Spaces:
Running

Running

add customer churn use case
Browse files- data/classification/churn/EDA_churn.png +0 -0
- data/classification/churn/churn_cm_train.pkl +3 -0
- data/classification/churn/churn_feature_importance.pkl +3 -0
- data/classification/churn/churn_test_pp.pkl +3 -0
- data/classification/churn/churn_test_raw.pkl +3 -0
- data/classification/churn/churn_train_raw.pkl +3 -0
- images/customer-churn.png +0 -0
- images/customer-churn.webp +0 -0
- notebooks/Supervised-Unsupervised/customer_churn.ipynb +0 -0
- pages/supervised_unsupervised_page.py +303 -7
- pretrained_models/supervised_learning/churn_model.pkl +3 -0
data/classification/churn/EDA_churn.png
ADDED
|
data/classification/churn/churn_cm_train.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4a7360924d1a9e7d2a0e93afdbeca7226c5ba0d2292fc1ba1fefe8dc52d7b86f
|
| 3 |
+
size 733
|
data/classification/churn/churn_feature_importance.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d95b8565af221ab29cba5fe0d8f982068c87ad2b90b6006c7d39b872113486e5
|
| 3 |
+
size 1311
|
data/classification/churn/churn_test_pp.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0a406bd34ff2df71ca5454979a01ccfe3e313041300b6885fff071918af3d6fa
|
| 3 |
+
size 201179
|
data/classification/churn/churn_test_raw.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:970db62984f6dc49cf3fbc80d38d53d308b0f440e8bfa1344393e3bad7364864
|
| 3 |
+
size 135341
|
data/classification/churn/churn_train_raw.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6a2c861f06e3ff8ee471b18a8a2b9c55f9d77aff19b402c8d80bbd06920f3a19
|
| 3 |
+
size 6148
|
images/customer-churn.png
ADDED

|
images/customer-churn.webp
ADDED

|
notebooks/Supervised-Unsupervised/customer_churn.ipynb
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pages/supervised_unsupervised_page.py
CHANGED
|
@@ -4,6 +4,7 @@ import streamlit as st
|
|
| 4 |
import pandas as pd
|
| 5 |
import numpy as np
|
| 6 |
import plotly.express as px
|
|
|
|
| 7 |
|
| 8 |
from utils import load_data_pickle, load_model_pickle
|
| 9 |
from annotated_text import annotated_text
|
|
@@ -226,6 +227,9 @@ if learning_type == "Supervised Learning":
|
|
| 226 |
|
| 227 |
st.markdown(" ")
|
| 228 |
st.markdown(" ")
|
|
|
|
|
|
|
|
|
|
| 229 |
st.markdown("#### Predict credit score 🆕")
|
| 230 |
st.info("You can only predict the credit score of new clients once the **model has been trained.**")
|
| 231 |
st.markdown(" ")
|
|
@@ -333,10 +337,303 @@ if learning_type == "Supervised Learning":
|
|
| 333 |
|
| 334 |
|
| 335 |
|
|
|
|
|
|
|
| 336 |
################################# CUSTOMER CHURN #####################################
|
| 337 |
|
| 338 |
elif sl_usecase == "Customer churn prediction ❌":
|
| 339 |
-
st.warning("This page is under construction")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 340 |
|
| 341 |
|
| 342 |
|
|
@@ -375,9 +672,9 @@ if learning_type == "Unsupervised Learning":
|
|
| 375 |
st.divider()
|
| 376 |
st.markdown("## Customer Segmentation (Clustering) 🧑🤝🧑")
|
| 377 |
|
| 378 |
-
st.info("""**Unsupervised learning**
|
| 379 |
-
|
| 380 |
-
|
| 381 |
""")
|
| 382 |
st.markdown(" ")
|
| 383 |
|
|
@@ -388,9 +685,8 @@ if learning_type == "Unsupervised Learning":
|
|
| 388 |
|
| 389 |
## About the use case
|
| 390 |
st.markdown("#### About the use case 📋")
|
| 391 |
-
st.markdown("""You are giving a database that contains information on around 2000 customers of a mass-market retailer.
