Spaces:
Sleeping

Sleeping
Upload 337 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- obsei_module/.github/ISSUE_TEMPLATE/bug_report.md +27 -0
- obsei_module/.github/ISSUE_TEMPLATE/feature_request.md +20 -0
- obsei_module/.github/dependabot.yml +7 -0
- obsei_module/.github/release-drafter.yml +33 -0
- obsei_module/.github/workflows/build.yml +54 -0
- obsei_module/.github/workflows/pypi_publish.yml +35 -0
- obsei_module/.github/workflows/release_draft.yml +15 -0
- obsei_module/.github/workflows/sdk_docker_publish.yml +50 -0
- obsei_module/.github/workflows/ui_docker_publish.yml +50 -0
- obsei_module/.gitignore +148 -0
- obsei_module/.pre-commit-config.yaml +21 -0
- obsei_module/.pyup.yml +5 -0
- obsei_module/ATTRIBUTION.md +18 -0
- obsei_module/CITATION.cff +14 -0
- obsei_module/CNAME +1 -0
- obsei_module/CODE_OF_CONDUCT.md +128 -0
- obsei_module/CONTRIBUTING.md +103 -0
- obsei_module/CONTRIBUTOR_LICENSE_AGREEMENT.md +3 -0
- obsei_module/Dockerfile +38 -0
- obsei_module/LICENSE +201 -0
- obsei_module/MANIFEST.in +3 -0
- obsei_module/README.md +1067 -0
- obsei_module/SECURITY.md +5 -0
- obsei_module/__init__.py +0 -0
- obsei_module/__pycache__/__init__.cpython-311.pyc +0 -0
- obsei_module/_config.yml +9 -0
- obsei_module/_includes/head-custom-google-analytics.html +9 -0
- obsei_module/binder/requirements.txt +2 -0
- obsei_module/example/app_store_scrapper_example.py +41 -0
- obsei_module/example/daily_get_example.py +77 -0
- obsei_module/example/elasticsearch_example.py +69 -0
- obsei_module/example/email_source_example.py +36 -0
- obsei_module/example/facebook_example.py +19 -0
- obsei_module/example/google_news_example.py +58 -0
- obsei_module/example/jira_example.py +77 -0
- obsei_module/example/maps_review_scrapper_example.py +22 -0
- obsei_module/example/pandas_sink_example.py +49 -0
- obsei_module/example/pandas_source_example.py +27 -0
- obsei_module/example/pii_analyzer_example.py +33 -0
- obsei_module/example/play_store_reviews_example.py +4 -0
- obsei_module/example/playstore_scrapper_example.py +40 -0
- obsei_module/example/playstore_scrapper_translator_example.py +86 -0
- obsei_module/example/reddit_example.py +50 -0
- obsei_module/example/reddit_scrapper_example.py +30 -0
- obsei_module/example/sdk.yaml +97 -0
- obsei_module/example/slack_example.py +66 -0
- obsei_module/example/twitter_source_example.py +98 -0
- obsei_module/example/web_crawler_example.py +43 -0
- obsei_module/example/with_sdk_config_file.py +28 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
obsei_module/images/obsei_flow.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
obsei_module/obsei-master/images/obsei_flow.gif filter=lfs diff=lfs merge=lfs -text
|
obsei_module/.github/ISSUE_TEMPLATE/bug_report.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Bug report
|
| 3 |
+
about: Create a report to help us improve
|
| 4 |
+
title: "[BUG]"
|
| 5 |
+
labels: bug
|
| 6 |
+
assignees: lalitpagaria
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Describe the bug**
|
| 11 |
+
A clear and concise description of what the bug is.
|
| 12 |
+
|
| 13 |
+
**To Reproduce**
|
| 14 |
+
Steps to reproduce the behavior:
|
| 15 |
+
|
| 16 |
+
**Expected behavior**
|
| 17 |
+
A clear and concise description of what you expected to happen.
|
| 18 |
+
|
| 19 |
+
**Stacktrace**
|
| 20 |
+
If applicable, add stacktrace to help explain your problem.
|
| 21 |
+
|
| 22 |
+
**Please complete the following information:**
|
| 23 |
+
- OS:
|
| 24 |
+
- Version:
|
| 25 |
+
|
| 26 |
+
**Additional context**
|
| 27 |
+
Add any other context about the problem here.
|
obsei_module/.github/ISSUE_TEMPLATE/feature_request.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Feature request
|
| 3 |
+
about: Suggest an idea for this project
|
| 4 |
+
title: ''
|
| 5 |
+
labels: enhancement
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Is your feature request related to a problem? Please describe.**
|
| 11 |
+
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
| 12 |
+
|
| 13 |
+
**Describe the solution you'd like**
|
| 14 |
+
A clear and concise description of what you want to happen.
|
| 15 |
+
|
| 16 |
+
**Describe alternatives you've considered**
|
| 17 |
+
A clear and concise description of any alternative solutions or features you've considered.
|
| 18 |
+
|
| 19 |
+
**Additional context**
|
| 20 |
+
Add any other context or screenshots about the feature request here.
|
obsei_module/.github/dependabot.yml
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2
|
| 2 |
+
updates:
|
| 3 |
+
# Maintain dependencies for GitHub Actions
|
| 4 |
+
- package-ecosystem: "github-actions"
|
| 5 |
+
directory: "/"
|
| 6 |
+
schedule:
|
| 7 |
+
interval: "daily"
|
obsei_module/.github/release-drafter.yml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name-template: 'v$RESOLVED_VERSION 🌈'
|
| 2 |
+
tag-template: 'v$RESOLVED_VERSION'
|
| 3 |
+
categories:
|
| 4 |
+
- title: '🚀 Features'
|
| 5 |
+
labels:
|
| 6 |
+
- 'feature'
|
| 7 |
+
- 'enhancement'
|
| 8 |
+
- title: '🐛 Bug Fixes'
|
| 9 |
+
labels:
|
| 10 |
+
- 'fix'
|
| 11 |
+
- 'bugfix'
|
| 12 |
+
- 'bug'
|
| 13 |
+
- title: '🧰 Maintenance'
|
| 14 |
+
label: 'chore'
|
| 15 |
+
- title: '⚠️Breaking Changes'
|
| 16 |
+
label: 'breaking changes'
|
| 17 |
+
change-template: '- $TITLE @$AUTHOR (#$NUMBER)'
|
| 18 |
+
change-title-escapes: '\<*_&' # You can add # and @ to disable mentions, and add ` to disable code blocks.
|
| 19 |
+
version-resolver:
|
| 20 |
+
major:
|
| 21 |
+
labels:
|
| 22 |
+
- 'major'
|
| 23 |
+
minor:
|
| 24 |
+
labels:
|
| 25 |
+
- 'minor'
|
| 26 |
+
patch:
|
| 27 |
+
labels:
|
| 28 |
+
- 'patch'
|
| 29 |
+
default: patch
|
| 30 |
+
template: |
|
| 31 |
+
## Changes
|
| 32 |
+
|
| 33 |
+
$CHANGES
|
obsei_module/.github/workflows/build.yml
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This workflow will install Python dependencies, run test and lint with a single version of Python
|
| 2 |
+
# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
|
| 3 |
+
|
| 4 |
+
name: CI
|
| 5 |
+
|
| 6 |
+
on:
|
| 7 |
+
push:
|
| 8 |
+
branches: [ master ]
|
| 9 |
+
pull_request:
|
| 10 |
+
branches: [ master ]
|
| 11 |
+
|
| 12 |
+
jobs:
|
| 13 |
+
type-check:
|
| 14 |
+
runs-on: ubuntu-latest
|
| 15 |
+
steps:
|
| 16 |
+
- uses: actions/checkout@v4
|
| 17 |
+
- uses: actions/setup-python@v5
|
| 18 |
+
with:
|
| 19 |
+
python-version: '3.10'
|
| 20 |
+
- name: Test with mypy
|
| 21 |
+
run: |
|
| 22 |
+
pip install mypy
|
| 23 |
+
# Refer http://mypy-lang.blogspot.com/2021/06/mypy-0900-released.html
|
| 24 |
+
pip install mypy types-requests types-python-dateutil types-PyYAML types-dateparser types-protobuf types-pytz
|
| 25 |
+
mypy obsei
|
| 26 |
+
|
| 27 |
+
build-and-test:
|
| 28 |
+
needs: type-check
|
| 29 |
+
runs-on: ${{ matrix.os }}
|
| 30 |
+
strategy:
|
| 31 |
+
fail-fast: false
|
| 32 |
+
matrix:
|
| 33 |
+
os: [ ubuntu-latest, macos-latest, windows-latest ]
|
| 34 |
+
python-version: ['3.8', '3.9', '3.10', '3.11']
|
| 35 |
+
|
| 36 |
+
steps:
|
| 37 |
+
- uses: actions/checkout@v4
|
| 38 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 39 |
+
uses: actions/setup-python@v5
|
| 40 |
+
with:
|
| 41 |
+
python-version: ${{ matrix.python-version }}
|
| 42 |
+
|
| 43 |
+
- name: Install dependencies
|
| 44 |
+
run: |
|
| 45 |
+
python -m pip install --upgrade pip
|
| 46 |
+
pip install '.[dev,all]'
|
| 47 |
+
pip install --upgrade --upgrade-strategy eager trafilatura
|
| 48 |
+
python -m spacy download en_core_web_lg
|
| 49 |
+
python -m spacy download en_core_web_sm
|
| 50 |
+
|
| 51 |
+
- name: Test with pytest
|
| 52 |
+
run: |
|
| 53 |
+
coverage run -m pytest
|
| 54 |
+
coverage report -m
|
obsei_module/.github/workflows/pypi_publish.yml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This workflows will upload a Python Package using Twine when a release is created
|
| 2 |
+
# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
|
| 3 |
+
|
| 4 |
+
name: Upload Python Package
|
| 5 |
+
|
| 6 |
+
on:
|
| 7 |
+
workflow_dispatch:
|
| 8 |
+
release:
|
| 9 |
+
types: [published]
|
| 10 |
+
|
| 11 |
+
jobs:
|
| 12 |
+
deploy-pypi-artifact:
|
| 13 |
+
runs-on: ubuntu-latest
|
| 14 |
+
|
| 15 |
+
steps:
|
| 16 |
+
- uses: actions/checkout@v4
|
| 17 |
+
|
| 18 |
+
- name: Set up Python
|
| 19 |
+
uses: actions/setup-python@v5
|
| 20 |
+
with:
|
| 21 |
+
python-version: '3.8'
|
| 22 |
+
|
| 23 |
+
- name: Install dependencies
|
| 24 |
+
run: |
|
| 25 |
+
python -m pip install --upgrade pip
|
| 26 |
+
pip install setuptools wheel twine hatch
|
| 27 |
+
|
| 28 |
+
- name: publish to PyPI
|
| 29 |
+
if: github.event_name != 'pull_request'
|
| 30 |
+
env:
|
| 31 |
+
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
| 32 |
+
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
| 33 |
+
run: |
|
| 34 |
+
hatch build
|
| 35 |
+
twine upload dist/*
|
obsei_module/.github/workflows/release_draft.yml
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: release draft
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
workflow_dispatch:
|
| 5 |
+
|
| 6 |
+
jobs:
|
| 7 |
+
draft-release:
|
| 8 |
+
# if: startsWith(github.ref, 'refs/tags/')
|
| 9 |
+
runs-on: ubuntu-latest
|
| 10 |
+
steps:
|
| 11 |
+
- uses: release-drafter/release-drafter@v6
|
| 12 |
+
with:
|
| 13 |
+
config-name: release-drafter.yml
|
| 14 |
+
env:
|
| 15 |
+
GITHUB_TOKEN: ${{ secrets.RELEASE_DRAFT_TOKEN }}
|
obsei_module/.github/workflows/sdk_docker_publish.yml
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This workflows will upload a Python Package using Twine when a release is created
|
| 2 |
+
# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
|
| 3 |
+
|
| 4 |
+
name: Publish SDK docker image
|
| 5 |
+
|
| 6 |
+
on:
|
| 7 |
+
workflow_dispatch:
|
| 8 |
+
inputs:
|
| 9 |
+
tag:
|
| 10 |
+
description: 'Image tag'
|
| 11 |
+
required: true
|
| 12 |
+
release:
|
| 13 |
+
types: [published]
|
| 14 |
+
|
| 15 |
+
jobs:
|
| 16 |
+
deploy-sdk-docker:
|
| 17 |
+
runs-on: ubuntu-latest
|
| 18 |
+
steps:
|
| 19 |
+
- uses: actions/checkout@v4
|
| 20 |
+
|
| 21 |
+
- name: Docker meta
|
| 22 |
+
id: docker_meta
|
| 23 |
+
uses: docker/metadata-action@v5
|
| 24 |
+
with:
|
| 25 |
+
images: obsei/obsei-sdk
|
| 26 |
+
|
| 27 |
+
- name: Set up QEMU
|
| 28 |
+
uses: docker/setup-qemu-action@v3
|
| 29 |
+
|
| 30 |
+
- name: Set up Docker Buildx
|
| 31 |
+
uses: docker/setup-buildx-action@v3
|
| 32 |
+
|
| 33 |
+
- name: Login to DockerHub
|
| 34 |
+
if: github.event_name != 'pull_request'
|
| 35 |
+
uses: docker/login-action@v3
|
| 36 |
+
with:
|
| 37 |
+
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
| 38 |
+
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
| 39 |
+
|
| 40 |
+
- name: Build and push
|
| 41 |
+
uses: docker/build-push-action@v5
|
| 42 |
+
with:
|
| 43 |
+
context: ./
|
| 44 |
+
file: ./Dockerfile
|
| 45 |
+
push: ${{ github.event_name != 'pull_request' }}
|
| 46 |
+
tags: ${{ steps.docker_meta.outputs.tags }}
|
| 47 |
+
labels: ${{ steps.docker_meta.outputs.labels }}
|
| 48 |
+
|
| 49 |
+
- name: Image digest
|
| 50 |
+
run: echo ${{ steps.docker_build.outputs.digest }}
|
obsei_module/.github/workflows/ui_docker_publish.yml
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This workflows will upload a Python Package using Twine when a release is created
|
| 2 |
+
# For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
|
| 3 |
+
|
| 4 |
+
name: Publish UI Docker image
|
| 5 |
+
|
| 6 |
+
on:
|
| 7 |
+
workflow_dispatch:
|
| 8 |
+
inputs:
|
| 9 |
+
tag:
|
| 10 |
+
description: 'Image tag'
|
| 11 |
+
required: true
|
| 12 |
+
release:
|
| 13 |
+
types: [published]
|
| 14 |
+
|
| 15 |
+
jobs:
|
| 16 |
+
deploy-ui-docker:
|
| 17 |
+
runs-on: ubuntu-latest
|
| 18 |
+
steps:
|
| 19 |
+
- uses: actions/checkout@v4
|
| 20 |
+
|
| 21 |
+
- name: Docker meta
|
| 22 |
+
id: docker_meta
|
| 23 |
+
uses: docker/metadata-action@v5
|
| 24 |
+
with:
|
| 25 |
+
images: obsei/obsei-ui-demo
|
| 26 |
+
|
| 27 |
+
- name: Set up QEMU
|
| 28 |
+
uses: docker/setup-qemu-action@v3
|
| 29 |
+
|
| 30 |
+
- name: Set up Docker Buildx
|
| 31 |
+
uses: docker/setup-buildx-action@v3
|
| 32 |
+
|
| 33 |
+
- name: Login to DockerHub
|
| 34 |
+
if: github.event_name != 'pull_request'
|
| 35 |
+
uses: docker/login-action@v3
|
| 36 |
+
with:
|
| 37 |
+
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
| 38 |
+
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
| 39 |
+
|
| 40 |
+
- name: Build and push
|
| 41 |
+
uses: docker/build-push-action@v5
|
| 42 |
+
with:
|
| 43 |
+
context: "{{defaultContext}}:sample-ui"
|
| 44 |
+
file: Dockerfile
|
| 45 |
+
push: ${{ github.event_name != 'pull_request' }}
|
| 46 |
+
tags: ${{ steps.docker_meta.outputs.tags }}
|
| 47 |
+
labels: ${{ steps.docker_meta.outputs.labels }}
|
| 48 |
+
|
| 49 |
+
- name: Image digest
|
| 50 |
+
run: echo ${{ steps.docker_build.outputs.digest }}
|
obsei_module/.gitignore
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 98 |
+
__pypackages__/
|
| 99 |
+
|
| 100 |
+
# Celery stuff
|
| 101 |
+
celerybeat-schedule
|
| 102 |
+
celerybeat.pid
|
| 103 |
+
|
| 104 |
+
# SageMath parsed files
|
| 105 |
+
*.sage.py
|
| 106 |
+
|
| 107 |
+
# Environments
|
| 108 |
+
.env
|
| 109 |
+
.venv
|
| 110 |
+
env/
|
| 111 |
+
venv/
|
| 112 |
+
ENV/
|
| 113 |
+
env.bak/
|
| 114 |
+
venv.bak/
|
| 115 |
+
|
| 116 |
+
# Spyder project settings
|
| 117 |
+
.spyderproject
|
| 118 |
+
.spyproject
|
| 119 |
+
|
| 120 |
+
# Rope project settings
|
| 121 |
+
.ropeproject
|
| 122 |
+
|
| 123 |
+
# mkdocs documentation
|
| 124 |
+
/site
|
| 125 |
+
|
| 126 |
+
# mypy
|
| 127 |
+
.mypy_cache/
|
| 128 |
+
.dmypy.json
|
| 129 |
+
dmypy.json
|
| 130 |
+
|
| 131 |
+
# Pyre type checker
|
| 132 |
+
.pyre/
|
| 133 |
+
|
| 134 |
+
# pytype static type analyzer
|
| 135 |
+
.pytype/
|
| 136 |
+
|
| 137 |
+
# Cython debug symbols
|
| 138 |
+
cython_debug/
|
| 139 |
+
|
| 140 |
+
/.idea/*
|
| 141 |
+
*.db
|
| 142 |
+
models*
|
| 143 |
+
|
| 144 |
+
# OSX custom attributes
|
| 145 |
+
.DS_Store
|
| 146 |
+
|
| 147 |
+
# VS code configuration
|
| 148 |
+
.vscode/*
|
obsei_module/.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
repos:
|
| 2 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 3 |
+
rev: v4.3.0
|
| 4 |
+
hooks:
|
| 5 |
+
- id: check-yaml
|
| 6 |
+
- id: trailing-whitespace
|
| 7 |
+
- id: requirements-txt-fixer
|
| 8 |
+
- id: end-of-file-fixer
|
| 9 |
+
|
| 10 |
+
- repo: https://github.com/psf/black
|
| 11 |
+
rev: 22.10.0
|
| 12 |
+
hooks:
|
| 13 |
+
- id: black
|
| 14 |
+
|
| 15 |
+
- repo: https://github.com/pre-commit/mirrors-mypy
|
| 16 |
+
rev: v0.991
|
| 17 |
+
hooks:
|
| 18 |
+
- id: mypy
|
| 19 |
+
args: [--ignore-missing-imports]
|
| 20 |
+
additional_dependencies: [types-all]
|
| 21 |
+
files: ^obsei/
|
obsei_module/.pyup.yml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# autogenerated pyup.io config file
|
| 2 |
+
# see https://pyup.io/docs/configuration/ for all available options
|
| 3 |
+
|
| 4 |
+
schedule: ''
|
| 5 |
+
update: insecure
|
obsei_module/ATTRIBUTION.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This could not have been possible without following open source software -
|
| 2 |
+
- [searchtweets-v2](https://github.com/twitterdev/search-tweets-python): For Twitter's API v2 wrapper
|
| 3 |
+
- [vaderSentiment](https://github.com/cjhutto/vaderSentiment): For rule-based sentiment analysis
|
| 4 |
+
- [transformers](https://github.com/huggingface/transformers): For text-classification pipeline
|
| 5 |
+
- [atlassian-python-api](https://github.com/atlassian-api/atlassian-python-api): To interact with Jira
|
| 6 |
+
- [elasticsearch](https://github.com/elastic/elasticsearch-py): To interact with Elasticsearch
|
| 7 |
+
- [pydantic](https://github.com/samuelcolvin/pydantic): For data validation
|
| 8 |
+
- [sqlalchemy](https://github.com/sqlalchemy/sqlalchemy): As SQL toolkit to access DB storage
|
| 9 |
+
- [google-play-scraper](https://github.com/JoMingyu/google-play-scraper): To fetch the Google Play Store review without authentication
|
| 10 |
+
- [praw](https://github.com/praw-dev/praw): For Reddit client
|
| 11 |
+
- [reddit-rss-reader](https://github.com/lalitpagaria/reddit-rss-reader): For Reddit scrapping
|
| 12 |
+
- [app-store-reviews-reader](https://github.com/lalitpagaria/app_store_reviews_reader): For App Store reviews scrapping
|
| 13 |
+
- [slack-sdk](https://github.com/slackapi/python-slack-sdk): For slack integration
|
| 14 |
+
- [presidio-anonymizer](https://github.com/microsoft/presidio): Personal information anonymizer
|
| 15 |
+
- [GoogleNews](https://github.com/Iceloof/GoogleNews): For Google News integration
|
| 16 |
+
- [python-facebook-api](https://github.com/sns-sdks/python-facebook): For facebook integration
|
| 17 |
+
- [youtube-comment-downloader](https://github.com/egbertbouman/youtube-comment-downloader): For Youtube video comments extraction code
|
| 18 |
+
- [dateparser](https://github.com/scrapinghub/dateparser): To parse date properly (where format is ambiguous)
|
obsei_module/CITATION.cff
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YAML 1.2
|
| 2 |
+
---
|
| 3 |
+
authors:
|
| 4 |
+
-
|
| 5 |
+
family-names: Pagaria
|
| 6 |
+
given-names: Lalit
|
| 7 |
+
|
| 8 |
+
cff-version: "1.1.0"
|
| 9 |
+
license: "Apache-2.0"
|
| 10 |
+
message: "If you use this software, please cite it using this metadata."
