Spaces:
Runtime error


Runtime error
File size: 14,511 Bytes
00cb073 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 |
#!/usr/bin/env python
from __future__ import annotations
import argparse
import pathlib
import torch
import gradio as gr
from vtoonify_model import Model
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument('--theme', type=str)
parser.add_argument('--share', action='store_true')
parser.add_argument('--port', type=int)
parser.add_argument('--disable-queue',
dest='enable_queue',
action='store_false')
return parser.parse_args()
DESCRIPTION = '''
<div align=center>
<h1 style="font-weight: 900; margin-bottom: 7px;">
Portrait Style Transfer with <a href="https://github.com/williamyang1991/VToonify">VToonify</a>
</h1>
<p>For faster inference without waiting in queue, you may duplicate the space and use the GPU setting.
<br/>
<a href="https://huggingface.co/spaces/PKUWilliamYang/VToonify?duplicate=true">
<img style="margin-top: 0em; margin-bottom: 0em" src="https://bit.ly/3gLdBN6" alt="Duplicate Space"></a>
<p/>
<video id="video" width=50% controls="" preload="none" poster="https://repository-images.githubusercontent.com/534480768/53715b0f-a2df-4daa-969c-0e74c102d339">
<source id="mp4" src="https://user-images.githubusercontent.com/18130694/189483939-0fc4a358-fb34-43cc-811a-b22adb820d57.mp4
" type="video/mp4">
</videos>
</div>
'''
FOOTER = '<div align=center><img id="visitor-badge" alt="visitor badge" src="https://visitor-badge.laobi.icu/badge?page_id=williamyang1991/VToonify" /></div>'
ARTICLE = r"""
If VToonify is helpful, please help to ⭐ the <a href='https://github.com/williamyang1991/VToonify' target='_blank'>Github Repo</a>. Thanks!
[](https://github.com/williamyang1991/VToonify)
---
📝 **Citation**
If our work is useful for your research, please consider citing:
```bibtex
@article{yang2022Vtoonify,
title={VToonify: Controllable High-Resolution Portrait Video Style Transfer},
author={Yang, Shuai and Jiang, Liming and Liu, Ziwei and Loy, Chen Change},
journal={ACM Transactions on Graphics (TOG)},
volume={41},
number={6},
articleno={203},
pages={1--15},
year={2022},
publisher={ACM New York, NY, USA},
doi={10.1145/3550454.3555437},
}
```
📋 **License**
This project is licensed under <a rel="license" href="https://github.com/williamyang1991/VToonify/blob/main/LICENSE.md">S-Lab License 1.0</a>.
Redistribution and use for non-commercial purposes should follow this license.
📧 **Contact**
If you have any questions, please feel free to reach me out at <b>williamyang@pku.edu.cn</b>.
"""
def update_slider(choice: str) -> dict:
if type(choice) == str and choice.endswith('-d'):
return gr.Slider.update(maximum=1, minimum=0, value=0.5)
else:
return gr.Slider.update(maximum=0.5, minimum=0.5, value=0.5)
def set_example_image(example: list) -> dict:
return gr.Image.update(value=example[0])
def set_example_video(example: list) -> dict:
return gr.Video.update(value=example[0]),
sample_video = ['./vtoonify/data/529_2.mp4','./vtoonify/data/7154235.mp4','./vtoonify/data/651.mp4','./vtoonify/data/908.mp4']
sample_vid = gr.Video(label='Video file') #for displaying the example
example_videos = gr.components.Dataset(components=[sample_vid], samples=[[path] for path in sample_video], type='values', label='Video Examples')
def main():
args = parse_args()
args.device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('*** Now using %s.'%(args.device))
model = Model(device=args.device)
with gr.Blocks(theme=args.theme, css='style.css') as demo:
gr.Markdown(DESCRIPTION)
with gr.Box():
gr.Markdown('''## Step 1(Select Style)
- Select **Style Type**.
- Type with `-d` means it supports style degree adjustment.
- Type without `-d` usually has better toonification quality.