|
| 392 |
-
The database's contains personal information (age, income, number of kids...), as well as information on the client
|
| 393 |
-
This includes what types of products were purchased by the client, how long has he been enrolled as a client and where these purchases were made. """, unsafe_allow_html=True)
|
| 394 |
|
| 395 |
see_data = st.checkbox('**See the data**', key="dataframe")
|
| 396 |
|
|
|
|
| 4 |
import pandas as pd
|
| 5 |
import numpy as np
|
| 6 |
import plotly.express as px
|
| 7 |
+
from PIL import Image
|
| 8 |
|
| 9 |
from utils import load_data_pickle, load_model_pickle
|
| 10 |
from annotated_text import annotated_text
|
|
|
|
| 227 |
|
| 228 |
st.markdown(" ")
|
| 229 |
st.markdown(" ")
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
## Make predictions
|
| 233 |
st.markdown("#### Predict credit score 🆕")
|
| 234 |
st.info("You can only predict the credit score of new clients once the **model has been trained.**")
|
| 235 |
st.markdown(" ")
|
|
|
|
| 337 |
|
| 338 |
|
| 339 |
|
| 340 |
+
|
| 341 |
+
|
| 342 |
################################# CUSTOMER CHURN #####################################
|
| 343 |
|
| 344 |
elif sl_usecase == "Customer churn prediction ❌":
|
| 345 |
+
#st.warning("This page is under construction")
|
| 346 |
+
path_churn = r"data\classification\churn"
|
| 347 |
+
|
| 348 |
+
## Description of the use case
|
| 349 |
+
st.divider()
|
| 350 |
+
st.markdown("## Customer churn prediction ❌")
|
| 351 |
+
st.info(""" Classification is a type of supervised learning model whose goal is to categorize input data into predefined classes or categories.
|
| 352 |
+
In this example, we will build a **customer churn classification model** that can predict whether a customer is likely to leave a company's service in the future using historical data.
|
| 353 |
+
""")
|
| 354 |
+
|
| 355 |
+
st.markdown(" ")
|
| 356 |
+
|
| 357 |
+
## Load data
|
| 358 |
+
churn_data = load_data_pickle(path_churn, "churn_train_raw.pkl")
|
| 359 |
+
|
| 360 |
+
_, col, _ = st.columns([0.1,0.8,0.1])
|
| 361 |
+
with col:
|
| 362 |
+
st.image("images/customer-churn.png", use_column_width=True)
|
| 363 |
+
|
| 364 |
+
st.markdown(" ")
|
| 365 |
+
|
| 366 |
+
## Learn about the data
|
| 367 |
+
st.markdown("#### About the data 📋")
|
| 368 |
+
st.markdown("""To train the customer churn classification model, you were provided a **labeled** database with around 7000 clients of a telecommunications company. <br>
|
| 369 |
+
The data contains information on which services the customer has signed for, information on his account as well as whether the customer churned or not (our label here).""",
|
| 370 |
+
unsafe_allow_html=True)
|
| 371 |
+
# st.markdown("This dataset is 'labeled' since it contains information on what we are trying to predict, which is the **Churn** variable.")
|
| 372 |
+
st.info("**Note**: The variables that had two possible values (Yes or No) where transformed into binary variables (0 or 1) with 0 being 'No' and 1 being 'Yes'.")
|
| 373 |
+
|
| 374 |
+
see_data = st.checkbox('**See the data**', key="churn-data")
|
| 375 |
+
|
| 376 |
+
if see_data:
|
| 377 |
+
st.warning("You can only view the first 30 customers in this section.")