|
| 11 |
+
repository-code: "https://github.com/obsei/obsei"
|
| 12 |
+
title: "Obsei - a low code AI powered automation tool"
|
| 13 |
+
version: "0.0.10"
|
| 14 |
+
...
|
obsei_module/CNAME
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
www.obsei.com
|
obsei_module/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributor Covenant Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
We as members, contributors, and leaders pledge to make participation in our
|
| 6 |
+
community a harassment-free experience for everyone, regardless of age, body
|
| 7 |
+
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
| 8 |
+
identity and expression, level of experience, education, socio-economic status,
|
| 9 |
+
nationality, personal appearance, race, religion, or sexual identity
|
| 10 |
+
and orientation.
|
| 11 |
+
|
| 12 |
+
We pledge to act and interact in ways that contribute to an open, welcoming,
|
| 13 |
+
diverse, inclusive, and healthy community.
|
| 14 |
+
|
| 15 |
+
## Our Standards
|
| 16 |
+
|
| 17 |
+
Examples of behavior that contributes to a positive environment for our
|
| 18 |
+
community include:
|
| 19 |
+
|
| 20 |
+
- Demonstrating empathy and kindness toward other people
|
| 21 |
+
- Being respectful of differing opinions, viewpoints, and experiences
|
| 22 |
+
- Giving and gracefully accepting constructive feedback
|
| 23 |
+
- Accepting responsibility and apologizing to those affected by our mistakes,
|
| 24 |
+
and learning from the experience
|
| 25 |
+
- Focusing on what is best not just for us as individuals, but for the
|
| 26 |
+
overall community
|
| 27 |
+
|
| 28 |
+
Examples of unacceptable behavior include:
|
| 29 |
+
|
| 30 |
+
- The use of sexualized language or imagery, and sexual attention or
|
| 31 |
+
advances of any kind
|
| 32 |
+
- Trolling, insulting or derogatory comments, and personal or political attacks
|
| 33 |
+
- Public or private harassment
|
| 34 |
+
- Publishing others' private information, such as a physical or email
|
| 35 |
+
address, without their explicit permission
|
| 36 |
+
- Other conduct which could reasonably be considered inappropriate in a
|
| 37 |
+
professional setting
|
| 38 |
+
|
| 39 |
+
## Enforcement Responsibilities
|
| 40 |
+
|
| 41 |
+
Community leaders are responsible for clarifying and enforcing our standards of
|
| 42 |
+
acceptable behavior and will take appropriate and fair corrective action in
|
| 43 |
+
response to any behavior that they deem inappropriate, threatening, offensive,
|
| 44 |
+
or harmful.
|
| 45 |
+
|
| 46 |
+
Community leaders have the right and responsibility to remove, edit, or reject
|
| 47 |
+
comments, commits, code, wiki edits, issues, and other contributions that are
|
| 48 |
+
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
| 49 |
+
decisions when appropriate.
|
| 50 |
+
|
| 51 |
+
## Scope
|
| 52 |
+
|
| 53 |
+
This Code of Conduct applies within all community spaces, and also applies when
|
| 54 |
+
an individual is officially representing the community in public spaces.
|
| 55 |
+
Examples of representing our community include using an official e-mail address,
|
| 56 |
+
posting via an official social media account, or acting as an appointed
|
| 57 |
+
representative at an online or offline event.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported to the community leaders responsible for enforcement at
|
| 63 |
+
obsei.tool@gmail.com
|
| 64 |
+
All complaints will be reviewed and investigated promptly and fairly.
|
| 65 |
+
|
| 66 |
+
All community leaders are obligated to respect the privacy and security of the
|
| 67 |
+
reporter of any incident.
|
| 68 |
+
|
| 69 |
+
## Enforcement Guidelines
|
| 70 |
+
|
| 71 |
+
Community leaders will follow these Community Impact Guidelines in determining
|
| 72 |
+
the consequences for any action they deem in violation of this Code of Conduct:
|
| 73 |
+
|
| 74 |
+
### 1. Correction
|
| 75 |
+
|
| 76 |
+
**Community Impact**: Use of inappropriate language or other behavior deemed
|
| 77 |
+
unprofessional or unwelcome in the community.
|
| 78 |
+
|
| 79 |
+
**Consequence**: A written warning from community leaders, providing
|
| 80 |
+
clarity around the nature of the violation and an explanation of why the
|
| 81 |
+
behavior was inappropriate. A public apology may be requested.
|
| 82 |
+
|
| 83 |
+
### 2. Warning
|
| 84 |
+
|
| 85 |
+
**Community Impact**: A violation through a single incident or series
|
| 86 |
+
of actions.
|
| 87 |
+
|
| 88 |
+
**Consequence**: A warning with consequences for continued behavior. No
|
| 89 |
+
interaction with the people involved, including unsolicited interaction with
|
| 90 |
+
those enforcing the Code of Conduct, for a specified period of time. This
|
| 91 |
+
includes avoiding interactions in community spaces as well as external channels
|
| 92 |
+
like social media. Violating these terms may lead to a temporary or
|
| 93 |
+
permanent ban.
|
| 94 |
+
|
| 95 |
+
### 3. Temporary Ban
|
| 96 |
+
|
| 97 |
+
**Community Impact**: A serious violation of community standards, including
|
| 98 |
+
sustained inappropriate behavior.
|
| 99 |
+
|
| 100 |
+
**Consequence**: A temporary ban from any sort of interaction or public
|
| 101 |
+
communication with the community for a specified period of time. No public or
|
| 102 |
+
private interaction with the people involved, including unsolicited interaction
|
| 103 |
+
with those enforcing the Code of Conduct, is allowed during this period.
|
| 104 |
+
Violating these terms may lead to a permanent ban.
|
| 105 |
+
|
| 106 |
+
### 4. Permanent Ban
|
| 107 |
+
|
| 108 |
+
**Community Impact**: Demonstrating a pattern of violation of community
|
| 109 |
+
standards, including sustained inappropriate behavior, harassment of an
|
| 110 |
+
individual, or aggression toward or disparagement of classes of individuals.
|
| 111 |
+
|
| 112 |
+
**Consequence**: A permanent ban from any sort of public interaction within
|
| 113 |
+
the community.
|
| 114 |
+
|
| 115 |
+
## Attribution
|
| 116 |
+
|
| 117 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
| 118 |
+
version 2.0, available at
|
| 119 |
+
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
| 120 |
+
|
| 121 |
+
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
| 122 |
+
enforcement ladder](https://github.com/mozilla/diversity).
|
| 123 |
+
|
| 124 |
+
[homepage]: https://www.contributor-covenant.org
|
| 125 |
+
|
| 126 |
+
For answers to common questions about this code of conduct, see the FAQ at
|
| 127 |
+
https://www.contributor-covenant.org/faq. Translations are available at
|
| 128 |
+
https://www.contributor-covenant.org/translations.
|
obsei_module/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 👐 Contributing to Obsei
|
| 2 |
+
|
| 3 |
+
First off, thank you for even considering contributing to this package, every contribution big or small is greatly appreciated.
|
| 4 |
+
Community contributions are what keep projects like this fueled and constantly improving, so a big thanks to you!
|
| 5 |
+
|
| 6 |
+
Below are some sections detailing the guidelines we'd like you to follow to make your contribution as seamless as possible.
|
| 7 |
+
|
| 8 |
+
- [Code of Conduct](#coc)
|
| 9 |
+
- [Asking a Question and Discussions](#question)
|
| 10 |
+
- [Issues, Bugs, and Feature Requests](#issue)
|
| 11 |
+
- [Submission Guidelines](#submit)
|
| 12 |
+
- [Code Style and Formatting](#code)
|
| 13 |
+
- [Contributor License Agreement](#cla)
|
| 14 |
+
|
| 15 |
+
## 📜 <a name="coc"></a> Code of Conduct
|
| 16 |
+
|
| 17 |
+
The [Code of Conduct](https://github.com/obsei/obsei/blob/master/CODE_OF_CONDUCT.md) applies within all community spaces.
|
| 18 |
+
If you are not familiar with our Code of Conduct policy, take a minute to read the policy before starting with your first contribution.
|
| 19 |
+
|
| 20 |
+
## 🗣️ <a name="question"></a> Query or Discussion
|
| 21 |
+
|
| 22 |
+
We would like to use [Github discussions](https://github.com/obsei/obsei/discussions) as the central hub for all
|
| 23 |
+
community discussions, questions, and everything else in between. While Github discussions is a new service (as of 2021)
|
| 24 |
+
we believe that it really helps keep this repo as one single source to find all relevant information. Our hope is that
|
| 25 |
+
discussion page functions as a record of all the conversations that help contribute to the project's development.
|
| 26 |
+
|
| 27 |
+
If you are new to [Github discussions](https://github.com/obsei/obsei/discussions) it is a very similar experience
|
| 28 |
+
to Stack Overflow with an added element of general discussion and discourse rather than solely being question and answer based.
|
| 29 |
+
|
| 30 |
+
## 🪲 <a name="issue"></a> Issues, Bugs, and Feature Requests
|
| 31 |
+
|
| 32 |
+
We are very open to community contributions and appreciate anything that improves **Obsei**. This includes fixings typos, adding missing documentation, fixing bugs or adding new features.
|
| 33 |
+
To avoid unnecessary work on either side, please stick to the following process:
|
| 34 |
+
|
| 35 |
+
1. If you feel like your issue is not specific and more of a general question about a design decision, or algorithm implementation maybe start a [discussion](https://github.com/obsei/obsei/discussions) instead, this helps keep the issues less cluttered and encourages more open-ended conversation.
|
| 36 |
+
2. Check if there is already [an related issue](https://github.com/obsei/obsei/issues).
|
| 37 |
+
3. If there is not, open a new one to start a discussion. Some features might be a nice idea, but don't fit in the scope of Obsei and we hate to close finished PRs.
|
| 38 |
+
4. If we came to the conclusion to move forward with your issue, we will be happy to accept a pull request. Make sure you create a pull request in an early draft version and ask for feedback.
|
| 39 |
+
5. Verify that all tests in the CI pass (and add new ones if you implement anything new)
|
| 40 |
+
|
| 41 |
+
See [below](#submit) for some guidelines.
|
| 42 |
+
|
| 43 |
+
## ✉️ <a name="submit"></a> Submission Guidelines
|
| 44 |
+
|
| 45 |
+
### Submitting an Issue
|
| 46 |
+
|
| 47 |
+
Before you submit your issue search the archive, maybe your question was already answered.
|
| 48 |
+
|
| 49 |
+
If your issue appears to be a bug, and hasn't been reported, open a new issue.
|
| 50 |
+
Help us to maximize the effort we can spend fixing issues and adding new
|
| 51 |
+
features, by not reporting duplicate issues. Providing the following information will increase the
|
| 52 |
+
chances of your issue being dealt with quickly:
|
| 53 |
+
|
| 54 |
+
- **Describe the bug** - A clear and concise description of what the bug is.
|
| 55 |
+
- **To Reproduce**- Steps to reproduce the behavior.
|
| 56 |
+
- **Expected behavior** - A clear and concise description of what you expected to happen.
|
| 57 |
+
- **Environment**
|
| 58 |
+
- Obsei version
|
| 59 |
+
- Python version
|
| 60 |
+
- OS
|
| 61 |
+
- **Suggest a Fix** - if you can't fix the bug yourself, perhaps you can point to what might be
|
| 62 |
+
causing the problem (line of code or commit)
|
| 63 |
+
|
| 64 |
+
When you submit a PR you will be presented with a PR template, please fill this in as best you can.
|
| 65 |
+
|
| 66 |
+
### Submitting a Pull Request
|
| 67 |
+
|
| 68 |
+
Before you submit your pull request consider the following guidelines:
|
| 69 |
+
|
| 70 |
+
- Search [GitHub](https://github.com/obsei/obsei/pulls) for an open or closed Pull Request
|
| 71 |
+
that relates to your submission. You don't want to duplicate effort.
|
| 72 |
+
- Fork the main repo if not already done
|
| 73 |
+
- Rebase fork with `upstream master`
|
| 74 |
+
- Create new branch and add the changes in that branch
|
| 75 |
+
- Add supporting test cases
|
| 76 |
+
- Follow our [Coding Rules](#rules).
|
| 77 |
+
- Avoid checking in files that shouldn't be tracked (e.g `dist`, `build`, `.tmp`, `.idea`).
|
| 78 |
+
We recommend using a [global](#global-gitignore) gitignore for this.
|
| 79 |
+
- Before you commit please run the test suite and make sure all tests are passing.
|
| 80 |
+
- Format your code appropriately:
|
| 81 |
+
- This package uses [black](https://black.readthedocs.io/en/stable/) as its formatter.
|
| 82 |
+
In order to format your code with black run `black . ` from the root of the package.
|
| 83 |
+
- Run `pre-commit run --all-files` if you're adding new hooks to pre-commit config file. By default, pre-commit will run on modified files when commiting changes.
|
| 84 |
+
- Commit your changes using a descriptive commit message.
|
| 85 |
+
- In GitHub, send a pull request to `obsei:master`.
|
| 86 |
+
- If we suggest changes then:
|
| 87 |
+
- Make the required updates.
|
| 88 |
+
- Rebase your branch and force push to your GitHub repository (this will update your Pull Request):
|
| 89 |
+
|
| 90 |
+
That's it! Thank you for your contribution!
|
| 91 |
+
|
| 92 |
+
## ✅ <a name="rules"></a> Coding Rules
|
| 93 |
+
|
| 94 |
+
We generally follow the [Google Python style guide](http://google.github.io/styleguide/pyguide.html).
|
| 95 |
+
|
| 96 |
+
## 📝 <a name="cla"></a> Contributor License Agreement
|
| 97 |
+
|
| 98 |
+
That we do not have any potential problems later it is sadly necessary to sign a [Contributor License Agreement](CONTRIBUTOR_LICENSE_AGREEMENT.md). That can be done literally with the push of a button.
|
| 99 |
+
|
| 100 |
+
---
|
| 101 |
+
|
| 102 |
+
_This guide was inspired by the [transformers-interpret](https://github.com/cdpierse/transformers-interpret/blob/master/CONTRIBUTING.md),
|
| 103 |
+
[Haystack](https://github.com/deepset-ai/haystack/blob/master/CONTRIBUTING.md) and [n8n](https://github.com/n8n-io/n8n/blob/master/CONTRIBUTOR_LICENSE_AGREEMENT.md)_
|
obsei_module/CONTRIBUTOR_LICENSE_AGREEMENT.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Obsei Contributor License Agreement
|
| 2 |
+
|
| 3 |
+
I give Obsei's Creator permission to license my contributions to any terms they like. I am giving them this license in order to make it possible for them to accept my contributions into their project.
