Spaces:
Running
on
Zero

Running
on
Zero

Feature(MInference): build demo
Browse files- .gitignore +415 -0
- LICENSE +21 -0
- README.md +130 -1
- app.py +145 -4
- images/MInference1_onepage.png +0 -0
- images/MInference_logo.png +0 -0
- images/benchmarks/needle_viz_LLaMA-3-8B-1M_ours_1K_1000K.png +0 -0
- images/benchmarks/ppl-LLaMA-3-262k.png +0 -0
- minference/__init__.py +27 -0
- minference/configs/Llama_3_8B_Instruct_262k_kv_out_v32_fit_o_best_pattern.json +1 -0
- minference/configs/Phi_3_mini_128k_instruct_kv_out_v32_fit_o_best_pattern.json +1 -0
- minference/configs/Yi_9B_200k_kv_out_v32_fit_o_best_pattern.json +1 -0
- minference/configs/model2path.py +17 -0
- minference/minference_configuration.py +49 -0
- minference/models_patch.py +100 -0
- minference/modules/inf_llm.py +1296 -0
- minference/modules/minference_forward.py +855 -0
- minference/modules/snap_kv.py +422 -0
- minference/ops/block_sparse_flash_attention.py +464 -0
- minference/ops/pit_sparse_flash_attention.py +740 -0
- minference/ops/pit_sparse_flash_attention_v2.py +735 -0
- minference/ops/streaming_kernel.py +763 -0
- minference/patch.py +1279 -0
- minference/version.py +14 -0
- requirements.txt +5 -0
.gitignore
ADDED
|
@@ -0,0 +1,415 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Ignore Visual Studio temporary files, build results, and
|
| 2 |
+
## files generated by popular Visual Studio add-ons.
|
| 3 |
+
##
|
| 4 |
+
## Get latest from https://github.com/github/gitignore/blob/main/VisualStudio.gitignore
|
| 5 |
+
|
| 6 |
+
# User-specific files
|
| 7 |
+
*.rsuser
|
| 8 |
+
*.suo
|
| 9 |
+
*.user
|
| 10 |
+
*.userosscache
|
| 11 |
+
*.sln.docstates
|
| 12 |
+
|
| 13 |
+
# User-specific files (MonoDevelop/Xamarin Studio)
|
| 14 |
+
*.userprefs
|
| 15 |
+
|
| 16 |
+
# Mono auto generated files
|
| 17 |
+
mono_crash.*
|
| 18 |
+
|
| 19 |
+
# Build results
|
| 20 |
+
[Dd]ebug/
|
| 21 |
+
[Dd]ebugPublic/
|
| 22 |
+
[Rr]elease/
|
| 23 |
+
[Rr]eleases/
|
| 24 |
+
x64/
|
| 25 |
+
x86/
|
| 26 |
+
[Ww][Ii][Nn]32/
|
| 27 |
+
[Aa][Rr][Mm]/
|
| 28 |
+
[Aa][Rr][Mm]64/
|
| 29 |
+
bld/
|
| 30 |
+
[Bb]in/
|
| 31 |
+
[Oo]bj/
|
| 32 |
+
[Ll]og/
|
| 33 |
+
[Ll]ogs/
|
| 34 |
+
|
| 35 |
+
# Visual Studio 2015/2017 cache/options directory
|
| 36 |
+
.vs/
|
| 37 |
+
# Uncomment if you have tasks that create the project's static files in wwwroot
|
| 38 |
+
#wwwroot/
|
| 39 |
+
|
| 40 |
+
# Visual Studio 2017 auto generated files
|
| 41 |
+
Generated\ Files/
|
| 42 |
+
|
| 43 |
+
# MSTest test Results
|
| 44 |
+
[Tt]est[Rr]esult*/
|
| 45 |
+
[Bb]uild[Ll]og.*
|
| 46 |
+
|
| 47 |
+
# NUnit
|
| 48 |
+
*.VisualState.xml
|
| 49 |
+
TestResult.xml
|
| 50 |
+
nunit-*.xml
|
| 51 |
+
|
| 52 |
+
# Build Results of an ATL Project
|
| 53 |
+
[Dd]ebugPS/
|
| 54 |
+
[Rr]eleasePS/
|
| 55 |
+
dlldata.c
|
| 56 |
+
|
| 57 |
+
# Benchmark Results
|
| 58 |
+
BenchmarkDotNet.Artifacts/
|
| 59 |
+
|
| 60 |
+
# .NET Core
|
| 61 |
+
project.lock.json
|
| 62 |
+
project.fragment.lock.json
|
| 63 |
+
artifacts/
|
| 64 |
+
|
| 65 |
+
# ASP.NET Scaffolding
|
| 66 |
+
ScaffoldingReadMe.txt
|
| 67 |
+
|
| 68 |
+
# StyleCop
|
| 69 |
+
StyleCopReport.xml
|
| 70 |
+
|
| 71 |
+
# Files built by Visual Studio
|
| 72 |
+
*_i.c
|
| 73 |
+
*_p.c
|
| 74 |
+
*_h.h
|
| 75 |
+
*.ilk
|
| 76 |
+
*.meta
|
| 77 |
+
*.obj
|
| 78 |
+
*.iobj
|
| 79 |
+
*.pch
|
| 80 |
+
*.pdb
|
| 81 |
+
*.ipdb
|
| 82 |
+
*.pgc
|
| 83 |
+
*.pgd
|
| 84 |
+
*.rsp
|
| 85 |
+
*.sbr
|
| 86 |
+
*.tlb
|
| 87 |
+
*.tli
|
| 88 |
+
*.tlh
|
| 89 |
+
*.tmp
|
| 90 |
+
*.tmp_proj
|
| 91 |
+
*_wpftmp.csproj
|
| 92 |
+
*.log
|
| 93 |
+
*.tlog
|
| 94 |
+
*.vspscc
|
| 95 |
+
*.vssscc
|
| 96 |
+
.builds
|
| 97 |
+
*.pidb
|
| 98 |
+
*.svclog
|
| 99 |
+
*.scc
|
| 100 |
+
|
| 101 |
+
# Chutzpah Test files
|
| 102 |
+
_Chutzpah*
|
| 103 |
+
|
| 104 |
+
# Visual C++ cache files
|
| 105 |
+
ipch/
|
| 106 |
+
*.aps
|
| 107 |
+
*.ncb
|
| 108 |
+
*.opendb
|
| 109 |
+
*.opensdf
|
| 110 |
+
*.sdf
|
| 111 |
+
*.cachefile
|
| 112 |
+
*.VC.db
|
| 113 |
+
*.VC.VC.opendb
|
| 114 |
+
|
| 115 |
+
# Visual Studio profiler
|
| 116 |
+
*.psess
|
| 117 |
+
*.vsp
|
| 118 |
+
*.vspx
|
| 119 |
+
*.sap
|
| 120 |
+
|
| 121 |
+
# Visual Studio Trace Files
|
| 122 |
+
*.e2e
|
| 123 |
+
|
| 124 |
+
# TFS 2012 Local Workspace
|
| 125 |
+
$tf/
|
| 126 |
+
|
| 127 |
+
# Guidance Automation Toolkit
|
| 128 |
+
*.gpState
|
| 129 |
+
|
| 130 |
+
# ReSharper is a .NET coding add-in
|
| 131 |
+
_ReSharper*/
|
| 132 |
+
*.[Rr]e[Ss]harper
|
| 133 |
+
*.DotSettings.user
|
| 134 |
+
|
| 135 |
+
# TeamCity is a build add-in
|
| 136 |
+
_TeamCity*
|
| 137 |
+
|
| 138 |
+
# DotCover is a Code Coverage Tool
|
| 139 |
+
*.dotCover
|
| 140 |
+
|
| 141 |
+
# AxoCover is a Code Coverage Tool
|
| 142 |
+
.axoCover/*
|
| 143 |
+
!.axoCover/settings.json
|
| 144 |
+
|
| 145 |
+
# Coverlet is a free, cross platform Code Coverage Tool
|
| 146 |
+
coverage*.json
|
| 147 |
+
coverage*.xml
|
| 148 |
+
coverage*.info
|
| 149 |
+
|
| 150 |
+
# Visual Studio code coverage results
|
| 151 |
+
*.coverage
|
| 152 |
+
*.coveragexml
|
| 153 |
+
|
| 154 |
+
# NCrunch
|
| 155 |
+
_NCrunch_*
|
| 156 |
+
.*crunch*.local.xml
|
| 157 |
+
nCrunchTemp_*
|
| 158 |
+
|
| 159 |
+
# MightyMoose
|
| 160 |
+
*.mm.*
|
| 161 |
+
AutoTest.Net/
|
| 162 |
+
|
| 163 |
+
# Web workbench (sass)
|
| 164 |
+
.sass-cache/
|
| 165 |
+
|
| 166 |
+
# Installshield output folder
|
| 167 |
+
[Ee]xpress/
|
| 168 |
+
|
| 169 |
+
# DocProject is a documentation generator add-in
|
| 170 |
+
DocProject/buildhelp/
|
| 171 |
+
DocProject/Help/*.HxT
|
| 172 |
+
DocProject/Help/*.HxC
|
| 173 |
+
DocProject/Help/*.hhc
|
| 174 |
+
DocProject/Help/*.hhk
|
| 175 |
+
DocProject/Help/*.hhp
|
| 176 |
+
DocProject/Help/Html2
|
| 177 |
+
DocProject/Help/html
|
| 178 |
+
|
| 179 |
+
# Click-Once directory
|
| 180 |
+
publish/
|
| 181 |
+
|
| 182 |
+
# Publish Web Output
|
| 183 |
+
*.[Pp]ublish.xml
|
| 184 |
+
*.azurePubxml
|
| 185 |
+
# Note: Comment the next line if you want to checkin your web deploy settings,
|
| 186 |
+
# but database connection strings (with potential passwords) will be unencrypted
|
| 187 |
+
*.pubxml
|
| 188 |
+
*.publishproj
|
| 189 |
+
|
| 190 |
+
# Microsoft Azure Web App publish settings. Comment the next line if you want to
|
| 191 |
+
# checkin your Azure Web App publish settings, but sensitive information contained
|
| 192 |
+
# in these scripts will be unencrypted
|
| 193 |
+
PublishScripts/
|
| 194 |
+
|
| 195 |
+
# NuGet Packages
|
| 196 |
+
*.nupkg
|
| 197 |
+
# NuGet Symbol Packages
|
| 198 |
+
*.snupkg
|
| 199 |
+
# The packages folder can be ignored because of Package Restore
|
| 200 |
+
**/[Pp]ackages/*
|
| 201 |
+
# except build/, which is used as an MSBuild target.
|
| 202 |
+
!**/[Pp]ackages/build/
|
| 203 |
+
# Uncomment if necessary however generally it will be regenerated when needed
|
| 204 |
+
#!**/[Pp]ackages/repositories.config
|
| 205 |
+
# NuGet v3's project.json files produces more ignorable files
|
| 206 |
+
*.nuget.props
|
| 207 |
+
*.nuget.targets
|
| 208 |
+
|
| 209 |
+
# Microsoft Azure Build Output
|
| 210 |
+
csx/
|
| 211 |
+
*.build.csdef
|
| 212 |
+
|
| 213 |
+
# Microsoft Azure Emulator
|
| 214 |
+
ecf/
|
| 215 |
+
rcf/
|
| 216 |
+
|
| 217 |
+
# Windows Store app package directories and files
|
| 218 |
+
AppPackages/
|
| 219 |
+
BundleArtifacts/
|
| 220 |
+
Package.StoreAssociation.xml
|
| 221 |
+
_pkginfo.txt
|
| 222 |
+
*.appx
|
| 223 |
+
*.appxbundle
|
| 224 |
+
*.appxupload
|
| 225 |
+
|
| 226 |
+
# Visual Studio cache files
|
| 227 |
+
# files ending in .cache can be ignored
|
| 228 |
+
*.[Cc]ache
|
| 229 |
+
# but keep track of directories ending in .cache
|
| 230 |
+
!?*.[Cc]ache/
|
| 231 |
+
|
| 232 |
+
# Others
|
| 233 |
+
ClientBin/
|
| 234 |
+
~$*
|
| 235 |
+
*~
|
| 236 |
+
*.dbmdl
|
| 237 |
+
*.dbproj.schemaview
|
| 238 |
+
*.jfm
|
| 239 |
+
*.pfx
|
| 240 |
+
*.publishsettings
|
| 241 |
+
orleans.codegen.cs
|
| 242 |
+
|
| 243 |
+
# Including strong name files can present a security risk
|
| 244 |
+
# (https://github.com/github/gitignore/pull/2483#issue-259490424)
|
| 245 |
+
#*.snk
|
| 246 |
+
|
| 247 |
+
# Since there are multiple workflows, uncomment next line to ignore bower_components
|
| 248 |
+
# (https://github.com/github/gitignore/pull/1529#issuecomment-104372622)
|
| 249 |
+
#bower_components/
|
| 250 |
+
|
| 251 |
+
# RIA/Silverlight projects
|
| 252 |
+
Generated_Code/
|
| 253 |
+
|
| 254 |
+
# Backup & report files from converting an old project file
|
| 255 |
+
# to a newer Visual Studio version. Backup files are not needed,
|
| 256 |
+
# because we have git ;-)
|
| 257 |
+
_UpgradeReport_Files/
|
| 258 |
+
Backup*/
|
| 259 |
+
UpgradeLog*.XML
|
| 260 |
+
UpgradeLog*.htm
|
| 261 |
+
ServiceFabricBackup/
|
| 262 |
+
*.rptproj.bak
|
| 263 |
+
|
| 264 |
+
# SQL Server files
|
| 265 |
+
*.mdf
|
| 266 |
+
*.ldf
|
| 267 |
+
*.ndf
|
| 268 |
+
|
| 269 |
+
# Business Intelligence projects
|
| 270 |
+
*.rdl.data
|
| 271 |
+
*.bim.layout
|
| 272 |
+
*.bim_*.settings
|
| 273 |
+
*.rptproj.rsuser
|
| 274 |
+
*- [Bb]ackup.rdl
|
| 275 |
+
*- [Bb]ackup ([0-9]).rdl
|
| 276 |
+
*- [Bb]ackup ([0-9][0-9]).rdl
|
| 277 |
+
|
| 278 |
+
# Microsoft Fakes
|
| 279 |
+
FakesAssemblies/
|
| 280 |
+
|
| 281 |
+
# GhostDoc plugin setting file
|
| 282 |
+
*.GhostDoc.xml
|
| 283 |
+
|
| 284 |
+
# Node.js Tools for Visual Studio
|
| 285 |
+
.ntvs_analysis.dat
|
| 286 |
+
node_modules/
|
| 287 |
+
|
| 288 |
+
# Visual Studio 6 build log
|
| 289 |
+
*.plg
|
| 290 |
+
|
| 291 |
+
# Visual Studio 6 workspace options file
|
| 292 |
+
*.opt
|
| 293 |
+
|
| 294 |
+
# Visual Studio 6 auto-generated workspace file (contains which files were open etc.)
|
| 295 |
+
*.vbw
|
| 296 |
+
|
| 297 |
+
# Visual Studio 6 auto-generated project file (contains which files were open etc.)
|
| 298 |
+
*.vbp
|
| 299 |
+
|
| 300 |
+
# Visual Studio 6 workspace and project file (working project files containing files to include in project)
|
| 301 |
+
*.dsw
|
| 302 |
+
*.dsp
|
| 303 |
+
|
| 304 |
+
# Visual Studio 6 technical files
|
| 305 |
+
*.ncb
|
| 306 |
+
*.aps
|
| 307 |
+
|
| 308 |
+
# Visual Studio LightSwitch build output
|
| 309 |
+
**/*.HTMLClient/GeneratedArtifacts
|
| 310 |
+
**/*.DesktopClient/GeneratedArtifacts
|
| 311 |
+
**/*.DesktopClient/ModelManifest.xml
|
| 312 |
+
**/*.Server/GeneratedArtifacts
|
| 313 |
+
**/*.Server/ModelManifest.xml
|
| 314 |
+
_Pvt_Extensions
|
| 315 |
+
|
| 316 |
+
# Paket dependency manager
|
| 317 |
+
.paket/paket.exe
|
| 318 |
+
paket-files/
|
| 319 |
+
|
| 320 |
+
# FAKE - F# Make
|
| 321 |
+
.fake/
|
| 322 |
+
|
| 323 |
+
# CodeRush personal settings
|
| 324 |
+
.cr/personal
|
| 325 |
+
|
| 326 |
+
# Python Tools for Visual Studio (PTVS)
|
| 327 |
+
__pycache__/
|
| 328 |
+
*.pyc
|
| 329 |
+
|
| 330 |
+
# Cake - Uncomment if you are using it
|
| 331 |
+
# tools/**
|
| 332 |
+
# !tools/packages.config
|
| 333 |
+
|
| 334 |
+
# Tabs Studio
|
| 335 |
+
*.tss
|
| 336 |
+
|
| 337 |
+
# Telerik's JustMock configuration file
|
| 338 |
+
*.jmconfig
|
| 339 |
+
|
| 340 |
+
# BizTalk build output
|
| 341 |
+
*.btp.cs
|
| 342 |
+
*.btm.cs
|
| 343 |
+
*.odx.cs
|
| 344 |
+
*.xsd.cs
|
| 345 |
+
|
| 346 |
+
# OpenCover UI analysis results
|
| 347 |
+
OpenCover/
|
| 348 |
+
|
| 349 |
+
# Azure Stream Analytics local run output
|
| 350 |
+
ASALocalRun/
|
| 351 |
+
|
| 352 |
+
# MSBuild Binary and Structured Log
|
| 353 |
+
*.binlog
|
| 354 |
+
|
| 355 |
+
# NVidia Nsight GPU debugger configuration file
|
| 356 |
+
*.nvuser
|
| 357 |
+
|
| 358 |
+
# MFractors (Xamarin productivity tool) working folder
|
| 359 |
+
.mfractor/
|
| 360 |
+
|
| 361 |
+
# Local History for Visual Studio
|
| 362 |
+
.localhistory/
|
| 363 |
+
|
| 364 |
+
# Visual Studio History (VSHistory) files
|
| 365 |
+
.vshistory/
|
| 366 |
+
|
| 367 |
+
# BeatPulse healthcheck temp database
|
| 368 |
+
healthchecksdb
|
| 369 |
+
|
| 370 |
+
# Backup folder for Package Reference Convert tool in Visual Studio 2017
|
| 371 |
+
MigrationBackup/
|
| 372 |
+
|
| 373 |
+
# Ionide (cross platform F# VS Code tools) working folder
|
| 374 |
+
.ionide/
|
| 375 |
+
|
| 376 |
+
# Fody - auto-generated XML schema
|
| 377 |
+
FodyWeavers.xsd
|
| 378 |
+
|
| 379 |
+
# VS Code files for those working on multiple tools
|
| 380 |
+
.vscode/*
|
| 381 |
+
!.vscode/settings.json
|
| 382 |
+
!.vscode/tasks.json
|
| 383 |
+
!.vscode/launch.json
|
| 384 |
+
!.vscode/extensions.json
|
| 385 |
+
*.code-workspace
|
| 386 |
+
|
| 387 |
+
# Local History for Visual Studio Code
|
| 388 |
+
.history/
|
| 389 |
+
|
| 390 |
+
# Windows Installer files from build outputs
|
| 391 |
+
*.cab
|
| 392 |
+
*.msi
|
| 393 |
+
*.msix
|
| 394 |
+
*.msm
|
| 395 |
+
*.msp
|
| 396 |
+
|
| 397 |
+
# JetBrains Rider
|
| 398 |
+
*.sln.iml
|
| 399 |
+
|
| 400 |
+
# Experiments
|
| 401 |
+
data
|
| 402 |
+
!experiments/ruler/data
|
| 403 |
+
needle
|
| 404 |
+
results
|
| 405 |
+
*.json
|
| 406 |
+
*.jsonl
|
| 407 |
+
.vscode/
|
| 408 |
+
*.pt
|
| 409 |
+
*.pkl
|
| 410 |
+
!minference/configs/*
|
| 411 |
+
|
| 412 |
+
__pycache__
|
| 413 |
+
build/
|
| 414 |
+
*.egg-info/
|
| 415 |
+
*.so
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Microsoft Corporation.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE
|
README.md
CHANGED
|
@@ -10,4 +10,133 @@ pinned: false
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
+
<div style="display: flex; align-items: center;">
|
| 14 |
+
<div style="width: 100px; margin-right: 10px; height:auto;" align="left">
|
| 15 |
+
<img src="images/MInference_logo.png" alt="MInference" width="100" align="left">
|
| 16 |
+
</div>
|
| 17 |
+
<div style="flex-grow: 1;" align="center">
|
| 18 |
+
<h2 align="center">MInference: Million-Tokens Prompt Inference for LLMs</h2>
|
| 19 |
+
</div>
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
<p align="center">
|
| 23 |
+
| <a href="https://llmlingua.com/"><b>Project Page</b></a> |
|
| 24 |
+
<a href="https://arxiv.org/abs/2406."><b>Paper</b></a> |
|
| 25 |
+
<a href="https://huggingface.co/spaces/microsoft/MInference"><b>Demo</b></a> |
|
| 26 |
+
</p>
|
| 27 |
+
|
| 28 |
+
https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-7123c81d6b19
|
| 29 |
+
|
| 30 |
+
## TL;DR
|
| 31 |
+
|
| 32 |
+
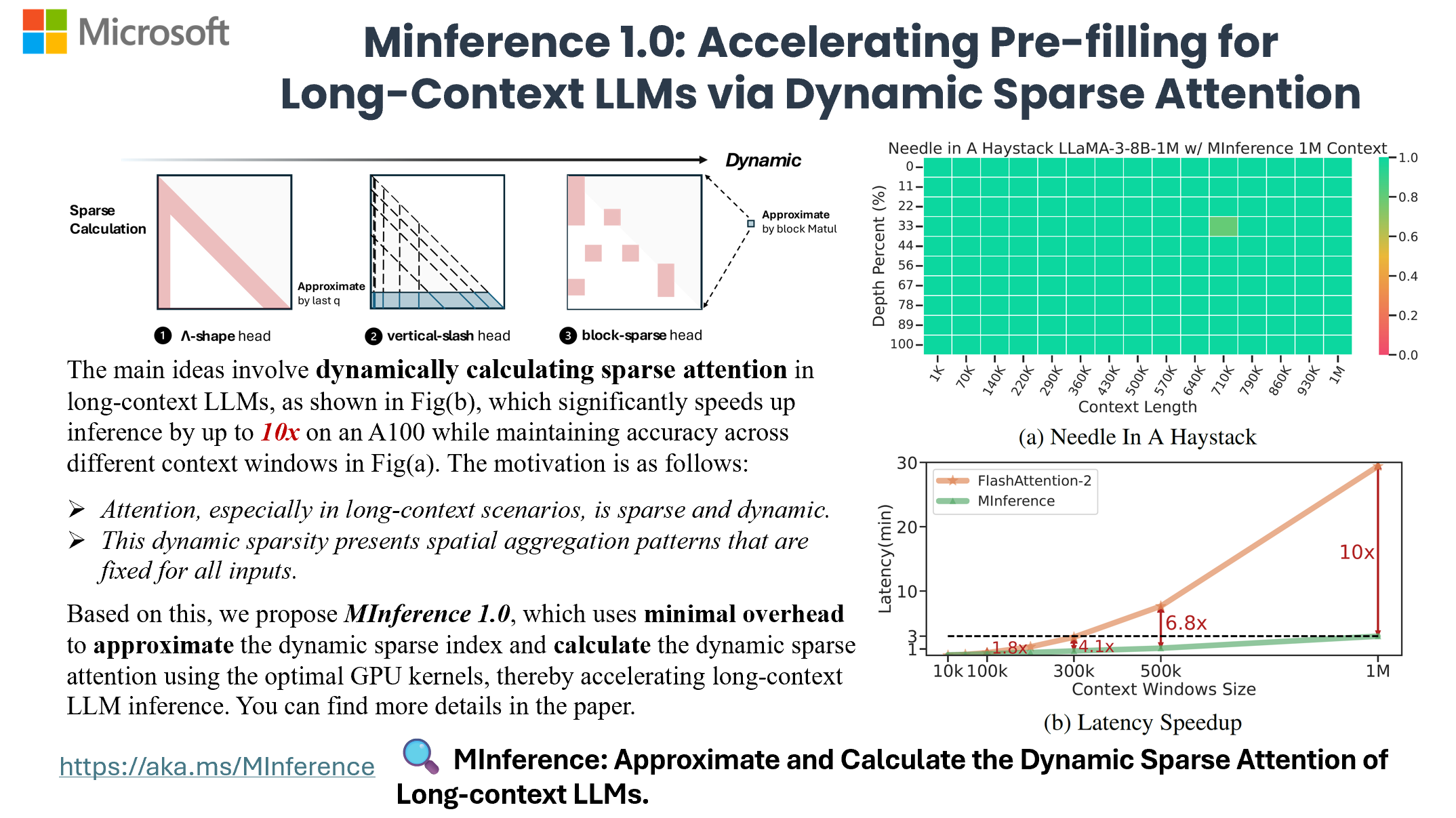
**MInference 1.0** leverages the dynamic sparse nature of LLMs' attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a **10x speedup** for pre-filling on an A100 while maintaining accuracy.
|
| 33 |
+
|
| 34 |
+
- [MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention](https://arxiv.org/abs/2406.) (Under Review)<br>
|
| 35 |
+
_Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu_
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## 🎥 Overview
|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+
## 🎯 Quick Start
|
| 43 |
+
|
| 44 |
+
### Requirements
|
| 45 |
+
|
| 46 |
+
- Torch
|
| 47 |
+
- FlashAttention-2
|
| 48 |
+
- Triton == 2.1.0
|
| 49 |
+
|
| 50 |
+
To get started with MInference, simply install it using pip:
|
| 51 |
+
|
| 52 |
+
```bash
|
| 53 |
+
pip install minference
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### How to use MInference
|
| 57 |
+
|
| 58 |
+
for HF,
|
| 59 |
+
```diff
|
| 60 |
+
from transformers import pipeline
|
| 61 |
+
+from minference import MInference
|
| 62 |
+
|
| 63 |
+
pipe = pipeline("text-generation", model=model_name, torch_dtype="auto", device_map="auto")
|
| 64 |
+
|
| 65 |
+
# Patch MInference Module
|
| 66 |
+
+minference_patch = MInference("minference", model_name)
|
| 67 |
+
+pipe.model = minference_patch(pipe.model)
|
| 68 |
+
|
| 69 |
+
pipe(prompt, max_length=10)
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
for vLLM,
|
| 73 |
+
|
| 74 |
+
```diff
|
| 75 |
+
from vllm import LLM, SamplingParams
|
| 76 |
+
+ from minference import MInference
|
| 77 |
+
|
| 78 |
+
llm = LLM(model_name, max_num_seqs=1, enforce_eager=True, max_model_len=128000)
|
| 79 |
+
|
| 80 |
+
# Patch MInference Module
|
| 81 |
+
+minference_patch = MInference("vllm", model_name)
|
| 82 |
+
+llm = minference_patch(llm)
|
| 83 |
+
|
| 84 |
+
outputs = llm.generate(prompts, sampling_params)
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
## FAQ
|
| 88 |
+
|
| 89 |
+
For more insights and answers, visit our [FAQ section](./Transparency_FAQ.md).
|
| 90 |
+
|
| 91 |
+
**Q1: How to effectively evaluate the impact of dynamic sparse attention on the capabilities of long-context LLMs?**
|
| 92 |
+
|
| 93 |
+
To effectively evaluate long-context LLM capabilities, we tested: 1) effective context window with RULER, 2) general long-context tasks with InfiniteBench, 3) retrieval tasks across different contexts and positions with Needle in a Haystack, and 4) language model prediction with PG-19.<br/>
|
| 94 |
+
We found that traditional methods perform poorly in retrieval tasks, with difficulty levels varying as follows: KV retrieval (every key as a needle) > Needle in a Haystack > Retrieval.Number > Retrieval PassKey. The key challenge is the semantic difference between needles and the haystack. Traditional methods perform better when the semantic difference is larger, as in passkey tasks. KV retrieval demands higher retrieval capabilities since any key can be a target, and multi-needle tasks are even more complex.<br/>
|
| 95 |
+
We will continue to update our results with more models and datasets in future versions.
|
| 96 |
+
|
| 97 |
+
**Q2: Does this dynamic sparse attention pattern only exist in long-context LLMs that are not fully trained?**
|
| 98 |
+
|
| 99 |
+
Firstly, attention is dynamically sparse, and this is true for both short- and long-contexts, a characteristic inherent to the attention mechanism.
|
| 100 |
+
Additionally, we selected the state-of-the-art open-source long-context LLM, LLaMA-3-8B-Instruct-1M, which has an effective context window size of 16K. With MInference, this can be extended to 32K.
|
| 101 |
+
We will continue to adapt our method to other advanced long-context LLMs and update our results. We will also explore the theoretical reasons behind this dynamic sparse attention pattern.
|
| 102 |
+
|
| 103 |
+
**Q3: What is the relationship between MInference, SSM, Linear Attention, and Sparse Attention?**
|
| 104 |
+
|
| 105 |
+
All four approaches (MInference, SSM, Linear Attention, and Sparse Attention) are efficient solutions for optimizing the high complexity of attention in Transformers, each introducing inductive bias from different perspectives. Notably, the latter three require training from scratch.
|
| 106 |
+
Additionally, recent works like Mamba-2 and Unified Implicit Attention Representation unify SSM and Linear Attention as static sparse attention. Mamba-2 itself is a block-wise sparse attention method.
|
| 107 |
+
Intuitively, the significant sparse redundancy in attention suggests that these approaches have potential. However, static sparse attention may not handle dynamic semantic associations well, especially in complex tasks. Dynamic sparse attention, on the other hand, holds potential for better managing these dynamic relationships.
|
| 108 |
+
|
| 109 |
+
## Citation
|
| 110 |
+
|
| 111 |
+
If you find MInference useful or relevant to your project and research, please kindly cite our paper:
|
| 112 |
+
|
| 113 |
+
```bibtex
|
| 114 |
+
@article{jiang2024minference,
|
| 115 |
+
title={MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention},
|
| 116 |
+
author={Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili},
|
| 117 |
+
journal={arXiv},
|
| 118 |
+
year={2024}
|
| 119 |
+
}
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
## Contributing
|
| 123 |
+
|
| 124 |
+
This project welcomes contributions and suggestions. Most contributions require you to agree to a
|
| 125 |
+
Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
|
| 126 |
+
the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
|
| 127 |
+
|
| 128 |
+
When you submit a pull request, a CLA bot will automatically determine whether you need to provide
|
| 129 |
+
a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
|
| 130 |
+
provided by the bot. You will only need to do this once across all repos using our CLA.
|
| 131 |
+
|
| 132 |
+
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
|
| 133 |
+
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
|
| 134 |
+
contact [opencode@microsoft.com](mailto:opencode@microsoft.com) with any additional questions or comments.
|
| 135 |
+
|
| 136 |
+
## Trademarks
|
| 137 |
+
|
| 138 |
+
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft
|
| 139 |
+
trademarks or logos is subject to and must follow
|
| 140 |
+
[Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general).
|
| 141 |
+
Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship.
|
| 142 |
+
Any use of third-party trademarks or logos are subject to those third-party's policies.
|
app.py
CHANGED
|
@@ -1,7 +1,148 @@
|
|
| 1 |
import gradio as gr
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
-
|
| 4 |
-
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
| 2 |
+
import os
|
| 3 |
+
import spaces
|
| 4 |
+
from transformers import GemmaTokenizer, AutoModelForCausalLM
|
| 5 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
|
| 6 |
+
from threading import Thread
|
| 7 |
+
from minference import MInference
|
| 8 |
|
| 9 |
+
# Set an environment variable
|
| 10 |
+
HF_TOKEN = os.environ.get("HF_TOKEN", None)
|
| 11 |
|
| 12 |
+
|
| 13 |
+
DESCRIPTION = '''
|
| 14 |
+
<div>
|
| 15 |
+
<h1 style="text-align: center;">Meta Llama3 8B</h1>
|
| 16 |
+
<p>This Space demonstrates the instruction-tuned model <a href="https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct"><b>Meta Llama3 8b Chat</b></a>. Meta Llama3 is the new open LLM and comes in two sizes: 8b and 70b. Feel free to play with it, or duplicate to run privately!</p>
|
| 17 |
+
<p>🔎 For more details about the Llama3 release and how to use the model with <code>transformers</code>, take a look <a href="https://huggingface.co/blog/llama3">at our blog post</a>.</p>
|
| 18 |
+
<p>🦕 Looking for an even more powerful model? Check out the <a href="https://huggingface.co/chat/"><b>Hugging Chat</b></a> integration for Meta Llama 3 70b</p>
|
| 19 |
+
</div>
|
| 20 |
+
'''
|
| 21 |
+
|
| 22 |
+
LICENSE = """
|
| 23 |
+
<p/>
|
| 24 |
+
---
|
| 25 |
+
Built with Meta Llama 3
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
PLACEHOLDER = """
|
| 29 |
+
<div style="padding: 30px; text-align: center; display: flex; flex-direction: column; align-items: center;">
|
| 30 |
+
<img src="https://ysharma-dummy-chat-app.hf.space/file=/tmp/gradio/8e75e61cc9bab22b7ce3dec85ab0e6db1da5d107/Meta_lockup_positive%20primary_RGB.jpg" style="width: 80%; max-width: 550px; height: auto; opacity: 0.55; ">
|
| 31 |
+
<h1 style="font-size: 28px; margin-bottom: 2px; opacity: 0.55;">Meta llama3</h1>
|
| 32 |
+
<p style="font-size: 18px; margin-bottom: 2px; opacity: 0.65;">Ask me anything...</p>
|
| 33 |
+
</div>
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
css = """
|
| 38 |
+
h1 {
|
| 39 |
+
text-align: center;
|
| 40 |
+
display: block;
|
| 41 |
+
}
|
| 42 |
+
#duplicate-button {
|
| 43 |
+
margin: auto;
|
| 44 |
+
color: white;
|
| 45 |
+
background: #1565c0;
|
| 46 |
+
border-radius: 100vh;
|
| 47 |
+
}
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
# Load the tokenizer and model
|
| 51 |
+
model_name = "gradientai/Llama-3-8B-Instruct-262k"
|
| 52 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 53 |
+
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto") # to("cuda:0")
|
| 54 |
+
minference_patch = MInference("minference", model_name)
|
| 55 |
+
model = minference_patch(model)
|
| 56 |
+
|
| 57 |
+
terminators = [
|
| 58 |
+
tokenizer.eos_token_id,
|
| 59 |
+
tokenizer.convert_tokens_to_ids("<|eot_id|>")
|
| 60 |
+
]
|
| 61 |
+
|
| 62 |
+
@spaces.GPU(duration=120)
|
| 63 |
+
def chat_llama3_8b(message: str,
|
| 64 |
+
history: list,
|
| 65 |
+
temperature: float,
|
| 66 |
+
max_new_tokens: int
|
| 67 |
+
) -> str:
|
| 68 |
+
"""
|
| 69 |
+
Generate a streaming response using the llama3-8b model.
|
| 70 |
+
Args:
|
| 71 |
+
message (str): The input message.
|
| 72 |
+
history (list): The conversation history used by ChatInterface.
|
| 73 |
+
temperature (float): The temperature for generating the response.
|
| 74 |
+
max_new_tokens (int): The maximum number of new tokens to generate.
|
| 75 |
+
Returns:
|
| 76 |
+
str: The generated response.
|
| 77 |
+
"""
|
| 78 |
+
conversation = []
|
| 79 |
+
for user, assistant in history:
|
| 80 |
+
conversation.extend([{"role": "user", "content": user}, {"role": "assistant", "content": assistant}])
|
| 81 |
+
conversation.append({"role": "user", "content": message})
|
| 82 |
+
|
| 83 |
+
input_ids = tokenizer.apply_chat_template(conversation, return_tensors="pt").to(model.device)
|
| 84 |
+
|
| 85 |
+
streamer = TextIteratorStreamer(tokenizer, timeout=10.0, skip_prompt=True, skip_special_tokens=True)
|
| 86 |
+
|
| 87 |
+
generate_kwargs = dict(
|
| 88 |
+
input_ids= input_ids,
|
| 89 |
+
streamer=streamer,
|
| 90 |
+
max_new_tokens=max_new_tokens,
|
| 91 |
+
do_sample=True,
|
| 92 |
+
temperature=temperature,
|
| 93 |
+
eos_token_id=terminators,
|
| 94 |
+
)
|
| 95 |
+
# This will enforce greedy generation (do_sample=False) when the temperature is passed 0, avoiding the crash.
|
| 96 |
+
if temperature == 0:
|
| 97 |
+
generate_kwargs['do_sample'] = False
|
| 98 |
+
|
| 99 |
+
t = Thread(target=model.generate, kwargs=generate_kwargs)
|
| 100 |
+
t.start()
|
| 101 |
+
|
| 102 |
+
outputs = []
|
| 103 |
+
for text in streamer:
|
| 104 |
+
outputs.append(text)
|
| 105 |
+
#print(outputs)
|
| 106 |
+
yield "".join(outputs)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
# Gradio block
|
| 110 |
+
chatbot=gr.Chatbot(height=450, placeholder=PLACEHOLDER, label='Gradio ChatInterface')
|
| 111 |
+
|
| 112 |
+
with gr.Blocks(fill_height=True, css=css) as demo:
|
| 113 |
+
|
| 114 |
+
gr.Markdown(DESCRIPTION)
|
| 115 |
+
gr.DuplicateButton(value="Duplicate Space for private use", elem_id="duplicate-button")
|
| 116 |
+
gr.ChatInterface(
|
| 117 |
+
fn=chat_llama3_8b,
|
| 118 |
+
chatbot=chatbot,
|
| 119 |
+
fill_height=True,
|
| 120 |
+
additional_inputs_accordion=gr.Accordion(label="⚙️ Parameters", open=False, render=False),
|
| 121 |
+
additional_inputs=[
|
| 122 |
+
gr.Slider(minimum=0,
|
| 123 |
+
maximum=1,
|
| 124 |
+
step=0.1,
|
| 125 |
+
value=0.95,
|
| 126 |
+
label="Temperature",
|
| 127 |
+
render=False),
|
| 128 |
+
gr.Slider(minimum=128,
|
| 129 |
+
maximum=4096,
|
| 130 |
+
step=1,
|
| 131 |
+
value=512,
|
| 132 |
+
label="Max new tokens",
|
| 133 |
+
render=False ),
|
| 134 |
+
],
|
| 135 |
+
examples=[
|
| 136 |
+
['How to setup a human base on Mars? Give short answer.'],
|
| 137 |
+
['Explain theory of relativity to me like I’m 8 years old.'],
|
| 138 |
+
['What is 9,000 * 9,000?'],
|
| 139 |
+
['Write a pun-filled happy birthday message to my friend Alex.'],
|
| 140 |
+
['Justify why a penguin might make a good king of the jungle.']
|
| 141 |
+
],
|
| 142 |
+
cache_examples=False,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
gr.Markdown(LICENSE)
|
| 146 |
+
|
| 147 |
+
if __name__ == "__main__":
|
| 148 |
+
demo.launch()
|
images/MInference1_onepage.png
ADDED
|
images/MInference_logo.png
ADDED
|
|
images/benchmarks/needle_viz_LLaMA-3-8B-1M_ours_1K_1000K.png
ADDED
|
images/benchmarks/ppl-LLaMA-3-262k.png
ADDED
|
minference/__init__.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Microsoft
|
| 2 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 3 |
+
# flake8: noqa
|
| 4 |
+
from .minference_configuration import MInferenceConfig
|
| 5 |
+
from .models_patch import MInference
|
| 6 |
+
from .ops.block_sparse_flash_attention import block_sparse_attention
|
| 7 |
+
from .ops.pit_sparse_flash_attention_v2 import vertical_slash_sparse_attention
|
| 8 |
+
from .ops.streaming_kernel import streaming_forward
|
| 9 |
+
from .patch import (
|
| 10 |
+
minference_patch,
|
| 11 |
+
minference_patch_kv_cache_cpu,
|
| 12 |
+
minference_patch_with_snapkv,
|
| 13 |
+
patch_hf,
|
| 14 |
+
)
|
| 15 |
+
from .version import VERSION as __version__
|
| 16 |
+
|
| 17 |
+
__all__ = [
|
| 18 |
+
"MInference",
|
| 19 |
+
"MInferenceConfig",
|
| 20 |
+
"minference_patch",
|
| 21 |
+
"minference_patch_kv_cache_cpu",
|
| 22 |
+
"minference_patch_with_snapkv",
|
| 23 |
+
"patch_hf",
|
| 24 |
+
"vertical_slash_sparse_attention",
|
| 25 |
+
"block_sparse_attention",
|
| 26 |
+
"streaming_forward",
|
| 27 |
+
]
|
minference/configs/Llama_3_8B_Instruct_262k_kv_out_v32_fit_o_best_pattern.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
[{"0": ["vertical_and_slash", 1000, 6096, 336], "1": ["vertical_and_slash", 1000, 6096, 26473], "2": ["vertical_and_slash", 1000, 6096, 0], "3": ["vertical_and_slash", 1000, 6096, 26958], "4": ["vertical_and_slash", 1000, 6096, 18905], "5": ["vertical_and_slash", 1000, 6096, 27990], "6": ["vertical_and_slash", 1000, 6096, 15162], "7": ["vertical_and_slash", 1000, 6096, 10529], "8": ["vertical_and_slash", 1000, 6096, 2], "9": ["vertical_and_slash", 1000, 6096, 828], "10": ["vertical_and_slash", 1000, 6096, 11405], "11": ["vertical_and_slash", 1000, 6096, 0], "12": ["vertical_and_slash", 1000, 6096, 55], "13": ["vertical_and_slash", 1000, 6096, 1], "14": ["vertical_and_slash", 1000, 6096, 0], "15": ["vertical_and_slash", 1000, 6096, 7021], "16": ["vertical_and_slash", 30, 800, 185169], "17": ["vertical_and_slash", 30, 800, 72929], "18": ["vertical_and_slash", 30, 800, 460008], "19": ["vertical_and_slash", 1000, 6096, 0], "20": ["vertical_and_slash", 1000, 6096, 71729], "21": ["vertical_and_slash", 1000, 6096, 52], "22": ["vertical_and_slash", 1000, 6096, 636], "23": ["vertical_and_slash", 1000, 6096, 75020], "24": ["vertical_and_slash", 1000, 6096, 23545], "25": ["vertical_and_slash", 1000, 6096, 90256], "26": ["vertical_and_slash", 1000, 6096, 45294], "27": ["vertical_and_slash", 1000, 6096, 32617], "28": ["vertical_and_slash", 3500, 100, 4777248], "29": ["vertical_and_slash", 3500, 100, 3996], "30": ["vertical_and_slash", 3500, 100, 590252], "31": ["vertical_and_slash", 3500, 100, 0]}, {"0": ["vertical_and_slash", 30, 800, 11048], "1": ["vertical_and_slash", 30, 800, 99768], "2": ["vertical_and_slash", 1000, 6096, 1393328], "3": ["vertical_and_slash", 30, 800, 97570], "4": ["vertical_and_slash", 30, 800, 9], "5": ["vertical_and_slash", 30, 800, 18], "6": ["vertical_and_slash", 30, 800, 216277], "7": ["vertical_and_slash", 30, 800, 148491], "8": ["vertical_and_slash", 100, 800, 543785], "9": ["vertical_and_slash", 1000, 6096, 2343829], "10": ["vertical_and_slash", 100, 800, 251542], "11": ["vertical_and_slash", 30, 800, 1064367], "12": ["vertical_and_slash", 1000, 6096, 6092], "13": ["vertical_and_slash", 30, 800, 12654], "14": ["vertical_and_slash", 1000, 6096, 0], "15": ["vertical_and_slash", 1000, 6096, 101], "16": ["vertical_and_slash", 30, 800, 21873], "17": ["vertical_and_slash", 30, 800, 107039], "18": ["vertical_and_slash", 30, 800, 9011], "19": ["vertical_and_slash", 30, 800, 445736], "20": ["vertical_and_slash", 30, 800, 1906], "21": ["vertical_and_slash", 30, 800, 3058], "22": ["vertical_and_slash", 1000, 6096, 430742], "23": ["vertical_and_slash", 1000, 6096, 181839], "24": ["vertical_and_slash", 30, 800, 125666], "25": ["vertical_and_slash", 30, 800, 704271], "26": ["vertical_and_slash", 30, 800, 14405], "27": ["vertical_and_slash", 30, 800, 70563], "28": ["vertical_and_slash", 1000, 6096, 38630], "29": ["vertical_and_slash", 1000, 6096, 68041], "30": ["vertical_and_slash", 30, 800, 6942], "31": ["vertical_and_slash", 1000, 6096, 35430]}, {"0": ["vertical_and_slash", 30, 800, 2720], "1": ["vertical_and_slash", 1000, 6096, 3045], "2": ["vertical_and_slash", 30, 800, 785], "3": ["vertical_and_slash", 1000, 6096, 14146], "4": ["vertical_and_slash", 100, 800, 315229], "5": ["vertical_and_slash", 1000, 6096, 195280], "6": ["vertical_and_slash", 1000, 6096, 1640055], "7": ["vertical_and_slash", 30, 800, 21026], "8": ["vertical_and_slash", 30, 800, 1082], "9": ["vertical_and_slash", 30, 800, 1851], "10": ["vertical_and_slash", 100, 800, 97766], "11": ["vertical_and_slash", 30, 800, 14401], "12": ["vertical_and_slash", 100, 800, 55741], "13": ["vertical_and_slash", 30, 800, 100674], "14": ["vertical_and_slash", 100, 800, 5597503], "15": ["vertical_and_slash", 1000, 6096, 437796], "16": ["vertical_and_slash", 30, 800, 9647], "17": ["vertical_and_slash", 30, 800, 4590], "18": ["vertical_and_slash", 30, 800, 73], "19": ["vertical_and_slash", 1000, 6096, 823400], "20": ["vertical_and_slash", 1000, 6096, 464893], "21": ["vertical_and_slash", 1000, 6096, 406520], "22": ["vertical_and_slash", 1000, 6096, 49477], "23": ["vertical_and_slash", 30, 800, 25445], "24": ["vertical_and_slash", 30, 800, 172935], "25": ["vertical_and_slash", 30, 800, 125813], "26": ["vertical_and_slash", 30, 800, 35964], "27": ["vertical_and_slash", 30, 800, 64113], "28": ["vertical_and_slash", 30, 800, 8780], "29": ["vertical_and_slash", 30, 800, 7883], "30": ["vertical_and_slash", 30, 800, 3944], "31": ["vertical_and_slash", 30, 800, 1049]}, {"0": ["vertical_and_slash", 1000, 6096, 119045], "1": ["vertical_and_slash", 1000, 6096, 21633], "2": ["vertical_and_slash", 1000, 6096, 54], "3": ["vertical_and_slash", 1000, 6096, 756], "4": ["vertical_and_slash", 30, 800, 1524], "5": ["vertical_and_slash", 30, 800, 7576], "6": ["vertical_and_slash", 30, 800, 212024], "7": ["vertical_and_slash", 30, 800, 106253], "8": ["vertical_and_slash", 30, 800, 4801], "9": ["vertical_and_slash", 30, 800, 311445], "10": ["vertical_and_slash", 30, 800, 31540], "11": ["vertical_and_slash", 30, 800, 7706], "12": ["vertical_and_slash", 1000, 6096, 397], "13": ["vertical_and_slash", 1000, 6096, 40], "14": ["vertical_and_slash", 100, 800, 181], "15": ["vertical_and_slash", 1000, 6096, 15], "16": ["vertical_and_slash", 30, 800, 424080], "17": ["vertical_and_slash", 30, 800, 66114], "18": ["vertical_and_slash", 30, 800, 132526], "19": ["vertical_and_slash", 30, 800, 1478993], "20": ["vertical_and_slash", 1000, 6096, 655153], "21": ["vertical_and_slash", 1000, 6096, 117322], "22": ["vertical_and_slash", 1000, 6096, 572237], "23": ["vertical_and_slash", 1000, 6096, 688623], "24": ["vertical_and_slash", 1000, 6096, 294], "25": ["vertical_and_slash", 1000, 6096, 5035], "26": ["vertical_and_slash", 30, 800, 3874], "27": ["vertical_and_slash", 1000, 6096, 618117], "28": ["vertical_and_slash", 30, 800, 545357], "29": ["vertical_and_slash", 30, 800, 1746675], "30": ["vertical_and_slash", 30, 800, 612225], "31": ["vertical_and_slash", 100, 800, 232415]}, {"0": ["vertical_and_slash", 100, 800, 5379826], "1": ["vertical_and_slash", 100, 800, 4399425], "2": ["vertical_and_slash", 100, 800, 5842], "3": ["vertical_and_slash", 30, 800, 178263], "4": ["vertical_and_slash", 30, 800, 356], "5": ["vertical_and_slash", 30, 800, 2387916], "6": ["vertical_and_slash", 1000, 6096, 216595], "7": ["vertical_and_slash", 30, 800, 466], "8": ["vertical_and_slash", 1000, 6096, 832044], "9": ["vertical_and_slash", 1000, 6096, 59709], "10": ["vertical_and_slash", 1000, 6096, 1194089], "11": ["vertical_and_slash", 1000, 6096, 356408], "12": ["vertical_and_slash", 30, 800, 30528], "13": ["vertical_and_slash", 30, 800, 22217], "14": ["vertical_and_slash", 30, 800, 9162], "15": ["vertical_and_slash", 100, 800, 1641325], "16": ["vertical_and_slash", 1000, 6096, 489936], "17": ["vertical_and_slash", 30, 800, 58107], "18": ["vertical_and_slash", 1000, 6096, 8539], "19": ["vertical_and_slash", 1000, 6096, 508038], "20": ["vertical_and_slash", 100, 800, 2632857], "21": ["vertical_and_slash", 1000, 6096, 79517], "22": ["vertical_and_slash", 30, 800, 330362], "23": ["vertical_and_slash", 1000, 6096, 85961], "24": ["vertical_and_slash", 30, 800, 23942], "25": ["vertical_and_slash", 30, 800, 75337], "26": ["vertical_and_slash", 30, 800, 3544417], "27": ["vertical_and_slash", 30, 800, 146427], "28": ["vertical_and_slash", 1000, 6096, 10561], "29": ["vertical_and_slash", 100, 800, 8759352], "30": ["vertical_and_slash", 100, 800, 8425], "31": ["vertical_and_slash", 30, 800, 22]}, {"0": ["vertical_and_slash", 30, 800, 50473], "1": ["vertical_and_slash", 1000, 6096, 277369], "2": ["vertical_and_slash", 30, 800, 59349], "3": ["vertical_and_slash", 30, 800, 27256], "4": ["vertical_and_slash", 30, 800, 112822], "5": ["vertical_and_slash", 1000, 6096, 346887], "6": ["vertical_and_slash", 1000, 6096, 84774], "7": ["vertical_and_slash", 1000, 6096, 954773], "8": ["vertical_and_slash", 1000, 6096, 1210908], "9": ["vertical_and_slash", 1000, 6096, 1679398], "10": ["vertical_and_slash", 1000, 6096, 2474351], "11": ["vertical_and_slash", 1000, 6096, 80495], "12": ["vertical_and_slash", 30, 800, 56761], "13": ["vertical_and_slash", 30, 800, 27757], "14": ["vertical_and_slash", 30, 800, 8811], "15": ["vertical_and_slash", 30, 800, 31547], "16": ["vertical_and_slash", 100, 800, 93167], "17": ["vertical_and_slash", 1000, 6096, 1464896], "18": ["vertical_and_slash", 1000, 6096, 434459], "19": ["vertical_and_slash", 30, 800, 1654521], "20": ["vertical_and_slash", 1000, 6096, 414], "21": ["vertical_and_slash", 1000, 6096, 76207], "22": ["vertical_and_slash", 1000, 6096, 8583], "23": ["vertical_and_slash", 1000, 6096, 1471], "24": ["vertical_and_slash", 1000, 6096, 231656], "25": ["vertical_and_slash", 500, 700, 95889], "26": ["vertical_and_slash", 30, 800, 62035], "27": ["vertical_and_slash", 1000, 6096, 43859], "28": ["vertical_and_slash", 30, 800, 23458], "29": ["vertical_and_slash", 30, 800, 53092], "30": ["vertical_and_slash", 30, 800, 74240], "31": ["vertical_and_slash", 30, 800, 45214]}, {"0": ["vertical_and_slash", 30, 800, 507], "1": ["vertical_and_slash", 100, 800, 8490], "2": ["vertical_and_slash", 100, 800, 3952118], "3": ["vertical_and_slash", 100, 800, 2475164], "4": ["vertical_and_slash", 100, 800, 8038], "5": ["vertical_and_slash", 30, 800, 2620494], "6": ["vertical_and_slash", 1000, 6096, 57306], "7": ["vertical_and_slash", 30, 800, 18889], "8": ["vertical_and_slash", 30, 800, 14900], "9": ["vertical_and_slash", 30, 800, 310453], "10": ["vertical_and_slash", 30, 800, 5494], "11": ["vertical_and_slash", 30, 800, 16096], "12": ["vertical_and_slash", 30, 800, 45897], "13": ["vertical_and_slash", 30, 800, 120295], "14": ["vertical_and_slash", 30, 800, 1446587], "15": ["vertical_and_slash", 30, 800, 133562], "16": ["vertical_and_slash", 30, 800, 81561], "17": ["vertical_and_slash", 100, 800, 1091558], "18": ["vertical_and_slash", 30, 800, 1104027], "19": ["vertical_and_slash", 30, 800, 95228], "20": ["vertical_and_slash", 1000, 6096, 81766], "21": ["vertical_and_slash", 1000, 6096, 1604474], "22": ["vertical_and_slash", 30, 800, 1720847], "23": ["vertical_and_slash", 30, 800, 254367], "24": ["vertical_and_slash", 1000, 6096, 69837], "25": ["vertical_and_slash", 1000, 6096, 1346498], "26": ["vertical_and_slash", 1000, 6096, 251707], "27": ["vertical_and_slash", 1000, 6096, 21055], "28": ["vertical_and_slash", 100, 800, 1310349], "29": ["vertical_and_slash", 1000, 6096, 523], "30": ["vertical_and_slash", 100, 800, 5], "31": ["vertical_and_slash", 1000, 6096, 4114]}, {"0": ["vertical_and_slash", 30, 800, 2076100], "1": ["vertical_and_slash", 30, 800, 742482], "2": ["vertical_and_slash", 30, 800, 84396], "3": ["vertical_and_slash", 100, 800, 6621015], "4": ["vertical_and_slash", 30, 800, 269671], "5": ["vertical_and_slash", 30, 800, 142041], "6": ["vertical_and_slash", 1000, 6096, 2493869], "7": ["vertical_and_slash", 1000, 6096, 2460341], "8": ["vertical_and_slash", 30, 800, 352690], "9": ["vertical_and_slash", 30, 800, 134441], "10": ["vertical_and_slash", 1000, 6096, 112278], "11": ["vertical_and_slash", 30, 800, 62933], "12": ["vertical_and_slash", 30, 800, 150459], "13": ["vertical_and_slash", 1000, 6096, 120036], "14": ["vertical_and_slash", 100, 800, 433238], "15": ["vertical_and_slash", 100, 800, 2723047], "16": ["vertical_and_slash", 1000, 6096, 112925], "17": ["vertical_and_slash", 1000, 6096, 23380], "18": ["vertical_and_slash", 1000, 6096, 92620], "19": ["vertical_and_slash", 1000, 6096, 37993], "20": ["vertical_and_slash", 100, 800, 74928], "21": ["vertical_and_slash", 3500, 100, 14191655], "22": ["vertical_and_slash", 1000, 6096, 514675], "23": ["vertical_and_slash", 100, 800, 9577073], "24": ["vertical_and_slash", 100, 800, 531136], "25": ["vertical_and_slash", 1000, 6096, 30007], "26": ["vertical_and_slash", 1000, 6096, 170687], "27": ["vertical_and_slash", 30, 800, 540287], "28": ["vertical_and_slash", 30, 800, 1435852], "29": ["vertical_and_slash", 30, 800, 948060], "30": ["vertical_and_slash", 1000, 6096, 37219], "31": ["vertical_and_slash", 1000, 6096, 211641]}, {"0": ["vertical_and_slash", 1000, 6096, 582795], "1": ["vertical_and_slash", 1000, 6096, 6289238], "2": ["vertical_and_slash", 1000, 6096, 570805], "3": ["vertical_and_slash", 1000, 6096, 198493], "4": ["vertical_and_slash", 30, 800, 112215], "5": ["vertical_and_slash", 30, 800, 5387246], "6": ["vertical_and_slash", 30, 800, 754350], "7": ["vertical_and_slash", 1000, 6096, 164737], "8": ["vertical_and_slash", 1000, 6096, 8597099], "9": ["vertical_and_slash", 1000, 6096, 13891466], "10": ["vertical_and_slash", 100, 800, 12184646], "11": ["vertical_and_slash", 1000, 6096, 3397834], "12": ["vertical_and_slash", 1000, 6096, 274297], "13": ["vertical_and_slash", 30, 800, 505818], "14": ["vertical_and_slash", 1000, 6096, 382749], "15": ["vertical_and_slash", 1000, 6096, 53485], "16": ["vertical_and_slash", 1000, 6096, 63748], "17": ["vertical_and_slash", 1000, 6096, 743437], "18": ["vertical_and_slash", 1000, 6096, 884226], "19": ["vertical_and_slash", 1000, 6096, 32754], "20": ["vertical_and_slash", 30, 800, 154807], "21": ["vertical_and_slash", 30, 800, 515833], "22": ["vertical_and_slash", 30, 800, 379827], "23": ["vertical_and_slash", 30, 800, 5140670], "24": ["vertical_and_slash", 1000, 6096, 8857], "25": ["vertical_and_slash", 1000, 6096, 9739], "26": ["vertical_and_slash", 1000, 6096, 3362559], "27": ["vertical_and_slash", 1000, 6096, 3602170], "28": ["vertical_and_slash", 1000, 6096, 286758], "29": ["vertical_and_slash", 1000, 6096, 1091568], "30": ["vertical_and_slash", 1000, 6096, 464410], "31": ["vertical_and_slash", 1000, 6096, 9113238]}, {"0": ["vertical_and_slash", 1000, 6096, 4112309], "1": ["vertical_and_slash", 1000, 6096, 6237157], "2": ["vertical_and_slash", 1000, 6096, 12411496], "3": ["vertical_and_slash", 1000, 6096, 3333545], "4": ["vertical_and_slash", 1000, 6096, 1082199], "5": ["vertical_and_slash", 1000, 6096, 3624535], "6": ["vertical_and_slash", 1000, 6096, 85587], "7": ["vertical_and_slash", 1000, 6096, 5060732], "8": ["vertical_and_slash", 30, 800, 981020], "9": ["vertical_and_slash", 30, 800, 647089], "10": ["vertical_and_slash", 30, 800, 1168497], "11": ["vertical_and_slash", 30, 800, 241811], "12": ["vertical_and_slash", 1000, 6096, 14258787], "13": ["vertical_and_slash", 1000, 6096, 13881708], "14": ["vertical_and_slash", 100, 800, 9807781], "15": ["vertical_and_slash", 1000, 6096, 11824390], "16": ["vertical_and_slash", 1000, 6096, 382173], "17": ["vertical_and_slash", 1000, 6096, 682553], "18": ["vertical_and_slash", 1000, 6096, 228115], "19": ["vertical_and_slash", 1000, 6096, 730935], "20": ["vertical_and_slash", 1000, 6096, 10237660], "21": ["vertical_and_slash", 1000, 6096, 210229], "22": ["vertical_and_slash", 1000, 6096, 4883397], "23": ["vertical_and_slash", 1000, 6096, 569329], "24": ["vertical_and_slash", 100, 800, 4152], "25": ["vertical_and_slash", 1000, 6096, 235235], "26": ["vertical_and_slash", 100, 800, 22473], "27": ["vertical_and_slash", 3500, 100, 14276508], "28": ["vertical_and_slash", 1000, 6096, 2277550], "29": ["vertical_and_slash", 1000, 6096, 1821096], "30": ["vertical_and_slash", 30, 800, 1212061], "31": ["vertical_and_slash", 1000, 6096, 13192107]}, {"0": ["vertical_and_slash", 1000, 6096, 812453], "1": ["vertical_and_slash", 1000, 6096, 6634405], "2": ["vertical_and_slash", 1000, 6096, 6896128], "3": ["vertical_and_slash", 1000, 6096, 12539813], "4": ["vertical_and_slash", 1000, 6096, 90867], "5": ["vertical_and_slash", 1000, 6096, 592412], "6": ["vertical_and_slash", 1000, 6096, 1863965], "7": ["vertical_and_slash", 1000, 6096, 1412714], "8": ["vertical_and_slash", 100, 800, 4723238], "9": ["vertical_and_slash", 30, 800, 73268], "10": ["vertical_and_slash", 1000, 6096, 522198], "11": ["vertical_and_slash", 30, 800, 144456], "12": ["vertical_and_slash", 1000, 6096, 218571], "13": ["vertical_and_slash", 1000, 6096, 4766244], "14": ["vertical_and_slash", 1000, 6096, 519409], "15": ["vertical_and_slash", 100, 800, 257427], "16": ["vertical_and_slash", 30, 800, 913307], "17": ["vertical_and_slash", 1000, 6096, 272105], "18": ["vertical_and_slash", 1000, 6096, 10253560], "19": ["vertical_and_slash", 1000, 6096, 103219], "20": ["vertical_and_slash", 1000, 6096, 825917], "21": ["vertical_and_slash", 1000, 6096, 1573906], "22": ["vertical_and_slash", 1000, 6096, 1401963], "23": ["vertical_and_slash", 1000, 6096, 903562], "24": ["vertical_and_slash", 1000, 6096, 116448], "25": ["vertical_and_slash", 500, 700, 10497021], "26": ["vertical_and_slash", 1000, 6096, 1451038], "27": ["vertical_and_slash", 100, 800, 9129837], "28": ["vertical_and_slash", 1000, 6096, 6069558], "29": ["vertical_and_slash", 100, 800, 4906900], "30": ["vertical_and_slash", 100, 800, 1935350], "31": ["vertical_and_slash", 1000, 6096, 13438131]}, {"0": ["vertical_and_slash", 1000, 6096, 200475], "1": ["vertical_and_slash", 1000, 6096, 2525357], "2": ["vertical_and_slash", 1000, 6096, 1581552], "3": ["vertical_and_slash", 1000, 6096, 1585962], "4": ["vertical_and_slash", 100, 800, 2468769], "5": ["vertical_and_slash", 1000, 6096, 2284149], "6": ["vertical_and_slash", 1000, 6096, 3954975], "7": ["vertical_and_slash", 1000, 6096, 12242517], "8": ["vertical_and_slash", 1000, 6096, 407981], "9": ["vertical_and_slash", 1000, 6096, 387918], "10": ["vertical_and_slash", 30, 800, 494970], "11": ["vertical_and_slash", 1000, 6096, 237593], "12": ["vertical_and_slash", 1000, 6096, 13227100], "13": ["vertical_and_slash", 1000, 6096, 7150283], "14": ["vertical_and_slash", 1000, 6096, 1460829], "15": ["vertical_and_slash", 1000, 6096, 5830515], "16": ["vertical_and_slash", 30, 800, 321990], "17": ["vertical_and_slash", 500, 700, 412885], "18": ["vertical_and_slash", 30, 800, 7754087], "19": ["vertical_and_slash", 30, 800, 593222], "20": ["vertical_and_slash", 1000, 6096, 9430066], "21": ["vertical_and_slash", 1000, 6096, 11445545], "22": ["vertical_and_slash", 1000, 6096, 10096832], "23": ["vertical_and_slash", 1000, 6096, 11108827], "24": ["vertical_and_slash", 1000, 6096, 2040566], "25": ["vertical_and_slash", 1000, 6096, 1293645], "26": ["vertical_and_slash", 1000, 6096, 1681146], "27": ["vertical_and_slash", 1000, 6096, 1621078], "28": ["vertical_and_slash", 3500, 100, 14482863], "29": ["vertical_and_slash", 3500, 100, 14306340], "30": ["vertical_and_slash", 3500, 100, 14736032], "31": ["vertical_and_slash", 30, 800, 59474]}, {"0": ["vertical_and_slash", 30, 800, 2015977], "1": ["vertical_and_slash", 1000, 6096, 1851908], "2": ["vertical_and_slash", 500, 700, 3019045], "3": ["vertical_and_slash", 30, 800, 2275137], "4": ["vertical_and_slash", 1000, 6096, 111007], "5": ["vertical_and_slash", 1000, 6096, 74876], "6": ["vertical_and_slash", 1000, 6096, 291657], "7": ["vertical_and_slash", 1000, 6096, 72059], "8": ["vertical_and_slash", 100, 800, 4966732], "9": ["vertical_and_slash", 30, 800, 1227926], "10": ["vertical_and_slash", 1000, 6096, 817635], "11": ["vertical_and_slash", 100, 800, 1996081], "12": ["vertical_and_slash", 30, 800, 320794], "13": ["vertical_and_slash", 30, 800, 641018], "14": ["vertical_and_slash", 1000, 6096, 784584], "15": ["vertical_and_slash", 500, 700, 615730], "16": ["vertical_and_slash", 30, 800, 130637], "17": ["vertical_and_slash", 500, 700, 237719], "18": ["vertical_and_slash", 30, 800, 484009], "19": ["vertical_and_slash", 30, 800, 71667], "20": ["vertical_and_slash", 30, 800, 6034932], "21": ["vertical_and_slash", 30, 800, 279606], "22": ["vertical_and_slash", 30, 800, 273046], "23": ["vertical_and_slash", 500, 700, 5343396], "24": ["vertical_and_slash", 30, 800, 424419], "25": ["vertical_and_slash", 30, 800, 268585], "26": ["vertical_and_slash", 500, 700, 469509], "27": ["vertical_and_slash", 30, 800, 1150183], "28": ["vertical_and_slash", 30, 800, 567665], "29": ["vertical_and_slash", 30, 800, 689969], "30": ["vertical_and_slash", 30, 800, 3124447], "31": ["vertical_and_slash", 500, 700, 1311816]}, {"0": ["vertical_and_slash", 1000, 6096, 13054849], "1": ["vertical_and_slash", 1000, 6096, 11676492], "2": ["vertical_and_slash", 1000, 6096, 13662962], "3": ["vertical_and_slash", 1000, 6096, 13009510], "4": ["vertical_and_slash", 1000, 6096, 13228770], "5": ["vertical_and_slash", 1000, 6096, 13738897], "6": ["vertical_and_slash", 1000, 6096, 4327684], "7": ["vertical_and_slash", 100, 800, 1780647], "8": ["vertical_and_slash", 1000, 6096, 12984525], "9": ["vertical_and_slash", 1000, 6096, 10106452], "10": ["vertical_and_slash", 1000, 6096, 13121645], "11": ["vertical_and_slash", 1000, 6096, 7143877], "12": ["vertical_and_slash", 1000, 6096, 1302273], "13": ["vertical_and_slash", 1000, 6096, 12189960], "14": ["vertical_and_slash", 1000, 6096, 10369892], "15": ["vertical_and_slash", 1000, 6096, 6251432], "16": ["vertical_and_slash", 1000, 6096, 13767358], "17": ["vertical_and_slash", 1000, 6096, 14264179], "18": ["vertical_and_slash", 1000, 6096, 14027354], "19": ["vertical_and_slash", 1000, 6096, 12810299], "20": ["vertical_and_slash", 1000, 6096, 11500719], "21": ["vertical_and_slash", 1000, 6096, 8729013], "22": ["vertical_and_slash", 100, 800, 1386474], "23": ["vertical_and_slash", 1000, 6096, 8809015], "24": ["vertical_and_slash", 30, 800, 1192385], "25": ["vertical_and_slash", 100, 800, 6597145], "26": ["vertical_and_slash", 100, 800, 11801029], "27": ["vertical_and_slash", 1000, 6096, 981847], "28": ["vertical_and_slash", 1000, 6096, 3790181], "29": ["vertical_and_slash", 30, 800, 1641474], "30": ["vertical_and_slash", 1000, 6096, 4214917], "31": ["vertical_and_slash", 1000, 6096, 3423871]}, {"0": ["vertical_and_slash", 1000, 6096, 7281028], "1": ["vertical_and_slash", 1000, 6096, 6327889], "2": ["vertical_and_slash", 1000, 6096, 5161807], "3": ["vertical_and_slash", 1000, 6096, 6944365], "4": ["vertical_and_slash", 1000, 6096, 10798408], "5": ["vertical_and_slash", 1000, 6096, 11848526], "6": ["vertical_and_slash", 1000, 6096, 5023703], "7": ["vertical_and_slash", 1000, 6096, 6869756], "8": ["vertical_and_slash", 30, 800, 2070673], "9": ["vertical_and_slash", 30, 800, 2108039], "10": ["vertical_and_slash", 30, 800, 2478923], "11": ["vertical_and_slash", 30, 800, 1062019], "12": ["vertical_and_slash", 1000, 6096, 10483422], "13": ["vertical_and_slash", 1000, 6096, 13220734], "14": ["vertical_and_slash", 1000, 6096, 10864461], "15": ["vertical_and_slash", 1000, 6096, 10380263], "16": ["vertical_and_slash", 1000, 6096, 12606664], "17": ["vertical_and_slash", 1000, 6096, 12755695], "18": ["vertical_and_slash", 1000, 6096, 14481440], "19": ["vertical_and_slash", 1000, 6096, 12125755], "20": ["vertical_and_slash", 1000, 6096, 13727938], "21": ["vertical_and_slash", 100, 800, 9986525], "22": ["vertical_and_slash", 1000, 6096, 13802294], "23": ["vertical_and_slash", 1000, 6096, 8589854], "24": ["vertical_and_slash", 1000, 6096, 8696624], "25": ["vertical_and_slash", 1000, 6096, 6711141], "26": ["vertical_and_slash", 30, 800, 11407], "27": ["vertical_and_slash", 1000, 6096, 10286733], "28": ["vertical_and_slash", 100, 800, 14346519], "29": ["vertical_and_slash", 3500, 100, 14822370], "30": ["vertical_and_slash", 1000, 6096, 13996996], "31": ["vertical_and_slash", 3500, 100, 13837843]}, {"0": ["vertical_and_slash", 30, 800, 187826], "1": ["vertical_and_slash", 1000, 6096, 319682], "2": ["vertical_and_slash", 1000, 6096, 717971], "3": ["vertical_and_slash", 1000, 6096, 12248225], "4": ["vertical_and_slash", 30, 800, 2311494], "5": ["vertical_and_slash", 1000, 6096, 354949], "6": ["vertical_and_slash", 30, 800, 2723442], "7": ["vertical_and_slash", 30, 800, 217627], "8": ["vertical_and_slash", 500, 700, 1800505], "9": ["vertical_and_slash", 30, 800, 5395314], "10": ["vertical_and_slash", 30, 800, 10715415], "11": ["vertical_and_slash", 100, 800, 13267898], "12": ["vertical_and_slash", 30, 800, 282819], "13": ["vertical_and_slash", 1000, 6096, 8417130], "14": ["vertical_and_slash", 1000, 6096, 5380564], "15": ["vertical_and_slash", 1000, 6096, 9802765], "16": ["vertical_and_slash", 1000, 6096, 385044], "17": ["vertical_and_slash", 1000, 6096, 2048601], "18": ["vertical_and_slash", 1000, 6096, 2798283], "19": ["vertical_and_slash", 100, 800, 11985153], "20": ["vertical_and_slash", 1000, 6096, 9560488], "21": ["vertical_and_slash", 1000, 6096, 8719957], "22": ["vertical_and_slash", 1000, 6096, 10883722], "23": ["vertical_and_slash", 1000, 6096, 11184293], "24": ["vertical_and_slash", 1000, 6096, 5049287], "25": ["vertical_and_slash", 1000, 6096, 6119952], "26": ["vertical_and_slash", 1000, 6096, 11948638], "27": ["vertical_and_slash", 1000, 6096, 4654529], "28": ["vertical_and_slash", 1000, 6096, 269543], "29": ["vertical_and_slash", 1000, 6096, 1183543], "30": ["vertical_and_slash", 1000, 6096, 4018748], "31": ["vertical_and_slash", 30, 800, 208750]}, {"0": ["vertical_and_slash", 3500, 100, 14712977], "1": ["vertical_and_slash", 1000, 6096, 7977346], "2": ["vertical_and_slash", 100, 800, 12022826], "3": ["vertical_and_slash", 100, 800, 7525648], "4": ["vertical_and_slash", 500, 700, 627445], "5": ["vertical_and_slash", 1000, 6096, 1067661], "6": ["vertical_and_slash", 500, 700, 199111], "7": ["vertical_and_slash", 100, 800, 1462908], "8": ["vertical_and_slash", 1000, 6096, 12608289], "9": ["vertical_and_slash", 1000, 6096, 3815760], "10": ["vertical_and_slash", 100, 800, 5050623], "11": ["vertical_and_slash", 3500, 100, 6790875], "12": ["vertical_and_slash", 30, 800, 284918], "13": ["vertical_and_slash", 500, 700, 277887], "14": ["vertical_and_slash", 500, 700, 236664], "15": ["vertical_and_slash", 30, 800, 3582148], "16": ["vertical_and_slash", 100, 800, 13373963], "17": ["vertical_and_slash", 100, 800, 