Spaces:
No application file

No application file
up
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- GenAD-main/LICENSE +201 -0
- GenAD-main/README.md +127 -0
- GenAD-main/assets/comparison.png +0 -0
- GenAD-main/assets/demo.gif +3 -0
- GenAD-main/assets/framework.png +0 -0
- GenAD-main/assets/results.png +0 -0
- GenAD-main/docs/install.md +66 -0
- GenAD-main/docs/visualization.md +10 -0
- GenAD-main/projects/__init__.py +0 -0
- GenAD-main/projects/__pycache__/__init__.cpython-38.pyc +0 -0
- GenAD-main/projects/configs/VAD/GenAD_config.py +443 -0
- GenAD-main/projects/configs/_base_/datasets/coco_instance.py +48 -0
- GenAD-main/projects/configs/_base_/datasets/kitti-3d-3class.py +140 -0
- GenAD-main/projects/configs/_base_/datasets/kitti-3d-car.py +138 -0
- GenAD-main/projects/configs/_base_/datasets/lyft-3d.py +136 -0
- GenAD-main/projects/configs/_base_/datasets/nuim_instance.py +59 -0
- GenAD-main/projects/configs/_base_/datasets/nus-3d.py +142 -0
- GenAD-main/projects/configs/_base_/datasets/nus-mono3d.py +100 -0
- GenAD-main/projects/configs/_base_/datasets/range100_lyft-3d.py +136 -0
- GenAD-main/projects/configs/_base_/datasets/s3dis-3d-5class.py +114 -0
- GenAD-main/projects/configs/_base_/datasets/s3dis_seg-3d-13class.py +139 -0
- GenAD-main/projects/configs/_base_/datasets/scannet-3d-18class.py +128 -0
- GenAD-main/projects/configs/_base_/datasets/scannet_seg-3d-20class.py +132 -0
- GenAD-main/projects/configs/_base_/datasets/sunrgbd-3d-10class.py +107 -0
- GenAD-main/projects/configs/_base_/datasets/waymoD5-3d-3class.py +145 -0
- GenAD-main/projects/configs/_base_/datasets/waymoD5-3d-car.py +143 -0
- GenAD-main/projects/configs/_base_/default_runtime.py +18 -0
- GenAD-main/projects/configs/_base_/models/3dssd.py +77 -0
- GenAD-main/projects/configs/_base_/models/cascade_mask_rcnn_r50_fpn.py +200 -0
- GenAD-main/projects/configs/_base_/models/centerpoint_01voxel_second_secfpn_nus.py +83 -0
- GenAD-main/projects/configs/_base_/models/centerpoint_02pillar_second_secfpn_nus.py +83 -0
- GenAD-main/projects/configs/_base_/models/fcos3d.py +74 -0
- GenAD-main/projects/configs/_base_/models/groupfree3d.py +71 -0
- GenAD-main/projects/configs/_base_/models/h3dnet.py +341 -0
- GenAD-main/projects/configs/_base_/models/hv_pointpillars_fpn_lyft.py +22 -0
- GenAD-main/projects/configs/_base_/models/hv_pointpillars_fpn_nus.py +96 -0
- GenAD-main/projects/configs/_base_/models/hv_pointpillars_fpn_range100_lyft.py +22 -0
- GenAD-main/projects/configs/_base_/models/hv_pointpillars_secfpn_kitti.py +93 -0
- GenAD-main/projects/configs/_base_/models/hv_pointpillars_secfpn_waymo.py +108 -0
- GenAD-main/projects/configs/_base_/models/hv_second_secfpn_kitti.py +89 -0
- GenAD-main/projects/configs/_base_/models/hv_second_secfpn_waymo.py +100 -0
- GenAD-main/projects/configs/_base_/models/imvotenet_image.py +108 -0
- GenAD-main/projects/configs/_base_/models/mask_rcnn_r50_fpn.py +124 -0
- GenAD-main/projects/configs/_base_/models/paconv_cuda_ssg.py +7 -0
- GenAD-main/projects/configs/_base_/models/paconv_ssg.py +49 -0
- GenAD-main/projects/configs/_base_/models/parta2.py +201 -0
- GenAD-main/projects/configs/_base_/models/pointnet2_msg.py +28 -0
- GenAD-main/projects/configs/_base_/models/pointnet2_ssg.py +35 -0
- GenAD-main/projects/configs/_base_/models/votenet.py +73 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
GenAD-main/assets/demo.gif filter=lfs diff=lfs merge=lfs -text
|
GenAD-main/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
GenAD-main/README.md
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GenAD: Generative End-to-End Autonomous Driving
|
| 2 |
+
|
| 3 |
+
### [Paper](https://arxiv.org/pdf/2402.11502)
|
| 4 |
+
|
| 5 |
+
> GenAD: Generative End-to-End Autonomous Driving
|
| 6 |
+
|
| 7 |
+
> [Wenzhao Zheng](https://wzzheng.net/)\*, Ruiqi Song\*, [Xianda Guo](https://scholar.google.com/citations?user=jPvOqgYAAAAJ)\* $\dagger$, Chenming Zhang, [Long Chen](https://scholar.google.com/citations?user=jzvXnkcAAAAJ)$\dagger$
|
| 8 |
+
|
| 9 |
+
\* Equal contributions $\dagger$ Corresponding authors
|
| 10 |
+
|
| 11 |
+
**GenAD casts autonomous driving as a generative modeling problem.**
|
| 12 |
+
|
| 13 |
+
## News
|
| 14 |
+
|
| 15 |
+
- **[2024/5/2]** Training and evaluation code release.
|
| 16 |
+
- **[2024/2/18]** Paper released on [arXiv](https://arxiv.org/pdf/2402.11502).
|
| 17 |
+
|
| 18 |
+
## Demo
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
## Overview
|
| 23 |
+
|
| 24 |
+

|
| 25 |
+
|
| 26 |
+
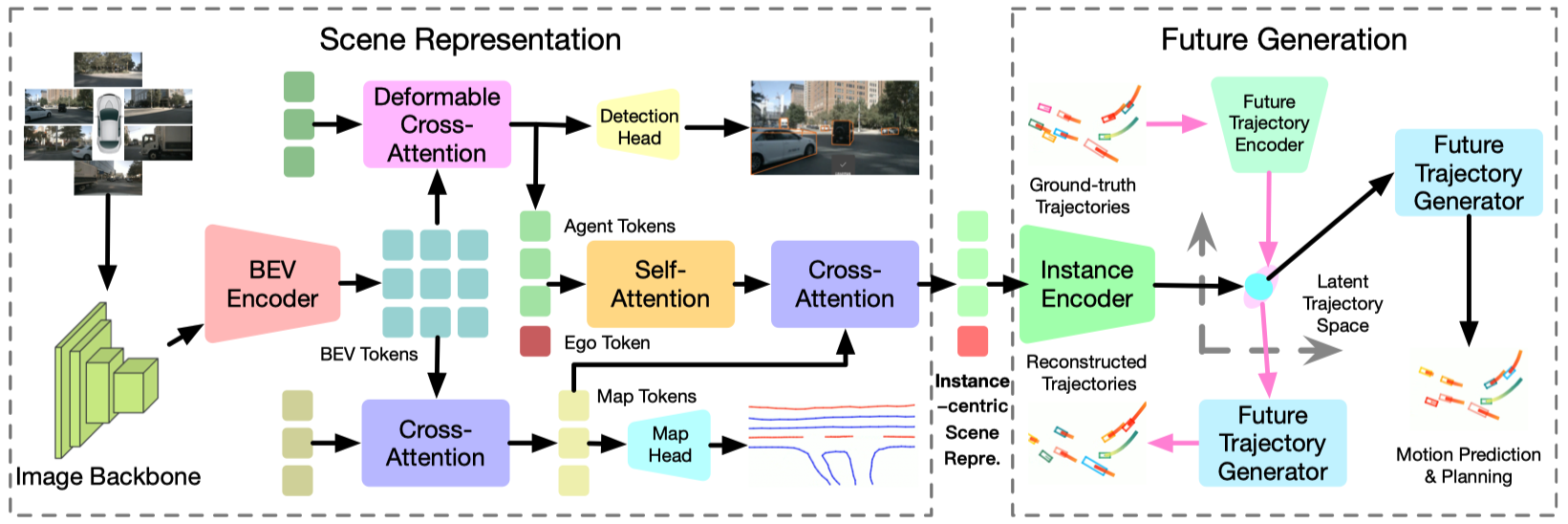
**Comparisons of the proposed generative end-to-end autonomous driving framework with the conventional pipeline.** Most existing methods follow a serial design of perception, prediction, and planning. They usually ignore the high-level interactions between the ego car and other agents and the structural prior of realistic trajectories. We model autonomous driving as a future generation problem and conduct motion prediction and ego planning simultaneously in a structural latent trajectory space.
|
| 27 |
+
|
| 28 |
+
## Results
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
## Code
|
| 33 |
+
### Dataset
|
| 34 |
+
|
| 35 |
+
Download nuScenes V1.0 full dataset data and CAN bus expansion data [HERE](https://www.nuscenes.org/download). Prepare nuscenes data as follows.
|
| 36 |
+
|
| 37 |
+
**Download CAN bus expansion**
|
| 38 |
+
|
| 39 |
+
```
|
| 40 |
+
# download 'can_bus.zip'
|
| 41 |
+
unzip can_bus.zip
|
| 42 |
+
# move can_bus to data dir
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
**Prepare nuScenes data**
|
| 46 |
+
|
| 47 |
+
*We genetate custom annotation files which are different from mmdet3d's*
|
| 48 |
+
|
| 49 |
+
Generate the train file and val file:
|
| 50 |
+
|
| 51 |
+
```
|
| 52 |
+
python tools/data_converter/genad_nuscenes_converter.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag genad_nuscenes --version v1.0 --canbus ./data
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
Using the above code will generate `genad_nuscenes_infos_temporal_{train,val}.pkl`.
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
**Folder structure**
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
GenAD
|
| 62 |
+
├── projects/
|
| 63 |
+
├── tools/
|
| 64 |
+
├── configs/
|
| 65 |
+
├── ckpts/
|
| 66 |
+
│ ├── resnet50-19c8e357.pth
|
| 67 |
+
├── data/
|
| 68 |
+
│ ├── can_bus/
|
| 69 |
+
│ ├── nuscenes/
|
| 70 |
+
│ │ ├── maps/
|
| 71 |
+
│ │ ├── samples/
|
| 72 |
+
│ │ ├── sweeps/
|
| 73 |
+
│ │ ├── v1.0-test/
|
| 74 |
+
| | ├── v1.0-trainval/
|
| 75 |
+
| | ├── genad_nuscenes_infos_train.pkl
|
| 76 |
+
| | ├── genad_nuscenes_infos_val.pkl
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
### installation
|
| 80 |
+
|
| 81 |
+
Detailed package versions can be found in [requirements.txt](../requirements.txt).
|
| 82 |
+
|
| 83 |
+
- [Installation](docs/install.md)
|
| 84 |
+
|
| 85 |
+
### Getting Started
|
| 86 |
+
|
| 87 |
+
**datasets**
|
| 88 |
+
|
| 89 |
+
https://drive.google.com/drive/folders/1gy7Ux-bk0sge77CsGgeEzPF9ImVn-WgJ?usp=drive_link
|
| 90 |
+
|
| 91 |
+
**Checkpoints**
|
| 92 |
+
|
| 93 |
+
https://drive.google.com/drive/folders/1nlAWJlvSHwqnTjEwlfiE99YJVRFKmqF9?usp=drive_link
|
| 94 |
+
|
| 95 |
+
Train GenAD with 8 GPUs
|
| 96 |
+
|
| 97 |
+
```shell
|
| 98 |
+
cd /path/to/GenAD
|
| 99 |
+
conda activate genad
|
| 100 |
+
python -m torch.distributed.run --nproc_per_node=8 --master_port=2333 tools/train.py projects/configs/GenAD/GenAD_config.py --launcher pytorch --deterministic --work-dir path/to/save/outputs
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
Eval GenAD with 1 GPU
|
| 104 |
+
|
| 105 |
+
```shell
|
| 106 |
+
cd /path/to/GenAD
|
| 107 |
+
conda activate genad
|
| 108 |
+
CUDA_VISIBLE_DEVICES=0 python tools/test.py projects/configs/VAD/GenAD_config.py /path/to/ckpt.pth --launcher none --eval bbox --tmpdir outputs
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
## Related Projects
|
| 114 |
+
|
| 115 |
+
Our code is based on [VAD](https://github.com/hustvl/VAD) and [UniAD](https://github.com/OpenDriveLab/UniAD).
|
| 116 |
+
|
| 117 |
+
## Citation
|
| 118 |
+
|
| 119 |
+
If you find this project helpful, please consider citing the following paper:
|
| 120 |
+
```
|
| 121 |
+
@article{zheng2024genad,
|
| 122 |
+
title={GenAD: Generative End-to-End Autonomous Driving},
|
| 123 |
+
author={Zheng, Wenzhao and Song, Ruiqi and Guo, Xianda and Zhang, Chenming and Chen, Long},
|
| 124 |
+
journal={arXiv preprint arXiv: 2402.11502},
|
| 125 |
+
year={2024}
|
| 126 |
+
}
|
| 127 |
+
```
|
GenAD-main/assets/comparison.png
ADDED

|
GenAD-main/assets/demo.gif
ADDED

|
Git LFS Details
|
GenAD-main/assets/framework.png
ADDED
|
GenAD-main/assets/results.png
ADDED

|
GenAD-main/docs/install.md
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# installation
|
| 2 |
+
|
| 3 |
+
Detailed package versions can be found in [requirements.txt](../requirements.txt).
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
**a. Create a conda virtual environment and activate it.**
|
| 8 |
+
```shell
|
| 9 |
+
conda create -n genad python=3.8 -y
|
| 10 |
+
conda activate genad
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
**b. Install PyTorch and torchvision following the [official instructions](https://pytorch.org/).**
|
| 14 |
+
```shell
|
| 15 |
+
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
|
| 16 |
+
# Recommended torch>=1.9
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
**c. Install gcc>=5 in conda env (optional).**
|
| 20 |
+
```shell
|
| 21 |
+
conda install -c omgarcia gcc-5 # gcc-6.2
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
**c. Install mmcv-full.**
|
| 25 |
+
```shell
|
| 26 |
+
pip install mmcv-full==1.4.0
|
| 27 |
+
# pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
**d. Install mmdet and mmseg.**
|
| 31 |
+
```shell
|
| 32 |
+
pip install mmdet==2.14.0
|
| 33 |
+
pip install mmsegmentation==0.14.1
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
**e. Install timm.**
|
| 37 |
+
```shell
|
| 38 |
+
pip install timm
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
**f. Install mmdet3d.**
|
| 42 |
+
```shell
|
| 43 |
+
conda activate genad
|
| 44 |
+
git clone https://github.com/open-mmlab/mmdetection3d.git
|
| 45 |
+
cd /path/to/mmdetection3d
|
| 46 |
+
git checkout -f v0.17.1
|
| 47 |
+
python setup.py develop
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
**g. Install nuscenes-devkit.**
|
| 51 |
+
```shell
|
| 52 |
+
pip install nuscenes-devkit==1.1.9
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
**h. Clone GenAD.**
|
| 56 |
+
```shell
|
| 57 |
+
git clone https://github.com/wzzheng/GenAD.git
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
**i. Prepare pretrained models.**
|
| 61 |
+
```shell
|
| 62 |
+
cd /path/to/GenAD
|
| 63 |
+
mkdir ckpts
|
| 64 |
+
cd ckpts
|
| 65 |
+
wget https://download.pytorch.org/models/resnet50-19c8e357.pth
|
| 66 |
+
```
|
GenAD-main/docs/visualization.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Visualization
|
| 2 |
+
|
| 3 |
+
We provide the script to visualize the VAD prediction to a video [here](../tools/analysis_tools/visualization.py).
|
| 4 |
+
|
| 5 |
+
```shell
|
| 6 |
+
cd /path/to/GenAD/
|
| 7 |
+
conda activate genad
|
| 8 |
+
python tools/analysis_tools/visualization.py --result-path /path/to/inference/results --save-path /path/to/save/visualization/results
|
| 9 |
+
```
|
| 10 |
+
|
GenAD-main/projects/__init__.py
ADDED
|
File without changes
|
GenAD-main/projects/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (142 Bytes). View file
|
|
|
GenAD-main/projects/configs/VAD/GenAD_config.py
ADDED
|
@@ -0,0 +1,443 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = [
|
| 2 |
+
'../datasets/custom_nus-3d.py',
|
| 3 |
+
'../_base_/default_runtime.py'
|
| 4 |
+
]
|
| 5 |
+
#
|
| 6 |
+
plugin = True
|
| 7 |
+
plugin_dir = 'projects/mmdet3d_plugin/'
|
| 8 |
+
|
| 9 |
+
# If point cloud range is changed, the models should also change their point
|
| 10 |
+
# cloud range accordingly
|
| 11 |
+
point_cloud_range = [-15.0, -30.0, -2.0, 15.0, 30.0, 2.0]
|
| 12 |
+
voxel_size = [0.15, 0.15, 4]
|
| 13 |
+
|
| 14 |
+
img_norm_cfg = dict(
|
| 15 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 16 |
+
# For nuScenes we usually do 10-class detection
|
| 17 |
+
class_names = [
|
| 18 |
+
'car', 'truck', 'construction_vehicle', 'bus', 'trailer', 'barrier',
|
| 19 |
+
'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'
|
| 20 |
+
]
|
| 21 |
+
num_classes = len(class_names)
|
| 22 |
+
|
| 23 |
+
# map has classes: divider, ped_crossing, boundary
|
| 24 |
+
map_classes = ['divider', 'ped_crossing', 'boundary']
|
| 25 |
+
map_num_vec = 100
|
| 26 |
+
map_fixed_ptsnum_per_gt_line = 20 # now only support fixed_pts > 0
|
| 27 |
+
map_fixed_ptsnum_per_pred_line = 20
|
| 28 |
+
map_eval_use_same_gt_sample_num_flag = True
|
| 29 |
+
map_num_classes = len(map_classes)
|
| 30 |
+
|
| 31 |
+
input_modality = dict(
|
| 32 |
+
use_lidar=False,
|
| 33 |
+
use_camera=True,
|
| 34 |
+
use_radar=False,
|
| 35 |
+
use_map=False,
|
| 36 |
+
use_external=True)
|
| 37 |
+
|
| 38 |
+
_dim_ = 256
|
| 39 |
+
_pos_dim_ = _dim_//2
|
| 40 |
+
_ffn_dim_ = _dim_*2
|
| 41 |
+
_num_levels_ = 1
|
| 42 |
+
bev_h_ = 100
|
| 43 |
+
bev_w_ = 100
|
| 44 |
+
queue_length = 3 # each sequence contains `queue_length` frames.
|
| 45 |
+
total_epochs = 60
|
| 46 |
+
|
| 47 |
+
model = dict(
|
| 48 |
+
type='VAD',
|
| 49 |
+
use_grid_mask=True,
|
| 50 |
+
video_test_mode=True,
|
| 51 |
+
pretrained=dict(img='torchvision://resnet50'),
|
| 52 |
+
img_backbone=dict(
|
| 53 |
+
type='ResNet',
|
| 54 |
+
depth=50,
|
| 55 |
+
num_stages=4,
|
| 56 |
+
out_indices=(3,),
|
| 57 |
+
frozen_stages=1,
|
| 58 |
+
norm_cfg=dict(type='BN', requires_grad=False),
|
| 59 |
+
norm_eval=True,
|
| 60 |
+
style='pytorch'),
|
| 61 |
+
img_neck=dict(
|
| 62 |
+
type='FPN',
|
| 63 |
+
in_channels=[2048],
|
| 64 |
+
out_channels=_dim_,
|
| 65 |
+
start_level=0,
|
| 66 |
+
add_extra_convs='on_output',
|
| 67 |
+
num_outs=_num_levels_,
|
| 68 |
+
relu_before_extra_convs=True),
|
| 69 |
+
pts_bbox_head=dict(
|
| 70 |
+
type='VADHead',
|
| 71 |
+
map_thresh=0.5,
|
| 72 |
+
dis_thresh=0.2,
|
| 73 |
+
pe_normalization=True,
|
| 74 |
+
tot_epoch=total_epochs,
|
| 75 |
+
use_traj_lr_warmup=False,
|
| 76 |
+
query_thresh=0.0,
|
| 77 |
+
query_use_fix_pad=False,
|
| 78 |
+
ego_his_encoder=None,
|
| 79 |
+
ego_lcf_feat_idx=None,
|
| 80 |
+
valid_fut_ts=6,
|
| 81 |
+
agent_dim = 300,
|
| 82 |
+
ego_agent_decoder=dict(
|
| 83 |
+
type='CustomTransformerDecoder',
|
| 84 |
+
num_layers=1,
|
| 85 |
+
return_intermediate=False,
|
| 86 |
+
transformerlayers=dict(
|
| 87 |
+
type='BaseTransformerLayer',
|
| 88 |
+
attn_cfgs=[
|
| 89 |
+
dict(
|
| 90 |
+
type='MultiheadAttention',
|
| 91 |
+
embed_dims=_dim_,
|
| 92 |
+
num_heads=8,
|
| 93 |
+
dropout=0.1),
|
| 94 |
+
],
|
| 95 |
+
feedforward_channels=_ffn_dim_,
|
| 96 |
+
ffn_dropout=0.1,
|
| 97 |
+
operation_order=('cross_attn', 'norm', 'ffn', 'norm'))),
|
| 98 |
+
ego_map_decoder=dict(
|
| 99 |
+
type='CustomTransformerDecoder',
|
| 100 |
+
num_layers=1,
|
| 101 |
+
return_intermediate=False,
|
| 102 |
+
transformerlayers=dict(
|
| 103 |
+
type='BaseTransformerLayer',
|
| 104 |
+
attn_cfgs=[
|
| 105 |
+
dict(
|
| 106 |
+
type='MultiheadAttention',
|
| 107 |
+
embed_dims=_dim_,
|
| 108 |
+
num_heads=8,
|
| 109 |
+
dropout=0.1),
|
| 110 |
+
],
|
| 111 |
+
feedforward_channels=_ffn_dim_,
|
| 112 |
+
ffn_dropout=0.1,
|
| 113 |
+
operation_order=('cross_attn', 'norm', 'ffn', 'norm'))),
|
| 114 |
+
motion_decoder=dict(
|
| 115 |
+
type='CustomTransformerDecoder',
|
| 116 |
+
num_layers=1,
|
| 117 |
+
return_intermediate=False,
|
| 118 |
+
transformerlayers=dict(
|
| 119 |
+
type='BaseTransformerLayer',
|
| 120 |
+
attn_cfgs=[
|
| 121 |
+
dict(
|
| 122 |
+
type='MultiheadAttention',
|
| 123 |
+
embed_dims=_dim_,
|
| 124 |
+
num_heads=8,
|
| 125 |
+
dropout=0.1),
|
| 126 |
+
],
|
| 127 |
+
feedforward_channels=_ffn_dim_,
|
| 128 |
+
ffn_dropout=0.1,
|
| 129 |
+
operation_order=('cross_attn', 'norm', 'ffn', 'norm'))),
|
| 130 |
+
motion_map_decoder=dict(
|
| 131 |
+
type='CustomTransformerDecoder',
|
| 132 |
+
num_layers=1,
|
| 133 |
+
return_intermediate=False,
|
| 134 |
+
transformerlayers=dict(
|
| 135 |
+
type='BaseTransformerLayer',
|
| 136 |
+
attn_cfgs=[
|
| 137 |
+
dict(
|
| 138 |
+
type='MultiheadAttention',
|
| 139 |
+
embed_dims=_dim_,
|
| 140 |
+
num_heads=8,
|
| 141 |
+
dropout=0.1),
|
| 142 |
+
],
|
| 143 |
+
feedforward_channels=_ffn_dim_,
|
| 144 |
+
ffn_dropout=0.1,
|
| 145 |
+
operation_order=('cross_attn', 'norm', 'ffn', 'norm'))),
|
| 146 |
+
use_pe=True,
|
| 147 |
+
bev_h=bev_h_,
|
| 148 |
+
bev_w=bev_w_,
|
| 149 |
+
num_query=300,
|
| 150 |
+
num_classes=num_classes,
|
| 151 |
+
in_channels=_dim_,
|
| 152 |
+
sync_cls_avg_factor=True,
|
| 153 |
+
with_box_refine=True,
|
| 154 |
+
as_two_stage=False,
|
| 155 |
+
map_num_vec=map_num_vec,
|
| 156 |
+
map_num_classes=map_num_classes,
|
| 157 |
+
map_num_pts_per_vec=map_fixed_ptsnum_per_pred_line,
|
| 158 |
+
map_num_pts_per_gt_vec=map_fixed_ptsnum_per_gt_line,
|
| 159 |
+
map_query_embed_type='instance_pts',
|
| 160 |
+
map_transform_method='minmax',
|
| 161 |
+
map_gt_shift_pts_pattern='v2',
|
| 162 |
+
map_dir_interval=1,
|
| 163 |
+
map_code_size=2,
|
| 164 |
+
map_code_weights=[1.0, 1.0, 1.0, 1.0],
|
| 165 |
+
transformer=dict(
|
| 166 |
+
type='VADPerceptionTransformer',
|
| 167 |
+
map_num_vec=map_num_vec,
|
| 168 |
+
map_num_pts_per_vec=map_fixed_ptsnum_per_pred_line,
|
| 169 |
+
rotate_prev_bev=True,
|
| 170 |
+
use_shift=True,
|
| 171 |
+
use_can_bus=True,
|
| 172 |
+
embed_dims=_dim_,
|
| 173 |
+
encoder=dict(
|
| 174 |
+
type='BEVFormerEncoder',
|
| 175 |
+
num_layers=3,
|
| 176 |
+
pc_range=point_cloud_range,
|
| 177 |
+
num_points_in_pillar=4,
|
| 178 |
+
return_intermediate=False,
|
| 179 |
+
transformerlayers=dict(
|
| 180 |
+
type='BEVFormerLayer',
|
| 181 |
+
attn_cfgs=[
|
| 182 |
+
dict(
|
| 183 |
+
type='TemporalSelfAttention',
|
| 184 |
+
embed_dims=_dim_,
|
| 185 |
+
num_levels=1),
|
| 186 |
+
dict(
|
| 187 |
+
type='SpatialCrossAttention',
|
| 188 |
+
pc_range=point_cloud_range,
|
| 189 |
+
deformable_attention=dict(
|
| 190 |
+
type='MSDeformableAttention3D',
|
| 191 |
+
embed_dims=_dim_,
|
| 192 |
+
num_points=8,
|
| 193 |
+
num_levels=_num_levels_),
|
| 194 |
+
embed_dims=_dim_,
|
| 195 |
+
)
|
| 196 |
+
],
|
| 197 |
+
feedforward_channels=_ffn_dim_,
|
| 198 |
+
ffn_dropout=0.1,
|
| 199 |
+
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
|
| 200 |
+
'ffn', 'norm'))),
|
| 201 |
+
decoder=dict(
|
| 202 |
+
type='DetectionTransformerDecoder',
|
| 203 |
+
num_layers=3,
|
| 204 |
+
return_intermediate=True,
|
| 205 |
+
transformerlayers=dict(
|
| 206 |
+
type='DetrTransformerDecoderLayer',
|
| 207 |
+
attn_cfgs=[
|
| 208 |
+
dict(
|
| 209 |
+
type='MultiheadAttention',
|
| 210 |
+
embed_dims=_dim_,
|
| 211 |
+
num_heads=8,
|
| 212 |
+
dropout=0.1),
|
| 213 |
+
dict(
|
| 214 |
+
type='CustomMSDeformableAttention',
|
| 215 |
+
embed_dims=_dim_,
|
| 216 |
+
num_levels=1),
|
| 217 |
+
],
|
| 218 |
+
feedforward_channels=_ffn_dim_,
|
| 219 |
+
ffn_dropout=0.1,
|
| 220 |
+
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
|
| 221 |
+
'ffn', 'norm'))),
|
| 222 |
+
map_decoder=dict(
|
| 223 |
+
type='MapDetectionTransformerDecoder',
|
| 224 |
+
num_layers=3,
|
| 225 |
+
return_intermediate=True,
|
| 226 |
+
transformerlayers=dict(
|
| 227 |
+
type='DetrTransformerDecoderLayer',
|
| 228 |
+
attn_cfgs=[
|
| 229 |
+
dict(
|
| 230 |
+
type='MultiheadAttention',
|
| 231 |
+
embed_dims=_dim_,
|
| 232 |
+
num_heads=8,
|
| 233 |
+
dropout=0.1),
|
| 234 |
+
dict(
|
| 235 |
+
type='CustomMSDeformableAttention',
|
| 236 |
+
embed_dims=_dim_,
|
| 237 |
+
num_levels=1),
|
| 238 |
+
],
|
| 239 |
+
feedforward_channels=_ffn_dim_,
|
| 240 |
+
ffn_dropout=0.1,
|
| 241 |
+
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
|
| 242 |
+
'ffn', 'norm')))),
|
| 243 |
+
bbox_coder=dict(
|
| 244 |
+
type='CustomNMSFreeCoder',
|
| 245 |
+
post_center_range=[-20, -35, -10.0, 20, 35, 10.0],
|
| 246 |
+
pc_range=point_cloud_range,
|
| 247 |
+
max_num=100,
|
| 248 |
+
voxel_size=voxel_size,
|
| 249 |
+
num_classes=num_classes),
|
| 250 |
+
map_bbox_coder=dict(
|
| 251 |
+
type='MapNMSFreeCoder',
|
| 252 |
+
post_center_range=[-20, -35, -20, -35, 20, 35, 20, 35],
|
| 253 |
+
pc_range=point_cloud_range,
|
| 254 |
+
max_num=50,
|
| 255 |
+
voxel_size=voxel_size,
|
| 256 |
+
num_classes=map_num_classes),
|
| 257 |
+
positional_encoding=dict(
|
| 258 |
+
type='LearnedPositionalEncoding',
|
| 259 |
+
num_feats=_pos_dim_,
|
| 260 |
+
row_num_embed=bev_h_,
|
| 261 |
+
col_num_embed=bev_w_,
|
| 262 |
+
),
|
| 263 |
+
loss_cls=dict(
|
| 264 |
+
type='FocalLoss',
|
| 265 |
+
use_sigmoid=True,
|
| 266 |
+
gamma=2.0,
|
| 267 |
+
alpha=0.25,
|
| 268 |
+
loss_weight=2.0),
|
| 269 |
+
loss_bbox=dict(type='L1Loss', loss_weight=0.25),
|
| 270 |
+
loss_traj=dict(type='L1Loss', loss_weight=0.2),
|
| 271 |
+
loss_traj_cls=dict(
|
| 272 |
+
type='FocalLoss',
|
| 273 |
+
use_sigmoid=True,
|
| 274 |
+
gamma=2.0,
|
| 275 |
+
alpha=0.25,
|
| 276 |
+
loss_weight=0.2),
|
| 277 |
+
loss_iou=dict(type='GIoULoss', loss_weight=0.0),
|
| 278 |
+
loss_map_cls=dict(
|
| 279 |
+
type='FocalLoss',
|
| 280 |
+
use_sigmoid=True,
|
| 281 |
+
gamma=2.0,
|
| 282 |
+
alpha=0.25,
|
| 283 |
+
loss_weight=2.0),
|
| 284 |
+
loss_map_bbox=dict(type='L1Loss', loss_weight=0.0),
|
| 285 |
+
loss_map_iou=dict(type='GIoULoss', loss_weight=0.0),
|
| 286 |
+
loss_map_pts=dict(type='PtsL1Loss', loss_weight=1.0),
|
| 287 |
+
loss_map_dir=dict(type='PtsDirCosLoss', loss_weight=0.005),
|
| 288 |
+
loss_plan_reg=dict(type='L1Loss', loss_weight=1.0),
|
| 289 |
+
loss_plan_bound=dict(type='PlanMapBoundLoss', loss_weight=1.0, dis_thresh=1.0),
|
| 290 |
+
loss_plan_col=dict(type='PlanCollisionLoss', loss_weight=1.0),
|
| 291 |
+
loss_plan_dir=dict(type='PlanMapDirectionLoss', loss_weight=0.5),
|
| 292 |
+
loss_vae_gen=dict(type='ProbabilisticLoss', loss_weight=1.0),
|
| 293 |
+
loss_diff_gen=dict(type='DiffusionLoss', loss_weight=0.5)),
|
| 294 |
+
# model training and testing settings
|
| 295 |
+
train_cfg=dict(pts=dict(
|
| 296 |
+
grid_size=[512, 512, 1],
|
| 297 |
+
voxel_size=voxel_size,
|
| 298 |
+
point_cloud_range=point_cloud_range,
|
| 299 |
+
out_size_factor=4,
|
| 300 |
+
assigner=dict(
|
| 301 |
+
type='HungarianAssigner3D',
|
| 302 |
+
cls_cost=dict(type='FocalLossCost', weight=2.0),
|
| 303 |
+
reg_cost=dict(type='BBox3DL1Cost', weight=0.25),
|
| 304 |
+
iou_cost=dict(type='IoUCost', weight=0.0), # Fake cost. This is just to make it compatible with DETR head.