|
obsei_module/Dockerfile
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is Docker file to Obsei SDK with dependencies installed
|
| 2 |
+
FROM python:3.10-slim-bullseye
|
| 3 |
+
|
| 4 |
+
RUN useradd --create-home user
|
| 5 |
+
WORKDIR /home/user
|
| 6 |
+
|
| 7 |
+
# env variable
|
| 8 |
+
ENV PIP_DISABLE_PIP_VERSION_CHECK 1
|
| 9 |
+
ENV PIP_NO_CACHE_DIR 1
|
| 10 |
+
ENV WORKFLOW_SCRIPT '/home/user/obsei/process_workflow.py'
|
| 11 |
+
ENV OBSEI_CONFIG_PATH ""
|
| 12 |
+
ENV OBSEI_CONFIG_FILENAME ""
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# Hack to install jre on debian
|
| 16 |
+
RUN mkdir -p /usr/share/man/man1
|
| 17 |
+
|
| 18 |
+
# install few required tools
|
| 19 |
+
RUN apt-get update && apt-get install -y --no-install-recommends curl git pkg-config cmake libncurses5 g++ \
|
| 20 |
+
&& apt-get clean autoclean && apt-get autoremove -y \
|
| 21 |
+
&& rm -rf /var/lib/{apt,dpkg,cache,log}/
|
| 22 |
+
|
| 23 |
+
# install as a package
|
| 24 |
+
COPY pyproject.toml README.md /home/user/
|
| 25 |
+
RUN pip install --upgrade pip
|
| 26 |
+
|
| 27 |
+
# copy README
|
| 28 |
+
COPY README.md /home/user/
|
| 29 |
+
|
| 30 |
+
# copy code
|
| 31 |
+
COPY obsei /home/user/obsei
|
| 32 |
+
RUN pip install -e .[all]
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
USER user
|
| 36 |
+
|
| 37 |
+
# cmd for running the API
|
| 38 |
+
CMD ["sh", "-c", "python ${WORKFLOW_SCRIPT}"]
|
obsei_module/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2020-2022 Oraika Technologies Private Limited (https://www.oraika.com)
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
obsei_module/MANIFEST.in
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
include LICENSE
|
| 2 |
+
include requirements.txt
|
| 3 |
+
include README.md
|
obsei_module/README.md
ADDED
|
@@ -0,0 +1,1067 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center">
|
| 2 |
+
<img src="https://raw.githubusercontent.com/obsei/obsei-resources/master/images/obsei-flyer.png" />
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
---
|
| 6 |
+
<p align="center">
|
| 7 |
+
<a href="https://www.oraika.com">
|
| 8 |
+
<img src="https://static.wixstatic.com/media/59bc4e_971f153f107e48c7912b9b2d4cd1b1a4~mv2.png/v1/fill/w_177,h_49,al_c,q_85,usm_0.66_1.00_0.01,enc_auto/3_edited.png" />
|
| 9 |
+
</a>
|
| 10 |
+
</p>
|
| 11 |
+
<p align="center">
|
| 12 |
+
<a href="https://github.com/obsei/obsei/actions">
|
| 13 |
+
<img alt="Test" src="https://github.com/obsei/obsei/workflows/CI/badge.svg?branch=master">
|
| 14 |
+
</a>
|
| 15 |
+
<a href="https://github.com/obsei/obsei/blob/master/LICENSE">
|
| 16 |
+
<img alt="License" src="https://img.shields.io/pypi/l/obsei">
|
| 17 |
+
</a>
|
| 18 |
+
<a href="https://pypi.org/project/obsei">
|
| 19 |
+
<img src="https://img.shields.io/pypi/pyversions/obsei" alt="PyPI - Python Version" />
|
| 20 |
+
</a>
|
| 21 |
+
<a href="https://pypi.org/project/obsei/">
|
| 22 |
+
<img alt="Release" src="https://img.shields.io/pypi/v/obsei">
|
| 23 |
+
</a>
|
| 24 |
+
<a href="https://pepy.tech/project/obsei">
|
| 25 |
+
<img src="https://pepy.tech/badge/obsei/month" alt="Downloads" />
|
| 26 |
+
</a>
|
| 27 |
+
<a href="https://huggingface.co/spaces/obsei/obsei-demo">
|
| 28 |
+
<img src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue" alt="HF Spaces" />
|
| 29 |
+
</a>
|
| 30 |
+
<a href="https://github.com/obsei/obsei/commits/master">
|
| 31 |
+
<img alt="Last commit" src="https://img.shields.io/github/last-commit/obsei/obsei">
|
| 32 |
+
</a>
|
| 33 |
+
<a href="https://github.com/obsei/obsei">
|
| 34 |
+
<img alt="Github stars" src="https://img.shields.io/github/stars/obsei/obsei?style=social">
|
| 35 |
+
</a>
|
| 36 |
+
<a href="https://www.youtube.com/channel/UCqdvgro1BzU13tkAfX3jCJA">
|
| 37 |
+
<img alt="YouTube Channel Subscribers" src="https://img.shields.io/youtube/channel/subscribers/UCqdvgro1BzU13tkAfX3jCJA?style=social">
|
| 38 |
+
</a>
|
| 39 |
+
<a href="https://join.slack.com/t/obsei-community/shared_invite/zt-r0wnuz02-FAkAmhTAUoc6pD4SLB9Ikg">
|
| 40 |
+
<img src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/Slack_join.svg" height="30">
|
| 41 |
+
</a>
|
| 42 |
+
<a href="https://twitter.com/ObseiAI">
|
| 43 |
+
<img src="https://img.shields.io/twitter/follow/ObseiAI?style=social">
|
| 44 |
+
</a>
|
| 45 |
+
</p>
|
| 46 |
+
|
| 47 |
+
---
|
| 48 |
+
|
| 49 |
+

|
| 50 |
+
|
| 51 |
+
---
|
| 52 |
+
|
| 53 |
+
<span style="color:red">
|
| 54 |
+
<b>Note</b>: Obsei is still in alpha stage hence carefully use it in Production. Also, as it is constantly undergoing development hence master branch may contain many breaking changes. Please use released version.
|
| 55 |
+
</span>
|
| 56 |
+
|
| 57 |
+
---
|
| 58 |
+
|
| 59 |
+
**Obsei** (pronounced "Ob see" | /əb-'sē/) is an open-source, low-code, AI powered automation tool. _Obsei_ consists of -
|
| 60 |
+
|
| 61 |
+
- **Observer**: Collect unstructured data from various sources like tweets from Twitter, Subreddit comments on Reddit, page post's comments from Facebook, App Stores reviews, Google reviews, Amazon reviews, News, Website, etc.
|
| 62 |
+
- **Analyzer**: Analyze unstructured data collected with various AI tasks like classification, sentiment analysis, translation, PII, etc.
|
| 63 |
+
- **Informer**: Send analyzed data to various destinations like ticketing platforms, data storage, dataframe, etc so that the user can take further actions and perform analysis on the data.
|
| 64 |
+
|
| 65 |
+
All the Observers can store their state in databases (Sqlite, Postgres, MySQL, etc.), making Obsei suitable for scheduled jobs or serverless applications.
|
| 66 |
+
|
| 67 |
+
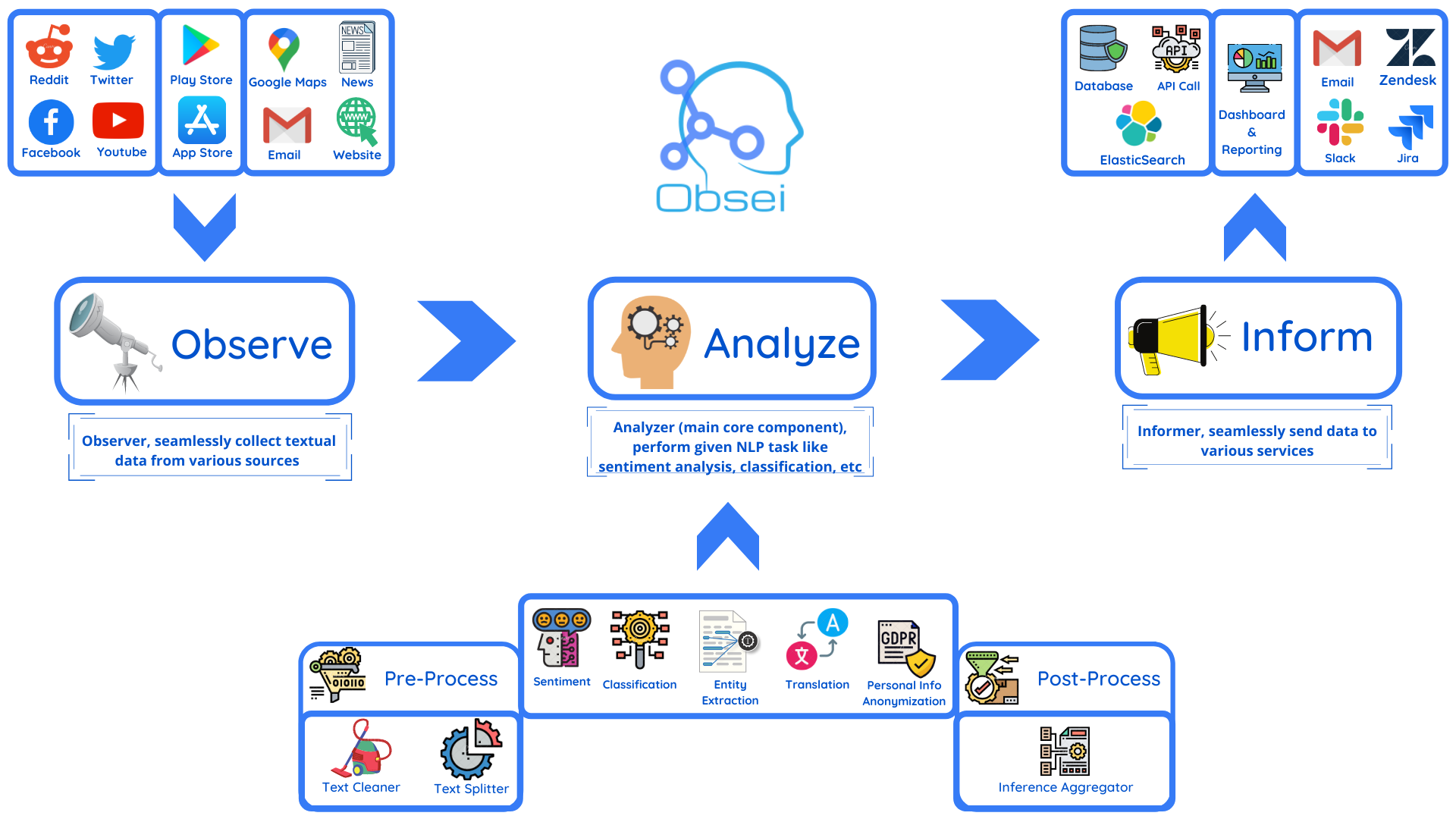
|
| 68 |
+
|
| 69 |
+
### Future direction -
|
| 70 |
+
|
| 71 |
+
- Text, Image, Audio, Documents and Video oriented workflows
|
| 72 |
+
- Collect data from every possible private and public channels
|
| 73 |
+
- Add every possible workflow to an AI downstream application to automate manual cognitive workflows
|
| 74 |
+
|
| 75 |
+
## Use cases
|
| 76 |
+
|
| 77 |
+
_Obsei_ use cases are following, but not limited to -
|
| 78 |
+
|
| 79 |
+
- Social listening: Listening about social media posts, comments, customer feedback, etc.
|
| 80 |
+
- Alerting/Notification: To get auto-alerts for events such as customer complaints, qualified sales leads, etc.
|
| 81 |
+
- Automatic customer issue creation based on customer complaints on Social Media, Email, etc.
|
| 82 |
+
- Automatic assignment of proper tags to tickets based content of customer complaint for example login issue, sign up issue, delivery issue, etc.
|
| 83 |
+
- Extraction of deeper insight from feedbacks on various platforms
|
| 84 |
+
- Market research
|
| 85 |
+
- Creation of dataset for various AI tasks
|
| 86 |
+
- Many more based on creativity 💡
|
| 87 |
+
|
| 88 |
+
## Installation
|
| 89 |
+
|
| 90 |
+
### Prerequisite
|
| 91 |
+
|
| 92 |
+
Install the following (if not present already) -
|
| 93 |
+
|
| 94 |
+
- Install [Python 3.7+](https://www.python.org/downloads/)
|
| 95 |
+
- Install [PIP](https://pip.pypa.io/en/stable/installing/)
|
| 96 |
+
|
| 97 |
+
### Install Obsei
|
| 98 |
+
|
| 99 |
+
You can install Obsei either via PIP or Conda based on your preference.
|
| 100 |
+
To install latest released version -
|
| 101 |
+
|
| 102 |
+
```shell
|
| 103 |
+
pip install obsei[all]
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
Install from master branch (if you want to try the latest features) -
|
| 107 |
+
|
| 108 |
+
```shell
|
| 109 |
+
git clone https://github.com/obsei/obsei.git
|
| 110 |
+
cd obsei
|
| 111 |
+
pip install --editable .[all]
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
Note: `all` option will install all the dependencies which might not be needed for your workflow, alternatively
|
| 115 |
+
following options are available to install minimal dependencies as per need -
|
| 116 |
+
- `pip install obsei[source]`: To install dependencies related to all observers
|
| 117 |
+
- `pip install obsei[sink]`: To install dependencies related to all informers
|
| 118 |
+
- `pip install obsei[analyzer]`: To install dependencies related to all analyzers, it will install pytorch as well
|
| 119 |
+
- `pip install obsei[twitter-api]`: To install dependencies related to Twitter observer
|
| 120 |
+
- `pip install obsei[google-play-scraper]`: To install dependencies related to Play Store review scrapper observer
|
| 121 |
+
- `pip install obsei[google-play-api]`: To install dependencies related to Google official play store review API based observer
|
| 122 |
+
- `pip install obsei[app-store-scraper]`: To install dependencies related to Apple App Store review scrapper observer
|
| 123 |
+
- `pip install obsei[reddit-scraper]`: To install dependencies related to Reddit post and comment scrapper observer
|
| 124 |
+
- `pip install obsei[reddit-api]`: To install dependencies related to Reddit official api based observer
|
| 125 |
+
- `pip install obsei[pandas]`: To install dependencies related to TSV/CSV/Pandas based observer and informer
|
| 126 |
+
- `pip install obsei[google-news-scraper]`: To install dependencies related to Google news scrapper observer
|
| 127 |
+
- `pip install obsei[facebook-api]`: To install dependencies related to Facebook official page post and comments api based observer
|
| 128 |
+
- `pip install obsei[atlassian-api]`: To install dependencies related to Jira official api based informer
|
| 129 |
+
- `pip install obsei[elasticsearch]`: To install dependencies related to elasticsearch informer
|
| 130 |
+
- `pip install obsei[slack-api]`:To install dependencies related to Slack official api based informer
|
| 131 |
+
|
| 132 |
+
You can also mix multiple dependencies together in single installation command. For example to install dependencies
|
| 133 |
+
Twitter observer, all analyzer, and Slack informer use following command -
|
| 134 |
+
```shell
|
| 135 |
+
pip install obsei[twitter-api, analyzer, slack-api]
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
## How to use
|
| 140 |
+
|
| 141 |
+
Expand the following steps and create a workflow -
|
| 142 |
+
|
| 143 |
+
<details><summary><b>Step 1: Configure Source/Observer</b></summary>
|
| 144 |
+
|
| 145 |
+
<table ><tbody ><tr></tr><tr>
|
| 146 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/twitter.png" width="20" height="20"><b>Twitter</b></summary><hr>
|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
from obsei.source.twitter_source import TwitterCredentials, TwitterSource, TwitterSourceConfig
|
| 150 |
+
|
| 151 |
+
# initialize twitter source config
|
| 152 |
+
source_config = TwitterSourceConfig(
|
| 153 |
+
keywords=["issue"], # Keywords, @user or #hashtags
|
| 154 |
+
lookup_period="1h", # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 155 |
+
cred_info=TwitterCredentials(
|
| 156 |
+
# Enter your twitter consumer key and secret. Get it from https://developer.twitter.com/en/apply-for-access
|
| 157 |
+
consumer_key="<twitter_consumer_key>",
|
| 158 |
+
consumer_secret="<twitter_consumer_secret>",
|
| 159 |
+
bearer_token='<ENTER BEARER TOKEN>',
|
| 160 |
+
)
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
# initialize tweets retriever
|
| 164 |
+
source = TwitterSource()
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
</details>
|
| 168 |
+
</td>
|
| 169 |
+
</tr>
|
| 170 |
+
<tr>
|
| 171 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/Youtube.png" width="20" height="20"><b>Youtube Scrapper</b></summary><hr>
|
| 172 |
+
|
| 173 |
+
```python
|
| 174 |
+
from obsei.source.youtube_scrapper import YoutubeScrapperSource, YoutubeScrapperConfig
|
| 175 |
+
|
| 176 |
+
# initialize Youtube source config
|
| 177 |
+
source_config = YoutubeScrapperConfig(
|
| 178 |
+
video_url="https://www.youtube.com/watch?v=uZfns0JIlFk", # Youtube video URL
|
| 179 |
+
fetch_replies=True, # Fetch replies to comments
|
| 180 |
+
max_comments=10, # Total number of comments and replies to fetch
|
| 181 |
+
lookup_period="1Y", # Lookup period from current time, format: `<number><d|h|m|M|Y>` (day|hour|minute|month|year)
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
# initialize Youtube comments retriever
|
| 185 |
+
source = YoutubeScrapperSource()
|
| 186 |
+
```
|
| 187 |
+
|
| 188 |
+
</details>
|
| 189 |
+
</td>
|
| 190 |
+
</tr>
|
| 191 |
+
<tr>
|
| 192 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/facebook.png" width="20" height="20"><b>Facebook</b></summary><hr>
|
| 193 |
+
|
| 194 |
+
```python
|
| 195 |
+
from obsei.source.facebook_source import FacebookCredentials, FacebookSource, FacebookSourceConfig
|
| 196 |
+
|
| 197 |
+
# initialize facebook source config
|
| 198 |
+
source_config = FacebookSourceConfig(
|
| 199 |
+
page_id="110844591144719", # Facebook page id, for example this one for Obsei
|
| 200 |
+
lookup_period="1h", # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 201 |
+
cred_info=FacebookCredentials(
|
| 202 |
+
# Enter your facebook app_id, app_secret and long_term_token. Get it from https://developers.facebook.com/apps/
|
| 203 |
+
app_id="<facebook_app_id>",
|
| 204 |
+
app_secret="<facebook_app_secret>",
|
| 205 |
+
long_term_token="<facebook_long_term_token>",
|
| 206 |
+
)
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# initialize facebook post comments retriever
|
| 210 |
+
source = FacebookSource()
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
</details>
|
| 214 |
+
</td>
|
| 215 |
+
</tr>
|
| 216 |
+
<tr>
|
| 217 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/gmail.png" width="20" height="20"><b>Email</b></summary><hr>
|
| 218 |
+
|
| 219 |
+
```python
|
| 220 |
+
from obsei.source.email_source import EmailConfig, EmailCredInfo, EmailSource
|
| 221 |
+
|
| 222 |
+
# initialize email source config
|
| 223 |
+
source_config = EmailConfig(
|
| 224 |
+
# List of IMAP servers for most commonly used email providers
|
| 225 |
+
# https://www.systoolsgroup.com/imap/
|
| 226 |
+
# Also, if you're using a Gmail account then make sure you allow less secure apps on your account -
|
| 227 |
+
# https://myaccount.google.com/lesssecureapps?pli=1
|
| 228 |
+
# Also enable IMAP access -
|
| 229 |
+
# https://mail.google.com/mail/u/0/#settings/fwdandpop
|
| 230 |
+
imap_server="imap.gmail.com", # Enter IMAP server
|
| 231 |
+
cred_info=EmailCredInfo(
|
| 232 |
+
# Enter your email account username and password
|
| 233 |
+
username="<email_username>",
|
| 234 |
+
password="<email_password>"
|
| 235 |
+
),
|
| 236 |
+
lookup_period="1h" # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
# initialize email retriever
|
| 240 |
+
source = EmailSource()
|
| 241 |
+
```
|
| 242 |
+
|
| 243 |
+
</details>
|
| 244 |
+
</td>
|
| 245 |
+
</tr>
|
| 246 |
+
<tr>
|
| 247 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/google_maps.png" width="20" height="20"><b>Google Maps Reviews Scrapper</b></summary><hr>
|
| 248 |
+
|
| 249 |
+
```python
|
| 250 |
+
from obsei.source.google_maps_reviews import OSGoogleMapsReviewsSource, OSGoogleMapsReviewsConfig
|
| 251 |
+
|
| 252 |
+
# initialize Outscrapper Maps review source config
|
| 253 |
+
source_config = OSGoogleMapsReviewsConfig(
|
| 254 |
+
# Collect API key from https://outscraper.com/
|
| 255 |
+
api_key="<Enter Your API Key>",
|
| 256 |
+
# Enter Google Maps link or place id
|
| 257 |
+
# For example below is for the "Taj Mahal"
|
| 258 |
+
queries=["https://www.google.co.in/maps/place/Taj+Mahal/@27.1751496,78.0399535,17z/data=!4m5!3m4!1s0x39747121d702ff6d:0xdd2ae4803f767dde!8m2!3d27.1751448!4d78.0421422"],
|
| 259 |
+
number_of_reviews=10,
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
# initialize Outscrapper Maps review retriever
|
| 264 |
+
source = OSGoogleMapsReviewsSource()
|
| 265 |
+
```
|
| 266 |
+
|
| 267 |
+
</details>
|
| 268 |
+
</td>
|
| 269 |
+
</tr>
|
| 270 |
+
<tr>
|
| 271 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/appstore.png" width="20" height="20"><b>AppStore Reviews Scrapper</b></summary><hr>
|
| 272 |
+
|
| 273 |
+
```python
|
| 274 |
+
from obsei.source.appstore_scrapper import AppStoreScrapperConfig, AppStoreScrapperSource
