
Upload 396 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +22 -0
- fengshen/API/main.py +76 -0
- fengshen/API/text_classification.json +46 -0
- fengshen/API/utils.py +167 -0
- fengshen/README.md +105 -0
- fengshen/__init__.py +19 -0
- fengshen/cli/fengshen_pipeline.py +34 -0
- fengshen/data/__init__.py +1 -0
- fengshen/data/bert_dataloader/auto_split.sh +10 -0
- fengshen/data/bert_dataloader/load.py +200 -0
- fengshen/data/bert_dataloader/preprocessing.py +110 -0
- fengshen/data/clip_dataloader/flickr.py +105 -0
- fengshen/data/data_utils/common_utils.py +4 -0
- fengshen/data/data_utils/mask_utils.py +285 -0
- fengshen/data/data_utils/sentence_split.py +35 -0
- fengshen/data/data_utils/sop_utils.py +32 -0
- fengshen/data/data_utils/token_type_utils.py +25 -0
- fengshen/data/data_utils/truncate_utils.py +19 -0
- fengshen/data/dreambooth_datasets/dreambooth_datasets.py +183 -0
- fengshen/data/hubert/hubert_dataset.py +361 -0
- fengshen/data/megatron_dataloader/Makefile +9 -0
- fengshen/data/megatron_dataloader/__init__.py +1 -0
- fengshen/data/megatron_dataloader/bart_dataset.py +443 -0
- fengshen/data/megatron_dataloader/bert_dataset.py +196 -0
- fengshen/data/megatron_dataloader/blendable_dataset.py +64 -0
- fengshen/data/megatron_dataloader/dataset_utils.py +788 -0
- fengshen/data/megatron_dataloader/helpers.cpp +794 -0
- fengshen/data/megatron_dataloader/indexed_dataset.py +585 -0
- fengshen/data/megatron_dataloader/utils.py +24 -0
- fengshen/data/mmap_dataloader/mmap_datamodule.py +68 -0
- fengshen/data/mmap_dataloader/mmap_index_dataset.py +53 -0
- fengshen/data/preprocess.py +1 -0
- fengshen/data/sequence_tagging_dataloader/sequence_tagging_collator.py +274 -0
- fengshen/data/sequence_tagging_dataloader/sequence_tagging_datasets.py +116 -0
- fengshen/data/t5_dataloader/t5_datasets.py +562 -0
- fengshen/data/t5_dataloader/t5_gen_datasets.py +391 -0
- fengshen/data/taiyi_stable_diffusion_datasets/taiyi_datasets.py +173 -0
- fengshen/data/task_dataloader/__init__.py +3 -0
- fengshen/data/task_dataloader/medicalQADataset.py +137 -0
- fengshen/data/task_dataloader/task_datasets.py +206 -0
- fengshen/data/universal_datamodule/__init__.py +4 -0
- fengshen/data/universal_datamodule/universal_datamodule.py +165 -0
- fengshen/data/universal_datamodule/universal_sampler.py +125 -0
- fengshen/examples/DAVAE/generate.py +36 -0
- fengshen/examples/FastDemo/README.md +105 -0
- fengshen/examples/FastDemo/YuyuanQA.py +71 -0
- fengshen/examples/FastDemo/image/demo.png +0 -0
- fengshen/examples/GAVAE/generate.py +23 -0
- fengshen/examples/PPVAE/generate.py +24 -0
- fengshen/examples/classification/demo_classification_afqmc_erlangshen_offload.sh +103 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,25 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
fengshen/examples/finetune_taiyi_stable_diffusion/demo_dataset/part_0/00000003.jpg filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
fengshen/examples/stable_diffusion_chinese_EN/result_examples/cat_eating_guoqiao_noodle.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
fengshen/examples/stable_diffusion_chinese_EN/result_examples/huskiy_wearing_space_suit.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
fengshen/examples/stable_diffusion_chinese_EN/result_examples/xiaoqiao_oil_painting.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
fengshen/examples/stable_diffusion_chinese_EN/result_examples/xiaoqiao_vangogh.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号4k壁纸.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号4k壁纸384.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号4k壁纸复杂.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号4k壁纸高清.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号4k壁纸精细.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号插画.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号水彩.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号素描.png filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上英文逗号油画.png filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上中文逗号.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上中文感叹号.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上中文句号.png filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上nega广告.png filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上nega广告符号.png filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
fengshen/examples/stable_diffusion_chinese/img/日出,海面上nega广告符号词汇.png filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
fengshen/examples/stable_diffusion_dreambooth/duck_result.png filter=lfs diff=lfs merge=lfs -text
|
fengshen/API/main.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import uvicorn
|
| 2 |
+
import click
|
| 3 |
+
import argparse
|
| 4 |
+
import json
|
| 5 |
+
from importlib import import_module
|
| 6 |
+
from fastapi import FastAPI, WebSocket
|
| 7 |
+
from starlette.middleware.cors import CORSMiddleware
|
| 8 |
+
from utils import user_config, api_logger, setup_logger, RequestDataStructure
|
| 9 |
+
|
| 10 |
+
# 命令行启动时只输入一个参数,即配置文件的名字,eg: text_classification.json
|
| 11 |
+
# 其余所有配置在该配置文件中设定,不在命令行中指定
|
| 12 |
+
total_parser = argparse.ArgumentParser("API")
|
| 13 |
+
total_parser.add_argument("config_path", type=str)
|
| 14 |
+
args = total_parser.parse_args()
|
| 15 |
+
|
| 16 |
+
# set up user config
|
| 17 |
+
user_config.setup_config(args)
|
| 18 |
+
|
| 19 |
+
# set up logger
|
| 20 |
+
setup_logger(api_logger, user_config)
|
| 21 |
+
|
| 22 |
+
# load pipeline
|
| 23 |
+
pipeline_class = getattr(import_module('fengshen.pipelines.' + user_config.pipeline_type), 'Pipeline')
|
| 24 |
+
model_settings = user_config.model_settings
|
| 25 |
+
model_args = argparse.Namespace(**model_settings)
|
| 26 |
+
pipeline = pipeline_class(
|
| 27 |
+
args = model_args,
|
| 28 |
+
model = user_config.model_name
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# initialize app
|
| 33 |
+
app = FastAPI(
|
| 34 |
+
title = user_config.PROJECT_NAME,
|
| 35 |
+
openapi_url = f"{user_config.API_PREFIX_STR}/openapi.json"
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
# api
|
| 40 |
+
# TODO
|
| 41 |
+
# 需要针对不同请求方法做不同判断,目前仅跑通了较通用的POST方法
|
| 42 |
+
# POST方法可以完成大多数 输入文本-返回结果 的请求任务
|
| 43 |
+
if(user_config.API_method == "POST"):
|
| 44 |
+
@app.post(user_config.API_path, tags = user_config.API_tags)
|
| 45 |
+
async def fengshen_post(data:RequestDataStructure):
|
| 46 |
+
# logging
|
| 47 |
+
api_logger.info(data.input_text)
|
| 48 |
+
|
| 49 |
+
input_text = data.input_text
|
| 50 |
+
|
| 51 |
+
result = pipeline(input_text)
|
| 52 |
+
|
| 53 |
+
return result
|
| 54 |
+
else:
|
| 55 |
+
print("only support POST method")
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# Set all CORS enabled origins
|
| 60 |
+
if user_config.BACKEND_CORS_ORIGINS:
|
| 61 |
+
app.add_middleware(
|
| 62 |
+
CORSMiddleware,
|
| 63 |
+
allow_origins = [str(origin) for origin in user_config.BACKEND_CORS_ORIGINS],
|
| 64 |
+
allow_credentials = user_config.allow_credentials,
|
| 65 |
+
allow_methods = user_config.allow_methods,
|
| 66 |
+
allow_headers = user_config.allow_headers,
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
if __name__ == '__main__':
|
| 71 |
+
|
| 72 |
+
# 启动后可在浏览器打开 host:port/docs 查看接口的具体信息,并可进行简单测试
|
| 73 |
+
# eg: 127.0.0.1:8990/docs
|
| 74 |
+
uvicorn.run(app, host = user_config.SERVER_HOST, port = user_config.SERVER_PORT)
|
| 75 |
+
|
| 76 |
+
|
fengshen/API/text_classification.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"SERVER": {
|
| 3 |
+
"SERVER_HOST": "127.0.0.1",
|
| 4 |
+
"SERVER_PORT": 8990,
|
| 5 |
+
"SERVER_NAME": "fengshen_demo",
|
| 6 |
+
"PROJECT_NAME": "fengshen_demo",
|
| 7 |
+
"API_PREFIX_STR": "/api",
|
| 8 |
+
|
| 9 |
+
"API_method" : "POST",
|
| 10 |
+
"API_path": "/TextClassification",
|
| 11 |
+
"API_tags": ["TextClassification"],
|
| 12 |
+
|
| 13 |
+
"BACKEND_CORS_ORIGINS": ["*"],
|
| 14 |
+
"allow_credentials": true,
|
| 15 |
+
"allow_methods": ["*"],
|
| 16 |
+
"allow_headers": ["*"]
|
| 17 |
+
|
| 18 |
+
},
|
| 19 |
+
"LOGGING": {
|
| 20 |
+
"log_file_path": "",
|
| 21 |
+
"log_level": "INFO"
|
| 22 |
+
},
|
| 23 |
+
|
| 24 |
+
"PIPELINE": {
|
| 25 |
+
"pipeline_type": "text_classification",
|
| 26 |
+
"model_name": "IDEA-CCNL/Erlangshen-Roberta-110M-Similarity",
|
| 27 |
+
"model_settings": {
|
| 28 |
+
"device": -1,
|
| 29 |
+
"texta_name": "sentence",
|
| 30 |
+
"textb_name": "sentence2",
|
| 31 |
+
"label_name": "label",
|
| 32 |
+
"max_length": 512,
|
| 33 |
+
"return_tensors": "pt",
|
| 34 |
+
"padding": "longest",
|
| 35 |
+
"truncation": true,
|
| 36 |
+
"skip_special_tokens": true,
|
| 37 |
+
"clean_up_tkenization_spaces": true,
|
| 38 |
+
|
| 39 |
+
"skip_steps": 10,
|
| 40 |
+
"clip_guidance_scale": 7500,
|
| 41 |
+
"init_scale": 10
|
| 42 |
+
}
|
| 43 |
+
}
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
|
fengshen/API/utils.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass, field
|
| 2 |
+
import os
|
| 3 |
+
import json
|
| 4 |
+
import logging
|
| 5 |
+
from argparse import Namespace
|
| 6 |
+
from typing import List, Literal, Optional, Union
|
| 7 |
+
from pydantic import AnyHttpUrl, BaseSettings, HttpUrl, validator, BaseModel
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
CURRENT_DIR_PATH = os.path.dirname(os.path.abspath(__file__))
|
| 11 |
+
|
| 12 |
+
# request body
|
| 13 |
+
# 使用pydantic对请求中的body数据进行验证
|
| 14 |
+
class RequestDataStructure(BaseModel):
|
| 15 |
+
input_text: List[str] = [""]
|
| 16 |
+
uuid: Optional[int]
|
| 17 |
+
|
| 18 |
+
# parameters for text2image model
|
| 19 |
+
input_image: Optional[str]
|
| 20 |
+
skip_steps: Optional[int]
|
| 21 |
+
clip_guidance_scale: Optional[int]
|
| 22 |
+
init_scale: Optional[int]
|
| 23 |
+
|
| 24 |
+
# API config
|
| 25 |
+
@dataclass
|
| 26 |
+
class APIConfig:
|
| 27 |
+
|
| 28 |
+
# server config
|
| 29 |
+
SERVER_HOST: AnyHttpUrl = "127.0.0.1"
|
| 30 |
+
SERVER_PORT: int = 8990
|
| 31 |
+
SERVER_NAME: str = ""
|
| 32 |
+
PROJECT_NAME: str = ""
|
| 33 |
+
API_PREFIX_STR: str = "/api"
|
| 34 |
+
|
| 35 |
+
# api config
|
| 36 |
+
API_method: Literal["POST","GET","PUT","OPTIONS","WEBSOCKET","PATCH","DELETE","TRACE","CONNECT"] = "POST"
|
| 37 |
+
API_path: str = "/TextClassification"
|
| 38 |
+
API_tags: List[str] = field(default_factory = lambda: [""])
|
| 39 |
+
|
| 40 |
+
# CORS config
|
| 41 |
+
BACKEND_CORS_ORIGINS: List[AnyHttpUrl] = field(default_factory = lambda: ["*"])
|
| 42 |
+
allow_credentials: bool = True
|
| 43 |
+
allow_methods: List[str] = field(default_factory = lambda: ["*"])
|
| 44 |
+
allow_headers: List[str] = field(default_factory = lambda: ["*"])
|
| 45 |
+
|
| 46 |
+
# log config
|
| 47 |
+
log_file_path: str = ""
|
| 48 |
+
log_level: str = "INFO"
|
| 49 |
+
|
| 50 |
+
# pipeline config
|
| 51 |
+
pipeline_type: str = ""
|
| 52 |
+
model_name: str = ""
|
| 53 |
+
|
| 54 |
+
# model config
|
| 55 |
+
# device: int = -1
|
| 56 |
+
# texta_name: Optional[str] = "sentence"
|
| 57 |
+
# textb_name: Optional[str] = "sentence2"
|
| 58 |
+
# label_name: Optional[str] = "label"
|
| 59 |
+
# max_length: int = 512
|
| 60 |
+
# return_tensors: str = "pt"
|
| 61 |
+
# padding: str = "longest"
|
| 62 |
+
# truncation: bool = True
|
| 63 |
+
# skip_special_tokens: bool = True
|
| 64 |
+
# clean_up_tkenization_spaces: bool = True
|
| 65 |
+
|
| 66 |
+
# # parameters for text2image model
|
| 67 |
+
# skip_steps: Optional[int] = 0
|
| 68 |
+
# clip_guidance_scale: Optional[int] = 0
|
| 69 |
+
# init_scale: Optional[int] = 0
|
| 70 |
+
|
| 71 |
+
def setup_config(self, args:Namespace) -> None:
|
| 72 |
+
|
| 73 |
+
# load config file
|
| 74 |
+
with open(CURRENT_DIR_PATH + "/" + args.config_path, "r") as jsonfile:
|
| 75 |
+
config = json.load(jsonfile)
|
| 76 |
+
|
| 77 |
+
server_config = config["SERVER"]
|
| 78 |
+
logging_config = config["LOGGING"]
|
| 79 |
+
pipeline_config = config["PIPELINE"]
|
| 80 |
+
|
| 81 |
+
# server config
|
| 82 |
+
self.SERVER_HOST: AnyHttpUrl = server_config["SERVER_HOST"]
|
| 83 |
+
self.SERVER_PORT: int = server_config["SERVER_PORT"]
|
| 84 |
+
self.SERVER_NAME: str = server_config["SERVER_NAME"]
|
| 85 |
+
self.PROJECT_NAME: str = server_config["PROJECT_NAME"]
|
| 86 |
+
self.API_PREFIX_STR: str = server_config["API_PREFIX_STR"]
|
| 87 |
+
|
| 88 |
+
# api config
|
| 89 |
+
self.API_method: Literal["POST","GET","PUT","OPTIONS","WEBSOCKET","PATCH","DELETE","TRACE","CONNECT"] = server_config["API_method"]
|
| 90 |
+
self.API_path: str = server_config["API_path"]
|
| 91 |
+
self.API_tags: List[str] = server_config["API_tags"]
|
| 92 |
+
|
| 93 |
+
# CORS config
|
| 94 |
+
self.BACKEND_CORS_ORIGINS: List[AnyHttpUrl] = server_config["BACKEND_CORS_ORIGINS"]
|
| 95 |
+
self.allow_credentials: bool = server_config["allow_credentials"]
|
| 96 |
+
self.allow_methods: List[str] = server_config["allow_methods"]
|
| 97 |
+
self.allow_headers: List[str] = server_config["allow_headers"]
|
| 98 |
+
|
| 99 |
+
# log config
|
| 100 |
+
self.log_file_path: str = logging_config["log_file_path"]
|
| 101 |
+
self.log_level: str = logging_config["log_level"]
|
| 102 |
+
|
| 103 |
+
# pipeline config
|
| 104 |
+
self.pipeline_type: str = pipeline_config["pipeline_type"]
|
| 105 |
+
self.model_name: str = pipeline_config["model_name"]
|
| 106 |
+
|
| 107 |
+
# general model config
|
| 108 |
+
self.model_settings: dict = pipeline_config["model_settings"]
|
| 109 |
+
|
| 110 |
+
# 由于pipeline本身会解析参数,后续参数可以不要
|
| 111 |
+
# 直接将model_settings字典转为Namespace后作为pipeline的args参数即可
|
| 112 |
+
|
| 113 |
+
# self.device: int = self.model_settings["device"]
|
| 114 |
+
# self.texta_name: Optional[str] = self.model_settings["texta_name"]
|
| 115 |
+
# self.textb_name: Optional[str] = self.model_settings["textb_name"]
|
| 116 |
+
# self.label_name: Optional[str] = self.model_settings["label_name"]
|
| 117 |
+
# self.max_length: int = self.model_settings["max_length"]
|
| 118 |
+
# self.return_tensors: str = self.model_settings["return_tensors"]
|
| 119 |
+
# self.padding: str = self.model_settings["padding"]
|
| 120 |
+
# self.truncation: bool = self.model_settings["truncation"]
|
| 121 |
+
# self.skip_special_tokens: bool = self.model_settings["skip_special_tokens"]
|
| 122 |
+
# self.clean_up_tkenization_spaces: bool = self.model_settings["clean_up_tkenization_spaces"]
|
| 123 |
+
|
| 124 |
+
# # specific parameters for text2image model
|
| 125 |
+
# self.skip_steps: Optional[int] = self.model_settings["skip_steps"]
|
| 126 |
+
# self.clip_guidance_scale: Optional[int] = self.model_settings["clip_guidance_scale"]
|
| 127 |
+
# self.init_scale: Optional[int] = self.model_settings["init_scale"]
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def setup_logger(logger, user_config: APIConfig):
|
| 132 |
+
|
| 133 |
+
# default level: INFO
|
| 134 |
+
|
| 135 |
+
logger.setLevel(getattr(logging, user_config.log_level, "INFO"))
|
| 136 |
+
ch = logging.StreamHandler()
|
| 137 |
+
|
| 138 |
+
if(user_config.log_file_path == ""):
|
| 139 |
+
fh = logging.FileHandler(filename = CURRENT_DIR_PATH + "/" + user_config.SERVER_NAME + ".log")
|
| 140 |
+
elif(".log" not in user_config.log_file_path[-5:-1]):
|
| 141 |
+
fh = logging.FileHandler(filename = user_config.log_file_path + "/" + user_config.SERVER_NAME + ".log")
|
| 142 |
+
else:
|
| 143 |
+
fh = logging.FileHandler(filename = user_config.log_file_path)
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
formatter = logging.Formatter(
|
| 147 |
+
"%(asctime)s - %(module)s - %(funcName)s - line:%(lineno)d - %(levelname)s - %(message)s"
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
ch.setFormatter(formatter)
|
| 151 |
+
fh.setFormatter(formatter)
|
| 152 |
+
logger.addHandler(ch) # Exporting logs to the screen
|
| 153 |
+
logger.addHandler(fh) # Exporting logs to a file
|
| 154 |
+
|
| 155 |
+
return logger
|
| 156 |
+
|
| 157 |
+
user_config = APIConfig()
|
| 158 |
+
api_logger = logging.getLogger()
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
|
fengshen/README.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 最新发布
|
| 2 |
+
|
| 3 |
+
* \[2022.09.13\] [更新ErLangShen系列DeBERTa预训练代码](https://huggingface.co/IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-Chinese)
|
| 4 |
+
* \[2022.09.13\] [更新RanDeng系列Bart预训练代码](https://huggingface.co/IDEA-CCNL/Randeng-BART-139M)
|
| 5 |
+
* \[2022.09.13\] [更新ErLangShen系列Bert预训练代码](https://huggingface.co/IDEA-CCNL/Erlangshen-MegatronBert-1.3B)
|
| 6 |
+
* \[2022.05.11\] [更新TaiYi系列VIT多模态模型及下游任务示例](https://fengshenbang-doc.readthedocs.io/zh/latest/docs/太乙系列/Taiyi-vit-87M-D.html)
|
| 7 |
+
* \[2022.05.11\] [更新BiGan系列Transformer-XL去噪模型及下游任务示例](https://fengshenbang-doc.readthedocs.io/zh/latest/docs/比干系列/Bigan-Transformer-XL-denoise-1.1B.html)
|
| 8 |
+
* \[2022.05.11\] [更新ErLangShen系列下游任务示例](https://fengshenbang-doc.readthedocs.io/zh/latest/docs/二郎神系列/Erlangshen-Roberta-110M-NLI.html)
|
| 9 |
+
|
| 10 |
+
# 导航
|
| 11 |
+
|
| 12 |
+
- [导航](#导航)
|
| 13 |
+
- [框架简介](#框架简介)
|
| 14 |
+
- [依赖环境](#依赖环境)
|
| 15 |
+
- [项目结构](#项目结构)
|
| 16 |
+
- [设计思路](#设计思路)
|
| 17 |
+
- [分类下游任务](#分类下游任务)
|
| 18 |
+
|
| 19 |
+
## 框架简介
|
| 20 |
+
|
| 21 |
+
FengShen训练框架是封神榜大模型开源计划的重要一环,在大模型的生产和应用中起到至关重要的作用。FengShen可以应用在基于海量数据的预训练以及各种下游任务的finetune中。封神榜专注于NLP大模型开源,然而模型的增大带来不仅仅是训练的问题,在使用上也存在诸多不便。为了解决训练和使用的问题,FengShen参考了目前开源的优秀方案并且重新设计了Pipeline,用户可以根据自己的需求,从封神榜中选取丰富的预训练模型,同时利用FengShen快速微调下游任务。
|
| 22 |
+
|
| 23 |
+
目前所有实例以及文档可以查看我们的[Wiki](https://fengshenbang-doc.readthedocs.io/zh/latest/index.html)
|
| 24 |
+
所有的模型可以在[Huggingface主页](https://huggingface.co/IDEA-CCNL)找到
|
| 25 |
+
|
| 26 |
+
通过我们的框架,你可以快速享受到:
|
| 27 |
+
|
| 28 |
+
1. 比原生torch更强的性能,训练速度提升<font color=#0000FF >**300%**</font>
|
| 29 |
+
2. 支持更大的模型,支持<font color=#0000FF >**百亿级别**</font>内模型训练及微调
|
| 30 |
+
3. 支持<font color=#0000FF >**TB级以上**</font>的数据集,在家用主机上即可享受预训练模型带来的效果提升
|
| 31 |
+
3. 丰富的预训练、下游任务示例,一键开始训练
|
| 32 |
+
4. 适应各种设备环境,支持在CPU、GPU、TPU等不同设备上运行
|
| 33 |
+
5. 集成主流的分布式训练逻辑,无需修改代码即可支持DDP、Zero Optimizer等分布式优化技术
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
## 依赖环境
|
| 38 |
+
|
| 39 |
+
* Python >= 3.8
|
| 40 |
+
* torch >= 1.8
|
| 41 |
+
* transformers >= 3.2.0
|
| 42 |
+
* pytorch-lightning >= 1.5.10
|
| 43 |
+
|
| 44 |
+
在Fengshenbang-LM根目录下
|
| 45 |
+
pip install --editable ./
|
| 46 |
+
|
| 47 |
+
## 项目结构
|
| 48 |
+
|
| 49 |
+
```
|
| 50 |
+
├── data # 支持多种数据处理方式以及数据集
|
| 51 |
+
│ ├── cbart_dataloader
|
| 52 |
+
| ├── fs_datasets # 基于transformers datasets的封装,新增中文数据集(开源计划中)
|
| 53 |
+
| ├── universal_datamodule # 打通fs_datasets与lightning datamodule,减少重复开发工作量
|
| 54 |
+
│ ├── megatron_dataloader # 支持基于Megatron实现的TB级别数据集处理、训练
|
| 55 |
+
│ ├── mmap_dataloader # 通用的Memmap形式的数据加载
|
| 56 |
+
│ └── task_dataloader # 支持多种下游任务
|
| 57 |
+
├── examples # 丰富的示例,从预训练到下游任务,应有尽有。
|
| 58 |
+
├── metric # 提供各种metric计算,支持用户自定义metric
|
| 59 |
+
├── losses # 同样支持loss自定义,满足定制化需求
|
| 60 |
+
├── tokenizer # 支持自定义tokenizer,比如我们使用的SentencePiece训练代码等
|
| 61 |
+
├── models # 模型库
|
| 62 |
+
│ ├── auto # 支持自动导入对应的模型
|
| 63 |
+
│ ├── bart
|
| 64 |
+
│ ├── longformer
|
| 65 |
+
│ ├── megatron_t5
|
| 66 |
+
│ └── roformer
|
| 67 |
+
└── utils # 实用函数
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
## 设计思路
|
| 71 |
+
|
| 72 |
+
FengShen框架目前整体基于Pytorch-Lightning & Transformer进行开发,在底层框架上不断开源基于中文的预训练模型,同时提供丰富的examples,每一个封神榜的模型都能找到对应的预训练、下游任务代码。
|
| 73 |
+
|
| 74 |
+
在FengShen上开发,整体可以按照下面的三个步骤进行:
|
| 75 |
+
|
| 76 |
+
1. 封装数据处理流程 -> pytorch_lightning.LightningDataModule
|
| 77 |
+
2. 封装模型结构 -> pytorch_lightning.LightningModule
|
| 78 |
+
3. 配置一些插件,比如log_monitor,checkpoint_callback等等。
|
| 79 |
+
|
| 80 |
+
一个完整的DEMO可以看Randeng-BART系列实例 -> [文档](https://fengshenbang-doc.readthedocs.io/zh/latest/docs/燃灯系列/BART-139M.html) [代码](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/hf-ds/fengshen/examples/pretrain_bart)
|
| 81 |
+
|
| 82 |
+
## 分类下游任务
|
| 83 |
+
|
| 84 |
+
在examples/classification目录下,我们提供丰富的分类任务的示例���其中我们提供三个一键式运行的示例。
|
| 85 |
+
|
| 86 |
+
* demo_classification_afqmc_roberta.sh 使用DDP微调roberta
|
| 87 |
+
* demo_classification_afqmc_roberta_deepspeed.sh 结合deepspeed微调roberta,获得更快的运算速度
|
| 88 |
+
* demo_classification_afqmc_erlangshen_offload.sh 仅需7G显存即可微调我们效果最好的二郎神系列模型
|
| 89 |
+
|
| 90 |
+
上述示例均采用AFQMC的数据集,关于数据集的介绍可以在[这里](https://www.cluebenchmarks.com/introduce.html)找到。
|
| 91 |
+
同时我们处理过的数据文件已经放在Huggingface上,点击[这里](https://huggingface.co/datasets/IDEA-CCNL/AFQMC)直达源文件。
|
| 92 |
+
仅需要按我们的格式稍微处理一下数据集,即可适配下游不同的分类任务。
|
| 93 |
+
在脚本示例中,仅需要修改如下参数即可适配本地文件
|
| 94 |
+
|
| 95 |
+
```
|
| 96 |
+
--dataset_name IDEA-CCNL/AFQMC \
|
| 97 |
+
|
| 98 |
+
-------> 修改为
|
| 99 |
+
|
| 100 |
+
--data_dir $DATA_DIR \ # 数据目录
|
| 101 |
+
--train_data train.json \ # 数据文件
|
| 102 |
+
--valid_data dev.json \
|
| 103 |
+
--test_data test.json \
|
| 104 |
+
|
| 105 |
+
```
|
fengshen/__init__.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2021 The IDEA Authors. All rights reserved.
|
| 3 |
+
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
from .models.longformer import LongformerConfig, LongformerModel
|
| 17 |
+
from .models.roformer import RoFormerConfig, RoFormerModel
|
| 18 |
+
from .models.megatron_t5 import T5Config, T5EncoderModel
|
| 19 |
+
from .models.ubert import UbertPipelines, UbertModel
|
fengshen/cli/fengshen_pipeline.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from importlib import import_module
|
| 3 |
+
from datasets import load_dataset
|
| 4 |
+
import argparse
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def main():
|
| 8 |
+
if len(sys.argv) < 3:
|
| 9 |
+
raise Exception(
|
| 10 |
+
'args len < 3, example: fengshen_pipeline text_classification predict xxxxx')
|
| 11 |
+
pipeline_name = sys.argv[1]
|
| 12 |
+
method = sys.argv[2]
|
| 13 |
+
pipeline_class = getattr(import_module('fengshen.pipelines.' + pipeline_name), 'Pipeline')
|
| 14 |
+
|
| 15 |
+
total_parser = argparse.ArgumentParser("FengShen Pipeline")
|
| 16 |
+
total_parser.add_argument('--model', default='', type=str)
|
| 17 |
+
total_parser.add_argument('--datasets', default='', type=str)
|
| 18 |
+
total_parser.add_argument('--text', default='', type=str)
|
| 19 |
+
total_parser = pipeline_class.add_pipeline_specific_args(total_parser)
|
| 20 |
+
args = total_parser.parse_args(args=sys.argv[3:])
|
| 21 |
+
pipeline = pipeline_class(args=args, model=args.model)
|
| 22 |
+
|
| 23 |
+
if method == 'predict':
|
| 24 |
+
print(pipeline(args.text))
|
| 25 |
+
elif method == 'train':
|
| 26 |
+
datasets = load_dataset(args.datasets)
|
| 27 |
+
pipeline.train(datasets)
|
| 28 |
+
else:
|
| 29 |
+
raise Exception(
|
| 30 |
+
'cmd not support, now only support {predict, train}')
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
if __name__ == '__main__':
|
| 34 |
+
main()
|
fengshen/data/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
fengshen/data/bert_dataloader/auto_split.sh
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
files=`find $1 -type f -size +1024M`
|
| 2 |
+
|
| 3 |
+
for p in $files
|
| 4 |
+
do
|
| 5 |
+
echo "processing $p"
|
| 6 |
+
name=`basename $p .json`
|
| 7 |
+
file=`dirname $p`
|
| 8 |
+
split -a 2 -C 300M $p $file/$name- && ls|grep -E "(-[a-zA-Z]{2})" |xargs -n1 -i{} mv {} {}.json
|
| 9 |
+
rm -f $p
|
| 10 |
+
done
|
fengshen/data/bert_dataloader/load.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import re
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
import glob
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from contextlib import ExitStack
|
| 7 |
+
import datasets
|
| 8 |
+
import multiprocessing
|
| 9 |
+
from typing import cast, TextIO
|
| 10 |
+
from itertools import chain
|
| 11 |
+
import json
|
| 12 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 13 |
+
from random import shuffle
|
| 14 |
+
from pytorch_lightning import LightningDataModule
|
| 15 |
+
from typing import Optional
|
| 16 |
+
|
| 17 |
+
from torch.utils.data import DataLoader
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# _SPLIT_DATA_PATH = '/data1/datas/wudao_180g_split/test'
|
| 21 |
+
_SPLIT_DATA_PATH = '/data1/datas/wudao_180g_split'
|
| 22 |
+
_CACHE_SPLIT_DATA_PATH = '/data1/datas/wudao_180g_FSData'
|
| 23 |
+
|
| 24 |
+
# feats = datasets.Features({"text": datasets.Value('string')})
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class BertDataGenerate(object):
|
| 28 |
+
|
| 29 |
+
def __init__(self,
|
| 30 |
+
data_files=_SPLIT_DATA_PATH,
|
| 31 |
+
save_path=_CACHE_SPLIT_DATA_PATH,
|
| 32 |
+
train_test_validation='950,49,1',
|
| 33 |
+
num_proc=1,
|
| 34 |
+
cache=True):
|
| 35 |
+
self.data_files = Path(data_files)
|
| 36 |
+
if save_path:
|
| 37 |
+
self.save_path = Path(save_path)
|
| 38 |
+
else:
|
| 39 |
+
self.save_path = self.file_check(
|
| 40 |
+
Path(self.data_files.parent, self.data_files.name+'_FSDataset'),
|
| 41 |
+
'save')
|
| 42 |
+
self.num_proc = num_proc
|
| 43 |
+
self.cache = cache
|
| 44 |
+
self.split_idx = self.split_train_test_validation_index(train_test_validation)
|
| 45 |
+
if cache:
|
| 46 |
+
self.cache_path = self.file_check(
|
| 47 |
+
Path(self.save_path.parent, 'FSDataCache', self.data_files.name), 'cache')
|
| 48 |
+
else:
|
| 49 |
+
self.cache_path = None
|
| 50 |
+
|
| 51 |
+
@staticmethod
|
| 52 |
+
def file_check(path, path_type):
|
| 53 |
+
print(path)
|
| 54 |
+
if not path.exists():
|
| 55 |
+
path.mkdir(parents=True)
|
| 56 |
+
print(f"Since no {path_type} directory is specified, the program will automatically create it in {path} directory.")
|
| 57 |
+
return str(path)
|
| 58 |
+
|
| 59 |
+
@staticmethod
|
| 60 |
+
def split_train_test_validation_index(train_test_validation):
|
| 61 |
+
split_idx_ = [int(i) for i in train_test_validation.split(',')]
|
| 62 |
+
idx_dict = {
|
| 63 |
+
'train_rate': split_idx_[0]/sum(split_idx_),
|
| 64 |
+
'test_rate': split_idx_[1]/sum(split_idx_[1:])
|
| 65 |
+
}
|
| 66 |
+
return idx_dict
|
| 67 |
+
|
| 68 |
+
def process(self, index, path):
|
| 69 |
+
print('saving dataset shard {}'.format(index))
|
| 70 |
+
|
| 71 |
+
ds = (datasets.load_dataset('json', data_files=str(path),
|
| 72 |
+
cache_dir=self.cache_path,
|
| 73 |
+
features=None))
|
| 74 |
+
# ds = ds.map(self.cut_sent,input_columns='text')
|
| 75 |
+
# print(d)
|
| 76 |
+
# print('!!!',ds)
|
| 77 |
+
ds = ds['train'].train_test_split(train_size=self.split_idx['train_rate'])
|
| 78 |
+
ds_ = ds['test'].train_test_split(train_size=self.split_idx['test_rate'])
|
| 79 |
+
ds = datasets.DatasetDict({
|
| 80 |
+
'train': ds['train'],
|
| 81 |
+
'test': ds_['train'],
|
| 82 |
+
'validation': ds_['test']
|
| 83 |
+
})
|
| 84 |
+
# print('!!!!',ds)
|
| 85 |
+
ds.save_to_disk(Path(self.save_path, path.name))
|
| 86 |
+
return 'saving dataset shard {} done'.format(index)
|
| 87 |
+
|
| 88 |
+
def generate_cache_arrow(self) -> None:
|
| 89 |
+
'''
|
| 90 |
+
生成HF支持的缓存文件,加速后续的加载
|
| 91 |
+
'''
|
| 92 |
+
data_dict_paths = self.data_files.rglob('*')
|
| 93 |
+
p = ProcessPoolExecutor(max_workers=self.num_proc)
|
| 94 |
+
res = list()
|
| 95 |
+
|
| 96 |
+
for index, path in enumerate(data_dict_paths):
|
| 97 |
+
res.append(p.submit(self.process, index, path))
|
| 98 |
+
|
| 99 |
+
p.shutdown(wait=True)
|
| 100 |
+
for future in res:
|
| 101 |
+
print(future.result(), flush=True)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def load_dataset(num_proc=4, **kargs):
|
| 105 |
+
cache_dict_paths = Path(_CACHE_SPLIT_DATA_PATH).glob('*')
|
| 106 |
+
ds = []
|
| 107 |
+
res = []
|
| 108 |
+
p = ProcessPoolExecutor(max_workers=num_proc)
|
| 109 |
+
for path in cache_dict_paths:
|
| 110 |
+
res.append(p.submit(datasets.load_from_disk,
|
| 111 |
+
str(path), **kargs))
|
| 112 |
+
|
| 113 |
+
p.shutdown(wait=True)
|
| 114 |
+
for future in res:
|
| 115 |
+
ds.append(future.result())
|
| 116 |
+
# print(future.result())
|
| 117 |
+
train = []
|
| 118 |
+
test = []
|
| 119 |
+
validation = []
|
| 120 |
+
for ds_ in ds:
|
| 121 |
+
train.append(ds_['train'])
|
| 122 |
+
test.append(ds_['test'])
|
| 123 |
+
validation.append(ds_['validation'])
|
| 124 |
+
# ds = datasets.concatenate_datasets(ds)
|
| 125 |
+
# print(ds)
|
| 126 |
+
return datasets.DatasetDict({
|
| 127 |
+
'train': datasets.concatenate_datasets(train),
|
| 128 |
+
'test': datasets.concatenate_datasets(test),
|
| 129 |
+
'validation': datasets.concatenate_datasets(validation)
|
| 130 |
+
})
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class BertDataModule(LightningDataModule):
|
| 134 |
+
@ staticmethod
|
| 135 |
+
def add_data_specific_args(parent_args):
|
| 136 |
+
parser = parent_args.add_argument_group('Universal DataModule')
|
| 137 |
+
parser.add_argument('--num_workers', default=8, type=int)
|
| 138 |
+
parser.add_argument('--train_batchsize', default=32, type=int)
|
| 139 |
+
parser.add_argument('--val_batchsize', default=32, type=int)
|
| 140 |
+
parser.add_argument('--test_batchsize', default=32, type=int)
|
| 141 |
+
parser.add_argument('--datasets_name', type=str)
|
| 142 |
+
# parser.add_argument('--datasets_name', type=str)
|
| 143 |
+
parser.add_argument('--train_datasets_field', type=str, default='train')
|
| 144 |
+
parser.add_argument('--val_datasets_field', type=str, default='validation')
|
| 145 |
+
parser.add_argument('--test_datasets_field', type=str, default='test')
|
| 146 |
+
return parent_args
|
| 147 |
+
|
| 148 |
+
def __init__(
|
| 149 |
+
self,
|
| 150 |
+
tokenizer,
|
| 151 |
+
collate_fn,
|
| 152 |
+
args,
|
| 153 |
+
**kwargs,
|
| 154 |
+
):
|
| 155 |
+
super().__init__()
|
| 156 |
+
self.datasets = load_dataset(num_proc=args.num_workers)
|
| 157 |
+
self.tokenizer = tokenizer
|
| 158 |
+
self.collate_fn = collate_fn
|
| 159 |
+
self.save_hyperparameters(args)
|
| 160 |
+
|
| 161 |
+
def setup(self, stage: Optional[str] = None) -> None:
|
| 162 |
+
self.train = DataLoader(
|
| 163 |
+
self.datasets[self.hparams.train_datasets_field],
|
| 164 |
+
batch_size=self.hparams.train_batchsize,
|
| 165 |
+
shuffle=True,
|
| 166 |
+
num_workers=self.hparams.num_workers,
|
| 167 |
+
collate_fn=self.collate_fn,
|
| 168 |
+
)
|
| 169 |
+
self.val = DataLoader(
|
| 170 |
+
self.datasets[self.hparams.val_datasets_field],
|
| 171 |
+
batch_size=self.hparams.val_batchsize,
|
| 172 |
+
shuffle=False,
|
| 173 |
+
num_workers=self.hparams.num_workers,
|
| 174 |
+
collate_fn=self.collate_fn,
|
| 175 |
+
)
|
| 176 |
+
self.test = DataLoader(
|
| 177 |
+
self.datasets[self.hparams.test_datasets_field],
|
| 178 |
+
batch_size=self.hparams.test_batchsize,
|
| 179 |
+
shuffle=False,
|
| 180 |
+
num_workers=self.hparams.num_workers,
|
| 181 |
+
collate_fn=self.collate_fn,
|
| 182 |
+
)
|
| 183 |
+
return
|
| 184 |
+
|
| 185 |
+
def train_dataloader(self):
|
| 186 |
+
return self.train
|
| 187 |
+
|
| 188 |
+
def val_dataloader(self):
|
| 189 |
+
return self.val
|
| 190 |
+
|
| 191 |
+
def test_dataloader(self):
|
| 192 |
+
return self.test
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
if __name__ == '__main__':
|
| 196 |
+
# pre = PreProcessing(_SPLIT_DATA_PATH)
|
| 197 |
+
# pre.processing()
|
| 198 |
+
|
| 199 |
+
dataset = BertDataGenerate(_SPLIT_DATA_PATH, num_proc=16)
|
| 200 |
+
dataset.generate_cache_arrow()
|
fengshen/data/bert_dataloader/preprocessing.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import json
|
| 3 |
+
import multiprocessing
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from itertools import chain
|
| 7 |
+
|
| 8 |
+
_SPLIT_DATA_PATH = '/data1/datas/wudao_180g'
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def cut_sent(path):
|
| 12 |
+
"""
|
| 13 |
+
中文分句,默认?、。、!、省略号分句,考虑双引号包裹的句子
|
| 14 |
+
采用分割替换的方式
|
| 15 |
+
"""
|
| 16 |
+
path = Path(path)
|
| 17 |
+
# print(path)
|
| 18 |
+
save_path = str(Path('/data1/datas/wudao_180g_split', path.name))
|
| 19 |
+
print('处理文件:', save_path)
|
| 20 |
+
with open(save_path, 'wt', encoding='utf-8') as w:
|
| 21 |
+
with open(path, 'rt', encoding='utf-8') as f:
|
| 22 |
+
for para in tqdm(f):
|
| 23 |
+
para = json.loads(para)
|
| 24 |
+
para_ = para['text'] + ' '
|
| 25 |
+
# print('sentence piece......')
|
| 26 |
+
# pep8中 正则不能些 \? 要写成\\?
|
| 27 |
+
para_ = re.sub('([?。!\\?\\!…]+)([^”’]|[”’])',
|
| 28 |
+
r'\1#####\2', para_)
|
| 29 |
+
para_ = re.sub('([\\.]{3,})([^”’])', r'\1#####\2', para_)
|
| 30 |
+
|
| 31 |
+
# 匹配 \1: 句子结束符紧挨’” \2: 非句子结束符号,被引号包裹的句子
|
| 32 |
+
para_ = re.sub(
|
| 33 |
+
'([。!?\\?\\!…][”’])([^,。!?\\?\\!]|\\s)', r'\1#####\2', para_)
|
| 34 |
+
para_ = re.sub(
|
| 35 |
+
'([\\.]{3,}[”’])([^,。!?\\?\\!]|\\s)', r'\1#####\2', para_)
|
| 36 |
+
para_ = re.sub(
|
| 37 |
+
'([#]{5})([”’])([^,。!?\\?\\!])', r'\2#####\3', para_)
|
| 38 |
+
para_ = para_.strip()
|
| 39 |
+
# 一个512里面多个样本
|
| 40 |
+
line_ = ''
|
| 41 |
+
for line in para_.split('#####'):
|
| 42 |
+
line = line.strip()
|
| 43 |
+
if len(line_) < 512 and len(line) > 0:
|
| 44 |
+
line_ += line
|
| 45 |
+
else:
|
| 46 |
+
w.writelines(json.dumps(
|
| 47 |
+
{'text': line_}, ensure_ascii=False)+'\n')
|
| 48 |
+
line_ = line
|
| 49 |
+
w.writelines(json.dumps(
|
| 50 |
+
{'text': line_}, ensure_ascii=False)+'\n')
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def chain_iter(*filenames):
|
| 54 |
+
"""
|
| 55 |
+
将多个文件读成一个迭代器
|
| 56 |
+
"""
|
| 57 |
+
reader = [open(file, 'r') for file in filenames]
|
| 58 |
+
return chain(*reader)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class Config(object):
|
| 62 |
+
|
| 63 |
+
def __init__(self, data_path=_SPLIT_DATA_PATH, num_worker=16, split_numb=600000, cut_sentence=True, output_file=None) -> None:
|
| 64 |
+
self.data_path = Path(data_path)
|
| 65 |
+
self.num_worker = num_worker
|
| 66 |
+
self.split_numb = split_numb
|
| 67 |
+
self.cut_sentence = cut_sentence
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def processing1():
|
| 71 |
+
args = Config()
|
| 72 |
+
p_ = [str(i) for i in args.data_path.glob('*')]
|
| 73 |
+
fin = chain_iter(*p_)
|
| 74 |
+
pool = multiprocessing.Pool(args.num_worker)
|
| 75 |
+
docs = pool.imap(cut_sent, fin, chunksize=args.num_worker)
|
| 76 |
+
|
| 77 |
+
if not Path(args.data_path.parent, args.data_path.name+'_split').exists():
|
| 78 |
+
Path(args.data_path.parent, args.data_path.name+'_split').mkdir()
|
| 79 |
+
writer = open(str(Path(args.data_path.parent, args.data_path.name +
|
| 80 |
+
'_split', 'sentence_level.json')), 'wt', encoding='utf-8')
|
| 81 |
+
for doc in tqdm(docs):
|
| 82 |
+
for sentence in doc:
|
| 83 |
+
writer.writelines(json.dumps(
|
| 84 |
+
{"text": sentence}, ensure_ascii=False)+'\n')
|
| 85 |
+
pool.close()
|
| 86 |
+
pool.join()
|
| 87 |
+
writer.close()
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
if __name__ == '__main__':
|
| 91 |
+
from time import process_time, perf_counter
|
| 92 |
+
from random import shuffle
|
| 93 |
+
st = process_time()
|
| 94 |
+
args = Config(num_worker=16)
|
| 95 |
+
|
| 96 |
+
if not Path(args.data_path.parent, args.data_path.name+'_split').exists():
|
| 97 |
+
Path(args.data_path.parent, args.data_path.name +
|
| 98 |
+
'_split').mkdir(parents=True)
|
| 99 |
+
|
| 100 |
+
p_ = [str(i) for i in args.data_path.glob('*')]
|
| 101 |
+
# 简单shuffle
|
| 102 |
+
shuffle(p_)
|
| 103 |
+
|
| 104 |
+
pool = multiprocessing.Pool(args.num_worker)
|
| 105 |
+
for item in p_:
|
| 106 |
+
pool.apply_async(func=cut_sent, args=(item,))
|
| 107 |
+
pool.close()
|
| 108 |
+
pool.join()
|
| 109 |
+
cost_time = process_time() - st
|
| 110 |
+
print('DONE!! cost time : %.5f' % cost_time)
|
fengshen/data/clip_dataloader/flickr.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import Dataset, DataLoader
|
| 2 |
+
from torchvision.transforms import Normalize, Compose, RandomResizedCrop, InterpolationMode, ToTensor, Resize, \
|
| 3 |
+
CenterCrop
|
| 4 |
+
from transformers import BertTokenizer
|
| 5 |
+
import pytorch_lightning as pl
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import os
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class flickr30k_CNA(Dataset):
|
| 11 |
+
def __init__(self, img_root_path,
|
| 12 |
+
annot_path,
|
| 13 |
+
transform=None):
|
| 14 |
+
self.images = []
|
| 15 |
+
self.captions = []
|
| 16 |
+
self.labels = []
|
| 17 |
+
self.root = img_root_path
|
| 18 |
+
with open(annot_path, 'r') as f:
|
| 19 |
+
for line in f:
|
| 20 |
+
line = line.strip().split('\t')
|
| 21 |
+
key, caption = line[0].split('#')[0], line[1]
|
| 22 |
+
img_path = key + '.jpg'
|
| 23 |
+
self.images.append(img_path)
|
| 24 |
+
self.captions.append(caption)
|
| 25 |
+
self.labels.append(key)
|
| 26 |
+
self.transforms = transform
|
| 27 |
+
self.tokenizer = BertTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
|
| 28 |
+
|
| 29 |
+
# NOTE large 模型
|
| 30 |
+
self.context_length = 77
|
| 31 |
+
|
| 32 |
+
def __len__(self):
|
| 33 |
+
return len(self.images)
|
| 34 |
+
|
| 35 |
+
def __getitem__(self, idx):
|
| 36 |
+
img_path = str(self.images[idx])
|
| 37 |
+
image = self.transforms(Image.open(os.path.join(self.root, img_path)))
|
| 38 |
+
text = self.tokenizer(str(self.captions[idx]), max_length=self.context_length,
|
| 39 |
+
padding='max_length', truncation=True, return_tensors='pt')['input_ids'][0]
|
| 40 |
+
label = self.labels[idx]
|
| 41 |
+
return image, text, label
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def _convert_to_rgb(image):
|
| 45 |
+
return image.convert('RGB')
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def image_transform(
|
| 49 |
+
image_size: int,
|
| 50 |
+
is_train: bool,
|
| 51 |
+
mean=(0.48145466, 0.4578275, 0.40821073),
|
| 52 |
+
std=(0.26862954, 0.26130258, 0.27577711)
|
| 53 |
+
):
|
| 54 |
+
normalize = Normalize(mean=mean, std=std)
|
| 55 |
+
if is_train:
|
| 56 |
+
return Compose([
|
| 57 |
+
RandomResizedCrop(image_size, scale=(0.9, 1.0), interpolation=InterpolationMode.BICUBIC),
|
| 58 |
+
_convert_to_rgb,
|
| 59 |
+
ToTensor(),
|
| 60 |
+
normalize,
|
| 61 |
+
])
|
| 62 |
+
else:
|
| 63 |
+
return Compose([
|
| 64 |
+
Resize(image_size, interpolation=InterpolationMode.BICUBIC),
|
| 65 |
+
CenterCrop(image_size),
|
| 66 |
+
_convert_to_rgb,
|
| 67 |
+
ToTensor(),
|
| 68 |
+
normalize,
|
| 69 |
+
])
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class FlickrDataModule(pl.LightningDataModule):
|
| 73 |
+
def __init__(self, args):
|
| 74 |
+
self.batch_size = args.batch_size
|
| 75 |
+
self.train_filename = args.train_filename # NOTE 标注的文件夹
|
| 76 |
+
self.train_root = args.train_root # NOTE 图片地址
|
| 77 |
+
self.val_filename = args.val_filename
|
| 78 |
+
self.val_root = args.val_root
|
| 79 |
+
self.test_filename = args.test_filename
|
| 80 |
+
self.test_root = args.test_root
|
| 81 |
+
|
| 82 |
+
self.pretrain_model = args.pretrain_model
|
| 83 |
+
self.image_size = 224
|
| 84 |
+
self.prepare_data_per_node = True
|
| 85 |
+
self._log_hyperparams = False
|
| 86 |
+
self.num_workers = args.num_workers
|
| 87 |
+
|
| 88 |
+
def setup(self, stage=None):
|
| 89 |
+
# dataset
|
| 90 |
+
train_transform = image_transform(224, True)
|
| 91 |
+
val_transform = image_transform(224, False)
|
| 92 |
+
test_transform = image_transform(224, False)
|
| 93 |
+
|
| 94 |
+
self.train_dataset = flickr30k_CNA(self.train_root, self.train_filename, transform=train_transform)
|
| 95 |
+
self.val_dataset = flickr30k_CNA(self.val_root, self.val_filename, transform=val_transform)
|
| 96 |
+
self.test_dataset = flickr30k_CNA(self.test_root, self.test_filename, transform=test_transform)
|
| 97 |
+
|
| 98 |
+
def train_dataloader(self):
|
| 99 |
+
return DataLoader(self.train_dataset, batch_size=self.batch_size, num_workers=self.num_workers)
|
| 100 |
+
|
| 101 |
+
def val_dataloader(self):
|
| 102 |
+
return DataLoader(self.val_dataset, batch_size=self.batch_size, num_workers=self.num_workers)
|
| 103 |
+
|
| 104 |
+
def test_dataloader(self):
|
| 105 |
+
return DataLoader(self.test_dataset, batch_size=self.batch_size, num_workers=self.num_workers)
|
fengshen/data/data_utils/common_utils.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def padding_to_maxlength(ids, max_length, pad_id):
|
| 2 |
+
cur_len = len(ids)
|
| 3 |
+
len_diff = max_length - len(ids)
|
| 4 |
+
return ids + [pad_id] * len_diff, [1] * cur_len + [0] * len_diff
|
fengshen/data/data_utils/mask_utils.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import collections
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
MaskedLmInstance = collections.namedtuple("MaskedLmInstance",
|
| 6 |
+
["index", "label"])
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def is_start_piece(piece):
|
| 10 |
+
"""Check if the current word piece is the starting piece (BERT)."""
