import subprocess
subprocess.run('pip install flash-attn --no-build-isolation', env={'FLASH_ATTENTION_SKIP_CUDA_BUILD': "TRUE"}, shell=True)
import os
import sys
import gradio as gr
# prototyping
# from demo_test import Text2Video, Video2Video
from demo.t2v import Text2Video
t2v_examples = [
['walk fast clean',16,],
['run fast clean',16,],
['standing up',16],
['doing the splits',16],
['doing backflips',16],
['a headstand',16],
['karate kick',16],
['crunch abs',16],
['doing push ups',16],
]
def do_nothing():
return
def demo(result_dir='./tmp/'):
text2video = Text2Video(result_dir)
# video2video = Video2Video(result_dir)
# tex
with gr.Blocks(analytics_enabled=False) as videocrafter_iface:
gr.Markdown(" \
\
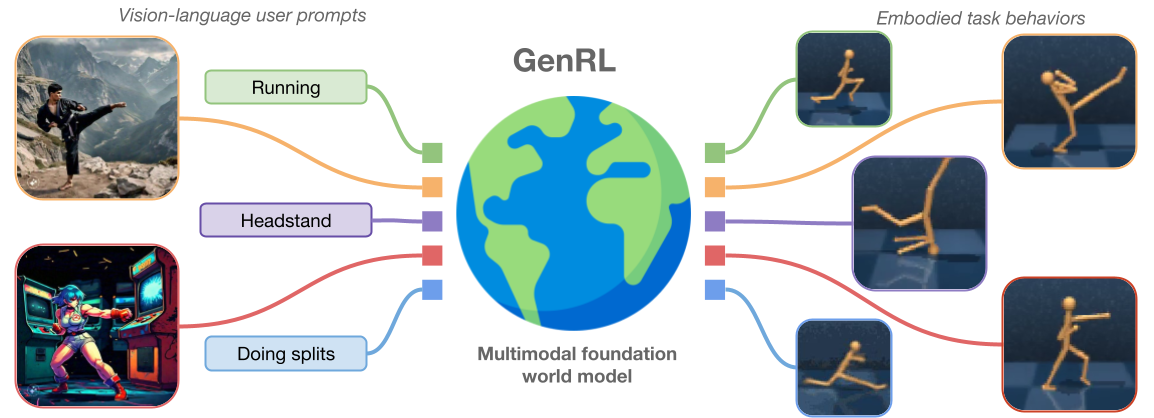 \
\
")
gr.Markdown(" Notes: ")
gr.Markdown(" - Low quality of the videos generated is expected, as the work focuses on visual-language alignment for behavior learning, not on video generation quality.")
gr.Markdown(" - The model is trained on small 64x64 images, and the videos are generated only from a small 512-dimensional embedding. ")
gr.Markdown(" - Some prompts require styling instructions, e.g. fast, clean, in order to work well. See some of the examples. ")
#######t2v#######
with gr.Tab(label="Text2Video"):
with gr.Column():
with gr.Row(): # .style(equal_height=False)
with gr.Column():
input_text = gr.Text(label='prompt')
duration = gr.Slider(minimum=8, maximum=32, elem_id=f"duration", label="duration", value=16, step=8)
send_btn = gr.Button("Send")
with gr.Column(): # label='result',
pass
with gr.Column(): # label='result',
output_video_1 = gr.Video(autoplay=True, width=256, height=256)
with gr.Row():
gr.Examples(examples=t2v_examples,
inputs=[input_text,duration],
outputs=[output_video_1],
fn=text2video.get_prompt,
cache_examples=False)
#cache_examples=os.getenv('SYSTEM') == 'spaces')
send_btn.click(
fn=text2video.get_prompt,
inputs=[input_text,duration],
outputs=[output_video_1],
)
input_text.submit(
fn=text2video.get_prompt,
inputs=[input_text,duration],
outputs=[output_video_1],
)
return videocrafter_iface
if __name__ == "__main__":
result_dir = os.path.join('./', 'results')
video_demo = demo(result_dir)
video_demo.queue()
video_demo.launch()