|
| 378 |
+
churn_data = load_data_pickle(path_churn, "churn_train_raw.pkl")
|
| 379 |
+
st.dataframe(churn_data)
|
| 380 |
+
|
| 381 |
+
learn_data = st.checkbox('**Learn more about the data**', key="churn-var")
|
| 382 |
+
if learn_data:
|
| 383 |
+
st.markdown("""
|
| 384 |
+
- **SeniorCitizen**: Whether the customer is a senior citizen or not (1, 0)
|
| 385 |
+
- **Partner**: Whether the customer has a partner or not (Yes, No)
|
| 386 |
+
- **Dependents**: Whether the customer has dependents or not (Yes, No)
|
| 387 |
+
- **tenure**: Number of months the customer has stayed with the company
|
| 388 |
+
- **PhoneService**: Whether the customer has a phone service or not (Yes, No)
|
| 389 |
+
- **MultipleLines**: Whether the customer has multiple lines or not (Yes, No)
|
| 390 |
+
- **InternetService**: Customer’s internet service provider (DSL, Fiber optic, No)
|
| 391 |
+
- **OnlineSecurity**: Whether the customer has online security or not (Yes, No)
|
| 392 |
+
- **OnlineBackup**: Whether the customer has online backup or not (Yes, No)
|
| 393 |
+
- **DeviceProtection**: Whether the customer has device protection or not (Yes, No)
|
| 394 |
+
- **TechSupport**: Whether the customer has tech support or not (Yes, No)
|
| 395 |
+
- **StreamingTV**: Whether the customer has streaming TV or not (Yes, No)
|
| 396 |
+
- **StreamingMovies**: Whether the customer has streaming movies or not (Yes, No)
|
| 397 |
+
- **Contract**: The contract term of the customer (Month-to-month, One year, Two year)
|
| 398 |
+
- **PaperlessBilling**: Whether the customer has paperless billing or not (Yes, No)
|
| 399 |
+
- **PaymentMethod**: The customer’s payment method (Electronic check, Mailed check, Bank transfer (automatic), Credit card (automatic))
|
| 400 |
+
- **MonthlyCharges**: The amount charged to the customer monthly
|
| 401 |
+
- **TotalCharges**: The total amount charged to the customer
|
| 402 |
+
- <span style="color: red;"> **Churn** (the variable we want to predict): Whether the customer churned or not (Yes or No) </span>
|
| 403 |
+
""", unsafe_allow_html=True)
|
| 404 |
+
|
| 405 |
+
st.markdown(" ")
|
| 406 |
+
st.markdown(" ")
|
| 407 |
+
|
| 408 |
+
|
| 409 |
+
## Exploratory data analysis
|
| 410 |
+
st.markdown("#### Exploratory Data Analysis 🔎")
|
| 411 |
+
st.markdown("""Exploratory Data Analysis (EDA) is a crucial step in the machine learning workflow.
|
| 412 |
+
It helps practitioners understand the structure, patterns, and characteristics of the data they are working with.
|
| 413 |
+
For this use case, we will perform EDA by analyzing the **proportion of clients who have churned or not** based on the dataset's other variables.""")
|
| 414 |
+
|
| 415 |
+
st.info("**Note**: EDA is usually preformed before model training as it helps inform decisions made by the model throughout the modeling process.")
