
- app.py +104 -0
- assets/clipper_example_coffeeMeeting.jpg +0 -0
- assets/clipper_example_room.jpg +0 -0
- assets/clipper_image_book_attack.jpg +0 -0
- assets/clipper_image_primes.jpg +0 -0
- assets/miniclip_teaser.jpg +0 -0
- assets/pharao.jpg +0 -0
- miniclip/imageWrangle.py +57 -0
- requirements.txt +7 -0
app.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import streamlit as st
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import torch
|
| 5 |
+
import clip
|
| 6 |
+
from torchray.attribution.grad_cam import grad_cam
|
| 7 |
+
from miniclip.imageWrangle import heatmap, min_max_norm, torch_to_rgba
|
| 8 |
+
|
| 9 |
+
st.set_page_config(layout="wide")
|
| 10 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@st.cache(show_spinner=True, allow_output_mutation=True)
|
| 14 |
+
def get_model():
|
| 15 |
+
return clip.load("RN50", device=device, jit=False)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# OPTIONS:
|
| 19 |
+
|
| 20 |
+
st.sidebar.header('Options')
|
| 21 |
+
alpha = st.sidebar.radio("select alpha", [0.5, 0.7, 0.8], index=1)
|
| 22 |
+
layer = st.sidebar.selectbox("select saliency layer", ['layer4.2.relu'], index=0)
|
| 23 |
+
|
| 24 |
+
st.header("Saliency Map demo for CLIP")
|
| 25 |
+
st.write(
|
| 26 |
+
"a quick experiment by [Hendrik Strobelt](http://hendrik.strobelt.com) ([MIT-IBM Watson AI Lab](https://mitibmwatsonailab.mit.edu/)) ")
|
| 27 |
+
with st.beta_expander('1. Upload Image', expanded=True):
|
| 28 |
+
imageFile = st.file_uploader("Select a file:", type=[".jpg", ".png", ".jpeg"])
|
| 29 |
+
|
| 30 |
+
# st.write("### (2) Enter some desriptive texts.")
|
| 31 |
+
with st.beta_expander('2. Write Descriptions', expanded=True):
|
| 32 |
+
textarea = st.text_area("Descriptions seperated by semicolon", "a car; a dog; a cat")
|
| 33 |
+
prefix = st.text_input("(optional) Prefix all descriptions with: ", "an image of")
|
| 34 |
+
|
| 35 |
+
if imageFile:
|
| 36 |
+
st.markdown("<hr style='border:black solid;'>", unsafe_allow_html=True)
|
| 37 |
+
image_raw = Image.open(imageFile)
|
| 38 |
+
model, preprocess = get_model()
|
| 39 |
+
|
| 40 |
+
# preprocess image:
|
| 41 |
+
image = preprocess(image_raw).unsqueeze(0).to(device)
|
| 42 |
+
|
| 43 |
+
# preprocess text
|
| 44 |
+
prefix = prefix.strip()
|
| 45 |
+
if len(prefix) > 0:
|
| 46 |
+
categories = [f"{prefix} {x.strip()}" for x in textarea.split(';')]
|
| 47 |
+
else:
|
| 48 |
+
categories = [x.strip() for x in textarea.split(';')]
|
| 49 |
+
text = clip.tokenize(categories).to(device)
|
| 50 |
+
# st.write(text)
|
| 51 |
+
# with st.echo():
|
| 52 |
+
with torch.no_grad():
|
| 53 |
+
image_features = model.encode_image(image)
|
| 54 |
+
text_features = model.encode_text(text)
|
| 55 |
+
image_features_norm = image_features.norm(dim=-1, keepdim=True)
|
| 56 |
+
image_features_new = image_features / image_features_norm
|
| 57 |
+
text_features_norm = text_features.norm(dim=-1, keepdim=True)
|
| 58 |
+
text_features_new = text_features / text_features_norm
|
| 59 |
+
logit_scale = model.logit_scale.exp()
|
| 60 |
+
logits_per_image = logit_scale * image_features_new @ text_features_new.t()
|
| 61 |
+
probs = logits_per_image.softmax(dim=-1).cpu().numpy().tolist()
|
| 62 |
+
|
| 63 |
+
saliency = grad_cam(model.visual, image.type(model.dtype), image_features, saliency_layer=layer)
|
| 64 |
+
hm = heatmap(image[0], saliency[0][0,].detach().type(torch.float32).cpu(), alpha=alpha)
|
| 65 |
+
|
| 66 |
+
collect_images = []
|
| 67 |
+
for i in range(len(categories)):
|
| 68 |
+
# mutliply the normalized text embedding with image norm to get approx image embedding
|
| 69 |
+
text_prediction = (text_features_new[[i]] * image_features_norm)
|
| 70 |
+
saliency = grad_cam(model.visual, image.type(model.dtype), text_prediction, saliency_layer=layer)
|
| 71 |
+
hm = heatmap(image[0], saliency[0][0,].detach().type(torch.float32).cpu(), alpha=alpha)
|
| 72 |
+
collect_images.append(hm)
|
| 73 |
+
logits = logits_per_image.cpu().numpy().tolist()[0]
|
| 74 |
+
st.write("### Grad Cam for text embeddings")
|
| 75 |
+
st.image(collect_images,
|
| 76 |
+
width=256,
|
| 77 |
+
caption=[f"{x} - {str(round(y, 3))}/{str(round(l, 2))}" for (x, y, l) in
|
| 78 |
+
zip(categories, probs[0], logits)])
|
| 79 |
+
|
| 80 |
+
st.write("### Original Image and Grad Cam for image embedding")
|
| 81 |
+
st.image([Image.fromarray((torch_to_rgba(image[0]).numpy() * 255.).astype(np.uint8)), hm],
|
| 82 |
+
caption=["original", "image gradcam"]) # , caption="Grad Cam for original embedding")
|
| 83 |
+
|
| 84 |
+
# st.image(imageFile)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# @st.cache
|
| 88 |
+
def get_readme():
|
| 89 |
+
with open('README.md') as f:
|
| 90 |
+
return "\n".join([x.strip() for x in f.readlines()])
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
st.markdown("<hr style='border:black solid;'>", unsafe_allow_html=True)
|
| 94 |
+
with st.beta_expander('Description', expanded=True):
|
| 95 |
+
st.markdown(get_readme(), unsafe_allow_html=True)
|
| 96 |
+
|
| 97 |
+
hide_streamlit_style = """
|
| 98 |
+
<style>
|
| 99 |
+
#MainMenu {visibility: hidden;}
|
| 100 |
+
footer {visibility: hidden;}
|
| 101 |
+
</style>
|
| 102 |
+
|
| 103 |
+
"""
|
| 104 |
+
st.markdown(hide_streamlit_style, unsafe_allow_html=True)
|
assets/clipper_example_coffeeMeeting.jpg
ADDED

