamp(
|
| 344 |
+
ifacialmocap_pose[EYE_BLINK_LEFT] / self.args.eye_blink_max_value, 0.0, 1.0)
|
| 345 |
+
pose[self.eye_happy_wink_right_index] = smile_degree * clamp(
|
| 346 |
+
ifacialmocap_pose[EYE_BLINK_RIGHT] / self.args.eye_blink_max_value, 0.0, 1.0)
|
| 347 |
+
|
| 348 |
+
# Lower eyelid
|
| 349 |
+
cheek_squint_denom = self.args.cheek_squint_max_value - self.args.cheek_squint_min_value
|
| 350 |
+
pose[self.eye_raised_lower_eyelid_left_index] = \
|
| 351 |
+
clamp(
|
| 352 |
+
(ifacialmocap_pose[CHEEK_SQUINT_LEFT] - self.args.cheek_squint_min_value) / cheek_squint_denom,
|
| 353 |
+
0.0, 1.0)
|
| 354 |
+
pose[self.eye_raised_lower_eyelid_right_index] = \
|
| 355 |
+
clamp(
|
| 356 |
+
(ifacialmocap_pose[CHEEK_SQUINT_RIGHT] - self.args.cheek_squint_min_value) / cheek_squint_denom,
|
| 357 |
+
0.0, 1.0)
|
| 358 |
+
|
| 359 |
+
# Iris rotation
|
| 360 |
+
if True:
|
| 361 |
+
eye_rotation_y = (ifacialmocap_pose[EYE_LOOK_IN_LEFT]
|
| 362 |
+
- ifacialmocap_pose[EYE_LOOK_OUT_LEFT]
|
| 363 |
+
- ifacialmocap_pose[EYE_LOOK_IN_RIGHT]
|
| 364 |
+
+ ifacialmocap_pose[EYE_LOOK_OUT_RIGHT]) / 2.0 * self.args.eye_rotation_factor
|
| 365 |
+
pose[self.iris_rotation_y_index] = clamp(eye_rotation_y, -1.0, 1.0)
|
| 366 |
+
|
| 367 |
+
eye_rotation_x = (ifacialmocap_pose[EYE_LOOK_UP_LEFT]
|
| 368 |
+
+ ifacialmocap_pose[EYE_LOOK_UP_RIGHT]
|
| 369 |
+
- ifacialmocap_pose[EYE_LOOK_DOWN_LEFT]
|
| 370 |
+
- ifacialmocap_pose[EYE_LOOK_DOWN_RIGHT]) / 2.0 * self.args.eye_rotation_factor
|
| 371 |
+
pose[self.iris_rotation_x_index] = clamp(eye_rotation_x, -1.0, 1.0)
|
| 372 |
+
|
| 373 |
+
# Iris size
|
| 374 |
+
if True:
|
| 375 |
+
pose[self.iris_small_left_index] = self.args.iris_small_left
|
| 376 |
+
pose[self.iris_small_right_index] = self.args.iris_small_right
|
| 377 |
+
|
| 378 |
+
# Head rotation
|
| 379 |
+
if True:
|
| 380 |
+
x_param = clamp(-ifacialmocap_pose[HEAD_BONE_X] * 180.0 / math.pi, -15.0, 15.0) / 15.0
|
| 381 |
+
pose[self.head_x_index] = x_param
|
| 382 |
+
|
| 383 |
+
y_param = clamp(-ifacialmocap_pose[HEAD_BONE_Y] * 180.0 / math.pi, -10.0, 10.0) / 10.0
|
| 384 |
+
pose[self.head_y_index] = y_param
|
| 385 |
+
pose[self.body_y_index] = y_param
|
| 386 |
+
|
| 387 |
+
z_param = clamp(ifacialmocap_pose[HEAD_BONE_Z] * 180.0 / math.pi, -15.0, 15.0) / 15.0
|
| 388 |
+
pose[self.neck_z_index] = z_param
|
| 389 |
+
pose[self.body_z_index] = z_param
|
| 390 |
+
|
| 391 |
+
# Mouth
|
| 392 |
+
if True:
|
| 393 |
+
jaw_open_denom = self.args.jaw_open_max_value - self.args.jaw_open_min_value
|
| 394 |
+
mouth_open = clamp((ifacialmocap_pose[JAW_OPEN] - self.args.jaw_open_min_value) / jaw_open_denom, 0.0, 1.0)
|
| 395 |
+
pose[self.mouth_aaa_index] = mouth_open
|
| 396 |
+
pose[self.mouth_raised_corner_left_index] = clamp(smile_value, 0.0, 1.0)
|
| 397 |
+
pose[self.mouth_raised_corner_right_index] = clamp(smile_value, 0.0, 1.0)
|
| 398 |
+
|
| 399 |
+
is_mouth_open = mouth_open > 0.0
|
| 400 |
+
if not is_mouth_open:
|
| 401 |
+
mouth_frown_value = clamp(
|
| 402 |
+
(ifacialmocap_pose[MOUTH_FROWN_LEFT] + ifacialmocap_pose[
|
| 403 |
+
MOUTH_FROWN_RIGHT]) / self.args.mouth_frown_max_value, 0.0, 1.0)
|
| 404 |
+
pose[self.mouth_lowered_corner_left_index] = mouth_frown_value
|
| 405 |
+
pose[self.mouth_lowered_corner_right_index] = mouth_frown_value
|
| 406 |
+
else:
|
| 407 |
+
mouth_lower_down = clamp(
|
| 408 |
+
ifacialmocap_pose[MOUTH_LOWER_DOWN_LEFT] + ifacialmocap_pose[MOUTH_LOWER_DOWN_RIGHT], 0.0, 1.0)
|
| 409 |
+
mouth_funnel = ifacialmocap_pose[MOUTH_FUNNEL]
|
| 410 |
+
mouth_pucker = ifacialmocap_pose[MOUTH_PUCKER]
|
| 411 |
+
|
| 412 |
+
mouth_point = [mouth_open, mouth_lower_down, mouth_funnel, mouth_pucker]
|
| 413 |
+
|
| 414 |
+
aaa_point = [1.0, 1.0, 0.0, 0.0]
|
| 415 |
+
iii_point = [0.0, 1.0, 0.0, 0.0]
|
| 416 |
+
uuu_point = [0.5, 0.3, 0.25, 0.75]
|
| 417 |
+
ooo_point = [1.0, 0.5, 0.5, 0.4]
|
| 418 |
+
|
| 419 |
+
decomp = numpy.array([0, 0, 0, 0])
|
| 420 |
+
M = numpy.array([
|
| 421 |
+
aaa_point,
|
| 422 |
+
iii_point,
|
| 423 |
+
uuu_point,
|
| 424 |
+
ooo_point
|
| 425 |
+
])
|
| 426 |
+
|
| 427 |
+
def loss(decomp):
|
| 428 |
+
return numpy.linalg.norm(numpy.matmul(decomp, M) - mouth_point) \
|
| 429 |
+
+ 0.01 * numpy.linalg.norm(decomp, ord=1)
|
| 430 |
+
|
| 431 |
+
opt_result = scipy.optimize.minimize(
|
| 432 |
+
loss, decomp, bounds=[(0.0, 1.0), (0.0, 1.0), (0.0, 1.0), (0.0, 1.0)])
|
| 433 |
+
decomp = opt_result["x"]
|
| 434 |
+
restricted_decomp = [decomp.item(0), decomp.item(1), decomp.item(2), decomp.item(3)]
|
| 435 |
+
pose[self.mouth_aaa_index] = restricted_decomp[0]
|
| 436 |
+
pose[self.mouth_iii_index] = restricted_decomp[1]
|
| 437 |
+
mouth_funnel_denom = self.args.mouth_funnel_max_value - self.args.mouth_funnel_min_value
|
| 438 |
+
ooo_alpha = clamp((mouth_funnel - self.args.mouth_funnel_min_value) / mouth_funnel_denom, 0.0, 1.0)
|
| 439 |
+
uo_value = clamp(restricted_decomp[2] + restricted_decomp[3], 0.0, 1.0)
|
| 440 |
+
pose[self.mouth_uuu_index] = uo_value * (1.0 - ooo_alpha)
|
| 441 |
+
pose[self.mouth_ooo_index] = uo_value * ooo_alpha
|
| 442 |
+
|
| 443 |
+
if self.panel is not None:
|
| 444 |
+
frequency = self.breathing_frequency_slider.GetValue()
|
| 445 |
+
if frequency == 0:
|
| 446 |
+
value = 0.0
|
| 447 |
+
pose[self.breathing_index] = value
|
| 448 |
+
self.breathing_start_time = time.time()
|
| 449 |
+
else:
|
| 450 |
+
period = 60.0 / frequency
|
| 451 |
+
now = time.time()
|
| 452 |
+
diff = now - self.breathing_start_time
|
| 453 |
+
frac = (diff % period) / period
|
| 454 |
+
value = (-math.cos(2 * math.pi * frac) + 1.0) / 2.0
|
| 455 |
+
pose[self.breathing_index] = value
|
| 456 |
+
self.breathing_gauge.SetValue(int(1000 * value))
|
| 457 |
+
|
| 458 |
+
return pose
|
| 459 |
+
|
| 460 |
+
|
| 461 |
+
def create_ifacialmocap_pose_converter(
|
| 462 |
+
args: Optional[IFacialMocapPoseConverter25Args] = None) -> IFacialMocapPoseConverter:
|
| 463 |
+
return IFacialMocapPoseConverter25(args)
|
tha3/mocap/ifacialmocap_v2.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
|
| 3 |
+
from tha3.mocap.ifacialmocap_constants import BLENDSHAPE_NAMES, HEAD_BONE_X, HEAD_BONE_Y, HEAD_BONE_Z, \
|
| 4 |
+
RIGHT_EYE_BONE_X, RIGHT_EYE_BONE_Y, RIGHT_EYE_BONE_Z, LEFT_EYE_BONE_X, LEFT_EYE_BONE_Y, LEFT_EYE_BONE_Z, \
|
| 5 |
+
HEAD_BONE_QUAT, LEFT_EYE_BONE_QUAT, RIGHT_EYE_BONE_QUAT
|
| 6 |
+
|
| 7 |
+
IFACIALMOCAP_PORT = 49983
|
| 8 |
+
IFACIALMOCAP_START_STRING = "iFacialMocap_sahuasouryya9218sauhuiayeta91555dy3719|sendDataVersion=v2".encode('utf-8')
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def parse_ifacialmocap_v2_pose(ifacialmocap_output):
|
| 12 |
+
output = {}
|
| 13 |
+
parts = ifacialmocap_output.split("|")
|
| 14 |
+
for part in parts:
|
| 15 |
+
part = part.strip()
|
| 16 |
+
if len(part) == 0:
|
| 17 |
+
continue
|
| 18 |
+
if "&" in part:
|
| 19 |
+
components = part.split("&")
|
| 20 |
+
assert len(components) == 2
|
| 21 |
+
key = components[0]
|
| 22 |
+
value = float(components[1]) / 100.0
|
| 23 |
+
if key.endswith("_L"):
|
| 24 |
+
key = key[:-2] + "Left"
|
| 25 |
+
elif key.endswith("_R"):
|
| 26 |
+
key = key[:-2] + "Right"
|
| 27 |
+
if key in BLENDSHAPE_NAMES:
|
| 28 |
+
output[key] = value
|
| 29 |
+
elif part.startswith("=head#"):
|
| 30 |
+
components = part[len("=head#"):].split(",")
|
| 31 |
+
assert len(components) == 6
|
| 32 |
+
output[HEAD_BONE_X] = float(components[0]) * math.pi / 180
|
| 33 |
+
output[HEAD_BONE_Y] = float(components[1]) * math.pi / 180
|
| 34 |
+
output[HEAD_BONE_Z] = float(components[2]) * math.pi / 180
|
| 35 |
+
elif part.startswith("rightEye#"):
|
| 36 |
+
components = part[len("rightEye#"):].split(",")
|
| 37 |
+
output[RIGHT_EYE_BONE_X] = float(components[0]) * math.pi / 180
|
| 38 |
+
output[RIGHT_EYE_BONE_Y] = float(components[1]) * math.pi / 180
|
| 39 |
+
output[RIGHT_EYE_BONE_Z] = float(components[2]) * math.pi / 180
|
| 40 |
+
elif part.startswith("leftEye#"):
|
| 41 |
+
components = part[len("leftEye#"):].split(",")
|
| 42 |
+
output[LEFT_EYE_BONE_X] = float(components[0]) * math.pi / 180
|
| 43 |
+
output[LEFT_EYE_BONE_Y] = float(components[1]) * math.pi / 180
|
| 44 |
+
output[LEFT_EYE_BONE_Z] = float(components[2]) * math.pi / 180
|
| 45 |
+
output[HEAD_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 46 |
+
output[LEFT_EYE_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 47 |
+
output[RIGHT_EYE_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 48 |
+
return output
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def parse_ifacialmocap_v1_pose(ifacialmocap_output):
|
| 52 |
+
output = {}
|
| 53 |
+
parts = ifacialmocap_output.split("|")
|
| 54 |
+
for part in parts:
|
| 55 |
+
part = part.strip()
|
| 56 |
+
if len(part) == 0:
|
| 57 |
+
continue
|
| 58 |
+
if part.startswith("=head#"):
|
| 59 |
+
components = part[len("=head#"):].split(",")
|
| 60 |
+
assert len(components) == 6
|
| 61 |
+
output[HEAD_BONE_X] = float(components[0]) * math.pi / 180
|
| 62 |
+
output[HEAD_BONE_Y] = float(components[1]) * math.pi / 180
|
| 63 |
+
output[HEAD_BONE_Z] = float(components[2]) * math.pi / 180
|
| 64 |
+
elif part.startswith("rightEye#"):
|
| 65 |
+
components = part[len("rightEye#"):].split(",")
|
| 66 |
+
output[RIGHT_EYE_BONE_X] = float(components[0]) * math.pi / 180
|
| 67 |
+
output[RIGHT_EYE_BONE_Y] = float(components[1]) * math.pi / 180
|
| 68 |
+
output[RIGHT_EYE_BONE_Z] = float(components[2]) * math.pi / 180
|
| 69 |
+
elif part.startswith("leftEye#"):
|
| 70 |
+
components = part[len("leftEye#"):].split(",")
|
| 71 |
+
output[LEFT_EYE_BONE_X] = float(components[0]) * math.pi / 180
|
| 72 |
+
output[LEFT_EYE_BONE_Y] = float(components[1]) * math.pi / 180
|
| 73 |
+
output[LEFT_EYE_BONE_Z] = float(components[2]) * math.pi / 180
|
| 74 |
+
else:
|
| 75 |
+
components = part.split("-")
|
| 76 |
+
assert len(components) == 2
|
| 77 |
+
key = components[0]
|
| 78 |
+
value = float(components[1]) / 100.0
|
| 79 |
+
if key.endswith("_L"):
|
| 80 |
+
key = key[:-2] + "Left"
|
| 81 |
+
elif key.endswith("_R"):
|
| 82 |
+
key = key[:-2] + "Right"
|
| 83 |
+
if key in BLENDSHAPE_NAMES:
|
| 84 |
+
output[key] = value
|
| 85 |
+
output[HEAD_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 86 |
+
output[LEFT_EYE_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 87 |
+
output[RIGHT_EYE_BONE_QUAT] = [0.0, 0.0, 0.0, 1.0]
|
| 88 |
+
return output
|
| 89 |
+
|
tha3/module/__init__.py
ADDED
|
File without changes
|
tha3/module/module_factory.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
|
| 3 |
+
from torch.nn import Module
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ModuleFactory(ABC):
|
| 7 |
+
@abstractmethod
|
| 8 |
+
def create(self) -> Module:
|
| 9 |
+
pass
|
tha3/nn/__init__.py
ADDED
|
File without changes
|
tha3/nn/common/__init__.py
ADDED
|
File without changes
|
tha3/nn/common/conv_block_factory.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
from tha3.nn.conv import create_conv7_block_from_block_args, create_conv3_block_from_block_args, \
|
| 4 |
+
create_downsample_block_from_block_args, create_conv3
|
| 5 |
+
from tha3.nn.resnet_block import ResnetBlock
|
| 6 |
+
from tha3.nn.resnet_block_seperable import ResnetBlockSeparable
|
| 7 |
+
from tha3.nn.separable_conv import create_separable_conv7_block, create_separable_conv3_block, \
|
| 8 |
+
create_separable_downsample_block, create_separable_conv3
|
| 9 |
+
from tha3.nn.util import BlockArgs
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class ConvBlockFactory:
|
| 13 |
+
def __init__(self,
|
| 14 |
+
block_args: BlockArgs,
|
| 15 |
+
use_separable_convolution: bool = False):
|
| 16 |
+
self.use_separable_convolution = use_separable_convolution
|
| 17 |
+
self.block_args = block_args
|
| 18 |
+
|
| 19 |
+
def create_conv3(self,
|
| 20 |
+
in_channels: int,
|
| 21 |
+
out_channels: int,
|
| 22 |
+
bias: bool,
|
| 23 |
+
initialization_method: Optional[str] = None):
|
| 24 |
+
if initialization_method is None:
|
| 25 |
+
initialization_method = self.block_args.initialization_method
|
| 26 |
+
if self.use_separable_convolution:
|
| 27 |
+
return create_separable_conv3(
|
| 28 |
+
in_channels, out_channels, bias, initialization_method, self.block_args.use_spectral_norm)
|
| 29 |
+
else:
|
| 30 |
+
return create_conv3(
|
| 31 |
+
in_channels, out_channels, bias, initialization_method, self.block_args.use_spectral_norm)
|
| 32 |
+
|
| 33 |
+
def create_conv7_block(self, in_channels: int, out_channels: int):
|
| 34 |
+
if self.use_separable_convolution:
|
| 35 |
+
