# Report v1.0.0
In March 2024, we launched a plan called Open-Sora-Plan, which aims to reproduce the OpenAI [Sora](https://openai.com/sora) through an open-source framework. As a foundational open-source framework, it enables training of video generation models, including Unconditioned Video Generation, Class Video Generation, and Text-to-Video Generation.
**Today, we are thrilled to present Open-Sora-Plan v1.0.0, which significantly enhances video generation quality and text control capabilities.**
Compared with previous video generation model, Open-Sora-Plan v1.0.0 has several improvements:
1. **Efficient training and inference with CausalVideoVAE**. We apply a spatial-temporal compression to the videos by 4×8×8.
2. **Joint image-video training for better quality**. Our CausalVideoVAE considers the first frame as an image, allowing for the simultaneous encoding of both images and videos in a natural manner. This allows the diffusion model to grasp more spatial-visual details to improve visual quality.
### Open-Source Release
We open-source the Open-Sora-Plan to facilitate future development of Video Generation in the community. Code, data, model will be made publicly available.
- Demo: Hugging Face demo [here](https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0). 🤝 Enjoying the [](https://replicate.com/camenduru/open-sora-plan-512x512) and [](https://colab.research.google.com/github/camenduru/Open-Sora-Plan-jupyter/blob/main/Open_Sora_Plan_jupyter.ipynb), created by [@camenduru](https://github.com/camenduru), who generously supports our research!
- Code: All training scripts and sample scripts.
- Model: Both Diffusion Model and CausalVideoVAE [here](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0).
- Data: Both raw videos and captions [here](https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0).
## Gallery
Open-Sora-Plan v1.0.0 supports joint training of images and videos. Here, we present the capabilities of Video/Image Reconstruction and Generation:
### CausalVideoVAE Reconstruction
**Video Reconstruction** with 720×1280. Since github can't upload large video, we put it here: [1](https://streamable.com/gqojal), [2](https://streamable.com/6nu3j8).
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/c100bb02-2420-48a3-9d7b-4608a41f14aa
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/8aa8f587-d9f1-4e8b-8a82-d3bf9ba91d68
**Image Reconstruction** in 1536×1024.

 **Text-to-Video Generation** with 65×1024×1024
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/2641a8aa-66ac-4cda-8279-86b2e6a6e011
**Text-to-Video Generation** with 65×512×512
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/37e3107e-56b3-4b09-8920-fa1d8d144b9e
**Text-to-Image Generation** with 512×512

## Detailed Technical Report
### CausalVideoVAE
#### Model Structure

The CausalVideoVAE architecture inherits from the [Stable-Diffusion Image VAE](https://github.com/CompVis/stable-diffusion/tree/main). To ensure that the pretrained weights of the Image VAE can be seamlessly applied to the Video VAE, the model structure has been designed as follows:
1. **CausalConv3D**: Converting Conv2D to CausalConv3D enables joint training of image and video data. CausalConv3D applies a special treatment to the first frame, as it does not have access to subsequent frames. For more specific details, please refer to https://github.com/PKU-YuanGroup/Open-Sora-Plan/pull/145
2. **Initialization**: There are two common [methods](https://github.com/hassony2/inflated_convnets_pytorch/blob/master/src/inflate.py#L5) to expand Conv2D to Conv3D: average initialization and center initialization. But we employ a specific initialization method (tail initialization). This initialization method ensures that without any training, the model is capable of directly reconstructing images, and even videos.