|
| 275 |
+
|
| 276 |
+
# initialize app store source config
|
| 277 |
+
source_config = AppStoreScrapperConfig(
|
| 278 |
+
# Need two parameters app_id and country.
|
| 279 |
+
# `app_id` can be found at the end of the url of app in app store.
|
| 280 |
+
# For example - https://apps.apple.com/us/app/xcode/id497799835
|
| 281 |
+
# `310633997` is the app_id for xcode and `us` is country.
|
| 282 |
+
countries=["us"],
|
| 283 |
+
app_id="310633997",
|
| 284 |
+
lookup_period="1h" # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
# initialize app store reviews retriever
|
| 289 |
+
source = AppStoreScrapperSource()
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
</details>
|
| 293 |
+
</td>
|
| 294 |
+
</tr>
|
| 295 |
+
<tr>
|
| 296 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/playstore.png" width="20" height="20"><b>Play Store Reviews Scrapper</b></summary><hr>
|
| 297 |
+
|
| 298 |
+
```python
|
| 299 |
+
from obsei.source.playstore_scrapper import PlayStoreScrapperConfig, PlayStoreScrapperSource
|
| 300 |
+
|
| 301 |
+
# initialize play store source config
|
| 302 |
+
source_config = PlayStoreScrapperConfig(
|
| 303 |
+
# Need two parameters package_name and country.
|
| 304 |
+
# `package_name` can be found at the end of the url of app in play store.
|
| 305 |
+
# For example - https://play.google.com/store/apps/details?id=com.google.android.gm&hl=en&gl=US
|
| 306 |
+
# `com.google.android.gm` is the package_name for xcode and `us` is country.
|
| 307 |
+
countries=["us"],
|
| 308 |
+
package_name="com.google.android.gm",
|
| 309 |
+
lookup_period="1h" # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
# initialize play store reviews retriever
|
| 313 |
+
source = PlayStoreScrapperSource()
|
| 314 |
+
```
|
| 315 |
+
|
| 316 |
+
</details>
|
| 317 |
+
</td>
|
| 318 |
+
</tr>
|
| 319 |
+
<tr>
|
| 320 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/reddit.png" width="20" height="20"><b>Reddit</b></summary><hr>
|
| 321 |
+
|
| 322 |
+
```python
|
| 323 |
+
from obsei.source.reddit_source import RedditConfig, RedditSource, RedditCredInfo
|
| 324 |
+
|
| 325 |
+
# initialize reddit source config
|
| 326 |
+
source_config = RedditConfig(
|
| 327 |
+
subreddits=["wallstreetbets"], # List of subreddits
|
| 328 |
+
# Reddit account username and password
|
| 329 |
+
# You can also enter reddit client_id and client_secret or refresh_token
|
| 330 |
+
# Create credential at https://www.reddit.com/prefs/apps
|
| 331 |
+
# Also refer https://praw.readthedocs.io/en/latest/getting_started/authentication.html
|
| 332 |
+
# Currently Password Flow, Read Only Mode and Saved Refresh Token Mode are supported
|
| 333 |
+
cred_info=RedditCredInfo(
|
| 334 |
+
username="<reddit_username>",
|
| 335 |
+
password="<reddit_password>"
|
| 336 |
+
),
|
| 337 |
+
lookup_period="1h" # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
# initialize reddit retriever
|
| 341 |
+
source = RedditSource()
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
</details>
|
| 345 |
+
</td>
|
| 346 |
+
</tr>
|
| 347 |
+
<tr>
|
| 348 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/reddit.png" width="20" height="20"><b>Reddit Scrapper</b></summary><hr>
|
| 349 |
+
|
| 350 |
+
<i>Note: Reddit heavily rate limit scrappers, hence use it to fetch small data during long period</i>
|
| 351 |
+
|
| 352 |
+
```python
|
| 353 |
+
from obsei.source.reddit_scrapper import RedditScrapperConfig, RedditScrapperSource
|
| 354 |
+
|
| 355 |
+
# initialize reddit scrapper source config
|
| 356 |
+
source_config = RedditScrapperConfig(
|
| 357 |
+
# Reddit subreddit, search etc rss url. For proper url refer following link -
|
| 358 |
+
# Refer https://www.reddit.com/r/pathogendavid/comments/tv8m9/pathogendavids_guide_to_rss_and_reddit/
|
| 359 |
+
url="https://www.reddit.com/r/wallstreetbets/comments/.rss?sort=new",
|
| 360 |
+
lookup_period="1h" # Lookup period from current time, format: `<number><d|h|m>` (day|hour|minute)
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
# initialize reddit retriever
|
| 364 |
+
source = RedditScrapperSource()
|
| 365 |
+
```
|
| 366 |
+
|
| 367 |
+
</details>
|
| 368 |
+
</td>
|
| 369 |
+
</tr>
|
| 370 |
+
<tr>
|
| 371 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/googlenews.png" width="20" height="20"><b>Google News</b></summary><hr>
|
| 372 |
+
|
| 373 |
+
```python
|
| 374 |
+
from obsei.source.google_news_source import GoogleNewsConfig, GoogleNewsSource
|
| 375 |
+
|
| 376 |
+
# initialize Google News source config
|
| 377 |
+
source_config = GoogleNewsConfig(
|
| 378 |
+
query='bitcoin',
|
| 379 |
+
max_results=5,
|
| 380 |
+
# To fetch full article text enable `fetch_article` flag
|
| 381 |
+
# By default google news gives title and highlight
|
| 382 |
+
fetch_article=True,
|
| 383 |
+
# proxy='http://127.0.0.1:8080'
|
| 384 |
+
)
|
| 385 |
+
|
| 386 |
+
# initialize Google News retriever
|
| 387 |
+
source = GoogleNewsSource()
|
| 388 |
+
```
|
| 389 |
+
|
| 390 |
+
</details>
|
| 391 |
+
</td>
|
| 392 |
+
</tr>
|
| 393 |
+
<tr>
|
| 394 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/webcrawler.png" width="20" height="20"><b>Web Crawler</b></summary><hr>
|
| 395 |
+
|
| 396 |
+
```python
|
| 397 |
+
from obsei.source.website_crawler_source import TrafilaturaCrawlerConfig, TrafilaturaCrawlerSource
|
| 398 |
+
|
| 399 |
+
# initialize website crawler source config
|
| 400 |
+
source_config = TrafilaturaCrawlerConfig(
|
| 401 |
+
urls=['https://obsei.github.io/obsei/']
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
# initialize website text retriever
|
| 405 |
+
source = TrafilaturaCrawlerSource()
|
| 406 |
+
```
|
| 407 |
+
|
| 408 |
+
</details>
|
| 409 |
+
</td>
|
| 410 |
+
</tr>
|
| 411 |
+
<tr>
|
| 412 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/pandas.svg" width="20" height="20"><b>Pandas DataFrame</b></summary><hr>
|
| 413 |
+
|
| 414 |
+
```python
|
| 415 |
+
import pandas as pd
|
| 416 |
+
from obsei.source.pandas_source import PandasSource, PandasSourceConfig
|
| 417 |
+
|
| 418 |
+
# Initialize your Pandas DataFrame from your sources like csv, excel, sql etc
|
| 419 |
+
# In following example we are reading csv which have two columns title and text
|
| 420 |
+
csv_file = "https://raw.githubusercontent.com/deepset-ai/haystack/master/tutorials/small_generator_dataset.csv"
|
| 421 |
+
dataframe = pd.read_csv(csv_file)
|
| 422 |
+
|
| 423 |
+
# initialize pandas sink config
|
| 424 |
+
sink_config = PandasSourceConfig(
|
| 425 |
+
dataframe=dataframe,
|
| 426 |
+
include_columns=["score"],
|
| 427 |
+
text_columns=["name", "degree"],
|
| 428 |
+
)
|
| 429 |
+
|
| 430 |
+
# initialize pandas sink
|
| 431 |
+
sink = PandasSource()
|
| 432 |
+
```
|
| 433 |
+
|
| 434 |
+
</details>
|
| 435 |
+
</td>
|
| 436 |
+
</tr>
|
| 437 |
+
</tbody>
|
| 438 |
+
</table>
|
| 439 |
+
|
| 440 |
+
</details>
|
| 441 |
+
|
| 442 |
+
<details><summary><b>Step 2: Configure Analyzer</b></summary>
|
| 443 |
+
|
| 444 |
+
<i>Note: To run transformers in an offline mode, check [transformers offline mode](https://huggingface.co/transformers/installation.html#offline-mode).</i>
|
| 445 |
+
|
| 446 |
+
<p>Some analyzer support GPU and to utilize pass <b>device</b> parameter.
|
| 447 |
+
List of possible values of <b>device</b> parameter (default value <i>auto</i>):
|
| 448 |
+
<ol>
|
| 449 |
+
<li> <b>auto</b>: GPU (cuda:0) will be used if available otherwise CPU will be used
|
| 450 |
+
<li> <b>cpu</b>: CPU will be used
|
| 451 |
+
<li> <b>cuda:{id}</b> - GPU will be used with provided CUDA device id
|
| 452 |
+
</ol>
|
| 453 |
+
</p>
|
| 454 |
+
|
| 455 |
+
<table ><tbody ><tr></tr><tr>
|
| 456 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/classification.png" width="20" height="20"><b>Text Classification</b></summary><hr>
|
| 457 |
+
|
| 458 |
+
Text classification: Classify text into user provided categories.
|
| 459 |
+
|
| 460 |
+
```python
|
| 461 |
+
from obsei.analyzer.classification_analyzer import ClassificationAnalyzerConfig, ZeroShotClassificationAnalyzer
|
| 462 |
+
|
| 463 |
+
# initialize classification analyzer config
|
| 464 |
+
# It can also detect sentiments if "positive" and "negative" labels are added.
|
| 465 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 466 |
+
labels=["service", "delay", "performance"],
|
| 467 |
+
)
|
| 468 |
+
|
| 469 |
+
# initialize classification analyzer
|
| 470 |
+
# For supported models refer https://huggingface.co/models?filter=zero-shot-classification
|
| 471 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 472 |
+
model_name_or_path="typeform/mobilebert-uncased-mnli",
|
| 473 |
+
device="auto"
|
| 474 |
+
)
|
| 475 |
+
```
|
| 476 |
+
|
| 477 |
+
</details>
|
| 478 |
+
</td>
|
| 479 |
+
</tr>
|
| 480 |
+
<tr>
|
| 481 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/sentiment.png" width="20" height="20"><b>Sentiment Analyzer</b></summary><hr>
|
| 482 |
+
|
| 483 |
+
Sentiment Analyzer: Detect the sentiment of the text. Text classification can also perform sentiment analysis but if you don't want to use heavy-duty NLP model then use less resource hungry dictionary based Vader Sentiment detector.
|
| 484 |
+
|
| 485 |
+
```python
|
| 486 |
+
from obsei.analyzer.sentiment_analyzer import VaderSentimentAnalyzer
|
| 487 |
+
|
| 488 |
+
# Vader does not need any configuration settings
|
| 489 |
+
analyzer_config=None
|
| 490 |
+
|
| 491 |
+
# initialize vader sentiment analyzer
|
| 492 |
+
text_analyzer = VaderSentimentAnalyzer()
|
| 493 |
+
```
|
| 494 |
+
|
| 495 |
+
</details>
|
| 496 |
+
</td>
|
| 497 |
+
</tr>
|
| 498 |
+
<tr>
|
| 499 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/ner.png" width="20" height="20"><b>NER Analyzer</b></summary><hr>
|
| 500 |
+
|
| 501 |
+
NER (Named-Entity Recognition) Analyzer: Extract information and classify named entities mentioned in text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc
|
| 502 |
+
|
| 503 |
+
```python
|
| 504 |
+
from obsei.analyzer.ner_analyzer import NERAnalyzer
|
| 505 |
+
|
| 506 |
+
# NER analyzer does not need configuration settings
|
| 507 |
+
analyzer_config=None
|
| 508 |
+
|
| 509 |
+
# initialize ner analyzer
|
| 510 |
+
# For supported models refer https://huggingface.co/models?filter=token-classification
|
| 511 |
+
text_analyzer = NERAnalyzer(
|
| 512 |
+
model_name_or_path="elastic/distilbert-base-cased-finetuned-conll03-english",
|
| 513 |
+
device = "auto"
|
| 514 |
+
)
|
| 515 |
+
```
|
| 516 |
+
|
| 517 |
+
</details>
|
| 518 |
+
</td>
|
| 519 |
+
</tr>
|
| 520 |
+
<tr>
|
| 521 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/translator.png" width="20" height="20"><b>Translator</b></summary><hr>
|
| 522 |
+
|
| 523 |
+
```python
|
| 524 |
+
from obsei.analyzer.translation_analyzer import TranslationAnalyzer
|
| 525 |
+
|
| 526 |
+
# Translator does not need analyzer config
|
| 527 |
+
analyzer_config = None
|
| 528 |
+
|
| 529 |
+
# initialize translator
|
| 530 |
+
# For supported models refer https://huggingface.co/models?pipeline_tag=translation
|
| 531 |
+
analyzer = TranslationAnalyzer(
|
| 532 |
+
model_name_or_path="Helsinki-NLP/opus-mt-hi-en",
|
| 533 |
+
device = "auto"
|
| 534 |
+
)
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
</details>
|
| 538 |
+
</td>
|
| 539 |
+
</tr>
|
| 540 |
+
<tr>
|
| 541 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/pii.png" width="20" height="20"><b>PII Anonymizer</b></summary><hr>
|
| 542 |
+
|
| 543 |
+
```python
|
| 544 |
+
from obsei.analyzer.pii_analyzer import PresidioEngineConfig, PresidioModelConfig, \
|
| 545 |
+
PresidioPIIAnalyzer, PresidioPIIAnalyzerConfig
|
| 546 |
+
|
| 547 |
+
# initialize pii analyzer's config
|
| 548 |
+
analyzer_config = PresidioPIIAnalyzerConfig(
|
| 549 |
+
# Whether to return only pii analysis or anonymize text
|
| 550 |
+
analyze_only=False,
|
| 551 |
+
# Whether to return detail information about anonymization decision
|
| 552 |
+
return_decision_process=True
|
| 553 |
+
)
|
| 554 |
+
|
| 555 |
+
# initialize pii analyzer
|
| 556 |
+
analyzer = PresidioPIIAnalyzer(
|
| 557 |
+
engine_config=PresidioEngineConfig(
|
| 558 |
+
# spacy and stanza nlp engines are supported
|
| 559 |
+
# For more info refer
|
| 560 |
+
# https://microsoft.github.io/presidio/analyzer/developing_recognizers/#utilize-spacy-or-stanza
|
| 561 |
+
nlp_engine_name="spacy",
|
| 562 |
+
# Update desired spacy model and language
|
| 563 |
+
models=[PresidioModelConfig(model_name="en_core_web_lg", lang_code="en")]
|
| 564 |
+
)
|
| 565 |
+
)
|
| 566 |
+
```
|
| 567 |
+
|
| 568 |
+
</details>
|
| 569 |
+
</td>
|
| 570 |
+
</tr>
|
| 571 |
+
<tr>
|
| 572 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/dummy.png" width="20" height="20"><b>Dummy Analyzer</b></summary><hr>
|
| 573 |
+
|
| 574 |
+
Dummy Analyzer: Does nothing. Its simply used for transforming the input (TextPayload) to output (TextPayload) and adding the user supplied dummy data.