return create_separable_conv7_block(in_channels, out_channels, self.block_args)
|
| 36 |
+
else:
|
| 37 |
+
return create_conv7_block_from_block_args(in_channels, out_channels, self.block_args)
|
| 38 |
+
|
| 39 |
+
def create_conv3_block(self, in_channels: int, out_channels: int):
|
| 40 |
+
if self.use_separable_convolution:
|
| 41 |
+
return create_separable_conv3_block(in_channels, out_channels, self.block_args)
|
| 42 |
+
else:
|
| 43 |
+
return create_conv3_block_from_block_args(in_channels, out_channels, self.block_args)
|
| 44 |
+
|
| 45 |
+
def create_downsample_block(self, in_channels: int, out_channels: int, is_output_1x1: bool):
|
| 46 |
+
if self.use_separable_convolution:
|
| 47 |
+
return create_separable_downsample_block(in_channels, out_channels, is_output_1x1, self.block_args)
|
| 48 |
+
else:
|
| 49 |
+
return create_downsample_block_from_block_args(in_channels, out_channels, is_output_1x1)
|
| 50 |
+
|
| 51 |
+
def create_resnet_block(self, num_channels: int, is_1x1: bool):
|
| 52 |
+
if self.use_separable_convolution:
|
| 53 |
+
return ResnetBlockSeparable.create(num_channels, is_1x1, block_args=self.block_args)
|
| 54 |
+
else:
|
| 55 |
+
return ResnetBlock.create(num_channels, is_1x1, block_args=self.block_args)
|
tha3/nn/common/poser_args.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
from torch.nn import Sigmoid, Sequential, Tanh
|
| 4 |
+
|
| 5 |
+
from tha3.nn.conv import create_conv3, create_conv3_from_block_args
|
| 6 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 7 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 8 |
+
from tha3.nn.util import BlockArgs
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class PoserArgs00:
|
| 12 |
+
def __init__(self,
|
| 13 |
+
image_size: int,
|
| 14 |
+
input_image_channels: int,
|
| 15 |
+
output_image_channels: int,
|
| 16 |
+
start_channels: int,
|
| 17 |
+
num_pose_params: int,
|
| 18 |
+
block_args: Optional[BlockArgs] = None):
|
| 19 |
+
self.num_pose_params = num_pose_params
|
| 20 |
+
self.start_channels = start_channels
|
| 21 |
+
self.output_image_channels = output_image_channels
|
| 22 |
+
self.input_image_channels = input_image_channels
|
| 23 |
+
self.image_size = image_size
|
| 24 |
+
if block_args is None:
|
| 25 |
+
self.block_args = BlockArgs(
|
| 26 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 27 |
+
nonlinearity_factory=ReLUFactory(inplace=True))
|
| 28 |
+
else:
|
| 29 |
+
self.block_args = block_args
|
| 30 |
+
|
| 31 |
+
def create_alpha_block(self):
|
| 32 |
+
from torch.nn import Sequential
|
| 33 |
+
return Sequential(
|
| 34 |
+
create_conv3(
|
| 35 |
+
in_channels=self.start_channels,
|
| 36 |
+
out_channels=1,
|
| 37 |
+
bias=True,
|
| 38 |
+
initialization_method=self.block_args.initialization_method,
|
| 39 |
+
use_spectral_norm=False),
|
| 40 |
+
Sigmoid())
|
| 41 |
+
|
| 42 |
+
def create_all_channel_alpha_block(self):
|
| 43 |
+
from torch.nn import Sequential
|
| 44 |
+
return Sequential(
|
| 45 |
+
create_conv3(
|
| 46 |
+
in_channels=self.start_channels,
|
| 47 |
+
out_channels=self.output_image_channels,
|
| 48 |
+
bias=True,
|
| 49 |
+
initialization_method=self.block_args.initialization_method,
|
| 50 |
+
use_spectral_norm=False),
|
| 51 |
+
Sigmoid())
|
| 52 |
+
|
| 53 |
+
def create_color_change_block(self):
|
| 54 |
+
return Sequential(
|
| 55 |
+
create_conv3_from_block_args(
|
| 56 |
+
in_channels=self.start_channels,
|
| 57 |
+
out_channels=self.output_image_channels,
|
| 58 |
+
bias=True,
|
| 59 |
+
block_args=self.block_args),
|
| 60 |
+
Tanh())
|
| 61 |
+
|
| 62 |
+
def create_grid_change_block(self):
|
| 63 |
+
return create_conv3(
|
| 64 |
+
in_channels=self.start_channels,
|
| 65 |
+
out_channels=2,
|
| 66 |
+
bias=False,
|
| 67 |
+
initialization_method='zero',
|
| 68 |
+
use_spectral_norm=False)
|
tha3/nn/common/poser_encoder_decoder_00.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Optional, List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import ModuleList, Module
|
| 7 |
+
|
| 8 |
+
from tha3.nn.common.poser_args import PoserArgs00
|
| 9 |
+
from tha3.nn.conv import create_conv3_block_from_block_args, create_downsample_block_from_block_args, \
|
| 10 |
+
create_upsample_block_from_block_args
|
| 11 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 12 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 13 |
+
from tha3.nn.resnet_block import ResnetBlock
|
| 14 |
+
from tha3.nn.util import BlockArgs
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class PoserEncoderDecoder00Args(PoserArgs00):
|
| 18 |
+
def __init__(self,
|
| 19 |
+
image_size: int,
|
| 20 |
+
input_image_channels: int,
|
| 21 |
+
output_image_channels: int,
|
| 22 |
+
num_pose_params: int ,
|
| 23 |
+
start_channels: int,
|
| 24 |
+
bottleneck_image_size,
|
| 25 |
+
num_bottleneck_blocks,
|
| 26 |
+
max_channels: int,
|
| 27 |
+
block_args: Optional[BlockArgs] = None):
|
| 28 |
+
super().__init__(
|
| 29 |
+
image_size, input_image_channels, output_image_channels, start_channels, num_pose_params, block_args)
|
| 30 |
+
self.max_channels = max_channels
|
| 31 |
+
self.num_bottleneck_blocks = num_bottleneck_blocks
|
| 32 |
+
self.bottleneck_image_size = bottleneck_image_size
|
| 33 |
+
assert bottleneck_image_size > 1
|
| 34 |
+
|
| 35 |
+
if block_args is None:
|
| 36 |
+
self.block_args = BlockArgs(
|
| 37 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 38 |
+
nonlinearity_factory=ReLUFactory(inplace=True))
|
| 39 |
+
else:
|
| 40 |
+
self.block_args = block_args
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class PoserEncoderDecoder00(Module):
|
| 44 |
+
def __init__(self, args: PoserEncoderDecoder00Args):
|
| 45 |
+
super().__init__()
|
| 46 |
+
self.args = args
|
| 47 |
+
|
| 48 |
+
self.num_levels = int(math.log2(args.image_size // args.bottleneck_image_size)) + 1
|
| 49 |
+
|
| 50 |
+
self.downsample_blocks = ModuleList()
|
| 51 |
+
self.downsample_blocks.append(
|
| 52 |
+
create_conv3_block_from_block_args(
|
| 53 |
+
args.input_image_channels,
|
| 54 |
+
args.start_channels,
|
| 55 |
+
args.block_args))
|
| 56 |
+
current_image_size = args.image_size
|
| 57 |
+
current_num_channels = args.start_channels
|
| 58 |
+
while current_image_size > args.bottleneck_image_size:
|
| 59 |
+
next_image_size = current_image_size // 2
|
| 60 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 61 |
+
self.downsample_blocks.append(create_downsample_block_from_block_args(
|
| 62 |
+
in_channels=current_num_channels,
|
| 63 |
+
out_channels=next_num_channels,
|
| 64 |
+
is_output_1x1=False,
|
| 65 |
+
block_args=args.block_args))
|
| 66 |
+
current_image_size = next_image_size
|
| 67 |
+
current_num_channels = next_num_channels
|
| 68 |
+
assert len(self.downsample_blocks) == self.num_levels
|
| 69 |
+
|
| 70 |
+
self.bottleneck_blocks = ModuleList()
|
| 71 |
+
self.bottleneck_blocks.append(create_conv3_block_from_block_args(
|
| 72 |
+
in_channels=current_num_channels + args.num_pose_params,
|
| 73 |
+
out_channels=current_num_channels,
|
| 74 |
+
block_args=args.block_args))
|
| 75 |
+
for i in range(1, args.num_bottleneck_blocks):
|
| 76 |
+
self.bottleneck_blocks.append(
|
| 77 |
+
ResnetBlock.create(
|
| 78 |
+
num_channels=current_num_channels,
|
| 79 |
+
is1x1=False,
|
| 80 |
+
block_args=args.block_args))
|
| 81 |
+
|
| 82 |
+
self.upsample_blocks = ModuleList()
|
| 83 |
+
while current_image_size < args.image_size:
|
| 84 |
+
next_image_size = current_image_size * 2
|
| 85 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 86 |
+
self.upsample_blocks.append(create_upsample_block_from_block_args(
|
| 87 |
+
in_channels=current_num_channels,
|
| 88 |
+
out_channels=next_num_channels,
|
| 89 |
+
block_args=args.block_args))
|
| 90 |
+
current_image_size = next_image_size
|
| 91 |
+
current_num_channels = next_num_channels
|
| 92 |
+
|
| 93 |
+
def get_num_output_channels_from_level(self, level: int):
|
| 94 |
+
return self.get_num_output_channels_from_image_size(self.args.image_size // (2 ** level))
|
| 95 |
+
|
| 96 |
+
def get_num_output_channels_from_image_size(self, image_size: int):
|
| 97 |
+
return min(self.args.start_channels * (self.args.image_size // image_size), self.args.max_channels)
|
| 98 |
+
|
| 99 |
+
def forward(self, image: Tensor, pose: Optional[Tensor] = None) -> List[Tensor]:
|
| 100 |
+
if self.args.num_pose_params != 0:
|
| 101 |
+
assert pose is not None
|
| 102 |
+
else:
|
| 103 |
+
assert pose is None
|
| 104 |
+
outputs = []
|
| 105 |
+
feature = image
|
| 106 |
+
outputs.append(feature)
|
| 107 |
+
for block in self.downsample_blocks:
|
| 108 |
+
feature = block(feature)
|
| 109 |
+
outputs.append(feature)
|
| 110 |
+
if pose is not None:
|
| 111 |
+
n, c = pose.shape
|
| 112 |
+
pose = pose.view(n, c, 1, 1).repeat(1, 1, self.args.bottleneck_image_size, self.args.bottleneck_image_size)
|
| 113 |
+
feature = torch.cat([feature, pose], dim=1)
|
| 114 |
+
for block in self.bottleneck_blocks:
|
| 115 |
+
feature = block(feature)
|
| 116 |
+
outputs.append(feature)
|
| 117 |
+
for block in self.upsample_blocks:
|
| 118 |
+
feature = block(feature)
|
| 119 |
+
outputs.append(feature)
|
| 120 |
+
outputs.reverse()
|
| 121 |
+
return outputs
|
tha3/nn/common/poser_encoder_decoder_00_separable.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Optional, List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import ModuleList, Module
|
| 7 |
+
|
| 8 |
+
from tha3.nn.common.poser_encoder_decoder_00 import PoserEncoderDecoder00Args
|
| 9 |
+
from tha3.nn.resnet_block_seperable import ResnetBlockSeparable
|
| 10 |
+
from tha3.nn.separable_conv import create_separable_conv3_block, create_separable_downsample_block, \
|
| 11 |
+
create_separable_upsample_block
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class PoserEncoderDecoder00Separable(Module):
|
| 15 |
+
def __init__(self, args: PoserEncoderDecoder00Args):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.args = args
|
| 18 |
+
|
| 19 |
+
self.num_levels = int(math.log2(args.image_size // args.bottleneck_image_size)) + 1
|
| 20 |
+
|
| 21 |
+
self.downsample_blocks = ModuleList()
|
| 22 |
+
self.downsample_blocks.append(
|
| 23 |
+
create_separable_conv3_block(
|
| 24 |
+
args.input_image_channels,
|
| 25 |
+
args.start_channels,
|
| 26 |
+
args.block_args))
|
| 27 |
+
current_image_size = args.image_size
|
| 28 |
+
current_num_channels = args.start_channels
|
| 29 |
+
while current_image_size > args.bottleneck_image_size:
|
| 30 |
+
next_image_size = current_image_size // 2
|
| 31 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 32 |
+
self.downsample_blocks.append(create_separable_downsample_block(
|
| 33 |
+
in_channels=current_num_channels,
|
| 34 |
+
out_channels=next_num_channels,
|
| 35 |
+
is_output_1x1=False,
|
| 36 |
+
block_args=args.block_args))
|
| 37 |
+
current_image_size = next_image_size
|
| 38 |
+
current_num_channels = next_num_channels
|
| 39 |
+
assert len(self.downsample_blocks) == self.num_levels
|
| 40 |
+
|
| 41 |
+
self.bottleneck_blocks = ModuleList()
|
| 42 |
+
self.bottleneck_blocks.append(create_separable_conv3_block(
|
| 43 |
+
in_channels=current_num_channels + args.num_pose_params,
|
| 44 |
+
out_channels=current_num_channels,
|
| 45 |
+
block_args=args.block_args))
|
| 46 |
+
for i in range(1, args.num_bottleneck_blocks):
|
| 47 |
+
self.bottleneck_blocks.append(
|
| 48 |
+
ResnetBlockSeparable.create(
|
| 49 |
+
num_channels=current_num_channels,
|
| 50 |
+
is1x1=False,
|
| 51 |
+
block_args=args.block_args))
|
| 52 |
+
|
| 53 |
+
self.upsample_blocks = ModuleList()
|
| 54 |
+
while current_image_size < args.image_size:
|
| 55 |
+
next_image_size = current_image_size * 2
|
| 56 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 57 |
+
self.upsample_blocks.append(create_separable_upsample_block(
|
| 58 |
+
in_channels=current_num_channels,
|
| 59 |
+
out_channels=next_num_channels,
|
| 60 |
+
block_args=args.block_args))
|
| 61 |
+
current_image_size = next_image_size
|
| 62 |
+
current_num_channels = next_num_channels
|
| 63 |
+
|
| 64 |
+
def get_num_output_channels_from_level(self, level: int):
|
| 65 |
+
return self.get_num_output_channels_from_image_size(self.args.image_size // (2 ** level))
|
| 66 |
+
|
| 67 |
+
def get_num_output_channels_from_image_size(self, image_size: int):
|
| 68 |
+
return min(self.args.start_channels * (self.args.image_size // image_size), self.args.max_channels)
|
| 69 |
+
|
| 70 |
+
def forward(self, image: Tensor, pose: Optional[Tensor] = None) -> List[Tensor]:
|
| 71 |
+
if self.args.num_pose_params != 0:
|
| 72 |