682950], "18": ["vertical_and_slash", 1000, 6096, 7136486], "19": ["vertical_and_slash", 1000, 6096, 13769505], "20": ["vertical_and_slash", 1000, 6096, 9883913], "21": ["vertical_and_slash", 1000, 6096, 10833503], "22": ["vertical_and_slash", 30, 800, 62940], "23": ["vertical_and_slash", 1000, 6096, 4652762], "24": ["vertical_and_slash", 1000, 6096, 5480379], "25": ["vertical_and_slash", 3500, 100, 14131887], "26": ["vertical_and_slash", 100, 800, 9221283], "27": ["vertical_and_slash", 1000, 6096, 4197162], "28": ["vertical_and_slash", 30, 800, 4438611], "29": ["vertical_and_slash", 30, 800, 354648], "30": ["vertical_and_slash", 30, 800, 7285775], "31": ["vertical_and_slash", 30, 800, 4392079]}, {"0": ["vertical_and_slash", 1000, 6096, 2131686], "1": ["vertical_and_slash", 1000, 6096, 3609919], "2": ["vertical_and_slash", 1000, 6096, 899481], "3": ["vertical_and_slash", 100, 800, 3219776], "4": ["vertical_and_slash", 3500, 100, 11460535], "5": ["vertical_and_slash", 1000, 6096, 154336], "6": ["vertical_and_slash", 3500, 100, 14438950], "7": ["vertical_and_slash", 100, 800, 6652113], "8": ["vertical_and_slash", 100, 800, 9133667], "9": ["vertical_and_slash", 100, 800, 8048731], "10": ["vertical_and_slash", 1000, 6096, 528931], "11": ["vertical_and_slash", 30, 800, 2635938], "12": ["vertical_and_slash", 30, 800, 8546455], "13": ["vertical_and_slash", 500, 700, 7229697], "14": ["vertical_and_slash", 1000, 6096, 32195], "15": ["vertical_and_slash", 1000, 6096, 230534], "16": ["vertical_and_slash", 100, 800, 2475909], "17": ["vertical_and_slash", 30, 800, 2484470], "18": ["vertical_and_slash", 100, 800, 8168145], "19": ["vertical_and_slash", 3500, 100, 6348588], "20": ["vertical_and_slash", 500, 700, 290337], "21": ["vertical_and_slash", 3500, 100, 12830116], "22": ["vertical_and_slash", 100, 800, 11406972], "23": ["vertical_and_slash", 1000, 6096, 9663426], "24": ["vertical_and_slash", 3500, 100, 14333500], "25": ["vertical_and_slash", 3500, 100, 14787732], "26": ["vertical_and_slash", 1000, 6096, 13209856], "27": ["vertical_and_slash", 100, 800, 14623240], "28": ["vertical_and_slash", 1000, 6096, 6321698], "29": ["vertical_and_slash", 1000, 6096, 10324255], "30": ["vertical_and_slash", 100, 800, 1338], "31": ["vertical_and_slash", 1000, 6096, 5182275]}, {"0": ["vertical_and_slash", 100, 800, 2653574], "1": ["vertical_and_slash", 1000, 6096, 156404], "2": ["vertical_and_slash", 1000, 6096, 3288754], "3": ["vertical_and_slash", 1000, 6096, 597358], "4": ["vertical_and_slash", 1000, 6096, 13162000], "5": ["vertical_and_slash", 100, 800, 3304599], "6": ["vertical_and_slash", 100, 800, 2334228], "7": ["vertical_and_slash", 30, 800, 151547], "8": ["vertical_and_slash", 1000, 6096, 8084555], "9": ["vertical_and_slash", 1000, 6096, 6986695], "10": ["vertical_and_slash", 30, 800, 1349542], "11": ["vertical_and_slash", 1000, 6096, 62139], "12": ["vertical_and_slash", 500, 700, 586215], "13": ["vertical_and_slash", 30, 800, 3339401], "14": ["vertical_and_slash", 500, 700, 9080591], "15": ["vertical_and_slash", 100, 800, 1860621], "16": ["vertical_and_slash", 1000, 6096, 11577402], "17": ["vertical_and_slash", 1000, 6096, 6483036], "18": ["vertical_and_slash", 1000, 6096, 10223119], "19": ["vertical_and_slash", 1000, 6096, 2516899], "20": ["vertical_and_slash", 100, 800, 14689692], "21": ["vertical_and_slash", 1000, 6096, 9574317], "22": ["vertical_and_slash", 1000, 6096, 14315469], "23": ["vertical_and_slash", 1000, 6096, 11084722], "24": ["vertical_and_slash", 30, 800, 5714332], "25": ["vertical_and_slash", 30, 800, 440501], "26": ["vertical_and_slash", 30, 800, 135011], "27": ["vertical_and_slash", 100, 800, 1143711], "28": ["vertical_and_slash", 1000, 6096, 10833817], "29": ["vertical_and_slash", 100, 800, 9389405], "30": ["vertical_and_slash", 1000, 6096, 7182171], "31": ["vertical_and_slash", 1000, 6096, 3116752]}, {"0": ["vertical_and_slash", 1000, 6096, 2272762], "1": ["vertical_and_slash", 100, 800, 9251901], "2": ["vertical_and_slash", 1000, 6096, 3172792], "3": ["vertical_and_slash", 1000, 6096, 11166637], "4": ["vertical_and_slash", 1000, 6096, 267179], "5": ["vertical_and_slash", 100, 800, 1956945], "6": ["vertical_and_slash", 1000, 6096, 431457], "7": ["vertical_and_slash", 100, 800, 215074], "8": ["vertical_and_slash", 30, 800, 160167], "9": ["vertical_and_slash", 1000, 6096, 13251530], "10": ["vertical_and_slash", 100, 800, 1045212], "11": ["vertical_and_slash", 1000, 6096, 7767754], "12": ["vertical_and_slash", 100, 800, 8430862], "13": ["vertical_and_slash", 100, 800, 12275346], "14": ["vertical_and_slash", 1000, 6096, 12967454], "15": ["vertical_and_slash", 1000, 6096, 776792], "16": ["vertical_and_slash", 30, 800, 4940981], "17": ["vertical_and_slash", 1000, 6096, 4687476], "18": ["vertical_and_slash", 30, 800, 3396568], "19": ["vertical_and_slash", 1000, 6096, 6330177], "20": ["vertical_and_slash", 100, 800, 10772100], "21": ["vertical_and_slash", 1000, 6096, 431927], "22": ["vertical_and_slash", 100, 800, 5368777], "23": ["vertical_and_slash", 100, 800, 11971880], "24": ["vertical_and_slash", 1000, 6096, 3355141], "25": ["vertical_and_slash", 30, 800, 7775685], "26": ["vertical_and_slash", 1000, 6096, 17862], "27": ["vertical_and_slash", 1000, 6096, 2368170], "28": ["vertical_and_slash", 1000, 6096, 887652], "29": ["vertical_and_slash", 1000, 6096, 342019], "30": ["vertical_and_slash", 1000, 6096, 2031], "31": ["vertical_and_slash", 100, 800, 851845]}, {"0": ["vertical_and_slash", 1000, 6096, 9577296], "1": ["vertical_and_slash", 1000, 6096, 6130994], "2": ["vertical_and_slash", 1000, 6096, 932158], "3": ["vertical_and_slash", 1000, 6096, 6193523], "4": ["vertical_and_slash", 30, 800, 4212495], "5": ["vertical_and_slash", 1000, 6096, 82539], "6": ["vertical_and_slash", 1000, 6096, 2033854], "7": ["vertical_and_slash", 100, 800, 973812], "8": ["vertical_and_slash", 1000, 6096, 96691], "9": ["vertical_and_slash", 1000, 6096, 7346123], "10": ["vertical_and_slash", 1000, 6096, 3425225], "11": ["vertical_and_slash", 1000, 6096, 5656378], "12": ["vertical_and_slash", 1000, 6096, 13585373], "13": ["vertical_and_slash", 3500, 100, 12228455], "14": ["vertical_and_slash", 100, 800, 14994473], "15": ["vertical_and_slash", 1000, 6096, 12825284], "16": ["vertical_and_slash", 1000, 6096, 8256], "17": ["vertical_and_slash", 1000, 6096, 287798], "18": ["vertical_and_slash", 1000, 6096, 3485339], "19": ["vertical_and_slash", 1000, 6096, 4049013], "20": ["vertical_and_slash", 1000, 6096, 10172329], "21": ["vertical_and_slash", 100, 800, 70376], "22": ["vertical_and_slash", 500, 700, 624964], "23": ["vertical_and_slash", 1000, 6096, 7478718], "24": ["vertical_and_slash", 1000, 6096, 11234418], "25": ["vertical_and_slash", 100, 800, 12774404], "26": ["vertical_and_slash", 1000, 6096, 10820183], "27": ["vertical_and_slash", 1000, 6096, 8669939], "28": ["vertical_and_slash", 100, 800, 46], "29": ["vertical_and_slash", 30, 800, 2478], "30": ["vertical_and_slash", 1000, 6096, 343890], "31": ["vertical_and_slash", 1000, 6096, 485618]}, {"0": ["vertical_and_slash", 1000, 6096, 2552], "1": ["vertical_and_slash", 1000, 6096, 3940587], "2": ["vertical_and_slash", 1000, 6096, 2070936], "3": ["vertical_and_slash", 1000, 6096, 232875], "4": ["vertical_and_slash", 30, 800, 751140], "5": ["vertical_and_slash", 100, 800, 231769], "6": ["vertical_and_slash", 30, 800, 2274515], "7": ["vertical_and_slash", 30, 800, 989564], "8": ["vertical_and_slash", 3500, 100, 14768346], "9": ["vertical_and_slash", 30, 800, 1208594], "10": ["vertical_and_slash", 30, 800, 1770328], "11": ["vertical_and_slash", 1000, 6096, 8752930], "12": ["vertical_and_slash", 3500, 100, 46312], "13": ["vertical_and_slash", 100, 800, 289542], "14": ["vertical_and_slash", 3500, 100, 306397], "15": ["vertical_and_slash", 3500, 100, 56350], "16": ["vertical_and_slash", 100, 800, 356204], "17": ["vertical_and_slash", 3500, 100, 1500240], "18": ["vertical_and_slash", 1000, 6096, 150152], "19": ["vertical_and_slash", 100, 800, 101799], "20": ["vertical_and_slash", 1000, 6096, 299393], "21": ["vertical_and_slash", 1000, 6096, 8627429], "22": ["vertical_and_slash", 1000, 6096, 3529325], "23": ["vertical_and_slash", 1000, 6096, 1448873], "24": ["vertical_and_slash", 1000, 6096, 1712901], "25": ["vertical_and_slash", 500, 700, 4048433], "26": ["vertical_and_slash", 1000, 6096, 3837844], "27": ["vertical_and_slash", 1000, 6096, 5399791], "28": ["vertical_and_slash", 1000, 6096, 5525857], "29": ["vertical_and_slash", 1000, 6096, 4847570], "30": ["vertical_and_slash", 1000, 6096, 7521944], "31": ["vertical_and_slash", 1000, 6096, 6944849]}, {"0": ["vertical_and_slash", 3500, 100, 12061195], "1": ["vertical_and_slash", 3500, 100, 13821114], "2": ["vertical_and_slash", 1000, 6096, 11831232], "3": ["vertical_and_slash", 1000, 6096, 1990608], "4": ["vertical_and_slash", 1000, 6096, 1126789], "5": ["vertical_and_slash", 1000, 6096, 164058], "6": ["vertical_and_slash", 1000, 6096, 1546250], "7": ["vertical_and_slash", 3500, 100, 3197616], "8": ["vertical_and_slash", 1000, 6096, 4347461], "9": ["vertical_and_slash", 100, 800, 6182587], "10": ["vertical_and_slash", 100, 800, 344594], "11": ["vertical_and_slash", 100, 800, 4476113], "12": ["vertical_and_slash", 1000, 6096, 13461002], "13": ["vertical_and_slash", 1000, 6096, 10764088], "14": ["vertical_and_slash", 1000, 6096, 12256526], "15": ["vertical_and_slash", 1000, 6096, 13680456], "16": ["vertical_and_slash", 30, 800, 247807], "17": ["vertical_and_slash", 30, 800, 283870], "18": ["vertical_and_slash", 30, 800, 8225577], "19": ["vertical_and_slash", 30, 800, 448632], "20": ["vertical_and_slash", 1000, 6096, 4175564], "21": ["vertical_and_slash", 1000, 6096, 2726117], "22": ["vertical_and_slash", 1000, 6096, 310838], "23": ["vertical_and_slash", 1000, 6096, 204919], "24": ["vertical_and_slash", 30, 800, 875524], "25": ["vertical_and_slash", 30, 800, 1182277], "26": ["vertical_and_slash", 30, 800, 4252580], "27": ["vertical_and_slash", 100, 800, 728402], "28": ["vertical_and_slash", 1000, 6096, 12755775], "29": ["vertical_and_slash", 1000, 6096, 13455097], "30": ["vertical_and_slash", 100, 800, 10492805], "31": ["vertical_and_slash", 3500, 100, 11957996]}, {"0": ["vertical_and_slash", 500, 700, 386640], "1": ["vertical_and_slash", 100, 800, 819517], "2": ["vertical_and_slash", 30, 800, 1170984], "3": ["vertical_and_slash", 100, 800, 626489], "4": ["vertical_and_slash", 1000, 6096, 5856605], "5": ["vertical_and_slash", 1000, 6096, 12960788], "6": ["vertical_and_slash", 1000, 6096, 13042017], "7": ["vertical_and_slash", 1000, 6096, 12542120], "8": ["vertical_and_slash", 1000, 6096, 24167], "9": ["vertical_and_slash", 100, 800, 440430], "10": ["vertical_and_slash", 3500, 100, 748759], "11": ["vertical_and_slash", 1000, 6096, 4655], "12": ["vertical_and_slash", 1000, 6096, 10739360], "13": ["vertical_and_slash", 1000, 6096, 9336615], "14": ["vertical_and_slash", 3500, 100, 14305575], "15": ["vertical_and_slash", 3500, 100, 13833292], "16": ["vertical_and_slash", 30, 800, 3412], "17": ["vertical_and_slash", 500, 700, 16614], "18": ["vertical_and_slash", 1000, 6096, 839930], "19": ["vertical_and_slash", 500, 700, 77296], "20": ["vertical_and_slash", 1000, 6096, 11148082], "21": ["vertical_and_slash", 100, 800, 2483383], "22": ["vertical_and_slash", 3500, 100, 11902907], "23": ["vertical_and_slash", 100, 800, 2194], "24": ["vertical_and_slash", 1000, 6096, 4441496], "25": ["vertical_and_slash", 3500, 100, 10827107], "26": ["vertical_and_slash", 100, 800, 105753], "27": ["vertical_and_slash", 1000, 6096, 5261357], "28": ["vertical_and_slash", 30, 800, 61603], "29": ["vertical_and_slash", 30, 800, 108480], "30": ["vertical_and_slash", 30, 800, 30219], "31": ["vertical_and_slash", 30, 800, 31426]}, {"0": ["vertical_and_slash", 1000, 6096, 136760], "1": ["vertical_and_slash", 100, 800, 827733], "2": ["vertical_and_slash", 100, 800, 670059], "3": ["vertical_and_slash", 3500, 100, 502020], "4": ["vertical_and_slash", 100, 800, 469444], "5": ["vertical_and_slash", 100, 800, 162670], "6": ["vertical_and_slash", 1000, 6096, 22310], "7": ["vertical_and_slash", 1000, 6096, 465], "8": ["vertical_and_slash", 30, 800, 951054], "9": ["vertical_and_slash", 30, 800, 799102], "10": ["vertical_and_slash", 30, 800, 936020], "11": ["vertical_and_slash", 30, 800, 2027181], "12": ["vertical_and_slash", 3500, 100, 5986265], "13": ["vertical_and_slash", 500, 700, 3941412], "14": ["vertical_and_slash", 100, 800, 10557303], "15": ["vertical_and_slash", 100, 800, 1533916], "16": ["vertical_and_slash", 3500, 100, 11870953], "17": ["vertical_and_slash", 3500, 100, 12342581], "18": ["vertical_and_slash", 3500, 100, 12699180], "19": ["vertical_and_slash", 1000, 6096, 5138869], "20": ["vertical_and_slash", 1000, 6096, 12477033], "21": ["vertical_and_slash", 1000, 6096, 872144], "22": ["vertical_and_slash", 3500, 100, 13382501], "23": ["vertical_and_slash", 1000, 6096, 11531397], "24": ["vertical_and_slash", 1000, 6096, 13884364], "25": ["vertical_and_slash", 1000, 6096, 13611635], "26": ["vertical_and_slash", 1000, 6096, 13516676], "27": ["vertical_and_slash", 1000, 6096, 12560863], "28": ["vertical_and_slash", 500, 700, 3865996], "29": ["vertical_and_slash", 30, 800, 3343532], "30": ["vertical_and_slash", 30, 800, 179777], "31": ["vertical_and_slash", 3500, 100, 3863085]}, {"0": ["vertical_and_slash", 3500, 100, 6771823], "1": ["vertical_and_slash", 3500, 100, 10770780], "2": ["vertical_and_slash", 1000, 6096, 108476], "3": ["vertical_and_slash", 1000, 6096, 917033], "4": ["vertical_and_slash", 3500, 100, 9994951], "5": ["vertical_and_slash", 3500, 100, 13503132], "6": ["vertical_and_slash", 3500, 100, 11843766], "7": ["vertical_and_slash", 3500, 100, 10714999], "8": ["vertical_and_slash", 100, 800, 650037], "9": ["vertical_and_slash", 30, 800, 321924], "10": ["vertical_and_slash", 100, 800, 306681], "11": ["vertical_and_slash", 100, 800, 76181], "12": ["vertical_and_slash", 3500, 100, 12194592], "13": ["vertical_and_slash", 1000, 6096, 12635491], "14": ["vertical_and_slash", 3500, 100, 11953805], "15": ["vertical_and_slash", 3500, 100, 12355730], "16": ["vertical_and_slash", 100, 800, 614284], "17": ["vertical_and_slash", 100, 800, 512751], "18": ["vertical_and_slash", 3500, 100, 2679940], "19": ["vertical_and_slash", 100, 800, 1749683], "20": ["vertical_and_slash", 30, 800, 563622], "21": ["vertical_and_slash", 30, 800, 9985639], "22": ["vertical_and_slash", 30, 800, 1055029], "23": ["vertical_and_slash", 30, 800, 501782], "24": ["vertical_and_slash", 30, 800, 68229], "25": ["vertical_and_slash", 100, 800, 211743], "26": ["vertical_and_slash", 100, 800, 1690702], "27": ["vertical_and_slash", 30, 800, 2720080], "28": ["vertical_and_slash", 30, 800, 3884686], "29": ["vertical_and_slash", 30, 800, 3303748], "30": ["vertical_and_slash", 30, 800, 3335960], "31": ["vertical_and_slash", 30, 800, 2469116]}, {"0": ["vertical_and_slash", 1000, 6096, 726797], "1": ["vertical_and_slash", 100, 800, 5833160], "2": ["vertical_and_slash", 1000, 6096, 1766748], "3": ["vertical_and_slash", 1000, 6096, 6021028], "4": ["vertical_and_slash", 1000, 6096, 3120126], "5": ["vertical_and_slash", 30, 800, 3103142], "6": ["vertical_and_slash", 1000, 6096, 22974], "7": ["vertical_and_slash", 1000, 6096, 616209], "8": ["vertical_and_slash", 100, 800, 5571258], "9": ["vertical_and_slash", 30, 800, 2259315], "10": ["vertical_and_slash", 1000, 6096, 438342], "11": ["vertical_and_slash", 100, 800, 5557528], "12": ["vertical_and_slash", 3500, 100, 12954645], "13": ["vertical_and_slash", 1000, 6096, 12677660], "14": ["vertical_and_slash", 3500, 100, 13038925], "15": ["vertical_and_slash", 1000, 6096, 11239328], "16": ["vertical_and_slash", 3500, 100, 5247646], "17": ["vertical_and_slash", 500, 700, 384866], "18": ["vertical_and_slash", 1000, 6096, 655131], "19": ["vertical_and_slash", 3500, 100, 8826025], "20": ["vertical_and_slash", 100, 800, 4478606], "21": ["vertical_and_slash", 100, 800, 3881052], "22": ["vertical_and_slash", 100, 800, 6027887], "23": ["vertical_and_slash", 3500, 100, 8475077], "24": ["vertical_and_slash", 1000, 6096, 103633], "25": ["vertical_and_slash", 1000, 6096, 76484], "26": ["vertical_and_slash", 100, 800, 22432], "27": ["vertical_and_slash", 1000, 6096, 1313063], "28": ["vertical_and_slash", 1000, 6096, 6617078], "29": ["vertical_and_slash", 3500, 100, 12355842], "30": ["vertical_and_slash", 100, 800, 1401085], "31": ["vertical_and_slash", 3500, 100, 11350169]}, {"0": ["vertical_and_slash", 100, 800, 142456], "1": ["vertical_and_slash", 500, 700, 290481], "2": ["vertical_and_slash", 30, 800, 195338], "3": ["vertical_and_slash", 30, 800, 235375], "4": ["vertical_and_slash", 3500, 100, 13220328], "5": ["vertical_and_slash", 1000, 6096, 13040738], "6": ["vertical_and_slash", 3500, 100, 14847993], "7": ["vertical_and_slash", 1000, 6096, 12236451], "8": ["vertical_and_slash", 30, 800, 1360565], "9": ["vertical_and_slash", 30, 800, 115757], "10": ["vertical_and_slash", 30, 800, 806615], "11": ["vertical_and_slash", 30, 800, 5655605], "12": ["vertical_and_slash", 1000, 6096, 803465], "13": ["vertical_and_slash", 1000, 6096, 7601845], "14": ["vertical_and_slash", 30, 800, 8869563], "15": ["vertical_and_slash", 100, 800, 9177143], "16": ["vertical_and_slash", 1000, 6096, 612999], "17": ["vertical_and_slash", 100, 800, 2657352], "18": ["vertical_and_slash", 1000, 6096, 297015], "19": ["vertical_and_slash", 1000, 6096, 309571], "20": ["vertical_and_slash", 1000, 6096, 13160644], "21": ["vertical_and_slash", 1000, 6096, 14006964], "22": ["vertical_and_slash", 3500, 100, 14287913], "23": ["vertical_and_slash", 3500, 100, 14586379], "24": ["vertical_and_slash", 1000, 6096, 12023244], "25": ["vertical_and_slash", 30, 800, 12092108], "26": ["vertical_and_slash", 500, 700, 6005169], "27": ["vertical_and_slash", 500, 700, 9574963], "28": ["vertical_and_slash", 1000, 6096, 1696021], "29": ["vertical_and_slash", 30, 800, 1516298], "30": ["vertical_and_slash", 1000, 6096, 2303483], "31": ["vertical_and_slash", 1000, 6096, 903636]}, {"0": ["vertical_and_slash", 3500, 100, 7496361], "1": ["vertical_and_slash", 30, 800, 571560], "2": ["vertical_and_slash", 100, 800, 3025676], "3": ["vertical_and_slash", 30, 800, 5167076], "4": ["vertical_and_slash", 30, 800, 501453], "5": ["vertical_and_slash", 30, 800, 342659], "6": ["vertical_and_slash", 30, 800, 2561588], "7": ["vertical_and_slash", 30, 800, 869660], "8": ["vertical_and_slash", 100, 800, 10740412], "9": ["vertical_and_slash", 30, 800, 87115], "10": ["vertical_and_slash", 3500, 100, 9800623], "11": ["vertical_and_slash", 30, 800, 9191448], "12": ["vertical_and_slash", 1000, 6096, 289817], "13": ["vertical_and_slash", 3500, 100, 9009480], "14": ["vertical_and_slash", 1000, 6096, 1799625], "15": ["vertical_and_slash", 1000, 6096, 4984031], "16": ["vertical_and_slash", 3500, 100, 3381538], "17": ["vertical_and_slash", 100, 800, 11456778], "18": ["vertical_and_slash", 3500, 100, 14316760], "19": ["vertical_and_slash", 100, 800, 5228661], "20": ["vertical_and_slash", 3500, 100, 5831971], "21": ["vertical_and_slash", 500, 700, 10184028], "22": ["vertical_and_slash", 30, 800, 578221], "23": ["vertical_and_slash", 3500, 100, 6213253], "24": ["vertical_and_slash", 1000, 6096, 6146366], "25": ["vertical_and_slash", 1000, 6096, 1477166], "26": ["vertical_and_slash", 30, 800, 318810], "27": ["vertical_and_slash", 1000, 6096, 8654738], "28": ["vertical_and_slash", 500, 700, 3294065], "29": ["vertical_and_slash", 100, 800, 8531992], "30": ["vertical_and_slash", 100, 800, 2564233], "31": ["vertical_and_slash", 100, 800, 113957]}, {"0": ["vertical_and_slash", 100, 800, 530019], "1": ["vertical_and_slash", 100, 800, 647580], "2": ["vertical_and_slash", 30, 800, 4990437], "3": ["vertical_and_slash", 30, 800, 317415], "4": ["vertical_and_slash", 100, 800, 365956], "5": ["vertical_and_slash", 100, 800, 1689094], "6": ["vertical_and_slash", 100, 800, 454281], "7": ["vertical_and_slash", 30, 800, 266331], "8": ["vertical_and_slash", 3500, 100, 3603593], "9": ["vertical_and_slash", 100, 800, 14614370], "10": ["vertical_and_slash", 1000, 6096, 5361097], "11": ["vertical_and_slash", 100, 800, 14371859], "12": ["vertical_and_slash", 30, 800, 1232558], "13": ["vertical_and_slash", 30, 800, 546028], "14": ["vertical_and_slash", 30, 800, 853313], "15": ["vertical_and_slash", 30, 800, 194933], "16": ["vertical_and_slash", 3500, 100, 14304381], "17": ["vertical_and_slash", 1000, 6096, 815541], "18": ["vertical_and_slash", 100, 800, 5138518], "19": ["vertical_and_slash", 3500, 100, 9565094], "20": ["vertical_and_slash", 1000, 6096, 2035169], "21": ["vertical_and_slash", 1000, 6096, 3375423], "22": ["vertical_and_slash", 1000, 6096, 3777615], "23": ["vertical_and_slash", 1000, 6096, 12354929], "24": ["vertical_and_slash", 30, 800, 1763576], "25": ["vertical_and_slash", 30, 800, 3727796], "26": ["vertical_and_slash", 30, 800, 2744406], "27": ["vertical_and_slash", 30, 800, 1997757], "28": ["vertical_and_slash", 1000, 6096, 12257], "29": ["vertical_and_slash", 1000, 6096, 1169443], "30": ["vertical_and_slash", 3500, 100, 5723144], "31": ["vertical_and_slash", 3500, 100, 5420298]}, {"0": ["vertical_and_slash", 1000, 6096, 2447512], "1": ["vertical_and_slash", 3500, 100, 10860908], "2": ["vertical_and_slash", 100, 800, 9108572], "3": ["vertical_and_slash", 3500, 100, 11624453], "4": ["vertical_and_slash", 100, 800, 6925192], "5": ["vertical_and_slash", 100, 800, 9369879], "6": ["vertical_and_slash", 3500, 100, 11865786], "7": ["vertical_and_slash", 30, 800, 9628595], "8": ["vertical_and_slash", 1000, 6096, 6302171], "9": ["vertical_and_slash", 3500, 100, 8455497], "10": ["vertical_and_slash", 30, 800, 6885122], "11": ["vertical_and_slash", 1000, 6096, 5076785], "12": ["vertical_and_slash", 1000, 6096, 12769698], "13": ["vertical_and_slash", 1000, 6096, 13513363], "14": ["vertical_and_slash", 1000, 6096, 14089388], "15": ["vertical_and_slash", 1000, 6096, 14501815], "16": ["vertical_and_slash", 1000, 6096, 1619566], "17": ["vertical_and_slash", 1000, 6096, 5031895], "18": ["vertical_and_slash", 1000, 6096, 3833561], "19": ["vertical_and_slash", 100, 800, 12325460], "20": ["vertical_and_slash", 1000, 6096, 320906], "21": ["vertical_and_slash", 3500, 100, 13924855], "22": ["vertical_and_slash", 100, 800, 10478874], "23": ["vertical_and_slash", 30, 800, 4410655], "24": ["vertical_and_slash", 3500, 100, 14767197], "25": ["vertical_and_slash", 1000, 6096, 4108672], "26": ["vertical_and_slash", 100, 800, 14797906], "27": ["vertical_and_slash", 3500, 100, 14643144], "28": ["vertical_and_slash", 100, 800, 10556268], "29": ["vertical_and_slash", 3500, 100, 14575250], "30": ["vertical_and_slash", 1000, 6096, 14076831], "31": ["vertical_and_slash", 1000, 6096, 10779010]}, {"0": ["vertical_and_slash", 30, 800, 4744885], "1": ["vertical_and_slash", 30, 800, 4794511], "2": ["vertical_and_slash", 30, 800, 9418373], "3": ["vertical_and_slash", 30, 800, 2291979], "4": ["vertical_and_slash", 30, 800, 10009392], "5": ["vertical_and_slash", 30, 800, 981769], "6": ["vertical_and_slash", 30, 800, 3395467], "7": ["vertical_and_slash", 100, 800, 5966942], "8": ["vertical_and_slash", 30, 800, 7092993], "9": ["vertical_and_slash", 30, 800, 2176489], "10": ["vertical_and_slash", 30, 800, 4330010], "11": ["vertical_and_slash", 1000, 6096, 2664159], "12": ["vertical_and_slash", 30, 800, 7282328], "13": ["vertical_and_slash", 30, 800, 14135136], "14": ["vertical_and_slash", 1000, 6096, 791118], "15": ["vertical_and_slash", 30, 800, 9266081], "16": ["vertical_and_slash", 3500, 100, 14422288], "17": ["vertical_and_slash", 3500, 100, 11457529], "18": ["vertical_and_slash", 30, 800, 4503306], "19": ["vertical_and_slash", 100, 800, 11937543], "20": ["vertical_and_slash", 3500, 100, 14538141], "21": ["vertical_and_slash", 3500, 100, 13564714], "22": ["vertical_and_slash", 100, 800, 9671640], "23": ["vertical_and_slash", 30, 800, 2841456], "24": ["vertical_and_slash", 30, 800, 1395156], "25": ["vertical_and_slash", 30, 800, 989026], "26": ["vertical_and_slash", 30, 800, 10617339], "27": ["vertical_and_slash", 30, 800, 8170836], "28": ["vertical_and_slash", 100, 800, 2032096], "29": ["vertical_and_slash", 3500, 100, 13931334], "30": ["vertical_and_slash", 3500, 100, 14790424], "31": ["vertical_and_slash", 1000, 6096, 4133248]}]
|
minference/configs/Phi_3_mini_128k_instruct_kv_out_v32_fit_o_best_pattern.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
[{"0": ["vertical_and_slash", 1000, 6096, 0.33349305391311646], "1": ["vertical_and_slash", 1000, 6096, 0.4378805160522461], "2": ["vertical_and_slash", 1000, 6096, 0.48282963037490845], "3": ["vertical_and_slash", 1000, 6096, 0.37695789337158203], "4": ["vertical_and_slash", 1000, 6096, 0.38924556970596313], "5": ["vertical_and_slash", 1000, 6096, 0.3510749340057373], "6": ["vertical_and_slash", 1000, 6096, 0.39886632561683655], "7": ["vertical_and_slash", 1000, 6096, 0.8939290046691895], "8": ["vertical_and_slash", 1000, 6096, 0.44007450342178345], "9": ["vertical_and_slash", 1000, 6096, 0.3897586464881897], "10": ["vertical_and_slash", 1000, 6096, 0.40355661511421204], "11": ["vertical_and_slash", 1000, 6096, 0.36381030082702637], "12": ["vertical_and_slash", 1000, 6096, 0.4459313154220581], "13": ["vertical_and_slash", 1000, 6096, 0.3341565728187561], "14": ["vertical_and_slash", 1000, 6096, 0.384276419878006], "15": ["vertical_and_slash", 1000, 6096, 0.34818336367607117], "16": ["vertical_and_slash", 1000, 6096, 0.3867861330509186], "17": ["vertical_and_slash", 1000, 6096, 0.3639705777168274], "18": ["vertical_and_slash", 1000, 6096, 0.3512721359729767], "19": ["vertical_and_slash", 1000, 6096, 0.4681489169597626], "20": ["vertical_and_slash", 1000, 6096, 0.4651115834712982], "21": ["vertical_and_slash", 1000, 6096, 0.3882596790790558], "22": ["vertical_and_slash", 1000, 6096, 0.47017091512680054], "23": ["vertical_and_slash", 1000, 6096, 0.8037586808204651], "24": ["vertical_and_slash", 1000, 6096, 0.3913174867630005], "25": ["vertical_and_slash", 1000, 6096, 0.5203016400337219], "26": ["vertical_and_slash", 1000, 6096, 0.47166702151298523], "27": ["vertical_and_slash", 1000, 6096, 0.760438084602356], "28": ["vertical_and_slash", 1000, 6096, 0.943070650100708], "29": ["vertical_and_slash", 1000, 6096, 0.4118039011955261], "30": ["vertical_and_slash", 1000, 6096, 0.6815055012702942], "31": ["vertical_and_slash", 1000, 6096, 0.6300445795059204]}, {"0": ["vertical_and_slash", 1000, 6096, 0.6439709663391113], "1": ["vertical_and_slash", 1000, 6096, 0.5207313895225525], "2": ["vertical_and_slash", 1000, 6096, 0.47401225566864014], "3": ["vertical_and_slash", 1000, 6096, 0.5988013744354248], "4": ["vertical_and_slash", 1000, 6096, 0.6021823287010193], "5": ["vertical_and_slash", 1000, 6096, 0.4162128269672394], "6": ["vertical_and_slash", 1000, 6096, 0.7858797311782837], "7": ["vertical_and_slash", 1000, 6096, 0.6350969672203064], "8": ["vertical_and_slash", 1000, 6096, 0.5817031860351562], "9": ["vertical_and_slash", 1000, 6096, 0.9291586875915527], "10": ["vertical_and_slash", 1000, 6096, 0.6078806519508362], "11": ["vertical_and_slash", 1000, 6096, 0.5813876986503601], "12": ["vertical_and_slash", 1000, 6096, 0.7652914524078369], "13": ["vertical_and_slash", 1000, 6096, 0.4502100944519043], "14": ["vertical_and_slash", 1000, 6096, 0.6180105209350586], "15": ["vertical_and_slash", 1000, 6096, 0.7175759673118591], "16": ["vertical_and_slash", 1000, 6096, 0.6323421597480774], "17": ["vertical_and_slash", 3500, 100, 0.479082852602005], "18": ["vertical_and_slash", 1000, 6096, 0.6011233329772949], "19": ["vertical_and_slash", 1000, 6096, 0.8908118605613708], "20": ["vertical_and_slash", 1000, 6096, 0.9255861639976501], "21": ["vertical_and_slash", 1000, 6096, 0.795491099357605], "22": ["vertical_and_slash", 1000, 6096, 0.5210989117622375], "23": ["vertical_and_slash", 1000, 6096, 0.5200297236442566], "24": ["vertical_and_slash", 1000, 6096, 0.5280771255493164], "25": ["vertical_and_slash", 1000, 6096, 0.7380014657974243], "26": ["vertical_and_slash", 1000, 6096, 0.9885807633399963], "27": ["vertical_and_slash", 30, 800, 0.8718840479850769], "28": ["vertical_and_slash", 1000, 6096, 0.6302862167358398], "29": ["vertical_and_slash", 1000, 6096, 0.5750876069068909], "30": ["vertical_and_slash", 1000, 6096, 0.45260417461395264], "31": ["vertical_and_slash", 1000, 6096, 0.6499432325363159]}, {"0": ["vertical_and_slash", 1000, 6096, 0.7977765798568726], "1": ["vertical_and_slash", 1000, 6096, 0.8083621859550476], "2": ["vertical_and_slash", 1000, 6096, 0.5935484170913696], "3": ["vertical_and_slash", 1000, 6096, 0.5435713529586792], "4": ["vertical_and_slash", 1000, 6096, 0.5687218904495239], "5": ["vertical_and_slash", 1000, 6096, 0.854501485824585], "6": ["vertical_and_slash", 1000, 6096, 0.6359673142433167], "7": ["vertical_and_slash", 1000, 6096, 0.5785433053970337], "8": ["vertical_and_slash", 1000, 6096, 0.8543683290481567], "9": ["vertical_and_slash", 1000, 6096, 0.762371838092804], "10": ["vertical_and_slash", 1000, 6096, 0.6970657706260681], "11": ["vertical_and_slash", 1000, 6096, 0.6844046115875244], "12": ["vertical_and_slash", 1000, 6096, 0.7364732623100281], "13": ["vertical_and_slash", 1000, 6096, 0.8335257172584534], "14": ["vertical_and_slash", 1000, 6096, 0.7734203934669495], "15": ["vertical_and_slash", 1000, 6096, 0.7341973185539246], "16": ["vertical_and_slash", 1000, 6096, 0.7554108500480652], "17": ["vertical_and_slash", 1000, 6096, 0.9054623246192932], "18": ["vertical_and_slash", 1000, 6096, 0.6300320029258728], "19": ["vertical_and_slash", 1000, 6096, 0.70512455701828], "20": ["vertical_and_slash", 1000, 6096, 0.6085258722305298], "21": ["vertical_and_slash", 1000, 6096, 0.6398192644119263], "22": ["vertical_and_slash", 1000, 6096, 0.5992570519447327], "23": ["vertical_and_slash", 1000, 6096, 0.7130728363990784], "24": ["vertical_and_slash", 1000, 6096, 0.8504863977432251], "25": ["vertical_and_slash", 1000, 6096, 0.5748745799064636], "26": ["vertical_and_slash", 1000, 6096, 0.7758736610412598], "27": ["vertical_and_slash", 1000, 6096, 0.5538337230682373], "28": ["vertical_and_slash", 1000, 6096, 0.7384650707244873], "29": ["vertical_and_slash", 1000, 6096, 0.6905707120895386], "30": ["vertical_and_slash", 1000, 6096, 0.6217074990272522], "31": ["vertical_and_slash", 1000, 6096, 0.9545422196388245]}, {"0": ["vertical_and_slash", 500, 700, 0.9924208521842957], "1": ["vertical_and_slash", 100, 750, 0.9987075924873352], "2": ["vertical_and_slash", 500, 700, 0.9915499687194824], "3": ["vertical_and_slash", 100, 750, 0.9940086007118225], "4": ["vertical_and_slash", 100, 750, 0.9947375655174255], "5": ["vertical_and_slash", 100, 750, 0.9920898675918579], "6": ["vertical_and_slash", 100, 750, 0.9960256218910217], "7": ["vertical_and_slash", 100, 750, 0.995691180229187], "8": ["vertical_and_slash", 100, 750, 0.9113738536834717], "9": ["vertical_and_slash", 100, 750, 0.9700976014137268], "10": ["vertical_and_slash", 3500, 100, 0.9520721435546875], "11": ["vertical_and_slash", 100, 750, 0.9561598300933838], "12": ["vertical_and_slash", 100, 750, 0.8256366848945618], "13": ["vertical_and_slash", 100, 750, 0.9905430674552917], "14": ["vertical_and_slash", 500, 700, 0.9822967648506165], "15": ["vertical_and_slash", 100, 750, 0.9880149960517883], "16": ["vertical_and_slash", 100, 750, 0.9570814967155457], "17": ["vertical_and_slash", 100, 750, 0.9678364396095276], "18": ["vertical_and_slash", 3500, 100, 0.9819864630699158], "19": ["vertical_and_slash", 100, 750, 0.9930639266967773], "20": ["vertical_and_slash", 3500, 100, 0.9928342700004578], "21": ["vertical_and_slash", 3500, 100, 0.9522428512573242], "22": ["vertical_and_slash", 100, 750, 0.9961853623390198], "23": ["vertical_and_slash", 100, 750, 0.9895046353340149], "24": ["vertical_and_slash", 100, 750, 0.9106875061988831], "25": ["vertical_and_slash", 100, 750, 0.9944272041320801], "26": ["vertical_and_slash", 100, 750, 0.9603897333145142], "27": ["vertical_and_slash", 100, 750, 0.9967218637466431], "28": ["vertical_and_slash", 100, 750, 0.9922856092453003], "29": ["vertical_and_slash", 100, 750, 0.9425711631774902], "30": ["vertical_and_slash", 1000, 6096, 0.6492345333099365], "31": ["vertical_and_slash", 500, 700, 0.957703709602356]}, {"0": ["vertical_and_slash", 100, 750, 0.9920511841773987], "1": ["vertical_and_slash", 3500, 100, 0.9784621000289917], "2": ["vertical_and_slash", 100, 750, 0.9945407509803772], "3": ["vertical_and_slash", 100, 750, 0.9613493084907532], "4": ["vertical_and_slash", 100, 750, 0.8482271432876587], "5": ["vertical_and_slash", 500, 700, 0.9943300485610962], "6": ["vertical_and_slash", 100, 750, 0.9810841083526611], "7": ["vertical_and_slash", 3500, 100, 0.9297769069671631], "8": ["vertical_and_slash", 100, 750, 0.8839191198348999], "9": ["vertical_and_slash", 100, 750, 0.9955653548240662], "10": ["vertical_and_slash", 100, 750, 0.9484658241271973], "11": ["vertical_and_slash", 100, 750, 0.994473397731781], "12": ["vertical_and_slash", 500, 700, 0.9420907497406006], "13": ["vertical_and_slash", 100, 750, 0.9161052107810974], "14": ["vertical_and_slash", 100, 750, 0.9645522832870483], "15": ["vertical_and_slash", 100, 750, 0.9875764846801758], "16": ["vertical_and_slash", 100, 750, 0.7891636490821838], "17": ["vertical_and_slash", 1000, 6096, 0.7788199186325073], "18": ["vertical_and_slash", 100, 750, 0.9488416910171509], "19": ["vertical_and_slash", 3500, 100, 0.9959850311279297], "20": ["vertical_and_slash", 100, 750, 0.9768155217170715], "21": ["vertical_and_slash", 100, 750, 0.995807945728302], "22": ["vertical_and_slash", 3500, 100, 0.8900895118713379], "23": ["vertical_and_slash", 100, 750, 0.9586788415908813], "24": ["vertical_and_slash", 100, 750, 0.9651024341583252], "25": ["vertical_and_slash", 3500, 100, 0.9384130239486694], "26": ["vertical_and_slash", 100, 750, 0.9855350255966187], "27": ["vertical_and_slash", 100, 750, 0.9657205939292908], "28": ["vertical_and_slash", 3500, 100, 0.9184022545814514], "29": ["vertical_and_slash", 100, 750, 0.866909384727478], "30": ["vertical_and_slash", 1000, 6096, 0.7826077342033386], "31": ["vertical_and_slash", 100, 750, 0.9975974559783936]}, {"0": ["vertical_and_slash", 100, 750, 0.9865456223487854], "1": ["vertical_and_slash", 100, 750, 0.9591361880302429], "2": ["vertical_and_slash", 100, 750, 0.9168012142181396], "3": ["vertical_and_slash", 500, 700, 0.9530511498451233], "4": ["vertical_and_slash", 1000, 6096, 0.8645423650741577], "5": ["vertical_and_slash", 500, 700, 0.9792267084121704], "6": ["vertical_and_slash", 100, 750, 0.9941954612731934], "7": ["vertical_and_slash", 100, 750, 0.960307776927948], "8": ["vertical_and_slash", 3500, 100, 0.9855586886405945], "9": ["vertical_and_slash", 100, 750, 0.9828901886940002], "10": ["vertical_and_slash", 100, 750, 0.8591288328170776], "11": ["vertical_and_slash", 100, 750, 0.917044460773468], "12": ["vertical_and_slash", 100, 750, 0.9849950075149536], "13": ["vertical_and_slash", 100, 750, 0.8859434723854065], "14": ["vertical_and_slash", 100, 750, 0.9971017241477966], "15": ["vertical_and_slash", 500, 700, 0.9620269536972046], "16": ["vertical_and_slash", 500, 700, 0.9597799181938171], "17": ["vertical_and_slash", 500, 700, 0.9934410452842712], "18": ["vertical_and_slash", 3500, 100, 0.9977172017097473], "19": ["vertical_and_slash", 500, 700, 0.9520473480224609], "20": ["vertical_and_slash", 3500, 100, 0.9906032085418701], "21": ["vertical_and_slash", 100, 750, 0.9745447635650635], "22": ["vertical_and_slash", 100, 750, 0.9957244396209717], "23": ["vertical_and_slash", 100, 750, 0.9829675555229187], "24": ["vertical_and_slash", 100, 750, 0.9565562009811401], "25": ["vertical_and_slash", 100, 750, 0.9823064804077148], "26": ["vertical_and_slash", 100, 750, 0.987698495388031], "27": ["vertical_and_slash", 1000, 6096, 0.8219541907310486], "28": ["vertical_and_slash", 1000, 6096, 0.7586351633071899], "29": ["vertical_and_slash", 100, 750, 0.9752539992332458], "30": ["vertical_and_slash", 100, 750, 0.9929803609848022], "31": ["vertical_and_slash", 100, 750, 0.9185792803764343]}, {"0": ["vertical_and_slash", 100, 750, 0.9146243333816528], "1": ["vertical_and_slash", 100, 750, 0.9178520441055298], "2": ["vertical_and_slash", 3500, 100, 0.9930599331855774], "3": ["vertical_and_slash", 100, 750, 0.9993709325790405], "4": ["vertical_and_slash", 500, 700, 0.9853806495666504], "5": ["vertical_and_slash", 100, 750, 0.9141497015953064], "6": ["vertical_and_slash", 100, 750, 0.992788553237915], "7": ["vertical_and_slash", 100, 750, 0.9772038459777832], "8": ["vertical_and_slash", 1000, 6096, 0.6869983673095703], "9": ["vertical_and_slash", 100, 750, 0.9871460795402527], "10": ["vertical_and_slash", 100, 750, 0.9741801619529724], "11": ["vertical_and_slash", 100, 750, 0.9956739544868469], "12": ["vertical_and_slash", 100, 750, 0.9555794596672058], "13": ["vertical_and_slash", 3500, 100, 0.8615856766700745], "14": ["vertical_and_slash", 3500, 100, 0.9012727737426758], "15": ["vertical_and_slash", 100, 750, 0.9786412715911865], "16": ["vertical_and_slash", 3500, 100, 0.7491975426673889], "17": ["vertical_and_slash", 100, 750, 0.9849361181259155], "18": ["vertical_and_slash", 3500, 100, 0.9097980856895447], "19": ["vertical_and_slash", 1000, 6096, 0.8621278405189514], "20": ["vertical_and_slash", 500, 700, 0.9943590760231018], "21": ["vertical_and_slash", 100, 750, 0.8645753264427185], "22": ["vertical_and_slash", 100, 750, 0.9920986294746399], "23": ["vertical_and_slash", 1000, 6096, 0.8657084703445435], "24": ["vertical_and_slash", 3500, 100, 0.9750965237617493], "25": ["vertical_and_slash", 3500, 100, 0.8507974147796631], "26": ["vertical_and_slash", 3500, 100, 0.9118348360061646], "27": ["vertical_and_slash", 3500, 100, 0.9703859090805054], "28": ["vertical_and_slash", 3500, 100, 0.9725451469421387], "29": ["vertical_and_slash", 1000, 6096, 0.7008982300758362], "30": ["vertical_and_slash", 1000, 6096, 0.838621199131012], "31": ["vertical_and_slash", 100, 750, 0.9929103255271912]}, {"0": ["vertical_and_slash", 1000, 6096, 0.7402030825614929], "1": ["vertical_and_slash", 1000, 6096, 0.8565414547920227], "2": ["vertical_and_slash", 100, 750, 0.9612839221954346], "3": ["vertical_and_slash", 1000, 6096, 0.9598837494850159], "4": ["vertical_and_slash", 1000, 6096, 0.7645464539527893], "5": ["vertical_and_slash", 100, 750, 0.9872377514839172], "6": ["vertical_and_slash", 1000, 6096, 0.7918620705604553], "7": ["vertical_and_slash", 500, 700, 0.9622856378555298], "8": ["vertical_and_slash", 100, 750, 0.8891160488128662], "9": ["vertical_and_slash", 500, 700, 0.9844319224357605], "10": ["vertical_and_slash", 500, 700, 0.9876360297203064], "11": ["vertical_and_slash", 500, 700, 0.9688720703125], "12": ["vertical_and_slash", 1000, 6096, 0.5671995878219604], "13": ["vertical_and_slash", 100, 750, 0.9620596170425415], "14": ["vertical_and_slash", 1000, 6096, 0.6478529572486877], "15": ["vertical_and_slash", 100, 750, 0.9807542562484741], "16": ["vertical_and_slash", 3500, 100, 0.9823787212371826], "17": ["vertical_and_slash", 100, 750, 0.8980384469032288], "18": ["vertical_and_slash", 1000, 6096, 0.8713955879211426], "19": ["vertical_and_slash", 100, 750, 0.9611169099807739], "20": ["vertical_and_slash", 100, 750, 0.9941024780273438], "21": ["vertical_and_slash", 100, 750, 0.9876882433891296], "22": ["vertical_and_slash", 3500, 100, 0.9474965333938599], "23": ["vertical_and_slash", 100, 750, 0.9415712952613831], "24": ["vertical_and_slash", 100, 750, 0.9960836172103882], "25": ["vertical_and_slash", 100, 750, 0.9898598194122314], "26": ["vertical_and_slash", 100, 750, 0.9720168113708496], "27": ["vertical_and_slash", 100, 750, 0.985356330871582], "28": ["vertical_and_slash", 3500, 100, 0.9795358180999756], "29": ["vertical_and_slash", 100, 750, 0.970496654510498], "30": ["vertical_and_slash", 3500, 100, 0.999195396900177], "31": ["vertical_and_slash", 100, 750, 0.9589951038360596]}, {"0": ["vertical_and_slash", 1000, 6096, 0.8079184889793396], "1": ["stream_llm", 100, 800, 0.96484375], "2": ["vertical_and_slash", 1000, 6096, 0.6607644557952881], "3": ["vertical_and_slash", 30, 800, 0.9899947047233582], "4": ["vertical_and_slash", 1000, 6096, 0.9565256237983704], "5": ["vertical_and_slash", 1000, 6096, 0.9755614995956421], "6": ["vertical_and_slash", 30, 800, 0.9720635414123535], "7": ["vertical_and_slash", 30, 800, 0.9191414713859558], "8": ["stream_llm", 100, 800, 0.9921875], "9": ["vertical_and_slash", 1000, 6096, 0.6984944939613342], "10": ["stream_llm", 100, 800, 0.97265625], "11": ["vertical_and_slash", 30, 800, 0.955635666847229], "12": ["vertical_and_slash", 1000, 6096, 0.9949175715446472], "13": ["vertical_and_slash", 30, 800, 0.9833577871322632], "14": ["vertical_and_slash", 1000, 6096, 0.612384021282196], "15": ["vertical_and_slash", 1000, 6096, 0.9294421076774597], "16": ["vertical_and_slash", 30, 800, 0.9978874921798706], "17": ["vertical_and_slash", 30, 800, 0.9265275001525879], "18": ["vertical_and_slash", 500, 700, 0.8441793322563171], "19": ["vertical_and_slash", 1000, 6096, 0.9973151087760925], "20": ["vertical_and_slash", 30, 800, 0.8883945941925049], "21": ["vertical_and_slash", 1000, 6096, 0.9890816807746887], "22": ["vertical_and_slash", 30, 800, 0.9924365282058716], "23": ["stream_llm", 100, 800, 0.98828125], "24": ["vertical_and_slash", 1000, 6096, 0.9733841419219971], "25": ["vertical_and_slash", 1000, 6096, 0.8846827149391174], "26": ["vertical_and_slash", 1000, 6096, 0.8909521698951721], "27": ["vertical_and_slash", 30, 800, 0.95379239320755], "28": ["vertical_and_slash", 30, 800, 0.989055871963501], "29": ["vertical_and_slash", 30, 800, 0.9804853796958923], "30": ["vertical_and_slash", 30, 800, 0.9921841621398926], "31": ["vertical_and_slash", 30, 800, 0.9727922677993774]}, {"0": ["stream_llm", 100, 800, 0.984375], "1": ["vertical_and_slash", 30, 800, 0.9801875352859497], "2": ["vertical_and_slash", 3500, 100, 0.9504685997962952], "3": ["vertical_and_slash", 500, 700, 0.5719053745269775], "4": ["vertical_and_slash", 30, 800, 0.9975548386573792], "5": ["vertical_and_slash", 30, 800, 0.9834421873092651], "6": ["vertical_and_slash", 500, 700, 0.876423180103302], "7": ["vertical_and_slash", 1000, 6096, 0.9761123657226562], "8": ["vertical_and_slash", 1000, 6096, 0.6793014407157898], "9": ["vertical_and_slash", 30, 800, 0.8573703765869141], "10": ["vertical_and_slash", 500, 700, 0.9037665128707886], "11": ["stream_llm", 100, 800, 0.94921875], "12": ["stream_llm", 100, 800, 0.59375], "13": ["vertical_and_slash", 30, 800, 0.9938877820968628], "14": ["vertical_and_slash", 30, 800, 0.9964749217033386], "15": ["stream_llm", 100, 800, 0.9765625], "16": ["vertical_and_slash", 500, 700, 0.9928801655769348], "17": ["stream_llm", 100, 800, 0.859375], "18": ["stream_llm", 100, 800, 0.93359375], "19": ["vertical_and_slash", 500, 700, 0.9897311329841614], "20": ["stream_llm", 100, 800, 0.96875], "21": ["stream_llm", 100, 800, 0.9296875], "22": ["vertical_and_slash", 1000, 6096, 0.49674782156944275], "23": ["vertical_and_slash", 1000, 6096, 0.5498730540275574], "24": ["vertical_and_slash", 1000, 6096, 0.6677294373512268], "25": ["vertical_and_slash", 30, 800, 0.8520674109458923], "26": ["vertical_and_slash", 30, 800, 0.9708148241043091], "27": ["vertical_and_slash", 1000, 6096, 0.9498739838600159], "28": ["vertical_and_slash", 30, 800, 0.9852201342582703], "29": ["vertical_and_slash", 30, 800, 0.9892252683639526], "30": ["vertical_and_slash", 30, 800, 0.9976245164871216], "31": ["stream_llm", 100, 800, 0.91796875]}, {"0": ["vertical_and_slash", 30, 800, 0.976232647895813], "1": ["vertical_and_slash", 1000, 6096, 0.850098729133606], "2": ["vertical_and_slash", 30, 800, 0.9943907260894775], "3": ["stream_llm", 100, 800, 0.984375], "4": ["vertical_and_slash", 1000, 6096, 0.9408355355262756], "5": ["stream_llm", 100, 800, 0.62109375], "6": ["vertical_and_slash", 30, 800, 0.9146958589553833], "7": ["stream_llm", 100, 800, 0.578125], "8": ["vertical_and_slash", 1000, 6096, 0.9866257905960083], "9": ["stream_llm", 100, 800, 0.8671875], "10": ["stream_llm", 100, 800, 0.98828125], "11": ["stream_llm", 100, 800, 0.80078125], "12": ["vertical_and_slash", 30, 800, 0.9795709252357483], "13": ["vertical_and_slash", 1000, 6096, 0.9181753396987915], "14": ["vertical_and_slash", 30, 800, 0.9088999032974243], "15": ["stream_llm", 100, 800, 1.0], "16": ["stream_llm", 100, 800, 0.93359375], "17": ["vertical_and_slash", 1000, 6096, 0.7872908115386963], "18": ["stream_llm", 100, 800, 0.96875], "19": ["vertical_and_slash", 30, 800, 0.9915726184844971], "20": ["vertical_and_slash", 30, 800, 0.9914611577987671], "21": ["stream_llm", 100, 800, 0.94921875], "22": ["stream_llm", 100, 800, 0.91796875], "23": ["vertical_and_slash", 3500, 100, 0.4178726077079773], "24": ["vertical_and_slash", 1000, 6096, 0.9209551811218262], "25": ["stream_llm", 100, 800, 0.953125], "26": ["vertical_and_slash", 1000, 6096, 0.8251335024833679], "27": ["vertical_and_slash", 1000, 6096, 0.7916073799133301], "28": ["stream_llm", 100, 800, 0.98046875], "29": ["vertical_and_slash", 30, 800, 0.9805914163589478], "30": ["vertical_and_slash", 30, 800, 0.9889715313911438], "31": ["vertical_and_slash", 30, 800, 0.7096468210220337]}, {"0": ["vertical_and_slash", 3500, 100, 0.9098867774009705], "1": ["vertical_and_slash", 1000, 6096, 0.9131186008453369], "2": ["vertical_and_slash", 1000, 6096, 0.6216369271278381], "3": ["vertical_and_slash", 3500, 100, 0.9781222939491272], "4": ["vertical_and_slash", 1000, 6096, 0.6995159983634949], "5": ["vertical_and_slash", 30, 800, 0.7733919620513916], "6": ["stream_llm", 100, 800, 0.8046875], "7": ["stream_llm", 100, 800, 0.9921875], "8": ["vertical_and_slash", 1000, 6096, 0.9208213686943054], "9": ["vertical_and_slash", 30, 800, 0.9892569780349731], "10": ["stream_llm", 100, 800, 0.65234375], "11": ["vertical_and_slash", 3500, 100, 0.8766616582870483], "12": ["stream_llm", 100, 800, 0.69140625], "13": ["vertical_and_slash", 30, 800, 0.9681114554405212], "14": ["vertical_and_slash", 30, 800, 0.954004168510437], "15": ["vertical_and_slash", 1000, 6096, 0.6683151721954346], "16": ["vertical_and_slash", 1000, 6096, 0.9404566287994385], "17": ["vertical_and_slash", 1000, 6096, 0.629856288433075], "18": ["vertical_and_slash", 500, 700, 0.9569997191429138], "19": ["vertical_and_slash", 1000, 6096, 0.9538705348968506], "20": ["stream_llm", 100, 800, 0.85546875], "21": ["vertical_and_slash", 1000, 6096, 0.8144884705543518], "22": ["vertical_and_slash", 30, 800, 0.95702064037323], "23": ["stream_llm", 100, 800, 0.99609375], "24": ["vertical_and_slash", 1000, 6096, 0.8552843928337097], "25": ["stream_llm", 100, 800, 0.93359375], "26": ["vertical_and_slash", 1000, 6096, 0.8885473012924194], "27": ["vertical_and_slash", 30, 800, 0.9034969210624695], "28": ["vertical_and_slash", 30, 800, 0.8834430575370789], "29": ["stream_llm", 100, 800, 0.59765625], "30": ["stream_llm", 100, 800, 0.98046875], "31": ["vertical_and_slash", 1000, 6096, 0.5801111459732056]}, {"0": ["vertical_and_slash", 1000, 6096, 0.9783773422241211], "1": ["vertical_and_slash", 1000, 6096, 0.9992927312850952], "2": ["vertical_and_slash", 30, 800, 0.9968302845954895], "3": ["vertical_and_slash", 3500, 100, 0.45828360319137573], "4": ["vertical_and_slash", 30, 800, 0.836064875125885], "5": ["vertical_and_slash", 1000, 6096, 0.8009666800498962], "6": ["vertical_and_slash", 3500, 100, 0.6518401503562927], "7": ["vertical_and_slash", 30, 800, 0.9921544790267944], "8": ["vertical_and_slash", 1000, 6096, 0.4855879545211792], "9": ["vertical_and_slash", 1000, 6096, 0.9904646277427673], "10": ["vertical_and_slash", 3500, 100, 0.8973155617713928], "11": ["vertical_and_slash", 1000, 6096, 0.8983845710754395], "12": ["stream_llm", 100, 800, 0.82421875], "13": ["vertical_and_slash", 1000, 6096, 0.8326148390769958], "14": ["vertical_and_slash", 1000, 6096, 0.44982603192329407], "15": ["vertical_and_slash", 30, 800, 0.9292823076248169], "16": ["stream_llm", 100, 800, 0.83203125], "17": ["vertical_and_slash", 500, 700, 0.8943775296211243], "18": ["vertical_and_slash", 3500, 100, 0.8824247121810913], "19": ["vertical_and_slash", 1000, 6096, 0.8916551470756531], "20": ["stream_llm", 100, 800, 0.84765625], "21": ["vertical_and_slash", 1000, 6096, 0.5656689405441284], "22": ["vertical_and_slash", 3500, 100, 0.9858580827713013], "23": ["vertical_and_slash", 3500, 100, 0.6534677743911743], "24": ["vertical_and_slash", 1000, 6096, 0.7796179056167603], "25": ["stream_llm", 100, 800, 0.984375], "26": ["stream_llm", 100, 800, 0.8125], "27": ["vertical_and_slash", 1000, 6096, 0.8051357269287109], "28": ["vertical_and_slash", 1000, 6096, 0.9759415984153748], "29": ["vertical_and_slash", 3500, 100, 0.9613996148109436], "30": ["vertical_and_slash", 30, 800, 0.9861305952072144], "31": ["vertical_and_slash", 1000, 6096, 0.5375377535820007]}, {"0": ["vertical_and_slash", 1000, 6096, 0.9526095390319824], "1": ["vertical_and_slash", 1000, 6096, 0.9219456315040588], "2": ["vertical_and_slash", 1000, 6096, 0.6329025626182556], "3": ["vertical_and_slash", 1000, 6096, 0.9703953862190247], "4": ["vertical_and_slash", 3500, 100, 0.9341285228729248], "5": ["stream_llm", 100, 800, 0.98828125], "6": ["vertical_and_slash", 3500, 100, 0.975139319896698], "7": ["vertical_and_slash", 30, 800, 0.9698626399040222], "8": ["vertical_and_slash", 1000, 6096, 0.8665440082550049], "9": ["vertical_and_slash", 1000, 6096, 0.9887139797210693], "10": ["vertical_and_slash", 1000, 6096, 0.9663894772529602], "11": ["vertical_and_slash", 500, 700, 0.9613908529281616], "12": ["vertical_and_slash", 1000, 6096, 0.9625579118728638], "13": ["vertical_and_slash", 3500, 100, 0.8293338418006897], "14": ["vertical_and_slash", 1000, 6096, 0.9918296933174133], "15": ["vertical_and_slash", 3500, 100, 0.6993081569671631], "16": ["vertical_and_slash", 1000, 6096, 0.7726790904998779], "17": ["vertical_and_slash", 30, 800, 0.9927448034286499], "18": ["vertical_and_slash", 3500, 100, 0.9216746091842651], "19": ["vertical_and_slash", 1000, 6096, 0.9197890758514404], "20": ["vertical_and_slash", 1000, 6096, 0.5418304800987244], "21": ["vertical_and_slash", 3500, 100, 0.7247577905654907], "22": ["vertical_and_slash", 1000, 6096, 0.8909022212028503], "23": ["vertical_and_slash", 3500, 100, 0.6162543892860413], "24": ["vertical_and_slash", 1000, 6096, 0.9798792600631714], "25": ["stream_llm", 100, 800, 0.9921875], "26": ["vertical_and_slash", 1000, 6096, 0.839588463306427], "27": ["stream_llm", 100, 800, 0.921875], "28": ["vertical_and_slash", 1000, 6096, 0.9863616228103638], "29": ["vertical_and_slash", 1000, 6096, 0.9895434975624084], "30": ["vertical_and_slash", 1000, 6096, 0.9338933825492859], "31": ["vertical_and_slash", 1000, 6096, 0.9152888655662537]}, {"0": ["vertical_and_slash", 100, 750, 0.7857484221458435], "1": ["vertical_and_slash", 3500, 100, 0.9863781332969666], "2": ["vertical_and_slash", 3500, 100, 0.9732434153556824], "3": ["vertical_and_slash", 1000, 6096, 0.7411113381385803], "4": ["vertical_and_slash", 1000, 6096, 0.9037321209907532], "5": ["vertical_and_slash", 1000, 6096, 0.7728227376937866], "6": ["vertical_and_slash", 3500, 100, 0.9566982388496399], "7": ["vertical_and_slash", 1000, 6096, 0.8955481648445129], "8": ["vertical_and_slash", 500, 700, 0.8905653357505798], "9": ["vertical_and_slash", 3500, 100, 0.9852890968322754], "10": ["vertical_and_slash", 1000, 6096, 0.5732011795043945], "11": ["vertical_and_slash", 3500, 100, 0.9701256155967712], "12": ["vertical_and_slash", 3500, 100, 0.8983554244041443], "13": ["vertical_and_slash", 100, 750, 0.9726784825325012], "14": ["vertical_and_slash", 3500, 100, 0.6008065938949585], "15": ["vertical_and_slash", 1000, 6096, 0.6582738161087036], "16": ["vertical_and_slash", 3500, 100, 0.9488815665245056], "17": ["vertical_and_slash", 100, 750, 0.9958171844482422], "18": ["vertical_and_slash", 3500, 100, 0.8186895847320557], "19": ["vertical_and_slash", 500, 700, 0.9635193347930908], "20": ["vertical_and_slash", 1000, 6096, 0.9248959422111511], "21": ["vertical_and_slash", 3500, 100, 0.9385164976119995], "22": ["vertical_and_slash", 100, 750, 0.9387568235397339], "23": ["vertical_and_slash", 1000, 6096, 0.8735635876655579], "24": ["vertical_and_slash", 500, 700, 0.890371561050415], "25": ["vertical_and_slash", 100, 750, 0.9905737638473511], "26": ["vertical_and_slash", 3500, 100, 0.946341335773468], "27": ["vertical_and_slash", 3500, 100, 0.942945659160614], "28": ["vertical_and_slash", 100, 750, 0.994683027267456], "29": ["vertical_and_slash", 500, 700, 0.9688966870307922], "30": ["vertical_and_slash", 1000, 6096, 0.9828435778617859], "31": ["vertical_and_slash", 1000, 6096, 0.8722150325775146]}, {"0": ["vertical_and_slash", 500, 700, 0.9728457927703857], "1": ["vertical_and_slash", 100, 750, 0.9586004018783569], "2": ["vertical_and_slash", 3500, 100, 0.9719207882881165], "3": ["vertical_and_slash", 3500, 100, 0.6680086851119995], "4": ["vertical_and_slash", 3500, 100, 0.970458984375], "5": ["vertical_and_slash", 3500, 100, 0.7634486556053162], "6": ["vertical_and_slash", 3500, 100, 0.7259127497673035], "7": ["vertical_and_slash", 100, 750, 0.9781140089035034], "8": ["vertical_and_slash", 3500, 100, 0.9952470064163208], "9": ["vertical_and_slash", 3500, 100, 0.9868772625923157], "10": ["vertical_and_slash", 3500, 100, 0.558458685874939], "11": ["vertical_and_slash", 1000, 6096, 0.7121242880821228], "12": ["vertical_and_slash", 1000, 6096, 0.7061645984649658], "13": ["vertical_and_slash", 3500, 100, 0.923751711845398], "14": ["vertical_and_slash", 1000, 6096, 0.8015576601028442], "15": ["vertical_and_slash", 500, 700, 0.9007270932197571], "16": ["vertical_and_slash", 3500, 100, 0.9591111540794373], "17": ["vertical_and_slash", 500, 700, 0.9750815033912659], "18": ["vertical_and_slash", 100, 750, 0.9805834293365479], "19": ["vertical_and_slash", 3500, 100, 0.8620939254760742], "20": ["vertical_and_slash", 3500, 100, 0.9881291389465332], "21": ["vertical_and_slash", 500, 700, 0.9975225925445557], "22": ["vertical_and_slash", 3500, 100, 0.9125117063522339], "23": ["vertical_and_slash", 3500, 100, 0.8796795010566711], "24": ["vertical_and_slash", 3500, 100, 