Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse files- LICENSE +21 -0
- README.md +110 -8
- __pycache__/llama_chat_format.cpython-39.pyc +0 -0
- images/huggingface_access_token.png +0 -0
- images/huggingface_llama2_access.png +0 -0
- llama.py +114 -0
- llama_chat_format.py +38 -0
- requirements.txt +6 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Martin Thissen
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,114 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: blue
|
| 5 |
-
colorTo: blue
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: llama2_local
|
| 3 |
+
app_file: llama.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 3.37.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# Llama2 on Your Local Computer
|
| 8 |
+
Run the new Llama2 and Llama2-Chat models on your local computer.
|
| 9 |
|
| 10 |
+
## Getting Started
|
| 11 |
+
|
| 12 |
+
### Installation
|
| 13 |
+
|
| 14 |
+
1. Clone the repository:
|
| 15 |
+
```
|
| 16 |
+
git clone https://github.com/thisserand/llama2_local.git
|
| 17 |
+
cd llama2_local
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
2. Install required dependencies:
|
| 21 |
+
```
|
| 22 |
+
pip install -r requirements.txt
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
### Prerequisites
|
| 26 |
+
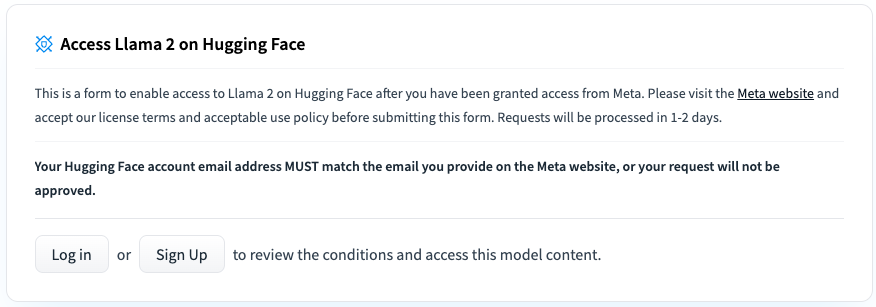
To be able to download the model weights and tokenizer from Huggingface, you firtst need to visit the [Meta AI website](https://ai.meta.com/resources/models-and-libraries/llama-downloads/) and accept their License (my request got approved within 30 minutes). Make sure that you state the email address that you are also using for your Huggingface account. Once your request got accepted, you need to go to one of the Llama2 Huggingface repositories (e.g., the Llama2-7B model) and request access for there again, as can be seen in the following image (access should be granted right away):
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
Once you are all set with your access requests the last step is to login to your huggingface account in your current runtime. For this we will use the following command:
|
| 30 |
+
```
|
| 31 |
+
huggingface-cli login
|
| 32 |
+
```
|
| 33 |
+
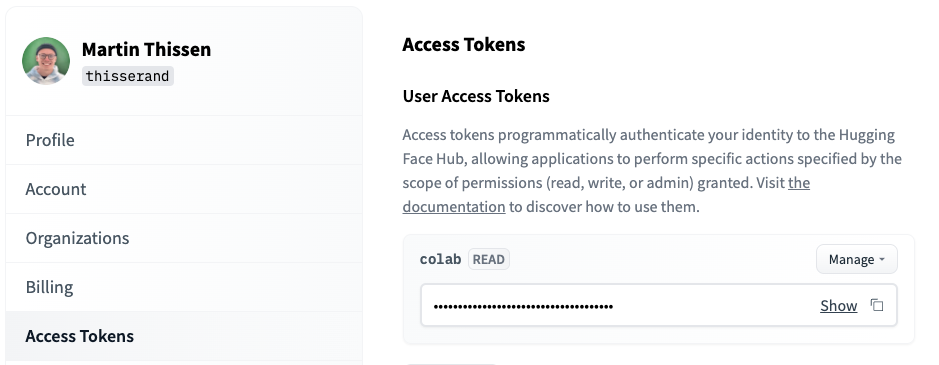
You can find your Access Token here (https://huggingface.co/settings/tokens):
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
### Windows
|
| 37 |
+
Make sure that you have gcc with version >=11 installed on your computer. Here are steps described by [Kevin Anthony Kaw
|
| 38 |
+
](https://github.com/kevinkaw) for a successful setup of gcc:
|
| 39 |
+
- CMake version cmake-3.27.0-windows-x86_64.msi installed to root directory ("C:")
|
| 40 |
+
- minGW64 version 11.0.0 extracted to root directory ("C:")
|
| 41 |
+
- set environment path variables for CMake and minGW64
|
| 42 |
+
- install visual studio build tools. It's way at the bottom under "Tools for Visual Studio" drop down list.
