Spaces:
Sleeping

Sleeping
Commit
•
edeaf50
1
Parent(s):
ff067ae
v1 of the app
Browse files- README.md +20 -12
- audio.mp3 +0 -0
- install-deps.sh +3 -0
- main.py +61 -0
- requirements.txt +19 -0
- result.png +0 -0
- run.sh +3 -0
README.md
CHANGED
|
@@ -1,13 +1,21 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
|
|
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
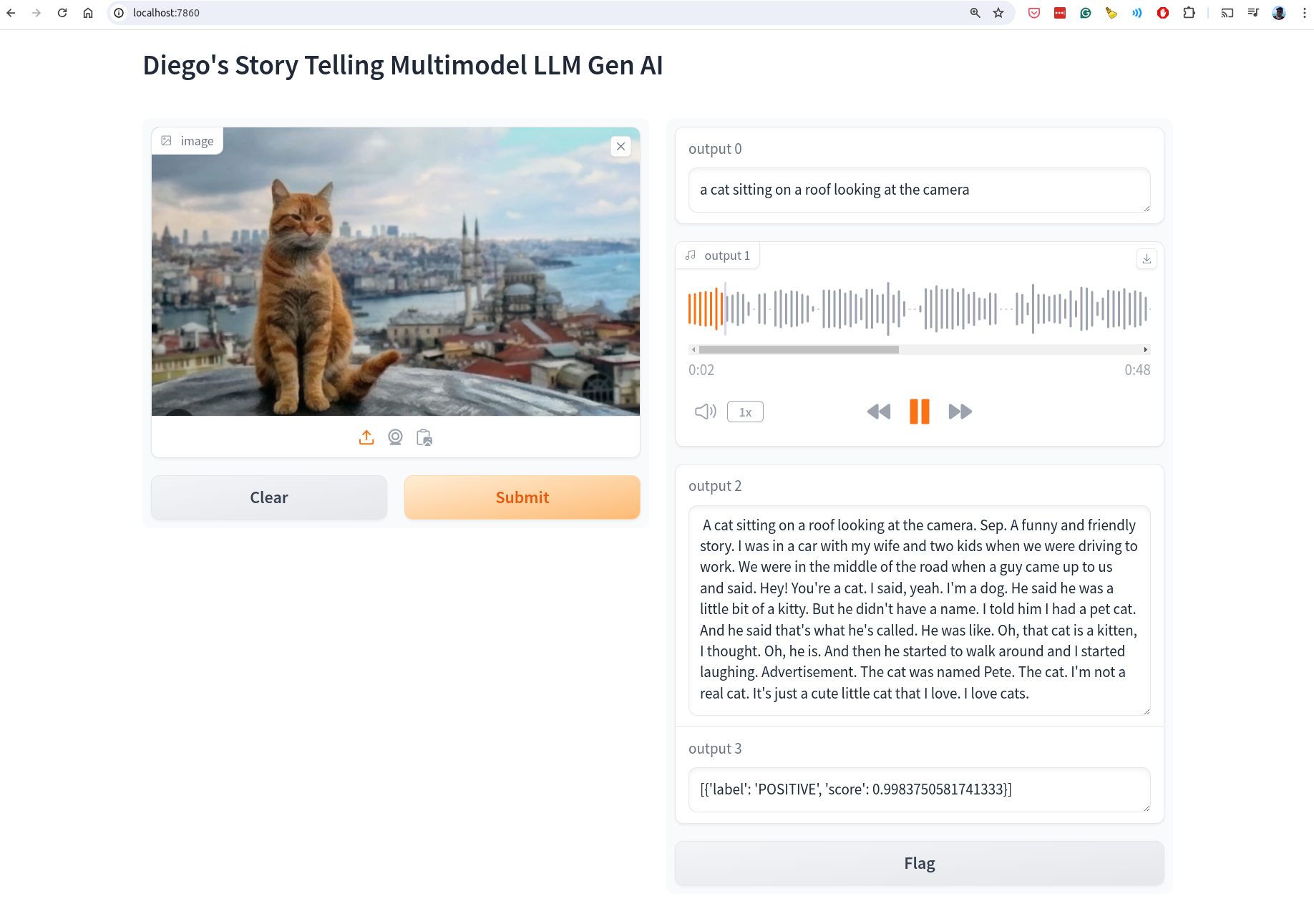
### Result
|
| 2 |
+
* Multi-models in action
|
| 3 |
+
* Story Telling
|
| 4 |
+
* Given a image
|
| 5 |
+
* Generate the caption for the image
|
| 6 |
+
* Generate an background story for the text
|
| 7 |
+
* Use LLM models:
|
| 8 |
+
* Salesforce/blip-image-captioning-base for image captioning
|
| 9 |
+
* gpt2 for text generation
|
| 10 |
+
* gTTS for text to speech, gTTS is a Python library and CLI tool to interface with Google Translate's text-to-speech API.
