Spaces:
Runtime error

Runtime error
Commit
•
b86e5c3
1
Parent(s):
c3c4f08
Synced repo using 'sync_with_huggingface' Github Action
Browse files- .dockerignore +9 -0
- Dockerfile +71 -0
- Makefile +0 -0
- compose.yaml +29 -0
- docker/cpu/Dockerfile +68 -0
- images/app_sample.png +0 -0
- notebooks/helloworld.ipynb +51 -0
- poetry.lock +0 -0
- pyproject.toml +58 -0
- scripts/genarate_tranrate_df.py +36 -0
- src/__init__.py +0 -0
- src/app.py +53 -0
- src/ocr_and_translate_en2jp/__init__.py +0 -0
- src/ocr_and_translate_en2jp/genarate_tranrate_df.py +59 -0
- src/ocr_and_translate_en2jp/ocr.py +32 -0
- src/ocr_and_translate_en2jp/translate.py +41 -0
- tests/ocr_and_translate_en2jp/__init__.py +0 -0
.dockerignore
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
html/*
|
| 2 |
+
.DS_Store
|
| 3 |
+
|
| 4 |
+
.venv
|
| 5 |
+
*.swp
|
| 6 |
+
.mypy_cache
|
| 7 |
+
.pytest_cache
|
| 8 |
+
.ipynb_checkpoints
|
| 9 |
+
__pycache__
|
Dockerfile
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM ubuntu:22.04 AS base
|
| 2 |
+
|
| 3 |
+
ARG PYTHON_VERSION=3.10
|
| 4 |
+
|
| 5 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 6 |
+
ENV WORKDIR /app/
|
| 7 |
+
|
| 8 |
+
WORKDIR /opt
|
| 9 |
+
|
| 10 |
+
# install dev tools
|
| 11 |
+
RUN apt-get update && apt-get install -y \
|
| 12 |
+
vim neovim nano \
|
| 13 |
+
git git-lfs \
|
| 14 |
+
zip unzip \
|
| 15 |
+
curl wget make build-essential xz-utils file tree \
|
| 16 |
+
sudo \
|
| 17 |
+
dnsutils \
|
| 18 |
+
tzdata language-pack-ja \
|
| 19 |
+
&& apt-get clean \
|
| 20 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 21 |
+
|
| 22 |
+
# for Japanese settings
|
| 23 |
+
# ENV TZ Asia/Tokyo
|
| 24 |
+
# ENV LANG ja_JP.utf8
|
| 25 |
+
|
| 26 |
+
# for US settings
|
| 27 |
+
ENV LANG en_US.UTF-8
|
| 28 |
+
ENV LANGUAGE en_US
|
| 29 |
+
|
| 30 |
+
# install Python
|
| 31 |
+
RUN apt-get update && apt-get -yV upgrade && DEBIAN_FRONTEND=noninteractive apt-get -yV install \
|
| 32 |
+
build-essential libssl-dev libffi-dev \
|
| 33 |
+
python${PYTHON_VERSION} python${PYTHON_VERSION}-distutils python${PYTHON_VERSION}-dev \
|
| 34 |
+
&& ln -s /usr/bin/python${PYTHON_VERSION} /usr/local/bin/python3 \
|
| 35 |
+
&& ln -s /usr/bin/python${PYTHON_VERSION} /usr/local/bin/python \
|
| 36 |
+
&& apt-get clean \
|
| 37 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 38 |
+
|
| 39 |
+
## install pip
|
| 40 |
+
RUN curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py \
|
| 41 |
+
&& python3 get-pip.py \
|
| 42 |
+
&& pip3 --no-cache-dir install --upgrade pip
|
| 43 |
+
|
| 44 |
+
## install Poetry
|
| 45 |
+
RUN curl -sSL https://install.python-poetry.org | python3 -
|
| 46 |
+
ENV PATH $PATH:/root/.local/bin
|
| 47 |
+
RUN poetry config virtualenvs.create true \