|
| 43 |
+
- In visual studio, check the "Desktop development with c++", click install.
|
| 44 |
+
|
| 45 |
+
## Usage
|
| 46 |
+
|
| 47 |
+
### Full Precision (Original)
|
| 48 |
+
|
| 49 |
+
Llama2-7B:
|
| 50 |
+
```
|
| 51 |
+
python llama.py --model_name="meta-llama/Llama-2-7b-hf"
|
| 52 |
+
```
|
| 53 |
+
Llama2-7B-Chat:
|
| 54 |
+
```
|
| 55 |
+
python llama.py --model_name="meta-llama/Llama-2-7b-chat-hf"
|
| 56 |
+
```
|
| 57 |
+
Llama2-13B:
|
| 58 |
+
```
|
| 59 |
+
python llama.py --model_name="meta-llama/Llama-2-13b-hf"
|
| 60 |
+
```
|
| 61 |
+
Llama2-13B-Chat:
|
| 62 |
+
```
|
| 63 |
+
python llama.py --model_name="meta-llama/Llama-2-13b-chat-hf"
|
| 64 |
+
```
|
| 65 |
+
Llama2-70B:
|
| 66 |
+
```
|
| 67 |
+
python llama.py --model_name="meta-llama/Llama-2-70b-hf"
|
| 68 |
+
```
|
| 69 |
+
Llama2-70B-Chat:
|
| 70 |
+
```
|
| 71 |
+
python llama.py --model_name="meta-llama/Llama-2-70b-chat-hf"
|
| 72 |
+
```
|
| 73 |
+
### GPTQ Quantized
|
| 74 |
+
Llama2-7B:
|
| 75 |
+
```
|
| 76 |
+
python llama.py --model_name="TheBloke/Llama-2-7B-GPTQ"
|
| 77 |
+
```
|
| 78 |
+
Llama2-7B-Chat:
|
| 79 |
+
```
|
| 80 |
+
python llama.py --model_name="TheBloke/Llama-2-7b-Chat-GPTQ"
|
| 81 |
+
```
|
| 82 |
+
Llama2-13B:
|
| 83 |
+
```
|
| 84 |
+
python llama.py --model_name="TheBloke/Llama-2-13B-GPTQ"
|
| 85 |
+
```
|
| 86 |
+
Llama2-13B-Chat:
|
| 87 |
+
```
|
| 88 |
+
python llama.py --model_name="TheBloke/Llama-2-13B-Chat-GPTQ"
|
| 89 |
+
```
|
| 90 |
+
Llama2-70B:
|
| 91 |
+
```
|
| 92 |
+
python llama.py --model_name="TheBloke/Llama-2-70B-GPTQ"
|
| 93 |
+
```
|
| 94 |
+
Llama2-70B-Chat:
|
| 95 |
+
```
|
| 96 |
+
python llama.py --model_name="TheBloke/Llama-2-70B-Chat-GPTQ"
|
| 97 |
+
```
|
| 98 |
+
### GGML Quantized
|
| 99 |
+
Llama2-7B:
|
| 100 |
+
```
|
| 101 |
+
python llama.py --model_name="TheBloke/Llama-2-7B-GGML" --file_name="llama-2-7b.ggmlv3.q4_K_M.bin"
|
| 102 |
+
```
|
| 103 |
+
Llama2-7B-Chat:
|
| 104 |
+
```
|
| 105 |
+
python llama.py --model_name="TheBloke/Llama-2-7B-Chat-GGML" --file_name="llama-2-7b-chat.ggmlv3.q4_K_M.bin"
|
| 106 |
+
```
|
| 107 |
+
Llama2-13B:
|
| 108 |
+
```
|
| 109 |
+
python llama.py --model_name="TheBloke/Llama-2-13B-GGML" --file_name="llama-2-13b.ggmlv3.q4_K_M.bin"
|
| 110 |
+
```
|
| 111 |
+
Llama2-13B-Chat:
|
| 112 |
+
```
|
| 113 |
+
python llama.py --model_name="TheBloke/Llama-2-13B-Chat-GGML" --file_name="llama-2-13b-chat.ggmlv3.q4_K_M.bin"
|
| 114 |
+
```
|
__pycache__/llama_chat_format.cpython-39.pyc
ADDED
|
Binary file (1.32 kB). View file
|
|
|
images/huggingface_access_token.png
ADDED
|
images/huggingface_llama2_access.png
ADDED
|
llama.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import gradio as gr
|
| 3 |
+
import fire
|
| 4 |
+
from enum import Enum
|
| 5 |
+
from threading import Thread
|
| 6 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 7 |
+
from auto_gptq import AutoGPTQForCausalLM
|
| 8 |
+
from llama_cpp import Llama
|
| 9 |
+
from huggingface_hub import hf_hub_download
|
| 10 |
+
from transformers import TextIteratorStreamer
|
| 11 |
+
from llama_chat_format import format_to_llama_chat_style
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# class syntax
|
| 15 |
+
class Model_Type(Enum):
|
| 16 |
+
gptq = 1
|
| 17 |
+
ggml = 2
|
| 18 |
+
full_precision = 3
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_model_type(model_name):
|
| 22 |
+