|
| 11 |
+
* openai/whisper-large-v2 for speach recognition
|
| 12 |
+
* pipeline/sentiment-analysis task for sentiment analysis of the text story
|
| 13 |
|
| 14 |
+
Result UI:
|
| 15 |
+
<img src='result.png' />
|
| 16 |
+
|
| 17 |
+
Audio Result:
|
| 18 |
+
|
| 19 |
+
<audio controls>
|
| 20 |
+
<source src="audio.mp3" type="audio/mpeg">
|
| 21 |
+
</audio>
|
audio.mp3
ADDED
|
Binary file (240 kB). View file
|
|
|
install-deps.sh
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
/bin/pip install -r requirements.txt
|
main.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from PIL import Image
|
| 3 |
+
from gtts import gTTS
|
| 4 |
+
import torch
|
| 5 |
+
import gradio as gr
|
| 6 |
+
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
|
| 7 |
+
from transformers import pipeline, GPT2LMHeadModel, GPT2Tokenizer
|
| 8 |
+
|
| 9 |
+
def describe_photo(image):
|
| 10 |
+
image = Image.fromarray(image.astype('uint8'), 'RGB')
|
| 11 |
+
captioner = pipeline("image-to-text",model="Salesforce/blip-image-captioning-base")
|
| 12 |
+
results = captioner(image)
|
| 13 |
+
text = results[0]['generated_text']
|
| 14 |
+
print(f"Image caption is: {text}")
|
| 15 |
+
return text
|
| 16 |
+
|
| 17 |
+
def generate_story(description):
|
| 18 |
+
model = GPT2LMHeadModel.from_pretrained("gpt2")
|
| 19 |
+
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
| 20 |
+
inputs = tokenizer.encode(description + " [SEP] A funny and friendly story:", return_tensors='pt')
|
| 21 |
+
outputs = model.generate(input_ids=inputs,
|
| 22 |
+
max_length=200,
|
| 23 |
+
num_return_sequences=1,
|
| 24 |
+
temperature=0.7,
|
| 25 |
+
no_repeat_ngram_size=2)
|
| 26 |
+
story = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 27 |
+
return story
|
| 28 |
+
|
| 29 |
+
def convert_to_audio(text):
|
| 30 |
+
tts = gTTS(text)
|
| 31 |
+
audio_file_path = "audio.mp3"
|
| 32 |
+
tts.save(audio_file_path)
|
| 33 |
+
return audio_file_path
|
| 34 |
+
|
| 35 |
+
def audio_to_text(audio_file_path):
|
| 36 |
+
pipe = pipeline("automatic-speech-recognition", "openai/whisper-large-v2")
|
| 37 |
+
result = pipe("audio.mp3")
|
| 38 |
+
print(result)
|
| 39 |
+
return result['text']
|
| 40 |
+
|
| 41 |
+
def sentiment_analysis(text):
|
| 42 |
+
sentiment_analyzer = pipeline("sentiment-analysis")
|
| 43 |
+
result = sentiment_analyzer(text)
|
| 44 |
+
print(result)
|
| 45 |
+
return result
|
| 46 |
+
|
| 47 |
+
def app(image):
|
| 48 |
+
description = describe_photo(image)
|
| 49 |
+
story = generate_story(description)
|
| 50 |
+
audio_file = convert_to_audio(story)
|
| 51 |
+
transcribed_text = audio_to_text(audio_file)
|
| 52 |
+
sentiment = sentiment_analysis(transcribed_text)
|
| 53 |
+
return description,audio_file,transcribed_text, sentiment
|
| 54 |
+
|
| 55 |
+
ui = gr.Interface(
|
| 56 |
+
fn=app,
|
| 57 |
+
inputs="image",
|
| 58 |
+
outputs=["text", "audio", "text", "text"],
|
| 59 |
+
title="Diego's Story Telling Multimodel LLM Gen AI"
|
| 60 |
+
)
|
| 61 |
+
ui.launch()
|
requirements.txt
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
transformers
|
| 3 |
+
sentence-transformers
|
| 4 |
+
seaborn
|
| 5 |
+
torch
|
| 6 |
+
torchvision
|
| 7 |
+
matplotlib
|
| 8 |
+
pandas
|
| 9 |
+
scikit-learn
|
| 10 |
+
nltk
|
| 11 |
+
gensim
|
| 12 |
+
tensorflow
|
| 13 |
+
keras
|
| 14 |
+
opencv-python
|
| 15 |
+
fastapi
|
| 16 |
+
uvicorn
|
| 17 |
+
gTTS
|
| 18 |
+
openai-clip
|
| 19 |
+
gradio
|
result.png
ADDED
|
run.sh
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
python app.py
|