|
assets/clipper_example_room.jpg
ADDED

|
assets/clipper_image_book_attack.jpg
ADDED

|
assets/clipper_image_primes.jpg
ADDED

|
assets/miniclip_teaser.jpg
ADDED
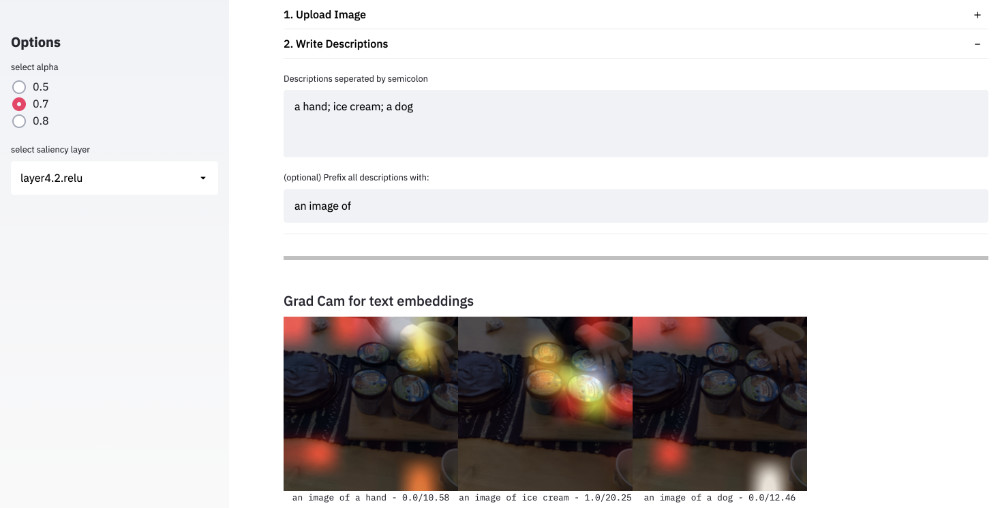
|
assets/pharao.jpg
ADDED

