{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"id": "b567a1d3-f625-4b98-9852-fcc3f3fe9609",
"metadata": {},
"outputs": [],
"source": [
"# To start with, we use the default stack\n",
"#!zenml init\n",
"\n",
"# We also need to connect to a remote ZenML Instance\n",
"#!zenml connect --url https://1cf18d95-zenml.cloudinfra.zenml.io"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c53367f1-3951-48c7-9540-21daf818fa5d",
"metadata": {},
"outputs": [],
"source": [
"# Do the imports at the top\n",
"\n",
"import random\n",
"from zenml import ExternalArtifact, pipeline \n",
"from zenml.client import Client\n",
"from zenml.logger import get_logger\n",
"from uuid import UUID\n",
"\n",
"import os\n",
"from typing import Optional, List\n",
"\n",
"from zenml import pipeline\n",
"from zenml.model.model_version import ModelVersion\n",
"\n",
"from pipelines import feature_engineering\n",
"\n",
"from steps import (\n",
" data_loader,\n",
" data_preprocessor,\n",
" data_splitter,\n",
" model_evaluator,\n",
" model_trainer,\n",
" inference_predict,\n",
" inference_preprocessor\n",
")\n",
"\n",
"logger = get_logger(__name__)\n",
"\n",
"client = Client()\n",
"client.activate_stack(\"local-mlflow-stack\")"
]
},
{
"cell_type": "markdown",
"id": "ab87746e-b804-4fab-88f6-d4967048cb45",
"metadata": {},
"source": [
"# Start local with a simple training pipeline\n",
"\n",
"Below you can see what the pipeline looks like. We will start by running this locally on the default-stack. This means the data between the steps is stored locally and the compute is also local."
]
},
{
"cell_type": "markdown",
"id": "33872b19-7329-4f5e-9a1e-cfc1fe9d560d",
"metadata": {
"jp-MarkdownHeadingCollapsed": true
},
"source": [
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "06625571-b281-4820-a7eb-3a085ba2e572",
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"from sklearn.datasets import load_breast_cancer\n",
"from zenml import step\n",
"from zenml.logger import get_logger\n",
"\n",
"logger = get_logger(__name__)\n",
"\n",
"# Here is what one of the steps in the pipeline looks like. Simple python function that just needs the `@step` decorator.\n",
"\n",
"@step\n",
"def data_loader() -> pd.DataFrame:\n",
" \"\"\"Dataset reader step.\"\"\"\n",
" dataset = load_breast_cancer(as_frame=True)\n",
" inference_size = int(len(dataset.target) * 0.05)\n",
" dataset: pd.DataFrame = dataset.frame\n",
" dataset.reset_index(drop=True, inplace=True)\n",
" logger.info(f\"Dataset with {len(dataset)} records loaded!\")\n",
"\n",
" return dataset\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "754a3069-9d13-4869-be64-a641071800cc",
"metadata": {},
"outputs": [],
"source": [
"# Here's an example of what this function returns\n",
"\n",
"data_loader()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8aa300f1-48df-4e62-87eb-0e2fc5735da8",
"metadata": {},
"outputs": [],
"source": [
"from zenml import pipeline\n",
"\n",
"@pipeline\n",
"def breast_cancer_training(\n",
" train_dataset_id: Optional[UUID] = None,\n",
" test_dataset_id: Optional[UUID] = None,\n",
" min_train_accuracy: float = 0.0,\n",
" min_test_accuracy: float = 0.0,\n",
"):\n",
" \"\"\"Model training pipeline.\"\"\"\n",
" # Execute Feature Engineering Pipeline\n",
" dataset_trn, dataset_tst = feature_engineering()\n",
"\n",
" model = model_trainer(\n",
" dataset_trn=dataset_trn,\n",
" )\n",
"\n",
" model_evaluator(\n",
" model=model,\n",
" dataset_trn=dataset_trn,\n",
" dataset_tst=dataset_tst,\n",
" min_train_accuracy=min_train_accuracy,\n",
" min_test_accuracy=min_test_accuracy,\n",
" )\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d55342bf-33c5-4646-b1ce-e599a99cf568",
"metadata": {},
"outputs": [],
"source": [
"model_version = ModelVersion(\n",
" name=\"breast_cancer_classifier_model\",\n",
" description=\"Classification of Breast Cancer Dataset.\",\n",
" delete_new_version_on_failure=True,\n",
" tags=[\"classification\", \"sklearn\"],\n",
")\n",
"\n",
"pipeline_args = {\n",
" \"enable_cache\": True, \n",
" \"model_version\": model_version\n",
"}\n",
"\n",
"# Model Version config\n",
"fe_t_configured = breast_cancer_training.with_options(**pipeline_args)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f5f4aed8-7d87-4e07-a25c-345d327ad636",
"metadata": {},
"outputs": [],
"source": [
"fe_t_configured()"
]
},
{
"cell_type": "markdown",
"id": "c3e6dc42-21b8-4b3c-90ec-d6e6d541907f",
"metadata": {},
"source": [
"# Let's outsource some compute to Sagemaker!"