|
| 575 |
+
|
| 576 |
+
```python
|
| 577 |
+
from obsei.analyzer.dummy_analyzer import DummyAnalyzer, DummyAnalyzerConfig
|
| 578 |
+
|
| 579 |
+
# initialize dummy analyzer's configuration settings
|
| 580 |
+
analyzer_config = DummyAnalyzerConfig()
|
| 581 |
+
|
| 582 |
+
# initialize dummy analyzer
|
| 583 |
+
analyzer = DummyAnalyzer()
|
| 584 |
+
```
|
| 585 |
+
|
| 586 |
+
</details>
|
| 587 |
+
</td>
|
| 588 |
+
</tr>
|
| 589 |
+
</tbody>
|
| 590 |
+
</table>
|
| 591 |
+
|
| 592 |
+
</details>
|
| 593 |
+
|
| 594 |
+
<details><summary><b>Step 3: Configure Sink/Informer</b></summary>
|
| 595 |
+
|
| 596 |
+
<table ><tbody ><tr></tr><tr>
|
| 597 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/slack.svg" width="25" height="25"><b>Slack</b></summary><hr>
|
| 598 |
+
|
| 599 |
+
```python
|
| 600 |
+
from obsei.sink.slack_sink import SlackSink, SlackSinkConfig
|
| 601 |
+
|
| 602 |
+
# initialize slack sink config
|
| 603 |
+
sink_config = SlackSinkConfig(
|
| 604 |
+
# Provide slack bot/app token
|
| 605 |
+
# For more detail refer https://slack.com/intl/en-de/help/articles/215770388-Create-and-regenerate-API-tokens
|
| 606 |
+
slack_token="<Slack_app_token>",
|
| 607 |
+
# To get channel id refer https://stackoverflow.com/questions/40940327/what-is-the-simplest-way-to-find-a-slack-team-id-and-a-channel-id
|
| 608 |
+
channel_id="C01LRS6CT9Q"
|
| 609 |
+
)
|
| 610 |
+
|
| 611 |
+
# initialize slack sink
|
| 612 |
+
sink = SlackSink()
|
| 613 |
+
```
|
| 614 |
+
|
| 615 |
+
</details>
|
| 616 |
+
</td>
|
| 617 |
+
</tr>
|
| 618 |
+
<tr>
|
| 619 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/zendesk.png" width="20" height="20"><b>Zendesk</b></summary><hr>
|
| 620 |
+
|
| 621 |
+
```python
|
| 622 |
+
from obsei.sink.zendesk_sink import ZendeskSink, ZendeskSinkConfig, ZendeskCredInfo
|
| 623 |
+
|
| 624 |
+
# initialize zendesk sink config
|
| 625 |
+
sink_config = ZendeskSinkConfig(
|
| 626 |
+
# provide zendesk domain
|
| 627 |
+
domain="zendesk.com",
|
| 628 |
+
# provide subdomain if you have one
|
| 629 |
+
subdomain=None,
|
| 630 |
+
# Enter zendesk user details
|
| 631 |
+
cred_info=ZendeskCredInfo(
|
| 632 |
+
email="<zendesk_user_email>",
|
| 633 |
+
password="<zendesk_password>"
|
| 634 |
+
)
|
| 635 |
+
)
|
| 636 |
+
|
| 637 |
+
# initialize zendesk sink
|
| 638 |
+
sink = ZendeskSink()
|
| 639 |
+
```
|
| 640 |
+
|
| 641 |
+
</details>
|
| 642 |
+
</td>
|
| 643 |
+
</tr>
|
| 644 |
+
<tr>
|
| 645 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/jira.png" width="20" height="20"><b>Jira</b></summary><hr>
|
| 646 |
+
|
| 647 |
+
```python
|
| 648 |
+
from obsei.sink.jira_sink import JiraSink, JiraSinkConfig
|
| 649 |
+
|
| 650 |
+
# For testing purpose you can start jira server locally
|
| 651 |
+
# Refer https://developer.atlassian.com/server/framework/atlassian-sdk/atlas-run-standalone/
|
| 652 |
+
|
| 653 |
+
# initialize Jira sink config
|
| 654 |
+
sink_config = JiraSinkConfig(
|
| 655 |
+
url="http://localhost:2990/jira", # Jira server url
|
| 656 |
+
# Jira username & password for user who have permission to create issue
|
| 657 |
+
username="<username>",
|
| 658 |
+
password="<password>",
|
| 659 |
+
# Which type of issue to be created
|
| 660 |
+
# For more information refer https://support.atlassian.com/jira-cloud-administration/docs/what-are-issue-types/
|
| 661 |
+
issue_type={"name": "Task"},
|
| 662 |
+
# Under which project issue to be created
|
| 663 |
+
# For more information refer https://support.atlassian.com/jira-software-cloud/docs/what-is-a-jira-software-project/
|
| 664 |
+
project={"key": "CUS"},
|
| 665 |
+
)
|
| 666 |
+
|
| 667 |
+
# initialize Jira sink
|
| 668 |
+
sink = JiraSink()
|
| 669 |
+
```
|
| 670 |
+
|
| 671 |
+
</details>
|
| 672 |
+
</td>
|
| 673 |
+
</tr>
|
| 674 |
+
<tr>
|
| 675 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/elastic.png" width="20" height="20"><b>ElasticSearch</b></summary><hr>
|
| 676 |
+
|
| 677 |
+
```python
|
| 678 |
+
from obsei.sink.elasticsearch_sink import ElasticSearchSink, ElasticSearchSinkConfig
|
| 679 |
+
|
| 680 |
+
# For testing purpose you can start Elasticsearch server locally via docker
|
| 681 |
+
# `docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:8.5.0`
|
| 682 |
+
|
| 683 |
+
# initialize Elasticsearch sink config
|
| 684 |
+
sink_config = ElasticSearchSinkConfig(
|
| 685 |
+
# Elasticsearch server
|
| 686 |
+
hosts="http://localhost:9200",
|
| 687 |
+
# Index name, it will create if not exist
|
| 688 |
+
index_name="test",
|
| 689 |
+
)
|
| 690 |
+
|
| 691 |
+
# initialize Elasticsearch sink
|
| 692 |
+
sink = ElasticSearchSink()
|
| 693 |
+
```
|
| 694 |
+
|
| 695 |
+
</details>
|
| 696 |
+
</td>
|
| 697 |
+
</tr>
|
| 698 |
+
<tr>
|
| 699 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/http_api.png" width="20" height="20"><b>Http</b></summary><hr>
|
| 700 |
+
|
| 701 |
+
```python
|
| 702 |
+
from obsei.sink.http_sink import HttpSink, HttpSinkConfig
|
| 703 |
+
|
| 704 |
+
# For testing purpose you can create mock http server via postman
|
| 705 |
+
# For more details refer https://learning.postman.com/docs/designing-and-developing-your-api/mocking-data/setting-up-mock/
|
| 706 |
+
|
| 707 |
+
# initialize http sink config (Currently only POST call is supported)
|
| 708 |
+
sink_config = HttpSinkConfig(
|
| 709 |
+
# provide http server url
|
| 710 |
+
url="https://localhost:8080/api/path",
|
| 711 |
+
# Here you can add headers you would like to pass with request
|
| 712 |
+
headers={
|
| 713 |
+
"Content-type": "application/json"
|
| 714 |
+
}
|
| 715 |
+
)
|
| 716 |
+
|
| 717 |
+
# To modify or converting the payload, create convertor class
|
| 718 |
+
# Refer obsei.sink.dailyget_sink.PayloadConvertor for example
|
| 719 |
+
|
| 720 |
+
# initialize http sink
|
| 721 |
+
sink = HttpSink()
|
| 722 |
+
```
|
| 723 |
+
|
| 724 |
+
</details>
|
| 725 |
+
</td>
|
| 726 |
+
</tr>
|
| 727 |
+
<tr>
|
| 728 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/pandas.svg" width="20" height="20"><b>Pandas DataFrame</b></summary><hr>
|
| 729 |
+
|
| 730 |
+
```python
|
| 731 |
+
from pandas import DataFrame
|
| 732 |
+
from obsei.sink.pandas_sink import PandasSink, PandasSinkConfig
|
| 733 |
+
|
| 734 |
+
# initialize pandas sink config
|
| 735 |
+
sink_config = PandasSinkConfig(
|
| 736 |
+
dataframe=DataFrame()
|
| 737 |
+
)
|
| 738 |
+
|
| 739 |
+
# initialize pandas sink
|
| 740 |
+
sink = PandasSink()
|
| 741 |
+
```
|
| 742 |
+
|
| 743 |
+
</details>
|
| 744 |
+
</td>
|
| 745 |
+
</tr>
|
| 746 |
+
<tr>
|
| 747 |
+
<td><details ><summary><img style="vertical-align:middle;margin:2px 10px" src="https://raw.githubusercontent.com/obsei/obsei-resources/master/logos/logger.png" width="20" height="20"><b>Logger</b></summary><hr>
|
| 748 |
+
|
| 749 |
+
This is useful for testing and dry running the pipeline.
|
| 750 |
+
|
| 751 |
+
```python
|
| 752 |
+
from obsei.sink.logger_sink import LoggerSink, LoggerSinkConfig
|
| 753 |
+
import logging
|
| 754 |
+
import sys
|
| 755 |
+
|
| 756 |
+
logger = logging.getLogger("Obsei")
|
| 757 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 758 |
+
|
| 759 |
+
# initialize logger sink config
|
| 760 |
+
sink_config = LoggerSinkConfig(
|
| 761 |
+
logger=logger,
|
| 762 |
+
level=logging.INFO
|
| 763 |
+
)
|
| 764 |
+
|
| 765 |
+
# initialize logger sink
|
| 766 |
+
sink = LoggerSink()
|
| 767 |
+
```
|
| 768 |
+
|
| 769 |
+
</details>
|
| 770 |
+
</td>
|
| 771 |
+
</tr>
|
| 772 |
+
</tbody>
|
| 773 |
+
</table>
|
| 774 |
+
|
| 775 |
+
</details>
|
| 776 |
+
|
| 777 |
+
<details><summary><b>Step 4: Join and create workflow</b></summary>
|
| 778 |
+
|
| 779 |
+
`source` will fetch data from the selected source, then feed it to the `analyzer` for processing, whose output we feed into a `sink` to get notified at that sink.
|
| 780 |
+
|
| 781 |
+
```python
|
| 782 |
+
# Uncomment if you want logger
|
| 783 |
+
# import logging
|
| 784 |
+
# import sys
|
| 785 |
+
# logger = logging.getLogger(__name__)
|
| 786 |
+
# logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 787 |
+
|
| 788 |
+
# This will fetch information from configured source ie twitter, app store etc
|
| 789 |
+
source_response_list = source.lookup(source_config)
|
| 790 |
+
|
| 791 |
+
# Uncomment if you want to log source response
|
| 792 |
+
# for idx, source_response in enumerate(source_response_list):
|
| 793 |
+
# logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 794 |
+
|
| 795 |
+
# This will execute analyzer (Sentiment, classification etc) on source data with provided analyzer_config
|
| 796 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 797 |
+
source_response_list=source_response_list,
|
| 798 |
+
analyzer_config=analyzer_config
|
| 799 |
+
)
|
| 800 |
+
|
| 801 |
+
# Uncomment if you want to log analyzer response
|
| 802 |
+
# for idx, an_response in enumerate(analyzer_response_list):
|
| 803 |
+
# logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
| 804 |
+
|
| 805 |
+
# Analyzer output added to segmented_data
|
| 806 |
+
# Uncomment to log it
|
| 807 |
+
# for idx, an_response in enumerate(analyzer_response_list):
|
| 808 |
+
# logger.info(f"analyzed_data#'{idx}'='{an_response.segmented_data.__dict__}'")
|
| 809 |
+
|
| 810 |
+
# This will send analyzed output to configure sink ie Slack, Zendesk etc
|
| 811 |
+
sink_response_list = sink.send_data(analyzer_response_list, sink_config)
|
| 812 |
+
|
| 813 |
+
# Uncomment if you want to log sink response
|
| 814 |
+
# for sink_response in sink_response_list:
|
| 815 |
+
# if sink_response is not None:
|
| 816 |
+
# logger.info(f"sink_response='{sink_response}'")
|
| 817 |
+
```
|
| 818 |
+
|
| 819 |
+
</details>
|
| 820 |
+
|
| 821 |
+
<details><summary><b>Step 5: Execute workflow</b></summary>
|
| 822 |
+
Copy the code snippets from <b>Steps 1 to 4</b> into a python file, for example <code>example.py</code> and execute the following command -
|
| 823 |
+
|
| 824 |
+
```shell
|
| 825 |
+
python example.py
|
| 826 |
+
```
|
| 827 |
+
|
| 828 |
+
</details>
|
| 829 |
+
|
| 830 |
+
## Demo
|
| 831 |
+
|
| 832 |
+
We have a minimal [streamlit](https://streamlit.io/) based UI that you can use to test Obsei.
|
| 833 |
+
|
| 834 |
+
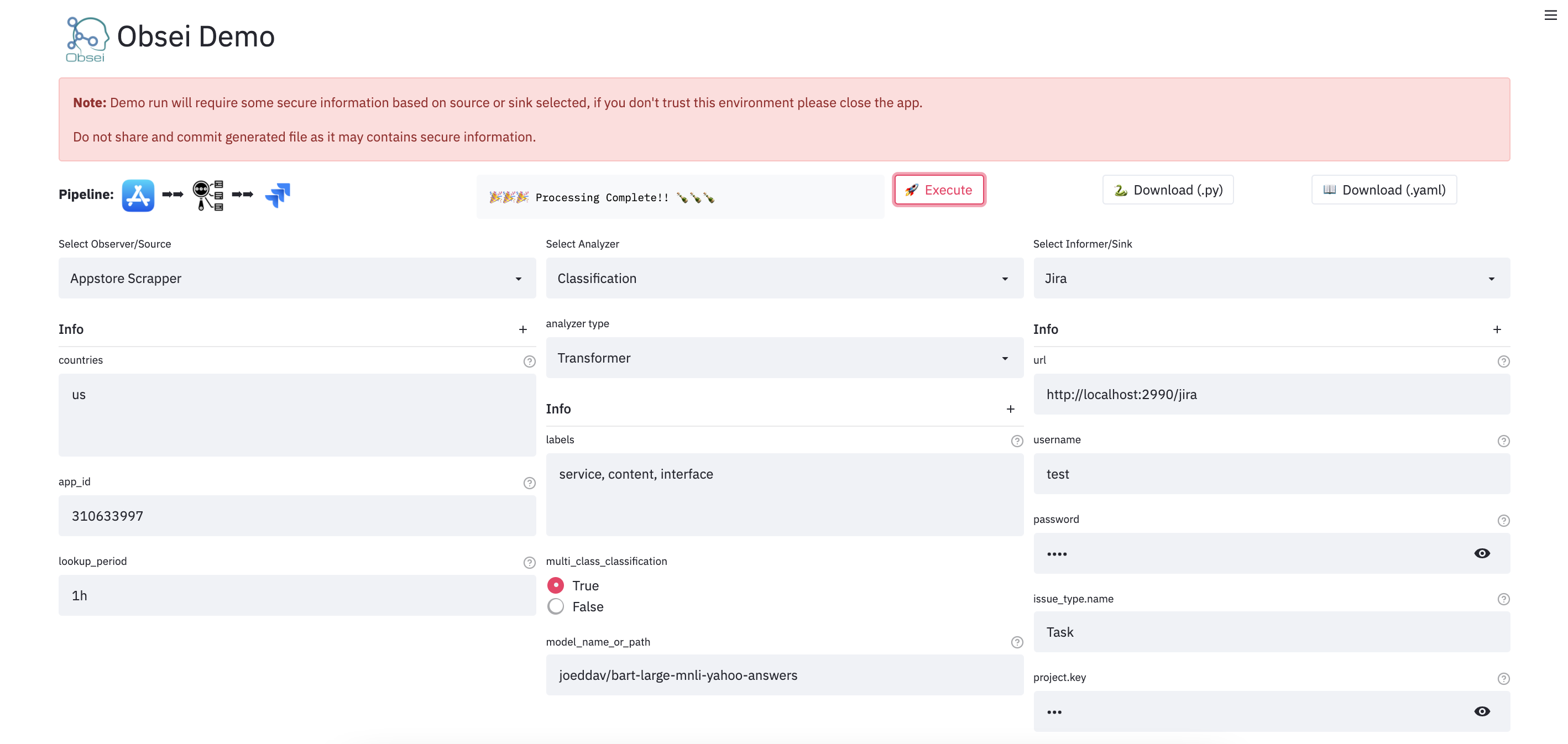
|
| 835 |
+
|
| 836 |
+
### Watch UI demo video
|
| 837 |
+
|
| 838 |
+
[](https://www.youtube.com/watch?v=GTF-Hy96gvY)
|
| 839 |
+
|
| 840 |
+
Check demo at [](https://huggingface.co/spaces/obsei/obsei-demo)
|
| 841 |
+
|
| 842 |
+
(**Note**: Sometimes the Streamlit demo might not work due to rate limiting, use the docker image (locally) in such cases.)
|
| 843 |
+
|
| 844 |
+
To test locally, just run
|
| 845 |
+
|
| 846 |
+
```
|
| 847 |
+
docker run -d --name obesi-ui -p 8501:8501 obsei/obsei-ui-demo
|
| 848 |
+
|
| 849 |
+
# You can find the UI at http://localhost:8501
|
| 850 |
+
```
|
| 851 |
+
|
| 852 |
+
**To run Obsei workflow easily using GitHub Actions (no sign ups and cloud hosting required), refer to this [repo](https://github.com/obsei/demo-workflow-action)**.
|
| 853 |
+
|
| 854 |
+
## Companies/Projects using Obsei
|
| 855 |
+
|
| 856 |
+
Here are some companies/projects (alphabetical order) using Obsei. To add your company/project to the list, please raise a PR or contact us via [email](contact@obsei.com).