0.9172841310501099], "25": ["vertical_and_slash", 1000, 6096, 0.8340160846710205], "26": ["vertical_and_slash", 1000, 6096, 0.8479950428009033], "27": ["vertical_and_slash", 3500, 100, 0.9778053164482117], "28": ["vertical_and_slash", 100, 750, 0.9912164211273193], "29": ["vertical_and_slash", 1000, 6096, 0.6634088754653931], "30": ["vertical_and_slash", 3500, 100, 0.9486925601959229], "31": ["vertical_and_slash", 3500, 100, 0.985546350479126]}, {"0": ["vertical_and_slash", 3500, 100, 0.7207826375961304], "1": ["vertical_and_slash", 1000, 6096, 0.7674809098243713], "2": ["vertical_and_slash", 1000, 6096, 0.5480814576148987], "3": ["vertical_and_slash", 3500, 100, 0.974454939365387], "4": ["vertical_and_slash", 100, 750, 0.9901475310325623], "5": ["vertical_and_slash", 3500, 100, 0.9111185073852539], "6": ["vertical_and_slash", 3500, 100, 0.8977652192115784], "7": ["vertical_and_slash", 500, 700, 0.8826637864112854], "8": ["vertical_and_slash", 3500, 100, 0.9674721956253052], "9": ["vertical_and_slash", 500, 700, 0.9511355757713318], "10": ["vertical_and_slash", 3500, 100, 0.9368802309036255], "11": ["vertical_and_slash", 3500, 100, 0.7037530541419983], "12": ["vertical_and_slash", 3500, 100, 0.8404982089996338], "13": ["vertical_and_slash", 3500, 100, 0.9477558732032776], "14": ["vertical_and_slash", 1000, 6096, 0.5408625602722168], "15": ["vertical_and_slash", 1000, 6096, 0.8930901288986206], "16": ["vertical_and_slash", 500, 700, 0.9620649814605713], "17": ["vertical_and_slash", 3500, 100, 0.9665637016296387], "18": ["vertical_and_slash", 3500, 100, 0.9973539710044861], "19": ["vertical_and_slash", 3500, 100, 0.9200847744941711], "20": ["vertical_and_slash", 100, 750, 0.9846996068954468], "21": ["vertical_and_slash", 3500, 100, 0.9522152543067932], "22": ["vertical_and_slash", 3500, 100, 0.9200462102890015], "23": ["vertical_and_slash", 3500, 100, 0.7189115285873413], "24": ["vertical_and_slash", 3500, 100, 0.9400286078453064], "25": ["vertical_and_slash", 3500, 100, 0.9140079617500305], "26": ["vertical_and_slash", 3500, 100, 0.9733141660690308], "27": ["vertical_and_slash", 3500, 100, 0.9182970523834229], "28": ["vertical_and_slash", 500, 700, 0.7845987677574158], "29": ["vertical_and_slash", 500, 700, 0.953305721282959], "30": ["vertical_and_slash", 1000, 6096, 0.9332642555236816], "31": ["vertical_and_slash", 500, 700, 0.8975687026977539]}, {"0": ["vertical_and_slash", 1000, 6096, 0.8796314001083374], "1": ["vertical_and_slash", 3500, 100, 0.9541191458702087], "2": ["vertical_and_slash", 3500, 100, 0.9853596091270447], "3": ["vertical_and_slash", 3500, 100, 0.9959757924079895], "4": ["vertical_and_slash", 500, 700, 0.942274272441864], "5": ["vertical_and_slash", 3500, 100, 0.9958774447441101], "6": ["vertical_and_slash", 3500, 100, 0.762219250202179], "7": ["vertical_and_slash", 3500, 100, 0.9778050780296326], "8": ["vertical_and_slash", 3500, 100, 0.9803900718688965], "9": ["vertical_and_slash", 3500, 100, 0.9493845701217651], "10": ["vertical_and_slash", 100, 750, 0.9833114147186279], "11": ["vertical_and_slash", 3500, 100, 0.9671387076377869], "12": ["vertical_and_slash", 3500, 100, 0.8459083437919617], "13": ["vertical_and_slash", 3500, 100, 0.9625062346458435], "14": ["vertical_and_slash", 3500, 100, 0.9926583766937256], "15": ["vertical_and_slash", 3500, 100, 0.9901418089866638], "16": ["vertical_and_slash", 3500, 100, 0.9975236058235168], "17": ["vertical_and_slash", 3500, 100, 0.8961046934127808], "18": ["vertical_and_slash", 3500, 100, 0.9677743315696716], "19": ["vertical_and_slash", 1000, 6096, 0.7324523329734802], "20": ["vertical_and_slash", 1000, 6096, 0.7565687298774719], "21": ["vertical_and_slash", 3500, 100, 0.9934558272361755], "22": ["vertical_and_slash", 1000, 6096, 0.695542573928833], "23": ["vertical_and_slash", 3500, 100, 0.9594518542289734], "24": ["vertical_and_slash", 3500, 100, 0.9845080375671387], "25": ["vertical_and_slash", 3500, 100, 0.9140312075614929], "26": ["vertical_and_slash", 3500, 100, 0.9816687107086182], "27": ["vertical_and_slash", 3500, 100, 0.9777555465698242], "28": ["vertical_and_slash", 3500, 100, 0.948824405670166], "29": ["vertical_and_slash", 3500, 100, 0.48502659797668457], "30": ["vertical_and_slash", 3500, 100, 0.9340038895606995], "31": ["vertical_and_slash", 3500, 100, 0.9162462949752808]}, {"0": ["vertical_and_slash", 3500, 100, 0.9923238754272461], "1": ["vertical_and_slash", 3500, 100, 0.9678853750228882], "2": ["vertical_and_slash", 100, 750, 0.9968323111534119], "3": ["vertical_and_slash", 500, 700, 0.9936473965644836], "4": ["vertical_and_slash", 3500, 100, 0.9588732123374939], "5": ["vertical_and_slash", 500, 700, 0.9791616797447205], "6": ["vertical_and_slash", 3500, 100, 0.919694721698761], "7": ["vertical_and_slash", 1000, 6096, 0.626932680606842], "8": ["vertical_and_slash", 3500, 100, 0.9546087980270386], "9": ["vertical_and_slash", 500, 700, 0.8930553793907166], "10": ["vertical_and_slash", 100, 750, 0.9767886996269226], "11": ["vertical_and_slash", 1000, 6096, 0.7312592267990112], "12": ["vertical_and_slash", 3500, 100, 0.9913722276687622], "13": ["vertical_and_slash", 3500, 100, 0.9425638914108276], "14": ["vertical_and_slash", 3500, 100, 0.9949523210525513], "15": ["vertical_and_slash", 100, 750, 0.7187187671661377], "16": ["vertical_and_slash", 3500, 100, 0.9734897017478943], "17": ["vertical_and_slash", 3500, 100, 0.9750894904136658], "18": ["vertical_and_slash", 3500, 100, 0.9543801546096802], "19": ["vertical_and_slash", 3500, 100, 0.94287109375], "20": ["vertical_and_slash", 1000, 6096, 0.7409213185310364], "21": ["vertical_and_slash", 3500, 100, 0.9789512753486633], "22": ["vertical_and_slash", 3500, 100, 0.9824472069740295], "23": ["vertical_and_slash", 3500, 100, 0.9614876508712769], "24": ["vertical_and_slash", 500, 700, 0.9097415208816528], "25": ["vertical_and_slash", 3500, 100, 0.7589483857154846], "26": ["vertical_and_slash", 3500, 100, 0.9711624979972839], "27": ["vertical_and_slash", 500, 700, 0.9924762845039368], "28": ["vertical_and_slash", 3500, 100, 0.8917614221572876], "29": ["vertical_and_slash", 500, 700, 0.9802823066711426], "30": ["vertical_and_slash", 3500, 100, 0.9433683156967163], "31": ["vertical_and_slash", 3500, 100, 0.9959222078323364]}, {"0": ["vertical_and_slash", 3500, 100, 0.8028379678726196], "1": ["vertical_and_slash", 3500, 100, 0.9934322237968445], "2": ["vertical_and_slash", 3500, 100, 0.9233330488204956], "3": ["vertical_and_slash", 500, 700, 0.9530222415924072], "4": ["vertical_and_slash", 1000, 6096, 0.7554510831832886], "5": ["vertical_and_slash", 3500, 100, 0.9931245446205139], "6": ["vertical_and_slash", 3500, 100, 0.8175129890441895], "7": ["vertical_and_slash", 500, 700, 0.9769982695579529], "8": ["vertical_and_slash", 3500, 100, 0.7803007364273071], "9": ["vertical_and_slash", 3500, 100, 0.8488234281539917], "10": ["vertical_and_slash", 1000, 6096, 0.7556964159011841], "11": ["vertical_and_slash", 100, 750, 0.9249212145805359], "12": ["vertical_and_slash", 1000, 6096, 0.5030975937843323], "13": ["vertical_and_slash", 3500, 100, 0.7736669778823853], "14": ["vertical_and_slash", 3500, 100, 0.8432313203811646], "15": ["vertical_and_slash", 3500, 100, 0.8078522086143494], "16": ["vertical_and_slash", 1000, 6096, 0.6152622699737549], "17": ["vertical_and_slash", 1000, 6096, 0.4801797866821289], "18": ["vertical_and_slash", 3500, 100, 0.7792356610298157], "19": ["vertical_and_slash", 3500, 100, 0.9260709285736084], "20": ["vertical_and_slash", 3500, 100, 0.9572370052337646], "21": ["vertical_and_slash", 500, 700, 0.9757252335548401], "22": ["vertical_and_slash", 100, 750, 0.9295142889022827], "23": ["vertical_and_slash", 100, 750, 0.8406566381454468], "24": ["vertical_and_slash", 500, 700, 0.9934183955192566], "25": ["vertical_and_slash", 3500, 100, 0.9811476469039917], "26": ["vertical_and_slash", 1000, 6096, 0.43748241662979126], "27": ["vertical_and_slash", 1000, 6096, 0.8173736929893494], "28": ["vertical_and_slash", 1000, 6096, 0.7964892983436584], "29": ["vertical_and_slash", 1000, 6096, 0.5660628080368042], "30": ["vertical_and_slash", 100, 750, 0.8858906626701355], "31": ["vertical_and_slash", 3500, 100, 0.7301779389381409]}, {"0": ["vertical_and_slash", 1000, 6096, 0.8143554925918579], "1": ["vertical_and_slash", 3500, 100, 0.8302785754203796], "2": ["vertical_and_slash", 3500, 100, 0.9859114289283752], "3": ["vertical_and_slash", 3500, 100, 0.6922958493232727], "4": ["vertical_and_slash", 3500, 100, 0.9597254991531372], "5": ["vertical_and_slash", 1000, 6096, 0.8074929714202881], "6": ["vertical_and_slash", 3500, 100, 0.7841739654541016], "7": ["vertical_and_slash", 3500, 100, 0.9443768262863159], "8": ["vertical_and_slash", 3500, 100, 0.9327424764633179], "9": ["vertical_and_slash", 3500, 100, 0.8796824812889099], "10": ["vertical_and_slash", 3500, 100, 0.9468095302581787], "11": ["vertical_and_slash", 3500, 100, 0.9797954559326172], "12": ["vertical_and_slash", 3500, 100, 0.9876496195793152], "13": ["vertical_and_slash", 100, 750, 0.9684455394744873], "14": ["vertical_and_slash", 3500, 100, 0.9720463156700134], "15": ["vertical_and_slash", 3500, 100, 0.9134085774421692], "16": ["vertical_and_slash", 100, 750, 0.9962508678436279], "17": ["vertical_and_slash", 3500, 100, 0.9967661499977112], "18": ["vertical_and_slash", 3500, 100, 0.9218150973320007], "19": ["vertical_and_slash", 3500, 100, 0.9165892601013184], "20": ["vertical_and_slash", 500, 700, 0.9811153411865234], "21": ["vertical_and_slash", 1000, 6096, 0.8401690721511841], "22": ["vertical_and_slash", 100, 750, 0.9827044606208801], "23": ["vertical_and_slash", 500, 700, 0.9265505075454712], "24": ["vertical_and_slash", 3500, 100, 0.8814885020256042], "25": ["vertical_and_slash", 1000, 6096, 0.8774723410606384], "26": ["vertical_and_slash", 1000, 6096, 0.8981026411056519], "27": ["vertical_and_slash", 100, 750, 0.995216429233551], "28": ["vertical_and_slash", 3500, 100, 0.9950628280639648], "29": ["vertical_and_slash", 500, 700, 0.9678530693054199], "30": ["vertical_and_slash", 100, 750, 0.9900303483009338], "31": ["vertical_and_slash", 3500, 100, 0.9148485064506531]}, {"0": ["vertical_and_slash", 3500, 100, 0.7734143137931824], "1": ["vertical_and_slash", 3500, 100, 0.9431662559509277], "2": ["vertical_and_slash", 100, 750, 0.9125087857246399], "3": ["vertical_and_slash", 3500, 100, 0.9382316470146179], "4": ["vertical_and_slash", 1000, 6096, 0.7059416174888611], "5": ["vertical_and_slash", 3500, 100, 0.6978054642677307], "6": ["vertical_and_slash", 3500, 100, 0.9927070140838623], "7": ["vertical_and_slash", 3500, 100, 0.9393529295921326], "8": ["vertical_and_slash", 100, 750, 0.9231113195419312], "9": ["vertical_and_slash", 3500, 100, 0.9985975623130798], "10": ["vertical_and_slash", 500, 700, 0.9555321335792542], "11": ["vertical_and_slash", 3500, 100, 0.9785676002502441], "12": ["vertical_and_slash", 500, 700, 0.9968464374542236], "13": ["vertical_and_slash", 3500, 100, 0.9894333481788635], "14": ["vertical_and_slash", 500, 700, 0.8927757740020752], "15": ["vertical_and_slash", 3500, 100, 0.9463996887207031], "16": ["vertical_and_slash", 3500, 100, 0.9756723642349243], "17": ["vertical_and_slash", 3500, 100, 0.970882773399353], "18": ["vertical_and_slash", 1000, 6096, 0.6809303164482117], "19": ["vertical_and_slash", 3500, 100, 0.9938862919807434], "20": ["vertical_and_slash", 3500, 100, 0.9821802973747253], "21": ["vertical_and_slash", 3500, 100, 0.9383650422096252], "22": ["vertical_and_slash", 3500, 100, 0.8643637299537659], "23": ["vertical_and_slash", 100, 750, 0.9771586656570435], "24": ["vertical_and_slash", 500, 700, 0.976405143737793], "25": ["vertical_and_slash", 3500, 100, 0.9743276238441467], "26": ["vertical_and_slash", 3500, 100, 0.9265220761299133], "27": ["vertical_and_slash", 3500, 100, 0.9841408729553223], "28": ["vertical_and_slash", 500, 700, 0.9391534328460693], "29": ["vertical_and_slash", 3500, 100, 0.9312986135482788], "30": ["vertical_and_slash", 3500, 100, 0.8832992911338806], "31": ["vertical_and_slash", 3500, 100, 0.9811874628067017]}, {"0": ["vertical_and_slash", 3500, 100, 0.9956807494163513], "1": ["vertical_and_slash", 3500, 100, 0.9670407772064209], "2": ["vertical_and_slash", 100, 750, 0.9973832964897156], "3": ["vertical_and_slash", 100, 750, 0.99891597032547], "4": ["vertical_and_slash", 3500, 100, 0.9931758642196655], "5": ["vertical_and_slash", 100, 750, 0.996113121509552], "6": ["vertical_and_slash", 3500, 100, 0.9983065724372864], "7": ["vertical_and_slash", 3500, 100, 0.9833848476409912], "8": ["vertical_and_slash", 3500, 100, 0.9948523640632629], "9": ["vertical_and_slash", 3500, 100, 0.8683006167411804], "10": ["vertical_and_slash", 3500, 100, 0.9931465983390808], "11": ["vertical_and_slash", 100, 750, 0.984261691570282], "12": ["vertical_and_slash", 100, 750, 0.9601353406906128], "13": ["vertical_and_slash", 500, 700, 0.9203216433525085], "14": ["vertical_and_slash", 3500, 100, 0.9650700092315674], "15": ["vertical_and_slash", 100, 750, 0.984341561794281], "16": ["vertical_and_slash", 3500, 100, 0.9989381432533264], "17": ["vertical_and_slash", 1000, 6096, 0.8591818809509277], "18": ["vertical_and_slash", 500, 700, 0.959535539150238], "19": ["vertical_and_slash", 3500, 100, 0.9685975909233093], "20": ["vertical_and_slash", 3500, 100, 0.9992274045944214], "21": ["vertical_and_slash", 3500, 100, 0.9054502248764038], "22": ["vertical_and_slash", 3500, 100, 0.9957486391067505], "23": ["vertical_and_slash", 3500, 100, 0.9970229864120483], "24": ["vertical_and_slash", 3500, 100, 0.933996319770813], "25": ["vertical_and_slash", 3500, 100, 0.9522771239280701], "26": ["vertical_and_slash", 3500, 100, 0.8640444278717041], "27": ["vertical_and_slash", 3500, 100, 0.9864702820777893], "28": ["vertical_and_slash", 1000, 6096, 0.8701584935188293], "29": ["vertical_and_slash", 3500, 100, 0.9872081279754639], "30": ["vertical_and_slash", 3500, 100, 0.9637035727500916], "31": ["vertical_and_slash", 3500, 100, 0.7964584827423096]}, {"0": ["vertical_and_slash", 500, 700, 0.944079577922821], "1": ["vertical_and_slash", 1000, 6096, 0.7686152458190918], "2": ["vertical_and_slash", 3500, 100, 0.9423201680183411], "3": ["vertical_and_slash", 3500, 100, 0.9597930908203125], "4": ["vertical_and_slash", 3500, 100, 0.9981894493103027], "5": ["vertical_and_slash", 100, 750, 0.9951789975166321], "6": ["vertical_and_slash", 3500, 100, 0.9678981304168701], "7": ["vertical_and_slash", 3500, 100, 0.8912110924720764], "8": ["vertical_and_slash", 100, 750, 0.9829361438751221], "9": ["vertical_and_slash", 500, 700, 0.9326693415641785], "10": ["vertical_and_slash", 3500, 100, 0.7954592108726501], "11": ["vertical_and_slash", 3500, 100, 0.9361847639083862], "12": ["vertical_and_slash", 3500, 100, 0.9777213335037231], "13": ["vertical_and_slash", 100, 750, 0.7402770519256592], "14": ["vertical_and_slash", 1000, 6096, 0.8369068503379822], "15": ["vertical_and_slash", 3500, 100, 0.8386251926422119], "16": ["vertical_and_slash", 500, 700, 0.9928125143051147], "17": ["vertical_and_slash", 3500, 100, 0.9980320930480957], "18": ["vertical_and_slash", 100, 750, 0.99200838804245], "19": ["vertical_and_slash", 3500, 100, 0.9937632083892822], "20": ["vertical_and_slash", 1000, 6096, 0.8582853674888611], "21": ["vertical_and_slash", 500, 700, 0.8901017308235168], "22": ["vertical_and_slash", 3500, 100, 0.9825611710548401], "23": ["vertical_and_slash", 3500, 100, 0.9956728219985962], "24": ["vertical_and_slash", 3500, 100, 0.992565929889679], "25": ["vertical_and_slash", 3500, 100, 0.9841880202293396], "26": ["vertical_and_slash", 1000, 6096, 0.8873481750488281], "27": ["vertical_and_slash", 100, 750, 0.9767672419548035], "28": ["vertical_and_slash", 3500, 100, 0.9931612610816956], "29": ["vertical_and_slash", 3500, 100, 0.9209384918212891], "30": ["vertical_and_slash", 100, 750, 0.7578334212303162], "31": ["vertical_and_slash", 3500, 100, 0.9578611850738525]}, {"0": ["vertical_and_slash", 100, 750, 0.9389412999153137], "1": ["vertical_and_slash", 100, 750, 0.9428157210350037], "2": ["vertical_and_slash", 3500, 100, 0.9956400990486145], "3": ["vertical_and_slash", 100, 750, 0.9144065976142883], "4": ["vertical_and_slash", 1000, 6096, 0.8475824594497681], "5": ["vertical_and_slash", 100, 750, 0.996335506439209], "6": ["vertical_and_slash", 3500, 100, 0.9988783597946167], "7": ["vertical_and_slash", 3500, 100, 0.94597989320755], "8": ["vertical_and_slash", 3500, 100, 0.9713111519813538], "9": ["vertical_and_slash", 100, 750, 0.9670871496200562], "10": ["vertical_and_slash", 3500, 100, 0.9996585249900818], "11": ["vertical_and_slash", 3500, 100, 0.9820530414581299], "12": ["vertical_and_slash", 3500, 100, 0.9983968138694763], "13": ["vertical_and_slash", 3500, 100, 0.9315072298049927], "14": ["vertical_and_slash", 3500, 100, 0.9930176138877869], "15": ["vertical_and_slash", 500, 700, 0.9945250749588013], "16": ["vertical_and_slash", 100, 750, 0.9049948453903198], "17": ["vertical_and_slash", 3500, 100, 0.9992651343345642], "18": ["vertical_and_slash", 500, 700, 0.9942126274108887], "19": ["vertical_and_slash", 500, 700, 0.9891477227210999], "20": ["vertical_and_slash", 3500, 100, 0.9028084874153137], "21": ["vertical_and_slash", 100, 750, 0.9475080370903015], "22": ["vertical_and_slash", 500, 700, 0.9690455794334412], "23": ["vertical_and_slash", 3500, 100, 0.9446419477462769], "24": ["vertical_and_slash", 3500, 100, 0.9801247715950012], "25": ["vertical_and_slash", 100, 750, 0.9777910113334656], "26": ["vertical_and_slash", 3500, 100, 0.7017547488212585], "27": ["vertical_and_slash", 3500, 100, 0.9493237137794495], "28": ["vertical_and_slash", 100, 750, 0.9993017315864563], "29": ["vertical_and_slash", 3500, 100, 0.893531858921051], "30": ["vertical_and_slash", 3500, 100, 0.9467594623565674], "31": ["vertical_and_slash", 3500, 100, 0.9743610620498657]}, {"0": ["vertical_and_slash", 3500, 100, 0.985114574432373], "1": ["vertical_and_slash", 500, 700, 0.9950987696647644], "2": ["vertical_and_slash", 3500, 100, 0.7027000784873962], "3": ["vertical_and_slash", 3500, 100, 0.9855831265449524], "4": ["vertical_and_slash", 3500, 100, 0.9874288439750671], "5": ["vertical_and_slash", 1000, 6096, 0.7125917673110962], "6": ["vertical_and_slash", 3500, 100, 0.9454708695411682], "7": ["vertical_and_slash", 3500, 100, 0.9898356199264526], "8": ["vertical_and_slash", 3500, 100, 0.9445544481277466], "9": ["vertical_and_slash", 3500, 100, 0.988140344619751], "10": ["vertical_and_slash", 500, 700, 0.981208860874176], "11": ["vertical_and_slash", 500, 700, 0.9874861836433411], "12": ["vertical_and_slash", 3500, 100, 0.9963038563728333], "13": ["vertical_and_slash", 100, 750, 0.9972052574157715], "14": ["vertical_and_slash", 3500, 100, 0.9943816065788269], "15": ["vertical_and_slash", 100, 750, 0.8364889025688171], "16": ["vertical_and_slash", 100, 750, 0.9870871901512146], "17": ["vertical_and_slash", 100, 750, 0.998099684715271], "18": ["vertical_and_slash", 3500, 100, 0.8674955368041992], "19": ["vertical_and_slash", 500, 700, 0.9969808459281921], "20": ["vertical_and_slash", 3500, 100, 0.8848986625671387], "21": ["vertical_and_slash", 1000, 6096, 0.867315411567688], "22": ["vertical_and_slash", 500, 700, 0.9908551573753357], "23": ["vertical_and_slash", 100, 750, 0.8952099680900574], "24": ["vertical_and_slash", 500, 700, 0.9714990854263306], "25": ["vertical_and_slash", 100, 750, 0.8733819723129272], "26": ["vertical_and_slash", 3500, 100, 0.9205271005630493], "27": ["vertical_and_slash", 3500, 100, 0.9833540916442871], "28": ["vertical_and_slash", 3500, 100, 0.9445760846138], "29": ["vertical_and_slash", 3500, 100, 0.9536135792732239], "30": ["vertical_and_slash", 500, 700, 0.9753504991531372], "31": ["vertical_and_slash", 1000, 6096, 0.8801259398460388]}, {"0": ["vertical_and_slash", 3500, 100, 0.9614631533622742], "1": ["vertical_and_slash", 3500, 100, 0.9763227105140686], "2": ["vertical_and_slash", 100, 750, 0.970956563949585], "3": ["vertical_and_slash", 100, 750, 0.9151788949966431], "4": ["vertical_and_slash", 3500, 100, 0.9920399188995361], "5": ["vertical_and_slash", 3500, 100, 0.9422896504402161], "6": ["vertical_and_slash", 3500, 100, 0.986482560634613], "7": ["vertical_and_slash", 3500, 100, 0.9976206421852112], "8": ["vertical_and_slash", 100, 750, 0.9943424463272095], "9": ["vertical_and_slash", 3500, 100, 0.9936824440956116], "10": ["vertical_and_slash", 3500, 100, 0.9882729649543762], "11": ["vertical_and_slash", 100, 750, 0.9862287640571594], "12": ["vertical_and_slash", 500, 700, 0.9886087775230408], "13": ["vertical_and_slash", 3500, 100, 0.9989089369773865], "14": ["vertical_and_slash", 3500, 100, 0.9651134610176086], "15": ["vertical_and_slash", 3500, 100, 0.9826948046684265], "16": ["vertical_and_slash", 3500, 100, 0.9450136423110962], "17": ["vertical_and_slash", 3500, 100, 0.9979375004768372], "18": ["vertical_and_slash", 3500, 100, 0.9520789384841919], "19": ["vertical_and_slash", 3500, 100, 0.9316532015800476], "20": ["vertical_and_slash", 100, 750, 0.9904720187187195], "21": ["vertical_and_slash", 3500, 100, 0.999125599861145], "22": ["vertical_and_slash", 3500, 100, 0.9995089769363403], "23": ["vertical_and_slash", 100, 750, 0.9886007308959961], "24": ["vertical_and_slash", 3500, 100, 0.9961583018302917], "25": ["vertical_and_slash", 3500, 100, 0.9961526393890381], "26": ["vertical_and_slash", 3500, 100, 0.9557645916938782], "27": ["vertical_and_slash", 3500, 100, 0.8775650262832642], "28": ["vertical_and_slash", 3500, 100, 0.986892580986023], "29": ["vertical_and_slash", 3500, 100, 0.9749740958213806], "30": ["vertical_and_slash", 3500, 100, 0.8765645027160645], "31": ["vertical_and_slash", 3500, 100, 0.9494763016700745]}, {"0": ["vertical_and_slash", 3500, 100, 0.9797922372817993], "1": ["vertical_and_slash", 3500, 100, 0.9958779811859131], "2": ["vertical_and_slash", 3500, 100, 0.9976977705955505], "3": ["vertical_and_slash", 3500, 100, 0.9764806628227234], "4": ["vertical_and_slash", 3500, 100, 0.9868356585502625], "5": ["vertical_and_slash", 1000, 6096, 0.8740545511245728], "6": ["vertical_and_slash", 3500, 100, 0.9939981698989868], "7": ["vertical_and_slash", 1000, 6096, 0.7613811492919922], "8": ["vertical_and_slash", 3500, 100, 0.9811347723007202], "9": ["vertical_and_slash", 3500, 100, 0.9840614795684814], "10": ["vertical_and_slash", 1000, 6096, 0.8657892346382141], "11": ["vertical_and_slash", 3500, 100, 0.9502456188201904], "12": ["vertical_and_slash", 100, 750, 0.9104490280151367], "13": ["vertical_and_slash", 3500, 100, 0.9950721263885498], "14": ["vertical_and_slash", 3500, 100, 0.9724959135055542], "15": ["vertical_and_slash", 1000, 6096, 0.8955191373825073], "16": ["vertical_and_slash", 3500, 100, 0.9936071038246155], "17": ["vertical_and_slash", 3500, 100, 0.9285928606987], "18": ["vertical_and_slash", 3500, 100, 0.756338357925415], "19": ["vertical_and_slash", 3500, 100, 0.9665532112121582], "20": ["vertical_and_slash", 100, 750, 0.9970663785934448], "21": ["vertical_and_slash", 3500, 100, 0.9806201457977295], "22": ["vertical_and_slash", 1000, 6096, 0.8115424513816833], "23": ["vertical_and_slash", 1000, 6096, 0.8631585836410522], "24": ["vertical_and_slash", 3500, 100, 0.9782901406288147], "25": ["vertical_and_slash", 3500, 100, 0.9858242273330688], "26": ["vertical_and_slash", 3500, 100, 0.9617720246315002], "27": ["vertical_and_slash", 3500, 100, 0.997412919998169], "28": ["vertical_and_slash", 3500, 100, 0.8432300090789795], "29": ["vertical_and_slash", 500, 700, 0.9955722093582153], "30": ["vertical_and_slash", 3500, 100, 0.9938695430755615], "31": ["vertical_and_slash", 3500, 100, 0.9511440396308899]}, {"0": ["vertical_and_slash", 3500, 100, 0.988155722618103], "1": ["vertical_and_slash", 3500, 100, 0.9747615456581116], "2": ["vertical_and_slash", 100, 750, 0.9718871712684631], "3": ["vertical_and_slash", 100, 750, 0.9756971597671509], "4": ["vertical_and_slash", 3500, 100, 0.947630763053894], "5": ["vertical_and_slash", 100, 750, 0.99262934923172], "6": ["vertical_and_slash", 3500, 100, 0.9955495595932007], "7": ["vertical_and_slash", 3500, 100, 0.8609271049499512], "8": ["vertical_and_slash", 3500, 100, 0.974815845489502], "9": ["vertical_and_slash", 3500, 100, 0.9884821772575378], "10": ["vertical_and_slash", 3500, 100, 0.9901348352432251], "11": ["vertical_and_slash", 100, 750, 0.9968274831771851], "12": ["vertical_and_slash", 3500, 100, 0.9918603897094727], "13": ["vertical_and_slash", 500, 700, 0.9757610559463501], "14": ["vertical_and_slash", 3500, 100, 0.9900703430175781], "15": ["vertical_and_slash", 500, 700, 0.9938023090362549], "16": ["vertical_and_slash", 1000, 6096, 0.8913345336914062], "17": ["vertical_and_slash", 500, 700, 0.9903258681297302], "18": ["vertical_and_slash", 100, 750, 0.9566823244094849], "19": ["vertical_and_slash", 100, 750, 0.9777167439460754], "20": ["vertical_and_slash", 3500, 100, 0.9674810767173767], "21": ["vertical_and_slash", 100, 750, 0.9178389310836792], "22": ["vertical_and_slash", 100, 750, 0.9882655143737793], "23": ["vertical_and_slash", 100, 750, 0.9989043474197388], "24": ["vertical_and_slash", 1000, 6096, 0.8574219942092896], "25": ["vertical_and_slash", 3500, 100, 0.9944363236427307], "26": ["vertical_and_slash", 3500, 100, 0.9970851540565491], "27": ["vertical_and_slash", 500, 700, 0.9904334545135498], "28": ["vertical_and_slash", 3500, 100, 0.9851230978965759], "29": ["vertical_and_slash", 3500, 100, 0.9900650978088379], "30": ["vertical_and_slash", 3500, 100, 0.9743545055389404], "31": ["vertical_and_slash", 500, 700, 0.9190711975097656]}, {"0": ["vertical_and_slash", 100, 750, 0.9716458320617676], "1": ["vertical_and_slash", 3500, 100, 0.9384027719497681], "2": ["vertical_and_slash", 3500, 100, 0.9696847796440125], "3": ["vertical_and_slash", 3500, 100, 0.9812428951263428], "4": ["vertical_and_slash", 1000, 6096, 0.5853931903839111], "5": ["vertical_and_slash", 3500, 100, 0.7994469404220581], "6": ["vertical_and_slash", 3500, 100, 0.9933062791824341], "7": ["vertical_and_slash", 3500, 100, 0.986369788646698], "8": ["vertical_and_slash", 3500, 100, 0.8895794153213501], "9": ["vertical_and_slash", 1000, 6096, 0.8238524794578552], "10": ["vertical_and_slash", 500, 700, 0.93126380443573], "11": ["vertical_and_slash", 3500, 100, 0.962100088596344], "12": ["vertical_and_slash", 3500, 100, 0.8438158631324768], "13": ["vertical_and_slash", 500, 700, 0.9969620108604431], "14": ["vertical_and_slash", 1000, 6096, 0.8904788494110107], "15": ["vertical_and_slash", 100, 750, 0.9925360679626465], "16": ["vertical_and_slash", 3500, 100, 0.9222993850708008], "17": ["vertical_and_slash", 1000, 6096, 0.6627880334854126], "18": ["vertical_and_slash", 1000, 6096, 0.8668970465660095], "19": ["vertical_and_slash", 3500, 100, 0.9340634346008301], "20": ["vertical_and_slash", 3500, 100, 0.9503065347671509], "21": ["vertical_and_slash", 3500, 100, 0.9436649680137634], "22": ["vertical_and_slash", 3500, 100, 0.9768727421760559], "23": ["vertical_and_slash", 100, 750, 0.988473653793335], "24": ["vertical_and_slash", 3500, 100, 0.8777113556861877], "25": ["vertical_and_slash", 3500, 100, 0.8750200271606445], "26": ["vertical_and_slash", 1000, 6096, 0.4957360625267029], "27": ["vertical_and_slash", 3500, 100, 0.9804278016090393], "28": ["vertical_and_slash", 1000, 6096, 0.8486401438713074], "29": ["vertical_and_slash", 3500, 100, 0.8954175114631653], "30": ["vertical_and_slash", 3500, 100, 0.9651874899864197], "31": ["vertical_and_slash", 3500, 100, 0.9620938301086426]}, {"0": ["vertical_and_slash", 100, 750, 0.920842707157135], "1": ["vertical_and_slash", 3500, 100, 0.7215947508811951], "2": ["vertical_and_slash", 3500, 100, 0.9858340620994568], "3": ["vertical_and_slash", 3500, 100, 0.7861597537994385], "4": ["vertical_and_slash", 3500, 100, 0.7639158964157104], "5": ["vertical_and_slash", 3500, 100, 0.887671947479248], "6": ["vertical_and_slash", 3500, 100, 0.8891316652297974], "7": ["vertical_and_slash", 1000, 6096, 0.8906923532485962], "8": ["vertical_and_slash", 3500, 100, 0.8836961984634399], "9": ["vertical_and_slash", 3500, 100, 0.7728190422058105], "10": ["vertical_and_slash", 3500, 100, 0.9507467746734619], "11": ["vertical_and_slash", 500, 700, 0.7829118967056274], "12": ["vertical_and_slash", 100, 750, 0.8214483857154846], "13": ["vertical_and_slash", 3500, 100, 0.7196475863456726], "14": ["vertical_and_slash", 500, 700, 0.8691932559013367], "15": ["vertical_and_slash", 1000, 6096, 0.6569814085960388], "16": ["vertical_and_slash", 100, 750, 0.9087151288986206], "17": ["vertical_and_slash", 3500, 100, 0.7609643936157227], "18": ["vertical_and_slash", 3500, 100, 0.8670530319213867], "19": ["vertical_and_slash", 1000, 6096, 0.7779831290245056], "20": ["vertical_and_slash", 100, 750, 0.923963725566864], "21": ["vertical_and_slash", 1000, 6096, 0.5714190006256104], "22": ["vertical_and_slash", 500, 700, 0.6351447105407715], "23": ["vertical_and_slash", 100, 750, 0.870464026927948], "24": ["vertical_and_slash", 1000, 6096, 0.6272542476654053], "25": ["vertical_and_slash", 1000, 6096, 0.7302500009536743], "26": ["vertical_and_slash", 3500, 100, 0.9410015940666199], "27": ["vertical_and_slash", 3500, 100, 0.793304979801178], "28": ["vertical_and_slash", 1000, 6096, 0.837500274181366], "29": ["vertical_and_slash", 1000, 6096, 0.766721248626709], "30": ["vertical_and_slash", 1000, 6096, 0.7082650065422058], "31": ["vertical_and_slash", 3500, 100, 0.8947907090187073]}, {"0": ["vertical_and_slash", 100, 750, 0.8983681797981262], "1": ["vertical_and_slash", 1000, 6096, 0.9650430083274841], "2": ["vertical_and_slash", 500, 700, 0.9532706141471863], "3": ["vertical_and_slash", 3500, 100, 0.8198072910308838], "4": ["vertical_and_slash", 1000, 6096, 0.840558648109436], "5": ["vertical_and_slash", 3500, 100, 0.8227204084396362], "6": ["vertical_and_slash", 1000, 6096, 0.5979130268096924], "7": ["vertical_and_slash", 1000, 6096, 0.7691975235939026], "8": ["vertical_and_slash", 1000, 6096, 0.8089779615402222], "9": ["vertical_and_slash", 100, 750, 0.8689324855804443], "10": ["vertical_and_slash", 100, 750, 0.8621079325675964], "11": ["vertical_and_slash", 500, 700, 0.9871177673339844], "12": ["vertical_and_slash", 1000, 6096, 0.9468575716018677], "13": ["vertical_and_slash", 100, 750, 0.9075571894645691], "14": ["vertical_and_slash", 1000, 6096, 0.911694347858429], "15": ["vertical_and_slash", 100, 750, 0.9817390441894531], "16": ["vertical_and_slash", 1000, 6096, 0.7491167783737183], "17": ["vertical_and_slash", 1000, 6096, 0.8255623579025269], "18": ["vertical_and_slash", 1000, 6096, 0.8701649308204651], "19": ["vertical_and_slash", 3500, 100, 0.838506817817688], "20": ["vertical_and_slash", 1000, 6096, 0.8749529123306274], "21": ["vertical_and_slash", 500, 700, 0.8783859610557556], "22": ["vertical_and_slash", 3500, 100, 0.9302544593811035], "23": ["vertical_and_slash", 100, 750, 0.9118035435676575], "24": ["vertical_and_slash", 1000, 6096, 0.7892093658447266], "25": ["vertical_and_slash", 100, 750, 0.904501736164093], "26": ["vertical_and_slash", 3500, 100, 0.947079598903656], "27": ["vertical_and_slash", 1000, 6096, 0.5719630718231201], "28": ["vertical_and_slash", 3500, 100, 0.9740545153617859], "29": ["vertical_and_slash", 100, 750, 0.8365178108215332], "30": ["vertical_and_slash", 3500, 100, 0.8893513083457947], "31": ["vertical_and_slash", 1000, 6096, 0.923209547996521]}]
|
minference/configs/Yi_9B_200k_kv_out_v32_fit_o_best_pattern.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
[{"0": ["vertical_and_slash", 1000, 4096, 12982], "1": ["vertical_and_slash", 1000, 4096, 54], "2": ["vertical_and_slash", 1000, 4096, 0], "3": ["vertical_and_slash", 1000, 4096, 5], "4": ["vertical_and_slash", 1000, 4096, 57], "5": ["vertical_and_slash", 1000, 4096, 93], "6": ["vertical_and_slash", 1000, 4096, 5], "7": ["vertical_and_slash", 1000, 4096, 0], "8": ["vertical_and_slash", 1000, 4096, 4], "9": ["vertical_and_slash", 1000, 4096, 8], "10": ["vertical_and_slash", 1000, 4096, 10020], "11": ["vertical_and_slash", 1000, 4096, 0], "12": ["vertical_and_slash", 1000, 4096, 222290], "13": ["vertical_and_slash", 1000, 4096, 162], "14": ["vertical_and_slash", 1000, 4096, 3], "15": ["vertical_and_slash", 1000, 4096, 11], "16": ["vertical_and_slash", 1000, 4096, 10], "17": ["vertical_and_slash", 1000, 4096, 4], "18": ["vertical_and_slash", 1000, 4096, 26297], "19": ["vertical_and_slash", 1000, 4096, 3], "20": ["vertical_and_slash", 1000, 4096, 0], "21": ["vertical_and_slash", 1000, 4096, 0], "22": ["vertical_and_slash", 1000, 4096, 1627], "23": ["vertical_and_slash", 1000, 4096, 7], "24": ["vertical_and_slash", 1000, 4096, 0], "25": ["vertical_and_slash", 1000, 4096, 859], "26": ["vertical_and_slash", 1000, 4096, 0], "27": ["vertical_and_slash", 1000, 4096, 0], "28": ["vertical_and_slash", 1000, 4096, 484], "29": ["vertical_and_slash", 1000, 4096, 1239], "30": ["vertical_and_slash", 1000, 4096, 0], "31": ["vertical_and_slash", 1000, 4096, 0]}, {"0": ["vertical_and_slash", 1000, 4096, 430388], "1": ["vertical_and_slash", 1000, 4096, 299591], "2": ["vertical_and_slash", 1000, 4096, 5802], "3": ["vertical_and_slash", 1000, 4096, 22390], "4": ["vertical_and_slash", 1000, 4096, 284950], "5": ["vertical_and_slash", 1000, 4096, 237516], "6": ["vertical_and_slash", 1000, 4096, 39541], "7": ["vertical_and_slash", 1000, 4096, 46216], "8": ["vertical_and_slash", 1000, 4096, 782645], "9": ["vertical_and_slash", 1000, 4096, 8], "10": ["vertical_and_slash", 1000, 4096, 18], "11": ["vertical_and_slash", 1000, 4096, 18890], "12": ["vertical_and_slash", 1000, 4096, 141], "13": ["vertical_and_slash", 1000, 4096, 53457], "14": ["vertical_and_slash", 1000, 4096, 34], "15": ["vertical_and_slash", 1000, 4096, 0], "16": ["vertical_and_slash", 1000, 4096, 246481], "17": ["vertical_and_slash", 1000, 4096, 135148], "18": ["vertical_and_slash", 1000, 4096, 48561], "19": ["vertical_and_slash", 1000, 4096, 54785], "20": ["vertical_and_slash", 1000, 4096, 95382], "21": ["vertical_and_slash", 1000, 4096, 387], "22": ["vertical_and_slash", 1000, 4096, 1750], "23": ["vertical_and_slash", 1000, 4096, 201661], "24": ["vertical_and_slash", 1000, 4096, 51272], "25": ["vertical_and_slash", 1000, 4096, 115255], "26": ["vertical_and_slash", 1000, 4096, 6], "27": ["vertical_and_slash", 1000, 4096, 6895], "28": ["vertical_and_slash", 1000, 4096, 2335], "29": ["vertical_and_slash", 1000, 4096, 23041], "30": ["vertical_and_slash", 1000, 4096, 6270087], "31": ["vertical_and_slash", 1000, 4096, 0]}, {"0": ["vertical_and_slash", 100, 800, 11], "1": ["vertical_and_slash", 30, 800, 5], "2": ["vertical_and_slash", 30, 800, 2790], "3": ["vertical_and_slash", 30, 800, 37], "4": ["vertical_and_slash", 30, 800, 2903], "5": ["vertical_and_slash", 30, 800, 1], "6": ["vertical_and_slash", 30, 800, 101], "7": ["vertical_and_slash", 100, 800, 16677], "8": ["vertical_and_slash", 1000, 4096, 99796], "9": ["vertical_and_slash", 30, 800, 8116], "10": ["vertical_and_slash", 30, 800, 1993], "11": ["vertical_and_slash", 1000, 4096, 2561], "12": ["vertical_and_slash", 30, 800, 21], "13": ["vertical_and_slash", 30, 800, 9624], "14": ["vertical_and_slash", 1000, 4096, 3894510], "15": ["vertical_and_slash", 1000, 4096, 66775], "16": ["vertical_and_slash", 30, 800, 1569], "17": ["vertical_and_slash", 1000, 4096, 146958], "18": ["vertical_and_slash", 30, 800, 29976], "19": ["vertical_and_slash", 1000, 4096, 269566], "20": ["vertical_and_slash", 100, 800, 50639], "21": ["vertical_and_slash", 30, 800, 114641], "22": ["vertical_and_slash", 1000, 4096, 238607], "23": ["vertical_and_slash", 100, 800, 302385], "24": ["vertical_and_slash", 1000, 4096, 4893], "25": ["vertical_and_slash", 30, 800, 322], "26": ["vertical_and_slash", 1000, 4096, 3639], "27": ["vertical_and_slash", 100, 800, 131], "28": ["vertical_and_slash", 1000, 4096, 348560], "29": ["vertical_and_slash", 1000, 4096, 14611], "30": ["vertical_and_slash", 30, 800, 86], "31": ["vertical_and_slash", 1000, 4096, 900]}, {"0": ["vertical_and_slash", 100, 800, 64], "1": ["vertical_and_slash", 1000, 4096, 10], "2": ["vertical_and_slash", 500, 700, 77], "3": ["vertical_and_slash", 1000, 4096, 4193], "4": ["vertical_and_slash", 100, 800, 83525], "5": ["vertical_and_slash", 1000, 4096, 6], "6": ["vertical_and_slash", 1000, 4096, 27907], "7": ["vertical_and_slash", 1000, 4096, 42], "8": ["vertical_and_slash", 30, 800, 21349], "9": ["vertical_and_slash", 30, 800, 5018], "10": ["vertical_and_slash", 30, 800, 1663], "11": ["vertical_and_slash", 30, 800, 86902], "12": ["vertical_and_slash", 30, 800, 781], "13": ["vertical_and_slash", 100, 800, 339811], "14": ["vertical_and_slash", 100, 800, 696206], "15": ["vertical_and_slash", 30, 800, 47681], "16": ["vertical_and_slash", 30, 800, 4251], "17": ["vertical_and_slash", 1000, 4096, 6373945], "18": ["vertical_and_slash", 100, 800, 289132], "19": ["vertical_and_slash", 1000, 4096, 10273], "20": ["vertical_and_slash", 1000, 4096, 457078], "21": ["vertical_and_slash", 1000, 4096, 1372461], "22": ["vertical_and_slash", 100, 800, 11108], "23": ["vertical_and_slash", 100, 800, 2979], "24": ["vertical_and_slash", 1000, 4096, 30365], "25": ["vertical_and_slash", 500, 700, 142429], "26": ["vertical_and_slash", 500, 700, 6300], "27": ["vertical_and_slash", 30, 800, 4711], "28": ["vertical_and_slash", 500, 700, 4810], "29": ["vertical_and_slash", 500, 700, 25571], "30": ["vertical_and_slash", 500, 700, 7924], "31": ["vertical_and_slash", 500, 700, 3337]}, {"0": ["vertical_and_slash", 30, 800, 34678], "1": ["vertical_and_slash", 30, 800, 13104], "2": ["vertical_and_slash", 30, 800, 4929], "3": ["vertical_and_slash", 100, 800, 9351380], "4": ["vertical_and_slash", 100, 800, 333814], "5": ["vertical_and_slash", 100, 800, 603408], "6": ["vertical_and_slash", 30, 800, 18975], "7": ["vertical_and_slash", 30, 800, 8848], "8": ["vertical_and_slash", 100, 800, 1690132], "9": ["vertical_and_slash", 30, 800, 59610], "10": ["vertical_and_slash", 500, 700, 1234], "11": ["vertical_and_slash", 1000, 4096, 74422], "12": ["vertical_and_slash", 1000, 4096, 504212], "13": ["vertical_and_slash", 30, 800, 3100], "14": ["vertical_and_slash", 100, 800, 1160], "15": ["vertical_and_slash", 500, 700, 5784], "16": ["vertical_and_slash", 30, 800, 18695], "17": ["vertical_and_slash", 30, 800, 2090], "18": ["vertical_and_slash", 30, 800, 28562], "19": ["vertical_and_slash", 30, 800, 34339], "20": ["vertical_and_slash", 30, 800, 2544], "21": ["vertical_and_slash", 30, 800, 1914], "22": ["vertical_and_slash", 30, 800, 83258], "23": ["vertical_and_slash", 30, 800, 7898], "24": ["vertical_and_slash", 30, 800, 11609], "25": ["vertical_and_slash", 1000, 4096, 64138], "26": ["vertical_and_slash", 1000, 4096, 514471], "27": ["vertical_and_slash", 500, 700, 39930], "28": ["vertical_and_slash", 30, 800, 477456], "29": ["vertical_and_slash", 100, 800, 4526], "30": ["vertical_and_slash", 1000, 4096, 30006], "31": ["vertical_and_slash", 30, 800, 92845]}, {"0": ["vertical_and_slash", 30, 800, 55378], "1": ["vertical_and_slash", 1000, 4096, 17441], "2": ["vertical_and_slash", 100, 800, 1890658], "3": ["vertical_and_slash", 30, 800, 39922], "4": ["vertical_and_slash", 30, 800, 3841], "5": ["vertical_and_slash", 30, 800, 16402], "6": ["vertical_and_slash", 30, 800, 9274], "7": ["vertical_and_slash", 100, 800, 2756], "8": ["vertical_and_slash", 100, 800, 190896], "9": ["vertical_and_slash", 1000, 4096, 30060], "10": ["vertical_and_slash", 1000, 4096, 1123342], "11": ["vertical_and_slash", 1000, 4096, 260812], "12": ["vertical_and_slash", 1000, 4096, 4395769], "13": ["vertical_and_slash", 1000, 4096, 1803359], "14": ["vertical_and_slash", 30, 800, 17625], "15": ["vertical_and_slash", 1000, 4096, 1501177], "16": ["vertical_and_slash", 1000, 4096, 236955], "17": ["vertical_and_slash", 1000, 4096, 27239], "18": ["vertical_and_slash", 1000, 4096, 84045], "19": ["vertical_and_slash", 1000, 4096, 112395], "20": ["vertical_and_slash", 1000, 4096, 289351], "21": ["vertical_and_slash", 1000, 4096, 1200493], "22": ["vertical_and_slash", 100, 800, 5628], "23": ["vertical_and_slash", 1000, 4096, 53], "24": ["vertical_and_slash", 30, 800, 1001179], "25": ["vertical_and_slash", 1000, 4096, 1417294], "26": ["vertical_and_slash", 100, 800, 712290], "27": ["vertical_and_slash", 1000, 4096, 111462], "28": ["vertical_and_slash", 1000, 4096, 2382091], "29": ["vertical_and_slash", 30, 800, 10632], "30": ["vertical_and_slash", 100, 800, 404628], "31": ["vertical_and_slash", 1000, 4096, 36025]}, {"0": ["vertical_and_slash", 1000, 4096, 683931], "1": ["vertical_and_slash", 1000, 4096, 1978224], "2": ["vertical_and_slash", 30, 800, 529064], "3": ["vertical_and_slash", 30, 800, 20483], "4": ["vertical_and_slash", 30, 800, 226587], "5": ["vertical_and_slash", 30, 800, 100650], "6": ["vertical_and_slash", 30, 800, 88814], "7": ["vertical_and_slash", 30, 800, 25415], "8": ["vertical_and_slash", 1000, 4096, 126846], "9": ["vertical_and_slash", 100, 800, 83585], "10": ["vertical_and_slash", 1000, 4096, 53117], "11": ["vertical_and_slash", 1000, 4096, 30196], "12": ["vertical_and_slash", 1000, 4096, 81511], "13": ["vertical_and_slash", 1000, 4096, 25087], "14": ["vertical_and_slash", 1000, 4096, 52332], "15": ["vertical_and_slash", 1000, 4096, 1662596], "16": ["vertical_and_slash", 30, 800, 26199], "17": ["vertical_and_slash", 30, 800, 72420], "18": ["vertical_and_slash", 30, 800, 74770], "19": ["vertical_and_slash", 30, 800, 94064], "20": ["vertical_and_slash", 30, 800, 10369], "21": ["vertical_and_slash", 1000, 4096, 2802268], "22": ["vertical_and_slash", 30, 800, 32077], "23": ["vertical_and_slash", 500, 700, 751949], "24": ["vertical_and_slash", 100, 800, 23111], "25": ["vertical_and_slash", 100, 800, 13161], "26": ["vertical_and_slash", 100, 800, 164196], "27": ["vertical_and_slash", 1000, 4096, 12766], "28": ["vertical_and_slash", 1000, 4096, 37748], "29": ["vertical_and_slash", 1000, 4096, 394580], "30": ["vertical_and_slash", 30, 800, 1161581], "31": ["vertical_and_slash", 1000, 4096, 1070988]}, {"0": ["vertical_and_slash", 100, 800, 4619], "1": ["vertical_and_slash", 1000, 4096, 3223], "2": ["vertical_and_slash", 100, 800, 65675], "3": ["vertical_and_slash", 30, 800, 56], "4": ["vertical_and_slash", 30, 800, 93], "5": ["vertical_and_slash", 30, 800, 72], "6": ["vertical_and_slash", 500, 700, 3523], "7": ["vertical_and_slash", 1000, 4096, 12230], "8": ["vertical_and_slash", 100, 800, 9301307], "9": ["vertical_and_slash", 1000, 4096, 418350], "10": ["vertical_and_slash", 1000, 4096, 994569], "11": ["vertical_and_slash", 100, 800, 399778], "12": ["vertical_and_slash", 1000, 4096, 2677334], "13": ["vertical_and_slash", 1000, 4096, 409432], "14": ["vertical_and_slash", 30, 800, 1233050], "15": ["vertical_and_slash", 1000, 4096, 5697704], "16": ["vertical_and_slash", 100, 800, 294], "17": ["vertical_and_slash", 30, 800, 50017], "18": ["vertical_and_slash", 30, 800, 1566], "19": ["vertical_and_slash", 30, 800, 2368], "20": ["vertical_and_slash", 30, 800, 3051012], "21": ["vertical_and_slash", 1000, 4096, 15983], "22": ["vertical_and_slash", 1000, 4096, 48], "23": ["vertical_and_slash", 1000, 4096, 312543], "24": ["vertical_and_slash", 30, 800, 4820], "25": ["vertical_and_slash", 30, 800, 100931], "26": ["vertical_and_slash", 30, 800, 69743], "27": ["vertical_and_slash", 30, 800, 22187], "28": ["vertical_and_slash", 30, 800, 3936], "29": ["vertical_and_slash", 30, 800, 4611], "30": ["vertical_and_slash", 30, 800, 21928], "31": ["vertical_and_slash", 30, 800, 133206]}, {"0": ["vertical_and_slash", 100, 800, 41811], "1": ["vertical_and_slash", 30, 800, 4226], "2": ["vertical_and_slash", 100, 800, 11930], "3": ["vertical_and_slash", 30, 800, 629146], "4": ["vertical_and_slash", 100, 800, 511736], "5": ["vertical_and_slash", 100, 800, 1408], "6": ["vertical_and_slash", 30, 800, 18012], "7": ["vertical_and_slash", 30, 800, 897], "8": ["vertical_and_slash", 30, 800, 107705], "9": ["vertical_and_slash", 30, 800, 152957], "10": ["vertical_and_slash", 30, 800, 272002], "11": ["vertical_and_slash", 30, 800, 5216722], "12": ["vertical_and_slash", 30, 800, 509504], "13": ["vertical_and_slash", 30, 800, 72091], "14": ["vertical_and_slash", 30, 800, 166293], "15": ["vertical_and_slash", 30, 800, 426344], "16": ["vertical_and_slash", 30, 800, 316624], "17": ["vertical_and_slash", 1000, 4096, 158902], "18": ["vertical_and_slash", 30, 800, 162502], "19": ["vertical_and_slash", 1000, 4096, 2464314], "20": ["vertical_and_slash", 1000, 4096, 5817909], "21": ["vertical_and_slash", 100, 800, 1141235], "22": ["vertical_and_slash", 30, 800, 452577], "23": ["vertical_and_slash", 30, 800, 193960], "24": ["vertical_and_slash", 30, 800, 538157], "25": ["vertical_and_slash", 30, 800, 1355759], "26": ["vertical_and_slash", 100, 800, 141236], "27": ["vertical_and_slash", 30, 800, 87608], "28": ["vertical_and_slash", 30, 800, 102946], "29": ["vertical_and_slash", 30, 800, 81254], "30": ["vertical_and_slash", 30, 800, 6194794], "31": ["vertical_and_slash", 30, 800, 2092660]}, {"0": ["vertical_and_slash", 30, 800, 278589], "1": ["vertical_and_slash", 30, 800, 1071731], "2": ["vertical_and_slash", 30, 800, 1991650], "3": ["vertical_and_slash", 30, 800, 308703], "4": ["vertical_and_slash", 30, 800, 1024242], "5": ["vertical_and_slash", 30, 800, 3107957], "6": ["vertical_and_slash", 30, 800, 926801], "7": ["vertical_and_slash", 30, 800, 2887199], "8": ["vertical_and_slash", 1000, 4096, 4152662], "9": ["vertical_and_slash", 100, 800, 15773492], "10": ["vertical_and_slash", 30, 800, 667496], "11": ["vertical_and_slash", 30, 800, 767325], "12": ["vertical_and_slash", 30, 800, 490706], "13": ["vertical_and_slash", 100, 800, 3083166], "14": ["vertical_and_slash", 100, 800, 14433242], "15": ["vertical_and_slash", 30, 800, 514502], "16": ["vertical_and_slash", 1000, 4096, 4574900], "17": ["vertical_and_slash", 1000, 4096, 1828093], "18": ["vertical_and_slash", 30, 800, 3790483], "19": ["vertical_and_slash", 1000, 4096, 9164424], "20": ["vertical_and_slash", 1000, 4096, 1011346], "21": ["vertical_and_slash", 1000, 4096, 1768867], "22": ["vertical_and_slash", 100, 800, 3253894], "23": ["vertical_and_slash", 1000, 4096, 882663], "24": ["vertical_and_slash", 100, 800, 1974998], "25": ["vertical_and_slash", 500, 700, 1452483], "26": ["vertical_and_slash", 100, 800, 12992816], "27": ["vertical_and_slash", 1000, 4096, 4441511], "28": ["vertical_and_slash", 100, 800, 3146531], "29": ["vertical_and_slash", 1000, 4096, 7002295], "30": ["vertical_and_slash", 100, 800, 7974855], "31": ["vertical_and_slash", 1000, 4096, 2767293]}, {"0": ["vertical_and_slash", 30, 800, 517042], "1": ["vertical_and_slash", 30, 800, 9471250], "2": ["vertical_and_slash", 30, 800, 67128], "3": ["vertical_and_slash", 100, 800, 13225828], "4": ["vertical_and_slash", 1000, 4096, 8138531], "5": ["vertical_and_slash", 30, 800, 169424], "6": ["vertical_and_slash", 30, 800, 165102], "7": ["vertical_and_slash", 1000, 4096, 898000], "8": ["vertical_and_slash", 100, 800, 498306], "9": ["vertical_and_slash", 100, 800, 12016777], "10": ["vertical_and_slash", 100, 800, 13078398], "11": ["vertical_and_slash", 1000, 4096, 569449], "12": ["vertical_and_slash", 1000, 4096, 4419468], "13": ["vertical_and_slash", 100, 800, 2308923], "14": ["vertical_and_slash", 100, 800, 188999], "15": ["vertical_and_slash", 30, 800, 685736], "16": ["vertical_and_slash", 100, 800, 161819], "17": ["vertical_and_slash", 100, 800, 1878966], "18": ["vertical_and_slash", 100, 800, 7840855], "19": ["vertical_and_slash", 30, 800, 207320], "20": ["vertical_and_slash", 100, 800, 2233365], "21": ["vertical_and_slash", 100, 800, 685239], "22": ["vertical_and_slash", 1000, 4096, 1493618], "23": ["vertical_and_slash", 30, 800, 1137958], "24": ["vertical_and_slash", 30, 800, 115113], "25": ["vertical_and_slash", 30, 800, 809754], "26": ["vertical_and_slash", 30, 800, 1328591], "27": ["vertical_and_slash", 30, 800, 697970], "28": ["vertical_and_slash", 1000, 4096, 14409], "29": ["vertical_and_slash", 30, 800, 376399], "30": ["vertical_and_slash", 30, 800, 71599], "31": ["vertical_and_slash", 30, 800, 431162]}, {"0": ["vertical_and_slash", 30, 800, 7073664], "1": ["vertical_and_slash", 100, 800, 4139486], "2": ["vertical_and_slash", 30, 800, 126298], "3": ["vertical_and_slash", 30, 800, 626891], "4": ["vertical_and_slash", 1000, 4096, 244457], "5": ["vertical_and_slash", 30, 800, 338124], "6": ["vertical_and_slash", 100, 800, 4247346], "7": ["vertical_and_slash", 100, 800, 1853876], "8": ["vertical_and_slash", 1000, 4096, 6355420], "9": ["vertical_and_slash", 100, 800, 988264], "10": ["vertical_and_slash", 1000, 4096, 984583], "11": ["vertical_and_slash", 100, 800, 914211], "12": ["vertical_and_slash", 1000, 4096, 570502], "13": ["vertical_and_slash", 1000, 4096, 10187572], "14": ["vertical_and_slash", 1000, 4096, 3408578], "15": ["vertical_and_slash", 1000, 4096, 11375984], "16": ["vertical_and_slash", 100, 800, 5144098], "17": ["vertical_and_slash", 1000, 4096, 350031], "18": ["vertical_and_slash", 1000, 4096, 1299268], "19": ["vertical_and_slash", 1000, 4096, 790117], "20": ["vertical_and_slash", 100, 800, 24094], "21": ["vertical_and_slash", 30, 800, 3856442], "22": ["vertical_and_slash", 100, 800, 383726], "23": ["vertical_and_slash", 500, 700, 832], "24": ["vertical_and_slash", 100, 800, 7717427], "25": ["vertical_and_slash", 1000, 4096, 4545251], "26": ["vertical_and_slash", 30, 800, 7922478], "27": ["vertical_and_slash", 1000, 4096, 2809849], "28": ["vertical_and_slash", 1000, 4096, 4392930], "29": ["vertical_and_slash", 100, 800, 2998060], "30": ["vertical_and_slash", 100, 800, 6173903], "31": ["vertical_and_slash", 1000, 4096, 2536227]}, {"0": ["vertical_and_slash", 30, 800, 1733117], "1": ["vertical_and_slash", 100, 800, 2514524], "2": ["vertical_and_slash", 1000, 4096, 12567570], "3": ["vertical_and_slash", 1000, 4096, 2817534], "4": ["vertical_and_slash", 1000, 4096, 10571712], "5": ["vertical_and_slash", 100, 800, 1311331], "6": ["vertical_and_slash", 30, 800, 4202358], "7": ["vertical_and_slash", 30, 800, 4970102], "8": ["vertical_and_slash", 30, 800, 88687], "9": ["vertical_and_slash", 30, 800, 293880], "10": ["vertical_and_slash", 500, 700, 70693], "11": ["vertical_and_slash", 30, 800, 13849], "12": ["vertical_and_slash", 30, 800, 238706], "13": ["vertical_and_slash", 30, 800, 78435], "14": ["vertical_and_slash", 30, 800, 164251], "15": ["vertical_and_slash", 30, 800, 199789], "16": ["vertical_and_slash", 30, 800, 200684], "17": ["vertical_and_slash", 1000, 4096, 1761919], "18": ["vertical_and_slash", 30, 800, 210071], "19": ["vertical_and_slash", 30, 800, 68554], "20": ["vertical_and_slash", 30, 800, 484345], "21": ["vertical_and_slash", 30, 800, 1489873], "22": ["vertical_and_slash", 30, 800, 301028], "23": ["vertical_and_slash", 30, 800, 1124431], "24": ["vertical_and_slash", 100, 800, 636179], "25": ["vertical_and_slash", 100, 800, 611008], "26": ["vertical_and_slash", 1000, 4096, 1639], "27": ["vertical_and_slash", 1000, 4096, 8255730], "28": ["vertical_and_slash", 1000, 4096, 6678469], "29": ["vertical_and_slash", 1000, 4096, 628985], "30": ["vertical_and_slash", 1000, 4096, 348316], "31": ["vertical_and_slash", 1000, 4096, 2159698]}, {"0": ["vertical_and_slash", 100, 800, 7105558], "1": ["vertical_and_slash", 30, 800, 1085603], "2": ["vertical_and_slash", 1000, 4096, 7896209], "3": ["vertical_and_slash", 30, 800, 193488], "4": ["vertical_and_slash", 100, 800, 1467223], "5": ["vertical_and_slash", 30, 800, 13794329], "6": ["vertical_and_slash", 1000, 4096, 15661583], "7": ["vertical_and_slash", 1000, 4096, 21334871], "8": ["vertical_and_slash", 1000, 4096, 6158120], "9": ["vertical_and_slash", 1000, 4096, 7414022], "10": ["vertical_and_slash", 100, 800, 14091447], "11": ["vertical_and_slash", 1000, 4096, 15589771], "12": ["vertical_and_slash", 1000, 4096, 14632639], "13": ["vertical_and_slash", 100, 800, 1695539], "14": ["vertical_and_slash", 30, 800, 2605978], "15": ["vertical_and_slash", 1000, 4096, 12495330], "16": ["vertical_and_slash", 1000, 4096, 14564586], "17": ["vertical_and_slash", 500, 700, 962969], "18": ["vertical_and_slash", 1000, 4096, 12281016], "19": ["vertical_and_slash", 1000, 4096, 4614742], "20": ["vertical_and_slash", 100, 800, 11940535], "21": ["vertical_and_slash", 100, 800, 2445981], "22": ["vertical_and_slash", 100, 800, 2485005], "23": ["vertical_and_slash", 1000, 4096, 6864324], "24": ["vertical_and_slash", 1000, 4096, 16230551], "25": ["vertical_and_slash", 100, 800, 9358656], "26": ["vertical_and_slash", 100, 800, 14973598], "27": ["vertical_and_slash", 1000, 4096, 14250781], "28": ["vertical_and_slash", 1000, 4096, 18030248], "29": ["vertical_and_slash", 1000, 4096, 20247786], "30": ["vertical_and_slash", 1000, 4096, 12736495], "31": ["vertical_and_slash", 100, 800, 9012943]}, {"0": ["vertical_and_slash", 100, 800, 4792757], "1": ["vertical_and_slash", 100, 800, 5568805], "2": ["vertical_and_slash", 1000, 4096, 12086343], "3": ["vertical_and_slash", 100, 800, 7359182], "4": ["vertical_and_slash", 100, 800, 13719718], "5": ["vertical_and_slash", 1000, 4096, 17051068], "6": ["vertical_and_slash", 100, 800, 15947388], "7": ["vertical_and_slash", 1000, 4096, 9143327], "8": ["vertical_and_slash", 1000, 4096, 21263361], "9": ["vertical_and_slash", 1000, 4096, 17189141], "10": ["vertical_and_slash", 1000, 4096, 7802422], "11": ["vertical_and_slash", 1000, 4096, 18488560], "12": ["vertical_and_slash", 100, 800, 14938800], "13": ["vertical_and_slash", 100, 800, 11012944], "14": ["vertical_and_slash", 1000, 4096, 19104830], "15": ["vertical_and_slash", 3500, 100, 32379], "16": ["vertical_and_slash", 100, 800, 3067742], "17": ["vertical_and_slash", 100, 800, 1977488], "18": ["vertical_and_slash", 1000, 4096, 15351109], "19": ["vertical_and_slash", 30, 800, 1627281], "20": ["vertical_and_slash", 30, 800, 1280991], "21": ["vertical_and_slash", 100, 800, 12133497], "22": ["vertical_and_slash", 1000, 4096, 17870425], "23": ["vertical_and_slash", 30, 800, 4040253], "24": ["vertical_and_slash", 1000, 4096, 6272625], "25": ["vertical_and_slash", 100, 800, 1225145], "26": ["vertical_and_slash", 100, 800, 2746332], "27": ["vertical_and_slash", 100, 800, 4525182], "28": ["vertical_and_slash", 100, 800, 