#### Training Details
**Text-to-Video Generation** with 65×1024×1024
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/2641a8aa-66ac-4cda-8279-86b2e6a6e011
**Text-to-Video Generation** with 65×512×512
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/62638829/37e3107e-56b3-4b09-8920-fa1d8d144b9e
**Text-to-Image Generation** with 512×512

## Detailed Technical Report
### CausalVideoVAE
#### Model Structure

The CausalVideoVAE architecture inherits from the [Stable-Diffusion Image VAE](https://github.com/CompVis/stable-diffusion/tree/main). To ensure that the pretrained weights of the Image VAE can be seamlessly applied to the Video VAE, the model structure has been designed as follows:
1. **CausalConv3D**: Converting Conv2D to CausalConv3D enables joint training of image and video data. CausalConv3D applies a special treatment to the first frame, as it does not have access to subsequent frames. For more specific details, please refer to https://github.com/PKU-YuanGroup/Open-Sora-Plan/pull/145
2. **Initialization**: There are two common [methods](https://github.com/hassony2/inflated_convnets_pytorch/blob/master/src/inflate.py#L5) to expand Conv2D to Conv3D: average initialization and center initialization. But we employ a specific initialization method (tail initialization). This initialization method ensures that without any training, the model is capable of directly reconstructing images, and even videos.
#### Training Details
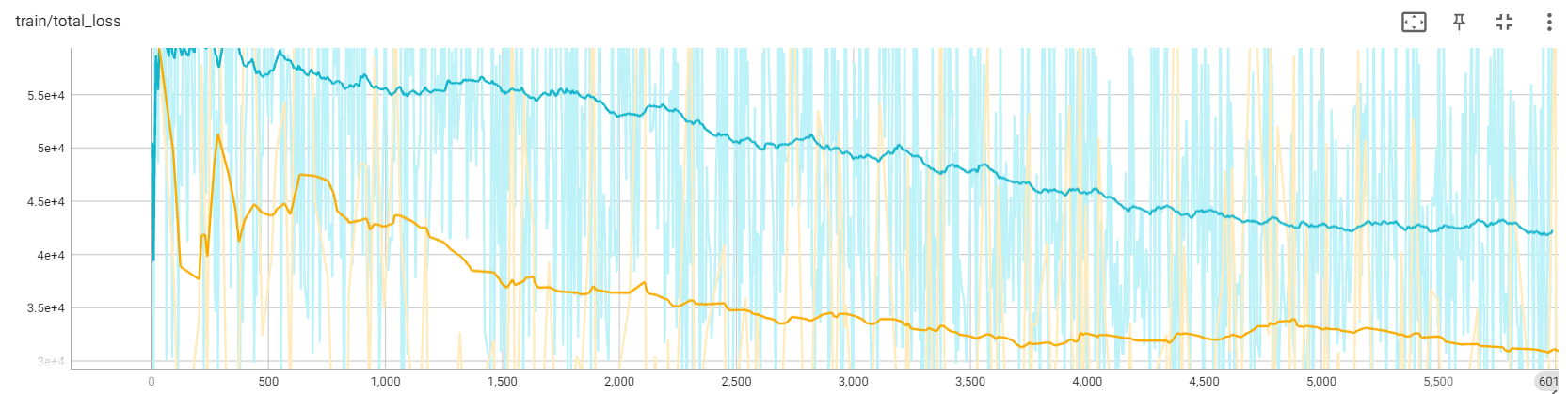 We present the loss curves for two distinct initialization methods under 17×256×256. The yellow curve represents the loss using tail init, while the blue curve corresponds to the loss from center initialization. As shown in the graph, tail initialization demonstrates better performance on the loss curve. Additionally, we found that center initialization leads to error accumulation, causing the collapse over extended durations.
#### Inference Tricks
Despite the VAE in Diffusion training being frozen, we still find it challenging to afford the cost of the CausalVideoVAE. In our case, with 80GB of GPU memory, we can only infer a video of either 256×512×512 or 32×1024×1024 resolution using half-precision, which limits our ability to scale up to longer and higher-resolution videos. Therefore, we adopt tile convolution, which allows us to infer videos of arbitrary duration or resolution with nearly constant memory usage.
### Data Construction
We define a high-quality video dataset based on two core principles: (1) No content-unrelated watermarks. (2) High-quality and dense captions.