|
| 11 |
+
# When a word has been split into
|
| 12 |
+
# WordPieces, the first token does not have any marker and any subsequence
|
| 13 |
+
# tokens are prefixed with ##. So whenever we see the ## token, we
|
| 14 |
+
# append it to the previous set of word indexes.
|
| 15 |
+
return not piece.startswith("##")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def create_masked_lm_predictions(tokens,
|
| 19 |
+
vocab_id_list, vocab_id_to_token_dict,
|
| 20 |
+
masked_lm_prob,
|
| 21 |
+
cls_id, sep_id, mask_id,
|
| 22 |
+
max_predictions_per_seq,
|
| 23 |
+
np_rng,
|
| 24 |
+
max_ngrams=3,
|
| 25 |
+
do_whole_word_mask=True,
|
| 26 |
+
favor_longer_ngram=False,
|
| 27 |
+
do_permutation=False,
|
| 28 |
+
geometric_dist=False,
|
| 29 |
+
masking_style="bert",
|
| 30 |
+
zh_tokenizer=None):
|
| 31 |
+
"""Creates the predictions for the masked LM objective.
|
| 32 |
+
Note: Tokens here are vocab ids and not text tokens."""
|
| 33 |
+
'''
|
| 34 |
+
modified from Megatron-LM
|
| 35 |
+
Args:
|
| 36 |
+
tokens: 输入
|
| 37 |
+
vocab_id_list: 词表token_id_list
|
| 38 |
+
vocab_id_to_token_dict: token_id到token字典
|
| 39 |
+
masked_lm_prob:mask概率
|
| 40 |
+
cls_id、sep_id、mask_id:特殊token
|
| 41 |
+
max_predictions_per_seq:最大mask个数
|
| 42 |
+
np_rng:mask随机数
|
| 43 |
+
max_ngrams:最大词长度
|
| 44 |
+
do_whole_word_mask:是否做全词掩码
|
| 45 |
+
favor_longer_ngram:优先用长的词
|
| 46 |
+
do_permutation:是否打乱
|
| 47 |
+
geometric_dist:用np_rng.geometric做随机
|
| 48 |
+
masking_style:mask类型
|
| 49 |
+
zh_tokenizer:WWM的分词器,比如用jieba.lcut做分词之类的
|
| 50 |
+
'''
|
| 51 |
+
cand_indexes = []
|
| 52 |
+
# Note(mingdachen): We create a list for recording if the piece is
|
| 53 |
+
# the starting piece of current token, where 1 means true, so that
|
| 54 |
+
# on-the-fly whole word masking is possible.
|
| 55 |
+
token_boundary = [0] * len(tokens)
|
| 56 |
+
# 如果没有指定中文分词器,那就直接按##算
|
| 57 |
+
if zh_tokenizer is None:
|
| 58 |
+
for (i, token) in enumerate(tokens):
|
| 59 |
+
if token == cls_id or token == sep_id:
|
| 60 |
+
token_boundary[i] = 1
|
| 61 |
+
continue
|
| 62 |
+
# Whole Word Masking means that if we mask all of the wordpieces
|
| 63 |
+
# corresponding to an original word.
|
| 64 |
+
#
|
| 65 |
+
# Note that Whole Word Masking does *not* change the training code
|
| 66 |
+
# at all -- we still predict each WordPiece independently, softmaxed
|
| 67 |
+
# over the entire vocabulary.
|
| 68 |
+
if (do_whole_word_mask and len(cand_indexes) >= 1 and
|
| 69 |
+
not is_start_piece(vocab_id_to_token_dict[token])):
|
| 70 |
+
cand_indexes[-1].append(i)
|
| 71 |
+
else:
|
| 72 |
+
cand_indexes.append([i])
|
| 73 |
+
if is_start_piece(vocab_id_to_token_dict[token]):
|
| 74 |
+
token_boundary[i] = 1
|
| 75 |
+
else:
|
| 76 |
+
# 如果指定了中文分词器,那就先用分词器分词,然后再进行判断
|
| 77 |
+
# 获取去掉CLS SEP的原始文本
|
| 78 |
+
raw_tokens = []
|
| 79 |
+
for t in tokens:
|
| 80 |
+
if t != cls_id and t != sep_id:
|
| 81 |
+
raw_tokens.append(t)
|
| 82 |
+
raw_tokens = [vocab_id_to_token_dict[i] for i in raw_tokens]
|
| 83 |
+
# 分词然后获取每次字开头的最长词的长度
|
| 84 |
+
word_list = set(zh_tokenizer(''.join(raw_tokens), HMM=True))
|
| 85 |
+
word_length_dict = {}
|
| 86 |
+
for w in word_list:
|
| 87 |
+
if len(w) < 1:
|
| 88 |
+
continue
|
| 89 |
+
if w[0] not in word_length_dict:
|
| 90 |
+
word_length_dict[w[0]] = len(w)
|
| 91 |
+
elif word_length_dict[w[0]] < len(w):
|
| 92 |
+
word_length_dict[w[0]] = len(w)
|
| 93 |
+
i = 0
|
| 94 |
+
# 从词表里面检索
|
| 95 |
+
while i < len(tokens):
|
| 96 |
+
token_id = tokens[i]
|
| 97 |
+
token = vocab_id_to_token_dict[token_id]
|
| 98 |
+
if len(token) == 0 or token_id == cls_id or token_id == sep_id:
|
| 99 |
+
token_boundary[i] = 1
|
| 100 |
+
i += 1
|
| 101 |
+
continue
|
| 102 |
+
word_max_length = 1
|
| 103 |
+
if token[0] in word_length_dict:
|
| 104 |
+
word_max_length = word_length_dict[token[0]]
|
| 105 |
+
j = 0
|
| 106 |
+
word = ''
|
| 107 |
+
word_end = i+1
|
| 108 |
+
# 兼容以前##的形式,如果后面的词是##开头的,那么直接把后面的拼到前面当作一个词
|
| 109 |
+
old_style = False
|
| 110 |
+
while word_end < len(tokens) and vocab_id_to_token_dict[tokens[word_end]].startswith('##'):
|
| 111 |
+
old_style = True
|
| 112 |
+
word_end += 1
|
| 113 |
+
if not old_style:
|
| 114 |
+
while j < word_max_length and i+j < len(tokens):
|
| 115 |
+
cur_token = tokens[i+j]
|
| 116 |
+
word += vocab_id_to_token_dict[cur_token]
|
| 117 |
+
j += 1
|
| 118 |
+
if word in word_list:
|
| 119 |
+
word_end = i+j
|
| 120 |
+
cand_indexes.append([p for p in range(i, word_end)])
|
| 121 |
+
token_boundary[i] = 1
|
| 122 |
+
i = word_end
|
| 123 |
+
|
| 124 |
+
output_tokens = list(tokens)
|
| 125 |
+
|
| 126 |
+
masked_lm_positions = []
|
| 127 |
+
masked_lm_labels = []
|
| 128 |
+
|
| 129 |
+
if masked_lm_prob == 0:
|
| 130 |
+
return (output_tokens, masked_lm_positions,
|
| 131 |
+
masked_lm_labels, token_boundary)
|
| 132 |
+
|
| 133 |
+
num_to_predict = min(max_predictions_per_seq,
|
| 134 |
+
max(1, int(round(len(tokens) * masked_lm_prob))))
|
| 135 |
+
|
| 136 |
+
ngrams = np.arange(1, max_ngrams + 1, dtype=np.int64)
|
| 137 |
+
if not geometric_dist:
|
| 138 |
+
# Note(mingdachen):
|
| 139 |
+
# By default, we set the probilities to favor shorter ngram sequences.
|
| 140 |
+
pvals = 1. / np.arange(1, max_ngrams + 1)
|
| 141 |
+
pvals /= pvals.sum(keepdims=True)
|
| 142 |
+
if favor_longer_ngram:
|
| 143 |
+
pvals = pvals[::-1]
|
| 144 |
+
# 获取一个ngram的idx,对于每个word,记录他的ngram的word
|
| 145 |
+
ngram_indexes = []
|
| 146 |
+
for idx in range(len(cand_indexes)):
|
| 147 |
+
ngram_index = []
|
| 148 |
+
for n in ngrams:
|
| 149 |
+
ngram_index.append(cand_indexes[idx:idx + n])
|
| 150 |
+
ngram_indexes.append(ngram_index)
|
| 151 |
+
|
| 152 |
+
np_rng.shuffle(ngram_indexes)
|
| 153 |
+
|
| 154 |
+
(masked_lms, masked_spans) = ([], [])
|
| 155 |
+
covered_indexes = set()
|
| 156 |
+
for cand_index_set in ngram_indexes:
|
| 157 |
+
if len(masked_lms) >= num_to_predict:
|
| 158 |
+
break
|
| 159 |
+
if not cand_index_set:
|
| 160 |
+
continue
|
| 161 |
+
# Note(mingdachen):
|
| 162 |
+
# Skip current piece if they are covered in lm masking or previous ngrams.
|
| 163 |
+
for index_set in cand_index_set[0]:
|
| 164 |
+
for index in index_set:
|
| 165 |
+
if index in covered_indexes:
|
| 166 |
+
continue
|
| 167 |
+
|
| 168 |
+
if not geometric_dist:
|
| 169 |
+
n = np_rng.choice(ngrams[:len(cand_index_set)],
|
| 170 |
+
p=pvals[:len(cand_index_set)] /
|
| 171 |
+
pvals[:len(cand_index_set)].sum(keepdims=True))
|
| 172 |
+
else:
|
| 173 |
+
# Sampling "n" from the geometric distribution and clipping it to
|
| 174 |
+
# the max_ngrams. Using p=0.2 default from the SpanBERT paper
|
| 175 |
+
# https://arxiv.org/pdf/1907.10529.pdf (Sec 3.1)
|
| 176 |
+
n = min(np_rng.geometric(0.2), max_ngrams)
|
| 177 |
+
|
| 178 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 179 |
+
n -= 1
|
| 180 |
+
# Note(mingdachen):
|
| 181 |
+
# Repeatedly looking for a candidate that does not exceed the
|
| 182 |
+
# maximum number of predictions by trying shorter ngrams.
|
| 183 |
+
while len(masked_lms) + len(index_set) > num_to_predict:
|
| 184 |
+
if n == 0:
|
| 185 |
+
break
|
| 186 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 187 |
+
n -= 1
|
| 188 |
+
# If adding a whole-word mask would exceed the maximum number of
|
| 189 |
+
# predictions, then just skip this candidate.
|
| 190 |
+
if len(masked_lms) + len(index_set) > num_to_predict:
|
| 191 |
+
continue
|
| 192 |
+
is_any_index_covered = False
|
| 193 |
+
for index in index_set:
|
| 194 |
+
if index in covered_indexes:
|
| 195 |
+
is_any_index_covered = True
|
| 196 |
+
break
|
| 197 |
+
if is_any_index_covered:
|
| 198 |
+
continue
|
| 199 |
+
for index in index_set:
|
| 200 |
+
covered_indexes.add(index)
|
| 201 |
+
masked_token = None
|
| 202 |
+
token_id = tokens[index]
|
| 203 |
+
if masking_style == "bert":
|
| 204 |
+
# 80% of the time, replace with [MASK]
|
| 205 |
+
if np_rng.random() < 0.8:
|
| 206 |
+
masked_token = mask_id
|
| 207 |
+
else:
|
| 208 |
+
# 10% of the time, keep original
|
| 209 |
+
if np_rng.random() < 0.5:
|
| 210 |
+
masked_token = tokens[index]
|
| 211 |
+
# 10% of the time, replace with random word
|
| 212 |
+
else:
|
| 213 |
+
masked_token = vocab_id_list[np_rng.randint(0, len(vocab_id_list))]
|
| 214 |
+
elif masking_style == "t5":
|
| 215 |
+
masked_token = mask_id
|
| 216 |
+
else:
|
| 217 |
+
raise ValueError("invalid value of masking style")
|
| 218 |
+
|
| 219 |
+
output_tokens[index] = masked_token
|
| 220 |
+
masked_lms.append(MaskedLmInstance(index=index, label=token_id))
|
| 221 |
+
|
| 222 |
+
masked_spans.append(MaskedLmInstance(
|
| 223 |
+
index=index_set,
|
| 224 |
+
label=[tokens[index] for index in index_set]))
|
| 225 |
+
|
| 226 |
+
assert len(masked_lms) <= num_to_predict
|
| 227 |
+
np_rng.shuffle(ngram_indexes)
|
| 228 |
+
|
| 229 |
+
select_indexes = set()
|
| 230 |
+
if do_permutation:
|
| 231 |
+
for cand_index_set in ngram_indexes:
|
| 232 |
+
if len(select_indexes) >= num_to_predict:
|
| 233 |
+
break
|
| 234 |
+
if not cand_index_set:
|
| 235 |
+
continue
|
| 236 |
+
# Note(mingdachen):
|
| 237 |
+
# Skip current piece if they are covered in lm masking or previous ngrams.
|
| 238 |
+
for index_set in cand_index_set[0]:
|
| 239 |
+
for index in index_set:
|
| 240 |
+
if index in covered_indexes or index in select_indexes:
|
| 241 |
+
continue
|
| 242 |
+
|
| 243 |
+
n = np.random.choice(ngrams[:len(cand_index_set)],
|
| 244 |
+
p=pvals[:len(cand_index_set)] /
|
| 245 |
+
pvals[:len(cand_index_set)].sum(keepdims=True))
|
| 246 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 247 |
+
n -= 1
|
| 248 |
+
|
| 249 |
+
while len(select_indexes) + len(index_set) > num_to_predict:
|
| 250 |
+
if n == 0:
|
| 251 |
+
break
|
| 252 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 253 |
+
n -= 1
|
| 254 |
+
# If adding a whole-word mask would exceed the maximum number of
|
| 255 |
+
# predictions, then just skip this candidate.
|
| 256 |
+
if len(select_indexes) + len(index_set) > num_to_predict:
|
| 257 |
+
continue
|
| 258 |
+
is_any_index_covered = False
|
| 259 |
+
for index in index_set:
|
| 260 |
+
if index in covered_indexes or index in select_indexes:
|
| 261 |
+
is_any_index_covered = True
|
| 262 |
+
break
|
| 263 |
+
if is_any_index_covered:
|
| 264 |
+
continue
|
| 265 |
+
for index in index_set:
|
| 266 |
+
select_indexes.add(index)
|
| 267 |
+
assert len(select_indexes) <= num_to_predict
|
| 268 |
+
|
| 269 |
+
select_indexes = sorted(select_indexes)
|
| 270 |
+
permute_indexes = list(select_indexes)
|
| 271 |
+
np_rng.shuffle(permute_indexes)
|
| 272 |
+
orig_token = list(output_tokens)
|
| 273 |
+
|
| 274 |
+
for src_i, tgt_i in zip(select_indexes, permute_indexes):
|
| 275 |
+
output_tokens[src_i] = orig_token[tgt_i]
|
| 276 |
+
masked_lms.append(MaskedLmInstance(index=src_i, label=orig_token[src_i]))
|
| 277 |
+
|
| 278 |
+
masked_lms = sorted(masked_lms, key=lambda x: x.index)
|
| 279 |
+
# Sort the spans by the index of the first span
|
| 280 |
+
masked_spans = sorted(masked_spans, key=lambda x: x.index[0])
|
| 281 |
+
|
| 282 |
+
for p in masked_lms:
|
| 283 |
+
masked_lm_positions.append(p.index)
|
| 284 |
+
masked_lm_labels.append(p.label)
|
| 285 |
+
return (output_tokens, masked_lm_positions, masked_lm_labels, token_boundary, masked_spans)
|
fengshen/data/data_utils/sentence_split.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class ChineseSentenceSplitter(object):
|
| 5 |
+
def merge_symmetry(self, sentences, symmetry=('“', '”')):
|
| 6 |
+
# '''合并对称符号,如双引号'''
|
| 7 |
+
effective_ = []
|
| 8 |
+
merged = True
|
| 9 |
+
for index in range(len(sentences)):
|
| 10 |
+
if symmetry[0] in sentences[index] and symmetry[1] not in sentences[index]:
|
| 11 |
+
merged = False
|
| 12 |
+
effective_.append(sentences[index])
|
| 13 |
+
elif symmetry[1] in sentences[index] and not merged:
|
| 14 |
+
merged = True
|
| 15 |
+
effective_[-1] += sentences[index]
|
| 16 |
+
elif symmetry[0] not in sentences[index] and symmetry[1] not in sentences[index] and not merged:
|
| 17 |
+
effective_[-1] += sentences[index]
|
| 18 |
+
else:
|
| 19 |
+
effective_.append(sentences[index])
|
| 20 |
+
return [i.strip() for i in effective_ if len(i.strip()) > 0]
|
| 21 |
+
|
| 22 |
+
def to_sentences(self, paragraph):
|
| 23 |
+
# """由段落切分成句子"""
|
| 24 |
+
sentences = re.split(r"(?|。|[!]+|!|\…\…)", paragraph)
|
| 25 |
+
sentences.append("")
|
| 26 |
+
sentences = ["".join(i) for i in zip(sentences[0::2], sentences[1::2])]
|
| 27 |
+
sentences = [i.strip() for i in sentences if len(i.strip()) > 0]
|
| 28 |
+
for j in range(1, len(sentences)):
|
| 29 |
+
if sentences[j][0] == '”':
|
| 30 |
+
sentences[j-1] = sentences[j-1] + '”'
|
| 31 |
+
sentences[j] = sentences[j][1:]
|
| 32 |
+
return self.merge_symmetry(sentences)
|
| 33 |
+
|
| 34 |
+
def tokenize(self, text):
|
| 35 |
+
return self.to_sentences(text)
|
fengshen/data/data_utils/sop_utils.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# copy from megatron
|
| 3 |
+
def get_a_and_b_segments(sample, np_rng):
|
| 4 |
+
"""Divide sample into a and b segments."""
|
| 5 |
+
|
| 6 |
+
# Number of sentences in the sample.
|
| 7 |
+
n_sentences = len(sample)
|
| 8 |
+
# Make sure we always have two sentences.
|
| 9 |
+
assert n_sentences > 1, 'make sure each sample has at least two sentences.'
|
| 10 |
+
|
| 11 |
+
# First part:
|
| 12 |
+
# `a_end` is how many sentences go into the `A`.
|
| 13 |
+
a_end = 1
|
| 14 |
+
if n_sentences >= 3:
|
| 15 |
+
# Note that randin in numpy is exclusive.
|
| 16 |
+
a_end = np_rng.randint(1, n_sentences)
|
| 17 |
+
tokens_a = []
|
| 18 |
+
for j in range(a_end):
|
| 19 |
+
tokens_a.extend(sample[j])
|
| 20 |
+
|
| 21 |
+
# Second part:
|
| 22 |
+
tokens_b = []
|
| 23 |
+
for j in range(a_end, n_sentences):
|
| 24 |
+
tokens_b.extend(sample[j])
|
| 25 |
+
|
| 26 |
+
# Random next:
|
| 27 |
+
is_next_random = False
|
| 28 |
+
if np_rng.random() < 0.5:
|
| 29 |
+
is_next_random = True
|
| 30 |
+
tokens_a, tokens_b = tokens_b, tokens_a
|
| 31 |
+
|
| 32 |
+
return tokens_a, tokens_b, is_next_random
|
fengshen/data/data_utils/token_type_utils.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def create_tokens_and_tokentypes(tokens_a, tokens_b, cls_id, sep_id):
|
| 2 |
+
"""Merge segments A and B, add [CLS] and [SEP] and build tokentypes."""
|
| 3 |
+
|
| 4 |
+
tokens = []
|
| 5 |
+
tokentypes = []
|
| 6 |
+
# [CLS].
|
| 7 |
+
tokens.append(cls_id)
|
| 8 |
+
tokentypes.append(0)
|
| 9 |
+
# Segment A.
|
| 10 |
+
for token in tokens_a:
|
| 11 |
+
tokens.append(token)
|
| 12 |
+
tokentypes.append(0)
|
| 13 |
+
# [SEP].
|
| 14 |
+
tokens.append(sep_id)
|
| 15 |
+
tokentypes.append(0)
|
| 16 |
+
# Segment B.
|
| 17 |
+
for token in tokens_b:
|
| 18 |
+
tokens.append(token)
|
| 19 |
+
tokentypes.append(1)
|
| 20 |
+
if tokens_b:
|
| 21 |
+
# [SEP].
|
| 22 |
+
tokens.append(sep_id)
|
| 23 |
+
tokentypes.append(1)
|
| 24 |
+
|
| 25 |
+
return tokens, tokentypes
|
fengshen/data/data_utils/truncate_utils.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
def truncate_segments(tokens_a, tokens_b, len_a, len_b, max_num_tokens, np_rng):
|
| 3 |
+
"""Truncates a pair of sequences to a maximum sequence length."""
|
| 4 |
+
# print(len_a, len_b, max_num_tokens)
|
| 5 |
+
assert len_a > 0
|
| 6 |
+
if len_a + len_b <= max_num_tokens:
|
| 7 |
+
return False
|
| 8 |
+
while len_a + len_b > max_num_tokens:
|
| 9 |
+
if len_a > len_b:
|
| 10 |
+
len_a -= 1
|
| 11 |
+
tokens = tokens_a
|
| 12 |
+
else:
|
| 13 |
+
len_b -= 1
|
| 14 |
+
tokens = tokens_b
|
| 15 |
+
if np_rng.random() < 0.5:
|
| 16 |
+
del tokens[0]
|
| 17 |
+
else:
|
| 18 |
+
tokens.pop()
|
| 19 |
+
return True
|
fengshen/data/dreambooth_datasets/dreambooth_datasets.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
'''
|
| 3 |
+
Copyright 2022 The International Digital Economy Academy (IDEA). CCNL team. All rights reserved.
|
| 4 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
you may not use this file except in compliance with the License.
|
| 6 |
+
You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
@File : dreambooth_datasets.py
|
| 14 |
+
@Time : 2022/11/10 00:20
|
| 15 |
+
@Author : Gan Ruyi
|
| 16 |
+
@Version : 1.0
|
| 17 |
+
@Contact : ganruyi@idea.edu.cn
|
| 18 |
+
@License : (C)Copyright 2022-2023, CCNL-IDEA
|
| 19 |
+
'''
|
| 20 |
+
from torch.utils.data import Dataset
|
| 21 |
+
from torchvision import transforms
|
| 22 |
+
from PIL import Image
|
| 23 |
+
from pathlib import Path
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def add_data_args(parent_args):
|
| 27 |
+
parser = parent_args.add_argument_group('taiyi stable diffusion data args')
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--instance_data_dir",
|
| 30 |
+
type=str,
|
| 31 |
+
default=None,
|
| 32 |
+
required=True,
|
| 33 |
+
help="A folder containing the training data of instance images.",
|
| 34 |
+
)
|
| 35 |
+
parser.add_argument(
|
| 36 |
+
"--class_data_dir",
|
| 37 |
+
type=str,
|
| 38 |
+
default=None,
|
| 39 |
+
required=False,
|
| 40 |
+
help="A folder containing the training data of class images.",
|
| 41 |
+
)
|
| 42 |
+
parser.add_argument(
|
| 43 |
+
"--instance_prompt",
|
| 44 |
+
type=str,
|
| 45 |
+
default=None,
|
| 46 |
+
help="The prompt with identifier specifying the instance",
|
| 47 |
+
)
|
| 48 |
+
parser.add_argument(
|
| 49 |
+
"--class_prompt",
|
| 50 |
+
type=str,
|
| 51 |
+
default=None,
|
| 52 |
+
help="The prompt to specify images in the same class as provided instance images.",
|
| 53 |
+
)
|
| 54 |
+
parser.add_argument(
|
| 55 |
+
"--with_prior_preservation",
|
| 56 |
+
default=False,
|
| 57 |
+
action="store_true",
|
| 58 |
+
help="Flag to add prior preservation loss.",
|
| 59 |
+
)
|
| 60 |
+
parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--num_class_images",
|
| 63 |
+
type=int,
|
| 64 |
+
default=100,
|
| 65 |
+
help=(
|
| 66 |
+
"Minimal class images for prior preservation loss. If not have enough images, additional images will be"
|
| 67 |
+
" sampled with class_prompt."
|
| 68 |
+
),
|
| 69 |
+
)
|
| 70 |
+
parser.add_argument(
|
| 71 |
+
"--resolution", type=int, default=512,
|
| 72 |
+
help=(
|
| 73 |
+
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
|
| 74 |
+
" resolution"
|
| 75 |
+
),
|
| 76 |
+
)
|
| 77 |
+
parser.add_argument(
|
| 78 |
+
"--center_crop", action="store_true", default=False,
|
| 79 |
+
help="Whether to center crop images before resizing to resolution"
|
| 80 |
+
)
|
| 81 |
+
parser.add_argument(
|
| 82 |
+
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
|
| 83 |
+
)
|
| 84 |
+
return parent_args
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class DreamBoothDataset(Dataset):
|
| 88 |
+
"""
|
| 89 |
+
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
|
| 90 |
+
It pre-processes the images and the tokenizes prompts.
|
| 91 |
+
"""
|
| 92 |
+
|
| 93 |
+
def __init__(
|
| 94 |
+
self,
|
| 95 |
+
instance_data_dir,
|
| 96 |
+
instance_prompt,
|
| 97 |
+
tokenizer,
|
| 98 |
+
class_data_dir=None,
|
| 99 |
+
class_prompt=None,
|
| 100 |
+
size=512,
|
| 101 |
+
center_crop=False,
|
| 102 |
+
):
|
| 103 |
+
self.size = size
|
| 104 |
+
self.center_crop = center_crop
|
| 105 |
+
self.tokenizer = tokenizer
|
| 106 |
+
|
| 107 |
+
self.instance_data_dir = Path(instance_data_dir)
|
| 108 |
+
if not self.instance_data_dir.exists():
|
| 109 |
+
raise ValueError("Instance images root doesn't exists.")
|
| 110 |
+
|
| 111 |
+
self.instance_images_path = list(Path(instance_data_dir).iterdir())
|
| 112 |
+
print(self.instance_images_path)
|
| 113 |
+
self.num_instance_images = len(self.instance_images_path)
|
| 114 |
+
self.instance_prompt = instance_prompt
|
| 115 |
+
self._length = self.num_instance_images
|
| 116 |
+
|
| 117 |
+
if class_data_dir is not None:
|
| 118 |
+
self.class_data_dir = Path(class_data_dir)
|
| 119 |
+
self.class_data_dir.mkdir(parents=True, exist_ok=True)
|
| 120 |
+
self.class_images_path = list(self.class_data_dir.iterdir())
|
| 121 |
+
self.num_class_images = len(self.class_images_path)
|
| 122 |
+
self._length = max(self.num_class_images, self.num_instance_images)
|
| 123 |
+
self.class_prompt = class_prompt
|
| 124 |
+
else:
|
| 125 |
+
self.class_data_dir = None
|
| 126 |
+
|
| 127 |
+
self.image_transforms = transforms.Compose(
|
| 128 |
+
[
|
| 129 |
+
transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
|
| 130 |
+
transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
|
| 131 |
+
transforms.ToTensor(),
|
| 132 |
+
transforms.Normalize([0.5], [0.5]),
|
| 133 |
+
]
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
def __len__(self):
|
| 137 |
+
return self._length
|
| 138 |
+
|
| 139 |
+
def __getitem__(self, index):
|
| 140 |
+
example = {}
|
| 141 |
+
instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
|
| 142 |
+
if not instance_image.mode == "RGB":
|
| 143 |
+
instance_image = instance_image.convert("RGB")
|
| 144 |
+
example["instance_images"] = self.image_transforms(instance_image)
|
| 145 |
+
example["instance_prompt_ids"] = self.tokenizer(
|
| 146 |
+
self.instance_prompt,
|
| 147 |
+
padding="do_not_pad",
|
| 148 |
+
truncation=True,
|
| 149 |
+
max_length=64,
|
| 150 |
+
# max_length=self.tokenizer.model_max_length,
|
| 151 |
+
).input_ids
|
| 152 |
+
|
| 153 |
+
if self.class_data_dir:
|
| 154 |
+
class_image = Image.open(self.class_images_path[index % self.num_class_images])
|
| 155 |
+
if not class_image.mode == "RGB":
|
| 156 |
+
class_image = class_image.convert("RGB")
|
| 157 |
+
example["class_images"] = self.image_transforms(class_image)
|
| 158 |
+
example["class_prompt_ids"] = self.tokenizer(
|
| 159 |
+
self.class_prompt,
|
| 160 |
+
padding="do_not_pad",
|
| 161 |
+
truncation=True,
|
| 162 |
+
# max_length=self.tokenizer.model_max_length,
|
| 163 |
+
max_length=64,
|
| 164 |
+
).input_ids
|
| 165 |
+
|
| 166 |
+
return example
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
class PromptDataset(Dataset):
|
| 170 |
+
"A simple dataset to prepare the prompts to generate class images on multiple GPUs."
|
| 171 |
+
|
| 172 |
+
def __init__(self, prompt, num_samples):
|
| 173 |
+
self.prompt = prompt
|
| 174 |
+
self.num_samples = num_samples
|
| 175 |
+
|
| 176 |
+
def __len__(self):
|
| 177 |
+
return self.num_samples
|
| 178 |
+
|
| 179 |
+
def __getitem__(self, index):
|
| 180 |
+
example = {}
|
| 181 |
+
example["prompt"] = self.prompt
|
| 182 |
+
example["index"] = index
|
| 183 |
+
return example
|
fengshen/data/hubert/hubert_dataset.py
ADDED
|
@@ -0,0 +1,361 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the MIT license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import itertools
|
| 7 |
+
import logging
|
| 8 |
+
import os
|
| 9 |
+
import sys
|
| 10 |
+
from typing import Any, List, Optional, Union
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from fairseq.data import data_utils
|
| 17 |
+
from fairseq.data.fairseq_dataset import FairseqDataset
|
| 18 |
+
|
| 19 |
+
logger = logging.getLogger(__name__)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def add_data_specific_args(parent_args):
|
| 23 |
+
parser = parent_args.add_argument_group('Hubert Dataset')
|
| 24 |
+
parser.add_argument('--data', type=str)
|
| 25 |
+
parser.add_argument('--sample_rate', type=float, default=16000)
|
| 26 |
+
parser.add_argument('--label_dir', type=str)
|
| 27 |
+
parser.add_argument('--labels', type=str, nargs='+')
|
| 28 |
+
parser.add_argument('--label_rate', type=float)
|
| 29 |
+
parser.add_argument('--max_keep_size', type=int, default=None)
|
| 30 |
+
parser.add_argument('--min_sample_size', type=int)
|
| 31 |
+
parser.add_argument('--max_sample_size', type=int)
|
| 32 |
+
parser.add_argument('--pad_audio', type=bool)
|
| 33 |
+
parser.add_argument('--normalize', type=bool)
|
| 34 |
+
parser.add_argument('--random_crop', type=bool)
|
| 35 |
+
parser.add_argument('--single_target', type=bool, default=False)
|
| 36 |
+
return parent_args
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def load_audio(manifest_path, max_keep, min_keep):
|
| 40 |
+
n_long, n_short = 0, 0
|
| 41 |
+
names, inds, sizes = [], [], []
|
| 42 |
+
with open(manifest_path) as f:
|
| 43 |
+
root = f.readline().strip()
|
| 44 |
+
for ind, line in enumerate(f):
|
| 45 |
+
items = line.strip().split("\t")
|
| 46 |
+
assert len(items) == 2, line
|
| 47 |
+
sz = int(items[1])
|
| 48 |
+
if min_keep is not None and sz < min_keep:
|
| 49 |
+
n_short += 1
|
| 50 |
+
elif max_keep is not None and sz > max_keep:
|
| 51 |
+
n_long += 1
|
| 52 |
+
else:
|
| 53 |
+
names.append(items[0])
|
| 54 |
+
inds.append(ind)
|
| 55 |
+
sizes.append(sz)
|
| 56 |
+
tot = ind + 1
|
| 57 |
+
logger.info(
|
| 58 |
+
(
|
| 59 |
+
f"max_keep={max_keep}, min_keep={min_keep}, "
|
| 60 |
+
f"loaded {len(names)}, skipped {n_short} short and {n_long} long, "
|
| 61 |
+
f"longest-loaded={max(sizes)}, shortest-loaded={min(sizes)}"
|
| 62 |
+
)
|
| 63 |
+
)
|
| 64 |
+
return root, names, inds, tot, sizes
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def load_label(label_path, inds, tot):
|
| 68 |
+
with open(label_path) as f:
|
| 69 |
+
labels = [line.rstrip() for line in f]
|
| 70 |
+
assert (
|
| 71 |
+
len(labels) == tot
|
| 72 |
+
), f"number of labels does not match ({len(labels)} != {tot})"
|
| 73 |
+
labels = [labels[i] for i in inds]
|
| 74 |
+
return labels
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def load_label_offset(label_path, inds, tot):
|
| 78 |
+
with open(label_path) as f:
|
| 79 |
+
code_lengths = [len(line.encode("utf-8")) for line in f]
|
| 80 |
+
assert (
|
| 81 |
+
len(code_lengths) == tot
|
| 82 |
+
), f"number of labels does not match ({len(code_lengths)} != {tot})"
|
| 83 |
+
offsets = list(itertools.accumulate([0] + code_lengths))
|
| 84 |
+
offsets = [(offsets[i], offsets[i + 1]) for i in inds]
|
| 85 |
+
return offsets
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def verify_label_lengths(
|
| 89 |
+
audio_sizes,
|
| 90 |
+
audio_rate,
|
| 91 |
+
label_path,
|
| 92 |
+
label_rate,
|
| 93 |
+
inds,
|
| 94 |
+
tot,
|
| 95 |
+
tol=0.1, # tolerance in seconds
|
| 96 |
+
):
|
| 97 |
+
if label_rate < 0:
|
| 98 |
+
logger.info(f"{label_path} is sequence label. skipped")
|
| 99 |
+
return
|
| 100 |
+
|
| 101 |
+
with open(label_path) as f:
|
| 102 |
+
lengths = [len(line.rstrip().split()) for line in f]
|
| 103 |
+
assert len(lengths) == tot
|
| 104 |
+
lengths = [lengths[i] for i in inds]
|
| 105 |
+
num_invalid = 0
|
| 106 |
+
for i, ind in enumerate(inds):
|
| 107 |
+
dur_from_audio = audio_sizes[i] / audio_rate
|
| 108 |
+
dur_from_label = lengths[i] / label_rate
|
| 109 |
+
if abs(dur_from_audio - dur_from_label) > tol:
|
| 110 |
+
logger.warning(
|
| 111 |
+
(
|
| 112 |
+
f"audio and label duration differ too much "
|
| 113 |
+
f"(|{dur_from_audio} - {dur_from_label}| > {tol}) "
|
| 114 |
+
f"in line {ind+1} of {label_path}. Check if `label_rate` "
|
| 115 |
+
f"is correctly set (currently {label_rate}). "
|
| 116 |
+
f"num. of samples = {audio_sizes[i]}; "
|
| 117 |
+
f"label length = {lengths[i]}"
|
| 118 |
+
)
|
| 119 |
+
)
|
| 120 |
+
num_invalid += 1
|
| 121 |
+
if num_invalid > 0:
|
| 122 |
+
logger.warning(
|
| 123 |
+
f"total {num_invalid} (audio, label) pairs with mismatched lengths"
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class HubertDataset(FairseqDataset):
|
| 128 |
+
def __init__(
|
| 129 |
+
self,
|
| 130 |
+
manifest_path: str,
|
| 131 |
+
sample_rate: float,
|
| 132 |
+
label_paths: List[str],
|
| 133 |
+
label_rates: Union[List[float], float], # -1 for sequence labels
|
| 134 |
+
pad_list: List[str],
|
| 135 |
+
eos_list: List[str],
|
| 136 |
+
label_processors: Optional[List[Any]] = None,
|
| 137 |
+
max_keep_sample_size: Optional[int] = None,
|
| 138 |
+
min_keep_sample_size: Optional[int] = None,
|
| 139 |
+
max_sample_size: Optional[int] = None,
|
| 140 |
+
shuffle: bool = True,
|
| 141 |
+
pad_audio: bool = False,
|
| 142 |
+
normalize: bool = False,
|
| 143 |
+
store_labels: bool = True,
|
| 144 |
+
random_crop: bool = False,
|
| 145 |
+
single_target: bool = False,
|
| 146 |
+
):
|
| 147 |
+
self.audio_root, self.audio_names, inds, tot, self.sizes = load_audio(
|
| 148 |
+
manifest_path, max_keep_sample_size, min_keep_sample_size
|
| 149 |
+
)
|
| 150 |
+
self.sample_rate = sample_rate
|
| 151 |
+
self.shuffle = shuffle
|
| 152 |
+
self.random_crop = random_crop
|
| 153 |
+
|
| 154 |
+
self.num_labels = len(label_paths)
|
| 155 |
+
self.pad_list = pad_list
|
| 156 |
+
self.eos_list = eos_list
|
| 157 |
+
self.label_processors = label_processors
|
| 158 |
+
self.single_target = single_target
|
| 159 |
+
self.label_rates = (
|
| 160 |
+
[label_rates for _ in range(len(label_paths))]
|
| 161 |
+
if isinstance(label_rates, float)
|
| 162 |
+
else label_rates
|
| 163 |
+
)
|
| 164 |
+
self.store_labels = store_labels
|
| 165 |
+
if store_labels:
|
| 166 |
+
self.label_list = [load_label(p, inds, tot) for p in label_paths]
|
| 167 |
+
else:
|
| 168 |
+
self.label_paths = label_paths
|
| 169 |
+
self.label_offsets_list = [
|
| 170 |
+
load_label_offset(p, inds, tot) for p in label_paths
|
| 171 |
+
]
|
| 172 |
+
assert label_processors is None or len(label_processors) == self.num_labels
|
| 173 |
+
for label_path, label_rate in zip(label_paths, self.label_rates):
|
| 174 |
+
verify_label_lengths(
|
| 175 |
+
self.sizes, sample_rate, label_path, label_rate, inds, tot
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
self.max_sample_size = (
|
| 179 |
+
max_sample_size if max_sample_size is not None else sys.maxsize
|
| 180 |
+
)
|
| 181 |
+
self.pad_audio = pad_audio
|
| 182 |
+
self.normalize = normalize
|
| 183 |
+
logger.info(
|
| 184 |
+
f"pad_audio={pad_audio}, random_crop={random_crop}, "
|
| 185 |
+
f"normalize={normalize}, max_sample_size={self.max_sample_size}"
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
def get_audio(self, index):
|
| 189 |
+
import soundfile as sf
|
| 190 |
+
|
| 191 |
+
wav_path = os.path.join(self.audio_root, self.audio_names[index])
|
| 192 |
+
wav, cur_sample_rate = sf.read(wav_path)
|
| 193 |
+
wav = torch.from_numpy(wav).float()
|
| 194 |
+
wav = self.postprocess(wav, cur_sample_rate)
|
| 195 |
+
return wav
|
| 196 |
+
|
| 197 |
+
def get_label(self, index, label_idx):
|
| 198 |
+
if self.store_labels:
|
| 199 |
+
label = self.label_list[label_idx][index]
|
| 200 |
+
else:
|
| 201 |
+
with open(self.label_paths[label_idx]) as f:
|
| 202 |
+
offset_s, offset_e = self.label_offsets_list[label_idx][index]
|
| 203 |
+
f.seek(offset_s)
|
| 204 |
+
label = f.read(offset_e - offset_s)
|
| 205 |
+
|
| 206 |
+
if self.label_processors is not None:
|
| 207 |
+
label = self.label_processors[label_idx](label)
|
| 208 |
+
return label
|
| 209 |
+
|
| 210 |
+
def get_labels(self, index):
|
| 211 |
+
return [self.get_label(index, i) for i in range(self.num_labels)]
|
| 212 |
+
|
| 213 |
+
def __getitem__(self, index):
|
| 214 |
+
wav = self.get_audio(index)
|
| 215 |
+
labels = self.get_labels(index)
|
| 216 |
+
return {"id": index, "source": wav, "label_list": labels}
|
| 217 |
+
|
| 218 |
+
def __len__(self):
|
| 219 |
+
return len(self.sizes)
|
| 220 |
+
|
| 221 |
+
def crop_to_max_size(self, wav, target_size):
|
| 222 |
+
size = len(wav)
|
| 223 |
+
diff = size - target_size
|
| 224 |
+
if diff <= 0:
|
| 225 |
+
return wav, 0
|
| 226 |
+
|
| 227 |
+
start, end = 0, target_size
|
| 228 |
+
if self.random_crop:
|
| 229 |
+
start = np.random.randint(0, diff + 1)
|
| 230 |
+
end = size - diff + start
|
| 231 |
+
return wav[start:end], start
|
| 232 |
+
|
| 233 |
+
def collater(self, samples):
|
| 234 |
+
# target = max(sizes) -> random_crop not used
|
| 235 |
+
# target = max_sample_size -> random_crop used for long
|
| 236 |
+
samples = [s for s in samples if s["source"] is not None]
|
| 237 |
+
if len(samples) == 0:
|
| 238 |
+
return {}
|
| 239 |
+
|
| 240 |
+
audios = [s["source"] for s in samples]
|
| 241 |
+
audio_sizes = [len(s) for s in audios]
|
| 242 |
+
if self.pad_audio:
|
| 243 |
+
audio_size = min(max(audio_sizes), self.max_sample_size)
|
| 244 |
+
else:
|
| 245 |
+
audio_size = min(min(audio_sizes), self.max_sample_size)
|
| 246 |
+
collated_audios, padding_mask, audio_starts = self.collater_audio(
|
| 247 |
+
audios, audio_size
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
targets_by_label = [
|
| 251 |
+
[s["label_list"][i] for s in samples] for i in range(self.num_labels)
|
| 252 |
+
]
|
| 253 |
+
targets_list, lengths_list, ntokens_list = self.collater_label(
|
| 254 |
+
targets_by_label, audio_size, audio_starts
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
net_input = {"source": collated_audios, "padding_mask": padding_mask}
|
| 258 |
+
batch = {
|
| 259 |
+
"id": torch.LongTensor([s["id"] for s in samples]),
|
| 260 |
+
"net_input": net_input,
|
| 261 |
+
}
|
| 262 |
+
|
| 263 |
+
if self.single_target:
|
| 264 |
+
batch["target_lengths"] = lengths_list[0]
|
| 265 |
+
batch["ntokens"] = ntokens_list[0]
|
| 266 |
+
batch["target"] = targets_list[0]
|
| 267 |
+
else:
|
| 268 |
+
batch["target_lengths_list"] = lengths_list
|
| 269 |
+
batch["ntokens_list"] = ntokens_list
|
| 270 |
+
batch["target_list"] = targets_list
|
| 271 |
+
return batch
|
| 272 |
+
|
| 273 |
+
def collater_audio(self, audios, audio_size):
|
| 274 |
+
collated_audios = audios[0].new_zeros(len(audios), audio_size)
|
| 275 |
+
padding_mask = (
|
| 276 |
+
torch.BoolTensor(collated_audios.shape).fill_(False)
|
| 277 |
+
# if self.pad_audio else None
|
| 278 |
+
)
|
| 279 |
+
audio_starts = [0 for _ in audios]
|
| 280 |
+
for i, audio in enumerate(audios):
|
| 281 |
+
diff = len(audio) - audio_size
|
| 282 |
+
if diff == 0:
|
| 283 |
+
collated_audios[i] = audio
|
| 284 |
+
elif diff < 0:
|
| 285 |
+
assert self.pad_audio
|
| 286 |
+
collated_audios[i] = torch.cat([audio, audio.new_full((-diff,), 0.0)])
|
| 287 |
+
padding_mask[i, diff:] = True
|
| 288 |
+
else:
|
| 289 |
+
collated_audios[i], audio_starts[i] = self.crop_to_max_size(
|
| 290 |
+
audio, audio_size
|
| 291 |
+
)
|
| 292 |
+
return collated_audios, padding_mask, audio_starts
|
| 293 |
+
|
| 294 |
+
def collater_frm_label(self, targets, audio_size, audio_starts, label_rate, pad):
|
| 295 |
+
assert label_rate > 0
|
| 296 |
+
s2f = label_rate / self.sample_rate
|
| 297 |
+
frm_starts = [int(round(s * s2f)) for s in audio_starts]
|
| 298 |
+
frm_size = int(round(audio_size * s2f))
|
| 299 |
+
if not self.pad_audio:
|
| 300 |
+
rem_size = [len(t) - s for t, s in zip(targets, frm_starts)]
|
| 301 |
+
frm_size = min(frm_size, *rem_size)
|
| 302 |
+
targets = [t[s: s + frm_size] for t, s in zip(targets, frm_starts)]
|
| 303 |
+
logger.debug(f"audio_starts={audio_starts}")
|
| 304 |
+
logger.debug(f"frame_starts={frm_starts}")
|
| 305 |
+
logger.debug(f"frame_size={frm_size}")
|
| 306 |
+
|
| 307 |
+
lengths = torch.LongTensor([len(t) for t in targets])
|
| 308 |
+
ntokens = lengths.sum().item()
|
| 309 |
+
targets = data_utils.collate_tokens(targets, pad_idx=pad, left_pad=False)
|
| 310 |
+
return targets, lengths, ntokens
|
| 311 |
+
|
| 312 |
+
def collater_seq_label(self, targets, pad):
|
| 313 |
+
lengths = torch.LongTensor([len(t) for t in targets])
|
| 314 |
+
ntokens = lengths.sum().item()
|
| 315 |
+
targets = data_utils.collate_tokens(targets, pad_idx=pad, left_pad=False)
|
| 316 |
+
return targets, lengths, ntokens
|
| 317 |
+
|
| 318 |
+
def collater_label(self, targets_by_label, audio_size, audio_starts):
|
| 319 |
+
targets_list, lengths_list, ntokens_list = [], [], []
|
| 320 |
+
itr = zip(targets_by_label, self.label_rates, self.pad_list)
|
| 321 |
+
for targets, label_rate, pad in itr:
|
| 322 |
+
if label_rate == -1.0:
|
| 323 |
+
targets, lengths, ntokens = self.collater_seq_label(targets, pad)
|
| 324 |
+
else:
|
| 325 |
+
targets, lengths, ntokens = self.collater_frm_label(
|
| 326 |
+
targets, audio_size, audio_starts, label_rate, pad
|
| 327 |
+
)
|
| 328 |
+
targets_list.append(targets)
|
| 329 |
+
lengths_list.append(lengths)
|
| 330 |
+
ntokens_list.append(ntokens)
|
| 331 |
+
return targets_list, lengths_list, ntokens_list
|
| 332 |
+
|
| 333 |
+
def num_tokens(self, index):
|
| 334 |
+
return self.size(index)
|
| 335 |
+
|
| 336 |
+
def size(self, index):
|
| 337 |
+
if self.pad_audio:
|
| 338 |
+
return self.sizes[index]
|
| 339 |
+
return min(self.sizes[index], self.max_sample_size)
|
| 340 |
+
|
| 341 |
+
def ordered_indices(self):
|
| 342 |
+
if self.shuffle:
|
| 343 |
+
order = [np.random.permutation(len(self))]
|
| 344 |
+
else:
|
| 345 |
+
order = [np.arange(len(self))]
|
| 346 |
+
|
| 347 |
+
order.append(self.sizes)
|
| 348 |
+
return np.lexsort(order)[::-1]
|
| 349 |
+
|
| 350 |
+
def postprocess(self, wav, cur_sample_rate):
|
| 351 |
+
if wav.dim() == 2:
|
| 352 |
+
wav = wav.mean(-1)
|
| 353 |
+
assert wav.dim() == 1, wav.dim()
|
| 354 |
+
|
| 355 |
+
if cur_sample_rate != self.sample_rate:
|
| 356 |
+
raise Exception(f"sr {cur_sample_rate} != {self.sample_rate}")
|
| 357 |
+
|
| 358 |
+
if self.normalize:
|
| 359 |
+
with torch.no_grad():
|
| 360 |
+
wav = F.layer_norm(wav, wav.shape)
|
| 361 |
+
return wav
|
fengshen/data/megatron_dataloader/Makefile
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
CXXFLAGS += -O3 -Wall -shared -std=c++11 -fPIC -fdiagnostics-color
|
| 2 |
+
CPPFLAGS += $(shell python3 -m pybind11 --includes)
|
| 3 |
+
LIBNAME = helpers
|
| 4 |
+
LIBEXT = $(shell python3-config --extension-suffix)
|
| 5 |
+
|
| 6 |
+
default: $(LIBNAME)$(LIBEXT)
|
| 7 |
+
|
| 8 |
+
%$(LIBEXT): %.cpp
|
| 9 |
+
$(CXX) $(CXXFLAGS) $(CPPFLAGS) $< -o $@
|
fengshen/data/megatron_dataloader/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from . import indexed_dataset
|
fengshen/data/megatron_dataloader/bart_dataset.py
ADDED
|
@@ -0,0 +1,443 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""BART Style dataset. Modified from fairseq."""