|
| 857 |
+
|
| 858 |
+
- [Oraika](https://www.oraika.com): Contextually understand customer feedback
|
| 859 |
+
- [1Page](https://www.get1page.com/): Giving a better context in meetings and calls
|
| 860 |
+
- [Spacepulse](http://spacepulse.in/): The operating system for spaces
|
| 861 |
+
- [Superblog](https://superblog.ai/): A blazing fast alternative to WordPress and Medium
|
| 862 |
+
- [Zolve](https://zolve.com/): Creating a financial world beyond borders
|
| 863 |
+
- [Utilize](https://www.utilize.app/): No-code app builder for businesses with a deskless workforce
|
| 864 |
+
|
| 865 |
+
## Articles
|
| 866 |
+
|
| 867 |
+
<table>
|
| 868 |
+
<thead>
|
| 869 |
+
<tr class="header">
|
| 870 |
+
<th>Sr. No.</th>
|
| 871 |
+
<th>Title</th>
|
| 872 |
+
<th>Author</th>
|
| 873 |
+
</tr>
|
| 874 |
+
</thead>
|
| 875 |
+
<tbody>
|
| 876 |
+
<tr>
|
| 877 |
+
<td>1</td>
|
| 878 |
+
<td>
|
| 879 |
+
<a href="https://reenabapna.medium.com/ai-based-comparative-customer-feedback-analysis-using-deep-learning-models-def0dc77aaee">AI based Comparative Customer Feedback Analysis Using Obsei</a>
|
| 880 |
+
</td>
|
| 881 |
+
<td>
|
| 882 |
+
<a href="linkedin.com/in/reena-bapna-66a8691a">Reena Bapna</a>
|
| 883 |
+
</td>
|
| 884 |
+
</tr>
|
| 885 |
+
<tr>
|
| 886 |
+
<td>2</td>
|
| 887 |
+
<td>
|
| 888 |
+
<a href="https://medium.com/mlearning-ai/linkedin-app-user-feedback-analysis-9c9f98464daa">LinkedIn App - User Feedback Analysis</a>
|
| 889 |
+
</td>
|
| 890 |
+
<td>
|
| 891 |
+
<a href="http://www.linkedin.com/in/himanshusharmads">Himanshu Sharma</a>
|
| 892 |
+
</td>
|
| 893 |
+
</tr>
|
| 894 |
+
</tbody>
|
| 895 |
+
</table>
|
| 896 |
+
|
| 897 |
+
## Tutorials
|
| 898 |
+
|
| 899 |
+
<table>
|
| 900 |
+
<thead>
|
| 901 |
+
<tr class="header">
|
| 902 |
+
<th>Sr. No.</th>
|
| 903 |
+
<th>Workflow</th>
|
| 904 |
+
<th>Colab</th>
|
| 905 |
+
<th>Binder</th>
|
| 906 |
+
</tr>
|
| 907 |
+
</thead>
|
| 908 |
+
<tbody>
|
| 909 |
+
<tr>
|
| 910 |
+
<td rowspan="2">1</td>
|
| 911 |
+
<td colspan="3">Observe app reviews from Google play store, Analyze them by performing text classification and then Inform them on console via logger</td>
|
| 912 |
+
</tr>
|
| 913 |
+
<tr>
|
| 914 |
+
<td>PlayStore Reviews → Classification → Logger</td>
|
| 915 |
+
<td>
|
| 916 |
+
<a href="https://colab.research.google.com/github/obsei/obsei/blob/master/tutorials/01_PlayStore_Classification_Logger.ipynb">
|
| 917 |
+
<img alt="Colab" src="https://colab.research.google.com/assets/colab-badge.svg">
|
| 918 |
+
</a>
|
| 919 |
+
</td>
|
| 920 |
+
<td>
|
| 921 |
+
<a href="https://mybinder.org/v2/gh/obsei/obsei/HEAD?filepath=tutorials%2F01_PlayStore_Classification_Logger.ipynb">
|
| 922 |
+
<img alt="Colab" src="https://mybinder.org/badge_logo.svg">
|
| 923 |
+
</a>
|
| 924 |
+
</td>
|
| 925 |
+
</tr>
|
| 926 |
+
<tr>
|
| 927 |
+
<td rowspan="2">2</td>
|
| 928 |
+
<td colspan="3">Observe app reviews from Google play store, PreProcess text via various text cleaning functions, Analyze them by performing text classification, Inform them to Pandas DataFrame and store resultant CSV to Google Drive</td>
|
| 929 |
+
</tr>
|
| 930 |
+
<tr>
|
| 931 |
+
<td>PlayStore Reviews → PreProcessing → Classification → Pandas DataFrame → CSV in Google Drive</td>
|
| 932 |
+
<td>
|
| 933 |
+
<a href="https://colab.research.google.com/github/obsei/obsei/blob/master/tutorials/02_PlayStore_PreProc_Classification_Pandas.ipynb">
|
| 934 |
+
<img alt="Colab" src="https://colab.research.google.com/assets/colab-badge.svg">
|
| 935 |
+
</a>
|
| 936 |
+
</td>
|
| 937 |
+
<td>
|
| 938 |
+
<a href="https://mybinder.org/v2/gh/obsei/obsei/HEAD?filepath=tutorials%2F02_PlayStore_PreProc_Classification_Pandas.ipynb">
|
| 939 |
+
<img alt="Colab" src="https://mybinder.org/badge_logo.svg">
|
| 940 |
+
</a>
|
| 941 |
+
</td>
|
| 942 |
+
</tr>
|
| 943 |
+
<tr>
|
| 944 |
+
<td rowspan="2">3</td>
|
| 945 |
+
<td colspan="3">Observe app reviews from Apple app store, PreProcess text via various text cleaning function, Analyze them by performing text classification, Inform them to Pandas DataFrame and store resultant CSV to Google Drive</td>
|
| 946 |
+
</tr>
|
| 947 |
+
<tr>
|
| 948 |
+
<td>AppStore Reviews → PreProcessing → Classification → Pandas DataFrame → CSV in Google Drive</td>
|
| 949 |
+
<td>
|
| 950 |
+
<a href="https://colab.research.google.com/github/obsei/obsei/blob/master/tutorials/03_AppStore_PreProc_Classification_Pandas.ipynb">
|
| 951 |
+
<img alt="Colab" src="https://colab.research.google.com/assets/colab-badge.svg">
|
| 952 |
+
</a>
|
| 953 |
+
</td>
|
| 954 |
+
<td>
|
| 955 |
+
<a href="https://mybinder.org/v2/gh/obsei/obsei/HEAD?filepath=tutorials%2F03_AppStore_PreProc_Classification_Pandas.ipynb">
|
| 956 |
+
<img alt="Colab" src="https://mybinder.org/badge_logo.svg">
|
| 957 |
+
</a>
|
| 958 |
+
</td>
|
| 959 |
+
</tr>
|
| 960 |
+
<tr>
|
| 961 |
+
<td rowspan="2">4</td>
|
| 962 |
+
<td colspan="3">Observe news article from Google news, PreProcess text via various text cleaning function, Analyze them via performing text classification while splitting text in small chunks and later computing final inference using given formula</td>
|
| 963 |
+
</tr>
|
| 964 |
+
<tr>
|
| 965 |
+
<td>Google News → Text Cleaner → Text Splitter → Classification → Inference Aggregator</td>
|
| 966 |
+
<td>
|
| 967 |
+
<a href="https://colab.research.google.com/github/obsei/obsei/blob/master/tutorials/04_GoogleNews_Cleaner_Splitter_Classification_Aggregator.ipynb">
|
| 968 |
+
<img alt="Colab" src="https://colab.research.google.com/assets/colab-badge.svg">
|
| 969 |
+
</a>
|
| 970 |
+
</td>
|
| 971 |
+
<td>
|
| 972 |
+
<a href="https://mybinder.org/v2/gh/obsei/obsei/HEAD?filepath=tutorials%2F04_GoogleNews_Cleaner_Splitter_Classification_Aggregator.ipynb">
|
| 973 |
+
<img alt="Colab" src="https://mybinder.org/badge_logo.svg">
|
| 974 |
+
</a>
|
| 975 |
+
</td>
|
| 976 |
+
</tr>
|
| 977 |
+
</tbody>
|
| 978 |
+
</table>
|
| 979 |
+
|
| 980 |
+
<details><summary><b>💡Tips: Handle large text classification via Obsei</b></summary>
|
| 981 |
+
|
| 982 |
+

|
| 983 |
+
|
| 984 |
+
</details>
|
| 985 |
+
|
| 986 |
+
## Documentation
|
| 987 |
+
|
| 988 |
+
For detailed installation instructions, usages and examples, refer to our [documentation](https://obsei.github.io/obsei/).
|
| 989 |
+
|
| 990 |
+
## Support and Release Matrix
|
| 991 |
+
|
| 992 |
+
<table>
|
| 993 |
+
<thead>
|
| 994 |
+
<tr class="header">
|
| 995 |
+
<th></th>
|
| 996 |
+
<th>Linux</th>
|
| 997 |
+
<th>Mac</th>
|
| 998 |
+
<th>Windows</th>
|
| 999 |
+
<th>Remark</th>
|
| 1000 |
+
</tr>
|
| 1001 |
+
</thead>
|
| 1002 |
+
<tbody>
|
| 1003 |
+
<tr>
|
| 1004 |
+
<td>Tests</td>
|
| 1005 |
+
<td style="text-align:center">✅</td>
|
| 1006 |
+
<td style="text-align:center">✅</td>
|
| 1007 |
+
<td style="text-align:center">✅</td>
|
| 1008 |
+
<td>Low Coverage as difficult to test 3rd party libs</td>
|
| 1009 |
+
</tr>
|
| 1010 |
+
<tr>
|
| 1011 |
+
<td>PIP</td>
|
| 1012 |
+
<td style="text-align:center">✅</td>
|
| 1013 |
+
<td style="text-align:center">✅</td>
|
| 1014 |
+
<td style="text-align:center">✅</td>
|
| 1015 |
+
<td>Fully Supported</td>
|
| 1016 |
+
</tr>
|
| 1017 |
+
<tr>
|
| 1018 |
+
<td>Conda</td>
|
| 1019 |
+
<td style="text-align:center">❌</td>
|
| 1020 |
+
<td style="text-align:center">❌</td>
|
| 1021 |
+
<td style="text-align:center">❌</td>
|
| 1022 |
+
<td>Not Supported</td>
|
| 1023 |
+
</tr>
|
| 1024 |
+
</tbody>
|
| 1025 |
+
</table>
|
| 1026 |
+
|
| 1027 |
+
## Discussion forum
|
| 1028 |
+
|
| 1029 |
+
Discussion about _Obsei_ can be done at [community forum](https://github.com/obsei/obsei/discussions)
|
| 1030 |
+
|
| 1031 |
+
## Changelogs
|
| 1032 |
+
|
| 1033 |
+
Refer [releases](https://github.com/obsei/obsei/releases) for changelogs
|
| 1034 |
+
|
| 1035 |
+
## Security Issue
|
| 1036 |
+
|
| 1037 |
+
For any security issue please contact us via [email](mailto:contact@oraika.com)
|
| 1038 |
+
|
| 1039 |
+
## Stargazers over time
|
| 1040 |
+
|
| 1041 |
+
[](https://starchart.cc/obsei/obsei)
|
| 1042 |
+
|
| 1043 |
+
## Maintainers
|
| 1044 |
+
|
| 1045 |
+
This project is being maintained by [Oraika Technologies](https://www.oraika.com). [Lalit Pagaria](https://github.com/lalitpagaria) and [Girish Patel](https://github.com/GirishPatel) are maintainers of this project.
|
| 1046 |
+
|
| 1047 |
+
## License
|
| 1048 |
+
|
| 1049 |
+
- Copyright holder: [Oraika Technologies](https://www.oraika.com)
|
| 1050 |
+
- Overall Apache 2.0 and you can read [License](https://github.com/obsei/obsei/blob/master/LICENSE) file.
|
| 1051 |
+
- Multiple other secondary permissive or weak copyleft licenses (LGPL, MIT, BSD etc.) for third-party components refer [Attribution](https://github.com/obsei/obsei/blob/master/ATTRIBUTION.md).
|
| 1052 |
+
- To make project more commercial friendly, we void third party components which have strong copyleft licenses (GPL, AGPL etc.) into the project.
|
| 1053 |
+
|
| 1054 |
+
## Attribution
|
| 1055 |
+
|
| 1056 |
+
This could not have been possible without these [open source softwares](https://github.com/obsei/obsei/blob/master/ATTRIBUTION.md).
|
| 1057 |
+
|
| 1058 |
+
## Contribution
|
| 1059 |
+
|
| 1060 |
+
First off, thank you for even considering contributing to this package, every contribution big or small is greatly appreciated.
|
| 1061 |
+
Please refer our [Contribution Guideline](https://github.com/obsei/obsei/blob/master/CONTRIBUTING.md) and [Code of Conduct](https://github.com/obsei/obsei/blob/master/CODE_OF_CONDUCT.md).
|
| 1062 |
+
|
| 1063 |
+
Thanks so much to all our contributors
|
| 1064 |
+
|
| 1065 |
+
<a href="https://github.com/obsei/obsei/graphs/contributors">
|
| 1066 |
+
<img src="https://contrib.rocks/image?repo=obsei/obsei" />
|
| 1067 |
+
</a>
|
obsei_module/SECURITY.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Security Policy
|
| 2 |
+
|
| 3 |
+
## Reporting a Vulnerability
|
| 4 |
+
|
| 5 |
+
For any security issue please report it via [email](mailto:contact@oraika.com).
|
obsei_module/__init__.py
ADDED
|
File without changes
|
obsei_module/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (166 Bytes). View file
|
|
|
obsei_module/_config.yml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
theme: jekyll-theme-primer
|
| 2 |
+
markdown: CommonMarkGhPages
|
| 3 |
+
commonmark:
|
| 4 |
+
options: ["UNSAFE", "SMART", "FOOTNOTES"]
|
| 5 |
+
extensions: ["strikethrough", "autolink", "table", "tagfilter"]
|
| 6 |
+
title: "Obsei: An open-source low-code AI powered automation tool"
|
| 7 |
+
description: "Obsei is an open-source low-code AI powered automation tool"
|
| 8 |
+
|
| 9 |
+
google_analytics: G-0E2FTKBK4T
|
obsei_module/_includes/head-custom-google-analytics.html
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- Global site tag (gtag.js) - Google Analytics -->
|
| 2 |
+
<script async src="https://www.googletagmanager.com/gtag/js?id=G-0E2FTKBK4T"></script>
|
| 3 |
+
<script>
|
| 4 |
+
window.dataLayer = window.dataLayer || [];
|
| 5 |
+
function gtag(){dataLayer.push(arguments);}
|
| 6 |
+
gtag('js', new Date());
|
| 7 |
+
|
| 8 |
+
gtag('config', 'G-0E2FTKBK4T');
|
| 9 |
+
</script>
|
obsei_module/binder/requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
git+https://github.com/obsei/obsei@master#egg=obsei[all]
|
| 2 |
+
trafilatura
|
obsei_module/example/app_store_scrapper_example.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
from datetime import datetime, timedelta
|
| 4 |
+
|
| 5 |
+
import pytz
|
| 6 |
+
|
| 7 |
+
from obsei.analyzer.classification_analyzer import ClassificationAnalyzerConfig, ZeroShotClassificationAnalyzer
|
| 8 |
+
from obsei.misc.utils import DATETIME_STRING_PATTERN
|
| 9 |
+
from obsei.source.appstore_scrapper import (
|
| 10 |
+
AppStoreScrapperConfig,
|
| 11 |
+
AppStoreScrapperSource,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
logger = logging.getLogger(__name__)
|
| 15 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 16 |
+
|
| 17 |
+
since_time = datetime.utcnow().astimezone(pytz.utc) + timedelta(days=-5)
|
| 18 |
+
source_config = AppStoreScrapperConfig(
|
| 19 |
+
app_url='https://apps.apple.com/us/app/gmail-email-by-google/id422689480',
|
| 20 |
+
lookup_period=since_time.strftime(DATETIME_STRING_PATTERN),
|
| 21 |
+
max_count=10,
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
source = AppStoreScrapperSource()
|
| 25 |
+
|
| 26 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 27 |
+
model_name_or_path="typeform/mobilebert-uncased-mnli", device="auto"
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
source_response_list = source.lookup(source_config)
|
| 31 |
+
for idx, source_response in enumerate(source_response_list):
|
| 32 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 33 |
+
|
| 34 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 35 |
+
source_response_list=source_response_list,
|
| 36 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 37 |
+
labels=["interface", "slow", "battery"],
|
| 38 |
+
),
|
| 39 |
+
)
|
| 40 |
+
for idx, an_response in enumerate(analyzer_response_list):
|
| 41 |
+
logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
obsei_module/example/daily_get_example.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
from obsei.sink.dailyget_sink import DailyGetSink, DailyGetSinkConfig
|
| 7 |
+
from obsei.source.twitter_source import TwitterSource, TwitterSourceConfig
|
| 8 |
+
from obsei.analyzer.classification_analyzer import (
|
| 9 |
+
ClassificationAnalyzerConfig,
|
| 10 |
+
ZeroShotClassificationAnalyzer,
|
| 11 |
+
)
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 15 |
+
|
| 16 |
+
sink_config = DailyGetSinkConfig(
|
| 17 |
+
url=os.environ["DAILYGET_URL"],
|
| 18 |
+
partner_id=os.environ["DAILYGET_PARTNER_ID"],
|
| 19 |
+
consumer_phone_number=os.environ["DAILYGET_CONSUMER_NUMBER"],
|
| 20 |
+
source_information="Twitter " + os.environ["DAILYGET_QUERY"],
|
| 21 |
+
base_payload={
|
| 22 |
+
"partnerId": os.environ["DAILYGET_PARTNER_ID"],
|
| 23 |
+
"consumerPhoneNumber": os.environ["DAILYGET_CONSUMER_NUMBER"],
|
| 24 |
+
},
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
dir_path = Path(__file__).resolve().parent.parent
|
| 28 |
+
source_config = TwitterSourceConfig(
|
| 29 |
+
keywords=[os.environ["DAILYGET_QUERY"]],
|
| 30 |
+
lookup_period=os.environ["DAILYGET_LOOKUP_PERIOD"],
|
| 31 |
+
tweet_fields=[
|
| 32 |
+
"author_id",
|
| 33 |
+
"conversation_id",
|
| 34 |
+
"created_at",
|
| 35 |
+
"id",
|
| 36 |
+
"public_metrics",
|
| 37 |
+
"text",
|
| 38 |
+
],
|
| 39 |
+
user_fields=["id", "name", "public_metrics", "username", "verified"],
|
| 40 |
+
expansions=["author_id"],
|
| 41 |
+
place_fields=None,
|
| 42 |
+
max_tweets=10,
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
source = TwitterSource()
|
| 46 |
+
sink = DailyGetSink()
|
| 47 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 48 |
+
model_name_or_path="joeddav/bart-large-mnli-yahoo-answers",
|
| 49 |
+
# model_name_or_path="joeddav/xlm-roberta-large-xnli",
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
source_response_list = source.lookup(source_config)
|
| 53 |
+
for idx, source_response in enumerate(source_response_list):
|
| 54 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 55 |
+
|
| 56 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 57 |
+
source_response_list=source_response_list,
|
| 58 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 59 |
+
labels=[
|
| 60 |
+
"service",
|
| 61 |
+
"delay",
|
| 62 |
+
"tracking",
|
| 63 |
+
"no response",
|
| 64 |
+
"missing items",
|
| 65 |
+
"delivery",
|
| 66 |
+
"mask",
|
| 67 |
+
],
|
| 68 |
+
),
|
| 69 |
+
)
|
| 70 |
+
for idx, an_response in enumerate(analyzer_response_list):
|
| 71 |
+
logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
| 72 |
+
|
| 73 |
+
# HTTP Sink
|
| 74 |
+
sink_response_list = sink.send_data(analyzer_response_list, sink_config)
|
| 75 |
+
for sink_response in sink_response_list:
|
| 76 |
+
if sink_response is not None:
|
| 77 |
+
logger.info(f"sink_response='{sink_response.__dict__}'")
|
obsei_module/example/elasticsearch_example.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
from obsei.sink.elasticsearch_sink import ElasticSearchSink, ElasticSearchSinkConfig
|
| 6 |
+
from obsei.source.twitter_source import TwitterSource, TwitterSourceConfig
|
| 7 |
+
from obsei.analyzer.classification_analyzer import (
|
| 8 |
+
ClassificationAnalyzerConfig,
|
| 9 |
+
ZeroShotClassificationAnalyzer,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
logger = logging.getLogger(__name__)
|
| 13 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 14 |
+
|
| 15 |
+
dir_path = Path(__file__).resolve().parent.parent
|
| 16 |
+
source_config = TwitterSourceConfig(
|
| 17 |
+
keywords="@Handle",
|
| 18 |
+
lookup_period="1h", # 1 Hour
|
| 19 |
+
tweet_fields=[
|
| 20 |
+
"author_id",
|
| 21 |
+
"conversation_id",
|
| 22 |
+
"created_at",
|
| 23 |
+
"id",
|
| 24 |
+
"public_metrics",
|
| 25 |
+
"text",
|
| 26 |
+
],
|
| 27 |
+
user_fields=["id", "name", "public_metrics", "username", "verified"],
|
| 28 |
+
expansions=["author_id"],
|
| 29 |
+
place_fields=None,
|
| 30 |
+
max_tweets=10,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
source = TwitterSource()
|
| 34 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 35 |
+
model_name_or_path="joeddav/bart-large-mnli-yahoo-answers",
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
# Start Elasticsearch server locally
|
| 39 |
+
# `docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.2`
|
| 40 |
+
sink_config = ElasticSearchSinkConfig(
|
| 41 |
+
host="localhost",
|
| 42 |
+
port=9200,
|
| 43 |
+
index_name="test",
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
source_response_list = source.lookup(source_config)
|
| 47 |
+
for idx, source_response in enumerate(source_response_list):
|
| 48 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 49 |
+
|
| 50 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 51 |
+
source_response_list=source_response_list,
|