6274770], "29": ["vertical_and_slash", 100, 800, 6919161], "30": ["vertical_and_slash", 100, 800, 3456148], "31": ["vertical_and_slash", 100, 800, 23867]}, {"0": ["vertical_and_slash", 1000, 4096, 7275761], "1": ["vertical_and_slash", 100, 800, 5068315], "2": ["vertical_and_slash", 100, 800, 11162394], "3": ["vertical_and_slash", 100, 800, 3672939], "4": ["vertical_and_slash", 3500, 100, 20894613], "5": ["vertical_and_slash", 1000, 4096, 7938372], "6": ["vertical_and_slash", 100, 800, 12544912], "7": ["vertical_and_slash", 100, 800, 2008695], "8": ["vertical_and_slash", 1000, 4096, 3368310], "9": ["vertical_and_slash", 30, 800, 1508993], "10": ["vertical_and_slash", 1000, 4096, 3495386], "11": ["vertical_and_slash", 3500, 100, 16438193], "12": ["vertical_and_slash", 100, 800, 7069375], "13": ["vertical_and_slash", 100, 800, 10686684], "14": ["vertical_and_slash", 30, 800, 501489], "15": ["vertical_and_slash", 100, 800, 6067001], "16": ["vertical_and_slash", 100, 800, 6935788], "17": ["vertical_and_slash", 1000, 4096, 3300792], "18": ["vertical_and_slash", 100, 800, 7398154], "19": ["vertical_and_slash", 100, 800, 5788636], "20": ["vertical_and_slash", 100, 800, 4456802], "21": ["vertical_and_slash", 100, 800, 2680176], "22": ["vertical_and_slash", 100, 800, 5544567], "23": ["vertical_and_slash", 1000, 4096, 13475356], "24": ["vertical_and_slash", 1000, 4096, 4901727], "25": ["vertical_and_slash", 1000, 4096, 3768996], "26": ["vertical_and_slash", 1000, 4096, 5368869], "27": ["vertical_and_slash", 3500, 100, 14218181], "28": ["vertical_and_slash", 1000, 4096, 13003444], "29": ["vertical_and_slash", 1000, 4096, 5716382], "30": ["vertical_and_slash", 3500, 100, 19916116], "31": ["vertical_and_slash", 1000, 4096, 11776798]}, {"0": ["vertical_and_slash", 100, 800, 13001986], "1": ["vertical_and_slash", 1000, 4096, 7570569], "2": ["vertical_and_slash", 100, 800, 951160], "3": ["vertical_and_slash", 100, 800, 11933179], "4": ["vertical_and_slash", 30, 800, 5365811], "5": ["vertical_and_slash", 100, 800, 10272574], "6": ["vertical_and_slash", 1000, 4096, 6527670], "7": ["vertical_and_slash", 100, 800, 12930014], "8": ["vertical_and_slash", 100, 800, 359537], "9": ["vertical_and_slash", 100, 800, 10654966], "10": ["vertical_and_slash", 100, 800, 1330316], "11": ["vertical_and_slash", 100, 800, 9971156], "12": ["vertical_and_slash", 1000, 4096, 5781478], "13": ["vertical_and_slash", 100, 800, 6032127], "14": ["vertical_and_slash", 100, 800, 1418329], "15": ["vertical_and_slash", 100, 800, 13069922], "16": ["vertical_and_slash", 100, 800, 8547563], "17": ["vertical_and_slash", 100, 800, 970921], "18": ["vertical_and_slash", 1000, 4096, 9256328], "19": ["vertical_and_slash", 1000, 4096, 12447206], "20": ["vertical_and_slash", 100, 800, 153856], "21": ["vertical_and_slash", 100, 800, 8022371], "22": ["vertical_and_slash", 3500, 100, 18626483], "23": ["vertical_and_slash", 100, 800, 3180643], "24": ["vertical_and_slash", 30, 800, 3549186], "25": ["vertical_and_slash", 100, 800, 2600992], "26": ["vertical_and_slash", 3500, 100, 21080570], "27": ["vertical_and_slash", 1000, 4096, 2995096], "28": ["vertical_and_slash", 30, 800, 13324952], "29": ["vertical_and_slash", 100, 800, 7015426], "30": ["vertical_and_slash", 100, 800, 17142326], "31": ["vertical_and_slash", 30, 800, 2059831]}, {"0": ["vertical_and_slash", 100, 800, 336984], "1": ["vertical_and_slash", 1000, 4096, 11908787], "2": ["vertical_and_slash", 1000, 4096, 11465673], "3": ["vertical_and_slash", 1000, 4096, 3870378], "4": ["vertical_and_slash", 1000, 4096, 1000373], "5": ["vertical_and_slash", 1000, 4096, 6450804], "6": ["vertical_and_slash", 1000, 4096, 6602987], "7": ["vertical_and_slash", 1000, 4096, 6552477], "8": ["vertical_and_slash", 30, 800, 8671938], "9": ["vertical_and_slash", 100, 800, 3906764], "10": ["vertical_and_slash", 1000, 4096, 7300294], "11": ["vertical_and_slash", 100, 800, 9068418], "12": ["vertical_and_slash", 100, 800, 5573415], "13": ["vertical_and_slash", 100, 800, 4302354], "14": ["vertical_and_slash", 30, 800, 969401], "15": ["vertical_and_slash", 100, 800, 132492], "16": ["vertical_and_slash", 1000, 4096, 10575265], "17": ["vertical_and_slash", 30, 800, 114557], "18": ["vertical_and_slash", 1000, 4096, 1669778], "19": ["vertical_and_slash", 30, 800, 244697], "20": ["vertical_and_slash", 30, 800, 401989], "21": ["vertical_and_slash", 1000, 4096, 257876], "22": ["vertical_and_slash", 100, 800, 1656276], "23": ["vertical_and_slash", 100, 800, 6627755], "24": ["vertical_and_slash", 100, 800, 17069094], "25": ["vertical_and_slash", 1000, 4096, 17310922], "26": ["vertical_and_slash", 3500, 100, 19238326], "27": ["vertical_and_slash", 100, 800, 10416201], "28": ["vertical_and_slash", 1000, 4096, 9125015], "29": ["vertical_and_slash", 100, 800, 17113558], "30": ["vertical_and_slash", 1000, 4096, 12041930], "31": ["vertical_and_slash", 1000, 4096, 6060396]}, {"0": ["vertical_and_slash", 1000, 4096, 9259982], "1": ["vertical_and_slash", 1000, 4096, 8618567], "2": ["vertical_and_slash", 100, 800, 3876940], "3": ["vertical_and_slash", 1000, 4096, 12767960], "4": ["vertical_and_slash", 1000, 4096, 6112941], "5": ["vertical_and_slash", 1000, 4096, 9851048], "6": ["vertical_and_slash", 1000, 4096, 5763271], "7": ["vertical_and_slash", 1000, 4096, 12744434], "8": ["vertical_and_slash", 100, 800, 12512293], "9": ["vertical_and_slash", 1000, 4096, 2367543], "10": ["vertical_and_slash", 100, 800, 12342103], "11": ["vertical_and_slash", 100, 800, 3126675], "12": ["vertical_and_slash", 1000, 4096, 13617286], "13": ["vertical_and_slash", 1000, 4096, 8094518], "14": ["vertical_and_slash", 1000, 4096, 851614], "15": ["vertical_and_slash", 1000, 4096, 10519480], "16": ["vertical_and_slash", 100, 800, 1706372], "17": ["vertical_and_slash", 100, 800, 248757], "18": ["vertical_and_slash", 100, 800, 4394336], "19": ["vertical_and_slash", 100, 800, 1886529], "20": ["vertical_and_slash", 1000, 4096, 6486541], "21": ["vertical_and_slash", 100, 800, 1175436], "22": ["vertical_and_slash", 100, 800, 7864652], "23": ["vertical_and_slash", 100, 800, 1001917], "24": ["vertical_and_slash", 100, 800, 2494293], "25": ["vertical_and_slash", 1000, 4096, 7698995], "26": ["vertical_and_slash", 100, 800, 2946712], "27": ["vertical_and_slash", 100, 800, 5464103], "28": ["vertical_and_slash", 100, 800, 2608538], "29": ["vertical_and_slash", 100, 800, 1606308], "30": ["vertical_and_slash", 1000, 4096, 5981702], "31": ["vertical_and_slash", 3500, 100, 18590832]}, {"0": ["vertical_and_slash", 100, 800, 4688244], "1": ["vertical_and_slash", 100, 800, 11368272], "2": ["vertical_and_slash", 100, 800, 2558719], "3": ["vertical_and_slash", 1000, 4096, 9536926], "4": ["vertical_and_slash", 1000, 4096, 12315283], "5": ["vertical_and_slash", 1000, 4096, 6272119], "6": ["vertical_and_slash", 1000, 4096, 4450200], "7": ["vertical_and_slash", 100, 800, 5822568], "8": ["vertical_and_slash", 1000, 4096, 13523232], "9": ["vertical_and_slash", 100, 800, 816607], "10": ["vertical_and_slash", 1000, 4096, 15825338], "11": ["vertical_and_slash", 100, 800, 1133867], "12": ["vertical_and_slash", 100, 800, 10722989], "13": ["vertical_and_slash", 100, 800, 2466001], "14": ["vertical_and_slash", 100, 800, 16732584], "15": ["vertical_and_slash", 100, 800, 1052553], "16": ["vertical_and_slash", 100, 800, 8602649], "17": ["vertical_and_slash", 100, 800, 8851217], "18": ["vertical_and_slash", 100, 800, 6104130], "19": ["vertical_and_slash", 1000, 4096, 18459502], "20": ["vertical_and_slash", 100, 800, 8076967], "21": ["vertical_and_slash", 1000, 4096, 4863209], "22": ["vertical_and_slash", 1000, 4096, 8892415], "23": ["vertical_and_slash", 1000, 4096, 9542798], "24": ["vertical_and_slash", 100, 800, 1384183], "25": ["vertical_and_slash", 100, 800, 4035455], "26": ["vertical_and_slash", 100, 800, 536763], "27": ["vertical_and_slash", 1000, 4096, 2058585], "28": ["vertical_and_slash", 100, 800, 4195607], "29": ["vertical_and_slash", 100, 800, 2407136], "30": ["vertical_and_slash", 100, 800, 2106926], "31": ["vertical_and_slash", 100, 800, 3807607]}, {"0": ["vertical_and_slash", 100, 800, 15975096], "1": ["vertical_and_slash", 3500, 100, 20664973], "2": ["vertical_and_slash", 1000, 4096, 943914], "3": ["vertical_and_slash", 100, 800, 14363276], "4": ["vertical_and_slash", 100, 800, 720326], "5": ["vertical_and_slash", 1000, 4096, 7725879], "6": ["vertical_and_slash", 1000, 4096, 11411255], "7": ["vertical_and_slash", 1000, 4096, 9492657], "8": ["vertical_and_slash", 1000, 4096, 16448227], "9": ["vertical_and_slash", 100, 800, 6180918], "10": ["vertical_and_slash", 1000, 4096, 10942342], "11": ["vertical_and_slash", 1000, 4096, 12047657], "12": ["vertical_and_slash", 100, 800, 2376658], "13": ["vertical_and_slash", 1000, 4096, 17780083], "14": ["vertical_and_slash", 1000, 4096, 8548356], "15": ["vertical_and_slash", 100, 800, 4545880], "16": ["vertical_and_slash", 30, 800, 2020350], "17": ["vertical_and_slash", 100, 800, 15875867], "18": ["vertical_and_slash", 30, 800, 661201], "19": ["vertical_and_slash", 1000, 4096, 14915782], "20": ["vertical_and_slash", 100, 800, 4106388], "21": ["vertical_and_slash", 30, 800, 14163451], "22": ["vertical_and_slash", 100, 800, 1759639], "23": ["vertical_and_slash", 1000, 4096, 2391070], "24": ["vertical_and_slash", 100, 800, 10749758], "25": ["vertical_and_slash", 100, 800, 8022438], "26": ["vertical_and_slash", 100, 800, 1013941], "27": ["vertical_and_slash", 100, 800, 3537516], "28": ["vertical_and_slash", 100, 800, 1252545], "29": ["vertical_and_slash", 100, 800, 1155740], "30": ["vertical_and_slash", 1000, 4096, 2590667], "31": ["vertical_and_slash", 100, 800, 3320946]}, {"0": ["vertical_and_slash", 1000, 4096, 8025205], "1": ["vertical_and_slash", 500, 700, 2286667], "2": ["vertical_and_slash", 1000, 4096, 2104863], "3": ["vertical_and_slash", 1000, 4096, 2160060], "4": ["vertical_and_slash", 1000, 4096, 4209178], "5": ["vertical_and_slash", 1000, 4096, 5703899], "6": ["vertical_and_slash", 100, 800, 15566139], "7": ["vertical_and_slash", 500, 700, 464012], "8": ["vertical_and_slash", 1000, 4096, 632556], "9": ["vertical_and_slash", 1000, 4096, 10933130], "10": ["vertical_and_slash", 3500, 100, 6376023], "11": ["vertical_and_slash", 30, 800, 53293], "12": ["vertical_and_slash", 3500, 100, 9195722], "13": ["vertical_and_slash", 100, 800, 130891], "14": ["vertical_and_slash", 100, 800, 1266310], "15": ["vertical_and_slash", 100, 800, 12042893], "16": ["vertical_and_slash", 100, 800, 1440252], "17": ["vertical_and_slash", 100, 800, 5003178], "18": ["vertical_and_slash", 100, 800, 9451180], "19": ["vertical_and_slash", 100, 800, 16518635], "20": ["vertical_and_slash", 1000, 4096, 16574448], "21": ["vertical_and_slash", 100, 800, 10001073], "22": ["vertical_and_slash", 100, 800, 6194150], "23": ["vertical_and_slash", 100, 800, 1990080], "24": ["vertical_and_slash", 100, 800, 14105574], "25": ["vertical_and_slash", 3500, 100, 49578], "26": ["vertical_and_slash", 100, 800, 1368613], "27": ["vertical_and_slash", 100, 800, 882483], "28": ["vertical_and_slash", 100, 800, 200592], "29": ["vertical_and_slash", 100, 800, 4144857], "30": ["vertical_and_slash", 30, 800, 2059620], "31": ["vertical_and_slash", 1000, 4096, 7650136]}, {"0": ["vertical_and_slash", 3500, 100, 20200147], "1": ["vertical_and_slash", 100, 800, 18033672], "2": ["vertical_and_slash", 100, 800, 19227421], "3": ["vertical_and_slash", 1000, 4096, 7658465], "4": ["vertical_and_slash", 100, 800, 4862174], "5": ["vertical_and_slash", 100, 800, 6197824], "6": ["vertical_and_slash", 100, 800, 5687873], "7": ["vertical_and_slash", 100, 800, 13005015], "8": ["vertical_and_slash", 1000, 4096, 6677727], "9": ["vertical_and_slash", 500, 700, 1282697], "10": ["vertical_and_slash", 30, 800, 3148411], "11": ["vertical_and_slash", 500, 700, 8985965], "12": ["vertical_and_slash", 100, 800, 11107850], "13": ["vertical_and_slash", 30, 800, 2077544], "14": ["vertical_and_slash", 1000, 4096, 10030857], "15": ["vertical_and_slash", 100, 800, 1625067], "16": ["vertical_and_slash", 100, 800, 332660], "17": ["vertical_and_slash", 3500, 100, 17539067], "18": ["vertical_and_slash", 500, 700, 97483], "19": ["vertical_and_slash", 30, 800, 10910089], "20": ["vertical_and_slash", 500, 700, 49927], "21": ["vertical_and_slash", 1000, 4096, 2959963], "22": ["vertical_and_slash", 1000, 4096, 1232910], "23": ["vertical_and_slash", 100, 800, 482216], "24": ["vertical_and_slash", 3500, 100, 2789809], "25": ["vertical_and_slash", 3500, 100, 1787013], "26": ["vertical_and_slash", 100, 800, 6121965], "27": ["vertical_and_slash", 100, 800, 10417031], "28": ["vertical_and_slash", 100, 800, 476098], "29": ["vertical_and_slash", 3500, 100, 13019985], "30": ["vertical_and_slash", 100, 800, 15057321], "31": ["vertical_and_slash", 100, 800, 7206530]}, {"0": ["vertical_and_slash", 30, 800, 3863946], "1": ["vertical_and_slash", 3500, 100, 373838], "2": ["vertical_and_slash", 30, 800, 2498107], "3": ["vertical_and_slash", 30, 800, 1774834], "4": ["vertical_and_slash", 30, 800, 13518574], "5": ["vertical_and_slash", 30, 800, 17864279], "6": ["vertical_and_slash", 30, 800, 4971247], "7": ["vertical_and_slash", 30, 800, 15064092], "8": ["vertical_and_slash", 1000, 4096, 173702], "9": ["vertical_and_slash", 100, 800, 2079528], "10": ["vertical_and_slash", 1000, 4096, 1395995], "11": ["vertical_and_slash", 100, 800, 16807189], "12": ["vertical_and_slash", 1000, 4096, 3387818], "13": ["vertical_and_slash", 1000, 4096, 215373], "14": ["vertical_and_slash", 1000, 4096, 7656048], "15": ["vertical_and_slash", 1000, 4096, 3284167], "16": ["vertical_and_slash", 100, 800, 208560], "17": ["vertical_and_slash", 100, 800, 12910224], "18": ["vertical_and_slash", 100, 800, 2482406], "19": ["vertical_and_slash", 100, 800, 591300], "20": ["vertical_and_slash", 500, 700, 2512230], "21": ["vertical_and_slash", 100, 800, 650819], "22": ["vertical_and_slash", 100, 800, 750172], "23": ["vertical_and_slash", 100, 800, 98380], "24": ["vertical_and_slash", 1000, 4096, 12591674], "25": ["vertical_and_slash", 100, 800, 7520129], "26": ["vertical_and_slash", 3500, 100, 19780031], "27": ["vertical_and_slash", 1000, 4096, 11324806], "28": ["vertical_and_slash", 100, 800, 2339301], "29": ["vertical_and_slash", 3500, 100, 20537162], "30": ["vertical_and_slash", 100, 800, 1802458], "31": ["vertical_and_slash", 1000, 4096, 4121953]}, {"0": ["vertical_and_slash", 100, 800, 1406058], "1": ["vertical_and_slash", 30, 800, 20495], "2": ["vertical_and_slash", 100, 800, 265247], "3": ["vertical_and_slash", 30, 800, 6044172], "4": ["vertical_and_slash", 100, 800, 15417162], "5": ["vertical_and_slash", 100, 800, 20101], "6": ["vertical_and_slash", 30, 800, 12443], "7": ["vertical_and_slash", 100, 800, 1029], "8": ["vertical_and_slash", 30, 800, 49334], "9": ["vertical_and_slash", 30, 800, 30976], "10": ["vertical_and_slash", 30, 800, 127540], "11": ["vertical_and_slash", 30, 800, 3597689], "12": ["vertical_and_slash", 30, 800, 32317], "13": ["vertical_and_slash", 30, 800, 202557], "14": ["vertical_and_slash", 30, 800, 531805], "15": ["vertical_and_slash", 30, 800, 606518], "16": ["vertical_and_slash", 30, 800, 1152706], "17": ["vertical_and_slash", 1000, 4096, 5604379], "18": ["vertical_and_slash", 30, 800, 663403], "19": ["vertical_and_slash", 1000, 4096, 11655952], "20": ["vertical_and_slash", 100, 800, 15102172], "21": ["vertical_and_slash", 100, 800, 4674143], "22": ["vertical_and_slash", 500, 700, 1539328], "23": ["vertical_and_slash", 100, 800, 3051857], "24": ["vertical_and_slash", 30, 800, 123576], "25": ["vertical_and_slash", 100, 800, 964667], "26": ["vertical_and_slash", 30, 800, 41505], "27": ["vertical_and_slash", 30, 800, 59560], "28": ["vertical_and_slash", 100, 800, 17208], "29": ["vertical_and_slash", 30, 800, 82626], "30": ["vertical_and_slash", 30, 800, 1815531], "31": ["vertical_and_slash", 100, 800, 2897668]}, {"0": ["vertical_and_slash", 30, 800, 48323], "1": ["vertical_and_slash", 30, 800, 689675], "2": ["vertical_and_slash", 30, 800, 542041], "3": ["vertical_and_slash", 30, 800, 8544], "4": ["vertical_and_slash", 30, 800, 102588], "5": ["vertical_and_slash", 100, 800, 2064154], "6": ["vertical_and_slash", 30, 800, 845227], "7": ["vertical_and_slash", 30, 800, 2922720], "8": ["vertical_and_slash", 1000, 4096, 2932415], "9": ["vertical_and_slash", 1000, 4096, 3062180], "10": ["vertical_and_slash", 100, 800, 485119], "11": ["vertical_and_slash", 30, 800, 215049], "12": ["vertical_and_slash", 100, 800, 387511], "13": ["vertical_and_slash", 100, 800, 1447813], "14": ["vertical_and_slash", 1000, 4096, 3878389], "15": ["vertical_and_slash", 100, 800, 376333], "16": ["vertical_and_slash", 3500, 100, 13506969], "17": ["vertical_and_slash", 100, 800, 12850708], "18": ["vertical_and_slash", 30, 800, 372529], "19": ["vertical_and_slash", 1000, 4096, 3746168], "20": ["vertical_and_slash", 100, 800, 170359], "21": ["vertical_and_slash", 100, 800, 1130785], "22": ["vertical_and_slash", 100, 800, 116224], "23": ["vertical_and_slash", 100, 800, 1001182], "24": ["vertical_and_slash", 100, 800, 335681], "25": ["vertical_and_slash", 100, 800, 3392285], "26": ["vertical_and_slash", 1000, 4096, 4420760], "27": ["vertical_and_slash", 3500, 100, 12258981], "28": ["vertical_and_slash", 500, 700, 1941188], "29": ["vertical_and_slash", 1000, 4096, 7639240], "30": ["vertical_and_slash", 500, 700, 8277346], "31": ["vertical_and_slash", 3500, 100, 3442659]}, {"0": ["vertical_and_slash", 30, 800, 945264], "1": ["vertical_and_slash", 1000, 4096, 3474994], "2": ["vertical_and_slash", 500, 700, 218918], "3": ["vertical_and_slash", 3500, 100, 20221076], "4": ["vertical_and_slash", 3500, 100, 21680113], "5": ["vertical_and_slash", 30, 800, 94866], "6": ["vertical_and_slash", 30, 800, 190907], "7": ["vertical_and_slash", 1000, 4096, 1708889], "8": ["vertical_and_slash", 100, 800, 2832752], "9": ["vertical_and_slash", 1000, 4096, 613061], "10": ["vertical_and_slash", 1000, 4096, 7381575], "11": ["vertical_and_slash", 1000, 4096, 1462120], "12": ["vertical_and_slash", 1000, 4096, 3338671], "13": ["vertical_and_slash", 100, 800, 1664528], "14": ["vertical_and_slash", 500, 700, 143074], "15": ["vertical_and_slash", 30, 800, 433035], "16": ["vertical_and_slash", 500, 700, 210886], "17": ["vertical_and_slash", 100, 800, 8632139], "18": ["vertical_and_slash", 100, 800, 17521811], "19": ["vertical_and_slash", 30, 800, 194306], "20": ["vertical_and_slash", 100, 800, 3156950], "21": ["vertical_and_slash", 100, 800, 2413125], "22": ["vertical_and_slash", 1000, 4096, 10110205], "23": ["vertical_and_slash", 100, 800, 695569], "24": ["vertical_and_slash", 30, 800, 32256], "25": ["vertical_and_slash", 30, 800, 396762], "26": ["vertical_and_slash", 30, 800, 726815], "27": ["vertical_and_slash", 30, 800, 499056], "28": ["vertical_and_slash", 30, 800, 24234], "29": ["vertical_and_slash", 30, 800, 87299], "30": ["vertical_and_slash", 30, 800, 82758], "31": ["vertical_and_slash", 30, 800, 447266]}, {"0": ["vertical_and_slash", 100, 800, 13520320], "1": ["vertical_and_slash", 100, 800, 1746572], "2": ["vertical_and_slash", 100, 800, 81358], "3": ["vertical_and_slash", 100, 800, 53915], "4": ["vertical_and_slash", 100, 800, 16824352], "5": ["vertical_and_slash", 100, 800, 124419], "6": ["vertical_and_slash", 100, 800, 5336412], "7": ["vertical_and_slash", 100, 800, 1005227], "8": ["vertical_and_slash", 1000, 4096, 17919472], "9": ["vertical_and_slash", 100, 800, 5089389], "10": ["vertical_and_slash", 1000, 4096, 2318753], "11": ["vertical_and_slash", 100, 800, 2351529], "12": ["vertical_and_slash", 1000, 4096, 1068220], "13": ["vertical_and_slash", 1000, 4096, 18765314], "14": ["vertical_and_slash", 1000, 4096, 11512280], "15": ["vertical_and_slash", 1000, 4096, 14722530], "16": ["vertical_and_slash", 100, 800, 1542041], "17": ["vertical_and_slash", 3500, 100, 19279869], "18": ["vertical_and_slash", 100, 800, 4711439], "19": ["vertical_and_slash", 3500, 100, 3688560], "20": ["vertical_and_slash", 3500, 100, 224250], "21": ["vertical_and_slash", 100, 800, 10537230], "22": ["vertical_and_slash", 100, 800, 749819], "23": ["vertical_and_slash", 100, 800, 25187], "24": ["vertical_and_slash", 100, 800, 13068183], "25": ["vertical_and_slash", 100, 800, 17508351], "26": ["vertical_and_slash", 100, 800, 12981109], "27": ["vertical_and_slash", 100, 800, 15314279], "28": ["vertical_and_slash", 100, 800, 15558838], "29": ["vertical_and_slash", 100, 800, 3774507], "30": ["vertical_and_slash", 100, 800, 6486179], "31": ["vertical_and_slash", 100, 800, 15420283]}, {"0": ["vertical_and_slash", 100, 800, 1793383], "1": ["vertical_and_slash", 100, 800, 8103093], "2": ["vertical_and_slash", 1000, 4096, 12596743], "3": ["vertical_and_slash", 1000, 4096, 5012316], "4": ["vertical_and_slash", 1000, 4096, 12870742], "5": ["vertical_and_slash", 100, 800, 3459141], "6": ["vertical_and_slash", 30, 800, 10224901], "7": ["vertical_and_slash", 100, 800, 3753981], "8": ["vertical_and_slash", 30, 800, 140040], "9": ["vertical_and_slash", 30, 800, 550671], "10": ["vertical_and_slash", 100, 800, 94454], "11": ["vertical_and_slash", 30, 800, 8909], "12": ["vertical_and_slash", 30, 800, 152077], "13": ["vertical_and_slash", 30, 800, 49171], "14": ["vertical_and_slash", 30, 800, 107813], "15": ["vertical_and_slash", 30, 800, 128764], "16": ["vertical_and_slash", 30, 800, 617322], "17": ["vertical_and_slash", 1000, 4096, 6019612], "18": ["vertical_and_slash", 100, 800, 766582], "19": ["vertical_and_slash", 30, 800, 52503], "20": ["vertical_and_slash", 30, 800, 300294], "21": ["vertical_and_slash", 30, 800, 1577098], "22": ["vertical_and_slash", 100, 800, 838126], "23": ["vertical_and_slash", 100, 800, 1218912], "24": ["vertical_and_slash", 100, 800, 1720664], "25": ["vertical_and_slash", 100, 800, 1377743], "26": ["vertical_and_slash", 1000, 4096, 900287], "27": ["vertical_and_slash", 1000, 4096, 12066126], "28": ["vertical_and_slash", 1000, 4096, 14264762], "29": ["vertical_and_slash", 1000, 4096, 71284], "30": ["vertical_and_slash", 1000, 4096, 3218291], "31": ["vertical_and_slash", 1000, 4096, 13215387]}, {"0": ["vertical_and_slash", 100, 800, 18645971], "1": ["vertical_and_slash", 30, 800, 587932], "2": ["vertical_and_slash", 1000, 4096, 10538505], "3": ["vertical_and_slash", 30, 800, 158559], "4": ["vertical_and_slash", 100, 800, 3376593], "5": ["vertical_and_slash", 100, 800, 18383338], "6": ["vertical_and_slash", 1000, 4096, 10074810], "7": ["vertical_and_slash", 1000, 4096, 19347044], "8": ["vertical_and_slash", 1000, 4096, 6794450], "9": ["vertical_and_slash", 1000, 4096, 3529136], "10": ["vertical_and_slash", 1000, 4096, 6952639], "11": ["vertical_and_slash", 1000, 4096, 9362393], "12": ["vertical_and_slash", 1000, 4096, 5368732], "13": ["vertical_and_slash", 100, 800, 705065], "14": ["vertical_and_slash", 100, 800, 628184], "15": ["vertical_and_slash", 1000, 4096, 7575979], "16": ["vertical_and_slash", 1000, 4096, 14825324], "17": ["vertical_and_slash", 100, 800, 584190], "18": ["vertical_and_slash", 1000, 4096, 14770220], "19": ["vertical_and_slash", 100, 800, 7324628], "20": ["vertical_and_slash", 100, 800, 13439080], "21": ["vertical_and_slash", 100, 800, 2173728], "22": ["vertical_and_slash", 100, 800, 1300676], "23": ["vertical_and_slash", 3500, 100, 20507565], "24": ["vertical_and_slash", 3500, 100, 20826931], "25": ["vertical_and_slash", 100, 800, 16503925], "26": ["vertical_and_slash", 3500, 100, 20607984], "27": ["vertical_and_slash", 1000, 4096, 9100775], "28": ["vertical_and_slash", 3500, 100, 20540180], "29": ["vertical_and_slash", 1000, 4096, 19978707], "30": ["vertical_and_slash", 100, 800, 18084829], "31": ["vertical_and_slash", 100, 800, 15584755]}, {"0": ["vertical_and_slash", 100, 800, 14519032], "1": ["vertical_and_slash", 100, 800, 13637880], "2": ["vertical_and_slash", 3500, 100, 19712241], "3": ["vertical_and_slash", 100, 800, 14417159], "4": ["vertical_and_slash", 100, 800, 18931772], "5": ["vertical_and_slash", 3500, 100, 20278735], "6": ["vertical_and_slash", 100, 800, 21000177], "7": ["vertical_and_slash", 3500, 100, 20181815], "8": ["vertical_and_slash", 1000, 4096, 20667264], "9": ["vertical_and_slash", 1000, 4096, 13546806], "10": ["vertical_and_slash", 1000, 4096, 8056555], "11": ["vertical_and_slash", 1000, 4096, 14544259], "12": ["vertical_and_slash", 3500, 100, 14988539], "13": ["vertical_and_slash", 100, 800, 9925552], "14": ["vertical_and_slash", 1000, 4096, 16502140], "15": ["vertical_and_slash", 3500, 100, 1394], "16": ["vertical_and_slash", 100, 800, 6786191], "17": ["vertical_and_slash", 100, 800, 5142369], "18": ["vertical_and_slash", 1000, 4096, 18139060], "19": ["vertical_and_slash", 100, 800, 1817633], "20": ["vertical_and_slash", 100, 800, 1586931], "21": ["vertical_and_slash", 1000, 4096, 2981991], "22": ["vertical_and_slash", 1000, 4096, 19814245], "23": ["vertical_and_slash", 100, 800, 3823591], "24": ["vertical_and_slash", 1000, 4096, 11968181], "25": ["vertical_and_slash", 100, 800, 4245870], "26": ["vertical_and_slash", 100, 800, 6065658], "27": ["vertical_and_slash", 100, 800, 17099315], "28": ["vertical_and_slash", 100, 800, 14002976], "29": ["vertical_and_slash", 100, 800, 15062395], "30": ["vertical_and_slash", 3500, 100, 9832421], "31": ["vertical_and_slash", 100, 800, 329163]}, {"0": ["vertical_and_slash", 100, 800, 17881284], "1": ["vertical_and_slash", 100, 800, 6096065], "2": ["vertical_and_slash", 100, 800, 19512309], "3": ["vertical_and_slash", 100, 800, 1361094], "4": ["vertical_and_slash", 3500, 100, 21385650], "5": ["vertical_and_slash", 100, 800, 14152330], "6": ["vertical_and_slash", 100, 800, 15379238], "7": ["vertical_and_slash", 100, 800, 936209], "8": ["vertical_and_slash", 3500, 100, 7644919], "9": ["vertical_and_slash", 100, 800, 162434], "10": ["vertical_and_slash", 100, 800, 11548456], "11": ["vertical_and_slash", 100, 800, 11141282], "12": ["vertical_and_slash", 3500, 100, 6011727], "13": ["vertical_and_slash", 100, 800, 16026110], "14": ["vertical_and_slash", 100, 800, 466578], "15": ["vertical_and_slash", 100, 800, 4799040], "16": ["vertical_and_slash", 100, 800, 15252019], "17": ["vertical_and_slash", 1000, 4096, 7350605], "18": ["vertical_and_slash", 100, 800, 16896477], "19": ["vertical_and_slash", 1000, 4096, 5715502], "20": ["vertical_and_slash", 100, 800, 9885275], "21": ["vertical_and_slash", 100, 800, 8062274], "22": ["vertical_and_slash", 100, 800, 11341966], "23": ["vertical_and_slash", 3500, 100, 21639689], "24": ["vertical_and_slash", 1000, 4096, 7313536], "25": ["vertical_and_slash", 1000, 4096, 1858640], "26": ["vertical_and_slash", 100, 800, 17665215], "27": ["vertical_and_slash", 100, 800, 13827567], "28": ["vertical_and_slash", 1000, 4096, 16279088], "29": ["vertical_and_slash", 1000, 4096, 2728376], "30": ["vertical_and_slash", 1000, 4096, 20378804], "31": ["vertical_and_slash", 1000, 4096, 11218561]}, {"0": ["vertical_and_slash", 100, 800, 10702989], "1": ["vertical_and_slash", 100, 800, 13911357], "2": ["vertical_and_slash", 100, 800, 2089505], "3": ["vertical_and_slash", 100, 800, 5795130], "4": ["vertical_and_slash", 100, 800, 6198580], "5": ["vertical_and_slash", 100, 800, 11025874], "6": ["vertical_and_slash", 1000, 4096, 4765707], "7": ["vertical_and_slash", 100, 800, 9275261], "8": ["vertical_and_slash", 100, 800, 356772], "9": ["vertical_and_slash", 100, 800, 6507763], "10": ["vertical_and_slash", 100, 800, 1057022], "11": ["vertical_and_slash", 100, 800, 16390639], "12": ["vertical_and_slash", 1000, 4096, 6504148], "13": ["vertical_and_slash", 100, 800, 5815163], "14": ["vertical_and_slash", 100, 800, 781258], "15": ["vertical_and_slash", 1000, 4096, 5306413], "16": ["vertical_and_slash", 100, 800, 7571947], "17": ["vertical_and_slash", 100, 800, 2246584], "18": ["vertical_and_slash", 1000, 4096, 6370179], "19": ["vertical_and_slash", 1000, 4096, 16329738], "20": ["vertical_and_slash", 100, 800, 810202], "21": ["vertical_and_slash", 100, 800, 9614219], "22": ["vertical_and_slash", 3500, 100, 21023608], "23": ["vertical_and_slash", 100, 800, 3697853], "24": ["vertical_and_slash", 500, 700, 623385], "25": ["vertical_and_slash", 100, 800, 2872545], "26": ["vertical_and_slash", 3500, 100, 21443890], "27": ["vertical_and_slash", 1000, 4096, 964593], "28": ["vertical_and_slash", 1000, 4096, 6046647], "29": ["vertical_and_slash", 1000, 4096, 3390663], "30": ["vertical_and_slash", 3500, 100, 21396110], "31": ["vertical_and_slash", 500, 700, 1185821]}, {"0": ["vertical_and_slash", 100, 800, 929038], "1": ["vertical_and_slash", 1000, 4096, 11917459], "2": ["vertical_and_slash", 1000, 4096, 11189817], "3": ["vertical_and_slash", 1000, 4096, 5290948], "4": ["vertical_and_slash", 100, 800, 2444153], "5": ["vertical_and_slash", 1000, 4096, 7367448], "6": ["vertical_and_slash", 1000, 4096, 3929914], "7": ["vertical_and_slash", 1000, 4096, 2907293], "8": ["vertical_and_slash", 30, 800, 8631190], "9": ["vertical_and_slash", 100, 800, 7657567], "10": ["vertical_and_slash", 1000, 4096, 5754225], "11": ["vertical_and_slash", 100, 800, 16484372], "12": ["vertical_and_slash", 100, 800, 7369987], "13": ["vertical_and_slash", 100, 800, 3365312], "14": ["vertical_and_slash", 30, 800, 461151], "15": ["vertical_and_slash", 500, 700, 315608], "16": ["vertical_and_slash", 1000, 4096, 16240364], "17": ["vertical_and_slash", 100, 800, 253597], "18": ["vertical_and_slash", 1000, 4096, 925109], "19": ["vertical_and_slash", 100, 800, 133339], "20": ["vertical_and_slash", 100, 800, 578256], "21": ["vertical_and_slash", 1000, 4096, 1817521], "22": ["vertical_and_slash", 3500, 100, 4918245], "23": ["vertical_and_slash", 1000, 4096, 114317], "24": ["vertical_and_slash", 3500, 100, 20949654], "25": ["vertical_and_slash", 3500, 100, 21380515], "26": ["vertical_and_slash", 1000, 4096, 20796309], "27": ["vertical_and_slash", 100, 800, 11897642], "28": ["vertical_and_slash", 1000, 4096, 17534343], "29": ["vertical_and_slash", 1000, 4096, 20051889], "30": ["vertical_and_slash", 1000, 4096, 20184777], "31": ["vertical_and_slash", 3500, 100, 20262011]}, {"0": ["vertical_and_slash", 1000, 4096, 8179346], "1": ["vertical_and_slash", 1000, 4096, 2423899], "2": ["vertical_and_slash", 100, 800, 13818895], "3": ["vertical_and_slash", 1000, 4096, 6522601], "4": ["vertical_and_slash", 1000, 4096, 1060263], "5": ["vertical_and_slash", 1000, 4096, 4157137], "6": ["vertical_and_slash", 1000, 4096, 6990380], "7": ["vertical_and_slash", 1000, 4096, 10763715], "8": ["vertical_and_slash", 100, 800, 10123257], "9": ["vertical_and_slash", 1000, 4096, 9156840], "10": ["vertical_and_slash", 1000, 4096, 16029616], "11": ["vertical_and_slash", 100, 800, 1673944], "12": ["vertical_and_slash", 1000, 4096, 15001358], "13": ["vertical_and_slash", 1000, 4096, 11496585], "14": ["vertical_and_slash", 100, 800, 9006039], "15": ["vertical_and_slash", 1000, 4096, 13032008], "16": ["vertical_and_slash", 100, 800, 4813070], "17": ["vertical_and_slash", 100, 800, 1475285], "18": ["vertical_and_slash", 100, 800, 8000337], "19": ["vertical_and_slash", 100, 800, 8837856], "20": ["vertical_and_slash", 1000, 4096, 16977677], "21": ["vertical_and_slash", 100, 800, 4416649], "22": ["vertical_and_slash", 100, 800, 17025902], "23": ["vertical_and_slash", 100, 800, 602195], "24": ["vertical_and_slash", 3500, 100, 5765045], "25": ["vertical_and_slash", 100, 800, 13009069], "26": ["vertical_and_slash", 100, 800, 3523767], "27": ["vertical_and_slash", 100, 800, 6546733], "28": ["vertical_and_slash", 3500, 100, 3452012], "29": ["vertical_and_slash", 100, 800, 1510491], "30": ["vertical_and_slash", 3500, 100, 17227596], "31": ["vertical_and_slash", 3500, 100, 19660969]}, {"0": ["vertical_and_slash", 3500, 100, 6623789], "1": ["vertical_and_slash", 3500, 100, 3902994], "2": ["vertical_and_slash", 3500, 100, 6994928], "3": ["vertical_and_slash", 1000, 4096, 5149770], "4": ["vertical_and_slash", 3500, 100, 14836158], "5": ["vertical_and_slash", 100, 800, 17515427], "6": ["vertical_and_slash", 3500, 100, 7911558], "7": ["vertical_and_slash", 3500, 100, 9338861], "8": ["vertical_and_slash", 3500, 100, 14090410], "9": ["vertical_and_slash", 100, 800, 2492955], "10": ["vertical_and_slash", 3500, 100, 21732500], "11": ["vertical_and_slash", 100, 800, 2898121], "12": ["vertical_and_slash", 3500, 100, 10852444], "13": ["vertical_and_slash", 100, 800, 1940039], "14": ["vertical_and_slash", 3500, 100, 16338195], "15": ["vertical_and_slash", 100, 800, 2006495], "16": ["vertical_and_slash", 3500, 100, 10259390], "17": ["vertical_and_slash", 100, 800, 4065419], "18": ["vertical_and_slash", 100, 800, 12733273], "19": ["vertical_and_slash", 1000, 4096, 11751394], "20": ["vertical_and_slash", 100, 800, 15251186], "21": ["vertical_and_slash", 1000, 4096, 12287035], "22": ["vertical_and_slash", 1000, 4096, 5114508], "23": ["vertical_and_slash", 1000, 4096, 13162100], "24": ["vertical_and_slash", 100, 800, 8000122], "25": ["vertical_and_slash", 100, 800, 9281634], "26": ["vertical_and_slash", 100, 800, 1846488], "27": ["vertical_and_slash", 3500, 100, 8590692], "28": ["vertical_and_slash", 100, 800, 8643063], "29": ["vertical_and_slash", 100, 800, 5758817], "30": ["vertical_and_slash", 100, 800, 5877183], "31": ["vertical_and_slash", 100, 800, 7796906]}, {"0": ["vertical_and_slash", 100, 800, 20597532], "1": ["vertical_and_slash", 3500, 100, 21758452], "2": ["vertical_and_slash", 1000, 4096, 4144141], "3": ["vertical_and_slash", 100, 800, 20261887], "4": ["vertical_and_slash", 1000, 4096, 2512370], "5": ["vertical_and_slash", 3500, 100, 17706009], "6": ["vertical_and_slash", 1000, 4096, 19693735], "7": ["vertical_and_slash", 1000, 4096, 12879585], "8": ["vertical_and_slash", 3500, 100, 18330550], "9": ["vertical_and_slash", 1000, 4096, 395315], "10": ["vertical_and_slash", 100, 800, 12936460], "11": ["vertical_and_slash", 3500, 100, 20489362], "12": ["vertical_and_slash", 100, 800, 2920447], "13": ["vertical_and_slash", 3500, 100, 19704987], "14": ["vertical_and_slash", 3500, 100, 19332279], "15": ["vertical_and_slash", 100, 800, 8771256], "16": ["vertical_and_slash", 100, 800, 5611994], "17": ["vertical_and_slash", 100, 800, 16087138], "18": ["vertical_and_slash", 500, 700, 891236], "19": ["vertical_and_slash", 3500, 100, 21427139], "20": ["vertical_and_slash", 100, 800, 1823410], "21": ["vertical_and_slash", 30, 800, 15408418], "22": ["vertical_and_slash", 500, 700, 9266226], "23": ["vertical_and_slash", 3500, 100, 17195724], "24": ["vertical_and_slash", 1000, 4096, 7809063], "25": ["vertical_and_slash", 100, 800, 14083150], "26": ["vertical_and_slash", 100, 800, 4139113], "27": ["vertical_and_slash", 100, 800, 10706318], "28": ["vertical_and_slash", 1000, 4096, 1105380], "29": ["vertical_and_slash", 100, 800, 3630717], "30": ["vertical_and_slash", 1000, 4096, 10664933], "31": ["vertical_and_slash", 100, 800, 9143007]}, {"0": ["vertical_and_slash", 1000, 4096, 301018], "1": ["vertical_and_slash", 3500, 100, 1784828], "2": ["vertical_and_slash", 3500, 100, 7055406], "3": ["vertical_and_slash", 3500, 100, 2086934], "4": ["vertical_and_slash", 1000, 4096, 4101320], "5": ["vertical_and_slash", 1000, 4096, 1042376], "6": ["vertical_and_slash", 3500, 100, 16976048], "7": ["vertical_and_slash", 500, 700, 1459641], "8": ["vertical_and_slash", 3500, 100, 1180323], "9": ["vertical_and_slash", 3500, 100, 21763195], "10": ["vertical_and_slash", 3500, 100, 5825008], "11": ["vertical_and_slash", 100, 800, 53453], "12": ["vertical_and_slash", 3500, 100, 11794796], "13": ["vertical_and_slash", 3500, 100, 1783957], "14": ["vertical_and_slash", 100, 800, 1440345], "15": ["vertical_and_slash", 100, 800, 16828397], "16": ["vertical_and_slash", 100, 800, 2469338], "17": ["vertical_and_slash", 100, 800, 4665593], "18": ["vertical_and_slash", 3500, 100, 10580848], "19": ["vertical_and_slash", 3500, 100, 19252331], "20": ["vertical_and_slash", 3500, 100, 20024825], "21": ["vertical_and_slash", 100, 800, 14850871], "22": ["vertical_and_slash", 3500, 100, 12678003], "23": ["vertical_and_slash", 100, 800, 1782447], "24": ["vertical_and_slash", 1000, 4096, 13287971], "25": ["vertical_and_slash", 3500, 100, 1097488], "26": ["vertical_and_slash", 1000, 4096, 2633009], "27": ["vertical_and_slash", 3500, 100, 1055757], "28": ["vertical_and_slash", 3500, 100, 742496], "29": ["vertical_and_slash", 1000, 4096, 4194904], "30": ["vertical_and_slash", 3500, 100, 1577446], "31": ["vertical_and_slash", 1000, 4096, 10526781]}, {"0": ["vertical_and_slash", 1000, 4096, 12079479], "1": ["vertical_and_slash", 3500, 100, 19962962], "2": ["vertical_and_slash", 1000, 4096, 12450062], "3": ["vertical_and_slash", 1000, 4096, 10400447], "4": ["vertical_and_slash", 100, 800, 11323650], "5": ["vertical_and_slash", 1000, 4096, 4102038], "6": ["vertical_and_slash", 1000, 4096, 3338557], "7": ["vertical_and_slash", 3500, 100, 9984816], "8": ["vertical_and_slash", 100, 800, 14524592], "9": ["vertical_and_slash", 100, 800, 2065326], "10": ["vertical_and_slash", 30, 800, 4596708], "11": ["vertical_and_slash", 500, 700, 10708236], "12": ["vertical_and_slash", 500, 700, 13397191], "13": ["vertical_and_slash", 500, 700, 1011260], "14": ["vertical_and_slash", 1000, 4096, 13165340], "15": ["vertical_and_slash", 1000, 4096, 825692], "16": ["vertical_and_slash", 3500, 100, 2810461], "17": ["vertical_and_slash", 3500, 100, 19569698], "18": ["vertical_and_slash", 3500, 100, 2251981], "19": ["vertical_and_slash", 500, 700, 5559642], "20": ["vertical_and_slash", 3500, 100, 1522515], "21": ["vertical_and_slash", 1000, 4096, 982286], "22": ["vertical_and_slash", 1000, 4096, 2085881], "23": ["vertical_and_slash", 100, 800, 2055023], "24": ["vertical_and_slash", 1000, 4096, 1242380], "25": ["vertical_and_slash", 3500, 100, 1869920], "26": ["vertical_and_slash", 3500, 100, 12180284], "27": ["vertical_and_slash", 3500, 100, 14622044], "28": ["vertical_and_slash", 1000, 4096, 557560], "29": ["vertical_and_slash", 1000, 4096, 6987039], "30": ["vertical_and_slash", 100, 800, 15769951], "31": ["vertical_and_slash", 100, 800, 7721569]}, {"0": ["vertical_and_slash", 500, 700, 4382254], "1": ["vertical_and_slash", 3500, 100, 84219], "2": ["vertical_and_slash", 500, 700, 4734463], "3": ["vertical_and_slash", 500, 700, 3186548], "4": ["vertical_and_slash", 1000, 4096, 4063246], "5": ["vertical_and_slash", 1000, 4096, 12708225], "6": ["vertical_and_slash", 500, 700, 7742943], "7": ["vertical_and_slash", 100, 800, 15424159], "8": ["vertical_and_slash", 1000, 4096, 6301506], "9": ["vertical_and_slash", 1000, 4096, 2079847], "10": ["vertical_and_slash", 1000, 4096, 4217027], "11": ["vertical_and_slash", 1000, 4096, 6297884], "12": ["vertical_and_slash", 3500, 100, 4824003], "13": ["vertical_and_slash", 1000, 4096, 3960801], "14": ["vertical_and_slash", 1000, 4096, 10405673], "15": ["vertical_and_slash", 1000, 4096, 8272702], "16": ["vertical_and_slash", 3500, 100, 2874719], "17": ["vertical_and_slash", 1000, 4096, 13248253], "18": ["vertical_and_slash", 3500, 100, 16731069], "19": ["vertical_and_slash", 1000, 4096, 3488474], "20": ["vertical_and_slash", 3500, 100, 4911794], "21": ["vertical_and_slash", 3500, 100, 3300649], "22": ["vertical_and_slash", 3500, 100, 2239972], "23": ["vertical_and_slash", 1000, 4096, 847410], "24": ["vertical_and_slash", 1000, 4096, 12556756], "25": ["vertical_and_slash", 3500, 100, 10893823], "26": ["vertical_and_slash", 1000, 4096, 14168165], "27": ["vertical_and_slash", 1000, 4096, 14127548], "28": ["vertical_and_slash", 1000, 4096, 5277617], "29": ["vertical_and_slash", 1000, 4096, 16652651], "30": ["vertical_and_slash", 1000, 4096, 7991739], "31": ["vertical_and_slash", 3500, 100, 16136482]}, {"0": ["vertical_and_slash", 100, 800, 3776409], "1": ["vertical_and_slash", 100, 800, 3972530], "2": ["vertical_and_slash", 100, 800, 10166976], "3": ["vertical_and_slash", 100, 800, 13449519], "4": ["vertical_and_slash", 30, 800, 4621777], "5": ["vertical_and_slash", 30, 800, 17026761], "6": ["vertical_and_slash", 30, 800, 11401344], "7": ["vertical_and_slash", 100, 800, 3178997], "8": ["vertical_and_slash", 1000, 4096, 14919677], "9": ["vertical_and_slash", 100, 800, 13489170], "10": ["vertical_and_slash", 1000, 4096, 12483196], "11": ["vertical_and_slash", 1000, 4096, 18647183], "12": ["vertical_and_slash", 1000, 4096, 18488628], "13": ["vertical_and_slash", 3500, 100, 18285318], "14": ["vertical_and_slash", 3500, 100, 19771087], "15": ["vertical_and_slash", 100, 800, 11952058], "16": ["vertical_and_slash", 1000, 4096, 671303], "17": ["vertical_and_slash", 3500, 100, 20413410], "18": ["vertical_and_slash", 1000, 4096, 693843], "19": ["vertical_and_slash", 3500, 100, 20183012], "20": ["vertical_and_slash", 3500, 100, 4751982], "21": ["vertical_and_slash", 1000, 4096, 1190840], "22": ["vertical_and_slash", 3500, 100, 8189368], "23": ["vertical_and_slash", 3500, 100, 4191516], "24": ["vertical_and_slash", 100, 800, 9072597], "25": ["vertical_and_slash", 3500, 100, 6214053], "26": ["vertical_and_slash", 1000, 4096, 8848124], "27": ["vertical_and_slash", 3500, 100, 1231805], "28": ["vertical_and_slash", 3500, 100, 3468573], "29": ["vertical_and_slash", 3500, 100, 16841594], "30": ["vertical_and_slash", 3500, 100, 12565098], "31": ["vertical_and_slash", 3500, 100, 4308210]}, {"0": ["vertical_and_slash", 100, 800, 405030], "1": ["vertical_and_slash", 3500, 100, 12737242], "2": ["vertical_and_slash", 1000, 4096, 6996254], "3": ["vertical_and_slash", 3500, 100, 4831216], "4": ["vertical_and_slash", 3500, 100, 5890590], "5": ["vertical_and_slash", 1000, 4096, 3008671], "6": ["vertical_and_slash", 1000, 4096, 4998230], "7": ["vertical_and_slash", 1000, 4096, 6509194], "8": ["vertical_and_slash", 3500, 100, 1774041], "9": ["vertical_and_slash", 3500, 100, 1372562], "10": ["vertical_and_slash", 3500, 100, 9111804], "11": ["vertical_and_slash", 1000, 4096, 1109182], "12": ["vertical_and_slash", 100, 800, 371771], "13": ["vertical_and_slash", 3500, 100, 905824], "14": ["vertical_and_slash", 1000, 4096, 4934535], "15": ["vertical_and_slash", 1000, 4096, 2841896], "16": ["vertical_and_slash", 3500, 100, 4614245], "17": ["vertical_and_slash", 3500, 100, 6900617], "18": ["vertical_and_slash", 3500, 100, 2824788], "19": ["vertical_and_slash", 100, 800, 6589423], "20": ["vertical_and_slash", 500, 700, 6357101], "21": ["vertical_and_slash", 30, 800, 5731632], "22": ["vertical_and_slash", 30, 800, 7261064], "23": ["vertical_and_slash", 500, 700, 9172114], "24": ["vertical_and_slash", 1000, 4096, 210349], "25": ["vertical_and_slash", 1000, 4096, 4526369], "26": ["vertical_and_slash", 1000, 4096, 2326769], "27": ["vertical_and_slash", 3500, 100, 5989844], "28": ["vertical_and_slash", 3500, 100, 1393004], "29": ["vertical_and_slash", 3500, 100, 2114704], "30": ["vertical_and_slash", 3500, 100, 776564], "31": ["vertical_and_slash", 3500, 100, 2826514]}, {"0": ["vertical_and_slash", 1000, 4096, 4747927], "1": ["vertical_and_slash", 3500, 100, 14468785], "2": ["vertical_and_slash", 3500, 100, 10124003], "3": ["vertical_and_slash", 3500, 100, 6702061], "4": ["vertical_and_slash", 1000, 4096, 2311190], "5": ["vertical_and_slash", 1000, 4096, 2412642], "6": ["vertical_and_slash", 1000, 4096, 2782532], "7": ["vertical_and_slash", 3500, 100, 6699063], "8": ["vertical_and_slash", 100, 800, 10899273], "9": ["vertical_and_slash", 100, 800, 571205], "10": ["vertical_and_slash", 1000, 4096, 2224039], "11": ["vertical_and_slash", 3500, 100, 5206481], "12": ["vertical_and_slash", 100, 800, 6039530], "13": ["vertical_and_slash", 3500, 100, 6121024], "14": ["vertical_and_slash", 1000, 4096, 915849], "15": ["vertical_and_slash", 3500, 100, 4393793], "16": ["vertical_and_slash", 1000, 4096, 4168491], "17": ["vertical_and_slash", 3500, 100, 5568206], "18": ["vertical_and_slash", 1000, 4096, 1087118], "19": ["vertical_and_slash", 1000, 4096, 2691708], "20": ["vertical_and_slash", 3500, 100, 4351677], "21": ["vertical_and_slash", 3500, 100, 3933999], "22": ["vertical_and_slash", 3500, 100, 3997663], "23": ["vertical_and_slash", 3500, 100, 3522236], "24": ["vertical_and_slash", 3500, 100, 9956224], "25": ["vertical_and_slash", 3500, 100, 4192895], "26": ["vertical_and_slash", 3500, 100, 9150842], "27": ["vertical_and_slash", 3500, 100, 12754903], "28": ["vertical_and_slash", 3500, 100, 7346979], "29": ["vertical_and_slash", 100, 800, 9422285], "30": ["vertical_and_slash", 100, 800, 3140769], "31": ["vertical_and_slash", 500, 700, 2415994]}, {"0": ["vertical_and_slash", 3500, 100, 4352921], "1": ["vertical_and_slash", 1000, 4096, 3398326], "2": ["vertical_and_slash", 3500, 100, 5788760], "3": ["vertical_and_slash", 1000, 4096, 2945608], "4": ["vertical_and_slash", 3500, 100, 1988612], "5": ["vertical_and_slash", 1000, 4096, 3736165], "6": ["vertical_and_slash", 1000, 4096, 9670660], "7": ["vertical_and_slash", 3500, 100, 3803388], "8": ["vertical_and_slash", 3500, 100, 3612542], "9": ["vertical_and_slash", 3500, 100, 4948698], "10": ["vertical_and_slash", 3500, 100, 4880140], "11": ["vertical_and_slash", 3500, 100, 2083345], "12": ["vertical_and_slash", 3500, 100, 4683160], "13": ["vertical_and_slash", 3500, 100, 3650326], "14": ["vertical_and_slash", 3500, 100, 1071456], "15": ["vertical_and_slash", 1000, 4096, 3490570], "16": ["vertical_and_slash", 1000, 4096, 1082160], "17": ["vertical_and_slash", 3500, 100, 6888781], "18": ["vertical_and_slash", 1000, 4096, 2664476], "19": ["vertical_and_slash", 3500, 100, 2759933], "20": ["vertical_and_slash", 100, 800, 653736], "21": ["vertical_and_slash", 3500, 100, 9517662], "22": ["vertical_and_slash", 3500, 100, 3973048], "23": ["vertical_and_slash", 3500, 100, 5761264], "24": ["vertical_and_slash", 3500, 100, 13615692], "25": ["vertical_and_slash", 1000, 4096, 5235320], "26": ["vertical_and_slash", 3500, 100, 10009513], "27": ["vertical_and_slash", 1000, 4096, 2682717], "28": ["vertical_and_slash", 3500, 100, 11382630], "29": ["vertical_and_slash", 3500, 100, 3802301], "30": ["vertical_and_slash", 1000, 4096, 3025864], "31": ["vertical_and_slash", 1000, 4096, 1725752]}, {"0": ["vertical_and_slash", 1000, 4096, 12877084], "1": ["vertical_and_slash", 1000, 4096, 11642564], "2": ["vertical_and_slash", 1000, 4096, 10978654], "3": ["vertical_and_slash", 3500, 100, 14674762], "4": ["vertical_and_slash", 1000, 4096, 8335239], "5": ["vertical_and_slash", 1000, 4096, 11808042], "6": ["vertical_and_slash", 1000, 4096, 10213550], "7": ["vertical_and_slash", 3500, 100, 14957853], "8": ["vertical_and_slash", 500, 700, 19867441], "9": ["vertical_and_slash", 100, 800, 10566603], "10": ["vertical_and_slash", 3500, 100, 19670449], "11": ["vertical_and_slash", 1000, 4096, 12608408], "12": ["vertical_and_slash", 3500, 100, 19432490], "13": ["vertical_and_slash", 3500, 100, 21127812], "14": ["vertical_and_slash", 3500, 100, 16648204], "15": ["vertical_and_slash", 1000, 4096, 10819630], "16": ["vertical_and_slash", 3500, 100, 5741199], "17": ["vertical_and_slash", 3500, 100, 2265976], "18": ["vertical_and_slash", 1000, 4096, 1571848], "19": ["vertical_and_slash", 3500, 100, 12168656], "20": ["vertical_and_slash", 3500, 100, 12687129], "21": ["vertical_and_slash", 1000, 4096, 4052254], "22": ["vertical_and_slash", 3500, 100, 9260206], "23": ["vertical_and_slash", 1000, 4096, 4467273], "24": ["vertical_and_slash", 100, 800, 17813181], "25": ["vertical_and_slash", 3500, 100, 21532596], "26": ["vertical_and_slash", 1000, 4096, 14291589], "27": ["vertical_and_slash", 1000, 4096, 17941032], "28": ["vertical_and_slash", 1000, 4096, 20269858], "29": ["vertical_and_slash", 100, 800, 16481898], "30": ["vertical_and_slash", 100, 800, 14035138], "31": ["vertical_and_slash", 3500, 100, 5218579]}, {"0": ["vertical_and_slash", 1000, 4096, 15472775], "1": ["vertical_and_slash", 500, 700, 16487444], "2": ["vertical_and_slash", 1000, 4096, 13062108], "3": ["vertical_and_slash", 1000, 4096, 17155780], "4": ["vertical_and_slash", 1000, 4096, 9528835], "5": ["vertical_and_slash", 1000, 4096, 18482684], "6": ["vertical_and_slash", 1000, 4096, 17086801], "7": ["vertical_and_slash", 100, 800, 16495168], "8": ["vertical_and_slash", 1000, 4096, 6931295], "9": ["vertical_and_slash", 3500, 100, 21960054], "10": ["vertical_and_slash", 1000, 4096, 13941150], "11": ["vertical_and_slash", 3500, 100, 6249722], "12": ["vertical_and_slash", 1000, 4096, 12292065], "13": ["vertical_and_slash", 3500, 100, 14056066], "14": ["vertical_and_slash", 1000, 4096, 17988711], "15": ["vertical_and_slash", 3500, 100, 13838932], "16": ["vertical_and_slash", 3500, 100, 11542474], "17": ["vertical_and_slash", 1000, 4096, 10272174], "18": ["vertical_and_slash", 3500, 100, 10106952], "19": ["vertical_and_slash", 1000, 4096, 11953729], "20": ["vertical_and_slash", 1000, 4096, 12125335], "21": ["vertical_and_slash", 1000, 4096, 5421557], "22": ["vertical_and_slash", 1000, 4096, 17046156], "23": ["vertical_and_slash", 1000, 4096, 13763363], "24": ["vertical_and_slash", 1000, 4096, 14971340], "25": ["vertical_and_slash", 1000, 4096, 13949429], "26": ["vertical_and_slash", 1000, 4096, 13427580], "27": ["vertical_and_slash", 1000, 4096, 12712355], "28": ["vertical_and_slash", 1000, 4096, 10262417], "29": ["vertical_and_slash", 1000, 4096, 14593517], "30": ["vertical_and_slash", 3500, 100, 19020287], "31": ["vertical_and_slash", 1000, 4096, 16309396]}, {"0": ["vertical_and_slash", 100, 800, 6402139], "1": ["vertical_and_slash", 500, 700, 8580595], "2": ["vertical_and_slash", 3500, 100, 6974040], "3": ["vertical_and_slash", 500, 700, 9230357], "4": ["vertical_and_slash", 500, 700, 1458178], "5": ["vertical_and_slash", 3500, 100, 12626929], "6": ["vertical_and_slash", 500, 700, 7367522], "7": ["vertical_and_slash", 30, 800, 16753754], "8": ["vertical_and_slash", 100, 800, 16185443], "9": ["vertical_and_slash", 30, 800, 13212259], "10": ["vertical_and_slash", 30, 800, 16869582], "11": ["vertical_and_slash", 100, 800, 8982160], "12": ["vertical_and_slash", 3500, 100, 15101824], "13": ["vertical_and_slash", 500, 700, 10028751], "14": ["vertical_and_slash", 30, 800, 18999889], "15": ["vertical_and_slash", 100, 800, 15535188], "16": ["vertical_and_slash", 1000, 4096, 3376934], "17": ["vertical_and_slash", 1000, 4096, 3838435], "18": ["vertical_and_slash", 1000, 4096, 2789787], "19": ["vertical_and_slash", 1000, 4096, 9668519], "20": ["vertical_and_slash", 500, 700, 16137894], "21": ["vertical_and_slash", 1000, 4096, 3380197], "22": ["vertical_and_slash", 500, 700, 6788616], "23": ["vertical_and_slash", 1000, 4096, 4978497], "24": ["vertical_and_slash", 3500, 100, 9896749], "25": ["vertical_and_slash", 500, 700, 20982412], "26": ["vertical_and_slash", 1000, 4096, 5738438], "27": ["vertical_and_slash", 1000, 4096, 14533987], "28": ["vertical_and_slash", 3500, 100, 11385648], "29": ["vertical_and_slash", 30, 800, 11091461], "30": ["vertical_and_slash", 1000, 4096, 7801211], "31": ["vertical_and_slash", 1000, 4096, 12946499]}, {"0": ["vertical_and_slash", 1000, 4096, 8005141], "1": ["vertical_and_slash", 30, 800, 9683398], "2": ["vertical_and_slash", 100, 800, 15684848], "3": ["vertical_and_slash", 30, 800, 10783581], "4": ["vertical_and_slash", 30, 800, 12674711], "5": ["vertical_and_slash", 100, 800, 17627426], "6": ["vertical_and_slash", 500, 700, 6603740], "7": ["vertical_and_slash", 30, 800, 8037793], "8": ["vertical_and_slash", 1000, 4096, 18603355], "9": ["vertical_and_slash", 100, 800, 18175297], "10": ["vertical_and_slash", 1000, 4096, 15415235], "11": ["vertical_and_slash", 100, 800, 8188133], "12": ["vertical_and_slash", 100, 800, 16790430], "13": ["vertical_and_slash", 1000, 4096, 4440951], "14": ["vertical_and_slash", 1000, 4096, 12155674], "15": ["vertical_and_slash", 3500, 100, 18728501], "16": ["vertical_and_slash", 30, 800, 8282869], "17": ["vertical_and_slash", 30, 800, 18611641], "18": ["vertical_and_slash", 30, 800, 7125529], "19": ["vertical_and_slash", 30, 800, 9867525], "20": ["vertical_and_slash", 100, 800, 8121064], "21": ["vertical_and_slash", 100, 800, 8406786], "22": ["vertical_and_slash", 30, 800, 11020990], "23": ["vertical_and_slash", 30, 800, 4944682], "24": ["vertical_and_slash", 30, 800, 16714152], "25": ["vertical_and_slash", 30, 800, 9194588], "26": ["vertical_and_slash", 500, 700, 9003731], "27": ["vertical_and_slash", 1000, 4096, 6939820], "28": ["vertical_and_slash", 500, 700, 10839557], "29": ["vertical_and_slash", 500, 700, 14432584], "30": ["vertical_and_slash", 100, 800, 12363347], "31": ["vertical_and_slash", 30, 800, 14465663]}]
|
minference/configs/model2path.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
|
| 4 |
+
MODEL2PATH = {
|
| 5 |
+
"gradientai/Llama-3-8B-Instruct-262k": os.path.join(
|
| 6 |
+
BASE_DIR, "Llama_3_8B_Instruct_262k_kv_out_v32_fit_o_best_pattern.json"
|
| 7 |
+
),
|
| 8 |
+
"gradientai/Llama-3-8B-Instruct-Gradient-1048k": os.path.join(
|
| 9 |
+
BASE_DIR, "Llama_3_8B_Instruct_262k_kv_out_v32_fit_o_best_pattern.json"
|
| 10 |
+
),
|
| 11 |
+
"01-ai/Yi-9B-200K": os.path.join(
|
| 12 |
+
BASE_DIR, "Yi_9B_200k_kv_out_v32_fit_o_best_pattern.json"
|
| 13 |
+
),
|
| 14 |
+
"microsoft/Phi-3-mini-128k-instruct": os.path.join(
|
| 15 |
+
BASE_DIR, "Phi_3_mini_128k_instruct_kv_out_v32_fit_o_best_pattern.json"
|
| 16 |
+
),
|
| 17 |
+
}
|
minference/minference_configuration.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from .configs.model2path import MODEL2PATH
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class MInferenceConfig:
|
| 7 |
+
ATTENTION_TYPES = [
|
| 8 |
+
"minference",
|
| 9 |
+
"minference_with_dense",
|
| 10 |
+
"static",
|
| 11 |
+
"dilated1",
|
| 12 |
+
"dilated2",
|
| 13 |
+
"streaming",
|
| 14 |
+
"inf_llm",
|
| 15 |
+
"vllm",
|
| 16 |
+
]
|
| 17 |
+
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
attn_type: str = "minference",
|
| 21 |
+
model_name: str = None,
|
| 22 |
+
config_path: str = None,
|
| 23 |
+
starting_layer: int = -1,
|
| 24 |
+
kv_cache_cpu: bool = False,
|
| 25 |
+
use_snapkv: bool = False,
|
| 26 |
+
is_search: bool = False,
|
| 27 |
+
attn_kwargs: dict = {},
|
| 28 |
+
**kwargs,
|
| 29 |
+
):
|
| 30 |
+
super(MInferenceConfig, self).__init__()
|
| 31 |
+
assert (
|
| 32 |
+
attn_type in self.ATTENTION_TYPES
|
| 33 |
+
), f"The attention_type {attn_type} you specified is not supported."