+
assert pose is not None
|
| 73 |
+
else:
|
| 74 |
+
assert pose is None
|
| 75 |
+
outputs = []
|
| 76 |
+
feature = image
|
| 77 |
+
outputs.append(feature)
|
| 78 |
+
for block in self.downsample_blocks:
|
| 79 |
+
feature = block(feature)
|
| 80 |
+
outputs.append(feature)
|
| 81 |
+
if pose is not None:
|
| 82 |
+
n, c = pose.shape
|
| 83 |
+
pose = pose.view(n, c, 1, 1).repeat(1, 1, self.args.bottleneck_image_size, self.args.bottleneck_image_size)
|
| 84 |
+
feature = torch.cat([feature, pose], dim=1)
|
| 85 |
+
for block in self.bottleneck_blocks:
|
| 86 |
+
feature = block(feature)
|
| 87 |
+
outputs.append(feature)
|
| 88 |
+
for block in self.upsample_blocks:
|
| 89 |
+
feature = block(feature)
|
| 90 |
+
outputs.append(feature)
|
| 91 |
+
outputs.reverse()
|
| 92 |
+
return outputs
|
tha3/nn/common/resize_conv_encoder_decoder.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Optional, List
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import Module, ModuleList, Sequential, Upsample
|
| 7 |
+
|
| 8 |
+
from tha3.nn.common.conv_block_factory import ConvBlockFactory
|
| 9 |
+
from tha3.nn.nonlinearity_factory import LeakyReLUFactory
|
| 10 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 11 |
+
from tha3.nn.util import BlockArgs
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class ResizeConvEncoderDecoderArgs:
|
| 15 |
+
def __init__(self,
|
| 16 |
+
image_size: int,
|
| 17 |
+
input_channels: int,
|
| 18 |
+
start_channels: int,
|
| 19 |
+
bottleneck_image_size,
|
| 20 |
+
num_bottleneck_blocks,
|
| 21 |
+
max_channels: int,
|
| 22 |
+
block_args: Optional[BlockArgs] = None,
|
| 23 |
+
upsample_mode: str = 'bilinear',
|
| 24 |
+
use_separable_convolution=False):
|
| 25 |
+
self.use_separable_convolution = use_separable_convolution
|
| 26 |
+
self.upsample_mode = upsample_mode
|
| 27 |
+
self.block_args = block_args
|
| 28 |
+
self.max_channels = max_channels
|
| 29 |
+
self.num_bottleneck_blocks = num_bottleneck_blocks
|
| 30 |
+
self.bottleneck_image_size = bottleneck_image_size
|
| 31 |
+
self.start_channels = start_channels
|
| 32 |
+
self.image_size = image_size
|
| 33 |
+
self.input_channels = input_channels
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class ResizeConvEncoderDecoder(Module):
|
| 37 |
+
def __init__(self, args: ResizeConvEncoderDecoderArgs):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.args = args
|
| 40 |
+
|
| 41 |
+
self.num_levels = int(math.log2(args.image_size // args.bottleneck_image_size)) + 1
|
| 42 |
+
|
| 43 |
+
conv_block_factory = ConvBlockFactory(args.block_args, args.use_separable_convolution)
|
| 44 |
+
|
| 45 |
+
self.downsample_blocks = ModuleList()
|
| 46 |
+
self.downsample_blocks.append(conv_block_factory.create_conv7_block(args.input_channels, args.start_channels))
|
| 47 |
+
current_image_size = args.image_size
|
| 48 |
+
current_num_channels = args.start_channels
|
| 49 |
+
while current_image_size > args.bottleneck_image_size:
|
| 50 |
+
next_image_size = current_image_size // 2
|
| 51 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 52 |
+
self.downsample_blocks.append(conv_block_factory.create_downsample_block(
|
| 53 |
+
in_channels=current_num_channels,
|
| 54 |
+
out_channels=next_num_channels,
|
| 55 |
+
is_output_1x1=False))
|
| 56 |
+
current_image_size = next_image_size
|
| 57 |
+
current_num_channels = next_num_channels
|
| 58 |
+
assert len(self.downsample_blocks) == self.num_levels
|
| 59 |
+
|
| 60 |
+
self.bottleneck_blocks = ModuleList()
|
| 61 |
+
for i in range(args.num_bottleneck_blocks):
|
| 62 |
+
self.bottleneck_blocks.append(conv_block_factory.create_resnet_block(current_num_channels, is_1x1=False))
|
| 63 |
+
|
| 64 |
+
self.output_image_sizes = [current_image_size]
|
| 65 |
+
self.output_num_channels = [current_num_channels]
|
| 66 |
+
self.upsample_blocks = ModuleList()
|
| 67 |
+
if args.upsample_mode == 'nearest':
|
| 68 |
+
align_corners = None
|
| 69 |
+
else:
|
| 70 |
+
align_corners = False
|
| 71 |
+
while current_image_size < args.image_size:
|
| 72 |
+
next_image_size = current_image_size * 2
|
| 73 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 74 |
+
self.upsample_blocks.append(
|
| 75 |
+
Sequential(
|
| 76 |
+
Upsample(scale_factor=2, mode=args.upsample_mode, align_corners=align_corners),
|
| 77 |
+
conv_block_factory.create_conv3_block(
|
| 78 |
+
in_channels=current_num_channels, out_channels=next_num_channels)))
|
| 79 |
+
current_image_size = next_image_size
|
| 80 |
+
current_num_channels = next_num_channels
|
| 81 |
+
self.output_image_sizes.append(current_image_size)
|
| 82 |
+
self.output_num_channels.append(current_num_channels)
|
| 83 |
+
|
| 84 |
+
def get_num_output_channels_from_level(self, level: int):
|
| 85 |
+
return self.get_num_output_channels_from_image_size(self.args.image_size // (2 ** level))
|
| 86 |
+
|
| 87 |
+
def get_num_output_channels_from_image_size(self, image_size: int):
|
| 88 |
+
return min(self.args.start_channels * (self.args.image_size // image_size), self.args.max_channels)
|
| 89 |
+
|
| 90 |
+
def forward(self, feature: Tensor) -> List[Tensor]:
|
| 91 |
+
outputs = []
|
| 92 |
+
for block in self.downsample_blocks:
|
| 93 |
+
feature = block(feature)
|
| 94 |
+
for block in self.bottleneck_blocks:
|
| 95 |
+
feature = block(feature)
|
| 96 |
+
outputs.append(feature)
|
| 97 |
+
for block in self.upsample_blocks:
|
| 98 |
+
feature = block(feature)
|
| 99 |
+
outputs.append(feature)
|
| 100 |
+
return outputs
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
if __name__ == "__main__":
|
| 104 |
+
device = torch.device('cuda')
|
| 105 |
+
args = ResizeConvEncoderDecoderArgs(
|
| 106 |
+
image_size=512,
|
| 107 |
+
input_channels=4 + 6,
|
| 108 |
+
start_channels=32,
|
| 109 |
+
bottleneck_image_size=32,
|
| 110 |
+
num_bottleneck_blocks=6,
|
| 111 |
+
max_channels=512,
|
| 112 |
+
use_separable_convolution=True,
|
| 113 |
+
block_args=BlockArgs(
|
| 114 |
+
initialization_method='he',
|
| 115 |
+
use_spectral_norm=False,
|
| 116 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 117 |
+
nonlinearity_factory=LeakyReLUFactory(inplace=False, negative_slope=0.1)))
|
| 118 |
+
module = ResizeConvEncoderDecoder(args).to(device)
|
| 119 |
+
print(module.output_image_sizes)
|
| 120 |
+
print(module.output_num_channels)
|
| 121 |
+
|
| 122 |
+
input = torch.zeros(8, 4 + 6, 512, 512, device=device)
|
| 123 |
+
outputs = module(input)
|
| 124 |
+
for output in outputs:
|
| 125 |
+
print(output.shape)
|
tha3/nn/common/resize_conv_unet.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import ModuleList, Module, Upsample
|
| 6 |
+
|
| 7 |
+
from tha3.nn.common.conv_block_factory import ConvBlockFactory
|
| 8 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 9 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 10 |
+
from tha3.nn.util import BlockArgs
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class ResizeConvUNetArgs:
|
| 14 |
+
def __init__(self,
|
| 15 |
+
image_size: int,
|
| 16 |
+
input_channels: int,
|
| 17 |
+
start_channels: int,
|
| 18 |
+
bottleneck_image_size: int,
|
| 19 |
+
num_bottleneck_blocks: int,
|
| 20 |
+
max_channels: int,
|
| 21 |
+
upsample_mode: str = 'bilinear',
|
| 22 |
+
block_args: Optional[BlockArgs] = None,
|
| 23 |
+
use_separable_convolution: bool = False):
|
| 24 |
+
if block_args is None:
|
| 25 |
+
block_args = BlockArgs(
|
| 26 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 27 |
+
nonlinearity_factory=ReLUFactory(inplace=False))
|
| 28 |
+
|
| 29 |
+
self.use_separable_convolution = use_separable_convolution
|
| 30 |
+
self.block_args = block_args
|
| 31 |
+
self.upsample_mode = upsample_mode
|
| 32 |
+
self.max_channels = max_channels
|
| 33 |
+
self.num_bottleneck_blocks = num_bottleneck_blocks
|
| 34 |
+
self.bottleneck_image_size = bottleneck_image_size
|
| 35 |
+
self.input_channels = input_channels
|
| 36 |
+
self.start_channels = start_channels
|
| 37 |
+
self.image_size = image_size
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class ResizeConvUNet(Module):
|
| 41 |
+
def __init__(self, args: ResizeConvUNetArgs):
|
| 42 |
+
super().__init__()
|
| 43 |
+
self.args = args
|
| 44 |
+
conv_block_factory = ConvBlockFactory(args.block_args, args.use_separable_convolution)
|
| 45 |
+
|
| 46 |
+
self.downsample_blocks = ModuleList()
|
| 47 |
+
self.downsample_blocks.append(conv_block_factory.create_conv3_block(
|
| 48 |
+
self.args.input_channels,
|
| 49 |
+
self.args.start_channels))
|
| 50 |
+
current_channels = self.args.start_channels
|
| 51 |
+
current_size = self.args.image_size
|
| 52 |
+
|
| 53 |
+
size_to_channel = {
|
| 54 |
+
current_size: current_channels
|
| 55 |
+
}
|
| 56 |
+
while current_size > self.args.bottleneck_image_size:
|
| 57 |
+
next_size = current_size // 2
|
| 58 |
+
next_channels = min(self.args.max_channels, current_channels * 2)
|
| 59 |
+
self.downsample_blocks.append(conv_block_factory.create_downsample_block(
|
| 60 |
+
current_channels,
|
| 61 |
+
next_channels,
|
| 62 |
+
is_output_1x1=False))
|
| 63 |
+
current_size = next_size
|
| 64 |
+
current_channels = next_channels
|
| 65 |
+
size_to_channel[current_size] = current_channels
|
| 66 |
+
|
| 67 |
+
self.bottleneck_blocks = ModuleList()
|
| 68 |
+
for i in range(self.args.num_bottleneck_blocks):
|
| 69 |
+
self.bottleneck_blocks.append(conv_block_factory.create_resnet_block(current_channels, is_1x1=False))
|
| 70 |
+
|
| 71 |
+
self.output_image_sizes = [current_size]
|
| 72 |
+
self.output_num_channels = [current_channels]
|
| 73 |
+
self.upsample_blocks = ModuleList()
|
| 74 |
+
while current_size < self.args.image_size:
|
| 75 |
+
next_size = current_size * 2
|
| 76 |
+
next_channels = size_to_channel[next_size]
|
| 77 |
+
self.upsample_blocks.append(conv_block_factory.create_conv3_block(
|
| 78 |
+
current_channels + next_channels,
|
| 79 |
+
next_channels))
|
| 80 |
+
current_size = next_size
|
| 81 |
+
current_channels = next_channels
|
| 82 |
+
self.output_image_sizes.append(current_size)
|
| 83 |
+
self.output_num_channels.append(current_channels)
|
| 84 |
+
|
| 85 |
+
if args.upsample_mode == 'nearest':
|
| 86 |
+
align_corners = None
|
| 87 |
+
else:
|
| 88 |
+
align_corners = False
|
| 89 |
+
self.double_resolution = Upsample(scale_factor=2, mode=args.upsample_mode, align_corners=align_corners)
|
| 90 |
+
|
| 91 |
+
def forward(self, feature: Tensor) -> List[Tensor]:
|
| 92 |
+
downsampled_features = []
|
| 93 |
+
for block in self.downsample_blocks:
|
| 94 |
+
feature = block(feature)
|
| 95 |
+
downsampled_features.append(feature)
|
| 96 |
+
|
| 97 |
+
for block in self.bottleneck_blocks:
|
| 98 |
+
feature = block(feature)
|
| 99 |
+
|
| 100 |
+
outputs = [feature]
|
| 101 |
+
for i in range(0, len(self.upsample_blocks)):
|
| 102 |
+
feature = self.double_resolution(feature)
|
| 103 |
+
feature = torch.cat([feature, downsampled_features[-i - 2]], dim=1)
|
| 104 |
+
feature = self.upsample_blocks[i](feature)
|
| 105 |
+
outputs.append(feature)
|
| 106 |
+
|
| 107 |
+
return outputs
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
if __name__ == "__main__":
|
| 111 |
+
device = torch.device('cuda')
|
| 112 |
+
|
| 113 |
+
image_size = 512
|
| 114 |
+
image_channels = 4
|
| 115 |
+
num_pose_params = 6
|
| 116 |
+
args = ResizeConvUNetArgs(
|
| 117 |
+
image_size=512,
|
| 118 |
+
input_channels=10,
|
| 119 |
+
start_channels=32,
|
| 120 |
+
bottleneck_image_size=32,
|
| 121 |
+
num_bottleneck_blocks=6,
|
| 122 |
+
max_channels=512,
|
| 123 |
+
upsample_mode='nearest',
|
| 124 |
+
use_separable_convolution=False,
|
| 125 |
+
block_args=BlockArgs(
|
| 126 |
+
initialization_method='he',
|
| 127 |
+
use_spectral_norm=False,
|
| 128 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 129 |
+
nonlinearity_factory=ReLUFactory(inplace=False)))
|
| 130 |
+
module = ResizeConvUNet(args).to(device)
|
| 131 |
+
|
| 132 |
+
image_count = 8
|
| 133 |
+
input = torch.zeros(image_count, 10, 512, 512, device=device)
|
| 134 |
+
outputs = module.forward(input)
|
| 135 |
+
for output in outputs:
|
| 136 |
+
print(output.shape)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
if True:
|
| 140 |
+
repeat = 100
|
| 141 |
+
acc = 0.0
|
| 142 |
+
for i in range(repeat + 2):
|
| 143 |
+
start = torch.cuda.Event(enable_timing=True)
|
| 144 |
+
end = torch.cuda.Event(enable_timing=True)
|
| 145 |
+
|
| 146 |
+
start.record()
|
| 147 |
+
module.forward(input)
|
| 148 |
+
end.record()
|
| 149 |
+
torch.cuda.synchronize()
|
| 150 |
+
if i >= 2:
|
| 151 |
+
elapsed_time = start.elapsed_time(end)