| 52 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 53 |
+
labels=[
|
| 54 |
+
"service",
|
| 55 |
+
"delay",
|
| 56 |
+
"tracking",
|
| 57 |
+
"no response",
|
| 58 |
+
"missing items",
|
| 59 |
+
"delivery",
|
| 60 |
+
"mask",
|
| 61 |
+
],
|
| 62 |
+
),
|
| 63 |
+
)
|
| 64 |
+
for idx, an_response in enumerate(analyzer_response_list):
|
| 65 |
+
logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
| 66 |
+
|
| 67 |
+
sink = ElasticSearchSink()
|
| 68 |
+
sink_response = sink.send_data(analyzer_response_list, sink_config)
|
| 69 |
+
logger.info(f"sink_response='{sink_response}'")
|
obsei_module/example/email_source_example.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
from datetime import datetime, timedelta
|
| 5 |
+
|
| 6 |
+
import pytz
|
| 7 |
+
|
| 8 |
+
from obsei.misc.utils import DATETIME_STRING_PATTERN
|
| 9 |
+
from obsei.source.email_source import EmailConfig, EmailCredInfo, EmailSource
|
| 10 |
+
|
| 11 |
+
logger = logging.getLogger(__name__)
|
| 12 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 13 |
+
|
| 14 |
+
since_time = datetime.utcnow().astimezone(pytz.utc) + timedelta(hours=-10)
|
| 15 |
+
|
| 16 |
+
# List of IMAP servers for most commonly used email providers
|
| 17 |
+
# https://www.systoolsgroup.com/imap/
|
| 18 |
+
# Also, if you're using a Gmail account then make sure you allow less secure apps on your account -
|
| 19 |
+
# https://myaccount.google.com/lesssecureapps?pli=1
|
| 20 |
+
# Also enable IMAP access -
|
| 21 |
+
# https://mail.google.com/mail/u/0/#settings/fwdandpop
|
| 22 |
+
source_config = EmailConfig(
|
| 23 |
+
imap_server="imap.gmail.com",
|
| 24 |
+
cred_info=EmailCredInfo(
|
| 25 |
+
# It will fetch username and password from environment variable
|
| 26 |
+
username=os.environ.get("email_username"),
|
| 27 |
+
password=os.environ.get("email_password"),
|
| 28 |
+
),
|
| 29 |
+
lookup_period=since_time.strftime(DATETIME_STRING_PATTERN),
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
source = EmailSource()
|
| 33 |
+
source_response_list = source.lookup(source_config)
|
| 34 |
+
|
| 35 |
+
for source_response in source_response_list:
|
| 36 |
+
logger.info(source_response.__dict__)
|
obsei_module/example/facebook_example.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from obsei.source.facebook_source import FacebookSource, FacebookSourceConfig
|
| 5 |
+
|
| 6 |
+
logger = logging.getLogger(__name__)
|
| 7 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 8 |
+
|
| 9 |
+
source_config = FacebookSourceConfig(page_id="110844591144719", lookup_period="2M")
|
| 10 |
+
source = FacebookSource()
|
| 11 |
+
source_response_list = source.lookup(source_config)
|
| 12 |
+
|
| 13 |
+
logger.info("DETAILS:")
|
| 14 |
+
for source_response in source_response_list:
|
| 15 |
+
logger.info(source_response)
|
| 16 |
+
|
| 17 |
+
logger.info("TEXT:")
|
| 18 |
+
for source_response in source_response_list:
|
| 19 |
+
logger.info(source_response.processed_text)
|
obsei_module/example/google_news_example.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from obsei.analyzer.classification_analyzer import (
|
| 2 |
+
ClassificationAnalyzerConfig,
|
| 3 |
+
ZeroShotClassificationAnalyzer,
|
| 4 |
+
)
|
| 5 |
+
from obsei.source.google_news_source import GoogleNewsConfig, GoogleNewsSource
|
| 6 |
+
|
| 7 |
+
# Only fetch title and highlight
|
| 8 |
+
source_config_without_full_text = GoogleNewsConfig(
|
| 9 |
+
query="ai",
|
| 10 |
+
max_results=150,
|
| 11 |
+
after_date='2023-12-01',
|
| 12 |
+
before_date='2023-12-31',
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
# Fetch full news article
|
| 16 |
+
source_config_with_full_text = GoogleNewsConfig(
|
| 17 |
+
query="ai",
|
| 18 |
+
max_results=5,
|
| 19 |
+
fetch_article=True,
|
| 20 |
+
lookup_period="1d",
|
| 21 |
+
# proxy="http://127.0.0.1:8080"
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
source = GoogleNewsSource()
|
| 25 |
+
|
| 26 |
+
analyzer_config = ClassificationAnalyzerConfig(
|
| 27 |
+
labels=["buy", "sell", "going up", "going down"],
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 31 |
+
model_name_or_path="typeform/mobilebert-uncased-mnli", device="auto"
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
news_articles_without_full_text = source.lookup(source_config_without_full_text)
|
| 35 |
+
|
| 36 |
+
news_articles_with_full_text = source.lookup(source_config_with_full_text)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
analyzer_responses_without_full_text = text_analyzer.analyze_input(
|
| 40 |
+
source_response_list=news_articles_without_full_text,
|
| 41 |
+
analyzer_config=analyzer_config,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
analyzer_responses_with_full_text = text_analyzer.analyze_input(
|
| 45 |
+
source_response_list=news_articles_with_full_text, analyzer_config=analyzer_config
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
for article in news_articles_without_full_text:
|
| 49 |
+
print(article.__dict__)
|
| 50 |
+
|
| 51 |
+
for response in analyzer_responses_without_full_text:
|
| 52 |
+
print(response.__dict__)
|
| 53 |
+
|
| 54 |
+
for article in news_articles_with_full_text:
|
| 55 |
+
print(article.__dict__)
|
| 56 |
+
|
| 57 |
+
for response in analyzer_responses_with_full_text:
|
| 58 |
+
print(response.__dict__)
|
obsei_module/example/jira_example.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Jira Sink
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
from pydantic import SecretStr
|
| 8 |
+
|
| 9 |
+
from obsei.sink.jira_sink import JiraSink, JiraSinkConfig
|
| 10 |
+
from obsei.source.twitter_source import (
|
| 11 |
+
TwitterCredentials,
|
| 12 |
+
TwitterSource,
|
| 13 |
+
TwitterSourceConfig,
|
| 14 |
+
)
|
| 15 |
+
from obsei.analyzer.classification_analyzer import (
|
| 16 |
+
ClassificationAnalyzerConfig,
|
| 17 |
+
ZeroShotClassificationAnalyzer,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
logger = logging.getLogger(__name__)
|
| 21 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 22 |
+
|
| 23 |
+
dir_path = Path(__file__).resolve().parent.parent
|
| 24 |
+
source_config = TwitterSourceConfig(
|
| 25 |
+
keywords=["facing issue"],
|
| 26 |
+
lookup_period="1h",
|
| 27 |
+
tweet_fields=[
|
| 28 |
+
"author_id",
|
| 29 |
+
"conversation_id",
|
| 30 |
+
"created_at",
|
| 31 |
+
"id",
|
| 32 |
+
"public_metrics",
|
| 33 |
+
"text",
|
| 34 |
+
],
|
| 35 |
+
user_fields=["id", "name", "public_metrics", "username", "verified"],
|
| 36 |
+
expansions=["author_id"],
|
| 37 |
+
place_fields=None,
|
| 38 |
+
max_tweets=10,
|
| 39 |
+
cred_info=TwitterCredentials(
|
| 40 |
+
consumer_key=SecretStr(os.environ["twitter_consumer_key"]),
|
| 41 |
+
consumer_secret=SecretStr(os.environ["twitter_consumer_secret"]),
|
| 42 |
+
),
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
source = TwitterSource()
|
| 46 |
+
|
| 47 |
+
# To start jira server locally `atlas-run-standalone --product jira`
|
| 48 |
+
jira_sink_config = JiraSinkConfig(
|
| 49 |
+
url="http://localhost:2990/jira",
|
| 50 |
+
username=SecretStr("admin"),
|
| 51 |
+
password=SecretStr("admin"),
|
| 52 |
+
issue_type={"name": "Task"},
|
| 53 |
+
project={"key": "CUS"},
|
| 54 |
+
)
|
| 55 |
+
jira_sink = JiraSink()
|
| 56 |
+
|
| 57 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 58 |
+
model_name_or_path="joeddav/bart-large-mnli-yahoo-answers"
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
source_response_list = source.lookup(source_config)
|
| 62 |
+
for idx, source_response in enumerate(source_response_list):
|
| 63 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 64 |
+
|
| 65 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 66 |
+
source_response_list=source_response_list,
|
| 67 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 68 |
+
labels=["service", "delay", "performance"],
|
| 69 |
+
),
|
| 70 |
+
)
|
| 71 |
+
for idx, an_response in enumerate(analyzer_response_list):
|
| 72 |
+
logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
| 73 |
+
|
| 74 |
+
sink_response_list = jira_sink.send_data(analyzer_response_list, jira_sink_config)
|
| 75 |
+
for sink_response in sink_response_list:
|
| 76 |
+
if sink_response is not None:
|
| 77 |
+
logger.info(f"sink_response='{sink_response}'")
|
obsei_module/example/maps_review_scrapper_example.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from obsei.source.google_maps_reviews import (OSGoogleMapsReviewsConfig,
|
| 5 |
+
OSGoogleMapsReviewsSource)
|
| 6 |
+
|
| 7 |
+
logger = logging.getLogger(__name__)
|
| 8 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 9 |
+
|
| 10 |
+
source_config = OSGoogleMapsReviewsConfig(
|
| 11 |
+
api_key="<Enter Your API Key>", # Get API key from https://outscraper.com/
|
| 12 |
+
queries=[
|
| 13 |
+
"https://www.google.co.in/maps/place/Taj+Mahal/@27.1751496,78.0399535,17z/data=!4m5!3m4!1s0x39747121d702ff6d:0xdd2ae4803f767dde!8m2!3d27.1751448!4d78.0421422"
|
| 14 |
+
],
|
| 15 |
+
number_of_reviews=3,
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
source = OSGoogleMapsReviewsSource()
|
| 19 |
+
|
| 20 |
+
source_response_list = source.lookup(source_config)
|
| 21 |
+
for source_response in source_response_list:
|
| 22 |
+
logger.info(source_response.__dict__)
|
obsei_module/example/pandas_sink_example.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from pandas import DataFrame
|
| 5 |
+
|
| 6 |
+
from obsei.analyzer.classification_analyzer import (
|
| 7 |
+
ClassificationAnalyzerConfig,
|
| 8 |
+
ZeroShotClassificationAnalyzer,
|
| 9 |
+
)
|
| 10 |
+
from obsei.sink.pandas_sink import PandasSink, PandasSinkConfig
|
| 11 |
+
from obsei.source.playstore_scrapper import (
|
| 12 |
+
PlayStoreScrapperConfig,
|
| 13 |
+
PlayStoreScrapperSource,
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 19 |
+
|
| 20 |
+
source_config = PlayStoreScrapperConfig(
|
| 21 |
+
countries=["us"], package_name="com.apcoaconnect", max_count=3
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
source = PlayStoreScrapperSource()
|
| 25 |
+
|
| 26 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 27 |
+
model_name_or_path="typeform/mobilebert-uncased-mnli", device="auto"
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
# initialize pandas sink config
|
| 31 |
+
sink_config = PandasSinkConfig(dataframe=DataFrame())
|
| 32 |
+
|
| 33 |
+
# initialize pandas sink
|
| 34 |
+
sink = PandasSink()
|
| 35 |
+
|
| 36 |
+
source_response_list = source.lookup(source_config)
|
| 37 |
+
|
| 38 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 39 |
+
source_response_list=source_response_list,
|
| 40 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 41 |
+
labels=["no parking", "registration issue", "app issue", "payment issue"],
|
| 42 |
+
),
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
dataframe = sink.send_data(
|
| 46 |
+
analyzer_responses=analyzer_response_list, config=sink_config
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
print(dataframe.to_csv())
|
obsei_module/example/pandas_source_example.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
|
| 3 |
+
from obsei.source.pandas_source import (
|
| 4 |
+
PandasSourceConfig,
|
| 5 |
+
PandasSource,
|
| 6 |
+
)
|
| 7 |
+
import logging
|
| 8 |
+
import sys
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 12 |
+
|
| 13 |
+
# Initialize your Pandas DataFrame from your sources like csv, excel, sql etc
|
| 14 |
+
# In following example we are reading csv which have two columns title and text
|
| 15 |
+
csv_file = "https://raw.githubusercontent.com/deepset-ai/haystack/master/tutorials/small_generator_dataset.csv"
|
| 16 |
+
dataframe = pd.read_csv(csv_file)
|
| 17 |
+
|
| 18 |
+
source_config = PandasSourceConfig(
|
| 19 |
+
dataframe=dataframe,
|
| 20 |
+
include_columns=["title"],
|
| 21 |
+
text_columns=["text"],
|
| 22 |
+
)
|
| 23 |
+
source = PandasSource()
|
| 24 |
+
|
| 25 |
+
source_response_list = source.lookup(source_config)
|
| 26 |
+
for idx, source_response in enumerate(source_response_list):
|
| 27 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
obsei_module/example/pii_analyzer_example.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from obsei.payload import TextPayload
|
| 5 |
+
from obsei.analyzer.pii_analyzer import (
|
| 6 |
+
PresidioEngineConfig,
|
| 7 |
+
PresidioModelConfig,
|
| 8 |
+
PresidioPIIAnalyzer,
|
| 9 |
+
PresidioPIIAnalyzerConfig,
|
| 10 |
+
)
|
| 11 |
+
|
| 12 |
+
logger = logging.getLogger(__name__)
|
| 13 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 14 |
+
|
| 15 |
+
analyzer_config = PresidioPIIAnalyzerConfig(
|
| 16 |
+
analyze_only=False, return_decision_process=True
|
| 17 |
+
)
|
| 18 |
+
analyzer = PresidioPIIAnalyzer(
|
| 19 |
+
engine_config=PresidioEngineConfig(
|
| 20 |
+
nlp_engine_name="spacy",
|
| 21 |
+
models=[PresidioModelConfig(model_name="en_core_web_lg", lang_code="en")],
|
| 22 |
+
)
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
text_to_anonymize = "His name is Mr. Jones and his phone number is 212-555-5555"
|
| 26 |
+
|
| 27 |
+
analyzer_results = analyzer.analyze_input(
|
| 28 |
+
source_response_list=[TextPayload(processed_text=text_to_anonymize)],
|
| 29 |
+
analyzer_config=analyzer_config,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
for analyzer_result in analyzer_results:
|
| 33 |
+
logging.info(analyzer_result.to_dict())
|
obsei_module/example/play_store_reviews_example.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TDB
|
| 2 |
+
|
| 3 |
+
# Need proper service account file to test the changes :(
|
| 4 |
+
print("TBD")
|
obsei_module/example/playstore_scrapper_example.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from obsei.analyzer.classification_analyzer import (
|
| 5 |
+
ClassificationAnalyzerConfig,
|
| 6 |
+
ZeroShotClassificationAnalyzer,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
from obsei.source.playstore_scrapper import (
|
| 10 |
+
PlayStoreScrapperConfig,
|
| 11 |
+
PlayStoreScrapperSource,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 17 |
+
|
| 18 |
+
source_config = PlayStoreScrapperConfig(
|
| 19 |
+
app_url='https://play.google.com/store/apps/details?id=com.google.android.gm&hl=en_IN&gl=US',
|
| 20 |
+
max_count=3
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
source = PlayStoreScrapperSource()
|
| 24 |
+
|
| 25 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 26 |
+
model_name_or_path="typeform/mobilebert-uncased-mnli", device="auto"
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
source_response_list = source.lookup(source_config)
|
| 30 |
+
for idx, source_response in enumerate(source_response_list):
|
| 31 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 32 |
+
|
| 33 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 34 |
+
source_response_list=source_response_list,
|
| 35 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 36 |
+
labels=["interface", "slow", "battery"],
|
| 37 |
+
),
|
| 38 |
+
)
|
| 39 |
+
for idx, an_response in enumerate(analyzer_response_list):
|
| 40 |
+
logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
obsei_module/example/playstore_scrapper_translator_example.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import sys
|
| 4 |
+
from datetime import datetime, timedelta
|
| 5 |
+
|
| 6 |
+
import pytz
|
| 7 |
+
|
| 8 |
+
from obsei.payload import TextPayload
|
| 9 |
+
from obsei.analyzer.classification_analyzer import (
|
| 10 |
+
ClassificationAnalyzerConfig,
|
| 11 |
+
ZeroShotClassificationAnalyzer,
|
| 12 |
+
)
|
| 13 |
+
from obsei.analyzer.translation_analyzer import TranslationAnalyzer
|
| 14 |
+
from obsei.misc.utils import DATETIME_STRING_PATTERN
|
| 15 |
+
from obsei.source.playstore_scrapper import (
|
| 16 |
+
PlayStoreScrapperConfig,
|
| 17 |
+
PlayStoreScrapperSource,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
logger = logging.getLogger(__name__)
|
| 22 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 23 |
+
source = PlayStoreScrapperSource()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def source_fetch():
|
| 27 |
+
since_time = datetime.utcnow().astimezone(pytz.utc) + timedelta(days=-1)
|
| 28 |
+
source_config = PlayStoreScrapperConfig(
|
| 29 |
+
countries=["us"],
|
| 30 |
+
package_name="com.color.apps.hindikeyboard.hindi.language",
|
| 31 |
+
lookup_period=since_time.strftime(
|
| 32 |
+
DATETIME_STRING_PATTERN
|
| 33 |
+
), # todo should be optional
|
| 34 |
+
max_count=5,
|
| 35 |
+
)
|
| 36 |
+
return source.lookup(source_config)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def translate_text(text_list):
|
| 40 |
+
translate_analyzer = TranslationAnalyzer(
|
| 41 |
+
model_name_or_path="Helsinki-NLP/opus-mt-hi-en", device="auto"
|
| 42 |
+
)
|
| 43 |
+
source_responses = [
|
| 44 |
+
TextPayload(processed_text=text.processed_text, source_name="sample")
|
| 45 |
+
for text in text_list
|
| 46 |
+
]
|
| 47 |
+
analyzer_responses = translate_analyzer.analyze_input(
|
| 48 |
+
source_response_list=source_responses
|
| 49 |
+
)
|
| 50 |
+
return [
|
| 51 |
+
TextPayload(
|
| 52 |
+
processed_text=response.segmented_data["translated_text"],
|
| 53 |
+
source_name="translator",
|
| 54 |
+
)
|
| 55 |
+
for response in analyzer_responses
|
| 56 |
+
]
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def classify_text(text_list):
|
| 60 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 61 |
+
model_name_or_path="joeddav/bart-large-mnli-yahoo-answers", device="cpu"
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
return text_analyzer.analyze_input(
|
| 65 |
+
source_response_list=text_list,
|
| 66 |
+
analyzer_config=ClassificationAnalyzerConfig(
|
| 67 |
+
labels=["no parking", "registration issue", "app issue", "payment issue"],
|
| 68 |
+
),
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def print_list(text_name, text_list):
|
| 73 |
+
for idx, text in enumerate(text_list):
|
| 74 |
+
json_response = json.dumps(text.__dict__, indent=4, sort_keys=True, default=str)
|
| 75 |
+
logger.info(f"\n{text_name}#'{idx}'='{json_response}'")
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
logger.info("Started...")