if "gptq" in model_name.lower():
|
| 23 |
+
return Model_Type.gptq
|
| 24 |
+
elif "ggml" in model_name.lower():
|
| 25 |
+
return Model_Type.ggml
|
| 26 |
+
else:
|
| 27 |
+
return Model_Type.full_precision
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def create_folder_if_not_exists(folder_path):
|
| 31 |
+
if not os.path.exists(folder_path):
|
| 32 |
+
os.makedirs(folder_path)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def initialize_gpu_model_and_tokenizer(model_name, model_type):
|
| 36 |
+
if model_type == Model_Type.gptq:
|
| 37 |
+
model = AutoGPTQForCausalLM.from_quantized(model_name, device_map="auto", use_safetensors=True, use_triton=False)
|
| 38 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 39 |
+
else:
|
| 40 |
+
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", token=True)
|
| 41 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, token=True)
|
| 42 |
+
return model, tokenizer
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def init_auto_model_and_tokenizer(model_name, model_type, file_name=None):
|
| 46 |
+
model_type = get_model_type(model_name)
|
| 47 |
+
|
| 48 |
+
if Model_Type.ggml == model_type:
|
| 49 |
+
models_folder = "./models"
|
| 50 |
+
create_folder_if_not_exists(models_folder)
|
| 51 |
+
file_path = hf_hub_download(repo_id=model_name, filename=file_name, local_dir=models_folder)
|
| 52 |
+
model = Llama(file_path, n_ctx=4096)
|
| 53 |
+
tokenizer = None
|
| 54 |
+
else:
|
| 55 |
+
model, tokenizer = initialize_gpu_model_and_tokenizer(model_name, model_type=model_type)
|
| 56 |
+
return model, tokenizer
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def run_ui(model, tokenizer, is_chat_model, model_type):
|
| 60 |
+
with gr.Blocks() as demo:
|
| 61 |
+
chatbot = gr.Chatbot()
|
| 62 |
+
msg = gr.Textbox()
|
| 63 |
+
clear = gr.Button("Clear")
|
| 64 |
+
|
| 65 |
+
def user(user_message, history):
|
| 66 |
+
return "", history + [[user_message, None]]
|
| 67 |
+
|
| 68 |
+
def bot(history):
|
| 69 |
+
if is_chat_model:
|
| 70 |
+
instruction = format_to_llama_chat_style(history)
|
| 71 |
+
else:
|
| 72 |
+
instruction = history[-1][0]
|
| 73 |
+
|
| 74 |
+
history[-1][1] = ""
|
| 75 |
+
kwargs = dict(temperature=0.6, top_p=0.9)
|
| 76 |
+
if model_type == Model_Type.ggml:
|
| 77 |
+
kwargs["max_tokens"] = 512
|
| 78 |
+
for chunk in model(prompt=instruction, stream=True, **kwargs):
|
| 79 |
+
token = chunk["choices"][0]["text"]
|
| 80 |
+
history[-1][1] += token
|
| 81 |
+
yield history
|
| 82 |
+
|
| 83 |
+
else:
|
| 84 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, Timeout=5)
|
| 85 |
+
inputs = tokenizer(instruction, return_tensors="pt").to(model.device)
|
| 86 |
+
kwargs["max_new_tokens"] = 512
|
| 87 |
+
kwargs["input_ids"] = inputs["input_ids"]
|
| 88 |
+
kwargs["streamer"] = streamer
|
| 89 |
+
thread = Thread(target=model.generate, kwargs=kwargs)
|
| 90 |
+
thread.start()
|
| 91 |
+
|
| 92 |
+
for token in streamer:
|
| 93 |
+
history[-1][1] += token
|
| 94 |
+
yield history
|
| 95 |
+
|
| 96 |
+
msg.submit(user, [msg, chatbot], [msg, chatbot], queue=False).then(bot, chatbot, chatbot)
|
| 97 |
+
clear.click(lambda: None, None, chatbot, queue=False)
|
| 98 |
+
demo.queue()
|
| 99 |
+
demo.launch(share=True, debug=True)
|
| 100 |
+
|
| 101 |
+
def main(model_name=None, file_name=None):
|
| 102 |
+
assert model_name is not None, "model_name argument is missing."