|
| 305 |
+
pc_range=point_cloud_range),
|
| 306 |
+
map_assigner=dict(
|
| 307 |
+
type='MapHungarianAssigner3D',
|
| 308 |
+
cls_cost=dict(type='FocalLossCost', weight=2.0),
|
| 309 |
+
reg_cost=dict(type='BBoxL1Cost', weight=0.0, box_format='xywh'),
|
| 310 |
+
iou_cost=dict(type='IoUCost', iou_mode='giou', weight=0.0),
|
| 311 |
+
pts_cost=dict(type='OrderedPtsL1Cost', weight=1.0),
|
| 312 |
+
pc_range=point_cloud_range))))
|
| 313 |
+
|
| 314 |
+
dataset_type = 'VADCustomNuScenesDataset'
|
| 315 |
+
data_root = 'xxx/nuscenes/'
|
| 316 |
+
file_client_args = dict(backend='disk')
|
| 317 |
+
|
| 318 |
+
train_pipeline = [
|
| 319 |
+
dict(type='LoadMultiViewImageFromFiles', to_float32=True),
|
| 320 |
+
dict(type='PhotoMetricDistortionMultiViewImage'),
|
| 321 |
+
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, with_attr_label=True),
|
| 322 |
+
dict(type='CustomObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 323 |
+
dict(type='CustomObjectNameFilter', classes=class_names),
|
| 324 |
+
dict(type='NormalizeMultiviewImage', **img_norm_cfg),
|
| 325 |
+
dict(type='RandomScaleImageMultiViewImage', scales=[0.4]),
|
| 326 |
+
dict(type='PadMultiViewImage', size_divisor=32),
|
| 327 |
+
dict(type='CustomDefaultFormatBundle3D', class_names=class_names, with_ego=True),
|
| 328 |
+
dict(type='CustomCollect3D',\
|
| 329 |
+
keys=['gt_bboxes_3d', 'gt_labels_3d', 'img', 'ego_his_trajs',
|
| 330 |
+
'ego_fut_trajs', 'ego_fut_masks', 'ego_fut_cmd', 'ego_lcf_feat', 'gt_attr_labels'])
|
| 331 |
+
]
|
| 332 |
+
|
| 333 |
+
test_pipeline = [
|
| 334 |
+
dict(type='LoadMultiViewImageFromFiles', to_float32=True),
|
| 335 |
+
dict(type='LoadPointsFromFile',
|
| 336 |
+
coord_type='LIDAR',
|
| 337 |
+
load_dim=5,
|
| 338 |
+
use_dim=5,
|
| 339 |
+
file_client_args=file_client_args),
|
| 340 |
+
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, with_attr_label=True),
|
| 341 |
+
dict(type='CustomObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 342 |
+
dict(type='CustomObjectNameFilter', classes=class_names),
|
| 343 |
+
dict(type='NormalizeMultiviewImage', **img_norm_cfg),
|
| 344 |
+
# dict(type='PadMultiViewImage', size_divisor=32),
|
| 345 |
+
dict(
|
| 346 |
+
type='MultiScaleFlipAug3D',
|
| 347 |
+
img_scale=(1600, 900),
|
| 348 |
+
pts_scale_ratio=1,
|
| 349 |
+
flip=False,
|
| 350 |
+
transforms=[
|
| 351 |
+
dict(type='RandomScaleImageMultiViewImage', scales=[0.4]),
|
| 352 |
+
dict(type='PadMultiViewImage', size_divisor=32),
|
| 353 |
+
dict(type='CustomDefaultFormatBundle3D', class_names=class_names, with_label=False, with_ego=True),
|
| 354 |
+
dict(type='CustomCollect3D',\
|
| 355 |
+
keys=['points', 'gt_bboxes_3d', 'gt_labels_3d', 'img', 'fut_valid_flag',
|
| 356 |
+
'ego_his_trajs', 'ego_fut_trajs', 'ego_fut_masks', 'ego_fut_cmd',
|
| 357 |
+
'ego_lcf_feat', 'gt_attr_labels'])])
|
| 358 |
+
]
|
| 359 |
+
|
| 360 |
+
data = dict(
|
| 361 |
+
samples_per_gpu=1,
|
| 362 |
+
workers_per_gpu=4,
|
| 363 |
+
train=dict(
|
| 364 |
+
type=dataset_type,
|
| 365 |
+
data_root=data_root,
|
| 366 |
+
ann_file=data_root + 'genad_nuscenes_infos_train.pkl',
|
| 367 |
+
pipeline=train_pipeline,
|
| 368 |
+
classes=class_names,
|
| 369 |
+
modality=input_modality,
|
| 370 |
+
test_mode=False,
|
| 371 |
+
use_valid_flag=True,
|
| 372 |
+
bev_size=(bev_h_, bev_w_),
|
| 373 |
+
pc_range=point_cloud_range,
|
| 374 |
+
queue_length=queue_length,
|
| 375 |
+
map_classes=map_classes,
|
| 376 |
+
map_fixed_ptsnum_per_line=map_fixed_ptsnum_per_gt_line,
|
| 377 |
+
map_eval_use_same_gt_sample_num_flag=map_eval_use_same_gt_sample_num_flag,
|
| 378 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 379 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 380 |
+
box_type_3d='LiDAR',
|
| 381 |
+
custom_eval_version='vad_nusc_detection_cvpr_2019'),
|
| 382 |
+
val=dict(type=dataset_type,
|
| 383 |
+
data_root=data_root,
|
| 384 |
+
pc_range=point_cloud_range,
|
| 385 |
+
ann_file=data_root + 'genad_nuscenes_infos_val.pkl',
|
| 386 |
+
pipeline=test_pipeline, bev_size=(bev_h_, bev_w_),
|
| 387 |
+
classes=class_names, modality=input_modality, samples_per_gpu=1,
|
| 388 |
+
map_classes=map_classes,
|
| 389 |
+
map_ann_file=data_root + 'nuscenes_map_anns_val.json',
|
| 390 |
+
map_fixed_ptsnum_per_line=map_fixed_ptsnum_per_gt_line,
|
| 391 |
+
map_eval_use_same_gt_sample_num_flag=map_eval_use_same_gt_sample_num_flag,
|
| 392 |
+
use_pkl_result=True,
|
| 393 |
+
custom_eval_version='vad_nusc_detection_cvpr_2019'),
|
| 394 |
+
test=dict(type=dataset_type,
|
| 395 |
+
data_root=data_root,
|
| 396 |
+
pc_range=point_cloud_range,
|
| 397 |
+
ann_file=data_root + 'genad_nuscenes_infos_val.pkl',
|
| 398 |
+
pipeline=test_pipeline, bev_size=(bev_h_, bev_w_),
|
| 399 |
+
classes=class_names, modality=input_modality, samples_per_gpu=1,
|
| 400 |
+
map_classes=map_classes,
|
| 401 |
+
map_ann_file=data_root + 'nuscenes_map_anns_val.json',
|
| 402 |
+
map_fixed_ptsnum_per_line=map_fixed_ptsnum_per_gt_line,
|
| 403 |
+
map_eval_use_same_gt_sample_num_flag=map_eval_use_same_gt_sample_num_flag,
|
| 404 |
+
use_pkl_result=True,
|
| 405 |
+
custom_eval_version='vad_nusc_detection_cvpr_2019'),
|
| 406 |
+
shuffler_sampler=dict(type='DistributedGroupSampler'),
|
| 407 |
+
nonshuffler_sampler=dict(type='DistributedSampler')
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
optimizer = dict(
|
| 411 |
+
type='AdamW',
|
| 412 |
+
lr=2e-4,
|
| 413 |
+
paramwise_cfg=dict(
|
| 414 |
+
custom_keys={
|
| 415 |
+
'img_backbone': dict(lr_mult=0.1),
|
| 416 |
+
}),
|
| 417 |
+
weight_decay=0.01)
|
| 418 |
+
|
| 419 |
+
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
|
| 420 |
+
# learning policy
|
| 421 |
+
lr_config = dict(
|
| 422 |
+
policy='CosineAnnealing',
|
| 423 |
+
warmup='linear',
|
| 424 |
+
warmup_iters=500,
|
| 425 |
+
warmup_ratio=1.0 / 3,
|
| 426 |
+
min_lr_ratio=1e-3)
|
| 427 |
+
|
| 428 |
+
evaluation = dict(interval=total_epochs, pipeline=test_pipeline, metric='bbox', map_metric='chamfer')
|
| 429 |
+
|
| 430 |
+
runner = dict(type='EpochBasedRunner', max_epochs=total_epochs)
|
| 431 |
+
|
| 432 |
+
log_config = dict(
|
| 433 |
+
interval=100,
|
| 434 |
+
hooks=[
|
| 435 |
+
dict(type='TextLoggerHook'),
|
| 436 |
+
dict(type='TensorboardLoggerHook')
|
| 437 |
+
])
|
| 438 |
+
# fp16 = dict(loss_scale=512.)
|
| 439 |
+
find_unused_parameters = True
|
| 440 |
+
checkpoint_config = dict(interval=1, max_keep_ckpts=total_epochs)
|
| 441 |
+
|
| 442 |
+
|
| 443 |
+
custom_hooks = [dict(type='CustomSetEpochInfoHook')]
|
GenAD-main/projects/configs/_base_/datasets/coco_instance.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset_type = 'CocoDataset'
|
| 2 |
+
data_root = 'data/coco/'
|
| 3 |
+
img_norm_cfg = dict(
|
| 4 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 5 |
+
train_pipeline = [
|
| 6 |
+
dict(type='LoadImageFromFile'),
|
| 7 |
+
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
|
| 8 |
+
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
|
| 9 |
+
dict(type='RandomFlip', flip_ratio=0.5),
|
| 10 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 11 |
+
dict(type='Pad', size_divisor=32),
|
| 12 |
+
dict(type='DefaultFormatBundle'),
|
| 13 |
+
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
|
| 14 |
+
]
|
| 15 |
+
test_pipeline = [
|
| 16 |
+
dict(type='LoadImageFromFile'),
|
| 17 |
+
dict(
|
| 18 |
+
type='MultiScaleFlipAug',
|
| 19 |
+
img_scale=(1333, 800),
|
| 20 |
+
flip=False,
|
| 21 |
+
transforms=[
|
| 22 |
+
dict(type='Resize', keep_ratio=True),
|
| 23 |
+
dict(type='RandomFlip'),
|
| 24 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 25 |
+
dict(type='Pad', size_divisor=32),
|
| 26 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 27 |
+
dict(type='Collect', keys=['img']),
|
| 28 |
+
])
|
| 29 |
+
]
|
| 30 |
+
data = dict(
|
| 31 |
+
samples_per_gpu=2,
|
| 32 |
+
workers_per_gpu=2,
|
| 33 |
+
train=dict(
|
| 34 |
+
type=dataset_type,
|
| 35 |
+
ann_file=data_root + 'annotations/instances_train2017.json',
|
| 36 |
+
img_prefix=data_root + 'train2017/',
|
| 37 |
+
pipeline=train_pipeline),
|
| 38 |
+
val=dict(
|
| 39 |
+
type=dataset_type,
|
| 40 |
+
ann_file=data_root + 'annotations/instances_val2017.json',
|
| 41 |
+
img_prefix=data_root + 'val2017/',
|
| 42 |
+
pipeline=test_pipeline),
|
| 43 |
+
test=dict(
|
| 44 |
+
type=dataset_type,
|
| 45 |
+
ann_file=data_root + 'annotations/instances_val2017.json',
|
| 46 |
+
img_prefix=data_root + 'val2017/',
|
| 47 |
+
pipeline=test_pipeline))
|
| 48 |
+
evaluation = dict(metric=['bbox', 'segm'])
|
GenAD-main/projects/configs/_base_/datasets/kitti-3d-3class.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
dataset_type = 'KittiDataset'
|
| 3 |
+
data_root = 'data/kitti/'
|
| 4 |
+
class_names = ['Pedestrian', 'Cyclist', 'Car']
|
| 5 |
+
point_cloud_range = [0, -40, -3, 70.4, 40, 1]
|
| 6 |
+
input_modality = dict(use_lidar=True, use_camera=False)
|
| 7 |
+
db_sampler = dict(
|
| 8 |
+
data_root=data_root,
|
| 9 |
+
info_path=data_root + 'kitti_dbinfos_train.pkl',
|
| 10 |
+
rate=1.0,
|
| 11 |
+
prepare=dict(
|
| 12 |
+
filter_by_difficulty=[-1],
|
| 13 |
+
filter_by_min_points=dict(Car=5, Pedestrian=10, Cyclist=10)),
|
| 14 |
+
classes=class_names,
|
| 15 |
+
sample_groups=dict(Car=12, Pedestrian=6, Cyclist=6))
|
| 16 |
+
|
| 17 |
+
file_client_args = dict(backend='disk')
|
| 18 |
+
# Uncomment the following if use ceph or other file clients.
|
| 19 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 20 |
+
# for more details.
|
| 21 |
+
# file_client_args = dict(
|
| 22 |
+
# backend='petrel', path_mapping=dict(data='s3://kitti_data/'))
|
| 23 |
+
|
| 24 |
+
train_pipeline = [
|
| 25 |
+
dict(
|
| 26 |
+
type='LoadPointsFromFile',
|
| 27 |
+
coord_type='LIDAR',
|
| 28 |
+
load_dim=4,
|
| 29 |
+
use_dim=4,
|
| 30 |
+
file_client_args=file_client_args),
|
| 31 |
+
dict(
|
| 32 |
+
type='LoadAnnotations3D',
|
| 33 |
+
with_bbox_3d=True,
|
| 34 |
+
with_label_3d=True,
|
| 35 |
+
file_client_args=file_client_args),
|
| 36 |
+
dict(type='ObjectSample', db_sampler=db_sampler),
|
| 37 |
+
dict(
|
| 38 |
+
type='ObjectNoise',
|
| 39 |
+
num_try=100,
|
| 40 |
+
translation_std=[1.0, 1.0, 0.5],
|
| 41 |
+
global_rot_range=[0.0, 0.0],
|
| 42 |
+
rot_range=[-0.78539816, 0.78539816]),
|
| 43 |
+
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
|
| 44 |
+
dict(
|
| 45 |
+
type='GlobalRotScaleTrans',
|
| 46 |
+
rot_range=[-0.78539816, 0.78539816],
|
| 47 |
+
scale_ratio_range=[0.95, 1.05]),
|
| 48 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 49 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 50 |
+
dict(type='PointShuffle'),
|
| 51 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 52 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 53 |
+
]
|
| 54 |
+
test_pipeline = [
|
| 55 |
+
dict(
|
| 56 |
+
type='LoadPointsFromFile',
|
| 57 |
+
coord_type='LIDAR',
|
| 58 |
+
load_dim=4,
|
| 59 |
+
use_dim=4,
|
| 60 |
+
file_client_args=file_client_args),
|
| 61 |
+
dict(
|
| 62 |
+
type='MultiScaleFlipAug3D',
|
| 63 |
+
img_scale=(1333, 800),
|
| 64 |
+
pts_scale_ratio=1,
|
| 65 |
+
flip=False,
|
| 66 |
+
transforms=[
|
| 67 |
+
dict(
|
| 68 |
+
type='GlobalRotScaleTrans',
|
| 69 |
+
rot_range=[0, 0],
|
| 70 |
+
scale_ratio_range=[1., 1.],
|
| 71 |
+
translation_std=[0, 0, 0]),
|
| 72 |
+
dict(type='RandomFlip3D'),
|
| 73 |
+
dict(
|
| 74 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 75 |
+
dict(
|
| 76 |
+
type='DefaultFormatBundle3D',
|
| 77 |
+
class_names=class_names,
|
| 78 |
+
with_label=False),
|
| 79 |
+
dict(type='Collect3D', keys=['points'])
|
| 80 |
+
])
|
| 81 |
+
]
|
| 82 |
+
# construct a pipeline for data and gt loading in show function
|
| 83 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 84 |
+
eval_pipeline = [
|
| 85 |
+
dict(
|
| 86 |
+
type='LoadPointsFromFile',
|
| 87 |
+
coord_type='LIDAR',
|
| 88 |
+
load_dim=4,
|
| 89 |
+
use_dim=4,
|
| 90 |
+
file_client_args=file_client_args),
|
| 91 |
+
dict(
|
| 92 |
+
type='DefaultFormatBundle3D',
|
| 93 |
+
class_names=class_names,
|
| 94 |
+
with_label=False),
|
| 95 |
+
dict(type='Collect3D', keys=['points'])
|
| 96 |
+
]
|
| 97 |
+
|
| 98 |
+
data = dict(
|
| 99 |
+
samples_per_gpu=6,
|
| 100 |
+
workers_per_gpu=4,
|
| 101 |
+
train=dict(
|
| 102 |
+
type='RepeatDataset',
|
| 103 |
+
times=2,
|
| 104 |
+
dataset=dict(
|
| 105 |
+
type=dataset_type,
|
| 106 |
+
data_root=data_root,
|
| 107 |
+
ann_file=data_root + 'kitti_infos_train.pkl',
|
| 108 |
+
split='training',
|
| 109 |
+
pts_prefix='velodyne_reduced',
|
| 110 |
+
pipeline=train_pipeline,
|
| 111 |
+
modality=input_modality,
|
| 112 |
+
classes=class_names,
|
| 113 |
+
test_mode=False,
|
| 114 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 115 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 116 |
+
box_type_3d='LiDAR')),
|
| 117 |
+
val=dict(
|
| 118 |
+
type=dataset_type,
|
| 119 |
+
data_root=data_root,
|
| 120 |
+
ann_file=data_root + 'kitti_infos_val.pkl',
|
| 121 |
+
split='training',
|
| 122 |
+
pts_prefix='velodyne_reduced',
|
| 123 |
+
pipeline=test_pipeline,
|
| 124 |
+
modality=input_modality,
|
| 125 |
+
classes=class_names,
|
| 126 |
+
test_mode=True,
|
| 127 |
+
box_type_3d='LiDAR'),
|
| 128 |
+
test=dict(
|
| 129 |
+
type=dataset_type,
|
| 130 |
+
data_root=data_root,
|
| 131 |
+
ann_file=data_root + 'kitti_infos_val.pkl',
|
| 132 |
+
split='training',
|
| 133 |
+
pts_prefix='velodyne_reduced',
|
| 134 |
+
pipeline=test_pipeline,
|
| 135 |
+
modality=input_modality,
|
| 136 |
+
classes=class_names,
|
| 137 |
+
test_mode=True,
|
| 138 |
+
box_type_3d='LiDAR'))
|
| 139 |
+
|
| 140 |
+
evaluation = dict(interval=1, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/kitti-3d-car.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
dataset_type = 'KittiDataset'
|
| 3 |
+
data_root = 'data/kitti/'
|
| 4 |
+
class_names = ['Car']
|
| 5 |
+
point_cloud_range = [0, -40, -3, 70.4, 40, 1]
|
| 6 |
+
input_modality = dict(use_lidar=True, use_camera=False)
|
| 7 |
+
db_sampler = dict(
|
| 8 |
+
data_root=data_root,
|
| 9 |
+
info_path=data_root + 'kitti_dbinfos_train.pkl',
|
| 10 |
+
rate=1.0,
|
| 11 |
+
prepare=dict(filter_by_difficulty=[-1], filter_by_min_points=dict(Car=5)),
|
| 12 |
+
classes=class_names,
|
| 13 |
+
sample_groups=dict(Car=15))
|
| 14 |
+
|
| 15 |
+
file_client_args = dict(backend='disk')
|
| 16 |
+
# Uncomment the following if use ceph or other file clients.
|
| 17 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 18 |
+
# for more details.
|
| 19 |
+
# file_client_args = dict(
|
| 20 |
+
# backend='petrel', path_mapping=dict(data='s3://kitti_data/'))
|
| 21 |
+
|
| 22 |
+
train_pipeline = [
|
| 23 |
+
dict(
|
| 24 |
+
type='LoadPointsFromFile',
|
| 25 |
+
coord_type='LIDAR',
|
| 26 |
+
load_dim=4,
|
| 27 |
+
use_dim=4,
|
| 28 |
+
file_client_args=file_client_args),
|
| 29 |
+
dict(
|
| 30 |
+
type='LoadAnnotations3D',
|
| 31 |
+
with_bbox_3d=True,
|
| 32 |
+
with_label_3d=True,
|
| 33 |
+
file_client_args=file_client_args),
|
| 34 |
+
dict(type='ObjectSample', db_sampler=db_sampler),
|
| 35 |
+
dict(
|
| 36 |
+
type='ObjectNoise',
|
| 37 |
+
num_try=100,
|
| 38 |
+
translation_std=[1.0, 1.0, 0.5],
|
| 39 |
+
global_rot_range=[0.0, 0.0],
|
| 40 |
+
rot_range=[-0.78539816, 0.78539816]),
|
| 41 |
+
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
|
| 42 |
+
dict(
|
| 43 |
+
type='GlobalRotScaleTrans',
|
| 44 |
+
rot_range=[-0.78539816, 0.78539816],
|
| 45 |
+
scale_ratio_range=[0.95, 1.05]),
|
| 46 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 47 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 48 |
+
dict(type='PointShuffle'),
|
| 49 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 50 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 51 |
+
]
|
| 52 |
+
test_pipeline = [
|
| 53 |
+
dict(
|
| 54 |
+
type='LoadPointsFromFile',
|
| 55 |
+
coord_type='LIDAR',
|
| 56 |
+
load_dim=4,
|
| 57 |
+
use_dim=4,
|
| 58 |
+
file_client_args=file_client_args),
|
| 59 |
+
dict(
|
| 60 |
+
type='MultiScaleFlipAug3D',
|
| 61 |
+
img_scale=(1333, 800),
|
| 62 |
+
pts_scale_ratio=1,
|
| 63 |
+
flip=False,
|
| 64 |
+
transforms=[
|
| 65 |
+
dict(
|
| 66 |
+
type='GlobalRotScaleTrans',
|
| 67 |
+
rot_range=[0, 0],
|
| 68 |
+
scale_ratio_range=[1., 1.],
|
| 69 |
+
translation_std=[0, 0, 0]),
|
| 70 |
+
dict(type='RandomFlip3D'),
|
| 71 |
+
dict(
|
| 72 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 73 |
+
dict(
|
| 74 |
+
type='DefaultFormatBundle3D',
|
| 75 |
+
class_names=class_names,
|
| 76 |
+
with_label=False),
|
| 77 |
+
dict(type='Collect3D', keys=['points'])
|
| 78 |
+
])
|
| 79 |
+
]
|
| 80 |
+
# construct a pipeline for data and gt loading in show function
|
| 81 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 82 |
+
eval_pipeline = [
|
| 83 |
+
dict(
|
| 84 |
+
type='LoadPointsFromFile',
|
| 85 |
+
coord_type='LIDAR',
|
| 86 |
+
load_dim=4,
|
| 87 |
+
use_dim=4,
|
| 88 |
+
file_client_args=file_client_args),
|
| 89 |
+
dict(
|
| 90 |
+
type='DefaultFormatBundle3D',
|
| 91 |
+
class_names=class_names,
|
| 92 |
+
with_label=False),
|
| 93 |
+
dict(type='Collect3D', keys=['points'])
|
| 94 |
+
]
|
| 95 |
+
|
| 96 |
+
data = dict(
|
| 97 |
+
samples_per_gpu=6,
|
| 98 |
+
workers_per_gpu=4,
|
| 99 |
+
train=dict(
|
| 100 |
+
type='RepeatDataset',
|
| 101 |
+
times=2,
|
| 102 |
+
dataset=dict(
|
| 103 |
+
type=dataset_type,
|
| 104 |
+
data_root=data_root,
|
| 105 |
+
ann_file=data_root + 'kitti_infos_train.pkl',
|
| 106 |
+
split='training',
|
| 107 |
+
pts_prefix='velodyne_reduced',
|
| 108 |
+
pipeline=train_pipeline,
|
| 109 |
+
modality=input_modality,
|
| 110 |
+
classes=class_names,
|
| 111 |
+
test_mode=False,
|
| 112 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 113 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 114 |
+
box_type_3d='LiDAR')),
|
| 115 |
+
val=dict(
|
| 116 |
+
type=dataset_type,
|
| 117 |
+
data_root=data_root,
|
| 118 |
+
ann_file=data_root + 'kitti_infos_val.pkl',
|
| 119 |
+
split='training',
|
| 120 |
+
pts_prefix='velodyne_reduced',
|
| 121 |
+
pipeline=test_pipeline,
|
| 122 |
+
modality=input_modality,
|
| 123 |
+
classes=class_names,
|
| 124 |
+
test_mode=True,
|
| 125 |
+
box_type_3d='LiDAR'),
|
| 126 |
+
test=dict(
|
| 127 |
+
type=dataset_type,
|
| 128 |
+
data_root=data_root,
|
| 129 |
+
ann_file=data_root + 'kitti_infos_val.pkl',
|
| 130 |
+
split='training',
|
| 131 |
+
pts_prefix='velodyne_reduced',
|
| 132 |
+
pipeline=test_pipeline,
|
| 133 |
+
modality=input_modality,
|
| 134 |
+
classes=class_names,
|
| 135 |
+
test_mode=True,
|
| 136 |
+
box_type_3d='LiDAR'))
|
| 137 |
+
|
| 138 |
+
evaluation = dict(interval=1, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/lyft-3d.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# If point cloud range is changed, the models should also change their point
|
| 2 |
+
# cloud range accordingly
|
| 3 |
+
point_cloud_range = [-80, -80, -5, 80, 80, 3]
|
| 4 |
+
# For Lyft we usually do 9-class detection
|
| 5 |
+
class_names = [
|
| 6 |
+
'car', 'truck', 'bus', 'emergency_vehicle', 'other_vehicle', 'motorcycle',
|
| 7 |
+
'bicycle', 'pedestrian', 'animal'
|
| 8 |
+
]
|
| 9 |
+
dataset_type = 'LyftDataset'
|
| 10 |
+
data_root = 'data/lyft/'
|
| 11 |
+
# Input modality for Lyft dataset, this is consistent with the submission
|
| 12 |
+
# format which requires the information in input_modality.
|
| 13 |
+
input_modality = dict(
|
| 14 |
+
use_lidar=True,
|
| 15 |
+
use_camera=False,
|
| 16 |
+
use_radar=False,
|
| 17 |
+
use_map=False,
|
| 18 |
+
use_external=False)
|
| 19 |
+
file_client_args = dict(backend='disk')