|
| 48 |
+
&& poetry config virtualenvs.in-project false
|
| 49 |
+
|
| 50 |
+
WORKDIR ${WORKDIR}
|
| 51 |
+
|
| 52 |
+
# install python packages
|
| 53 |
+
COPY poetry.lock pyproject.toml ./
|
| 54 |
+
COPY src ./src
|
| 55 |
+
RUN poetry install --no-dev
|
| 56 |
+
|
| 57 |
+
FROM base AS dev
|
| 58 |
+
WORKDIR ${WORKDIR}
|
| 59 |
+
|
| 60 |
+
# install python packages
|
| 61 |
+
COPY poetry.lock pyproject.toml ./
|
| 62 |
+
COPY src ./src
|
| 63 |
+
RUN poetry install
|
| 64 |
+
|
| 65 |
+
# install ocr tools
|
| 66 |
+
RUN apt-get update && apt-get install -y \
|
| 67 |
+
tesseract-ocr tesseract-ocr-jpn \
|
| 68 |
+
poppler-utils
|
| 69 |
+
|
| 70 |
+
# Hugging Face Hub Settings
|
| 71 |
+
CMD ["poetry", "run", "streamlit", "run", "src/app.py", "--server.port", "7860"]
|
Makefile
ADDED
|
File without changes
|
compose.yaml
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3.2"
|
| 2 |
+
services:
|
| 3 |
+
ocr_and_translate_en2jp:
|
| 4 |
+
tty: true
|
| 5 |
+
stdin_open: true
|
| 6 |
+
user: root
|
| 7 |
+
working_dir: /app
|
| 8 |
+
build:
|
| 9 |
+
context: .
|
| 10 |
+
dockerfile: docker/cpu/Dockerfile
|
| 11 |
+
target: dev
|
| 12 |
+
# secrets:
|
| 13 |
+
# - github_token
|
| 14 |
+
args:
|
| 15 |
+
progress: plain
|
| 16 |
+
volumes:
|
| 17 |
+
- type: bind
|
| 18 |
+
source: ./
|
| 19 |
+
target: /app
|
| 20 |
+
ports:
|
| 21 |
+
- "8501:8501"
|
| 22 |
+
command:
|
| 23 |
+
poetry run streamlit run src/app.py
|
| 24 |
+
environment:
|
| 25 |
+
PYTHONPATH: "/app/src"
|
| 26 |
+
PYTHONUNBUFFERED: 1
|
| 27 |
+
# secrets:
|
| 28 |
+
# github_token:
|
| 29 |
+
# file: ${HOME}/.git-credentials
|
docker/cpu/Dockerfile
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM ubuntu:22.04 AS base
|
| 2 |
+
|
| 3 |
+
ARG PYTHON_VERSION=3.10
|
| 4 |
+
|
| 5 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 6 |
+
ENV WORKDIR /app/
|
| 7 |
+
|
| 8 |
+
WORKDIR /opt
|
| 9 |
+
|
| 10 |
+
# install dev tools
|
| 11 |
+
RUN apt-get update && apt-get install -y \
|
| 12 |
+
vim neovim nano \
|
| 13 |
+
git git-lfs \
|
| 14 |
+
zip unzip \
|
| 15 |
+
curl wget make build-essential xz-utils file tree \
|
| 16 |
+
sudo \
|
| 17 |
+
dnsutils \
|
| 18 |
+
tzdata language-pack-ja \
|
| 19 |
+
&& apt-get clean \
|
| 20 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 21 |
+
|
| 22 |
+
# for Japanese settings
|
| 23 |
+
# ENV TZ Asia/Tokyo
|
| 24 |
+
# ENV LANG ja_JP.utf8
|
| 25 |
+
|
| 26 |
+
# for US settings
|
| 27 |
+
ENV LANG en_US.UTF-8
|
| 28 |
+
ENV LANGUAGE en_US
|
| 29 |
+
|
| 30 |
+
# install Python
|
| 31 |
+
RUN apt-get update && apt-get -yV upgrade && DEBIAN_FRONTEND=noninteractive apt-get -yV install \
|
| 32 |
+
build-essential libssl-dev libffi-dev \
|
| 33 |
+