|
| 79 |
+
|
| 80 |
+
source_responses_list = source_fetch()
|
| 81 |
+
translated_text_list = translate_text(source_responses_list)
|
| 82 |
+
analyzer_response_list = classify_text(translated_text_list)
|
| 83 |
+
|
| 84 |
+
print_list("source_response", source_responses_list)
|
| 85 |
+
print_list("translator_response", translated_text_list)
|
| 86 |
+
print_list("classifier_response", analyzer_response_list)
|
obsei_module/example/reddit_example.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
import time
|
| 4 |
+
from datetime import datetime, timedelta
|
| 5 |
+
|
| 6 |
+
import pytz
|
| 7 |
+
|
| 8 |
+
from obsei.misc.utils import DATETIME_STRING_PATTERN
|
| 9 |
+
from obsei.source.reddit_source import RedditConfig, RedditSource
|
| 10 |
+
from obsei.workflow.store import WorkflowStore
|
| 11 |
+
from obsei.workflow.workflow import Workflow, WorkflowConfig
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def print_state(id: str):
|
| 15 |
+
logger.info(f"Source State: {source.store.get_source_state(id)}")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger(__name__)
|
| 19 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 20 |
+
|
| 21 |
+
since_time = datetime.utcnow().astimezone(pytz.utc) + timedelta(hours=-2)
|
| 22 |
+
# Credentials will be fetched from env variable named reddit_client_id and reddit_client_secret
|
| 23 |
+
source_config = RedditConfig(
|
| 24 |
+
subreddits=["wallstreetbets"],
|
| 25 |
+
lookup_period=since_time.strftime(DATETIME_STRING_PATTERN),
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
source = RedditSource(store=WorkflowStore())
|
| 29 |
+
|
| 30 |
+
workflow = Workflow(
|
| 31 |
+
config=WorkflowConfig(
|
| 32 |
+
source_config=source_config,
|
| 33 |
+
),
|
| 34 |
+
)
|
| 35 |
+
source.store.add_workflow(workflow)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
for i in range(1, 4):
|
| 39 |
+
print_state(workflow.id)
|
| 40 |
+
source_response_list = source.lookup(source_config, id=workflow.id)
|
| 41 |
+
|
| 42 |
+
if source_response_list is None or len(source_response_list) == 0:
|
| 43 |
+
break
|
| 44 |
+
|
| 45 |
+
for source_response in source_response_list:
|
| 46 |
+
logger.info(source_response.__dict__)
|
| 47 |
+
|
| 48 |
+
time.sleep(10)
|
| 49 |
+
|
| 50 |
+
print_state(workflow.id)
|
obsei_module/example/reddit_scrapper_example.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
from datetime import datetime, timedelta
|
| 4 |
+
|
| 5 |
+
import pytz
|
| 6 |
+
|
| 7 |
+
from obsei.misc.utils import DATETIME_STRING_PATTERN
|
| 8 |
+
from obsei.source.reddit_scrapper import RedditScrapperConfig, RedditScrapperSource
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def print_state(id: str):
|
| 12 |
+
logger.info(f"Source State: {source.store.get_source_state(id)}")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 17 |
+
|
| 18 |
+
since_time = datetime.utcnow().astimezone(pytz.utc) + timedelta(days=-1)
|
| 19 |
+
|
| 20 |
+
source_config = RedditScrapperConfig(
|
| 21 |
+
url="https://www.reddit.com/r/wallstreetbets/comments/.rss?sort=new",
|
| 22 |
+
user_agent="testscript by u/FitStatistician7378",
|
| 23 |
+
lookup_period=since_time.strftime(DATETIME_STRING_PATTERN),
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
source = RedditScrapperSource()
|
| 27 |
+
|
| 28 |
+
source_response_list = source.lookup(source_config)
|
| 29 |
+
for source_response in source_response_list:
|
| 30 |
+
logger.info(source_response.__dict__)
|
obsei_module/example/sdk.yaml
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
twitter_source:
|
| 2 |
+
_target_: obsei.source.twitter_source.TwitterSourceConfig
|
| 3 |
+
keywords:
|
| 4 |
+
- "@sample"
|
| 5 |
+
lookup_period: "1d"
|
| 6 |
+
tweet_fields:
|
| 7 |
+
- "author_id"
|
| 8 |
+
- "conversation_id"
|
| 9 |
+
- "created_at"
|
| 10 |
+
- "id"
|
| 11 |
+
- "public_metrics"
|
| 12 |
+
- "text"
|
| 13 |
+
user_fields:
|
| 14 |
+
- "id"
|
| 15 |
+
- "name"
|
| 16 |
+
- "public_metrics"
|
| 17 |
+
- "username"
|
| 18 |
+
- "verified"
|
| 19 |
+
expansions:
|
| 20 |
+
- "author_id"
|
| 21 |
+
place_fields: []
|
| 22 |
+
max_tweets: 10
|
| 23 |
+
credential:
|
| 24 |
+
_target_: obsei.source.twitter_source.TwitterCredentials
|
| 25 |
+
bearer_token: "bearer_token"
|
| 26 |
+
|
| 27 |
+
play_store_source:
|
| 28 |
+
_target_: obsei.source.playstore_reviews.PlayStoreConfig
|
| 29 |
+
package_name: "com.company.package"
|
| 30 |
+
max_results: 10
|
| 31 |
+
num_retries: 2
|
| 32 |
+
cred_info:
|
| 33 |
+
_target_: obsei.source.playstore_reviews.GoogleCredInfo
|
| 34 |
+
service_cred_file: "foo/credential.json"
|
| 35 |
+
developer_key: "test_key"
|
| 36 |
+
|
| 37 |
+
daily_get_sink:
|
| 38 |
+
_target_: obsei.sink.dailyget_sink.DailyGetSinkConfig
|
| 39 |
+
url: "http://localhost:8080/sample"
|
| 40 |
+
partner_id: "123456"
|
| 41 |
+
consumer_phone_number: "1234567890"
|
| 42 |
+
source_information: "Twitter @sample"
|
| 43 |
+
base_payload:
|
| 44 |
+
partnerId: daily_get_sink.partner_id
|
| 45 |
+
consumerPhoneNumber: daily_get_sink.consumer_phone_number
|
| 46 |
+
|
| 47 |
+
http_sink:
|
| 48 |
+
_target_: obsei.sink.http_sink.HttpSinkConfig
|
| 49 |
+
url: "http://localhost:8080/sample"
|
| 50 |
+
|
| 51 |
+
elasticsearch_sink:
|
| 52 |
+
_target_: obsei.sink.elasticsearch_sink.ElasticSearchSinkConfig
|
| 53 |
+
host: "localhost"
|
| 54 |
+
port: 9200
|
| 55 |
+
index_name: "test"
|
| 56 |
+
|
| 57 |
+
jira_sink:
|
| 58 |
+
_target_: obsei.sink.jira_sink.JiraSinkConfig
|
| 59 |
+
url: "http://localhost:2990/jira"
|
| 60 |
+
username: "user"
|
| 61 |
+
password: "pass"
|
| 62 |
+
issue_type:
|
| 63 |
+
name: "Task"
|
| 64 |
+
project:
|
| 65 |
+
key: "CUS"
|
| 66 |
+
|
| 67 |
+
analyzer_config:
|
| 68 |
+
_target_: obsei.analyzer.classification_analyzer.ClassificationAnalyzerConfig
|
| 69 |
+
labels:
|
| 70 |
+
- "service"
|
| 71 |
+
- "delay"
|
| 72 |
+
- "tracking"
|
| 73 |
+
- "no response"
|
| 74 |
+
add_positive_negative_labels: false
|
| 75 |
+
|
| 76 |
+
analyzer:
|
| 77 |
+
_target_: obsei.analyzer.classification_analyzer.ZeroShotClassificationAnalyzer
|
| 78 |
+
model_name_or_path: "typeform/mobilebert-uncased-mnli"
|
| 79 |
+
device: "auto"
|
| 80 |
+
|
| 81 |
+
slack_sink:
|
| 82 |
+
_target_: obsei.sink.SlackSink
|
| 83 |
+
|
| 84 |
+
slack_sink_config:
|
| 85 |
+
_target_: obsei.sink.SlackSinkConfig
|
| 86 |
+
slack_token: 'Enter token'
|
| 87 |
+
channel_id: 'slack channel id'
|
| 88 |
+
jinja_template: |
|
| 89 |
+
```
|
| 90 |
+
{%- for key, value in payload.items() recursive%}
|
| 91 |
+
{%- if value is mapping -%}
|
| 92 |
+
{{loop(value.items())}}
|
| 93 |
+
{%- else %}
|
| 94 |
+
{{key}}: {{value}}
|
| 95 |
+
{%- endif %}
|
| 96 |
+
{%- endfor%}
|
| 97 |
+
```
|
obsei_module/example/slack_example.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
from obsei.analyzer.dummy_analyzer import DummyAnalyzer, DummyAnalyzerConfig
|
| 6 |
+
from obsei.processor import Processor
|
| 7 |
+
from obsei.sink.slack_sink import SlackSink, SlackSinkConfig
|
| 8 |
+
from obsei.source.playstore_scrapper import (PlayStoreScrapperConfig,
|
| 9 |
+
PlayStoreScrapperSource)
|
| 10 |
+
from obsei.workflow.store import WorkflowStore
|
| 11 |
+
from obsei.workflow.workflow import Workflow, WorkflowConfig
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def print_state(identifier: str):
|
| 15 |
+
logger.info(f"Source State: {source.store.get_source_state(identifier)}")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger(__name__)
|
| 19 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
workflow_store = WorkflowStore()
|
| 23 |
+
|
| 24 |
+
source_config = PlayStoreScrapperConfig(
|
| 25 |
+
app_url='https://play.google.com/store/apps/details?id=com.google.android.gm&hl=en_IN&gl=US',
|
| 26 |
+
max_count=3
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
source = PlayStoreScrapperSource(store=workflow_store)
|
| 30 |
+
|
| 31 |
+
sink_config = SlackSinkConfig(
|
| 32 |
+
slack_token=os.environ["SLACK_TOKEN"],
|
| 33 |
+
channel_id="C01TUPZ23NZ",
|
| 34 |
+
jinja_template="""
|
| 35 |
+
```
|
| 36 |
+
{%- for key, value in payload.items() recursive%}
|
| 37 |
+
{%- if value is mapping -%}
|
| 38 |
+
{{loop(value.items())}}
|
| 39 |
+
{%- else %}
|
| 40 |
+
{{key}}: {{value}}
|
| 41 |
+
{%- endif %}
|
| 42 |
+
{%- endfor%}
|
| 43 |
+
```
|
| 44 |
+
"""
|
| 45 |
+
)
|
| 46 |
+
sink = SlackSink(store=workflow_store)
|
| 47 |
+
|
| 48 |
+
analyzer_config = DummyAnalyzerConfig()
|
| 49 |
+
analyzer = DummyAnalyzer()
|
| 50 |
+
|
| 51 |
+
workflow = Workflow(
|
| 52 |
+
config=WorkflowConfig(
|
| 53 |
+
source_config=source_config,
|
| 54 |
+
sink_config=sink_config,
|
| 55 |
+
analyzer_config=analyzer_config,
|
| 56 |
+
),
|
| 57 |
+
)
|
| 58 |
+
workflow_store.add_workflow(workflow)
|
| 59 |
+
|
| 60 |
+
processor = Processor(
|
| 61 |
+
analyzer=analyzer, sink=sink, source=source, analyzer_config=analyzer_config
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
processor.process(workflow=workflow)
|
| 65 |
+
|
| 66 |
+
print_state(workflow.id)
|
obsei_module/example/twitter_source_example.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from obsei.analyzer.classification_analyzer import ZeroShotClassificationAnalyzer, ClassificationAnalyzerConfig
|
| 5 |
+
from obsei.sink.slack_sink import SlackSinkConfig, SlackSink
|
| 6 |
+
from obsei.source.twitter_source import TwitterSourceConfig, TwitterSource, TwitterCredentials
|
| 7 |
+
|
| 8 |
+
logger = logging.getLogger(__name__)
|
| 9 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 10 |
+
|
| 11 |
+
twitter_cred_info = None
|
| 12 |
+
|
| 13 |
+
# Enter your twitter credentials
|
| 14 |
+
# Get it from https://developer.twitter.com/en/apply-for-access
|
| 15 |
+
# Currently it will fetch from environment variables: twitter_bearer_token, twitter_consumer_key, twitter_consumer_secret
|
| 16 |
+
# Uncomment below lines if you like to pass credentials directly instead of env variables
|
| 17 |
+
|
| 18 |
+
# twitter_cred_info = TwitterCredentials(
|
| 19 |
+
# bearer_token='<Enter bearer_token>',
|
| 20 |
+
# consumer_key="<Enter consumer_key>",
|
| 21 |
+
# consumer_secret="<Enter consumer_secret>"
|
| 22 |
+
# )
|
| 23 |
+
|
| 24 |
+
source_config = TwitterSourceConfig(
|
| 25 |
+
query="bitcoin",
|
| 26 |
+
lookup_period="1h",
|
| 27 |
+
tweet_fields=[
|
| 28 |
+
"author_id",
|
| 29 |
+
"conversation_id",
|
| 30 |
+
"created_at",
|
| 31 |
+
"id",
|
| 32 |
+
"public_metrics",
|
| 33 |
+
"text",
|
| 34 |
+
],
|
| 35 |
+
user_fields=["id", "name", "public_metrics", "username", "verified"],
|
| 36 |
+
expansions=["author_id"],
|
| 37 |
+
place_fields=None,
|
| 38 |
+
max_tweets=10,
|
| 39 |
+
cred_info=twitter_cred_info or None
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
source = TwitterSource()
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
sink_config = SlackSinkConfig(
|
| 46 |
+
# Uncomment below lines if you like to pass credentials directly instead of env variables
|
| 47 |
+
# slack_token="SLACK_TOKEN",
|
| 48 |
+
# channel_id="CHANNEL_ID",
|
| 49 |
+
jinja_template="""
|
| 50 |
+
:bell: Hi there!, a new `<{{payload['meta']['tweet_url']}}|tweet>` of interest is found by *Obsei*
|
| 51 |
+
>📝 Content:
|
| 52 |
+
```{{payload['meta']['text']}}```
|
| 53 |
+
>ℹ️Information:
|
| 54 |
+
```
|
| 55 |
+
User Name: {{payload['meta']['author_info']['name']}} ({{payload['meta']['author_info']['user_url']}})
|
| 56 |
+
Tweet Metrics: Retweets={{payload['meta']['public_metrics']['retweet_count']}}, Likes={{payload['meta']['public_metrics']['like_count']}}
|
| 57 |
+
Author Metrics: Verified={{payload['meta']['author_info']['verified']}}, Followers={{payload['meta']['author_info']['public_metrics']['followers_count']}}
|
| 58 |
+
```
|
| 59 |
+
>🧠 AI Engine Data:
|
| 60 |
+
```
|
| 61 |
+
{%- for key, value in payload['segmented_data']['classifier_data'].items() recursive%}
|
| 62 |
+
{%- if value is mapping -%}
|
| 63 |
+
{{loop(value.items())}}
|
| 64 |
+
{%- else %}
|
| 65 |
+
{{key}}: {{value}}
|
| 66 |
+
{%- endif %}
|
| 67 |
+
{%- endfor%}
|
| 68 |
+
```
|
| 69 |
+
"""
|
| 70 |
+
)
|
| 71 |
+
sink = SlackSink()
|
| 72 |
+
|
| 73 |
+
text_analyzer = ZeroShotClassificationAnalyzer(
|
| 74 |
+
model_name_or_path="typeform/mobilebert-uncased-mnli", device="auto"
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
analyzer_config = ClassificationAnalyzerConfig(
|
| 78 |
+
labels=["going up", "going down"],
|
| 79 |
+
add_positive_negative_labels=False,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
source_response_list = source.lookup(source_config)
|
| 83 |
+
for idx, source_response in enumerate(source_response_list):
|
| 84 |
+
logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
|
| 85 |
+
|
| 86 |
+
analyzer_response_list = text_analyzer.analyze_input(
|
| 87 |
+
source_response_list=source_response_list,
|
| 88 |
+
analyzer_config=analyzer_config,
|
| 89 |
+
)
|
| 90 |
+
|
| 91 |
+
for idx, an_response in enumerate(analyzer_response_list):
|
| 92 |
+
logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
|
| 93 |
+
|
| 94 |
+
sink_response_list = sink.send_data(
|
| 95 |
+
analyzer_responses=analyzer_response_list, config=sink_config, id=id
|
| 96 |
+
)
|
| 97 |
+
for idx, sink_response in enumerate(sink_response_list):
|
| 98 |
+
logger.info(f"source_response#'{idx}'='{sink_response.__dict__}'")
|
obsei_module/example/web_crawler_example.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Fetch full news article
|
| 2 |
+
from obsei.source.website_crawler_source import (
|
| 3 |
+
TrafilaturaCrawlerConfig,
|
| 4 |
+
TrafilaturaCrawlerSource,
|
| 5 |
+
)
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def print_list(response_list):
|
| 9 |
+
for response in response_list:
|
| 10 |
+
print(response.__dict__)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# Single URL
|
| 14 |
+
source_config = TrafilaturaCrawlerConfig(urls=["https://obsei.github.io/obsei/"])
|
| 15 |
+
|
| 16 |
+
source = TrafilaturaCrawlerSource()
|
| 17 |
+
|
| 18 |
+
source_response_list = source.lookup(source_config)
|
| 19 |
+
print_list(source_response_list)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# RSS feed (Note it will take lot of time)
|
| 23 |
+
source_config = TrafilaturaCrawlerConfig(
|
| 24 |
+
urls=["https://news.google.com/rss/search?q=bitcoin&hl=en&gl=US&ceid=US:en"],
|
| 25 |
+
is_feed=True,
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
source = TrafilaturaCrawlerSource()
|
| 29 |
+
|
| 30 |
+
source_response_list = source.lookup(source_config)
|
| 31 |
+
print_list(source_response_list)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# Full website (Note it will take lot of time)
|
| 35 |
+
source_config = TrafilaturaCrawlerConfig(
|
| 36 |
+
urls=["https://haystack.deepset.ai/"],
|
| 37 |
+
is_sitemap=True,
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
source = TrafilaturaCrawlerSource()
|
| 41 |
+
|
| 42 |
+
source_response_list = source.lookup(source_config)
|
| 43 |
+
print_list(source_response_list)
|
obsei_module/example/with_sdk_config_file.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from obsei.configuration import ObseiConfiguration
|
| 5 |
+
|
| 6 |
+
logger = logging.getLogger(__name__)
|
| 7 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 8 |
+
|
| 9 |
+
obsei_configuration = ObseiConfiguration(
|
| 10 |
+
config_path="../example",
|
| 11 |
+
config_filename="sdk.yaml",
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
text_analyzer = obsei_configuration.initialize_instance("analyzer")
|
| 15 |
+
analyzer_config = obsei_configuration.initialize_instance("analyzer_config")
|
| 16 |
+
slack_source_config = obsei_configuration.initialize_instance("slack_sink_config")
|
| 17 |
+
slack_sink = obsei_configuration.initialize_instance("slack_sink")
|
| 18 |
+
|
| 19 |
+
play_store_source_config = obsei_configuration.initialize_instance("play_store_source")
|
| 20 |
+
twitter_source_config = obsei_configuration.initialize_instance("twitter_source")
|
| 21 |
+
http_sink_config = obsei_configuration.initialize_instance("http_sink")
|
| 22 |
+
daily_get_sink_config = obsei_configuration.initialize_instance("daily_get_sink")
|
| 23 |
+
# docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.2
|
| 24 |
+
elasticsearch_sink_config = obsei_configuration.initialize_instance(
|
| 25 |
+
"elasticsearch_sink"
|
| 26 |
+
)
|
| 27 |
+
# Start jira server locally `atlas-run-standalone --product jira`
|
| 28 |
+
jira_sink_config = obsei_configuration.initialize_instance("jira_sink")
|