|
| 152 |
+
print("%d:" % i, elapsed_time)
|
| 153 |
+
acc = acc + elapsed_time
|
| 154 |
+
|
| 155 |
+
print("average:", acc / repeat)
|
tha3/nn/conv.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Union, Callable
|
| 2 |
+
|
| 3 |
+
from torch.nn import Conv2d, Module, Sequential, ConvTranspose2d
|
| 4 |
+
|
| 5 |
+
from tha3.module.module_factory import ModuleFactory
|
| 6 |
+
from tha3.nn.nonlinearity_factory import resolve_nonlinearity_factory
|
| 7 |
+
from tha3.nn.normalization import NormalizationLayerFactory
|
| 8 |
+
from tha3.nn.util import wrap_conv_or_linear_module, BlockArgs
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def create_conv7(in_channels: int, out_channels: int,
|
| 12 |
+
bias: bool = False,
|
| 13 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 14 |
+
use_spectral_norm: bool = False) -> Module:
|
| 15 |
+
return wrap_conv_or_linear_module(
|
| 16 |
+
Conv2d(in_channels, out_channels, kernel_size=7, stride=1, padding=3, bias=bias),
|
| 17 |
+
initialization_method,
|
| 18 |
+
use_spectral_norm)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def create_conv7_from_block_args(in_channels: int,
|
| 22 |
+
out_channels: int,
|
| 23 |
+
bias: bool = False,
|
| 24 |
+
block_args: Optional[BlockArgs] = None) -> Module:
|
| 25 |
+
if block_args is None:
|
| 26 |
+
block_args = BlockArgs()
|
| 27 |
+
return create_conv7(
|
| 28 |
+
in_channels, out_channels, bias,
|
| 29 |
+
block_args.initialization_method,
|
| 30 |
+
block_args.use_spectral_norm)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def create_conv3(in_channels: int,
|
| 34 |
+
out_channels: int,
|
| 35 |
+
bias: bool = False,
|
| 36 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 37 |
+
use_spectral_norm: bool = False) -> Module:
|
| 38 |
+
return wrap_conv_or_linear_module(
|
| 39 |
+
Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=bias),
|
| 40 |
+
initialization_method,
|
| 41 |
+
use_spectral_norm)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def create_conv3_from_block_args(in_channels: int, out_channels: int,
|
| 45 |
+
bias: bool = False,
|
| 46 |
+
block_args: Optional[BlockArgs] = None):
|
| 47 |
+
if block_args is None:
|
| 48 |
+
block_args = BlockArgs()
|
| 49 |
+
return create_conv3(in_channels, out_channels, bias,
|
| 50 |
+
block_args.initialization_method,
|
| 51 |
+
block_args.use_spectral_norm)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def create_conv1(in_channels: int, out_channels: int,
|
| 55 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 56 |
+
bias: bool = False,
|
| 57 |
+
use_spectral_norm: bool = False) -> Module:
|
| 58 |
+
return wrap_conv_or_linear_module(
|
| 59 |
+
Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
|
| 60 |
+
initialization_method,
|
| 61 |
+
use_spectral_norm)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def create_conv1_from_block_args(in_channels: int,
|
| 65 |
+
out_channels: int,
|
| 66 |
+
bias: bool = False,
|
| 67 |
+
block_args: Optional[BlockArgs] = None) -> Module:
|
| 68 |
+
if block_args is None:
|
| 69 |
+
block_args = BlockArgs()
|
| 70 |
+
return create_conv1(
|
| 71 |
+
in_channels=in_channels,
|
| 72 |
+
out_channels=out_channels,
|
| 73 |
+
initialization_method=block_args.initialization_method,
|
| 74 |
+
bias=bias,
|
| 75 |
+
use_spectral_norm=block_args.use_spectral_norm)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def create_conv7_block(in_channels: int, out_channels: int,
|
| 79 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 80 |
+
nonlinearity_factory: Optional[ModuleFactory] = None,
|
| 81 |
+
normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
|
| 82 |
+
use_spectral_norm: bool = False) -> Module:
|
| 83 |
+
nonlinearity_factory = resolve_nonlinearity_factory(nonlinearity_factory)
|
| 84 |
+
return Sequential(
|
| 85 |
+
create_conv7(in_channels, out_channels,
|
| 86 |
+
bias=False, initialization_method=initialization_method, use_spectral_norm=use_spectral_norm),
|
| 87 |
+
NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
|
| 88 |
+
resolve_nonlinearity_factory(nonlinearity_factory).create())
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def create_conv7_block_from_block_args(
|
| 92 |
+
in_channels: int, out_channels: int,
|
| 93 |
+
block_args: Optional[BlockArgs] = None) -> Module:
|
| 94 |
+
if block_args is None:
|
| 95 |
+
block_args = BlockArgs()
|
| 96 |
+
return create_conv7_block(in_channels, out_channels,
|
| 97 |
+
block_args.initialization_method,
|
| 98 |
+
block_args.nonlinearity_factory,
|
| 99 |
+
block_args.normalization_layer_factory,
|
| 100 |
+
block_args.use_spectral_norm)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def create_conv3_block(in_channels: int, out_channels: int,
|
| 104 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 105 |
+
nonlinearity_factory: Optional[ModuleFactory] = None,
|
| 106 |
+
normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
|
| 107 |
+
use_spectral_norm: bool = False) -> Module:
|
| 108 |
+
nonlinearity_factory = resolve_nonlinearity_factory(nonlinearity_factory)
|
| 109 |
+
return Sequential(
|
| 110 |
+
create_conv3(in_channels, out_channels,
|
| 111 |
+
bias=False, initialization_method=initialization_method, use_spectral_norm=use_spectral_norm),
|
| 112 |
+
NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
|
| 113 |
+
resolve_nonlinearity_factory(nonlinearity_factory).create())
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def create_conv3_block_from_block_args(
|
| 117 |
+
in_channels: int, out_channels: int, block_args: Optional[BlockArgs] = None):
|
| 118 |
+
if block_args is None:
|
| 119 |
+
block_args = BlockArgs()
|
| 120 |
+
return create_conv3_block(in_channels, out_channels,
|
| 121 |
+
block_args.initialization_method,
|
| 122 |
+
block_args.nonlinearity_factory,
|
| 123 |
+
block_args.normalization_layer_factory,
|
| 124 |
+
block_args.use_spectral_norm)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def create_downsample_block(in_channels: int, out_channels: int,
|
| 128 |
+
is_output_1x1: bool = False,
|
| 129 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 130 |
+
nonlinearity_factory: Optional[ModuleFactory] = None,
|
| 131 |
+
normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
|
| 132 |
+
use_spectral_norm: bool = False) -> Module:
|
| 133 |
+
if is_output_1x1:
|
| 134 |
+
return Sequential(
|
| 135 |
+
wrap_conv_or_linear_module(
|
| 136 |
+
Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
|
| 137 |
+
initialization_method,
|
| 138 |
+
use_spectral_norm),
|
| 139 |
+
resolve_nonlinearity_factory(nonlinearity_factory).create())
|
| 140 |
+
else:
|
| 141 |
+
return Sequential(
|
| 142 |
+
wrap_conv_or_linear_module(
|
| 143 |
+
Conv2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
|
| 144 |
+
initialization_method,
|
| 145 |
+
use_spectral_norm),
|
| 146 |
+
NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
|
| 147 |
+
resolve_nonlinearity_factory(nonlinearity_factory).create())
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def create_downsample_block_from_block_args(in_channels: int, out_channels: int,
|
| 151 |
+
is_output_1x1: bool = False,
|
| 152 |
+
block_args: Optional[BlockArgs] = None):
|
| 153 |
+
if block_args is None:
|
| 154 |
+
block_args = BlockArgs()
|
| 155 |
+
return create_downsample_block(
|
| 156 |
+
in_channels, out_channels,
|
| 157 |
+
is_output_1x1,
|
| 158 |
+
block_args.initialization_method,
|
| 159 |
+
block_args.nonlinearity_factory,
|
| 160 |
+
block_args.normalization_layer_factory,
|
| 161 |
+
block_args.use_spectral_norm)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def create_upsample_block(in_channels: int,
|
| 165 |
+
out_channels: int,
|
| 166 |
+
initialization_method: Union[str, Callable[[Module], Module]] = 'he',
|
| 167 |
+
nonlinearity_factory: Optional[ModuleFactory] = None,
|
| 168 |
+
normalization_layer_factory: Optional[NormalizationLayerFactory] = None,
|
| 169 |
+
use_spectral_norm: bool = False) -> Module:
|
| 170 |
+
nonlinearity_factory = resolve_nonlinearity_factory(nonlinearity_factory)
|
| 171 |
+
return Sequential(
|
| 172 |
+
wrap_conv_or_linear_module(
|
| 173 |
+
ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
|
| 174 |
+
initialization_method,
|
| 175 |
+
use_spectral_norm),
|
| 176 |
+
NormalizationLayerFactory.resolve_2d(normalization_layer_factory).create(out_channels, affine=True),
|
| 177 |
+
resolve_nonlinearity_factory(nonlinearity_factory).create())
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def create_upsample_block_from_block_args(in_channels: int,
|
| 181 |
+
out_channels: int,
|
| 182 |
+
block_args: Optional[BlockArgs] = None) -> Module:
|
| 183 |
+
if block_args is None:
|
| 184 |
+
block_args = BlockArgs()
|
| 185 |
+
return create_upsample_block(in_channels, out_channels,
|
| 186 |
+
block_args.initialization_method,
|
| 187 |
+
block_args.nonlinearity_factory,
|
| 188 |
+
block_args.normalization_layer_factory,
|
| 189 |
+
block_args.use_spectral_norm)
|
tha3/nn/editor/__init__.py
ADDED
|
File without changes
|
tha3/nn/editor/editor_07.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from matplotlib import pyplot
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import Module, Sequential, Tanh, Sigmoid
|
| 7 |
+
|
| 8 |
+
from tha3.nn.image_processing_util import GridChangeApplier, apply_color_change
|
| 9 |
+
from tha3.nn.common.resize_conv_unet import ResizeConvUNet, ResizeConvUNetArgs
|
| 10 |
+
from tha3.util import numpy_linear_to_srgb
|
| 11 |
+
from tha3.module.module_factory import ModuleFactory
|
| 12 |
+
from tha3.nn.conv import create_conv3_from_block_args, create_conv3
|
| 13 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 14 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 15 |
+
from tha3.nn.util import BlockArgs
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Editor07Args:
|
| 19 |
+
def __init__(self,
|
| 20 |
+
image_size: int = 512,
|
| 21 |
+
image_channels: int = 4,
|
| 22 |
+
num_pose_params: int = 6,
|
| 23 |
+
start_channels: int = 32,
|
| 24 |
+
bottleneck_image_size=32,
|
| 25 |
+
num_bottleneck_blocks=6,
|
| 26 |
+
max_channels: int = 512,
|
| 27 |
+
upsampling_mode: str = 'nearest',
|
| 28 |
+
block_args: Optional[BlockArgs] = None,
|
| 29 |
+
use_separable_convolution: bool = False):
|
| 30 |
+
if block_args is None:
|
| 31 |
+
block_args = BlockArgs(
|
| 32 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 33 |
+
nonlinearity_factory=ReLUFactory(inplace=False))
|
| 34 |
+
|
| 35 |
+
self.block_args = block_args
|
| 36 |
+
self.upsampling_mode = upsampling_mode
|
| 37 |
+
self.max_channels = max_channels
|
| 38 |
+
self.num_bottleneck_blocks = num_bottleneck_blocks
|
| 39 |
+
self.bottleneck_image_size = bottleneck_image_size
|
| 40 |
+
self.start_channels = start_channels
|
| 41 |
+
self.num_pose_params = num_pose_params
|
| 42 |
+
self.image_channels = image_channels
|
| 43 |
+
self.image_size = image_size
|
| 44 |
+
self.use_separable_convolution = use_separable_convolution
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class Editor07(Module):
|
| 48 |
+
def __init__(self, args: Editor07Args):
|
| 49 |
+
super().__init__()
|
| 50 |
+
self.args = args
|
| 51 |
+
|
| 52 |
+
self.body = ResizeConvUNet(ResizeConvUNetArgs(
|
| 53 |
+
image_size=args.image_size,
|
| 54 |
+
input_channels=2 * args.image_channels + args.num_pose_params + 2,
|
| 55 |
+
start_channels=args.start_channels,
|
| 56 |
+
bottleneck_image_size=args.bottleneck_image_size,
|
| 57 |
+
num_bottleneck_blocks=args.num_bottleneck_blocks,
|
| 58 |
+
max_channels=args.max_channels,
|
| 59 |
+
upsample_mode=args.upsampling_mode,
|
| 60 |
+
block_args=args.block_args,
|
| 61 |
+
use_separable_convolution=args.use_separable_convolution))
|
| 62 |
+
self.color_change_creator = Sequential(
|
| 63 |
+
create_conv3_from_block_args(
|
| 64 |
+
in_channels=self.args.start_channels,
|
| 65 |
+
out_channels=self.args.image_channels,
|
| 66 |
+
bias=True,
|
| 67 |
+
block_args=self.args.block_args),
|
| 68 |
+
Tanh())
|
| 69 |
+
self.alpha_creator = Sequential(
|
| 70 |
+
create_conv3_from_block_args(
|
| 71 |
+
in_channels=self.args.start_channels,
|
| 72 |
+
out_channels=self.args.image_channels,
|
| 73 |
+
bias=True,
|
| 74 |
+
block_args=self.args.block_args),
|
| 75 |
+
Sigmoid())
|
| 76 |
+
self.grid_change_creator = create_conv3(
|
| 77 |
+
in_channels=self.args.start_channels,
|
| 78 |
+
out_channels=2,
|
| 79 |
+
bias=False,
|
| 80 |
+
initialization_method='zero',
|