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import math
|
| 6 |
+
import re
|
| 7 |
+
|
| 8 |
+
from fengshen.data.megatron_dataloader.dataset_utils import (
|
| 9 |
+
get_samples_mapping
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class BartDataset(torch.utils.data.Dataset):
|
| 14 |
+
def __init__(self, name, indexed_dataset, data_prefix,
|
| 15 |
+
num_epochs, max_num_samples, masked_lm_prob,
|
| 16 |
+
max_seq_length, short_seq_prob, seed, tokenizer, zh_tokenizer):
|
| 17 |
+
|
| 18 |
+
# Params to store.
|
| 19 |
+
self.name = name
|
| 20 |
+
self.seed = seed
|
| 21 |
+
self.masked_lm_prob = masked_lm_prob
|
| 22 |
+
self.max_seq_length = max_seq_length
|
| 23 |
+
|
| 24 |
+
# Dataset.
|
| 25 |
+
self.indexed_dataset = indexed_dataset
|
| 26 |
+
|
| 27 |
+
# Build the samples mapping.
|
| 28 |
+
self.samples_mapping = get_samples_mapping(self.indexed_dataset,
|
| 29 |
+
data_prefix,
|
| 30 |
+
num_epochs,
|
| 31 |
+
max_num_samples,
|
| 32 |
+
self.max_seq_length - 3, # account for added tokens
|
| 33 |
+
short_seq_prob,
|
| 34 |
+
self.seed,
|
| 35 |
+
self.name,
|
| 36 |
+
False)
|
| 37 |
+
|
| 38 |
+
# Vocab stuff.
|
| 39 |
+
self.vocab_size = tokenizer.vocab_size
|
| 40 |
+
inv_vocab = {v: k for k, v in tokenizer.vocab.items()}
|
| 41 |
+
self.vocab_id_list = list(inv_vocab.keys())
|
| 42 |
+
self.vocab_id_to_token_dict = inv_vocab
|
| 43 |
+
self.cls_id = tokenizer.cls_token_id
|
| 44 |
+
self.sep_id = tokenizer.sep_token_id
|
| 45 |
+
self.mask_id = tokenizer.mask_token_id
|
| 46 |
+
self.pad_id = tokenizer.pad_token_id
|
| 47 |
+
self.tokenizer = tokenizer
|
| 48 |
+
|
| 49 |
+
seg_tokens = ['。', ';', ';', '!', '!', '?', '?']
|
| 50 |
+
seg_token_ids = []
|
| 51 |
+
for t in seg_tokens:
|
| 52 |
+
if t in tokenizer.vocab:
|
| 53 |
+
seg_token_ids.append(tokenizer.vocab[t])
|
| 54 |
+
else:
|
| 55 |
+
print('seg_token "{}" not in vocab'.format(t))
|
| 56 |
+
self.seg_token_ids = set(seg_token_ids)
|
| 57 |
+
|
| 58 |
+
self.zh_tokenizer = zh_tokenizer
|
| 59 |
+
|
| 60 |
+
# Denoising ratios
|
| 61 |
+
self.permute_sentence_ratio = 1.0
|
| 62 |
+
self.mask_ratio = masked_lm_prob # 0.15
|
| 63 |
+
self.random_ratio = 0.1
|
| 64 |
+
self.insert_ratio = 0.0
|
| 65 |
+
self.rotate_ratio = 0.0
|
| 66 |
+
self.mask_whole_word = 1
|
| 67 |
+
self.item_transform_func = None
|
| 68 |
+
|
| 69 |
+
self.mask_span_distribution = None
|
| 70 |
+
if False:
|
| 71 |
+
_lambda = 3 # Poisson lambda
|
| 72 |
+
|
| 73 |
+
lambda_to_the_k = 1
|
| 74 |
+
e_to_the_minus_lambda = math.exp(-_lambda)
|
| 75 |
+
k_factorial = 1
|
| 76 |
+
ps = []
|
| 77 |
+
for k in range(0, 128):
|
| 78 |
+
ps.append(e_to_the_minus_lambda * lambda_to_the_k / k_factorial)
|
| 79 |
+
lambda_to_the_k *= _lambda
|
| 80 |
+
k_factorial *= k + 1
|
| 81 |
+
if ps[-1] < 0.0000001:
|
| 82 |
+
break
|
| 83 |
+
ps = torch.FloatTensor(ps)
|
| 84 |
+
self.mask_span_distribution = torch.distributions.Categorical(ps)
|
| 85 |
+
|
| 86 |
+
def __len__(self):
|
| 87 |
+
return self.samples_mapping.shape[0]
|
| 88 |
+
|
| 89 |
+
def __getitem__(self, idx):
|
| 90 |
+
start_idx, end_idx, seq_length = self.samples_mapping[idx]
|
| 91 |
+
sample = [self.indexed_dataset[i] for i in range(start_idx, end_idx)]
|
| 92 |
+
# Note that this rng state should be numpy and not python since
|
| 93 |
+
# python randint is inclusive whereas the numpy one is exclusive.
|
| 94 |
+
# We % 2**32 since numpy requres the seed to be between 0 and 2**32 - 1
|
| 95 |
+
np_rng = np.random.RandomState(seed=((self.seed + idx) % 2**32))
|
| 96 |
+
return self.build_training_sample(sample, self.max_seq_length, np_rng)
|
| 97 |
+
|
| 98 |
+
def build_training_sample(self, sample, max_seq_length, np_rng):
|
| 99 |
+
"""Biuld training sample.
|
| 100 |
+
|
| 101 |
+
Arguments:
|
| 102 |
+
sample: A list of sentences in which each sentence is a list token ids.
|
| 103 |
+
max_seq_length: Desired sequence length.
|
| 104 |
+
np_rng: Random number genenrator. Note that this rng state should be
|
| 105 |
+
numpy and not python since python randint is inclusive for
|
| 106 |
+
the opper bound whereas the numpy one is exclusive.
|
| 107 |
+
"""
|
| 108 |
+
# permute sentences
|
| 109 |
+
full_stops = []
|
| 110 |
+
tokens = [self.cls_id]
|
| 111 |
+
for sent in sample:
|
| 112 |
+
for t in sent:
|
| 113 |
+
token = self.vocab_id_to_token_dict[t]
|
| 114 |
+
if len(re.findall('##[\u4E00-\u9FA5]', token)) > 0:
|
| 115 |
+
# 兼容erlangshen ##的方式做whole word mask
|
| 116 |
+
t = self.tokenizer.convert_tokens_to_ids(token[2:])
|
| 117 |
+
tokens.append(t)
|
| 118 |
+
if t in self.seg_token_ids:
|
| 119 |
+
tokens.append(self.sep_id)
|
| 120 |
+
if tokens[-1] != self.sep_id:
|
| 121 |
+
tokens.append(self.sep_id)
|
| 122 |
+
|
| 123 |
+
if len(tokens) > max_seq_length:
|
| 124 |
+
tokens = tokens[:max_seq_length]
|
| 125 |
+
tokens[-1] = self.sep_id
|
| 126 |
+
tokens = torch.LongTensor(tokens)
|
| 127 |
+
full_stops = (tokens == self.sep_id).long()
|
| 128 |
+
assert (max_seq_length - tokens.shape[0]) >= 0, (tokens.size(), tokens[-1], max_seq_length)
|
| 129 |
+
|
| 130 |
+
source, target = tokens, tokens[1:].clone()
|
| 131 |
+
use_decoder = 1
|
| 132 |
+
# if torch.rand(1).item() < 0.5:
|
| 133 |
+
# use_decoder = 0
|
| 134 |
+
|
| 135 |
+
if self.permute_sentence_ratio > 0.0 and use_decoder == 1:
|
| 136 |
+
source = self.permute_sentences(source, full_stops, self.permute_sentence_ratio)
|
| 137 |
+
|
| 138 |
+
if self.mask_ratio > 0.0:
|
| 139 |
+
replace_length = 1 if use_decoder else -1
|
| 140 |
+
mask_ratio = self.mask_ratio * 2 if use_decoder else self.mask_ratio
|
| 141 |
+
source = self.add_whole_word_mask(source, mask_ratio, replace_length)
|
| 142 |
+
|
| 143 |
+
if self.insert_ratio > 0.0:
|
| 144 |
+
raise NotImplementedError
|
| 145 |
+
source = self.add_insertion_noise(source, self.insert_ratio)
|
| 146 |
+
|
| 147 |
+
if self.rotate_ratio > 0.0 and np.random.random() < self.rotate_ratio:
|
| 148 |
+
raise NotImplementedError
|
| 149 |
+
source = self.add_rolling_noise(source)
|
| 150 |
+
|
| 151 |
+
# there can additional changes to make:
|
| 152 |
+
if self.item_transform_func is not None:
|
| 153 |
+
source, target = self.item_transform_func(source, target)
|
| 154 |
+
|
| 155 |
+
assert (source >= 0).all()
|
| 156 |
+
# assert (source[1:-1] >= 1).all()
|
| 157 |
+
assert (source <= self.vocab_size).all()
|
| 158 |
+
assert source[0] == self.cls_id
|
| 159 |
+
assert source[-1] == self.sep_id
|
| 160 |
+
|
| 161 |
+
# tokenizer = get_tokenizer()
|
| 162 |
+
# print(' '.join(tokenizer.tokenizer.convert_ids_to_tokens(source)))
|
| 163 |
+
# print(tokenizer.detokenize(target))
|
| 164 |
+
# print(tokenizer.detokenize(source))
|
| 165 |
+
# print()
|
| 166 |
+
|
| 167 |
+
prev_output_tokens = torch.zeros_like(target)
|
| 168 |
+
prev_output_tokens[0] = self.sep_id # match the preprocessing in fairseq
|
| 169 |
+
prev_output_tokens[1:] = target[:-1]
|
| 170 |
+
|
| 171 |
+
# src_padding_length = max_seq_length - source.shape[0]
|
| 172 |
+
# tgt_padding_length = max_seq_length - target.shape[0]
|
| 173 |
+
# assert src_padding_length >= 0, (source.size(), source[-1], max_seq_length)
|
| 174 |
+
# assert tgt_padding_length >= 0, (target.size(), target[-1], max_seq_length)
|
| 175 |
+
source_ = torch.full((max_seq_length,), self.pad_id, dtype=torch.long)
|
| 176 |
+
source_[:source.shape[0]] = source
|
| 177 |
+
target_ = torch.full((max_seq_length,), -100, dtype=torch.long)
|
| 178 |
+
# decoder not need bos in the front
|
| 179 |
+
target_[:target.shape[0]] = target
|
| 180 |
+
prev_output_tokens_ = torch.full((max_seq_length,), self.pad_id, dtype=torch.long)
|
| 181 |
+
prev_output_tokens_[:prev_output_tokens.shape[0]] = prev_output_tokens
|
| 182 |
+
|
| 183 |
+
return {
|
| 184 |
+
"input_ids": source_,
|
| 185 |
+
"labels": target_,
|
| 186 |
+
# "decoder_input_ids": prev_output_tokens_,
|
| 187 |
+
"attention_mask": (source_ != self.pad_id).long()
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
def permute_sentences(self, source, full_stops, p=1.0):
|
| 191 |
+
# Tokens that are full stops, where the previous token is not
|
| 192 |
+
sentence_ends = (full_stops[1:] * ~full_stops[:-1]).nonzero(as_tuple=False) + 2
|
| 193 |
+
result = source.clone()
|
| 194 |
+
|
| 195 |
+
num_sentences = sentence_ends.size(0)
|
| 196 |
+
num_to_permute = math.ceil((num_sentences * 2 * p) / 2.0)
|
| 197 |
+
substitutions = torch.randperm(num_sentences)[:num_to_permute]
|
| 198 |
+
ordering = torch.arange(0, num_sentences)
|
| 199 |
+
ordering[substitutions] = substitutions[torch.randperm(num_to_permute)]
|
| 200 |
+
|
| 201 |
+
# Ignore <bos> at start
|
| 202 |
+
index = 1
|
| 203 |
+
for i in ordering:
|
| 204 |
+
sentence = source[(sentence_ends[i - 1] if i > 0 else 1): sentence_ends[i]]
|
| 205 |
+
result[index: index + sentence.size(0)] = sentence
|
| 206 |
+
index += sentence.size(0)
|
| 207 |
+
return result
|
| 208 |
+
|
| 209 |
+
def word_starts_en(self, source):
|
| 210 |
+
if self.mask_whole_word is not None:
|
| 211 |
+
is_word_start = self.mask_whole_word.gather(0, source)
|
| 212 |
+
else:
|
| 213 |
+
is_word_start = torch.ones(source.size())
|
| 214 |
+
is_word_start[0] = 0
|
| 215 |
+
is_word_start[-1] = 0
|
| 216 |
+
return is_word_start
|
| 217 |
+
|
| 218 |
+
def word_starts(self, source):
|
| 219 |
+
if self.mask_whole_word is None:
|
| 220 |
+
is_word_start = torch.ones(source.size())
|
| 221 |
+
is_word_start[0] = 0
|
| 222 |
+
is_word_start[-1] = 0
|
| 223 |
+
return is_word_start
|
| 224 |
+
raw_tokens = [self.vocab_id_to_token_dict[i] for i in source.tolist()]
|
| 225 |
+
words = [raw_tokens[0]] + \
|
| 226 |
+
self.zh_tokenizer(''.join(raw_tokens[1:-1]), HMM=True) + [raw_tokens[-1]]
|
| 227 |
+
|
| 228 |
+
def _is_chinese_char(c):
|
| 229 |
+
"""Checks whether CP is the #codepoint of a CJK character."""
|
| 230 |
+
# This defines a "chinese character" as anything in the CJK Unicode block:
|
| 231 |
+
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
|
| 232 |
+
#
|
| 233 |
+
# Note that the CJK Unicode block is NOT all Japanese and Korean characters,
|
| 234 |
+
# despite its name. The modern Korean Hangul alphabet is a different block,
|
| 235 |
+
# as is Japanese Hiragana and Katakana. Those alphabets are used to write
|
| 236 |
+
# space-separated words, so they are not treated specially and handled
|
| 237 |
+
# like the all of the other languages.
|
| 238 |
+
if len(c) > 1:
|
| 239 |
+
return all([_is_chinese_char(c_i) for c_i in c])
|
| 240 |
+
cp = ord(c)
|
| 241 |
+
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
|
| 242 |
+
(cp >= 0x3400 and cp <= 0x4DBF) or #
|
| 243 |
+
(cp >= 0x20000 and cp <= 0x2A6DF) or #
|
| 244 |
+
(cp >= 0x2A700 and cp <= 0x2B73F) or #
|
| 245 |
+
(cp >= 0x2B740 and cp <= 0x2B81F) or #
|
| 246 |
+
(cp >= 0x2B820 and cp <= 0x2CEAF) or
|
| 247 |
+
(cp >= 0xF900 and cp <= 0xFAFF) or #
|
| 248 |
+
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
|
| 249 |
+
return True
|
| 250 |
+
|
| 251 |
+
return False
|
| 252 |
+
|
| 253 |
+
def align_linear(atokens, btokens):
|
| 254 |
+
a2c = []
|
| 255 |
+
c2b = []
|
| 256 |
+
a2b = []
|
| 257 |
+
length = 0
|
| 258 |
+
for tok in atokens:
|
| 259 |
+
a2c.append([length + i for i in range(len(tok))])
|
| 260 |
+
length += len(tok)
|
| 261 |
+
for i, tok in enumerate(btokens):
|
| 262 |
+
c2b.extend([i for _ in range(len(tok))])
|
| 263 |
+
|
| 264 |
+
for i, amap in enumerate(a2c):
|
| 265 |
+
bmap = [c2b[ci] for ci in amap]
|
| 266 |
+
a2b.append(list(set(bmap)))
|
| 267 |
+
return a2b
|
| 268 |
+
|
| 269 |
+
raw_to_word_align = align_linear(raw_tokens, words)
|
| 270 |
+
is_word_start = torch.zeros(source.size())
|
| 271 |
+
word_starts = []
|
| 272 |
+
skip_cur_word = True
|
| 273 |
+
for i in range(1, len(raw_to_word_align)):
|
| 274 |
+
if raw_to_word_align[i-1] == raw_to_word_align[i]:
|
| 275 |
+
# not a word start, as they align to the same word
|
| 276 |
+
if not skip_cur_word and not _is_chinese_char(raw_tokens[i]):
|
| 277 |
+
word_starts.pop(-1)
|
| 278 |
+
skip_cur_word = True
|
| 279 |
+
continue
|
| 280 |
+
else:
|
| 281 |
+
is_word_start[i] = 1
|
| 282 |
+
if _is_chinese_char(raw_tokens[i]):
|
| 283 |
+
word_starts.append(i)
|
| 284 |
+
skip_cur_word = False
|
| 285 |
+
is_word_start[0] = 0
|
| 286 |
+
is_word_start[-1] = 0
|
| 287 |
+
word_starts = torch.tensor(word_starts).long().view(-1, 1)
|
| 288 |
+
return is_word_start, word_starts
|
| 289 |
+
|
| 290 |
+
def add_whole_word_mask(self, source, p, replace_length=1):
|
| 291 |
+
is_word_start, word_starts = self.word_starts(source)
|
| 292 |
+
num_to_mask_word = int(math.ceil(word_starts.size(0) * p))
|
| 293 |
+
num_to_mask_char = int(math.ceil(word_starts.size(0) * p * 0.1))
|
| 294 |
+
num_to_mask = num_to_mask_word + num_to_mask_char
|
| 295 |
+
if num_to_mask > word_starts.size(0):
|
| 296 |
+
word_starts = is_word_start.nonzero(as_tuple=False)
|
| 297 |
+
num_inserts = 0
|
| 298 |
+
if num_to_mask == 0:
|
| 299 |
+
return source
|
| 300 |
+
|
| 301 |
+
if self.mask_span_distribution is not None:
|
| 302 |
+
lengths = self.mask_span_distribution.sample(sample_shape=(num_to_mask,))
|
| 303 |
+
|
| 304 |
+
# Make sure we have enough to mask
|
| 305 |
+
cum_length = torch.cumsum(lengths, 0)
|
| 306 |
+
while cum_length[-1] < num_to_mask:
|
| 307 |
+
lengths = torch.cat(
|
| 308 |
+
[
|
| 309 |
+
lengths,
|
| 310 |
+
self.mask_span_distribution.sample(sample_shape=(num_to_mask,)),
|
| 311 |
+
],
|
| 312 |
+
dim=0,
|
| 313 |
+
)
|
| 314 |
+
cum_length = torch.cumsum(lengths, 0)
|
| 315 |
+
|
| 316 |
+
# Trim to masking budget
|
| 317 |
+
i = 0
|
| 318 |
+
while cum_length[i] < num_to_mask:
|
| 319 |
+
i += 1
|
| 320 |
+
lengths[i] = num_to_mask - (0 if i == 0 else cum_length[i - 1])
|
| 321 |
+
num_to_mask = i + 1
|
| 322 |
+
lengths = lengths[:num_to_mask]
|
| 323 |
+
|
| 324 |
+
# Handle 0-length mask (inserts) separately
|
| 325 |
+
lengths = lengths[lengths > 0]
|
| 326 |
+
num_inserts = num_to_mask - lengths.size(0)
|
| 327 |
+
num_to_mask -= num_inserts
|
| 328 |
+
if num_to_mask == 0:
|
| 329 |
+
return self.add_insertion_noise(source, num_inserts / source.size(0))
|
| 330 |
+
|
| 331 |
+
assert (lengths > 0).all()
|
| 332 |
+
else:
|
| 333 |
+
lengths = torch.ones((num_to_mask,)).long()
|
| 334 |
+
assert is_word_start[-1] == 0
|
| 335 |
+
indices = word_starts[
|
| 336 |
+
torch.randperm(word_starts.size(0))[:num_to_mask]
|
| 337 |
+
].squeeze(1)
|
| 338 |
+
mask_random = torch.FloatTensor(num_to_mask).uniform_() < self.random_ratio
|
| 339 |
+
source_length = source.size(0)
|
| 340 |
+
assert source_length - 1 not in indices
|
| 341 |
+
to_keep = torch.ones(source_length, dtype=torch.bool)
|
| 342 |
+
is_word_start[
|
| 343 |
+
-1
|
| 344 |
+
] = 255 # acts as a long length, so spans don't go over the end of doc
|
| 345 |
+
if replace_length == 0:
|
| 346 |
+
to_keep[indices] = 0
|
| 347 |
+
else:
|
| 348 |
+
# keep index, but replace it with [MASK]
|
| 349 |
+
# print(source.size(), word_starts.size(), indices.size(), mask_random.size())
|
| 350 |
+
source[indices] = self.mask_id
|
| 351 |
+
source[indices[mask_random]] = torch.randint(
|
| 352 |
+
1, self.vocab_size, size=(mask_random.sum(),)
|
| 353 |
+
)
|
| 354 |
+
# sorted_indices = torch.sort(indices)[0]
|
| 355 |
+
# continue_mask_pos = ((sorted_indices + 1)[:-1] == sorted_indices[1:])
|
| 356 |
+
# continue_mask_indices = sorted_indices[1:][continue_mask_pos]
|
| 357 |
+
# to_keep[continue_mask_indices] = 0
|
| 358 |
+
|
| 359 |
+
# for char indices, we already masked, the following loop handles word mask
|
| 360 |
+
indices = indices[:num_to_mask_word]
|
| 361 |
+
mask_random = mask_random[:num_to_mask_word]
|
| 362 |
+
if self.mask_span_distribution is not None:
|
| 363 |
+
assert len(lengths.size()) == 1
|
| 364 |
+
assert lengths.size() == indices.size()
|
| 365 |
+
lengths -= 1
|
| 366 |
+
while indices.size(0) > 0:
|
| 367 |
+
assert lengths.size() == indices.size()
|
| 368 |
+
lengths -= is_word_start[indices + 1].long()
|
| 369 |
+
uncompleted = lengths >= 0
|
| 370 |
+
indices = indices[uncompleted] + 1
|
| 371 |
+
mask_random = mask_random[uncompleted]
|
| 372 |
+
lengths = lengths[uncompleted]
|
| 373 |
+
if replace_length != -1:
|
| 374 |
+
# delete token
|
| 375 |
+
to_keep[indices] = 0
|
| 376 |
+
else:
|
| 377 |
+
# keep index, but replace it with [MASK]
|
| 378 |
+
source[indices] = self.mask_id
|
| 379 |
+
source[indices[mask_random]] = torch.randint(
|
| 380 |
+
1, self.vocab_size, size=(mask_random.sum(),)
|
| 381 |
+
)
|
| 382 |
+
else:
|
| 383 |
+
# A bit faster when all lengths are 1
|
| 384 |
+
while indices.size(0) > 0:
|
| 385 |
+
uncompleted = is_word_start[indices + 1] == 0
|
| 386 |
+
indices = indices[uncompleted] + 1
|
| 387 |
+
mask_random = mask_random[uncompleted]
|
| 388 |
+
if replace_length != -1:
|
| 389 |
+
# delete token
|
| 390 |
+
to_keep[indices] = 0
|
| 391 |
+
else:
|
| 392 |
+
# keep index, but replace it with [MASK]
|
| 393 |
+
source[indices] = self.mask_id
|
| 394 |
+
source[indices[mask_random]] = torch.randint(
|
| 395 |
+
1, self.vocab_size, size=(mask_random.sum(),)
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
assert source_length - 1 not in indices
|
| 399 |
+
|
| 400 |
+
source = source[to_keep]
|
| 401 |
+
|
| 402 |
+
if num_inserts > 0:
|
| 403 |
+
source = self.add_insertion_noise(source, num_inserts / source.size(0))
|
| 404 |
+
|
| 405 |
+
return source
|
| 406 |
+
|
| 407 |
+
def add_permuted_noise(self, tokens, p):
|
| 408 |
+
num_words = len(tokens)
|
| 409 |
+
num_to_permute = math.ceil(((num_words * 2) * p) / 2.0)
|
| 410 |
+
substitutions = torch.randperm(num_words - 2)[:num_to_permute] + 1
|
| 411 |
+
tokens[substitutions] = tokens[substitutions[torch.randperm(num_to_permute)]]
|
| 412 |
+
return tokens
|
| 413 |
+
|
| 414 |
+
def add_rolling_noise(self, tokens):
|
| 415 |
+
offset = np.random.randint(1, max(1, tokens.size(-1) - 1) + 1)
|
| 416 |
+
tokens = torch.cat(
|
| 417 |
+
(tokens[0:1], tokens[offset:-1], tokens[1:offset], tokens[-1:]),
|
| 418 |
+
dim=0,
|
| 419 |
+
)
|
| 420 |
+
return tokens
|
| 421 |
+
|
| 422 |
+
def add_insertion_noise(self, tokens, p):
|
| 423 |
+
if p == 0.0:
|
| 424 |
+
return tokens
|
| 425 |
+
|
| 426 |
+
num_tokens = len(tokens)
|
| 427 |
+
n = int(math.ceil(num_tokens * p))
|
| 428 |
+
|
| 429 |
+
noise_indices = torch.randperm(num_tokens + n - 2)[:n] + 1
|
| 430 |
+
noise_mask = torch.zeros(size=(num_tokens + n,), dtype=torch.bool)
|
| 431 |
+
noise_mask[noise_indices] = 1
|
| 432 |
+
result = torch.LongTensor(n + len(tokens)).fill_(-1)
|
| 433 |
+
|
| 434 |
+
num_random = int(math.ceil(n * self.random_ratio))
|
| 435 |
+
result[noise_indices[num_random:]] = self.mask_id
|
| 436 |
+
result[noise_indices[:num_random]] = torch.randint(
|
| 437 |
+
low=1, high=self.vocab_size, size=(num_random,)
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
result[~noise_mask] = tokens
|
| 441 |
+
|
| 442 |
+
assert (result >= 0).all()
|
| 443 |
+
return result
|
fengshen/data/megatron_dataloader/bert_dataset.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
"""BERT Style dataset."""
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import torch
|
| 21 |
+
|
| 22 |
+
from fengshen.data.megatron_dataloader.dataset_utils import (
|
| 23 |
+
get_samples_mapping,
|
| 24 |
+
get_a_and_b_segments,
|
| 25 |
+
create_masked_lm_predictions,
|
| 26 |
+
create_tokens_and_tokentypes,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class BertDataset(torch.utils.data.Dataset):
|
| 31 |
+
|
| 32 |
+
def __init__(self, name, indexed_dataset, data_prefix,
|
| 33 |
+
num_epochs, max_num_samples, masked_lm_prob,
|
| 34 |
+
max_seq_length, short_seq_prob, seed, binary_head, tokenizer, masking_style):
|
| 35 |
+
# Params to store.
|
| 36 |
+
self.name = name
|
| 37 |
+
self.seed = seed
|
| 38 |
+
self.masked_lm_prob = masked_lm_prob
|
| 39 |
+
self.max_seq_length = max_seq_length
|
| 40 |
+
self.short_seq_prob = short_seq_prob
|
| 41 |
+
self.binary_head = binary_head
|
| 42 |
+
self.masking_style = masking_style
|
| 43 |
+
|
| 44 |
+
# Dataset.
|
| 45 |
+
self.indexed_dataset = indexed_dataset
|
| 46 |
+
|
| 47 |
+
# Build the samples mapping.
|
| 48 |
+
self.samples_mapping = get_samples_mapping(self.indexed_dataset,
|
| 49 |
+
data_prefix,
|
| 50 |
+
num_epochs,
|
| 51 |
+
max_num_samples,
|
| 52 |
+
# account for added tokens
|
| 53 |
+
self.max_seq_length - 3,
|
| 54 |
+
short_seq_prob,
|
| 55 |
+
self.seed,
|
| 56 |
+
self.name,
|
| 57 |
+
self.binary_head)
|
| 58 |
+
inv_vocab = {v: k for k, v in tokenizer.vocab.items()}
|
| 59 |
+
self.vocab_id_list = list(inv_vocab.keys())
|
| 60 |
+
self.vocab_id_to_token_dict = inv_vocab
|
| 61 |
+
self.cls_id = tokenizer.cls_token_id
|
| 62 |
+
self.sep_id = tokenizer.sep_token_id
|
| 63 |
+
self.mask_id = tokenizer.mask_token_id
|
| 64 |
+
self.pad_id = tokenizer.pad_token_id
|
| 65 |
+
self.tokenizer = tokenizer
|
| 66 |
+
|
| 67 |
+
def __len__(self):
|
| 68 |
+
return self.samples_mapping.shape[0]
|
| 69 |
+
|
| 70 |
+
def __getitem__(self, idx):
|
| 71 |
+
start_idx, end_idx, seq_length = self.samples_mapping[idx]
|
| 72 |
+
sample = [self.indexed_dataset[i] for i in range(start_idx, end_idx)]
|
| 73 |
+
# Note that this rng state should be numpy and not python since
|
| 74 |
+
# python randint is inclusive whereas the numpy one is exclusive.
|
| 75 |
+
# We % 2**32 since numpy requres the seed to be between 0 and 2**32 - 1
|
| 76 |
+
np_rng = np.random.RandomState(seed=((self.seed + idx) % 2**32))
|
| 77 |
+
return build_training_sample(sample, seq_length,
|
| 78 |
+
self.max_seq_length, # needed for padding
|
| 79 |
+
self.vocab_id_list,
|
| 80 |
+
self.vocab_id_to_token_dict,
|
| 81 |
+
self.cls_id, self.sep_id,
|
| 82 |
+
self.mask_id, self.pad_id,
|
| 83 |
+
self.masked_lm_prob, np_rng,
|
| 84 |
+
self.binary_head,
|
| 85 |
+
tokenizer=self.tokenizer,
|
| 86 |
+
masking_style=self.masking_style)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def build_training_sample(sample,
|
| 90 |
+
target_seq_length, max_seq_length,
|
| 91 |
+
vocab_id_list, vocab_id_to_token_dict,
|
| 92 |
+
cls_id, sep_id, mask_id, pad_id,
|
| 93 |
+
masked_lm_prob, np_rng, binary_head,
|
| 94 |
+
tokenizer,
|
| 95 |
+
masking_style='bert'):
|
| 96 |
+
"""Biuld training sample.
|
| 97 |
+
|
| 98 |
+
Arguments:
|
| 99 |
+
sample: A list of sentences in which each sentence is a list token ids.
|
| 100 |
+
target_seq_length: Desired sequence length.
|
| 101 |
+
max_seq_length: Maximum length of the sequence. All values are padded to
|
| 102 |
+
this length.
|
| 103 |
+
vocab_id_list: List of vocabulary ids. Used to pick a random id.
|
| 104 |
+
vocab_id_to_token_dict: A dictionary from vocab ids to text tokens.
|
| 105 |
+
cls_id: Start of example id.
|
| 106 |
+
sep_id: Separator id.
|
| 107 |
+
mask_id: Mask token id.
|
| 108 |
+
pad_id: Padding token id.
|
| 109 |
+
masked_lm_prob: Probability to mask tokens.
|
| 110 |
+
np_rng: Random number genenrator. Note that this rng state should be
|
| 111 |
+
numpy and not python since python randint is inclusive for
|
| 112 |
+
the opper bound whereas the numpy one is exclusive.
|
| 113 |
+
"""
|
| 114 |
+
|
| 115 |
+
if binary_head:
|
| 116 |
+
# We assume that we have at least two sentences in the sample
|
| 117 |
+
assert len(sample) > 1
|
| 118 |
+
assert target_seq_length <= max_seq_length
|
| 119 |
+
|
| 120 |
+
# Divide sample into two segments (A and B).
|
| 121 |
+
if binary_head:
|
| 122 |
+
tokens_a, tokens_b, is_next_random = get_a_and_b_segments(sample,
|
| 123 |
+
np_rng)
|
| 124 |
+
else:
|
| 125 |
+
tokens_a = []
|
| 126 |
+
for j in range(len(sample)):
|
| 127 |
+
tokens_a.extend(sample[j])
|
| 128 |
+
tokens_b = []
|
| 129 |
+
is_next_random = False
|
| 130 |
+
|
| 131 |
+
if len(tokens_a) >= max_seq_length-3:
|
| 132 |
+
tokens_a = tokens_a[:max_seq_length-3]
|
| 133 |
+
|
| 134 |
+
# Truncate to `target_sequence_length`.
|
| 135 |
+
max_num_tokens = target_seq_length
|
| 136 |
+
''''
|
| 137 |
+
truncated = truncate_segments(tokens_a, tokens_b, len(tokens_a),
|
| 138 |
+
len(tokens_b), max_num_tokens, np_rng)
|
| 139 |
+
'''
|
| 140 |
+
|
| 141 |
+
# Build tokens and toketypes.
|
| 142 |
+
tokens, tokentypes = create_tokens_and_tokentypes(tokens_a, tokens_b,
|
| 143 |
+
cls_id, sep_id)
|
| 144 |
+
# Masking.
|
| 145 |
+
max_predictions_per_seq = masked_lm_prob * max_num_tokens
|
| 146 |
+
(tokens, masked_positions, masked_labels, _, _) = create_masked_lm_predictions(
|
| 147 |
+
tokens, vocab_id_list, vocab_id_to_token_dict, masked_lm_prob,
|
| 148 |
+
cls_id, sep_id, mask_id, max_predictions_per_seq, np_rng,
|
| 149 |
+
tokenizer=tokenizer,
|
| 150 |
+
masking_style=masking_style)
|
| 151 |
+
|
| 152 |
+
# Padding.
|
| 153 |
+
tokens_np, tokentypes_np, labels_np, padding_mask_np, loss_mask_np \
|
| 154 |
+
= pad_and_convert_to_numpy(tokens, tokentypes, masked_positions,
|
| 155 |
+
masked_labels, pad_id, max_seq_length)
|
| 156 |
+
|
| 157 |
+
train_sample = {
|
| 158 |
+
'input_ids': tokens_np,
|
| 159 |
+
'token_type_ids': tokentypes_np,
|
| 160 |
+
'labels': labels_np,
|
| 161 |
+
'next_sentence_label': int(is_next_random),
|
| 162 |
+
'attention_mask': padding_mask_np}
|
| 163 |
+
return train_sample
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def pad_and_convert_to_numpy(tokens, tokentypes, masked_positions,
|
| 167 |
+
masked_labels, pad_id, max_seq_length):
|
| 168 |
+
"""Pad sequences and convert them to numpy."""
|
| 169 |
+
|
| 170 |
+
# Some checks.
|
| 171 |
+
num_tokens = len(tokens)
|
| 172 |
+
padding_length = max_seq_length - num_tokens
|
| 173 |
+
assert padding_length >= 0
|
| 174 |
+
assert len(tokentypes) == num_tokens
|
| 175 |
+
assert len(masked_positions) == len(masked_labels)
|
| 176 |
+
|
| 177 |
+
# Tokens and token types.
|
| 178 |
+
filler = [pad_id] * padding_length
|
| 179 |
+
tokens_np = np.array(tokens + filler, dtype=np.int64)
|
| 180 |
+
tokentypes_np = np.array(tokentypes + filler, dtype=np.int64)
|
| 181 |
+
|
| 182 |
+
# Padding mask.
|
| 183 |
+
padding_mask_np = np.array([1] * num_tokens + [0] * padding_length,
|
| 184 |
+
dtype=np.int64)
|
| 185 |
+
|
| 186 |
+
# Lables and loss mask.
|
| 187 |
+
labels = [-100] * max_seq_length
|
| 188 |
+
loss_mask = [0] * max_seq_length
|
| 189 |
+
for i in range(len(masked_positions)):
|
| 190 |
+
assert masked_positions[i] < num_tokens
|
| 191 |
+
labels[masked_positions[i]] = masked_labels[i]
|
| 192 |
+
loss_mask[masked_positions[i]] = 1
|
| 193 |
+
labels_np = np.array(labels, dtype=np.int64)
|
| 194 |
+
loss_mask_np = np.array(loss_mask, dtype=np.int64)
|
| 195 |
+
|
| 196 |
+
return tokens_np, tokentypes_np, labels_np, padding_mask_np, loss_mask_np
|
fengshen/data/megatron_dataloader/blendable_dataset.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
"""Blendable dataset."""
|
| 17 |
+
|
| 18 |
+
import time
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
import torch
|
| 22 |
+
|
| 23 |
+
from fengshen.data.megatron_dataloader.utils import print_rank_0
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class BlendableDataset(torch.utils.data.Dataset):
|
| 27 |
+
|
| 28 |
+
def __init__(self, datasets, weights):
|
| 29 |
+
|
| 30 |
+
self.datasets = datasets
|
| 31 |
+
num_datasets = len(datasets)
|
| 32 |
+
assert num_datasets == len(weights)
|
| 33 |
+
|
| 34 |
+
self.size = 0
|
| 35 |
+
for dataset in self.datasets:
|
| 36 |
+
self.size += len(dataset)
|
| 37 |
+
|
| 38 |
+
# Normalize weights.
|
| 39 |
+
weights = np.array(weights, dtype=np.float64)
|
| 40 |
+
sum_weights = np.sum(weights)
|
| 41 |
+
assert sum_weights > 0.0
|
| 42 |
+
weights /= sum_weights
|
| 43 |
+
|
| 44 |
+
# Build indecies.
|
| 45 |
+
start_time = time.time()
|
| 46 |
+
assert num_datasets < 255
|
| 47 |
+
self.dataset_index = np.zeros(self.size, dtype=np.uint8)
|
| 48 |
+
self.dataset_sample_index = np.zeros(self.size, dtype=np.int64)
|
| 49 |
+
|
| 50 |
+
from fengshen.data.megatron_dataloader import helpers
|
| 51 |
+
helpers.build_blending_indices(self.dataset_index,
|
| 52 |
+
self.dataset_sample_index,
|
| 53 |
+
weights, num_datasets, self.size,
|
| 54 |
+
torch.distributed.get_rank() == 0)
|
| 55 |
+
print_rank_0('> elapsed time for building blendable dataset indices: '
|
| 56 |
+
'{:.2f} (sec)'.format(time.time() - start_time))
|
| 57 |
+
|
| 58 |
+
def __len__(self):
|
| 59 |
+
return self.size
|
| 60 |
+
|
| 61 |
+
def __getitem__(self, idx):
|
| 62 |
+
dataset_idx = self.dataset_index[idx]
|
| 63 |
+
sample_idx = self.dataset_sample_index[idx]
|
| 64 |
+
return self.datasets[dataset_idx][sample_idx]
|
fengshen/data/megatron_dataloader/dataset_utils.py
ADDED
|
@@ -0,0 +1,788 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors, and NVIDIA.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# Most of the code here has been copied from:
|
| 18 |
+
# https://github.com/google-research/albert/blob/master/create_pretraining_data.py
|
| 19 |
+
# with some modifications.
|
| 20 |
+
|
| 21 |
+
import math
|
| 22 |
+
import time
|
| 23 |
+
import collections
|
| 24 |
+
|
| 25 |
+
import numpy as np
|
| 26 |
+
import re
|
| 27 |
+
|
| 28 |
+
from fengshen.data.megatron_dataloader.utils import (
|
| 29 |
+
print_rank_0
|
| 30 |
+
)
|
| 31 |
+
from fengshen.data.megatron_dataloader.blendable_dataset import BlendableDataset
|
| 32 |
+
from fengshen.data.megatron_dataloader.indexed_dataset import make_dataset as make_indexed_dataset
|
| 33 |
+
|
| 34 |
+
DSET_TYPE_BERT = 'standard_bert'
|
| 35 |
+
DSET_TYPE_ICT = 'ict'
|
| 36 |
+
DSET_TYPE_T5 = 't5'
|
| 37 |
+
DSET_TYPE_BERT_CN_WWM = 'bert_cn_wwm'
|
| 38 |
+
DSET_TYPE_BART = 'bart'
|
| 39 |
+
DSET_TYPE_COCOLM = 'coco_lm'
|
| 40 |
+
|
| 41 |
+
DSET_TYPES = [DSET_TYPE_BERT, DSET_TYPE_ICT,
|
| 42 |
+
DSET_TYPE_T5, DSET_TYPE_BERT_CN_WWM,
|
| 43 |
+
DSET_TYPE_BART, DSET_TYPE_COCOLM]
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_datasets_weights_and_num_samples(data_prefix,
|
| 47 |
+
train_valid_test_num_samples):
|
| 48 |
+
|
| 49 |
+
# The data prefix should be in the format of:
|
| 50 |
+
# weight-1, data-prefix-1, weight-2, data-prefix-2, ..
|
| 51 |
+
assert len(data_prefix) % 2 == 0
|
| 52 |
+
num_datasets = len(data_prefix) // 2
|
| 53 |
+
weights = [0] * num_datasets
|
| 54 |
+
prefixes = [0] * num_datasets
|
| 55 |
+
for i in range(num_datasets):
|
| 56 |
+
weights[i] = float(data_prefix[2 * i])
|
| 57 |
+
prefixes[i] = (data_prefix[2 * i + 1]).strip()
|
| 58 |
+
# Normalize weights
|
| 59 |
+
weight_sum = 0.0
|
| 60 |
+
for weight in weights:
|
| 61 |
+
weight_sum += weight
|
| 62 |
+
assert weight_sum > 0.0
|
| 63 |
+
weights = [weight / weight_sum for weight in weights]
|
| 64 |
+
|
| 65 |
+
# Add 0.5% (the 1.005 factor) so in case the bleding dataset does
|
| 66 |
+
# not uniformly distribute the number of samples, we still have
|
| 67 |
+
# samples left to feed to the network.
|
| 68 |
+
datasets_train_valid_test_num_samples = []
|
| 69 |
+
for weight in weights:
|
| 70 |
+
datasets_train_valid_test_num_samples.append(
|
| 71 |
+
[int(math.ceil(val * weight * 1.005))
|
| 72 |
+
for val in train_valid_test_num_samples])
|
| 73 |
+
|
| 74 |
+
return prefixes, weights, datasets_train_valid_test_num_samples
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def compile_helper():
|
| 78 |
+
"""Compile helper function ar runtime. Make sure this
|
| 79 |
+
is invoked on a single process."""
|
| 80 |
+
import os
|
| 81 |
+
import subprocess
|
| 82 |
+
path = os.path.abspath(os.path.dirname(__file__))
|
| 83 |
+
ret = subprocess.run(['make', '-C', path])
|
| 84 |
+
if ret.returncode != 0:
|
| 85 |
+
print("Making C++ dataset helpers module failed, exiting.")
|
| 86 |
+
import sys
|
| 87 |
+
sys.exit(1)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def get_a_and_b_segments(sample, np_rng):
|
| 91 |
+
"""Divide sample into a and b segments."""
|
| 92 |
+
|
| 93 |
+
# Number of sentences in the sample.
|
| 94 |
+
n_sentences = len(sample)
|
| 95 |
+
# Make sure we always have two sentences.
|
| 96 |
+
assert n_sentences > 1, 'make sure each sample has at least two sentences.'
|
| 97 |
+
|
| 98 |
+
# First part:
|
| 99 |
+
# `a_end` is how many sentences go into the `A`.
|
| 100 |
+
a_end = 1
|
| 101 |
+
if n_sentences >= 3:
|
| 102 |
+
# Note that randin in numpy is exclusive.
|
| 103 |
+
a_end = np_rng.randint(1, n_sentences)
|
| 104 |
+
tokens_a = []
|
| 105 |
+
for j in range(a_end):
|
| 106 |
+
tokens_a.extend(sample[j])
|
| 107 |
+
|
| 108 |
+
# Second part:
|
| 109 |
+
tokens_b = []
|
| 110 |
+
for j in range(a_end, n_sentences):
|
| 111 |
+
tokens_b.extend(sample[j])
|
| 112 |
+
|
| 113 |
+
# Random next:
|
| 114 |
+
is_next_random = False
|
| 115 |
+
if np_rng.random() < 0.5:
|
| 116 |
+
is_next_random = True
|
| 117 |
+
tokens_a, tokens_b = tokens_b, tokens_a
|
| 118 |
+
|
| 119 |
+
return tokens_a, tokens_b, is_next_random
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def truncate_segments(tokens_a, tokens_b, len_a, len_b, max_num_tokens, np_rng):
|
| 123 |
+
"""Truncates a pair of sequences to a maximum sequence length."""
|
| 124 |
+
# print(len_a, len_b, max_num_tokens)
|
| 125 |
+
assert len_a > 0
|
| 126 |
+
if len_a + len_b <= max_num_tokens:
|
| 127 |
+
return False
|
| 128 |
+
while len_a + len_b > max_num_tokens:
|
| 129 |
+
if len_a > len_b:
|
| 130 |
+
len_a -= 1
|
| 131 |
+
tokens = tokens_a
|
| 132 |
+
else:
|
| 133 |
+
len_b -= 1
|
| 134 |
+
tokens = tokens_b
|
| 135 |
+
if np_rng.random() < 0.5:
|
| 136 |
+
del tokens[0]
|
| 137 |
+
else:
|
| 138 |
+
tokens.pop()
|
| 139 |
+
return True
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def create_tokens_and_tokentypes(tokens_a, tokens_b, cls_id, sep_id):
|
| 143 |
+
"""Merge segments A and B, add [CLS] and [SEP] and build tokentypes."""
|
| 144 |
+
|
| 145 |
+
tokens = []
|
| 146 |
+
tokentypes = []
|
| 147 |
+
# [CLS].
|
| 148 |
+
tokens.append(cls_id)
|
| 149 |
+
tokentypes.append(0)
|
| 150 |
+
# Segment A.
|
| 151 |
+
for token in tokens_a:
|
| 152 |
+
tokens.append(token)
|
| 153 |
+
tokentypes.append(0)
|
| 154 |
+
# [SEP].
|
| 155 |
+
tokens.append(sep_id)
|
| 156 |
+
tokentypes.append(0)
|
| 157 |
+
# Segment B.
|
| 158 |
+
for token in tokens_b:
|
| 159 |
+
tokens.append(token)
|
| 160 |
+
tokentypes.append(1)
|
| 161 |
+
if tokens_b:
|
| 162 |
+
# [SEP].
|
| 163 |
+
tokens.append(sep_id)
|
| 164 |
+
tokentypes.append(1)
|
| 165 |
+
|
| 166 |
+
return tokens, tokentypes
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
MaskedLmInstance = collections.namedtuple("MaskedLmInstance",
|
| 170 |
+
["index", "label"])
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def is_start_piece(piece):
|
| 174 |
+
"""Check if the current word piece is the starting piece (BERT)."""
|
| 175 |
+
# When a word has been split into
|
| 176 |
+
# WordPieces, the first token does not have any marker and any subsequence
|
| 177 |
+
# tokens are prefixed with ##. So whenever we see the ## token, we
|
| 178 |
+
# append it to the previous set of word indexes.
|
| 179 |
+
return not piece.startswith("##")
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
def create_masked_lm_predictions(tokens,
|
| 183 |
+
vocab_id_list, vocab_id_to_token_dict,
|
| 184 |
+
masked_lm_prob,
|
| 185 |
+
cls_id, sep_id, mask_id,
|
| 186 |
+
max_predictions_per_seq,
|
| 187 |
+
np_rng,
|
| 188 |
+
tokenizer,
|
| 189 |
+
max_ngrams=3,
|
| 190 |
+
do_whole_word_mask=True,
|
| 191 |
+
favor_longer_ngram=False,
|
| 192 |
+
do_permutation=False,
|
| 193 |
+
geometric_dist=False,
|
| 194 |
+
masking_style="bert",
|
| 195 |
+
zh_tokenizer=None):
|
| 196 |
+
"""Creates the predictions for the masked LM objective.
|
| 197 |
+
Note: Tokens here are vocab ids and not text tokens."""