|
| 416 |
+
|
| 417 |
+
see_EDA = st.checkbox('**View the analysis**', key="churn-EDA")
|
| 418 |
+
if see_EDA:
|
| 419 |
+
st.markdown(" ")
|
| 420 |
+
|
| 421 |
+
# Show EDA image
|
| 422 |
+
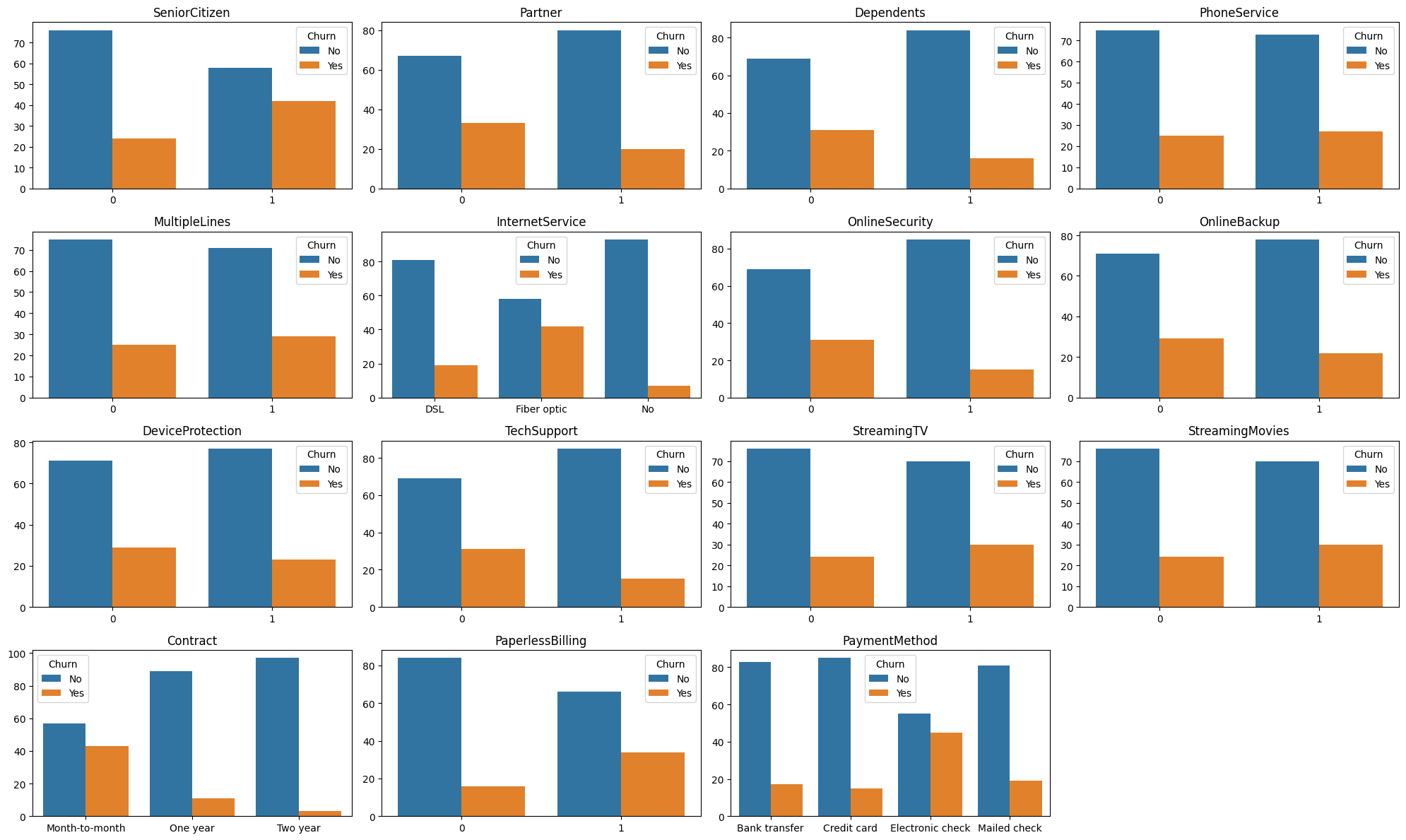
st.markdown("""Exploratory Data Analysis has been preformed between the predicted variable `Churn` with 15 other variables present in the dataset. <br>
|
| 423 |
+
Each graphs shows the proportion of churned and not churned customer based on the variable's possible values.""", unsafe_allow_html=True)
|
| 424 |
+
st.markdown(" ")
|
| 425 |
+
|
| 426 |
+
img_eda = os.path.join(path_churn, "EDA_churn.png")
|
| 427 |
+
st.image(img_eda)
|
| 428 |
+
|
| 429 |
+
st.markdown(" ")
|
| 430 |
+
|
| 431 |
+
# Intepretation
|
| 432 |
+
st.markdown("""**Interpretation** <br>
|
| 433 |
+
For variables such as `Contract`, `PaperlessBilling`, `PaymentMethod` and `InternetService`, we can see a significant difference in the proportion of churned customers based on the variable's value.