''')
with gr.Row():
with gr.Column():
gr.Markdown('''Select Style Type''')
with gr.Row():
style_type = gr.Radio(label='Style Type',
choices=['cartoon1','cartoon1-d','cartoon2-d','cartoon3-d',
'cartoon4','cartoon4-d','cartoon5-d','comic1-d',
'comic2-d','arcane1','arcane1-d','arcane2', 'arcane2-d',
'caricature1','caricature2','pixar','pixar-d',
'illustration1-d', 'illustration2-d', 'illustration3-d', 'illustration4-d', 'illustration5-d',
]
)
exstyle = gr.Variable()
with gr.Row():
loadmodel_button = gr.Button('Load Model')
with gr.Row():
load_info = gr.Textbox(label='Process Information', interactive=False, value='No model loaded.')
with gr.Column():
gr.Markdown('''Reference Styles
''')
with gr.Box():
gr.Markdown('''## Step 2 (Preprocess Input Image / Video)
- Drop an image/video containing a near-frontal face to the **Input Image**/**Input Video**.
- Hit the **Rescale Image**/**Rescale First Frame** button.
- Rescale the input to make it best fit the model.
- The final image result will be based on this **Rescaled Face**. Use padding parameters to adjust the background space.
- **<font color=red>Solution to [Error: no face detected!]</font>**: VToonify uses dlib.get_frontal_face_detector but sometimes it fails to detect a face. You can try several times or use other images until a face is detected, then switch back to the original image.
- For video input, further hit the **Rescale Video** button.
- The final video result will be based on this **Rescaled Video**. To avoid overload, video is cut to at most **100/300** frames for CPU/GPU, respectively.
''')
with gr.Row():
with gr.Box():
with gr.Column():
gr.Markdown('''Choose the padding parameters.
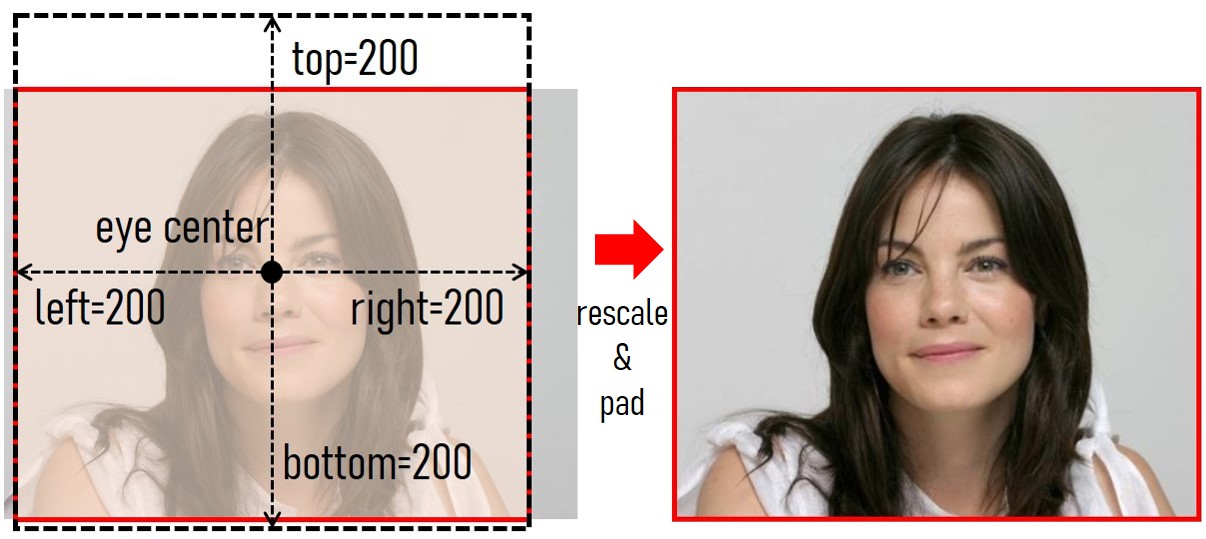''')
with gr.Row():
top = gr.Slider(128,
256,
value=200,
step=8,
label='top')
with gr.Row():
bottom = gr.Slider(128,
256,
value=200,
step=8,
label='bottom')
with gr.Row():
left = gr.Slider(128,
256,
value=200,
step=8,
label='left')
with gr.Row():
right = gr.Slider(128,
256,
value=200,
step=8,
label='right')
with gr.Box():
with gr.Column():
gr.Markdown('''Input''')
with gr.Row():
input_image = gr.Image(label='Input Image',
type='filepath')
with gr.Row():
preprocess_image_button = gr.Button('Rescale Image')
with gr.Row():
input_video = gr.Video(label='Input Video',
mirror_webcam=False,
type='filepath')
with gr.Row():
preprocess_video0_button = gr.Button('Rescale First Frame')
preprocess_video1_button = gr.Button('Rescale Video')
with gr.Box():
with gr.Column():
gr.Markdown('''View''')
with gr.Row():
input_info = gr.Textbox(label='Process Information', interactive=False, value='n.a.')