|
| 198 |
+
|
| 199 |
+
cand_indexes = []
|
| 200 |
+
# Note(mingdachen): We create a list for recording if the piece is
|
| 201 |
+
# the starting piece of current token, where 1 means true, so that
|
| 202 |
+
# on-the-fly whole word masking is possible.
|
| 203 |
+
token_boundary = [0] * len(tokens)
|
| 204 |
+
|
| 205 |
+
# 如果没有指定中文分词器,那就直接按##算
|
| 206 |
+
if zh_tokenizer is None:
|
| 207 |
+
for (i, token) in enumerate(tokens):
|
| 208 |
+
if token == cls_id or token == sep_id:
|
| 209 |
+
token_boundary[i] = 1
|
| 210 |
+
continue
|
| 211 |
+
# Whole Word Masking means that if we mask all of the wordpieces
|
| 212 |
+
# corresponding to an original word.
|
| 213 |
+
#
|
| 214 |
+
# Note that Whole Word Masking does *not* change the training code
|
| 215 |
+
# at all -- we still predict each WordPiece independently, softmaxed
|
| 216 |
+
# over the entire vocabulary.
|
| 217 |
+
if (do_whole_word_mask and len(cand_indexes) >= 1 and
|
| 218 |
+
not is_start_piece(vocab_id_to_token_dict[token])):
|
| 219 |
+
cand_indexes[-1].append(i)
|
| 220 |
+
else:
|
| 221 |
+
cand_indexes.append([i])
|
| 222 |
+
if is_start_piece(vocab_id_to_token_dict[token]):
|
| 223 |
+
token_boundary[i] = 1
|
| 224 |
+
else:
|
| 225 |
+
# 如果指定了中文分词器,那就先用分词器分词,然后再进行判断
|
| 226 |
+
# 获取去掉CLS SEP的原始文本
|
| 227 |
+
raw_tokens = []
|
| 228 |
+
for t in tokens:
|
| 229 |
+
if t != cls_id and t != sep_id:
|
| 230 |
+
raw_tokens.append(t)
|
| 231 |
+
raw_tokens = [vocab_id_to_token_dict[i] for i in raw_tokens]
|
| 232 |
+
# 分词然后获取每次字开头的最长词的长度
|
| 233 |
+
word_list = set(zh_tokenizer(''.join(raw_tokens), HMM=True))
|
| 234 |
+
word_length_dict = {}
|
| 235 |
+
for w in word_list:
|
| 236 |
+
if len(w) < 1:
|
| 237 |
+
continue
|
| 238 |
+
if w[0] not in word_length_dict:
|
| 239 |
+
word_length_dict[w[0]] = len(w)
|
| 240 |
+
elif word_length_dict[w[0]] < len(w):
|
| 241 |
+
word_length_dict[w[0]] = len(w)
|
| 242 |
+
i = 0
|
| 243 |
+
# 从词表里面检索
|
| 244 |
+
while i < len(tokens):
|
| 245 |
+
token_id = tokens[i]
|
| 246 |
+
token = vocab_id_to_token_dict[token_id]
|
| 247 |
+
if len(token) == 0 or token_id == cls_id or token_id == sep_id:
|
| 248 |
+
token_boundary[i] = 1
|
| 249 |
+
i += 1
|
| 250 |
+
continue
|
| 251 |
+
word_max_length = 1
|
| 252 |
+
if token[0] in word_length_dict:
|
| 253 |
+
word_max_length = word_length_dict[token[0]]
|
| 254 |
+
j = 0
|
| 255 |
+
word = ''
|
| 256 |
+
word_end = i+1
|
| 257 |
+
# 兼容以前##的形式,如果后面的词是##开头的,那么直接把后面的拼到前面当作一个词
|
| 258 |
+
old_style = False
|
| 259 |
+
while word_end < len(tokens) and vocab_id_to_token_dict[tokens[word_end]].startswith('##'):
|
| 260 |
+
old_style = True
|
| 261 |
+
word_end += 1
|
| 262 |
+
if not old_style:
|
| 263 |
+
while j < word_max_length and i+j < len(tokens):
|
| 264 |
+
cur_token = tokens[i+j]
|
| 265 |
+
word += vocab_id_to_token_dict[cur_token]
|
| 266 |
+
j += 1
|
| 267 |
+
if word in word_list:
|
| 268 |
+
word_end = i+j
|
| 269 |
+
cand_indexes.append([p for p in range(i, word_end)])
|
| 270 |
+
token_boundary[i] = 1
|
| 271 |
+
i = word_end
|
| 272 |
+
|
| 273 |
+
output_tokens = list(tokens)
|
| 274 |
+
# add by ganruyi
|
| 275 |
+
if masking_style == 'bert-cn-wwm':
|
| 276 |
+
# if non chinese is False, that means it is chinese
|
| 277 |
+
# then try to remove "##" which is added previously
|
| 278 |
+
new_token_ids = []
|
| 279 |
+
for token_id in output_tokens:
|
| 280 |
+
token = tokenizer.convert_ids_to_tokens([token_id])[0]
|
| 281 |
+
if len(re.findall('##[\u4E00-\u9FA5]', token)) > 0:
|
| 282 |
+
token = token[2:]
|
| 283 |
+
new_token_id = tokenizer.convert_tokens_to_ids([token])[
|
| 284 |
+
0]
|
| 285 |
+
new_token_ids.append(new_token_id)
|
| 286 |
+
output_tokens = new_token_ids
|
| 287 |
+
|
| 288 |
+
masked_lm_positions = []
|
| 289 |
+
masked_lm_labels = []
|
| 290 |
+
|
| 291 |
+
if masked_lm_prob == 0:
|
| 292 |
+
return (output_tokens, masked_lm_positions,
|
| 293 |
+
masked_lm_labels, token_boundary)
|
| 294 |
+
|
| 295 |
+
num_to_predict = min(max_predictions_per_seq,
|
| 296 |
+
max(1, int(round(len(tokens) * masked_lm_prob))))
|
| 297 |
+
|
| 298 |
+
ngrams = np.arange(1, max_ngrams + 1, dtype=np.int64)
|
| 299 |
+
if not geometric_dist:
|
| 300 |
+
# Note(mingdachen):
|
| 301 |
+
# By default, we set the probilities to favor shorter ngram sequences.
|
| 302 |
+
pvals = 1. / np.arange(1, max_ngrams + 1)
|
| 303 |
+
pvals /= pvals.sum(keepdims=True)
|
| 304 |
+
if favor_longer_ngram:
|
| 305 |
+
pvals = pvals[::-1]
|
| 306 |
+
# 获取一个ngram的idx,对于每个word,记录他的ngram的word
|
| 307 |
+
ngram_indexes = []
|
| 308 |
+
for idx in range(len(cand_indexes)):
|
| 309 |
+
ngram_index = []
|
| 310 |
+
for n in ngrams:
|
| 311 |
+
ngram_index.append(cand_indexes[idx:idx + n])
|
| 312 |
+
ngram_indexes.append(ngram_index)
|
| 313 |
+
|
| 314 |
+
np_rng.shuffle(ngram_indexes)
|
| 315 |
+
|
| 316 |
+
(masked_lms, masked_spans) = ([], [])
|
| 317 |
+
covered_indexes = set()
|
| 318 |
+
for cand_index_set in ngram_indexes:
|
| 319 |
+
if len(masked_lms) >= num_to_predict:
|
| 320 |
+
break
|
| 321 |
+
if not cand_index_set:
|
| 322 |
+
continue
|
| 323 |
+
# Note(mingdachen):
|
| 324 |
+
# Skip current piece if they are covered in lm masking or previous ngrams.
|
| 325 |
+
for index_set in cand_index_set[0]:
|
| 326 |
+
for index in index_set:
|
| 327 |
+
if index in covered_indexes:
|
| 328 |
+
continue
|
| 329 |
+
|
| 330 |
+
if not geometric_dist:
|
| 331 |
+
n = np_rng.choice(ngrams[:len(cand_index_set)],
|
| 332 |
+
p=pvals[:len(cand_index_set)] /
|
| 333 |
+
pvals[:len(cand_index_set)].sum(keepdims=True))
|
| 334 |
+
else:
|
| 335 |
+
# Sampling "n" from the geometric distribution and clipping it to
|
| 336 |
+
# the max_ngrams. Using p=0.2 default from the SpanBERT paper
|
| 337 |
+
# https://arxiv.org/pdf/1907.10529.pdf (Sec 3.1)
|
| 338 |
+
n = min(np_rng.geometric(0.2), max_ngrams)
|
| 339 |
+
|
| 340 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 341 |
+
n -= 1
|
| 342 |
+
# Note(mingdachen):
|
| 343 |
+
# Repeatedly looking for a candidate that does not exceed the
|
| 344 |
+
# maximum number of predictions by trying shorter ngrams.
|
| 345 |
+
while len(masked_lms) + len(index_set) > num_to_predict:
|
| 346 |
+
if n == 0:
|
| 347 |
+
break
|
| 348 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 349 |
+
n -= 1
|
| 350 |
+
# If adding a whole-word mask would exceed the maximum number of
|
| 351 |
+
# predictions, then just skip this candidate.
|
| 352 |
+
if len(masked_lms) + len(index_set) > num_to_predict:
|
| 353 |
+
continue
|
| 354 |
+
is_any_index_covered = False
|
| 355 |
+
for index in index_set:
|
| 356 |
+
if index in covered_indexes:
|
| 357 |
+
is_any_index_covered = True
|
| 358 |
+
break
|
| 359 |
+
if is_any_index_covered:
|
| 360 |
+
continue
|
| 361 |
+
for index in index_set:
|
| 362 |
+
covered_indexes.add(index)
|
| 363 |
+
masked_token = None
|
| 364 |
+
if masking_style == "bert":
|
| 365 |
+
# 80% of the time, replace with [MASK]
|
| 366 |
+
if np_rng.random() < 0.8:
|
| 367 |
+
masked_token = mask_id
|
| 368 |
+
else:
|
| 369 |
+
# 10% of the time, keep original
|
| 370 |
+
if np_rng.random() < 0.5:
|
| 371 |
+
masked_token = tokens[index]
|
| 372 |
+
# 10% of the time, replace with random word
|
| 373 |
+
else:
|
| 374 |
+
masked_token = vocab_id_list[np_rng.randint(0, len(vocab_id_list))]
|
| 375 |
+
elif masking_style == 'bert-cn-wwm':
|
| 376 |
+
# 80% of the time, replace with [MASK]
|
| 377 |
+
if np_rng.random() < 0.8:
|
| 378 |
+
masked_token = mask_id
|
| 379 |
+
else:
|
| 380 |
+
# 10% of the time, keep original
|
| 381 |
+
if np_rng.random() < 0.5:
|
| 382 |
+
# 如果是中文全词mask,去掉tokens里的##
|
| 383 |
+
token_id = tokens[index]
|
| 384 |
+
token = tokenizer.convert_ids_to_tokens([token_id])[
|
| 385 |
+
0]
|
| 386 |
+
if len(re.findall('##[\u4E00-\u9FA5]', token)) > 0:
|
| 387 |
+
token = token[2:]
|
| 388 |
+
new_token_id = tokenizer.convert_tokens_to_ids([token])[
|
| 389 |
+
0]
|
| 390 |
+
masked_token = new_token_id
|
| 391 |
+
# 10% of the time, replace with random word
|
| 392 |
+
else:
|
| 393 |
+
masked_token = vocab_id_list[np_rng.randint(
|
| 394 |
+
0, len(vocab_id_list))]
|
| 395 |
+
elif masking_style == "t5":
|
| 396 |
+
masked_token = mask_id
|
| 397 |
+
else:
|
| 398 |
+
raise ValueError("invalid value of masking style")
|
| 399 |
+
|
| 400 |
+
output_tokens[index] = masked_token
|
| 401 |
+
masked_lms.append(MaskedLmInstance(
|
| 402 |
+
index=index, label=tokens[index]))
|
| 403 |
+
|
| 404 |
+
masked_spans.append(MaskedLmInstance(
|
| 405 |
+
index=index_set,
|
| 406 |
+
label=[tokens[index] for index in index_set]))
|
| 407 |
+
|
| 408 |
+
assert len(masked_lms) <= num_to_predict
|
| 409 |
+
np_rng.shuffle(ngram_indexes)
|
| 410 |
+
|
| 411 |
+
select_indexes = set()
|
| 412 |
+
if do_permutation:
|
| 413 |
+
for cand_index_set in ngram_indexes:
|
| 414 |
+
if len(select_indexes) >= num_to_predict:
|
| 415 |
+
break
|
| 416 |
+
if not cand_index_set:
|
| 417 |
+
continue
|
| 418 |
+
# Note(mingdachen):
|
| 419 |
+
# Skip current piece if they are covered in lm masking or previous ngrams.
|
| 420 |
+
for index_set in cand_index_set[0]:
|
| 421 |
+
for index in index_set:
|
| 422 |
+
if index in covered_indexes or index in select_indexes:
|
| 423 |
+
continue
|
| 424 |
+
|
| 425 |
+
n = np.random.choice(ngrams[:len(cand_index_set)],
|
| 426 |
+
p=pvals[:len(cand_index_set)] /
|
| 427 |
+
pvals[:len(cand_index_set)].sum(keepdims=True))
|
| 428 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 429 |
+
n -= 1
|
| 430 |
+
|
| 431 |
+
while len(select_indexes) + len(index_set) > num_to_predict:
|
| 432 |
+
if n == 0:
|
| 433 |
+
break
|
| 434 |
+
index_set = sum(cand_index_set[n - 1], [])
|
| 435 |
+
n -= 1
|
| 436 |
+
# If adding a whole-word mask would exceed the maximum number of
|
| 437 |
+
# predictions, then just skip this candidate.
|
| 438 |
+
if len(select_indexes) + len(index_set) > num_to_predict:
|
| 439 |
+
continue
|
| 440 |
+
is_any_index_covered = False
|
| 441 |
+
for index in index_set:
|
| 442 |
+
if index in covered_indexes or index in select_indexes:
|
| 443 |
+
is_any_index_covered = True
|
| 444 |
+
break
|
| 445 |
+
if is_any_index_covered:
|
| 446 |
+
continue
|
| 447 |
+
for index in index_set:
|
| 448 |
+
select_indexes.add(index)
|
| 449 |
+
assert len(select_indexes) <= num_to_predict
|
| 450 |
+
|
| 451 |
+
select_indexes = sorted(select_indexes)
|
| 452 |
+
permute_indexes = list(select_indexes)
|
| 453 |
+
np_rng.shuffle(permute_indexes)
|
| 454 |
+
orig_token = list(output_tokens)
|
| 455 |
+
|
| 456 |
+
for src_i, tgt_i in zip(select_indexes, permute_indexes):
|
| 457 |
+
output_tokens[src_i] = orig_token[tgt_i]
|
| 458 |
+
masked_lms.append(MaskedLmInstance(
|
| 459 |
+
index=src_i, label=orig_token[src_i]))
|
| 460 |
+
|
| 461 |
+
masked_lms = sorted(masked_lms, key=lambda x: x.index)
|
| 462 |
+
# Sort the spans by the index of the first span
|
| 463 |
+
masked_spans = sorted(masked_spans, key=lambda x: x.index[0])
|
| 464 |
+
|
| 465 |
+
for p in masked_lms:
|
| 466 |
+
masked_lm_positions.append(p.index)
|
| 467 |
+
masked_lm_labels.append(p.label)
|
| 468 |
+
return (output_tokens, masked_lm_positions, masked_lm_labels, token_boundary, masked_spans)
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
def pad_and_convert_to_numpy(tokens, tokentypes, masked_positions,
|
| 472 |
+
masked_labels, pad_id, max_seq_length):
|
| 473 |
+
"""Pad sequences and convert them to numpy."""
|
| 474 |
+
|
| 475 |
+
# Some checks.
|
| 476 |
+
num_tokens = len(tokens)
|
| 477 |
+
padding_length = max_seq_length - num_tokens
|
| 478 |
+
assert padding_length >= 0
|
| 479 |
+
assert len(tokentypes) == num_tokens
|
| 480 |
+
assert len(masked_positions) == len(masked_labels)
|
| 481 |
+
|
| 482 |
+
# Tokens and token types.
|
| 483 |
+
filler = [pad_id] * padding_length
|
| 484 |
+
tokens_np = np.array(tokens + filler, dtype=np.int64)
|
| 485 |
+
tokentypes_np = np.array(tokentypes + filler, dtype=np.int64)
|
| 486 |
+
|
| 487 |
+
# Padding mask.
|
| 488 |
+
padding_mask_np = np.array([1] * num_tokens + [0] * padding_length,
|
| 489 |
+
dtype=np.int64)
|
| 490 |
+
|
| 491 |
+
# Lables and loss mask.
|
| 492 |
+
labels = [-1] * max_seq_length
|
| 493 |
+
loss_mask = [0] * max_seq_length
|
| 494 |
+
for i in range(len(masked_positions)):
|
| 495 |
+
assert masked_positions[i] < num_tokens
|
| 496 |
+
labels[masked_positions[i]] = masked_labels[i]
|
| 497 |
+
loss_mask[masked_positions[i]] = 1
|
| 498 |
+
labels_np = np.array(labels, dtype=np.int64)
|
| 499 |
+
loss_mask_np = np.array(loss_mask, dtype=np.int64)
|
| 500 |
+
|
| 501 |
+
return tokens_np, tokentypes_np, labels_np, padding_mask_np, loss_mask_np
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
def build_train_valid_test_datasets(data_prefix, data_impl, splits_string,
|
| 505 |
+
train_valid_test_num_samples,
|
| 506 |
+
max_seq_length,
|
| 507 |
+
masked_lm_prob, short_seq_prob, seed,
|
| 508 |
+
tokenizer,
|
| 509 |
+
skip_warmup, binary_head=False,
|
| 510 |
+
max_seq_length_dec=None,
|
| 511 |
+
dataset_type='standard_bert',
|
| 512 |
+
zh_tokenizer=None,
|
| 513 |
+
span=None):
|
| 514 |
+
|
| 515 |
+
if len(data_prefix) == 1:
|
| 516 |
+
return _build_train_valid_test_datasets(data_prefix[0],
|
| 517 |
+
data_impl, splits_string,
|
| 518 |
+
train_valid_test_num_samples,
|
| 519 |
+
max_seq_length, masked_lm_prob,
|
| 520 |
+
short_seq_prob, seed,
|
| 521 |
+
skip_warmup,
|
| 522 |
+
binary_head,
|
| 523 |
+
max_seq_length_dec,
|
| 524 |
+
tokenizer,
|
| 525 |
+
dataset_type=dataset_type,
|
| 526 |
+
zh_tokenizer=zh_tokenizer,
|
| 527 |
+
span=span)
|
| 528 |
+
# Blending dataset.
|
| 529 |
+
# Parse the values.
|
| 530 |
+
output = get_datasets_weights_and_num_samples(data_prefix,
|
| 531 |
+
train_valid_test_num_samples)
|
| 532 |
+
prefixes, weights, datasets_train_valid_test_num_samples = output
|
| 533 |
+
|
| 534 |
+
# Build individual datasets.
|
| 535 |
+
train_datasets = []
|
| 536 |
+
valid_datasets = []
|
| 537 |
+
test_datasets = []
|
| 538 |
+
for i in range(len(prefixes)):
|
| 539 |
+
train_ds, valid_ds, test_ds = _build_train_valid_test_datasets(
|
| 540 |
+
prefixes[i], data_impl, splits_string,
|
| 541 |
+
datasets_train_valid_test_num_samples[i],
|
| 542 |
+
max_seq_length, masked_lm_prob, short_seq_prob,
|
| 543 |
+
seed, skip_warmup, binary_head, max_seq_length_dec,
|
| 544 |
+
tokenizer, dataset_type=dataset_type, zh_tokenizer=zh_tokenizer)
|
| 545 |
+
if train_ds:
|
| 546 |
+
train_datasets.append(train_ds)
|
| 547 |
+
if valid_ds:
|
| 548 |
+
valid_datasets.append(valid_ds)
|
| 549 |
+
if test_ds:
|
| 550 |
+
test_datasets.append(test_ds)
|
| 551 |
+
|
| 552 |
+
# Blend.
|
| 553 |
+
blending_train_dataset = None
|
| 554 |
+
if train_datasets:
|
| 555 |
+
blending_train_dataset = BlendableDataset(train_datasets, weights)
|
| 556 |
+
blending_valid_dataset = None
|
| 557 |
+
if valid_datasets:
|
| 558 |
+
blending_valid_dataset = BlendableDataset(valid_datasets, weights)
|
| 559 |
+
blending_test_dataset = None
|
| 560 |
+
if test_datasets:
|
| 561 |
+
blending_test_dataset = BlendableDataset(test_datasets, weights)
|
| 562 |
+
|
| 563 |
+
return (blending_train_dataset, blending_valid_dataset,
|
| 564 |
+
blending_test_dataset)
|
| 565 |
+
|
| 566 |
+
|
| 567 |
+
def _build_train_valid_test_datasets(data_prefix, data_impl, splits_string,
|
| 568 |
+
train_valid_test_num_samples,
|
| 569 |
+
max_seq_length,
|
| 570 |
+
masked_lm_prob, short_seq_prob, seed,
|
| 571 |
+
skip_warmup, binary_head,
|
| 572 |
+
max_seq_length_dec,
|
| 573 |
+
tokenizer,
|
| 574 |
+
dataset_type='standard_bert',
|
| 575 |
+
zh_tokenizer=None,
|
| 576 |
+
span=None):
|
| 577 |
+
|
| 578 |
+
if dataset_type not in DSET_TYPES:
|
| 579 |
+
raise ValueError("Invalid dataset_type: ", dataset_type)
|
| 580 |
+
|
| 581 |
+
# Indexed dataset.
|
| 582 |
+
indexed_dataset = get_indexed_dataset_(data_prefix,
|
| 583 |
+
data_impl,
|
| 584 |
+
skip_warmup)
|
| 585 |
+
|
| 586 |
+
# Get start and end indices of train/valid/train into doc-idx
|
| 587 |
+
# Note that doc-idx is desinged to be num-docs + 1 so we can
|
| 588 |
+
# easily iterate over it.
|
| 589 |
+
total_num_of_documents = indexed_dataset.doc_idx.shape[0] - 1
|
| 590 |
+
splits = get_train_valid_test_split_(splits_string, total_num_of_documents)
|
| 591 |
+
|
| 592 |
+
# Print stats about the splits.
|
| 593 |
+
print_rank_0(' > dataset split:')
|
| 594 |
+
|
| 595 |
+
def print_split_stats(name, index):
|
| 596 |
+
print_rank_0(' {}:'.format(name))
|
| 597 |
+
print_rank_0(' document indices in [{}, {}) total of {} '
|
| 598 |
+
'documents'.format(splits[index], splits[index + 1],
|
| 599 |
+
splits[index + 1] - splits[index]))
|
| 600 |
+
start_index = indexed_dataset.doc_idx[splits[index]]
|
| 601 |
+
end_index = indexed_dataset.doc_idx[splits[index + 1]]
|
| 602 |
+
print_rank_0(' sentence indices in [{}, {}) total of {} '
|
| 603 |
+
'sentences'.format(start_index, end_index,
|
| 604 |
+
end_index - start_index))
|
| 605 |
+
print_split_stats('train', 0)
|
| 606 |
+
print_split_stats('validation', 1)
|
| 607 |
+
print_split_stats('test', 2)
|
| 608 |
+
|
| 609 |
+
def build_dataset(index, name):
|
| 610 |
+
from fengshen.data.megatron_dataloader.bert_dataset import BertDataset
|
| 611 |
+
from fengshen.data.megatron_dataloader.bart_dataset import BartDataset
|
| 612 |
+
from fengshen.data.megatron_dataloader.cocolm_dataset import COCOLMDataset
|
| 613 |
+
dataset = None
|
| 614 |
+
if splits[index + 1] > splits[index]:
|
| 615 |
+
# Get the pointer to the original doc-idx so we can set it later.
|
| 616 |
+
doc_idx_ptr = indexed_dataset.get_doc_idx()
|
| 617 |
+
# Slice the doc-idx
|
| 618 |
+
start_index = splits[index]
|
| 619 |
+
# Add +1 so we can index into the dataset to get the upper bound.
|
| 620 |
+
end_index = splits[index + 1] + 1
|
| 621 |
+
# New doc_idx view.
|
| 622 |
+
indexed_dataset.set_doc_idx(doc_idx_ptr[start_index:end_index])
|
| 623 |
+
# Build the dataset accordingly.
|
| 624 |
+
kwargs = dict(
|
| 625 |
+
name=name,
|
| 626 |
+
data_prefix=data_prefix,
|
| 627 |
+
num_epochs=None,
|
| 628 |
+
max_num_samples=train_valid_test_num_samples[index],
|
| 629 |
+
max_seq_length=max_seq_length,
|
| 630 |
+
seed=seed,
|
| 631 |
+
)
|
| 632 |
+
|
| 633 |
+
if dataset_type == DSET_TYPE_BERT or dataset_type == DSET_TYPE_BERT_CN_WWM:
|
| 634 |
+
dataset = BertDataset(
|
| 635 |
+
indexed_dataset=indexed_dataset,
|
| 636 |
+
masked_lm_prob=masked_lm_prob,
|
| 637 |
+
short_seq_prob=short_seq_prob,
|
| 638 |
+
binary_head=binary_head,
|
| 639 |
+
# 增加参数区分bert和bert-cn-wwm
|
| 640 |
+
tokenizer=tokenizer,
|
| 641 |
+
masking_style='bert' if dataset_type == DSET_TYPE_BERT else 'bert-cn-wwm',
|
| 642 |
+
**kwargs
|
| 643 |
+
)
|
| 644 |
+
elif dataset_type == DSET_TYPE_BART:
|
| 645 |
+
dataset = BartDataset(
|
| 646 |
+
indexed_dataset=indexed_dataset,
|
| 647 |
+
masked_lm_prob=masked_lm_prob,
|
| 648 |
+
short_seq_prob=short_seq_prob,
|
| 649 |
+
tokenizer=tokenizer,
|
| 650 |
+
zh_tokenizer=zh_tokenizer,
|
| 651 |
+
**kwargs
|
| 652 |
+
)
|
| 653 |
+
elif dataset_type == DSET_TYPE_COCOLM:
|
| 654 |
+
dataset = COCOLMDataset(
|
| 655 |
+
indexed_dataset=indexed_dataset,
|
| 656 |
+
masked_lm_prob=masked_lm_prob,
|
| 657 |
+
short_seq_prob=short_seq_prob,
|
| 658 |
+
tokenizer=tokenizer,
|
| 659 |
+
masking_style='bert',
|
| 660 |
+
span=span,
|
| 661 |
+
**kwargs
|
| 662 |
+
)
|
| 663 |
+
else:
|
| 664 |
+
raise NotImplementedError(
|
| 665 |
+
"Dataset type not fully implemented.")
|
| 666 |
+
|
| 667 |
+
# Set the original pointer so dataset remains the main dataset.
|
| 668 |
+
indexed_dataset.set_doc_idx(doc_idx_ptr)
|
| 669 |
+
# Checks.
|
| 670 |
+
assert indexed_dataset.doc_idx[0] == 0
|
| 671 |
+
assert indexed_dataset.doc_idx.shape[0] == \
|
| 672 |
+
(total_num_of_documents + 1)
|
| 673 |
+
return dataset
|
| 674 |
+
|
| 675 |
+
train_dataset = build_dataset(0, 'train')
|
| 676 |
+
valid_dataset = build_dataset(1, 'valid')
|
| 677 |
+
test_dataset = build_dataset(2, 'test')
|
| 678 |
+
|
| 679 |
+
return (train_dataset, valid_dataset, test_dataset)
|
| 680 |
+
|
| 681 |
+
|
| 682 |
+
def get_indexed_dataset_(data_prefix, data_impl, skip_warmup):
|
| 683 |
+
|
| 684 |
+
print_rank_0(' > building dataset index ...')
|
| 685 |
+
|
| 686 |
+
start_time = time.time()
|
| 687 |
+
indexed_dataset = make_indexed_dataset(data_prefix,
|
| 688 |
+
data_impl,
|
| 689 |
+
skip_warmup)
|
| 690 |
+
assert indexed_dataset.sizes.shape[0] == indexed_dataset.doc_idx[-1]
|
| 691 |
+
print_rank_0(' > finished creating indexed dataset in {:4f} '
|
| 692 |
+
'seconds'.format(time.time() - start_time))
|
| 693 |
+
|
| 694 |
+
print_rank_0(' > indexed dataset stats:')
|
| 695 |
+
print_rank_0(' number of documents: {}'.format(
|
| 696 |
+
indexed_dataset.doc_idx.shape[0] - 1))
|
| 697 |
+
print_rank_0(' number of sentences: {}'.format(
|
| 698 |
+
indexed_dataset.sizes.shape[0]))
|
| 699 |
+
|
| 700 |
+
return indexed_dataset
|
| 701 |
+
|
| 702 |
+
|
| 703 |
+
def get_train_valid_test_split_(splits_string, size):
|
| 704 |
+
""" Get dataset splits from comma or '/' separated string list."""
|
| 705 |
+
|
| 706 |
+
splits = []
|
| 707 |
+
if splits_string.find(',') != -1:
|
| 708 |
+
splits = [float(s) for s in splits_string.split(',')]
|
| 709 |
+
elif splits_string.find('/') != -1:
|
| 710 |
+
splits = [float(s) for s in splits_string.split('/')]
|
| 711 |
+
else:
|
| 712 |
+
splits = [float(splits_string)]
|
| 713 |
+
while len(splits) < 3:
|
| 714 |
+
splits.append(0.)
|
| 715 |
+
splits = splits[:3]
|
| 716 |
+
splits_sum = sum(splits)
|
| 717 |
+
assert splits_sum > 0.0
|
| 718 |
+
splits = [split / splits_sum for split in splits]
|
| 719 |
+
splits_index = [0]
|
| 720 |
+
for index, split in enumerate(splits):
|
| 721 |
+
splits_index.append(splits_index[index] +
|
| 722 |
+
int(round(split * float(size))))
|
| 723 |
+
diff = splits_index[-1] - size
|
| 724 |
+
for index in range(1, len(splits_index)):
|
| 725 |
+
splits_index[index] -= diff
|
| 726 |
+
assert len(splits_index) == 4
|
| 727 |
+
assert splits_index[-1] == size
|
| 728 |
+
return splits_index
|
| 729 |
+
|
| 730 |
+
|
| 731 |
+
def get_samples_mapping(indexed_dataset,
|
| 732 |
+
data_prefix,
|
| 733 |
+
num_epochs,
|
| 734 |
+
max_num_samples,
|
| 735 |
+
max_seq_length,
|
| 736 |
+
short_seq_prob,
|
| 737 |
+
seed,
|
| 738 |
+
name,
|
| 739 |
+
binary_head):
|
| 740 |
+
"""Get a list that maps a sample index to a starting
|
| 741 |
+
sentence index, end sentence index, and length"""
|
| 742 |
+
|
| 743 |
+
if not num_epochs:
|
| 744 |
+
if not max_num_samples:
|
| 745 |
+
raise ValueError("Need to specify either max_num_samples "
|
| 746 |
+
"or num_epochs")
|
| 747 |
+
num_epochs = np.iinfo(np.int32).max - 1
|
| 748 |
+
if not max_num_samples:
|
| 749 |
+
max_num_samples = np.iinfo(np.int64).max - 1
|
| 750 |
+
|
| 751 |
+
# Filename of the index mapping
|
| 752 |
+
indexmap_filename = data_prefix
|
| 753 |
+
indexmap_filename += '_{}_indexmap'.format(name)
|
| 754 |
+
if num_epochs != (np.iinfo(np.int32).max - 1):
|
| 755 |
+
indexmap_filename += '_{}ep'.format(num_epochs)
|
| 756 |
+
if max_num_samples != (np.iinfo(np.int64).max - 1):
|
| 757 |
+
indexmap_filename += '_{}mns'.format(max_num_samples)
|
| 758 |
+
indexmap_filename += '_{}msl'.format(max_seq_length)
|
| 759 |
+
indexmap_filename += '_{:0.2f}ssp'.format(short_seq_prob)
|
| 760 |
+
indexmap_filename += '_{}s'.format(seed)
|
| 761 |
+
indexmap_filename += '.npy'
|
| 762 |
+
|
| 763 |
+
# This should be a barrier but nccl barrier assumes
|
| 764 |
+
# device_index=rank which is not the case for model
|
| 765 |
+
# parallel case
|
| 766 |
+
# ganruyi comment
|
| 767 |
+
# counts = torch.cuda.LongTensor([1])
|
| 768 |
+
# torch.distributed.all_reduce(
|
| 769 |
+
# counts, group=mpu.get_data_parallel_group())
|
| 770 |
+
# torch.distributed.all_reduce(
|
| 771 |
+
# counts, group=mpu.get_pipeline_model_parallel_group())
|
| 772 |
+
# assert counts[0].item() == (
|
| 773 |
+
# torch.distributed.get_world_size() //
|
| 774 |
+
# torch.distributed.get_world_size(
|
| 775 |
+
# group=mpu.get_tensor_model_parallel_group()))
|
| 776 |
+
|
| 777 |
+
# Load indexed dataset.
|
| 778 |
+
print_rank_0(' > loading indexed mapping from {}'.format(
|
| 779 |
+
indexmap_filename))
|
| 780 |
+
start_time = time.time()
|
| 781 |
+
samples_mapping = np.load(
|
| 782 |
+
indexmap_filename, allow_pickle=True, mmap_mode='r')
|
| 783 |
+
print_rank_0(' loaded indexed file in {:3.3f} seconds'.format(
|
| 784 |
+
time.time() - start_time))
|
| 785 |
+
print_rank_0(' total number of samples: {}'.format(
|
| 786 |
+
samples_mapping.shape[0]))
|
| 787 |
+
|
| 788 |
+
return samples_mapping
|
fengshen/data/megatron_dataloader/helpers.cpp
ADDED
|
@@ -0,0 +1,794 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
coding=utf-8
|
| 3 |
+
Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
|
| 5 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
you may not use this file except in compliance with the License.
|
| 7 |
+
You may obtain a copy of the License at
|
| 8 |
+
|
| 9 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
|
| 11 |
+
Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
See the License for the specific language governing permissions and
|
| 15 |
+
limitations under the License.
|
| 16 |
+
*/
|
| 17 |
+
|
| 18 |
+
/* Helper methods for fast index mapping builds */
|
| 19 |
+
|
| 20 |
+
#include <algorithm>
|
| 21 |
+
#include <iostream>
|
| 22 |
+
#include <limits>
|
| 23 |
+
#include <math.h>
|
| 24 |
+
#include <stdexcept>
|
| 25 |
+
#include <pybind11/pybind11.h>
|
| 26 |
+
#include <pybind11/numpy.h>
|
| 27 |
+
#include <random>
|
| 28 |
+
|
| 29 |
+
namespace py = pybind11;
|
| 30 |
+
using namespace std;
|
| 31 |
+
|
| 32 |
+
const int32_t LONG_SENTENCE_LEN = 512;
|
| 33 |
+
|
| 34 |
+
void build_blending_indices(py::array_t<uint8_t> &dataset_index,
|
| 35 |
+
py::array_t<int64_t> &dataset_sample_index,
|
| 36 |
+
const py::array_t<double> &weights,
|
| 37 |
+
const int32_t num_datasets,
|
| 38 |
+
const int64_t size, const bool verbose)
|
| 39 |
+
{
|
| 40 |
+
/* Given multiple datasets and a weighting array, build samples
|
| 41 |
+
such that it follows those wieghts.*/
|
| 42 |
+
|
| 43 |
+
if (verbose)
|
| 44 |
+
{
|
| 45 |
+
std::cout << "> building indices for blendable datasets ..." << std::endl;
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
// Get the pointer access without the checks.
|
| 49 |
+
auto dataset_index_ptr = dataset_index.mutable_unchecked<1>();
|
| 50 |
+
auto dataset_sample_index_ptr = dataset_sample_index.mutable_unchecked<1>();
|
| 51 |
+
auto weights_ptr = weights.unchecked<1>();
|
| 52 |
+
|
| 53 |
+
// Initialize buffer for number of samples used for each dataset.
|
| 54 |
+
int64_t current_samples[num_datasets];
|
| 55 |
+
for (int64_t i = 0; i < num_datasets; ++i)
|
| 56 |
+
{
|
| 57 |
+
current_samples[i] = 0;
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
// For each sample:
|
| 61 |
+
for (int64_t sample_idx = 0; sample_idx < size; ++sample_idx)
|
| 62 |
+
{
|
| 63 |
+
|
| 64 |
+
// Determine where the max error in sampling is happening.
|
| 65 |
+
auto sample_idx_double = std::max(static_cast<double>(sample_idx), 1.0);
|
| 66 |
+
int64_t max_error_index = 0;
|
| 67 |
+
double max_error = weights_ptr[0] * sample_idx_double -
|
| 68 |
+
static_cast<double>(current_samples[0]);
|
| 69 |
+
for (int64_t dataset_idx = 1; dataset_idx < num_datasets; ++dataset_idx)
|
| 70 |
+
{
|
| 71 |
+
double error = weights_ptr[dataset_idx] * sample_idx_double -
|
| 72 |
+
static_cast<double>(current_samples[dataset_idx]);
|
| 73 |
+
if (error > max_error)
|
| 74 |
+
{
|
| 75 |
+
max_error = error;
|
| 76 |
+
max_error_index = dataset_idx;
|
| 77 |
+
}
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
// Populate the indices.
|
| 81 |
+
dataset_index_ptr[sample_idx] = static_cast<uint8_t>(max_error_index);
|
| 82 |
+
dataset_sample_index_ptr[sample_idx] = current_samples[max_error_index];
|
| 83 |
+
|
| 84 |
+
// Update the total samples.
|
| 85 |
+
current_samples[max_error_index] += 1;
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
// print info
|
| 89 |
+
if (verbose)
|
| 90 |
+
{
|
| 91 |
+
std::cout << " > sample ratios:" << std::endl;
|
| 92 |
+
for (int64_t dataset_idx = 0; dataset_idx < num_datasets; ++dataset_idx)
|
| 93 |
+
{
|
| 94 |
+
auto ratio = static_cast<double>(current_samples[dataset_idx]) /
|
| 95 |
+
static_cast<double>(size);
|
| 96 |
+
std::cout << " dataset " << dataset_idx << ", input: " << weights_ptr[dataset_idx] << ", achieved: " << ratio << std::endl;
|
| 97 |
+
}
|
| 98 |
+
}
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
py::array build_sample_idx(const py::array_t<int32_t> &sizes_,
|
| 102 |
+
const py::array_t<int32_t> &doc_idx_,
|
| 103 |
+
const int32_t seq_length,
|
| 104 |
+
const int32_t num_epochs,
|
| 105 |
+
const int64_t tokens_per_epoch)
|
| 106 |
+
{
|
| 107 |
+
/* Sample index (sample_idx) is used for gpt2 like dataset for which
|
| 108 |
+
the documents are flattened and the samples are built based on this
|
| 109 |
+
1-D flatten array. It is a 2D array with sizes [number-of-samples + 1, 2]
|
| 110 |
+
where [..., 0] contains the index into `doc_idx` and [..., 1] is the
|
| 111 |
+
starting offset in that document.*/
|
| 112 |
+
|
| 113 |
+
// Consistency checks.
|
| 114 |
+
assert(seq_length > 1);
|
| 115 |
+
assert(num_epochs > 0);
|
| 116 |
+
assert(tokens_per_epoch > 1);
|
| 117 |
+
|
| 118 |
+
// Remove bound checks.
|
| 119 |
+
auto sizes = sizes_.unchecked<1>();
|
| 120 |
+
auto doc_idx = doc_idx_.unchecked<1>();
|
| 121 |
+
|
| 122 |
+
// Mapping and it's length (1D).
|
| 123 |
+
int64_t num_samples = (num_epochs * tokens_per_epoch - 1) / seq_length;
|
| 124 |
+
int32_t *sample_idx = new int32_t[2 * (num_samples + 1)];
|
| 125 |
+
|
| 126 |
+
cout << " using:" << endl
|
| 127 |
+
<< std::flush;
|
| 128 |
+
cout << " number of documents: " << doc_idx_.shape(0) / num_epochs << endl
|
| 129 |
+
<< std::flush;
|
| 130 |
+
cout << " number of epochs: " << num_epochs << endl
|
| 131 |
+
<< std::flush;
|
| 132 |
+
cout << " sequence length: " << seq_length << endl
|
| 133 |
+
<< std::flush;
|
| 134 |
+
cout << " total number of samples: " << num_samples << endl
|
| 135 |
+
<< std::flush;
|
| 136 |
+
|
| 137 |
+
// Index into sample_idx.
|
| 138 |
+
int64_t sample_index = 0;
|
| 139 |
+
// Index into doc_idx.
|
| 140 |
+
int64_t doc_idx_index = 0;
|
| 141 |
+
// Begining offset for each document.
|
| 142 |
+
int32_t doc_offset = 0;
|
| 143 |
+
// Start with first document and no offset.
|
| 144 |
+
sample_idx[2 * sample_index] = doc_idx_index;
|
| 145 |
+
sample_idx[2 * sample_index + 1] = doc_offset;
|
| 146 |
+
++sample_index;
|
| 147 |
+
|
| 148 |
+
while (sample_index <= num_samples)
|
| 149 |
+
{
|
| 150 |
+
// Start with a fresh sequence.
|
| 151 |
+
int32_t remaining_seq_length = seq_length + 1;
|
| 152 |
+
while (remaining_seq_length != 0)
|
| 153 |
+
{
|
| 154 |
+
// Get the document length.
|
| 155 |
+
auto doc_id = doc_idx[doc_idx_index];
|
| 156 |
+
auto doc_length = sizes[doc_id] - doc_offset;
|
| 157 |
+
// And add it to the current sequence.
|
| 158 |
+
remaining_seq_length -= doc_length;
|
| 159 |
+
// If we have more than a full sequence, adjust offset and set
|
| 160 |
+
// remaining length to zero so we return from the while loop.
|
| 161 |
+
// Note that -1 here is for the same reason we have -1 in
|
| 162 |
+
// `_num_epochs` calculations.
|
| 163 |
+
if (remaining_seq_length <= 0)
|
| 164 |
+
{
|
| 165 |
+
doc_offset += (remaining_seq_length + doc_length - 1);
|
| 166 |
+
remaining_seq_length = 0;
|
| 167 |
+
}
|
| 168 |
+
else
|
| 169 |
+
{
|
| 170 |
+
// Otherwise, start from the begining of the next document.
|
| 171 |
+
++doc_idx_index;
|
| 172 |
+
doc_offset = 0;
|
| 173 |
+
}
|
| 174 |
+
}
|
| 175 |
+
// Record the sequence.
|
| 176 |
+
sample_idx[2 * sample_index] = doc_idx_index;
|
| 177 |
+
sample_idx[2 * sample_index + 1] = doc_offset;
|
| 178 |
+
++sample_index;
|
| 179 |
+
}
|
| 180 |
+
|
| 181 |
+
// Method to deallocate memory.
|
| 182 |
+
py::capsule free_when_done(sample_idx, [](void *mem_)
|
| 183 |
+
{
|
| 184 |
+
int32_t *mem = reinterpret_cast<int32_t *>(mem_);
|
| 185 |
+
delete[] mem;
|
| 186 |
+
});
|
| 187 |
+
|
| 188 |
+
// Return the numpy array.
|
| 189 |
+
const auto byte_size = sizeof(int32_t);
|
| 190 |
+
return py::array(std::vector<int64_t>{num_samples + 1, 2}, // shape
|
| 191 |
+
{2 * byte_size, byte_size}, // C-style contiguous strides
|
| 192 |
+
sample_idx, // the data pointer
|
| 193 |
+
free_when_done); // numpy array references
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
inline int32_t get_target_sample_len(const int32_t short_seq_ratio,
|
| 197 |
+
const int32_t max_length,
|
| 198 |
+
std::mt19937 &rand32_gen)
|
| 199 |
+
{
|
| 200 |
+
/* Training sample length. */
|
| 201 |
+
if (short_seq_ratio == 0)
|
| 202 |
+
{
|
| 203 |
+
return max_length;
|
| 204 |
+
}
|
| 205 |
+
const auto random_number = rand32_gen();
|
| 206 |
+
if ((random_number % short_seq_ratio) == 0)
|
| 207 |
+
{
|
| 208 |
+
return 2 + random_number % (max_length - 1);
|
| 209 |
+
}
|
| 210 |
+
return max_length;
|
| 211 |
+
}
|
| 212 |
+
|
| 213 |
+
template <typename DocIdx>
|
| 214 |
+
py::array build_mapping_impl(const py::array_t<int64_t> &docs_,
|
| 215 |
+
const py::array_t<int32_t> &sizes_,
|
| 216 |
+
const int32_t num_epochs,
|
| 217 |
+
const uint64_t max_num_samples,
|
| 218 |
+
const int32_t max_seq_length,
|
| 219 |
+
const double short_seq_prob,
|
| 220 |
+
const int32_t seed,
|
| 221 |
+
const bool verbose,
|
| 222 |
+
const int32_t min_num_sent)
|
| 223 |
+
{
|
| 224 |
+
/* Build a mapping of (start-index, end-index, sequence-length) where
|
| 225 |
+
start and end index are the indices of the sentences in the sample
|
| 226 |
+
and sequence-length is the target sequence length.
|
| 227 |
+
*/
|
| 228 |
+
|
| 229 |
+
// Consistency checks.
|
| 230 |
+
assert(num_epochs > 0);
|
| 231 |
+
assert(max_seq_length > 1);
|
| 232 |
+
assert(short_seq_prob >= 0.0);
|
| 233 |
+
assert(short_seq_prob <= 1.0);
|
| 234 |
+
assert(seed > 0);
|
| 235 |
+
|
| 236 |
+
// Remove bound checks.
|
| 237 |
+
auto docs = docs_.unchecked<1>();
|
| 238 |
+
auto sizes = sizes_.unchecked<1>();
|
| 239 |
+
|
| 240 |
+
// For efficiency, convert probability to ratio. Note: rand() generates int.
|
| 241 |
+
int32_t short_seq_ratio = 0;
|
| 242 |
+
if (short_seq_prob > 0)
|
| 243 |
+
{
|
| 244 |
+
short_seq_ratio = static_cast<int32_t>(round(1.0 / short_seq_prob));
|
| 245 |
+
}
|
| 246 |
+
|
| 247 |
+
if (verbose)
|
| 248 |
+
{
|
| 249 |
+
const auto sent_start_index = docs[0];
|
| 250 |
+
const auto sent_end_index = docs[docs_.shape(0) - 1];
|
| 251 |
+
const auto num_sentences = sent_end_index - sent_start_index;
|
| 252 |
+
cout << " using:" << endl
|
| 253 |
+
<< std::flush;
|
| 254 |
+
cout << " number of documents: " << docs_.shape(0) - 1 << endl
|
| 255 |
+
<< std::flush;
|
| 256 |
+
cout << " sentences range: [" << sent_start_index << ", " << sent_end_index << ")" << endl
|
| 257 |
+
<< std::flush;
|
| 258 |
+
cout << " total number of sentences: " << num_sentences << endl
|
| 259 |
+
<< std::flush;
|
| 260 |
+
cout << " number of epochs: " << num_epochs << endl
|
| 261 |
+
<< std::flush;
|
| 262 |
+
cout << " maximum number of samples: " << max_num_samples << endl
|
| 263 |
+
<< std::flush;
|
| 264 |
+
cout << " maximum sequence length: " << max_seq_length << endl
|
| 265 |
+
<< std::flush;
|
| 266 |
+
cout << " short sequence probability: " << short_seq_prob << endl
|
| 267 |
+
<< std::flush;
|
| 268 |
+
cout << " short sequence ration (1/prob): " << short_seq_ratio << endl
|
| 269 |
+
<< std::flush;
|
| 270 |
+
cout << " seed: " << seed << endl
|
| 271 |
+
<< std::flush;
|
| 272 |
+
}
|
| 273 |
+
|
| 274 |
+
// Mapping and it's length (1D).
|
| 275 |
+
int64_t num_samples = -1;
|
| 276 |
+
DocIdx *maps = NULL;
|
| 277 |
+
|
| 278 |
+
// Perform two iterations, in the first iteration get the size
|
| 279 |
+
// and allocate memory and in the second iteration populate the map.
|
| 280 |
+
bool second = false;
|
| 281 |
+
for (int32_t iteration = 0; iteration < 2; ++iteration)
|
| 282 |
+
{
|
| 283 |
+
|
| 284 |
+
// Set the seed so both iterations produce the same results.
|
| 285 |
+
std::mt19937 rand32_gen(seed);
|
| 286 |
+
|
| 287 |
+
// Set the flag on second iteration.
|
| 288 |
+
second = (iteration == 1);
|
| 289 |
+
|
| 290 |
+
// Counters:
|
| 291 |
+
uint64_t empty_docs = 0;
|
| 292 |
+
uint64_t one_sent_docs = 0;
|
| 293 |
+
uint64_t long_sent_docs = 0;
|
| 294 |
+
|
| 295 |
+
// Current map index.
|
| 296 |
+
uint64_t map_index = 0;
|
| 297 |
+
|
| 298 |
+
// For each epoch:
|
| 299 |
+
for (int32_t epoch = 0; epoch < num_epochs; ++epoch)
|
| 300 |
+
{
|
| 301 |
+
if (map_index >= max_num_samples)
|
| 302 |
+
{
|
| 303 |
+
if (verbose && (!second))
|
| 304 |
+
{
|
| 305 |
+
cout << " reached " << max_num_samples << " samples after "
|
| 306 |
+
<< epoch << " epochs ..." << endl
|
| 307 |
+
<< std::flush;
|
| 308 |
+
}
|
| 309 |
+
break;
|
| 310 |
+
}
|
| 311 |
+
// For each document:
|
| 312 |
+
for (int32_t doc = 0; doc < (docs.shape(0) - 1); ++doc)
|
| 313 |
+
{
|
| 314 |
+
|
| 315 |
+
// Document sentences are in [sent_index_first, sent_index_last)
|
| 316 |
+
const auto sent_index_first = docs[doc];
|
| 317 |
+
const auto sent_index_last = docs[doc + 1];
|
| 318 |
+
|
| 319 |
+
// At the begining of the document previous index is the
|
| 320 |
+
// start index.
|
| 321 |
+
auto prev_start_index = sent_index_first;
|
| 322 |
+
|
| 323 |
+
// Remaining documents.
|
| 324 |
+
auto num_remain_sent = sent_index_last - sent_index_first;
|
| 325 |
+
|
| 326 |
+
// Some bookkeeping
|
| 327 |
+
if ((epoch == 0) && (!second))
|
| 328 |
+
{
|
| 329 |
+
if (num_remain_sent == 0)
|
| 330 |
+
{
|
| 331 |
+
++empty_docs;
|
| 332 |
+
}
|
| 333 |
+
if (num_remain_sent == 1)
|
| 334 |
+
{
|
| 335 |
+
++one_sent_docs;
|
| 336 |
+
}
|
| 337 |
+
}
|
| 338 |
+
|
| 339 |
+
// Detect documents with long sentences.
|
| 340 |
+
bool contains_long_sentence = false;
|
| 341 |
+
if (num_remain_sent > 1)
|
| 342 |
+
{
|
| 343 |
+
for (auto sent_index = sent_index_first;
|
| 344 |
+
sent_index < sent_index_last; ++sent_index)
|
| 345 |
+
{
|
| 346 |
+
if (sizes[sent_index] > LONG_SENTENCE_LEN)
|
| 347 |
+
{
|
| 348 |
+
if ((epoch == 0) && (!second))
|
| 349 |
+
{
|
| 350 |
+
++long_sent_docs;
|
| 351 |
+
}
|
| 352 |
+
contains_long_sentence = true;
|
| 353 |
+
break;
|
| 354 |
+
}
|
| 355 |
+
}
|
| 356 |
+
}
|
| 357 |
+
|
| 358 |
+
// If we have more than two sentences.
|
| 359 |
+
if ((num_remain_sent >= min_num_sent) && (!contains_long_sentence))
|
| 360 |
+
{
|
| 361 |
+
|
| 362 |
+
// Set values.
|
| 363 |
+
auto seq_len = int32_t{0};
|
| 364 |
+
auto num_sent = int32_t{0};
|
| 365 |
+
auto target_seq_len = get_target_sample_len(short_seq_ratio,
|
| 366 |
+
max_seq_length,
|
| 367 |
+
rand32_gen);
|
| 368 |
+
|
| 369 |
+
// Loop through sentences.
|
| 370 |
+
for (auto sent_index = sent_index_first;
|
| 371 |
+
sent_index < sent_index_last; ++sent_index)
|
| 372 |
+
{
|
| 373 |
+
|
| 374 |
+
// Add the size and number of sentences.
|
| 375 |
+
seq_len += sizes[sent_index];
|
| 376 |
+
++num_sent;
|
| 377 |
+
--num_remain_sent;
|
| 378 |
+
|
| 379 |
+
// If we have reached the target length.
|
| 380 |
+
// and if not only one sentence is left in the document.
|
| 381 |
+
// and if we have at least two sentneces.
|
| 382 |
+
// and if we have reached end of the document.
|
| 383 |
+
if (((seq_len >= target_seq_len) &&
|
| 384 |
+
(num_remain_sent > 1) &&
|
| 385 |
+
(num_sent >= min_num_sent)) ||
|
| 386 |
+
(num_remain_sent == 0))
|
| 387 |
+
{
|
| 388 |
+
|
| 389 |
+
// Check for overflow.
|
| 390 |
+
if ((3 * map_index + 2) >
|
| 391 |
+
std::numeric_limits<int64_t>::max())
|
| 392 |
+
{
|
| 393 |
+
cout << "number of samples exceeded maximum "
|
| 394 |
+
<< "allowed by type int64: "
|
| 395 |
+
<< std::numeric_limits<int64_t>::max()
|
| 396 |
+
<< endl;
|
| 397 |
+
throw std::overflow_error("Number of samples");
|
| 398 |
+
}
|
| 399 |
+
|
| 400 |
+
// Populate the map.
|
| 401 |
+
if (second)
|
| 402 |
+
{
|
| 403 |
+
const auto map_index_0 = 3 * map_index;
|
| 404 |
+
maps[map_index_0] = static_cast<DocIdx>(prev_start_index);
|
| 405 |
+
maps[map_index_0 + 1] = static_cast<DocIdx>(sent_index + 1);
|
| 406 |
+
maps[map_index_0 + 2] = static_cast<DocIdx>(target_seq_len);
|
| 407 |
+
}
|
| 408 |
+
|
| 409 |
+
// Update indices / counters.
|
| 410 |
+
++map_index;
|
| 411 |
+
prev_start_index = sent_index + 1;
|
| 412 |
+
target_seq_len = get_target_sample_len(short_seq_ratio,
|
| 413 |
+
max_seq_length,
|
| 414 |
+
rand32_gen);
|
| 415 |
+
seq_len = 0;
|
| 416 |
+
num_sent = 0;
|
| 417 |
+
}
|
| 418 |
+
|
| 419 |
+
} // for (auto sent_index=sent_index_first; ...