|
| 434 |
+
In the *Contract* graph, clients with a 'Month-to-Month' tend to churn more often than those with a longer contract.
|
| 435 |
+
In the *InternetService* graph, clients with a 'Fiber optic' service are more likely to churn than those with DSL or no internet service. """, unsafe_allow_html=True)
|
| 436 |
+
|
| 437 |
+
st.info("""**Note**: Performing EDA can give us an indication as to which variables might be more significant in the customer churn model.
|
| 438 |
+
It can be a valuable tool to study the relationship between two variables but can sometimes be too simplistic. Some relationships might be top complex to be seen through EDA.""")
|
| 439 |
+
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
st.markdown(""" """)
|
| 443 |
+
st.markdown(""" """)
|
| 444 |
+
|
| 445 |
+
## Train the algorithm
|
| 446 |
+
st.markdown("#### Train the algorithm ⚙️")
|
| 447 |
+
st.markdown("""**Training the model** means feeding it data that contains multiple examples of what you are trying to predict (here it is `Churn`).
|
| 448 |
+
This allows the model to **learn relationships** between the `Churn` variable and the additional variables provided for the analysis and make accuracte predictions.""")
|
| 449 |
+
st.info("**Note**: A model is always trained before it can used to make predictions on new 'unlabeled' data.")
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
if 'model_train_churn' not in st.session_state:
|
| 453 |
+
st.session_state['model_train_churn'] = False
|
| 454 |
+
|
| 455 |
+
if st.session_state.model_train_churn:
|
| 456 |
+
st.write("The model has already been trained.")
|
| 457 |
+
else:
|
| 458 |
+
st.write("The model hasn't been trained yet")
|
| 459 |
+
|
| 460 |
+
run_churn_model = st.button("**Train the model**")
|
| 461 |
+
|
| 462 |
+
|
| 463 |
+
if run_churn_model:
|
| 464 |
+
st.session_state.model_train_churn = True
|
| 465 |
+
with st.spinner('Wait for it...'):
|
| 466 |
+
st.markdown(" ")
|
| 467 |
+
st.markdown(" ")
|
| 468 |
+
time.sleep(2)
|
| 469 |
+
st.markdown("#### See the results ☑️")
|
| 470 |
+
tab1, tab2 = st.tabs(["Performance", "Explainability"])
|
| 471 |
+
|
| 472 |
+
######## MODEL PERFORMANCE
|
| 473 |
+
with tab1:
|
| 474 |
+
results_train = load_data_pickle(path_churn,"churn_cm_train.pkl")
|
| 475 |
+
results_train = results_train.to_numpy()
|
| 476 |
+
accuracy = np.round(results_train.diagonal()*100)
|
| 477 |
+
df_accuracy = pd.DataFrame({"Churn":["No","Yes"],
|
| 478 |
+
"Accuracy":accuracy})
|
| 479 |
+
|
| 480 |
+
df_accuracy["Accuracy"] = np.round(df_accuracy["Accuracy"]/100)
|
| 481 |
+
|
| 482 |
+
st.markdown(" ")
|
| 483 |
+
st.info("""**Note**: Evaluating a model's performance helps provide a quantitative measure of the model's ability to make accurate decisions.
|
| 484 |
+
In this use case, the performance of the customer churn model was measured by comparing the clients' churn variables with the value predicted by the trained model.""")
