Spaces:
Runtime error

Runtime error
Commit
•
696bf27
1
Parent(s):
1fab4b7
feat(readme): improved readme
Browse files- README.md +15 -4
- images/training_overview.png +0 -0
README.md
CHANGED
|
@@ -1,12 +1,23 @@
|
|
| 1 |
---
|
| 2 |
title: Homepage2vec
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
|
|
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 4.11.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: Homepage2vec
|
| 3 |
+
emoji: 🌐
|
| 4 |
+
colorFrom: purple
|
| 5 |
+
colorTo: blue
|
| 6 |
+
python_version: 3.10
|
| 7 |
sdk: gradio
|
| 8 |
sdk_version: 4.11.0
|
| 9 |
app_file: app.py
|
| 10 |
pinned: false
|
| 11 |
+
tags: ["llm", "gpt", "homepage2vec", "multi-lingual", "multi-label", "classification"]
|
| 12 |
---
|
| 13 |
|
| 14 |
+
# 🌐 Advancing Homepage2Vec with LLM-Generated Datasets for Multilingual Website Classification
|
| 15 |
+
|
| 16 |
+
This project was developed in collaboration with the Data Science Lab ([DLab](https://dlab.epfl.ch/)) at EPFL as part of the [Machine Learning](https://www.epfl.ch/labs/mlo/machine-learning-cs-433/) (CS-433) course. We thank [Prof. Robert West](https://people.epfl.ch/robert.west) for enabling the project and [Tiziano Piccardi](https://tizianopiccardi.github.io/) for his guidance and support throughout the project.
|
| 17 |
+
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## 📚 Abstract
|
| 22 |
+
|
| 23 |
+
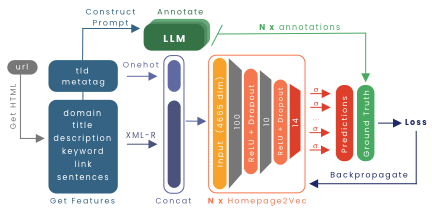
Homepage2Vec, a state-of-the-art open-source model for multilingual, multilabel website classification, has proven powerful in accurately classifying website topics. However, it is limited by its initial training data, which on average only contains a single topic for a website. This study explores the use of Large Language Models (LLMs) for creating a high-quality finetuning dataset that more accurately reflects the topic diversity of a website. We assess various LLM-based labelers and select the best one through comparison to crowdsourced annotations. We generate two variants of a new 10,000-website dataset, `curlie-gpt3.5-10k` and `curlie-gpt4-10k`, for finetuning Homepage2Vec. We show that finetuning Homepage2Vec with these datasets improves its macro F1 from 38% to 42%. Finally, we release both LLM-annotated datasets publicly.
|
images/training_overview.png
ADDED
|