|
| 20 |
+
# Uncomment the following if use ceph or other file clients.
|
| 21 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 22 |
+
# for more details.
|
| 23 |
+
# file_client_args = dict(
|
| 24 |
+
# backend='petrel',
|
| 25 |
+
# path_mapping=dict({
|
| 26 |
+
# './data/lyft/': 's3://lyft/lyft/',
|
| 27 |
+
# 'data/lyft/': 's3://lyft/lyft/'
|
| 28 |
+
# }))
|
| 29 |
+
train_pipeline = [
|
| 30 |
+
dict(
|
| 31 |
+
type='LoadPointsFromFile',
|
| 32 |
+
coord_type='LIDAR',
|
| 33 |
+
load_dim=5,
|
| 34 |
+
use_dim=5,
|
| 35 |
+
file_client_args=file_client_args),
|
| 36 |
+
dict(
|
| 37 |
+
type='LoadPointsFromMultiSweeps',
|
| 38 |
+
sweeps_num=10,
|
| 39 |
+
file_client_args=file_client_args),
|
| 40 |
+
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
|
| 41 |
+
dict(
|
| 42 |
+
type='GlobalRotScaleTrans',
|
| 43 |
+
rot_range=[-0.3925, 0.3925],
|
| 44 |
+
scale_ratio_range=[0.95, 1.05],
|
| 45 |
+
translation_std=[0, 0, 0]),
|
| 46 |
+
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
|
| 47 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 48 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 49 |
+
dict(type='PointShuffle'),
|
| 50 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 51 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 52 |
+
]
|
| 53 |
+
test_pipeline = [
|
| 54 |
+
dict(
|
| 55 |
+
type='LoadPointsFromFile',
|
| 56 |
+
coord_type='LIDAR',
|
| 57 |
+
load_dim=5,
|
| 58 |
+
use_dim=5,
|
| 59 |
+
file_client_args=file_client_args),
|
| 60 |
+
dict(
|
| 61 |
+
type='LoadPointsFromMultiSweeps',
|
| 62 |
+
sweeps_num=10,
|
| 63 |
+
file_client_args=file_client_args),
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiScaleFlipAug3D',
|
| 66 |
+
img_scale=(1333, 800),
|
| 67 |
+
pts_scale_ratio=1,
|
| 68 |
+
flip=False,
|
| 69 |
+
transforms=[
|
| 70 |
+
dict(
|
| 71 |
+
type='GlobalRotScaleTrans',
|
| 72 |
+
rot_range=[0, 0],
|
| 73 |
+
scale_ratio_range=[1., 1.],
|
| 74 |
+
translation_std=[0, 0, 0]),
|
| 75 |
+
dict(type='RandomFlip3D'),
|
| 76 |
+
dict(
|
| 77 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 78 |
+
dict(
|
| 79 |
+
type='DefaultFormatBundle3D',
|
| 80 |
+
class_names=class_names,
|
| 81 |
+
with_label=False),
|
| 82 |
+
dict(type='Collect3D', keys=['points'])
|
| 83 |
+
])
|
| 84 |
+
]
|
| 85 |
+
# construct a pipeline for data and gt loading in show function
|
| 86 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 87 |
+
eval_pipeline = [
|
| 88 |
+
dict(
|
| 89 |
+
type='LoadPointsFromFile',
|
| 90 |
+
coord_type='LIDAR',
|
| 91 |
+
load_dim=5,
|
| 92 |
+
use_dim=5,
|
| 93 |
+
file_client_args=file_client_args),
|
| 94 |
+
dict(
|
| 95 |
+
type='LoadPointsFromMultiSweeps',
|
| 96 |
+
sweeps_num=10,
|
| 97 |
+
file_client_args=file_client_args),
|
| 98 |
+
dict(
|
| 99 |
+
type='DefaultFormatBundle3D',
|
| 100 |
+
class_names=class_names,
|
| 101 |
+
with_label=False),
|
| 102 |
+
dict(type='Collect3D', keys=['points'])
|
| 103 |
+
]
|
| 104 |
+
|
| 105 |
+
data = dict(
|
| 106 |
+
samples_per_gpu=2,
|
| 107 |
+
workers_per_gpu=2,
|
| 108 |
+
train=dict(
|
| 109 |
+
type=dataset_type,
|
| 110 |
+
data_root=data_root,
|
| 111 |
+
ann_file=data_root + 'lyft_infos_train.pkl',
|
| 112 |
+
pipeline=train_pipeline,
|
| 113 |
+
classes=class_names,
|
| 114 |
+
modality=input_modality,
|
| 115 |
+
test_mode=False),
|
| 116 |
+
val=dict(
|
| 117 |
+
type=dataset_type,
|
| 118 |
+
data_root=data_root,
|
| 119 |
+
ann_file=data_root + 'lyft_infos_val.pkl',
|
| 120 |
+
pipeline=test_pipeline,
|
| 121 |
+
classes=class_names,
|
| 122 |
+
modality=input_modality,
|
| 123 |
+
test_mode=True),
|
| 124 |
+
test=dict(
|
| 125 |
+
type=dataset_type,
|
| 126 |
+
data_root=data_root,
|
| 127 |
+
ann_file=data_root + 'lyft_infos_test.pkl',
|
| 128 |
+
pipeline=test_pipeline,
|
| 129 |
+
classes=class_names,
|
| 130 |
+
modality=input_modality,
|
| 131 |
+
test_mode=True))
|
| 132 |
+
# For Lyft dataset, we usually evaluate the model at the end of training.
|
| 133 |
+
# Since the models are trained by 24 epochs by default, we set evaluation
|
| 134 |
+
# interval to be 24. Please change the interval accordingly if you do not
|
| 135 |
+
# use a default schedule.
|
| 136 |
+
evaluation = dict(interval=24, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/nuim_instance.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset_type = 'CocoDataset'
|
| 2 |
+
data_root = 'data/nuimages/'
|
| 3 |
+
class_names = [
|
| 4 |
+
'car', 'truck', 'trailer', 'bus', 'construction_vehicle', 'bicycle',
|
| 5 |
+
'motorcycle', 'pedestrian', 'traffic_cone', 'barrier'
|
| 6 |
+
]
|
| 7 |
+
img_norm_cfg = dict(
|
| 8 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 9 |
+
train_pipeline = [
|
| 10 |
+
dict(type='LoadImageFromFile'),
|
| 11 |
+
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
|
| 12 |
+
dict(
|
| 13 |
+
type='Resize',
|
| 14 |
+
img_scale=[(1280, 720), (1920, 1080)],
|
| 15 |
+
multiscale_mode='range',
|
| 16 |
+
keep_ratio=True),
|
| 17 |
+
dict(type='RandomFlip', flip_ratio=0.5),
|
| 18 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 19 |
+
dict(type='Pad', size_divisor=32),
|
| 20 |
+
dict(type='DefaultFormatBundle'),
|
| 21 |
+
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
|
| 22 |
+
]
|
| 23 |
+
test_pipeline = [
|
| 24 |
+
dict(type='LoadImageFromFile'),
|
| 25 |
+
dict(
|
| 26 |
+
type='MultiScaleFlipAug',
|
| 27 |
+
img_scale=(1600, 900),
|
| 28 |
+
flip=False,
|
| 29 |
+
transforms=[
|
| 30 |
+
dict(type='Resize', keep_ratio=True),
|
| 31 |
+
dict(type='RandomFlip'),
|
| 32 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 33 |
+
dict(type='Pad', size_divisor=32),
|
| 34 |
+
dict(type='ImageToTensor', keys=['img']),
|
| 35 |
+
dict(type='Collect', keys=['img']),
|
| 36 |
+
])
|
| 37 |
+
]
|
| 38 |
+
data = dict(
|
| 39 |
+
samples_per_gpu=2,
|
| 40 |
+
workers_per_gpu=2,
|
| 41 |
+
train=dict(
|
| 42 |
+
type=dataset_type,
|
| 43 |
+
ann_file=data_root + 'annotations/nuimages_v1.0-train.json',
|
| 44 |
+
img_prefix=data_root,
|
| 45 |
+
classes=class_names,
|
| 46 |
+
pipeline=train_pipeline),
|
| 47 |
+
val=dict(
|
| 48 |
+
type=dataset_type,
|
| 49 |
+
ann_file=data_root + 'annotations/nuimages_v1.0-val.json',
|
| 50 |
+
img_prefix=data_root,
|
| 51 |
+
classes=class_names,
|
| 52 |
+
pipeline=test_pipeline),
|
| 53 |
+
test=dict(
|
| 54 |
+
type=dataset_type,
|
| 55 |
+
ann_file=data_root + 'annotations/nuimages_v1.0-val.json',
|
| 56 |
+
img_prefix=data_root,
|
| 57 |
+
classes=class_names,
|
| 58 |
+
pipeline=test_pipeline))
|
| 59 |
+
evaluation = dict(metric=['bbox', 'segm'])
|
GenAD-main/projects/configs/_base_/datasets/nus-3d.py
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# If point cloud range is changed, the models should also change their point
|
| 2 |
+
# cloud range accordingly
|
| 3 |
+
point_cloud_range = [-50, -50, -5, 50, 50, 3]
|
| 4 |
+
# For nuScenes we usually do 10-class detection
|
| 5 |
+
class_names = [
|
| 6 |
+
'car', 'truck', 'trailer', 'bus', 'construction_vehicle', 'bicycle',
|
| 7 |
+
'motorcycle', 'pedestrian', 'traffic_cone', 'barrier'
|
| 8 |
+
]
|
| 9 |
+
dataset_type = 'NuScenesDataset'
|
| 10 |
+
data_root = 'data/nuscenes/'
|
| 11 |
+
# Input modality for nuScenes dataset, this is consistent with the submission
|
| 12 |
+
# format which requires the information in input_modality.
|
| 13 |
+
input_modality = dict(
|
| 14 |
+
use_lidar=True,
|
| 15 |
+
use_camera=False,
|
| 16 |
+
use_radar=False,
|
| 17 |
+
use_map=False,
|
| 18 |
+
use_external=False)
|
| 19 |
+
file_client_args = dict(backend='disk')
|
| 20 |
+
# Uncomment the following if use ceph or other file clients.
|
| 21 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 22 |
+
# for more details.
|
| 23 |
+
# file_client_args = dict(
|
| 24 |
+
# backend='petrel',
|
| 25 |
+
# path_mapping=dict({
|
| 26 |
+
# './data/nuscenes/': 's3://nuscenes/nuscenes/',
|
| 27 |
+
# 'data/nuscenes/': 's3://nuscenes/nuscenes/'
|
| 28 |
+
# }))
|
| 29 |
+
train_pipeline = [
|
| 30 |
+
dict(
|
| 31 |
+
type='LoadPointsFromFile',
|
| 32 |
+
coord_type='LIDAR',
|
| 33 |
+
load_dim=5,
|
| 34 |
+
use_dim=5,
|
| 35 |
+
file_client_args=file_client_args),
|
| 36 |
+
dict(
|
| 37 |
+
type='LoadPointsFromMultiSweeps',
|
| 38 |
+
sweeps_num=10,
|
| 39 |
+
file_client_args=file_client_args),
|
| 40 |
+
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
|
| 41 |
+
dict(
|
| 42 |
+
type='GlobalRotScaleTrans',
|
| 43 |
+
rot_range=[-0.3925, 0.3925],
|
| 44 |
+
scale_ratio_range=[0.95, 1.05],
|
| 45 |
+
translation_std=[0, 0, 0]),
|
| 46 |
+
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
|
| 47 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 48 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 49 |
+
dict(type='ObjectNameFilter', classes=class_names),
|
| 50 |
+
dict(type='PointShuffle'),
|
| 51 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 52 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 53 |
+
]
|
| 54 |
+
test_pipeline = [
|
| 55 |
+
dict(
|
| 56 |
+
type='LoadPointsFromFile',
|
| 57 |
+
coord_type='LIDAR',
|
| 58 |
+
load_dim=5,
|
| 59 |
+
use_dim=5,
|
| 60 |
+
file_client_args=file_client_args),
|
| 61 |
+
dict(
|
| 62 |
+
type='LoadPointsFromMultiSweeps',
|
| 63 |
+
sweeps_num=10,
|
| 64 |
+
file_client_args=file_client_args),
|
| 65 |
+
dict(
|
| 66 |
+
type='MultiScaleFlipAug3D',
|
| 67 |
+
img_scale=(1333, 800),
|
| 68 |
+
pts_scale_ratio=1,
|
| 69 |
+
flip=False,
|
| 70 |
+
transforms=[
|
| 71 |
+
dict(
|
| 72 |
+
type='GlobalRotScaleTrans',
|
| 73 |
+
rot_range=[0, 0],
|
| 74 |
+
scale_ratio_range=[1., 1.],
|
| 75 |
+
translation_std=[0, 0, 0]),
|
| 76 |
+
dict(type='RandomFlip3D'),
|
| 77 |
+
dict(
|
| 78 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 79 |
+
dict(
|
| 80 |
+
type='DefaultFormatBundle3D',
|
| 81 |
+
class_names=class_names,
|
| 82 |
+
with_label=False),
|
| 83 |
+
dict(type='Collect3D', keys=['points'])
|
| 84 |
+
])
|
| 85 |
+
]
|
| 86 |
+
# construct a pipeline for data and gt loading in show function
|
| 87 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 88 |
+
eval_pipeline = [
|
| 89 |
+
dict(
|
| 90 |
+
type='LoadPointsFromFile',
|
| 91 |
+
coord_type='LIDAR',
|
| 92 |
+
load_dim=5,
|
| 93 |
+
use_dim=5,
|
| 94 |
+
file_client_args=file_client_args),
|
| 95 |
+
dict(
|
| 96 |
+
type='LoadPointsFromMultiSweeps',
|
| 97 |
+
sweeps_num=10,
|
| 98 |
+
file_client_args=file_client_args),
|
| 99 |
+
dict(
|
| 100 |
+
type='DefaultFormatBundle3D',
|
| 101 |
+
class_names=class_names,
|
| 102 |
+
with_label=False),
|
| 103 |
+
dict(type='Collect3D', keys=['points'])
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
data = dict(
|
| 107 |
+
samples_per_gpu=4,
|
| 108 |
+
workers_per_gpu=4,
|
| 109 |
+
train=dict(
|
| 110 |
+
type=dataset_type,
|
| 111 |
+
data_root=data_root,
|
| 112 |
+
ann_file=data_root + 'nuscenes_infos_train.pkl',
|
| 113 |
+
pipeline=train_pipeline,
|
| 114 |
+
classes=class_names,
|
| 115 |
+
modality=input_modality,
|
| 116 |
+
test_mode=False,
|
| 117 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 118 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 119 |
+
box_type_3d='LiDAR'),
|
| 120 |
+
val=dict(
|
| 121 |
+
type=dataset_type,
|
| 122 |
+
data_root=data_root,
|
| 123 |
+
ann_file=data_root + 'nuscenes_infos_val.pkl',
|
| 124 |
+
pipeline=test_pipeline,
|
| 125 |
+
classes=class_names,
|
| 126 |
+
modality=input_modality,
|
| 127 |
+
test_mode=True,
|
| 128 |
+
box_type_3d='LiDAR'),
|
| 129 |
+
test=dict(
|
| 130 |
+
type=dataset_type,
|
| 131 |
+
data_root=data_root,
|
| 132 |
+
ann_file=data_root + 'nuscenes_infos_val.pkl',
|
| 133 |
+
pipeline=test_pipeline,
|
| 134 |
+
classes=class_names,
|
| 135 |
+
modality=input_modality,
|
| 136 |
+
test_mode=True,
|
| 137 |
+
box_type_3d='LiDAR'))
|
| 138 |
+
# For nuScenes dataset, we usually evaluate the model at the end of training.
|
| 139 |
+
# Since the models are trained by 24 epochs by default, we set evaluation
|
| 140 |
+
# interval to be 24. Please change the interval accordingly if you do not
|
| 141 |
+
# use a default schedule.
|
| 142 |
+
evaluation = dict(interval=24, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/nus-mono3d.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset_type = 'CustomNuScenesMonoDataset'
|
| 2 |
+
data_root = 'data/nuscenes/'
|
| 3 |
+
class_names = [
|
| 4 |
+
'car', 'truck', 'trailer', 'bus', 'construction_vehicle', 'bicycle',
|
| 5 |
+
'motorcycle', 'pedestrian', 'traffic_cone', 'barrier'
|
| 6 |
+
]
|
| 7 |
+
# Input modality for nuScenes dataset, this is consistent with the submission
|
| 8 |
+
# format which requires the information in input_modality.
|
| 9 |
+
input_modality = dict(
|
| 10 |
+
use_lidar=False,
|
| 11 |
+
use_camera=True,
|
| 12 |
+
use_radar=False,
|
| 13 |
+
use_map=False,
|
| 14 |
+
use_external=False)
|
| 15 |
+
img_norm_cfg = dict(
|
| 16 |
+
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 17 |
+
train_pipeline = [
|
| 18 |
+
dict(type='LoadImageFromFileMono3D'),
|
| 19 |
+
dict(
|
| 20 |
+
type='LoadAnnotations3D',
|
| 21 |
+
with_bbox=True,
|
| 22 |
+
with_label=True,
|
| 23 |
+
with_attr_label=True,
|
| 24 |
+
with_bbox_3d=True,
|
| 25 |
+
with_label_3d=True,
|
| 26 |
+
with_bbox_depth=True),
|
| 27 |
+
dict(type='Resize', img_scale=(1600, 900), keep_ratio=True),
|
| 28 |
+
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
|
| 29 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 30 |
+
dict(type='Pad', size_divisor=32),
|
| 31 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 32 |
+
dict(
|
| 33 |
+
type='Collect3D',
|
| 34 |
+
keys=[
|
| 35 |
+
'img', 'gt_bboxes', 'gt_labels', 'attr_labels', 'gt_bboxes_3d',
|
| 36 |
+
'gt_labels_3d', 'centers2d', 'depths'
|
| 37 |
+
]),
|
| 38 |
+
]
|
| 39 |
+
test_pipeline = [
|
| 40 |
+
dict(type='LoadImageFromFileMono3D'),
|
| 41 |
+
dict(
|
| 42 |
+
type='MultiScaleFlipAug',
|
| 43 |
+
scale_factor=1.0,
|
| 44 |
+
flip=False,
|
| 45 |
+
transforms=[
|
| 46 |
+
dict(type='RandomFlip3D'),
|
| 47 |
+
dict(type='Normalize', **img_norm_cfg),
|
| 48 |
+
dict(type='Pad', size_divisor=32),
|
| 49 |
+
dict(
|
| 50 |
+
type='DefaultFormatBundle3D',
|
| 51 |
+
class_names=class_names,
|
| 52 |
+
with_label=False),
|
| 53 |
+
dict(type='Collect3D', keys=['img']),
|
| 54 |
+
])
|
| 55 |
+
]
|
| 56 |
+
# construct a pipeline for data and gt loading in show function
|
| 57 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 58 |
+
eval_pipeline = [
|
| 59 |
+
dict(type='LoadImageFromFileMono3D'),
|
| 60 |
+
dict(
|
| 61 |
+
type='DefaultFormatBundle3D',
|
| 62 |
+
class_names=class_names,
|
| 63 |
+
with_label=False),
|
| 64 |
+
dict(type='Collect3D', keys=['img'])
|
| 65 |
+
]
|
| 66 |
+
|
| 67 |
+
data = dict(
|
| 68 |
+
samples_per_gpu=2,
|
| 69 |
+
workers_per_gpu=2,
|
| 70 |
+
train=dict(
|
| 71 |
+
type=dataset_type,
|
| 72 |
+
data_root=data_root,
|
| 73 |
+
ann_file=data_root + 'nuscenes_infos_train_mono3d.coco.json',
|
| 74 |
+
img_prefix=data_root,
|
| 75 |
+
classes=class_names,
|
| 76 |
+
pipeline=train_pipeline,
|
| 77 |
+
modality=input_modality,
|
| 78 |
+
test_mode=False,
|
| 79 |
+
box_type_3d='Camera'),
|
| 80 |
+
val=dict(
|
| 81 |
+
type=dataset_type,
|
| 82 |
+
data_root=data_root,
|
| 83 |
+
ann_file=data_root + 'nuscenes_infos_val_mono3d.coco.json',
|
| 84 |
+
img_prefix=data_root,
|
| 85 |
+
classes=class_names,
|
| 86 |
+
pipeline=test_pipeline,
|
| 87 |
+
modality=input_modality,
|
| 88 |
+
test_mode=True,
|
| 89 |
+
box_type_3d='Camera'),
|
| 90 |
+
test=dict(
|
| 91 |
+
type=dataset_type,
|
| 92 |
+
data_root=data_root,
|
| 93 |
+
ann_file=data_root + 'nuscenes_infos_val_mono3d.coco.json',
|
| 94 |
+
img_prefix=data_root,
|
| 95 |
+
classes=class_names,
|
| 96 |
+
pipeline=test_pipeline,
|
| 97 |
+
modality=input_modality,
|
| 98 |
+
test_mode=True,
|
| 99 |
+
box_type_3d='Camera'))
|
| 100 |
+
evaluation = dict(interval=2)
|
GenAD-main/projects/configs/_base_/datasets/range100_lyft-3d.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# If point cloud range is changed, the models should also change their point
|
| 2 |
+
# cloud range accordingly
|
| 3 |
+
point_cloud_range = [-100, -100, -5, 100, 100, 3]
|
| 4 |
+
# For Lyft we usually do 9-class detection
|
| 5 |
+
class_names = [
|
| 6 |
+
'car', 'truck', 'bus', 'emergency_vehicle', 'other_vehicle', 'motorcycle',
|
| 7 |
+
'bicycle', 'pedestrian', 'animal'
|
| 8 |
+
]
|
| 9 |
+
dataset_type = 'LyftDataset'
|
| 10 |
+
data_root = 'data/lyft/'
|
| 11 |
+
# Input modality for Lyft dataset, this is consistent with the submission
|
| 12 |
+
# format which requires the information in input_modality.
|
| 13 |
+
input_modality = dict(
|
| 14 |
+
use_lidar=True,
|
| 15 |
+
use_camera=False,
|
| 16 |
+
use_radar=False,
|
| 17 |
+
use_map=False,
|
| 18 |
+
use_external=False)
|
| 19 |
+
file_client_args = dict(backend='disk')
|
| 20 |
+
# Uncomment the following if use ceph or other file clients.
|
| 21 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 22 |
+
# for more details.
|
| 23 |
+
# file_client_args = dict(
|
| 24 |
+
# backend='petrel',
|
| 25 |
+
# path_mapping=dict({
|
| 26 |
+
# './data/lyft/': 's3://lyft/lyft/',
|
| 27 |
+
# 'data/lyft/': 's3://lyft/lyft/'
|
| 28 |
+
# }))
|
| 29 |
+
train_pipeline = [
|
| 30 |
+
dict(
|
| 31 |
+
type='LoadPointsFromFile',
|
| 32 |
+
coord_type='LIDAR',
|
| 33 |
+
load_dim=5,
|
| 34 |
+
use_dim=5,
|
| 35 |
+
file_client_args=file_client_args),
|
| 36 |
+
dict(
|
| 37 |
+
type='LoadPointsFromMultiSweeps',
|
| 38 |
+
sweeps_num=10,
|
| 39 |
+
file_client_args=file_client_args),
|
| 40 |
+
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
|
| 41 |
+
dict(
|
| 42 |
+
type='GlobalRotScaleTrans',
|
| 43 |
+
rot_range=[-0.3925, 0.3925],
|
| 44 |
+
scale_ratio_range=[0.95, 1.05],
|
| 45 |
+
translation_std=[0, 0, 0]),
|
| 46 |
+
dict(type='RandomFlip3D', flip_ratio_bev_horizontal=0.5),
|
| 47 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 48 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 49 |
+
dict(type='PointShuffle'),
|
| 50 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 51 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 52 |
+
]
|
| 53 |
+
test_pipeline = [
|
| 54 |
+
dict(
|
| 55 |
+
type='LoadPointsFromFile',
|
| 56 |
+
coord_type='LIDAR',
|
| 57 |
+
load_dim=5,
|
| 58 |
+
use_dim=5,
|
| 59 |
+
file_client_args=file_client_args),
|
| 60 |
+
dict(
|
| 61 |
+
type='LoadPointsFromMultiSweeps',
|
| 62 |
+
sweeps_num=10,
|
| 63 |
+
file_client_args=file_client_args),
|
| 64 |
+
dict(
|
| 65 |
+
type='MultiScaleFlipAug3D',
|
| 66 |
+
img_scale=(1333, 800),
|
| 67 |
+
pts_scale_ratio=1,
|
| 68 |
+
flip=False,
|
| 69 |
+
transforms=[
|
| 70 |
+
dict(
|
| 71 |
+
type='GlobalRotScaleTrans',
|
| 72 |
+
rot_range=[0, 0],
|
| 73 |
+
scale_ratio_range=[1., 1.],
|
| 74 |
+
translation_std=[0, 0, 0]),
|
| 75 |
+
dict(type='RandomFlip3D'),
|
| 76 |
+
dict(
|
| 77 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 78 |
+
dict(
|
| 79 |
+
type='DefaultFormatBundle3D',
|
| 80 |
+
class_names=class_names,
|
| 81 |
+
with_label=False),
|
| 82 |
+
dict(type='Collect3D', keys=['points'])
|
| 83 |
+
])
|
| 84 |
+
]
|
| 85 |
+
# construct a pipeline for data and gt loading in show function
|
| 86 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 87 |
+
eval_pipeline = [
|
| 88 |
+
dict(
|
| 89 |
+
type='LoadPointsFromFile',
|
| 90 |
+
coord_type='LIDAR',
|
| 91 |
+
load_dim=5,
|
| 92 |
+
use_dim=5,
|
| 93 |
+
file_client_args=file_client_args),
|
| 94 |
+
dict(
|
| 95 |
+
type='LoadPointsFromMultiSweeps',
|
| 96 |
+
sweeps_num=10,
|
| 97 |
+
file_client_args=file_client_args),
|
| 98 |
+
dict(
|
| 99 |
+
type='DefaultFormatBundle3D',
|
| 100 |
+
class_names=class_names,
|
| 101 |
+
with_label=False),
|
| 102 |
+
dict(type='Collect3D', keys=['points'])
|
| 103 |
+
]
|
| 104 |
+
|
| 105 |
+
data = dict(
|
| 106 |
+
samples_per_gpu=2,
|
| 107 |
+
workers_per_gpu=2,
|
| 108 |
+
train=dict(
|
| 109 |
+
type=dataset_type,
|
| 110 |
+
data_root=data_root,
|
| 111 |
+
ann_file=data_root + 'lyft_infos_train.pkl',
|
| 112 |
+
pipeline=train_pipeline,
|
| 113 |
+
classes=class_names,
|
| 114 |
+
modality=input_modality,
|
| 115 |
+
test_mode=False),
|
| 116 |
+
val=dict(
|
| 117 |
+
type=dataset_type,
|
| 118 |
+
data_root=data_root,
|
| 119 |
+
ann_file=data_root + 'lyft_infos_val.pkl',
|
| 120 |
+
pipeline=test_pipeline,
|
| 121 |
+
classes=class_names,
|
| 122 |
+
modality=input_modality,
|
| 123 |
+
test_mode=True),
|
| 124 |
+
test=dict(
|
| 125 |
+
type=dataset_type,
|
| 126 |
+
data_root=data_root,
|
| 127 |
+
ann_file=data_root + 'lyft_infos_test.pkl',
|
| 128 |
+
pipeline=test_pipeline,
|
| 129 |
+
classes=class_names,
|
| 130 |
+
modality=input_modality,
|
| 131 |
+
test_mode=True))
|
| 132 |
+
# For Lyft dataset, we usually evaluate the model at the end of training.
|
| 133 |
+
# Since the models are trained by 24 epochs by default, we set evaluation
|
| 134 |
+
# interval to be 24. Please change the interval accordingly if you do not
|
| 135 |
+
# use a default schedule.
|
| 136 |
+
evaluation = dict(interval=24, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/s3dis-3d-5class.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
dataset_type = 'S3DISDataset'
|
| 3 |
+
data_root = './data/s3dis/'
|
| 4 |
+
class_names = ('table', 'chair', 'sofa', 'bookcase', 'board')
|
| 5 |
+
train_area = [1, 2, 3, 4, 6]
|
| 6 |
+
test_area = 5
|
| 7 |
+
|
| 8 |
+
train_pipeline = [
|
| 9 |
+
dict(
|
| 10 |
+
type='LoadPointsFromFile',
|
| 11 |
+
coord_type='DEPTH',
|
| 12 |
+
shift_height=True,
|
| 13 |
+
load_dim=6,
|
| 14 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 15 |
+
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True),
|
| 16 |
+
dict(type='PointSample', num_points=40000),
|
| 17 |
+
dict(
|
| 18 |
+
type='RandomFlip3D',
|
| 19 |
+
sync_2d=False,
|
| 20 |
+
flip_ratio_bev_horizontal=0.5,
|
| 21 |
+
flip_ratio_bev_vertical=0.5),
|
| 22 |
+
dict(
|
| 23 |
+
type='GlobalRotScaleTrans',
|
| 24 |
+
# following ScanNet dataset the rotation range is 5 degrees
|
| 25 |
+
rot_range=[-0.087266, 0.087266],
|
| 26 |
+
scale_ratio_range=[1.0, 1.0],
|
| 27 |
+
shift_height=True),
|
| 28 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 29 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 30 |
+
]
|
| 31 |
+
test_pipeline = [
|
| 32 |
+
dict(
|
| 33 |
+
type='LoadPointsFromFile',
|
| 34 |
+
coord_type='DEPTH',
|
| 35 |
+
shift_height=True,
|
| 36 |
+
load_dim=6,
|
| 37 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 38 |
+
dict(
|
| 39 |
+
type='MultiScaleFlipAug3D',
|
| 40 |
+
img_scale=(1333, 800),
|
| 41 |
+
pts_scale_ratio=1,
|
| 42 |
+
flip=False,
|
| 43 |
+
transforms=[
|
| 44 |
+
dict(
|
| 45 |
+
type='GlobalRotScaleTrans',
|
| 46 |
+
rot_range=[0, 0],
|
| 47 |
+
scale_ratio_range=[1., 1.],
|
| 48 |
+
translation_std=[0, 0, 0]),
|
| 49 |
+
dict(
|
| 50 |
+
type='RandomFlip3D',
|
| 51 |
+
sync_2d=False,
|
| 52 |
+
flip_ratio_bev_horizontal=0.5,
|
| 53 |
+
flip_ratio_bev_vertical=0.5),
|
| 54 |
+
dict(type='PointSample', num_points=40000),
|
| 55 |
+
dict(
|
| 56 |
+
type='DefaultFormatBundle3D',
|
| 57 |
+
class_names=class_names,
|
| 58 |
+
with_label=False),
|
| 59 |
+
dict(type='Collect3D', keys=['points'])
|
| 60 |
+
])
|
| 61 |
+
]
|
| 62 |
+
# construct a pipeline for data and gt loading in show function
|
| 63 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 64 |
+
eval_pipeline = [
|
| 65 |
+
dict(
|
| 66 |
+
type='LoadPointsFromFile',
|
| 67 |
+
coord_type='DEPTH',
|
| 68 |
+
shift_height=False,
|
| 69 |
+
load_dim=6,
|
| 70 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 71 |
+
dict(
|
| 72 |
+
type='DefaultFormatBundle3D',
|
| 73 |
+
class_names=class_names,
|
| 74 |
+
with_label=False),
|
| 75 |
+
dict(type='Collect3D', keys=['points'])
|
| 76 |
+
]
|
| 77 |
+
|
| 78 |
+
data = dict(
|
| 79 |
+
samples_per_gpu=8,
|
| 80 |
+
workers_per_gpu=4,
|
| 81 |
+
train=dict(
|
| 82 |
+
type='RepeatDataset',
|
| 83 |
+
times=5,
|
| 84 |
+
dataset=dict(
|
| 85 |
+
type='ConcatDataset',
|
| 86 |
+
datasets=[
|
| 87 |
+
dict(
|
| 88 |
+
type=dataset_type,
|
| 89 |
+
data_root=data_root,
|
| 90 |
+
ann_file=data_root + f's3dis_infos_Area_{i}.pkl',
|
| 91 |
+
pipeline=train_pipeline,
|
| 92 |
+
filter_empty_gt=False,
|
| 93 |
+
classes=class_names,
|
| 94 |
+
box_type_3d='Depth') for i in train_area
|
| 95 |
+
],
|
| 96 |
+
separate_eval=False)),
|
| 97 |
+
val=dict(
|
| 98 |
+
type=dataset_type,
|
| 99 |
+
data_root=data_root,
|
| 100 |
+
ann_file=data_root + f's3dis_infos_Area_{test_area}.pkl',
|
| 101 |
+
pipeline=test_pipeline,
|
| 102 |
+
classes=class_names,
|
| 103 |
+
test_mode=True,
|
| 104 |
+
box_type_3d='Depth'),
|
| 105 |
+
test=dict(
|
| 106 |
+
type=dataset_type,
|
| 107 |
+
data_root=data_root,
|
| 108 |
+
ann_file=data_root + f's3dis_infos_Area_{test_area}.pkl',
|
| 109 |
+
pipeline=test_pipeline,
|
| 110 |
+
classes=class_names,
|
| 111 |
+
test_mode=True,
|
| 112 |
+
box_type_3d='Depth'))
|
| 113 |
+
|
| 114 |
+
evaluation = dict(pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/s3dis_seg-3d-13class.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
dataset_type = 'S3DISSegDataset'
|
| 3 |
+
data_root = './data/s3dis/'
|
| 4 |
+
class_names = ('ceiling', 'floor', 'wall', 'beam', 'column', 'window', 'door',
|
| 5 |
+
'table', 'chair', 'sofa', 'bookcase', 'board', 'clutter')
|
| 6 |
+
num_points = 4096
|
| 7 |
+
train_area = [1, 2, 3, 4, 6]
|
| 8 |
+
test_area = 5
|
| 9 |
+
train_pipeline = [
|
| 10 |
+
dict(
|
| 11 |
+
type='LoadPointsFromFile',
|
| 12 |
+
coord_type='DEPTH',
|
| 13 |
+
shift_height=False,
|
| 14 |
+
use_color=True,
|
| 15 |
+
load_dim=6,
|
| 16 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 17 |
+
dict(
|
| 18 |
+
type='LoadAnnotations3D',
|
| 19 |
+
with_bbox_3d=False,
|
| 20 |
+
with_label_3d=False,
|
| 21 |
+
with_mask_3d=False,
|
| 22 |
+
with_seg_3d=True),
|
| 23 |
+
dict(
|
| 24 |
+
type='PointSegClassMapping',
|
| 25 |
+
valid_cat_ids=tuple(range(len(class_names))),
|
| 26 |
+
max_cat_id=13),
|
| 27 |
+
dict(
|
| 28 |
+
type='IndoorPatchPointSample',
|
| 29 |
+
num_points=num_points,
|
| 30 |
+
block_size=1.0,
|
| 31 |
+
ignore_index=len(class_names),
|
| 32 |
+
use_normalized_coord=True,
|
| 33 |
+
enlarge_size=0.2,
|
| 34 |
+
min_unique_num=None),
|
| 35 |
+
dict(type='NormalizePointsColor', color_mean=None),
|
| 36 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 37 |
+
dict(type='Collect3D', keys=['points', 'pts_semantic_mask'])
|
| 38 |
+
]
|
| 39 |
+
test_pipeline = [
|
| 40 |
+
dict(
|
| 41 |
+
type='LoadPointsFromFile',
|
| 42 |
+
coord_type='DEPTH',
|
| 43 |
+
shift_height=False,
|
| 44 |
+
use_color=True,
|
| 45 |
+
load_dim=6,
|
| 46 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 47 |
+
dict(type='NormalizePointsColor', color_mean=None),
|
| 48 |
+
dict(
|
| 49 |
+
# a wrapper in order to successfully call test function
|
| 50 |
+
# actually we don't perform test-time-aug
|
| 51 |
+
type='MultiScaleFlipAug3D',
|
| 52 |
+
img_scale=(1333, 800),
|
| 53 |
+
pts_scale_ratio=1,
|
| 54 |
+
flip=False,
|
| 55 |
+
transforms=[
|
| 56 |
+
dict(
|
| 57 |
+
type='GlobalRotScaleTrans',
|
| 58 |
+
rot_range=[0, 0],
|
| 59 |
+
scale_ratio_range=[1., 1.],
|
| 60 |
+
translation_std=[0, 0, 0]),
|
| 61 |
+
dict(
|
| 62 |
+
type='RandomFlip3D',
|
| 63 |
+
sync_2d=False,
|
| 64 |
+
flip_ratio_bev_horizontal=0.0,
|
| 65 |
+
flip_ratio_bev_vertical=0.0),
|
| 66 |
+
dict(
|
| 67 |
+
type='DefaultFormatBundle3D',
|
| 68 |
+
class_names=class_names,
|
| 69 |
+
with_label=False),
|
| 70 |
+
dict(type='Collect3D', keys=['points'])
|
| 71 |
+
])
|
| 72 |
+
]