|
| 34 |
+
self.attn_type = attn_type
|
| 35 |
+
self.config_path = self.update_config_path(config_path, model_name)
|
| 36 |
+
self.model_name = model_name
|
| 37 |
+
self.is_search = is_search
|
| 38 |
+
self.starting_layer = starting_layer
|
| 39 |
+
self.kv_cache_cpu = kv_cache_cpu
|
| 40 |
+
self.use_snapkv = use_snapkv
|
| 41 |
+
self.attn_kwargs = attn_kwargs
|
| 42 |
+
|
| 43 |
+
def update_config_path(self, config_path: str, model_name: str):
|
| 44 |
+
if config_path is not None:
|
| 45 |
+
return config_path
|
| 46 |
+
assert (
|
| 47 |
+
model_name in MODEL2PATH
|
| 48 |
+
), f"The model {model_name} you specified is not supported. You are welcome to add it and open a PR :)"
|
| 49 |
+
return MODEL2PATH[model_name]
|
minference/models_patch.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from .minference_configuration import MInferenceConfig
|
| 4 |
+
from .patch import minference_patch, minference_patch_vllm, patch_hf
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class MInference:
|
| 8 |
+
def __init__(
|
| 9 |
+
self,
|
| 10 |
+
attn_type: str = "minference",
|
| 11 |
+
model_name: str = None,
|
| 12 |
+
config_path: str = None,
|
| 13 |
+
starting_layer: int = -1,
|
| 14 |
+
kv_cache_cpu: bool = False,
|
| 15 |
+
use_snapkv: bool = False,
|
| 16 |
+
is_search: bool = False,
|
| 17 |
+
attn_kwargs: dict = {},
|
| 18 |
+
**kwargs,
|
| 19 |
+
):
|
| 20 |
+
super(MInference, self).__init__()
|
| 21 |
+
self.config = MInferenceConfig(
|
| 22 |
+
attn_type=attn_type,
|
| 23 |
+
model_name=model_name,
|
| 24 |
+
config_path=config_path,
|
| 25 |
+
starting_layer=starting_layer,
|
| 26 |
+
kv_cache_cpu=kv_cache_cpu,
|
| 27 |
+
use_snapkv=use_snapkv,
|
| 28 |
+
is_search=is_search,
|
| 29 |
+
attn_kwargs=attn_kwargs,
|
| 30 |
+
**kwargs,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
def __call__(self, model):
|
| 34 |
+
return self.patch_model(model)
|
| 35 |
+
|
| 36 |
+
def patch_model(self, model):
|
| 37 |
+
if self.config.attn_type != "vllm":
|
| 38 |
+
model.config.starting_layer = self.config.starting_layer
|
| 39 |
+
model.config.config_path = self.config.config_path
|
| 40 |
+
|
| 41 |
+
if self.config.attn_type == "minference":
|
| 42 |
+
model.config.is_search = self.config.is_search
|
| 43 |
+
model = minference_patch(model, self.config)
|
| 44 |
+
|
| 45 |
+
elif self.config.attn_type == "minference_with_dense":
|
| 46 |
+
model.config.dense = True
|
| 47 |
+
model = minference_patch(model, self.config)
|
| 48 |
+
|
| 49 |
+
elif self.config.attn_type == "dilated1":
|
| 50 |
+
model.config.dilated1 = True
|
| 51 |
+
model = minference_patch(model, self.config)
|
| 52 |
+
|
| 53 |
+
elif self.config.attn_type == "static":
|
| 54 |
+
model.config.static_pattern = True
|
| 55 |
+
model = minference_patch(model, self.config)
|
| 56 |
+
|
| 57 |
+
elif self.config.attn_type == "dilated2":
|
| 58 |
+
model.config.dilated2 = True
|
| 59 |
+
model = minference_patch(model, self.config)
|
| 60 |
+
|
| 61 |
+
elif self.config.attn_type == "streaming":
|
| 62 |
+
model.config.streaming = True
|
| 63 |
+
model.config.streaming_kwargs = {
|
| 64 |
+
"n_local": 3968,
|
| 65 |
+
"n_init": 128,
|
| 66 |
+
**self.config.attn_kwargs,
|
| 67 |
+
}
|
| 68 |
+
model = minference_patch(model, self.config)
|
| 69 |
+
|
| 70 |
+
elif self.config.attn_type == "streaming2":
|
| 71 |
+
model = patch_hf(
|
| 72 |
+
model,
|
| 73 |
+
attn_type="streaming",
|
| 74 |
+
attn_kwargs={"n_local": 3968, "n_init": 128, **self.config.attn_kwargs},
|
| 75 |
+
)
|
| 76 |
+
elif self.config.attn_type == "inf_llm":
|
| 77 |
+
model = patch_hf(
|
| 78 |
+
model,
|
| 79 |
+
attn_type="inf_llm",
|
| 80 |
+
attn_kwargs={
|
| 81 |
+
"block_size": 128,
|
| 82 |
+
"n_init": 128,
|
| 83 |
+
"n_local": 4096,
|
| 84 |
+
"topk": 16,
|
| 85 |
+
"repr_topk": 4,
|
| 86 |
+
"max_cached_block": 32,
|
| 87 |
+
"exc_block_size": 512,
|
| 88 |
+
"base": 1000000,
|
| 89 |
+
"distance_scale": 1.0,
|
| 90 |
+
"dense_decoding": True,
|
| 91 |
+
**self.config.attn_kwargs,
|
| 92 |
+
},
|
| 93 |
+
)
|
| 94 |
+
elif self.config.attn_type == "vllm":
|
| 95 |
+
model = minference_patch_vllm(model, self.config.config_path)
|
| 96 |
+
else:
|
| 97 |
+
raise ValueError(
|
| 98 |
+
f"The attention type {self.config.attn_type} you specified is not supported."
|
| 99 |
+
)
|
| 100 |
+
return model
|
minference/modules/inf_llm.py
ADDED
|
@@ -0,0 +1,1296 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from copy import deepcopy
|
| 2 |
+
from typing import Optional, Tuple
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from flash_attn import flash_attn_func
|
| 6 |
+
from transformers.modeling_outputs import CausalLMOutput
|
| 7 |
+
|
| 8 |
+
from ..ops.streaming_kernel import TritonMultiStageDotProductionAttention
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class CudaCache:
|
| 12 |
+
def __init__(self, num_units, unit_size, dtype):
|
| 13 |
+
self.num_units = num_units
|
| 14 |
+
self.unit_size = unit_size
|
| 15 |
+
self.dtype = dtype
|
| 16 |
+
self.data = torch.empty((num_units, unit_size), device="cuda", dtype=dtype)
|
| 17 |
+
self.idle_set = set(list(range(num_units)))
|
| 18 |
+
|
| 19 |
+
def alloc(self):
|
| 20 |
+
assert len(self.idle_set) > 0
|
| 21 |
+
|
| 22 |
+
idx = self.idle_set.pop()
|
| 23 |
+
return self.data[idx], idx
|
| 24 |
+
|
| 25 |
+
def delete(self, idx):
|
| 26 |
+
assert idx not in self.idle_set
|
| 27 |
+
self.idle_set.add(idx)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class MemoryUnit:
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
kv: Tuple[torch.Tensor, torch.Tensor],
|
| 34 |
+
cache: CudaCache,
|
| 35 |
+
load_to_cache: bool = False,
|
| 36 |
+
pin_memory: bool = False,
|
| 37 |
+
):
|
| 38 |
+
self.cache = cache
|
| 39 |
+
|
| 40 |
+
if kv[0].is_cuda:
|
| 41 |
+
cpu_data = tuple(_t.contiguous().to("cpu", non_blocking=True) for _t in kv)
|
| 42 |
+
else:
|
| 43 |
+
cpu_data = tuple(_t.contiguous() for _t in kv)
|
| 44 |
+
|
| 45 |
+
if pin_memory:
|
| 46 |
+
cpu_data = tuple(_t.pin_memory() for _t in cpu_data)
|
| 47 |
+
|
| 48 |
+
if load_to_cache:
|
| 49 |
+
gpu_data, gpu_data_id = cache.alloc()
|
| 50 |
+
gpu_data = gpu_data.view((2,) + kv[0].shape)
|
| 51 |
+
gpu_data[0].copy_(kv[0], non_blocking=True)
|
| 52 |
+
gpu_data[1].copy_(kv[1], non_blocking=True)
|
| 53 |
+
event = torch.cuda.Event()
|
| 54 |
+
event.record(torch.cuda.current_stream())
|
| 55 |
+
else:
|
| 56 |
+
gpu_data, gpu_data_id = None, None
|
| 57 |
+
event = None
|
| 58 |
+
|
| 59 |
+
self.cpu_data = cpu_data
|
| 60 |
+
self.gpu_data = gpu_data
|
| 61 |
+
self.gpu_data_id = gpu_data_id
|
| 62 |
+
self.event = event
|
| 63 |
+
|
| 64 |
+
def load(self, target: Optional[Tuple[torch.Tensor, torch.Tensor]] = None) -> bool:
|
| 65 |
+
if self.gpu_data is not None:
|
| 66 |
+
if target is not None:
|
| 67 |
+
target[0].copy_(self.gpu_data[0], non_blocking=True)
|
| 68 |
+
target[1].copy_(self.gpu_data[1], non_blocking=True)
|
| 69 |
+
target_event = torch.cuda.Event()
|
| 70 |
+
target_event.record(torch.cuda.current_stream())
|
| 71 |
+
else:
|
| 72 |
+
target_event = None
|
| 73 |
+
|
| 74 |
+
return False, target_event
|
| 75 |
+
|
| 76 |
+
gpu_data, gpu_data_id = self.cache.alloc()
|
| 77 |
+
gpu_data = gpu_data.view((2,) + self.cpu_data[0].shape)
|
| 78 |
+
if target is not None:
|
| 79 |
+
target[0].copy_(self.cpu_data[0], non_blocking=True)
|
| 80 |
+
target[1].copy_(self.cpu_data[1], non_blocking=True)
|
| 81 |
+
target_event = torch.cuda.Event()
|
| 82 |
+
target_event.record(torch.cuda.current_stream())
|
| 83 |
+
gpu_data[0].copy_(target[0], non_blocking=True)
|
| 84 |
+
gpu_data[1].copy_(target[1], non_blocking=True)
|
| 85 |
+
|
| 86 |
+
else:
|
| 87 |
+
gpu_data[0].copy_(self.cpu_data[0], non_blocking=True)
|
| 88 |
+
gpu_data[1].copy_(self.cpu_data[1], non_blocking=True)
|
| 89 |
+
|
| 90 |
+
event = torch.cuda.Event()
|
| 91 |
+
event.record(torch.cuda.current_stream())
|
| 92 |
+
self.event = event
|
| 93 |
+
self.gpu_data = gpu_data
|
| 94 |
+
self.gpu_data_id = gpu_data_id
|
| 95 |
+
|
| 96 |
+
return True, target_event
|
| 97 |
+
|
| 98 |
+
def get(self):
|
| 99 |
+
assert self.gpu_data is not None
|
| 100 |
+
self.event.wait()
|
| 101 |
+
return self.gpu_data
|
| 102 |
+
|
| 103 |
+
def offload(self):
|
| 104 |
+
assert self.gpu_data is not None
|
| 105 |
+
self.event.wait()
|
| 106 |
+
self.gpu_data = None
|
| 107 |
+
self.cache.delete(self.gpu_data_id)
|
| 108 |
+
self.gpu_data_id = None
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class VectorTensor:
|
| 112 |
+
def __init__(self, hidden_size, element_dtype):
|
| 113 |
+
init_cached_size = 16
|
| 114 |
+
self.data = torch.empty(
|
| 115 |
+
(init_cached_size, hidden_size), dtype=element_dtype, device="cuda"
|
| 116 |
+
)
|
| 117 |
+
self.length = 0
|
| 118 |
+
self.cache_size = init_cached_size
|
| 119 |
+
self.hidden_size = hidden_size
|
| 120 |
+
|
| 121 |
+
def append_cache(self):
|
| 122 |
+
new_cache_size = self.cache_size * 2
|
| 123 |
+
data_shape = self.data.shape
|
| 124 |
+
new_data = torch.empty(
|
| 125 |
+
(new_cache_size,) + data_shape[1:], device="cuda", dtype=self.data.dtype
|
| 126 |
+
)
|
| 127 |
+
new_data[: self.cache_size, ...].copy_(self.data)
|
| 128 |
+
self.data = new_data
|
| 129 |
+
self.cache_size = new_cache_size
|
| 130 |
+
|
| 131 |
+
def append(self, tensor: torch.Tensor):
|
| 132 |
+
assert tensor.dtype == self.data.dtype
|
| 133 |
+
assert tensor.size(1) == self.hidden_size
|
| 134 |
+
assert tensor.is_contiguous()
|
| 135 |
+
|
| 136 |
+
append_l = tensor.size(0)
|
| 137 |
+
|
| 138 |
+
while self.length + append_l > self.cache_size:
|
| 139 |
+
self.append_cache()
|
| 140 |
+
|
| 141 |
+
self.data[self.length : self.length + append_l, ...].copy_(tensor)
|
| 142 |
+
|
| 143 |
+
self.length += append_l
|
| 144 |
+
|
| 145 |
+
def get_data(self):
|
| 146 |
+
return self.data[: self.length, ...]
|
| 147 |
+
|
| 148 |
+
def get_topk(self, tensor: torch.Tensor, topk): # inner product
|
| 149 |
+
assert tensor.dim() == 1 and tensor.size(0) == self.hidden_size
|
| 150 |
+
logits = torch.matmul(self.data[: self.length], tensor[:, None]).squeeze(dim=-1)
|
| 151 |
+
assert logits.dim() == 1 and logits.size(0) == self.length
|
| 152 |
+
return logits.topk(topk, dim=0).indices.cpu().tolist()
|
| 153 |
+
|
| 154 |
+
def __len__(self):
|
| 155 |
+
return self.length
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
class Faiss:
|
| 159 |
+
def __init__(self, hidden_size, element_dtype):
|
| 160 |
+
import faiss
|
| 161 |
+
|
| 162 |
+
# We use the CPU index here because the GPU index requires a long initialization time
|
| 163 |
+
self.index = faiss.IndexFlatIP(hidden_size)
|
| 164 |
+
self.hidden_size = hidden_size
|
| 165 |
+
|
| 166 |
+
def append(self, tensor: torch.Tensor):
|
| 167 |
+
assert tensor.dim() == 2 and tensor.size(1) == self.hidden_size
|
| 168 |
+
self.index.add(tensor.cpu().float().numpy().astype("float32"))
|
| 169 |
+
|
| 170 |
+
def get_data(self):
|
| 171 |
+
raise ValueError
|
| 172 |
+
|
| 173 |
+
def get_topk(self, tensor: torch.Tensor, topk):
|
| 174 |
+
assert tensor.dim() == 1 and tensor.size(0) == self.hidden_size
|
| 175 |
+
xq = tensor[None, :].cpu().float().numpy().astype("float32")
|
| 176 |
+
topk_index = self.index.search(xq, topk)[1][0].tolist()
|
| 177 |
+
return topk_index
|
| 178 |
+
|
| 179 |
+
def __len__(self):
|
| 180 |
+
return self.index.ntotal
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
GLOBAL_STREAM = None
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
class ContextManager:
|
| 187 |
+
def __init__(
|
| 188 |
+
self,
|
| 189 |
+
position_embedding,
|
| 190 |
+
n_init,
|
| 191 |
+
n_local,
|
| 192 |
+
block_size,
|
| 193 |
+
max_cached_block,
|
| 194 |
+
topk,
|
| 195 |
+
exc_block_size,
|
| 196 |
+
score_decay: Optional[float] = None,
|
| 197 |
+
repr_topk: int = 1,
|
| 198 |
+
cache_strategy="lru",
|
| 199 |
+
chunk_topk_calc: Optional[int] = None,
|
| 200 |
+
async_global_stream: bool = False,
|
| 201 |
+
pin_memory: bool = False,
|
| 202 |
+
faiss: bool = False,
|
| 203 |
+
perhead: bool = False,
|
| 204 |
+
dense_decoding: bool = False,
|
| 205 |
+
):
|
| 206 |
+
self.length = 0
|
| 207 |
+
self.position_embedding = position_embedding
|
| 208 |
+
self.n_init = n_init
|
| 209 |
+
self.n_local = n_local
|
| 210 |
+
self.block_size = block_size
|
| 211 |
+
self.max_cached_block = max_cached_block
|
| 212 |
+
self.exc_block_size = exc_block_size
|
| 213 |
+
self.score_decay = score_decay
|
| 214 |
+
assert exc_block_size <= n_local # no global token in input
|
| 215 |
+
self.topk = topk
|
| 216 |
+
self.Attn = TritonMultiStageDotProductionAttention
|
| 217 |
+
self.initialized = False
|
| 218 |
+
self.repr_topk = repr_topk
|
| 219 |
+
self.cache_strategy = cache_strategy
|
| 220 |
+
self.load_count = 0
|
| 221 |
+
self.chunk_topk_calc = chunk_topk_calc
|
| 222 |
+
self.async_global_stream = async_global_stream
|
| 223 |
+
self.pin_memory = pin_memory
|
| 224 |
+
self.faiss = faiss
|
| 225 |
+
self.perhead = perhead
|
| 226 |
+
|
| 227 |
+
self.dense_decoding = dense_decoding
|
| 228 |
+
|
| 229 |
+
global GLOBAL_STREAM
|
| 230 |
+
if self.async_global_stream and GLOBAL_STREAM is None:
|
| 231 |
+
GLOBAL_STREAM = torch.cuda.Stream()
|
| 232 |
+
|
| 233 |
+
assert cache_strategy in ["lru", "lru-s"]
|
| 234 |
+
|
| 235 |
+
if cache_strategy == "lru-s":
|
| 236 |
+
self.calc_block_score = True
|
| 237 |
+
else:
|
| 238 |
+
self.calc_block_score = False
|
| 239 |
+
|
| 240 |
+
def remove_lru_blocks(
|
| 241 |
+
self, u, num_remove: Optional[int] = None, ignore_blocks=None
|
| 242 |
+
):
|
| 243 |
+
if num_remove is None:
|
| 244 |
+
num_remove = len(self.cached_blocks[u]) - self.max_cached_block
|
| 245 |
+
|
| 246 |
+
if num_remove <= 0:
|
| 247 |
+
return
|
| 248 |
+
|
| 249 |
+
lst = list(self.cached_blocks[u].items())
|
| 250 |
+
lst.sort(key=lambda x: x[1])
|
| 251 |
+
|
| 252 |
+
removed = 0
|
| 253 |
+
for i in range(len(lst)):
|
| 254 |
+
idx = lst[i][0]
|
| 255 |
+
if ignore_blocks is None or (idx not in ignore_blocks):
|
| 256 |
+
self.global_blocks[u][idx].offload()
|
| 257 |
+
self.cached_blocks[u].pop(idx)
|
| 258 |
+
removed += 1
|
| 259 |
+
|
| 260 |
+
if removed >= num_remove:
|
| 261 |
+
return
|
| 262 |
+
|
| 263 |
+
def get_block_k(self, k, score):
|
| 264 |
+
assert isinstance(score, torch.Tensor)
|
| 265 |
+
assert k.dim() >= 2
|
| 266 |
+
k = self.from_group_kv(k)
|
| 267 |
+
assert k.shape[:-1] == score.shape
|
| 268 |
+
assert k.shape[-2] == self.block_size
|
| 269 |
+
score_topk = score.topk(self.repr_topk, dim=-1).indices
|
| 270 |
+
assert score_topk.shape == (self.num_units, self.unit_size, self.repr_topk)
|
| 271 |
+
ret = torch.gather(
|
| 272 |
+
k,
|
| 273 |
+
-2,
|
| 274 |
+
score_topk[:, :, :, None].expand(
|
| 275 |
+
self.num_units, self.unit_size, self.repr_topk, self.dim_head
|
| 276 |
+
),
|
| 277 |
+
)
|
| 278 |
+
return ret
|
| 279 |
+
|
| 280 |
+
def from_group_kv(self, tensor):
|
| 281 |
+
assert tensor.dim() == 4
|
| 282 |
+
assert tensor.size(1) == self.num_heads_kv
|
| 283 |
+
if self.num_heads == self.num_heads_kv:
|
| 284 |
+
return tensor
|
| 285 |
+
_, _, length, dim_head = tensor.shape
|
| 286 |
+
num_group = self.num_heads // self.num_heads_kv
|
| 287 |
+
tensor = tensor.view((self.num_units, self.unit_size_kv, 1, length, dim_head))
|
| 288 |
+
tensor = tensor.expand(
|
| 289 |
+
(self.num_units, self.unit_size_kv, num_group, length, dim_head)
|
| 290 |
+
).reshape((self.num_units, self.num_heads, length, dim_head))
|
| 291 |
+
return tensor
|
| 292 |
+
|
| 293 |
+
def init(self, local_q, local_k, local_v, global_q, global_k, global_v):
|
| 294 |
+
assert local_q.dim() == 4
|
| 295 |
+
batch_size, num_heads, len_q, dim_head = local_q.shape
|
| 296 |
+
num_heads_kv = local_k.size(1)
|
| 297 |
+
|
| 298 |
+
for _t in [local_q, local_k, local_v, global_q, global_k, global_v]:
|
| 299 |
+
assert _t.size(0) == batch_size
|
| 300 |
+
assert _t.size(1) == num_heads or _t.size(1) == num_heads_kv
|
| 301 |
+
assert _t.size(2) == len_q
|
| 302 |
+
assert _t.size(3) == dim_head
|
| 303 |
+
assert _t.is_cuda
|
| 304 |
+
|
| 305 |
+
self.batch_size = batch_size
|
| 306 |
+
self.num_heads = num_heads
|
| 307 |
+
self.num_heads_kv = num_heads_kv
|
| 308 |
+
self.dim_head = dim_head
|
| 309 |
+
self.num_units = batch_size
|
| 310 |
+
self.unit_size = num_heads
|
| 311 |
+
self.unit_size_kv = num_heads_kv
|
| 312 |
+
|
| 313 |
+
self.global_blocks = [[] for _ in range(self.num_units)] # [[memory_unit]]
|
| 314 |
+
self.cached_blocks = [
|
| 315 |
+
{} for _ in range(self.num_units)
|
| 316 |
+
] # [[block_id: block_score]
|
| 317 |
+
self.num_global_block = 0
|
| 318 |
+
|
| 319 |
+
if self.faiss:
|
| 320 |
+
self.block_k = [
|
| 321 |
+
Faiss(dim_head * self.unit_size, global_k.dtype)
|
| 322 |
+
for _ in range(self.num_units)
|
| 323 |
+
]
|
| 324 |
+
else:
|
| 325 |
+
self.block_k = [
|
| 326 |
+
VectorTensor(dim_head * self.unit_size, global_k.dtype)
|
| 327 |
+
for _ in range(self.num_units)
|
| 328 |
+
]
|
| 329 |
+
|
| 330 |
+
self.local_k = torch.empty(
|
| 331 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 332 |
+
dtype=local_k.dtype,
|
| 333 |
+
device=local_k.device,
|
| 334 |
+
)
|
| 335 |
+
self.local_v = torch.empty(
|
| 336 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 337 |
+
dtype=local_v.dtype,
|
| 338 |
+
device=local_v.device,
|
| 339 |
+
)
|
| 340 |
+
|
| 341 |
+
if self.dense_decoding:
|
| 342 |
+
self.dense_k = torch.empty(
|
| 343 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 344 |
+
dtype=local_k.dtype,
|
| 345 |
+
device=local_k.device,
|
| 346 |
+
)
|
| 347 |
+
self.dense_v = torch.empty(
|
| 348 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 349 |
+
dtype=local_v.dtype,
|
| 350 |
+
device=local_v.device,
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
self.global_remainder = (
|
| 354 |
+
torch.empty(
|
| 355 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 356 |
+
dtype=global_k.dtype,
|
| 357 |
+
device=global_k.device,
|
| 358 |
+
),
|
| 359 |
+
torch.empty(
|
| 360 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 361 |
+
dtype=global_v.dtype,
|
| 362 |
+
device=global_v.device,
|
| 363 |
+
),
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
self.global_remainder_local_score = torch.empty(
|
| 367 |
+
(self.num_units, self.unit_size, 0),
|
| 368 |
+
dtype=global_k.dtype,
|
| 369 |
+
device=global_k.device,
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
self.init_k = torch.empty(
|
| 373 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 374 |
+
dtype=global_k.dtype,
|
| 375 |
+
device=global_k.device,
|
| 376 |
+
)
|
| 377 |
+
self.init_v = torch.empty(
|
| 378 |
+
(self.num_units, self.unit_size_kv, 0, dim_head),
|
| 379 |
+
dtype=global_k.dtype,
|
| 380 |
+
device=global_k.device,
|
| 381 |
+
)
|
| 382 |
+
self.init_exc = False
|
| 383 |
+
self.dtype = local_q.dtype
|
| 384 |
+
self.position_embedding._update_cos_sin_tables_len(
|
| 385 |
+
self.n_local + self.exc_block_size + 1, local_k.device, local_k.dim()
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
buffer_len = (
|
| 389 |
+
self.topk * self.block_size
|
| 390 |
+
+ self.exc_block_size
|
| 391 |
+
+ self.block_size
|
| 392 |
+
+ self.n_init
|
| 393 |
+
)
|
| 394 |
+
self.global_buffer = torch.zeros(
|
| 395 |
+
(2, self.num_units, self.unit_size_kv, buffer_len, dim_head),
|
| 396 |
+
dtype=global_k.dtype,
|
| 397 |
+
device=global_k.device,
|
| 398 |
+
)
|
| 399 |
+
self.global_buffer_block_id_list = [
|
| 400 |
+
[-1] * self.topk for _ in range(self.num_units)
|
| 401 |
+
]
|
| 402 |
+
self.global_buffer_init_st = 0
|
| 403 |
+
self.global_buffer_init_ed = 0
|
| 404 |
+
self.cuda_cache = CudaCache(
|
| 405 |
+
self.max_cached_block * self.num_units,
|
| 406 |
+
self.unit_size_kv * self.block_size * dim_head * 2,
|
| 407 |
+
local_k.dtype,
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
self.initialized = True
|
| 411 |
+
|
| 412 |
+
def calc_block_topk(self, global_h_q):
|
| 413 |
+
if not self._use_chunk_topk:
|
| 414 |
+
if self.num_global_block <= self.topk:
|
| 415 |
+
return [
|
| 416 |
+
list(range(len(self.global_blocks[0])))
|
| 417 |
+
for _ in range(self.num_units)
|
| 418 |
+
]
|
| 419 |
+
|
| 420 |
+
global_h_q = global_h_q.mean(dim=2, keepdim=False)
|
| 421 |
+
assert global_h_q.shape == (self.num_units, self.unit_size, self.dim_head)
|
| 422 |
+
global_h_q = global_h_q.reshape(
|
| 423 |
+
self.num_units, self.dim_head * self.unit_size
|
| 424 |
+
)
|
| 425 |
+
ret = []
|
| 426 |
+
for u in range(self.num_units):
|
| 427 |
+
ret.append(self.block_k[u].get_topk(global_h_q[u], self.topk))
|
| 428 |
+
|
| 429 |
+
else:
|
| 430 |
+
return self._cached_topk[self._topk_cur]
|
| 431 |
+
|
| 432 |
+
return ret
|
| 433 |
+
|
| 434 |
+
def get_global_hidden_and_mask(self, len_q, block_topk):
|
| 435 |
+
assert len(block_topk) == self.num_units
|
| 436 |
+
global_block_map = [[] for _ in range(self.num_units)]
|
| 437 |
+
global_remainder_len = max(
|
| 438 |
+
self._global_remainder_ed
|
| 439 |
+
- self._global_remainder_st
|
| 440 |
+
+ len_q
|
| 441 |
+
- self.n_local,
|
| 442 |
+
0,
|
| 443 |
+
)
|
| 444 |
+
init_len = self.init_k.size(-2)
|
| 445 |
+
sliding_window = None
|
| 446 |
+
|
| 447 |
+
global_h_k = self.global_buffer[0]
|
| 448 |
+
global_h_v = self.global_buffer[1]
|
| 449 |
+
|
| 450 |
+
block_num = len(block_topk[0])
|
| 451 |
+
for u in range(self.num_units):
|
| 452 |
+
assert len(block_topk[u]) == block_num
|
| 453 |
+
|
| 454 |
+
block_topk[u].sort()
|
| 455 |
+
global_block_map[u] = deepcopy(self.global_buffer_block_id_list[u])
|
| 456 |
+
for b_idx in block_topk[u]:
|
| 457 |
+
if b_idx in global_block_map[u]:
|
| 458 |
+
continue
|
| 459 |
+
|
| 460 |
+
st = -1
|
| 461 |
+
ed = -1
|
| 462 |
+
for j in range(self.topk):
|
| 463 |
+
if (
|
| 464 |
+
global_block_map[u][j] == -1
|
| 465 |
+
or global_block_map[u][j] not in block_topk[u]
|
| 466 |
+
):
|
| 467 |
+
st = j * self.block_size
|
| 468 |
+
ed = st + self.block_size
|
| 469 |
+
global_block_map[u][j] = b_idx
|
| 470 |
+
break
|
| 471 |
+
|
| 472 |
+
assert b_idx in self.cached_blocks[u]
|
| 473 |
+
self.global_blocks[u][b_idx].load(
|
| 474 |
+
(global_h_k[u, :, st:ed, :], global_h_v[u, :, st:ed, :])
|
| 475 |
+
)
|
| 476 |
+
|
| 477 |
+
init_st = block_num * self.block_size
|
| 478 |
+
init_ed = init_st + init_len
|
| 479 |
+
if (
|
| 480 |
+
self.global_buffer_init_st != init_st
|
| 481 |
+
or self.global_buffer_init_ed != init_ed
|
| 482 |
+
):
|
| 483 |
+
global_h_k[:, :, init_st:init_ed, :].copy_(self.init_k, non_blocking=True)
|
| 484 |
+
global_h_v[:, :, init_st:init_ed, :].copy_(self.init_v, non_blocking=True)
|
| 485 |
+
|
| 486 |
+
ed = init_ed
|
| 487 |
+
|
| 488 |
+
rmd_st = init_ed
|
| 489 |
+
rmd_ed = rmd_st + global_remainder_len
|
| 490 |
+
ed = rmd_ed
|
| 491 |
+
global_h_k[:, :, rmd_st:rmd_ed, :].copy_(
|
| 492 |
+
self.global_remainder[0][
|
| 493 |
+
:,
|
| 494 |
+
:,
|
| 495 |
+
self._global_remainder_st : self._global_remainder_st
|
| 496 |
+
+ global_remainder_len,
|
| 497 |
+
:,
|
| 498 |
+
],
|
| 499 |
+
non_blocking=True,
|
| 500 |
+
)
|
| 501 |
+
global_h_v[:, :, rmd_st:rmd_ed, :].copy_(
|
| 502 |
+
self.global_remainder[1][
|
| 503 |
+
:,
|
| 504 |
+
:,
|
| 505 |
+
self._global_remainder_st : self._global_remainder_st
|
| 506 |
+
+ global_remainder_len,
|
| 507 |
+
:,
|
| 508 |
+
],
|
| 509 |
+
non_blocking=True,
|
| 510 |
+
)
|
| 511 |
+
|
| 512 |
+
sliding_window = (self.global_remainder[0].size(-2) + rmd_st, self.n_local)
|
| 513 |
+
|
| 514 |
+
self.global_buffer_block_id_list = deepcopy(global_block_map)
|
| 515 |
+
self.global_buffer_init_st = init_st
|
| 516 |
+
self.global_buffer_init_ed = init_ed
|
| 517 |
+
|
| 518 |
+
for u in range(self.num_units):
|
| 519 |
+
assert max(global_block_map[u][block_num:] + [-1]) == -1
|
| 520 |
+
assert min(global_block_map[u][:block_num] + [0]) > -1
|
| 521 |
+
global_block_map[u] = list(global_block_map[u][:block_num])
|
| 522 |
+
|
| 523 |
+
global_h_k = global_h_k[:, :, :ed, :]
|
| 524 |
+
global_h_v = global_h_v[:, :, :ed, :]
|
| 525 |
+
return global_h_k, global_h_v, sliding_window, global_block_map, block_num
|
| 526 |
+
|
| 527 |
+
def update_block_score(
|
| 528 |
+
self, global_score: torch.FloatTensor, global_block_map, global_block_num
|
| 529 |
+
):
|
| 530 |
+
if global_score is not None:
|
| 531 |
+
global_score = global_score[:, :, : global_block_num * self.block_size]
|
| 532 |
+
assert global_score.shape == (
|
| 533 |
+
self.num_units,
|
| 534 |
+
self.unit_size,
|
| 535 |
+
global_block_num * self.block_size,
|
| 536 |
+
)
|
| 537 |
+
global_score = global_score.view(
|
| 538 |
+
self.num_units, self.unit_size, global_block_num, self.block_size
|
| 539 |
+
)
|
| 540 |
+
global_score = global_score.sum(dim=-1).sum(dim=1)
|
| 541 |
+
assert global_score.shape == (self.num_units, global_block_num)
|
| 542 |
+
global_score = global_score.to(
|
| 543 |
+
device="cpu", non_blocking=False
|
| 544 |
+
) # (num_units, global_block_num)
|
| 545 |
+
for u in range(self.num_units):
|
| 546 |
+
for k, v in self.cached_blocks[u].items():
|
| 547 |
+
self.cached_blocks[u][k] = v * self.score_decay
|
| 548 |
+
score = global_score[u].tolist()
|
| 549 |
+
assert len(score) >= len(global_block_map[u])
|
| 550 |
+
for s, i in zip(score, global_block_map[u]):
|
| 551 |
+
self.cached_blocks[u][i] += s
|
| 552 |
+
|
| 553 |
+
def _append(self, local_q, local_k, local_v, global_q):
|
| 554 |
+
# get local_h_q, local_h_k, local_h_v
|
| 555 |
+
local_h_q, local_h_k = self.position_embedding(local_q, local_k)
|
| 556 |
+
local_h_v = local_v
|
| 557 |
+
|
| 558 |
+
# calc local result first to overlap host-device communication
|
| 559 |
+
attn = self.Attn(local_h_q.shape, local_h_q.dtype, local_h_q.device)
|
| 560 |
+
attn.append(
|
| 561 |
+
local_h_q, local_h_k, local_h_v, get_score=True, sliding_window=self.n_local
|
| 562 |
+
)
|
| 563 |
+
|
| 564 |
+
# calc topk global repr k and load cache
|
| 565 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 566 |
+
block_topk = self.calc_block_topk(global_q)
|
| 567 |
+
|
| 568 |
+
for u in range(self.num_units):
|
| 569 |
+
num_remove = len(self.cached_blocks[u]) - self.max_cached_block
|
| 570 |
+
for bidx in block_topk[u]:
|
| 571 |
+
if bidx not in self.cached_blocks[u]:
|
| 572 |
+
num_remove += 1
|
| 573 |
+
|
| 574 |
+
# update cache
|
| 575 |
+
self.remove_lru_blocks(u, num_remove, block_topk[u])
|
| 576 |
+
|
| 577 |
+
if self.cache_strategy == "lru":
|
| 578 |
+
self.load_count += 1
|
| 579 |
+
for u in range(self.num_units):
|
| 580 |
+
for bidx in block_topk[u]:
|
| 581 |
+
self.cached_blocks[u][bidx] = self.load_count
|
| 582 |
+
|
| 583 |
+
elif self.cache_strategy == "lru-s":
|
| 584 |
+
for u in range(self.num_units):
|
| 585 |
+
for bidx in block_topk[u]:
|
| 586 |
+
self.cached_blocks[u][bidx] = 0
|
| 587 |
+
else:
|
| 588 |
+
raise ValueError
|
| 589 |
+
|
| 590 |
+
# get global_h_k, global_h_v, global_mask
|
| 591 |
+
# Beacuse exc_block_size <= n_local, no global_k, global_v used in global part
|
| 592 |
+
global_h_q = global_q
|
| 593 |
+
(
|
| 594 |
+
global_h_k,
|
| 595 |
+
global_h_v,
|
| 596 |
+
global_sliding_window,
|
| 597 |
+
global_block_map,
|
| 598 |
+
global_block_num,
|
| 599 |
+
) = self.get_global_hidden_and_mask(local_h_q.size(-2), block_topk)
|
| 600 |
+
|
| 601 |
+
if self.async_global_stream:
|
| 602 |
+
torch.cuda.current_stream().wait_stream(GLOBAL_STREAM)
|
| 603 |
+
|
| 604 |
+
# calc global result
|
| 605 |
+
attn.append(
|
| 606 |
+
global_h_q,
|
| 607 |
+
global_h_k,
|
| 608 |
+
global_h_v,
|
| 609 |
+
end=True,
|
| 610 |
+
get_score=self.calc_block_score,
|
| 611 |
+
sliding_window=global_sliding_window,
|
| 612 |
+
complement_sliding_window=True,
|
| 613 |
+
)
|
| 614 |
+
|
| 615 |
+
o, score_list = attn.get_result()
|
| 616 |
+
loc_score = score_list[0]
|
| 617 |
+
glb_score = score_list[1]
|
| 618 |
+
|
| 619 |
+
if self.async_global_stream:
|
| 620 |
+
GLOBAL_STREAM.wait_stream(torch.cuda.current_stream())
|
| 621 |
+
|
| 622 |
+
# update global score
|
| 623 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 624 |
+
self.update_block_score(glb_score, global_block_map, global_block_num)
|
| 625 |
+
|
| 626 |
+
return o.view((self.batch_size, self.num_heads, -1, self.dim_head)), loc_score
|
| 627 |
+
|
| 628 |
+
def get_batched_topk(self, global_q):
|
| 629 |
+
length = global_q.shape[2]
|
| 630 |
+
exc_num = (length + self.exc_block_size - 1) // self.exc_block_size
|
| 631 |
+
exc_block_num = length // self.exc_block_size
|
| 632 |
+
ret = []
|
| 633 |
+
if self.num_global_block <= self.topk:
|
| 634 |
+
for _ in range(exc_num):
|
| 635 |
+
ret.append(
|
| 636 |
+
[
|
| 637 |
+
list(range(len(self.global_blocks[0])))
|
| 638 |
+
for _ in range(self.num_units)
|
| 639 |
+
]
|
| 640 |
+
)
|
| 641 |
+
return ret
|
| 642 |
+
|
| 643 |
+
global_h_q = global_q
|
| 644 |
+
assert global_h_q.dim() == 4
|
| 645 |
+
assert global_h_q.shape[:2] == (self.num_units, self.unit_size)
|
| 646 |
+
assert global_h_q.shape[3] == self.dim_head
|
| 647 |
+
|
| 648 |
+
block_k = torch.cat(
|
| 649 |
+
[self.block_k[u].get_data()[None, :, :] for u in range(self.num_units)],
|
| 650 |
+
dim=0,
|
| 651 |
+
)
|
| 652 |
+
assert block_k.shape == (
|
| 653 |
+
self.num_units,
|
| 654 |
+
self.num_global_block,
|
| 655 |
+
self.dim_head * self.unit_size,
|
| 656 |
+
)
|
| 657 |
+
block_k = (
|
| 658 |
+
block_k.reshape(
|
| 659 |
+
self.num_units, self.num_global_block, self.unit_size, self.dim_head
|
| 660 |
+
)
|
| 661 |
+
.permute(0, 2, 1, 3)
|
| 662 |
+
.contiguous()
|
| 663 |
+
)
|
| 664 |
+
|
| 665 |
+
if exc_block_num > 0:
|
| 666 |
+
tmp_global_h_q = (
|
| 667 |
+
global_h_q[:, :, : exc_block_num * self.exc_block_size, :]
|
| 668 |
+
.reshape(
|
| 669 |
+
self.num_units,
|
| 670 |
+
self.unit_size,
|
| 671 |
+
exc_block_num,
|
| 672 |
+
self.exc_block_size,
|
| 673 |
+
self.dim_head,
|
| 674 |
+
)
|
| 675 |
+
.mean(dim=-2)
|
| 676 |
+
)
|
| 677 |
+
assert tmp_global_h_q.shape == (
|
| 678 |
+
self.num_units,
|
| 679 |
+
self.unit_size,
|
| 680 |
+
exc_block_num,
|
| 681 |
+
self.dim_head,
|
| 682 |
+
)
|
| 683 |
+
block_score = torch.matmul(tmp_global_h_q, block_k.transpose(-1, -2)).mean(
|
| 684 |
+
dim=1
|
| 685 |
+
) # (num_units, exc_block_num, num_global_block)
|
| 686 |
+
assert block_score.shape == (
|
| 687 |
+
self.num_units,
|
| 688 |
+
exc_block_num,
|
| 689 |
+
self.num_global_block,
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
indices = block_score.topk(self.topk, dim=-1).indices.cpu()
|
| 693 |
+
for b in range(exc_block_num):
|
| 694 |
+
tmp = []
|
| 695 |
+
for u in range(self.num_units):
|
| 696 |
+
tmp.append(indices[u, b].tolist())
|
| 697 |
+
assert len(tmp[-1]) == self.topk
|
| 698 |
+
|
| 699 |
+
ret.append(tmp)
|
| 700 |
+
|
| 701 |
+
if exc_block_num != exc_num:
|
| 702 |
+
tmp_global_h_q = (
|
| 703 |
+
global_h_q[:, :, exc_block_num * self.exc_block_size :, :]
|
| 704 |
+
.reshape(
|
| 705 |
+
self.num_units,
|
| 706 |
+
self.unit_size,
|
| 707 |
+
length - exc_block_num * self.exc_block_size,
|
| 708 |
+
self.dim_head,
|
| 709 |
+
)
|
| 710 |
+
.mean(dim=-2, keepdim=True)
|
| 711 |
+
)
|
| 712 |
+
assert tmp_global_h_q.shape == (
|
| 713 |
+
self.num_units,
|
| 714 |
+
self.unit_size,
|
| 715 |
+
1,
|
| 716 |
+
self.dim_head,
|
| 717 |
+
)
|
| 718 |
+
block_score = torch.matmul(tmp_global_h_q, block_k.transpose(-1, -2))
|
| 719 |
+
assert block_score.shape == (
|
| 720 |
+
self.num_units,
|
| 721 |
+
self.unit_size,
|
| 722 |
+
1,
|
| 723 |
+
self.num_global_block,
|
| 724 |
+
)
|
| 725 |
+
block_score = block_score.squeeze(dim=2).mean(dim=1)
|
| 726 |
+
assert block_score.shape == (self.num_units, self.num_global_block)
|
| 727 |
+
indices = block_score.topk(self.topk, dim=-1).indices.cpu()
|
| 728 |
+
tmp = []
|
| 729 |
+
for u in range(self.num_units):
|
| 730 |
+
tmp.append(indices[u].tolist())
|
| 731 |
+
assert len(tmp[-1]) == self.topk
|
| 732 |
+
|
| 733 |
+
ret.append(tmp)
|
| 734 |
+
|
| 735 |
+
return ret
|
| 736 |
+
|
| 737 |
+
def append_global(self, exc_length, kv_length, local_score):
|
| 738 |
+
global_remainder_ed = self._global_remainder_ed + exc_length
|
| 739 |
+
global_remainder_st = self._global_remainder_st
|
| 740 |
+
|
| 741 |
+
global_remainder_len = global_remainder_ed - global_remainder_st
|
| 742 |
+
|
| 743 |
+
assert local_score.shape[:3] == (self.num_units, self.unit_size, kv_length)
|
| 744 |
+
local_score = local_score[:, :, -exc_length - self.n_local :]
|
| 745 |
+
self.global_remainder_local_score[
|
| 746 |
+
:, :, global_remainder_ed - local_score.size(-1) : global_remainder_ed
|
| 747 |
+
].add_(local_score)
|
| 748 |
+
|
| 749 |
+
if not self.init_exc and global_remainder_len > self.n_local:
|
| 750 |
+
global_k = self.global_remainder[0]
|
| 751 |
+
global_v = self.global_remainder[1]
|
| 752 |
+
|
| 753 |
+
append_init_len = min(
|
| 754 |
+
self.n_init - self.init_k.size(-2), global_remainder_len - self.n_local
|
| 755 |
+
)
|
| 756 |
+
self.init_k = torch.cat(
|
| 757 |
+
(
|
| 758 |
+
self.init_k,
|
| 759 |
+
global_k[
|
| 760 |
+
:,
|
| 761 |
+
:,
|
| 762 |
+
global_remainder_st : global_remainder_st + append_init_len,
|
| 763 |
+
:,
|
| 764 |
+
],
|
| 765 |
+
),
|
| 766 |
+
dim=-2,
|
| 767 |
+
)
|
| 768 |
+
self.init_v = torch.cat(
|
| 769 |
+
(
|
| 770 |
+
self.init_v,
|
| 771 |
+
global_v[
|
| 772 |
+
:,
|
| 773 |
+
:,
|
| 774 |
+
global_remainder_st : global_remainder_st + append_init_len,
|
| 775 |
+
:,
|
| 776 |
+
],
|
| 777 |
+
),
|
| 778 |
+
dim=-2,
|
| 779 |
+
)
|
| 780 |
+
global_remainder_st += append_init_len
|
| 781 |
+
global_remainder_len -= append_init_len
|
| 782 |
+
|
| 783 |
+
if self.init_k.size(-2) == self.n_init:
|
| 784 |
+
self.init_exc = True
|
| 785 |
+
|
| 786 |
+
while global_remainder_len - self.block_size >= self.n_local:
|
| 787 |
+
global_remainder_len -= self.block_size
|
| 788 |
+
for u in range(self.num_units):
|
| 789 |
+
self.global_blocks[u].append(
|
| 790 |
+
(
|
| 791 |
+
MemoryUnit(
|
| 792 |
+
(
|
| 793 |
+
self.global_remainder[0][
|
| 794 |
+
u,
|
| 795 |
+
:,
|
| 796 |
+
global_remainder_st : global_remainder_st
|
| 797 |
+
+ self.block_size,
|
| 798 |
+
:,
|
| 799 |
+
],
|
| 800 |
+
self.global_remainder[1][
|
| 801 |
+
u,
|
| 802 |
+
:,
|
| 803 |
+
global_remainder_st : global_remainder_st
|
| 804 |
+
+ self.block_size,
|
| 805 |
+
:,
|
| 806 |
+
],
|
| 807 |
+
),
|
| 808 |
+
self.cuda_cache,
|
| 809 |
+
False,
|
| 810 |
+
self.pin_memory,
|
| 811 |
+
)
|
| 812 |
+
)
|
| 813 |
+
)
|
| 814 |
+
|
| 815 |
+
global_block_k = self.get_block_k(
|
| 816 |
+
self.global_remainder[0][
|
| 817 |
+
:, :, global_remainder_st : global_remainder_st + self.block_size, :
|
| 818 |
+
],
|
| 819 |
+
self.global_remainder_local_score[
|
| 820 |
+
:, :, global_remainder_st : global_remainder_st + self.block_size
|
| 821 |
+
],
|
| 822 |
+
)
|
| 823 |
+
assert global_block_k.shape == (
|
| 824 |
+
self.num_units,
|
| 825 |
+
self.unit_size,
|
| 826 |
+
self.repr_topk,
|
| 827 |
+
self.dim_head,
|
| 828 |
+
)
|
| 829 |
+
global_block_k = global_block_k.mean(dim=-2, keepdim=False)
|
| 830 |
+
global_block_k = global_block_k.reshape(
|
| 831 |
+
self.num_units, self.unit_size * self.dim_head
|
| 832 |
+
)
|
| 833 |
+
global_block_k = global_block_k[:, None, :]
|
| 834 |
+
|
| 835 |
+
self.num_global_block += 1
|
| 836 |
+
for u in range(self.num_units):
|
| 837 |
+
self.block_k[u].append(global_block_k[u])
|
| 838 |
+
global_remainder_st += self.block_size
|
| 839 |
+
|
| 840 |
+
self._global_remainder_ed = global_remainder_ed
|
| 841 |
+
self._global_remainder_st = global_remainder_st
|
| 842 |
+
|
| 843 |
+
def append(
|
| 844 |
+
self,
|
| 845 |
+
local_q,
|
| 846 |
+
local_k,
|
| 847 |
+
local_v,
|
| 848 |
+
global_q,
|
| 849 |
+
global_k,
|
| 850 |
+
global_v,
|
| 851 |
+
):
|
| 852 |
+
batch_size = local_q.size(0)
|
| 853 |
+
input_length = local_q.size(-2)
|
| 854 |
+
|
| 855 |
+
if self.perhead:
|
| 856 |
+
num_heads = local_q.size(1)
|
| 857 |
+
num_heads_kv = local_v.size(1)
|
| 858 |
+
|
| 859 |
+
def repeat_kv(t):
|
| 860 |
+
t = t.view(batch_size, num_heads_kv, 1, input_length, -1)
|
| 861 |
+
t = t.expand(
|
| 862 |
+
batch_size,
|
| 863 |
+
num_heads_kv,
|
| 864 |
+
num_heads // num_heads_kv,
|
| 865 |
+
input_length,
|
| 866 |
+
-1,
|
| 867 |
+
)
|
| 868 |
+
t = t.reshape(batch_size * num_heads, 1, input_length, -1)
|
| 869 |
+
return t
|
| 870 |
+
|
| 871 |
+
local_q = local_q.view(batch_size * num_heads, 1, input_length, -1)
|
| 872 |
+
local_k = repeat_kv(local_k)
|
| 873 |
+
local_v = repeat_kv(local_v)
|
| 874 |
+
global_q = global_q.view(batch_size * num_heads, 1, input_length, -1)
|
| 875 |
+
global_k = repeat_kv(global_k)
|
| 876 |
+
global_v = repeat_kv(global_v)
|
| 877 |
+
|
| 878 |
+
if not self.initialized:
|
| 879 |
+
self.init(local_q, local_k, local_v, global_q, global_k, global_v)
|
| 880 |
+
|
| 881 |
+
input_length = local_q.size(-2)
|
| 882 |
+
|
| 883 |
+
if self.async_global_stream:
|
| 884 |
+
GLOBAL_STREAM.wait_stream(torch.cuda.current_stream())
|
| 885 |
+
|
| 886 |
+
# append local and global tensor
|
| 887 |
+
self.local_k = torch.cat((self.local_k, local_k), dim=-2)
|
| 888 |
+
self.local_v = torch.cat((self.local_v, local_v), dim=-2)
|
| 889 |
+
kv_length = self.local_k.size(-2)
|
| 890 |
+
|
| 891 |
+
if self.dense_decoding:
|
| 892 |
+
self.dense_k = torch.cat((self.dense_k, local_k), dim=-2)
|
| 893 |
+
self.dense_v = torch.cat((self.dense_v, local_v), dim=-2)
|
| 894 |
+
|
| 895 |
+
# append global remainder
|
| 896 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 897 |
+
self._global_remainder_st = 0
|
| 898 |
+
self._global_remainder_ed = self.global_remainder[0].size(-2)
|
| 899 |
+
|
| 900 |
+
self.global_remainder = (
|
| 901 |
+
torch.cat((self.global_remainder[0], global_k), dim=-2),
|
| 902 |
+
torch.cat((self.global_remainder[1], global_v), dim=-2),
|
| 903 |
+
)
|
| 904 |
+
|
| 905 |
+
self.global_remainder_local_score = torch.cat(
|
| 906 |
+
(
|
| 907 |
+
self.global_remainder_local_score,
|
| 908 |
+
torch.zeros(
|
| 909 |
+
(self.num_units, self.unit_size, global_k.size(-2)),
|
| 910 |
+
dtype=global_k.dtype,
|
| 911 |
+
device=global_k.device,
|
| 912 |
+
),
|
| 913 |
+
),
|
| 914 |
+
dim=-1,
|
| 915 |
+
)
|
| 916 |
+
|
| 917 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 918 |
+
global_q = self.position_embedding.apply_rotary_pos_emb_one_angle(
|
| 919 |
+
global_q, self.n_local
|
| 920 |
+
)
|
| 921 |
+
|
| 922 |
+
use_chunk_topk = self.chunk_topk_calc is not None and input_length > 1
|
| 923 |
+
self._use_chunk_topk = use_chunk_topk
|
| 924 |
+
if use_chunk_topk:
|
| 925 |
+
exc_block_num = input_length // self.exc_block_size
|
| 926 |
+
exc_block_per_topk_chunk = self.chunk_topk_calc // self.exc_block_size
|
| 927 |
+
calc_cur_list = [
|
| 928 |
+
i * self.exc_block_size
|
| 929 |
+
for i in range(0, exc_block_num + 1, exc_block_per_topk_chunk)
|
| 930 |
+
]
|
| 931 |
+
if calc_cur_list[-1] < input_length:
|
| 932 |
+
calc_cur_list.append(input_length)
|
| 933 |
+
self._topk_cur = 0
|
| 934 |
+
self._topk_calc_cur = -1
|
| 935 |
+
|
| 936 |
+
o_list = []
|
| 937 |
+
|
| 938 |
+
for st in range(0, input_length, self.exc_block_size):
|
| 939 |
+
ed = min(st + self.exc_block_size, input_length)
|
| 940 |
+
if use_chunk_topk and calc_cur_list[self._topk_calc_cur + 1] < ed:
|
| 941 |
+
# calculate topk and sync with host here
|
| 942 |
+
assert ed <= calc_cur_list[self._topk_calc_cur + 2]
|
| 943 |
+
self._topk_calc_cur += 1
|
| 944 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 945 |
+
self._cached_topk = self.get_batched_topk(
|
| 946 |
+
global_q[
|
| 947 |
+
:,
|
| 948 |
+
:,
|
| 949 |
+
calc_cur_list[self._topk_calc_cur] : calc_cur_list[
|
| 950 |
+
self._topk_calc_cur + 1
|
| 951 |
+
],
|
| 952 |
+
:,
|
| 953 |
+
]
|
| 954 |
+
)
|
| 955 |
+
self._topk_cur = 0
|
| 956 |
+
|
| 957 |
+
kv_st = max(kv_length + st - input_length - self.n_local, 0)
|
| 958 |
+
kv_ed = kv_length + ed - input_length
|
| 959 |
+
chunk_o, local_score = self._append(
|
| 960 |
+
local_q[:, :, st:ed, :],
|
| 961 |
+
self.local_k[:, :, kv_st:kv_ed, :],
|
| 962 |
+
self.local_v[:, :, kv_st:kv_ed, :],
|
| 963 |
+
global_q[:, :, st:ed, :],
|
| 964 |
+
)
|
| 965 |
+
o_list.append(chunk_o)
|
| 966 |
+
|
| 967 |
+
# append global
|
| 968 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 969 |
+
self.append_global(ed - st, kv_ed - kv_st, local_score)
|
| 970 |
+
|
| 971 |
+
if self.async_global_stream:
|
| 972 |
+
torch.cuda.current_stream().wait_stream(GLOBAL_STREAM)
|
| 973 |
+
|
| 974 |
+
if use_chunk_topk:
|
| 975 |
+
self._topk_cur += 1
|
| 976 |
+
|
| 977 |
+
self.length += input_length
|
| 978 |
+
|
| 979 |
+
# update local and global tensor
|
| 980 |
+
if self.local_k.size(-2) >= self.n_local:
|
| 981 |
+
self.local_k = self.local_k[:, :, -self.n_local :, :]
|
| 982 |
+
self.local_v = self.local_v[:, :, -self.n_local :, :]
|
| 983 |
+
|
| 984 |
+
assert self._global_remainder_ed == self.global_remainder[0].size(-2)
|
| 985 |
+
with torch.cuda.stream(GLOBAL_STREAM):
|
| 986 |
+
self.global_remainder = (
|
| 987 |
+
self.global_remainder[0][:, :, self._global_remainder_st :, :],
|
| 988 |
+
self.global_remainder[1][:, :, self._global_remainder_st :, :],
|
| 989 |
+
)
|
| 990 |
+
self.global_remainder_local_score = self.global_remainder_local_score[
|
| 991 |
+
:, :, self._global_remainder_st :
|
| 992 |
+
]
|
| 993 |
+
|
| 994 |
+
ret = torch.cat(o_list, dim=-2)
|
| 995 |
+
|
| 996 |
+
if self.perhead:
|
| 997 |
+
ret = ret.view(batch_size, num_heads, input_length, -1)
|
| 998 |
+
|
| 999 |
+
return ret
|
| 1000 |
+
|
| 1001 |
+
def size(self, *args, **kwargs):
|
| 1002 |
+
return self.length
|
| 1003 |
+
|
| 1004 |
+
|
| 1005 |
+
def inf_llm_forward(
|
| 1006 |
+
n_local,
|
| 1007 |
+
n_init,
|
| 1008 |
+
topk,
|
| 1009 |
+
block_size,
|
| 1010 |
+
max_cached_block,
|
| 1011 |
+
exc_block_size,
|
| 1012 |
+
repr_topk: int = 1,
|
| 1013 |
+
cache_strategy="lru",
|
| 1014 |
+
score_decay=None,
|
| 1015 |
+
chunk_topk_calc=None,
|
| 1016 |
+
async_global_stream=True,
|
| 1017 |
+
pin_memory=False,
|
| 1018 |
+
faiss=False,
|
| 1019 |
+
perhead=False,
|
| 1020 |
+
dense_decoding=False,
|
| 1021 |
+
*args,
|
| 1022 |
+
**kwargs
|
| 1023 |
+
):
|
| 1024 |
+
def forward(
|
| 1025 |
+
self,
|
| 1026 |
+
query: torch.Tensor,
|
| 1027 |
+
key_value: torch.Tensor,
|
| 1028 |
+
position_bias: Optional[torch.Tensor],
|
| 1029 |
+
use_cache: bool,
|
| 1030 |
+
past_key_value,
|
| 1031 |
+
project_q,
|
| 1032 |
+
project_k,
|
| 1033 |
+
project_v,
|
| 1034 |
+
attention_out,
|
| 1035 |
+
dim_head,
|
| 1036 |
+
num_heads,
|
| 1037 |
+
num_heads_kv,
|
| 1038 |
+
):
|
| 1039 |
+
batch_size = query.size(0)
|
| 1040 |
+
len_q = query.size(1)
|
| 1041 |
+
len_k = key_value.size(1)
|
| 1042 |
+
|
| 1043 |
+
# assert use_cache
|
| 1044 |
+
|
| 1045 |
+
h_q = project_q(query) # (batch, len_q, num_heads * dim_head)
|
| 1046 |
+
h_k = project_k(key_value) # (batch, len_k, num_heads * dim_head)
|
| 1047 |
+
h_v = project_v(key_value) # (batch, len_k, num_heads * dim_head)
|
| 1048 |
+
|
| 1049 |
+
h_q = (
|
| 1050 |
+
h_q.view(batch_size, len_q, num_heads, dim_head)
|
| 1051 |
+
.permute(0, 2, 1, 3)
|
| 1052 |
+
.contiguous()
|
| 1053 |
+
) # (batch, num_heads, len_q, dim_head)
|
| 1054 |
+
h_k = (
|
| 1055 |
+
h_k.view(batch_size, len_k, num_heads_kv, dim_head)
|
| 1056 |
+
.permute(0, 2, 1, 3)
|
| 1057 |
+
.contiguous()
|
| 1058 |
+
) # (batch, num_heads_kv, len_k, dim_head)
|
| 1059 |
+
h_v = (
|
| 1060 |
+
h_v.view(batch_size, len_k, num_heads_kv, dim_head)
|
| 1061 |
+
.permute(0, 2, 1, 3)
|
| 1062 |
+
.contiguous()
|
| 1063 |
+
) # (batch, num_heads_kv, len_k, dim_head)
|
| 1064 |
+
|
| 1065 |
+