python${PYTHON_VERSION} python${PYTHON_VERSION}-distutils python${PYTHON_VERSION}-dev \
|
| 34 |
+
&& ln -s /usr/bin/python${PYTHON_VERSION} /usr/local/bin/python3 \
|
| 35 |
+
&& ln -s /usr/bin/python${PYTHON_VERSION} /usr/local/bin/python \
|
| 36 |
+
&& apt-get clean \
|
| 37 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 38 |
+
|
| 39 |
+
## install pip
|
| 40 |
+
RUN curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py \
|
| 41 |
+
&& python3 get-pip.py \
|
| 42 |
+
&& pip3 --no-cache-dir install --upgrade pip
|
| 43 |
+
|
| 44 |
+
## install Poetry
|
| 45 |
+
RUN curl -sSL https://install.python-poetry.org | python3 -
|
| 46 |
+
ENV PATH $PATH:/root/.local/bin
|
| 47 |
+
RUN poetry config virtualenvs.create true \
|
| 48 |
+
&& poetry config virtualenvs.in-project false
|
| 49 |
+
|
| 50 |
+
WORKDIR ${WORKDIR}
|
| 51 |
+
|
| 52 |
+
# install python packages
|
| 53 |
+
COPY poetry.lock pyproject.toml ./
|
| 54 |
+
COPY src ./src
|
| 55 |
+
RUN poetry install --no-dev
|
| 56 |
+
|
| 57 |
+
FROM base AS dev
|
| 58 |
+
WORKDIR ${WORKDIR}
|
| 59 |
+
|
| 60 |
+
# install python packages
|
| 61 |
+
COPY poetry.lock pyproject.toml ./
|
| 62 |
+
COPY src ./src
|
| 63 |
+
RUN poetry install
|
| 64 |
+
|
| 65 |
+
# install ocr tools
|
| 66 |
+
RUN apt-get update && apt-get install -y \
|
| 67 |
+
tesseract-ocr tesseract-ocr-jpn \
|
| 68 |
+
poppler-utils
|
images/app_sample.png
ADDED
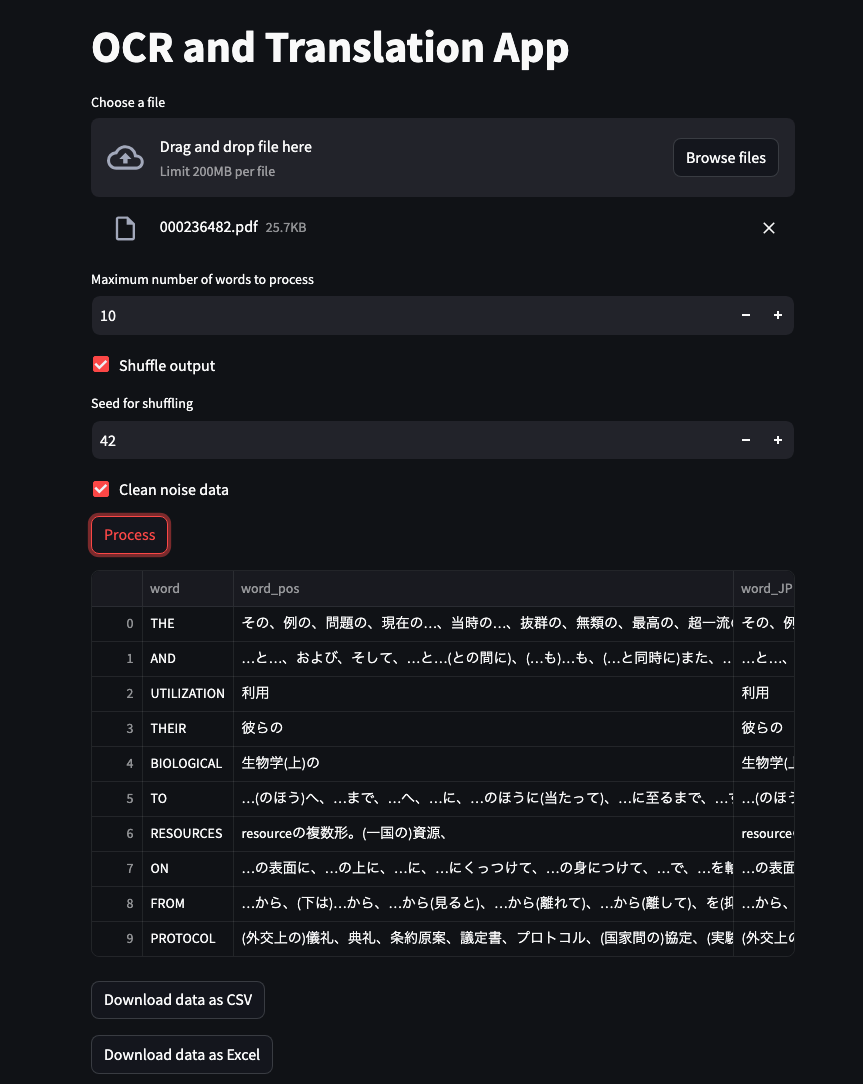
|
notebooks/helloworld.ipynb
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": 1,
|
| 6 |
+
"id": "18edcb70-64a5-4d17-94c0-a86ecc435be4",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [
|
| 9 |
+
{
|
| 10 |
+
"name": "stdout",
|
| 11 |
+
"output_type": "stream",
|
| 12 |
+
"text": [
|
| 13 |
+
"hello world\n"
|
| 14 |
+
]
|
| 15 |
+
}
|
| 16 |
+
],
|
| 17 |
+
"source": [
|
| 18 |
+
"print(\"hello world\")"
|
| 19 |
+
]
|
| 20 |
+
},
|
| 21 |
+
{
|
| 22 |
+
"cell_type": "code",
|
| 23 |
+
"execution_count": null,
|
| 24 |
+
"id": "b90e3e1f-5aa1-43a0-b9e2-1d1bcaf9ff94",
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": []
|
| 28 |
+
}
|
| 29 |
+
],
|
| 30 |
+
"metadata": {
|
| 31 |
+
"kernelspec": {
|
| 32 |
+
"display_name": "Python 3 (ipykernel)",
|
| 33 |
+
"language": "python",
|
| 34 |
+
"name": "python3"
|
| 35 |
+
},
|
| 36 |
+
"language_info": {
|
| 37 |
+
"codemirror_mode": {
|
| 38 |
+
"name": "ipython",
|
| 39 |
+
"version": 3
|
| 40 |
+
},
|
| 41 |
+
"file_extension": ".py",
|
| 42 |
+
"mimetype": "text/x-python",
|
| 43 |
+
"name": "python",
|
| 44 |
+
"nbconvert_exporter": "python",
|
| 45 |
+
"pygments_lexer": "ipython3",
|
| 46 |
+
"version": "3.9.5"
|
| 47 |
+
}
|
| 48 |
+
},
|
| 49 |
+
"nbformat": 4,
|
| 50 |
+
"nbformat_minor": 5
|
| 51 |
+
}
|
poetry.lock