| 81 |
+
use_spectral_norm=False)
|
| 82 |
+
self.grid_change_applier = GridChangeApplier()
|
| 83 |
+
|
| 84 |
+
def forward(self,
|
| 85 |
+
input_original_image: Tensor,
|
| 86 |
+
input_warped_image: Tensor,
|
| 87 |
+
input_grid_change: Tensor,
|
| 88 |
+
pose: Tensor,
|
| 89 |
+
*args) -> List[Tensor]:
|
| 90 |
+
n, c = pose.shape
|
| 91 |
+
pose = pose.view(n, c, 1, 1).repeat(1, 1, self.args.image_size, self.args.image_size)
|
| 92 |
+
feature = torch.cat([input_original_image, input_warped_image, input_grid_change, pose], dim=1)
|
| 93 |
+
|
| 94 |
+
feature = self.body.forward(feature)[-1]
|
| 95 |
+
output_grid_change = input_grid_change + self.grid_change_creator(feature)
|
| 96 |
+
|
| 97 |
+
output_color_change = self.color_change_creator(feature)
|
| 98 |
+
output_color_change_alpha = self.alpha_creator(feature)
|
| 99 |
+
output_warped_image = self.grid_change_applier.apply(output_grid_change, input_original_image)
|
| 100 |
+
output_color_changed = apply_color_change(output_color_change_alpha, output_color_change, output_warped_image)
|
| 101 |
+
|
| 102 |
+
return [
|
| 103 |
+
output_color_changed,
|
| 104 |
+
output_color_change_alpha,
|
| 105 |
+
output_color_change,
|
| 106 |
+
output_warped_image,
|
| 107 |
+
output_grid_change,
|
| 108 |
+
]
|
| 109 |
+
|
| 110 |
+
COLOR_CHANGED_IMAGE_INDEX = 0
|
| 111 |
+
COLOR_CHANGE_ALPHA_INDEX = 1
|
| 112 |
+
COLOR_CHANGE_IMAGE_INDEX = 2
|
| 113 |
+
WARPED_IMAGE_INDEX = 3
|
| 114 |
+
GRID_CHANGE_INDEX = 4
|
| 115 |
+
OUTPUT_LENGTH = 5
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class Editor07Factory(ModuleFactory):
|
| 119 |
+
def __init__(self, args: Editor07Args):
|
| 120 |
+
super().__init__()
|
| 121 |
+
self.args = args
|
| 122 |
+
|
| 123 |
+
def create(self) -> Module:
|
| 124 |
+
return Editor07(self.args)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def show_image(pytorch_image):
|
| 128 |
+
numpy_image = ((pytorch_image + 1.0) / 2.0).squeeze(0).numpy()
|
| 129 |
+
numpy_image[0:3, :, :] = numpy_linear_to_srgb(numpy_image[0:3, :, :])
|
| 130 |
+
c, h, w = numpy_image.shape
|
| 131 |
+
numpy_image = numpy_image.reshape((c, h * w)).transpose().reshape((h, w, c))
|
| 132 |
+
pyplot.imshow(numpy_image)
|
| 133 |
+
pyplot.show()
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
if __name__ == "__main__":
|
| 137 |
+
cuda = torch.device('cuda')
|
| 138 |
+
|
| 139 |
+
image_size = 512
|
| 140 |
+
image_channels = 4
|
| 141 |
+
num_pose_params = 6
|
| 142 |
+
args = Editor07Args(
|
| 143 |
+
image_size=512,
|
| 144 |
+
image_channels=4,
|
| 145 |
+
start_channels=32,
|
| 146 |
+
num_pose_params=6,
|
| 147 |
+
bottleneck_image_size=32,
|
| 148 |
+
num_bottleneck_blocks=6,
|
| 149 |
+
max_channels=512,
|
| 150 |
+
upsampling_mode='nearest',
|
| 151 |
+
block_args=BlockArgs(
|
| 152 |
+
initialization_method='he',
|
| 153 |
+
use_spectral_norm=False,
|
| 154 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 155 |
+
nonlinearity_factory=ReLUFactory(inplace=False)))
|
| 156 |
+
module = Editor07(args).to(cuda)
|
| 157 |
+
|
| 158 |
+
image_count = 1
|
| 159 |
+
input_image = torch.zeros(image_count, 4, image_size, image_size, device=cuda)
|
| 160 |
+
direct_image = torch.zeros(image_count, 4, image_size, image_size, device=cuda)
|
| 161 |
+
warped_image = torch.zeros(image_count, 4, image_size, image_size, device=cuda)
|
| 162 |
+
grid_change = torch.zeros(image_count, 2, image_size, image_size, device=cuda)
|
| 163 |
+
pose = torch.zeros(image_count, num_pose_params, device=cuda)
|
| 164 |
+
|
| 165 |
+
repeat = 100
|
| 166 |
+
acc = 0.0
|
| 167 |
+
for i in range(repeat + 2):
|
| 168 |
+
start = torch.cuda.Event(enable_timing=True)
|
| 169 |
+
end = torch.cuda.Event(enable_timing=True)
|
| 170 |
+
|
| 171 |
+
start.record()
|
| 172 |
+
module.forward(input_image, warped_image, grid_change, pose)
|
| 173 |
+
end.record()
|
| 174 |
+
torch.cuda.synchronize()
|
| 175 |
+
if i >= 2:
|
| 176 |
+
elapsed_time = start.elapsed_time(end)
|
| 177 |
+
print("%d:" % i, elapsed_time)
|
| 178 |
+
acc = acc + elapsed_time
|
| 179 |
+
|
| 180 |
+
print("average:", acc / repeat)
|
tha3/nn/eyebrow_decomposer/__init__.py
ADDED
|
File without changes
|
tha3/nn/eyebrow_decomposer/eyebrow_decomposer_00.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Module
|
| 6 |
+
|
| 7 |
+
from tha3.nn.common.poser_encoder_decoder_00 import PoserEncoderDecoder00Args, PoserEncoderDecoder00
|
| 8 |
+
from tha3.nn.image_processing_util import apply_color_change
|
| 9 |
+
from tha3.module.module_factory import ModuleFactory
|
| 10 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 11 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 12 |
+
from tha3.nn.util import BlockArgs
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class EyebrowDecomposer00Args(PoserEncoderDecoder00Args):
|
| 16 |
+
def __init__(self,
|
| 17 |
+
image_size: int = 128,
|
| 18 |
+
image_channels: int = 4,
|
| 19 |
+
start_channels: int = 64,
|
| 20 |
+
bottleneck_image_size=16,
|
| 21 |
+
num_bottleneck_blocks=6,
|
| 22 |
+
max_channels: int = 512,
|
| 23 |
+
block_args: Optional[BlockArgs] = None):
|
| 24 |
+
super().__init__(
|
| 25 |
+
image_size,
|
| 26 |
+
image_channels,
|
| 27 |
+
image_channels,
|
| 28 |
+
0,
|
| 29 |
+
start_channels,
|
| 30 |
+
bottleneck_image_size,
|
| 31 |
+
num_bottleneck_blocks,
|
| 32 |
+
max_channels,
|
| 33 |
+
block_args)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class EyebrowDecomposer00(Module):
|
| 37 |
+
def __init__(self, args: EyebrowDecomposer00Args):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.args = args
|
| 40 |
+
self.body = PoserEncoderDecoder00(args)
|
| 41 |
+
self.background_layer_alpha = self.args.create_alpha_block()
|
| 42 |
+
self.background_layer_color_change = self.args.create_color_change_block()
|
| 43 |
+
self.eyebrow_layer_alpha = self.args.create_alpha_block()
|
| 44 |
+
self.eyebrow_layer_color_change = self.args.create_color_change_block()
|
| 45 |
+
|
| 46 |
+
def forward(self, image: Tensor, *args) -> List[Tensor]:
|
| 47 |
+
feature = self.body(image)[0]
|
| 48 |
+
|
| 49 |
+
background_layer_alpha = self.background_layer_alpha(feature)
|
| 50 |
+
background_layer_color_change = self.background_layer_color_change(feature)
|
| 51 |
+
background_layer_1 = apply_color_change(background_layer_alpha, background_layer_color_change, image)
|
| 52 |
+
|
| 53 |
+
eyebrow_layer_alpha = self.eyebrow_layer_alpha(feature)
|
| 54 |
+
eyebrow_layer_color_change = self.eyebrow_layer_color_change(feature)
|
| 55 |
+
eyebrow_layer = apply_color_change(eyebrow_layer_alpha, image, eyebrow_layer_color_change)
|
| 56 |
+
|
| 57 |
+
return [
|
| 58 |
+
eyebrow_layer, # 0
|
| 59 |
+
eyebrow_layer_alpha, # 1
|
| 60 |
+
eyebrow_layer_color_change, # 2
|
| 61 |
+
background_layer_1, # 3
|
| 62 |
+
background_layer_alpha, # 4
|
| 63 |
+
background_layer_color_change, # 5
|
| 64 |
+
]
|
| 65 |
+
|
| 66 |
+
EYEBROW_LAYER_INDEX = 0
|
| 67 |
+
EYEBROW_LAYER_ALPHA_INDEX = 1
|
| 68 |
+
EYEBROW_LAYER_COLOR_CHANGE_INDEX = 2
|
| 69 |
+
BACKGROUND_LAYER_INDEX = 3
|
| 70 |
+
BACKGROUND_LAYER_ALPHA_INDEX = 4
|
| 71 |
+
BACKGROUND_LAYER_COLOR_CHANGE_INDEX = 5
|
| 72 |
+
OUTPUT_LENGTH = 6
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class EyebrowDecomposer00Factory(ModuleFactory):
|
| 76 |
+
def __init__(self, args: EyebrowDecomposer00Args):
|
| 77 |
+
super().__init__()
|
| 78 |
+
self.args = args
|
| 79 |
+
|
| 80 |
+
def create(self) -> Module:
|
| 81 |
+
return EyebrowDecomposer00(self.args)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
if __name__ == "__main__":
|
| 85 |
+
cuda = torch.device('cuda')
|
| 86 |
+
args = EyebrowDecomposer00Args(
|
| 87 |
+
image_size=128,
|
| 88 |
+
image_channels=4,
|
| 89 |
+
start_channels=64,
|
| 90 |
+
bottleneck_image_size=16,
|
| 91 |
+
num_bottleneck_blocks=3,
|
| 92 |
+
block_args=BlockArgs(
|
| 93 |
+
initialization_method='xavier',
|
| 94 |
+
use_spectral_norm=False,
|
| 95 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 96 |
+
nonlinearity_factory=ReLUFactory(inplace=True)))
|
| 97 |
+
face_morpher = EyebrowDecomposer00(args).to(cuda)
|
| 98 |
+
|
| 99 |
+
image = torch.randn(8, 4, 128, 128, device=cuda)
|
| 100 |
+
outputs = face_morpher.forward(image)
|
| 101 |
+
for i in range(len(outputs)):
|
| 102 |
+
print(i, outputs[i].shape)
|
tha3/nn/eyebrow_decomposer/eyebrow_decomposer_03.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Module
|
| 6 |
+
|
| 7 |
+
from tha3.nn.common.poser_encoder_decoder_00 import PoserEncoderDecoder00Args
|
| 8 |
+
from tha3.nn.common.poser_encoder_decoder_00_separable import PoserEncoderDecoder00Separable
|
| 9 |
+
from tha3.nn.image_processing_util import apply_color_change
|
| 10 |
+
from tha3.module.module_factory import ModuleFactory
|
| 11 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 12 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 13 |
+
from tha3.nn.util import BlockArgs
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class EyebrowDecomposer03Args(PoserEncoderDecoder00Args):
|
| 17 |
+
def __init__(self,
|
| 18 |
+
image_size: int = 128,
|
| 19 |
+
image_channels: int = 4,
|
| 20 |
+
start_channels: int = 64,
|
| 21 |
+
bottleneck_image_size=16,
|
| 22 |
+
num_bottleneck_blocks=6,
|
| 23 |
+
max_channels: int = 512,
|
| 24 |
+
block_args: Optional[BlockArgs] = None):
|
| 25 |
+
super().__init__(
|
| 26 |
+
image_size,
|
| 27 |
+
image_channels,
|
| 28 |
+
image_channels,
|
| 29 |
+
0,
|
| 30 |
+
start_channels,
|
| 31 |
+
bottleneck_image_size,
|
| 32 |
+
num_bottleneck_blocks,
|
| 33 |
+
max_channels,
|
| 34 |
+
block_args)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class EyebrowDecomposer03(Module):
|
| 38 |
+
def __init__(self, args: EyebrowDecomposer03Args):
|
| 39 |
+
super().__init__()
|
| 40 |
+
self.args = args
|
| 41 |
+
self.body = PoserEncoderDecoder00Separable(args)
|
| 42 |
+
self.background_layer_alpha = self.args.create_alpha_block()
|
| 43 |
+
self.background_layer_color_change = self.args.create_color_change_block()
|
| 44 |
+
self.eyebrow_layer_alpha = self.args.create_alpha_block()
|
| 45 |
+
self.eyebrow_layer_color_change = self.args.create_color_change_block()
|
| 46 |
+
|
| 47 |
+
def forward(self, image: Tensor, *args) -> List[Tensor]:
|
| 48 |
+
feature = self.body(image)[0]
|
| 49 |
+
|
| 50 |
+
background_layer_alpha = self.background_layer_alpha(feature)
|
| 51 |
+
background_layer_color_change = self.background_layer_color_change(feature)
|
| 52 |
+
background_layer_1 = apply_color_change(background_layer_alpha, background_layer_color_change, image)
|
| 53 |
+
|
| 54 |
+
eyebrow_layer_alpha = self.eyebrow_layer_alpha(feature)
|
| 55 |
+
eyebrow_layer_color_change = self.eyebrow_layer_color_change(feature)
|
| 56 |
+
eyebrow_layer = apply_color_change(eyebrow_layer_alpha, image, eyebrow_layer_color_change)
|
| 57 |
+
|
| 58 |
+
return [
|
| 59 |
+
eyebrow_layer, # 0
|
| 60 |
+
eyebrow_layer_alpha, # 1
|
| 61 |
+
eyebrow_layer_color_change, # 2
|
| 62 |
+
background_layer_1, # 3
|
| 63 |
+
background_layer_alpha, # 4
|
| 64 |
+
background_layer_color_change, # 5
|
| 65 |
+
]
|
| 66 |
+
|
| 67 |
+
EYEBROW_LAYER_INDEX = 0
|
| 68 |
+
EYEBROW_LAYER_ALPHA_INDEX = 1
|
| 69 |
+
EYEBROW_LAYER_COLOR_CHANGE_INDEX = 2
|
| 70 |
+
BACKGROUND_LAYER_INDEX = 3
|
| 71 |
+
BACKGROUND_LAYER_ALPHA_INDEX = 4
|
| 72 |
+
BACKGROUND_LAYER_COLOR_CHANGE_INDEX = 5
|
| 73 |
+
OUTPUT_LENGTH = 6
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class EyebrowDecomposer03Factory(ModuleFactory):
|
| 77 |
+
def __init__(self, args: EyebrowDecomposer03Args):
|
| 78 |
+
super().__init__()
|
| 79 |
+
self.args = args
|
| 80 |
+
|
| 81 |
+
def create(self) -> Module:
|
| 82 |
+
return EyebrowDecomposer03(self.args)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
if __name__ == "__main__":
|
| 86 |
+
cuda = torch.device('cuda')
|
| 87 |
+
args = EyebrowDecomposer03Args(
|
| 88 |
+
image_size=128,
|
| 89 |
+
image_channels=4,
|
| 90 |
+
start_channels=64,
|
| 91 |
+
bottleneck_image_size=16,
|
| 92 |
+
num_bottleneck_blocks=6,
|
| 93 |
+
block_args=BlockArgs(
|
| 94 |
+
initialization_method='xavier',
|
| 95 |
+
use_spectral_norm=False,
|
| 96 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 97 |
+
nonlinearity_factory=ReLUFactory(inplace=True)))
|
| 98 |
+
face_morpher = EyebrowDecomposer03(args).to(cuda)
|
| 99 |
+
|
| 100 |
+
#image = torch.randn(8, 4, 128, 128, device=cuda)
|
| 101 |
+
#outputs = face_morpher.forward(image)
|
| 102 |
+
#for i in range(len(outputs)):
|
| 103 |
+