if len_q == 1 and dense_decoding:
|
| 1066 |
+
past_k = past_key_value.dense_k
|
| 1067 |
+
past_v = past_key_value.dense_v
|
| 1068 |
+
|
| 1069 |
+
h_k = torch.cat((past_k, h_k), dim=-2)
|
| 1070 |
+
h_v = torch.cat((past_v, h_v), dim=-2)
|
| 1071 |
+
|
| 1072 |
+
past_key_value.dense_k = h_k
|
| 1073 |
+
past_key_value.dense_v = h_v
|
| 1074 |
+
|
| 1075 |
+
h_q, h_k = position_bias(h_q, h_k)
|
| 1076 |
+
|
| 1077 |
+
# (batch_size, seqlen, nheads, headdim)
|
| 1078 |
+
h_q = h_q.transpose(1, 2)
|
| 1079 |
+
h_k = h_k.transpose(1, 2)
|
| 1080 |
+
h_v = h_v.transpose(1, 2)
|
| 1081 |
+
|
| 1082 |
+
# (batch_size, seqlen, nheads, headdim)
|
| 1083 |
+
o = flash_attn_func(h_q, h_k, h_v, causal=True)
|
| 1084 |
+
|
| 1085 |
+
o = o.reshape(batch_size, len_q, dim_head * num_heads)
|
| 1086 |
+
o = attention_out(o)
|
| 1087 |
+
|
| 1088 |
+
if use_cache:
|
| 1089 |
+
return o, past_key_value
|
| 1090 |
+
else:
|
| 1091 |
+
return o
|
| 1092 |
+
|
| 1093 |
+
if past_key_value is None:
|
| 1094 |
+
past_key_value = ContextManager(
|
| 1095 |
+
position_bias,
|
| 1096 |
+
n_init,
|
| 1097 |
+
n_local,
|
| 1098 |
+
block_size,
|
| 1099 |
+
max_cached_block,
|
| 1100 |
+
topk,
|
| 1101 |
+
exc_block_size,
|
| 1102 |
+
score_decay,
|
| 1103 |
+
repr_topk,
|
| 1104 |
+
cache_strategy,
|
| 1105 |
+
chunk_topk_calc,
|
| 1106 |
+
async_global_stream,
|
| 1107 |
+
pin_memory,
|
| 1108 |
+
faiss,
|
| 1109 |
+
perhead,
|
| 1110 |
+
dense_decoding=dense_decoding,
|
| 1111 |
+
)
|
| 1112 |
+
|
| 1113 |
+
local_q, local_k, local_v = h_q, h_k, h_v
|
| 1114 |
+
global_q, global_k, global_v = h_q, h_k, h_v
|
| 1115 |
+
|
| 1116 |
+
o = past_key_value.append(
|
| 1117 |
+
local_q,
|
| 1118 |
+
local_k,
|
| 1119 |
+
local_v,
|
| 1120 |
+
global_q,
|
| 1121 |
+
global_k,
|
| 1122 |
+
global_v,
|
| 1123 |
+
)
|
| 1124 |
+
|
| 1125 |
+
o = o.view(batch_size, num_heads, len_q, dim_head).permute(0, 2, 1, 3)
|
| 1126 |
+
o = o.reshape(batch_size, len_q, dim_head * num_heads)
|
| 1127 |
+
o = attention_out(o)
|
| 1128 |
+
|
| 1129 |
+
if use_cache:
|
| 1130 |
+
return o, past_key_value
|
| 1131 |
+
else:
|
| 1132 |
+
return o
|
| 1133 |
+
|
| 1134 |
+
return forward
|
| 1135 |
+
|
| 1136 |
+
|
| 1137 |
+
class GreedySearch:
|
| 1138 |
+
def __init__(self, model, tokenizer):
|
| 1139 |
+
model.eval()
|
| 1140 |
+
self.device = model.device
|
| 1141 |
+
self.model = model
|
| 1142 |
+
self.tokenizer = tokenizer
|
| 1143 |
+
self.past_kv = None
|
| 1144 |
+
|
| 1145 |
+
def clear(self):
|
| 1146 |
+
self.past_kv = None
|
| 1147 |
+
|
| 1148 |
+
def _process_texts(self, input_text):
|
| 1149 |
+
model_inputs = {}
|
| 1150 |
+
input_ids = self.tokenizer.encode(input_text)
|
| 1151 |
+
|
| 1152 |
+
model_inputs["input_ids"] = input_ids
|
| 1153 |
+
model_inputs["attention_mask"] = [1] * len(model_inputs["input_ids"])
|
| 1154 |
+
|
| 1155 |
+
for key in model_inputs:
|
| 1156 |
+
model_inputs[key] = (
|
| 1157 |
+
torch.tensor(model_inputs[key]).int().unsqueeze(0).cuda()
|
| 1158 |
+
)
|
| 1159 |
+
|
| 1160 |
+
return model_inputs
|
| 1161 |
+
|
| 1162 |
+
def generate(self, text=None, input_ids=None, **kwargs):
|
| 1163 |
+
if input_ids is None:
|
| 1164 |
+
model_inputs = self._process_texts(text)
|
| 1165 |
+
input_ids = model_inputs["input_ids"]
|
| 1166 |
+
|
| 1167 |
+
with torch.inference_mode():
|
| 1168 |
+
result = self._decode(input_ids, **kwargs)
|
| 1169 |
+
|
| 1170 |
+
self.clear()
|
| 1171 |
+
return result
|
| 1172 |
+
|
| 1173 |
+
def _decode(
|
| 1174 |
+
self,
|
| 1175 |
+
input_ids,
|
| 1176 |
+
max_length=100,
|
| 1177 |
+
extra_end_token_ids=[],
|
| 1178 |
+
chunk_size: int = 4096,
|
| 1179 |
+
output=False,
|
| 1180 |
+
):
|
| 1181 |
+
if input_ids.dim() == 1:
|
| 1182 |
+
input_ids = input_ids[None, :]
|
| 1183 |
+
input_ids = input_ids.cuda()
|
| 1184 |
+
attention_mask = torch.ones_like(input_ids)
|
| 1185 |
+
assert input_ids.size(0) == 1
|
| 1186 |
+
length = input_ids.size(1)
|
| 1187 |
+
end_token_ids = extra_end_token_ids + [self.tokenizer.eos_token_id]
|
| 1188 |
+
logits = None
|
| 1189 |
+
past_key_values = self.past_kv
|
| 1190 |
+
if output:
|
| 1191 |
+
output_text = ""
|
| 1192 |
+
|
| 1193 |
+
for i in range(max_length + 1):
|
| 1194 |
+
if i == 0:
|
| 1195 |
+
if chunk_size is None:
|
| 1196 |
+
chunk_size = input_ids.size(1)
|
| 1197 |
+
for st in range(0, input_ids.size(1) - 1, chunk_size):
|
| 1198 |
+
ed = min(input_ids.size(1) - 1, st + chunk_size)
|
| 1199 |
+
out = self.model(
|
| 1200 |
+
input_ids=input_ids[:, st:ed],
|
| 1201 |
+
attention_mask=attention_mask[:, :ed],
|
| 1202 |
+
use_cache=True,
|
| 1203 |
+
return_dict=True,
|
| 1204 |
+
past_key_values=past_key_values,
|
| 1205 |
+
)
|
| 1206 |
+
logits, past_key_values = out.logits, out.past_key_values
|
| 1207 |
+
|
| 1208 |
+
out = self.model(
|
| 1209 |
+
input_ids=input_ids[:, -1:],
|
| 1210 |
+
attention_mask=attention_mask,
|
| 1211 |
+
use_cache=True,
|
| 1212 |
+
return_dict=True,
|
| 1213 |
+
past_key_values=past_key_values,
|
| 1214 |
+
)
|
| 1215 |
+
logits, past_key_values = out.logits, out.past_key_values
|
| 1216 |
+
else:
|
| 1217 |
+
out = self.model(
|
| 1218 |
+
input_ids=input_ids[:, -1:],
|
| 1219 |
+
attention_mask=attention_mask,
|
| 1220 |
+
past_key_values=past_key_values,
|
| 1221 |
+
use_cache=True,
|
| 1222 |
+
return_dict=True,
|
| 1223 |
+
)
|
| 1224 |
+
logits, past_key_values = out.logits, out.past_key_values
|
| 1225 |
+
|
| 1226 |
+
logits = logits[:, -1, :]
|
| 1227 |
+
word = logits.argmax(dim=-1)
|
| 1228 |
+
if word.item() in end_token_ids or i == max_length:
|
| 1229 |
+
break
|
| 1230 |
+
|
| 1231 |
+
input_ids = torch.cat((input_ids, word.view(1, 1)), dim=-1)
|
| 1232 |
+
attention_mask = torch.cat(
|
| 1233 |
+
(
|
| 1234 |
+
attention_mask,
|
| 1235 |
+
torch.ones(
|
| 1236 |
+
(attention_mask.size(0), 1),
|
| 1237 |
+
dtype=torch.int,
|
| 1238 |
+
device=attention_mask.device,
|
| 1239 |
+
),
|
| 1240 |
+
),
|
| 1241 |
+
dim=-1,
|
| 1242 |
+
)
|
| 1243 |
+
if output:
|
| 1244 |
+
tmp = self.tokenizer.decode(input_ids.squeeze(0)[length:])
|
| 1245 |
+
if len(tmp) > len(output_text):
|
| 1246 |
+
import sys
|
| 1247 |
+
|
| 1248 |
+
sys.stdout.write(tmp[len(output_text) :])
|
| 1249 |
+
sys.stdout.flush()
|
| 1250 |
+
output_text = tmp
|
| 1251 |
+
|
| 1252 |
+
self.past_kv = past_key_values
|
| 1253 |
+
|
| 1254 |
+
if output:
|
| 1255 |
+
sys.stdout.write("\n")
|
| 1256 |
+
sys.stdout.flush()
|
| 1257 |
+
|
| 1258 |
+
# return [self.tokenizer.decode(input_ids.squeeze(0)[length:])]
|
| 1259 |
+
return input_ids
|
| 1260 |
+
|
| 1261 |
+
|
| 1262 |
+
class InfLLMGenerator(GreedySearch):
|
| 1263 |
+
def generate(
|
| 1264 |
+
self,
|
| 1265 |
+
input_ids=None,
|
| 1266 |
+
generation_config=None,
|
| 1267 |
+
pad_token_id=None,
|
| 1268 |
+
max_new_tokens=None,
|
| 1269 |
+
):
|
| 1270 |
+
if max_new_tokens is not None:
|
| 1271 |
+
max_new_tokens = max_new_tokens
|
| 1272 |
+
else:
|
| 1273 |
+
max_new_tokens = generation_config.max_new_tokens
|
| 1274 |
+
return super().generate(
|
| 1275 |
+
text=None,
|
| 1276 |
+
input_ids=input_ids,
|
| 1277 |
+
max_length=max_new_tokens,
|
| 1278 |
+
chunk_size=8192,
|
| 1279 |
+
extra_end_token_ids=[pad_token_id] if pad_token_id is not None else [],
|
| 1280 |
+
)
|
| 1281 |
+
|
| 1282 |
+
@torch.no_grad()
|
| 1283 |
+
def __call__(self, input_ids=None, *args, **kwargs):
|
| 1284 |
+
# chunked forward
|
| 1285 |
+
chunk_size = 8192
|
| 1286 |
+
all_logits = torch.empty(0, dtype=torch.bfloat16).to(input_ids.device)
|
| 1287 |
+
for st in range(0, input_ids.size(1), chunk_size):
|
| 1288 |
+
torch.cuda.empty_cache()
|
| 1289 |
+
ed = min(input_ids.size(1), st + chunk_size)
|
| 1290 |
+
out = self.model(
|
| 1291 |
+
input_ids=input_ids[:, st:ed],
|
| 1292 |
+
)
|
| 1293 |
+
logits = out.logits.to(torch.bfloat16)
|
| 1294 |
+
all_logits = torch.cat((all_logits, logits), dim=1)
|
| 1295 |
+
|
| 1296 |
+
return CausalLMOutput(logits=all_logits)
|
minference/modules/minference_forward.py
ADDED
|
@@ -0,0 +1,855 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
from importlib import import_module
|
| 5 |
+
|
| 6 |
+
from transformers.models.llama.modeling_llama import *
|
| 7 |
+
from vllm.attention.backends.flash_attn import *
|
| 8 |
+
|
| 9 |
+
from ..ops.block_sparse_flash_attention import block_sparse_attention
|
| 10 |
+
from ..ops.pit_sparse_flash_attention_v2 import vertical_slash_sparse_attention
|
| 11 |
+
from ..ops.streaming_kernel import streaming_forward, streaming_forward2
|
| 12 |
+
from .snap_kv import *
|
| 13 |
+
|
| 14 |
+
last_q = 64
|
| 15 |
+
arange = torch.arange(last_q, device="cuda")
|
| 16 |
+
LAST_Q_MASK = arange[None, None, :, None] >= arange[None, None, None, :]
|
| 17 |
+
ROPE_TYPE = None
|
| 18 |
+
SEARCH_MASK = None
|
| 19 |
+
|
| 20 |
+
def init_minference_parameters(self):
|
| 21 |
+
config = self.config.to_dict()
|
| 22 |
+
self.starting_layer = config.get("starting_layer", 0)
|
| 23 |
+
self.is_search = config.get("is_search", False)
|
| 24 |
+
|
| 25 |
+
# self.n_init = config.get("n_init", 128)
|
| 26 |
+
# self.n_local = config.get("n_local", 3968)
|
| 27 |
+
|
| 28 |
+
self.ne_inf = None
|
| 29 |
+
self.config_path = config.get("config_path", "")
|
| 30 |
+
if os.path.exists(self.config_path) and self.layer_idx < len(json.load(open(self.config_path))):
|
| 31 |
+
self.best_pattern = {int(ii): jj for ii, jj in json.load(open(self.config_path))[self.layer_idx].items()}
|
| 32 |
+
else:
|
| 33 |
+
self.best_pattern = {}
|
| 34 |
+
self.vertical, self.slash = None, None
|
| 35 |
+
|
| 36 |
+
# import apply_rotary_pos_emb
|
| 37 |
+
if "apply_rotary_pos_emb" not in self.__dict__:
|
| 38 |
+
global apply_rotary_pos_emb
|
| 39 |
+
model_path = self.rotary_emb.__class__.__module__
|
| 40 |
+
apply_rotary_pos_emb = getattr(import_module(model_path), "apply_rotary_pos_emb")
|
| 41 |
+
self.apply_rotary_pos_emb = True
|
| 42 |
+
|
| 43 |
+
def sum_all_diagonal_matrix(mat: torch.tensor):
|
| 44 |
+
b, h, n, m = mat.shape
|
| 45 |
+
zero_mat = torch.zeros((b, h, n, n)).to(mat.device) # Zero matrix used for padding
|
| 46 |
+
mat_padded = torch.cat((zero_mat, mat, zero_mat), -1) # pads the matrix on left and right
|
| 47 |
+
mat_strided = mat_padded.as_strided((1, 1, n, n + m), (1, n * (2 * n + m), 2 * n + m + 1, 1)) # Change the strides
|
| 48 |
+
sum_diags = torch.sum(mat_strided, 2) # Sums the resulting matrix's columns
|
| 49 |
+
return sum_diags[:,:,1:]
|
| 50 |
+
|
| 51 |
+
def gather(t, dim, i):
|
| 52 |
+
"""A broadcasting version of torch.gather."""
|
| 53 |
+
dim += (dim < 0) * t.ndim
|
| 54 |
+
return t.gather(dim, i.expand(*t.shape[:dim], i.shape[dim], *t.shape[dim + 1 :]))
|
| 55 |
+
|
| 56 |
+
def gather_qkv(q, k, v, attention_mask):
|
| 57 |
+
attn_weights = torch.matmul(q, k.transpose(2, 3)) / math.sqrt(q.size(-1)) + attention_mask
|
| 58 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
|
| 59 |
+
attn_output = torch.matmul(attn_weights, v)
|
| 60 |
+
return attn_output
|
| 61 |
+
|
| 62 |
+
def search_pattern(q, k, head):
|
| 63 |
+
q_len = q.shape[2]
|
| 64 |
+
head_dim = q.shape[-1]
|
| 65 |
+
|
| 66 |
+
def vertical_and_slash(vertical_size, slash_size):
|
| 67 |
+
last_q = 64
|
| 68 |
+
q_len = q.shape[2]
|
| 69 |
+
qk_idxs = [ii + q_len for ii in list(range(-last_q, 0, 1))]
|
| 70 |
+
qk = torch.matmul(q[:,:,qk_idxs,:], k.transpose(2, 3))/ math.sqrt(head_dim) + attention_mask[:,:,qk_idxs]
|
| 71 |
+
qk = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32)
|
| 72 |
+
vertical = qk.sum(-2, keepdim=True)
|
| 73 |
+
vertical[...,:30] = 10000
|
| 74 |
+
vertical_topk = torch.topk(-vertical, q_len - vertical_size, -1).indices
|
| 75 |
+
|
| 76 |
+
slash = sum_all_diagonal_matrix(qk)[...,:-last_q + 1]
|
| 77 |
+
slash[...,-30:] = 10000
|
| 78 |
+
slash_topk = slash
|
| 79 |
+
slash = torch.topk(slash, slash_size, -1).indices - (q_len - 1)
|
| 80 |
+
slash = torch.stack([torch.sparse.spdiags(torch.ones(slash_size, q_len), slash.cpu()[0][_], (q_len, q_len)).to_dense() for _ in range(1)]).to(q.device)
|
| 81 |
+
|
| 82 |
+
est_attn = torch.ones_like(attn_weights)
|
| 83 |
+
dim = 3
|
| 84 |
+
est_attn = est_attn.scatter(3, vertical_topk.expand(*est_attn.shape[:dim], vertical_topk.shape[dim], *est_attn.shape[dim + 1 :]), 0)
|
| 85 |
+
est_attn = est_attn + slash
|
| 86 |
+
|
| 87 |
+
est_attn = (est_attn > 0).float()
|
| 88 |
+
est_attn = torch.tril(est_attn)
|
| 89 |
+
attn_weights_x = attn_weights * est_attn
|
| 90 |
+
res3 = attn_weights_x[:,:,2500:].sum(-1).mean(-1).squeeze().float().detach().cpu().numpy()
|
| 91 |
+
return res3
|
| 92 |
+
|
| 93 |
+
def stream_llm(vertical_size, slash_size):
|
| 94 |
+
q_len = q.shape[2]
|
| 95 |
+
|
| 96 |
+
mask = torch.triu(torch.tril(torch.ones(q_len, q_len), 0), -slash_size).to(q)
|
| 97 |
+
mask[:,:vertical_size] = 1
|
| 98 |
+
mask = mask.unsqueeze(0).unsqueeze(1)
|
| 99 |
+
|
| 100 |
+
est_attn = torch.tril(mask)
|
| 101 |
+
attn_weights_x = attn_weights * est_attn
|
| 102 |
+
res3 = attn_weights_x[:,:,2500:].sum(-1).mean(-1).squeeze().float().detach().cpu().numpy()
|
| 103 |
+
return res3
|
| 104 |
+
|
| 105 |
+
def block_sparse(topk_ratio, slash_size=None):
|
| 106 |
+
block_num = (q_len -1) // 32 + 1
|
| 107 |
+
block_q = torch.zeros(1,1,block_num * 32,head_dim).to(q)
|
| 108 |
+
block_q[:,:,:q_len] = q
|
| 109 |
+
block_q = block_q.reshape(1,1,block_num,32,-1).mean(-2)
|
| 110 |
+
block_k = torch.zeros(1,1,block_num * 32,head_dim).to(k)
|
| 111 |
+
block_k[:,:,:q_len] = k
|
| 112 |
+
block_k = block_k.reshape(1,1,block_num,32,-1).mean(-2)
|
| 113 |
+
|
| 114 |
+
qk = torch.matmul(block_q, block_k.transpose(2, 3)) + attention_mask[:,:,:block_num,:block_num]
|
| 115 |
+
est_attn = torch.ones_like(qk)
|
| 116 |
+
block_topk = torch.topk(-qk, block_num - block_num//topk_ratio, -1).indices
|
| 117 |
+
|
| 118 |
+
dim = 3
|
| 119 |
+
est_attn = est_attn.scatter(3, block_topk.expand(*est_attn.shape[:dim], block_topk.shape[dim], *est_attn.shape[dim + 1 :]), 0)
|
| 120 |
+
est_attn = est_attn.unsqueeze(3).unsqueeze(-1).repeat(1,1,1,32,1,32).reshape(1,1,block_num * 32, block_num * 32)[...,:q_len,:q_len]
|
| 121 |
+
est_attn = torch.tril(est_attn)
|
| 122 |
+
|
| 123 |
+
attn_weights_x = attn_weights * est_attn
|
| 124 |
+
res2 = attn_weights_x[:,:,2500:].sum(-1).mean(-1).squeeze().float().detach().cpu().numpy()
|
| 125 |
+
return res2
|
| 126 |
+
|
| 127 |
+
global SEARCH_MASK
|
| 128 |
+
if SEARCH_MASK is None:
|
| 129 |
+
attention_mask = torch.full((q_len, q_len), torch.finfo(q.dtype).min, device="cuda")
|
| 130 |
+
mask_cond = torch.arange(attention_mask.size(-1), device="cuda")
|
| 131 |
+
attention_mask.masked_fill_(mask_cond < (mask_cond + 1).view(attention_mask.size(-1), 1), 0)
|
| 132 |
+
attention_mask = attention_mask[None, None, :]
|
| 133 |
+
SEARCH_MASK = attention_mask
|
| 134 |
+
else:
|
| 135 |
+
attention_mask = SEARCH_MASK
|
| 136 |
+
attn_weights = torch.matmul(q, k.transpose(2, 3)) / math.sqrt(head_dim) + attention_mask
|
| 137 |
+
attn_weights = torch.nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(q.dtype)
|
| 138 |
+
best_s, best_v, best_score, best_ty = 0, 0, 0, ""
|
| 139 |
+
all_info = []
|
| 140 |
+
for ty, fc in [("stream_llm", stream_llm), ("vertical_and_slash", vertical_and_slash), ("block_sparse", block_sparse)]:
|
| 141 |
+
if ty == "stream_llm":
|
| 142 |
+
vs_list = [(100, 800)]
|
| 143 |
+
elif ty == "vertical_and_slash":
|
| 144 |
+
vs_list = [(30, 800), (100, 750), (500, 700), (3500, 100)]
|
| 145 |
+
else:
|
| 146 |
+
vs_list = [(8, 1)]
|
| 147 |
+
for v_size, s_size in vs_list:
|
| 148 |
+
score = fc(v_size, s_size)
|
| 149 |
+
score = score.item()
|
| 150 |
+
all_info.append([ty, v_size, s_size, score])
|
| 151 |
+
if score > best_score:
|
| 152 |
+
best_score = score
|
| 153 |
+
best_s, best_v = s_size, v_size
|
| 154 |
+
best_ty = ty
|
| 155 |
+
if best_ty == "stream_llm":
|
| 156 |
+
best_ty = "vertical_and_slash"
|
| 157 |
+
if best_ty == "block_sparse":
|
| 158 |
+
best_ty, best_v, best_s = "vertical_and_slash", 1000, 6096
|
| 159 |
+
print(head, best_ty, best_v, best_s, best_score)
|
| 160 |
+
return (best_ty, best_v, best_s, best_score)
|
| 161 |
+
|
| 162 |
+
def search_pattern_v2(q, k, v, head):
|
| 163 |
+
q_len = q.shape[2]
|
| 164 |
+
head_dim = q.shape[-1]
|
| 165 |
+
def vertical_and_slash_kernel(q, k, v, vertical_size, slash_size):
|
| 166 |
+
vertical_size, slash_size = min(q_len, max(vertical_size, 30)), min(q_len, max(slash_size, 50))
|
| 167 |
+
last_q = 64
|
| 168 |
+
qk = torch.einsum(f'bhmk, bhnk -> bhmn', q[:,:,-last_q:,:], k)
|
| 169 |
+
qk[:, :, :, -last_q:] = torch.where(LAST_Q_MASK, qk[:, :, :, -last_q:], -torch.inf)
|
| 170 |
+
qk = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32)
|
| 171 |
+
vertical = qk.sum(-2, keepdim=True)
|
| 172 |
+
vertical[...,:30] = torch.inf
|
| 173 |
+
vertical_topk = torch.topk(vertical, vertical_size, -1).indices
|
| 174 |
+
|
| 175 |
+
slash = sum_all_diagonal_matrix(qk)[...,:-last_q + 1]
|
| 176 |
+
slash[...,-30:] = torch.inf
|
| 177 |
+
slash_topk = slash
|
| 178 |
+
slash = (q_len - 1) - torch.topk(slash, slash_size, -1).indices
|
| 179 |
+
|
| 180 |
+
return vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
|
| 181 |
+
def dense(q, k, v, vertical_size=None, slash_size=None):
|
| 182 |
+
return flash_attn_func(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1,2), 0.0, softmax_scale=None, causal=q_len != 1).view(bsz, 1, q_len, head_dim)
|
| 183 |
+
def block_sparse_kernel(q, k, v, vertical_size=None, slash_size=None):
|
| 184 |
+
topk = 100
|
| 185 |
+
return block_sparse_attention(q, k, v, topk)
|
| 186 |
+
|
| 187 |
+
best_s, best_v, best_score, best_ty = 0, 0, float("inf"), ""
|
| 188 |
+
bsz = q.shape[0]
|
| 189 |
+
all_info = []
|
| 190 |
+
ref = dense(q, k, v)
|
| 191 |
+
for ty, fc in [("stream_llm", streaming_forward), ("vertical_and_slash", vertical_and_slash_kernel), ("block_sparse", block_sparse_kernel)]:
|
| 192 |
+
if ty == "stream_llm":
|
| 193 |
+
vs_list = [(100, 800)]
|
| 194 |
+
elif ty == "vertical_and_slash":
|
| 195 |
+
vs_list = [(30, 800), (100, 800), (100, 750), (500, 700), (3500, 100), (1000, 4096)]
|
| 196 |
+
else:
|
| 197 |
+
vs_list = [(10, 1)]
|
| 198 |
+
for v_size, s_size in vs_list:
|
| 199 |
+
score = fc(q, k, v, v_size, s_size)
|
| 200 |
+
# delta = (ref - score).abs().sum()
|
| 201 |
+
delta = ((ref - score).abs() > 5e-3).sum()
|
| 202 |
+
score = delta.item()
|
| 203 |
+
all_info.append([ty, v_size, s_size, score])
|
| 204 |
+
if score < best_score:
|
| 205 |
+
best_score = score
|
| 206 |
+
best_s, best_v = s_size, v_size
|
| 207 |
+
best_ty = ty
|
| 208 |
+
print(head, best_ty, best_v, best_s, best_score)
|
| 209 |
+
return all_info
|
| 210 |
+
|
| 211 |
+
def shift_matrix(mat):
|
| 212 |
+
b, h, _, n = mat.shape
|
| 213 |
+
zero_mat = torch.zeros((b, h, n, n)).to(mat.device) # Zero matrix used for padding
|
| 214 |
+
mat_padded = torch.cat((zero_mat, mat, zero_mat), -1) # pads the matrix on left and right
|
| 215 |
+
mat_strided = mat_padded.as_strided((1, 1, n, n + 2 * n), (1, n * (2 * n + n), 2 * n + n - 1, 1)) # Change the strides
|
| 216 |
+
return mat_strided[...,2 * n-1:-1]
|
| 217 |
+
|
| 218 |
+
def repeat(self, q, k, v, attention_mask):
|
| 219 |
+
q_len = q.shape[2]
|
| 220 |
+
if q_len == 1:
|
| 221 |
+
return gather_qkv(q, k, v, attention_mask)
|
| 222 |
+
qk = torch.matmul(q[:,:,-1:,:], k.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 223 |
+
qk = qk.repeat(1,1,q_len, 1)
|
| 224 |
+
qk = shift_matrix(qk) + attention_mask
|
| 225 |
+
attn_weights = nn.functional.softmax(qk, dim=-1, dtype=torch.float32).to(q.dtype)
|
| 226 |
+
attn_output = torch.matmul(attn_weights, v)
|
| 227 |
+
return attn_output
|
| 228 |
+
|
| 229 |
+
def gather_last_q_vertical_slash_topk_v4(self, q, k, v, head_id):
|
| 230 |
+
kv_seq_len = k.size(2)
|
| 231 |
+
|
| 232 |
+
def vertical_and_slash(attn_weights, vertical_size, slash_size):
|
| 233 |
+
last_q = 64
|
| 234 |
+
q_len = q.shape[2]
|
| 235 |
+
vertical_size, slash_size = min(q_len, max(vertical_size, 30)), min(q_len, max(slash_size, 50))
|
| 236 |
+
qk_idxs = [ii + q_len for ii in list(range(-last_q, 0, 1))]
|
| 237 |
+
qk = torch.matmul(q[:,:,qk_idxs,:], k.transpose(2, 3))/ math.sqrt(self.head_dim) + attention_mask[:,:,qk_idxs]
|
| 238 |
+
qk = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32)
|
| 239 |
+
vertical = qk.sum(-2, keepdim=True)
|
| 240 |
+
vertical[...,:30] = -self.ne_inf
|
| 241 |
+
vertical_topk = torch.topk(-vertical, q_len - vertical_size, -1).indices
|
| 242 |
+
|
| 243 |
+
slash = sum_all_diagonal_matrix(qk)[...,:-last_q + 1]
|
| 244 |
+
slash[...,-30:] = -self.ne_inf
|
| 245 |
+
slash_topk = slash
|
| 246 |
+
slash = torch.topk(slash, slash_size, -1).indices - (q_len - 1)
|
| 247 |
+
slash = torch.stack([torch.sparse.spdiags(torch.ones(slash_size, q_len), slash.cpu()[0][_], (q_len, q_len)).to_dense() for _ in range(1)]).to(q.device)
|
| 248 |
+
|
| 249 |
+
est_attn = torch.ones_like(attn_weights)
|
| 250 |
+
dim = 3
|
| 251 |
+
est_attn = est_attn.scatter(3, vertical_topk.expand(*est_attn.shape[:dim], vertical_topk.shape[dim], *est_attn.shape[dim + 1 :]), 0)
|
| 252 |
+
est_attn = est_attn + slash
|
| 253 |
+
|
| 254 |
+
est_attn = (est_attn > 0).float()
|
| 255 |
+
est_attn = torch.tril(est_attn)
|
| 256 |
+
est_attn = (est_attn == 0).int() * self.ne_inf
|
| 257 |
+
attn_weights = attn_weights + est_attn
|
| 258 |
+
if self.kv_cache_compressed_v4:
|
| 259 |
+
self.vertical = torch.topk(vertical, vertical_size * 4, -1).indices
|
| 260 |
+
self.slash = (torch.topk(slash_topk, slash_size * 4, -1).indices - (q_len - 1)).unsqueeze(2)
|
| 261 |
+
return attn_weights
|
| 262 |
+
|
| 263 |
+
def stream_llm(attn_weights, vertical_size, slash_size):
|
| 264 |
+
q_len = q.shape[2]
|
| 265 |
+
vertical_size, slash_size = min(q_len, max(vertical_size, 30)), min(q_len, max(slash_size, 50))
|
| 266 |
+
mask = torch.triu(torch.tril(torch.ones(q_len, q_len), 0), -slash_size).to(q)
|
| 267 |
+
mask[:,:vertical_size] = 1
|
| 268 |
+
mask = mask.unsqueeze(0).unsqueeze(1)
|
| 269 |
+
|
| 270 |
+
est_attn = torch.tril(mask)
|
| 271 |
+
est_attn = (est_attn == 0).int() * self.ne_inf
|
| 272 |
+
attn_weights = attn_weights + est_attn
|
| 273 |
+
if self.kv_cache_compressed_v4:
|
| 274 |
+
self.vertical = torch.Tensor(list(range(vertical_size * 4))).long().to(q.device).unsqueeze(0).unsqueeze(0).unsqueeze(0)
|
| 275 |
+
self.slash = torch.Tensor(list(range(-slash_size * 4, 1))).long().to(q.device).unsqueeze(0).unsqueeze(0).unsqueeze(0)
|
| 276 |
+
return attn_weights
|
| 277 |
+
|
| 278 |
+
def block_sparse(attn_weights, topk_ratio, slash_size=None, block_size=8):
|
| 279 |
+
block_num = (q_len -1) // block_size + 1
|
| 280 |
+
block_q = torch.zeros(1,1,block_num * block_size,head_dim).to(q)
|
| 281 |
+
block_q[:,:,:q_len] = q
|
| 282 |
+
block_q = block_q.reshape(1,1,block_num,block_size,-1).mean(-2)
|
| 283 |
+
block_k = torch.zeros(1,1,block_num * block_size,head_dim).to(k)
|
| 284 |
+
block_k[:,:,:q_len] = k
|
| 285 |
+
block_k = block_k.reshape(1,1,block_num,block_size,-1).mean(-2)
|
| 286 |
+
|
| 287 |
+
qk = torch.matmul(block_q, block_k.transpose(2, 3)) + attention_mask[:,:,:block_num,:block_num]
|
| 288 |
+
est_attn = torch.ones_like(qk)
|
| 289 |
+
block_topk = torch.topk(-qk, block_num - block_num//topk_ratio, -1).indices
|
| 290 |
+
|
| 291 |
+
dim = 3
|
| 292 |
+
est_attn = est_attn.scatter(3, block_topk.expand(*est_attn.shape[:dim], block_topk.shape[dim], *est_attn.shape[dim + 1 :]), 0)
|
| 293 |
+
est_attn = est_attn.unsqueeze(3).unsqueeze(-1).repeat(1,1,1,block_size,1,block_size).reshape(1,1,block_num * block_size, block_num * block_size)[...,:q_len,:q_len]
|
| 294 |
+
est_attn = torch.tril(est_attn)
|
| 295 |
+
est_attn = (est_attn == 0).int()
|
| 296 |
+
attn_weights = attn_weights + est_attn
|
| 297 |
+
return attn_weights
|
| 298 |
+
|
| 299 |
+
def dialted(q,k,v, type):
|
| 300 |
+
q_len = q.shape[2]
|
| 301 |
+
n_init = min(1024, q_len)
|
| 302 |
+
vertical_topk = torch.arange(0, n_init, device=q.device)[None, None, None, :]
|
| 303 |
+
|
| 304 |
+
slash = torch.arange(0, q_len, device=q.device)
|
| 305 |
+
if type == 'dilated1':
|
| 306 |
+
# 8k local with 1 interval
|
| 307 |
+
slash = slash[-8192::2][None, None, :]
|
| 308 |
+
elif type == 'dilated2':
|
| 309 |
+
# 2k dense local + 4k local with 1 interval
|
| 310 |
+
slash = torch.cat([slash[-2048:], slash[-6144:-2048:2]], 0)[None, None, :]
|
| 311 |
+
|
| 312 |
+
slash = (q_len - 1) - slash
|
| 313 |
+
return vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
|
| 314 |
+
|
| 315 |
+
def vertical_and_slash_kernel(q, k, v, vertical_size, slash_size):
|
| 316 |
+
vertical_size, slash_size = min(q_len, max(vertical_size, 30)), min(q_len, max(slash_size, 50))
|
| 317 |
+
last_q = min(64, q_len)
|
| 318 |
+
qk = torch.einsum(f'bhmk, bhnk -> bhmn', q[:,:,-last_q:,:], k)
|
| 319 |
+
qk[:, :, :, -last_q:] = torch.where(LAST_Q_MASK[...,-last_q:,-last_q:].to(q.device), qk[:, :, :, -last_q:], -torch.inf)
|
| 320 |
+
qk = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32)
|
| 321 |
+
vertical = qk.sum(-2, keepdim=True)
|
| 322 |
+
vertical[...,:30] = torch.inf
|
| 323 |
+
vertical_topk = torch.topk(vertical, vertical_size, -1).indices
|
| 324 |
+
|
| 325 |
+
slash = sum_all_diagonal_matrix(qk)[...,:-last_q + 1]
|
| 326 |
+
slash[...,-100:] = torch.inf
|
| 327 |
+
slash_topk = slash
|
| 328 |
+
slash = (q_len - 1) - torch.topk(slash, slash_size, -1).indices
|
| 329 |
+
|
| 330 |
+
return vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
|
| 331 |
+
|
| 332 |
+
def vertical_and_slash_kernel_static(q, k, v, vertical_size, slash_size):
|
| 333 |
+
if "vs" in self.__dict__:
|
| 334 |
+
vertical_topk, slash = self.vs
|
| 335 |
+
else:
|
| 336 |
+
vertical_size, slash_size = min(q_len, max(vertical_size, 30)), min(q_len, max(slash_size, 50))
|
| 337 |
+
last_q = 64
|
| 338 |
+
qk = torch.einsum(f'bhmk, bhnk -> bhmn', q[:,:,-last_q:,:], k)
|
| 339 |
+
qk[:, :, :, -last_q:] = torch.where(LAST_Q_MASK, qk[:, :, :, -last_q:], -torch.inf)
|
| 340 |
+
qk = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32)
|
| 341 |
+
vertical = qk.sum(-2, keepdim=True)
|
| 342 |
+
vertical[...,:30] = torch.inf
|
| 343 |
+
vertical_topk = torch.topk(vertical, vertical_size, -1).indices
|
| 344 |
+
|
| 345 |
+
slash = sum_all_diagonal_matrix(qk)[...,:-last_q + 1]
|
| 346 |
+
slash[...,-30:] = torch.inf
|
| 347 |
+
slash_topk = slash
|
| 348 |
+
slash = (q_len - 1) - torch.topk(slash, slash_size, -1).indices
|
| 349 |
+
self.vs = vertical_topk, slash
|
| 350 |
+
|
| 351 |
+
return vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
|
| 352 |
+
def dense(q, k, v, vertical_size=None, slash_size=None):
|
| 353 |
+
return flash_attn_func(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1,2), 0.0, softmax_scale=None, causal=q_len != 1).view(bsz, 1, q_len, self.head_dim)
|
| 354 |
+
def block_sparse_kernel(q, k, v, vertical_size=None, slash_size=None):
|
| 355 |
+
topk = 100
|
| 356 |
+
return block_sparse_attention(q, k, v, topk)
|
| 357 |
+
|
| 358 |
+
q_len = q.shape[2]
|
| 359 |
+
bsz = q.shape[0]
|
| 360 |
+
|
| 361 |
+
if self.config.to_dict().get("dilated1", False):
|
| 362 |
+
return dialted(q, k, v, 'dilated1')
|
| 363 |
+
if self.config.to_dict().get("dilated2", False):
|
| 364 |
+
return dialted(q, k, v, 'dilated2')
|
| 365 |
+
if self.config.to_dict().get("dense", False):
|
| 366 |
+
return dense(q, k, v)
|
| 367 |
+
if self.config.to_dict().get("streaming", False):
|
| 368 |
+
return streaming_forward(q, k, v, self.config.streaming_kwargs["n_init"], self.config.streaming_kwargs["n_local"])
|
| 369 |
+
|
| 370 |
+
ty, vertical_size, slash_size, _ = self.best_pattern.get(head_id, ("vertical_and_slash", 1000, 6096, 1))
|
| 371 |
+
|
| 372 |
+
if self.config.to_dict().get("static_pattern", False):
|
| 373 |
+
return vertical_and_slash_kernel_static(q, k, v, vertical_size, slash_size)
|
| 374 |
+
if self.config.to_dict().get("vs_only", False):
|
| 375 |
+
return vertical_and_slash_kernel(q, k, v, vertical_size, slash_size)
|
| 376 |
+
|
| 377 |
+
if q_len == 1:
|
| 378 |
+
return dense(q, k, v)
|
| 379 |
+
|
| 380 |
+
fc = {
|
| 381 |
+
"stream_llm": streaming_forward,
|
| 382 |
+
"vertical_and_slash": vertical_and_slash_kernel,
|
| 383 |
+
"block_sparse": block_sparse_kernel,
|
| 384 |
+
}[ty]
|
| 385 |
+
return fc(q, k, v, vertical_size, slash_size)
|
| 386 |
+
|
| 387 |
+
def apply_rotary_pos_emb_single(q, cos, sin, position_ids, unsqueeze_dim=1):
|
| 388 |
+
# cos = cos[position_ids].unsqueeze(unsqueeze_dim)
|
| 389 |
+
# sin = sin[position_ids].unsqueeze(unsqueeze_dim)
|
| 390 |
+
cos = cos.unsqueeze(unsqueeze_dim)
|
| 391 |
+
sin = sin.unsqueeze(unsqueeze_dim)
|
| 392 |
+
return (q * cos) + (rotate_half(q) * sin)
|
| 393 |
+
|
| 394 |
+
def minference_forward():
|
| 395 |
+
def forward(
|
| 396 |
+
self,
|
| 397 |
+
hidden_states,
|
| 398 |
+
attention_mask,
|
| 399 |
+
position_ids,
|
| 400 |
+
past_key_value,
|
| 401 |
+
output_attentions,
|
| 402 |
+
use_cache,
|
| 403 |
+
**kwargs,
|
| 404 |
+
):
|
| 405 |
+
self.init_minference_parameters()
|
| 406 |
+
self.ne_inf = torch.finfo(hidden_states.dtype).min
|
| 407 |
+
|
| 408 |
+
bsz, q_len, _ = hidden_states.size()
|
| 409 |
+
|
| 410 |
+
if "q_proj" in self.__dict__["_modules"]:
|
| 411 |
+
query_states = self.q_proj(hidden_states)
|
| 412 |
+
key_states = self.k_proj(hidden_states)
|
| 413 |
+
value_states = self.v_proj(hidden_states)
|
| 414 |
+
else:
|
| 415 |
+
qkv = self.qkv_proj(hidden_states)
|
| 416 |
+
query_pos = self.num_heads * self.head_dim
|
| 417 |
+
query_states, key_states, value_states = torch.split(qkv, query_pos, -1)
|
| 418 |
+
|
| 419 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 420 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 421 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 422 |
+
|
| 423 |
+
kv_seq_len = key_states.shape[-2]
|
| 424 |
+
if past_key_value is not None:
|
| 425 |
+
if self.layer_idx is None:
|
| 426 |
+
raise ValueError(
|
| 427 |
+
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
|
| 428 |
+
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
|
| 429 |
+
"with a layer index."
|
| 430 |
+
)
|
| 431 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 432 |
+
global ROPE_TYPE
|
| 433 |
+
if ROPE_TYPE is None:
|
| 434 |
+
ROPE_TYPE = "seq_len" in inspect.signature(self.rotary_emb.forward).parameters
|
| 435 |
+
if ROPE_TYPE:
|
| 436 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 437 |
+
else:
|
| 438 |
+
cos, sin = self.rotary_emb(value_states, position_ids)
|
| 439 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 440 |
+
|
| 441 |
+
if past_key_value is not None:
|
| 442 |
+
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 443 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 444 |
+
|
| 445 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 446 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 447 |
+
if self.is_search:
|
| 448 |
+
if os.path.exists(self.config_path):
|
| 449 |
+
config_list = json.load(open(self.config_path))
|
| 450 |
+
if self.layer_idx < len(config_list):
|
| 451 |
+
assert False
|
| 452 |
+
else:
|
| 453 |
+
config_list = []
|
| 454 |
+
config = {}
|
| 455 |
+
print("Layer", self.layer_idx)
|
| 456 |
+
if q_len != 1:
|
| 457 |
+
output = torch.empty_like(query_states)
|
| 458 |
+
for head in range(query_states.size(1)):
|
| 459 |
+
q = query_states[:, head, :, :].unsqueeze(1)
|
| 460 |
+
k = key_states[:, head, :, :].unsqueeze(1)
|
| 461 |
+
v = value_states[:, head, :, :].unsqueeze(1)
|
| 462 |
+
if self.is_search:
|
| 463 |
+
config[head] = search_pattern(q, k, head)
|
| 464 |
+
if self.layer_idx >= self.starting_layer and not self.is_search:
|
| 465 |
+
attn_output = self.gather_last_q_vertical_slash_topk_v4(q, k, v, head)
|
| 466 |
+
elif is_flash_attn_2_available():
|
| 467 |
+
attn_output = flash_attn_func(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1,2), 0.0, softmax_scale=None, causal=q_len != 1).view(bsz, 1, q_len, self.head_dim)
|
| 468 |
+
else:
|
| 469 |
+
attn_output = gather_qkv(q, k, v, attention_mask)
|
| 470 |
+
output[:, head:head + 1] = attn_output
|
| 471 |
+
if self.is_search:
|
| 472 |
+
config_list.append(config)
|
| 473 |
+
with open(self.config_path, 'w') as json_file:
|
| 474 |
+
json.dump(config_list, json_file)
|
| 475 |
+
else:
|
| 476 |
+
output = flash_attn_func(query_states.transpose(1, 2), key_states.transpose(1, 2), value_states.transpose(1,2), 0.0, softmax_scale=None, causal=q_len != 1).view(bsz, query_states.size(1), q_len, self.head_dim)
|
| 477 |
+
attn_output = output.transpose(1, 2).contiguous()
|
| 478 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 479 |
+
attn_output = self.o_proj(attn_output)
|
| 480 |
+
|
| 481 |
+
return attn_output, None, past_key_value
|
| 482 |
+
|
| 483 |
+
return forward
|
| 484 |
+
|
| 485 |
+
def minference_kv_cache_cpu_forward():
|
| 486 |
+
def forward(
|
| 487 |
+
self,
|
| 488 |
+
hidden_states,
|
| 489 |
+
attention_mask,
|
| 490 |
+
position_ids,
|
| 491 |
+
past_key_value,
|
| 492 |
+
output_attentions,
|
| 493 |
+
use_cache,
|
| 494 |
+
**kwargs,
|
| 495 |
+
):
|
| 496 |
+
self.init_minference_parameters()
|
| 497 |
+
self.ne_inf = torch.finfo(hidden_states.dtype).min
|
| 498 |
+
|
| 499 |
+
bsz, q_len, hidden_dim = hidden_states.size()
|
| 500 |
+
kv_seq_len = q_len
|
| 501 |
+
if use_cache and past_key_value is not None:
|
| 502 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 503 |
+
|
| 504 |
+
global ROPE_TYPE
|
| 505 |
+
if ROPE_TYPE is None:
|
| 506 |
+
ROPE_TYPE = "seq_len" in inspect.signature(self.rotary_emb.forward).parameters
|
| 507 |
+
if ROPE_TYPE:
|
| 508 |
+
cos, sin = self.rotary_emb(hidden_states, seq_len=kv_seq_len)
|
| 509 |
+
else:
|
| 510 |
+
cos, sin = self.rotary_emb(hidden_states, position_ids)
|
| 511 |
+
cache_kwargs = {"sin": sin, "cos": cos}
|
| 512 |
+
|
| 513 |
+
attn_out = torch.empty_like(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
|
| 514 |
+
act_num_heads = self.num_heads // self.num_key_value_groups
|
| 515 |
+
if use_cache:
|
| 516 |
+
k = torch.zeros(bsz, act_num_heads, q_len, self.head_dim).to(hidden_states.dtype).cpu()
|
| 517 |
+
v = torch.zeros(bsz, act_num_heads, q_len, self.head_dim).to(hidden_states.dtype).cpu()
|
| 518 |
+
part_k, part_v = None, None
|
| 519 |
+
for head in range(self.num_heads):
|
| 520 |
+
if "q_proj" in self.__dict__["_modules"]:
|
| 521 |
+
part_q = F.linear(hidden_states, self.q_proj.weight.view(self.num_heads, self.head_dim, hidden_dim)[head]).unsqueeze(2)
|
| 522 |
+
else:
|
| 523 |
+
part_q = F.linear(hidden_states, self.qkv_proj.weight.view(3, self.num_heads, self.head_dim, hidden_dim)[0][head]).unsqueeze(2)
|
| 524 |
+
part_q = apply_rotary_pos_emb_single(part_q.transpose(1, 2), cos, sin, position_ids)
|
| 525 |
+
|
| 526 |
+
if head % self.num_key_value_groups == 0:
|
| 527 |
+
if "q_proj" in self.__dict__["_modules"]:
|
| 528 |
+
part_k = F.linear(hidden_states, self.k_proj.weight.view(act_num_heads, self.head_dim, hidden_dim)[head // self.num_key_value_groups]).unsqueeze(2)
|
| 529 |
+
part_v = F.linear(hidden_states, self.v_proj.weight.view(act_num_heads, self.head_dim, hidden_dim)[head // self.num_key_value_groups]).unsqueeze(2).transpose(1, 2)
|
| 530 |
+
else:
|
| 531 |
+
part_k = F.linear(hidden_states, self.qkv_proj.weight.view(3, act_num_heads, self.head_dim, hidden_dim)[1][head // self.num_key_value_groups]).unsqueeze(2)
|
| 532 |
+
part_v = F.linear(hidden_states, self.qkv_proj.weight.view(3, act_num_heads, self.head_dim, hidden_dim)[2][head // self.num_key_value_groups]).unsqueeze(2).transpose(1, 2)
|
| 533 |
+
|
| 534 |
+
part_k = apply_rotary_pos_emb_single(part_k.transpose(1, 2), cos, sin, position_ids)
|
| 535 |
+
if use_cache and past_key_value is not None:
|
| 536 |
+
k[:,head // self.num_key_value_groups] = part_k.cpu()
|
| 537 |
+
v[:,head // self.num_key_value_groups] = part_v.cpu()
|
| 538 |
+
part_k, part_v = past_key_value.get(part_k, part_v, self.layer_idx, head // self.num_key_value_groups, cache_kwargs)
|
| 539 |
+
|
| 540 |
+
if self.layer_idx >= self.starting_layer:
|
| 541 |
+
part_o = self.gather_last_q_vertical_slash_topk_v4(part_q, part_k, part_v, head)
|
| 542 |
+
else:
|
| 543 |
+
part_o = flash_attn_func(part_q, part_k, part_v.transpose(1, 2), 0.0, softmax_scale=None, causal=True).view(bsz, part_q.shape[1], self.head_dim)
|
| 544 |
+
attn_out[:, :, head, :] = part_o
|
| 545 |
+
|
| 546 |
+
if use_cache and past_key_value is not None:
|
| 547 |
+
past_key_value.update(k, v, self.layer_idx, cache_kwargs)
|
| 548 |
+
torch.matmul(attn_out.view(bsz, q_len, hidden_dim), self.o_proj.weight.T, out=hidden_states)
|
| 549 |
+
torch.cuda.empty_cache()
|
| 550 |
+
return (hidden_states, None, past_key_value)
|
| 551 |
+
|
| 552 |
+
return forward
|
| 553 |
+
|
| 554 |
+
def minference_with_snapkv_forward():
|
| 555 |
+
def forward(
|
| 556 |
+
self,
|
| 557 |
+
hidden_states,
|
| 558 |
+
attention_mask,
|
| 559 |
+
position_ids,
|
| 560 |
+
past_key_value,
|
| 561 |
+
output_attentions,
|
| 562 |
+
use_cache,
|
| 563 |
+
**kwargs,
|
| 564 |
+
):
|
| 565 |
+
self.init_minference_parameters()
|
| 566 |
+
self.ne_inf = torch.finfo(hidden_states.dtype).min
|
| 567 |
+
|
| 568 |
+
init_snapkv(self)
|
| 569 |
+
|
| 570 |
+
bsz, q_len, _ = hidden_states.size()
|
| 571 |
+
|
| 572 |
+
query_states = self.q_proj(hidden_states)
|
| 573 |
+
key_states = self.k_proj(hidden_states)
|
| 574 |
+
value_states = self.v_proj(hidden_states)
|
| 575 |
+
|
| 576 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 577 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 578 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 579 |
+
|
| 580 |
+
kv_seq_len = key_states.shape[-2]
|
| 581 |
+
if past_key_value is not None:
|
| 582 |
+
if self.layer_idx is None:
|
| 583 |
+
raise ValueError(
|
| 584 |
+
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
|
| 585 |
+
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
|
| 586 |
+
"with a layer index."
|
| 587 |
+
)
|
| 588 |
+
|
| 589 |
+
if hasattr(self, "kv_seq_len"): #[SnapKV] add kv_seq_len
|
| 590 |
+
if self.kv_seq_len != 0:
|
| 591 |
+
kv_seq_len += self.kv_seq_len
|
| 592 |
+
else:
|
| 593 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 594 |
+
else:
|
| 595 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 596 |
+
global ROPE_TYPE
|
| 597 |
+
if ROPE_TYPE is None:
|
| 598 |
+
ROPE_TYPE = "seq_len" in inspect.signature(self.rotary_emb.forward).parameters
|
| 599 |
+
if ROPE_TYPE:
|
| 600 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 601 |
+
else:
|
| 602 |
+
cos, sin = self.rotary_emb(value_states, position_ids)
|
| 603 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 604 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 605 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 606 |
+
|
| 607 |
+
if past_key_value is not None:
|
| 608 |
+
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 609 |
+
if key_states.shape[-2] == kv_seq_len: # [SnapKV] add kv_cluster
|
| 610 |
+
self.kv_seq_len = kv_seq_len # [SnapKV] register kv_seq_len
|
| 611 |
+
key_states_compress, value_states_compress = self.kv_cluster.update_kv(key_states, query_states, value_states, attention_mask, self.num_key_value_groups)
|
| 612 |
+
past_key_value.update(key_states_compress, value_states_compress, self.layer_idx, cache_kwargs)
|
| 613 |
+
else:
|
| 614 |
+
self.kv_seq_len += q_len
|
| 615 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 616 |
+
|
| 617 |
+
if self.layer_idx >= self.starting_layer:
|
| 618 |
+
assert query_states.size(1) == key_states.size(1) == value_states.size(1)
|
| 619 |
+
output = torch.empty_like(query_states)
|
| 620 |
+
for head in range(query_states.size(1)):
|
| 621 |
+
q = query_states[:, head, :, :].unsqueeze(1)
|
| 622 |
+
k = key_states[:, head, :, :].unsqueeze(1)
|
| 623 |
+
v = value_states[:, head, :, :].unsqueeze(1)
|
| 624 |
+
output[:, head:head + 1] = self.gather_last_q_vertical_slash_topk_v4(q, k, v, head)
|
| 625 |
+
|
| 626 |
+
attn_output = output.transpose(1, 2).contiguous()
|
| 627 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 628 |
+
attn_output = self.o_proj(attn_output)
|
| 629 |
+
return attn_output, None, past_key_value
|
| 630 |
+
|
| 631 |
+
else:
|
| 632 |
+
output = torch.empty_like(query_states)
|
| 633 |
+
for head in range(query_states.size(1)):
|
| 634 |
+
q = query_states[:, head, :, :].unsqueeze(1)
|
| 635 |
+
k = key_states[:, head, :, :].unsqueeze(1)
|
| 636 |
+
v = value_states[:, head, :, :].unsqueeze(1)
|
| 637 |
+
if is_flash_attn_2_available():
|
| 638 |
+
attn_output = flash_attn_func(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1,2), 0.0, softmax_scale=None, causal=q_len != 1).view(bsz, 1, q.shape[2], self.head_dim)
|
| 639 |
+
else:
|
| 640 |
+
attn_output = gather_qkv(q, k, v, attention_mask)
|
| 641 |
+
output[:, head:head + 1] = attn_output
|
| 642 |
+
attn_output = output.transpose(1, 2).contiguous()
|
| 643 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 644 |
+
attn_output = self.o_proj(attn_output)
|
| 645 |
+
|
| 646 |
+
return attn_output, None, past_key_value
|
| 647 |
+
|
| 648 |
+
return forward
|
| 649 |
+
|
| 650 |
+
def gather_last_q_vertical_slash_topk_vllm(self, q, k, v, head_id):
|
| 651 |
+
kv_seq_len = k.size(2)
|
| 652 |
+
head_dim = q.size(-1)
|
| 653 |
+
|
| 654 |
+
def vertical_and_slash_kernel(q, k, v, vertical_size, slash_size):
|
| 655 |
+
vertical_size, slash_size = min(q_len, max(vertical_size, 30)), min(q_len, max(slash_size, 50))
|
| 656 |
+
last_q = min(64, q_len)
|
| 657 |
+
qk = torch.einsum(f'bhmk, bhnk -> bhmn', q[:,:,-last_q:,:], k)
|
| 658 |
+
|
| 659 |
+
qk[:, :, :, -last_q:] = torch.where(LAST_Q_MASK[...,-last_q:,-last_q:], qk[:, :, :, -last_q:], -torch.inf)
|
| 660 |
+
qk = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32)
|
| 661 |
+
vertical = qk.sum(-2, keepdim=True)
|
| 662 |
+
vertical[...,:30] = torch.inf
|
| 663 |
+
vertical_topk = torch.topk(vertical, vertical_size, -1).indices
|
| 664 |
+
|
| 665 |
+
slash = sum_all_diagonal_matrix(qk)[...,:-last_q + 1]
|
| 666 |
+
slash[...,-100:] = torch.inf
|
| 667 |
+
slash_topk = slash
|
| 668 |
+
slash = (q_len - 1) - torch.topk(slash, slash_size, -1).indices
|
| 669 |
+
|
| 670 |
+
return vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
|
| 671 |
+
|
| 672 |
+
def block_sparse_kernel(q, k, v, vertical_size=None, slash_size=None):
|
| 673 |
+
topk = 100
|
| 674 |
+
return block_sparse_attention(q, k, v, topk)
|
| 675 |
+
|
| 676 |
+
def dense(q, k, v, vertical_size=None, slash_size=None):
|
| 677 |
+
return flash_attn_func(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1,2), 0.0, softmax_scale=None, causal=q_len != 1).view(bsz, 1, q_len, head_dim)
|
| 678 |
+
|
| 679 |
+
q_len = q.shape[2]
|
| 680 |
+
bsz = q.shape[0]
|
| 681 |
+
|
| 682 |
+
ty, vertical_size, slash_size, _ = self.best_pattern[head_id]
|
| 683 |
+
|
| 684 |
+
if q_len == 1:
|
| 685 |
+
return dense(q, k, v)
|
| 686 |
+
|
| 687 |
+
fc = {
|
| 688 |
+
"stream_llm": streaming_forward,
|
| 689 |
+
"vertical_and_slash": vertical_and_slash_kernel,
|
| 690 |
+
"block_sparse": block_sparse_kernel,
|
| 691 |
+
}[ty]
|
| 692 |
+
return fc(q, k, v, vertical_size, slash_size)
|
| 693 |
+
|
| 694 |
+
def minference_vllm_forward(
|
| 695 |
+
pattern_config
|
| 696 |
+
):
|
| 697 |
+
def forward(
|
| 698 |
+
self,
|
| 699 |
+
query: torch.Tensor,
|
| 700 |
+
key: torch.Tensor,
|
| 701 |
+
value: torch.Tensor,
|
| 702 |
+
kv_cache: torch.Tensor,
|
| 703 |
+
attn_metadata: AttentionMetadata[FlashAttentionMetadata],
|
| 704 |
+
kv_scale: float,
|
| 705 |
+
layer_idx: int,
|
| 706 |
+
) -> torch.Tensor:
|
| 707 |
+
"""Forward pass with FlashAttention and PagedAttention.