|
| 420 |
+
} // if (num_remain_sent > 1) {
|
| 421 |
+
} // for (int doc=0; doc < num_docs; ++doc) {
|
| 422 |
+
} // for (int epoch=0; epoch < num_epochs; ++epoch) {
|
| 423 |
+
|
| 424 |
+
if (!second)
|
| 425 |
+
{
|
| 426 |
+
if (verbose)
|
| 427 |
+
{
|
| 428 |
+
cout << " number of empty documents: " << empty_docs << endl
|
| 429 |
+
<< std::flush;
|
| 430 |
+
cout << " number of documents with one sentence: " << one_sent_docs << endl
|
| 431 |
+
<< std::flush;
|
| 432 |
+
cout << " number of documents with long sentences: " << long_sent_docs << endl
|
| 433 |
+
<< std::flush;
|
| 434 |
+
cout << " will create mapping for " << map_index << " samples" << endl
|
| 435 |
+
<< std::flush;
|
| 436 |
+
}
|
| 437 |
+
assert(maps == NULL);
|
| 438 |
+
assert(num_samples < 0);
|
| 439 |
+
maps = new DocIdx[3 * map_index];
|
| 440 |
+
num_samples = static_cast<int64_t>(map_index);
|
| 441 |
+
}
|
| 442 |
+
|
| 443 |
+
} // for (int iteration=0; iteration < 2; ++iteration) {
|
| 444 |
+
|
| 445 |
+
// Shuffle.
|
| 446 |
+
// We need a 64 bit random number generator as we might have more
|
| 447 |
+
// than 2 billion samples.
|
| 448 |
+
std::mt19937_64 rand64_gen(seed + 1);
|
| 449 |
+
for (auto i = (num_samples - 1); i > 0; --i)
|
| 450 |
+
{
|
| 451 |
+
const auto j = static_cast<int64_t>(rand64_gen() % (i + 1));
|
| 452 |
+
const auto i0 = 3 * i;
|
| 453 |
+
const auto j0 = 3 * j;
|
| 454 |
+
// Swap values.
|
| 455 |
+
swap(maps[i0], maps[j0]);
|
| 456 |
+
swap(maps[i0 + 1], maps[j0 + 1]);
|
| 457 |
+
swap(maps[i0 + 2], maps[j0 + 2]);
|
| 458 |
+
}
|
| 459 |
+
|
| 460 |
+
// Method to deallocate memory.
|
| 461 |
+
py::capsule free_when_done(maps, [](void *mem_)
|
| 462 |
+
{
|
| 463 |
+
DocIdx *mem = reinterpret_cast<DocIdx *>(mem_);
|
| 464 |
+
delete[] mem;
|
| 465 |
+
});
|
| 466 |
+
|
| 467 |
+
// Return the numpy array.
|
| 468 |
+
const auto byte_size = sizeof(DocIdx);
|
| 469 |
+
return py::array(std::vector<int64_t>{num_samples, 3}, // shape
|
| 470 |
+
{3 * byte_size, byte_size}, // C-style contiguous strides
|
| 471 |
+
maps, // the data pointer
|
| 472 |
+
free_when_done); // numpy array references
|
| 473 |
+
}
|
| 474 |
+
|
| 475 |
+
py::array build_mapping(const py::array_t<int64_t> &docs_,
|
| 476 |
+
const py::array_t<int> &sizes_,
|
| 477 |
+
const int num_epochs,
|
| 478 |
+
const uint64_t max_num_samples,
|
| 479 |
+
const int max_seq_length,
|
| 480 |
+
const double short_seq_prob,
|
| 481 |
+
const int seed,
|
| 482 |
+
const bool verbose,
|
| 483 |
+
const int32_t min_num_sent)
|
| 484 |
+
{
|
| 485 |
+
|
| 486 |
+
if (sizes_.size() > std::numeric_limits<uint32_t>::max())
|
| 487 |
+
{
|
| 488 |
+
if (verbose)
|
| 489 |
+
{
|
| 490 |
+
cout << " using uint64 for data mapping..." << endl
|
| 491 |
+
<< std::flush;
|
| 492 |
+
}
|
| 493 |
+
return build_mapping_impl<uint64_t>(docs_, sizes_, num_epochs,
|
| 494 |
+
max_num_samples, max_seq_length,
|
| 495 |
+
short_seq_prob, seed, verbose,
|
| 496 |
+
min_num_sent);
|
| 497 |
+
}
|
| 498 |
+
else
|
| 499 |
+
{
|
| 500 |
+
if (verbose)
|
| 501 |
+
{
|
| 502 |
+
cout << " using uint32 for data mapping..." << endl
|
| 503 |
+
<< std::flush;
|
| 504 |
+
}
|
| 505 |
+
return build_mapping_impl<uint32_t>(docs_, sizes_, num_epochs,
|
| 506 |
+
max_num_samples, max_seq_length,
|
| 507 |
+
short_seq_prob, seed, verbose,
|
| 508 |
+
min_num_sent);
|
| 509 |
+
}
|
| 510 |
+
}
|
| 511 |
+
|
| 512 |
+
template <typename DocIdx>
|
| 513 |
+
py::array build_blocks_mapping_impl(const py::array_t<int64_t> &docs_,
|
| 514 |
+
const py::array_t<int32_t> &sizes_,
|
| 515 |
+
const py::array_t<int32_t> &titles_sizes_,
|
| 516 |
+
const int32_t num_epochs,
|
| 517 |
+
const uint64_t max_num_samples,
|
| 518 |
+
const int32_t max_seq_length,
|
| 519 |
+
const int32_t seed,
|
| 520 |
+
const bool verbose,
|
| 521 |
+
const bool use_one_sent_blocks)
|
| 522 |
+
{
|
| 523 |
+
/* Build a mapping of (start-index, end-index, sequence-length) where
|
| 524 |
+
start and end index are the indices of the sentences in the sample
|
| 525 |
+
and sequence-length is the target sequence length.
|
| 526 |
+
*/
|
| 527 |
+
|
| 528 |
+
// Consistency checks.
|
| 529 |
+
assert(num_epochs > 0);
|
| 530 |
+
assert(max_seq_length > 1);
|
| 531 |
+
assert(seed > 0);
|
| 532 |
+
|
| 533 |
+
// Remove bound checks.
|
| 534 |
+
auto docs = docs_.unchecked<1>();
|
| 535 |
+
auto sizes = sizes_.unchecked<1>();
|
| 536 |
+
auto titles_sizes = titles_sizes_.unchecked<1>();
|
| 537 |
+
|
| 538 |
+
if (verbose)
|
| 539 |
+
{
|
| 540 |
+
const auto sent_start_index = docs[0];
|
| 541 |
+
const auto sent_end_index = docs[docs_.shape(0) - 1];
|
| 542 |
+
const auto num_sentences = sent_end_index - sent_start_index;
|
| 543 |
+
cout << " using:" << endl
|
| 544 |
+
<< std::flush;
|
| 545 |
+
cout << " number of documents: " << docs_.shape(0) - 1 << endl
|
| 546 |
+
<< std::flush;
|
| 547 |
+
cout << " sentences range: [" << sent_start_index << ", " << sent_end_index << ")" << endl
|
| 548 |
+
<< std::flush;
|
| 549 |
+
cout << " total number of sentences: " << num_sentences << endl
|
| 550 |
+
<< std::flush;
|
| 551 |
+
cout << " number of epochs: " << num_epochs << endl
|
| 552 |
+
<< std::flush;
|
| 553 |
+
cout << " maximum number of samples: " << max_num_samples << endl
|
| 554 |
+
<< std::flush;
|
| 555 |
+
cout << " maximum sequence length: " << max_seq_length << endl
|
| 556 |
+
<< std::flush;
|
| 557 |
+
cout << " seed: " << seed << endl
|
| 558 |
+
<< std::flush;
|
| 559 |
+
}
|
| 560 |
+
|
| 561 |
+
// Mapping and its length (1D).
|
| 562 |
+
int64_t num_samples = -1;
|
| 563 |
+
DocIdx *maps = NULL;
|
| 564 |
+
|
| 565 |
+
// Acceptable number of sentences per block.
|
| 566 |
+
int min_num_sent = 2;
|
| 567 |
+
if (use_one_sent_blocks)
|
| 568 |
+
{
|
| 569 |
+
min_num_sent = 1;
|
| 570 |
+
}
|
| 571 |
+
|
| 572 |
+
// Perform two iterations, in the first iteration get the size
|
| 573 |
+
// and allocate memory and in the second iteration populate the map.
|
| 574 |
+
bool second = false;
|
| 575 |
+
for (int32_t iteration = 0; iteration < 2; ++iteration)
|
| 576 |
+
{
|
| 577 |
+
|
| 578 |
+
// Set the flag on second iteration.
|
| 579 |
+
second = (iteration == 1);
|
| 580 |
+
|
| 581 |
+
// Current map index.
|
| 582 |
+
uint64_t map_index = 0;
|
| 583 |
+
|
| 584 |
+
uint64_t empty_docs = 0;
|
| 585 |
+
uint64_t one_sent_docs = 0;
|
| 586 |
+
uint64_t long_sent_docs = 0;
|
| 587 |
+
// For each epoch:
|
| 588 |
+
for (int32_t epoch = 0; epoch < num_epochs; ++epoch)
|
| 589 |
+
{
|
| 590 |
+
// assign every block a unique id
|
| 591 |
+
int32_t block_id = 0;
|
| 592 |
+
|
| 593 |
+
if (map_index >= max_num_samples)
|
| 594 |
+
{
|
| 595 |
+
if (verbose && (!second))
|
| 596 |
+
{
|
| 597 |
+
cout << " reached " << max_num_samples << " samples after "
|
| 598 |
+
<< epoch << " epochs ..." << endl
|
| 599 |
+
<< std::flush;
|
| 600 |
+
}
|
| 601 |
+
break;
|
| 602 |
+
}
|
| 603 |
+
// For each document:
|
| 604 |
+
for (int32_t doc = 0; doc < (docs.shape(0) - 1); ++doc)
|
| 605 |
+
{
|
| 606 |
+
|
| 607 |
+
// Document sentences are in [sent_index_first, sent_index_last)
|
| 608 |
+
const auto sent_index_first = docs[doc];
|
| 609 |
+
const auto sent_index_last = docs[doc + 1];
|
| 610 |
+
const auto target_seq_len = max_seq_length - titles_sizes[doc];
|
| 611 |
+
|
| 612 |
+
// At the begining of the document previous index is the
|
| 613 |
+
// start index.
|
| 614 |
+
auto prev_start_index = sent_index_first;
|
| 615 |
+
|
| 616 |
+
// Remaining documents.
|
| 617 |
+
auto num_remain_sent = sent_index_last - sent_index_first;
|
| 618 |
+
|
| 619 |
+
// Some bookkeeping
|
| 620 |
+
if ((epoch == 0) && (!second))
|
| 621 |
+
{
|
| 622 |
+
if (num_remain_sent == 0)
|
| 623 |
+
{
|
| 624 |
+
++empty_docs;
|
| 625 |
+
}
|
| 626 |
+
if (num_remain_sent == 1)
|
| 627 |
+
{
|
| 628 |
+
++one_sent_docs;
|
| 629 |
+
}
|
| 630 |
+
}
|
| 631 |
+
// Detect documents with long sentences.
|
| 632 |
+
bool contains_long_sentence = false;
|
| 633 |
+
if (num_remain_sent >= min_num_sent)
|
| 634 |
+
{
|
| 635 |
+
for (auto sent_index = sent_index_first;
|
| 636 |
+
sent_index < sent_index_last; ++sent_index)
|
| 637 |
+
{
|
| 638 |
+
if (sizes[sent_index] > LONG_SENTENCE_LEN)
|
| 639 |
+
{
|
| 640 |
+
if ((epoch == 0) && (!second))
|
| 641 |
+
{
|
| 642 |
+
++long_sent_docs;
|
| 643 |
+
}
|
| 644 |
+
contains_long_sentence = true;
|
| 645 |
+
break;
|
| 646 |
+
}
|
| 647 |
+
}
|
| 648 |
+
}
|
| 649 |
+
// If we have enough sentences and no long sentences.
|
| 650 |
+
if ((num_remain_sent >= min_num_sent) && (!contains_long_sentence))
|
| 651 |
+
{
|
| 652 |
+
|
| 653 |
+
// Set values.
|
| 654 |
+
auto seq_len = int32_t{0};
|
| 655 |
+
auto num_sent = int32_t{0};
|
| 656 |
+
|
| 657 |
+
// Loop through sentences.
|
| 658 |
+
for (auto sent_index = sent_index_first;
|
| 659 |
+
sent_index < sent_index_last; ++sent_index)
|
| 660 |
+
{
|
| 661 |
+
|
| 662 |
+
// Add the size and number of sentences.
|
| 663 |
+
seq_len += sizes[sent_index];
|
| 664 |
+
++num_sent;
|
| 665 |
+
--num_remain_sent;
|
| 666 |
+
|
| 667 |
+
// If we have reached the target length.
|
| 668 |
+
// and there are an acceptable number of sentences left
|
| 669 |
+
// and if we have at least the minimum number of sentences.
|
| 670 |
+
// or if we have reached end of the document.
|
| 671 |
+
if (((seq_len >= target_seq_len) &&
|
| 672 |
+
(num_remain_sent >= min_num_sent) &&
|
| 673 |
+
(num_sent >= min_num_sent)) ||
|
| 674 |
+
(num_remain_sent == 0))
|
| 675 |
+
{
|
| 676 |
+
|
| 677 |
+
// Populate the map.
|
| 678 |
+
if (second)
|
| 679 |
+
{
|
| 680 |
+
const auto map_index_0 = 4 * map_index;
|
| 681 |
+
// Each sample has 4 items: the starting sentence index, ending sentence index,
|
| 682 |
+
// the index of the document from which the block comes (used for fetching titles)
|
| 683 |
+
// and the unique id of the block (used for creating block indexes)
|
| 684 |
+
|
| 685 |
+
maps[map_index_0] = static_cast<DocIdx>(prev_start_index);
|
| 686 |
+
maps[map_index_0 + 1] = static_cast<DocIdx>(sent_index + 1);
|
| 687 |
+
maps[map_index_0 + 2] = static_cast<DocIdx>(doc);
|
| 688 |
+
maps[map_index_0 + 3] = static_cast<DocIdx>(block_id);
|
| 689 |
+
}
|
| 690 |
+
|
| 691 |
+
// Update indices / counters.
|
| 692 |
+
++map_index;
|
| 693 |
+
++block_id;
|
| 694 |
+
prev_start_index = sent_index + 1;
|
| 695 |
+
seq_len = 0;
|
| 696 |
+
num_sent = 0;
|
| 697 |
+
}
|
| 698 |
+
} // for (auto sent_index=sent_index_first; ...
|
| 699 |
+
} // if (num_remain_sent > 1) {
|
| 700 |
+
} // for (int doc=0; doc < num_docs; ++doc) {
|
| 701 |
+
} // for (int epoch=0; epoch < num_epochs; ++epoch) {
|
| 702 |
+
|
| 703 |
+
if (!second)
|
| 704 |
+
{
|
| 705 |
+
if (verbose)
|
| 706 |
+
{
|
| 707 |
+
cout << " number of empty documents: " << empty_docs << endl
|
| 708 |
+
<< std::flush;
|
| 709 |
+
cout << " number of documents with one sentence: " << one_sent_docs << endl
|
| 710 |
+
<< std::flush;
|
| 711 |
+
cout << " number of documents with long sentences: " << long_sent_docs << endl
|
| 712 |
+
<< std::flush;
|
| 713 |
+
cout << " will create mapping for " << map_index << " samples" << endl
|
| 714 |
+
<< std::flush;
|
| 715 |
+
}
|
| 716 |
+
assert(maps == NULL);
|
| 717 |
+
assert(num_samples < 0);
|
| 718 |
+
maps = new DocIdx[4 * map_index];
|
| 719 |
+
num_samples = static_cast<int64_t>(map_index);
|
| 720 |
+
}
|
| 721 |
+
|
| 722 |
+
} // for (int iteration=0; iteration < 2; ++iteration) {
|
| 723 |
+
|
| 724 |
+
// Shuffle.
|
| 725 |
+
// We need a 64 bit random number generator as we might have more
|
| 726 |
+
// than 2 billion samples.
|
| 727 |
+
std::mt19937_64 rand64_gen(seed + 1);
|
| 728 |
+
for (auto i = (num_samples - 1); i > 0; --i)
|
| 729 |
+
{
|
| 730 |
+
const auto j = static_cast<int64_t>(rand64_gen() % (i + 1));
|
| 731 |
+
const auto i0 = 4 * i;
|
| 732 |
+
const auto j0 = 4 * j;
|
| 733 |
+
// Swap values.
|
| 734 |
+
swap(maps[i0], maps[j0]);
|
| 735 |
+
swap(maps[i0 + 1], maps[j0 + 1]);
|
| 736 |
+
swap(maps[i0 + 2], maps[j0 + 2]);
|
| 737 |
+
swap(maps[i0 + 3], maps[j0 + 3]);
|
| 738 |
+
}
|
| 739 |
+
|
| 740 |
+
// Method to deallocate memory.
|
| 741 |
+
py::capsule free_when_done(maps, [](void *mem_)
|
| 742 |
+
{
|
| 743 |
+
DocIdx *mem = reinterpret_cast<DocIdx *>(mem_);
|
| 744 |
+
delete[] mem;
|
| 745 |
+
});
|
| 746 |
+
|
| 747 |
+
// Return the numpy array.
|
| 748 |
+
const auto byte_size = sizeof(DocIdx);
|
| 749 |
+
return py::array(std::vector<int64_t>{num_samples, 4}, // shape
|
| 750 |
+
{4 * byte_size, byte_size}, // C-style contiguous strides
|
| 751 |
+
maps, // the data pointer
|
| 752 |
+
free_when_done); // numpy array references
|
| 753 |
+
}
|
| 754 |
+
|
| 755 |
+
py::array build_blocks_mapping(const py::array_t<int64_t> &docs_,
|
| 756 |
+
const py::array_t<int> &sizes_,
|
| 757 |
+
const py::array_t<int> &titles_sizes_,
|
| 758 |
+
const int num_epochs,
|
| 759 |
+
const uint64_t max_num_samples,
|
| 760 |
+
const int max_seq_length,
|
| 761 |
+
const int seed,
|
| 762 |
+
const bool verbose,
|
| 763 |
+
const bool use_one_sent_blocks)
|
| 764 |
+
{
|
| 765 |
+
|
| 766 |
+
if (sizes_.size() > std::numeric_limits<uint32_t>::max())
|
| 767 |
+
{
|
| 768 |
+
if (verbose)
|
| 769 |
+
{
|
| 770 |
+
cout << " using uint64 for data mapping..." << endl
|
| 771 |
+
<< std::flush;
|
| 772 |
+
}
|
| 773 |
+
return build_blocks_mapping_impl<uint64_t>(docs_, sizes_, titles_sizes_,
|
| 774 |
+
num_epochs, max_num_samples, max_seq_length, seed, verbose, use_one_sent_blocks);
|
| 775 |
+
}
|
| 776 |
+
else
|
| 777 |
+
{
|
| 778 |
+
if (verbose)
|
| 779 |
+
{
|
| 780 |
+
cout << " using uint32 for data mapping..." << endl
|
| 781 |
+
<< std::flush;
|
| 782 |
+
}
|
| 783 |
+
return build_blocks_mapping_impl<uint32_t>(docs_, sizes_, titles_sizes_,
|
| 784 |
+
num_epochs, max_num_samples, max_seq_length, seed, verbose, use_one_sent_blocks);
|
| 785 |
+
}
|
| 786 |
+
}
|
| 787 |
+
|
| 788 |
+
PYBIND11_MODULE(helpers, m)
|
| 789 |
+
{
|
| 790 |
+
m.def("build_mapping", &build_mapping);
|
| 791 |
+
m.def("build_blocks_mapping", &build_blocks_mapping);
|
| 792 |
+
m.def("build_sample_idx", &build_sample_idx);
|
| 793 |
+
m.def("build_blending_indices", &build_blending_indices);
|
| 794 |
+
}
|
fengshen/data/megatron_dataloader/indexed_dataset.py
ADDED
|
@@ -0,0 +1,585 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the MIT license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
# copied from fairseq/fairseq/data/indexed_dataset.py
|
| 8 |
+
# Removed IndexedRawTextDataset since it relied on Fairseq dictionary
|
| 9 |
+
# other slight modifications to remove fairseq dependencies
|
| 10 |
+
# Added document index to index file and made it accessible.
|
| 11 |
+
# An empty sentence no longer separates documents.
|
| 12 |
+
|
| 13 |
+
from functools import lru_cache
|
| 14 |
+
import os
|
| 15 |
+
import shutil
|
| 16 |
+
import struct
|
| 17 |
+
from itertools import accumulate
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import torch
|
| 21 |
+
from fengshen.data.megatron_dataloader.utils import print_rank_0
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def __best_fitting_dtype(vocab_size=None):
|
| 25 |
+
if vocab_size is not None and vocab_size < 65500:
|
| 26 |
+
return np.uint16
|
| 27 |
+
else:
|
| 28 |
+
return np.int32
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def get_available_dataset_impl():
|
| 32 |
+
return ['lazy', 'cached', 'mmap']
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def infer_dataset_impl(path):
|
| 36 |
+
if IndexedDataset.exists(path):
|
| 37 |
+
with open(index_file_path(path), 'rb') as f:
|
| 38 |
+
magic = f.read(8)
|
| 39 |
+
if magic == IndexedDataset._HDR_MAGIC:
|
| 40 |
+
return 'cached'
|
| 41 |
+
elif magic == MMapIndexedDataset.Index._HDR_MAGIC[:8]:
|
| 42 |
+
return 'mmap'
|
| 43 |
+
else:
|
| 44 |
+
return None
|
| 45 |
+
else:
|
| 46 |
+
print(f"Dataset does not exist: {path}")
|
| 47 |
+
print("Path should be a basename that both .idx and "
|
| 48 |
+
".bin can be appended to get full filenames.")
|
| 49 |
+
return None
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def make_builder(out_file, impl, vocab_size=None):
|
| 53 |
+
if impl == 'mmap':
|
| 54 |
+
return MMapIndexedDatasetBuilder(out_file,
|
| 55 |
+
dtype=__best_fitting_dtype(vocab_size))
|
| 56 |
+
else:
|
| 57 |
+
return IndexedDatasetBuilder(out_file)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def make_dataset(path, impl, skip_warmup=False):
|
| 61 |
+
if not IndexedDataset.exists(path):
|
| 62 |
+
print(f"Dataset does not exist: {path}")
|
| 63 |
+
print("Path should be a basename that both .idx "
|
| 64 |
+
"and .bin can be appended to get full filenames.")
|
| 65 |
+
return None
|
| 66 |
+
if impl == 'infer':
|
| 67 |
+
impl = infer_dataset_impl(path)
|
| 68 |
+
if impl == 'lazy' and IndexedDataset.exists(path):
|
| 69 |
+
return IndexedDataset(path)
|
| 70 |
+
elif impl == 'cached' and IndexedDataset.exists(path):
|
| 71 |
+
return IndexedCachedDataset(path)
|
| 72 |
+
elif impl == 'mmap' and MMapIndexedDataset.exists(path):
|
| 73 |
+
return MMapIndexedDataset(path, skip_warmup)
|
| 74 |
+
print(f"Unknown dataset implementation: {impl}")
|
| 75 |
+
return None
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def dataset_exists(path, impl):
|
| 79 |
+
if impl == 'mmap':
|
| 80 |
+
return MMapIndexedDataset.exists(path)
|
| 81 |
+
else:
|
| 82 |
+
return IndexedDataset.exists(path)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def read_longs(f, n):
|
| 86 |
+
a = np.empty(n, dtype=np.int64)
|
| 87 |
+
f.readinto(a)
|
| 88 |
+
return a
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def write_longs(f, a):
|
| 92 |
+
f.write(np.array(a, dtype=np.int64))
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
dtypes = {
|
| 96 |
+
1: np.uint8,
|
| 97 |
+
2: np.int8,
|
| 98 |
+
3: np.int16,
|
| 99 |
+
4: np.int32,
|
| 100 |
+
5: np.int64,
|
| 101 |
+
6: np.float,
|
| 102 |
+
7: np.double,
|
| 103 |
+
8: np.uint16
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def code(dtype):
|
| 108 |
+
for k in dtypes.keys():
|
| 109 |
+
if dtypes[k] == dtype:
|
| 110 |
+
return k
|
| 111 |
+
raise ValueError(dtype)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def index_file_path(prefix_path):
|
| 115 |
+
return prefix_path + '.idx'
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def data_file_path(prefix_path):
|
| 119 |
+
return prefix_path + '.bin'
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def create_doc_idx(sizes):
|
| 123 |
+
doc_idx = [0]
|
| 124 |
+
for i, s in enumerate(sizes):
|
| 125 |
+
if s == 0:
|
| 126 |
+
doc_idx.append(i + 1)
|
| 127 |
+
return doc_idx
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
class IndexedDataset(torch.utils.data.Dataset):
|
| 131 |
+
"""Loader for IndexedDataset"""
|
| 132 |
+
_HDR_MAGIC = b'TNTIDX\x00\x00'
|
| 133 |
+
|
| 134 |
+
def __init__(self, path):
|
| 135 |
+
super().__init__()
|
| 136 |
+
self.path = path
|
| 137 |
+
self.data_file = None
|
| 138 |
+
self.read_index(path)
|
| 139 |
+
|
| 140 |
+
def read_index(self, path):
|
| 141 |
+
with open(index_file_path(path), 'rb') as f:
|
| 142 |
+
magic = f.read(8)
|
| 143 |
+
assert magic == self._HDR_MAGIC, (
|
| 144 |
+
'Index file doesn\'t match expected format. '
|
| 145 |
+
'Make sure that --dataset-impl is configured properly.'
|
| 146 |
+
)
|
| 147 |
+
version = f.read(8)
|
| 148 |
+
assert struct.unpack('<Q', version) == (1,)
|
| 149 |
+
code, self.element_size = struct.unpack('<QQ', f.read(16))
|
| 150 |
+
self.dtype = dtypes[code]
|
| 151 |
+
self._len, self.s = struct.unpack('<QQ', f.read(16))
|
| 152 |
+
self.doc_count = struct.unpack('<Q', f.read(8))
|
| 153 |
+
self.dim_offsets = read_longs(f, self._len + 1)
|
| 154 |
+
self.data_offsets = read_longs(f, self._len + 1)
|
| 155 |
+
self.sizes = read_longs(f, self.s)
|
| 156 |
+
self.doc_idx = read_longs(f, self.doc_count)
|
| 157 |
+
|
| 158 |
+
def read_data(self, path):
|
| 159 |
+
self.data_file = open(data_file_path(path), 'rb', buffering=0)
|
| 160 |
+
|
| 161 |
+
def check_index(self, i):
|
| 162 |
+
if i < 0 or i >= self._len:
|
| 163 |
+
raise IndexError('index out of range')
|
| 164 |
+
|
| 165 |
+
def __del__(self):
|
| 166 |
+
if self.data_file:
|
| 167 |
+
self.data_file.close()
|
| 168 |
+
|
| 169 |
+
# @lru_cache(maxsize=8)
|
| 170 |
+
def __getitem__(self, idx):
|
| 171 |
+
if not self.data_file:
|
| 172 |
+
self.read_data(self.path)
|
| 173 |
+
if isinstance(idx, int):
|
| 174 |
+
i = idx
|
| 175 |
+
self.check_index(i)
|
| 176 |
+
tensor_size = self.sizes[
|
| 177 |
+
self.dim_offsets[i]:self.dim_offsets[i + 1]]
|
| 178 |
+
a = np.empty(tensor_size, dtype=self.dtype)
|
| 179 |
+
self.data_file.seek(self.data_offsets[i] * self.element_size)
|
| 180 |
+
self.data_file.readinto(a)
|
| 181 |
+
return a
|
| 182 |
+
elif isinstance(idx, slice):
|
| 183 |
+
start, stop, step = idx.indices(len(self))
|
| 184 |
+
if step != 1:
|
| 185 |
+
raise ValueError(
|
| 186 |
+
"Slices into indexed_dataset must be contiguous")
|
| 187 |
+
sizes = self.sizes[self.dim_offsets[start]:self.dim_offsets[stop]]
|
| 188 |
+
size = sum(sizes)
|
| 189 |
+
a = np.empty(size, dtype=self.dtype)
|
| 190 |
+
self.data_file.seek(self.data_offsets[start] * self.element_size)
|
| 191 |
+
self.data_file.readinto(a)
|
| 192 |
+
offsets = list(accumulate(sizes))
|
| 193 |
+
sents = np.split(a, offsets[:-1])
|
| 194 |
+
return sents
|
| 195 |
+
|
| 196 |
+
def __len__(self):
|
| 197 |
+
return self._len
|
| 198 |
+
|
| 199 |
+
def num_tokens(self, index):
|
| 200 |
+
return self.sizes[index]
|
| 201 |
+
|
| 202 |
+
def size(self, index):
|
| 203 |
+
return self.sizes[index]
|
| 204 |
+
|
| 205 |
+
@staticmethod
|
| 206 |
+
def exists(path):
|
| 207 |
+
return (
|
| 208 |
+
os.path.exists(index_file_path(path)) and os.path.exists(
|
| 209 |
+
data_file_path(path))
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
@property
|
| 213 |
+
def supports_prefetch(self):
|
| 214 |
+
return False # avoid prefetching to save memory
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
class IndexedCachedDataset(IndexedDataset):
|
| 218 |
+
|
| 219 |
+
def __init__(self, path):
|
| 220 |
+
super().__init__(path)
|
| 221 |
+
self.cache = None
|
| 222 |
+
self.cache_index = {}
|
| 223 |
+
|
| 224 |
+
@property
|
| 225 |
+
def supports_prefetch(self):
|
| 226 |
+
return True
|
| 227 |
+
|
| 228 |
+
def prefetch(self, indices):
|
| 229 |
+
if all(i in self.cache_index for i in indices):
|
| 230 |
+
return
|
| 231 |
+
if not self.data_file:
|
| 232 |
+
self.read_data(self.path)
|
| 233 |
+
indices = sorted(set(indices))
|
| 234 |
+
total_size = 0
|
| 235 |
+
for i in indices:
|
| 236 |
+
total_size += self.data_offsets[i + 1] - self.data_offsets[i]
|
| 237 |
+
self.cache = np.empty(total_size, dtype=self.dtype)
|
| 238 |
+
ptx = 0
|
| 239 |
+
self.cache_index.clear()
|
| 240 |
+
for i in indices:
|
| 241 |
+
self.cache_index[i] = ptx
|
| 242 |
+
size = self.data_offsets[i + 1] - self.data_offsets[i]
|
| 243 |
+
a = self.cache[ptx: ptx + size]
|
| 244 |
+
self.data_file.seek(self.data_offsets[i] * self.element_size)
|
| 245 |
+
self.data_file.readinto(a)
|
| 246 |
+
ptx += size
|
| 247 |
+
if self.data_file:
|
| 248 |
+
# close and delete data file after prefetch so we can pickle
|
| 249 |
+
self.data_file.close()
|
| 250 |
+
self.data_file = None
|
| 251 |
+
|
| 252 |
+
# @lru_cache(maxsize=8)
|
| 253 |
+
def __getitem__(self, idx):
|
| 254 |
+
if isinstance(idx, int):
|
| 255 |
+
i = idx
|
| 256 |
+
self.check_index(i)
|
| 257 |
+
tensor_size = self.sizes[
|
| 258 |
+
self.dim_offsets[i]:self.dim_offsets[i + 1]]
|
| 259 |
+
a = np.empty(tensor_size, dtype=self.dtype)
|
| 260 |
+
ptx = self.cache_index[i]
|
| 261 |
+
np.copyto(a, self.cache[ptx: ptx + a.size])
|
| 262 |
+
return a
|
| 263 |
+
elif isinstance(idx, slice):
|
| 264 |
+
# Hack just to make this work, can optimizer later if necessary
|
| 265 |
+
sents = []
|
| 266 |
+
for i in range(*idx.indices(len(self))):
|
| 267 |
+
sents.append(self[i])
|
| 268 |
+
return sents
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class IndexedDatasetBuilder(object):
|
| 272 |
+
element_sizes = {
|
| 273 |
+
np.uint8: 1,
|
| 274 |
+
np.int8: 1,
|
| 275 |
+
np.int16: 2,
|
| 276 |
+
np.int32: 4,
|
| 277 |
+
np.int64: 8,
|
| 278 |
+
np.float: 4,
|
| 279 |
+
np.double: 8
|
| 280 |
+
}
|
| 281 |
+
|
| 282 |
+
def __init__(self, out_file, dtype=np.int32):
|
| 283 |
+
self.out_file = open(out_file, 'wb')
|
| 284 |
+
self.dtype = dtype
|
| 285 |
+
self.data_offsets = [0]
|
| 286 |
+
self.dim_offsets = [0]
|
| 287 |
+
self.sizes = []
|
| 288 |
+
self.element_size = self.element_sizes[self.dtype]
|
| 289 |
+
self.doc_idx = [0]
|
| 290 |
+
|
| 291 |
+
def add_item(self, tensor):
|
| 292 |
+
bytes = self.out_file.write(np.array(tensor.numpy(), dtype=self.dtype))
|
| 293 |
+
self.data_offsets.append(
|
| 294 |
+
self.data_offsets[-1] + bytes / self.element_size)
|
| 295 |
+
for s in tensor.size():
|
| 296 |
+
self.sizes.append(s)
|
| 297 |
+
self.dim_offsets.append(self.dim_offsets[-1] + len(tensor.size()))
|
| 298 |
+
|
| 299 |
+
def end_document(self):
|
| 300 |
+
self.doc_idx.append(len(self.sizes))
|
| 301 |
+
|
| 302 |
+
def merge_file_(self, another_file):
|
| 303 |
+
index = IndexedDataset(another_file)
|
| 304 |
+
assert index.dtype == self.dtype
|
| 305 |
+
|
| 306 |
+
begin = self.data_offsets[-1]
|
| 307 |
+
for offset in index.data_offsets[1:]:
|
| 308 |
+
self.data_offsets.append(begin + offset)
|
| 309 |
+
self.sizes.extend(index.sizes)
|
| 310 |
+
begin = self.dim_offsets[-1]
|
| 311 |
+
for dim_offset in index.dim_offsets[1:]:
|
| 312 |
+
self.dim_offsets.append(begin + dim_offset)
|
| 313 |
+
|
| 314 |
+
with open(data_file_path(another_file), 'rb') as f:
|
| 315 |
+
while True:
|
| 316 |
+
data = f.read(1024)
|
| 317 |
+
if data:
|
| 318 |
+
self.out_file.write(data)
|
| 319 |
+
else:
|
| 320 |
+
break
|
| 321 |
+
|
| 322 |
+
def finalize(self, index_file):
|
| 323 |
+
self.out_file.close()
|
| 324 |
+
index = open(index_file, 'wb')
|
| 325 |
+
index.write(b'TNTIDX\x00\x00')
|
| 326 |
+
index.write(struct.pack('<Q', 1))
|
| 327 |
+
index.write(struct.pack('<QQ', code(self.dtype), self.element_size))
|
| 328 |
+
index.write(struct.pack('<QQ', len(
|
| 329 |
+
self.data_offsets) - 1, len(self.sizes)))
|
| 330 |
+
index.write(struct.pack('<Q', len(self.doc_idx)))
|
| 331 |
+
write_longs(index, self.dim_offsets)
|
| 332 |
+
write_longs(index, self.data_offsets)
|
| 333 |
+
write_longs(index, self.sizes)
|
| 334 |
+
write_longs(index, self.doc_idx)
|
| 335 |
+
index.close()
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
def _warmup_mmap_file(path):
|
| 339 |
+
with open(path, 'rb') as stream:
|
| 340 |
+
while stream.read(100 * 1024 * 1024):
|
| 341 |
+
pass
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
class MMapIndexedDataset(torch.utils.data.Dataset):
|
| 345 |
+
class Index(object):
|
| 346 |
+
_HDR_MAGIC = b'MMIDIDX\x00\x00'
|
| 347 |
+
|
| 348 |
+
@classmethod
|
| 349 |
+
def writer(cls, path, dtype):
|
| 350 |
+
class _Writer(object):
|
| 351 |
+
def __enter__(self):
|
| 352 |
+
self._file = open(path, 'wb')
|
| 353 |
+
|
| 354 |
+
self._file.write(cls._HDR_MAGIC)
|
| 355 |
+
self._file.write(struct.pack('<Q', 1))
|
| 356 |
+
self._file.write(struct.pack('<B', code(dtype)))
|
| 357 |
+
|
| 358 |
+
return self
|
| 359 |
+
|
| 360 |
+
@staticmethod
|
| 361 |
+
def _get_pointers(sizes):
|
| 362 |
+
dtype_size = dtype().itemsize
|
| 363 |
+
address = 0
|
| 364 |
+
pointers = []
|
| 365 |
+
|
| 366 |
+
for size in sizes:
|
| 367 |
+
pointers.append(address)
|
| 368 |
+
address += size * dtype_size
|
| 369 |
+
|
| 370 |
+
return pointers
|
| 371 |
+
|
| 372 |
+
def write(self, sizes, doc_idx):
|
| 373 |
+
pointers = self._get_pointers(sizes)
|
| 374 |
+
|
| 375 |
+
self._file.write(struct.pack('<Q', len(sizes)))
|
| 376 |
+
self._file.write(struct.pack('<Q', len(doc_idx)))
|
| 377 |
+
|
| 378 |
+
sizes = np.array(sizes, dtype=np.int32)
|
| 379 |
+
self._file.write(sizes.tobytes(order='C'))
|
| 380 |
+
del sizes
|
| 381 |
+
|
| 382 |
+
pointers = np.array(pointers, dtype=np.int64)
|
| 383 |
+
self._file.write(pointers.tobytes(order='C'))
|
| 384 |
+
del pointers
|
| 385 |
+
|
| 386 |
+
doc_idx = np.array(doc_idx, dtype=np.int64)
|
| 387 |
+
self._file.write(doc_idx.tobytes(order='C'))
|
| 388 |
+
|
| 389 |
+
def __exit__(self, exc_type, exc_val, exc_tb):
|
| 390 |
+
self._file.close()
|
| 391 |
+
|
| 392 |
+
return _Writer()
|
| 393 |
+
|
| 394 |
+
def __init__(self, path, skip_warmup=False):
|
| 395 |
+
with open(path, 'rb') as stream:
|
| 396 |
+
magic_test = stream.read(9)
|
| 397 |
+
assert self._HDR_MAGIC == magic_test, (
|
| 398 |
+
'Index file doesn\'t match expected format. '
|
| 399 |
+
'Make sure that --dataset-impl is configured properly.'
|
| 400 |
+
)
|
| 401 |
+
version = struct.unpack('<Q', stream.read(8))
|
| 402 |
+
assert (1,) == version
|
| 403 |
+
|
| 404 |
+
dtype_code, = struct.unpack('<B', stream.read(1))
|
| 405 |
+
self._dtype = dtypes[dtype_code]
|
| 406 |
+
self._dtype_size = self._dtype().itemsize
|
| 407 |
+
|
| 408 |
+
self._len = struct.unpack('<Q', stream.read(8))[0]
|
| 409 |
+
self._doc_count = struct.unpack('<Q', stream.read(8))[0]
|
| 410 |
+
offset = stream.tell()
|
| 411 |
+
|
| 412 |
+
if not skip_warmup:
|
| 413 |
+
print_rank_0(" warming up index mmap file...")
|
| 414 |
+
_warmup_mmap_file(path)
|
| 415 |
+
|
| 416 |
+
self._bin_buffer_mmap = np.memmap(path, mode='r', order='C')
|
| 417 |
+
self._bin_buffer = memoryview(self._bin_buffer_mmap)
|
| 418 |
+
print_rank_0(" reading sizes...")
|
| 419 |
+
self._sizes = np.frombuffer(
|
| 420 |
+
self._bin_buffer,
|
| 421 |
+
dtype=np.int32,
|
| 422 |
+
count=self._len,
|
| 423 |
+
offset=offset)
|
| 424 |
+
print_rank_0(" reading pointers...")
|
| 425 |
+
self._pointers = np.frombuffer(self._bin_buffer,
|
| 426 |
+
dtype=np.int64, count=self._len,
|
| 427 |
+
offset=offset + self._sizes.nbytes)
|
| 428 |
+
print_rank_0(" reading document index...")
|
| 429 |
+
self._doc_idx = np.frombuffer(
|
| 430 |
+
self._bin_buffer,
|
| 431 |
+
dtype=np.int64, count=self._doc_count,
|
| 432 |
+
offset=offset + self._sizes.nbytes + self._pointers.nbytes)
|
| 433 |
+
|
| 434 |
+
def __del__(self):
|
| 435 |
+
self._bin_buffer_mmap._mmap.close()
|
| 436 |
+
del self._bin_buffer_mmap
|
| 437 |
+
|
| 438 |
+
@property
|
| 439 |
+
def dtype(self):
|
| 440 |
+
return self._dtype
|
| 441 |
+
|
| 442 |
+
@property
|
| 443 |
+
def sizes(self):
|
| 444 |
+
return self._sizes
|
| 445 |
+
|
| 446 |
+
@property
|
| 447 |
+
def doc_idx(self):
|
| 448 |
+
return self._doc_idx
|
| 449 |
+
|
| 450 |
+
@lru_cache(maxsize=8)
|
| 451 |
+
def __getitem__(self, i):
|
| 452 |
+
return self._pointers[i], self._sizes[i]
|
| 453 |
+
|
| 454 |
+
def __len__(self):
|
| 455 |
+
return self._len
|
| 456 |
+
|
| 457 |
+
def __init__(self, path, skip_warmup=False):
|
| 458 |
+
super().__init__()
|
| 459 |
+
|
| 460 |
+
self._path = None
|
| 461 |
+
self._index = None
|
| 462 |
+
self._bin_buffer = None
|
| 463 |
+
|
| 464 |
+
self._do_init(path, skip_warmup)
|
| 465 |
+
|
| 466 |
+
def __getstate__(self):
|
| 467 |
+
return self._path
|
| 468 |
+
|
| 469 |
+
def __setstate__(self, state):
|
| 470 |
+
self._do_init(state)
|
| 471 |
+
|
| 472 |
+
def _do_init(self, path, skip_warmup):
|
| 473 |
+
self._path = path
|
| 474 |
+
self._index = self.Index(index_file_path(self._path), skip_warmup)
|
| 475 |
+
|
| 476 |
+
if not skip_warmup:
|
| 477 |
+
print_rank_0(" warming up data mmap file...")
|
| 478 |
+
_warmup_mmap_file(data_file_path(self._path))
|
| 479 |
+
print_rank_0(" creating numpy buffer of mmap...")
|
| 480 |
+
self._bin_buffer_mmap = np.memmap(
|
| 481 |
+
data_file_path(self._path), mode='r', order='C')
|
| 482 |
+
print_rank_0(" creating memory view of numpy buffer...")
|
| 483 |
+
self._bin_buffer = memoryview(self._bin_buffer_mmap)
|
| 484 |
+
|
| 485 |
+
def __del__(self):
|
| 486 |
+
self._bin_buffer_mmap._mmap.close()
|
| 487 |
+
del self._bin_buffer_mmap
|
| 488 |
+
del self._index
|
| 489 |
+
|
| 490 |
+
def __len__(self):
|
| 491 |
+
return len(self._index)
|
| 492 |
+
|
| 493 |
+
# @lru_cache(maxsize=8)
|
| 494 |
+
def __getitem__(self, idx):
|
| 495 |
+
if isinstance(idx, int):
|
| 496 |
+
ptr, size = self._index[idx]
|
| 497 |
+
np_array = np.frombuffer(self._bin_buffer, dtype=self._index.dtype,
|
| 498 |
+
count=size, offset=ptr)
|
| 499 |
+
return np_array
|
| 500 |
+
elif isinstance(idx, slice):
|
| 501 |
+
start, stop, step = idx.indices(len(self))
|
| 502 |
+
if step != 1:
|
| 503 |
+
raise ValueError(
|
| 504 |
+
"Slices into indexed_dataset must be contiguous")
|
| 505 |
+
ptr = self._index._pointers[start]
|
| 506 |
+
sizes = self._index._sizes[idx]
|
| 507 |
+
offsets = list(accumulate(sizes))
|
| 508 |
+
total_size = sum(sizes)
|
| 509 |
+
np_array = np.frombuffer(self._bin_buffer, dtype=self._index.dtype,
|
| 510 |
+
count=total_size, offset=ptr)
|
| 511 |
+
sents = np.split(np_array, offsets[:-1])
|
| 512 |
+
return sents
|
| 513 |
+
|
| 514 |
+
def get(self, idx, offset=0, length=None):
|
| 515 |
+
""" Retrieves a single item from the dataset with the option to only
|
| 516 |
+
return a portion of the item.
|
| 517 |
+
|
| 518 |
+
get(idx) is the same as [idx] but get() does not support slicing.
|
| 519 |
+
"""
|
| 520 |
+
ptr, size = self._index[idx]
|
| 521 |
+
if length is None:
|
| 522 |
+
length = size - offset
|
| 523 |
+
ptr += offset * np.dtype(self._index.dtype).itemsize
|
| 524 |
+
np_array = np.frombuffer(self._bin_buffer, dtype=self._index.dtype,
|
| 525 |
+
count=length, offset=ptr)
|
| 526 |
+
return np_array
|
| 527 |
+
|
| 528 |
+
@property
|
| 529 |
+
def sizes(self):
|
| 530 |
+
return self._index.sizes
|
| 531 |
+
|
| 532 |
+
@property
|
| 533 |
+
def doc_idx(self):
|
| 534 |
+
return self._index.doc_idx
|
| 535 |
+
|
| 536 |
+
def get_doc_idx(self):
|
| 537 |
+
return self._index._doc_idx
|
| 538 |
+
|
| 539 |
+
def set_doc_idx(self, doc_idx_):
|
| 540 |
+
self._index._doc_idx = doc_idx_
|
| 541 |
+
|
| 542 |
+
@property
|
| 543 |
+
def supports_prefetch(self):
|
| 544 |
+
return False
|
| 545 |
+
|
| 546 |
+
@staticmethod
|
| 547 |
+
def exists(path):
|
| 548 |
+
return (
|
| 549 |
+
os.path.exists(index_file_path(path)) and os.path.exists(
|
| 550 |
+
data_file_path(path))
|
| 551 |
+
)
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
class MMapIndexedDatasetBuilder(object):
|
| 555 |
+
def __init__(self, out_file, dtype=np.int64):
|
| 556 |
+
self._data_file = open(out_file, 'wb', buffering=5000000)
|
| 557 |
+
self._dtype = dtype
|
| 558 |
+
self._sizes = []
|
| 559 |
+
self._doc_idx = [0]
|
| 560 |
+
|
| 561 |
+
def add_item(self, tensor):
|
| 562 |
+
np_array = np.array(tensor.numpy(), dtype=self._dtype)
|
| 563 |
+
self._data_file.write(np_array.tobytes(order='C'))
|
| 564 |
+
self._sizes.append(np_array.size)
|
| 565 |
+
|
| 566 |
+
def end_document(self):
|
| 567 |
+
self._doc_idx.append(len(self._sizes))
|
| 568 |
+
|
| 569 |
+
def merge_file_(self, another_file):
|
| 570 |
+
# Concatenate index
|
| 571 |
+
index = MMapIndexedDataset.Index(index_file_path(another_file))
|
| 572 |
+
assert index.dtype == self._dtype
|
| 573 |
+
|
| 574 |
+
for size in index.sizes:
|
| 575 |
+
self._sizes.append(size)
|
| 576 |
+
|
| 577 |
+
# Concatenate data
|
| 578 |
+
with open(data_file_path(another_file), 'rb') as f:
|
| 579 |
+
shutil.copyfileobj(f, self._data_file)
|
| 580 |
+
|
| 581 |
+
def finalize(self, index_file):
|
| 582 |
+
self._data_file.close()
|
| 583 |
+
|
| 584 |
+
with MMapIndexedDataset.Index.writer(index_file, self._dtype) as index:
|
| 585 |
+
index.write(self._sizes, self._doc_idx)
|
fengshen/data/megatron_dataloader/utils.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
import torch
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def print_rank_0(message):
|
| 19 |
+
"""If distributed is initialized, print only on rank 0."""