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pyproject.toml
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[tool.poetry]
|
| 2 |
+
name = "ocr_and_translate_en2jp"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = ""
|
| 5 |
+
authors = ["iamtatsuki05 <tatsukio0522@gmail.com>"]
|
| 6 |
+
packages = [
|
| 7 |
+
{ include = "ocr_and_translate_en2jp", from = "src/" },
|
| 8 |
+
]
|
| 9 |
+
|
| 10 |
+
[tool.poetry.dependencies]
|
| 11 |
+
python = "^3.10"
|
| 12 |
+
python-dotenv = "^1.0.0"
|
| 13 |
+
setuptools = "^69.0.3"
|
| 14 |
+
fire = "^0.5.0"
|
| 15 |
+
pydantic = "^2.5.3"
|
| 16 |
+
beautifulsoup4 = "^4.12.2"
|
| 17 |
+
selenium = "^4.16.0"
|
| 18 |
+
fastapi = "^0.108.0"
|
| 19 |
+
uvicorn = "^0.25.0"
|
| 20 |
+
matplotlib = "^3.5.1"
|
| 21 |
+
pandas = "^1.4.2"
|
| 22 |
+
seaborn = "^0.11.2"
|
| 23 |
+
japanize-matplotlib = "^1.1.3"
|
| 24 |
+
numpy = "^1.22.3"
|
| 25 |
+
jupyterlab = "^3.3.4"
|
| 26 |
+
tqdm = "^4.64.0"
|
| 27 |
+
scikit-learn = "^1.1.1"
|
| 28 |
+
openpyxl = "^3.1.2"
|
| 29 |
+
pytesseract = "^0.3.10"
|
| 30 |
+
pdf2image = "^1.16.0"
|
| 31 |
+
streamlit = "^1.34.0"
|
| 32 |
+
|
| 33 |
+
[tool.poetry.group.dev.dependencies]
|
| 34 |
+
pytest = "^7.0.0"
|
| 35 |
+
ipykernel = ">=6.13.0"
|
| 36 |
+
autopep8 = ">=1.6.0"
|
| 37 |
+
autoflake = ">=1.4"
|
| 38 |
+
flake8 = ">=4.0.1"
|
| 39 |
+
flake8-isort = ">=4.1.1"
|
| 40 |
+
flake8-print = ">=4.0.0"
|
| 41 |
+
isort = ">=5.10.1"
|
| 42 |
+
black = ">=22.10.0"
|
| 43 |
+
mypy = ">=0.971"
|
| 44 |
+
tox = ">=3.25.1"
|
| 45 |
+
pre-commit = ">=3.3.3"
|
| 46 |
+
nbstripout = "0.6.1"
|
| 47 |
+
|
| 48 |
+
[tool.isort]
|
| 49 |
+
line_length = 88
|
| 50 |
+
multi_line_output = 3
|
| 51 |
+
include_trailing_comma = true
|
| 52 |
+
|
| 53 |
+
[tool.black]
|
| 54 |
+
skip-string-normalization = true
|
| 55 |
+
|
| 56 |
+
[build-system]
|
| 57 |
+
requires = ["poetry-core>=1.0.0"]
|
| 58 |
+
build-backend = "poetry.core.masonry.api"
|
scripts/genarate_tranrate_df.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
from typing import Optional, Union
|
| 3 |
+
|
| 4 |
+
import fire
|
| 5 |
+
|
| 6 |
+
from ocr_and_translate_en2jp.genarate_tranrate_df import df_generator, output_results
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def df_generator_wrapper(
|
| 10 |
+
file_path: Union[str, Path],
|
| 11 |
+
output_dir: Optional[Union[str, Path]] = './',
|
| 12 |
+
output_file_name: str = 'output',
|
| 13 |
+
max_words: Optional[int] = None,
|
| 14 |
+
do_shuffle_output: bool = False,
|
| 15 |
+
seed: Optional[int] = None,
|
| 16 |
+
do_output_csv: Optional[bool] = True,
|
| 17 |
+
do_output_excel: Optional[bool] = False,
|
| 18 |
+
do_clean_noise_data: Optional[bool] = True,
|
| 19 |
+
) -> None:
|
| 20 |