# print(i, outputs[i].shape)
|
| 104 |
+
|
| 105 |
+
state_dict = face_morpher.state_dict()
|
| 106 |
+
index = 0
|
| 107 |
+
for key in state_dict:
|
| 108 |
+
print(f"[{index}]", key, state_dict[key].shape)
|
| 109 |
+
index += 1
|
tha3/nn/eyebrow_morphing_combiner/__init__.py
ADDED
|
File without changes
|
tha3/nn/eyebrow_morphing_combiner/eyebrow_morphing_combiner_00.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Module
|
| 6 |
+
|
| 7 |
+
from tha3.nn.common.poser_encoder_decoder_00 import PoserEncoderDecoder00Args, PoserEncoderDecoder00
|
| 8 |
+
from tha3.nn.image_processing_util import apply_color_change, apply_grid_change, apply_rgb_change
|
| 9 |
+
from tha3.module.module_factory import ModuleFactory
|
| 10 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 11 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 12 |
+
from tha3.nn.util import BlockArgs
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class EyebrowMorphingCombiner00Args(PoserEncoderDecoder00Args):
|
| 16 |
+
def __init__(self,
|
| 17 |
+
image_size: int = 128,
|
| 18 |
+
image_channels: int = 4,
|
| 19 |
+
num_pose_params: int = 12,
|
| 20 |
+
start_channels: int = 64,
|
| 21 |
+
bottleneck_image_size=16,
|
| 22 |
+
num_bottleneck_blocks=6,
|
| 23 |
+
max_channels: int = 512,
|
| 24 |
+
block_args: Optional[BlockArgs] = None):
|
| 25 |
+
super().__init__(
|
| 26 |
+
image_size,
|
| 27 |
+
2 * image_channels,
|
| 28 |
+
image_channels,
|
| 29 |
+
num_pose_params,
|
| 30 |
+
start_channels,
|
| 31 |
+
bottleneck_image_size,
|
| 32 |
+
num_bottleneck_blocks,
|
| 33 |
+
max_channels,
|
| 34 |
+
block_args)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class EyebrowMorphingCombiner00(Module):
|
| 38 |
+
def __init__(self, args: EyebrowMorphingCombiner00Args):
|
| 39 |
+
super().__init__()
|
| 40 |
+
self.args = args
|
| 41 |
+
self.body = PoserEncoderDecoder00(args)
|
| 42 |
+
self.morphed_eyebrow_layer_grid_change = self.args.create_grid_change_block()
|
| 43 |
+
self.morphed_eyebrow_layer_alpha = self.args.create_alpha_block()
|
| 44 |
+
self.morphed_eyebrow_layer_color_change = self.args.create_color_change_block()
|
| 45 |
+
self.combine_alpha = self.args.create_alpha_block()
|
| 46 |
+
|
| 47 |
+
def forward(self, background_layer: Tensor, eyebrow_layer: Tensor, pose: Tensor, *args) -> List[Tensor]:
|
| 48 |
+
combined_image = torch.cat([background_layer, eyebrow_layer], dim=1)
|
| 49 |
+
feature = self.body(combined_image, pose)[0]
|
| 50 |
+
|
| 51 |
+
morphed_eyebrow_layer_grid_change = self.morphed_eyebrow_layer_grid_change(feature)
|
| 52 |
+
morphed_eyebrow_layer_alpha = self.morphed_eyebrow_layer_alpha(feature)
|
| 53 |
+
morphed_eyebrow_layer_color_change = self.morphed_eyebrow_layer_color_change(feature)
|
| 54 |
+
warped_eyebrow_layer = apply_grid_change(morphed_eyebrow_layer_grid_change, eyebrow_layer)
|
| 55 |
+
morphed_eyebrow_layer = apply_color_change(
|
| 56 |
+
morphed_eyebrow_layer_alpha, morphed_eyebrow_layer_color_change, warped_eyebrow_layer)
|
| 57 |
+
|
| 58 |
+
combine_alpha = self.combine_alpha(feature)
|
| 59 |
+
eyebrow_image = apply_rgb_change(combine_alpha, morphed_eyebrow_layer, background_layer)
|
| 60 |
+
eyebrow_image_no_combine_alpha = apply_rgb_change(
|
| 61 |
+
(morphed_eyebrow_layer[:, 3:4, :, :] + 1.0) / 2.0, morphed_eyebrow_layer, background_layer)
|
| 62 |
+
|
| 63 |
+
return [
|
| 64 |
+
eyebrow_image, # 0
|
| 65 |
+
combine_alpha, # 1
|
| 66 |
+
eyebrow_image_no_combine_alpha, # 2
|
| 67 |
+
morphed_eyebrow_layer, # 3
|
| 68 |
+
morphed_eyebrow_layer_alpha, # 4
|
| 69 |
+
morphed_eyebrow_layer_color_change, # 5
|
| 70 |
+
warped_eyebrow_layer, # 6
|
| 71 |
+
morphed_eyebrow_layer_grid_change, # 7
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
EYEBROW_IMAGE_INDEX = 0
|
| 75 |
+
COMBINE_ALPHA_INDEX = 1
|
| 76 |
+
EYEBROW_IMAGE_NO_COMBINE_ALPHA_INDEX = 2
|
| 77 |
+
MORPHED_EYEBROW_LAYER_INDEX = 3
|
| 78 |
+
MORPHED_EYEBROW_LAYER_ALPHA_INDEX = 4
|
| 79 |
+
MORPHED_EYEBROW_LAYER_COLOR_CHANGE_INDEX = 5
|
| 80 |
+
WARPED_EYEBROW_LAYER_INDEX = 6
|
| 81 |
+
MORPHED_EYEBROW_LAYER_GRID_CHANGE_INDEX = 7
|
| 82 |
+
OUTPUT_LENGTH = 8
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class EyebrowMorphingCombiner00Factory(ModuleFactory):
|
| 86 |
+
def __init__(self, args: EyebrowMorphingCombiner00Args):
|
| 87 |
+
super().__init__()
|
| 88 |
+
self.args = args
|
| 89 |
+
|
| 90 |
+
def create(self) -> Module:
|
| 91 |
+
return EyebrowMorphingCombiner00(self.args)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
if __name__ == "__main__":
|
| 95 |
+
cuda = torch.device('cuda')
|
| 96 |
+
args = EyebrowMorphingCombiner00Args(
|
| 97 |
+
image_size=128,
|
| 98 |
+
image_channels=4,
|
| 99 |
+
num_pose_params=12,
|
| 100 |
+
start_channels=64,
|
| 101 |
+
bottleneck_image_size=16,
|
| 102 |
+
num_bottleneck_blocks=3,
|
| 103 |
+
block_args=BlockArgs(
|
| 104 |
+
initialization_method='xavier',
|
| 105 |
+
use_spectral_norm=False,
|
| 106 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 107 |
+
nonlinearity_factory=ReLUFactory(inplace=True)))
|
| 108 |
+
face_morpher = EyebrowMorphingCombiner00(args).to(cuda)
|
| 109 |
+
|
| 110 |
+
background_layer = torch.randn(8, 4, 128, 128, device=cuda)
|
| 111 |
+
eyebrow_layer = torch.randn(8, 4, 128, 128, device=cuda)
|
| 112 |
+
pose = torch.randn(8, 12, device=cuda)
|
| 113 |
+
outputs = face_morpher.forward(background_layer, eyebrow_layer, pose)
|
| 114 |
+
for i in range(len(outputs)):
|
| 115 |
+
print(i, outputs[i].shape)
|
tha3/nn/eyebrow_morphing_combiner/eyebrow_morphing_combiner_03.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Module
|
| 6 |
+
|
| 7 |
+
from tha3.nn.common.poser_encoder_decoder_00 import PoserEncoderDecoder00Args
|
| 8 |
+
from tha3.nn.common.poser_encoder_decoder_00_separable import PoserEncoderDecoder00Separable
|
| 9 |
+
from tha3.nn.image_processing_util import apply_color_change, apply_rgb_change, GridChangeApplier
|
| 10 |
+
from tha3.module.module_factory import ModuleFactory
|
| 11 |
+
from tha3.nn.nonlinearity_factory import ReLUFactory
|
| 12 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 13 |
+
from tha3.nn.util import BlockArgs
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class EyebrowMorphingCombiner03Args(PoserEncoderDecoder00Args):
|
| 17 |
+
def __init__(self,
|
| 18 |
+
image_size: int = 128,
|
| 19 |
+
image_channels: int = 4,
|
| 20 |
+
num_pose_params: int = 12,
|
| 21 |
+
start_channels: int = 64,
|
| 22 |
+
bottleneck_image_size=16,
|
| 23 |
+
num_bottleneck_blocks=6,
|
| 24 |
+
max_channels: int = 512,
|
| 25 |
+
block_args: Optional[BlockArgs] = None):
|
| 26 |
+
super().__init__(
|
| 27 |
+
image_size,
|
| 28 |
+
2 * image_channels,
|
| 29 |
+
image_channels,
|
| 30 |
+
num_pose_params,
|
| 31 |
+
start_channels,
|
| 32 |
+
bottleneck_image_size,
|
| 33 |
+
num_bottleneck_blocks,
|
| 34 |
+
max_channels,
|
| 35 |
+
block_args)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class EyebrowMorphingCombiner03(Module):
|
| 39 |
+
def __init__(self, args: EyebrowMorphingCombiner03Args):
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.args = args
|
| 42 |
+
self.body = PoserEncoderDecoder00Separable(args)
|
| 43 |
+
self.morphed_eyebrow_layer_grid_change = self.args.create_grid_change_block()
|
| 44 |
+
self.morphed_eyebrow_layer_alpha = self.args.create_alpha_block()
|
| 45 |
+
self.morphed_eyebrow_layer_color_change = self.args.create_color_change_block()
|
| 46 |
+
self.combine_alpha = self.args.create_alpha_block()
|
| 47 |
+
self.grid_change_applier = GridChangeApplier()
|
| 48 |
+
|
| 49 |
+
def forward(self, background_layer: Tensor, eyebrow_layer: Tensor, pose: Tensor, *args) -> List[Tensor]:
|
| 50 |
+
combined_image = torch.cat([background_layer, eyebrow_layer], dim=1)
|
| 51 |
+
feature = self.body(combined_image, pose)[0]
|
| 52 |
+
|
| 53 |
+
morphed_eyebrow_layer_grid_change = self.morphed_eyebrow_layer_grid_change(feature)
|
| 54 |
+
morphed_eyebrow_layer_alpha = self.morphed_eyebrow_layer_alpha(feature)
|
| 55 |
+
morphed_eyebrow_layer_color_change = self.morphed_eyebrow_layer_color_change(feature)
|
| 56 |
+
warped_eyebrow_layer = self.grid_change_applier.apply(morphed_eyebrow_layer_grid_change, eyebrow_layer)
|
| 57 |
+
morphed_eyebrow_layer = apply_color_change(
|
| 58 |
+
morphed_eyebrow_layer_alpha, morphed_eyebrow_layer_color_change, warped_eyebrow_layer)
|
| 59 |
+
|
| 60 |
+
combine_alpha = self.combine_alpha(feature)
|
| 61 |
+
eyebrow_image = apply_rgb_change(combine_alpha, morphed_eyebrow_layer, background_layer)
|
| 62 |
+
eyebrow_image_no_combine_alpha = apply_rgb_change(
|
| 63 |
+
(morphed_eyebrow_layer[:, 3:4, :, :] + 1.0) / 2.0, morphed_eyebrow_layer, background_layer)
|
| 64 |
+
|
| 65 |
+
return [
|
| 66 |
+
eyebrow_image, # 0
|
| 67 |
+
combine_alpha, # 1
|
| 68 |
+
eyebrow_image_no_combine_alpha, # 2
|
| 69 |
+
morphed_eyebrow_layer, # 3
|
| 70 |
+
morphed_eyebrow_layer_alpha, # 4
|
| 71 |
+
morphed_eyebrow_layer_color_change, # 5
|
| 72 |
+
warped_eyebrow_layer, # 6
|
| 73 |
+
morphed_eyebrow_layer_grid_change, # 7
|
| 74 |
+
]
|
| 75 |
+
|
| 76 |
+
EYEBROW_IMAGE_INDEX = 0
|
| 77 |
+
COMBINE_ALPHA_INDEX = 1
|
| 78 |
+
EYEBROW_IMAGE_NO_COMBINE_ALPHA_INDEX = 2
|
| 79 |
+
MORPHED_EYEBROW_LAYER_INDEX = 3
|
| 80 |
+
MORPHED_EYEBROW_LAYER_ALPHA_INDEX = 4
|
| 81 |
+
MORPHED_EYEBROW_LAYER_COLOR_CHANGE_INDEX = 5
|
| 82 |
+
WARPED_EYEBROW_LAYER_INDEX = 6
|
| 83 |
+
MORPHED_EYEBROW_LAYER_GRID_CHANGE_INDEX = 7
|
| 84 |
+
OUTPUT_LENGTH = 8
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class EyebrowMorphingCombiner03Factory(ModuleFactory):
|
| 88 |
+
def __init__(self, args: EyebrowMorphingCombiner03Args):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.args = args
|
| 91 |
+
|
| 92 |
+
def create(self) -> Module:
|
| 93 |
+
return EyebrowMorphingCombiner03(self.args)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
if __name__ == "__main__":
|
| 97 |
+
cuda = torch.device('cuda')
|
| 98 |
+
args = EyebrowMorphingCombiner03Args(
|
| 99 |
+
image_size=128,
|
| 100 |
+
image_channels=4,
|
| 101 |
+
num_pose_params=12,
|
| 102 |
+
start_channels=64,
|
| 103 |
+
bottleneck_image_size=16,
|
| 104 |
+
num_bottleneck_blocks=3,
|
| 105 |
+
block_args=BlockArgs(
|
| 106 |
+
initialization_method='xavier',
|
| 107 |
+
use_spectral_norm=False,
|
| 108 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 109 |
+
nonlinearity_factory=ReLUFactory(inplace=True)))
|
| 110 |
+
face_morpher = EyebrowMorphingCombiner03(args).to(cuda)
|
| 111 |
+
|
| 112 |
+
background_layer = torch.randn(8, 4, 128, 128, device=cuda)
|
| 113 |
+
eyebrow_layer = torch.randn(8, 4, 128, 128, device=cuda)
|
| 114 |
+
pose = torch.randn(8, 12, device=cuda)
|
| 115 |
+
outputs = face_morpher.forward(background_layer, eyebrow_layer, pose)
|
| 116 |
+
for i in range(len(outputs)):
|
| 117 |
+
print(i, outputs[i].shape)
|
tha3/nn/face_morpher/__init__.py
ADDED
|
File without changes
|
tha3/nn/face_morpher/face_morpher_08.py
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import List, Optional
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import ModuleList, Sequential, Sigmoid, Tanh, Module
|
| 7 |
+
from torch.nn.functional import affine_grid, grid_sample
|
| 8 |
+
|
| 9 |
+
from tha3.module.module_factory import ModuleFactory
|
| 10 |
+
from tha3.nn.conv import create_conv3_block_from_block_args, \
|
| 11 |
+
create_downsample_block_from_block_args, create_upsample_block_from_block_args, create_conv3_from_block_args, \
|
| 12 |
+
create_conv3
|
| 13 |
+
from tha3.nn.nonlinearity_factory import LeakyReLUFactory
|
| 14 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 15 |
+
from tha3.nn.resnet_block import ResnetBlock
|
| 16 |
+
from tha3.nn.util import BlockArgs
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class FaceMorpher08Args:
|
| 20 |
+
def __init__(self,
|
| 21 |
+
image_size: int = 256,
|
| 22 |
+
image_channels: int = 4,
|
| 23 |
+
num_expression_params: int = 67,
|
| 24 |
+
start_channels: int = 16,
|
| 25 |
+
bottleneck_image_size=4,
|
| 26 |
+
num_bottleneck_blocks=3,
|
| 27 |
+
max_channels: int = 512,
|
| 28 |
+
block_args: Optional[BlockArgs] = None):
|
| 29 |
+
self.max_channels = max_channels
|
| 30 |
+
self.num_bottleneck_blocks = num_bottleneck_blocks
|
| 31 |
+
assert bottleneck_image_size > 1
|
| 32 |
+
self.bottleneck_image_size = bottleneck_image_size
|
| 33 |
+
self.start_channels = start_channels
|
| 34 |
+
self.image_channels = image_channels
|
| 35 |
+
self.num_expression_params = num_expression_params
|
| 36 |
+