|
| 708 |
+
|
| 709 |
+
Args:
|
| 710 |
+
query: shape = [num_tokens, num_heads * head_size]
|
| 711 |
+
key: shape = [num_tokens, num_kv_heads * head_size]
|
| 712 |
+
value: shape = [num_tokens, num_kv_heads * head_size]
|
| 713 |
+
kv_cache = [2, num_blocks, block_size * num_kv_heads * head_size]
|
| 714 |
+
attn_metadata: Metadata for attention.
|
| 715 |
+
Returns:
|
| 716 |
+
shape = [num_tokens, num_heads * head_size]
|
| 717 |
+
"""
|
| 718 |
+
self.best_pattern = {int(ii): jj for ii, jj in pattern_config[layer_idx].items()}
|
| 719 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 720 |
+
"""
|
| 721 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 722 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 723 |
+
"""
|
| 724 |
+
slen, num_key_value_heads, head_dim = hidden_states.shape
|
| 725 |
+
if n_rep == 1:
|
| 726 |
+
return hidden_states
|
| 727 |
+
hidden_states = hidden_states[:, None, :, :].expand(slen, n_rep, num_key_value_heads, head_dim)
|
| 728 |
+
return hidden_states.reshape(slen, num_key_value_heads * n_rep, head_dim)
|
| 729 |
+
|
| 730 |
+
def minference_prefill_func(
|
| 731 |
+
q, k, v,
|
| 732 |
+
|
| 733 |
+
):
|
| 734 |
+
# (seq_len, num_heads, head_size)
|
| 735 |
+
if q.size(-2) != k.size(-2):
|
| 736 |
+
k = repeat_kv(k, q.size(-2) // k.size(-2))
|
| 737 |
+
v = repeat_kv(v, q.size(-2) // v.size(-2))
|
| 738 |
+
|
| 739 |
+
output = torch.empty_like(q)
|
| 740 |
+
for head in range(q.size(-2)):
|
| 741 |
+
q_head = q[:, head, :].unsqueeze(1)
|
| 742 |
+
k_head = k[:, head, :].unsqueeze(1)
|
| 743 |
+
v_head = v[:, head, :].unsqueeze(1)
|
| 744 |
+
|
| 745 |
+
# (1, seq_len, num_heads, head_size)
|
| 746 |
+
q_head = q_head[None, ...]
|
| 747 |
+
k_head = k_head[None, ...]
|
| 748 |
+
v_head = v_head[None, ...]
|
| 749 |
+
|
| 750 |
+
q_head = q_head.transpose(1, 2)
|
| 751 |
+
k_head = k_head.transpose(1, 2)
|
| 752 |
+
v_head = v_head.transpose(1, 2)
|
| 753 |
+
|
| 754 |
+
out = self.gather_last_q_vertical_slash_topk_vllm(q_head, k_head, v_head, head)
|
| 755 |
+
|
| 756 |
+
out = out.transpose(1, 2).squeeze(0).contiguous()
|
| 757 |
+
output[:, head:head+1, :] = out
|
| 758 |
+
return output
|
| 759 |
+
|
| 760 |
+
num_tokens, hidden_size = query.shape
|
| 761 |
+
# Reshape the query, key, and value tensors.
|
| 762 |
+
query = query.view(-1, self.num_heads, self.head_size)
|
| 763 |
+
key = key.view(-1, self.num_kv_heads, self.head_size)
|
| 764 |
+
value = value.view(-1, self.num_kv_heads, self.head_size)
|
| 765 |
+
|
| 766 |
+
if kv_cache is not None:
|
| 767 |
+
key_cache, value_cache = PagedAttention.split_kv_cache(
|
| 768 |
+
kv_cache, self.num_kv_heads, self.head_size)
|
| 769 |
+
|
| 770 |
+
# Reshape the input keys and values and store them in the cache.
|
| 771 |
+
# If kv_cache is not provided, the new key and value tensors are
|
| 772 |
+
# not cached. This happens during the initial memory profiling run.
|
| 773 |
+
PagedAttention.write_to_paged_cache(key, value, key_cache,
|
| 774 |
+
value_cache,
|
| 775 |
+
attn_metadata.slot_mapping,
|
| 776 |
+
attn_metadata.kv_cache_dtype,
|
| 777 |
+
kv_scale)
|
| 778 |
+
|
| 779 |
+
num_prefill_tokens = attn_metadata.num_prefill_tokens
|
| 780 |
+
num_decode_tokens = attn_metadata.num_decode_tokens
|
| 781 |
+
assert key.shape[0] == num_prefill_tokens + num_decode_tokens
|
| 782 |
+
assert value.shape[0] == num_prefill_tokens + num_decode_tokens
|
| 783 |
+
|
| 784 |
+
output = torch.empty_like(query)
|
| 785 |
+
# Query for decode. KV is not needed because it is already cached.
|
| 786 |
+
decode_query = query[num_prefill_tokens:]
|
| 787 |
+
# QKV for prefill.
|
| 788 |
+
query = query[:num_prefill_tokens]
|
| 789 |
+
key = key[:num_prefill_tokens]
|
| 790 |
+
value = value[:num_prefill_tokens]
|
| 791 |
+
|
| 792 |
+
assert query.shape[0] == num_prefill_tokens
|
| 793 |
+
assert decode_query.shape[0] == num_decode_tokens
|
| 794 |
+
|
| 795 |
+
if prefill_meta := attn_metadata.prefill_metadata:
|
| 796 |
+
# Prompt run.
|
| 797 |
+
if kv_cache is None or prefill_meta.block_tables.numel() == 0:
|
| 798 |
+
# normal attention
|
| 799 |
+
# When block_tables are not filled, it means q and k are the
|
| 800 |
+
# prompt, and they have the same length.
|
| 801 |
+
# (seq_len, num_heads, head_size)
|
| 802 |
+
# out = flash_attn_varlen_func(
|
| 803 |
+
# q=query,
|
| 804 |
+
# k=key,
|
| 805 |
+
# v=value,
|
| 806 |
+
# cu_seqlens_q=prefill_meta.seq_start_loc,
|
| 807 |
+
# cu_seqlens_k=prefill_meta.seq_start_loc,
|
| 808 |
+
# max_seqlen_q=prefill_meta.max_prompt_len,
|
| 809 |
+
# max_seqlen_k=prefill_meta.max_prompt_len,
|
| 810 |
+
# softmax_scale=self.scale,
|
| 811 |
+
# causal=True,
|
| 812 |
+
# window_size=self.sliding_window,
|
| 813 |
+
# alibi_slopes=self.alibi_slopes,
|
| 814 |
+
# )
|
| 815 |
+
out = minference_prefill_func(query, key, value)
|
| 816 |
+
assert output[:num_prefill_tokens].shape == out.shape
|
| 817 |
+
output[:num_prefill_tokens] = out
|
| 818 |
+
else:
|
| 819 |
+
# prefix-enabled attention
|
| 820 |
+
# TODO(Hai) this triton kernel has regression issue (broke) to
|
| 821 |
+
# deal with different data types between KV and FP8 KV cache,
|
| 822 |
+
# to be addressed separately.
|
| 823 |
+
output[:num_prefill_tokens] = PagedAttention.forward_prefix(
|
| 824 |
+
query,
|
| 825 |
+
key,
|
| 826 |
+
value,
|
| 827 |
+
key_cache,
|
| 828 |
+
value_cache,
|
| 829 |
+
prefill_meta.block_tables,
|
| 830 |
+
prefill_meta.subquery_start_loc,
|
| 831 |
+
prefill_meta.prompt_lens_tensor,
|
| 832 |
+
prefill_meta.context_lens,
|
| 833 |
+
prefill_meta.max_subquery_len,
|
| 834 |
+
self.alibi_slopes,
|
| 835 |
+
)
|
| 836 |
+
if decode_meta := attn_metadata.decode_metadata:
|
| 837 |
+
# Decoding run.
|
| 838 |
+
output[num_prefill_tokens:] = PagedAttention.forward_decode(
|
| 839 |
+
decode_query,
|
| 840 |
+
key_cache,
|
| 841 |
+
value_cache,
|
| 842 |
+
decode_meta.block_tables,
|
| 843 |
+
decode_meta.context_lens,
|
| 844 |
+
decode_meta.max_context_len,
|
| 845 |
+
attn_metadata.kv_cache_dtype,
|
| 846 |
+
self.num_kv_heads,
|
| 847 |
+
self.scale,
|
| 848 |
+
self.alibi_slopes,
|
| 849 |
+
kv_scale,
|
| 850 |
+
)
|
| 851 |
+
|
| 852 |
+
# Reshape the output tensor.
|
| 853 |
+
return output.view(num_tokens, hidden_size)
|
| 854 |
+
|
| 855 |
+
return forward
|
minference/modules/snap_kv.py
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import time
|
| 3 |
+
import warnings
|
| 4 |
+
from importlib.metadata import version
|
| 5 |
+
from typing import List, Optional, Tuple, Union
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import transformers
|
| 11 |
+
from transformers.cache_utils import Cache, DynamicCache
|
| 12 |
+
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb, repeat_kv
|
| 13 |
+
from transformers.utils import logging
|
| 14 |
+
|
| 15 |
+
logger = logging.get_logger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# https://github.com/huggingface/transformers/blob/v4.37-release/src/transformers/models/llama/modeling_llama.py
|
| 19 |
+
def llama_flash_attn2_forward(
|
| 20 |
+
self,
|
| 21 |
+
hidden_states: torch.Tensor,
|
| 22 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 23 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 24 |
+
past_key_value: Optional[Cache] = None,
|
| 25 |
+
output_attentions: bool = False,
|
| 26 |
+
use_cache: bool = False,
|
| 27 |
+
**kwargs,
|
| 28 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 29 |
+
# [SnapKV] register kv_cluster
|
| 30 |
+
init_snapkv(self)
|
| 31 |
+
# LlamaFlashAttention2 attention does not support output_attentions
|
| 32 |
+
if "padding_mask" in kwargs:
|
| 33 |
+
warnings.warn(
|
| 34 |
+
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
# overwrite attention_mask with padding_mask
|
| 38 |
+
attention_mask = kwargs.pop("padding_mask")
|
| 39 |
+
|
| 40 |
+
output_attentions = False
|
| 41 |
+
|
| 42 |
+
bsz, q_len, _ = hidden_states.size()
|
| 43 |
+
|
| 44 |
+
query_states = self.q_proj(hidden_states)
|
| 45 |
+
key_states = self.k_proj(hidden_states)
|
| 46 |
+
value_states = self.v_proj(hidden_states)
|
| 47 |
+
|
| 48 |
+
# Flash attention requires the input to have the shape
|
| 49 |
+
# batch_size x seq_length x head_dim x hidden_dim
|
| 50 |
+
# therefore we just need to keep the original shape
|
| 51 |
+
query_states = query_states.view(
|
| 52 |
+
bsz, q_len, self.num_heads, self.head_dim
|
| 53 |
+
).transpose(1, 2)
|
| 54 |
+
key_states = key_states.view(
|
| 55 |
+
bsz, q_len, self.num_key_value_heads, self.head_dim
|
| 56 |
+
).transpose(1, 2)
|
| 57 |
+
value_states = value_states.view(
|
| 58 |
+
bsz, q_len, self.num_key_value_heads, self.head_dim
|
| 59 |
+
).transpose(1, 2)
|
| 60 |
+
|
| 61 |
+
kv_seq_len = key_states.shape[-2]
|
| 62 |
+
# if past_key_value is not None:
|
| 63 |
+
# kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 64 |
+
if past_key_value is not None:
|
| 65 |
+
if self.layer_idx is None:
|
| 66 |
+
raise ValueError(
|
| 67 |
+
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
|
| 68 |
+
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
|
| 69 |
+
"with a layer index."
|
| 70 |
+
)
|
| 71 |
+
if hasattr(self, "kv_seq_len"): # [SnapKV] add kv_seq_len
|
| 72 |
+
if self.kv_seq_len != 0:
|
| 73 |
+
kv_seq_len += self.kv_seq_len
|
| 74 |
+
else:
|
| 75 |
+
kv_seq_len += past_key_value.get_usable_length(
|
| 76 |
+
kv_seq_len, self.layer_idx
|
| 77 |
+
)
|
| 78 |
+
else:
|
| 79 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 80 |
+
|
| 81 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 82 |
+
query_states, key_states = apply_rotary_pos_emb(
|
| 83 |
+
query_states, key_states, cos, sin, position_ids
|
| 84 |
+
)
|
| 85 |
+
# [SnapKV] move to ahead
|
| 86 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 87 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 88 |
+
|
| 89 |
+
if past_key_value is not None:
|
| 90 |
+
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 91 |
+
# key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 92 |
+
# print('kv_seq_len:', kv_seq_len)
|
| 93 |
+
# print('key_states.shape:', key_states.shape)
|
| 94 |
+
if key_states.shape[-2] == kv_seq_len: # [SnapKV] add kv_cluster
|
| 95 |
+
self.kv_seq_len = kv_seq_len # [SnapKV] register kv_seq_len
|
| 96 |
+
key_states_compress, value_states_compress = self.kv_cluster.update_kv(
|
| 97 |
+
key_states,
|
| 98 |
+
query_states,
|
| 99 |
+
value_states,
|
| 100 |
+
attention_mask,
|
| 101 |
+
self.num_key_value_groups,
|
| 102 |
+
)
|
| 103 |
+
past_key_value.update(
|
| 104 |
+
key_states_compress, value_states_compress, self.layer_idx, cache_kwargs
|
| 105 |
+
)
|
| 106 |
+
else:
|
| 107 |
+
self.kv_seq_len += q_len
|
| 108 |
+
key_states, value_states = past_key_value.update(
|
| 109 |
+
key_states, value_states, self.layer_idx, cache_kwargs
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
|
| 113 |
+
# to be able to avoid many of these transpose/reshape/view.
|
| 114 |
+
query_states = query_states.transpose(1, 2)
|
| 115 |
+
key_states = key_states.transpose(1, 2)
|
| 116 |
+
value_states = value_states.transpose(1, 2)
|
| 117 |
+
|
| 118 |
+
dropout_rate = self.attention_dropout if self.training else 0.0
|
| 119 |
+
|
| 120 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 121 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 122 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 123 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 124 |
+
# in fp32. (LlamaRMSNorm handles it correctly)
|
| 125 |
+
|
| 126 |
+
input_dtype = query_states.dtype
|
| 127 |
+
if input_dtype == torch.float32:
|
| 128 |
+
if torch.is_autocast_enabled():
|
| 129 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 130 |
+
# Handle the case where the model is quantized
|
| 131 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 132 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 133 |
+
else:
|
| 134 |
+
target_dtype = self.q_proj.weight.dtype
|
| 135 |
+
|
| 136 |
+
logger.warning_once(
|
| 137 |
+
f"The input hidden states seems to be silently casted in float32, this might be related to"
|
| 138 |
+
f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 139 |
+
f" {target_dtype}."
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
query_states = query_states.to(target_dtype)
|
| 143 |
+
key_states = key_states.to(target_dtype)
|
| 144 |
+
value_states = value_states.to(target_dtype)
|
| 145 |
+
|
| 146 |
+
attn_output = self._flash_attention_forward(
|
| 147 |
+
query_states,
|
| 148 |
+
key_states,
|
| 149 |
+
value_states,
|
| 150 |
+
attention_mask,
|
| 151 |
+
q_len,
|
| 152 |
+
dropout=dropout_rate,
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 156 |
+
attn_output = self.o_proj(attn_output)
|
| 157 |
+
|
| 158 |
+
if not output_attentions:
|
| 159 |
+
attn_weights = None
|
| 160 |
+
|
| 161 |
+
return attn_output, attn_weights, past_key_value
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def prepare_inputs_for_generation_llama(
|
| 165 |
+
self,
|
| 166 |
+
input_ids,
|
| 167 |
+
past_key_values=None,
|
| 168 |
+
attention_mask=None,
|
| 169 |
+
inputs_embeds=None,
|
| 170 |
+
**kwargs,
|
| 171 |
+
):
|
| 172 |
+
if past_key_values is None: # [SnapKV]
|
| 173 |
+
for layer in self.model.layers:
|
| 174 |
+
layer.self_attn.kv_seq_len = 0
|
| 175 |
+
if past_key_values is not None:
|
| 176 |
+
if isinstance(past_key_values, Cache):
|
| 177 |
+
cache_length = past_key_values.get_seq_length()
|
| 178 |
+
past_length = past_key_values.seen_tokens
|
| 179 |
+
max_cache_length = past_key_values.get_max_length()
|
| 180 |
+
else:
|
| 181 |
+
# cache_length = past_length = past_key_values[0][0].shape[2]
|
| 182 |
+
# max_cache_length = None
|
| 183 |
+
cache_length = past_length = self.model.layers[0].self_attn.kv_seq_len
|
| 184 |
+
max_cache_length = None
|
| 185 |
+
# Keep only the unprocessed tokens:
|
| 186 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 187 |
+
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
| 188 |
+
# input)
|
| 189 |
+
if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
|
| 190 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 191 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 192 |
+
# input_ids based on the past_length.
|
| 193 |
+
elif past_length < input_ids.shape[1]:
|
| 194 |
+
input_ids = input_ids[:, past_length:]
|
| 195 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 196 |
+
|
| 197 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 198 |
+
if (
|
| 199 |
+
max_cache_length is not None
|
| 200 |
+
and attention_mask is not None
|
| 201 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 202 |
+
):
|
| 203 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 204 |
+
|
| 205 |
+
position_ids = kwargs.get("position_ids", None)
|
| 206 |
+
if attention_mask is not None and position_ids is None:
|
| 207 |
+
# create position_ids on the fly for batch generation
|
| 208 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 209 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 210 |
+
if past_key_values:
|
| 211 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 212 |
+
|
| 213 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 214 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 215 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 216 |
+
else:
|
| 217 |
+
model_inputs = {"input_ids": input_ids}
|
| 218 |
+
|
| 219 |
+
model_inputs.update(
|
| 220 |
+
{
|
| 221 |
+
"position_ids": position_ids,
|
| 222 |
+
"past_key_values": past_key_values,
|
| 223 |
+
"use_cache": kwargs.get("use_cache"),
|
| 224 |
+
"attention_mask": attention_mask,
|
| 225 |
+
}
|
| 226 |
+
)
|
| 227 |
+
return model_inputs
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
llama_flash_attn2_forward_4_37 = llama_flash_attn2_forward
|
| 231 |
+
prepare_inputs_for_generation_llama_4_37 = prepare_inputs_for_generation_llama
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
@torch.no_grad()
|
| 235 |
+
def rope_forward(self, x, seq_len):
|
| 236 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 237 |
+
position_ids = torch.arange(seq_len, device=x.device).unsqueeze(0)
|
| 238 |
+
inv_freq_expanded = (
|
| 239 |
+
self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
|
| 240 |
+
)
|
| 241 |
+
position_ids_expanded = position_ids[:, None, :].float()
|
| 242 |
+
# Force float32 since bfloat16 loses precision on long contexts
|
| 243 |
+
# See https://github.com/huggingface/transformers/pull/29285
|
| 244 |
+
device_type = x.device.type
|
| 245 |
+
device_type = (
|
| 246 |
+
device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
|
| 247 |
+
)
|
| 248 |
+
with torch.autocast(device_type=device_type, enabled=False):
|
| 249 |
+
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(
|
| 250 |
+
1, 2
|
| 251 |
+
)
|
| 252 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 253 |
+
cos = emb.cos()
|
| 254 |
+
sin = emb.sin()
|
| 255 |
+
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
##################
|
| 259 |
+
|
| 260 |
+
# perform qk calculation and get indices
|
| 261 |
+
# this version will not update in inference mode
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
# Copied from transformers.models.llama.modeling_llama.repeat_kv
|
| 265 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 266 |
+
"""
|
| 267 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 268 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 269 |
+
"""
|
| 270 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 271 |
+
if n_rep == 1:
|
| 272 |
+
return hidden_states
|
| 273 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(
|
| 274 |
+
batch, num_key_value_heads, n_rep, slen, head_dim
|
| 275 |
+
)
|
| 276 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
class SnapKVCluster:
|
| 280 |
+
def __init__(
|
| 281 |
+
self,
|
| 282 |
+
window_size=64,
|
| 283 |
+
max_capacity_prompt=256 + 64,
|
| 284 |
+
kernel_size=5,
|
| 285 |
+
pooling="avgpool",
|
| 286 |
+
):
|
| 287 |
+
self.window_size = window_size
|
| 288 |
+
self.max_capacity_prompt = max_capacity_prompt
|
| 289 |
+
assert self.max_capacity_prompt - self.window_size > 0
|
| 290 |
+
self.kernel_size = kernel_size
|
| 291 |
+
self.pooling = pooling
|
| 292 |
+
|
| 293 |
+
def reset(
|
| 294 |
+
self,
|
| 295 |
+
window_size=64,
|
| 296 |
+
max_capacity_prompt=256 + 64,
|
| 297 |
+
kernel_size=5,
|
| 298 |
+
pooling="avgpool",
|
| 299 |
+
):
|
| 300 |
+
self.window_size = window_size
|
| 301 |
+
self.max_capacity_prompt = max_capacity_prompt
|
| 302 |
+
assert self.max_capacity_prompt - self.window_size > 0
|
| 303 |
+
self.kernel_size = kernel_size
|
| 304 |
+
self.pooling = pooling
|
| 305 |
+
|
| 306 |
+
def update_kv(
|
| 307 |
+
self,
|
| 308 |
+
key_states,
|
| 309 |
+
query_states,
|
| 310 |
+
value_states,
|
| 311 |
+
attention_mask,
|
| 312 |
+
num_key_value_groups,
|
| 313 |
+
):
|
| 314 |
+
# check if prefix phase
|
| 315 |
+
assert key_states.shape[-2] == query_states.shape[-2]
|
| 316 |
+
bsz, num_heads, q_len, head_dim = query_states.shape
|
| 317 |
+
if q_len < self.max_capacity_prompt:
|
| 318 |
+
return key_states, value_states
|
| 319 |
+
else:
|
| 320 |
+
attn_weights = torch.matmul(
|
| 321 |
+
query_states[..., -self.window_size :, :], key_states.transpose(2, 3)
|
| 322 |
+
) / math.sqrt(head_dim)
|
| 323 |
+
mask = torch.full(
|
| 324 |
+
(self.window_size, self.window_size),
|
| 325 |
+
torch.finfo(attn_weights.dtype).min,
|
| 326 |
+
device=attn_weights.device,
|
| 327 |
+
)
|
| 328 |
+
mask_cond = torch.arange(mask.size(-1), device=attn_weights.device)
|
| 329 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 330 |
+
mask = mask.to(attn_weights.device)
|
| 331 |
+
attention_mask = mask[None, None, :, :]
|
| 332 |
+
|
| 333 |
+
attn_weights[
|
| 334 |
+
:, :, -self.window_size :, -self.window_size :
|
| 335 |
+
] += attention_mask
|
| 336 |
+
|
| 337 |
+
attn_weights = nn.functional.softmax(
|
| 338 |
+
attn_weights, dim=-1, dtype=torch.float32
|
| 339 |
+
).to(query_states.dtype)
|
| 340 |
+
attn_weights_sum = attn_weights[
|
| 341 |
+
:, :, -self.window_size :, : -self.window_size
|
| 342 |
+
].sum(dim=-2)
|
| 343 |
+
if self.pooling == "avgpool":
|
| 344 |
+
attn_cache = F.avg_pool1d(
|
| 345 |
+
attn_weights_sum,
|
| 346 |
+
kernel_size=self.kernel_size,
|
| 347 |
+
padding=self.kernel_size // 2,
|
| 348 |
+
stride=1,
|
| 349 |
+
)
|
| 350 |
+
elif self.pooling == "maxpool":
|
| 351 |
+
attn_cache = F.max_pool1d(
|
| 352 |
+
attn_weights_sum,
|
| 353 |
+
kernel_size=self.kernel_size,
|
| 354 |
+
padding=self.kernel_size // 2,
|
| 355 |
+
stride=1,
|
| 356 |
+
)
|
| 357 |
+
else:
|
| 358 |
+
raise ValueError("Pooling method not supported")
|
| 359 |
+
indices = attn_cache.topk(
|
| 360 |
+
self.max_capacity_prompt - self.window_size, dim=-1
|
| 361 |
+
).indices
|
| 362 |
+
indices = indices.unsqueeze(-1).expand(-1, -1, -1, head_dim)
|
| 363 |
+
k_past_compress = key_states[:, :, : -self.window_size, :].gather(
|
| 364 |
+
dim=2, index=indices
|
| 365 |
+
)
|
| 366 |
+
v_past_compress = value_states[:, :, : -self.window_size, :].gather(
|
| 367 |
+
dim=2, index=indices
|
| 368 |
+
)
|
| 369 |
+
k_cur = key_states[:, :, -self.window_size :, :]
|
| 370 |
+
v_cur = value_states[:, :, -self.window_size :, :]
|
| 371 |
+
key_states = torch.cat([k_past_compress, k_cur], dim=2)
|
| 372 |
+
value_states = torch.cat([v_past_compress, v_cur], dim=2)
|
| 373 |
+
return key_states, value_states
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
def init_snapkv(self):
|
| 377 |
+
if not hasattr(self, "kv_cluster"):
|
| 378 |
+
if not hasattr(self.config, "window_size"):
|
| 379 |
+
self.config.window_size = 64
|
| 380 |
+
if not hasattr(self.config, "max_capacity_prompt"):
|
| 381 |
+
self.config.max_capacity_prompt = 4096
|
| 382 |
+
if not hasattr(self.config, "kernel_size"):
|
| 383 |
+
self.config.kernel_size = 13
|
| 384 |
+
if not hasattr(self.config, "pooling"):
|
| 385 |
+
self.config.pooling = "avgpool"
|
| 386 |
+
self.kv_cluster = SnapKVCluster(
|
| 387 |
+
window_size=self.config.window_size,
|
| 388 |
+
max_capacity_prompt=self.config.max_capacity_prompt,
|
| 389 |
+
kernel_size=self.config.kernel_size,
|
| 390 |
+
pooling=self.config.pooling,
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
|
| 394 |
+
############
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
def check_version():
|
| 398 |
+
try:
|
| 399 |
+
transformers_version = version("transformers")
|
| 400 |
+
except Exception as e:
|
| 401 |
+
print(f"Transformers not installed: {e}")
|
| 402 |
+
return transformers_version
|
| 403 |
+
|
| 404 |
+
|
| 405 |
+
def replace_llama():
|
| 406 |
+
transformers_version = check_version()
|
| 407 |
+
version_list = ["4.37"]
|
| 408 |
+
warning_flag = True
|
| 409 |
+
for version in version_list:
|
| 410 |
+
if version in transformers_version:
|
| 411 |
+
warning_flag = False
|
| 412 |
+
break
|
| 413 |
+
if warning_flag:
|
| 414 |
+
warnings.warn(
|
| 415 |
+
f"Transformers version {transformers_version} might not be compatible with SnapKV. SnapKV is tested with Transformers version {version_list}."
|
| 416 |
+
)
|
| 417 |
+
transformers.models.llama.modeling_llama.LlamaForCausalLM.prepare_inputs_for_generation = (
|
| 418 |
+
prepare_inputs_for_generation_llama_4_37
|
| 419 |
+
)
|
| 420 |
+
transformers.models.llama.modeling_llama.LlamaFlashAttention2.forward = (
|
| 421 |
+
llama_flash_attn2_forward_4_37
|
| 422 |
+
)
|
minference/ops/block_sparse_flash_attention.py
ADDED
|
@@ -0,0 +1,464 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
import triton
|
| 5 |
+
import triton.language as tl
|
| 6 |
+
import pycuda.autoprimaryctx
|
| 7 |
+
from pycuda.compiler import SourceModule
|
| 8 |
+
|
| 9 |
+
from flash_attn import flash_attn_varlen_func
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# @triton.autotune(
|
| 13 |
+
# configs=[
|
| 14 |
+
# triton.Config({}, num_stages=1, num_warps=4),
|
| 15 |
+
# triton.Config({}, num_stages=1, num_warps=8),
|
| 16 |
+
# triton.Config({}, num_stages=2, num_warps=4),
|
| 17 |
+
# triton.Config({}, num_stages=2, num_warps=8),
|
| 18 |
+
# triton.Config({}, num_stages=3, num_warps=4),
|
| 19 |
+
# triton.Config({}, num_stages=3, num_warps=8),
|
| 20 |
+
# triton.Config({}, num_stages=4, num_warps=4),
|
| 21 |
+
# triton.Config({}, num_stages=4, num_warps=8),
|
| 22 |
+
# triton.Config({}, num_stages=5, num_warps=4),
|
| 23 |
+
# triton.Config({}, num_stages=5, num_warps=8),
|
| 24 |
+
# ],
|
| 25 |
+
# key=['N_CTX'],
|
| 26 |
+
# )
|
| 27 |
+
@triton.jit
|
| 28 |
+
def triton_block_sparse_attn_kernel(
|
| 29 |
+
Q, K, V, seqlens, sm_scale,
|
| 30 |
+
block_index,
|
| 31 |
+
Out,
|
| 32 |
+
stride_qz, stride_qh, stride_qm, stride_qk,
|
| 33 |
+
stride_kz, stride_kh, stride_kn, stride_kk,
|
| 34 |
+
stride_vz, stride_vh, stride_vn, stride_vk,
|
| 35 |
+
stride_oz, stride_oh, stride_om, stride_ok,
|
| 36 |
+
Z, H, N_CTX,
|
| 37 |
+
NUM_ROWS, MAX_BLOCKS_PRE_ROW,
|
| 38 |
+
BLOCK_M: tl.constexpr,
|
| 39 |
+
BLOCK_N: tl.constexpr,
|
| 40 |
+
BLOCK_DMODEL: tl.constexpr,
|
| 41 |
+
dtype: tl.constexpr,
|
| 42 |
+
):
|
| 43 |
+
start_m = tl.program_id(0)
|
| 44 |
+
off_hz = tl.program_id(1)
|
| 45 |
+
|
| 46 |
+
seqlen = tl.load(seqlens + off_hz // H)
|
| 47 |
+
if start_m * BLOCK_M >= seqlen:
|
| 48 |
+
return
|
| 49 |
+
|
| 50 |
+
# initialize offsets
|
| 51 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 52 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 53 |
+
offs_d = tl.arange(0, BLOCK_DMODEL)
|
| 54 |
+
|
| 55 |
+
qo_offset = (off_hz // H) * stride_qz + (off_hz % H) * stride_qh
|
| 56 |
+
kv_offset = (off_hz // H) * stride_kz + (off_hz % H) * stride_kh
|
| 57 |
+
|
| 58 |
+
q_ptrs = Q + qo_offset + offs_m[:, None] * stride_qm + offs_d[None, :] * stride_qk
|
| 59 |
+
k_ptrs = K + kv_offset + offs_d[:, None] * stride_kk
|
| 60 |
+
v_ptrs = V + kv_offset + offs_d[None, :] * stride_vk
|
| 61 |
+
o_ptrs = Out + qo_offset + offs_m[:, None] * stride_om + offs_d[None, :] * stride_ok
|
| 62 |
+
|
| 63 |
+
blocks_ptr = block_index + (off_hz * NUM_ROWS + start_m) * MAX_BLOCKS_PRE_ROW
|
| 64 |
+
|
| 65 |
+
# initialize pointer to m and l
|
| 66 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 67 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 68 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 69 |
+
# scale sm_scale by log_2(e) and use
|
| 70 |
+
# 2^x instead of exp in the loop because CSE and LICM
|
| 71 |
+
# don't work as expected with `exp` in the loop
|
| 72 |
+
qk_scale = sm_scale * 1.44269504
|
| 73 |
+
# load q: it will stay in SRAM throughout
|
| 74 |
+
q = tl.load(q_ptrs)
|
| 75 |
+
q = (q * qk_scale).to(dtype)
|
| 76 |
+
|
| 77 |
+
# loop over k, v and update accumulator
|
| 78 |
+
m_mask = offs_m[:, None] < seqlen
|
| 79 |
+
block_count = tl.minimum((start_m + 1) * BLOCK_M // BLOCK_N, MAX_BLOCKS_PRE_ROW)
|
| 80 |
+
|
| 81 |
+
for sparse_block_idx in range(block_count):
|
| 82 |
+
real_block_idx = tl.load(blocks_ptr + sparse_block_idx)
|
| 83 |
+
start_n = real_block_idx * BLOCK_N
|
| 84 |
+
cols = start_n + offs_n
|
| 85 |
+
# -- load k, v --
|
| 86 |
+
k = tl.load(k_ptrs + cols[None, :] * stride_kn)
|
| 87 |
+
v = tl.load(v_ptrs + cols[:, None] * stride_vn)
|
| 88 |
+
# -- compute qk --
|
| 89 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 90 |
+
# if start_n + BLOCK_N < seqlen:
|
| 91 |
+
# qk = tl.where(m_mask, qk, float("-inf"))
|
| 92 |
+
# else:
|
| 93 |
+
causal_mask = cols[None, :] <= offs_m[:, None]
|
| 94 |
+
qk = tl.where(m_mask & causal_mask, qk, float("-inf"))
|
| 95 |
+
qk += tl.dot(q, k)
|
| 96 |
+
# -- compute scaling constant --
|
| 97 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 98 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 99 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 100 |
+
# -- scale and update acc --
|
| 101 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 102 |
+
acc *= acc_scale[:, None]
|
| 103 |
+
acc += tl.dot(p.to(dtype), v)
|
| 104 |
+
# -- update m_i and l_i --
|
| 105 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 106 |
+
m_i = m_i_new
|
| 107 |
+
|
| 108 |
+
# write back O
|
| 109 |
+
acc /= l_i[:, None]
|
| 110 |
+
tl.store(o_ptrs, acc.to(dtype), mask=m_mask)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def triton_block_sparse_forward(
|
| 114 |
+
q, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 115 |
+
k, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 116 |
+
v, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 117 |
+
seqlens, # [BATCH, ]
|
| 118 |
+
block_index, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), MAX_BLOCKS_PRE_ROW]
|
| 119 |
+
sm_scale,
|
| 120 |
+
block_size_M=64,
|
| 121 |
+
block_size_N=64,
|
| 122 |
+
) -> torch.Tensor:
|
| 123 |
+
# shape constraints
|
| 124 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 125 |
+
assert Lq == Lk and Lk == Lv
|
| 126 |
+
assert Lk in {16, 32, 64, 128}
|
| 127 |
+
o = torch.zeros_like(q)
|
| 128 |
+
grid = (triton.cdiv(q.shape[2], block_size_M), q.shape[0] * q.shape[1], 1)
|
| 129 |
+
dtype = tl.bfloat16 if q.dtype == torch.bfloat16 else tl.float16
|
| 130 |
+
triton_block_sparse_attn_kernel[grid](
|
| 131 |
+
q, k, v, seqlens, sm_scale,
|
| 132 |
+
block_index,
|
| 133 |
+
o,
|
| 134 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 135 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 136 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
|
| 137 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
|
| 138 |
+
q.shape[0], q.shape[1], q.shape[2],
|
| 139 |
+
block_index.shape[-2], block_index.shape[-1],
|
| 140 |
+
BLOCK_M=block_size_M, BLOCK_N=block_size_N,
|
| 141 |
+
BLOCK_DMODEL=Lk,
|
| 142 |
+
dtype=dtype,
|
| 143 |
+
num_warps=4, num_stages=2,
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
return o
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def torch_build_index(
|
| 150 |
+
query: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 151 |
+
key: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 152 |
+
top_k: int,
|
| 153 |
+
block_size_M: int = 64,
|
| 154 |
+
block_size_N: int = 64,
|
| 155 |
+
):
|
| 156 |
+
batch_size, num_heads, context_size, head_dim = query.shape
|
| 157 |
+
query_pool = query.reshape((batch_size, num_heads, -1, block_size_M, head_dim)).mean(dim=-2)
|
| 158 |
+
key_pool = key.reshape((batch_size, num_heads, -1, block_size_N, head_dim)).mean(dim=-2)
|
| 159 |
+
arange_M = torch.arange(query_pool.shape[-2], dtype=torch.int32, device=query.device) * block_size_M
|
| 160 |
+
arange_N = torch.arange(key_pool.shape[-2], dtype=torch.int32, device=key.device) * block_size_N
|
| 161 |
+
p_pool = torch.einsum(f'bhmk, bhnk -> bhmn', query_pool, key_pool)
|
| 162 |
+
p_pool = p_pool.where(arange_M[None, None, :, None] >= arange_N[None, None, None, :], -torch.inf)
|
| 163 |
+
top_k = min(top_k, context_size // block_size_N)
|
| 164 |
+
return torch.topk(p_pool, top_k, dim=-1).indices.to(torch.int32).sort(dim=-1).values
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def make_causal_mask(seqlens, device, context_size):
|
| 168 |
+
batch_size = seqlens.shape[0]
|
| 169 |
+
arange = torch.arange(context_size, dtype=torch.int32, device=device)
|
| 170 |
+
causal_mask = arange[None, None, :, None] >= arange[None, None, None, :]
|
| 171 |
+
causal_mask = causal_mask.repeat((batch_size, 1, 1, 1))
|
| 172 |
+
for b, seqlen in enumerate(seqlens):
|
| 173 |
+
causal_mask[b, :, seqlen:, :] = False
|
| 174 |
+
causal_mask[b, :, :, seqlen:] = False
|
| 175 |
+
return causal_mask
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def make_block_mask(block_index, causal_mask, device, block_size_M=64, block_size_N=64):
|
| 179 |
+
batch_size, num_heads, num_rows, max_blocks_per_row = block_index.shape
|
| 180 |
+
context_size = causal_mask.shape[-1]
|
| 181 |
+
block_mask = torch.zeros((batch_size, num_heads, context_size, context_size), dtype=torch.bool, device=device)
|
| 182 |
+
for b in range(batch_size):
|
| 183 |
+
for h in range(num_heads):
|
| 184 |
+
for i in range(num_rows):
|
| 185 |
+
start_m = i * block_size_M
|
| 186 |
+
end_m = start_m + block_size_M
|
| 187 |
+
for j in range(max_blocks_per_row):
|
| 188 |
+
real_j = block_index[b, h, i, j]
|
| 189 |
+
start_n = real_j * block_size_N
|
| 190 |
+
end_n = start_n + block_size_N
|
| 191 |
+
block_mask[b, h, start_m:end_m, start_n:end_n] = True
|
| 192 |
+
block_mask.logical_and_(causal_mask)
|
| 193 |
+
return block_mask
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def plot_mask(mask, name, batch=0, head=0):
|
| 197 |
+
import matplotlib.pyplot as plt
|
| 198 |
+
import seaborn as sns
|
| 199 |
+
plt.figure(figsize=(16, 12))
|
| 200 |
+
plt.clf()
|
| 201 |
+
mask = mask[batch, head].cpu().numpy()
|
| 202 |
+
sns.heatmap(mask)
|
| 203 |
+
plt.savefig(name)
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
@triton.jit
|
| 207 |
+
def triton_dense_fwd_kernel(
|
| 208 |
+
Q, K, V, seqlens, sm_scale,
|
| 209 |
+
Out,
|
| 210 |
+
stride_qz, stride_qh, stride_qm, stride_qk,
|
| 211 |
+
stride_kz, stride_kh, stride_kn, stride_kk,
|
| 212 |
+
stride_vz, stride_vh, stride_vn, stride_vk,
|
| 213 |
+
stride_oz, stride_oh, stride_om, stride_ok,
|
| 214 |
+
Z, H, N_CTX,
|
| 215 |
+
BLOCK_M: tl.constexpr, BLOCK_DMODEL: tl.constexpr,
|
| 216 |
+
BLOCK_N: tl.constexpr,
|
| 217 |
+
dtype: tl.constexpr,
|
| 218 |
+
):
|
| 219 |
+
start_m = tl.program_id(0)
|
| 220 |
+
off_hz = tl.program_id(1)
|
| 221 |
+
|
| 222 |
+
seqlen = tl.load(seqlens + off_hz // H)
|
| 223 |
+
if start_m * BLOCK_M >= seqlen:
|
| 224 |
+
return
|
| 225 |
+
|
| 226 |
+
qo_offset = (off_hz // H) * stride_qz + (off_hz % H) * stride_qh
|
| 227 |
+
kv_offset = (off_hz // H) * stride_kz + (off_hz % H) * stride_kh
|
| 228 |
+
Q_block_ptr = tl.make_block_ptr(
|
| 229 |
+
base=Q + qo_offset,
|
| 230 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 231 |
+
strides=(stride_qm, stride_qk),
|
| 232 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 233 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 234 |
+
order=(1, 0)
|
| 235 |
+
)
|
| 236 |
+
K_block_ptr = tl.make_block_ptr(
|
| 237 |
+
base=K + kv_offset,
|
| 238 |
+
shape=(BLOCK_DMODEL, N_CTX),
|
| 239 |
+
strides=(stride_kk, stride_kn),
|
| 240 |
+
offsets=(0, 0),
|
| 241 |
+
block_shape=(BLOCK_DMODEL, BLOCK_N),
|
| 242 |
+
order=(0, 1)
|
| 243 |
+
)
|
| 244 |
+
V_block_ptr = tl.make_block_ptr(
|
| 245 |
+
base=V + kv_offset,
|
| 246 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 247 |
+
strides=(stride_vn, stride_vk),
|
| 248 |
+
offsets=(0, 0),
|
| 249 |
+
block_shape=(BLOCK_N, BLOCK_DMODEL),
|
| 250 |
+
order=(1, 0)
|
| 251 |
+
)
|
| 252 |
+
# initialize offsets
|
| 253 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 254 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 255 |
+
# initialize pointer to m and l
|
| 256 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 257 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 258 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 259 |
+
# scale sm_scale by log_2(e) and use
|
| 260 |
+
# 2^x instead of exp in the loop because CSE and LICM
|
| 261 |
+
# don't work as expected with `exp` in the loop
|
| 262 |
+
qk_scale = sm_scale * 1.44269504
|
| 263 |
+
# load q: it will stay in SRAM throughout
|
| 264 |
+
q = tl.load(Q_block_ptr)
|
| 265 |
+
q = (q * qk_scale).to(dtype)
|
| 266 |
+
# loop over k, v and update accumulator
|
| 267 |
+
lo = 0
|
| 268 |
+
hi = (start_m + 1) * BLOCK_M
|
| 269 |
+
m_mask = offs_m[:, None] < seqlen
|
| 270 |
+
|
| 271 |
+
for start_n in range(lo, hi, BLOCK_N):
|
| 272 |
+
n_mask = (start_n + offs_n[None, :]) <= offs_m[:, None]
|
| 273 |
+
# -- load k, v --
|
| 274 |
+
k = tl.load(K_block_ptr)
|
| 275 |
+
v = tl.load(V_block_ptr)
|
| 276 |
+
# -- compute qk --
|
| 277 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 278 |
+
qk = tl.where(m_mask & n_mask, qk, float("-inf"))
|
| 279 |
+
qk += tl.dot(q, k)
|
| 280 |
+
# -- compute scaling constant --
|
| 281 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 282 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 283 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 284 |
+
# -- scale and update acc --
|
| 285 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 286 |
+
acc *= acc_scale[:, None]
|
| 287 |
+
acc += tl.dot(p.to(dtype), v)
|
| 288 |
+
# -- update m_i and l_i --
|
| 289 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 290 |
+
m_i = m_i_new
|
| 291 |
+
# update pointers
|
| 292 |
+
K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
|
| 293 |
+
V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
|
| 294 |
+
# write back O
|
| 295 |
+
acc = tl.where(m_mask, acc / l_i[:, None], 0.0)
|
| 296 |
+
O_block_ptr = tl.make_block_ptr(
|
| 297 |
+
base=Out + qo_offset,
|
| 298 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 299 |
+
strides=(stride_om, stride_ok),
|
| 300 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 301 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 302 |
+
order=(1, 0)
|
| 303 |
+
)
|
| 304 |
+
tl.store(O_block_ptr, acc.to(dtype))
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
def triton_dense_forward(q, k, v, seqlens, sm_scale, block_size_M=128, block_size_N=64) -> torch.Tensor:
|
| 308 |
+
# shape constraints
|
| 309 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 310 |
+
assert Lq == Lk and Lk == Lv
|
| 311 |
+
assert Lk in {16, 32, 64, 128}
|
| 312 |
+
o = torch.zeros_like(q)
|
| 313 |
+
grid = (triton.cdiv(q.shape[2], block_size_M), q.shape[0] * q.shape[1], 1)
|
| 314 |
+
num_warps = 4 if Lk <= 64 else 8 # 4
|
| 315 |
+
dtype = tl.bfloat16 if q.dtype == torch.bfloat16 else tl.float16
|
| 316 |
+
triton_dense_fwd_kernel[grid](
|
| 317 |
+
q, k, v, seqlens, sm_scale,
|
| 318 |
+
o,
|
| 319 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 320 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 321 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
|
| 322 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
|
| 323 |
+
q.shape[0], q.shape[1], q.shape[2],
|
| 324 |
+
BLOCK_M=block_size_M, BLOCK_N=block_size_N,
|
| 325 |
+
BLOCK_DMODEL=Lk,
|
| 326 |
+
dtype=dtype,
|
| 327 |
+
num_warps=num_warps, num_stages=4,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
return o
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
def flash_attn_forward(q, k, v, seqlens, sm_scale, context_size) -> torch.Tensor:
|
| 334 |
+
return flash_attn_varlen_func(
|
| 335 |
+
q,
|
| 336 |
+
k,
|
| 337 |
+
v,
|
| 338 |
+
cu_seqlens_q=seqlens,
|
| 339 |
+
cu_seqlens_k=seqlens,
|
| 340 |
+
max_seqlen_q=context_size,
|
| 341 |
+
max_seqlen_k=context_size,
|
| 342 |
+
dropout_p=0.0,
|
| 343 |
+
softmax_scale=sm_scale,
|
| 344 |
+
causal=True,
|
| 345 |
+
)
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
def torch_forward(
|
| 349 |
+
query: torch.Tensor,
|
| 350 |
+
key: torch.Tensor,
|
| 351 |
+
value: torch.Tensor,
|
| 352 |
+
mask: torch.Tensor,
|
| 353 |
+
sm_scale: float,
|
| 354 |
+
) -> torch.Tensor:
|
| 355 |
+
p = torch.einsum(f'bhmk, bhnk -> bhmn', query, key) * sm_scale
|
| 356 |
+
p = p.where(mask, -torch.inf)
|
| 357 |
+
p_max = p.max(-1, keepdim=True).values
|
| 358 |
+
p_max = torch.where(p_max < 0, 0.0, p_max)
|
| 359 |
+
p_exp = torch.exp(p - p_max)
|
| 360 |
+
s = p_exp / (p_exp.sum(-1, keepdim=True) + 1e-6)
|
| 361 |
+
out = torch.einsum(f'bhmn, bhnk -> bhmk', s, value)
|
| 362 |
+
return out
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
def profile(fn, total_flops, tag, warmup=25, rep=100):
|
| 366 |
+
ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
|
| 367 |
+
gflops = total_flops / ms * 1e-9
|
| 368 |
+
print(f'{tag}: {ms:.3f} ms | {gflops:.3f} GFLOP/s')
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
def test_flash_attention(
|
| 372 |
+
seqlens=None,
|
| 373 |
+
dtype=torch.float16,
|
| 374 |
+
device="cuda",
|
| 375 |
+
torch_test=True,
|
| 376 |
+
batch_size=4,
|
| 377 |
+
num_heads=32,
|
| 378 |
+
context_size=1024,
|
| 379 |
+
head_dim=128,
|
| 380 |
+
top_k=5,
|
| 381 |
+
block_size_M=64,
|
| 382 |
+
block_size_N=64,
|
| 383 |
+
):
|
| 384 |
+
print('========================================')
|
| 385 |
+
print(f'BATCH={batch_size}, N_CTX={context_size}, N_HEADS={num_heads}, D_HEAD={head_dim}')
|
| 386 |
+
q = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 387 |
+
k = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 388 |
+
v = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 389 |
+
if seqlens is None:
|
| 390 |
+
seqlens = torch.randint(context_size // 2, context_size, (batch_size, ), dtype=torch.int32, device=device)
|
| 391 |
+
else:
|
| 392 |
+
seqlens = torch.tensor(seqlens, dtype=torch.int32, device=device)
|
| 393 |
+
dense_mask_nnz = seqlens.to(torch.float32).square().sum().item() * num_heads / 2
|
| 394 |
+
sm_scale = head_dim ** -0.5
|
| 395 |
+
|
| 396 |
+
causal_mask = make_causal_mask(seqlens, device, context_size)
|
| 397 |
+
if torch_test:
|
| 398 |
+
ref_o_dense = torch_forward(q, k, v, causal_mask, sm_scale)
|
| 399 |
+
|
| 400 |
+
block_index = torch_build_index(q, k, top_k, block_size_M, block_size_N)
|
| 401 |
+
arange_M = torch.arange(block_index.shape[-2], device=device)
|
| 402 |
+
block_index_mask = arange_M[None, None, :, None] * block_size_M >= block_index * block_size_N
|
| 403 |
+
sparse_mask_nnz = block_index_mask.to(torch.float32).sum().item() * block_size_M * block_size_N
|
| 404 |
+
print(f'block mask sparsity: {1 - sparse_mask_nnz / dense_mask_nnz}')
|
| 405 |
+
torch_build_index_fn = lambda: torch_build_index(q, k, top_k, block_size_M, block_size_N)
|
| 406 |
+
profile(torch_build_index_fn, 0., 'torch-index')
|
| 407 |
+
|
| 408 |
+
if torch_test:
|
| 409 |
+
block_mask = make_block_mask(block_index, causal_mask, device, block_size_M, block_size_N)
|
| 410 |
+
ref_o_sparse = torch_forward(q, k, v, block_mask, sm_scale)
|
| 411 |
+
|
| 412 |
+
triton_dense_fn = lambda: triton_dense_forward(q, k, v, seqlens, sm_scale)
|
| 413 |
+
output = triton_dense_fn()
|
| 414 |
+
if torch_test:
|
| 415 |
+
torch.testing.assert_close(output, ref_o_dense, atol=1e-2, rtol=0)
|
| 416 |
+
profile(triton_dense_fn, 2. * head_dim * dense_mask_nnz, 'triton-dense')
|
| 417 |
+
|
| 418 |
+
triton_sparse_fn = lambda: triton_block_sparse_forward(q, k, v, seqlens, block_index, sm_scale, block_size_M, block_size_N)
|
| 419 |
+
output = triton_sparse_fn()
|
| 420 |
+
if torch_test:
|
| 421 |
+
torch.testing.assert_close(output, ref_o_sparse, atol=1e-2, rtol=0)
|
| 422 |
+
profile(triton_sparse_fn, 2. * head_dim * sparse_mask_nnz, 'triton-sparse')
|
| 423 |
+
|
| 424 |
+
q = q.swapaxes(1, 2).contiguous()
|
| 425 |
+
k = k.swapaxes(1, 2).contiguous()
|
| 426 |
+
v = v.swapaxes(1, 2).contiguous()
|
| 427 |
+
q = torch.concatenate([q[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 428 |
+
k = torch.concatenate([k[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 429 |
+
v = torch.concatenate([v[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 430 |
+
seqlens = torch.nn.functional.pad(torch.cumsum(seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 431 |
+
|
| 432 |
+
flash_fn = lambda: flash_attn_forward(q, k, v, seqlens, sm_scale, context_size)
|
| 433 |
+
output = flash_fn()
|
| 434 |
+
output = torch.stack([
|
| 435 |
+
torch.nn.functional.pad(
|
| 436 |
+
output[seqlens[i]:seqlens[i + 1], :, :],
|
| 437 |
+
(0, 0, 0, 0, 0, context_size + seqlens[i] - seqlens[i + 1])
|
| 438 |
+
)
|
| 439 |
+
for i in range(batch_size)
|
| 440 |
+
]).swapaxes(1, 2).contiguous()
|
| 441 |
+
if torch_test:
|
| 442 |
+
torch.testing.assert_close(output, ref_o_dense, atol=1e-2, rtol=0)
|
| 443 |
+
profile(flash_fn, 2. * head_dim * dense_mask_nnz, 'flash-dense')
|
| 444 |
+
print('========================================\n')
|
| 445 |
+
|
| 446 |
+
|
| 447 |
+
def block_sparse_flash_attention_forward(
|
| 448 |
+
query: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 449 |
+
key: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 450 |
+
value: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 451 |
+
top_k: int,
|
| 452 |
+
block_size_M: int = 64,
|
| 453 |
+
block_size_N: int = 64,
|
| 454 |
+
):
|
| 455 |
+
batch_size, num_heads, context_size, head_dim = query.shape
|
| 456 |
+
pad = block_size_M - (query.shape[2] & (block_size_M - 1))
|
| 457 |
+
query = torch.nn.functional.pad(query, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 458 |
+
key = torch.nn.functional.pad(key, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 459 |
+
value = torch.nn.functional.pad(value, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 460 |
+
seqlens = torch.tensor([context_size], dtype=torch.int32, device=query.device)
|
| 461 |
+
sm_scale = head_dim ** -0.5
|
| 462 |
+
block_index = torch_build_index(query, key, top_k, block_size_N, block_size_N)
|
| 463 |
+
out = triton_block_sparse_forward(query, key, value, seqlens, block_index, sm_scale, block_size_M, block_size_N)
|
| 464 |
+
return out[..., :context_size, :]
|
minference/ops/pit_sparse_flash_attention.py
ADDED
|
@@ -0,0 +1,740 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import pycuda.autoprimaryctx
|
| 3 |
+
import torch
|
| 4 |
+
import triton
|
| 5 |
+
import triton.language as tl
|
| 6 |
+
from flash_attn import flash_attn_varlen_func
|
| 7 |
+
from pycuda.compiler import SourceModule
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@triton.autotune(
|
| 11 |
+
configs=[
|
| 12 |
+
triton.Config({}, num_stages=1, num_warps=4),
|
| 13 |
+
triton.Config({}, num_stages=1, num_warps=8),
|
| 14 |
+
triton.Config({}, num_stages=2, num_warps=4),
|
| 15 |
+
triton.Config({}, num_stages=2, num_warps=8),
|
| 16 |
+
triton.Config({}, num_stages=3, num_warps=4),
|
| 17 |
+
triton.Config({}, num_stages=3, num_warps=8),
|
| 18 |
+
triton.Config({}, num_stages=4, num_warps=4),
|
| 19 |
+
triton.Config({}, num_stages=4, num_warps=8),
|
| 20 |
+
triton.Config({}, num_stages=5, num_warps=4),
|
| 21 |
+
triton.Config({}, num_stages=5, num_warps=8),
|
| 22 |
+
],
|
| 23 |
+
key=['N_CTX'],
|
| 24 |
+
)
|
| 25 |
+
@triton.jit
|
| 26 |
+
def triton_sparse_fwd_kernel(
|
| 27 |
+
Q, K, V, seqlens, sm_scale,
|
| 28 |
+
col_count, col_index,
|
| 29 |
+
Out,
|
| 30 |
+
stride_qz, stride_qh, stride_qm, stride_qk,
|
| 31 |
+
stride_kz, stride_kh, stride_kn, stride_kk,
|
| 32 |
+
stride_vz, stride_vh, stride_vn, stride_vk,
|
| 33 |
+
stride_oz, stride_oh, stride_om, stride_ok,
|
| 34 |
+
Z, H, N_CTX,
|
| 35 |
+
NUM_ROWS, MAX_COLS_PRE_ROW,
|
| 36 |
+
BLOCK_M: tl.constexpr,
|
| 37 |
+
BLOCK_N: tl.constexpr,
|
| 38 |
+
BLOCK_DMODEL: tl.constexpr,
|
| 39 |
+
dtype: tl.constexpr,
|
| 40 |
+
):
|
| 41 |
+
start_m = tl.program_id(0)
|
| 42 |
+
off_hz = tl.program_id(1)
|
| 43 |
+
|
| 44 |
+
seqlen = tl.load(seqlens + off_hz // H)
|
| 45 |
+
if start_m * BLOCK_M >= seqlen:
|
| 46 |
+
return
|
| 47 |
+
|
| 48 |
+
# initialize offsets
|
| 49 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 50 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 51 |
+
offs_d = tl.arange(0, BLOCK_DMODEL)
|
| 52 |
+
|
| 53 |
+
qo_offset = (off_hz // H) * stride_qz + (off_hz % H) * stride_qh
|
| 54 |
+
kv_offset = (off_hz // H) * stride_kz + (off_hz % H) * stride_kh
|
| 55 |
+
|
| 56 |
+
q_ptrs = Q + qo_offset + offs_m[:, None] * stride_qm + offs_d[None, :] * stride_qk
|
| 57 |
+
k_ptrs = K + kv_offset + offs_d[:, None] * stride_kk
|
| 58 |
+
v_ptrs = V + kv_offset + offs_d[None, :] * stride_vk
|
| 59 |
+
o_ptrs = Out + qo_offset + offs_m[:, None] * stride_om + offs_d[None, :] * stride_ok
|
| 60 |
+
|
| 61 |
+
num_cols = tl.load(col_count + off_hz * NUM_ROWS + start_m)
|
| 62 |
+
cols_ptr = col_index + (off_hz * NUM_ROWS + start_m) * MAX_COLS_PRE_ROW
|
| 63 |
+
|
| 64 |
+
# initialize pointer to m and l
|
| 65 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 66 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 67 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 68 |
+
# scale sm_scale by log_2(e) and use
|
| 69 |
+
# 2^x instead of exp in the loop because CSE and LICM
|
| 70 |
+
# don't work as expected with `exp` in the loop
|
| 71 |
+
qk_scale = sm_scale * 1.44269504
|
| 72 |
+
# load q: it will stay in SRAM throughout
|
| 73 |
+
q = tl.load(q_ptrs)
|
| 74 |
+
q = (q * qk_scale).to(dtype)
|
| 75 |
+
|
| 76 |
+
# loop over k, v and update accumulator
|
| 77 |
+
m_mask = offs_m[:, None] < seqlen
|
| 78 |
+
split = tl.maximum(num_cols - BLOCK_N, 0) & ~(BLOCK_N - 1)
|
| 79 |
+
|
| 80 |
+
for start_n in range(0, split, BLOCK_N):
|
| 81 |
+
cols = tl.load(cols_ptr + start_n + offs_n)
|
| 82 |
+
# -- load k, v --
|
| 83 |
+
k = tl.load(k_ptrs + cols[None, :] * stride_kn)
|
| 84 |
+
v = tl.load(v_ptrs + cols[:, None] * stride_vn)
|
| 85 |
+
# -- compute qk --
|
| 86 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 87 |
+
qk = tl.where(m_mask, qk, float("-inf"))
|
| 88 |
+
qk += tl.dot(q, k)
|
| 89 |
+
# -- compute scaling constant --
|
| 90 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 91 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 92 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 93 |
+
# -- scale and update acc --
|
| 94 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 95 |
+
acc *= acc_scale[:, None]
|
| 96 |
+
acc += tl.dot(p.to(dtype), v)
|
| 97 |
+
# -- update m_i and l_i --
|
| 98 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 99 |
+
m_i = m_i_new
|
| 100 |
+
|
| 101 |
+
for start_n in range(split, num_cols, BLOCK_N):
|
| 102 |
+
n_mask = start_n + offs_n < num_cols
|
| 103 |
+
cols = tl.load(cols_ptr + start_n + offs_n, mask=n_mask, other=N_CTX - 1)
|
| 104 |
+
causal_mask = cols[None, :] <= offs_m[:, None]
|
| 105 |
+
# -- load k, v --
|
| 106 |
+
k = tl.load(k_ptrs + cols[None, :] * stride_kn)
|
| 107 |
+
v = tl.load(v_ptrs + cols[:, None] * stride_vn)
|
| 108 |
+
# -- compute qk --
|
| 109 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 110 |
+
qk = tl.where(m_mask & causal_mask, qk, float("-inf"))
|
| 111 |
+
qk += tl.dot(q, k)
|
| 112 |
+
# -- compute scaling constant --
|
| 113 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 114 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 115 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 116 |
+
# -- scale and update acc --
|
| 117 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 118 |
+
acc *= acc_scale[:, None]
|
| 119 |
+
acc += tl.dot(p.to(dtype), v)
|
| 120 |
+
# -- update m_i and l_i --
|
| 121 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 122 |
+
m_i = m_i_new
|
| 123 |
+
|
| 124 |
+
# write back O
|
| 125 |
+
acc = tl.where(m_mask, acc / l_i[:, None], 0.0)
|
| 126 |
+
tl.store(o_ptrs, acc.to(dtype), mask=m_mask)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def triton_sparse_forward(
|
| 130 |
+
q, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 131 |
+
k, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 132 |
+
v, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 133 |
+
seqlens, # [BATCH, ]
|
| 134 |
+
col_count, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M)]
|
| 135 |
+
col_index, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), MAX_COLS_PRE_ROW]
|
| 136 |
+
sm_scale,
|
| 137 |
+
block_size_M=64,
|
| 138 |
+
block_size_N=64,
|
| 139 |
+
) -> torch.Tensor:
|
| 140 |
+
# shape constraints
|
| 141 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 142 |
+
assert Lq == Lk and Lk == Lv
|
| 143 |
+
assert Lk in {16, 32, 64, 128}
|
| 144 |
+
o = torch.zeros_like(q)
|
| 145 |
+
grid = (triton.cdiv(q.shape[2], block_size_M), q.shape[0] * q.shape[1], 1)
|
| 146 |
+
num_warps = 4 if (Lk <= 64 or block_size_M <= 64) else 8 # 4
|
| 147 |
+
dtype = tl.bfloat16 if q.dtype == torch.bfloat16 else tl.float16
|
| 148 |
+
triton_sparse_fwd_kernel[grid](
|
| 149 |
+
q, k, v, seqlens, sm_scale,
|
| 150 |
+
col_count, col_index,
|
| 151 |
+
o,
|
| 152 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 153 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 154 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
|
| 155 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
|
| 156 |
+
q.shape[0], q.shape[1], q.shape[2],
|
| 157 |
+