|
| 103 |
+
|
| 104 |
+
is_chat_model = 'chat' in model_name.lower()
|
| 105 |
+
model_type = get_model_type(model_name)
|
| 106 |
+
|
| 107 |
+
if model_type == Model_Type.ggml:
|
| 108 |
+
assert file_name is not None, "When model_name is provided for a GGML quantized model, file_name argument must also be provided."
|
| 109 |
+
|
| 110 |
+
model, tokenizer = init_auto_model_and_tokenizer(model_name, model_type, file_name)
|
| 111 |
+
run_ui(model, tokenizer, is_chat_model, model_type)
|
| 112 |
+
|
| 113 |
+
if __name__ == '__main__':
|
| 114 |
+
fire.Fire(main)
|
llama_chat_format.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BOS, EOS = "<s>", "</s>"
|
| 2 |
+
B_INST, E_INST = "[INST]", "[/INST]"
|
| 3 |
+
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
|
| 4 |
+
DEFAULT_SYSTEM_PROMPT = """\
|
| 5 |
+
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
| 6 |
+
|
| 7 |
+
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information."""
|
| 8 |
+
|
| 9 |
+
def format_to_llama_chat_style(history) -> str:
|
| 10 |
+
# history has the following structure:
|
| 11 |
+
# - dialogs
|
| 12 |
+
# --- instruction
|
| 13 |
+
# --- response (None for the most recent dialog)
|
| 14 |
+
prompt = ""
|
| 15 |
+
for i, dialog in enumerate(history[:-1]):
|
| 16 |
+
instruction, response = dialog[0], dialog[1]
|
| 17 |
+
# prepend system instruction before first instruction
|
| 18 |
+
if i == 0:
|
| 19 |
+
instruction = f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}" + instruction
|
| 20 |
+
else:
|
| 21 |
+
# the tokenizer automatically adds a bos_token during encoding,
|
| 22 |
+
# for this reason the bos_token is not added for the first instruction
|
| 23 |
+
prompt += BOS
|
| 24 |
+
prompt += f"{B_INST} {instruction.strip()} {E_INST} {response.strip()} " + EOS
|
| 25 |
+
|
| 26 |
+
# new instruction from the user
|
| 27 |
+
new_instruction = history[-1][0].strip()
|
| 28 |
+
|
| 29 |
+
# the tokenizer automatically adds a bos_token during encoding,
|
| 30 |
+
# for this reason the bos_token is not added for the first instruction
|
| 31 |
+
if len(history) > 1:
|
| 32 |
+
prompt += BOS
|
| 33 |
+
else:
|
| 34 |
+
# prepend system instruction before first instruction
|
| 35 |
+
new_instruction = f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}" + new_instruction
|
| 36 |
+
|
| 37 |
+
prompt += f"{B_INST} {new_instruction} {E_INST}"
|
| 38 |
+
return prompt
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
transformers==4.31.0
|
| 2 |
+
auto-gptq==0.3.0
|
| 3 |
+
langchain==0.0.237
|
| 4 |
+
gradio==3.37.0
|
| 5 |
+
llama-cpp-python==0.1.73
|
| 6 |
+
fire==0.5.0
|