|
| 485 |
+
|
| 486 |
+
fig = px.bar(df_accuracy, y='Accuracy', x='Churn', color="Churn", title="Model performance", text_auto=True)
|
| 487 |
+
fig.update_traces(textfont_size=16)
|
| 488 |
+
#fig.update_traces(textposition='inside', textfont=dict(color='white'))
|
| 489 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 490 |
+
|
| 491 |
+
# st.markdown("""<i>The model's accuracy was measured for both Churn and No Churn.</i>
|
| 492 |
+
# <i>This is crucial as to understand whether the model is consistant in its performance, or whether it has trouble distinguishing between two kinds of credit score.</i>""",
|
| 493 |
+
# unsafe_allow_html=True)
|
| 494 |
+
|
| 495 |
+
st.markdown(" ")
|
| 496 |
+
|
| 497 |
+
st.markdown("""**Interpretation**: <br>
|
| 498 |
+
The model has a 88% accuracy in predicting customer that haven't churned, and a 94% accurate in predicting customer who have churned. <br>
|
| 499 |
+
This means that the model's overall performance is good (at around 91%) but isn't equally as good for both predicted classes.
|
| 500 |
+
""", unsafe_allow_html=True)
|
| 501 |
+
|
| 502 |
+
##### MODEL EXPLAINABILITY
|
| 503 |
+
with tab2:
|
| 504 |
+
st.markdown(" ")
|
| 505 |
+
st.info("""**Note**: Explainability in AI refers to the ability to understand which variable used by a model during training had the most impact on the final predictions and how to quantify this impact.
|
| 506 |
+
Understanding the inner workings of a model helps build trust among users and stakeholders, as well as increase acceptance.""")
|
| 507 |
+
|
| 508 |
+
# Import feature importance dataframe
|
| 509 |
+
df_var_importance = load_data_pickle(path_churn, "churn_feature_importance.pkl")
|
| 510 |
+
df_var_importance.rename({"importance":"score"}, axis=1, inplace=True)
|
| 511 |
+
df_var_importance.sort_values(by=["score"], inplace=True)
|
| 512 |
+
df_var_importance["score"] = df_var_importance["score"].round(3)
|
| 513 |
+
|
| 514 |
+
# Feature importance plot with plotly
|
| 515 |
+
fig = px.bar(df_var_importance, x='score', y='variable', color="score", orientation="h", title="Model explainability")
|
| 516 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 517 |
+
|
| 518 |
+
st.markdown("""<b>Interpretation</b> <br>
|
| 519 |
+
The client's tenure, amount of Monthly and Total Charges, as well as the type of Contract had the most impact on the model's churn predictions.
|
| 520 |
+
On the other hand, whether the client is subscribed to a streaming platform, he is covered by device protection or he has or not phone service had a very contribution in the final predictions.
|
| 521 |
+
""", unsafe_allow_html=True)
|
| 522 |
+
|
| 523 |
+
st.markdown(" ")
|
| 524 |
+
st.markdown(" ")
|
| 525 |
+
|
| 526 |
+
st.markdown("#### Predict customer churn 🆕")
|
| 527 |
+
st.markdown("Once you have trained the model, you can use it predict whether a client will churn or not on new data.")