|
| 20 |
+
if torch.distributed.is_initialized():
|
| 21 |
+
if torch.distributed.get_rank() == 0:
|
| 22 |
+
print(message, flush=True)
|
| 23 |
+
else:
|
| 24 |
+
print(message, flush=True)
|
fengshen/data/mmap_dataloader/mmap_datamodule.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional
|
| 2 |
+
from pytorch_lightning import LightningDataModule
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
from fengshen.data.mmap_index_dataset import MMapIndexDataset
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class MMapDataModule(LightningDataModule):
|
| 8 |
+
@ staticmethod
|
| 9 |
+
def add_data_specific_args(parent_args):
|
| 10 |
+
parser = parent_args.add_argument_group('MMAP DataModule')
|
| 11 |
+
parser.add_argument('--num_workers', default=8, type=int)
|
| 12 |
+
parser.add_argument('--train_batchsize', default=32, type=int)
|
| 13 |
+
parser.add_argument('--eval_batchsize', default=32, type=int)
|
| 14 |
+
parser.add_argument('--test_batchsize', default=32, type=int)
|
| 15 |
+
parser.add_argument('--train_datas', default=[
|
| 16 |
+
'./train_datas'
|
| 17 |
+
], type=str, nargs='+')
|
| 18 |
+
parser.add_argument('--valid_datas', default=[
|
| 19 |
+
'./valid_datas'
|
| 20 |
+
], type=str, nargs='+')
|
| 21 |
+
parser.add_argument('--test_datas', default=[
|
| 22 |
+
'./test_datas'],
|
| 23 |
+
type=str, nargs='+')
|
| 24 |
+
parser.add_argument('--input_tensor_name', default=['input_ids'], type=str, nargs='+')
|
| 25 |
+
return parent_args
|
| 26 |
+
|
| 27 |
+
def __init__(
|
| 28 |
+
self,
|
| 29 |
+
collate_fn,
|
| 30 |
+
args,
|
| 31 |
+
**kwargs,
|
| 32 |
+
):
|
| 33 |
+
super().__init__()
|
| 34 |
+
self.collate_fn = collate_fn
|
| 35 |
+
self.train_dataset = MMapIndexDataset(args.train_datas, args.input_tensor_name)
|
| 36 |
+
self.valid_dataset = MMapIndexDataset(args.valid_datas, args.input_tensor_name)
|
| 37 |
+
self.test_dataset = MMapIndexDataset(args.test_datas, args.input_tensor_name)
|
| 38 |
+
self.save_hyperparameters(args)
|
| 39 |
+
|
| 40 |
+
def setup(self, stage: Optional[str] = None) -> None:
|
| 41 |
+
return super().setup(stage)
|
| 42 |
+
|
| 43 |
+
def train_dataloader(self):
|
| 44 |
+
return DataLoader(
|
| 45 |
+
self.train_dataset,
|
| 46 |
+
batch_size=self.hparams.train_batchsize,
|
| 47 |
+
shuffle=True,
|
| 48 |
+
num_workers=self.hparams.num_workers,
|
| 49 |
+
collate_fn=self.collate_fn,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
def val_dataloader(self):
|
| 53 |
+
return DataLoader(
|
| 54 |
+
self.valid_dataset,
|
| 55 |
+
batch_size=self.hparams.eval_batchsize,
|
| 56 |
+
shuffle=True,
|
| 57 |
+
num_workers=self.hparams.num_workers,
|
| 58 |
+
collate_fn=self.collate_fn,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
def test_dataloader(self):
|
| 62 |
+
return DataLoader(
|
| 63 |
+
self.test_dataset,
|
| 64 |
+
batch_size=self.hparams.test_batchsize,
|
| 65 |
+
shuffle=True,
|
| 66 |
+
num_workers=self.hparams.num_workers,
|
| 67 |
+
collate_fn=self.collate_fn,
|
| 68 |
+
)
|
fengshen/data/mmap_dataloader/mmap_index_dataset.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from typing import List
|
| 4 |
+
from torch.utils.data import Dataset
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class MMapIndexDataset(Dataset):
|
| 8 |
+
# datapaths 是所有的内存映射文件的路径
|
| 9 |
+
# input_tensor_name 是输入的tensor的名字 例如 ['input_ids'] 会存储在对应的文件里面
|
| 10 |
+
def __init__(self, datapaths: List[str], input_tensor_name: List[str]):
|
| 11 |
+
dict_idx_fp = {}
|
| 12 |
+
dict_bin_fp = {}
|
| 13 |
+
idx_len = []
|
| 14 |
+
for tensor_name in input_tensor_name:
|
| 15 |
+
idx_fp = []
|
| 16 |
+
bin_fp = []
|
| 17 |
+
len = 0
|
| 18 |
+
for data_path in datapaths:
|
| 19 |
+
idx_fp += [np.load(
|
| 20 |
+
data_path + '_' + tensor_name + '.npy', mmap_mode='r')]
|
| 21 |
+
bin_fp += [np.memmap(
|
| 22 |
+
data_path + '_' + tensor_name + '.bin',
|
| 23 |
+
dtype='long',
|
| 24 |
+
mode='r')]
|
| 25 |
+
len += idx_fp[-1].shape[0]
|
| 26 |
+
idx_len += [idx_fp[-1].shape[0]]
|
| 27 |
+
dict_idx_fp[tensor_name] = idx_fp
|
| 28 |
+
dict_bin_fp[tensor_name] = bin_fp
|
| 29 |
+
# 通常情况下不同的tensor的长度是一样的
|
| 30 |
+
self._len = len
|
| 31 |
+
|
| 32 |
+
self._input_tensor_name = input_tensor_name
|
| 33 |
+
self._dict_idx_fp = dict_idx_fp
|
| 34 |
+
self._dict_bin_fp = dict_bin_fp
|
| 35 |
+
self._idx_len = idx_len
|
| 36 |
+
|
| 37 |
+
def __len__(self):
|
| 38 |
+
return self._len
|
| 39 |
+
|
| 40 |
+
def __getitem__(self, idx):
|
| 41 |
+
sample = {}
|
| 42 |
+
for i in range(len(self._idx_len)):
|
| 43 |
+
if idx >= self._idx_len[i]:
|
| 44 |
+
idx -= self._idx_len[i]
|
| 45 |
+
else:
|
| 46 |
+
break
|
| 47 |
+
for tensor_name in self._input_tensor_name:
|
| 48 |
+
sample[tensor_name] = torch.tensor(self._dict_bin_fp[tensor_name][i][
|
| 49 |
+
self._dict_idx_fp[tensor_name][i][idx, 0]:
|
| 50 |
+
self._dict_idx_fp[tensor_name][i][idx, 1]
|
| 51 |
+
], dtype=torch.long)
|
| 52 |
+
# print(sample)
|
| 53 |
+
return sample
|
fengshen/data/preprocess.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
fengshen/data/sequence_tagging_dataloader/sequence_tagging_collator.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from torch.utils.data._utils.collate import default_collate
|
| 3 |
+
|
| 4 |
+
import copy
|
| 5 |
+
import torch
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
@dataclass
|
| 9 |
+
class CollatorForLinear:
|
| 10 |
+
args = None
|
| 11 |
+
tokenizer = None
|
| 12 |
+
label2id = None
|
| 13 |
+
|
| 14 |
+
def __call__(self, samples):
|
| 15 |
+
cls_token = "[CLS]"
|
| 16 |
+
sep_token = "[SEP]"
|
| 17 |
+
pad_token = 0
|
| 18 |
+
special_tokens_count = 2
|
| 19 |
+
segment_id = 0
|
| 20 |
+
|
| 21 |
+
features=[]
|
| 22 |
+
|
| 23 |
+
for (ex_index, example) in enumerate(samples):
|
| 24 |
+
tokens = copy.deepcopy(example['text_a'])
|
| 25 |
+
|
| 26 |
+
label_ids = [self.label2id[x] for x in example['labels']]
|
| 27 |
+
|
| 28 |
+
if len(tokens) > self.args.max_seq_length - special_tokens_count:
|
| 29 |
+
tokens = tokens[: (self.args.max_seq_length - special_tokens_count)]
|
| 30 |
+
label_ids = label_ids[: (self.args.max_seq_length - special_tokens_count)]
|
| 31 |
+
|
| 32 |
+
tokens += [sep_token]
|
| 33 |
+
label_ids += [self.label2id["O"]]
|
| 34 |
+
segment_ids = [segment_id] * len(tokens)
|
| 35 |
+
|
| 36 |
+
tokens = [cls_token] + tokens
|
| 37 |
+
label_ids = [self.label2id["O"]] + label_ids
|
| 38 |
+
segment_ids = [segment_id] + segment_ids
|
| 39 |
+
|
| 40 |
+
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
|
| 41 |
+
input_mask = [1] * len(input_ids)
|
| 42 |
+
input_len = len(label_ids)
|
| 43 |
+
padding_length = self.args.max_seq_length - len(input_ids)
|
| 44 |
+
|
| 45 |
+
input_ids += [pad_token] * padding_length
|
| 46 |
+
input_mask += [0] * padding_length
|
| 47 |
+
segment_ids += [segment_id] * padding_length
|
| 48 |
+
label_ids += [pad_token] * padding_length
|
| 49 |
+
|
| 50 |
+
assert len(input_ids) == self.args.max_seq_length
|
| 51 |
+
assert len(input_mask) == self.args.max_seq_length
|
| 52 |
+
assert len(segment_ids) == self.args.max_seq_length
|
| 53 |
+
assert len(label_ids) == self.args.max_seq_length
|
| 54 |
+
|
| 55 |
+
features.append({
|
| 56 |
+
'input_ids':torch.tensor(input_ids),
|
| 57 |
+
'attention_mask':torch.tensor(input_mask),
|
| 58 |
+
'input_len':torch.tensor(input_len),
|
| 59 |
+
'token_type_ids':torch.tensor(segment_ids),
|
| 60 |
+
'labels':torch.tensor(label_ids),
|
| 61 |
+
})
|
| 62 |
+
|
| 63 |
+
return default_collate(features)
|
| 64 |
+
|
| 65 |
+
@dataclass
|
| 66 |
+
class CollatorForCrf:
|
| 67 |
+
args = None
|
| 68 |
+
tokenizer = None
|
| 69 |
+
label2id = None
|
| 70 |
+
|
| 71 |
+
def __call__(self, samples):
|
| 72 |
+
features = []
|
| 73 |
+
cls_token = "[CLS]"
|
| 74 |
+
sep_token = "[SEP]"
|
| 75 |
+
pad_token = 0
|
| 76 |
+
special_tokens_count = 2
|
| 77 |
+
segment_id = 0
|
| 78 |
+
|
| 79 |
+
for (ex_index, example) in enumerate(samples):
|
| 80 |
+
tokens = copy.deepcopy(example['text_a'])
|
| 81 |
+
|
| 82 |
+
label_ids = [self.label2id[x] for x in example['labels']]
|
| 83 |
+
|
| 84 |
+
if len(tokens) > self.args.max_seq_length - special_tokens_count:
|
| 85 |
+
tokens = tokens[: (self.args.max_seq_length - special_tokens_count)]
|
| 86 |
+
label_ids = label_ids[: (self.args.max_seq_length - special_tokens_count)]
|
| 87 |
+
|
| 88 |
+
tokens += [sep_token]
|
| 89 |
+
label_ids += [self.label2id["O"]]
|
| 90 |
+
segment_ids = [segment_id] * len(tokens)
|
| 91 |
+
|
| 92 |
+
tokens = [cls_token] + tokens
|
| 93 |
+
label_ids = [self.label2id["O"]] + label_ids
|
| 94 |
+
segment_ids = [segment_id] + segment_ids
|
| 95 |
+
|
| 96 |
+
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
|
| 97 |
+
input_mask = [1] * len(input_ids)
|
| 98 |
+
input_len = len(label_ids)
|
| 99 |
+
padding_length = self.args.max_seq_length - len(input_ids)
|
| 100 |
+
|
| 101 |
+
input_ids += [pad_token] * padding_length
|
| 102 |
+
input_mask += [0] * padding_length
|
| 103 |
+
segment_ids += [segment_id] * padding_length
|
| 104 |
+
label_ids += [pad_token] * padding_length
|
| 105 |
+
|
| 106 |
+
assert len(input_ids) == self.args.max_seq_length
|
| 107 |
+
assert len(input_mask) == self.args.max_seq_length
|
| 108 |
+
assert len(segment_ids) == self.args.max_seq_length
|
| 109 |
+
assert len(label_ids) == self.args.max_seq_length
|
| 110 |
+
|
| 111 |
+
features.append({
|
| 112 |
+
'input_ids':torch.tensor(input_ids),
|
| 113 |
+
'attention_mask':torch.tensor(input_mask),
|
| 114 |
+
'input_len':torch.tensor(input_len),
|
| 115 |
+
'token_type_ids':torch.tensor(segment_ids),
|
| 116 |
+
'labels':torch.tensor(label_ids),
|
| 117 |
+
})
|
| 118 |
+
|
| 119 |
+
return default_collate(features)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
@dataclass
|
| 123 |
+
class CollatorForSpan:
|
| 124 |
+
args = None
|
| 125 |
+
tokenizer = None
|
| 126 |
+
label2id = None
|
| 127 |
+
|
| 128 |
+
def __call__(self, samples):
|
| 129 |
+
|
| 130 |
+
features = []
|
| 131 |
+
cls_token = "[CLS]"
|
| 132 |
+
sep_token = "[SEP]"
|
| 133 |
+
pad_token = 0
|
| 134 |
+
special_tokens_count = 2
|
| 135 |
+
max_entities_count = 100
|
| 136 |
+
segment_id = 0
|
| 137 |
+
|
| 138 |
+
for (ex_index, example) in enumerate(samples):
|
| 139 |
+
subjects = copy.deepcopy(example['subject'])
|
| 140 |
+
tokens = copy.deepcopy(example['text_a'])
|
| 141 |
+
start_ids = [0] * len(tokens)
|
| 142 |
+
end_ids = [0] * len(tokens)
|
| 143 |
+
subject_ids = []
|
| 144 |
+
for subject in subjects:
|
| 145 |
+
label = subject[0]
|
| 146 |
+
start = subject[1]
|
| 147 |
+
end = subject[2]
|
| 148 |
+
start_ids[start] = self.label2id[label]
|
| 149 |
+
end_ids[end] = self.label2id[label]
|
| 150 |
+
subject_ids.append([self.label2id[label], start, end])
|
| 151 |
+
|
| 152 |
+
subject_ids+=[[-1,-1,-1]]*(max_entities_count-len(subject_ids))
|
| 153 |
+
|
| 154 |
+
if len(tokens) > self.args.max_seq_length - special_tokens_count:
|
| 155 |
+
tokens = tokens[: (self.args.max_seq_length - special_tokens_count)]
|
| 156 |
+
start_ids = start_ids[: (self.args.max_seq_length - special_tokens_count)]
|
| 157 |
+
end_ids = end_ids[: (self.args.max_seq_length - special_tokens_count)]
|
| 158 |
+
|
| 159 |
+
tokens += [sep_token]
|
| 160 |
+
start_ids += [0]
|
| 161 |
+
end_ids += [0]
|
| 162 |
+
segment_ids = [segment_id] * len(tokens)
|
| 163 |
+
|
| 164 |
+
tokens = [cls_token] + tokens
|
| 165 |
+
start_ids = [0] + start_ids
|
| 166 |
+
end_ids = [0] + end_ids
|
| 167 |
+
segment_ids = [segment_id] + segment_ids
|
| 168 |
+
|
| 169 |
+
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
|
| 170 |
+
input_mask = [1] * len(input_ids)
|
| 171 |
+
input_len = len(input_ids)
|
| 172 |
+
padding_length = self.args.max_seq_length - len(input_ids)
|
| 173 |
+
|
| 174 |
+
input_ids += [pad_token] * padding_length
|
| 175 |
+
input_mask += [0] * padding_length
|
| 176 |
+
segment_ids += [segment_id] * padding_length
|
| 177 |
+
start_ids += [0] * padding_length
|
| 178 |
+
end_ids += [0] * padding_length
|
| 179 |
+
|
| 180 |
+
assert len(input_ids) == self.args.max_seq_length
|
| 181 |
+
assert len(input_mask) == self.args.max_seq_length
|
| 182 |
+
assert len(segment_ids) == self.args.max_seq_length
|
| 183 |
+
assert len(start_ids) == self.args.max_seq_length
|
| 184 |
+
assert len(end_ids) == self.args.max_seq_length
|
| 185 |
+
|
| 186 |
+
features.append({
|
| 187 |
+
'input_ids': torch.tensor(np.array(input_ids)),
|
| 188 |
+
'attention_mask': torch.tensor(np.array(input_mask)),
|
| 189 |
+
'token_type_ids': torch.tensor(np.array(segment_ids)),
|
| 190 |
+
'start_positions': torch.tensor(np.array(start_ids)),
|
| 191 |
+
'end_positions': torch.tensor(np.array(end_ids)),
|
| 192 |
+
"subjects": torch.tensor(np.array(subject_ids)),
|
| 193 |
+
'input_len': torch.tensor(np.array(input_len)),
|
| 194 |
+
})
|
| 195 |
+
|
| 196 |
+
return default_collate(features)
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
@dataclass
|
| 200 |
+
class CollatorForBiaffine:
|
| 201 |
+
args = None
|
| 202 |
+
tokenizer = None
|
| 203 |
+
label2id = None
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def __call__(self, samples):
|
| 207 |
+
|
| 208 |
+
features = []
|
| 209 |
+
cls_token = "[CLS]"
|
| 210 |
+
sep_token = "[SEP]"
|
| 211 |
+
pad_token = 0
|
| 212 |
+
special_tokens_count = 2
|
| 213 |
+
segment_id = 0
|
| 214 |
+
|
| 215 |
+
for (ex_index, example) in enumerate(samples):
|
| 216 |
+
subjects = copy.deepcopy(example['subject'])
|
| 217 |
+
tokens = copy.deepcopy(example['text_a'])
|
| 218 |
+
|
| 219 |
+
span_labels = np.zeros((self.args.max_seq_length,self.args.max_seq_length))
|
| 220 |
+
span_labels[:] = self.label2id["O"]
|
| 221 |
+
|
| 222 |
+
for subject in subjects:
|
| 223 |
+
label = subject[0]
|
| 224 |
+
start = subject[1]
|
| 225 |
+
end = subject[2]
|
| 226 |
+
if start < self.args.max_seq_length - special_tokens_count and end < self.args.max_seq_length - special_tokens_count:
|
| 227 |
+
span_labels[start + 1, end + 1] = self.label2id[label]
|
| 228 |
+
|
| 229 |
+
if len(tokens) > self.args.max_seq_length - special_tokens_count:
|
| 230 |
+
tokens = tokens[: (self.args.max_seq_length - special_tokens_count)]
|
| 231 |
+
|
| 232 |
+
tokens += [sep_token]
|
| 233 |
+
span_labels[len(tokens), :] = self.label2id["O"]
|
| 234 |
+
span_labels[:, len(tokens)] = self.label2id["O"]
|
| 235 |
+
segment_ids = [segment_id] * len(tokens)
|
| 236 |
+
|
| 237 |
+
tokens = [cls_token] + tokens
|
| 238 |
+
span_labels[0, :] = self.label2id["O"]
|
| 239 |
+
span_labels[:, 0] = self.label2id["O"]
|
| 240 |
+
segment_ids = [segment_id] + segment_ids
|
| 241 |
+
|
| 242 |
+
input_ids = self.tokenizer.convert_tokens_to_ids(tokens)
|
| 243 |
+
input_mask = [0] * len(input_ids)
|
| 244 |
+
span_mask = np.ones(span_labels.shape)
|
| 245 |
+
input_len = len(input_ids)
|
| 246 |
+
|
| 247 |
+
padding_length = self.args.max_seq_length - len(input_ids)
|
| 248 |
+
|
| 249 |
+
input_ids += [pad_token] * padding_length
|
| 250 |
+
input_mask += [0] * padding_length
|
| 251 |
+
segment_ids += [segment_id] * padding_length
|
| 252 |
+
span_labels[input_len:, :] = 0
|
| 253 |
+
span_labels[:, input_len:] = 0
|
| 254 |
+
span_mask[input_len:, :] = 0
|
| 255 |
+
span_mask[:, input_len:] = 0
|
| 256 |
+
span_mask=np.triu(span_mask,0)
|
| 257 |
+
span_mask=np.tril(span_mask,10)
|
| 258 |
+
|
| 259 |
+
assert len(input_ids) == self.args.max_seq_length
|
| 260 |
+
assert len(input_mask) == self.args.max_seq_length
|
| 261 |
+
assert len(segment_ids) == self.args.max_seq_length
|
| 262 |
+
assert len(span_labels) == self.args.max_seq_length
|
| 263 |
+
assert len(span_labels[0]) == self.args.max_seq_length
|
| 264 |
+
|
| 265 |
+
features.append({
|
| 266 |
+
'input_ids': torch.tensor(np.array(input_ids)),
|
| 267 |
+
'attention_mask': torch.tensor(np.array(input_mask)),
|
| 268 |
+
'token_type_ids': torch.tensor(np.array(segment_ids)),
|
| 269 |
+
'span_labels': torch.tensor(np.array(span_labels)),
|
| 270 |
+
'span_mask': torch.tensor(np.array(span_mask)),
|
| 271 |
+
'input_len': torch.tensor(np.array(input_len)),
|
| 272 |
+
})
|
| 273 |
+
|
| 274 |
+
return default_collate(features)
|
fengshen/data/sequence_tagging_dataloader/sequence_tagging_datasets.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import Dataset
|
| 2 |
+
from fengshen.metric.utils_ner import get_entities
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
def get_datasets(args):
|
| 7 |
+
processor = DataProcessor(args.data_dir, args.decode_type)
|
| 8 |
+
|
| 9 |
+
train_data = TaskDataset(processor=processor, mode="train")
|
| 10 |
+
valid_data = TaskDataset(processor=processor, mode="dev")
|
| 11 |
+
test_data = TaskDataset(processor=processor, mode="dev")
|
| 12 |
+
|
| 13 |
+
return {"train":train_data,"validation":valid_data,"test":test_data}
|
| 14 |
+
|
| 15 |
+
# def get_labels(decode_type):
|
| 16 |
+
# with open("/cognitive_comp/lujunyu/data_zh/NER_Aligned/weibo/labels.txt") as f:
|
| 17 |
+
# label_list = ["[PAD]", "[START]", "[END]"]
|
| 18 |
+
|
| 19 |
+
# if decode_type=="crf" or decode_type=="linear":
|
| 20 |
+
# for line in f.readlines():
|
| 21 |
+
# label_list.append(line.strip())
|
| 22 |
+
# elif decode_type=="biaffine" or decode_type=="span":
|
| 23 |
+
# for line in f.readlines():
|
| 24 |
+
# tag = line.strip().split("-")
|
| 25 |
+
# if len(tag) == 1 and tag[0] not in label_list:
|
| 26 |
+
# label_list.append(tag[0])
|
| 27 |
+
# elif tag[1] not in label_list:
|
| 28 |
+
# label_list.append(tag[1])
|
| 29 |
+
|
| 30 |
+
# label2id={label:id for id,label in enumerate(label_list)}
|
| 31 |
+
# id2label={id:label for id,label in enumerate(label_list)}
|
| 32 |
+
# return label2id, id2label
|
| 33 |
+
|
| 34 |
+
class DataProcessor(object):
|
| 35 |
+
def __init__(self, data_dir, decode_type) -> None:
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.data_dir = data_dir
|
| 38 |
+
self.decode_type = decode_type
|
| 39 |
+
|
| 40 |
+
def get_examples(self, mode):
|
| 41 |
+
return self._create_examples(self._read_text(os.path.join(self.data_dir, mode + ".all.bmes")), mode)
|
| 42 |
+
|
| 43 |
+
@staticmethod
|
| 44 |
+
def get_labels(args):
|
| 45 |
+
with open(os.path.join(args.data_dir, "labels.txt")) as f:
|
| 46 |
+
label_list = ["[PAD]", "[START]", "[END]"]
|
| 47 |
+
|
| 48 |
+
if args.decode_type=="crf" or args.decode_type=="linear":
|
| 49 |
+
for line in f.readlines():
|
| 50 |
+
label_list.append(line.strip())
|
| 51 |
+
elif args.decode_type=="biaffine" or args.decode_type=="span":
|
| 52 |
+
for line in f.readlines():
|
| 53 |
+
tag = line.strip().split("-")
|
| 54 |
+
if len(tag) == 1 and tag[0] not in label_list:
|
| 55 |
+
label_list.append(tag[0])
|
| 56 |
+
elif tag[1] not in label_list:
|
| 57 |
+
label_list.append(tag[1])
|
| 58 |
+
|
| 59 |
+
label2id = {label: i for i, label in enumerate(label_list)}
|
| 60 |
+
id2label={id:label for id,label in enumerate(label_list)}
|
| 61 |
+
return label2id,id2label
|
| 62 |
+
|
| 63 |
+
def _create_examples(self, lines, set_type):
|
| 64 |
+
examples = []
|
| 65 |
+
for (i, line) in enumerate(lines):
|
| 66 |
+
guid = "%s-%s" % (set_type, i)
|
| 67 |
+
text_a = line['words']
|
| 68 |
+
labels = []
|
| 69 |
+
for x in line['labels']:
|
| 70 |
+
if 'M-' in x:
|
| 71 |
+
labels.append(x.replace('M-', 'I-'))
|
| 72 |
+
else:
|
| 73 |
+
labels.append(x)
|
| 74 |
+
subject = get_entities(labels, id2label=None, markup='bioes')
|
| 75 |
+
examples.append({'guid':guid, 'text_a':text_a, 'labels':labels, 'subject':subject})
|
| 76 |
+
return examples
|
| 77 |
+
|
| 78 |
+
@classmethod
|
| 79 |
+
def _read_text(self, input_file):
|
| 80 |
+
lines = []
|
| 81 |
+
with open(input_file, 'r') as f:
|
| 82 |
+
words = []
|
| 83 |
+
labels = []
|
| 84 |
+
for line in f:
|
| 85 |
+
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
|
| 86 |
+
if words:
|
| 87 |
+
lines.append({"words": words, "labels": labels})
|
| 88 |
+
words = []
|
| 89 |
+
labels = []
|
| 90 |
+
else:
|
| 91 |
+
splits = line.split()
|
| 92 |
+
words.append(splits[0])
|
| 93 |
+
if len(splits) > 1:
|
| 94 |
+
labels.append(splits[-1].replace("\n", ""))
|
| 95 |
+
else:
|
| 96 |
+
# Examples could have no label for mode = "test"
|
| 97 |
+
labels.append("O")
|
| 98 |
+
if words:
|
| 99 |
+
lines.append({"words": words, "labels": labels})
|
| 100 |
+
return lines
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class TaskDataset(Dataset):
|
| 104 |
+
def __init__(self, processor, mode='train'):
|
| 105 |
+
super().__init__()
|
| 106 |
+
self.data = self.load_data(processor, mode)
|
| 107 |
+
|
| 108 |
+
def __len__(self):
|
| 109 |
+
return len(self.data)
|
| 110 |
+
|
| 111 |
+
def __getitem__(self, index):
|
| 112 |
+
return self.data[index]
|
| 113 |
+
|
| 114 |
+
def load_data(self, processor, mode):
|
| 115 |
+
examples = processor.get_examples(mode)
|
| 116 |
+
return examples
|
fengshen/data/t5_dataloader/t5_datasets.py
ADDED
|
@@ -0,0 +1,562 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf8
|
| 2 |
+
import json
|
| 3 |
+
from torch.utils.data import Dataset, DataLoader
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
from transformers import BertTokenizer, MT5Config, MT5Tokenizer, BatchEncoding
|
| 6 |
+
import torch
|
| 7 |
+
import pytorch_lightning as pl
|
| 8 |
+
import numpy as np
|
| 9 |
+
from itertools import chain
|
| 10 |
+
import sys
|
| 11 |
+
sys.path.append('../../')
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def compute_input_and_target_lengths(inputs_length, noise_density, mean_noise_span_length):
|
| 15 |
+
"""This function is copy of `random_spans_helper <https://github.com/google-research/
|
| 16 |
+
text-to-text-transfer-transformer/blob/84f8bcc14b5f2c03de51bd3587609ba8f6bbd1cd/t5/data/preprocessors.py#L2466>`__ .
|
| 17 |
+
Training parameters to avoid padding with random_spans_noise_mask.
|
| 18 |
+
When training a model with random_spans_noise_mask, we would like to set the other
|
| 19 |
+
training hyperparmeters in a way that avoids padding.
|
| 20 |
+
This function helps us compute these hyperparameters.
|
| 21 |
+
We assume that each noise span in the input is replaced by extra_tokens_per_span_inputs sentinel tokens,
|
| 22 |
+
and each non-noise span in the targets is replaced by extra_tokens_per_span_targets sentinel tokens.
|
| 23 |
+
This function tells us the required number of tokens in the raw example (for split_tokens())
|
| 24 |
+
as well as the length of the encoded targets. Note that this function assumes
|
| 25 |
+
the inputs and targets will have EOS appended and includes that in the reported length.
|
| 26 |
+
Args:
|
| 27 |
+
inputs_length: an integer - desired length of the tokenized inputs sequence
|
| 28 |
+
noise_density: a float
|
| 29 |
+
mean_noise_span_length: a float
|
| 30 |
+
Returns:
|
| 31 |
+
tokens_length: length of original text in tokens
|
| 32 |
+
targets_length: an integer - length in tokens of encoded targets sequence
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def _tokens_length_to_inputs_length_targets_length(tokens_length):
|
| 36 |
+
num_noise_tokens = int(round(tokens_length * noise_density))
|
| 37 |
+
num_nonnoise_tokens = tokens_length - num_noise_tokens
|
| 38 |
+
num_noise_spans = int(round(num_noise_tokens / mean_noise_span_length))
|
| 39 |
+
# inputs contain all nonnoise tokens, sentinels for all noise spans
|
| 40 |
+
# and one EOS token.
|
| 41 |
+
_input_length = num_nonnoise_tokens + num_noise_spans + 1
|
| 42 |
+
_output_length = num_noise_tokens + num_noise_spans + 1
|
| 43 |
+
return _input_length, _output_length
|
| 44 |
+
|
| 45 |
+
tokens_length = inputs_length
|
| 46 |
+
|
| 47 |
+
while _tokens_length_to_inputs_length_targets_length(tokens_length + 1)[0] <= inputs_length:
|
| 48 |
+
tokens_length += 1
|
| 49 |
+
|
| 50 |
+
inputs_length, targets_length = _tokens_length_to_inputs_length_targets_length(
|
| 51 |
+
tokens_length)
|
| 52 |
+
|
| 53 |
+
# minor hack to get the targets length to be equal to inputs length
|
| 54 |
+
# which is more likely to have been set to a nice round number.
|
| 55 |
+
if noise_density == 0.5 and targets_length > inputs_length:
|
| 56 |
+
tokens_length -= 1
|
| 57 |
+
targets_length -= 1
|
| 58 |
+
return tokens_length, targets_length
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class UnsuperviseT5Dataset(Dataset):
|
| 62 |
+
'''
|
| 63 |
+
Dataset Used for T5 unsuprvise pretrain.
|
| 64 |
+
load_data_type = 0: load raw data from data path and save tokenized data, call function load_data
|
| 65 |
+
load_data_type = 1: load tokenized data from path, call function load_tokenized_data
|
| 66 |
+
load_data_type = 2: load tokenized data from memery data, call function load_tokenized_memory_data
|
| 67 |
+
'''
|
| 68 |
+
|
| 69 |
+
def __init__(self, data_path, args, load_data_type=0, data=None):
|
| 70 |
+
super().__init__()
|
| 71 |
+
|
| 72 |
+
if args.tokenizer_type == 't5_tokenizer':
|
| 73 |
+
if args.new_vocab_path is not None:
|
| 74 |
+
self.tokenizer = MT5Tokenizer.from_pretrained(args.new_vocab_path)
|
| 75 |
+
else:
|
| 76 |
+
self.tokenizer = MT5Tokenizer.from_pretrained(args.pretrained_model_path)
|
| 77 |
+
else:
|
| 78 |
+
self.tokenizer = BertTokenizer.from_pretrained(args.pretrained_model_path)
|
| 79 |
+
self.noise_density = 0.15
|
| 80 |
+
self.mean_noise_span_length = 3
|
| 81 |
+
self.text_column_name = args.text_column_name
|
| 82 |
+
self.dataset_num_workers = args.dataset_num_workers
|
| 83 |
+
self.max_seq_length = args.max_seq_length
|
| 84 |
+
self.remove_columns = args.remove_columns
|
| 85 |
+
# whether load tokenieze data
|
| 86 |
+
self.load_data_type = load_data_type
|
| 87 |
+
|
| 88 |
+
if self.load_data_type == 0:
|
| 89 |
+
# T5-like span masked language modeling will fuse consecutively masked tokens to a single sentinel token.
|
| 90 |
+
# To ensure that the input length is `max_seq_length`, we need to increase the maximum length
|
| 91 |
+
# according to `mlm_probability` and `mean_noise_span_length`.
|
| 92 |
+
# We can also define the label length accordingly.
|
| 93 |
+
self.expanded_inputs_length, self.targets_length = compute_input_and_target_lengths(
|
| 94 |
+
inputs_length=self.max_seq_length,
|
| 95 |
+
noise_density=self.noise_density,
|
| 96 |
+
mean_noise_span_length=self.mean_noise_span_length,
|
| 97 |
+
)
|
| 98 |
+
print('self.expanded_inputs_length, self.targets_length:{},{}'.format(
|
| 99 |
+
self.expanded_inputs_length, self.targets_length))
|
| 100 |
+
self.data = self.load_data(data_path)
|
| 101 |
+
elif self.load_data_type == 1:
|
| 102 |
+
self.data = self.load_tokenized_data(data_path)
|
| 103 |
+
else:
|
| 104 |
+
assert data is not None
|
| 105 |
+
self.data = self.load_tokenized_memory_data(data)
|
| 106 |
+
|
| 107 |
+
def __len__(self):
|
| 108 |
+
return len(self.data)
|
| 109 |
+
|
| 110 |
+
def __getitem__(self, index):
|
| 111 |
+
return self.data[index]
|
| 112 |
+
|
| 113 |
+
def load_data(self, data_path):
|
| 114 |
+
# TODO: large data process
|
| 115 |
+
from data.fs_datasets import load_dataset
|
| 116 |
+
samples = load_dataset(
|
| 117 |
+
# samples = datasets.load_from_disk(data_path)['train']
|
| 118 |
+
data_path, num_proc=self.dataset_num_workers)['train']
|
| 119 |
+
# print(samples)
|
| 120 |
+
tokenized_datasets = samples.map(
|
| 121 |
+
self.tokenize_function,
|
| 122 |
+
batched=True,
|
| 123 |
+
num_proc=self.dataset_num_workers,
|
| 124 |
+
# load_from_cache_file=not data_args.overwrite_cache,
|
| 125 |
+
).map(
|
| 126 |
+
batched=True,
|
| 127 |
+
num_proc=self.dataset_num_workers,
|
| 128 |
+
remove_columns=self.remove_columns)
|
| 129 |
+
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
|
| 130 |
+
# remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
|
| 131 |
+
# might be slower to preprocess.
|
| 132 |
+
#
|
| 133 |
+
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
|
| 134 |
+
# https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.map
|
| 135 |
+
tokenized_datasets = tokenized_datasets.map(
|
| 136 |
+
self.group_texts,
|
| 137 |
+
batched=True,
|
| 138 |
+
num_proc=self.dataset_num_workers,
|
| 139 |
+
# load_from_cache_file=not data_args.overwrite_cache,
|
| 140 |
+
)
|
| 141 |
+
return tokenized_datasets
|
| 142 |
+
'''
|
| 143 |
+
The function load tokenized data saved from load_data function.
|
| 144 |
+
'''
|
| 145 |
+
|
| 146 |
+
def load_tokenized_data(self, data_path):
|
| 147 |
+
from data.fs_datasets import load_dataset
|
| 148 |
+
samples = load_dataset(data_path)['train']
|
| 149 |
+
return samples
|
| 150 |
+
|
| 151 |
+
def load_tokenized_memory_data(self, data):
|
| 152 |
+
return data
|
| 153 |
+
|
| 154 |
+
# Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
|
| 155 |
+
# Since we make sure that all sequences are of the same length, no attention_mask is needed.
|
| 156 |
+
def tokenize_function(self, examples):
|
| 157 |
+
# 这里add_special_tokens=False,避免句子中间出现eos
|
| 158 |
+
return self.tokenizer(examples[self.text_column_name],
|
| 159 |
+
add_special_tokens=False,
|
| 160 |
+
return_attention_mask=False)
|
| 161 |
+
|
| 162 |
+
# Main data processing function that will concatenate all texts from our dataset
|
| 163 |
+
# and generate chunks of expanded_inputs_length.
|
| 164 |
+
def group_texts(self, examples):
|
| 165 |
+
# Concatenate all texts.
|
| 166 |
+
concatenated_examples = {
|
| 167 |
+
k: list(chain(*examples[k])) for k in examples.keys()}
|
| 168 |
+
total_length = len(concatenated_examples[list(examples.keys())[0]])
|
| 169 |
+
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
|
| 170 |
+
# customize this part to your needs.
|
| 171 |
+
if total_length >= self.expanded_inputs_length:
|
| 172 |
+
total_length = (
|
| 173 |
+
total_length // self.expanded_inputs_length) * self.expanded_inputs_length
|
| 174 |
+
# Split by chunks of max_len.
|
| 175 |
+
result = {
|
| 176 |
+
k: [t[i: i + self.expanded_inputs_length]
|
| 177 |
+
for i in range(0, total_length, self.expanded_inputs_length)]
|
| 178 |
+
for k, t in concatenated_examples.items()
|
| 179 |
+
}
|
| 180 |
+
return result
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
class UnsuperviseT5DataModel(pl.LightningDataModule):
|
| 184 |
+
@staticmethod
|
| 185 |
+
def add_data_specific_args(parent_args):
|
| 186 |
+
parser = parent_args.add_argument_group('UnsuperviseT5DataModel')
|
| 187 |
+
parser.add_argument('--dataset_num_workers', default=8, type=int)
|
| 188 |
+
parser.add_argument('--dataloader_num_workers', default=4, type=int)
|
| 189 |
+
parser.add_argument(
|
| 190 |
+
'--train_data_path', default='wudao_180g_mt5_tokenized', type=str)
|
| 191 |
+
parser.add_argument('--train_batchsize', default=2, type=int)
|
| 192 |
+
parser.add_argument('--valid_batchsize', default=2, type=int)
|
| 193 |
+
parser.add_argument('--train_split_size', default=None, type=float)
|
| 194 |
+
parser.add_argument('--tokenizer_type', default='t5_tokenizer', choices=['t5_tokenizer', 'bert_tokenizer'])
|
| 195 |
+
parser.add_argument('--text_column_name', default='text')
|
| 196 |
+
parser.add_argument('--remove_columns', nargs='+', default=[])
|
| 197 |
+
return parent_args
|
| 198 |
+
|
| 199 |
+
def __init__(self, args):
|
| 200 |
+
super().__init__()
|
| 201 |
+
self.save_hyperparameters(args)
|
| 202 |
+
if args.train_split_size is not None:
|
| 203 |
+
from data.fs_datasets import load_dataset
|
| 204 |
+
data_splits = load_dataset(args.train_data_path, num_proc=args.dataset_num_workers)
|
| 205 |
+
train_split = data_splits['train']
|
| 206 |
+
test_split = data_splits['test']
|
| 207 |
+
print('train:', train_split, '\ntest_data:', test_split)
|
| 208 |
+
self.train_dataset = UnsuperviseT5Dataset('', args, load_data_type=2, data=train_split)
|
| 209 |
+
self.test_dataset = UnsuperviseT5Dataset('', args, load_data_type=2, data=test_split)
|
| 210 |
+
else:
|
| 211 |
+
self.train_data = UnsuperviseT5Dataset(args.train_data_path, args, load_data_type=1)
|
| 212 |
+
|
| 213 |
+
self.config = MT5Config.from_pretrained(args.pretrained_model_path)
|
| 214 |
+
self.noise_density = 0.15
|
| 215 |
+
self.mean_noise_span_length = 3
|
| 216 |
+
self.pad_token_id = self.config.pad_token_id
|
| 217 |
+
self.decoder_start_token_id = self.config.decoder_start_token_id
|
| 218 |
+
self.eos_token_id = self.config.eos_token_id
|
| 219 |
+
self.vocab_size = self.config.vocab_size
|
| 220 |
+
self.max_seq_length = args.max_seq_length
|
| 221 |
+
# 因为加载旧的spm里面已经包括了exrta_ids,但是T5Tokenizer会在spm的基础上再增加100个extra_ids,所以需要指定extra_ids=0
|
| 222 |
+
if args.tokenizer_type == 't5_tokenizer' and args.new_vocab_path is not None:
|
| 223 |
+
self.tokenizer = MT5Tokenizer.from_pretrained(args.new_vocab_path, extra_ids=0)
|
| 224 |
+
# 如果是刚开始加载mt5,需要更新vocab_size为提取中英词之后的new_vocab_size
|
| 225 |
+
self.vocab_size = len(self.tokenizer)
|
| 226 |
+
|
| 227 |
+
# T5-like span masked language modeling will fuse consecutively masked tokens to a single sentinel token.
|
| 228 |
+
# To ensure that the input length is `max_seq_length`, we need to increase the maximum length
|
| 229 |
+
# according to `mlm_probability` and `mean_noise_span_length`. We can also define the label length accordingly.
|
| 230 |
+
self.expanded_inputs_length, self.targets_length = compute_input_and_target_lengths(
|
| 231 |
+
inputs_length=self.max_seq_length,
|
| 232 |
+
noise_density=self.noise_density,
|
| 233 |
+
mean_noise_span_length=self.mean_noise_span_length,
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
def train_dataloader(self):
|
| 237 |
+
from fengshen.data.universal_datamodule.universal_sampler import PretrainingSampler
|
| 238 |
+
from fengshen.data.universal_datamodule.universal_datamodule import get_consume_samples
|
| 239 |
+
# 采用自定义的sampler,确保继续训练能正确取到数据
|
| 240 |
+
consumed_samples = get_consume_samples(self)
|
| 241 |
+
batch_sampler = PretrainingSampler(
|
| 242 |
+
total_samples=len(self.train_dataset),
|
| 243 |
+
consumed_samples=consumed_samples,
|
| 244 |
+
micro_batch_size=self.hparams.train_batchsize,
|
| 245 |
+
data_parallel_rank=self.trainer.global_rank,
|
| 246 |
+
data_parallel_size=self.trainer.world_size,
|
| 247 |
+
)
|
| 248 |
+
return DataLoader(
|
| 249 |
+
self.train_dataset,
|
| 250 |
+
batch_sampler=batch_sampler,
|
| 251 |
+
pin_memory=True,
|
| 252 |
+
num_workers=self.hparams.dataloader_num_workers,
|
| 253 |
+
collate_fn=self.collate_fn,
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
def val_dataloader(self):
|
| 257 |
+
sampler = torch.utils.data.distributed.DistributedSampler(
|
| 258 |
+
self.test_dataset, shuffle=False)
|
| 259 |
+
return DataLoader(
|
| 260 |
+
self.test_dataset,
|
| 261 |
+
sampler=sampler,
|
| 262 |
+
shuffle=False,
|
| 263 |
+
batch_size=self.hparams.valid_batchsize,
|
| 264 |
+
pin_memory=True,
|
| 265 |
+
num_workers=self.hparams.dataloader_num_workers,
|
| 266 |
+
collate_fn=self.collate_fn,
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
def predict_dataloader(self):
|
| 270 |
+
sampler = torch.utils.data.distributed.DistributedSampler(
|
| 271 |
+
self.test_dataset, shuffle=False)
|
| 272 |
+
return DataLoader(
|
| 273 |
+
self.test_data,
|
| 274 |
+
sampler=sampler,
|
| 275 |
+
shuffle=False,
|
| 276 |
+
batch_size=self.hparams.valid_batchsize,
|
| 277 |
+
pin_memory=True,
|
| 278 |
+
num_workers=self.hparams.dataloader_num_workers,
|
| 279 |
+
collate_fn=self.collate_fn,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
def collate_fn(self, examples):
|
| 283 |
+
# convert list to dict and tensorize input
|
| 284 |
+
batch = BatchEncoding(
|
| 285 |
+
{k: np.array([examples[i][k] for i in range(len(examples))])
|
| 286 |
+
for k, v in examples[0].items()}
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
input_ids = np.array(batch['input_ids'])
|
| 290 |
+
batch_size, expanded_input_length = input_ids.shape
|
| 291 |
+
mask_indices = np.asarray([self.random_spans_noise_mask(
|
| 292 |
+
expanded_input_length) for i in range(batch_size)])
|
| 293 |
+
labels_mask = ~mask_indices
|
| 294 |
+
|
| 295 |
+
input_ids_sentinel = self.create_sentinel_ids(
|
| 296 |
+
mask_indices.astype(np.int8))
|
| 297 |
+
labels_sentinel = self.create_sentinel_ids(labels_mask.astype(np.int8))
|
| 298 |
+
|
| 299 |
+
batch["input_ids"] = self.filter_input_ids(
|
| 300 |
+
input_ids, input_ids_sentinel)
|
| 301 |
+
batch["labels"] = self.filter_input_ids(input_ids, labels_sentinel)
|
| 302 |
+
|
| 303 |
+
if batch["input_ids"].shape[-1] != self.max_seq_length:
|
| 304 |
+
raise ValueError(
|
| 305 |
+
f"`input_ids` are incorrectly preprocessed. `input_ids` length is \
|
| 306 |
+
{batch['input_ids'].shape[-1]}, but should be {self.targets_length}."
|
| 307 |
+
)
|
| 308 |
+
|
| 309 |
+
if batch["labels"].shape[-1] != self.targets_length:
|
| 310 |
+
raise ValueError(
|
| 311 |
+
f"`labels` are incorrectly preprocessed. `labels` length is \
|
| 312 |
+
{batch['labels'].shape[-1]}, but should be {self.targets_length}."