]
},
{
"cell_type": "markdown",
"id": "14a840b1-288d-4713-98f4-bbe8d6e06140",
"metadata": {},
"source": [
"Let's farm some compute to AWS with a training job with a certain number of CPUs and Memory. This can easily be done without and changes to the actual implementation of the pipeline. "
]
},
{
"cell_type": "markdown",
"id": "fa9308fb-3556-472c-8fc7-7f2f88d1c455",
"metadata": {},
"source": [
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "06625571-b281-4820-a7eb-3a085ba2e572",
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"from sklearn.datasets import load_breast_cancer\n",
"from zenml import step\n",
"from zenml.logger import get_logger\n",
"\n",
"logger = get_logger(__name__)\n",
"\n",
"# Here is what one of the steps in the pipeline looks like. Simple python function that just needs the `@step` decorator.\n",
"\n",
"@step\n",
"def data_loader() -> pd.DataFrame:\n",
" \"\"\"Dataset reader step.\"\"\"\n",
" dataset = load_breast_cancer(as_frame=True)\n",
" inference_size = int(len(dataset.target) * 0.05)\n",
" dataset: pd.DataFrame = dataset.frame\n",
" dataset.reset_index(drop=True, inplace=True)\n",
" logger.info(f\"Dataset with {len(dataset)} records loaded!\")\n",
"\n",
" return dataset\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "754a3069-9d13-4869-be64-a641071800cc",
"metadata": {},
"outputs": [],
"source": [
"# Here's an example of what this function returns\n",
"\n",
"data_loader()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8aa300f1-48df-4e62-87eb-0e2fc5735da8",
"metadata": {},
"outputs": [],
"source": [
"from zenml import pipeline\n",
"\n",
"@pipeline\n",
"def breast_cancer_training(\n",
" train_dataset_id: Optional[UUID] = None,\n",
" test_dataset_id: Optional[UUID] = None,\n",
" min_train_accuracy: float = 0.0,\n",
" min_test_accuracy: float = 0.0,\n",
"):\n",
" \"\"\"Model training pipeline.\"\"\"\n",
" # Execute Feature Engineering Pipeline\n",
" dataset_trn, dataset_tst = feature_engineering()\n",
"\n",
" model = model_trainer(\n",
" dataset_trn=dataset_trn,\n",
" )\n",
"\n",
" model_evaluator(\n",
" model=model,\n",
" dataset_trn=dataset_trn,\n",
" dataset_tst=dataset_tst,\n",
" min_train_accuracy=min_train_accuracy,\n",
" min_test_accuracy=min_test_accuracy,\n",
" )\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d55342bf-33c5-4646-b1ce-e599a99cf568",
"metadata": {},
"outputs": [],
"source": [
"model_version = ModelVersion(\n",
" name=\"breast_cancer_classifier_model\",\n",
" description=\"Classification of Breast Cancer Dataset.\",\n",
" delete_new_version_on_failure=True,\n",
" tags=[\"classification\", \"sklearn\"],\n",
")\n",
"\n",
"pipeline_args = {\n",
" \"enable_cache\": True, \n",
" \"model_version\": model_version\n",
"}\n",
"\n",
"# Model Version config\n",
"fe_t_configured = breast_cancer_training.with_options(**pipeline_args)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f5f4aed8-7d87-4e07-a25c-345d327ad636",
"metadata": {},
"outputs": [],
"source": [
"fe_t_configured()"
]
},
{
"cell_type": "markdown",
"id": "c3e6dc42-21b8-4b3c-90ec-d6e6d541907f",
"metadata": {},
"source": [
"# Let's outsource some compute to Sagemaker!"