self.image_size = image_size
|
| 37 |
+
|
| 38 |
+
if block_args is None:
|
| 39 |
+
self.block_args = BlockArgs(
|
| 40 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 41 |
+
nonlinearity_factory=LeakyReLUFactory(negative_slope=0.2, inplace=True))
|
| 42 |
+
else:
|
| 43 |
+
self.block_args = block_args
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class FaceMorpher08(Module):
|
| 47 |
+
def __init__(self, args: FaceMorpher08Args):
|
| 48 |
+
super().__init__()
|
| 49 |
+
self.args = args
|
| 50 |
+
self.num_levels = int(math.log2(args.image_size // args.bottleneck_image_size)) + 1
|
| 51 |
+
|
| 52 |
+
self.downsample_blocks = ModuleList()
|
| 53 |
+
self.downsample_blocks.append(
|
| 54 |
+
create_conv3_block_from_block_args(
|
| 55 |
+
args.image_channels,
|
| 56 |
+
args.start_channels,
|
| 57 |
+
args.block_args))
|
| 58 |
+
current_image_size = args.image_size
|
| 59 |
+
current_num_channels = args.start_channels
|
| 60 |
+
while current_image_size > args.bottleneck_image_size:
|
| 61 |
+
next_image_size = current_image_size // 2
|
| 62 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 63 |
+
self.downsample_blocks.append(create_downsample_block_from_block_args(
|
| 64 |
+
in_channels=current_num_channels,
|
| 65 |
+
out_channels=next_num_channels,
|
| 66 |
+
is_output_1x1=False,
|
| 67 |
+
block_args=args.block_args))
|
| 68 |
+
current_image_size = next_image_size
|
| 69 |
+
current_num_channels = next_num_channels
|
| 70 |
+
assert len(self.downsample_blocks) == self.num_levels
|
| 71 |
+
|
| 72 |
+
self.bottleneck_blocks = ModuleList()
|
| 73 |
+
self.bottleneck_blocks.append(create_conv3_block_from_block_args(
|
| 74 |
+
in_channels=current_num_channels + args.num_expression_params,
|
| 75 |
+
out_channels=current_num_channels,
|
| 76 |
+
block_args=args.block_args))
|
| 77 |
+
for i in range(1, args.num_bottleneck_blocks):
|
| 78 |
+
self.bottleneck_blocks.append(
|
| 79 |
+
ResnetBlock.create(
|
| 80 |
+
num_channels=current_num_channels,
|
| 81 |
+
is1x1=False,
|
| 82 |
+
block_args=args.block_args))
|
| 83 |
+
|
| 84 |
+
self.upsample_blocks = ModuleList()
|
| 85 |
+
while current_image_size < args.image_size:
|
| 86 |
+
next_image_size = current_image_size * 2
|
| 87 |
+
next_num_channels = self.get_num_output_channels_from_image_size(next_image_size)
|
| 88 |
+
self.upsample_blocks.append(create_upsample_block_from_block_args(
|
| 89 |
+
in_channels=current_num_channels,
|
| 90 |
+
out_channels=next_num_channels,
|
| 91 |
+
block_args=args.block_args))
|
| 92 |
+
current_image_size = next_image_size
|
| 93 |
+
current_num_channels = next_num_channels
|
| 94 |
+
|
| 95 |
+
self.iris_mouth_grid_change = self.create_grid_change_block()
|
| 96 |
+
self.iris_mouth_color_change = self.create_color_change_block()
|
| 97 |
+
self.iris_mouth_alpha = self.create_alpha_block()
|
| 98 |
+
|
| 99 |
+
self.eye_color_change = self.create_color_change_block()
|
| 100 |
+
self.eye_alpha = self.create_alpha_block()
|
| 101 |
+
|
| 102 |
+
def create_alpha_block(self):
|
| 103 |
+
return Sequential(
|
| 104 |
+
create_conv3(
|
| 105 |
+
in_channels=self.args.start_channels,
|
| 106 |
+
out_channels=1,
|
| 107 |
+
bias=True,
|
| 108 |
+
initialization_method=self.args.block_args.initialization_method,
|
| 109 |
+
use_spectral_norm=False),
|
| 110 |
+
Sigmoid())
|
| 111 |
+
|
| 112 |
+
def create_color_change_block(self):
|
| 113 |
+
return Sequential(
|
| 114 |
+
create_conv3_from_block_args(
|
| 115 |
+
in_channels=self.args.start_channels,
|
| 116 |
+
out_channels=self.args.image_channels,
|
| 117 |
+
bias=True,
|
| 118 |
+
block_args=self.args.block_args),
|
| 119 |
+
Tanh())
|
| 120 |
+
|
| 121 |
+
def create_grid_change_block(self):
|
| 122 |
+
return create_conv3(
|
| 123 |
+
in_channels=self.args.start_channels,
|
| 124 |
+
out_channels=2,
|
| 125 |
+
bias=False,
|
| 126 |
+
initialization_method='zero',
|
| 127 |
+
use_spectral_norm=False)
|
| 128 |
+
|
| 129 |
+
def get_num_output_channels_from_level(self, level: int):
|
| 130 |
+
return self.get_num_output_channels_from_image_size(self.args.image_size // (2 ** level))
|
| 131 |
+
|
| 132 |
+
def get_num_output_channels_from_image_size(self, image_size: int):
|
| 133 |
+
return min(self.args.start_channels * (self.args.image_size // image_size), self.args.max_channels)
|
| 134 |
+
|
| 135 |
+
def merge_down(self, top_layer: Tensor, bottom_layer: Tensor):
|
| 136 |
+
top_layer_rgb = top_layer[:, 0:3, :, :]
|
| 137 |
+
top_layer_a = top_layer[:, 3:4, :, :]
|
| 138 |
+
return bottom_layer * (1-top_layer_a) + torch.cat([top_layer_rgb * top_layer_a, top_layer_a], dim=1)
|
| 139 |
+
|
| 140 |
+
def apply_grid_change(self, grid_change, image: Tensor) -> Tensor:
|
| 141 |
+
n, c, h, w = image.shape
|
| 142 |
+
device = grid_change.device
|
| 143 |
+
grid_change = torch.transpose(grid_change.view(n, 2, h * w), 1, 2).view(n, h, w, 2)
|
| 144 |
+
identity = torch.tensor(
|
| 145 |
+
[[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]],
|
| 146 |
+
device=device,
|
| 147 |
+
dtype=grid_change.dtype).unsqueeze(0).repeat(n, 1, 1)
|
| 148 |
+
base_grid = affine_grid(identity, [n, c, h, w], align_corners=False)
|
| 149 |
+
grid = base_grid + grid_change
|
| 150 |
+
resampled_image = grid_sample(image, grid, mode='bilinear', padding_mode='border', align_corners=False)
|
| 151 |
+
return resampled_image
|
| 152 |
+
|
| 153 |
+
def apply_color_change(self, alpha, color_change, image: Tensor) -> Tensor:
|
| 154 |
+
return color_change * alpha + image * (1 - alpha)
|
| 155 |
+
|
| 156 |
+
def forward(self, image: Tensor, pose: Tensor, *args) -> List[Tensor]:
|
| 157 |
+
feature = image
|
| 158 |
+
for block in self.downsample_blocks:
|
| 159 |
+
feature = block(feature)
|
| 160 |
+
n, c = pose.shape
|
| 161 |
+
pose = pose.view(n, c, 1, 1).repeat(1, 1, self.args.bottleneck_image_size, self.args.bottleneck_image_size)
|
| 162 |
+
feature = torch.cat([feature, pose], dim=1)
|
| 163 |
+
for block in self.bottleneck_blocks:
|
| 164 |
+
feature = block(feature)
|
| 165 |
+
for block in self.upsample_blocks:
|
| 166 |
+
feature = block(feature)
|
| 167 |
+
|
| 168 |
+
iris_mouth_grid_change = self.iris_mouth_grid_change(feature)
|
| 169 |
+
iris_mouth_image_0 = self.apply_grid_change(iris_mouth_grid_change, image)
|
| 170 |
+
iris_mouth_color_change = self.iris_mouth_color_change(feature)
|
| 171 |
+
iris_mouth_alpha = self.iris_mouth_alpha(feature)
|
| 172 |
+
iris_mouth_image_1 = self.apply_color_change(iris_mouth_alpha, iris_mouth_color_change, iris_mouth_image_0)
|
| 173 |
+
|
| 174 |
+
eye_color_change = self.eye_color_change(feature)
|
| 175 |
+
eye_alpha = self.eye_alpha(feature)
|
| 176 |
+
output_image = self.apply_color_change(eye_alpha, eye_color_change, iris_mouth_image_1.detach())
|
| 177 |
+
|
| 178 |
+
return [
|
| 179 |
+
output_image, #0
|
| 180 |
+
eye_alpha, #1
|
| 181 |
+
eye_color_change, #2
|
| 182 |
+
iris_mouth_image_1, #3
|
| 183 |
+
iris_mouth_alpha, #4
|
| 184 |
+
iris_mouth_color_change, #5
|
| 185 |
+
iris_mouth_image_0, #6
|
| 186 |
+
]
|
| 187 |
+
|
| 188 |
+
OUTPUT_IMAGE_INDEX = 0
|
| 189 |
+
EYE_ALPHA_INDEX = 1
|
| 190 |
+
EYE_COLOR_CHANGE_INDEX = 2
|
| 191 |
+
IRIS_MOUTH_IMAGE_1_INDEX = 3
|
| 192 |
+
IRIS_MOUTH_ALPHA_INDEX = 4
|
| 193 |
+
IRIS_MOUTH_COLOR_CHANGE_INDEX = 5
|
| 194 |
+
IRIS_MOUTh_IMAGE_0_INDEX = 6
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class FaceMorpher08Factory(ModuleFactory):
|
| 198 |
+
def __init__(self, args: FaceMorpher08Args):
|
| 199 |
+
super().__init__()
|
| 200 |
+
self.args = args
|
| 201 |
+
|
| 202 |
+
def create(self) -> Module:
|
| 203 |
+
return FaceMorpher08(self.args)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
if __name__ == "__main__":
|
| 207 |
+
cuda = torch.device('cuda')
|
| 208 |
+
args = FaceMorpher08Args(
|
| 209 |
+
image_size=256,
|
| 210 |
+
image_channels=4,
|
| 211 |
+
num_expression_params=12,
|
| 212 |
+
start_channels=64,
|
| 213 |
+
bottleneck_image_size=32,
|
| 214 |
+
num_bottleneck_blocks=6,
|
| 215 |
+
block_args=BlockArgs(
|
| 216 |
+
initialization_method='he',
|
| 217 |
+
use_spectral_norm=False,
|
| 218 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 219 |
+
nonlinearity_factory=LeakyReLUFactory(inplace=True, negative_slope=0.2)))
|
| 220 |
+
module = FaceMorpher08(args).to(cuda)
|
| 221 |
+
|
| 222 |
+
image = torch.zeros(16, 4, 256, 256, device=cuda)
|
| 223 |
+
pose = torch.zeros(16, 12, device=cuda)
|
| 224 |
+
|
| 225 |
+
repeat = 100
|
| 226 |
+
acc = 0.0
|
| 227 |
+
for i in range(repeat + 2):
|
| 228 |
+
start = torch.cuda.Event(enable_timing=True)
|
| 229 |
+
end = torch.cuda.Event(enable_timing=True)
|
| 230 |
+
|
| 231 |
+
start.record()
|
| 232 |
+
module.forward(image, pose)
|
| 233 |
+
end.record()
|
| 234 |
+
torch.cuda.synchronize()
|
| 235 |
+
|
| 236 |
+
if i >= 2:
|
| 237 |
+
elapsed_time = start.elapsed_time(end)
|
| 238 |
+
print("%d:" % i, elapsed_time)
|
| 239 |
+
acc += elapsed_time
|
| 240 |
+
|
| 241 |
+
print("average:", acc / repeat)
|
tha3/nn/face_morpher/face_morpher_09.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Optional
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import Tensor
|
| 5 |
+
from torch.nn import Sequential, Sigmoid, Tanh, Module
|
| 6 |
+
from torch.nn.functional import affine_grid, grid_sample
|
| 7 |
+
|
| 8 |
+
from tha3.nn.common.poser_encoder_decoder_00 import PoserEncoderDecoder00Args
|
| 9 |
+
from tha3.nn.common.poser_encoder_decoder_00_separable import PoserEncoderDecoder00Separable
|
| 10 |
+
from tha3.nn.image_processing_util import GridChangeApplier
|
| 11 |
+
from tha3.module.module_factory import ModuleFactory
|
| 12 |
+
from tha3.nn.conv import create_conv3_from_block_args, create_conv3
|
| 13 |
+
from tha3.nn.nonlinearity_factory import LeakyReLUFactory
|
| 14 |
+
from tha3.nn.normalization import InstanceNorm2dFactory
|
| 15 |
+
from tha3.nn.util import BlockArgs
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class FaceMorpher09Args(PoserEncoderDecoder00Args):
|
| 19 |
+
def __init__(self,
|
| 20 |
+
image_size: int = 256,
|
| 21 |
+
image_channels: int = 4,
|
| 22 |
+
num_pose_params: int = 67,
|
| 23 |
+
start_channels: int = 16,
|
| 24 |
+
bottleneck_image_size=4,
|
| 25 |
+
num_bottleneck_blocks=3,
|
| 26 |
+
max_channels: int = 512,
|
| 27 |
+
block_args: Optional[BlockArgs] = None):
|
| 28 |
+
super().__init__(
|
| 29 |
+
image_size,
|
| 30 |
+
image_channels,
|
| 31 |
+
image_channels,
|
| 32 |
+
num_pose_params,
|
| 33 |
+
start_channels,
|
| 34 |
+
bottleneck_image_size,
|
| 35 |
+
num_bottleneck_blocks,
|
| 36 |
+
max_channels,
|
| 37 |
+
block_args)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class FaceMorpher09(Module):
|
| 41 |
+
def __init__(self, args: FaceMorpher09Args):
|
| 42 |
+
super().__init__()
|
| 43 |
+
self.args = args
|
| 44 |
+
self.body = PoserEncoderDecoder00Separable(args)
|
| 45 |
+
|
| 46 |
+
self.iris_mouth_grid_change = self.create_grid_change_block()
|
| 47 |
+
self.iris_mouth_color_change = self.create_color_change_block()
|
| 48 |
+
self.iris_mouth_alpha = self.create_alpha_block()
|
| 49 |
+
|
| 50 |
+
self.eye_color_change = self.create_color_change_block()
|
| 51 |
+
self.eye_alpha = self.create_alpha_block()
|
| 52 |
+
|
| 53 |
+
self.grid_change_applier = GridChangeApplier()
|
| 54 |
+
|
| 55 |
+
def create_alpha_block(self):
|
| 56 |
+
return Sequential(
|
| 57 |
+
create_conv3(
|
| 58 |
+
in_channels=self.args.start_channels,
|
| 59 |
+
out_channels=1,
|
| 60 |
+
bias=True,
|
| 61 |
+
initialization_method=self.args.block_args.initialization_method,
|
| 62 |
+
use_spectral_norm=False),
|
| 63 |
+
Sigmoid())
|
| 64 |
+
|
| 65 |
+
def create_color_change_block(self):
|
| 66 |
+
return Sequential(
|
| 67 |
+
create_conv3_from_block_args(
|
| 68 |
+
in_channels=self.args.start_channels,
|
| 69 |
+
out_channels=self.args.input_image_channels,
|
| 70 |
+
bias=True,
|
| 71 |
+
block_args=self.args.block_args),
|
| 72 |
+
Tanh())
|
| 73 |
+
|
| 74 |
+
def create_grid_change_block(self):
|
| 75 |
+
return create_conv3(
|
| 76 |
+
in_channels=self.args.start_channels,
|
| 77 |
+
out_channels=2,
|
| 78 |
+
bias=False,
|
| 79 |
+
initialization_method='zero',
|
| 80 |
+
use_spectral_norm=False)
|
| 81 |
+
|
| 82 |
+
def get_num_output_channels_from_level(self, level: int):
|
| 83 |
+
return self.get_num_output_channels_from_image_size(self.args.image_size // (2 ** level))
|
| 84 |
+
|
| 85 |
+
def get_num_output_channels_from_image_size(self, image_size: int):
|
| 86 |
+