|
| 73 |
+
# construct a pipeline for data and gt loading in show function
|
| 74 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 75 |
+
# we need to load gt seg_mask!
|
| 76 |
+
eval_pipeline = [
|
| 77 |
+
dict(
|
| 78 |
+
type='LoadPointsFromFile',
|
| 79 |
+
coord_type='DEPTH',
|
| 80 |
+
shift_height=False,
|
| 81 |
+
use_color=True,
|
| 82 |
+
load_dim=6,
|
| 83 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 84 |
+
dict(
|
| 85 |
+
type='LoadAnnotations3D',
|
| 86 |
+
with_bbox_3d=False,
|
| 87 |
+
with_label_3d=False,
|
| 88 |
+
with_mask_3d=False,
|
| 89 |
+
with_seg_3d=True),
|
| 90 |
+
dict(
|
| 91 |
+
type='PointSegClassMapping',
|
| 92 |
+
valid_cat_ids=tuple(range(len(class_names))),
|
| 93 |
+
max_cat_id=13),
|
| 94 |
+
dict(
|
| 95 |
+
type='DefaultFormatBundle3D',
|
| 96 |
+
with_label=False,
|
| 97 |
+
class_names=class_names),
|
| 98 |
+
dict(type='Collect3D', keys=['points', 'pts_semantic_mask'])
|
| 99 |
+
]
|
| 100 |
+
|
| 101 |
+
data = dict(
|
| 102 |
+
samples_per_gpu=8,
|
| 103 |
+
workers_per_gpu=4,
|
| 104 |
+
# train on area 1, 2, 3, 4, 6
|
| 105 |
+
# test on area 5
|
| 106 |
+
train=dict(
|
| 107 |
+
type=dataset_type,
|
| 108 |
+
data_root=data_root,
|
| 109 |
+
ann_files=[
|
| 110 |
+
data_root + f's3dis_infos_Area_{i}.pkl' for i in train_area
|
| 111 |
+
],
|
| 112 |
+
pipeline=train_pipeline,
|
| 113 |
+
classes=class_names,
|
| 114 |
+
test_mode=False,
|
| 115 |
+
ignore_index=len(class_names),
|
| 116 |
+
scene_idxs=[
|
| 117 |
+
data_root + f'seg_info/Area_{i}_resampled_scene_idxs.npy'
|
| 118 |
+
for i in train_area
|
| 119 |
+
]),
|
| 120 |
+
val=dict(
|
| 121 |
+
type=dataset_type,
|
| 122 |
+
data_root=data_root,
|
| 123 |
+
ann_files=data_root + f's3dis_infos_Area_{test_area}.pkl',
|
| 124 |
+
pipeline=test_pipeline,
|
| 125 |
+
classes=class_names,
|
| 126 |
+
test_mode=True,
|
| 127 |
+
ignore_index=len(class_names),
|
| 128 |
+
scene_idxs=data_root +
|
| 129 |
+
f'seg_info/Area_{test_area}_resampled_scene_idxs.npy'),
|
| 130 |
+
test=dict(
|
| 131 |
+
type=dataset_type,
|
| 132 |
+
data_root=data_root,
|
| 133 |
+
ann_files=data_root + f's3dis_infos_Area_{test_area}.pkl',
|
| 134 |
+
pipeline=test_pipeline,
|
| 135 |
+
classes=class_names,
|
| 136 |
+
test_mode=True,
|
| 137 |
+
ignore_index=len(class_names)))
|
| 138 |
+
|
| 139 |
+
evaluation = dict(pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/scannet-3d-18class.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
dataset_type = 'ScanNetDataset'
|
| 3 |
+
data_root = './data/scannet/'
|
| 4 |
+
class_names = ('cabinet', 'bed', 'chair', 'sofa', 'table', 'door', 'window',
|
| 5 |
+
'bookshelf', 'picture', 'counter', 'desk', 'curtain',
|
| 6 |
+
'refrigerator', 'showercurtrain', 'toilet', 'sink', 'bathtub',
|
| 7 |
+
'garbagebin')
|
| 8 |
+
train_pipeline = [
|
| 9 |
+
dict(
|
| 10 |
+
type='LoadPointsFromFile',
|
| 11 |
+
coord_type='DEPTH',
|
| 12 |
+
shift_height=True,
|
| 13 |
+
load_dim=6,
|
| 14 |
+
use_dim=[0, 1, 2]),
|
| 15 |
+
dict(
|
| 16 |
+
type='LoadAnnotations3D',
|
| 17 |
+
with_bbox_3d=True,
|
| 18 |
+
with_label_3d=True,
|
| 19 |
+
with_mask_3d=True,
|
| 20 |
+
with_seg_3d=True),
|
| 21 |
+
dict(type='GlobalAlignment', rotation_axis=2),
|
| 22 |
+
dict(
|
| 23 |
+
type='PointSegClassMapping',
|
| 24 |
+
valid_cat_ids=(3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28, 33, 34,
|
| 25 |
+
36, 39),
|
| 26 |
+
max_cat_id=40),
|
| 27 |
+
dict(type='PointSample', num_points=40000),
|
| 28 |
+
dict(
|
| 29 |
+
type='RandomFlip3D',
|
| 30 |
+
sync_2d=False,
|
| 31 |
+
flip_ratio_bev_horizontal=0.5,
|
| 32 |
+
flip_ratio_bev_vertical=0.5),
|
| 33 |
+
dict(
|
| 34 |
+
type='GlobalRotScaleTrans',
|
| 35 |
+
rot_range=[-0.087266, 0.087266],
|
| 36 |
+
scale_ratio_range=[1.0, 1.0],
|
| 37 |
+
shift_height=True),
|
| 38 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 39 |
+
dict(
|
| 40 |
+
type='Collect3D',
|
| 41 |
+
keys=[
|
| 42 |
+
'points', 'gt_bboxes_3d', 'gt_labels_3d', 'pts_semantic_mask',
|
| 43 |
+
'pts_instance_mask'
|
| 44 |
+
])
|
| 45 |
+
]
|
| 46 |
+
test_pipeline = [
|
| 47 |
+
dict(
|
| 48 |
+
type='LoadPointsFromFile',
|
| 49 |
+
coord_type='DEPTH',
|
| 50 |
+
shift_height=True,
|
| 51 |
+
load_dim=6,
|
| 52 |
+
use_dim=[0, 1, 2]),
|
| 53 |
+
dict(type='GlobalAlignment', rotation_axis=2),
|
| 54 |
+
dict(
|
| 55 |
+
type='MultiScaleFlipAug3D',
|
| 56 |
+
img_scale=(1333, 800),
|
| 57 |
+
pts_scale_ratio=1,
|
| 58 |
+
flip=False,
|
| 59 |
+
transforms=[
|
| 60 |
+
dict(
|
| 61 |
+
type='GlobalRotScaleTrans',
|
| 62 |
+
rot_range=[0, 0],
|
| 63 |
+
scale_ratio_range=[1., 1.],
|
| 64 |
+
translation_std=[0, 0, 0]),
|
| 65 |
+
dict(
|
| 66 |
+
type='RandomFlip3D',
|
| 67 |
+
sync_2d=False,
|
| 68 |
+
flip_ratio_bev_horizontal=0.5,
|
| 69 |
+
flip_ratio_bev_vertical=0.5),
|
| 70 |
+
dict(type='PointSample', num_points=40000),
|
| 71 |
+
dict(
|
| 72 |
+
type='DefaultFormatBundle3D',
|
| 73 |
+
class_names=class_names,
|
| 74 |
+
with_label=False),
|
| 75 |
+
dict(type='Collect3D', keys=['points'])
|
| 76 |
+
])
|
| 77 |
+
]
|
| 78 |
+
# construct a pipeline for data and gt loading in show function
|
| 79 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 80 |
+
eval_pipeline = [
|
| 81 |
+
dict(
|
| 82 |
+
type='LoadPointsFromFile',
|
| 83 |
+
coord_type='DEPTH',
|
| 84 |
+
shift_height=False,
|
| 85 |
+
load_dim=6,
|
| 86 |
+
use_dim=[0, 1, 2]),
|
| 87 |
+
dict(type='GlobalAlignment', rotation_axis=2),
|
| 88 |
+
dict(
|
| 89 |
+
type='DefaultFormatBundle3D',
|
| 90 |
+
class_names=class_names,
|
| 91 |
+
with_label=False),
|
| 92 |
+
dict(type='Collect3D', keys=['points'])
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
data = dict(
|
| 96 |
+
samples_per_gpu=8,
|
| 97 |
+
workers_per_gpu=4,
|
| 98 |
+
train=dict(
|
| 99 |
+
type='RepeatDataset',
|
| 100 |
+
times=5,
|
| 101 |
+
dataset=dict(
|
| 102 |
+
type=dataset_type,
|
| 103 |
+
data_root=data_root,
|
| 104 |
+
ann_file=data_root + 'scannet_infos_train.pkl',
|
| 105 |
+
pipeline=train_pipeline,
|
| 106 |
+
filter_empty_gt=False,
|
| 107 |
+
classes=class_names,
|
| 108 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 109 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 110 |
+
box_type_3d='Depth')),
|
| 111 |
+
val=dict(
|
| 112 |
+
type=dataset_type,
|
| 113 |
+
data_root=data_root,
|
| 114 |
+
ann_file=data_root + 'scannet_infos_val.pkl',
|
| 115 |
+
pipeline=test_pipeline,
|
| 116 |
+
classes=class_names,
|
| 117 |
+
test_mode=True,
|
| 118 |
+
box_type_3d='Depth'),
|
| 119 |
+
test=dict(
|
| 120 |
+
type=dataset_type,
|
| 121 |
+
data_root=data_root,
|
| 122 |
+
ann_file=data_root + 'scannet_infos_val.pkl',
|
| 123 |
+
pipeline=test_pipeline,
|
| 124 |
+
classes=class_names,
|
| 125 |
+
test_mode=True,
|
| 126 |
+
box_type_3d='Depth'))
|
| 127 |
+
|
| 128 |
+
evaluation = dict(pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/scannet_seg-3d-20class.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
dataset_type = 'ScanNetSegDataset'
|
| 3 |
+
data_root = './data/scannet/'
|
| 4 |
+
class_names = ('wall', 'floor', 'cabinet', 'bed', 'chair', 'sofa', 'table',
|
| 5 |
+
'door', 'window', 'bookshelf', 'picture', 'counter', 'desk',
|
| 6 |
+
'curtain', 'refrigerator', 'showercurtrain', 'toilet', 'sink',
|
| 7 |
+
'bathtub', 'otherfurniture')
|
| 8 |
+
num_points = 8192
|
| 9 |
+
train_pipeline = [
|
| 10 |
+
dict(
|
| 11 |
+
type='LoadPointsFromFile',
|
| 12 |
+
coord_type='DEPTH',
|
| 13 |
+
shift_height=False,
|
| 14 |
+
use_color=True,
|
| 15 |
+
load_dim=6,
|
| 16 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 17 |
+
dict(
|
| 18 |
+
type='LoadAnnotations3D',
|
| 19 |
+
with_bbox_3d=False,
|
| 20 |
+
with_label_3d=False,
|
| 21 |
+
with_mask_3d=False,
|
| 22 |
+
with_seg_3d=True),
|
| 23 |
+
dict(
|
| 24 |
+
type='PointSegClassMapping',
|
| 25 |
+
valid_cat_ids=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28,
|
| 26 |
+
33, 34, 36, 39),
|
| 27 |
+
max_cat_id=40),
|
| 28 |
+
dict(
|
| 29 |
+
type='IndoorPatchPointSample',
|
| 30 |
+
num_points=num_points,
|
| 31 |
+
block_size=1.5,
|
| 32 |
+
ignore_index=len(class_names),
|
| 33 |
+
use_normalized_coord=False,
|
| 34 |
+
enlarge_size=0.2,
|
| 35 |
+
min_unique_num=None),
|
| 36 |
+
dict(type='NormalizePointsColor', color_mean=None),
|
| 37 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 38 |
+
dict(type='Collect3D', keys=['points', 'pts_semantic_mask'])
|
| 39 |
+
]
|
| 40 |
+
test_pipeline = [
|
| 41 |
+
dict(
|
| 42 |
+
type='LoadPointsFromFile',
|
| 43 |
+
coord_type='DEPTH',
|
| 44 |
+
shift_height=False,
|
| 45 |
+
use_color=True,
|
| 46 |
+
load_dim=6,
|
| 47 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 48 |
+
dict(type='NormalizePointsColor', color_mean=None),
|
| 49 |
+
dict(
|
| 50 |
+
# a wrapper in order to successfully call test function
|
| 51 |
+
# actually we don't perform test-time-aug
|
| 52 |
+
type='MultiScaleFlipAug3D',
|
| 53 |
+
img_scale=(1333, 800),
|
| 54 |
+
pts_scale_ratio=1,
|
| 55 |
+
flip=False,
|
| 56 |
+
transforms=[
|
| 57 |
+
dict(
|
| 58 |
+
type='GlobalRotScaleTrans',
|
| 59 |
+
rot_range=[0, 0],
|
| 60 |
+
scale_ratio_range=[1., 1.],
|
| 61 |
+
translation_std=[0, 0, 0]),
|
| 62 |
+
dict(
|
| 63 |
+
type='RandomFlip3D',
|
| 64 |
+
sync_2d=False,
|
| 65 |
+
flip_ratio_bev_horizontal=0.0,
|
| 66 |
+
flip_ratio_bev_vertical=0.0),
|
| 67 |
+
dict(
|
| 68 |
+
type='DefaultFormatBundle3D',
|
| 69 |
+
class_names=class_names,
|
| 70 |
+
with_label=False),
|
| 71 |
+
dict(type='Collect3D', keys=['points'])
|
| 72 |
+
])
|
| 73 |
+
]
|
| 74 |
+
# construct a pipeline for data and gt loading in show function
|
| 75 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 76 |
+
# we need to load gt seg_mask!
|
| 77 |
+
eval_pipeline = [
|
| 78 |
+
dict(
|
| 79 |
+
type='LoadPointsFromFile',
|
| 80 |
+
coord_type='DEPTH',
|
| 81 |
+
shift_height=False,
|
| 82 |
+
use_color=True,
|
| 83 |
+
load_dim=6,
|
| 84 |
+
use_dim=[0, 1, 2, 3, 4, 5]),
|
| 85 |
+
dict(
|
| 86 |
+
type='LoadAnnotations3D',
|
| 87 |
+
with_bbox_3d=False,
|
| 88 |
+
with_label_3d=False,
|
| 89 |
+
with_mask_3d=False,
|
| 90 |
+
with_seg_3d=True),
|
| 91 |
+
dict(
|
| 92 |
+
type='PointSegClassMapping',
|
| 93 |
+
valid_cat_ids=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 24, 28,
|
| 94 |
+
33, 34, 36, 39),
|
| 95 |
+
max_cat_id=40),
|
| 96 |
+
dict(
|
| 97 |
+
type='DefaultFormatBundle3D',
|
| 98 |
+
with_label=False,
|
| 99 |
+
class_names=class_names),
|
| 100 |
+
dict(type='Collect3D', keys=['points', 'pts_semantic_mask'])
|
| 101 |
+
]
|
| 102 |
+
|
| 103 |
+
data = dict(
|
| 104 |
+
samples_per_gpu=8,
|
| 105 |
+
workers_per_gpu=4,
|
| 106 |
+
train=dict(
|
| 107 |
+
type=dataset_type,
|
| 108 |
+
data_root=data_root,
|
| 109 |
+
ann_file=data_root + 'scannet_infos_train.pkl',
|
| 110 |
+
pipeline=train_pipeline,
|
| 111 |
+
classes=class_names,
|
| 112 |
+
test_mode=False,
|
| 113 |
+
ignore_index=len(class_names),
|
| 114 |
+
scene_idxs=data_root + 'seg_info/train_resampled_scene_idxs.npy'),
|
| 115 |
+
val=dict(
|
| 116 |
+
type=dataset_type,
|
| 117 |
+
data_root=data_root,
|
| 118 |
+
ann_file=data_root + 'scannet_infos_val.pkl',
|
| 119 |
+
pipeline=test_pipeline,
|
| 120 |
+
classes=class_names,
|
| 121 |
+
test_mode=True,
|
| 122 |
+
ignore_index=len(class_names)),
|
| 123 |
+
test=dict(
|
| 124 |
+
type=dataset_type,
|
| 125 |
+
data_root=data_root,
|
| 126 |
+
ann_file=data_root + 'scannet_infos_val.pkl',
|
| 127 |
+
pipeline=test_pipeline,
|
| 128 |
+
classes=class_names,
|
| 129 |
+
test_mode=True,
|
| 130 |
+
ignore_index=len(class_names)))
|
| 131 |
+
|
| 132 |
+
evaluation = dict(pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/sunrgbd-3d-10class.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset_type = 'SUNRGBDDataset'
|
| 2 |
+
data_root = 'data/sunrgbd/'
|
| 3 |
+
class_names = ('bed', 'table', 'sofa', 'chair', 'toilet', 'desk', 'dresser',
|
| 4 |
+
'night_stand', 'bookshelf', 'bathtub')
|
| 5 |
+
train_pipeline = [
|
| 6 |
+
dict(
|
| 7 |
+
type='LoadPointsFromFile',
|
| 8 |
+
coord_type='DEPTH',
|
| 9 |
+
shift_height=True,
|
| 10 |
+
load_dim=6,
|
| 11 |
+
use_dim=[0, 1, 2]),
|
| 12 |
+
dict(type='LoadAnnotations3D'),
|
| 13 |
+
dict(
|
| 14 |
+
type='RandomFlip3D',
|
| 15 |
+
sync_2d=False,
|
| 16 |
+
flip_ratio_bev_horizontal=0.5,
|
| 17 |
+
),
|
| 18 |
+
dict(
|
| 19 |
+
type='GlobalRotScaleTrans',
|
| 20 |
+
rot_range=[-0.523599, 0.523599],
|
| 21 |
+
scale_ratio_range=[0.85, 1.15],
|
| 22 |
+
shift_height=True),
|
| 23 |
+
dict(type='PointSample', num_points=20000),
|
| 24 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 25 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 26 |
+
]
|
| 27 |
+
test_pipeline = [
|
| 28 |
+
dict(
|
| 29 |
+
type='LoadPointsFromFile',
|
| 30 |
+
coord_type='DEPTH',
|
| 31 |
+
shift_height=True,
|
| 32 |
+
load_dim=6,
|
| 33 |
+
use_dim=[0, 1, 2]),
|
| 34 |
+
dict(
|
| 35 |
+
type='MultiScaleFlipAug3D',
|
| 36 |
+
img_scale=(1333, 800),
|
| 37 |
+
pts_scale_ratio=1,
|
| 38 |
+
flip=False,
|
| 39 |
+
transforms=[
|
| 40 |
+
dict(
|
| 41 |
+
type='GlobalRotScaleTrans',
|
| 42 |
+
rot_range=[0, 0],
|
| 43 |
+
scale_ratio_range=[1., 1.],
|
| 44 |
+
translation_std=[0, 0, 0]),
|
| 45 |
+
dict(
|
| 46 |
+
type='RandomFlip3D',
|
| 47 |
+
sync_2d=False,
|
| 48 |
+
flip_ratio_bev_horizontal=0.5,
|
| 49 |
+
),
|
| 50 |
+
dict(type='PointSample', num_points=20000),
|
| 51 |
+
dict(
|
| 52 |
+
type='DefaultFormatBundle3D',
|
| 53 |
+
class_names=class_names,
|
| 54 |
+
with_label=False),
|
| 55 |
+
dict(type='Collect3D', keys=['points'])
|
| 56 |
+
])
|
| 57 |
+
]
|
| 58 |
+
# construct a pipeline for data and gt loading in show function
|
| 59 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 60 |
+
eval_pipeline = [
|
| 61 |
+
dict(
|
| 62 |
+
type='LoadPointsFromFile',
|
| 63 |
+
coord_type='DEPTH',
|
| 64 |
+
shift_height=False,
|
| 65 |
+
load_dim=6,
|
| 66 |
+
use_dim=[0, 1, 2]),
|
| 67 |
+
dict(
|
| 68 |
+
type='DefaultFormatBundle3D',
|
| 69 |
+
class_names=class_names,
|
| 70 |
+
with_label=False),
|
| 71 |
+
dict(type='Collect3D', keys=['points'])
|
| 72 |
+
]
|
| 73 |
+
|
| 74 |
+
data = dict(
|
| 75 |
+
samples_per_gpu=16,
|
| 76 |
+
workers_per_gpu=4,
|
| 77 |
+
train=dict(
|
| 78 |
+
type='RepeatDataset',
|
| 79 |
+
times=5,
|
| 80 |
+
dataset=dict(
|
| 81 |
+
type=dataset_type,
|
| 82 |
+
data_root=data_root,
|
| 83 |
+
ann_file=data_root + 'sunrgbd_infos_train.pkl',
|
| 84 |
+
pipeline=train_pipeline,
|
| 85 |
+
classes=class_names,
|
| 86 |
+
filter_empty_gt=False,
|
| 87 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 88 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 89 |
+
box_type_3d='Depth')),
|
| 90 |
+
val=dict(
|
| 91 |
+
type=dataset_type,
|
| 92 |
+
data_root=data_root,
|
| 93 |
+
ann_file=data_root + 'sunrgbd_infos_val.pkl',
|
| 94 |
+
pipeline=test_pipeline,
|
| 95 |
+
classes=class_names,
|
| 96 |
+
test_mode=True,
|
| 97 |
+
box_type_3d='Depth'),
|
| 98 |
+
test=dict(
|
| 99 |
+
type=dataset_type,
|
| 100 |
+
data_root=data_root,
|
| 101 |
+
ann_file=data_root + 'sunrgbd_infos_val.pkl',
|
| 102 |
+
pipeline=test_pipeline,
|
| 103 |
+
classes=class_names,
|
| 104 |
+
test_mode=True,
|
| 105 |
+
box_type_3d='Depth'))
|
| 106 |
+
|
| 107 |
+
evaluation = dict(pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/waymoD5-3d-3class.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
# D5 in the config name means the whole dataset is divided into 5 folds
|
| 3 |
+
# We only use one fold for efficient experiments
|
| 4 |
+
dataset_type = 'LidarWaymoDataset'
|
| 5 |
+
data_root = 'data/waymo-full/kitti_format/'
|
| 6 |
+
file_client_args = dict(backend='disk')
|
| 7 |
+
# Uncomment the following if use ceph or other file clients.
|
| 8 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 9 |
+
# for more details.
|
| 10 |
+
# file_client_args = dict(
|
| 11 |
+
# backend='petrel', path_mapping=dict(data='s3://waymo_data/'))
|
| 12 |
+
|
| 13 |
+
class_names = ['Car', 'Pedestrian', 'Cyclist']
|
| 14 |
+
point_cloud_range = [-74.88, -74.88, -2, 74.88, 74.88, 4]
|
| 15 |
+
input_modality = dict(use_lidar=True, use_camera=False)
|
| 16 |
+
db_sampler = dict(
|
| 17 |
+
data_root=data_root,
|
| 18 |
+
info_path=data_root + 'waymo_dbinfos_train.pkl',
|
| 19 |
+
rate=1.0,
|
| 20 |
+
prepare=dict(
|
| 21 |
+
filter_by_difficulty=[-1],
|
| 22 |
+
filter_by_min_points=dict(Car=5, Pedestrian=10, Cyclist=10)),
|
| 23 |
+
classes=class_names,
|
| 24 |
+
sample_groups=dict(Car=15, Pedestrian=10, Cyclist=10),
|
| 25 |
+
points_loader=dict(
|
| 26 |
+
type='LoadPointsFromFile',
|
| 27 |
+
coord_type='LIDAR',
|
| 28 |
+
load_dim=5,
|
| 29 |
+
use_dim=[0, 1, 2, 3, 4],
|
| 30 |
+
file_client_args=file_client_args))
|
| 31 |
+
|
| 32 |
+
train_pipeline = [
|
| 33 |
+
dict(
|
| 34 |
+
type='LoadPointsFromFile',
|
| 35 |
+
coord_type='LIDAR',
|
| 36 |
+
load_dim=6,
|
| 37 |
+
use_dim=5,
|
| 38 |
+
file_client_args=file_client_args),
|
| 39 |
+
dict(
|
| 40 |
+
type='LoadAnnotations3D',
|
| 41 |
+
with_bbox_3d=True,
|
| 42 |
+
with_label_3d=True,
|
| 43 |
+
file_client_args=file_client_args),
|
| 44 |
+
dict(type='ObjectSample', db_sampler=db_sampler),
|
| 45 |
+
dict(
|
| 46 |
+
type='RandomFlip3D',
|
| 47 |
+
sync_2d=False,
|
| 48 |
+
flip_ratio_bev_horizontal=0.5,
|
| 49 |
+
flip_ratio_bev_vertical=0.5),
|
| 50 |
+
dict(
|
| 51 |
+
type='GlobalRotScaleTrans',
|
| 52 |
+
rot_range=[-0.78539816, 0.78539816],
|
| 53 |
+
scale_ratio_range=[0.95, 1.05]),
|
| 54 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 55 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 56 |
+
dict(type='PointShuffle'),
|
| 57 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 58 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 59 |
+
]
|
| 60 |
+
test_pipeline = [
|
| 61 |
+
dict(
|
| 62 |
+
type='LoadPointsFromFile',
|
| 63 |
+
coord_type='LIDAR',
|
| 64 |
+
load_dim=6,
|
| 65 |
+
use_dim=5,
|
| 66 |
+
file_client_args=file_client_args),
|
| 67 |
+
dict(
|
| 68 |
+
type='MultiScaleFlipAug3D',
|
| 69 |
+
img_scale=(1333, 800),
|
| 70 |
+
pts_scale_ratio=1,
|
| 71 |
+
flip=False,
|
| 72 |
+
transforms=[
|
| 73 |
+
dict(
|
| 74 |
+
type='GlobalRotScaleTrans',
|
| 75 |
+
rot_range=[0, 0],
|
| 76 |
+
scale_ratio_range=[1., 1.],
|
| 77 |
+
translation_std=[0, 0, 0]),
|
| 78 |
+
dict(type='RandomFlip3D'),
|
| 79 |
+
dict(
|
| 80 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 81 |
+
dict(
|
| 82 |
+
type='DefaultFormatBundle3D',
|
| 83 |
+
class_names=class_names,
|
| 84 |
+
with_label=False),
|
| 85 |
+
dict(type='Collect3D', keys=['points'])
|
| 86 |
+
])
|
| 87 |
+
]
|
| 88 |
+
# construct a pipeline for data and gt loading in show function
|
| 89 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 90 |
+
eval_pipeline = [
|
| 91 |
+
dict(
|
| 92 |
+
type='LoadPointsFromFile',
|
| 93 |
+
coord_type='LIDAR',
|
| 94 |
+
load_dim=6,
|
| 95 |
+
use_dim=5,
|
| 96 |
+
file_client_args=file_client_args),
|
| 97 |
+
dict(
|
| 98 |
+
type='DefaultFormatBundle3D',
|
| 99 |
+
class_names=class_names,
|
| 100 |
+
with_label=False),
|
| 101 |
+
dict(type='Collect3D', keys=['points'])
|
| 102 |
+
]
|
| 103 |
+
|
| 104 |
+
data = dict(
|
| 105 |
+
samples_per_gpu=2,
|
| 106 |
+
workers_per_gpu=4,
|
| 107 |
+
train=dict(
|
| 108 |
+
type='RepeatDataset',
|
| 109 |
+
times=2,
|
| 110 |
+
dataset=dict(
|
| 111 |
+
type=dataset_type,
|
| 112 |
+
data_root=data_root,
|
| 113 |
+
ann_file=data_root + 'waymo_infos_train.pkl',
|
| 114 |
+
split='training',
|
| 115 |
+
pipeline=train_pipeline,
|
| 116 |
+
modality=input_modality,
|
| 117 |
+
classes=class_names,
|
| 118 |
+
test_mode=False,
|
| 119 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 120 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 121 |
+
box_type_3d='LiDAR',
|
| 122 |
+
# load one frame every five frames
|
| 123 |
+
load_interval=5)),
|
| 124 |
+
val=dict(
|
| 125 |
+
type=dataset_type,
|
| 126 |
+
data_root=data_root,
|
| 127 |
+
ann_file=data_root + 'waymo_infos_val.pkl',
|
| 128 |
+
split='training',
|
| 129 |
+
pipeline=test_pipeline,
|
| 130 |
+
modality=input_modality,
|
| 131 |
+
classes=class_names,
|
| 132 |
+
test_mode=True,
|
| 133 |
+
box_type_3d='LiDAR'),
|
| 134 |
+
test=dict(
|
| 135 |
+
type=dataset_type,
|
| 136 |
+
data_root=data_root,
|
| 137 |
+
ann_file=data_root + 'waymo_infos_val.pkl',
|
| 138 |
+
split='training',
|
| 139 |
+
pipeline=test_pipeline,
|
| 140 |
+
modality=input_modality,
|
| 141 |
+
classes=class_names,
|
| 142 |
+
test_mode=True,
|
| 143 |
+
box_type_3d='LiDAR'))
|
| 144 |
+
|
| 145 |
+
evaluation = dict(interval=24, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/datasets/waymoD5-3d-car.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dataset settings
|
| 2 |
+
# D5 in the config name means the whole dataset is divided into 5 folds
|
| 3 |
+
# We only use one fold for efficient experiments
|
| 4 |
+
dataset_type = 'WaymoDataset'
|
| 5 |
+
data_root = 'data/waymo/kitti_format/'
|
| 6 |
+
file_client_args = dict(backend='disk')