+
file_path = Path(file_path)
|
| 21 |
+
output_dir = Path(output_dir)
|
| 22 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 23 |
+
|
| 24 |
+
df = df_generator(
|
| 25 |
+
file_path=file_path,
|
| 26 |
+
max_words=max_words,
|
| 27 |
+
do_shuffle_output=do_shuffle_output,
|
| 28 |
+
seed=seed,
|
| 29 |
+
do_clean_noise_data=do_clean_noise_data,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
output_results(df, output_dir, output_file_name, do_output_csv, do_output_excel)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
if __name__ == '__main__':
|
| 36 |
+
fire.Fire(df_generator)
|
src/__init__.py
ADDED
|
File without changes
|
src/app.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import shutil
|
| 2 |
+
import tempfile
|
| 3 |
+
from io import BytesIO
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
import streamlit as st
|
| 7 |
+
|
| 8 |
+
from ocr_and_translate_en2jp.genarate_tranrate_df import df_generator
|
| 9 |
+
|
| 10 |
+
st.title('OCR and Translation App')
|
| 11 |
+
|
| 12 |
+
uploaded_file = st.file_uploader('Choose a file')
|
| 13 |
+
if uploaded_file is not None:
|
| 14 |
+
with tempfile.NamedTemporaryFile(
|
| 15 |
+
delete=False, suffix=Path(uploaded_file.name).suffix
|
| 16 |
+
) as tmpfile:
|
| 17 |
+
shutil.copyfileobj(uploaded_file, tmpfile)
|
| 18 |
+
uploaded_file_path = tmpfile.name
|
| 19 |
+
|
| 20 |
+
max_words = st.number_input(
|
| 21 |
+
'Maximum number of words to process', min_value=1, value=50
|
| 22 |
+
)
|
| 23 |
+
do_shuffle = st.checkbox('Shuffle output')
|
| 24 |
+
seed = (
|
| 25 |
+
st.number_input('Seed for shuffling', min_value=0, value=42)
|
| 26 |
+
if do_shuffle
|
| 27 |
+
else None
|
| 28 |
+
)
|
| 29 |
+
do_clean_noise_data = st.checkbox('Clean noise data', value=True)
|
| 30 |
+
|
| 31 |
+
if st.button('Process'):
|
| 32 |
+
df = df_generator(
|
| 33 |
+
uploaded_file_path, max_words, do_shuffle, seed, do_clean_noise_data
|
| 34 |
+
)
|
| 35 |
+
st.dataframe(df)
|
| 36 |
+
|
| 37 |
+
csv = df.to_csv(index=False).encode('utf-8')
|
| 38 |
+
st.download_button(
|
| 39 |
+
label='Download data as CSV',
|
| 40 |
+
data=csv,
|
| 41 |
+
file_name='processed_data.csv',
|
| 42 |
+
mime='text/csv',
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
# REF: https://qiita.com/nyakiri_0726/items/2ae8cfb926c48072b190
|
| 46 |
+
df.to_excel(buf := BytesIO(), index=False)
|
| 47 |
+
|
| 48 |
+
st.download_button(
|
| 49 |
+
label="Download data as Excel",
|
| 50 |
+
data=buf.getvalue(),
|
| 51 |
+
file_name='processed_data.xlsx',
|
| 52 |
+
mime='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',
|
| 53 |
+
)
|
src/ocr_and_translate_en2jp/__init__.py
ADDED
|
File without changes
|
src/ocr_and_translate_en2jp/genarate_tranrate_df.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