|
| 528 |
+
|
| 529 |
+
st.markdown(" ")
|
| 530 |
+
|
| 531 |
+
col1, col2 = st.columns([0.25,0.75], gap="medium")
|
| 532 |
+
|
| 533 |
+
churn_test = load_data_pickle(path_churn,"churn_test_raw.pkl")
|
| 534 |
+
churn_test.reset_index(drop=True, inplace=True)
|
| 535 |
+
churn_test.insert(0, "Client ID", [f"{i}" for i in range(churn_test.shape[0])])
|
| 536 |
+
|
| 537 |
+
with col1:
|
| 538 |
+
st.markdown("""<b>Filter the data</b> <br>
|
| 539 |
+
You can select clients based on their *Tenure*, *Total Charges* or *Contract*.""",
|
| 540 |
+
unsafe_allow_html=True)
|
| 541 |
+
|
| 542 |
+
select_image_box = st.radio(" ",
|
| 543 |
+
["Filter by Tenure", "Filter by Total Charges", "Filter by Contract", "No filters"],
|
| 544 |
+
label_visibility="collapsed")
|
| 545 |
+
|
| 546 |
+
if select_image_box == "Filter by Tenure":
|
| 547 |
+
st.markdown(" ")
|
| 548 |
+
min_tenure, max_tenure = st.slider('Select a range', churn_test["tenure"].astype(int).min(), churn_test["tenure"].astype(int).max(), (1,50),
|
| 549 |
+
key="tenure", label_visibility="collapsed")
|
| 550 |
+
churn_test = churn_test.loc[churn_test["tenure"].between(min_tenure,max_tenure)]
|
| 551 |
+
|
| 552 |
+
if select_image_box == "Filter by Total Charges":
|
| 553 |
+
st.markdown(" ")
|
| 554 |
+
min_charges, max_charges = st.slider('Select a range', churn_test["TotalCharges"].astype(int).min(), churn_test["TotalCharges"].astype(int).max(), (50, 5000),
|
| 555 |
+
label_visibility="collapsed", key="totalcharges")
|
| 556 |
+
churn_test = churn_test.loc[churn_test["TotalCharges"].between(min_charges, max_charges)]
|
| 557 |
+
|
| 558 |
+
if select_image_box == "Filter by Contract":
|
| 559 |
+
contract = st.selectbox('Select a type of contract', churn_test["Contract"].unique(), index=0, label_visibility="collapsed", key="contract",
|
| 560 |
+
placeholder = "Choose one or more options")
|
| 561 |
+
churn_test = churn_test.loc[churn_test["Contract"]==contract]
|
| 562 |
+
|
| 563 |
+
if select_image_box == "No filters":
|
| 564 |
+
pass
|
| 565 |
+
|
| 566 |
+
st.markdown(" ")
|
| 567 |
+
st.markdown("""<b>Select a threshold for the alert</b> <br>
|
| 568 |
+
A warning message will be displayed if the percentage of churned customers exceeds this threshold.
|
| 569 |
+
""", unsafe_allow_html=True)
|
| 570 |
+
warning_threshold = st.slider('Select a value', min_value=20, max_value=100, step=10,
|
| 571 |
+
label_visibility="collapsed", key="warning")
|
| 572 |
+
|
| 573 |
+
st.markdown(" ")
|
| 574 |
+
st.write("The threshold is at", warning_threshold, "%")
|
| 575 |
+
|
| 576 |
+
|
| 577 |
+
with col2:
|
| 578 |
+
#st.markdown("**View the database**")
|
| 579 |
+
st.dataframe(churn_test)
|
| 580 |
+
|
| 581 |
+
|
| 582 |
+
# Button to make predictions
|
| 583 |
+
make_predictions = st.button("**Make predictions**")
|
| 584 |
+
st.markdown(" ")
|
| 585 |
+
|
| 586 |
+
if make_predictions:
|
| 587 |
+
if st.session_state.model_train_churn is True:
|
| 588 |
+
|
| 589 |
+
## Load preprocessed test data and model
|
| 590 |
+
churn_test_pp = load_data_pickle(path_churn, "churn_test_pp.pkl")
|
| 591 |
+
churn_model = load_model_pickle(path_pretrained_supervised,"churn_model.pkl")
|
| 592 |
+
|
| 593 |
+
X_test = churn_test_pp.iloc[churn_test.index,:].to_numpy()
|
| 594 |
+
predictions = churn_model.predict(X_test)
|
| 595 |
+
predictions = ["No" if x==0 else "Yes" for x in predictions]
|
| 596 |
+
|
| 597 |
+
df_results_pred = churn_test.copy()