|
| 7 |
+
# Uncomment the following if use ceph or other file clients.
|
| 8 |
+
# See https://mmcv.readthedocs.io/en/latest/api.html#mmcv.fileio.FileClient
|
| 9 |
+
# for more details.
|
| 10 |
+
# file_client_args = dict(
|
| 11 |
+
# backend='petrel', path_mapping=dict(data='s3://waymo_data/'))
|
| 12 |
+
|
| 13 |
+
class_names = ['Car']
|
| 14 |
+
point_cloud_range = [-74.88, -74.88, -2, 74.88, 74.88, 4]
|
| 15 |
+
input_modality = dict(use_lidar=True, use_camera=False)
|
| 16 |
+
db_sampler = dict(
|
| 17 |
+
data_root=data_root,
|
| 18 |
+
info_path=data_root + 'waymo_dbinfos_train.pkl',
|
| 19 |
+
rate=1.0,
|
| 20 |
+
prepare=dict(filter_by_difficulty=[-1], filter_by_min_points=dict(Car=5)),
|
| 21 |
+
classes=class_names,
|
| 22 |
+
sample_groups=dict(Car=15),
|
| 23 |
+
points_loader=dict(
|
| 24 |
+
type='LoadPointsFromFile',
|
| 25 |
+
coord_type='LIDAR',
|
| 26 |
+
load_dim=5,
|
| 27 |
+
use_dim=[0, 1, 2, 3, 4],
|
| 28 |
+
file_client_args=file_client_args))
|
| 29 |
+
|
| 30 |
+
train_pipeline = [
|
| 31 |
+
dict(
|
| 32 |
+
type='LoadPointsFromFile',
|
| 33 |
+
coord_type='LIDAR',
|
| 34 |
+
load_dim=6,
|
| 35 |
+
use_dim=5,
|
| 36 |
+
file_client_args=file_client_args),
|
| 37 |
+
dict(
|
| 38 |
+
type='LoadAnnotations3D',
|
| 39 |
+
with_bbox_3d=True,
|
| 40 |
+
with_label_3d=True,
|
| 41 |
+
file_client_args=file_client_args),
|
| 42 |
+
dict(type='ObjectSample', db_sampler=db_sampler),
|
| 43 |
+
dict(
|
| 44 |
+
type='RandomFlip3D',
|
| 45 |
+
sync_2d=False,
|
| 46 |
+
flip_ratio_bev_horizontal=0.5,
|
| 47 |
+
flip_ratio_bev_vertical=0.5),
|
| 48 |
+
dict(
|
| 49 |
+
type='GlobalRotScaleTrans',
|
| 50 |
+
rot_range=[-0.78539816, 0.78539816],
|
| 51 |
+
scale_ratio_range=[0.95, 1.05]),
|
| 52 |
+
dict(type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 53 |
+
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
|
| 54 |
+
dict(type='PointShuffle'),
|
| 55 |
+
dict(type='DefaultFormatBundle3D', class_names=class_names),
|
| 56 |
+
dict(type='Collect3D', keys=['points', 'gt_bboxes_3d', 'gt_labels_3d'])
|
| 57 |
+
]
|
| 58 |
+
test_pipeline = [
|
| 59 |
+
dict(
|
| 60 |
+
type='LoadPointsFromFile',
|
| 61 |
+
coord_type='LIDAR',
|
| 62 |
+
load_dim=6,
|
| 63 |
+
use_dim=5,
|
| 64 |
+
file_client_args=file_client_args),
|
| 65 |
+
dict(
|
| 66 |
+
type='MultiScaleFlipAug3D',
|
| 67 |
+
img_scale=(1333, 800),
|
| 68 |
+
pts_scale_ratio=1,
|
| 69 |
+
flip=False,
|
| 70 |
+
transforms=[
|
| 71 |
+
dict(
|
| 72 |
+
type='GlobalRotScaleTrans',
|
| 73 |
+
rot_range=[0, 0],
|
| 74 |
+
scale_ratio_range=[1., 1.],
|
| 75 |
+
translation_std=[0, 0, 0]),
|
| 76 |
+
dict(type='RandomFlip3D'),
|
| 77 |
+
dict(
|
| 78 |
+
type='PointsRangeFilter', point_cloud_range=point_cloud_range),
|
| 79 |
+
dict(
|
| 80 |
+
type='DefaultFormatBundle3D',
|
| 81 |
+
class_names=class_names,
|
| 82 |
+
with_label=False),
|
| 83 |
+
dict(type='Collect3D', keys=['points'])
|
| 84 |
+
])
|
| 85 |
+
]
|
| 86 |
+
# construct a pipeline for data and gt loading in show function
|
| 87 |
+
# please keep its loading function consistent with test_pipeline (e.g. client)
|
| 88 |
+
eval_pipeline = [
|
| 89 |
+
dict(
|
| 90 |
+
type='LoadPointsFromFile',
|
| 91 |
+
coord_type='LIDAR',
|
| 92 |
+
load_dim=6,
|
| 93 |
+
use_dim=5,
|
| 94 |
+
file_client_args=file_client_args),
|
| 95 |
+
dict(
|
| 96 |
+
type='DefaultFormatBundle3D',
|
| 97 |
+
class_names=class_names,
|
| 98 |
+
with_label=False),
|
| 99 |
+
dict(type='Collect3D', keys=['points'])
|
| 100 |
+
]
|
| 101 |
+
|
| 102 |
+
data = dict(
|
| 103 |
+
samples_per_gpu=2,
|
| 104 |
+
workers_per_gpu=4,
|
| 105 |
+
train=dict(
|
| 106 |
+
type='RepeatDataset',
|
| 107 |
+
times=2,
|
| 108 |
+
dataset=dict(
|
| 109 |
+
type=dataset_type,
|
| 110 |
+
data_root=data_root,
|
| 111 |
+
ann_file=data_root + 'waymo_infos_train.pkl',
|
| 112 |
+
split='training',
|
| 113 |
+
pipeline=train_pipeline,
|
| 114 |
+
modality=input_modality,
|
| 115 |
+
classes=class_names,
|
| 116 |
+
test_mode=False,
|
| 117 |
+
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
|
| 118 |
+
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
|
| 119 |
+
box_type_3d='LiDAR',
|
| 120 |
+
# load one frame every five frames
|
| 121 |
+
load_interval=5)),
|
| 122 |
+
val=dict(
|
| 123 |
+
type=dataset_type,
|
| 124 |
+
data_root=data_root,
|
| 125 |
+
ann_file=data_root + 'waymo_infos_val.pkl',
|
| 126 |
+
split='training',
|
| 127 |
+
pipeline=test_pipeline,
|
| 128 |
+
modality=input_modality,
|
| 129 |
+
classes=class_names,
|
| 130 |
+
test_mode=True,
|
| 131 |
+
box_type_3d='LiDAR'),
|
| 132 |
+
test=dict(
|
| 133 |
+
type=dataset_type,
|
| 134 |
+
data_root=data_root,
|
| 135 |
+
ann_file=data_root + 'waymo_infos_val.pkl',
|
| 136 |
+
split='training',
|
| 137 |
+
pipeline=test_pipeline,
|
| 138 |
+
modality=input_modality,
|
| 139 |
+
classes=class_names,
|
| 140 |
+
test_mode=True,
|
| 141 |
+
box_type_3d='LiDAR'))
|
| 142 |
+
|
| 143 |
+
evaluation = dict(interval=24, pipeline=eval_pipeline)
|
GenAD-main/projects/configs/_base_/default_runtime.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
checkpoint_config = dict(interval=1)
|
| 2 |
+
# yapf:disable push
|
| 3 |
+
# By default we use textlogger hook and tensorboard
|
| 4 |
+
# For more loggers see
|
| 5 |
+
# https://mmcv.readthedocs.io/en/latest/api.html#mmcv.runner.LoggerHook
|
| 6 |
+
log_config = dict(
|
| 7 |
+
interval=50,
|
| 8 |
+
hooks=[
|
| 9 |
+
dict(type='TextLoggerHook'),
|
| 10 |
+
dict(type='TensorboardLoggerHook')
|
| 11 |
+
])
|
| 12 |
+
# yapf:enable
|
| 13 |
+
dist_params = dict(backend='nccl')
|
| 14 |
+
log_level = 'INFO'
|
| 15 |
+
work_dir = None
|
| 16 |
+
load_from = None
|
| 17 |
+
resume_from = None
|
| 18 |
+
workflow = [('train', 1)]
|
GenAD-main/projects/configs/_base_/models/3dssd.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='SSD3DNet',
|
| 3 |
+
backbone=dict(
|
| 4 |
+
type='PointNet2SAMSG',
|
| 5 |
+
in_channels=4,
|
| 6 |
+
num_points=(4096, 512, (256, 256)),
|
| 7 |
+
radii=((0.2, 0.4, 0.8), (0.4, 0.8, 1.6), (1.6, 3.2, 4.8)),
|
| 8 |
+
num_samples=((32, 32, 64), (32, 32, 64), (32, 32, 32)),
|
| 9 |
+
sa_channels=(((16, 16, 32), (16, 16, 32), (32, 32, 64)),
|
| 10 |
+
((64, 64, 128), (64, 64, 128), (64, 96, 128)),
|
| 11 |
+
((128, 128, 256), (128, 192, 256), (128, 256, 256))),
|
| 12 |
+
aggregation_channels=(64, 128, 256),
|
| 13 |
+
fps_mods=(('D-FPS'), ('FS'), ('F-FPS', 'D-FPS')),
|
| 14 |
+
fps_sample_range_lists=((-1), (-1), (512, -1)),
|
| 15 |
+
norm_cfg=dict(type='BN2d', eps=1e-3, momentum=0.1),
|
| 16 |
+
sa_cfg=dict(
|
| 17 |
+
type='PointSAModuleMSG',
|
| 18 |
+
pool_mod='max',
|
| 19 |
+
use_xyz=True,
|
| 20 |
+
normalize_xyz=False)),
|
| 21 |
+
bbox_head=dict(
|
| 22 |
+
type='SSD3DHead',
|
| 23 |
+
in_channels=256,
|
| 24 |
+
vote_module_cfg=dict(
|
| 25 |
+
in_channels=256,
|
| 26 |
+
num_points=256,
|
| 27 |
+
gt_per_seed=1,
|
| 28 |
+
conv_channels=(128, ),
|
| 29 |
+
conv_cfg=dict(type='Conv1d'),
|
| 30 |
+
norm_cfg=dict(type='BN1d', eps=1e-3, momentum=0.1),
|
| 31 |
+
with_res_feat=False,
|
| 32 |
+
vote_xyz_range=(3.0, 3.0, 2.0)),
|
| 33 |
+
vote_aggregation_cfg=dict(
|
| 34 |
+
type='PointSAModuleMSG',
|
| 35 |
+
num_point=256,
|
| 36 |
+
radii=(4.8, 6.4),
|
| 37 |
+
sample_nums=(16, 32),
|
| 38 |
+
mlp_channels=((256, 256, 256, 512), (256, 256, 512, 1024)),
|
| 39 |
+
norm_cfg=dict(type='BN2d', eps=1e-3, momentum=0.1),
|
| 40 |
+
use_xyz=True,
|
| 41 |
+
normalize_xyz=False,
|
| 42 |
+
bias=True),
|
| 43 |
+
pred_layer_cfg=dict(
|
| 44 |
+
in_channels=1536,
|
| 45 |
+
shared_conv_channels=(512, 128),
|
| 46 |
+
cls_conv_channels=(128, ),
|
| 47 |
+
reg_conv_channels=(128, ),
|
| 48 |
+
conv_cfg=dict(type='Conv1d'),
|
| 49 |
+
norm_cfg=dict(type='BN1d', eps=1e-3, momentum=0.1),
|
| 50 |
+
bias=True),
|
| 51 |
+
conv_cfg=dict(type='Conv1d'),
|
| 52 |
+
norm_cfg=dict(type='BN1d', eps=1e-3, momentum=0.1),
|
| 53 |
+
objectness_loss=dict(
|
| 54 |
+
type='CrossEntropyLoss',
|
| 55 |
+
use_sigmoid=True,
|
| 56 |
+
reduction='sum',
|
| 57 |
+
loss_weight=1.0),
|
| 58 |
+
center_loss=dict(
|
| 59 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=1.0),
|
| 60 |
+
dir_class_loss=dict(
|
| 61 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 62 |
+
dir_res_loss=dict(
|
| 63 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=1.0),
|
| 64 |
+
size_res_loss=dict(
|
| 65 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=1.0),
|
| 66 |
+
corner_loss=dict(
|
| 67 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=1.0),
|
| 68 |
+
vote_loss=dict(type='SmoothL1Loss', reduction='sum', loss_weight=1.0)),
|
| 69 |
+
# model training and testing settings
|
| 70 |
+
train_cfg=dict(
|
| 71 |
+
sample_mod='spec', pos_distance_thr=10.0, expand_dims_length=0.05),
|
| 72 |
+
test_cfg=dict(
|
| 73 |
+
nms_cfg=dict(type='nms', iou_thr=0.1),
|
| 74 |
+
sample_mod='spec',
|
| 75 |
+
score_thr=0.0,
|
| 76 |
+
per_class_proposal=True,
|
| 77 |
+
max_output_num=100))
|
GenAD-main/projects/configs/_base_/models/cascade_mask_rcnn_r50_fpn.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
model = dict(
|
| 3 |
+
type='CascadeRCNN',
|
| 4 |
+
pretrained='torchvision://resnet50',
|
| 5 |
+
backbone=dict(
|
| 6 |
+
type='ResNet',
|
| 7 |
+
depth=50,
|
| 8 |
+
num_stages=4,
|
| 9 |
+
out_indices=(0, 1, 2, 3),
|
| 10 |
+
frozen_stages=1,
|
| 11 |
+
norm_cfg=dict(type='BN', requires_grad=True),
|
| 12 |
+
norm_eval=True,
|
| 13 |
+
style='pytorch'),
|
| 14 |
+
neck=dict(
|
| 15 |
+
type='FPN',
|
| 16 |
+
in_channels=[256, 512, 1024, 2048],
|
| 17 |
+
out_channels=256,
|
| 18 |
+
num_outs=5),
|
| 19 |
+
rpn_head=dict(
|
| 20 |
+
type='RPNHead',
|
| 21 |
+
in_channels=256,
|
| 22 |
+
feat_channels=256,
|
| 23 |
+
anchor_generator=dict(
|
| 24 |
+
type='AnchorGenerator',
|
| 25 |
+
scales=[8],
|
| 26 |
+
ratios=[0.5, 1.0, 2.0],
|
| 27 |
+
strides=[4, 8, 16, 32, 64]),
|
| 28 |
+
bbox_coder=dict(
|
| 29 |
+
type='DeltaXYWHBBoxCoder',
|
| 30 |
+
target_means=[.0, .0, .0, .0],
|
| 31 |
+
target_stds=[1.0, 1.0, 1.0, 1.0]),
|
| 32 |
+
loss_cls=dict(
|
| 33 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
| 34 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
|
| 35 |
+
roi_head=dict(
|
| 36 |
+
type='CascadeRoIHead',
|
| 37 |
+
num_stages=3,
|
| 38 |
+
stage_loss_weights=[1, 0.5, 0.25],
|
| 39 |
+
bbox_roi_extractor=dict(
|
| 40 |
+
type='SingleRoIExtractor',
|
| 41 |
+
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
|
| 42 |
+
out_channels=256,
|
| 43 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 44 |
+
bbox_head=[
|
| 45 |
+
dict(
|
| 46 |
+
type='Shared2FCBBoxHead',
|
| 47 |
+
in_channels=256,
|
| 48 |
+
fc_out_channels=1024,
|
| 49 |
+
roi_feat_size=7,
|
| 50 |
+
num_classes=80,
|
| 51 |
+
bbox_coder=dict(
|
| 52 |
+
type='DeltaXYWHBBoxCoder',
|
| 53 |
+
target_means=[0., 0., 0., 0.],
|
| 54 |
+
target_stds=[0.1, 0.1, 0.2, 0.2]),
|
| 55 |
+
reg_class_agnostic=True,
|
| 56 |
+
loss_cls=dict(
|
| 57 |
+
type='CrossEntropyLoss',
|
| 58 |
+
use_sigmoid=False,
|
| 59 |
+
loss_weight=1.0),
|
| 60 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
|
| 61 |
+
loss_weight=1.0)),
|
| 62 |
+
dict(
|
| 63 |
+
type='Shared2FCBBoxHead',
|
| 64 |
+
in_channels=256,
|
| 65 |
+
fc_out_channels=1024,
|
| 66 |
+
roi_feat_size=7,
|
| 67 |
+
num_classes=80,
|
| 68 |
+
bbox_coder=dict(
|
| 69 |
+
type='DeltaXYWHBBoxCoder',
|
| 70 |
+
target_means=[0., 0., 0., 0.],
|
| 71 |
+
target_stds=[0.05, 0.05, 0.1, 0.1]),
|
| 72 |
+
reg_class_agnostic=True,
|
| 73 |
+
loss_cls=dict(
|
| 74 |
+
type='CrossEntropyLoss',
|
| 75 |
+
use_sigmoid=False,
|
| 76 |
+
loss_weight=1.0),
|
| 77 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
|
| 78 |
+
loss_weight=1.0)),
|
| 79 |
+
dict(
|
| 80 |
+
type='Shared2FCBBoxHead',
|
| 81 |
+
in_channels=256,
|
| 82 |
+
fc_out_channels=1024,
|
| 83 |
+
roi_feat_size=7,
|
| 84 |
+
num_classes=80,
|
| 85 |
+
bbox_coder=dict(
|
| 86 |
+
type='DeltaXYWHBBoxCoder',
|
| 87 |
+
target_means=[0., 0., 0., 0.],
|
| 88 |
+
target_stds=[0.033, 0.033, 0.067, 0.067]),
|
| 89 |
+
reg_class_agnostic=True,
|
| 90 |
+
loss_cls=dict(
|
| 91 |
+
type='CrossEntropyLoss',
|
| 92 |
+
use_sigmoid=False,
|
| 93 |
+
loss_weight=1.0),
|
| 94 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
|
| 95 |
+
],
|
| 96 |
+
mask_roi_extractor=dict(
|
| 97 |
+
type='SingleRoIExtractor',
|
| 98 |
+
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
|
| 99 |
+
out_channels=256,
|
| 100 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 101 |
+
mask_head=dict(
|
| 102 |
+
type='FCNMaskHead',
|
| 103 |
+
num_convs=4,
|
| 104 |
+
in_channels=256,
|
| 105 |
+
conv_out_channels=256,
|
| 106 |
+
num_classes=80,
|
| 107 |
+
loss_mask=dict(
|
| 108 |
+
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
|
| 109 |
+
# model training and testing settings
|
| 110 |
+
train_cfg=dict(
|
| 111 |
+
rpn=dict(
|
| 112 |
+
assigner=dict(
|
| 113 |
+
type='MaxIoUAssigner',
|
| 114 |
+
pos_iou_thr=0.7,
|
| 115 |
+
neg_iou_thr=0.3,
|
| 116 |
+
min_pos_iou=0.3,
|
| 117 |
+
match_low_quality=True,
|
| 118 |
+
ignore_iof_thr=-1),
|
| 119 |
+
sampler=dict(
|
| 120 |
+
type='RandomSampler',
|
| 121 |
+
num=256,
|
| 122 |
+
pos_fraction=0.5,
|
| 123 |
+
neg_pos_ub=-1,
|
| 124 |
+
add_gt_as_proposals=False),
|
| 125 |
+
allowed_border=0,
|
| 126 |
+
pos_weight=-1,
|
| 127 |
+
debug=False),
|
| 128 |
+
rpn_proposal=dict(
|
| 129 |
+
nms_across_levels=False,
|
| 130 |
+
nms_pre=2000,
|
| 131 |
+
nms_post=2000,
|
| 132 |
+
max_num=2000,
|
| 133 |
+
nms_thr=0.7,
|
| 134 |
+
min_bbox_size=0),
|
| 135 |
+
rcnn=[
|
| 136 |
+
dict(
|
| 137 |
+
assigner=dict(
|
| 138 |
+
type='MaxIoUAssigner',
|
| 139 |
+
pos_iou_thr=0.5,
|
| 140 |
+
neg_iou_thr=0.5,
|
| 141 |
+
min_pos_iou=0.5,
|
| 142 |
+
match_low_quality=False,
|
| 143 |
+
ignore_iof_thr=-1),
|
| 144 |
+
sampler=dict(
|
| 145 |
+
type='RandomSampler',
|
| 146 |
+
num=512,
|
| 147 |
+
pos_fraction=0.25,
|
| 148 |
+
neg_pos_ub=-1,
|
| 149 |
+
add_gt_as_proposals=True),
|
| 150 |
+
mask_size=28,
|
| 151 |
+
pos_weight=-1,
|
| 152 |
+
debug=False),
|
| 153 |
+
dict(
|
| 154 |
+
assigner=dict(
|
| 155 |
+
type='MaxIoUAssigner',
|
| 156 |
+
pos_iou_thr=0.6,
|
| 157 |
+
neg_iou_thr=0.6,
|
| 158 |
+
min_pos_iou=0.6,
|
| 159 |
+
match_low_quality=False,
|
| 160 |
+
ignore_iof_thr=-1),
|
| 161 |
+
sampler=dict(
|
| 162 |
+
type='RandomSampler',
|
| 163 |
+
num=512,
|
| 164 |
+
pos_fraction=0.25,
|
| 165 |
+
neg_pos_ub=-1,
|
| 166 |
+
add_gt_as_proposals=True),
|
| 167 |
+
mask_size=28,
|
| 168 |
+
pos_weight=-1,
|
| 169 |
+
debug=False),
|
| 170 |
+
dict(
|
| 171 |
+
assigner=dict(
|
| 172 |
+
type='MaxIoUAssigner',
|
| 173 |
+
pos_iou_thr=0.7,
|
| 174 |
+
neg_iou_thr=0.7,
|
| 175 |
+
min_pos_iou=0.7,
|
| 176 |
+
match_low_quality=False,
|
| 177 |
+
ignore_iof_thr=-1),
|
| 178 |
+
sampler=dict(
|
| 179 |
+
type='RandomSampler',
|
| 180 |
+
num=512,
|
| 181 |
+
pos_fraction=0.25,
|
| 182 |
+
neg_pos_ub=-1,
|
| 183 |
+
add_gt_as_proposals=True),
|
| 184 |
+
mask_size=28,
|
| 185 |
+
pos_weight=-1,
|
| 186 |
+
debug=False)
|
| 187 |
+
]),
|
| 188 |
+
test_cfg=dict(
|
| 189 |
+
rpn=dict(
|
| 190 |
+
nms_across_levels=False,
|
| 191 |
+
nms_pre=1000,
|
| 192 |
+
nms_post=1000,
|
| 193 |
+
max_num=1000,
|
| 194 |
+
nms_thr=0.7,
|
| 195 |
+
min_bbox_size=0),
|
| 196 |
+
rcnn=dict(
|
| 197 |
+
score_thr=0.05,
|
| 198 |
+
nms=dict(type='nms', iou_threshold=0.5),
|
| 199 |
+
max_per_img=100,
|
| 200 |
+
mask_thr_binary=0.5)))
|
GenAD-main/projects/configs/_base_/models/centerpoint_01voxel_second_secfpn_nus.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
voxel_size = [0.1, 0.1, 0.2]
|
| 2 |
+
model = dict(
|
| 3 |
+
type='CenterPoint',
|
| 4 |
+
pts_voxel_layer=dict(
|
| 5 |
+
max_num_points=10, voxel_size=voxel_size, max_voxels=(90000, 120000)),
|
| 6 |
+
pts_voxel_encoder=dict(type='HardSimpleVFE', num_features=5),
|
| 7 |
+
pts_middle_encoder=dict(
|
| 8 |
+
type='SparseEncoder',
|
| 9 |
+
in_channels=5,
|
| 10 |
+
sparse_shape=[41, 1024, 1024],
|
| 11 |
+
output_channels=128,
|
| 12 |
+
order=('conv', 'norm', 'act'),
|
| 13 |
+
encoder_channels=((16, 16, 32), (32, 32, 64), (64, 64, 128), (128,
|
| 14 |
+
128)),
|
| 15 |
+
encoder_paddings=((0, 0, 1), (0, 0, 1), (0, 0, [0, 1, 1]), (0, 0)),
|
| 16 |
+
block_type='basicblock'),
|
| 17 |
+
pts_backbone=dict(
|
| 18 |
+
type='SECOND',
|
| 19 |
+
in_channels=256,
|
| 20 |
+
out_channels=[128, 256],
|
| 21 |
+
layer_nums=[5, 5],
|
| 22 |
+
layer_strides=[1, 2],
|
| 23 |
+
norm_cfg=dict(type='BN', eps=1e-3, momentum=0.01),
|
| 24 |
+
conv_cfg=dict(type='Conv2d', bias=False)),
|
| 25 |
+
pts_neck=dict(
|
| 26 |
+
type='SECONDFPN',
|
| 27 |
+
in_channels=[128, 256],
|
| 28 |
+
out_channels=[256, 256],
|
| 29 |
+
upsample_strides=[1, 2],
|
| 30 |
+
norm_cfg=dict(type='BN', eps=1e-3, momentum=0.01),
|
| 31 |
+
upsample_cfg=dict(type='deconv', bias=False),
|
| 32 |
+
use_conv_for_no_stride=True),
|
| 33 |
+
pts_bbox_head=dict(
|
| 34 |
+
type='CenterHead',
|
| 35 |
+
in_channels=sum([256, 256]),
|
| 36 |
+
tasks=[
|
| 37 |
+
dict(num_class=1, class_names=['car']),
|
| 38 |
+
dict(num_class=2, class_names=['truck', 'construction_vehicle']),
|
| 39 |
+
dict(num_class=2, class_names=['bus', 'trailer']),
|
| 40 |
+
dict(num_class=1, class_names=['barrier']),
|
| 41 |
+
dict(num_class=2, class_names=['motorcycle', 'bicycle']),
|
| 42 |
+
dict(num_class=2, class_names=['pedestrian', 'traffic_cone']),
|
| 43 |
+
],
|
| 44 |
+
common_heads=dict(
|
| 45 |
+
reg=(2, 2), height=(1, 2), dim=(3, 2), rot=(2, 2), vel=(2, 2)),
|
| 46 |
+
share_conv_channel=64,
|
| 47 |
+
bbox_coder=dict(
|
| 48 |
+
type='CenterPointBBoxCoder',
|
| 49 |
+
post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
|
| 50 |
+
max_num=500,
|
| 51 |
+
score_threshold=0.1,
|
| 52 |
+
out_size_factor=8,
|
| 53 |
+
voxel_size=voxel_size[:2],
|
| 54 |
+
code_size=9),
|
| 55 |
+
separate_head=dict(
|
| 56 |
+
type='SeparateHead', init_bias=-2.19, final_kernel=3),
|
| 57 |
+
loss_cls=dict(type='GaussianFocalLoss', reduction='mean'),
|
| 58 |
+
loss_bbox=dict(type='L1Loss', reduction='mean', loss_weight=0.25),
|
| 59 |
+
norm_bbox=True),
|
| 60 |
+
# model training and testing settings
|
| 61 |
+
train_cfg=dict(
|
| 62 |
+
pts=dict(
|
| 63 |
+
grid_size=[1024, 1024, 40],
|
| 64 |
+
voxel_size=voxel_size,
|
| 65 |
+
out_size_factor=8,
|
| 66 |
+
dense_reg=1,
|
| 67 |
+
gaussian_overlap=0.1,
|
| 68 |
+
max_objs=500,
|
| 69 |
+
min_radius=2,
|
| 70 |
+
code_weights=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.2, 0.2])),
|
| 71 |
+
test_cfg=dict(
|
| 72 |
+
pts=dict(
|
| 73 |
+
post_center_limit_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
|
| 74 |
+
max_per_img=500,
|
| 75 |
+
max_pool_nms=False,
|
| 76 |
+
min_radius=[4, 12, 10, 1, 0.85, 0.175],
|
| 77 |
+
score_threshold=0.1,
|
| 78 |
+
out_size_factor=8,
|
| 79 |
+
voxel_size=voxel_size[:2],
|
| 80 |
+
nms_type='rotate',
|
| 81 |
+
pre_max_size=1000,
|
| 82 |
+
post_max_size=83,
|
| 83 |
+
nms_thr=0.2)))
|
GenAD-main/projects/configs/_base_/models/centerpoint_02pillar_second_secfpn_nus.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
voxel_size = [0.2, 0.2, 8]
|
| 2 |
+
model = dict(
|
| 3 |
+
type='CenterPoint',
|
| 4 |
+
pts_voxel_layer=dict(
|
| 5 |
+
max_num_points=20, voxel_size=voxel_size, max_voxels=(30000, 40000)),
|
| 6 |
+
pts_voxel_encoder=dict(
|
| 7 |
+
type='PillarFeatureNet',
|
| 8 |
+
in_channels=5,
|
| 9 |
+
feat_channels=[64],
|
| 10 |
+
with_distance=False,
|
| 11 |
+
voxel_size=(0.2, 0.2, 8),
|
| 12 |
+
norm_cfg=dict(type='BN1d', eps=1e-3, momentum=0.01),
|
| 13 |
+
legacy=False),
|
| 14 |
+
pts_middle_encoder=dict(
|
| 15 |
+
type='PointPillarsScatter', in_channels=64, output_shape=(512, 512)),
|
| 16 |
+
pts_backbone=dict(