**For principles 1**, we crawled approximately 40,000 videos from open-source websites under the CC0 license. Specifically, we obtained 1,244 videos from [mixkit](https://mixkit.co/), 7,408 videos from [pexels](https://www.pexels.com/), and 31,617 videos from [pixabay](https://pixabay.com/). These videos adhere to the principle of having no content-unrelated watermarks. According to the scene transformation and clipping script provided by [Panda70M](https://github.com/snap-research/Panda-70M/blob/main/splitting/README.md), we have divided these videos into approximately 434,000 video clips. In fact, based on our clipping results, 99% of the videos obtained from these online sources are found to contain single scenes. Additionally, we have observed that over 60% of the crawled data comprises landscape videos.
**For principles 2**, it is challenging to directly crawl a large quantity of high-quality dense captions from the internet. Therefore, we utilize a mature Image-captioner model to obtain high-quality dense captions. We conducted ablation experiments on two multimodal large models: [ShareGPT4V-Captioner-7B](https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/README.md) and [LLaVA-1.6-34B](https://github.com/haotian-liu/LLaVA). The former is specifically designed for caption generation, while the latter is a general-purpose multimodal large model. After conducting our ablation experiments, we found that they are comparable in performance. However, there is a significant difference in their inference speed on the A800 GPU: 40s/it of batch size of 12 for ShareGPT4V-Captioner-7B, 15s/it of batch size of 1 for LLaVA-1.6-34B. We open-source all annotations [here](https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0)。
### Training Diffusion Model
Similar to previous work, we employ a multi-stage cascaded training approach, which consumes a total of 2,048 A800 GPU hours. We found that joint training with images significantly accelerates model convergence and enhances visual perception, aligning with the findings of [Latte](https://github.com/Vchitect/Latte). Below is our training card:
| Name | Stage 1 | Stage 2 | Stage 3 | Stage 4 |
|---|---|---|---|---|
| Training Video Size | 17×256×256 | 65×256×256 | 65×512×512 | 65×1024×1024 |
| Compute (#A800 GPU x #Hours) | 32 × 40 | 32 × 18 | 32 × 6 | Under training |
| Checkpoint | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/17x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x512x512) | Under training |
| Log | [wandb](https://api.wandb.ai/links/linbin/p6n3evym) | [wandb](https://api.wandb.ai/links/linbin/t2g53sew) | [wandb](https://api.wandb.ai/links/linbin/uomr0xzb) | Under training |
| Training Data | ~40k videos | ~40k videos | ~40k videos | ~40k videos |
## Next Release Preview
### CausalVideoVAE
Currently, the released version of CausalVideoVAE (v1.0.0) has two main drawbacks: **motion blurring** and **gridding effect**. We have made a series of improvements to CausalVideoVAE to reduce its inference cost and enhance its performance. We are currently referring to this enhanced version as the "preview version," which will be released in the next update. Preview reconstruction is as follows:
**1 min Video Reconstruction with 720×1280**. Since github can't put too big video, we put it here: [origin video](https://streamable.com/u4onbb), [reconstruction video](https://streamable.com/qt8ncc).
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/cdcfa9a3-4de0-42d4-94c0-0669710e407b
We randomly selected 100 samples from the validation set of Kinetics-400 for evaluation, and the results are presented in the following table:
| | SSIM↑ | LPIPS↓ | PSNR↑ | FLOLPIPS↓ |
|---|---|---|---|---|
| v1.0.0 | 0.829 | 0.106 | 27.171 | 0.119 |
| Preview | 0.877 | 0.064 | 29.695 | 0.070 |
#### Motion Blurring
| **v1.0.0** | **Preview** |
| --- | --- |
|  |  |
#### Gridding effect
| **v1.0.0** | **Preview** |
| --- | --- |
|  |  |
### Data Construction
**Data source**. As mentioned earlier, over 60% of our dataset consists of landscape videos. This implies that our ability to generate videos in other domains is limited. However, most of the current large-scale open-source datasets are primarily obtained through web scraping from platforms like YouTube. While these datasets provide a vast quantity of videos, we have concerns about the quality of the videos themselves. Therefore, we will continue to collect high-quality datasets and also welcome recommendations from the open-source community.