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
batch["decoder_input_ids"] = self.shift_tokens_right(
|
| 316 |
+
batch["labels"], self.pad_token_id, self.decoder_start_token_id
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
for k, v in batch.items():
|
| 320 |
+
batch[k] = torch.tensor(v)
|
| 321 |
+
# print(k, batch[k], self.tokenizer.batch_decode(batch[k]), '\n', flush=True)
|
| 322 |
+
return batch
|
| 323 |
+
|
| 324 |
+
def create_sentinel_ids(self, mask_indices):
|
| 325 |
+
"""
|
| 326 |
+
Sentinel ids creation given the indices that should be masked.
|
| 327 |
+
The start indices of each mask are replaced by the sentinel ids in increasing
|
| 328 |
+
order. Consecutive mask indices to be deleted are replaced with `-1`.
|
| 329 |
+
"""
|
| 330 |
+
start_indices = mask_indices - \
|
| 331 |
+
np.roll(mask_indices, 1, axis=-1) * mask_indices
|
| 332 |
+
start_indices[:, 0] = mask_indices[:, 0]
|
| 333 |
+
|
| 334 |
+
sentinel_ids = np.where(start_indices != 0, np.cumsum(
|
| 335 |
+
start_indices, axis=-1), start_indices)
|
| 336 |
+
sentinel_ids = np.where(
|
| 337 |
+
sentinel_ids != 0, (self.vocab_size - sentinel_ids), 0)
|
| 338 |
+
sentinel_ids -= mask_indices - start_indices
|
| 339 |
+
|
| 340 |
+
return sentinel_ids
|
| 341 |
+
|
| 342 |
+
def filter_input_ids(self, input_ids, sentinel_ids):
|
| 343 |
+
"""
|
| 344 |
+
Puts sentinel mask on `input_ids` and fuse consecutive mask tokens into a single mask token by deleting.
|
| 345 |
+
This will reduce the sequence length from `expanded_inputs_length` to `input_length`.
|
| 346 |
+
"""
|
| 347 |
+
batch_size = input_ids.shape[0]
|
| 348 |
+
|
| 349 |
+
input_ids_full = np.where(sentinel_ids != 0, sentinel_ids, input_ids)
|
| 350 |
+
# input_ids tokens and sentinel tokens are >= 0, tokens < 0 are
|
| 351 |
+
# masked tokens coming after sentinel tokens and should be removed
|
| 352 |
+
input_ids = input_ids_full[input_ids_full >=
|
| 353 |
+
0].reshape((batch_size, -1))
|
| 354 |
+
input_ids = np.concatenate(
|
| 355 |
+
[input_ids, np.full((batch_size, 1), self.eos_token_id, dtype=np.int32)], axis=-1
|
| 356 |
+
)
|
| 357 |
+
return input_ids
|
| 358 |
+
|
| 359 |
+
# Copied from transformers.models.bart.modeling_flax_bart.shift_tokens_right
|
| 360 |
+
def shift_tokens_right(self, input_ids: np.array, pad_token_id: int, decoder_start_token_id: int) -> np.ndarray:
|
| 361 |
+
"""
|
| 362 |
+
Shift input ids one token to the right.
|
| 363 |
+
"""
|
| 364 |
+
shifted_input_ids = np.zeros_like(input_ids)
|
| 365 |
+
shifted_input_ids[:, 1:] = input_ids[:, :-1]
|
| 366 |
+
shifted_input_ids[:, 0] = decoder_start_token_id
|
| 367 |
+
|
| 368 |
+
shifted_input_ids = np.where(
|
| 369 |
+
shifted_input_ids == -100, pad_token_id, shifted_input_ids)
|
| 370 |
+
return shifted_input_ids
|
| 371 |
+
|
| 372 |
+
def random_spans_noise_mask(self, length):
|
| 373 |
+
"""This function is copy of `random_spans_helper <https://github.com/google-research/text-to-text-transfer-transformer/
|
| 374 |
+
blob/84f8bcc14b5f2c03de51bd3587609ba8f6bbd1cd/t5/data/preprocessors.py#L2682>`__ .
|
| 375 |
+
Noise mask consisting of random spans of noise tokens.
|
| 376 |
+
The number of noise tokens and the number of noise spans and non-noise spans
|
| 377 |
+
are determined deterministically as follows:
|
| 378 |
+
num_noise_tokens = round(length * noise_density)
|
| 379 |
+
num_nonnoise_spans = num_noise_spans = round(num_noise_tokens / mean_noise_span_length)
|
| 380 |
+
Spans alternate between non-noise and noise, beginning with non-noise.
|
| 381 |
+
Subject to the above restrictions, all masks are equally likely.
|
| 382 |
+
Args:
|
| 383 |
+
length: an int32 scalar (length of the incoming token sequence)
|
| 384 |
+
noise_density: a float - approximate density of output mask
|
| 385 |
+
mean_noise_span_length: a number
|
| 386 |
+
Returns:
|
| 387 |
+
a boolean tensor with shape [length]
|
| 388 |
+
"""
|
| 389 |
+
|
| 390 |
+
orig_length = length
|
| 391 |
+
|
| 392 |
+
num_noise_tokens = int(np.round(length * self.noise_density))
|
| 393 |
+
# avoid degeneracy by ensuring positive numbers of noise and nonnoise tokens.
|
| 394 |
+
num_noise_tokens = min(max(num_noise_tokens, 1), length - 1)
|
| 395 |
+
num_noise_spans = int(
|
| 396 |
+
np.round(num_noise_tokens / self.mean_noise_span_length))
|
| 397 |
+
|
| 398 |
+
# avoid degeneracy by ensuring positive number of noise spans
|
| 399 |
+
num_noise_spans = max(num_noise_spans, 1)
|
| 400 |
+
num_nonnoise_tokens = length - num_noise_tokens
|
| 401 |
+
|
| 402 |
+
# pick the lengths of the noise spans and the non-noise spans
|
| 403 |
+
def _random_segmentation(num_items, num_segments):
|
| 404 |
+
"""Partition a sequence of items randomly into non-empty segments.
|
| 405 |
+
Args:
|
| 406 |
+
num_items: an integer scalar > 0
|
| 407 |
+
num_segments: an integer scalar in [1, num_items]
|
| 408 |
+
Returns:
|
| 409 |
+
a Tensor with shape [num_segments] containing positive integers that add
|
| 410 |
+
up to num_items
|
| 411 |
+
"""
|
| 412 |
+
mask_indices = np.arange(num_items - 1) < (num_segments - 1)
|
| 413 |
+
np.random.shuffle(mask_indices)
|
| 414 |
+
first_in_segment = np.pad(mask_indices, [[1, 0]])
|
| 415 |
+
segment_id = np.cumsum(first_in_segment)
|
| 416 |
+
# count length of sub segments assuming that list is sorted
|
| 417 |
+
_, segment_length = np.unique(segment_id, return_counts=True)
|
| 418 |
+
return segment_length
|
| 419 |
+
|
| 420 |
+
noise_span_lengths = _random_segmentation(
|
| 421 |
+
num_noise_tokens, num_noise_spans)
|
| 422 |
+
nonnoise_span_lengths = _random_segmentation(
|
| 423 |
+
num_nonnoise_tokens, num_noise_spans)
|
| 424 |
+
|
| 425 |
+
interleaved_span_lengths = np.reshape(
|
| 426 |
+
np.stack([nonnoise_span_lengths, noise_span_lengths],
|
| 427 |
+
axis=1), [num_noise_spans * 2]
|
| 428 |
+
)
|
| 429 |
+
span_starts = np.cumsum(interleaved_span_lengths)[:-1]
|
| 430 |
+
span_start_indicator = np.zeros((length,), dtype=np.int8)
|
| 431 |
+
span_start_indicator[span_starts] = True
|
| 432 |
+
span_num = np.cumsum(span_start_indicator)
|
| 433 |
+
is_noise = np.equal(span_num % 2, 1)
|
| 434 |
+
|
| 435 |
+
return is_noise[:orig_length]
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
class TaskT5Dataset(Dataset):
|
| 439 |
+
def __init__(self, data_path, args):
|
| 440 |
+
super().__init__()
|
| 441 |
+
self.max_length = args.max_seq_length
|
| 442 |
+
if args.tokenizer_type == 't5_tokenizer':
|
| 443 |
+
self.tokenizer = MT5Tokenizer.from_pretrained(args.pretrained_model_path)
|
| 444 |
+
else:
|
| 445 |
+
self.tokenizer = BertTokenizer.from_pretrained(args.pretrained_model_path)
|
| 446 |
+
self.data = self.load_data(data_path)
|
| 447 |
+
|
| 448 |
+
def __len__(self):
|
| 449 |
+
return len(self.data)
|
| 450 |
+
|
| 451 |
+
def __getitem__(self, index):
|
| 452 |
+
return self.encode(self.data[index])
|
| 453 |
+
|
| 454 |
+
def load_data(self, data_path):
|
| 455 |
+
samples = []
|
| 456 |
+
with open(data_path, 'r', encoding='utf8') as f:
|
| 457 |
+
lines = f.readlines()
|
| 458 |
+
for line in tqdm(lines):
|
| 459 |
+
samples.append(json.loads(line))
|
| 460 |
+
return samples
|
| 461 |
+
|
| 462 |
+
def encode(self, item):
|
| 463 |
+
if item["textb"] != "":
|
| 464 |
+
text = item['question'] + ','.join(item['choice'])+'。' + f"""{item["texta"]}""" + f"""{item["textb"]}"""
|
| 465 |
+
else:
|
| 466 |
+
text = f"""{item["question"]}""" + ",".join(item["choice"]) + "。" + f"""{item["texta"]}"""
|
| 467 |
+
label = item['answer']
|
| 468 |
+
encode_dict = self.tokenizer.encode_plus(text, max_length=self.max_length, padding='max_length',
|
| 469 |
+
truncation=True, return_tensors='pt')
|
| 470 |
+
decode_dict = self.tokenizer.encode_plus(label, max_length=16, padding='max_length',
|
| 471 |
+
truncation=True)
|
| 472 |
+
|
| 473 |
+
answer_token = []
|
| 474 |
+
max_label_len = 0
|
| 475 |
+
choice_encode = [] # 用来确定模型生成的最大长度
|
| 476 |
+
for a in item['choice']:
|
| 477 |
+
answer_encode = self.tokenizer.encode(a)
|
| 478 |
+
choice_encode.append(answer_encode)
|
| 479 |
+
if len(answer_encode) > max_label_len:
|
| 480 |
+
max_label_len = len(answer_encode)
|
| 481 |
+
for an in answer_encode:
|
| 482 |
+
if an not in answer_token:
|
| 483 |
+
answer_token.append(an)
|
| 484 |
+
|
| 485 |
+
# bad_words_ids = [[i] for i in range(self.tokenizer.vocab_size) if i not in answer_token] #不生成这些token
|
| 486 |
+
|
| 487 |
+
# while len(bad_words_ids)<self.tokenizer.vocab_size:
|
| 488 |
+
# bad_words_ids.append(bad_words_ids[0])
|
| 489 |
+
|
| 490 |
+
# bad_words_ids = [[423],[67],[878]]
|
| 491 |
+
|
| 492 |
+
encode_sent = encode_dict['input_ids'].squeeze()
|
| 493 |
+
attention_mask = encode_dict['attention_mask'].squeeze()
|
| 494 |
+
target = decode_dict['input_ids']
|
| 495 |
+
labels = torch.tensor(target)
|
| 496 |
+
labels[target == self.tokenizer.pad_token_id] = -100
|
| 497 |
+
|
| 498 |
+
return {
|
| 499 |
+
"input_ids": torch.tensor(encode_sent).long(),
|
| 500 |
+
"attention_mask": torch.tensor(attention_mask).float(),
|
| 501 |
+
"labels": torch.tensor(target).long(),
|
| 502 |
+
"force_words_ids": answer_token,
|
| 503 |
+
}
|
| 504 |
+
|
| 505 |
+
|
| 506 |
+
class TaskT5DataModel(pl.LightningDataModule):
|
| 507 |
+
@staticmethod
|
| 508 |
+
def add_data_specific_args(parent_args):
|
| 509 |
+
parser = parent_args.add_argument_group('TaskT5DataModel')
|
| 510 |
+
parser.add_argument('--dataset_num_workers', default=8, type=int)
|
| 511 |
+
parser.add_argument('--dataloader_num_workers', default=4, type=int)
|
| 512 |
+
parser.add_argument(
|
| 513 |
+
'--train_data_path', default='wudao_180g_mt5_tokenized', type=str)
|
| 514 |
+
parser.add_argument(
|
| 515 |
+
'--valid_data_path', default='wudao_180g_mt5_tokenized', type=str)
|
| 516 |
+
parser.add_argument('--train_batchsize', default=2, type=int)
|
| 517 |
+
parser.add_argument('--valid_batchsize', default=2, type=int)
|
| 518 |
+
parser.add_argument('--train_split_size', default=None, type=float)
|
| 519 |
+
parser.add_argument('--tokenizer_type', default='t5_tokenizer', choices=['t5_tokenizer', 'bert_tokenizer'])
|
| 520 |
+
parser.add_argument('--text_column_name', default='text')
|
| 521 |
+
parser.add_argument('--remove_columns', nargs='+', default=[])
|
| 522 |
+
return parent_args
|
| 523 |
+
|
| 524 |
+
def __init__(self, args):
|
| 525 |
+
super().__init__()
|
| 526 |
+
self.save_hyperparameters(args)
|
| 527 |
+
self.train_dataset = TaskT5Dataset(args.train_data_path, args)
|
| 528 |
+
self.valid_dataset = TaskT5Dataset(args.valid_data_path, args)
|
| 529 |
+
|
| 530 |
+
def train_dataloader(self):
|
| 531 |
+
from fengshen.data.universal_datamodule.universal_sampler import PretrainingSampler
|
| 532 |
+
from fengshen.data.universal_datamodule.universal_datamodule import get_consume_samples
|
| 533 |
+
# 采用自定��的sampler,确保继续训练能正确取到数据
|
| 534 |
+
consumed_samples = get_consume_samples(self)
|
| 535 |
+
# batch_sampler = PretrainingRandomSampler(
|
| 536 |
+
batch_sampler = PretrainingSampler(
|
| 537 |
+
total_samples=len(self.train_dataset),
|
| 538 |
+
consumed_samples=consumed_samples,
|
| 539 |
+
micro_batch_size=self.hparams.train_batchsize,
|
| 540 |
+
data_parallel_rank=self.trainer.global_rank,
|
| 541 |
+
data_parallel_size=self.trainer.world_size,
|
| 542 |
+
)
|
| 543 |
+
# epoch=self.trainer.current_epoch
|
| 544 |
+
# )
|
| 545 |
+
return DataLoader(
|
| 546 |
+
self.train_dataset,
|
| 547 |
+
batch_sampler=batch_sampler,
|
| 548 |
+
pin_memory=True,
|
| 549 |
+
num_workers=self.hparams.dataloader_num_workers
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
def val_dataloader(self):
|
| 553 |
+
sampler = torch.utils.data.distributed.DistributedSampler(
|
| 554 |
+
self.valid_dataset, shuffle=False)
|
| 555 |
+
return DataLoader(
|
| 556 |
+
self.valid_dataset,
|
| 557 |
+
sampler=sampler,
|
| 558 |
+
shuffle=False,
|
| 559 |
+
batch_size=self.hparams.valid_batchsize,
|
| 560 |
+
pin_memory=True,
|
| 561 |
+
num_workers=self.hparams.dataloader_num_workers
|
| 562 |
+
)
|
fengshen/data/t5_dataloader/t5_gen_datasets.py
ADDED
|
@@ -0,0 +1,391 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
'''
|
| 3 |
+
@File : t5_gen_datasets.py
|
| 4 |
+
@Time : 2022/10/24 19:29
|
| 5 |
+
@Author : He Junqing
|
| 6 |
+
@Version : 1.0
|
| 7 |
+
@Contact : hejunqing@idea.edu.cn
|
| 8 |
+
@License : (C)Copyright 2022-2023, CCNL-IDEA
|
| 9 |
+
'''
|
| 10 |
+
|
| 11 |
+
from logging import exception
|
| 12 |
+
from transformers import (
|
| 13 |
+
BertTokenizer,
|
| 14 |
+
MT5Config,
|
| 15 |
+
MT5Tokenizer,
|
| 16 |
+
MT5ForConditionalGeneration,
|
| 17 |
+
)
|
| 18 |
+
import torch
|
| 19 |
+
from torch.utils.data import Dataset, DataLoader
|
| 20 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 21 |
+
import pytorch_lightning as pl
|
| 22 |
+
import numpy as np
|
| 23 |
+
import sys
|
| 24 |
+
|
| 25 |
+
sys.path.append("../../")
|
| 26 |
+
|
| 27 |
+
special_token_dict = {
|
| 28 |
+
"additional_special_tokens": [
|
| 29 |
+
"[CTSTART]",
|
| 30 |
+
"[CTEND]",
|
| 31 |
+
"[SEP]",
|
| 32 |
+
"[KNSTART]",
|
| 33 |
+
"[KNEND]",
|
| 34 |
+
]
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class DialogDataset(Dataset):
|
| 39 |
+
def __init__(self, data_path, args, data, load_data_type=1) -> None:
|
| 40 |
+
super().__init__()
|
| 41 |
+
|
| 42 |
+
if args.tokenizer_type == "t5_tokenizer":
|
| 43 |
+
self.tokenizer = MT5Tokenizer.from_pretrained(
|
| 44 |
+
args.pretrained_model_path)
|
| 45 |
+
if len(self.tokenizer) == 32596:
|
| 46 |
+
self.tokenizer.add_special_tokens(special_token_dict)
|
| 47 |
+
print(
|
| 48 |
+
"add special tokens to tokenizer,vocab size:",
|
| 49 |
+
len(self.tokenizer)
|
| 50 |
+
)
|
| 51 |
+
self.model = MT5ForConditionalGeneration.from_pretrained(
|
| 52 |
+
args.pretrained_model_path
|
| 53 |
+
)
|
| 54 |
+
self.model.resize_token_embeddings(len(self.tokenizer))
|
| 55 |
+
self.model.save_pretrained(args.new_vocab_path)
|
| 56 |
+
self.tokenizer.save_pretrained(
|
| 57 |
+
args.new_vocab_path)
|
| 58 |
+
else:
|
| 59 |
+
self.tokenizer = BertTokenizer.from_pretrained(
|
| 60 |
+
args.pretrained_model_path)
|
| 61 |
+
|
| 62 |
+
self.load_data_type = load_data_type
|
| 63 |
+
self.data_split = data
|
| 64 |
+
self.num_workers = args.preprocessing_num_workers
|
| 65 |
+
self.max_seq_length = args.max_seq_length
|
| 66 |
+
self.max_knowledge_length = args.max_knowledge_length
|
| 67 |
+
self.max_target_length = args.max_target_length
|
| 68 |
+
|
| 69 |
+
# tokenizer config
|
| 70 |
+
self.config = MT5Config.from_pretrained(args.pretrained_model_path)
|
| 71 |
+
self.decoder_start_token_id = self.config.decoder_start_token_id
|
| 72 |
+
self.eos_token_id = self.config.eos_token_id
|
| 73 |
+
self.vocab_size = self.config.vocab_size
|
| 74 |
+
# print(self.tokenizer.decode([2]))
|
| 75 |
+
|
| 76 |
+
# load from raw data or hf dataset
|
| 77 |
+
|
| 78 |
+
if self.load_data_type == 0:
|
| 79 |
+
self.data = self.load_data(data_path)
|
| 80 |
+
elif self.load_data_type == 1:
|
| 81 |
+
self.data = self.load_packed_data(data_path)
|
| 82 |
+
else: # for testing
|
| 83 |
+
self.data = data_path
|
| 84 |
+
|
| 85 |
+
def load_packed_data(self, data_path):
|
| 86 |
+
from fengshen.data.fs_datasets import load_dataset
|
| 87 |
+
|
| 88 |
+
samples = load_dataset(data_path,
|
| 89 |
+
num_proc=self.num_workers)[self.data_split]
|
| 90 |
+
tokenized_samples = samples.map(
|
| 91 |
+
self.regular_tokenize, batched=False,
|
| 92 |
+
num_proc=self.num_workers
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
return tokenized_samples
|
| 96 |
+
|
| 97 |
+
def load_data(self, data_path):
|
| 98 |
+
"""
|
| 99 |
+
load data from raw data
|
| 100 |
+
return untokoenized data
|
| 101 |
+
"""
|
| 102 |
+
from datasets import load_dataset
|
| 103 |
+
|
| 104 |
+
ds = load_dataset("json", data_files=data_path)['train']
|
| 105 |
+
samples = ds.map(self.regular_tokenize, batched=False, num_proc=self.num_workers
|
| 106 |
+
)
|
| 107 |
+
return samples
|
| 108 |
+
|
| 109 |
+
def __getitem__(self, index):
|
| 110 |
+
return self.data[index]
|
| 111 |
+
|
| 112 |
+
def __len__(self):
|
| 113 |
+
return len(self.data)
|
| 114 |
+
|
| 115 |
+
def regular_tokenize(self, sample):
|
| 116 |
+
# print(len(sample['context']))
|
| 117 |
+
context_ids = self.tokenizer(
|
| 118 |
+
sample["context"],
|
| 119 |
+
add_special_tokens=True,
|
| 120 |
+
return_attention_mask=False,
|
| 121 |
+
return_token_type_ids=True,
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
context_types = self.get_token_type(
|
| 125 |
+
sample["context"], context_ids["token_type_ids"]
|
| 126 |
+
)
|
| 127 |
+
# print('context',sample['context'])
|
| 128 |
+
# print('context_ids',context_ids['input_ids'])
|
| 129 |
+
knowledge_ids = self.tokenizer.encode(
|
| 130 |
+
sample["knowledge"], add_special_tokens=False
|
| 131 |
+
)
|
| 132 |
+
# print('knowledge_ids',knowledge_ids)
|
| 133 |
+
if isinstance(knowledge_ids, int):
|
| 134 |
+
knowledge_ids = [knowledge_ids]
|
| 135 |
+
target_ids = self.tokenizer.encode(
|
| 136 |
+
sample["target"],
|
| 137 |
+
add_special_tokens=False,
|
| 138 |
+
max_length=self.max_target_length - 1,
|
| 139 |
+
truncation=True,
|
| 140 |
+
)
|
| 141 |
+
# print('target',sample['target'])
|
| 142 |
+
# print('target_ids',target_ids)
|
| 143 |
+
# print('decode target',self.tokenizer.decode(target_ids))
|
| 144 |
+
# truncate
|
| 145 |
+
|
| 146 |
+
knowledge_ids = (
|
| 147 |
+
[self.tokenizer.convert_tokens_to_ids("[KNSTART]")]
|
| 148 |
+
+ knowledge_ids[: self.max_knowledge_length - 2]
|
| 149 |
+
+ [self.tokenizer.convert_tokens_to_ids("[KNEND]")]
|
| 150 |
+
)
|
| 151 |
+
l_kn = len(knowledge_ids)
|
| 152 |
+
knowledge_types = [2] * l_kn
|
| 153 |
+
|
| 154 |
+
flatten_context = []
|
| 155 |
+
for line in context_ids["input_ids"]:
|
| 156 |
+
flatten_context.extend(line)
|
| 157 |
+
l_ct = min(len(flatten_context), self.max_seq_length - l_kn - 2)
|
| 158 |
+
context_ids = (
|
| 159 |
+
[self.tokenizer.convert_tokens_to_ids("[CTSTART]")]
|
| 160 |
+
+ flatten_context[-l_ct:]
|
| 161 |
+
+ [self.tokenizer.convert_tokens_to_ids("[CTEND]")]
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
context_types = context_types[-l_ct:] + [0]
|
| 165 |
+
context_types.insert(0, context_types[0])
|
| 166 |
+
assert len(context_ids) == len(
|
| 167 |
+
context_types
|
| 168 |
+
), "len of context ids and token types unmatch, context:{},ids:{} types:{},len {}:{}".format(
|
| 169 |
+
sample["context"],
|
| 170 |
+
context_ids,
|
| 171 |
+
context_types,
|
| 172 |
+
len(context_ids),
|
| 173 |
+
len(context_types),
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
try:
|
| 177 |
+
target_ids = target_ids + [self.eos_token_id]
|
| 178 |
+
except exception:
|
| 179 |
+
print(sample["target"], target_ids, self.eos_token_id)
|
| 180 |
+
|
| 181 |
+
tokenized = {}
|
| 182 |
+
tokenized["input_ids"] = np.array(context_ids + knowledge_ids, dtype=np.int32)
|
| 183 |
+
tokenized["token_types"] = np.array(
|
| 184 |
+
context_types + knowledge_types, dtype=np.int32
|
| 185 |
+
)
|
| 186 |
+
tokenized["attention_mask"] = np.ones(
|
| 187 |
+
len(context_types + knowledge_types), dtype=np.int8
|
| 188 |
+
)
|
| 189 |
+
tokenized["labels"] = np.array(target_ids, dtype=np.int32)
|
| 190 |
+
|
| 191 |
+
return tokenized
|
| 192 |
+
|
| 193 |
+
def get_token_type(self, context, tokentypes=None):
|
| 194 |
+
# token_type fail in tokenizer, all zero
|
| 195 |
+
context_token_types = []
|
| 196 |
+
for i, line in enumerate(context):
|
| 197 |
+
if tokentypes:
|
| 198 |
+
if i % 2 == 0:
|
| 199 |
+
token_type = [0] * len(tokentypes[i])
|
| 200 |
+
else:
|
| 201 |
+
token_type = [1] * len(tokentypes[i])
|
| 202 |
+
else:
|
| 203 |
+
if i % 2 == 0:
|
| 204 |
+
token_type = [0] * (1 + len(line))
|
| 205 |
+
else:
|
| 206 |
+
token_type = [1] * (1 + len(line))
|
| 207 |
+
|
| 208 |
+
context_token_types.extend(token_type)
|
| 209 |
+
|
| 210 |
+
return context_token_types
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
class DialogDataModel(pl.LightningDataModule):
|
| 214 |
+
@staticmethod
|
| 215 |
+
def add_data_specific_args(parent_args):
|
| 216 |
+
parser = parent_args.add_argument_group("SuperviseT5DataModel")
|
| 217 |
+
parser.add_argument("--dataset_num_workers", default=8, type=int)
|
| 218 |
+
parser.add_argument("--dataloader_num_workers", default=4, type=int)
|
| 219 |
+
parser.add_argument("--train_data_path", default="dialog_4g_test", type=str)
|
| 220 |
+
parser.add_argument(
|
| 221 |
+
"--valid_data_path", default="wudao_180g_mt5_tokenized", type=str
|
| 222 |
+
)
|
| 223 |
+
parser.add_argument("--train_batchsize", default=2, type=int)
|
| 224 |
+
parser.add_argument("--valid_batchsize", default=2, type=int)
|
| 225 |
+
parser.add_argument("--max_seq_length", default=512, type=int)
|
| 226 |
+
parser.add_argument("--max_knowledge_length", default=128, type=int)
|
| 227 |
+
parser.add_argument("--max_target_length", default=128, type=int)
|
| 228 |
+
|
| 229 |
+
return parent_args
|
| 230 |
+
|
| 231 |
+
def __init__(self, args):
|
| 232 |
+
super().__init__()
|
| 233 |
+
self.save_hyperparameters(args)
|
| 234 |
+
self.load_data(args)
|
| 235 |
+
self.epochs = args.max_epochs
|
| 236 |
+
|
| 237 |
+
def load_data(self, args):
|
| 238 |
+
if args.train_split_size is not None:
|
| 239 |
+
from fengshen.data.fs_datasets import load_dataset
|
| 240 |
+
|
| 241 |
+
data_splits = load_dataset(
|
| 242 |
+
args.train_data_path, num_proc=args.dataset_num_workers
|
| 243 |
+
)
|
| 244 |
+
train_split = data_splits['train']
|
| 245 |
+
test_split = data_splits['test']
|
| 246 |
+
print('train:', train_split, '\ntest_data:', test_split)
|
| 247 |
+
self.train_dataset = DialogDataset(
|
| 248 |
+
args.train_data_path, args, load_data_type=1, data="train"
|
| 249 |
+
)
|
| 250 |
+
self.test_dataset = DialogDataset(
|
| 251 |
+
args.train_data_path, args, load_data_type=1, data="test"
|
| 252 |
+
)
|
| 253 |
+
else:
|
| 254 |
+
self.train_data = DialogDataset(
|
| 255 |
+
args.train_data_path, args, load_data_type=1
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
self.config = MT5Config.from_pretrained(args.pretrained_model_path)
|
| 259 |
+
self.pad_token_id = self.config.pad_token_id
|
| 260 |
+
self.decoder_start_token_id = self.config.decoder_start_token_id
|
| 261 |
+
print("bos id:", self.decoder_start_token_id)
|
| 262 |
+
|
| 263 |
+
def collate_fn(self, samples):
|
| 264 |
+
batch = {
|
| 265 |
+
k: [
|
| 266 |
+
torch.tensor(samples[i][k], dtype=torch.int64)
|
| 267 |
+
for i in range(len(samples))
|
| 268 |
+
]
|
| 269 |
+
for k in ["input_ids", "token_types", "attention_mask", "labels"]
|
| 270 |
+
}
|
| 271 |
+
|
| 272 |
+
# print(batch)
|
| 273 |
+
for k, v in batch.items():
|
| 274 |
+
if k != "labels":
|
| 275 |
+
batch[k] = pad_sequence(
|
| 276 |
+
v, batch_first=True, padding_value=self.pad_token_id
|
| 277 |
+
)
|
| 278 |
+
else:
|
| 279 |
+
batch[k] = pad_sequence(v, batch_first=True, padding_value=-100)
|
| 280 |
+
batch["decoder_input_ids"] = torch.tensor(
|
| 281 |
+
self.shift_tokens_right(
|
| 282 |
+
batch["labels"], self.pad_token_id, self.decoder_start_token_id
|
| 283 |
+
),
|
| 284 |
+
dtype=torch.long,
|
| 285 |
+
)
|
| 286 |
+
return batch
|
| 287 |
+
|
| 288 |
+
def shift_tokens_right(
|
| 289 |
+
self, input_ids: np.array, pad_token_id: int, decoder_start_token_id: int
|
| 290 |
+
) -> np.ndarray:
|
| 291 |
+
"""
|
| 292 |
+
Shift input ids one token to the right.
|
| 293 |
+
"""
|
| 294 |
+
shifted_input_ids = np.zeros_like(input_ids)
|
| 295 |
+
shifted_input_ids[:, 1:] = input_ids[:, :-1]
|
| 296 |
+
shifted_input_ids[:, 0] = decoder_start_token_id
|
| 297 |
+
|
| 298 |
+
shifted_input_ids = np.where(
|
| 299 |
+
shifted_input_ids == -100, pad_token_id, shifted_input_ids
|
| 300 |
+
)
|
| 301 |
+
return shifted_input_ids
|
| 302 |
+
|
| 303 |
+
def train_dataloader(self):
|
| 304 |
+
from fengshen.data.universal_datamodule.universal_sampler import (
|
| 305 |
+
PretrainingRandomSampler,
|
| 306 |
+
)
|
| 307 |
+
from fengshen.data.universal_datamodule.universal_datamodule import (
|
| 308 |
+
get_consume_samples,
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
# 采用自定义的sampler,确保继续训练能正确取到数据
|
| 312 |
+
consumed_samples = get_consume_samples(self)
|
| 313 |
+
batch_sampler = PretrainingRandomSampler(
|
| 314 |
+
epoch=self.epochs,
|
| 315 |
+
total_samples=len(self.train_dataset),
|
| 316 |
+
consumed_samples=consumed_samples,
|
| 317 |
+
micro_batch_size=self.hparams.train_batchsize,
|
| 318 |
+
data_parallel_rank=self.trainer.global_rank, # gpu idx
|
| 319 |
+
data_parallel_size=self.trainer.world_size, # gpu num
|
| 320 |
+
)
|
| 321 |
+
return DataLoader(
|
| 322 |
+
self.train_dataset,
|
| 323 |
+
batch_sampler=batch_sampler,
|
| 324 |
+
pin_memory=True,
|
| 325 |
+
num_workers=self.hparams.dataloader_num_workers,
|
| 326 |
+
collate_fn=self.collate_fn,
|
| 327 |
+
)
|
| 328 |
+
|
| 329 |
+
def val_dataloader(self):
|
| 330 |
+
sampler = torch.utils.data.distributed.DistributedSampler(
|
| 331 |
+
self.test_dataset, shuffle=False
|
| 332 |
+
)
|
| 333 |
+
return DataLoader(
|
| 334 |
+
self.test_dataset,
|
| 335 |
+
sampler=sampler,
|
| 336 |
+
shuffle=False,
|
| 337 |
+
batch_size=self.hparams.valid_batchsize,
|
| 338 |
+
pin_memory=True,
|
| 339 |
+
num_workers=self.hparams.dataloader_num_workers,
|
| 340 |
+
collate_fn=self.collate_fn,
|
| 341 |
+
)
|
| 342 |
+
|
| 343 |
+
def predict_dataloader(self):
|
| 344 |
+
sampler = torch.utils.data.distributed.DistributedSampler(
|
| 345 |
+
self.test_dataset, shuffle=False
|
| 346 |
+
)
|
| 347 |
+
return DataLoader(
|
| 348 |
+
self.test_dataset,
|
| 349 |
+
sampler=sampler,
|
| 350 |
+
shuffle=False,
|
| 351 |
+
batch_size=self.hparams.valid_batchsize,
|
| 352 |
+
pin_memory=True,
|
| 353 |
+
num_workers=self.hparams.dataloader_num_workers,
|
| 354 |
+
collate_fn=self.collate_fn,
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
if __name__ == "__main__":
|
| 359 |
+
# test
|
| 360 |
+
import argparse
|
| 361 |
+
|
| 362 |
+
total_parser = argparse.ArgumentParser("DATASET parser")
|
| 363 |
+
total_parser.add_argument(
|
| 364 |
+
"--tokenizer_type",
|
| 365 |
+
default="t5_tokenizer",
|
| 366 |
+
choices=["bert_tokenizer", "t5_tokenizer"],
|
| 367 |
+
)
|
| 368 |
+
total_parser.add_argument("--preprocessing_num_workers", default="10", type=int)
|
| 369 |
+
total_parser.add_argument(
|
| 370 |
+
"--new_vocab_path",
|
| 371 |
+
default="/cognitive_comp/hejunqing/projects/Dialog_pretrain/randeng_t5_newvocab_784M",
|
| 372 |
+
type=str,
|
| 373 |
+
)
|
| 374 |
+
total_parser.add_argument("--train_split_size", default=0.995, type=int)
|
| 375 |
+
total_parser.add_argument(
|
| 376 |
+
"--pretrained_model_path",
|
| 377 |
+
default="/cognitive_comp/hejunqing/projects/Dialog_pretrain/randeng_t5_newvocab_784M",
|
| 378 |
+
)
|
| 379 |
+
total_parser = DialogDataModel.add_data_specific_args(total_parser)
|
| 380 |
+
args = total_parser.parse_args()
|
| 381 |
+
dl = DialogDataModel(args)
|
| 382 |
+
|
| 383 |
+
for i in range(5):
|
| 384 |
+
for batch in dl.train_dataloader():
|
| 385 |
+
print(batch)
|
| 386 |
+
print(batch["input_ids"])
|
| 387 |
+
print(batch["token_types"])
|
| 388 |
+
print(batch["decoder_input_ids"])
|
| 389 |
+
print(batch["labels"])
|
| 390 |
+
|
| 391 |
+
print("test finish")
|
fengshen/data/taiyi_stable_diffusion_datasets/taiyi_datasets.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import Dataset, ConcatDataset
|
| 2 |
+
import os
|
| 3 |
+
from concurrent.futures import ProcessPoolExecutor
|
| 4 |
+
import pandas as pd
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def add_data_args(parent_args):
|
| 8 |
+
parser = parent_args.add_argument_group('taiyi stable diffusion data args')
|
| 9 |
+
# 支持传入多个路径,分别加载
|
| 10 |
+
parser.add_argument(
|
| 11 |
+
"--datasets_path", type=str, default=None, required=True, nargs='+',
|
| 12 |
+
help="A folder containing the training data of instance images.",
|
| 13 |
+
)
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"--datasets_type", type=str, default=None, required=True, choices=['txt', 'csv', 'fs_datasets'], nargs='+',
|
| 16 |
+
help="dataset type, txt or csv, same len as datasets_path",
|
| 17 |
+
)
|
| 18 |
+
parser.add_argument(
|
| 19 |
+
"--resolution", type=int, default=512,
|
| 20 |
+
help=(
|
| 21 |
+
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
|
| 22 |
+
" resolution"
|
| 23 |
+
),
|
| 24 |
+
)
|
| 25 |
+
parser.add_argument(
|
| 26 |
+
"--center_crop", action="store_true", default=False,
|
| 27 |
+
help="Whether to center crop images before resizing to resolution"
|
| 28 |
+
)
|
| 29 |
+
parser.add_argument("--thres", type=float, default=0.2)
|
| 30 |
+
return parent_args
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class TXTDataset(Dataset):
|
| 34 |
+
# 添加Txt数据集读取,主要是针对Zero23m数据集。
|
| 35 |
+
def __init__(self,
|
| 36 |
+
foloder_name,
|
| 37 |
+
thres=0.2):
|
| 38 |
+
super().__init__()
|
| 39 |
+
# print(f'Loading folder data from {foloder_name}.')
|
| 40 |
+
self.image_paths = []
|
| 41 |
+
'''
|
| 42 |
+
暂时没有开源这部分文件
|
| 43 |
+
score_data = pd.read_csv(os.path.join(foloder_name, 'score.csv'))
|
| 44 |
+
img_path2score = {score_data['image_path'][i]: score_data['score'][i]
|
| 45 |
+
for i in range(len(score_data))}
|
| 46 |
+
'''
|
| 47 |
+
# print(img_path2score)
|
| 48 |
+
# 这里都存的是地址,避免初始化时间过多。
|
| 49 |
+
for each_file in os.listdir(foloder_name):
|
| 50 |
+
if each_file.endswith('.jpg'):
|
| 51 |
+
self.image_paths.append(os.path.join(foloder_name, each_file))
|
| 52 |
+
|
| 53 |
+
# print('Done loading data. Len of images:', len(self.image_paths))
|
| 54 |
+
|
| 55 |
+
def __len__(self):
|
| 56 |
+
return len(self.image_paths)
|
| 57 |
+
|
| 58 |
+
def __getitem__(self, idx):
|
| 59 |
+
img_path = str(self.image_paths[idx])
|
| 60 |
+
caption_path = img_path.replace('.jpg', '.txt') # 图片名称和文本名称一致。
|
| 61 |
+
with open(caption_path, 'r') as f:
|
| 62 |
+
caption = f.read()
|
| 63 |
+
return {'img_path': img_path, 'caption': caption}
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# NOTE 加速读取数据,直接用原版的,在外部使用并行读取策略。30min->3min
|
| 67 |
+
class CSVDataset(Dataset):
|
| 68 |
+
def __init__(self,
|
| 69 |
+
input_filename,
|
| 70 |
+
image_root,
|
| 71 |
+
img_key,
|
| 72 |
+
caption_key,
|
| 73 |
+
thres=0.2):
|
| 74 |
+
super().__init__()
|
| 75 |
+
# logging.debug(f'Loading csv data from {input_filename}.')
|
| 76 |
+
print(f'Loading csv data from {input_filename}.')
|
| 77 |
+
self.images = []
|
| 78 |
+
self.captions = []
|
| 79 |
+
|
| 80 |
+
if input_filename.endswith('.csv'):
|
| 81 |
+
# print(f"Load Data from{input_filename}")
|
| 82 |
+
df = pd.read_csv(input_filename, index_col=0, on_bad_lines='skip')
|
| 83 |
+
print(f'file {input_filename} datalen {len(df)}')
|
| 84 |
+
# 这个图片的路径也需要根据数据集的结构稍微做点修改
|
| 85 |
+
self.images.extend(df[img_key].tolist())
|
| 86 |
+
self.captions.extend(df[caption_key].tolist())
|
| 87 |
+
self.image_root = image_root
|
| 88 |
+
|
| 89 |
+
def __len__(self):
|
| 90 |
+
return len(self.images)
|
| 91 |
+
|
| 92 |
+
def __getitem__(self, idx):
|
| 93 |
+
img_path = os.path.join(self.image_root, str(self.images[idx]))
|
| 94 |
+
return {'img_path': img_path, 'caption': self.captions[idx]}
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def if_final_dir(path: str) -> bool:
|
| 98 |
+
# 如果当前目录有一个文件,那就算是终极目录
|
| 99 |
+
for f in os.scandir(path):
|
| 100 |
+
if f.is_file():
|
| 101 |
+
return True
|
| 102 |
+
return False
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def process_pool_read_txt_dataset(args,
|
| 106 |
+
input_root=None,
|
| 107 |
+
thres=0.2):
|
| 108 |
+
p = ProcessPoolExecutor(max_workers=20)
|
| 109 |
+
all_datasets = []
|
| 110 |
+
res = []
|
| 111 |
+
|
| 112 |
+
# 遍历该目录下所有的子目录
|
| 113 |
+
def traversal_files(path: str):
|
| 114 |
+
list_subfolders_with_paths = [f.path for f in os.scandir(path) if f.is_dir()]
|
| 115 |
+
for dir_path in list_subfolders_with_paths:
|
| 116 |
+
if if_final_dir(dir_path):
|
| 117 |
+
res.append(p.submit(TXTDataset,
|
| 118 |
+
dir_path,
|
| 119 |
+
thres))
|
| 120 |
+
else:
|
| 121 |
+
traversal_files(dir_path)
|
| 122 |
+
traversal_files(input_root)
|
| 123 |
+
p.shutdown()
|
| 124 |
+
for future in res:
|
| 125 |
+
all_datasets.append(future.result())
|
| 126 |
+
dataset = ConcatDataset(all_datasets)
|
| 127 |
+
return dataset
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def process_pool_read_csv_dataset(args,
|
| 131 |
+
input_root,
|
| 132 |
+
thres=0.20):
|
| 133 |
+
# here input_filename is a directory containing a CSV file
|
| 134 |
+
all_csvs = os.listdir(os.path.join(input_root, 'release'))
|
| 135 |
+
image_root = os.path.join(input_root, 'images')
|
| 136 |
+
# csv_with_score = [each for each in all_csvs if 'score' in each]
|
| 137 |
+
all_datasets = []
|
| 138 |
+
res = []
|
| 139 |
+
p = ProcessPoolExecutor(max_workers=150)
|
| 140 |
+
for path in all_csvs:
|
| 141 |
+
each_csv_path = os.path.join(input_root, 'release', path)
|
| 142 |
+
res.append(p.submit(CSVDataset,
|
| 143 |
+
each_csv_path,
|
| 144 |
+
image_root,
|
| 145 |
+
img_key="name",
|
| 146 |
+
caption_key="caption",
|
| 147 |
+
thres=thres))
|
| 148 |
+
p.shutdown()
|
| 149 |
+
for future in res:
|
| 150 |
+
all_datasets.append(future.result())
|
| 151 |
+
dataset = ConcatDataset(all_datasets)
|
| 152 |
+
return dataset
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def load_data(args, global_rank=0):
|
| 156 |
+
assert len(args.datasets_path) == len(args.datasets_type), \
|
| 157 |
+
"datasets_path num not equal to datasets_type"
|
| 158 |
+
all_datasets = []
|
| 159 |
+
for path, type in zip(args.datasets_path, args.datasets_type):
|
| 160 |
+
if type == 'txt':
|
| 161 |
+
all_datasets.append(process_pool_read_txt_dataset(
|
| 162 |
+
args, input_root=path, thres=args.thres))
|
| 163 |
+
elif type == 'csv':
|
| 164 |
+
all_datasets.append(process_pool_read_csv_dataset(
|
| 165 |
+
args, input_root=path, thres=args.thres))
|
| 166 |
+
elif type == 'fs_datasets':
|
| 167 |
+
from fengshen.data.fs_datasets import load_dataset
|
| 168 |
+
all_datasets.append(load_dataset(path, num_proc=args.num_workers,
|
| 169 |
+
thres=args.thres, global_rank=global_rank)['train'])
|
| 170 |
+
else:
|
| 171 |
+
raise ValueError('unsupport dataset type: %s' % type)
|
| 172 |
+
print(f'load datasset {type} {path} len {len(all_datasets[-1])}')
|
| 173 |
+
return {'train': ConcatDataset(all_datasets)}
|
fengshen/data/task_dataloader/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
from .task_datasets import LCSTSDataModel, LCSTSDataset
|
| 3 |
+
__all__ = ['LCSTSDataModel', 'LCSTSDataset']
|
fengshen/data/task_dataloader/medicalQADataset.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf8
|
| 2 |
+
import os
|
| 3 |
+
import pytorch_lightning as pl
|
| 4 |
+
from torch.utils.data import DataLoader, Dataset
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from transformers import AutoTokenizer
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class GPT2QADataset(Dataset):
|
| 10 |
+
'''
|
| 11 |
+
Dataset Used for yuyuan medical qa task.
|
| 12 |
+
Just surpport small datasets, when deal with large datasets it may be slowly.
|
| 13 |
+
for large datasets please use mmapdatasets(doing)
|
| 14 |
+
'''
|
| 15 |
+
|
| 16 |
+
def __init__(self, data_path, name, args):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.tokenizer = AutoTokenizer.from_pretrained(
|
| 19 |
+
args.pretrained_model_path)
|
| 20 |
+
if self.tokenizer.pad_token is None:
|
| 21 |
+
self.tokenizer.add_special_tokens({'pad_token': '<|endoftext|>'})
|
| 22 |
+
self.data_size = os.path.getsize(data_path)/1024/1024/1024
|
| 23 |
+
self.data_type_name = name
|
| 24 |
+
self.data = self.load_data(data_path)
|
| 25 |
+
self.max_seq_length = args.max_seq_length
|
| 26 |
+
|
| 27 |
+
def __len__(self):
|
| 28 |
+
return len(self.data)
|
| 29 |
+
|
| 30 |
+
def __getitem__(self, index):
|
| 31 |
+
return self.encode(self.data[index])
|
| 32 |
+
|
| 33 |
+
def load_data(self, data_path):
|
| 34 |
+
# 有进度条展示
|
| 35 |
+
if self.data_size <= 5:
|
| 36 |
+
with open(data_path, "rt", encoding='utf8') as f:
|
| 37 |
+
lines = f.readlines()
|
| 38 |
+
total_num = len(lines)
|
| 39 |
+
data_gen = lines
|
| 40 |
+
else:
|
| 41 |
+
data_gen = open(data_path, "rt", encoding='utf8')
|
| 42 |
+
total_num = None
|
| 43 |
+
|
| 44 |
+
data = []
|
| 45 |
+
with tqdm(total=total_num, desc=f'{self.data_type_name}处理进度', mininterval=0.3) as bar:
|
| 46 |
+
for idx, line in enumerate(data_gen):
|
| 47 |
+
data.append(self.data_parse(line))
|
| 48 |
+
bar.update()
|
| 49 |
+
|
| 50 |
+
if self.data_size > 5:
|
| 51 |
+
data_gen.close()
|
| 52 |
+
return data
|
| 53 |
+
|
| 54 |
+
def data_parse(self, line):
|
| 55 |
+
"""
|
| 56 |
+
解析不同格式的数据
|
| 57 |
+
"""
|
| 58 |
+
dic = eval(line.strip())
|
| 59 |
+
return dic
|
| 60 |
+
|
| 61 |
+
def encode(self, item):
|
| 62 |
+
"""
|
| 63 |
+
将数据转换成模型训练的输入
|
| 64 |
+
"""
|
| 65 |
+
inputs_dict = self.tokenizer.encode_plus(item['Question']+item['answer'],
|
| 66 |
+
max_length=self.max_seq_length, padding='max_length',
|
| 67 |
+
truncation=True, return_tensors='pt')
|
| 68 |
+
target = inputs_dict['input_ids']
|
| 69 |
+
labels = target.clone().detach()
|
| 70 |
+
labels[target == self.tokenizer.pad_token_id] = -100
|
| 71 |
+
return {
|
| 72 |
+
"input_ids": inputs_dict['input_ids'].squeeze(),
|
| 73 |
+
"attention_mask": inputs_dict['attention_mask'].squeeze(),
|
| 74 |
+
"labels": labels.squeeze(),
|
| 75 |
+
"question": item['Question'],
|
| 76 |
+
"answer": item['answer']
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class GPT2QADataModel(pl.LightningDataModule):
|
| 81 |
+
@staticmethod
|
| 82 |
+
def add_data_specific_args(parent_args):
|
| 83 |
+
parser = parent_args.add_argument_group('GPT2QADataModel')
|
| 84 |
+
parser.add_argument('--data_dir', type=str, required=True)
|
| 85 |
+
parser.add_argument('--num_workers', default=2, type=int)
|
| 86 |
+
parser.add_argument('--train_data', default='train.txt', type=str)
|
| 87 |
+
parser.add_argument('--valid_data', default='valid.txt', type=str)
|
| 88 |
+
parser.add_argument('--test_data', default='test.txt', type=str)
|
| 89 |
+
parser.add_argument('--train_batchsize', type=int, required=True)
|
| 90 |
+
parser.add_argument('--valid_batchsize', type=int, required=True)
|
| 91 |
+
parser.add_argument('--max_seq_length', default=1024, type=int)
|
| 92 |
+
return parent_args
|
| 93 |
+
|
| 94 |
+
def __init__(self, args):
|
| 95 |
+
super().__init__()
|
| 96 |
+
self.args = args
|
| 97 |
+
self.train_batchsize = args.train_batchsize
|
| 98 |
+
self.valid_batchsize = args.valid_batchsize
|
| 99 |
+
if not args.do_eval_only:
|
| 100 |
+
self.train_data = GPT2QADataset(os.path.join(
|
| 101 |
+
args.data_dir, args.train_data), '训练集', args)
|
| 102 |
+
self.valid_data = GPT2QADataset(os.path.join(
|
| 103 |
+
args.data_dir, args.valid_data), '验证集', args)
|
| 104 |
+
self.test_data = GPT2QADataset(os.path.join(
|
| 105 |
+
args.data_dir, args.test_data), '测试集', args)
|
| 106 |
+
|
| 107 |
+
def train_dataloader(self):
|
| 108 |
+
return DataLoader(
|
| 109 |
+
self.train_data, shuffle=True,
|
| 110 |
+
batch_size=self.train_batchsize,
|
| 111 |
+
pin_memory=False, num_workers=self.args.num_workers)
|
| 112 |
+
|
| 113 |
+
def val_dataloader(self):
|
| 114 |
+
return DataLoader(self.valid_data, shuffle=False,
|
| 115 |
+
batch_size=self.valid_batchsize,
|
| 116 |
+
pin_memory=False, num_workers=self.args.num_workers)
|
| 117 |
+
|
| 118 |
+
def predict_dataloader(self):
|
| 119 |
+
return DataLoader(self.test_data, shuffle=False,
|
| 120 |
+
batch_size=self.valid_batchsize, pin_memory=False,
|
| 121 |
+
num_workers=self.args.num_workers)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
if __name__ == '__main__':
|
| 125 |
+
import argparse
|
| 126 |
+
modelfile = '/cognitive_comp/wuziwei/pretrained_model_hf/medical_v2'
|
| 127 |
+
datafile = '/cognitive_comp/wuziwei/task-data/medical_qa/medical_qa_train.txt'
|
| 128 |
+
parser = argparse.ArgumentParser(description='hf test', allow_abbrev=False)
|
| 129 |
+
group = parser.add_argument_group(title='test args')
|
| 130 |
+
group.add_argument('--pretrained-model-path', type=str, default=modelfile,
|
| 131 |
+
help='Number of transformer layers.')
|
| 132 |
+
group.add_argument('--max-seq-length', type=int, default=1024)
|
| 133 |
+
args = parser.parse_args()
|
| 134 |
+
|
| 135 |
+
testml = GPT2QADataset(datafile, 'medical_qa', args=args)
|
| 136 |
+
|
| 137 |
+
print(testml[10])
|
fengshen/data/task_dataloader/task_datasets.py
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf8
|
| 2 |
+
from torch.utils.data import Dataset, DataLoader
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
from transformers import AutoTokenizer
|
| 5 |
+
import json
|
| 6 |
+
import torch
|
| 7 |
+
import pytorch_lightning as pl
|
| 8 |
+
import os
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class AbstractCollator:
|
| 12 |
+
"""
|
| 13 |
+
collector for summary task
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, tokenizer, max_enc_length, max_dec_length, prompt):
|
| 17 |
+
self.tokenizer = tokenizer
|
| 18 |
+
self.max_enc_length = max_enc_length
|
| 19 |
+
self.max_dec_length = max_dec_length
|
| 20 |
+
self.prompt = prompt
|
| 21 |
+
|
| 22 |
+
def __call__(self, samples):
|
| 23 |
+
|
| 24 |
+
labels = []
|
| 25 |
+
attn_mask = []
|
| 26 |
+
# decoder_attn_mask = []
|
| 27 |
+
source_inputs = []
|
| 28 |
+
for sample in samples:
|
| 29 |
+
encode_dict = self.tokenizer.encode_plus(
|
| 30 |
+
self.prompt + sample['text'],
|
| 31 |
+
max_length=self.max_enc_length,
|
| 32 |
+
padding='max_length',
|
| 33 |
+
truncation=True,
|
| 34 |
+
return_tensors='pt')
|
| 35 |
+
decode_dict = self.tokenizer.encode_plus(
|
| 36 |
+
sample['summary'],
|
| 37 |
+
max_length=self.max_dec_length,
|
| 38 |
+
padding='max_length',
|
| 39 |
+
truncation=True,
|
| 40 |
+
return_tensors='pt')
|
| 41 |
+
source_inputs.append(encode_dict['input_ids'].squeeze())
|
| 42 |
+
labels.append(decode_dict['input_ids'].squeeze())
|
| 43 |
+
attn_mask.append(encode_dict['attention_mask'].squeeze())
|
| 44 |
+
# decoder_attn_mask.append(decode_dict['attention_mask'].squeeze())
|
| 45 |
+
# labels = torch.tensor(decode_dict['input'])
|
| 46 |
+
|
| 47 |
+
source_inputs = torch.stack(source_inputs)
|
| 48 |
+
labels = torch.stack(labels)
|
| 49 |
+
attn_mask = torch.stack(attn_mask)
|
| 50 |
+
# decoder_attn_mask = torch.stack(decoder_attn_mask)
|
| 51 |
+
# decode_input_idxs = shift_tokens_right(labels, self.tokenizer.pad_token_id, self.tokenizer.pad_token_id)
|
| 52 |
+
end_token_index = torch.where(labels == self.tokenizer.eos_token_id)[1]
|
| 53 |
+
for idx, end_idx in enumerate(end_token_index):
|
| 54 |
+
labels[idx][end_idx + 1:] = -100
|
| 55 |
+
|
| 56 |
+
return {
|
| 57 |
+
"input_ids": source_inputs,
|
| 58 |
+
"attention_mask": attn_mask,
|
| 59 |
+
"labels": labels,
|
| 60 |
+
"text": [sample['text'] for sample in samples],
|
| 61 |
+
"summary": [sample['summary'] for sample in samples]
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class LCSTSDataset(Dataset):
|
| 66 |
+
'''
|
| 67 |
+
Dataset Used for LCSTS summary task.