|
| 17 |
+
type='SECOND',
|
| 18 |
+
in_channels=64,
|
| 19 |
+
out_channels=[64, 128, 256],
|
| 20 |
+
layer_nums=[3, 5, 5],
|
| 21 |
+
layer_strides=[2, 2, 2],
|
| 22 |
+
norm_cfg=dict(type='BN', eps=1e-3, momentum=0.01),
|
| 23 |
+
conv_cfg=dict(type='Conv2d', bias=False)),
|
| 24 |
+
pts_neck=dict(
|
| 25 |
+
type='SECONDFPN',
|
| 26 |
+
in_channels=[64, 128, 256],
|
| 27 |
+
out_channels=[128, 128, 128],
|
| 28 |
+
upsample_strides=[0.5, 1, 2],
|
| 29 |
+
norm_cfg=dict(type='BN', eps=1e-3, momentum=0.01),
|
| 30 |
+
upsample_cfg=dict(type='deconv', bias=False),
|
| 31 |
+
use_conv_for_no_stride=True),
|
| 32 |
+
pts_bbox_head=dict(
|
| 33 |
+
type='CenterHead',
|
| 34 |
+
in_channels=sum([128, 128, 128]),
|
| 35 |
+
tasks=[
|
| 36 |
+
dict(num_class=1, class_names=['car']),
|
| 37 |
+
dict(num_class=2, class_names=['truck', 'construction_vehicle']),
|
| 38 |
+
dict(num_class=2, class_names=['bus', 'trailer']),
|
| 39 |
+
dict(num_class=1, class_names=['barrier']),
|
| 40 |
+
dict(num_class=2, class_names=['motorcycle', 'bicycle']),
|
| 41 |
+
dict(num_class=2, class_names=['pedestrian', 'traffic_cone']),
|
| 42 |
+
],
|
| 43 |
+
common_heads=dict(
|
| 44 |
+
reg=(2, 2), height=(1, 2), dim=(3, 2), rot=(2, 2), vel=(2, 2)),
|
| 45 |
+
share_conv_channel=64,
|
| 46 |
+
bbox_coder=dict(
|
| 47 |
+
type='CenterPointBBoxCoder',
|
| 48 |
+
post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
|
| 49 |
+
max_num=500,
|
| 50 |
+
score_threshold=0.1,
|
| 51 |
+
out_size_factor=4,
|
| 52 |
+
voxel_size=voxel_size[:2],
|
| 53 |
+
code_size=9),
|
| 54 |
+
separate_head=dict(
|
| 55 |
+
type='SeparateHead', init_bias=-2.19, final_kernel=3),
|
| 56 |
+
loss_cls=dict(type='GaussianFocalLoss', reduction='mean'),
|
| 57 |
+
loss_bbox=dict(type='L1Loss', reduction='mean', loss_weight=0.25),
|
| 58 |
+
norm_bbox=True),
|
| 59 |
+
# model training and testing settings
|
| 60 |
+
train_cfg=dict(
|
| 61 |
+
pts=dict(
|
| 62 |
+
grid_size=[512, 512, 1],
|
| 63 |
+
voxel_size=voxel_size,
|
| 64 |
+
out_size_factor=4,
|
| 65 |
+
dense_reg=1,
|
| 66 |
+
gaussian_overlap=0.1,
|
| 67 |
+
max_objs=500,
|
| 68 |
+
min_radius=2,
|
| 69 |
+
code_weights=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.2, 0.2])),
|
| 70 |
+
test_cfg=dict(
|
| 71 |
+
pts=dict(
|
| 72 |
+
post_center_limit_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
|
| 73 |
+
max_per_img=500,
|
| 74 |
+
max_pool_nms=False,
|
| 75 |
+
min_radius=[4, 12, 10, 1, 0.85, 0.175],
|
| 76 |
+
score_threshold=0.1,
|
| 77 |
+
pc_range=[-51.2, -51.2],
|
| 78 |
+
out_size_factor=4,
|
| 79 |
+
voxel_size=voxel_size[:2],
|
| 80 |
+
nms_type='rotate',
|
| 81 |
+
pre_max_size=1000,
|
| 82 |
+
post_max_size=83,
|
| 83 |
+
nms_thr=0.2)))
|
GenAD-main/projects/configs/_base_/models/fcos3d.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='FCOSMono3D',
|
| 3 |
+
pretrained='open-mmlab://detectron2/resnet101_caffe',
|
| 4 |
+
backbone=dict(
|
| 5 |
+
type='ResNet',
|
| 6 |
+
depth=101,
|
| 7 |
+
num_stages=4,
|
| 8 |
+
out_indices=(0, 1, 2, 3),
|
| 9 |
+
frozen_stages=1,
|
| 10 |
+
norm_cfg=dict(type='BN', requires_grad=False),
|
| 11 |
+
norm_eval=True,
|
| 12 |
+
style='caffe'),
|
| 13 |
+
neck=dict(
|
| 14 |
+
type='FPN',
|
| 15 |
+
in_channels=[256, 512, 1024, 2048],
|
| 16 |
+
out_channels=256,
|
| 17 |
+
start_level=1,
|
| 18 |
+
add_extra_convs='on_output',
|
| 19 |
+
num_outs=5,
|
| 20 |
+
relu_before_extra_convs=True),
|
| 21 |
+
bbox_head=dict(
|
| 22 |
+
type='FCOSMono3DHead',
|
| 23 |
+
num_classes=10,
|
| 24 |
+
in_channels=256,
|
| 25 |
+
stacked_convs=2,
|
| 26 |
+
feat_channels=256,
|
| 27 |
+
use_direction_classifier=True,
|
| 28 |
+
diff_rad_by_sin=True,
|
| 29 |
+
pred_attrs=True,
|
| 30 |
+
pred_velo=True,
|
| 31 |
+
dir_offset=0.7854, # pi/4
|
| 32 |
+
strides=[8, 16, 32, 64, 128],
|
| 33 |
+
group_reg_dims=(2, 1, 3, 1, 2), # offset, depth, size, rot, velo
|
| 34 |
+
cls_branch=(256, ),
|
| 35 |
+
reg_branch=(
|
| 36 |
+
(256, ), # offset
|
| 37 |
+
(256, ), # depth
|
| 38 |
+
(256, ), # size
|
| 39 |
+
(256, ), # rot
|
| 40 |
+
() # velo
|
| 41 |
+
),
|
| 42 |
+
dir_branch=(256, ),
|
| 43 |
+
attr_branch=(256, ),
|
| 44 |
+
loss_cls=dict(
|
| 45 |
+
type='FocalLoss',
|
| 46 |
+
use_sigmoid=True,
|
| 47 |
+
gamma=2.0,
|
| 48 |
+
alpha=0.25,
|
| 49 |
+
loss_weight=1.0),
|
| 50 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
|
| 51 |
+
loss_dir=dict(
|
| 52 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
| 53 |
+
loss_attr=dict(
|
| 54 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
| 55 |
+
loss_centerness=dict(
|
| 56 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
| 57 |
+
norm_on_bbox=True,
|
| 58 |
+
centerness_on_reg=True,
|
| 59 |
+
center_sampling=True,
|
| 60 |
+
conv_bias=True,
|
| 61 |
+
dcn_on_last_conv=True),
|
| 62 |
+
train_cfg=dict(
|
| 63 |
+
allowed_border=0,
|
| 64 |
+
code_weight=[1.0, 1.0, 0.2, 1.0, 1.0, 1.0, 1.0, 0.05, 0.05],
|
| 65 |
+
pos_weight=-1,
|
| 66 |
+
debug=False),
|
| 67 |
+
test_cfg=dict(
|
| 68 |
+
use_rotate_nms=True,
|
| 69 |
+
nms_across_levels=False,
|
| 70 |
+
nms_pre=1000,
|
| 71 |
+
nms_thr=0.8,
|
| 72 |
+
score_thr=0.05,
|
| 73 |
+
min_bbox_size=0,
|
| 74 |
+
max_per_img=200))
|
GenAD-main/projects/configs/_base_/models/groupfree3d.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='GroupFree3DNet',
|
| 3 |
+
backbone=dict(
|
| 4 |
+
type='PointNet2SASSG',
|
| 5 |
+
in_channels=3,
|
| 6 |
+
num_points=(2048, 1024, 512, 256),
|
| 7 |
+
radius=(0.2, 0.4, 0.8, 1.2),
|
| 8 |
+
num_samples=(64, 32, 16, 16),
|
| 9 |
+
sa_channels=((64, 64, 128), (128, 128, 256), (128, 128, 256),
|
| 10 |
+
(128, 128, 256)),
|
| 11 |
+
fp_channels=((256, 256), (256, 288)),
|
| 12 |
+
norm_cfg=dict(type='BN2d'),
|
| 13 |
+
sa_cfg=dict(
|
| 14 |
+
type='PointSAModule',
|
| 15 |
+
pool_mod='max',
|
| 16 |
+
use_xyz=True,
|
| 17 |
+
normalize_xyz=True)),
|
| 18 |
+
bbox_head=dict(
|
| 19 |
+
type='GroupFree3DHead',
|
| 20 |
+
in_channels=288,
|
| 21 |
+
num_decoder_layers=6,
|
| 22 |
+
num_proposal=256,
|
| 23 |
+
transformerlayers=dict(
|
| 24 |
+
type='BaseTransformerLayer',
|
| 25 |
+
attn_cfgs=dict(
|
| 26 |
+
type='GroupFree3DMHA',
|
| 27 |
+
embed_dims=288,
|
| 28 |
+
num_heads=8,
|
| 29 |
+
attn_drop=0.1,
|
| 30 |
+
dropout_layer=dict(type='Dropout', drop_prob=0.1)),
|
| 31 |
+
ffn_cfgs=dict(
|
| 32 |
+
embed_dims=288,
|
| 33 |
+
feedforward_channels=2048,
|
| 34 |
+
ffn_drop=0.1,
|
| 35 |
+
act_cfg=dict(type='ReLU', inplace=True)),
|
| 36 |
+
operation_order=('self_attn', 'norm', 'cross_attn', 'norm', 'ffn',
|
| 37 |
+
'norm')),
|
| 38 |
+
pred_layer_cfg=dict(
|
| 39 |
+
in_channels=288, shared_conv_channels=(288, 288), bias=True),
|
| 40 |
+
sampling_objectness_loss=dict(
|
| 41 |
+
type='FocalLoss',
|
| 42 |
+
use_sigmoid=True,
|
| 43 |
+
gamma=2.0,
|
| 44 |
+
alpha=0.25,
|
| 45 |
+
loss_weight=8.0),
|
| 46 |
+
objectness_loss=dict(
|
| 47 |
+
type='FocalLoss',
|
| 48 |
+
use_sigmoid=True,
|
| 49 |
+
gamma=2.0,
|
| 50 |
+
alpha=0.25,
|
| 51 |
+
loss_weight=1.0),
|
| 52 |
+
center_loss=dict(
|
| 53 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 54 |
+
dir_class_loss=dict(
|
| 55 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 56 |
+
dir_res_loss=dict(
|
| 57 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 58 |
+
size_class_loss=dict(
|
| 59 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 60 |
+
size_res_loss=dict(
|
| 61 |
+
type='SmoothL1Loss', beta=1.0, reduction='sum', loss_weight=10.0),
|
| 62 |
+
semantic_loss=dict(
|
| 63 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0)),
|
| 64 |
+
# model training and testing settings
|
| 65 |
+
train_cfg=dict(sample_mod='kps'),
|
| 66 |
+
test_cfg=dict(
|
| 67 |
+
sample_mod='kps',
|
| 68 |
+
nms_thr=0.25,
|
| 69 |
+
score_thr=0.0,
|
| 70 |
+
per_class_proposal=True,
|
| 71 |
+
prediction_stages='last'))
|
GenAD-main/projects/configs/_base_/models/h3dnet.py
ADDED
|
@@ -0,0 +1,341 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
primitive_z_cfg = dict(
|
| 2 |
+
type='PrimitiveHead',
|
| 3 |
+
num_dims=2,
|
| 4 |
+
num_classes=18,
|
| 5 |
+
primitive_mode='z',
|
| 6 |
+
upper_thresh=100.0,
|
| 7 |
+
surface_thresh=0.5,
|
| 8 |
+
vote_module_cfg=dict(
|
| 9 |
+
in_channels=256,
|
| 10 |
+
vote_per_seed=1,
|
| 11 |
+
gt_per_seed=1,
|
| 12 |
+
conv_channels=(256, 256),
|
| 13 |
+
conv_cfg=dict(type='Conv1d'),
|
| 14 |
+
norm_cfg=dict(type='BN1d'),
|
| 15 |
+
norm_feats=True,
|
| 16 |
+
vote_loss=dict(
|
| 17 |
+
type='ChamferDistance',
|
| 18 |
+
mode='l1',
|
| 19 |
+
reduction='none',
|
| 20 |
+
loss_dst_weight=10.0)),
|
| 21 |
+
vote_aggregation_cfg=dict(
|
| 22 |
+
type='PointSAModule',
|
| 23 |
+
num_point=1024,
|
| 24 |
+
radius=0.3,
|
| 25 |
+
num_sample=16,
|
| 26 |
+
mlp_channels=[256, 128, 128, 128],
|
| 27 |
+
use_xyz=True,
|
| 28 |
+
normalize_xyz=True),
|
| 29 |
+
feat_channels=(128, 128),
|
| 30 |
+
conv_cfg=dict(type='Conv1d'),
|
| 31 |
+
norm_cfg=dict(type='BN1d'),
|
| 32 |
+
objectness_loss=dict(
|
| 33 |
+
type='CrossEntropyLoss',
|
| 34 |
+
class_weight=[0.4, 0.6],
|
| 35 |
+
reduction='mean',
|
| 36 |
+
loss_weight=30.0),
|
| 37 |
+
center_loss=dict(
|
| 38 |
+
type='ChamferDistance',
|
| 39 |
+
mode='l1',
|
| 40 |
+
reduction='sum',
|
| 41 |
+
loss_src_weight=0.5,
|
| 42 |
+
loss_dst_weight=0.5),
|
| 43 |
+
semantic_reg_loss=dict(
|
| 44 |
+
type='ChamferDistance',
|
| 45 |
+
mode='l1',
|
| 46 |
+
reduction='sum',
|
| 47 |
+
loss_src_weight=0.5,
|
| 48 |
+
loss_dst_weight=0.5),
|
| 49 |
+
semantic_cls_loss=dict(
|
| 50 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 51 |
+
train_cfg=dict(
|
| 52 |
+
dist_thresh=0.2,
|
| 53 |
+
var_thresh=1e-2,
|
| 54 |
+
lower_thresh=1e-6,
|
| 55 |
+
num_point=100,
|
| 56 |
+
num_point_line=10,
|
| 57 |
+
line_thresh=0.2))
|
| 58 |
+
|
| 59 |
+
primitive_xy_cfg = dict(
|
| 60 |
+
type='PrimitiveHead',
|
| 61 |
+
num_dims=1,
|
| 62 |
+
num_classes=18,
|
| 63 |
+
primitive_mode='xy',
|
| 64 |
+
upper_thresh=100.0,
|
| 65 |
+
surface_thresh=0.5,
|
| 66 |
+
vote_module_cfg=dict(
|
| 67 |
+
in_channels=256,
|
| 68 |
+
vote_per_seed=1,
|
| 69 |
+
gt_per_seed=1,
|
| 70 |
+
conv_channels=(256, 256),
|
| 71 |
+
conv_cfg=dict(type='Conv1d'),
|
| 72 |
+
norm_cfg=dict(type='BN1d'),
|
| 73 |
+
norm_feats=True,
|
| 74 |
+
vote_loss=dict(
|
| 75 |
+
type='ChamferDistance',
|
| 76 |
+
mode='l1',
|
| 77 |
+
reduction='none',
|
| 78 |
+
loss_dst_weight=10.0)),
|
| 79 |
+
vote_aggregation_cfg=dict(
|
| 80 |
+
type='PointSAModule',
|
| 81 |
+
num_point=1024,
|
| 82 |
+
radius=0.3,
|
| 83 |
+
num_sample=16,
|
| 84 |
+
mlp_channels=[256, 128, 128, 128],
|
| 85 |
+
use_xyz=True,
|
| 86 |
+
normalize_xyz=True),
|
| 87 |
+
feat_channels=(128, 128),
|
| 88 |
+
conv_cfg=dict(type='Conv1d'),
|
| 89 |
+
norm_cfg=dict(type='BN1d'),
|
| 90 |
+
objectness_loss=dict(
|
| 91 |
+
type='CrossEntropyLoss',
|
| 92 |
+
class_weight=[0.4, 0.6],
|
| 93 |
+
reduction='mean',
|
| 94 |
+
loss_weight=30.0),
|
| 95 |
+
center_loss=dict(
|
| 96 |
+
type='ChamferDistance',
|
| 97 |
+
mode='l1',
|
| 98 |
+
reduction='sum',
|
| 99 |
+
loss_src_weight=0.5,
|
| 100 |
+
loss_dst_weight=0.5),
|
| 101 |
+
semantic_reg_loss=dict(
|
| 102 |
+
type='ChamferDistance',
|
| 103 |
+
mode='l1',
|
| 104 |
+
reduction='sum',
|
| 105 |
+
loss_src_weight=0.5,
|
| 106 |
+
loss_dst_weight=0.5),
|
| 107 |
+
semantic_cls_loss=dict(
|
| 108 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 109 |
+
train_cfg=dict(
|
| 110 |
+
dist_thresh=0.2,
|
| 111 |
+
var_thresh=1e-2,
|
| 112 |
+
lower_thresh=1e-6,
|
| 113 |
+
num_point=100,
|
| 114 |
+
num_point_line=10,
|
| 115 |
+
line_thresh=0.2))
|
| 116 |
+
|
| 117 |
+
primitive_line_cfg = dict(
|
| 118 |
+
type='PrimitiveHead',
|
| 119 |
+
num_dims=0,
|
| 120 |
+
num_classes=18,
|
| 121 |
+
primitive_mode='line',
|
| 122 |
+
upper_thresh=100.0,
|
| 123 |
+
surface_thresh=0.5,
|
| 124 |
+
vote_module_cfg=dict(
|
| 125 |
+
in_channels=256,
|
| 126 |
+
vote_per_seed=1,
|
| 127 |
+
gt_per_seed=1,
|
| 128 |
+
conv_channels=(256, 256),
|
| 129 |
+
conv_cfg=dict(type='Conv1d'),
|
| 130 |
+
norm_cfg=dict(type='BN1d'),
|
| 131 |
+
norm_feats=True,
|
| 132 |
+
vote_loss=dict(
|
| 133 |
+
type='ChamferDistance',
|
| 134 |
+
mode='l1',
|
| 135 |
+
reduction='none',
|
| 136 |
+
loss_dst_weight=10.0)),
|
| 137 |
+
vote_aggregation_cfg=dict(
|
| 138 |
+
type='PointSAModule',
|
| 139 |
+
num_point=1024,
|
| 140 |
+
radius=0.3,
|
| 141 |
+
num_sample=16,
|
| 142 |
+
mlp_channels=[256, 128, 128, 128],
|
| 143 |
+
use_xyz=True,
|
| 144 |
+
normalize_xyz=True),
|
| 145 |
+
feat_channels=(128, 128),
|
| 146 |
+
conv_cfg=dict(type='Conv1d'),
|
| 147 |
+
norm_cfg=dict(type='BN1d'),
|
| 148 |
+
objectness_loss=dict(
|
| 149 |
+
type='CrossEntropyLoss',
|
| 150 |
+
class_weight=[0.4, 0.6],
|
| 151 |
+
reduction='mean',
|
| 152 |
+
loss_weight=30.0),
|
| 153 |
+
center_loss=dict(
|
| 154 |
+
type='ChamferDistance',
|
| 155 |
+
mode='l1',
|
| 156 |
+
reduction='sum',
|
| 157 |
+
loss_src_weight=1.0,
|
| 158 |
+
loss_dst_weight=1.0),
|
| 159 |
+
semantic_reg_loss=dict(
|
| 160 |
+
type='ChamferDistance',
|
| 161 |
+
mode='l1',
|
| 162 |
+
reduction='sum',
|
| 163 |
+
loss_src_weight=1.0,
|
| 164 |
+
loss_dst_weight=1.0),
|
| 165 |
+
semantic_cls_loss=dict(
|
| 166 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=2.0),
|
| 167 |
+
train_cfg=dict(
|
| 168 |
+
dist_thresh=0.2,
|
| 169 |
+
var_thresh=1e-2,
|
| 170 |
+
lower_thresh=1e-6,
|
| 171 |
+
num_point=100,
|
| 172 |
+
num_point_line=10,
|
| 173 |
+
line_thresh=0.2))
|
| 174 |
+
|
| 175 |
+
model = dict(
|
| 176 |
+
type='H3DNet',
|
| 177 |
+
backbone=dict(
|
| 178 |
+
type='MultiBackbone',
|
| 179 |
+
num_streams=4,
|
| 180 |
+
suffixes=['net0', 'net1', 'net2', 'net3'],
|
| 181 |
+
conv_cfg=dict(type='Conv1d'),
|
| 182 |
+
norm_cfg=dict(type='BN1d', eps=1e-5, momentum=0.01),
|
| 183 |
+
act_cfg=dict(type='ReLU'),
|
| 184 |
+
backbones=dict(
|
| 185 |
+
type='PointNet2SASSG',
|
| 186 |
+
in_channels=4,
|
| 187 |
+
num_points=(2048, 1024, 512, 256),
|
| 188 |
+
radius=(0.2, 0.4, 0.8, 1.2),
|
| 189 |
+
num_samples=(64, 32, 16, 16),
|
| 190 |
+
sa_channels=((64, 64, 128), (128, 128, 256), (128, 128, 256),
|
| 191 |
+
(128, 128, 256)),
|
| 192 |
+
fp_channels=((256, 256), (256, 256)),
|
| 193 |
+
norm_cfg=dict(type='BN2d'),
|
| 194 |
+
sa_cfg=dict(
|
| 195 |
+
type='PointSAModule',
|
| 196 |
+
pool_mod='max',
|
| 197 |
+
use_xyz=True,
|
| 198 |
+
normalize_xyz=True))),
|
| 199 |
+
rpn_head=dict(
|
| 200 |
+
type='VoteHead',
|
| 201 |
+
vote_module_cfg=dict(
|
| 202 |
+
in_channels=256,
|
| 203 |
+
vote_per_seed=1,
|
| 204 |
+
gt_per_seed=3,
|
| 205 |
+
conv_channels=(256, 256),
|
| 206 |
+
conv_cfg=dict(type='Conv1d'),
|
| 207 |
+
norm_cfg=dict(type='BN1d'),
|
| 208 |
+
norm_feats=True,
|
| 209 |
+
vote_loss=dict(
|
| 210 |
+
type='ChamferDistance',
|
| 211 |
+
mode='l1',
|
| 212 |
+
reduction='none',
|
| 213 |
+
loss_dst_weight=10.0)),
|
| 214 |
+
vote_aggregation_cfg=dict(
|
| 215 |
+
type='PointSAModule',
|
| 216 |
+
num_point=256,
|
| 217 |
+
radius=0.3,
|
| 218 |
+
num_sample=16,
|
| 219 |
+
mlp_channels=[256, 128, 128, 128],
|
| 220 |
+
use_xyz=True,
|
| 221 |
+
normalize_xyz=True),
|
| 222 |
+
pred_layer_cfg=dict(
|
| 223 |
+
in_channels=128, shared_conv_channels=(128, 128), bias=True),
|
| 224 |
+
conv_cfg=dict(type='Conv1d'),
|
| 225 |
+
norm_cfg=dict(type='BN1d'),
|
| 226 |
+
objectness_loss=dict(
|
| 227 |
+
type='CrossEntropyLoss',
|
| 228 |
+
class_weight=[0.2, 0.8],
|
| 229 |
+
reduction='sum',
|
| 230 |
+
loss_weight=5.0),
|
| 231 |
+
center_loss=dict(
|
| 232 |
+
type='ChamferDistance',
|
| 233 |
+
mode='l2',
|
| 234 |
+
reduction='sum',
|
| 235 |
+
loss_src_weight=10.0,
|
| 236 |
+
loss_dst_weight=10.0),
|
| 237 |
+
dir_class_loss=dict(
|
| 238 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 239 |
+
dir_res_loss=dict(
|
| 240 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 241 |
+
size_class_loss=dict(
|
| 242 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 243 |
+
size_res_loss=dict(
|
| 244 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 245 |
+
semantic_loss=dict(
|
| 246 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0)),
|
| 247 |
+
roi_head=dict(
|
| 248 |
+
type='H3DRoIHead',
|
| 249 |
+
primitive_list=[primitive_z_cfg, primitive_xy_cfg, primitive_line_cfg],
|
| 250 |
+
bbox_head=dict(
|
| 251 |
+
type='H3DBboxHead',
|
| 252 |
+
gt_per_seed=3,
|
| 253 |
+
num_proposal=256,
|
| 254 |
+
suface_matching_cfg=dict(
|
| 255 |
+
type='PointSAModule',
|
| 256 |
+
num_point=256 * 6,
|
| 257 |
+
radius=0.5,
|
| 258 |
+
num_sample=32,
|
| 259 |
+
mlp_channels=[128 + 6, 128, 64, 32],
|
| 260 |
+
use_xyz=True,
|
| 261 |
+
normalize_xyz=True),
|
| 262 |
+
line_matching_cfg=dict(
|
| 263 |
+
type='PointSAModule',
|
| 264 |
+
num_point=256 * 12,
|
| 265 |
+
radius=0.5,
|
| 266 |
+
num_sample=32,
|
| 267 |
+
mlp_channels=[128 + 12, 128, 64, 32],
|
| 268 |
+
use_xyz=True,
|
| 269 |
+
normalize_xyz=True),
|
| 270 |
+
feat_channels=(128, 128),
|
| 271 |
+
primitive_refine_channels=[128, 128, 128],
|
| 272 |
+
upper_thresh=100.0,
|
| 273 |
+
surface_thresh=0.5,
|
| 274 |
+
line_thresh=0.5,
|
| 275 |
+
conv_cfg=dict(type='Conv1d'),
|
| 276 |
+
norm_cfg=dict(type='BN1d'),
|
| 277 |
+
objectness_loss=dict(
|
| 278 |
+
type='CrossEntropyLoss',
|
| 279 |
+
class_weight=[0.2, 0.8],
|
| 280 |
+
reduction='sum',
|
| 281 |
+
loss_weight=5.0),
|
| 282 |
+
center_loss=dict(
|
| 283 |
+
type='ChamferDistance',
|
| 284 |
+
mode='l2',
|
| 285 |
+
reduction='sum',
|
| 286 |
+
loss_src_weight=10.0,
|
| 287 |
+
loss_dst_weight=10.0),
|
| 288 |
+
dir_class_loss=dict(
|
| 289 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=0.1),
|
| 290 |
+
dir_res_loss=dict(
|
| 291 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 292 |
+
size_class_loss=dict(
|
| 293 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=0.1),
|
| 294 |
+
size_res_loss=dict(
|
| 295 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 296 |
+
semantic_loss=dict(
|
| 297 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=0.1),
|
| 298 |
+
cues_objectness_loss=dict(
|
| 299 |
+
type='CrossEntropyLoss',
|
| 300 |
+
class_weight=[0.3, 0.7],
|
| 301 |
+
reduction='mean',
|
| 302 |
+
loss_weight=5.0),
|
| 303 |
+
cues_semantic_loss=dict(
|
| 304 |
+
type='CrossEntropyLoss',
|
| 305 |
+
class_weight=[0.3, 0.7],
|
| 306 |
+
reduction='mean',
|
| 307 |
+
loss_weight=5.0),
|
| 308 |
+
proposal_objectness_loss=dict(
|
| 309 |
+
type='CrossEntropyLoss',
|
| 310 |
+
class_weight=[0.2, 0.8],
|
| 311 |
+
reduction='none',
|
| 312 |
+
loss_weight=5.0),
|
| 313 |
+
primitive_center_loss=dict(
|
| 314 |
+
type='MSELoss', reduction='none', loss_weight=1.0))),
|
| 315 |
+
# model training and testing settings
|
| 316 |
+
train_cfg=dict(
|
| 317 |
+
rpn=dict(
|
| 318 |
+
pos_distance_thr=0.3, neg_distance_thr=0.6, sample_mod='vote'),
|
| 319 |
+
rpn_proposal=dict(use_nms=False),
|
| 320 |
+
rcnn=dict(
|
| 321 |
+
pos_distance_thr=0.3,
|
| 322 |
+
neg_distance_thr=0.6,
|
| 323 |
+
sample_mod='vote',
|
| 324 |
+
far_threshold=0.6,
|
| 325 |
+
near_threshold=0.3,
|
| 326 |
+
mask_surface_threshold=0.3,
|
| 327 |
+
label_surface_threshold=0.3,
|
| 328 |
+
mask_line_threshold=0.3,
|
| 329 |
+
label_line_threshold=0.3)),
|
| 330 |
+
test_cfg=dict(
|
| 331 |
+
rpn=dict(
|
| 332 |
+
sample_mod='seed',
|
| 333 |
+
nms_thr=0.25,
|
| 334 |
+
score_thr=0.05,
|
| 335 |
+
per_class_proposal=True,
|
| 336 |
+
use_nms=False),
|
| 337 |
+
rcnn=dict(
|
| 338 |
+
sample_mod='seed',
|
| 339 |
+
nms_thr=0.25,
|
| 340 |
+
score_thr=0.05,
|
| 341 |
+
per_class_proposal=True)))
|
GenAD-main/projects/configs/_base_/models/hv_pointpillars_fpn_lyft.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = './hv_pointpillars_fpn_nus.py'