**Caption Generation Pipeline**. As the video duration increases, we need to consider more efficient methods for video caption generation instead of relying solely on large multimodal image models. We are currently developing a new video caption generation pipeline that provides robust support for long videos. We are excited to share more details with you in the near future. Stay tuned!
### Training Diffusion Model
Although v1.0.0 has shown promising results, we acknowledge that we still have a ways to go to reach the level of Sora. In our upcoming work, we will primarily focus on three aspects:
1. **Training support for dynamic resolution and duration**: We aim to develop techniques that enable training models with varying resolutions and durations, allowing for more flexible and adaptable training processes.
2. **Support for longer video generation**: We will explore methods to extend the generation capabilities of our models, enabling them to produce longer videos beyond the current limitations.
3. **Enhanced conditional control**: We seek to enhance the conditional control capabilities of our models, providing users with more options and control over the generated videos.
Furthermore, through careful observation of the generated videos, we have noticed the presence of some non-physiological speckles or abnormal flow. This can be attributed to the limited performance of CausalVideoVAE, as mentioned earlier. In future experiments, we plan to retrain a diffusion model using a more powerful version of CausalVideoVAE to address these issues.
We present the loss curves for two distinct initialization methods under 17×256×256. The yellow curve represents the loss using tail init, while the blue curve corresponds to the loss from center initialization. As shown in the graph, tail initialization demonstrates better performance on the loss curve. Additionally, we found that center initialization leads to error accumulation, causing the collapse over extended durations.
#### Inference Tricks
Despite the VAE in Diffusion training being frozen, we still find it challenging to afford the cost of the CausalVideoVAE. In our case, with 80GB of GPU memory, we can only infer a video of either 256×512×512 or 32×1024×1024 resolution using half-precision, which limits our ability to scale up to longer and higher-resolution videos. Therefore, we adopt tile convolution, which allows us to infer videos of arbitrary duration or resolution with nearly constant memory usage.
### Data Construction
We define a high-quality video dataset based on two core principles: (1) No content-unrelated watermarks. (2) High-quality and dense captions.
**For principles 1**, we crawled approximately 40,000 videos from open-source websites under the CC0 license. Specifically, we obtained 1,244 videos from [mixkit](https://mixkit.co/), 7,408 videos from [pexels](https://www.pexels.com/), and 31,617 videos from [pixabay](https://pixabay.com/). These videos adhere to the principle of having no content-unrelated watermarks. According to the scene transformation and clipping script provided by [Panda70M](https://github.com/snap-research/Panda-70M/blob/main/splitting/README.md), we have divided these videos into approximately 434,000 video clips. In fact, based on our clipping results, 99% of the videos obtained from these online sources are found to contain single scenes. Additionally, we have observed that over 60% of the crawled data comprises landscape videos.