|
| 68 |
+
'''
|
| 69 |
+
|
| 70 |
+
def __init__(self, data_path, args):
|
| 71 |
+
super().__init__()
|
| 72 |
+
self.tokenizer = AutoTokenizer.from_pretrained(
|
| 73 |
+
args.pretrained_model_path, use_fast=False)
|
| 74 |
+
self.data = self.load_data(data_path)
|
| 75 |
+
self.prompt = args.prompt
|
| 76 |
+
self.max_enc_length = args.max_enc_length
|
| 77 |
+
self.max_dec_length = args.max_dec_length
|
| 78 |
+
|
| 79 |
+
def __len__(self):
|
| 80 |
+
return len(self.data)
|
| 81 |
+
|
| 82 |
+
def __getitem__(self, index):
|
| 83 |
+
return self.encode(self.data[index])
|
| 84 |
+
|
| 85 |
+
def load_data(self, data_path):
|
| 86 |
+
with open(data_path, "r", encoding='utf8') as f:
|
| 87 |
+
lines = f.readlines()
|
| 88 |
+
samples = []
|
| 89 |
+
for line in tqdm(lines):
|
| 90 |
+
obj = json.loads(line)
|
| 91 |
+
source = obj['text']
|
| 92 |
+
target = obj['summary']
|
| 93 |
+
samples.append({
|
| 94 |
+
"text": source,
|
| 95 |
+
"summary": target
|
| 96 |
+
})
|
| 97 |
+
return samples
|
| 98 |
+
|
| 99 |
+
def cal_data(self, data_path):
|
| 100 |
+
with open(data_path, "r", encoding='utf8') as f:
|
| 101 |
+
lines = f.readlines()
|
| 102 |
+
samples = []
|
| 103 |
+
enc_sizes = []
|
| 104 |
+
dec_sizes = []
|
| 105 |
+
for line in tqdm(lines):
|
| 106 |
+
obj = json.loads(line.strip())
|
| 107 |
+
source = obj['text']
|
| 108 |
+
target = obj['summary']
|
| 109 |
+
enc_input_ids = self.tokenizer.encode(source)
|
| 110 |
+
target = self.tokenizer.encode(target)
|
| 111 |
+
enc_sizes.append(len(enc_input_ids))
|
| 112 |
+
dec_sizes.append(len(target)-1)
|
| 113 |
+
samples.append({
|
| 114 |
+
"enc_input_ids": enc_input_ids,
|
| 115 |
+
"dec_input_ids": target[:-1],
|
| 116 |
+
"label_ids": target[1:]
|
| 117 |
+
})
|
| 118 |
+
max_enc_len = max(enc_sizes)
|
| 119 |
+
max_dec_len = max(dec_sizes)
|
| 120 |
+
import numpy as np
|
| 121 |
+
# mean of len(enc_input_ids): 74.68041911345998
|
| 122 |
+
# mean of len(dec_input_ids): 14.02265483791283
|
| 123 |
+
# max of len(enc_input_ids): 132
|
| 124 |
+
# max of len(dec_input_ids): 31
|
| 125 |
+
print('mean of len(enc_input_ids):', np.mean(enc_sizes),
|
| 126 |
+
'mean of len(dec_input_ids):', np.mean(dec_sizes),
|
| 127 |
+
'max of len(enc_input_ids):', max_enc_len,
|
| 128 |
+
'max of len(dec_input_ids):', max_dec_len)
|
| 129 |
+
return samples
|
| 130 |
+
|
| 131 |
+
def encode(self, item):
|
| 132 |
+
encode_dict = self.tokenizer.encode_plus(
|
| 133 |
+
self.prompt + item['text'],
|
| 134 |
+
max_length=self.max_enc_length,
|
| 135 |
+
padding='max_length',
|
| 136 |
+
truncation=True,
|
| 137 |
+
return_tensors='pt')
|
| 138 |
+
decode_dict = self.tokenizer.encode_plus(
|
| 139 |
+
item['summary'],
|
| 140 |
+
max_length=self.max_dec_length,
|
| 141 |
+
padding='max_length',
|
| 142 |
+
truncation=True)
|
| 143 |
+
|
| 144 |
+
target = decode_dict['input_ids']
|
| 145 |
+
# print('encode_dict shape:', encode_dict['input_ids'].shape)
|
| 146 |
+
labels = torch.tensor(target)
|
| 147 |
+
labels[target == self.tokenizer.pad_token_id] = -100
|
| 148 |
+
return {
|
| 149 |
+
"input_ids": encode_dict['input_ids'].squeeze(),
|
| 150 |
+
"attention_mask": encode_dict['attention_mask'].squeeze(),
|
| 151 |
+
"labels": labels.squeeze(),
|
| 152 |
+
"text": item['text'],
|
| 153 |
+
"summary": item['summary']
|
| 154 |
+
}
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
class LCSTSDataModel(pl.LightningDataModule):
|
| 158 |
+
@staticmethod
|
| 159 |
+
def add_data_specific_args(parent_args):
|
| 160 |
+
parser = parent_args.add_argument_group('LCSTSDataModel')
|
| 161 |
+
parser.add_argument(
|
| 162 |
+
'--data_dir', default='/cognitive_comp/ganruyi/data_datasets_LCSTS_LCSTS/', type=str)
|
| 163 |
+
parser.add_argument('--num_workers', default=8, type=int)
|
| 164 |
+
parser.add_argument('--train_data', default='train.jsonl', type=str)
|
| 165 |
+
parser.add_argument('--valid_data', default='valid.jsonl', type=str)
|
| 166 |
+
parser.add_argument('--test_data', default='test_public.jsonl', type=str)
|
| 167 |
+
parser.add_argument('--train_batchsize', default=128, type=int)
|
| 168 |
+
parser.add_argument('--valid_batchsize', default=128, type=int)
|
| 169 |
+
parser.add_argument('--max_enc_length', default=128, type=int)
|
| 170 |
+
parser.add_argument('--max_dec_length', default=30, type=int)
|
| 171 |
+
parser.add_argument('--prompt', default='summarize:', type=str)
|
| 172 |
+
return parent_args
|
| 173 |
+
|
| 174 |
+
def __init__(self, args):
|
| 175 |
+
super().__init__()
|
| 176 |
+
self.args = args
|
| 177 |
+
self.train_batchsize = args.train_batchsize
|
| 178 |
+
self.valid_batchsize = args.valid_batchsize
|
| 179 |
+
if not args.do_eval_only:
|
| 180 |
+
self.train_data = LCSTSDataset(os.path.join(
|
| 181 |
+
args.data_dir, args.train_data), args)
|
| 182 |
+
self.valid_data = LCSTSDataset(os.path.join(
|
| 183 |
+
args.data_dir, args.valid_data), args)
|
| 184 |
+
self.test_data = LCSTSDataset(os.path.join(
|
| 185 |
+
args.data_dir, args.test_data), args)
|
| 186 |
+
|
| 187 |
+
def train_dataloader(self):
|
| 188 |
+
return DataLoader(self.train_data,
|
| 189 |
+
shuffle=True,
|
| 190 |
+
batch_size=self.train_batchsize,
|
| 191 |
+
pin_memory=False,
|
| 192 |
+
num_workers=self.args.num_workers)
|
| 193 |
+
|
| 194 |
+
def val_dataloader(self):
|
| 195 |
+
return DataLoader(self.valid_data,
|
| 196 |
+
shuffle=False,
|
| 197 |
+
batch_size=self.valid_batchsize,
|
| 198 |
+
pin_memory=False,
|
| 199 |
+
num_workers=self.args.num_workers)
|
| 200 |
+
|
| 201 |
+
def predict_dataloader(self):
|
| 202 |
+
return DataLoader(self.test_data,
|
| 203 |
+
shuffle=False,
|
| 204 |
+
batch_size=self.valid_batchsize,
|
| 205 |
+
pin_memory=False,
|
| 206 |
+
num_workers=self.args.num_workers)
|
fengshen/data/universal_datamodule/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .universal_datamodule import UniversalDataModule
|
| 2 |
+
from .universal_sampler import PretrainingSampler, PretrainingRandomSampler
|
| 3 |
+
|
| 4 |
+
__all__ = ['UniversalDataModule', 'PretrainingSampler', 'PretrainingRandomSampler']
|
fengshen/data/universal_datamodule/universal_datamodule.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pytorch_lightning import LightningDataModule
|
| 2 |
+
from typing import Optional
|
| 3 |
+
|
| 4 |
+
from torch.utils.data import DataLoader, DistributedSampler
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def get_consume_samples(data_model: LightningDataModule) -> int:
|
| 8 |
+
if hasattr(data_model.trainer.lightning_module, 'consumed_samples'):
|
| 9 |
+
consumed_samples = data_model.trainer.lightning_module.consumed_samples
|
| 10 |
+
print('get consumed samples from model: {}'.format(consumed_samples))
|
| 11 |
+
else:
|
| 12 |
+
world_size = data_model.trainer.world_size
|
| 13 |
+
consumed_samples = max(0, data_model.trainer.global_step - 1) * \
|
| 14 |
+
data_model.hparams.train_batchsize * world_size * data_model.trainer.accumulate_grad_batches
|
| 15 |
+
print('calculate consumed samples: {}'.format(consumed_samples))
|
| 16 |
+
return consumed_samples
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class UniversalDataModule(LightningDataModule):
|
| 20 |
+
@ staticmethod
|
| 21 |
+
def add_data_specific_args(parent_args):
|
| 22 |
+
parser = parent_args.add_argument_group('Universal DataModule')
|
| 23 |
+
parser.add_argument('--num_workers', default=8, type=int)
|
| 24 |
+
parser.add_argument('--dataloader_workers', default=2, type=int)
|
| 25 |
+
parser.add_argument('--train_batchsize', default=16, type=int)
|
| 26 |
+
parser.add_argument('--val_batchsize', default=16, type=int)
|
| 27 |
+
parser.add_argument('--test_batchsize', default=16, type=int)
|
| 28 |
+
parser.add_argument('--datasets_name', type=str, default=None)
|
| 29 |
+
parser.add_argument('--train_datasets_field', type=str, default='train')
|
| 30 |
+
parser.add_argument('--val_datasets_field', type=str, default='validation')
|
| 31 |
+
parser.add_argument('--test_datasets_field', type=str, default='test')
|
| 32 |
+
parser.add_argument('--train_file', type=str, default=None)
|
| 33 |
+
parser.add_argument('--val_file', type=str, default=None)
|
| 34 |
+
parser.add_argument('--test_file', type=str, default=None)
|
| 35 |
+
parser.add_argument('--raw_file_type', type=str, default='json')
|
| 36 |
+
parser.add_argument('--sampler_type', type=str,
|
| 37 |
+
choices=['single',
|
| 38 |
+
'random'],
|
| 39 |
+
default='random')
|
| 40 |
+
return parent_args
|
| 41 |
+
|
| 42 |
+
def __init__(
|
| 43 |
+
self,
|
| 44 |
+
tokenizer,
|
| 45 |
+
collate_fn,
|
| 46 |
+
args,
|
| 47 |
+
datasets=None,
|
| 48 |
+
**kwargs,
|
| 49 |
+
):
|
| 50 |
+
super().__init__()
|
| 51 |
+
# 如果不传入datasets的名字,则可以在对象外部替换内部的datasets为模型需要的
|
| 52 |
+
if datasets is not None:
|
| 53 |
+
self.datasets = datasets
|
| 54 |
+
elif args.datasets_name is not None:
|
| 55 |
+
from fengshen.data.fs_datasets import load_dataset
|
| 56 |
+
print('---------begin to load datasets {}'.format(args.datasets_name))
|
| 57 |
+
self.datasets = load_dataset(
|
| 58 |
+
args.datasets_name, num_proc=args.num_workers)
|
| 59 |
+
print('---------ending load datasets {}'.format(args.datasets_name))
|
| 60 |
+
else:
|
| 61 |
+
print('---------begin to load datasets from local file')
|
| 62 |
+
from datasets import load_dataset
|
| 63 |
+
self.datasets = load_dataset(args.raw_file_type,
|
| 64 |
+
data_files={
|
| 65 |
+
args.train_datasets_field: args.train_file,
|
| 66 |
+
args.val_datasets_field: args.val_file,
|
| 67 |
+
args.test_datasets_field: args.test_file})
|
| 68 |
+
print('---------end to load datasets from local file')
|
| 69 |
+
|
| 70 |
+
self.tokenizer = tokenizer
|
| 71 |
+
self.collate_fn = collate_fn
|
| 72 |
+
self.save_hyperparameters(args)
|
| 73 |
+
|
| 74 |
+
def get_custom_sampler(self, ds):
|
| 75 |
+
from .universal_sampler import PretrainingRandomSampler
|
| 76 |
+
from .universal_sampler import PretrainingSampler
|
| 77 |
+
world_size = self.trainer.world_size
|
| 78 |
+
consumed_samples = get_consume_samples(self)
|
| 79 |
+
# use the user default sampler
|
| 80 |
+
if self.hparams.sampler_type == 'random':
|
| 81 |
+
return PretrainingRandomSampler(
|
| 82 |
+
total_samples=len(ds),
|
| 83 |
+
# consumed_samples cal by global steps
|
| 84 |
+
consumed_samples=consumed_samples,
|
| 85 |
+
micro_batch_size=self.hparams.train_batchsize,
|
| 86 |
+
data_parallel_rank=self.trainer.global_rank,
|
| 87 |
+
data_parallel_size=world_size,
|
| 88 |
+
epoch=self.trainer.current_epoch,
|
| 89 |
+
)
|
| 90 |
+
elif self.hparams.sampler_type == 'single':
|
| 91 |
+
return PretrainingSampler(
|
| 92 |
+
total_samples=len(ds),
|
| 93 |
+
# consumed_samples cal by global steps
|
| 94 |
+
consumed_samples=consumed_samples,
|
| 95 |
+
micro_batch_size=self.hparams.train_batchsize,
|
| 96 |
+
data_parallel_rank=self.trainer.global_rank,
|
| 97 |
+
data_parallel_size=world_size,
|
| 98 |
+
)
|
| 99 |
+
else:
|
| 100 |
+
raise Exception('Unknown sampler type: {}'.format(self.hparams.sampler_type))
|
| 101 |
+
|
| 102 |
+
def setup(self, stage: Optional[str] = None) -> None:
|
| 103 |
+
return
|
| 104 |
+
|
| 105 |
+
def train_dataloader(self):
|
| 106 |
+
ds = self.datasets[self.hparams.train_datasets_field]
|
| 107 |
+
|
| 108 |
+
collate_fn = self.collate_fn
|
| 109 |
+
if hasattr(ds, 'collate_fn'):
|
| 110 |
+
collate_fn = ds.collate_fn
|
| 111 |
+
|
| 112 |
+
if self.hparams.replace_sampler_ddp is False:
|
| 113 |
+
return DataLoader(
|
| 114 |
+
ds,
|
| 115 |
+
batch_sampler=self.get_custom_sampler(ds),
|
| 116 |
+
num_workers=self.hparams.dataloader_workers,
|
| 117 |
+
collate_fn=collate_fn,
|
| 118 |
+
pin_memory=True,
|
| 119 |
+
)
|
| 120 |
+
return DataLoader(
|
| 121 |
+
ds,
|
| 122 |
+
batch_size=self.hparams.train_batchsize,
|
| 123 |
+
num_workers=self.hparams.dataloader_workers,
|
| 124 |
+
collate_fn=collate_fn,
|
| 125 |
+
pin_memory=True,
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
def val_dataloader(self):
|
| 129 |
+
ds = self.datasets[self.hparams.val_datasets_field]
|
| 130 |
+
collate_fn = self.collate_fn
|
| 131 |
+
if hasattr(ds, 'collate_fn'):
|
| 132 |
+
collate_fn = ds.collate_fn
|
| 133 |
+
|
| 134 |
+
return DataLoader(
|
| 135 |
+
ds,
|
| 136 |
+
batch_size=self.hparams.val_batchsize,
|
| 137 |
+
shuffle=False,
|
| 138 |
+
num_workers=self.hparams.dataloader_workers,
|
| 139 |
+
collate_fn=collate_fn,
|
| 140 |
+
sampler=DistributedSampler(
|
| 141 |
+
ds, shuffle=False),
|
| 142 |
+
pin_memory=True,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
# return DataLoader(
|
| 146 |
+
# ds, shuffle=False, batch_size=self.hparams.val_batchsize, pin_memory=False, collate_fn=collate_fn,
|
| 147 |
+
# )
|
| 148 |
+
|
| 149 |
+
def test_dataloader(self):
|
| 150 |
+
ds = self.datasets[self.hparams.test_datasets_field]
|
| 151 |
+
|
| 152 |
+
collate_fn = self.collate_fn
|
| 153 |
+
if collate_fn is None and hasattr(ds, 'collater'):
|
| 154 |
+
collate_fn = ds.collater
|
| 155 |
+
|
| 156 |
+
return DataLoader(
|
| 157 |
+
ds,
|
| 158 |
+
batch_size=self.hparams.test_batchsize,
|
| 159 |
+
shuffle=False,
|
| 160 |
+
num_workers=self.hparams.dataloader_workers,
|
| 161 |
+
collate_fn=collate_fn,
|
| 162 |
+
sampler=DistributedSampler(
|
| 163 |
+
ds, shuffle=False),
|
| 164 |
+
pin_memory=True,
|
| 165 |
+
)
|
fengshen/data/universal_datamodule/universal_sampler.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
"""Dataloaders."""
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class PretrainingSampler:
|
| 23 |
+
|
| 24 |
+
def __init__(self, total_samples, consumed_samples, micro_batch_size,
|
| 25 |
+
data_parallel_rank, data_parallel_size, drop_last=True):
|
| 26 |
+
# Keep a copy of input params for later use.
|
| 27 |
+
self.total_samples = total_samples
|
| 28 |
+
self.consumed_samples = consumed_samples
|
| 29 |
+
self.micro_batch_size = micro_batch_size
|
| 30 |
+
self.data_parallel_rank = data_parallel_rank
|
| 31 |
+
self.micro_batch_times_data_parallel_size = \
|
| 32 |
+
self.micro_batch_size * data_parallel_size
|
| 33 |
+
self.drop_last = drop_last
|
| 34 |
+
|
| 35 |
+
# Sanity checks.
|
| 36 |
+
assert self.total_samples > 0, \
|
| 37 |
+
'no sample to consume: {}'.format(self.total_samples)
|
| 38 |
+
assert self.consumed_samples < self.total_samples, \
|
| 39 |
+
'no samples left to consume: {}, {}'.format(self.consumed_samples,
|
| 40 |
+
self.total_samples)
|
| 41 |
+
assert self.micro_batch_size > 0
|
| 42 |
+
assert data_parallel_size > 0
|
| 43 |
+
assert self.data_parallel_rank < data_parallel_size, \
|
| 44 |
+
'data_parallel_rank should be smaller than data size: {}, ' \
|
| 45 |
+
'{}'.format(self.data_parallel_rank, data_parallel_size)
|
| 46 |
+
|
| 47 |
+
def __len__(self):
|
| 48 |
+
return self.total_samples // self.micro_batch_times_data_parallel_size
|
| 49 |
+
|
| 50 |
+
def get_start_end_idx(self):
|
| 51 |
+
start_idx = self.data_parallel_rank * self.micro_batch_size
|
| 52 |
+
end_idx = start_idx + self.micro_batch_size
|
| 53 |
+
return start_idx, end_idx
|
| 54 |
+
|
| 55 |
+
def __iter__(self):
|
| 56 |
+
batch = []
|
| 57 |
+
# Last batch will be dropped if drop_last is not set False
|
| 58 |
+
for idx in range(self.consumed_samples, self.total_samples):
|
| 59 |
+
batch.append(idx)
|
| 60 |
+
if len(batch) == self.micro_batch_times_data_parallel_size:
|
| 61 |
+
start_idx, end_idx = self.get_start_end_idx()
|
| 62 |
+
yield batch[start_idx:end_idx]
|
| 63 |
+
batch = []
|
| 64 |
+
|
| 65 |
+
# Check the last partial batch and see drop_last is set
|
| 66 |
+
if len(batch) > 0 and not self.drop_last:
|
| 67 |
+
start_idx, end_idx = self.get_start_end_idx()
|
| 68 |
+
yield batch[start_idx:end_idx]
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class PretrainingRandomSampler:
|
| 72 |
+
|
| 73 |
+
def __init__(self, total_samples, consumed_samples, micro_batch_size,
|
| 74 |
+
data_parallel_rank, data_parallel_size, epoch):
|
| 75 |
+
# Keep a copy of input params for later use.
|
| 76 |
+
self.total_samples = total_samples
|
| 77 |
+
self.consumed_samples = consumed_samples
|
| 78 |
+
self.micro_batch_size = micro_batch_size
|
| 79 |
+
self.data_parallel_rank = data_parallel_rank
|
| 80 |
+
self.data_parallel_size = data_parallel_size
|
| 81 |
+
self.micro_batch_times_data_parallel_size = \
|
| 82 |
+
self.micro_batch_size * data_parallel_size
|
| 83 |
+
self.last_batch_size = \
|
| 84 |
+
self.total_samples % self.micro_batch_times_data_parallel_size
|
| 85 |
+
self.epoch = epoch
|
| 86 |
+
|
| 87 |
+
# Sanity checks.
|
| 88 |
+
assert self.total_samples > 0, \
|
| 89 |
+
'no sample to consume: {}'.format(self.total_samples)
|
| 90 |
+
assert self.micro_batch_size > 0
|
| 91 |
+
assert data_parallel_size > 0
|
| 92 |
+
assert self.data_parallel_rank < data_parallel_size, \
|
| 93 |
+
'data_parallel_rank should be smaller than data size: {}, ' \
|
| 94 |
+
'{}'.format(self.data_parallel_rank, data_parallel_size)
|
| 95 |
+
|
| 96 |
+
def __len__(self):
|
| 97 |
+
return self.total_samples // self.micro_batch_times_data_parallel_size
|
| 98 |
+
|
| 99 |
+
def __iter__(self):
|
| 100 |
+
active_total_samples = self.total_samples - self.last_batch_size
|
| 101 |
+
current_epoch_samples = self.consumed_samples % active_total_samples
|
| 102 |
+
assert current_epoch_samples % self.micro_batch_times_data_parallel_size == 0
|
| 103 |
+
|
| 104 |
+
# data sharding and random sampling
|
| 105 |
+
bucket_size = (self.total_samples // self.micro_batch_times_data_parallel_size) \
|
| 106 |
+
* self.micro_batch_size
|
| 107 |
+
bucket_offset = current_epoch_samples // self.data_parallel_size
|
| 108 |
+
start_idx = self.data_parallel_rank * bucket_size
|
| 109 |
+
|
| 110 |
+
g = torch.Generator()
|
| 111 |
+
g.manual_seed(self.epoch)
|
| 112 |
+
random_idx = torch.randperm(bucket_size, generator=g).tolist()
|
| 113 |
+
idx_range = [start_idx + x for x in random_idx[bucket_offset:]]
|
| 114 |
+
|
| 115 |
+
batch = []
|
| 116 |
+
# Last batch if not complete will be dropped.
|
| 117 |
+
for idx in idx_range:
|
| 118 |
+
batch.append(idx)
|
| 119 |
+
if len(batch) == self.micro_batch_size:
|
| 120 |
+
self.consumed_samples += self.micro_batch_times_data_parallel_size
|
| 121 |
+
yield batch
|
| 122 |
+
batch = []
|
| 123 |
+
|
| 124 |
+
def set_epoch(self, epoch):
|
| 125 |
+
self.epoch = epoch
|
fengshen/examples/DAVAE/generate.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
'''
|
| 3 |
+
Copyright 2022 The International Digital Economy Academy (IDEA). CCNL team. All rights reserved.
|
| 4 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
you may not use this file except in compliance with the License.
|
| 6 |
+
You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
@File : generate.py
|
| 14 |
+
@Time : 2022/11/04 19:17
|
| 15 |
+
@Author : Liang Yuxin
|
| 16 |
+
@Version : 1.0
|
| 17 |
+
@Contact : liangyuxin@idea.edu.cn
|
| 18 |
+
@License : (C)Copyright 2022-2023, CCNL-IDEA
|
| 19 |
+
'''
|
| 20 |
+
# here put the import lib
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
from fengshen.models.DAVAE.DAVAEModel import DAVAEModel
|
| 24 |
+
from transformers import BertTokenizer,T5Tokenizer
|
| 25 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 26 |
+
|
| 27 |
+
encoder_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Randeng-DAVAE-1.2B-General-Chinese")
|
| 28 |
+
decoder_tokenizer = T5Tokenizer.from_pretrained("IDEA-CCNL/Randeng-DAVAE-1.2B-General-Chinese", eos_token = '<|endoftext|>', pad_token = '<pad>',extra_ids=0)
|
| 29 |
+
decoder_tokenizer.add_special_tokens({'bos_token':'<bos>'})
|
| 30 |
+
vae_model = DAVAEModel.from_pretrained("IDEA-CCNL/Randeng-DAVAE-1.2B-General-Chinese").to(device)
|
| 31 |
+
input_texts = [
|
| 32 |
+
"针对电力系统中的混沌振荡对整个互联电网的危害问题,提出了一种基于非线性光滑函数的滑模控制方法.",
|
| 33 |
+
"超市面积不算大.挺方便附近的居民购买的. 生活用品也比较齐全.价格适用中.",
|
| 34 |
+
]
|
| 35 |
+
output_texts = vae_model.simulate_batch(encoder_tokenizer,decoder_tokenizer,input_texts)
|
| 36 |
+
print(output_texts)
|
fengshen/examples/FastDemo/README.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 「streamlit」快速搭建你的算法demo
|
| 2 |
+
在搭建demo之前,首先得做好这些准备工作:
|
| 3 |
+
- 模型训练完毕
|
| 4 |
+
- 模型的入参确定
|
| 5 |
+
- 安装streamlit库,`pip install streamlit` 就可以安装。
|
| 6 |
+
|
| 7 |
+
streamlit脚本的启动方式是 `streamlit run demo.py`,很简单就启动了一个demo页面,页面会随着脚本代码的改变实时刷新的。所以在没有经验的时候,可以创建一个demo.py的文件,照着下面的教程一步一步添加代码,看页面的展示情况。下面开始上干货,具体细节在代码注释中有说明!
|
| 8 |
+
|
| 9 |
+
### 第一步 导包
|
| 10 |
+
```python
|
| 11 |
+
import streamlit as st
|
| 12 |
+
# 其他包更具你的需要导入
|
| 13 |
+
```
|
| 14 |
+
[streamlit](https://streamlit.io)是一个用于构建机器学习、深度学习、数据可视化demo的python框架。它不需要你有web开发的经验,会写python就可以高效的开发你的demo。
|
| 15 |
+
|
| 16 |
+
### 第二步 页面导航信息以及布局配置
|
| 17 |
+
|
| 18 |
+
```python
|
| 19 |
+
st.set_page_config(
|
| 20 |
+
page_title="余元医疗问答", # 页面标签标题
|
| 21 |
+
page_icon=":shark:", # 页面标签图标
|
| 22 |
+
layout="wide", # 页面的布局
|
| 23 |
+
initial_sidebar_state="expanded", # 左侧的sidebar的布局方式
|
| 24 |
+
# 配置菜单按钮的信息
|
| 25 |
+
menu_items={
|
| 26 |
+
'Get Help': 'https://www.extremelycoolapp.com/help',
|
| 27 |
+
'Report a bug': "https://www.extremelycoolapp.com/bug",
|
| 28 |
+
'About': "# This is a header. This is an *extremely* cool app!"
|
| 29 |
+
}
|
| 30 |
+
)
|
| 31 |
+
```
|
| 32 |
+
这一步可以省略,如果想让app更加个性化,可以添加这些设置。
|
| 33 |
+
|
| 34 |
+
### 第三步 设置demo标题
|
| 35 |
+
```python
|
| 36 |
+
st.title('Demo for MedicalQA')
|
| 37 |
+
```
|
| 38 |
+
streamlit的每一个小组件对应于页面都有一个默认的样式展示。
|
| 39 |
+
|
| 40 |
+
### 第四步 配置demo的参数
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
# 此处是用的sidebar,侧边栏作为参数配置模块
|
| 44 |
+
st.sidebar.header("参数配置")
|
| 45 |
+
# 这里是在sidebar里面创建了表单,每个表单一定有一个标题和提交按钮
|
| 46 |
+
sbform = st.sidebar.form("固定参数设置")
|
| 47 |
+
# slider是滑动条组建,可以配置数值型参数
|
| 48 |
+
n_sample = sbform.slider("设置返回条数",min_value=1,max_value=10,value=3)
|
| 49 |
+
text_length = sbform.slider('生成长度:',min_value=32,max_value=512,value=64,step=32)
|
| 50 |
+
text_level = sbform.slider('文本多样性:',min_value=0.1,max_value=1.0,value=0.9,step=0.1)
|
| 51 |
+
# number_input也可以配置数值型参数
|
| 52 |
+
model_id = sbform.number_input('选择模型号:',min_value=0,max_value=13,value=13,step=1)
|
| 53 |
+
# selectbox选择组建,只能选择配置的选项
|
| 54 |
+
trans = sbform.selectbox('选择翻译内核',['百度通用','医疗生物'])
|
| 55 |
+
# 提交表单的配置,这些参数的赋值才生效
|
| 56 |
+
sbform.form_submit_button("提交配置")
|
| 57 |
+
|
| 58 |
+
# 这里是页面中的参数配置,也是demo的主体之一
|
| 59 |
+
form = st.form("参数设置")
|
| 60 |
+
# 本demo是qa demo,所以要录入用户的文本输入,text_input组建可以实现
|
| 61 |
+
input_text = form.text_input('请输入你的问题:',value='',placeholder='例如:糖尿病的症状有哪些?')
|
| 62 |
+
form.form_submit_button("提交")
|
| 63 |
+
```
|
| 64 |
+
以上就把demo的参数基本配置完成了。
|
| 65 |
+
|
| 66 |
+
### 第五步 模型预测
|
| 67 |
+
```python
|
| 68 |
+
# 定义一个前向预测的方法
|
| 69 |
+
# @st.cache(suppress_st_warning=True)
|
| 70 |
+
def generate_qa(input_text,n_sample,model_id='7',length=64,translator='baidu',level=0.7):
|
| 71 |
+
# 这里我们是把模型用fastapi搭建了一个api服务
|
| 72 |
+
URL = 'http://192.168.190.63:6605/qa'
|
| 73 |
+
data = {
|
| 74 |
+
"text":input_text,"n_sample":n_sample,
|
| 75 |
+
"model_id":model_id,"length":length,
|
| 76 |
+
'translator':translator,'level':level
|
| 77 |
+
}
|
| 78 |
+
r = requests.get(URL,params=data)
|
| 79 |
+
return r.text
|
| 80 |
+
# 模型预测结果
|
| 81 |
+
results = generate_qa(input_text,n_sample,model_id=str(model_id),
|
| 82 |
+
translator=translator,length=text_length,level=text_level)
|
| 83 |
+
```
|
| 84 |
+
这里说明一下,由于demo展示机器没有GPU,所以模型部署采用的是Fastapi部署在后台的。如果demo展示的机器可以直接部署模型,这里可以直接把模型预测的方法写在这里,不需要另外部署模型,再用api的方式调用。这样做有一个值得注意的地方,因为streamlit的代码每一次运行,都是从头到尾执行一遍,就导致模型可能会重复加载,所以这里需要用到st.cache组建,当内容没有更新的时候,会把这一步的结果缓存,而不会重新执行。保证了效率不会因此而下降。
|
| 85 |
+
|
| 86 |
+
### 第六步 结果展示
|
| 87 |
+
```python
|
| 88 |
+
with st.spinner('老夫正在思考中🤔...'):
|
| 89 |
+
if input_text:
|
| 90 |
+
results = generate_qa(input_text,n_sample,model_id=str(model_id),
|
| 91 |
+
translator=translator,length=text_length,level=text_level)
|
| 92 |
+
for idx,item in enumerate(eval(results),start=1):
|
| 93 |
+
st.markdown(f"""
|
| 94 |
+
**候选回答「{idx}」:**\n
|
| 95 |
+
""")
|
| 96 |
+
st.info('中文:%s'%item['fy_next_sentence'])
|
| 97 |
+
st.info('英文:%s'%item['next_sentence'])
|
| 98 |
+
```
|
| 99 |
+
streamlit对不同格式的内容展示,有丰富的组建,对于文本可以用`st.markdown`组建以及`st.text`和`st.write`展示。更多组建和功能可以参考官方文档:https://docs.streamlit.io
|
| 100 |
+
|
| 101 |
+
至此,一个完整的demo展示就完成了。效果图如下:
|
| 102 |
+
|
| 103 |
+

|
| 104 |
+
|
| 105 |
+
完整的代码可以参考:`Fengshenbang-LM/fengshen/examples/FastDemo/YuyuanQA.py`
|
fengshen/examples/FastDemo/YuyuanQA.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import langid
|
| 3 |
+
import streamlit as st
|
| 4 |
+
from translate import baiduTranslatorMedical
|
| 5 |
+
from translate import baiduTranslator
|
| 6 |
+
|
| 7 |
+
langid.set_languages(['en', 'zh'])
|
| 8 |
+
lang_dic = {'zh': 'en', 'en': 'zh'}
|
| 9 |
+
|
| 10 |
+
st.set_page_config(
|
| 11 |
+
page_title="余元医疗问答",
|
| 12 |
+
page_icon=":shark:",
|
| 13 |
+
# layout="wide",
|
| 14 |
+
initial_sidebar_state="expanded",
|
| 15 |
+
menu_items={
|
| 16 |
+
'Get Help': 'https://www.extremelycoolapp.com/help',
|
| 17 |
+
'Report a bug': "https://www.extremelycoolapp.com/bug",
|
| 18 |
+
'About': "# This is a header. This is an *extremely* cool app!"
|
| 19 |
+
}
|
| 20 |
+
)
|
| 21 |
+
st.title('Demo for MedicalQA')
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
st.sidebar.header("参数配置")
|
| 25 |
+
sbform = st.sidebar.form("固定参数设置")
|
| 26 |
+
n_sample = sbform.slider("设置返回条数", min_value=1, max_value=10, value=3)
|
| 27 |
+
text_length = sbform.slider('生成长度:', min_value=32, max_value=512, value=64, step=32)
|
| 28 |
+
text_level = sbform.slider('文本多样性:', min_value=0.1, max_value=1.0, value=0.9, step=0.1)
|
| 29 |
+
model_id = sbform.number_input('选择模型号:', min_value=0, max_value=13, value=13, step=1)
|
| 30 |
+
trans = sbform.selectbox('选择翻译内核', ['百度通用', '医疗生物'])
|
| 31 |
+
sbform.form_submit_button("配置")
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
form = st.form("参数设置")
|
| 35 |
+
input_text = form.text_input('请输入你的问题:', value='', placeholder='例如:糖尿病的症状有哪些?')
|
| 36 |
+
if trans == '百度通用':
|
| 37 |
+
translator = 'baidu_common'
|
| 38 |
+
else:
|
| 39 |
+
translator = 'baidu'
|
| 40 |
+
if input_text:
|
| 41 |
+
lang = langid.classify(input_text)[0]
|
| 42 |
+
if translator == 'baidu':
|
| 43 |
+
st.write('**你的问题是:**', baiduTranslatorMedical(input_text, src=lang, dest=lang_dic[lang]).text)
|
| 44 |
+
else:
|
| 45 |
+
st.write('**你的问题是:**', baiduTranslator(input_text, src=lang, dest=lang_dic[lang]).text)
|
| 46 |
+
|
| 47 |
+
form.form_submit_button("提交")
|
| 48 |
+
|
| 49 |
+
# @st.cache(suppress_st_warning=True)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def generate_qa(input_text, n_sample, model_id='7', length=64, translator='baidu', level=0.7):
|
| 53 |
+
# st.write('调用了generate函数')
|
| 54 |
+
URL = 'http://192.168.190.63:6605/qa'
|
| 55 |
+
data = {"text": input_text, "n_sample": n_sample, "model_id": model_id,
|
| 56 |
+
"length": length, 'translator': translator, 'level': level}
|
| 57 |
+
r = requests.get(URL, params=data)
|
| 58 |
+
return r.text
|
| 59 |
+
# my_bar = st.progress(80)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
with st.spinner('老夫正在思考中🤔...'):
|
| 63 |
+
if input_text:
|
| 64 |
+
results = generate_qa(input_text, n_sample, model_id=str(model_id),
|
| 65 |
+
translator=translator, length=text_length, level=text_level)
|
| 66 |
+
for idx, item in enumerate(eval(results), start=1):
|
| 67 |
+
st.markdown(f"""
|
| 68 |
+
**候选回答「{idx}」:**\n
|
| 69 |
+
""")
|
| 70 |
+
st.info('中文:%s' % item['fy_next_sentence'])
|
| 71 |
+
st.info('英文:%s' % item['next_sentence'])
|
fengshen/examples/FastDemo/image/demo.png
ADDED
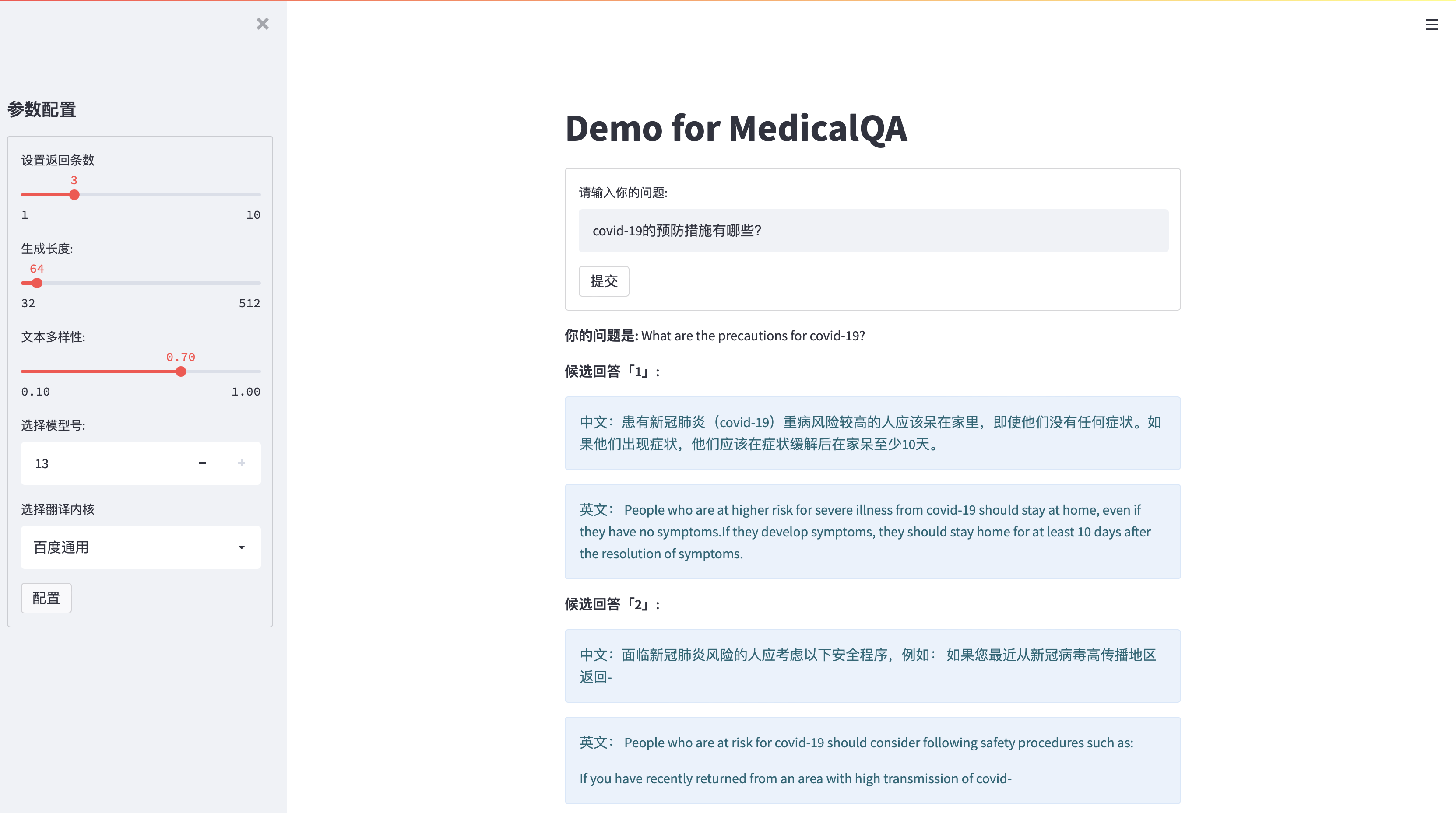
|
fengshen/examples/GAVAE/generate.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import BertTokenizer,T5Tokenizer
|
| 3 |
+
from fengshen.models.GAVAE.GAVAEModel import GAVAEModel
|
| 4 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 5 |
+
|
| 6 |
+
encoder_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Randeng-GAVAE-1.2B-Augmentation-Chinese")
|
| 7 |
+
decoder_tokenizer = T5Tokenizer.from_pretrained("IDEA-CCNL/Randeng-GAVAE-1.2B-Augmentation-Chinese", eos_token = '<|endoftext|>', pad_token = '<pad>',extra_ids=0)
|
| 8 |
+
decoder_tokenizer.add_special_tokens({'bos_token':'<bos>'})
|
| 9 |
+
input_texts = [
|
| 10 |
+
"非常好的一个博物馆,是我所有去过的博物馆里感觉最正规的一家,凭有效证件可以入馆,可以自助免费存小件物品,讲解员和馆内外的工作人员也非常认真,其他的服务人员也很热情,非常好的!馆内的藏品也让人非常震撼!希望继续保持~",
|
| 11 |
+
"这是我来长沙最最期待的一定要去的地方,总算今天特地去瞻仰千古遗容了,开车到门口大屏幕显示着门票已发完的字样,心里一惊以为今天是白来了。但进了停车场才知道凭停车卡和有效身份证里面也能领,停车还不花钱,真好。",
|
| 12 |
+
"地方很大 很气派~~可以逛很久~~~去的时候是免费的~不过要安检~~~里面的马王堆~幸追夫人~还是很不错的~~~~去的时候有一个吴越文化特别展~~~东西也很多~~~~~很好看",
|
| 13 |
+
"我们到达的时候是下午3点,门票已经发完了。当时正焦虑的不知道怎么办才好,门卫大哥给我们俩补办了门票,这才得以入馆。非常感谢!绝对不虚此行!相当震撼的展览!原来古人也化妆,还有假发。记忆最深的是那个藕汤。可惜真颜已不得见。",
|
| 14 |
+
"去过三次,个人认为这是长沙最值得去的地方,博物馆的重点就是辛追,遗憾的是,每次去我都会感到悲哀,虽然我三次去的时候都要门票,但是每次看到辛追,都觉得现代的人类不应该挖她出来,除了第一次我觉得辛追像刚死去一样,后来两次我觉得太惨不忍睹了。建议大家要去就早去,以后肯定越来越腐烂",
|
| 15 |
+
"上大学时候去的,当时学生证是半价25,后来凭有效证件就不要钱了。非常喜欢的一家博物馆,里面可看的东西很多,当然最吸引我的就是那个辛追夫人和“素纱单衣”,果然不是盖的~里面的讲解员大部分都是师大学历史类的,非常专业和有耐心。虽然不在长沙了,不过对那里还是很有感情的,赞~~~",
|
| 16 |
+
"这两年也有很多机会去博物馆。。。不过还是想说湖南省博物馆是非常有特色的。。。应该说整个展览分成两个部分吧。。。一个部分是马王堆的主体展。。。另一个就是湖南的一些考古发现。。。其实来省博大部分的游客还是冲着马王堆来的吧。。。博物馆也很有心的为每一批游客安排了讲解员。。。从马王堆的发现到马王堆出土文物的介绍再到最后棺木和辛追的介绍。。。真是上了一节很生动的历史课。",
|
| 17 |
+
"网上订票去的,还是很顺利的就进去了,里面挺清净的,外围的环境也不错,还有鸽子可以喂。那天不是很闹,兜了一圈感觉还是很顺畅的,老娘娘和金缕玉衣挺震撼的。到此一游还是挺需要的",
|
| 18 |
+
]
|
| 19 |
+
gavae_model = GAVAEModel.from_pretrained("IDEA-CCNL/Randeng-GAVAE-1.2B-Augmentation-Chinese").to(device)
|
| 20 |
+
gavae_model.train_gan(encoder_tokenizer,decoder_tokenizer,input_texts)
|
| 21 |
+
# n:输出样本数量
|
| 22 |
+
texts = gavae_model.generate(n=5)
|
| 23 |
+
print(texts)
|
fengshen/examples/PPVAE/generate.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import BertTokenizer,T5Tokenizer
|
| 3 |
+
from fengshen.models.PPVAE.pluginVAE import PPVAEModel
|
| 4 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 5 |
+
|
| 6 |
+
encoder_tokenizer = BertTokenizer.from_pretrained("IDEA-CCNL/Randeng-PPVAE-1.2B-Augmentation-Chinese")
|
| 7 |
+
decoder_tokenizer = T5Tokenizer.from_pretrained("IDEA-CCNL/Randeng-PPVAE-1.2B-Augmentation-Chinese", eos_token = '<|endoftext|>', pad_token = '<pad>',extra_ids=0)
|
| 8 |
+
decoder_tokenizer.add_special_tokens({'bos_token':'<bos>'})
|
| 9 |
+
ppvae_model = PPVAEModel.from_pretrained("IDEA-CCNL/Randeng-PPVAE-1.2B-Augmentation-Chinese").to(device)
|
| 10 |
+
input_texts = [
|
| 11 |
+
"非常好的一个博物馆,是我所有去过的博物馆里感觉最正规的一家,凭有效证件可以入馆,可以自助免费存小件物品,讲解员和馆内外的工作人员也非常认真,其他的服务人员也很热情,非常好的!馆内的藏品也让人非常震撼!希望继续保持~",
|
| 12 |
+
"这是我来长沙最最期待的一定要去的地方,总算今天特地去瞻仰千古遗容了,开车到门口大屏幕显示着门票已发完的字样,心里一惊以为今天是白来了。但进了停车场才知道凭停车卡和有效身份证里面也能领,停车还不花钱,真好。",
|
| 13 |
+
"地方很大 很气派~~可以逛很久~~~去的时候是免费的~不过要安检~~~里面的马王堆~幸追夫人~还是很不错的~~~~去的时候有一个吴越文化特别展~~~东西也很多~~~~~很好看",
|
| 14 |
+
"我们到达的时候是下午3点,门票已经发完了。当时正焦虑的不知道怎么办才好,门卫大哥给我们俩补办了门票,这才得以入馆。非常感谢!绝对不虚此行!相当震撼的展览!原来古人也化妆,还有假发。记忆最深的是那个藕汤。可惜真颜已不得见。",
|
| 15 |
+
"去过三次,个人认为这是长沙最值得去的地方,博物馆的重点就是辛追,遗憾的是,每次去我都会感到悲哀,虽然我三次去的时候都要门票,但是每次看到辛追,都觉得现代的人类不应该挖她出来,除了第一次我觉得辛追像刚死去一样,后来两次我觉得太惨不忍睹了。建议大家要去就早去,以后肯定越来越腐烂",
|
| 16 |
+
"上大学时候去的,当时学生证是半价25,后来凭有效证件就不要钱了。非常喜欢的一家博物馆,里面可看的东西很多,当然最吸引我的就是那个辛追夫人和“素纱单衣”,果然不是盖的~里面的讲解员大部分都是师大学历史类的,非常专业和有耐心。虽然不在长沙了,不过对那里还是很有感情的,赞~~~",
|
| 17 |
+
"这两年也有很多机会去博物馆。。。不过还是想说湖南省博物馆是非常有特色的。。。应该说整个展览分成两个部分吧。。。一个部分是马王堆的主体展。。。另一个就是湖南的一些考古发现。。。其实来省博大部分的游客还是冲着马王堆来的吧。。。博物馆也很有心的为每一批游客安排了讲解员。。。从马王堆的发现到马王堆出土文物的介绍再到最后棺木和辛追的介绍。。。真是上了一节很生动的历史课。",
|
| 18 |
+
"网上订票去的,还是很顺利的就进去了,里面挺清净的,外围的环境也不错,还有鸽子可以喂。那天不是很闹,兜了一圈感觉还是很顺畅的,老娘娘和金缕玉衣挺震撼的。到此一游还是挺需要的",
|
| 19 |
+
]
|
| 20 |
+
|
| 21 |
+
ppvae_model.train_plugin(encoder_tokenizer,decoder_tokenizer,input_texts,negative_samples=None)
|
| 22 |
+
# n:输出样本数量
|
| 23 |
+
texts = ppvae_model.generate(n=5)
|
| 24 |
+
print(texts)
|
fengshen/examples/classification/demo_classification_afqmc_erlangshen_offload.sh
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL_NAME="IDEA-CCNL/Erlangshen-MegatronBert-1.3B"
|
| 2 |
+
|
| 3 |
+
TEXTA_NAME=sentence1
|
| 4 |
+
TEXTB_NAME=sentence2
|
| 5 |
+
LABEL_NAME=label
|
| 6 |
+
ID_NAME=id
|
| 7 |
+
|
| 8 |
+
BATCH_SIZE=1
|
| 9 |
+
VAL_BATCH_SIZE=1
|
| 10 |
+
ZERO_STAGE=3
|
| 11 |
+
config_json="./ds_config.json"
|
| 12 |
+
|
| 13 |
+
cat <<EOT > $config_json
|
| 14 |
+
{
|
| 15 |
+
"train_micro_batch_size_per_gpu": $BATCH_SIZE,
|
| 16 |
+
"steps_per_print": 1000,
|
| 17 |
+
"gradient_clipping": 1,
|
| 18 |
+
"zero_optimization": {
|
| 19 |
+
"stage": ${ZERO_STAGE},
|
| 20 |
+
"offload_optimizer": {
|
| 21 |
+
"device": "cpu",
|
| 22 |
+
"pin_memory": true
|
| 23 |
+
},
|
| 24 |
+
"offload_param": {
|
| 25 |
+
"device": "cpu",
|
| 26 |
+
"pin_memory": true
|
| 27 |
+
},
|
| 28 |
+
"overlap_comm": true,
|
| 29 |
+
"contiguous_gradients": true,
|
| 30 |
+
"sub_group_size": 1e9,
|
| 31 |
+
"stage3_max_live_parameters": 1e9,
|
| 32 |
+
"stage3_max_reuse_distance": 1e9
|
| 33 |
+
},
|
| 34 |
+
"zero_allow_untested_optimizer": false,
|
| 35 |
+
"fp16": {
|
| 36 |
+
"enabled": true,
|
| 37 |
+
"loss_scale": 0,
|
| 38 |
+
"loss_scale_window": 1000,
|
| 39 |
+
"hysteresis": 2,
|
| 40 |
+
"min_loss_scale": 1
|
| 41 |
+
},
|
| 42 |
+
"activation_checkpointing": {
|
| 43 |
+
"partition_activations": false,
|
| 44 |
+
"contiguous_memory_optimization": false
|
| 45 |
+
},
|
| 46 |
+
"wall_clock_breakdown": false
|
| 47 |
+
}
|
| 48 |
+
EOT
|
| 49 |
+
|
| 50 |
+
export PL_DEEPSPEED_CONFIG_PATH=$config_json
|
| 51 |
+
|
| 52 |
+
DATA_ARGS="\
|
| 53 |
+
--dataset_name IDEA-CCNL/AFQMC \
|
| 54 |
+
--train_batchsize $BATCH_SIZE \
|
| 55 |
+
--valid_batchsize $VAL_BATCH_SIZE \
|
| 56 |
+
--max_length 128 \
|
| 57 |
+
--texta_name $TEXTA_NAME \
|
| 58 |
+
--textb_name $TEXTB_NAME \
|
| 59 |
+
--label_name $LABEL_NAME \
|
| 60 |
+
--id_name $ID_NAME \
|
| 61 |
+
"
|
| 62 |
+
|
| 63 |
+
MODEL_ARGS="\
|
| 64 |
+
--learning_rate 1e-5 \
|
| 65 |
+
--weight_decay 1e-1 \
|
| 66 |
+
--warmup_ratio 0.01 \
|
| 67 |
+
--num_labels 2 \
|
| 68 |
+
--model_type huggingface-auto \
|
| 69 |
+
"
|
| 70 |
+
|
| 71 |
+
MODEL_CHECKPOINT_ARGS="\
|
| 72 |
+
--monitor val_acc \
|
| 73 |
+
--save_top_k 3 \
|
| 74 |
+
--mode max \
|
| 75 |
+
--every_n_train_steps 0 \
|
| 76 |
+
--save_weights_only True \
|
| 77 |
+
--dirpath . \
|
| 78 |
+
--filename model-{epoch:02d}-{val_acc:.4f} \
|
| 79 |
+
"
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
TRAINER_ARGS="\
|
| 83 |
+
--max_epochs 67 \
|
| 84 |
+
--gpus 1 \
|
| 85 |
+
--num_nodes 1 \
|
| 86 |
+
--strategy deepspeed_stage_${ZERO_STAGE}_offload \
|
| 87 |
+
--gradient_clip_val 1.0 \
|
| 88 |
+
--check_val_every_n_epoch 1 \
|
| 89 |
+
--val_check_interval 1.0 \
|
| 90 |
+
--precision 16 \
|
| 91 |
+
--default_root_dir . \
|
| 92 |
+
"
|
| 93 |
+
|
| 94 |
+
options=" \
|
| 95 |
+
--pretrained_model_path $MODEL_NAME \
|
| 96 |
+
$DATA_ARGS \
|
| 97 |
+
$MODEL_ARGS \
|
| 98 |
+
$MODEL_CHECKPOINT_ARGS \
|
| 99 |
+
$TRAINER_ARGS \
|
| 100 |
+
"
|
| 101 |
+
|
| 102 |
+
python3 finetune_classification.py $options
|
| 103 |
+
|