|
| 2 |
+
|
| 3 |
+
# model settings (based on nuScenes model settings)
|
| 4 |
+
# Voxel size for voxel encoder
|
| 5 |
+
# Usually voxel size is changed consistently with the point cloud range
|
| 6 |
+
# If point cloud range is modified, do remember to change all related
|
| 7 |
+
# keys in the config.
|
| 8 |
+
model = dict(
|
| 9 |
+
pts_voxel_layer=dict(
|
| 10 |
+
max_num_points=20,
|
| 11 |
+
point_cloud_range=[-80, -80, -5, 80, 80, 3],
|
| 12 |
+
max_voxels=(60000, 60000)),
|
| 13 |
+
pts_voxel_encoder=dict(
|
| 14 |
+
feat_channels=[64], point_cloud_range=[-80, -80, -5, 80, 80, 3]),
|
| 15 |
+
pts_middle_encoder=dict(output_shape=[640, 640]),
|
| 16 |
+
pts_bbox_head=dict(
|
| 17 |
+
num_classes=9,
|
| 18 |
+
anchor_generator=dict(
|
| 19 |
+
ranges=[[-80, -80, -1.8, 80, 80, -1.8]], custom_values=[]),
|
| 20 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder', code_size=7)),
|
| 21 |
+
# model training settings (based on nuScenes model settings)
|
| 22 |
+
train_cfg=dict(pts=dict(code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0])))
|
GenAD-main/projects/configs/_base_/models/hv_pointpillars_fpn_nus.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
# Voxel size for voxel encoder
|
| 3 |
+
# Usually voxel size is changed consistently with the point cloud range
|
| 4 |
+
# If point cloud range is modified, do remember to change all related
|
| 5 |
+
# keys in the config.
|
| 6 |
+
voxel_size = [0.25, 0.25, 8]
|
| 7 |
+
model = dict(
|
| 8 |
+
type='MVXFasterRCNN',
|
| 9 |
+
pts_voxel_layer=dict(
|
| 10 |
+
max_num_points=64,
|
| 11 |
+
point_cloud_range=[-50, -50, -5, 50, 50, 3],
|
| 12 |
+
voxel_size=voxel_size,
|
| 13 |
+
max_voxels=(30000, 40000)),
|
| 14 |
+
pts_voxel_encoder=dict(
|
| 15 |
+
type='HardVFE',
|
| 16 |
+
in_channels=4,
|
| 17 |
+
feat_channels=[64, 64],
|
| 18 |
+
with_distance=False,
|
| 19 |
+
voxel_size=voxel_size,
|
| 20 |
+
with_cluster_center=True,
|
| 21 |
+
with_voxel_center=True,
|
| 22 |
+
point_cloud_range=[-50, -50, -5, 50, 50, 3],
|
| 23 |
+
norm_cfg=dict(type='naiveSyncBN1d', eps=1e-3, momentum=0.01)),
|
| 24 |
+
pts_middle_encoder=dict(
|
| 25 |
+
type='PointPillarsScatter', in_channels=64, output_shape=[400, 400]),
|
| 26 |
+
pts_backbone=dict(
|
| 27 |
+
type='SECOND',
|
| 28 |
+
in_channels=64,
|
| 29 |
+
norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
|
| 30 |
+
layer_nums=[3, 5, 5],
|
| 31 |
+
layer_strides=[2, 2, 2],
|
| 32 |
+
out_channels=[64, 128, 256]),
|
| 33 |
+
pts_neck=dict(
|
| 34 |
+
type='FPN',
|
| 35 |
+
norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
|
| 36 |
+
act_cfg=dict(type='ReLU'),
|
| 37 |
+
in_channels=[64, 128, 256],
|
| 38 |
+
out_channels=256,
|
| 39 |
+
start_level=0,
|
| 40 |
+
num_outs=3),
|
| 41 |
+
pts_bbox_head=dict(
|
| 42 |
+
type='Anchor3DHead',
|
| 43 |
+
num_classes=10,
|
| 44 |
+
in_channels=256,
|
| 45 |
+
feat_channels=256,
|
| 46 |
+
use_direction_classifier=True,
|
| 47 |
+
anchor_generator=dict(
|
| 48 |
+
type='AlignedAnchor3DRangeGenerator',
|
| 49 |
+
ranges=[[-50, -50, -1.8, 50, 50, -1.8]],
|
| 50 |
+
scales=[1, 2, 4],
|
| 51 |
+
sizes=[
|
| 52 |
+
[0.8660, 2.5981, 1.], # 1.5/sqrt(3)
|
| 53 |
+
[0.5774, 1.7321, 1.], # 1/sqrt(3)
|
| 54 |
+
[1., 1., 1.],
|
| 55 |
+
[0.4, 0.4, 1],
|
| 56 |
+
],
|
| 57 |
+
custom_values=[0, 0],
|
| 58 |
+
rotations=[0, 1.57],
|
| 59 |
+
reshape_out=True),
|
| 60 |
+
assigner_per_size=False,
|
| 61 |
+
diff_rad_by_sin=True,
|
| 62 |
+
dir_offset=0.7854, # pi/4
|
| 63 |
+
dir_limit_offset=0,
|
| 64 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder', code_size=9),
|
| 65 |
+
loss_cls=dict(
|
| 66 |
+
type='FocalLoss',
|
| 67 |
+
use_sigmoid=True,
|
| 68 |
+
gamma=2.0,
|
| 69 |
+
alpha=0.25,
|
| 70 |
+
loss_weight=1.0),
|
| 71 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
|
| 72 |
+
loss_dir=dict(
|
| 73 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
|
| 74 |
+
# model training and testing settings
|
| 75 |
+
train_cfg=dict(
|
| 76 |
+
pts=dict(
|
| 77 |
+
assigner=dict(
|
| 78 |
+
type='MaxIoUAssigner',
|
| 79 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 80 |
+
pos_iou_thr=0.6,
|
| 81 |
+
neg_iou_thr=0.3,
|
| 82 |
+
min_pos_iou=0.3,
|
| 83 |
+
ignore_iof_thr=-1),
|
| 84 |
+
allowed_border=0,
|
| 85 |
+
code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.2, 0.2],
|
| 86 |
+
pos_weight=-1,
|
| 87 |
+
debug=False)),
|
| 88 |
+
test_cfg=dict(
|
| 89 |
+
pts=dict(
|
| 90 |
+
use_rotate_nms=True,
|
| 91 |
+
nms_across_levels=False,
|
| 92 |
+
nms_pre=1000,
|
| 93 |
+
nms_thr=0.2,
|
| 94 |
+
score_thr=0.05,
|
| 95 |
+
min_bbox_size=0,
|
| 96 |
+
max_num=500)))
|
GenAD-main/projects/configs/_base_/models/hv_pointpillars_fpn_range100_lyft.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = './hv_pointpillars_fpn_nus.py'
|
| 2 |
+
|
| 3 |
+
# model settings (based on nuScenes model settings)
|
| 4 |
+
# Voxel size for voxel encoder
|
| 5 |
+
# Usually voxel size is changed consistently with the point cloud range
|
| 6 |
+
# If point cloud range is modified, do remember to change all related
|
| 7 |
+
# keys in the config.
|
| 8 |
+
model = dict(
|
| 9 |
+
pts_voxel_layer=dict(
|
| 10 |
+
max_num_points=20,
|
| 11 |
+
point_cloud_range=[-100, -100, -5, 100, 100, 3],
|
| 12 |
+
max_voxels=(60000, 60000)),
|
| 13 |
+
pts_voxel_encoder=dict(
|
| 14 |
+
feat_channels=[64], point_cloud_range=[-100, -100, -5, 100, 100, 3]),
|
| 15 |
+
pts_middle_encoder=dict(output_shape=[800, 800]),
|
| 16 |
+
pts_bbox_head=dict(
|
| 17 |
+
num_classes=9,
|
| 18 |
+
anchor_generator=dict(
|
| 19 |
+
ranges=[[-100, -100, -1.8, 100, 100, -1.8]], custom_values=[]),
|
| 20 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder', code_size=7)),
|
| 21 |
+
# model training settings (based on nuScenes model settings)
|
| 22 |
+
train_cfg=dict(pts=dict(code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0])))
|
GenAD-main/projects/configs/_base_/models/hv_pointpillars_secfpn_kitti.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
voxel_size = [0.16, 0.16, 4]
|
| 2 |
+
|
| 3 |
+
model = dict(
|
| 4 |
+
type='VoxelNet',
|
| 5 |
+
voxel_layer=dict(
|
| 6 |
+
max_num_points=32, # max_points_per_voxel
|
| 7 |
+
point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1],
|
| 8 |
+
voxel_size=voxel_size,
|
| 9 |
+
max_voxels=(16000, 40000) # (training, testing) max_voxels
|
| 10 |
+
),
|
| 11 |
+
voxel_encoder=dict(
|
| 12 |
+
type='PillarFeatureNet',
|
| 13 |
+
in_channels=4,
|
| 14 |
+
feat_channels=[64],
|
| 15 |
+
with_distance=False,
|
| 16 |
+
voxel_size=voxel_size,
|
| 17 |
+
point_cloud_range=[0, -39.68, -3, 69.12, 39.68, 1]),
|
| 18 |
+
middle_encoder=dict(
|
| 19 |
+
type='PointPillarsScatter', in_channels=64, output_shape=[496, 432]),
|
| 20 |
+
backbone=dict(
|
| 21 |
+
type='SECOND',
|
| 22 |
+
in_channels=64,
|
| 23 |
+
layer_nums=[3, 5, 5],
|
| 24 |
+
layer_strides=[2, 2, 2],
|
| 25 |
+
out_channels=[64, 128, 256]),
|
| 26 |
+
neck=dict(
|
| 27 |
+
type='SECONDFPN',
|
| 28 |
+
in_channels=[64, 128, 256],
|
| 29 |
+
upsample_strides=[1, 2, 4],
|
| 30 |
+
out_channels=[128, 128, 128]),
|
| 31 |
+
bbox_head=dict(
|
| 32 |
+
type='Anchor3DHead',
|
| 33 |
+
num_classes=3,
|
| 34 |
+
in_channels=384,
|
| 35 |
+
feat_channels=384,
|
| 36 |
+
use_direction_classifier=True,
|
| 37 |
+
anchor_generator=dict(
|
| 38 |
+
type='Anchor3DRangeGenerator',
|
| 39 |
+
ranges=[
|
| 40 |
+
[0, -39.68, -0.6, 70.4, 39.68, -0.6],
|
| 41 |
+
[0, -39.68, -0.6, 70.4, 39.68, -0.6],
|
| 42 |
+
[0, -39.68, -1.78, 70.4, 39.68, -1.78],
|
| 43 |
+
],
|
| 44 |
+
sizes=[[0.6, 0.8, 1.73], [0.6, 1.76, 1.73], [1.6, 3.9, 1.56]],
|
| 45 |
+
rotations=[0, 1.57],
|
| 46 |
+
reshape_out=False),
|
| 47 |
+
diff_rad_by_sin=True,
|
| 48 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
|
| 49 |
+
loss_cls=dict(
|
| 50 |
+
type='FocalLoss',
|
| 51 |
+
use_sigmoid=True,
|
| 52 |
+
gamma=2.0,
|
| 53 |
+
alpha=0.25,
|
| 54 |
+
loss_weight=1.0),
|
| 55 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=2.0),
|
| 56 |
+
loss_dir=dict(
|
| 57 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
|
| 58 |
+
# model training and testing settings
|
| 59 |
+
train_cfg=dict(
|
| 60 |
+
assigner=[
|
| 61 |
+
dict( # for Pedestrian
|
| 62 |
+
type='MaxIoUAssigner',
|
| 63 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 64 |
+
pos_iou_thr=0.5,
|
| 65 |
+
neg_iou_thr=0.35,
|
| 66 |
+
min_pos_iou=0.35,
|
| 67 |
+
ignore_iof_thr=-1),
|
| 68 |
+
dict( # for Cyclist
|
| 69 |
+
type='MaxIoUAssigner',
|
| 70 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 71 |
+
pos_iou_thr=0.5,
|
| 72 |
+
neg_iou_thr=0.35,
|
| 73 |
+
min_pos_iou=0.35,
|
| 74 |
+
ignore_iof_thr=-1),
|
| 75 |
+
dict( # for Car
|
| 76 |
+
type='MaxIoUAssigner',
|
| 77 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 78 |
+
pos_iou_thr=0.6,
|
| 79 |
+
neg_iou_thr=0.45,
|
| 80 |
+
min_pos_iou=0.45,
|
| 81 |
+
ignore_iof_thr=-1),
|
| 82 |
+
],
|
| 83 |
+
allowed_border=0,
|
| 84 |
+
pos_weight=-1,
|
| 85 |
+
debug=False),
|
| 86 |
+
test_cfg=dict(
|
| 87 |
+
use_rotate_nms=True,
|
| 88 |
+
nms_across_levels=False,
|
| 89 |
+
nms_thr=0.01,
|
| 90 |
+
score_thr=0.1,
|
| 91 |
+
min_bbox_size=0,
|
| 92 |
+
nms_pre=100,
|
| 93 |
+
max_num=50))
|
GenAD-main/projects/configs/_base_/models/hv_pointpillars_secfpn_waymo.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
# Voxel size for voxel encoder
|
| 3 |
+
# Usually voxel size is changed consistently with the point cloud range
|
| 4 |
+
# If point cloud range is modified, do remember to change all related
|
| 5 |
+
# keys in the config.
|
| 6 |
+
voxel_size = [0.32, 0.32, 6]
|
| 7 |
+
model = dict(
|
| 8 |
+
type='MVXFasterRCNN',
|
| 9 |
+
pts_voxel_layer=dict(
|
| 10 |
+
max_num_points=20,
|
| 11 |
+
point_cloud_range=[-74.88, -74.88, -2, 74.88, 74.88, 4],
|
| 12 |
+
voxel_size=voxel_size,
|
| 13 |
+
max_voxels=(32000, 32000)),
|
| 14 |
+
pts_voxel_encoder=dict(
|
| 15 |
+
type='HardVFE',
|
| 16 |
+
in_channels=5,
|
| 17 |
+
feat_channels=[64],
|
| 18 |
+
with_distance=False,
|
| 19 |
+
voxel_size=voxel_size,
|
| 20 |
+
with_cluster_center=True,
|
| 21 |
+
with_voxel_center=True,
|
| 22 |
+
point_cloud_range=[-74.88, -74.88, -2, 74.88, 74.88, 4],
|
| 23 |
+
norm_cfg=dict(type='naiveSyncBN1d', eps=1e-3, momentum=0.01)),
|
| 24 |
+
pts_middle_encoder=dict(
|
| 25 |
+
type='PointPillarsScatter', in_channels=64, output_shape=[468, 468]),
|
| 26 |
+
pts_backbone=dict(
|
| 27 |
+
type='SECOND',
|
| 28 |
+
in_channels=64,
|
| 29 |
+
norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
|
| 30 |
+
layer_nums=[3, 5, 5],
|
| 31 |
+
layer_strides=[1, 2, 2],
|
| 32 |
+
out_channels=[64, 128, 256]),
|
| 33 |
+
pts_neck=dict(
|
| 34 |
+
type='SECONDFPN',
|
| 35 |
+
norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
|
| 36 |
+
in_channels=[64, 128, 256],
|
| 37 |
+
upsample_strides=[1, 2, 4],
|
| 38 |
+
out_channels=[128, 128, 128]),
|
| 39 |
+
pts_bbox_head=dict(
|
| 40 |
+
type='Anchor3DHead',
|
| 41 |
+
num_classes=3,
|
| 42 |
+
in_channels=384,
|
| 43 |
+
feat_channels=384,
|
| 44 |
+
use_direction_classifier=True,
|
| 45 |
+
anchor_generator=dict(
|
| 46 |
+
type='AlignedAnchor3DRangeGenerator',
|
| 47 |
+
ranges=[[-74.88, -74.88, -0.0345, 74.88, 74.88, -0.0345],
|
| 48 |
+
[-74.88, -74.88, -0.1188, 74.88, 74.88, -0.1188],
|
| 49 |
+
[-74.88, -74.88, 0, 74.88, 74.88, 0]],
|
| 50 |
+
sizes=[
|
| 51 |
+
[2.08, 4.73, 1.77], # car
|
| 52 |
+
[0.84, 1.81, 1.77], # cyclist
|
| 53 |
+
[0.84, 0.91, 1.74] # pedestrian
|
| 54 |
+
],
|
| 55 |
+
rotations=[0, 1.57],
|
| 56 |
+
reshape_out=False),
|
| 57 |
+
diff_rad_by_sin=True,
|
| 58 |
+
dir_offset=0.7854, # pi/4
|
| 59 |
+
dir_limit_offset=0,
|
| 60 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder', code_size=7),
|
| 61 |
+
loss_cls=dict(
|
| 62 |
+
type='FocalLoss',
|
| 63 |
+
use_sigmoid=True,
|
| 64 |
+
gamma=2.0,
|
| 65 |
+
alpha=0.25,
|
| 66 |
+
loss_weight=1.0),
|
| 67 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
|
| 68 |
+
loss_dir=dict(
|
| 69 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
|
| 70 |
+
# model training and testing settings
|
| 71 |
+
train_cfg=dict(
|
| 72 |
+
pts=dict(
|
| 73 |
+
assigner=[
|
| 74 |
+
dict( # car
|
| 75 |
+
type='MaxIoUAssigner',
|
| 76 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 77 |
+
pos_iou_thr=0.55,
|
| 78 |
+
neg_iou_thr=0.4,
|
| 79 |
+
min_pos_iou=0.4,
|
| 80 |
+
ignore_iof_thr=-1),
|
| 81 |
+
dict( # cyclist
|
| 82 |
+
type='MaxIoUAssigner',
|
| 83 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 84 |
+
pos_iou_thr=0.5,
|
| 85 |
+
neg_iou_thr=0.3,
|
| 86 |
+
min_pos_iou=0.3,
|
| 87 |
+
ignore_iof_thr=-1),
|
| 88 |
+
dict( # pedestrian
|
| 89 |
+
type='MaxIoUAssigner',
|
| 90 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 91 |
+
pos_iou_thr=0.5,
|
| 92 |
+
neg_iou_thr=0.3,
|
| 93 |
+
min_pos_iou=0.3,
|
| 94 |
+
ignore_iof_thr=-1),
|
| 95 |
+
],
|
| 96 |
+
allowed_border=0,
|
| 97 |
+
code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
|
| 98 |
+
pos_weight=-1,
|
| 99 |
+
debug=False)),
|
| 100 |
+
test_cfg=dict(
|
| 101 |
+
pts=dict(
|
| 102 |
+
use_rotate_nms=True,
|
| 103 |
+
nms_across_levels=False,
|
| 104 |
+
nms_pre=4096,
|
| 105 |
+
nms_thr=0.25,
|
| 106 |
+
score_thr=0.1,
|
| 107 |
+
min_bbox_size=0,
|
| 108 |
+
max_num=500)))
|
GenAD-main/projects/configs/_base_/models/hv_second_secfpn_kitti.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
voxel_size = [0.05, 0.05, 0.1]
|
| 2 |
+
|
| 3 |
+
model = dict(
|
| 4 |
+
type='VoxelNet',
|
| 5 |
+
voxel_layer=dict(
|
| 6 |
+
max_num_points=5,
|
| 7 |
+
point_cloud_range=[0, -40, -3, 70.4, 40, 1],
|
| 8 |
+
voxel_size=voxel_size,
|
| 9 |
+
max_voxels=(16000, 40000)),
|
| 10 |
+
voxel_encoder=dict(type='HardSimpleVFE'),
|
| 11 |
+
middle_encoder=dict(
|
| 12 |
+
type='SparseEncoder',
|
| 13 |
+
in_channels=4,
|
| 14 |
+
sparse_shape=[41, 1600, 1408],
|
| 15 |
+
order=('conv', 'norm', 'act')),
|
| 16 |
+
backbone=dict(
|
| 17 |
+
type='SECOND',
|
| 18 |
+
in_channels=256,
|
| 19 |
+
layer_nums=[5, 5],
|
| 20 |
+
layer_strides=[1, 2],
|
| 21 |
+
out_channels=[128, 256]),
|
| 22 |
+
neck=dict(
|
| 23 |
+
type='SECONDFPN',
|
| 24 |
+
in_channels=[128, 256],
|
| 25 |
+
upsample_strides=[1, 2],
|
| 26 |
+
out_channels=[256, 256]),
|
| 27 |
+
bbox_head=dict(
|
| 28 |
+
type='Anchor3DHead',
|
| 29 |
+
num_classes=3,
|
| 30 |
+
in_channels=512,
|
| 31 |
+
feat_channels=512,
|
| 32 |
+
use_direction_classifier=True,
|
| 33 |
+
anchor_generator=dict(
|
| 34 |
+
type='Anchor3DRangeGenerator',
|
| 35 |
+
ranges=[
|
| 36 |
+
[0, -40.0, -0.6, 70.4, 40.0, -0.6],
|
| 37 |
+
[0, -40.0, -0.6, 70.4, 40.0, -0.6],
|
| 38 |
+
[0, -40.0, -1.78, 70.4, 40.0, -1.78],
|
| 39 |
+
],
|
| 40 |
+
sizes=[[0.6, 0.8, 1.73], [0.6, 1.76, 1.73], [1.6, 3.9, 1.56]],
|
| 41 |
+
rotations=[0, 1.57],
|
| 42 |
+
reshape_out=False),
|
| 43 |
+
diff_rad_by_sin=True,
|
| 44 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
|
| 45 |
+
loss_cls=dict(
|
| 46 |
+
type='FocalLoss',
|
| 47 |
+
use_sigmoid=True,
|
| 48 |
+
gamma=2.0,
|
| 49 |
+
alpha=0.25,
|
| 50 |
+
loss_weight=1.0),
|
| 51 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=2.0),
|
| 52 |
+
loss_dir=dict(
|
| 53 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
|
| 54 |
+
# model training and testing settings
|
| 55 |
+
train_cfg=dict(
|
| 56 |
+
assigner=[
|
| 57 |
+
dict( # for Pedestrian
|
| 58 |
+
type='MaxIoUAssigner',
|
| 59 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 60 |
+
pos_iou_thr=0.35,
|
| 61 |
+
neg_iou_thr=0.2,
|
| 62 |
+
min_pos_iou=0.2,
|
| 63 |
+
ignore_iof_thr=-1),
|
| 64 |
+
dict( # for Cyclist
|
| 65 |
+
type='MaxIoUAssigner',
|
| 66 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 67 |
+
pos_iou_thr=0.35,
|
| 68 |
+
neg_iou_thr=0.2,
|
| 69 |
+
min_pos_iou=0.2,
|
| 70 |
+
ignore_iof_thr=-1),
|
| 71 |
+
dict( # for Car
|
| 72 |
+
type='MaxIoUAssigner',
|
| 73 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 74 |
+
pos_iou_thr=0.6,
|
| 75 |
+
neg_iou_thr=0.45,
|
| 76 |
+
min_pos_iou=0.45,
|
| 77 |
+
ignore_iof_thr=-1),
|
| 78 |
+
],
|
| 79 |
+
allowed_border=0,
|
| 80 |
+
pos_weight=-1,
|
| 81 |
+
debug=False),
|
| 82 |
+
test_cfg=dict(
|
| 83 |
+
use_rotate_nms=True,
|
| 84 |
+
nms_across_levels=False,
|
| 85 |
+
nms_thr=0.01,
|
| 86 |
+
score_thr=0.1,
|
| 87 |
+
min_bbox_size=0,
|
| 88 |
+
nms_pre=100,
|
| 89 |
+
max_num=50))
|
GenAD-main/projects/configs/_base_/models/hv_second_secfpn_waymo.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