]
},
{
"cell_type": "markdown",
"id": "14a840b1-288d-4713-98f4-bbe8d6e06140",
"metadata": {},
"source": [
"Let's farm some compute to AWS with a training job with a certain number of CPUs and Memory. This can easily be done without and changes to the actual implementation of the pipeline. "
]
},
{
"cell_type": "markdown",
"id": "fa9308fb-3556-472c-8fc7-7f2f88d1c455",
"metadata": {},
"source": [
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "48be8f60-9fbe-4d19-92e4-d9cd8289dbf7",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# This pip installs the requirements locally\n",
"!zenml integration install aws s3 mlflow -y"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4cb26018-aa7d-497d-a0e2-855d3becb70d",
"metadata": {},
"outputs": [],
"source": [
"client.activate_stack(\"local-sagemaker-step-operator-stack\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5683a1c9-f5c1-4ba1-ad7c-1e427fd265df",
"metadata": {},
"outputs": [],
"source": [
"from zenml.config import DockerSettings\n",
"\n",
"# The actual code will stay the same, all that needs to be done is some configuration\n",
"step_args = {}\n",
"\n",
"# We configure which step operator should be used\n",
"step_args[\"step_operator\"] = \"sagemaker-eu\"\n",
"\n",
"# M5 Large is what we need for this big data!\n",
"step_args[\"settings\"] = {\"step_operator.sagemaker\": {\"estimator_args\": {\"instance_type\" : \"ml.m5.large\"}}}\n",
"\n",
"# Update the step. We could also do this in YAML\n",
"model_trainer = model_trainer.with_options(**step_args)\n",
"\n",
"docker_settings = DockerSettings(\n",
" requirements=[\n",
" \"pyarrow\",\n",
" \"scikit-learn==1.1.1\"\n",
" ],\n",
")\n",
"\n",
"pipeline_args = {\n",
" \"enable_cache\": True, \n",
" \"model_version\": model_version,\n",
" \"settings\": {\"docker\": docker_settings}\n",
"}\n",
"\n",
"fe_t_configured = breast_cancer_training.with_options(**pipeline_args)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "85179f52-68f0-4c8d-9808-6b080bec72c3",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# Lets run the pipeline\n",
"fe_t_configured()"
]
},
{
"cell_type": "markdown",
"id": "0841f93b-9eb5-4af6-bba7-cec167024ccf",
"metadata": {},
"source": [
"# Switch to full Sagemaker Stack\n",
"\n",
"Just one command will allow you to switch the full code execution over to sagemaker. No Sagemaker domain knowledge necessary. No setup of VMs or Kubernetes clusters necessary. No maintenance of any infrastructure either.\n",
"\n",
"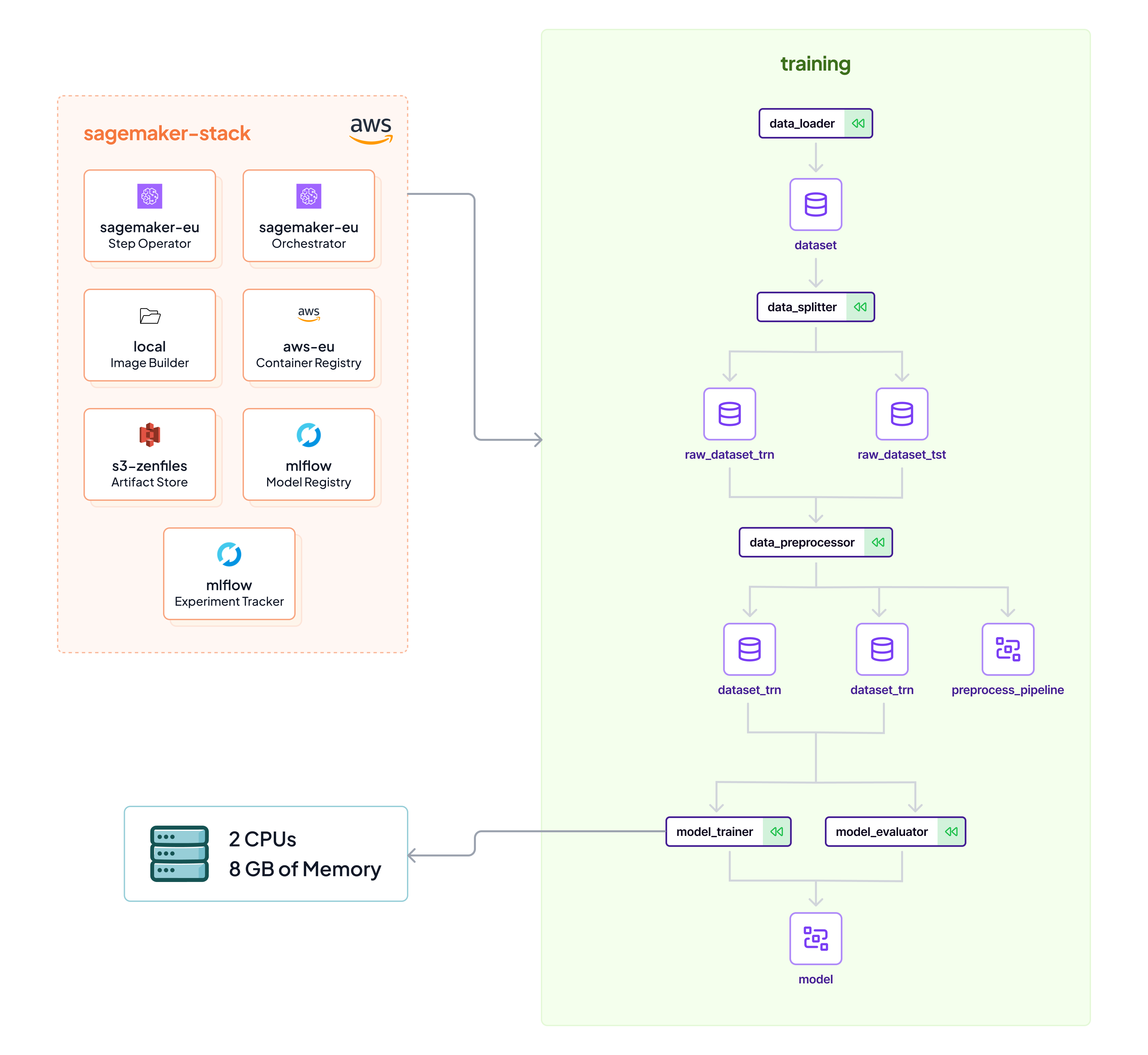\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d8e33484-3377-4f0e-83fa-87d7c0ca4d72",
"metadata": {},
"outputs": [],
"source": [
"# Finally, this is all that needs to be done to fully switch the code to be run fully on sagemaker\n",