with gr.Row():
aligned_face = gr.Image(label='Rescaled Face',
type='numpy',
interactive=False)
instyle = gr.Variable()
with gr.Row():
aligned_video = gr.Video(label='Rescaled Video',
type='mp4',
interactive=False)
with gr.Row():
with gr.Column():
paths = ['./vtoonify/data/pexels-andrea-piacquadio-733872.jpg','./vtoonify/data/i5R8hbZFDdc.jpg','./vtoonify/data/yRpe13BHdKw.jpg','./vtoonify/data/ILip77SbmOE.jpg','./vtoonify/data/077436.jpg','./vtoonify/data/081680.jpg']
example_images = gr.Dataset(components=[input_image],
samples=[[path] for path in paths],
label='Image Examples')
with gr.Column():
#example_videos = gr.Dataset(components=[input_video], samples=[['./vtoonify/data/529.mp4']], type='values')
#to render video example on mouse hover/click
example_videos.render()
#to load sample video into input_video upon clicking on it
def load_examples(video):
#print("****** inside load_example() ******")
#print("in_video is : ", video[0])
return video[0]
example_videos.click(load_examples, example_videos, input_video)
with gr.Box():
gr.Markdown('''## Step 3 (Generate Style Transferred Image/Video)''')
with gr.Row():
with gr.Column():
gr.Markdown('''
- Adjust **Style Degree**.
- Hit **Toonify!** to toonify one frame. Hit **VToonify!** to toonify full video.
- Estimated time on 1600x1440 video of 300 frames: 1 hour (CPU); 2 mins (GPU)
''')
style_degree = gr.Slider(0,
1,
value=0.5,
step=0.05,
label='Style Degree')
with gr.Column():
gr.Markdown('''
''')
with gr.Row():
output_info = gr.Textbox(label='Process Information', interactive=False, value='n.a.')
with gr.Row():
with gr.Column():
with gr.Row():
result_face = gr.Image(label='Result Image',
type='numpy',
interactive=False)
with gr.Row():
toonify_button = gr.Button('Toonify!')
with gr.Column():
with gr.Row():
result_video = gr.Video(label='Result Video',
type='mp4',
interactive=False)
with gr.Row():
vtoonify_button = gr.Button('VToonify!')
gr.Markdown(ARTICLE)
gr.Markdown(FOOTER)
loadmodel_button.click(fn=model.load_model,
inputs=[style_type],
outputs=[exstyle, load_info])
style_type.change(fn=update_slider,
inputs=style_type,
outputs=style_degree)
preprocess_image_button.click(fn=model.detect_and_align_image,
inputs=[input_image, top, bottom, left, right],
outputs=[aligned_face, instyle, input_info])
preprocess_video0_button.click(fn=model.detect_and_align_video,
inputs=[input_video, top, bottom, left, right],
outputs=[aligned_face, instyle, input_info])
preprocess_video1_button.click(fn=model.detect_and_align_full_video,
inputs=[input_video, top, bottom, left, right],
outputs=[aligned_video, instyle, input_info])
toonify_button.click(fn=model.image_toonify,
inputs=[aligned_face, instyle, exstyle, style_degree, style_type],
outputs=[result_face, output_info])
vtoonify_button.click(fn=model.video_tooniy,
inputs=[aligned_video, instyle, exstyle, style_degree, style_type],
outputs=[result_video, output_info])
example_images.click(fn=set_example_image,
inputs=example_images,
outputs=example_images.components)
demo.launch(
enable_queue=args.enable_queue,
server_port=args.port,
share=args.share,
)
if __name__ == '__main__':
main()
|