# Voxel size for voxel encoder
|
| 3 |
+
# Usually voxel size is changed consistently with the point cloud range
|
| 4 |
+
# If point cloud range is modified, do remember to change all related
|
| 5 |
+
# keys in the config.
|
| 6 |
+
voxel_size = [0.08, 0.08, 0.1]
|
| 7 |
+
model = dict(
|
| 8 |
+
type='VoxelNet',
|
| 9 |
+
voxel_layer=dict(
|
| 10 |
+
max_num_points=10,
|
| 11 |
+
point_cloud_range=[-76.8, -51.2, -2, 76.8, 51.2, 4],
|
| 12 |
+
voxel_size=voxel_size,
|
| 13 |
+
max_voxels=(80000, 90000)),
|
| 14 |
+
voxel_encoder=dict(type='HardSimpleVFE', num_features=5),
|
| 15 |
+
middle_encoder=dict(
|
| 16 |
+
type='SparseEncoder',
|
| 17 |
+
in_channels=5,
|
| 18 |
+
sparse_shape=[61, 1280, 1920],
|
| 19 |
+
order=('conv', 'norm', 'act')),
|
| 20 |
+
backbone=dict(
|
| 21 |
+
type='SECOND',
|
| 22 |
+
in_channels=384,
|
| 23 |
+
norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
|
| 24 |
+
layer_nums=[5, 5],
|
| 25 |
+
layer_strides=[1, 2],
|
| 26 |
+
out_channels=[128, 256]),
|
| 27 |
+
neck=dict(
|
| 28 |
+
type='SECONDFPN',
|
| 29 |
+
norm_cfg=dict(type='naiveSyncBN2d', eps=1e-3, momentum=0.01),
|
| 30 |
+
in_channels=[128, 256],
|
| 31 |
+
upsample_strides=[1, 2],
|
| 32 |
+
out_channels=[256, 256]),
|
| 33 |
+
bbox_head=dict(
|
| 34 |
+
type='Anchor3DHead',
|
| 35 |
+
num_classes=3,
|
| 36 |
+
in_channels=512,
|
| 37 |
+
feat_channels=512,
|
| 38 |
+
use_direction_classifier=True,
|
| 39 |
+
anchor_generator=dict(
|
| 40 |
+
type='AlignedAnchor3DRangeGenerator',
|
| 41 |
+
ranges=[[-76.8, -51.2, -0.0345, 76.8, 51.2, -0.0345],
|
| 42 |
+
[-76.8, -51.2, 0, 76.8, 51.2, 0],
|
| 43 |
+
[-76.8, -51.2, -0.1188, 76.8, 51.2, -0.1188]],
|
| 44 |
+
sizes=[
|
| 45 |
+
[2.08, 4.73, 1.77], # car
|
| 46 |
+
[0.84, 0.91, 1.74], # pedestrian
|
| 47 |
+
[0.84, 1.81, 1.77] # cyclist
|
| 48 |
+
],
|
| 49 |
+
rotations=[0, 1.57],
|
| 50 |
+
reshape_out=False),
|
| 51 |
+
diff_rad_by_sin=True,
|
| 52 |
+
dir_offset=0.7854, # pi/4
|
| 53 |
+
dir_limit_offset=0,
|
| 54 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder', code_size=7),
|
| 55 |
+
loss_cls=dict(
|
| 56 |
+
type='FocalLoss',
|
| 57 |
+
use_sigmoid=True,
|
| 58 |
+
gamma=2.0,
|
| 59 |
+
alpha=0.25,
|
| 60 |
+
loss_weight=1.0),
|
| 61 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
|
| 62 |
+
loss_dir=dict(
|
| 63 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
|
| 64 |
+
# model training and testing settings
|
| 65 |
+
train_cfg=dict(
|
| 66 |
+
assigner=[
|
| 67 |
+
dict( # car
|
| 68 |
+
type='MaxIoUAssigner',
|
| 69 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 70 |
+
pos_iou_thr=0.55,
|
| 71 |
+
neg_iou_thr=0.4,
|
| 72 |
+
min_pos_iou=0.4,
|
| 73 |
+
ignore_iof_thr=-1),
|
| 74 |
+
dict( # pedestrian
|
| 75 |
+
type='MaxIoUAssigner',
|
| 76 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 77 |
+
pos_iou_thr=0.5,
|
| 78 |
+
neg_iou_thr=0.3,
|
| 79 |
+
min_pos_iou=0.3,
|
| 80 |
+
ignore_iof_thr=-1),
|
| 81 |
+
dict( # cyclist
|
| 82 |
+
type='MaxIoUAssigner',
|
| 83 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 84 |
+
pos_iou_thr=0.5,
|
| 85 |
+
neg_iou_thr=0.3,
|
| 86 |
+
min_pos_iou=0.3,
|
| 87 |
+
ignore_iof_thr=-1)
|
| 88 |
+
],
|
| 89 |
+
allowed_border=0,
|
| 90 |
+
code_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0],
|
| 91 |
+
pos_weight=-1,
|
| 92 |
+
debug=False),
|
| 93 |
+
test_cfg=dict(
|
| 94 |
+
use_rotate_nms=True,
|
| 95 |
+
nms_across_levels=False,
|
| 96 |
+
nms_pre=4096,
|
| 97 |
+
nms_thr=0.25,
|
| 98 |
+
score_thr=0.1,
|
| 99 |
+
min_bbox_size=0,
|
| 100 |
+
max_num=500))
|
GenAD-main/projects/configs/_base_/models/imvotenet_image.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='ImVoteNet',
|
| 3 |
+
img_backbone=dict(
|
| 4 |
+
type='ResNet',
|
| 5 |
+
depth=50,
|
| 6 |
+
num_stages=4,
|
| 7 |
+
out_indices=(0, 1, 2, 3),
|
| 8 |
+
frozen_stages=1,
|
| 9 |
+
norm_cfg=dict(type='BN', requires_grad=False),
|
| 10 |
+
norm_eval=True,
|
| 11 |
+
style='caffe'),
|
| 12 |
+
img_neck=dict(
|
| 13 |
+
type='FPN',
|
| 14 |
+
in_channels=[256, 512, 1024, 2048],
|
| 15 |
+
out_channels=256,
|
| 16 |
+
num_outs=5),
|
| 17 |
+
img_rpn_head=dict(
|
| 18 |
+
type='RPNHead',
|
| 19 |
+
in_channels=256,
|
| 20 |
+
feat_channels=256,
|
| 21 |
+
anchor_generator=dict(
|
| 22 |
+
type='AnchorGenerator',
|
| 23 |
+
scales=[8],
|
| 24 |
+
ratios=[0.5, 1.0, 2.0],
|
| 25 |
+
strides=[4, 8, 16, 32, 64]),
|
| 26 |
+
bbox_coder=dict(
|
| 27 |
+
type='DeltaXYWHBBoxCoder',
|
| 28 |
+
target_means=[.0, .0, .0, .0],
|
| 29 |
+
target_stds=[1.0, 1.0, 1.0, 1.0]),
|
| 30 |
+
loss_cls=dict(
|
| 31 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
| 32 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
| 33 |
+
img_roi_head=dict(
|
| 34 |
+
type='StandardRoIHead',
|
| 35 |
+
bbox_roi_extractor=dict(
|
| 36 |
+
type='SingleRoIExtractor',
|
| 37 |
+
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
|
| 38 |
+
out_channels=256,
|
| 39 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 40 |
+
bbox_head=dict(
|
| 41 |
+
type='Shared2FCBBoxHead',
|
| 42 |
+
in_channels=256,
|
| 43 |
+
fc_out_channels=1024,
|
| 44 |
+
roi_feat_size=7,
|
| 45 |
+
num_classes=10,
|
| 46 |
+
bbox_coder=dict(
|
| 47 |
+
type='DeltaXYWHBBoxCoder',
|
| 48 |
+
target_means=[0., 0., 0., 0.],
|
| 49 |
+
target_stds=[0.1, 0.1, 0.2, 0.2]),
|
| 50 |
+
reg_class_agnostic=False,
|
| 51 |
+
loss_cls=dict(
|
| 52 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
| 53 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
|
| 54 |
+
|
| 55 |
+
# model training and testing settings
|
| 56 |
+
train_cfg=dict(
|
| 57 |
+
img_rpn=dict(
|
| 58 |
+
assigner=dict(
|
| 59 |
+
type='MaxIoUAssigner',
|
| 60 |
+
pos_iou_thr=0.7,
|
| 61 |
+
neg_iou_thr=0.3,
|
| 62 |
+
min_pos_iou=0.3,
|
| 63 |
+
match_low_quality=True,
|
| 64 |
+
ignore_iof_thr=-1),
|
| 65 |
+
sampler=dict(
|
| 66 |
+
type='RandomSampler',
|
| 67 |
+
num=256,
|
| 68 |
+
pos_fraction=0.5,
|
| 69 |
+
neg_pos_ub=-1,
|
| 70 |
+
add_gt_as_proposals=False),
|
| 71 |
+
allowed_border=-1,
|
| 72 |
+
pos_weight=-1,
|
| 73 |
+
debug=False),
|
| 74 |
+
img_rpn_proposal=dict(
|
| 75 |
+
nms_across_levels=False,
|
| 76 |
+
nms_pre=2000,
|
| 77 |
+
nms_post=1000,
|
| 78 |
+
max_per_img=1000,
|
| 79 |
+
nms=dict(type='nms', iou_threshold=0.7),
|
| 80 |
+
min_bbox_size=0),
|
| 81 |
+
img_rcnn=dict(
|
| 82 |
+
assigner=dict(
|
| 83 |
+
type='MaxIoUAssigner',
|
| 84 |
+
pos_iou_thr=0.5,
|
| 85 |
+
neg_iou_thr=0.5,
|
| 86 |
+
min_pos_iou=0.5,
|
| 87 |
+
match_low_quality=False,
|
| 88 |
+
ignore_iof_thr=-1),
|
| 89 |
+
sampler=dict(
|
| 90 |
+
type='RandomSampler',
|
| 91 |
+
num=512,
|
| 92 |
+
pos_fraction=0.25,
|
| 93 |
+
neg_pos_ub=-1,
|
| 94 |
+
add_gt_as_proposals=True),
|
| 95 |
+
pos_weight=-1,
|
| 96 |
+
debug=False)),
|
| 97 |
+
test_cfg=dict(
|
| 98 |
+
img_rpn=dict(
|
| 99 |
+
nms_across_levels=False,
|
| 100 |
+
nms_pre=1000,
|
| 101 |
+
nms_post=1000,
|
| 102 |
+
max_per_img=1000,
|
| 103 |
+
nms=dict(type='nms', iou_threshold=0.7),
|
| 104 |
+
min_bbox_size=0),
|
| 105 |
+
img_rcnn=dict(
|
| 106 |
+
score_thr=0.05,
|
| 107 |
+
nms=dict(type='nms', iou_threshold=0.5),
|
| 108 |
+
max_per_img=100)))
|
GenAD-main/projects/configs/_base_/models/mask_rcnn_r50_fpn.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
model = dict(
|
| 3 |
+
type='MaskRCNN',
|
| 4 |
+
pretrained='torchvision://resnet50',
|
| 5 |
+
backbone=dict(
|
| 6 |
+
type='ResNet',
|
| 7 |
+
depth=50,
|
| 8 |
+
num_stages=4,
|
| 9 |
+
out_indices=(0, 1, 2, 3),
|
| 10 |
+
frozen_stages=1,
|
| 11 |
+
norm_cfg=dict(type='BN', requires_grad=True),
|
| 12 |
+
norm_eval=True,
|
| 13 |
+
style='pytorch'),
|
| 14 |
+
neck=dict(
|
| 15 |
+
type='FPN',
|
| 16 |
+
in_channels=[256, 512, 1024, 2048],
|
| 17 |
+
out_channels=256,
|
| 18 |
+
num_outs=5),
|
| 19 |
+
rpn_head=dict(
|
| 20 |
+
type='RPNHead',
|
| 21 |
+
in_channels=256,
|
| 22 |
+
feat_channels=256,
|
| 23 |
+
anchor_generator=dict(
|
| 24 |
+
type='AnchorGenerator',
|
| 25 |
+
scales=[8],
|
| 26 |
+
ratios=[0.5, 1.0, 2.0],
|
| 27 |
+
strides=[4, 8, 16, 32, 64]),
|
| 28 |
+
bbox_coder=dict(
|
| 29 |
+
type='DeltaXYWHBBoxCoder',
|
| 30 |
+
target_means=[.0, .0, .0, .0],
|
| 31 |
+
target_stds=[1.0, 1.0, 1.0, 1.0]),
|
| 32 |
+
loss_cls=dict(
|
| 33 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
|
| 34 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
| 35 |
+
roi_head=dict(
|
| 36 |
+
type='StandardRoIHead',
|
| 37 |
+
bbox_roi_extractor=dict(
|
| 38 |
+
type='SingleRoIExtractor',
|
| 39 |
+
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
|
| 40 |
+
out_channels=256,
|
| 41 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 42 |
+
bbox_head=dict(
|
| 43 |
+
type='Shared2FCBBoxHead',
|
| 44 |
+
in_channels=256,
|
| 45 |
+
fc_out_channels=1024,
|
| 46 |
+
roi_feat_size=7,
|
| 47 |
+
num_classes=80,
|
| 48 |
+
bbox_coder=dict(
|
| 49 |
+
type='DeltaXYWHBBoxCoder',
|
| 50 |
+
target_means=[0., 0., 0., 0.],
|
| 51 |
+
target_stds=[0.1, 0.1, 0.2, 0.2]),
|
| 52 |
+
reg_class_agnostic=False,
|
| 53 |
+
loss_cls=dict(
|
| 54 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
|
| 55 |
+
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
|
| 56 |
+
mask_roi_extractor=dict(
|
| 57 |
+
type='SingleRoIExtractor',
|
| 58 |
+
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
|
| 59 |
+
out_channels=256,
|
| 60 |
+
featmap_strides=[4, 8, 16, 32]),
|
| 61 |
+
mask_head=dict(
|
| 62 |
+
type='FCNMaskHead',
|
| 63 |
+
num_convs=4,
|
| 64 |
+
in_channels=256,
|
| 65 |
+
conv_out_channels=256,
|
| 66 |
+
num_classes=80,
|
| 67 |
+
loss_mask=dict(
|
| 68 |
+
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
|
| 69 |
+
# model training and testing settings
|
| 70 |
+
train_cfg=dict(
|
| 71 |
+
rpn=dict(
|
| 72 |
+
assigner=dict(
|
| 73 |
+
type='MaxIoUAssigner',
|
| 74 |
+
pos_iou_thr=0.7,
|
| 75 |
+
neg_iou_thr=0.3,
|
| 76 |
+
min_pos_iou=0.3,
|
| 77 |
+
match_low_quality=True,
|
| 78 |
+
ignore_iof_thr=-1),
|
| 79 |
+
sampler=dict(
|
| 80 |
+
type='RandomSampler',
|
| 81 |
+
num=256,
|
| 82 |
+
pos_fraction=0.5,
|
| 83 |
+
neg_pos_ub=-1,
|
| 84 |
+
add_gt_as_proposals=False),
|
| 85 |
+
allowed_border=-1,
|
| 86 |
+
pos_weight=-1,
|
| 87 |
+
debug=False),
|
| 88 |
+
rpn_proposal=dict(
|
| 89 |
+
nms_across_levels=False,
|
| 90 |
+
nms_pre=2000,
|
| 91 |
+
nms_post=1000,
|
| 92 |
+
max_num=1000,
|
| 93 |
+
nms_thr=0.7,
|
| 94 |
+
min_bbox_size=0),
|
| 95 |
+
rcnn=dict(
|
| 96 |
+
assigner=dict(
|
| 97 |
+
type='MaxIoUAssigner',
|
| 98 |
+
pos_iou_thr=0.5,
|
| 99 |
+
neg_iou_thr=0.5,
|
| 100 |
+
min_pos_iou=0.5,
|
| 101 |
+
match_low_quality=True,
|
| 102 |
+
ignore_iof_thr=-1),
|
| 103 |
+
sampler=dict(
|
| 104 |
+
type='RandomSampler',
|
| 105 |
+
num=512,
|
| 106 |
+
pos_fraction=0.25,
|
| 107 |
+
neg_pos_ub=-1,
|
| 108 |
+
add_gt_as_proposals=True),
|
| 109 |
+
mask_size=28,
|
| 110 |
+
pos_weight=-1,
|
| 111 |
+
debug=False)),
|
| 112 |
+
test_cfg=dict(
|
| 113 |
+
rpn=dict(
|
| 114 |
+
nms_across_levels=False,
|
| 115 |
+
nms_pre=1000,
|
| 116 |
+
nms_post=1000,
|
| 117 |
+
max_num=1000,
|
| 118 |
+
nms_thr=0.7,
|
| 119 |
+
min_bbox_size=0),
|
| 120 |
+
rcnn=dict(
|
| 121 |
+
score_thr=0.05,
|
| 122 |
+
nms=dict(type='nms', iou_threshold=0.5),
|
| 123 |
+
max_per_img=100,
|
| 124 |
+
mask_thr_binary=0.5)))
|
GenAD-main/projects/configs/_base_/models/paconv_cuda_ssg.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = './paconv_ssg.py'
|
| 2 |
+
|
| 3 |
+
model = dict(
|
| 4 |
+
backbone=dict(
|
| 5 |
+
sa_cfg=dict(
|
| 6 |
+
type='PAConvCUDASAModule',
|
| 7 |
+
scorenet_cfg=dict(mlp_channels=[8, 16, 16]))))
|
GenAD-main/projects/configs/_base_/models/paconv_ssg.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
model = dict(
|
| 3 |
+
type='EncoderDecoder3D',
|
| 4 |
+
backbone=dict(
|
| 5 |
+
type='PointNet2SASSG',
|
| 6 |
+
in_channels=9, # [xyz, rgb, normalized_xyz]
|
| 7 |
+
num_points=(1024, 256, 64, 16),
|
| 8 |
+
radius=(None, None, None, None), # use kNN instead of ball query
|
| 9 |
+
num_samples=(32, 32, 32, 32),
|
| 10 |
+
sa_channels=((32, 32, 64), (64, 64, 128), (128, 128, 256), (256, 256,
|
| 11 |
+
512)),
|
| 12 |
+
fp_channels=(),
|
| 13 |
+
norm_cfg=dict(type='BN2d', momentum=0.1),
|
| 14 |
+
sa_cfg=dict(
|
| 15 |
+
type='PAConvSAModule',
|
| 16 |
+
pool_mod='max',
|
| 17 |
+
use_xyz=True,
|
| 18 |
+
normalize_xyz=False,
|
| 19 |
+
paconv_num_kernels=[16, 16, 16],
|
| 20 |
+
paconv_kernel_input='w_neighbor',
|
| 21 |
+
scorenet_input='w_neighbor_dist',
|
| 22 |
+
scorenet_cfg=dict(
|
| 23 |
+
mlp_channels=[16, 16, 16],
|
| 24 |
+
score_norm='softmax',
|
| 25 |
+
temp_factor=1.0,
|
| 26 |
+
last_bn=False))),
|
| 27 |
+
decode_head=dict(
|
| 28 |
+
type='PAConvHead',
|
| 29 |
+
# PAConv model's decoder takes skip connections from beckbone
|
| 30 |
+
# different from PointNet++, it also concats input features in the last
|
| 31 |
+
# level of decoder, leading to `128 + 6` as the channel number
|
| 32 |
+
fp_channels=((768, 256, 256), (384, 256, 256), (320, 256, 128),
|
| 33 |
+
(128 + 6, 128, 128, 128)),
|
| 34 |
+
channels=128,
|
| 35 |
+
dropout_ratio=0.5,
|
| 36 |
+
conv_cfg=dict(type='Conv1d'),
|
| 37 |
+
norm_cfg=dict(type='BN1d'),
|
| 38 |
+
act_cfg=dict(type='ReLU'),
|
| 39 |
+
loss_decode=dict(
|
| 40 |
+
type='CrossEntropyLoss',
|
| 41 |
+
use_sigmoid=False,
|
| 42 |
+
class_weight=None, # should be modified with dataset
|
| 43 |
+
loss_weight=1.0)),
|
| 44 |
+
# correlation loss to regularize PAConv's kernel weights
|
| 45 |
+
loss_regularization=dict(
|
| 46 |
+
type='PAConvRegularizationLoss', reduction='sum', loss_weight=10.0),
|
| 47 |
+
# model training and testing settings
|
| 48 |
+
train_cfg=dict(),
|
| 49 |
+
test_cfg=dict(mode='slide'))
|
GenAD-main/projects/configs/_base_/models/parta2.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
voxel_size = [0.05, 0.05, 0.1]
|
| 3 |
+
point_cloud_range = [0, -40, -3, 70.4, 40, 1]
|
| 4 |
+
|
| 5 |
+
model = dict(
|
| 6 |
+
type='PartA2',
|
| 7 |
+
voxel_layer=dict(
|
| 8 |
+
max_num_points=5, # max_points_per_voxel
|
| 9 |
+
point_cloud_range=point_cloud_range,
|
| 10 |
+
voxel_size=voxel_size,
|
| 11 |
+
max_voxels=(16000, 40000) # (training, testing) max_voxels
|
| 12 |
+
),
|
| 13 |
+
voxel_encoder=dict(type='HardSimpleVFE'),
|
| 14 |
+
middle_encoder=dict(
|
| 15 |
+
type='SparseUNet',
|
| 16 |
+
in_channels=4,
|
| 17 |
+
sparse_shape=[41, 1600, 1408],
|
| 18 |
+
order=('conv', 'norm', 'act')),
|
| 19 |
+
backbone=dict(
|
| 20 |
+
type='SECOND',
|
| 21 |
+
in_channels=256,
|
| 22 |
+
layer_nums=[5, 5],
|
| 23 |
+
layer_strides=[1, 2],
|
| 24 |
+
out_channels=[128, 256]),
|
| 25 |
+
neck=dict(
|
| 26 |
+
type='SECONDFPN',
|
| 27 |
+
in_channels=[128, 256],
|
| 28 |
+
upsample_strides=[1, 2],
|
| 29 |
+
out_channels=[256, 256]),
|
| 30 |
+
rpn_head=dict(
|
| 31 |
+
type='PartA2RPNHead',
|
| 32 |
+
num_classes=3,
|
| 33 |
+
in_channels=512,
|
| 34 |
+
feat_channels=512,
|
| 35 |
+
use_direction_classifier=True,
|
| 36 |
+
anchor_generator=dict(
|
| 37 |
+
type='Anchor3DRangeGenerator',
|
| 38 |
+
ranges=[[0, -40.0, -0.6, 70.4, 40.0, -0.6],
|
| 39 |
+
[0, -40.0, -0.6, 70.4, 40.0, -0.6],
|
| 40 |
+
[0, -40.0, -1.78, 70.4, 40.0, -1.78]],
|
| 41 |
+
sizes=[[0.6, 0.8, 1.73], [0.6, 1.76, 1.73], [1.6, 3.9, 1.56]],
|
| 42 |
+
rotations=[0, 1.57],
|
| 43 |
+
reshape_out=False),
|
| 44 |
+
diff_rad_by_sin=True,
|
| 45 |
+
assigner_per_size=True,
|
| 46 |
+
assign_per_class=True,
|
| 47 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
|
| 48 |
+
loss_cls=dict(
|
| 49 |
+
type='FocalLoss',
|
| 50 |
+
use_sigmoid=True,
|
| 51 |
+
gamma=2.0,
|
| 52 |
+
alpha=0.25,
|
| 53 |
+
loss_weight=1.0),
|
| 54 |
+
loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=2.0),
|
| 55 |
+
loss_dir=dict(
|
| 56 |
+
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.2)),
|
| 57 |
+
roi_head=dict(
|
| 58 |
+
type='PartAggregationROIHead',
|
| 59 |
+
num_classes=3,
|
| 60 |
+
semantic_head=dict(
|
| 61 |
+
type='PointwiseSemanticHead',
|
| 62 |
+
in_channels=16,
|
| 63 |
+
extra_width=0.2,
|
| 64 |
+
seg_score_thr=0.3,
|
| 65 |
+
num_classes=3,
|
| 66 |
+
loss_seg=dict(
|
| 67 |
+
type='FocalLoss',
|
| 68 |
+
use_sigmoid=True,
|
| 69 |
+
reduction='sum',
|
| 70 |
+
gamma=2.0,
|
| 71 |
+
alpha=0.25,
|
| 72 |
+
loss_weight=1.0),
|
| 73 |
+
loss_part=dict(
|
| 74 |
+
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
|
| 75 |
+
seg_roi_extractor=dict(
|
| 76 |
+
type='Single3DRoIAwareExtractor',
|
| 77 |
+
roi_layer=dict(
|
| 78 |
+
type='RoIAwarePool3d',
|
| 79 |
+
out_size=14,
|
| 80 |
+
max_pts_per_voxel=128,
|
| 81 |
+
mode='max')),
|
| 82 |
+
part_roi_extractor=dict(
|
| 83 |
+
type='Single3DRoIAwareExtractor',
|
| 84 |
+
roi_layer=dict(
|
| 85 |
+
type='RoIAwarePool3d',
|
| 86 |
+
out_size=14,
|
| 87 |
+
max_pts_per_voxel=128,
|
| 88 |
+
mode='avg')),
|
| 89 |
+
bbox_head=dict(
|
| 90 |
+
type='PartA2BboxHead',
|
| 91 |
+
num_classes=3,
|
| 92 |
+
seg_in_channels=16,
|
| 93 |
+
part_in_channels=4,
|
| 94 |
+
seg_conv_channels=[64, 64],
|
| 95 |
+
part_conv_channels=[64, 64],
|
| 96 |
+
merge_conv_channels=[128, 128],
|
| 97 |
+
down_conv_channels=[128, 256],
|
| 98 |
+
bbox_coder=dict(type='DeltaXYZWLHRBBoxCoder'),
|
| 99 |
+
shared_fc_channels=[256, 512, 512, 512],
|
| 100 |
+
cls_channels=[256, 256],
|
| 101 |
+
reg_channels=[256, 256],
|
| 102 |
+
dropout_ratio=0.1,
|
| 103 |
+
roi_feat_size=14,
|
| 104 |
+
with_corner_loss=True,
|
| 105 |
+
loss_bbox=dict(
|
| 106 |
+
type='SmoothL1Loss',
|
| 107 |
+
beta=1.0 / 9.0,
|
| 108 |
+
reduction='sum',
|
| 109 |
+
loss_weight=1.0),
|
| 110 |
+
loss_cls=dict(
|
| 111 |
+
type='CrossEntropyLoss',
|
| 112 |
+
use_sigmoid=True,
|
| 113 |
+
reduction='sum',
|
| 114 |
+
loss_weight=1.0))),
|
| 115 |
+
# model training and testing settings
|
| 116 |
+
train_cfg=dict(
|
| 117 |
+
rpn=dict(
|
| 118 |
+
assigner=[
|
| 119 |
+
dict( # for Pedestrian
|
| 120 |
+
type='MaxIoUAssigner',
|
| 121 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 122 |
+
pos_iou_thr=0.5,
|
| 123 |
+
neg_iou_thr=0.35,
|
| 124 |
+
min_pos_iou=0.35,
|
| 125 |
+
ignore_iof_thr=-1),
|
| 126 |
+
dict( # for Cyclist
|
| 127 |
+
type='MaxIoUAssigner',
|
| 128 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 129 |
+
pos_iou_thr=0.5,
|
| 130 |
+
neg_iou_thr=0.35,
|
| 131 |
+
min_pos_iou=0.35,
|
| 132 |
+
ignore_iof_thr=-1),
|
| 133 |
+
dict( # for Car
|
| 134 |
+
type='MaxIoUAssigner',
|
| 135 |
+
iou_calculator=dict(type='BboxOverlapsNearest3D'),
|
| 136 |
+
pos_iou_thr=0.6,
|
| 137 |
+
neg_iou_thr=0.45,
|
| 138 |
+
min_pos_iou=0.45,
|
| 139 |
+
ignore_iof_thr=-1)
|
| 140 |
+
],
|
| 141 |
+
allowed_border=0,
|
| 142 |
+
pos_weight=-1,
|
| 143 |
+
debug=False),
|
| 144 |
+
rpn_proposal=dict(
|
| 145 |
+
nms_pre=9000,
|
| 146 |
+
nms_post=512,
|
| 147 |
+
max_num=512,
|
| 148 |
+
nms_thr=0.8,
|
| 149 |
+
score_thr=0,
|
| 150 |
+
use_rotate_nms=False),
|
| 151 |
+
rcnn=dict(
|
| 152 |
+
assigner=[
|
| 153 |
+
dict( # for Pedestrian
|
| 154 |
+
type='MaxIoUAssigner',
|
| 155 |
+
iou_calculator=dict(
|
| 156 |
+
type='BboxOverlaps3D', coordinate='lidar'),
|
| 157 |
+
pos_iou_thr=0.55,
|
| 158 |
+
neg_iou_thr=0.55,
|
| 159 |
+
min_pos_iou=0.55,
|
| 160 |
+
ignore_iof_thr=-1),
|
| 161 |
+
dict( # for Cyclist
|
| 162 |
+
type='MaxIoUAssigner',
|
| 163 |
+
iou_calculator=dict(
|
| 164 |
+
type='BboxOverlaps3D', coordinate='lidar'),
|
| 165 |
+
pos_iou_thr=0.55,
|
| 166 |
+
neg_iou_thr=0.55,
|
| 167 |
+
min_pos_iou=0.55,
|
| 168 |
+
ignore_iof_thr=-1),
|
| 169 |
+
dict( # for Car
|
| 170 |
+
type='MaxIoUAssigner',
|
| 171 |
+
iou_calculator=dict(
|
| 172 |
+
type='BboxOverlaps3D', coordinate='lidar'),
|
| 173 |
+
pos_iou_thr=0.55,
|
| 174 |
+
neg_iou_thr=0.55,
|
| 175 |
+
min_pos_iou=0.55,
|
| 176 |
+
ignore_iof_thr=-1)
|
| 177 |
+
],
|
| 178 |
+
sampler=dict(
|
| 179 |
+
type='IoUNegPiecewiseSampler',
|
| 180 |
+
num=128,
|
| 181 |
+
pos_fraction=0.55,
|
| 182 |
+
neg_piece_fractions=[0.8, 0.2],
|
| 183 |
+
neg_iou_piece_thrs=[0.55, 0.1],
|
| 184 |
+
neg_pos_ub=-1,
|
| 185 |
+
add_gt_as_proposals=False,
|
| 186 |
+
return_iou=True),
|
| 187 |
+
cls_pos_thr=0.75,
|
| 188 |
+
cls_neg_thr=0.25)),
|
| 189 |
+
test_cfg=dict(
|
| 190 |
+
rpn=dict(
|
| 191 |
+
nms_pre=1024,
|
| 192 |
+
nms_post=100,
|
| 193 |
+
max_num=100,
|
| 194 |
+
nms_thr=0.7,
|
| 195 |
+
score_thr=0,
|
| 196 |
+
use_rotate_nms=True),
|
| 197 |
+
rcnn=dict(
|
| 198 |
+
use_rotate_nms=True,
|
| 199 |
+
use_raw_score=True,
|
| 200 |
+
nms_thr=0.01,
|
| 201 |
+
score_thr=0.1)))
|
GenAD-main/projects/configs/_base_/models/pointnet2_msg.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = './pointnet2_ssg.py'
|
| 2 |
+
|
| 3 |
+
# model settings
|
| 4 |
+
model = dict(
|
| 5 |
+
backbone=dict(
|
| 6 |
+
_delete_=True,
|
| 7 |
+
type='PointNet2SAMSG',
|
| 8 |
+
in_channels=6, # [xyz, rgb], should be modified with dataset
|
| 9 |
+
num_points=(1024, 256, 64, 16),
|
| 10 |
+
radii=((0.05, 0.1), (0.1, 0.2), (0.2, 0.4), (0.4, 0.8)),
|
| 11 |
+
num_samples=((16, 32), (16, 32), (16, 32), (16, 32)),
|
| 12 |
+
sa_channels=(((16, 16, 32), (32, 32, 64)), ((64, 64, 128), (64, 96,
|
| 13 |
+
128)),
|
| 14 |
+
((128, 196, 256), (128, 196, 256)), ((256, 256, 512),
|
| 15 |
+
(256, 384, 512))),
|
| 16 |
+
aggregation_channels=(None, None, None, None),
|
| 17 |
+
fps_mods=(('D-FPS'), ('D-FPS'), ('D-FPS'), ('D-FPS')),
|
| 18 |
+
fps_sample_range_lists=((-1), (-1), (-1), (-1)),
|
| 19 |
+
dilated_group=(False, False, False, False),
|
| 20 |
+
out_indices=(0, 1, 2, 3),
|
| 21 |
+
sa_cfg=dict(
|
| 22 |
+
type='PointSAModuleMSG',
|
| 23 |
+
pool_mod='max',
|
| 24 |
+
use_xyz=True,
|
| 25 |
+
normalize_xyz=False)),
|
| 26 |
+
decode_head=dict(
|
| 27 |
+
fp_channels=((1536, 256, 256), (512, 256, 256), (352, 256, 128),
|
| 28 |
+
(128, 128, 128, 128))))
|
GenAD-main/projects/configs/_base_/models/pointnet2_ssg.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# model settings
|
| 2 |
+
model = dict(
|
| 3 |
+
type='EncoderDecoder3D',
|
| 4 |
+
backbone=dict(
|
| 5 |
+
type='PointNet2SASSG',
|
| 6 |
+
in_channels=6, # [xyz, rgb], should be modified with dataset
|
| 7 |
+
num_points=(1024, 256, 64, 16),
|
| 8 |
+
radius=(0.1, 0.2, 0.4, 0.8),
|
| 9 |
+
num_samples=(32, 32, 32, 32),
|
| 10 |
+
sa_channels=((32, 32, 64), (64, 64, 128), (128, 128, 256), (256, 256,
|
| 11 |
+
512)),
|
| 12 |
+
fp_channels=(),
|
| 13 |
+
norm_cfg=dict(type='BN2d'),
|
| 14 |
+
sa_cfg=dict(
|
| 15 |
+
type='PointSAModule',
|
| 16 |
+
pool_mod='max',
|
| 17 |
+
use_xyz=True,
|
| 18 |
+
normalize_xyz=False)),
|
| 19 |
+
decode_head=dict(
|
| 20 |
+
type='PointNet2Head',
|
| 21 |
+
fp_channels=((768, 256, 256), (384, 256, 256), (320, 256, 128),
|
| 22 |
+
(128, 128, 128, 128)),
|
| 23 |
+
channels=128,
|
| 24 |
+
dropout_ratio=0.5,
|
| 25 |
+
conv_cfg=dict(type='Conv1d'),
|
| 26 |
+
norm_cfg=dict(type='BN1d'),
|
| 27 |
+
act_cfg=dict(type='ReLU'),
|
| 28 |
+
loss_decode=dict(
|
| 29 |
+
type='CrossEntropyLoss',
|
| 30 |
+
use_sigmoid=False,
|
| 31 |
+
class_weight=None, # should be modified with dataset
|
| 32 |
+
loss_weight=1.0)),
|
| 33 |
+
# model training and testing settings
|
| 34 |
+
train_cfg=dict(),
|
| 35 |
+
test_cfg=dict(mode='slide'))
|
GenAD-main/projects/configs/_base_/models/votenet.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model = dict(
|
| 2 |
+
type='VoteNet',
|
| 3 |
+
backbone=dict(
|
| 4 |
+
type='PointNet2SASSG',
|
| 5 |
+
in_channels=4,
|
| 6 |
+
num_points=(2048, 1024, 512, 256),
|
| 7 |
+
radius=(0.2, 0.4, 0.8, 1.2),
|
| 8 |
+
num_samples=(64, 32, 16, 16),
|
| 9 |
+
sa_channels=((64, 64, 128), (128, 128, 256), (128, 128, 256),
|
| 10 |
+
(128, 128, 256)),
|
| 11 |
+
fp_channels=((256, 256), (256, 256)),
|
| 12 |
+
norm_cfg=dict(type='BN2d'),
|
| 13 |
+
sa_cfg=dict(
|
| 14 |
+
type='PointSAModule',
|
| 15 |
+
pool_mod='max',
|
| 16 |
+
use_xyz=True,
|
| 17 |
+
normalize_xyz=True)),
|
| 18 |
+
bbox_head=dict(
|
| 19 |
+
type='VoteHead',
|
| 20 |
+
vote_module_cfg=dict(
|
| 21 |
+
in_channels=256,
|
| 22 |
+
vote_per_seed=1,
|
| 23 |
+
gt_per_seed=3,
|
| 24 |
+
conv_channels=(256, 256),
|
| 25 |
+
conv_cfg=dict(type='Conv1d'),
|
| 26 |
+
norm_cfg=dict(type='BN1d'),
|
| 27 |
+
norm_feats=True,
|
| 28 |
+
vote_loss=dict(
|
| 29 |
+
type='ChamferDistance',
|
| 30 |
+
mode='l1',
|
| 31 |
+
reduction='none',
|
| 32 |
+
loss_dst_weight=10.0)),
|
| 33 |
+
vote_aggregation_cfg=dict(
|
| 34 |
+
type='PointSAModule',
|
| 35 |
+
num_point=256,
|
| 36 |
+
radius=0.3,
|
| 37 |
+
num_sample=16,
|
| 38 |
+
mlp_channels=[256, 128, 128, 128],
|
| 39 |
+
use_xyz=True,
|
| 40 |
+
normalize_xyz=True),
|
| 41 |
+
pred_layer_cfg=dict(
|
| 42 |
+
in_channels=128, shared_conv_channels=(128, 128), bias=True),
|
| 43 |
+
conv_cfg=dict(type='Conv1d'),
|
| 44 |
+
norm_cfg=dict(type='BN1d'),
|
| 45 |
+
objectness_loss=dict(
|
| 46 |
+
type='CrossEntropyLoss',
|
| 47 |
+
class_weight=[0.2, 0.8],
|
| 48 |
+
reduction='sum',
|
| 49 |
+
loss_weight=5.0),
|
| 50 |
+
center_loss=dict(
|
| 51 |
+
type='ChamferDistance',
|
| 52 |
+
mode='l2',
|
| 53 |
+
reduction='sum',
|
| 54 |
+
loss_src_weight=10.0,
|
| 55 |
+
loss_dst_weight=10.0),
|
| 56 |
+
dir_class_loss=dict(
|
| 57 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 58 |
+
dir_res_loss=dict(
|
| 59 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0),
|
| 60 |
+
size_class_loss=dict(
|
| 61 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0),
|
| 62 |
+
size_res_loss=dict(
|
| 63 |
+
type='SmoothL1Loss', reduction='sum', loss_weight=10.0 / 3.0),
|
| 64 |
+
semantic_loss=dict(
|
| 65 |
+
type='CrossEntropyLoss', reduction='sum', loss_weight=1.0)),
|
| 66 |
+
# model training and testing settings
|
| 67 |
+
train_cfg=dict(
|
| 68 |
+
pos_distance_thr=0.3, neg_distance_thr=0.6, sample_mod='vote'),
|
| 69 |
+
test_cfg=dict(
|
| 70 |
+
sample_mod='seed',
|
| 71 |
+
nms_thr=0.25,
|
| 72 |
+
score_thr=0.05,
|
| 73 |
+
per_class_proposal=True))
|