|
miniclip/imageWrangle.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image
|
| 2 |
+
import numpy as np
|
| 3 |
+
from streamlit.logger import update_formatter
|
| 4 |
+
import torch
|
| 5 |
+
from matplotlib import cm
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def min_max_norm(array):
|
| 10 |
+
lim = [array.min(), array.max()]
|
| 11 |
+
array = array - lim[0]
|
| 12 |
+
array.mul_(1 / (1.e-10+ (lim[1] - lim[0])))
|
| 13 |
+
# array = torch.clamp(array, min=0, max=1)
|
| 14 |
+
return array
|
| 15 |
+
|
| 16 |
+
def torch_to_rgba(img):
|
| 17 |
+
img = min_max_norm(img)
|
| 18 |
+
rgba_im = img.permute(1, 2, 0).cpu()
|
| 19 |
+
if rgba_im.shape[2] == 3:
|
| 20 |
+
rgba_im = torch.cat((rgba_im, torch.ones(*rgba_im.shape[:2], 1)), dim=2)
|
| 21 |
+
assert rgba_im.shape[2] == 4
|
| 22 |
+
return rgba_im
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def numpy_to_image(img, size):
|
| 26 |
+
"""
|
| 27 |
+
takes a [0..1] normalized rgba input and returns resized image as [0...255] rgba image
|
| 28 |
+
"""
|
| 29 |
+
resized = Image.fromarray((img*255.).astype(np.uint8)).resize((size, size))
|
| 30 |
+
return resized
|
| 31 |
+
|
| 32 |
+
def upscale_pytorch(img:np.array, size):
|
| 33 |
+
torch_img = torch.from_numpy(img).unsqueeze(0).permute(0,3,1,2)
|
| 34 |
+
print(torch_img)
|
| 35 |
+
upsampler = torch.nn.Upsample(size=size)
|
| 36 |
+
return upsampler(torch_img)[0].permute(1,2,0).cpu().numpy()
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def heatmap(image:torch.Tensor, heatmap: torch.Tensor, size=None, alpha=.6):
|
| 40 |
+
if not size:
|
| 41 |
+
size = image.shape[1]
|
| 42 |
+
# print(heatmap)
|
| 43 |
+
# print(min_max_norm(heatmap))
|
| 44 |
+
|
| 45 |
+
img = torch_to_rgba(image).numpy() # [0...1] rgba numpy "image"
|
| 46 |
+
hm = cm.hot(min_max_norm(heatmap).numpy()) # [0...1] rgba numpy "image"
|
| 47 |
+
|
| 48 |
+
# print(hm.shape, hm)
|
| 49 |
+
#
|
| 50 |
+
|
| 51 |
+
img = np.array(numpy_to_image(img,size))
|
| 52 |
+
hm = np.array(numpy_to_image(hm, size))
|
| 53 |
+
# hm = upscale_pytorch(hm, size)
|
| 54 |
+
# print (hm)
|
| 55 |
+
|
| 56 |
+
return Image.fromarray((alpha * hm + (1-alpha)*img).astype(np.uint8))
|
| 57 |
+
# return Image.fromarray(hm)
|
requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy~=1.20.1
|
| 2 |
+
streamlit~=0.78.0
|
| 3 |
+
torch~=1.7.1
|
| 4 |
+
pillow~=8.1.2
|
| 5 |
+
torchray~=1.0.0.2
|
| 6 |
+
matplotlib~=3.3.4
|
| 7 |
+
git+https://github.com/openai/CLIP.git
|