"client.activate_stack(\"sagemaker-stack\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a03c95e9-df2e-446c-8d61-9cc37ad8a46a",
"metadata": {},
"outputs": [],
"source": [
"fe_t_configured()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "48be8f60-9fbe-4d19-92e4-d9cd8289dbf7",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# This pip installs the requirements locally\n",
"!zenml integration install aws s3 mlflow -y"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4cb26018-aa7d-497d-a0e2-855d3becb70d",
"metadata": {},
"outputs": [],
"source": [
"client.activate_stack(\"local-sagemaker-step-operator-stack\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5683a1c9-f5c1-4ba1-ad7c-1e427fd265df",
"metadata": {},
"outputs": [],
"source": [
"from zenml.config import DockerSettings\n",
"\n",
"# The actual code will stay the same, all that needs to be done is some configuration\n",
"step_args = {}\n",
"\n",
"# We configure which step operator should be used\n",
"step_args[\"step_operator\"] = \"sagemaker-eu\"\n",
"\n",
"# M5 Large is what we need for this big data!\n",
"step_args[\"settings\"] = {\"step_operator.sagemaker\": {\"estimator_args\": {\"instance_type\" : \"ml.m5.large\"}}}\n",
"\n",
"# Update the step. We could also do this in YAML\n",
"model_trainer = model_trainer.with_options(**step_args)\n",
"\n",
"docker_settings = DockerSettings(\n",
" requirements=[\n",
" \"pyarrow\",\n",
" \"scikit-learn==1.1.1\"\n",
" ],\n",
")\n",
"\n",
"pipeline_args = {\n",
" \"enable_cache\": True, \n",
" \"model_version\": model_version,\n",
" \"settings\": {\"docker\": docker_settings}\n",
"}\n",
"\n",
"fe_t_configured = breast_cancer_training.with_options(**pipeline_args)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "85179f52-68f0-4c8d-9808-6b080bec72c3",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# Lets run the pipeline\n",
"fe_t_configured()"
]
},
{
"cell_type": "markdown",
"id": "0841f93b-9eb5-4af6-bba7-cec167024ccf",
"metadata": {},
"source": [
"# Switch to full Sagemaker Stack\n",
"\n",
"Just one command will allow you to switch the full code execution over to sagemaker. No Sagemaker domain knowledge necessary. No setup of VMs or Kubernetes clusters necessary. No maintenance of any infrastructure either.\n",
"\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d8e33484-3377-4f0e-83fa-87d7c0ca4d72",
"metadata": {},
"outputs": [],
"source": [
"# Finally, this is all that needs to be done to fully switch the code to be run fully on sagemaker\n",
"client.activate_stack(\"sagemaker-stack\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a03c95e9-df2e-446c-8d61-9cc37ad8a46a",
"metadata": {},
"outputs": [],
"source": [
"fe_t_configured()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
}
},
"nbformat": 4,
"nbformat_minor": 5
}