return min(self.args.start_channels * (self.args.image_size // image_size), self.args.max_channels)
|
| 87 |
+
|
| 88 |
+
def forward(self, image: Tensor, pose: Tensor, *args) -> List[Tensor]:
|
| 89 |
+
feature = self.body(image, pose)[0]
|
| 90 |
+
|
| 91 |
+
iris_mouth_grid_change = self.iris_mouth_grid_change(feature)
|
| 92 |
+
iris_mouth_image_0 = self.grid_change_applier.apply(iris_mouth_grid_change, image)
|
| 93 |
+
iris_mouth_color_change = self.iris_mouth_color_change(feature)
|
| 94 |
+
iris_mouth_alpha = self.iris_mouth_alpha(feature)
|
| 95 |
+
iris_mouth_image_1 = self.apply_color_change(iris_mouth_alpha, iris_mouth_color_change, iris_mouth_image_0)
|
| 96 |
+
|
| 97 |
+
eye_color_change = self.eye_color_change(feature)
|
| 98 |
+
eye_alpha = self.eye_alpha(feature)
|
| 99 |
+
output_image = self.apply_color_change(eye_alpha, eye_color_change, iris_mouth_image_1.detach())
|
| 100 |
+
|
| 101 |
+
return [
|
| 102 |
+
output_image, # 0
|
| 103 |
+
eye_alpha, # 1
|
| 104 |
+
eye_color_change, # 2
|
| 105 |
+
iris_mouth_image_1, # 3
|
| 106 |
+
iris_mouth_alpha, # 4
|
| 107 |
+
iris_mouth_color_change, # 5
|
| 108 |
+
iris_mouth_image_0, # 6
|
| 109 |
+
]
|
| 110 |
+
|
| 111 |
+
OUTPUT_IMAGE_INDEX = 0
|
| 112 |
+
EYE_ALPHA_INDEX = 1
|
| 113 |
+
EYE_COLOR_CHANGE_INDEX = 2
|
| 114 |
+
IRIS_MOUTH_IMAGE_1_INDEX = 3
|
| 115 |
+
IRIS_MOUTH_ALPHA_INDEX = 4
|
| 116 |
+
IRIS_MOUTH_COLOR_CHANGE_INDEX = 5
|
| 117 |
+
IRIS_MOUTh_IMAGE_0_INDEX = 6
|
| 118 |
+
|
| 119 |
+
def merge_down(self, top_layer: Tensor, bottom_layer: Tensor):
|
| 120 |
+
top_layer_rgb = top_layer[:, 0:3, :, :]
|
| 121 |
+
top_layer_a = top_layer[:, 3:4, :, :]
|
| 122 |
+
return bottom_layer * (1 - top_layer_a) + torch.cat([top_layer_rgb * top_layer_a, top_layer_a], dim=1)
|
| 123 |
+
|
| 124 |
+
def apply_grid_change(self, grid_change, image: Tensor) -> Tensor:
|
| 125 |
+
n, c, h, w = image.shape
|
| 126 |
+
device = grid_change.device
|
| 127 |
+
grid_change = torch.transpose(grid_change.view(n, 2, h * w), 1, 2).view(n, h, w, 2)
|
| 128 |
+
identity = torch.tensor([[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]], device=device).unsqueeze(0).repeat(n, 1, 1)
|
| 129 |
+
base_grid = affine_grid(identity, [n, c, h, w], align_corners=False)
|
| 130 |
+
grid = base_grid + grid_change
|
| 131 |
+
resampled_image = grid_sample(image, grid, mode='bilinear', padding_mode='border', align_corners=False)
|
| 132 |
+
return resampled_image
|
| 133 |
+
|
| 134 |
+
def apply_color_change(self, alpha, color_change, image: Tensor) -> Tensor:
|
| 135 |
+
return color_change * alpha + image * (1 - alpha)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class FaceMorpher09Factory(ModuleFactory):
|
| 139 |
+
def __init__(self, args: FaceMorpher09Args):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.args = args
|
| 142 |
+
|
| 143 |
+
def create(self) -> Module:
|
| 144 |
+
return FaceMorpher09(self.args)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
if __name__ == "__main__":
|
| 148 |
+
cuda = torch.device('cuda')
|
| 149 |
+
args = FaceMorpher09Args(
|
| 150 |
+
image_size=256,
|
| 151 |
+
image_channels=4,
|
| 152 |
+
num_pose_params=12,
|
| 153 |
+
start_channels=64,
|
| 154 |
+
bottleneck_image_size=32,
|
| 155 |
+
num_bottleneck_blocks=6,
|
| 156 |
+
block_args=BlockArgs(
|
| 157 |
+
initialization_method='xavier',
|
| 158 |
+
use_spectral_norm=False,
|
| 159 |
+
normalization_layer_factory=InstanceNorm2dFactory(),
|
| 160 |
+
nonlinearity_factory=LeakyReLUFactory(inplace=True, negative_slope=0.2)))
|
| 161 |
+
module = FaceMorpher09(args).to(cuda)
|
| 162 |
+
|
| 163 |
+
image = torch.zeros(16, 4, 256, 256, device=cuda)
|
| 164 |
+
pose = torch.zeros(16, 12, device=cuda)
|
| 165 |
+
|
| 166 |
+
state_dict = module.state_dict()
|
| 167 |
+
for key in state_dict:
|
| 168 |
+
print(key, state_dict[key].shape)
|
| 169 |
+
|
| 170 |
+
if False:
|
| 171 |
+
repeat = 100
|
| 172 |
+
acc = 0.0
|
| 173 |
+
for i in range(repeat + 2):
|
| 174 |
+
start = torch.cuda.Event(enable_timing=True)
|
| 175 |
+
end = torch.cuda.Event(enable_timing=True)
|
| 176 |
+
|
| 177 |
+
start.record()
|
| 178 |
+
module.forward(image, pose)
|
| 179 |
+
end.record()
|
| 180 |
+
torch.cuda.synchronize()
|
| 181 |
+
|
| 182 |
+
if i >= 2:
|
| 183 |
+
elapsed_time = start.elapsed_time(end)
|
| 184 |
+
print("%d:" % i, elapsed_time)
|
| 185 |
+
acc += elapsed_time
|
| 186 |
+
|
| 187 |
+
print("average:", acc / repeat)
|
tha3/nn/image_processing_util.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import Tensor
|
| 3 |
+
from torch.nn.functional import affine_grid, grid_sample
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def apply_rgb_change(alpha: Tensor, color_change: Tensor, image: Tensor):
|
| 7 |
+
image_rgb = image[:, 0:3, :, :]
|
| 8 |
+
color_change_rgb = color_change[:, 0:3, :, :]
|
| 9 |
+
output_rgb = color_change_rgb * alpha + image_rgb * (1 - alpha)
|
| 10 |
+
return torch.cat([output_rgb, image[:, 3:4, :, :]], dim=1)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def apply_grid_change(grid_change, image: Tensor) -> Tensor:
|
| 14 |
+
n, c, h, w = image.shape
|
| 15 |
+
device = grid_change.device
|
| 16 |
+
grid_change = torch.transpose(grid_change.view(n, 2, h * w), 1, 2).view(n, h, w, 2)
|
| 17 |
+
identity = torch.tensor(
|
| 18 |
+
[[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]],
|
| 19 |
+
dtype=grid_change.dtype,
|
| 20 |
+
device=device).unsqueeze(0).repeat(n, 1, 1)
|
| 21 |
+
base_grid = affine_grid(identity, [n, c, h, w], align_corners=False)
|
| 22 |
+
grid = base_grid + grid_change
|
| 23 |
+
resampled_image = grid_sample(image, grid, mode='bilinear', padding_mode='border', align_corners=False)
|
| 24 |
+
return resampled_image
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class GridChangeApplier:
|
| 28 |
+
def __init__(self):
|
| 29 |
+
self.last_n = None
|
| 30 |
+
self.last_device = None
|
| 31 |
+
self.last_identity = None
|
| 32 |
+
|
| 33 |
+
def apply(self, grid_change: Tensor, image: Tensor, align_corners: bool = False) -> Tensor:
|
| 34 |
+
n, c, h, w = image.shape
|
| 35 |
+
device = grid_change.device
|
| 36 |
+
grid_change = torch.transpose(grid_change.view(n, 2, h * w), 1, 2).view(n, h, w, 2)
|
| 37 |
+
|
| 38 |
+
if n == self.last_n and device == self.last_device:
|
| 39 |
+
identity = self.last_identity
|
| 40 |
+
else:
|
| 41 |
+
identity = torch.tensor(
|
| 42 |
+
[[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]],
|
| 43 |
+
dtype=grid_change.dtype,
|
| 44 |
+
device=device,
|
| 45 |
+
requires_grad=False) \
|
| 46 |
+
.unsqueeze(0).repeat(n, 1, 1)
|
| 47 |
+
self.last_identity = identity
|
| 48 |
+
self.last_n = n
|
| 49 |
+
self.last_device = device
|
| 50 |
+
base_grid = affine_grid(identity, [n, c, h, w], align_corners=align_corners)
|
| 51 |
+
|
| 52 |
+
grid = base_grid + grid_change
|
| 53 |
+
resampled_image = grid_sample(image, grid, mode='bilinear', padding_mode='border', align_corners=align_corners)
|
| 54 |
+
return resampled_image
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def apply_color_change(alpha, color_change, image: Tensor) -> Tensor:
|
| 58 |
+
return color_change * alpha + image * (1 - alpha)
|
tha3/nn/init_function.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Callable
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from torch import zero_
|
| 5 |
+
from torch.nn import Module
|
| 6 |
+
from torch.nn.init import kaiming_normal_, xavier_normal_, normal_
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def create_init_function(method: str = 'none') -> Callable[[Module], Module]:
|
| 10 |
+
def init(module: Module):
|
| 11 |
+
if method == 'none':
|
| 12 |
+
return module
|
| 13 |
+
elif method == 'he':
|
| 14 |
+
kaiming_normal_(module.weight)
|
| 15 |
+
return module
|
| 16 |
+
elif method == 'xavier':
|
| 17 |
+
xavier_normal_(module.weight)
|
| 18 |
+
return module
|
| 19 |
+
elif method == 'dcgan':
|
| 20 |
+
normal_(module.weight, 0.0, 0.02)
|
| 21 |
+
return module
|
| 22 |
+
elif method == 'dcgan_001':
|
| 23 |
+
normal_(module.weight, 0.0, 0.01)
|
| 24 |
+
return module
|
| 25 |
+
elif method == "zero":
|
| 26 |
+
with torch.no_grad():
|
| 27 |
+
zero_(module.weight)
|
| 28 |
+
return module
|
| 29 |
+
else:
|
| 30 |
+
raise ("Invalid initialization method %s" % method)
|
| 31 |
+
|
| 32 |
+
return init
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class HeInitialization:
|
| 36 |
+
def __init__(self, a: int = 0, mode: str = 'fan_in', nonlinearity: str = 'leaky_relu'):
|
| 37 |
+
self.nonlinearity = nonlinearity
|
| 38 |
+
self.mode = mode
|
| 39 |
+
self.a = a
|
| 40 |
+
|
| 41 |
+
def __call__(self, module: Module) -> Module:
|
| 42 |
+
with torch.no_grad():
|
| 43 |
+
kaiming_normal_(module.weight, a=self.a, mode=self.mode, nonlinearity=self.nonlinearity)
|
| 44 |
+
return module
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class NormalInitialization:
|
| 48 |
+
def __init__(self, mean: float = 0.0, std: float = 1.0):
|
| 49 |
+
self.std = std
|
| 50 |
+
self.mean = mean
|
| 51 |
+
|
| 52 |
+
def __call__(self, module: Module) -> Module:
|
| 53 |
+
with torch.no_grad():
|
| 54 |
+
normal_(module.weight, self.mean, self.std)
|
| 55 |
+
return module
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class XavierInitialization:
|
| 59 |
+
def __init__(self, gain: float = 1.0):
|
| 60 |
+
self.gain = gain
|
| 61 |
+
|
| 62 |
+
def __call__(self, module: Module) -> Module:
|
| 63 |
+
with torch.no_grad():
|
| 64 |
+
xavier_normal_(module.weight, self.gain)
|
| 65 |
+
return module
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class ZeroInitialization:
|
| 69 |
+
def __call__(self, module: Module) -> Module:
|
| 70 |
+
with torch.no_grad:
|
| 71 |
+
zero_(module.weight)
|
| 72 |
+
return module
|
| 73 |
+
|
| 74 |
+
class NoInitialization:
|
| 75 |
+
def __call__(self, module: Module) -> Module:
|
| 76 |
+
return module
|
tha3/nn/nonlinearity_factory.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
|
| 3 |
+
from torch.nn import Module, ReLU, LeakyReLU, ELU, ReLU6, Hardswish, SiLU, Tanh, Sigmoid
|
| 4 |
+
|
| 5 |
+
from tha3.module.module_factory import ModuleFactory
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ReLUFactory(ModuleFactory):
|
| 9 |
+
def __init__(self, inplace: bool = False):
|
| 10 |
+
self.inplace = inplace
|
| 11 |
+
|
| 12 |
+
def create(self) -> Module:
|
| 13 |
+
return ReLU(self.inplace)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class LeakyReLUFactory(ModuleFactory):
|
| 17 |
+
def __init__(self, inplace: bool = False, negative_slope: float = 1e-2):
|
| 18 |
+
self.negative_slope = negative_slope
|
| 19 |
+
self.inplace = inplace
|
| 20 |
+
|
| 21 |
+
def create(self) -> Module:
|
| 22 |
+
return LeakyReLU(inplace=self.inplace, negative_slope=self.negative_slope)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class ELUFactory(ModuleFactory):
|
| 26 |
+
def __init__(self, inplace: bool = False, alpha: float = 1.0):
|
| 27 |
+
self.alpha = alpha
|
| 28 |
+
self.inplace = inplace
|
| 29 |
+
|
| 30 |
+
def create(self) -> Module:
|
| 31 |
+
return ELU(inplace=self.inplace, alpha=self.alpha)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class ReLU6Factory(ModuleFactory):
|
| 35 |
+
def __init__(self, inplace: bool = False):
|
| 36 |
+
self.inplace = inplace
|
| 37 |
+
|
| 38 |
+
def create(self) -> Module:
|
| 39 |
+
return ReLU6(inplace=self.inplace)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class SiLUFactory(ModuleFactory):
|
| 43 |
+
def __init__(self, inplace: bool = False):
|
| 44 |
+
self.inplace = inplace
|
| 45 |
+
|
| 46 |
+
def create(self) -> Module:
|
| 47 |
+
return SiLU(inplace=self.inplace)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class HardswishFactory(ModuleFactory):
|
| 51 |
+
def __init__(self, inplace: bool = False):
|
| 52 |
+
self.inplace = inplace
|
| 53 |
+
|
| 54 |
+
def create(self) -> Module:
|
| 55 |
+
return Hardswish(inplace=self.inplace)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class TanhFactory(ModuleFactory):
|
| 59 |
+
def create(self) -> Module:
|
| 60 |
+
return Tanh()
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class SigmoidFactory(ModuleFactory):
|
| 64 |
+
def create(self) -> Module:
|
| 65 |
+
return Sigmoid()
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def resolve_nonlinearity_factory(nonlinearity_fatory: Optional[ModuleFactory]) -> ModuleFactory:
|
| 69 |
+
if nonlinearity_fatory is None:
|
| 70 |
+
return ReLUFactory(inplace=False)
|
| 71 |
+
else:
|
| 72 |
+
return nonlinearity_fatory
|