from typing import Optional, Union
|
| 3 |
+
|
| 4 |
+
import pandas as pd
|
| 5 |
+
from tqdm.auto import tqdm
|
| 6 |
+
|
| 7 |
+
from ocr_and_translate_en2jp.ocr import ocr_image
|
| 8 |
+
from ocr_and_translate_en2jp.translate import get_translation, get_word_type_japanese
|
| 9 |
+
|
| 10 |
+
tqdm.pandas()
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def clean_data(df: pd.DataFrame) -> pd.DataFrame:
|
| 14 |
+
df = df[df['word'].str.contains('[a-zA-Z]', na=False)].reset_index(drop=True)
|
| 15 |
+
df['word_pos'] = df['word'].progress_apply(get_word_type_japanese)
|
| 16 |
+
df = df[df['word_pos'].notnull()].reset_index(drop=True)
|
| 17 |
+
df['word_JP'] = df['word'].progress_apply(get_translation)
|
| 18 |
+
return df[df['word_JP'].notnull()].reset_index(drop=True)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def output_results(
|
| 22 |
+
df: pd.DataFrame,
|
| 23 |
+
output_dir: Path,
|
| 24 |
+
output_file_name: str,
|
| 25 |
+
do_output_csv: bool,
|
| 26 |
+
do_output_excel: bool,
|
| 27 |
+
) -> None:
|
| 28 |
+
if do_output_csv:
|
| 29 |
+
output_path = output_dir / f'{output_file_name}.csv'
|
| 30 |
+
df.to_csv(output_path, index=False)
|
| 31 |
+
if do_output_excel:
|
| 32 |
+
output_path = output_dir / f'{output_file_name}.xlsx'
|
| 33 |
+
df.to_excel(output_path, index=False)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def df_generator(
|
| 37 |
+
file_path: Union[str, Path],
|
| 38 |
+
max_words: Optional[int] = None,
|
| 39 |
+
do_shuffle_output: bool = False,
|
| 40 |
+
seed: Optional[int] = None,
|
| 41 |
+
do_clean_noise_data: Optional[bool] = True,
|
| 42 |
+
) -> pd.DataFrame:
|
| 43 |
+
file_path = Path(file_path)
|
| 44 |
+
ocr_result = list(set(ocr_image(file_path, is_return_list=True)))
|
| 45 |
+
df = pd.DataFrame(ocr_result, columns=['word'])
|
| 46 |
+
|
| 47 |
+
if do_clean_noise_data:
|
| 48 |
+
df = clean_data(df)
|
| 49 |
+
|
| 50 |
+
max_words = max_words or len(df)
|
| 51 |
+
if max_words > len(df):
|
| 52 |
+
max_words = len(df)
|
| 53 |
+
df = (
|
| 54 |
+
df.sample(n=max_words, random_state=seed, ignore_index=True)
|
| 55 |
+
if do_shuffle_output
|
| 56 |
+
else df.head(max_words)
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
return df
|
src/ocr_and_translate_en2jp/ocr.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
from typing import Final, Optional, Union
|
| 3 |
+
|
| 4 |
+
from pdf2image import convert_from_path
|
| 5 |
+
from PIL import Image
|
| 6 |
+
from pytesseract import pytesseract
|
| 7 |
+
|
| 8 |
+
pytesseract.tesseract_cmd = '/usr/bin/tesseract'
|
| 9 |
+
|
| 10 |
+
PICTURE_EXTENSIONS: Final[list[str]] = ['.jpg', '.jpeg', '.png', '.gif', '.bmp']