|
| 598 |
+
df_results_pred["Churn"] = predictions
|
| 599 |
+
df_mean_pred = df_results_pred["Churn"].value_counts().to_frame().reset_index()
|
| 600 |
+
df_mean_pred.columns = ["Churn", "Proportion"]
|
| 601 |
+
df_mean_pred["Proportion"] = (100*df_mean_pred["Proportion"]/df_results_pred.shape[0]).round()
|
| 602 |
+
|
| 603 |
+
perct_churned = df_mean_pred.loc[df_mean_pred["Churn"]=="Yes"]["Proportion"].to_numpy()
|
| 604 |
+
|
| 605 |
+
if perct_churned >= warning_threshold:
|
| 606 |
+
st.error(f"The proportion of clients that have churned is above {warning_threshold}% (at {perct_churned[0]}%)⚠️")
|
| 607 |
+
|
| 608 |
+
st.markdown(" ")
|
| 609 |
+
|
| 610 |
+
col1, col2 = st.columns([0.4,0.6], gap="large")
|
| 611 |
+
with col1:
|
| 612 |
+
st.markdown("**Proporition of predicted churn**")
|
| 613 |
+
fig = px.pie(df_mean_pred, values='Proportion', names='Churn', color="Churn",
|
| 614 |
+
color_discrete_map={'No':'royalblue', 'Yes':'red'})
|
| 615 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 616 |
+
|
| 617 |
+
with col2:
|
| 618 |
+
df_show_results = df_results_pred[["Churn","Client ID"] + [col for col in df_results_pred.columns if col not in ["Client ID","Churn"]]]
|
| 619 |
+
columns_float = df_show_results.select_dtypes(include="float").columns
|
| 620 |
+
df_show_results[columns_float] = df_show_results[columns_float].astype(int)
|
| 621 |
+
|
| 622 |
+
def highlight_score(val):
|
| 623 |
+
if val == "No":
|
| 624 |
+
color = 'royalblue'
|
| 625 |
+
if val == 'Yes':
|
| 626 |
+
color= "red"
|
| 627 |
+
return f'color: {color}'
|
| 628 |
+
|
| 629 |
+
df_show_results_color = df_show_results.style.applymap(highlight_score, subset=['Churn'])
|
| 630 |
+
|
| 631 |
+
st.markdown("**Overall results**")
|
| 632 |
+
st.dataframe(df_show_results_color)
|
| 633 |
+
|
| 634 |
+
else:
|
| 635 |
+
st.error("You have to train the credit score model first.")
|
| 636 |
+
|
| 637 |
|
| 638 |
|
| 639 |
|
|
|
|
| 672 |
st.divider()
|
| 673 |
st.markdown("## Customer Segmentation (Clustering) 🧑🤝🧑")
|
| 674 |
|
| 675 |
+
st.info("""**Unsupervised learning** models are valulable tools for cases where you want your model to discover patterns by itself, without having to give it examples to learn from (especially if you don't have labeled data).
|
| 676 |
+
In this use case, we will show how they can be useful for **Customer Segmentation** to detect unknown groups of clients in a company's customer base.
|
| 677 |
+
Using this previously unknown segmentation, companies can then create more targeted add campaigns based on their consumer's behavior and preferences.
|
| 678 |
""")
|
| 679 |
st.markdown(" ")
|
| 680 |
|
|
|
|
| 685 |
|
| 686 |
## About the use case
|
| 687 |
st.markdown("#### About the use case 📋")
|
| 688 |
+
st.markdown("""You are giving a database that contains information on around **2000 customers** of a mass-market retailer.
|
| 689 |
+
The database's contains **personal information** (age, income, number of kids...), as well as information on what types of products were purchased by the client, how long has he been enrolled as a client and where these purchases were made. """, unsafe_allow_html=True)
|
|
|
|
| 690 |
|
| 691 |
see_data = st.checkbox('**See the data**', key="dataframe")
|
| 692 |
|
pretrained_models/supervised_learning/churn_model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:10f3d99a69381ae5625ae9c35a370c365caa31e0fc1808a23d8002484cabf3ab
|
| 3 |
+
size 7866941
|