**For principles 2**, it is challenging to directly crawl a large quantity of high-quality dense captions from the internet. Therefore, we utilize a mature Image-captioner model to obtain high-quality dense captions. We conducted ablation experiments on two multimodal large models: [ShareGPT4V-Captioner-7B](https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/README.md) and [LLaVA-1.6-34B](https://github.com/haotian-liu/LLaVA). The former is specifically designed for caption generation, while the latter is a general-purpose multimodal large model. After conducting our ablation experiments, we found that they are comparable in performance. However, there is a significant difference in their inference speed on the A800 GPU: 40s/it of batch size of 12 for ShareGPT4V-Captioner-7B, 15s/it of batch size of 1 for LLaVA-1.6-34B. We open-source all annotations [here](https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0)。
### Training Diffusion Model
Similar to previous work, we employ a multi-stage cascaded training approach, which consumes a total of 2,048 A800 GPU hours. We found that joint training with images significantly accelerates model convergence and enhances visual perception, aligning with the findings of [Latte](https://github.com/Vchitect/Latte). Below is our training card:
| Name | Stage 1 | Stage 2 | Stage 3 | Stage 4 |
|---|---|---|---|---|
| Training Video Size | 17×256×256 | 65×256×256 | 65×512×512 | 65×1024×1024 |
| Compute (#A800 GPU x #Hours) | 32 × 40 | 32 × 18 | 32 × 6 | Under training |
| Checkpoint | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/17x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x256x256) | [HF](https://huggingface.co/LanguageBind/Open-Sora-Plan-v1.0.0/tree/main/65x512x512) | Under training |
| Log | [wandb](https://api.wandb.ai/links/linbin/p6n3evym) | [wandb](https://api.wandb.ai/links/linbin/t2g53sew) | [wandb](https://api.wandb.ai/links/linbin/uomr0xzb) | Under training |
| Training Data | ~40k videos | ~40k videos | ~40k videos | ~40k videos |
## Next Release Preview
### CausalVideoVAE
Currently, the released version of CausalVideoVAE (v1.0.0) has two main drawbacks: **motion blurring** and **gridding effect**. We have made a series of improvements to CausalVideoVAE to reduce its inference cost and enhance its performance. We are currently referring to this enhanced version as the "preview version," which will be released in the next update. Preview reconstruction is as follows:
**1 min Video Reconstruction with 720×1280**. Since github can't put too big video, we put it here: [origin video](https://streamable.com/u4onbb), [reconstruction video](https://streamable.com/qt8ncc).
https://github.com/PKU-YuanGroup/Open-Sora-Plan/assets/88202804/cdcfa9a3-4de0-42d4-94c0-0669710e407b
We randomly selected 100 samples from the validation set of Kinetics-400 for evaluation, and the results are presented in the following table:
| | SSIM↑ | LPIPS↓ | PSNR↑ | FLOLPIPS↓ |
|---|---|---|---|---|
| v1.0.0 | 0.829 | 0.106 | 27.171 | 0.119 |
| Preview | 0.877 | 0.064 | 29.695 | 0.070 |
#### Motion Blurring
| **v1.0.0** | **Preview** |
| --- | --- |
|  |  |
#### Gridding effect
| **v1.0.0** | **Preview** |
| --- | --- |
|  |  |
### Data Construction
**Data source**. As mentioned earlier, over 60% of our dataset consists of landscape videos. This implies that our ability to generate videos in other domains is limited. However, most of the current large-scale open-source datasets are primarily obtained through web scraping from platforms like YouTube. While these datasets provide a vast quantity of videos, we have concerns about the quality of the videos themselves. Therefore, we will continue to collect high-quality datasets and also welcome recommendations from the open-source community.
**Caption Generation Pipeline**. As the video duration increases, we need to consider more efficient methods for video caption generation instead of relying solely on large multimodal image models. We are currently developing a new video caption generation pipeline that provides robust support for long videos. We are excited to share more details with you in the near future. Stay tuned!
### Training Diffusion Model
Although v1.0.0 has shown promising results, we acknowledge that we still have a ways to go to reach the level of Sora. In our upcoming work, we will primarily focus on three aspects:
1. **Training support for dynamic resolution and duration**: We aim to develop techniques that enable training models with varying resolutions and durations, allowing for more flexible and adaptable training processes.
2. **Support for longer video generation**: We will explore methods to extend the generation capabilities of our models, enabling them to produce longer videos beyond the current limitations.
3. **Enhanced conditional control**: We seek to enhance the conditional control capabilities of our models, providing users with more options and control over the generated videos.
Furthermore, through careful observation of the generated videos, we have noticed the presence of some non-physiological speckles or abnormal flow. This can be attributed to the limited performance of CausalVideoVAE, as mentioned earlier. In future experiments, we plan to retrain a diffusion model using a more powerful version of CausalVideoVAE to address these issues.