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def load_file(file_path: Union[str, Path]) -> Optional[Union[Image.Image, list]]:
|
| 14 |
+
file_path = Path(file_path)
|
| 15 |
+
file_extension = file_path.suffix
|
| 16 |
+
if file_extension == '.pdf':
|
| 17 |
+
return convert_from_path(str(file_path))
|
| 18 |
+
elif file_extension in PICTURE_EXTENSIONS:
|
| 19 |
+
return [Image.open(str(file_path))]
|
| 20 |
+
return None
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def ocr_image(
|
| 24 |
+
file_path: Union[str, Path], is_return_list: Optional[bool] = False
|
| 25 |
+
) -> Union[str, list]:
|
| 26 |
+
images = load_file(file_path)
|
| 27 |
+
if images is None:
|
| 28 |
+
return []
|
| 29 |
+
ocr_result = ''.join(
|
| 30 |
+
pytesseract.image_to_string(img, lang='eng+jpn') for img in images
|
| 31 |
+
)
|
| 32 |
+
return ocr_result.split() if is_return_list else ocr_result
|
src/ocr_and_translate_en2jp/translate.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Final, Optional
|
| 2 |
+
|
| 3 |
+
import requests
|
| 4 |
+
from bs4 import BeautifulSoup
|
| 5 |
+
|
| 6 |
+
BASE_URL: Final[str] = 'https://ejje.weblio.jp/content/'
|
| 7 |
+
WORD_TYPE_JAPANESE_HTML_CLASS: Final[str] = 'content-explanation'
|
| 8 |
+
TRANSLATION_HTML_CLASS: Final[str] = 'content-explanation ej'
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def generate_soup_from_url(word: str) -> BeautifulSoup:
|
| 12 |
+
response = requests.get(BASE_URL + word)
|
| 13 |
+
return BeautifulSoup(response.text, 'html.parser')
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_text_from_class(soup: BeautifulSoup, class_name: str) -> Optional[str]:
|
| 17 |
+
try:
|
| 18 |
+
return soup.find(class_=class_name).get_text().strip()
|
| 19 |
+
except AttributeError:
|
| 20 |
+
return None
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def get_word_type_japanese(word: str) -> Optional[str]:
|
| 24 |
+
soup = generate_soup_from_url(word)
|
| 25 |
+
text = get_text_from_class(soup, WORD_TYPE_JAPANESE_HTML_CLASS)
|
| 26 |
+
return text.split(' ')[0] if text else None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_translation(word: str) -> Optional[str]:
|
| 30 |
+
soup = generate_soup_from_url(word)
|
| 31 |
+
return get_text_from_class(soup, TRANSLATION_HTML_CLASS)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def translate_english_to_japanese(word: str) -> dict[str, Optional[str]]:
|
| 35 |
+
japanese_word_type = get_word_type_japanese(word)
|
| 36 |
+
japanese_translation = get_translation(word)
|
| 37 |
+
return {
|
| 38 |
+
'word': word,
|
| 39 |
+
'japanese_word': japanese_translation,
|
| 40 |
+
'word_type': japanese_word_type,
|
| 41 |
+
}
|
tests/ocr_and_translate_en2jp/__init__.py
ADDED
|
File without changes
|