col_index.shape[-2], col_index.shape[-1],
|
| 158 |
+
BLOCK_M=block_size_M, BLOCK_N=block_size_N,
|
| 159 |
+
BLOCK_DMODEL=Lk,
|
| 160 |
+
dtype=dtype,
|
| 161 |
+
# num_warps=num_warps, num_stages=4,
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
return o
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def torch_build_index(seqlens, vertical_indexes, slash_indexes, block_size_M=64):
|
| 168 |
+
max_cols_per_row = (seqlens.max().item() + 3) & (-4)
|
| 169 |
+
batch_size, num_heads, NNZ_S = slash_indexes.shape
|
| 170 |
+
NNZ_V = vertical_indexes.shape[-1]
|
| 171 |
+
num_rows = triton.cdiv(max_cols_per_row, block_size_M)
|
| 172 |
+
max_cols_per_row = max_cols_per_row
|
| 173 |
+
col_count = torch.zeros((batch_size, num_heads, num_rows), dtype=torch.int32)
|
| 174 |
+
col_index = torch.zeros((batch_size, num_heads, num_rows, max_cols_per_row), dtype=torch.int32)
|
| 175 |
+
for b in range(batch_size):
|
| 176 |
+
seqlen = seqlens[b]
|
| 177 |
+
for h in range(num_heads):
|
| 178 |
+
for m, start_m in enumerate(range(0, seqlen, block_size_M)):
|
| 179 |
+
end_m = start_m + block_size_M
|
| 180 |
+
tmp_col_count = 0
|
| 181 |
+
cursor, s, v = -1, 0, 0
|
| 182 |
+
v_idx = vertical_indexes[b, h, v].item()
|
| 183 |
+
while s < NNZ_S and slash_indexes[b, h, s] >= end_m:
|
| 184 |
+
s += 1
|
| 185 |
+
if s < NNZ_S:
|
| 186 |
+
s_idx = end_m - slash_indexes[b, h, s].item()
|
| 187 |
+
s_range = min(s_idx, block_size_M)
|
| 188 |
+
else:
|
| 189 |
+
s_idx = seqlen
|
| 190 |
+
s_range = 0
|
| 191 |
+
while s_idx <= end_m and v_idx < end_m:
|
| 192 |
+
if v_idx < s_idx:
|
| 193 |
+
if v_idx < s_idx - s_range:
|
| 194 |
+
col_index[b, h, m, tmp_col_count] = v_idx
|
| 195 |
+
tmp_col_count += 1
|
| 196 |
+
v += 1
|
| 197 |
+
if v < NNZ_V:
|
| 198 |
+
v_idx = vertical_indexes[b, h, v].item()
|
| 199 |
+
else:
|
| 200 |
+
break
|
| 201 |
+
else:
|
| 202 |
+
for idx in range(max(cursor, s_idx - s_range), min(s_idx, seqlen)):
|
| 203 |
+
col_index[b, h, m, tmp_col_count] = idx
|
| 204 |
+
tmp_col_count += 1
|
| 205 |
+
cursor = s_idx
|
| 206 |
+
s += 1
|
| 207 |
+
if s < NNZ_S:
|
| 208 |
+
s_idx = end_m - slash_indexes[b, h, s].item()
|
| 209 |
+
s_range = min(s_idx, block_size_M)
|
| 210 |
+
else:
|
| 211 |
+
break
|
| 212 |
+
while s_idx <= end_m and s < NNZ_S:
|
| 213 |
+
for idx in range(max(cursor, s_idx - s_range), min(s_idx, seqlen)):
|
| 214 |
+
col_index[b, h, m, tmp_col_count] = idx
|
| 215 |
+
tmp_col_count += 1
|
| 216 |
+
cursor = s_idx
|
| 217 |
+
s += 1
|
| 218 |
+
if s < NNZ_S:
|
| 219 |
+
s_idx = end_m - slash_indexes[b, h, s].item()
|
| 220 |
+
s_range = min(s_idx, block_size_M)
|
| 221 |
+
else:
|
| 222 |
+
break
|
| 223 |
+
while v_idx < end_m and v < NNZ_V:
|
| 224 |
+
if v_idx < s_idx - s_range:
|
| 225 |
+
col_index[b, h, m, tmp_col_count] = v_idx
|
| 226 |
+
tmp_col_count += 1
|
| 227 |
+
v += 1
|
| 228 |
+
if v < NNZ_V:
|
| 229 |
+
v_idx = vertical_indexes[b, h, v].item()
|
| 230 |
+
else:
|
| 231 |
+
break
|
| 232 |
+
col_count[b, h, m] = tmp_col_count
|
| 233 |
+
return col_count.to(seqlens.device), col_index.to(seqlens.device)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
PYCUDA_BUILD_INDEX_KERNEL_CODE = '''\
|
| 238 |
+
__device__ int min(int x, int y) {
|
| 239 |
+
return x < y ? x : y;
|
| 240 |
+
}
|
| 241 |
+
|
| 242 |
+
__device__ int max(int x, int y) {
|
| 243 |
+
return x > y ? x : y;
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
__device__ void save_list(int* output, int loop_start, int loop_end, int& offset) {
|
| 247 |
+
if (loop_start + 4 >= loop_end) {
|
| 248 |
+
for (int idx = loop_start; idx < loop_end; idx++, offset++) {
|
| 249 |
+
output[offset] = idx;
|
| 250 |
+
}
|
| 251 |
+
return;
|
| 252 |
+
}
|
| 253 |
+
int4 tmp_int4;
|
| 254 |
+
int int4_start = ((offset + 3) & (-4)) - offset + loop_start;
|
| 255 |
+
int int4_end = ((offset + loop_end - loop_start) & (-4)) - offset + loop_start;
|
| 256 |
+
for (int idx = loop_start; idx < int4_start; idx++, offset++) {
|
| 257 |
+
output[offset] = idx;
|
| 258 |
+
}
|
| 259 |
+
for (int idx = int4_start; idx < int4_end; idx += 4, offset += 4) {
|
| 260 |
+
tmp_int4.x = idx + 0;
|
| 261 |
+
tmp_int4.y = idx + 1;
|
| 262 |
+
tmp_int4.z = idx + 2;
|
| 263 |
+
tmp_int4.w = idx + 3;
|
| 264 |
+
(reinterpret_cast<int4*>(&output[offset]))[0] = tmp_int4;
|
| 265 |
+
}
|
| 266 |
+
for (int idx = int4_end; idx < loop_end; idx++, offset++) {
|
| 267 |
+
output[offset] = idx;
|
| 268 |
+
}
|
| 269 |
+
}
|
| 270 |
+
|
| 271 |
+
__global__ void PYCUDA_BUILD_INDEX_KERNEL(
|
| 272 |
+
const int* seqlens, // [BATCH, ]
|
| 273 |
+
const int* vertical_indexes, // [BATCH, N_HEADS, NNZ_V]
|
| 274 |
+
const int* slash_indexes, // [BATCH, N_HEADS, NNZ_S]
|
| 275 |
+
int* col_count, // [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M)]
|
| 276 |
+
int* col_index, // [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), N_CTX]
|
| 277 |
+
int N_HEADS,
|
| 278 |
+
int N_CTX,
|
| 279 |
+
int BLOCK_SIZE_M,
|
| 280 |
+
int N_ROWS,
|
| 281 |
+
int NNZ_V,
|
| 282 |
+
int NNZ_S
|
| 283 |
+
) {
|
| 284 |
+
const int batch_idx = blockIdx.y;
|
| 285 |
+
const int head_idx = blockIdx.x;
|
| 286 |
+
const int group_idx = blockIdx.z;
|
| 287 |
+
|
| 288 |
+
int seqlen = seqlens[batch_idx];
|
| 289 |
+
int block_idx_m = group_idx * blockDim.x + threadIdx.x;
|
| 290 |
+
int start_m = block_idx_m * BLOCK_SIZE_M;
|
| 291 |
+
if (start_m >= seqlen) {
|
| 292 |
+
return;
|
| 293 |
+
}
|
| 294 |
+
int end_m = start_m + BLOCK_SIZE_M;
|
| 295 |
+
vertical_indexes += (batch_idx * N_HEADS + head_idx) * NNZ_V;
|
| 296 |
+
slash_indexes += (batch_idx * N_HEADS + head_idx) * NNZ_S;
|
| 297 |
+
int row_offset = (batch_idx * N_HEADS + head_idx) * N_ROWS + block_idx_m;
|
| 298 |
+
col_count += row_offset;
|
| 299 |
+
col_index += row_offset * N_CTX;
|
| 300 |
+
|
| 301 |
+
int tmp_col_count = 0, cursor = -1, s = 0, v = 0;
|
| 302 |
+
int v_idx = vertical_indexes[v];
|
| 303 |
+
/*
|
| 304 |
+
int left = 0, right = NNZ_S - 1;
|
| 305 |
+
int tmp_s_idx = 0, target = end_m - 1;
|
| 306 |
+
s = (left + right) >> 1;
|
| 307 |
+
while (left + 1 < right) {
|
| 308 |
+
tmp_s_idx = slash_indexes[s];
|
| 309 |
+
if (tmp_s_idx > target) {
|
| 310 |
+
left = s;
|
| 311 |
+
} else if (tmp_s_idx < target) {
|
| 312 |
+
right = s;
|
| 313 |
+
} else {
|
| 314 |
+
break;
|
| 315 |
+
}
|
| 316 |
+
s = (left + right) >> 1;
|
| 317 |
+
}
|
| 318 |
+
*/
|
| 319 |
+
while (s < NNZ_S && slash_indexes[s] >= end_m) s++;
|
| 320 |
+
|
| 321 |
+
int s_idx = (s < NNZ_S) ? (end_m - slash_indexes[s]) : seqlen;
|
| 322 |
+
int s_range = (s < NNZ_S) ? min(s_idx, BLOCK_SIZE_M) : 0;
|
| 323 |
+
|
| 324 |
+
while (s_idx <= end_m && v_idx < end_m) {
|
| 325 |
+
if (v_idx < s_idx) {
|
| 326 |
+
if (v_idx < s_idx - s_range) {
|
| 327 |
+
col_index[tmp_col_count] = v_idx;
|
| 328 |
+
tmp_col_count++;
|
| 329 |
+
}
|
| 330 |
+
v++;
|
| 331 |
+
if (v < NNZ_V) {
|
| 332 |
+
v_idx = vertical_indexes[v];
|
| 333 |
+
} else {
|
| 334 |
+
break;
|
| 335 |
+
}
|
| 336 |
+
} else {
|
| 337 |
+
save_list(col_index, max(cursor, s_idx - s_range), min(s_idx, seqlen), tmp_col_count);
|
| 338 |
+
cursor = s_idx;
|
| 339 |
+
s++;
|
| 340 |
+
if (s < NNZ_S) {
|
| 341 |
+
s_idx = end_m - slash_indexes[s];
|
| 342 |
+
s_range = min(s_idx, BLOCK_SIZE_M);
|
| 343 |
+
} else {
|
| 344 |
+
break;
|
| 345 |
+
}
|
| 346 |
+
}
|
| 347 |
+
}
|
| 348 |
+
while (s_idx <= end_m && s < NNZ_S) {
|
| 349 |
+
save_list(col_index, max(cursor, s_idx - s_range), min(s_idx, seqlen), tmp_col_count);
|
| 350 |
+
cursor = s_idx;
|
| 351 |
+
s++;
|
| 352 |
+
if (s < NNZ_S) {
|
| 353 |
+
s_idx = end_m - slash_indexes[s];
|
| 354 |
+
s_range = min(s_idx, BLOCK_SIZE_M);
|
| 355 |
+
} else {
|
| 356 |
+
break;
|
| 357 |
+
}
|
| 358 |
+
}
|
| 359 |
+
while (v_idx < end_m && v < NNZ_V) {
|
| 360 |
+
if (v_idx < s_idx - s_range) {
|
| 361 |
+
col_index[tmp_col_count] = v_idx;
|
| 362 |
+
tmp_col_count++;
|
| 363 |
+
}
|
| 364 |
+
v++;
|
| 365 |
+
if (v < NNZ_V) {
|
| 366 |
+
v_idx = vertical_indexes[v];
|
| 367 |
+
} else {
|
| 368 |
+
break;
|
| 369 |
+
}
|
| 370 |
+
}
|
| 371 |
+
col_count[0] = tmp_col_count;
|
| 372 |
+
}
|
| 373 |
+
'''
|
| 374 |
+
PYCUDA_BUILD_INDEX_KERNEL = SourceModule(
|
| 375 |
+
PYCUDA_BUILD_INDEX_KERNEL_CODE,
|
| 376 |
+
options=['-std=c++14', '-O3'],
|
| 377 |
+
).get_function(f'PYCUDA_BUILD_INDEX_KERNEL')
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
def pycuda_build_index(seqlens, vertical_indexes, slash_indexes, block_size_M=64):
|
| 381 |
+
max_cols_per_row = (seqlens.max().item() + 3) & (-4)
|
| 382 |
+
batch_size, num_heads, NNZ_S = slash_indexes.shape
|
| 383 |
+
NNZ_V = vertical_indexes.shape[-1]
|
| 384 |
+
num_rows = triton.cdiv(max_cols_per_row, block_size_M)
|
| 385 |
+
max_cols_per_row = max_cols_per_row
|
| 386 |
+
col_count = torch.zeros((batch_size, num_heads, num_rows), dtype=torch.int32, device=seqlens.device)
|
| 387 |
+
col_index = torch.zeros((batch_size, num_heads, num_rows, max_cols_per_row), dtype=torch.int32, device=seqlens.device)
|
| 388 |
+
num_threads = 64
|
| 389 |
+
PYCUDA_BUILD_INDEX_KERNEL(
|
| 390 |
+
seqlens, vertical_indexes, slash_indexes,
|
| 391 |
+
col_count, col_index,
|
| 392 |
+
np.int32(num_heads), np.int32(max_cols_per_row), np.int32(block_size_M), np.int32(num_rows),
|
| 393 |
+
np.int32(NNZ_V), np.int32(NNZ_S),
|
| 394 |
+
# grid=(triton.cdiv(num_rows, num_threads), N_HEADS, BATCH),
|
| 395 |
+
grid=(num_heads, batch_size, triton.cdiv(num_rows, num_threads)),
|
| 396 |
+
block=(num_threads, 1, 1),
|
| 397 |
+
)
|
| 398 |
+
return col_count, col_index
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
def make_causal_mask(seqlens, device, context_size):
|
| 402 |
+
batch_size = seqlens.shape[0]
|
| 403 |
+
arange = torch.arange(context_size, dtype=torch.int32, device=device)
|
| 404 |
+
causal_mask = arange[None, None, :, None] >= arange[None, None, None, :]
|
| 405 |
+
causal_mask = causal_mask.repeat((batch_size, 1, 1, 1))
|
| 406 |
+
for b, seqlen in enumerate(seqlens):
|
| 407 |
+
causal_mask[b, :, seqlen:, :] = False
|
| 408 |
+
causal_mask[b, :, :, seqlen:] = False
|
| 409 |
+
return causal_mask
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
def make_finegrained_mask(vertical_indexes, slash_indexes, causal_mask, device):
|
| 413 |
+
batch_size, num_heads, _ = vertical_indexes.shape
|
| 414 |
+
context_size = causal_mask.shape[-1]
|
| 415 |
+
arange = torch.arange(context_size, dtype=torch.int32, device=device)
|
| 416 |
+
sparse_mask = torch.zeros((batch_size, num_heads, context_size, context_size), dtype=torch.bool, device=device)
|
| 417 |
+
for b in range(batch_size):
|
| 418 |
+
for h in range(num_heads):
|
| 419 |
+
for vertical_index in vertical_indexes[b, h]:
|
| 420 |
+
sparse_mask[b, h, :, vertical_index] = True
|
| 421 |
+
for slash_index in slash_indexes[b, h]:
|
| 422 |
+
sparse_mask[b, h].logical_or_(arange[:, None] - arange[None, :] == slash_index)
|
| 423 |
+
sparse_mask.logical_and_(causal_mask)
|
| 424 |
+
return sparse_mask
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
def make_block_mask(col_count, col_index, seqlens, causal_mask, device, block_size_M=64):
|
| 428 |
+
batch_size, num_heads, _ = col_count.shape
|
| 429 |
+
context_size = causal_mask.shape[-1]
|
| 430 |
+
block_mask = torch.zeros((batch_size, num_heads, context_size, context_size), dtype=torch.bool, device=device)
|
| 431 |
+
for b in range(batch_size):
|
| 432 |
+
for h in range(num_heads):
|
| 433 |
+
for m, start_m in enumerate(range(0, seqlens[b], block_size_M)):
|
| 434 |
+
end_m = start_m + block_size_M
|
| 435 |
+
for c in range(col_count[b, h, m]):
|
| 436 |
+
block_mask[b, h, start_m:end_m, col_index[b, h, m, c]] = True
|
| 437 |
+
block_mask.logical_and_(causal_mask)
|
| 438 |
+
return block_mask
|
| 439 |
+
|
| 440 |
+
|
| 441 |
+
def plot_mask(mask, name, batch=0, head=0):
|
| 442 |
+
import matplotlib.pyplot as plt
|
| 443 |
+
import seaborn as sns
|
| 444 |
+
plt.figure(figsize=(16, 12))
|
| 445 |
+
plt.clf()
|
| 446 |
+
mask = mask[batch, head].cpu().numpy()
|
| 447 |
+
sns.heatmap(mask)
|
| 448 |
+
plt.savefig(name)
|
| 449 |
+
|
| 450 |
+
|
| 451 |
+
@triton.jit
|
| 452 |
+
def triton_dense_fwd_kernel(
|
| 453 |
+
Q, K, V, seqlens, sm_scale,
|
| 454 |
+
Out,
|
| 455 |
+
stride_qz, stride_qh, stride_qm, stride_qk,
|
| 456 |
+
stride_kz, stride_kh, stride_kn, stride_kk,
|
| 457 |
+
stride_vz, stride_vh, stride_vn, stride_vk,
|
| 458 |
+
stride_oz, stride_oh, stride_om, stride_ok,
|
| 459 |
+
Z, H, N_CTX,
|
| 460 |
+
BLOCK_M: tl.constexpr, BLOCK_DMODEL: tl.constexpr,
|
| 461 |
+
BLOCK_N: tl.constexpr,
|
| 462 |
+
dtype: tl.constexpr,
|
| 463 |
+
):
|
| 464 |
+
start_m = tl.program_id(0)
|
| 465 |
+
off_hz = tl.program_id(1)
|
| 466 |
+
|
| 467 |
+
seqlen = tl.load(seqlens + off_hz // H)
|
| 468 |
+
if start_m * BLOCK_M >= seqlen:
|
| 469 |
+
return
|
| 470 |
+
|
| 471 |
+
qo_offset = (off_hz // H) * stride_qz + (off_hz % H) * stride_qh
|
| 472 |
+
kv_offset = (off_hz // H) * stride_kz + (off_hz % H) * stride_kh
|
| 473 |
+
Q_block_ptr = tl.make_block_ptr(
|
| 474 |
+
base=Q + qo_offset,
|
| 475 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 476 |
+
strides=(stride_qm, stride_qk),
|
| 477 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 478 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 479 |
+
order=(1, 0)
|
| 480 |
+
)
|
| 481 |
+
K_block_ptr = tl.make_block_ptr(
|
| 482 |
+
base=K + kv_offset,
|
| 483 |
+
shape=(BLOCK_DMODEL, N_CTX),
|
| 484 |
+
strides=(stride_kk, stride_kn),
|
| 485 |
+
offsets=(0, 0),
|
| 486 |
+
block_shape=(BLOCK_DMODEL, BLOCK_N),
|
| 487 |
+
order=(0, 1)
|
| 488 |
+
)
|
| 489 |
+
V_block_ptr = tl.make_block_ptr(
|
| 490 |
+
base=V + kv_offset,
|
| 491 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 492 |
+
strides=(stride_vn, stride_vk),
|
| 493 |
+
offsets=(0, 0),
|
| 494 |
+
block_shape=(BLOCK_N, BLOCK_DMODEL),
|
| 495 |
+
order=(1, 0)
|
| 496 |
+
)
|
| 497 |
+
# initialize offsets
|
| 498 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 499 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 500 |
+
# initialize pointer to m and l
|
| 501 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 502 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 503 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 504 |
+
# scale sm_scale by log_2(e) and use
|
| 505 |
+
# 2^x instead of exp in the loop because CSE and LICM
|
| 506 |
+
# don't work as expected with `exp` in the loop
|
| 507 |
+
qk_scale = sm_scale * 1.44269504
|
| 508 |
+
# load q: it will stay in SRAM throughout
|
| 509 |
+
q = tl.load(Q_block_ptr)
|
| 510 |
+
q = (q * qk_scale).to(dtype)
|
| 511 |
+
# loop over k, v and update accumulator
|
| 512 |
+
lo = 0
|
| 513 |
+
hi = (start_m + 1) * BLOCK_M
|
| 514 |
+
m_mask = offs_m[:, None] < seqlen
|
| 515 |
+
|
| 516 |
+
for start_n in range(lo, hi, BLOCK_N):
|
| 517 |
+
n_mask = (start_n + offs_n[None, :]) <= offs_m[:, None]
|
| 518 |
+
# -- load k, v --
|
| 519 |
+
k = tl.load(K_block_ptr)
|
| 520 |
+
v = tl.load(V_block_ptr)
|
| 521 |
+
# -- compute qk --
|
| 522 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 523 |
+
qk = tl.where(m_mask & n_mask, qk, float("-inf"))
|
| 524 |
+
qk += tl.dot(q, k)
|
| 525 |
+
# -- compute scaling constant --
|
| 526 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 527 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 528 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 529 |
+
# -- scale and update acc --
|
| 530 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 531 |
+
acc *= acc_scale[:, None]
|
| 532 |
+
acc += tl.dot(p.to(dtype), v)
|
| 533 |
+
# -- update m_i and l_i --
|
| 534 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 535 |
+
m_i = m_i_new
|
| 536 |
+
# update pointers
|
| 537 |
+
K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
|
| 538 |
+
V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
|
| 539 |
+
# write back O
|
| 540 |
+
acc = tl.where(m_mask, acc / l_i[:, None], 0.0)
|
| 541 |
+
O_block_ptr = tl.make_block_ptr(
|
| 542 |
+
base=Out + qo_offset,
|
| 543 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 544 |
+
strides=(stride_om, stride_ok),
|
| 545 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 546 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 547 |
+
order=(1, 0)
|
| 548 |
+
)
|
| 549 |
+
tl.store(O_block_ptr, acc.to(dtype), mask=m_mask)
|
| 550 |
+
|
| 551 |
+
|
| 552 |
+
def triton_dense_forward(q, k, v, seqlens, sm_scale, block_size_M=128, block_size_N=64) -> torch.Tensor:
|
| 553 |
+
# shape constraints
|
| 554 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 555 |
+
assert Lq == Lk and Lk == Lv
|
| 556 |
+
assert Lk in {16, 32, 64, 128}
|
| 557 |
+
o = torch.zeros_like(q)
|
| 558 |
+
grid = (triton.cdiv(q.shape[2], block_size_M), q.shape[0] * q.shape[1], 1)
|
| 559 |
+
num_warps = 4 if Lk <= 64 else 8 # 4
|
| 560 |
+
dtype = tl.bfloat16 if q.dtype == torch.bfloat16 else tl.float16
|
| 561 |
+
triton_dense_fwd_kernel[grid](
|
| 562 |
+
q, k, v, seqlens, sm_scale,
|
| 563 |
+
o,
|
| 564 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 565 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 566 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
|
| 567 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
|
| 568 |
+
q.shape[0], q.shape[1], q.shape[2],
|
| 569 |
+
BLOCK_M=block_size_M, BLOCK_N=block_size_N,
|
| 570 |
+
BLOCK_DMODEL=Lk,
|
| 571 |
+
dtype=dtype,
|
| 572 |
+
num_warps=num_warps, num_stages=4,
|
| 573 |
+
)
|
| 574 |
+
|
| 575 |
+
return o
|
| 576 |
+
|
| 577 |
+
|
| 578 |
+
def flash_attn_forward(q, k, v, seqlens, sm_scale, context_size) -> torch.Tensor:
|
| 579 |
+
return flash_attn_varlen_func(
|
| 580 |
+
q,
|
| 581 |
+
k,
|
| 582 |
+
v,
|
| 583 |
+
cu_seqlens_q=seqlens,
|
| 584 |
+
cu_seqlens_k=seqlens,
|
| 585 |
+
max_seqlen_q=context_size,
|
| 586 |
+
max_seqlen_k=context_size,
|
| 587 |
+
dropout_p=0.0,
|
| 588 |
+
softmax_scale=sm_scale,
|
| 589 |
+
causal=True,
|
| 590 |
+
)
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
def torch_forward(
|
| 594 |
+
query: torch.Tensor,
|
| 595 |
+
key: torch.Tensor,
|
| 596 |
+
value: torch.Tensor,
|
| 597 |
+
mask: torch.Tensor,
|
| 598 |
+
sm_scale: float,
|
| 599 |
+
) -> torch.Tensor:
|
| 600 |
+
p = torch.einsum(f'bhmk, bhnk -> bhmn', query, key) * sm_scale
|
| 601 |
+
p = p.where(mask, -torch.inf)
|
| 602 |
+
p_max = p.max(-1, keepdim=True).values
|
| 603 |
+
p_max = torch.where(p_max < 0, 0.0, p_max)
|
| 604 |
+
p_exp = torch.exp(p - p_max)
|
| 605 |
+
s = p_exp / (p_exp.sum(-1, keepdim=True) + 1e-6)
|
| 606 |
+
out = torch.einsum(f'bhmn, bhnk -> bhmk', s, value)
|
| 607 |
+
return out
|
| 608 |
+
|
| 609 |
+
|
| 610 |
+
def profile(fn, total_flops, tag, warmup=25, rep=100):
|
| 611 |
+
ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
|
| 612 |
+
gflops = total_flops / ms * 1e-9
|
| 613 |
+
print(f'{tag}: {ms:.3f} ms | {gflops:.3f} GFLOP/s')
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
def test_flash_attention(
|
| 617 |
+
seqlens=None,
|
| 618 |
+
vertical_indexes=None,
|
| 619 |
+
slash_indexes=None,
|
| 620 |
+
dtype=torch.float16,
|
| 621 |
+
device="cuda",
|
| 622 |
+
torch_test=True,
|
| 623 |
+
batch_size=4,
|
| 624 |
+
num_heads=32,
|
| 625 |
+
context_size=1024,
|
| 626 |
+
head_dim=128,
|
| 627 |
+
sparsity=0.995,
|
| 628 |
+
block_size_M=64,
|
| 629 |
+
block_size_N=64,
|
| 630 |
+
):
|
| 631 |
+
print('========================================')
|
| 632 |
+
print(f'BATCH={batch_size}, N_CTX={context_size}, N_HEADS={num_heads}, D_HEAD={head_dim}')
|
| 633 |
+
q = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 634 |
+
k = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 635 |
+
v = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 636 |
+
if seqlens is None:
|
| 637 |
+
seqlens = torch.randint(context_size // 2, context_size, (batch_size, ), dtype=torch.int32, device=device)
|
| 638 |
+
else:
|
| 639 |
+
seqlens = torch.tensor(seqlens, dtype=torch.int32, device=device)
|
| 640 |
+
dense_mask_nnz = seqlens.to(torch.float32).square().sum().item() * num_heads / 2
|
| 641 |
+
sm_scale = head_dim ** -0.5
|
| 642 |
+
|
| 643 |
+
causal_mask = make_causal_mask(seqlens, device, context_size)
|
| 644 |
+
if torch_test:
|
| 645 |
+
ref_o_dense = torch_forward(q, k, v, causal_mask, sm_scale)
|
| 646 |
+
|
| 647 |
+
if vertical_indexes is None or slash_indexes is None:
|
| 648 |
+
nnz = int((1 - sparsity) * context_size)
|
| 649 |
+
vertical_indexes = torch.stack([
|
| 650 |
+
torch.stack([
|
| 651 |
+
torch.randperm(seqlen, dtype=torch.int32, device=device)[:nnz].sort(descending=False)[0]
|
| 652 |
+
for _ in range(num_heads)
|
| 653 |
+
])
|
| 654 |
+
for seqlen in seqlens
|
| 655 |
+
])
|
| 656 |
+
slash_indexes = torch.concatenate([
|
| 657 |
+
torch.stack([
|
| 658 |
+
torch.stack([
|
| 659 |
+
torch.randperm(seqlen - 1, dtype=torch.int32, device=device)[:nnz].sort(descending=True)[0] + 1
|
| 660 |
+
for _ in range(num_heads)
|
| 661 |
+
])
|
| 662 |
+
for seqlen in seqlens
|
| 663 |
+
]),
|
| 664 |
+
torch.zeros((batch_size, num_heads, 1), dtype=torch.int32, device=device)
|
| 665 |
+
], dim=-1)
|
| 666 |
+
col_count, col_index = pycuda_build_index(seqlens, vertical_indexes, slash_indexes, block_size_M)
|
| 667 |
+
if torch_test:
|
| 668 |
+
col_count_ref, col_index_ref = torch_build_index(seqlens, vertical_indexes, slash_indexes, block_size_M)
|
| 669 |
+
# import ipdb; ipdb.set_trace()
|
| 670 |
+
torch.testing.assert_close(col_count_ref, col_count)
|
| 671 |
+
torch.testing.assert_close(col_index_ref, col_index)
|
| 672 |
+
sparse_mask_nnz = col_count.to(torch.float32).sum().item() * block_size_M
|
| 673 |
+
print(f'block mask sparsity: {1 - sparse_mask_nnz / dense_mask_nnz}')
|
| 674 |
+
pycuda_build_index_fn = lambda: pycuda_build_index(seqlens, vertical_indexes, slash_indexes, block_size_M)
|
| 675 |
+
profile(pycuda_build_index_fn, 0., 'pycuda-index')
|
| 676 |
+
|
| 677 |
+
if torch_test:
|
| 678 |
+
finegrained_mask = make_finegrained_mask(vertical_indexes, slash_indexes, causal_mask, device)
|
| 679 |
+
block_mask = make_block_mask(col_count, col_index, seqlens, causal_mask, device, block_size_M)
|
| 680 |
+
# plot_mask(finegrained_mask, 'mask.png', 2, 26)
|
| 681 |
+
# plot_mask(block_mask, 'mask-1.png', 2, 26)
|
| 682 |
+
ref_o_sparse = torch_forward(q, k, v, block_mask, sm_scale)
|
| 683 |
+
|
| 684 |
+
triton_dense_fn = lambda: triton_dense_forward(q, k, v, seqlens, sm_scale)
|
| 685 |
+
output = triton_dense_fn()
|
| 686 |
+
if torch_test:
|
| 687 |
+
torch.testing.assert_close(output, ref_o_dense, atol=1e-2, rtol=0)
|
| 688 |
+
profile(triton_dense_fn, 2. * head_dim * dense_mask_nnz, 'triton-dense')
|
| 689 |
+
|
| 690 |
+
triton_sparse_fn = lambda: triton_sparse_forward(q, k, v, seqlens, col_count, col_index, sm_scale, block_size_M, block_size_N)
|
| 691 |
+
output = triton_sparse_fn()
|
| 692 |
+
if torch_test:
|
| 693 |
+
torch.testing.assert_close(output, ref_o_sparse, atol=1e-2, rtol=0)
|
| 694 |
+
profile(triton_sparse_fn, 2. * head_dim * sparse_mask_nnz, 'triton-sparse')
|
| 695 |
+
|
| 696 |
+
q = q.swapaxes(1, 2).contiguous()
|
| 697 |
+
k = k.swapaxes(1, 2).contiguous()
|
| 698 |
+
v = v.swapaxes(1, 2).contiguous()
|
| 699 |
+
q = torch.concatenate([q[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 700 |
+
k = torch.concatenate([k[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 701 |
+
v = torch.concatenate([v[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 702 |
+
seqlens = torch.nn.functional.pad(torch.cumsum(seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 703 |
+
|
| 704 |
+
flash_fn = lambda: flash_attn_forward(q, k, v, seqlens, sm_scale, context_size)
|
| 705 |
+
output = flash_fn()
|
| 706 |
+
output = torch.stack([
|
| 707 |
+
torch.nn.functional.pad(
|
| 708 |
+
output[seqlens[i]:seqlens[i + 1], :, :],
|
| 709 |
+
(0, 0, 0, 0, 0, context_size + seqlens[i] - seqlens[i + 1])
|
| 710 |
+
)
|
| 711 |
+
for i in range(batch_size)
|
| 712 |
+
]).swapaxes(1, 2).contiguous()
|
| 713 |
+
if torch_test:
|
| 714 |
+
torch.testing.assert_close(output, ref_o_dense, atol=1e-2, rtol=0)
|
| 715 |
+
profile(flash_fn, 2. * head_dim * dense_mask_nnz, 'flash-dense')
|
| 716 |
+
print('========================================\n')
|
| 717 |
+
|
| 718 |
+
|
| 719 |
+
def pit_sparse_flash_attention_forward(
|
| 720 |
+
query: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 721 |
+
key: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 722 |
+
value: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 723 |
+
v_idx: torch.Tensor, # [BATCH, N_HEADS, NNZ_V]
|
| 724 |
+
s_idx: torch.Tensor, # [BATCH, N_HEADS, NNZ_S]
|
| 725 |
+
block_size_M: int = 64,
|
| 726 |
+
block_size_N: int = 64,
|
| 727 |
+
):
|
| 728 |
+
q_len = query.shape[2]
|
| 729 |
+
pad = block_size_M - (query.shape[2] & (block_size_M - 1))
|
| 730 |
+
query = torch.nn.functional.pad(query, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 731 |
+
key = torch.nn.functional.pad(key, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 732 |
+
value = torch.nn.functional.pad(value, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 733 |
+
batch_size, num_heads, context_size, head_dim = query.shape
|
| 734 |
+
v_idx = v_idx.to(torch.int32).reshape((batch_size, num_heads, -1)).sort(dim=-1, descending=False)[0]
|
| 735 |
+
s_idx = s_idx.to(torch.int32).reshape((batch_size, num_heads, -1)).sort(dim=-1, descending=True)[0]
|
| 736 |
+
seqlens = torch.tensor([context_size], dtype=torch.int32, device=query.device)
|
| 737 |
+
sm_scale = head_dim ** -0.5
|
| 738 |
+
col_count, col_index = pycuda_build_index(seqlens, v_idx, s_idx, block_size_M)
|
| 739 |
+
out = triton_sparse_forward(query, key, value, seqlens, col_count, col_index, sm_scale, block_size_M, block_size_N)[...,:q_len,:]
|
| 740 |
+
return out
|
minference/ops/pit_sparse_flash_attention_v2.py
ADDED
|
@@ -0,0 +1,735 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
import triton
|
| 6 |
+
import triton.language as tl
|
| 7 |
+
import pycuda.autoprimaryctx
|
| 8 |
+
from pycuda.compiler import SourceModule
|
| 9 |
+
|
| 10 |
+
from flash_attn import flash_attn_varlen_func
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# @triton.autotune(
|
| 14 |
+
# configs=[
|
| 15 |
+
# triton.Config({}, num_stages=1, num_warps=4),
|
| 16 |
+
# triton.Config({}, num_stages=1, num_warps=8),
|
| 17 |
+
# triton.Config({}, num_stages=2, num_warps=4),
|
| 18 |
+
# triton.Config({}, num_stages=2, num_warps=8),
|
| 19 |
+
# triton.Config({}, num_stages=3, num_warps=4),
|
| 20 |
+
# triton.Config({}, num_stages=3, num_warps=8),
|
| 21 |
+
# triton.Config({}, num_stages=4, num_warps=4),
|
| 22 |
+
# triton.Config({}, num_stages=4, num_warps=8),
|
| 23 |
+
# triton.Config({}, num_stages=5, num_warps=4),
|
| 24 |
+
# triton.Config({}, num_stages=5, num_warps=8),
|
| 25 |
+
# ],
|
| 26 |
+
# key=['N_CTX'],
|
| 27 |
+
# )
|
| 28 |
+
@triton.jit
|
| 29 |
+
def triton_sparse_fwd_kernel(
|
| 30 |
+
Q, K, V, seqlens, sm_scale,
|
| 31 |
+
block_count, block_offset, column_count, column_index,
|
| 32 |
+
Out,
|
| 33 |
+
stride_qz, stride_qh, stride_qm, stride_qk,
|
| 34 |
+
stride_kz, stride_kh, stride_kn, stride_kk,
|
| 35 |
+
stride_vz, stride_vh, stride_vn, stride_vk,
|
| 36 |
+
stride_oz, stride_oh, stride_om, stride_ok,
|
| 37 |
+
Z, H, N_CTX,
|
| 38 |
+
NUM_ROWS, NNZ_S, NNZ_V,
|
| 39 |
+
BLOCK_M: tl.constexpr,
|
| 40 |
+
BLOCK_N: tl.constexpr,
|
| 41 |
+
BLOCK_DMODEL: tl.constexpr,
|
| 42 |
+
dtype: tl.constexpr,
|
| 43 |
+
):
|
| 44 |
+
start_m = tl.program_id(0)
|
| 45 |
+
off_hz = tl.program_id(1)
|
| 46 |
+
|
| 47 |
+
seqlen = tl.load(seqlens + off_hz // H)
|
| 48 |
+
if start_m * BLOCK_M >= seqlen:
|
| 49 |
+
return
|
| 50 |
+
|
| 51 |
+
# initialize offsets
|
| 52 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 53 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 54 |
+
offs_d = tl.arange(0, BLOCK_DMODEL)
|
| 55 |
+
|
| 56 |
+
qo_offset = (off_hz // H) * stride_qz + (off_hz % H) * stride_qh
|
| 57 |
+
kv_offset = (off_hz // H) * stride_kz + (off_hz % H) * stride_kh
|
| 58 |
+
|
| 59 |
+
q_ptrs = Q + qo_offset + offs_m[:, None] * stride_qm + offs_d[None, :] * stride_qk
|
| 60 |
+
k_ptrs = K + kv_offset + offs_d[:, None] * stride_kk
|
| 61 |
+
v_ptrs = V + kv_offset + offs_d[None, :] * stride_vk
|
| 62 |
+
o_ptrs = Out + qo_offset + offs_m[:, None] * stride_om + offs_d[None, :] * stride_ok
|
| 63 |
+
|
| 64 |
+
num_blks = tl.load(block_count + off_hz * NUM_ROWS + start_m)
|
| 65 |
+
blks_ptr = block_offset + (off_hz * NUM_ROWS + start_m) * NNZ_S
|
| 66 |
+
num_cols = tl.load(column_count + off_hz * NUM_ROWS + start_m)
|
| 67 |
+
cols_ptr = column_index + (off_hz * NUM_ROWS + start_m) * NNZ_V
|
| 68 |
+
|
| 69 |
+
# initialize pointer to m and l
|
| 70 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 71 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 72 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 73 |
+
# scale sm_scale by log_2(e) and use
|
| 74 |
+
# 2^x instead of exp in the loop because CSE and LICM
|
| 75 |
+
# don't work as expected with `exp` in the loop
|
| 76 |
+
qk_scale = sm_scale * 1.44269504
|
| 77 |
+
# load q: it will stay in SRAM throughout
|
| 78 |
+
q = tl.load(q_ptrs)
|
| 79 |
+
q = (q * qk_scale).to(dtype)
|
| 80 |
+
|
| 81 |
+
# loop over k, v and update accumulator
|
| 82 |
+
m_mask = offs_m[:, None] < seqlen
|
| 83 |
+
|
| 84 |
+
for block_index in range(num_blks):
|
| 85 |
+
start_n = tl.load(blks_ptr + block_index)
|
| 86 |
+
cols = start_n + offs_n
|
| 87 |
+
n_mask = cols < seqlen
|
| 88 |
+
# -- load k, v --
|
| 89 |
+
k = tl.load(k_ptrs + cols[None, :] * stride_kn, mask=n_mask[None, :], other=0.0)
|
| 90 |
+
v = tl.load(v_ptrs + cols[:, None] * stride_vn, mask=n_mask[:, None], other=0.0)
|
| 91 |
+
# -- compute qk --
|
| 92 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 93 |
+
causal_mask = cols[None, :] <= offs_m[:, None]
|
| 94 |
+
qk = tl.where(m_mask & causal_mask, qk, float("-inf"))
|
| 95 |
+
qk += tl.dot(q, k)
|
| 96 |
+
# -- compute scaling constant --
|
| 97 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 98 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 99 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 100 |
+
# -- scale and update acc --
|
| 101 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 102 |
+
acc *= acc_scale[:, None]
|
| 103 |
+
acc += tl.dot(p.to(dtype), v)
|
| 104 |
+
# -- update m_i and l_i --
|
| 105 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 106 |
+
m_i = m_i_new
|
| 107 |
+
|
| 108 |
+
for start_n in range(0, num_cols, BLOCK_N):
|
| 109 |
+
n_mask = start_n + offs_n < num_cols
|
| 110 |
+
cols = tl.load(cols_ptr + start_n + offs_n, mask=n_mask, other=0)
|
| 111 |
+
# -- load k, v --
|
| 112 |
+
k = tl.load(k_ptrs + cols[None, :] * stride_kn, mask=n_mask[None, :], other=0.0)
|
| 113 |
+
v = tl.load(v_ptrs + cols[:, None] * stride_vn, mask=n_mask[:, None], other=0.0)
|
| 114 |
+
# -- compute qk --
|
| 115 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 116 |
+
qk = tl.where(m_mask & n_mask, qk, float("-inf"))
|
| 117 |
+
qk += tl.dot(q, k)
|
| 118 |
+
# -- compute scaling constant --
|
| 119 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 120 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 121 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 122 |
+
# -- scale and update acc --
|
| 123 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 124 |
+
acc *= acc_scale[:, None]
|
| 125 |
+
acc += tl.dot(p.to(dtype), v)
|
| 126 |
+
# -- update m_i and l_i --
|
| 127 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 128 |
+
m_i = m_i_new
|
| 129 |
+
|
| 130 |
+
# write back O
|
| 131 |
+
acc /= l_i[:, None]
|
| 132 |
+
# acc = tl.where(m_mask, acc / l_i[:, None], 0.0)
|
| 133 |
+
tl.store(o_ptrs, acc.to(dtype), mask=m_mask)
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def triton_sparse_forward(
|
| 137 |
+
q: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 138 |
+
k: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 139 |
+
v: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 140 |
+
seqlens: torch.Tensor, # [BATCH, ]
|
| 141 |
+
block_count: torch.Tensor, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M)]
|
| 142 |
+
block_offset: torch.Tensor, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), NNZ_S]
|
| 143 |
+
column_count: torch.Tensor, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M)]
|
| 144 |
+
column_index: torch.Tensor, # [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), NNZ_V]
|
| 145 |
+
sm_scale: float,
|
| 146 |
+
block_size_M: int = 64,
|
| 147 |
+
block_size_N: int = 64,
|
| 148 |
+
) -> torch.Tensor:
|
| 149 |
+
# shape constraints
|
| 150 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 151 |
+
assert Lq == Lk and Lk == Lv
|
| 152 |
+
assert Lk in {16, 32, 64, 128}
|
| 153 |
+
o = torch.zeros_like(q)
|
| 154 |
+
grid = (triton.cdiv(q.shape[2], block_size_M), q.shape[0] * q.shape[1], 1)
|
| 155 |
+
dtype = tl.bfloat16 if q.dtype == torch.bfloat16 else tl.float16
|
| 156 |
+
triton_sparse_fwd_kernel[grid](
|
| 157 |
+
q, k, v, seqlens, sm_scale,
|
| 158 |
+
block_count, block_offset, column_count, column_index,
|
| 159 |
+
o,
|
| 160 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 161 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 162 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
|
| 163 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
|
| 164 |
+
q.shape[0], q.shape[1], q.shape[2],
|
| 165 |
+
block_count.shape[-1], block_offset.shape[-1], column_index.shape[-1],
|
| 166 |
+
BLOCK_M=block_size_M, BLOCK_N=block_size_N,
|
| 167 |
+
BLOCK_DMODEL=Lk,
|
| 168 |
+
dtype=dtype,
|
| 169 |
+
num_warps=4, num_stages=2,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
return o
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def torch_build_index(seqlens, vertical_indexes, slash_indexes, context_size, block_size_M=64, block_size_N=64):
|
| 176 |
+
device = seqlens.device
|
| 177 |
+
batch_size, num_heads, NNZ_S = slash_indexes.shape
|
| 178 |
+
NNZ_V = vertical_indexes.shape[-1]
|
| 179 |
+
num_rows = triton.cdiv(context_size, block_size_M)
|
| 180 |
+
block_count = torch.zeros((batch_size, num_heads, num_rows), dtype=torch.int32)
|
| 181 |
+
block_offset = torch.zeros((batch_size, num_heads, num_rows, NNZ_S), dtype=torch.int32)
|
| 182 |
+
column_count = torch.zeros((batch_size, num_heads, num_rows), dtype=torch.int32)
|
| 183 |
+
column_index = torch.zeros((batch_size, num_heads, num_rows, NNZ_V), dtype=torch.int32)
|
| 184 |
+
|
| 185 |
+
for b in range(batch_size):
|
| 186 |
+
seqlen = seqlens[b]
|
| 187 |
+
for h in range(num_heads):
|
| 188 |
+
for m, start_m in enumerate(range(0, seqlen, block_size_M)):
|
| 189 |
+
end_m = start_m + block_size_M
|
| 190 |
+
s = 0
|
| 191 |
+
while slash_indexes[b, h, s] >= end_m:
|
| 192 |
+
s += 1
|
| 193 |
+
s_idx = max(end_m - slash_indexes[b, h, s], block_size_M)
|
| 194 |
+
s += 1
|
| 195 |
+
range_start = s_idx - block_size_M
|
| 196 |
+
range_end = s_idx
|
| 197 |
+
tmp_blocks = []
|
| 198 |
+
while s < NNZ_S:
|
| 199 |
+
s_idx = max(end_m - slash_indexes[b, h, s], block_size_M)
|
| 200 |
+
if s_idx > range_end + block_size_M:
|
| 201 |
+
tmp_blocks += list(range(range_start, range_end, block_size_N))
|
| 202 |
+
range_start = s_idx - block_size_M
|
| 203 |
+
range_end = s_idx
|
| 204 |
+
elif s_idx > range_end:
|
| 205 |
+
range_end += block_size_M
|
| 206 |
+
s += 1
|
| 207 |
+
tmp_blocks += list(range(range_start, range_end, block_size_N))
|
| 208 |
+
block_count[b, h, m] = len(tmp_blocks)
|
| 209 |
+
block_offset[b, h, m, :len(tmp_blocks)] = torch.tensor(tmp_blocks, dtype=block_offset.dtype)
|
| 210 |
+
tmp_columns = vertical_indexes[b, h].cpu().numpy().tolist()
|
| 211 |
+
tmp_columns = [col for col in tmp_columns if col < range_end]
|
| 212 |
+
for range_start in tmp_blocks:
|
| 213 |
+
range_end = range_start + block_size_N
|
| 214 |
+
tmp_columns = [col for col in tmp_columns if col < range_start or col >= range_end]
|
| 215 |
+
column_count[b, h, m] = len(tmp_columns)
|
| 216 |
+
column_index[b, h, m, :len(tmp_columns)] = torch.tensor(tmp_columns, dtype=block_offset.dtype)
|
| 217 |
+
|
| 218 |
+
return block_count.to(device), block_offset.to(device), column_count.to(device), column_index.to(device)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
PYCUDA_BUILD_INDEX_KERNEL_CODE = '''\
|
| 222 |
+
__device__ int min(int x, int y) {
|
| 223 |
+
return x < y ? x : y;
|
| 224 |
+
}
|
| 225 |
+
|
| 226 |
+
__device__ int max(int x, int y) {
|
| 227 |
+
return x > y ? x : y;
|
| 228 |
+
}
|
| 229 |
+
|
| 230 |
+
__device__ void save_blocks(int* block_offset, int range_start, int range_end, int block_size, int& block_count) {
|
| 231 |
+
for (int idx = range_start; idx < range_end; idx += block_size) {
|
| 232 |
+
block_offset[block_count++] = idx;
|
| 233 |
+
}
|
| 234 |
+
}
|
| 235 |
+
|
| 236 |
+
__global__ void PYCUDA_BUILD_INDEX_KERNEL(
|
| 237 |
+
const int* seqlens, // [BATCH, ]
|
| 238 |
+
const int* vertical_indexes, // [BATCH, N_HEADS, NNZ_V]
|
| 239 |
+
const int* slash_indexes, // [BATCH, N_HEADS, NNZ_S]
|
| 240 |
+
int* block_count, // [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M)]
|
| 241 |
+
int* block_offset, // [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), NNZ_S]
|
| 242 |
+
int* column_count, // [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M)]
|
| 243 |
+
int* column_index, // [BATCH, N_HEADS, cdiv(N_CTX, BLOCK_SIZE_M), NNZ_V]
|
| 244 |
+
int N_HEADS,
|
| 245 |
+
int N_ROWS,
|
| 246 |
+
int BLOCK_SIZE_M,
|
| 247 |
+
int BLOCK_SIZE_N,
|
| 248 |
+
int NNZ_V,
|
| 249 |
+
int NNZ_S
|
| 250 |
+
) {
|
| 251 |
+
const int batch_idx = blockIdx.y;
|
| 252 |
+
const int head_idx = blockIdx.x;
|
| 253 |
+
const int group_idx = blockIdx.z;
|
| 254 |
+
|
| 255 |
+
int seqlen = seqlens[batch_idx];
|
| 256 |
+
int block_idx_m = group_idx * blockDim.x + threadIdx.x;
|
| 257 |
+
int start_m = block_idx_m * BLOCK_SIZE_M;
|
| 258 |
+
if (start_m >= seqlen) {
|
| 259 |
+
return;
|
| 260 |
+
}
|
| 261 |
+
int end_m = start_m + BLOCK_SIZE_M;
|
| 262 |
+
vertical_indexes += (batch_idx * N_HEADS + head_idx) * NNZ_V;
|
| 263 |
+
slash_indexes += (batch_idx * N_HEADS + head_idx) * NNZ_S;
|
| 264 |
+
int row_offset = (batch_idx * N_HEADS + head_idx) * N_ROWS + block_idx_m;
|
| 265 |
+
block_count += row_offset;
|
| 266 |
+
block_offset += row_offset * NNZ_S;
|
| 267 |
+
column_count += row_offset;
|
| 268 |
+
column_index += row_offset * NNZ_V;
|
| 269 |
+
|
| 270 |
+
int tmp_col_cnt = 0, tmp_blk_cnt = 0;
|
| 271 |
+
int s = 0, v = 0;
|
| 272 |
+
int v_idx = vertical_indexes[v++];
|
| 273 |
+
int s_idx = slash_indexes[s++];
|
| 274 |
+
while (s_idx >= end_m) {
|
| 275 |
+
s_idx = slash_indexes[s++];
|
| 276 |
+
}
|
| 277 |
+
s_idx = max(end_m - s_idx, BLOCK_SIZE_M);
|
| 278 |
+
int range_start = s_idx - BLOCK_SIZE_M, range_end = s_idx;
|
| 279 |
+
while (1) {
|
| 280 |
+
if (v_idx < range_end) {
|
| 281 |
+
if (v_idx < range_start) {
|
| 282 |
+
column_index[tmp_col_cnt++] = v_idx;
|
| 283 |
+
}
|
| 284 |
+
if (v < NNZ_V) {
|
| 285 |
+
v_idx = vertical_indexes[v++];
|
| 286 |
+
} else {
|
| 287 |
+
v_idx = end_m + BLOCK_SIZE_M;
|
| 288 |
+
}
|
| 289 |
+
} else {
|
| 290 |
+
if (s < NNZ_S) {
|
| 291 |
+
s_idx = max(end_m - slash_indexes[s++], BLOCK_SIZE_M);
|
| 292 |
+
} else {
|
| 293 |
+
save_blocks(block_offset, range_start, range_end, BLOCK_SIZE_N, tmp_blk_cnt);
|
| 294 |
+
break;
|
| 295 |
+
}
|
| 296 |
+
if (s_idx > range_end + BLOCK_SIZE_M) {
|
| 297 |
+
save_blocks(block_offset, range_start, range_end, BLOCK_SIZE_N, tmp_blk_cnt);
|
| 298 |
+
range_start = s_idx - BLOCK_SIZE_M;
|
| 299 |
+
range_end = s_idx;
|
| 300 |
+
} else if (s_idx > range_end) {
|
| 301 |
+
range_end += BLOCK_SIZE_M;
|
| 302 |
+
}
|
| 303 |
+
}
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
block_count[0] = tmp_blk_cnt;
|
| 307 |
+
column_count[0] = tmp_col_cnt;
|
| 308 |
+
}
|
| 309 |
+
'''
|
| 310 |
+
PYCUDA_BUILD_INDEX_KERNEL = SourceModule(
|
| 311 |
+
PYCUDA_BUILD_INDEX_KERNEL_CODE,
|
| 312 |
+
options=['-std=c++14', '-O3'],
|
| 313 |
+
).get_function(f'PYCUDA_BUILD_INDEX_KERNEL')
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
def pycuda_build_index(seqlens, vertical_indexes, slash_indexes, context_size, block_size_M=64, block_size_N=64):
|
| 317 |
+
batch_size, num_heads, NNZ_S = slash_indexes.shape
|
| 318 |
+
NNZ_V = vertical_indexes.shape[-1]
|
| 319 |
+
num_rows = triton.cdiv(context_size, block_size_M)
|
| 320 |
+
block_count = torch.zeros((batch_size, num_heads, num_rows), dtype=torch.int32, device=seqlens.device)
|
| 321 |
+
block_offset = torch.zeros((batch_size, num_heads, num_rows, NNZ_S), dtype=torch.int32, device=seqlens.device)
|
| 322 |
+
column_count = torch.zeros((batch_size, num_heads, num_rows), dtype=torch.int32, device=seqlens.device)
|
| 323 |
+
column_index = torch.zeros((batch_size, num_heads, num_rows, NNZ_V), dtype=torch.int32, device=seqlens.device)
|
| 324 |
+
num_threads = 64
|
| 325 |
+
# import ipdb; ipdb.set_trace()
|
| 326 |
+
PYCUDA_BUILD_INDEX_KERNEL(
|
| 327 |
+
seqlens, vertical_indexes, slash_indexes,
|
| 328 |
+
block_count, block_offset, column_count, column_index,
|
| 329 |
+
np.int32(num_heads), np.int32(num_rows),
|
| 330 |
+
np.int32(block_size_M), np.int32(block_size_N),
|
| 331 |
+
np.int32(NNZ_V), np.int32(NNZ_S),
|
| 332 |
+
# grid=(triton.cdiv(num_rows, num_threads), N_HEADS, BATCH),
|
| 333 |
+
grid=(num_heads, batch_size, triton.cdiv(num_rows, num_threads)),
|
| 334 |
+
block=(num_threads, 1, 1),
|
| 335 |
+
)
|
| 336 |
+
return block_count, block_offset, column_count, column_index
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
def make_causal_mask(seqlens, device, context_size):
|
| 340 |
+
batch_size = seqlens.shape[0]
|
| 341 |
+
arange = torch.arange(context_size, dtype=torch.int32, device=device)
|
| 342 |
+
causal_mask = arange[None, None, :, None] >= arange[None, None, None, :]
|
| 343 |
+
causal_mask = causal_mask.repeat((batch_size, 1, 1, 1))
|
| 344 |
+
for b, seqlen in enumerate(seqlens):
|
| 345 |
+
causal_mask[b, :, seqlen:, :] = False
|
| 346 |
+
causal_mask[b, :, :, seqlen:] = False
|
| 347 |
+
return causal_mask
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
def make_finegrained_mask(vertical_indexes, slash_indexes, causal_mask, device):
|
| 351 |
+
batch_size, num_heads, _ = vertical_indexes.shape
|
| 352 |
+
context_size = causal_mask.shape[-1]
|
| 353 |
+
arange = torch.arange(context_size, dtype=torch.int32, device=device)
|
| 354 |
+
sparse_mask = torch.zeros((batch_size, num_heads, context_size, context_size), dtype=torch.bool, device=device)
|
| 355 |
+
for b in range(batch_size):
|
| 356 |
+
for h in range(num_heads):
|
| 357 |
+
for vertical_index in vertical_indexes[b, h]:
|
| 358 |
+
sparse_mask[b, h, :, vertical_index] = True
|
| 359 |
+
for slash_index in slash_indexes[b, h]:
|
| 360 |
+
sparse_mask[b, h].logical_or_(arange[:, None] - arange[None, :] == slash_index)
|
| 361 |
+
sparse_mask.logical_and_(causal_mask)
|
| 362 |
+
return sparse_mask
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
def make_block_mask(
|
| 366 |
+
block_count: torch.Tensor,
|
| 367 |
+
block_offset: torch.Tensor,
|
| 368 |
+
column_count: torch.Tensor,
|
| 369 |
+
column_index: torch.Tensor,
|
| 370 |
+
seqlens: torch.Tensor,
|
| 371 |
+
causal_mask: torch.Tensor,
|
| 372 |
+
device: torch.device,
|
| 373 |
+
block_size_M: int = 64,
|
| 374 |
+
block_size_N: int = 64.
|
| 375 |
+
):
|
| 376 |
+
batch_size, num_heads, _ = block_count.shape
|
| 377 |
+
context_size = causal_mask.shape[-1]
|
| 378 |
+
block_mask = torch.zeros((batch_size, num_heads, context_size, context_size), dtype=torch.bool, device=device)
|
| 379 |
+
for b in range(batch_size):
|
| 380 |
+
for h in range(num_heads):
|
| 381 |
+
for m, start_m in enumerate(range(0, seqlens[b], block_size_M)):
|
| 382 |
+
end_m = start_m + block_size_M
|
| 383 |
+
for col_idx in range(column_count[b, h, m]):
|
| 384 |
+
block_mask[b, h, start_m:end_m, column_index[b, h, m, col_idx]] = True
|
| 385 |
+
for blk_idx in range(block_count[b, h, m]):
|
| 386 |
+
blk_start = block_offset[b, h, m, blk_idx].item()
|
| 387 |
+
blk_end = blk_start + block_size_N
|
| 388 |
+
block_mask[b, h, start_m:end_m, blk_start:blk_end] = True
|
| 389 |
+
block_mask.logical_and_(causal_mask)
|
| 390 |
+
return block_mask
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
def plot_mask(mask, name, batch=0, head=0):
|
| 394 |
+
import matplotlib.pyplot as plt
|
| 395 |
+
import seaborn as sns
|
| 396 |
+
plt.figure(figsize=(16, 12))
|
| 397 |
+
plt.clf()
|
| 398 |
+
mask = mask[batch, head].cpu().numpy()
|
| 399 |
+
sns.heatmap(mask)
|
| 400 |
+
plt.savefig(name)
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
@triton.jit
|
| 404 |
+
def triton_dense_fwd_kernel(
|
| 405 |
+
Q, K, V, seqlens, sm_scale,
|
| 406 |
+
Out,
|
| 407 |
+
stride_qz, stride_qh, stride_qm, stride_qk,
|
| 408 |
+
stride_kz, stride_kh, stride_kn, stride_kk,
|
| 409 |
+
stride_vz, stride_vh, stride_vn, stride_vk,
|
| 410 |
+
stride_oz, stride_oh, stride_om, stride_ok,
|
| 411 |
+
Z, H, N_CTX,
|
| 412 |
+
BLOCK_M: tl.constexpr, BLOCK_DMODEL: tl.constexpr,
|
| 413 |
+
BLOCK_N: tl.constexpr,
|
| 414 |
+
dtype: tl.constexpr,
|
| 415 |
+
):
|
| 416 |
+
start_m = tl.program_id(0)
|
| 417 |
+
off_hz = tl.program_id(1)
|
| 418 |
+
|
| 419 |
+
seqlen = tl.load(seqlens + off_hz // H)
|
| 420 |
+
if start_m * BLOCK_M >= seqlen:
|
| 421 |
+
return
|
| 422 |
+
|
| 423 |
+
qo_offset = (off_hz // H) * stride_qz + (off_hz % H) * stride_qh
|
| 424 |
+
kv_offset = (off_hz // H) * stride_kz + (off_hz % H) * stride_kh
|
| 425 |
+
Q_block_ptr = tl.make_block_ptr(
|
| 426 |
+
base=Q + qo_offset,
|
| 427 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 428 |
+
strides=(stride_qm, stride_qk),
|
| 429 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 430 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 431 |
+
order=(1, 0)
|
| 432 |
+
)
|
| 433 |
+
K_block_ptr = tl.make_block_ptr(
|
| 434 |
+
base=K + kv_offset,
|
| 435 |
+
shape=(BLOCK_DMODEL, N_CTX),
|
| 436 |
+
strides=(stride_kk, stride_kn),
|
| 437 |
+
offsets=(0, 0),
|
| 438 |
+
block_shape=(BLOCK_DMODEL, BLOCK_N),
|
| 439 |
+
order=(0, 1)
|
| 440 |
+
)
|
| 441 |
+
V_block_ptr = tl.make_block_ptr(
|
| 442 |
+
base=V + kv_offset,
|
| 443 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 444 |
+
strides=(stride_vn, stride_vk),
|
| 445 |
+
offsets=(0, 0),
|
| 446 |
+
block_shape=(BLOCK_N, BLOCK_DMODEL),
|
| 447 |
+
order=(1, 0)
|
| 448 |
+
)
|
| 449 |
+
# initialize offsets
|
| 450 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 451 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 452 |
+
# initialize pointer to m and l
|
| 453 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 454 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 455 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 456 |
+
# scale sm_scale by log_2(e) and use
|
| 457 |
+
# 2^x instead of exp in the loop because CSE and LICM
|
| 458 |
+
# don't work as expected with `exp` in the loop
|
| 459 |
+
qk_scale = sm_scale * 1.44269504
|
| 460 |
+
# load q: it will stay in SRAM throughout
|
| 461 |
+
q = tl.load(Q_block_ptr)
|
| 462 |
+
q = (q * qk_scale).to(dtype)
|
| 463 |
+
# loop over k, v and update accumulator
|
| 464 |
+
lo = 0
|
| 465 |
+
hi = (start_m + 1) * BLOCK_M
|
| 466 |
+
m_mask = offs_m[:, None] < seqlen
|
| 467 |
+
|
| 468 |
+
for start_n in range(lo, hi, BLOCK_N):
|
| 469 |
+
n_mask = (start_n + offs_n[None, :]) <= offs_m[:, None]
|
| 470 |
+
# -- load k, v --
|
| 471 |
+
k = tl.load(K_block_ptr)
|
| 472 |
+
v = tl.load(V_block_ptr)
|
| 473 |
+
# -- compute qk --
|
| 474 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 475 |
+
qk = tl.where(m_mask & n_mask, qk, float("-inf"))
|
| 476 |
+
qk += tl.dot(q, k)
|
| 477 |
+
# -- compute scaling constant --
|
| 478 |
+
m_i_new = tl.maximum(m_i, tl.max(qk, 1))
|
| 479 |
+
alpha = tl.math.exp2(m_i - m_i_new)
|
| 480 |
+
p = tl.math.exp2(qk - m_i_new[:, None])
|
| 481 |
+
# -- scale and update acc --
|
| 482 |
+
acc_scale = l_i * 0 + alpha # workaround some compiler bug
|
| 483 |
+
acc *= acc_scale[:, None]
|
| 484 |
+
acc += tl.dot(p.to(dtype), v)
|
| 485 |
+
# -- update m_i and l_i --
|
| 486 |
+
l_i = l_i * alpha + tl.sum(p, 1)
|
| 487 |
+
m_i = m_i_new
|
| 488 |
+
# update pointers
|
| 489 |
+
K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
|
| 490 |
+
V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
|
| 491 |
+
# write back O
|
| 492 |
+
acc = tl.where(m_mask, acc / l_i[:, None], 0.0)
|
| 493 |
+
O_block_ptr = tl.make_block_ptr(
|
| 494 |
+
base=Out + qo_offset,
|
| 495 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 496 |
+
strides=(stride_om, stride_ok),
|
| 497 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 498 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 499 |
+
order=(1, 0)
|
| 500 |
+
)
|
| 501 |
+
tl.store(O_block_ptr, acc.to(dtype))
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
def triton_dense_forward(q, k, v, seqlens, sm_scale, block_size_M=128, block_size_N=64) -> torch.Tensor:
|
| 505 |
+
# shape constraints
|
| 506 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 507 |
+
assert Lq == Lk and Lk == Lv
|
| 508 |
+
assert Lk in {16, 32, 64, 128}
|
| 509 |
+
o = torch.zeros_like(q)
|
| 510 |
+
grid = (triton.cdiv(q.shape[2], block_size_M), q.shape[0] * q.shape[1], 1)
|
| 511 |
+
num_warps = 4 if Lk <= 64 else 8 # 4
|
| 512 |
+
dtype = tl.bfloat16 if q.dtype == torch.bfloat16 else tl.float16
|
| 513 |
+
triton_dense_fwd_kernel[grid](
|
| 514 |
+
q, k, v, seqlens, sm_scale,
|
| 515 |
+
o,
|
| 516 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 517 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 518 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3),
|
| 519 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3),
|
| 520 |
+
q.shape[0], q.shape[1], q.shape[2],
|
| 521 |
+
BLOCK_M=block_size_M, BLOCK_N=block_size_N,
|
| 522 |
+
BLOCK_DMODEL=Lk,
|
| 523 |
+
dtype=dtype,
|
| 524 |
+
num_warps=num_warps, num_stages=4,
|
| 525 |
+
)
|
| 526 |
+
|
| 527 |
+
return o
|
| 528 |
+
|
| 529 |
+
|
| 530 |
+
def flash_attn_forward(q, k, v, seqlens, sm_scale, context_size) -> torch.Tensor:
|
| 531 |
+
return flash_attn_varlen_func(
|
| 532 |
+
q,
|
| 533 |
+
k,
|
| 534 |
+
v,
|
| 535 |
+
cu_seqlens_q=seqlens,
|
| 536 |
+
cu_seqlens_k=seqlens,
|
| 537 |
+
max_seqlen_q=context_size,
|
| 538 |
+
max_seqlen_k=context_size,
|
| 539 |
+
dropout_p=0.0,
|
| 540 |
+
softmax_scale=sm_scale,
|
| 541 |
+
causal=True,
|
| 542 |
+
)
|
| 543 |
+
|
| 544 |
+
|
| 545 |
+
def torch_forward(
|
| 546 |
+
query: torch.Tensor,
|
| 547 |
+
key: torch.Tensor,
|
| 548 |
+
value: torch.Tensor,
|
| 549 |
+
mask: torch.Tensor,
|
| 550 |
+
sm_scale: float,
|
| 551 |
+
) -> torch.Tensor:
|
| 552 |
+
p = torch.einsum(f'bhmk, bhnk -> bhmn', query, key) * sm_scale
|
| 553 |
+
p = p.where(mask, -torch.inf)
|
| 554 |
+
p_max = p.max(-1, keepdim=True).values
|
| 555 |
+
p_max = torch.where(p_max < 0, 0.0, p_max)
|
| 556 |
+
p_exp = torch.exp(p - p_max)
|
| 557 |
+
s = p_exp / (p_exp.sum(-1, keepdim=True) + 1e-6)
|
| 558 |
+
out = torch.einsum(f'bhmn, bhnk -> bhmk', s, value)
|
| 559 |
+
return out
|
| 560 |
+
|
| 561 |
+
|
| 562 |
+
def profile(fn, total_flops, tag, warmup=25, rep=100):
|
| 563 |
+
ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
|
| 564 |
+
gflops = total_flops / ms * 1e-9
|
| 565 |
+
print(f'{tag}: {ms:.3f} ms | {gflops:.3f} GFLOP/s')
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
def test_flash_attention(
|
| 569 |
+
query=None,
|
| 570 |
+
key=None,
|
| 571 |
+
value=None,
|
| 572 |
+
seqlens=None,
|
| 573 |
+
vertical_indexes=None,
|
| 574 |
+
slash_indexes=None,
|
| 575 |
+
dtype=torch.float16,
|
| 576 |
+
device="cuda",
|
| 577 |
+
torch_test=True,
|
| 578 |
+
batch_size=4,
|
| 579 |
+
num_heads=32,
|
| 580 |
+
context_size=2048,
|
| 581 |
+
head_dim=128,
|
| 582 |
+
nnz_v=100,
|
| 583 |
+
nnz_s=10,
|
| 584 |
+
block_size_M=64,
|
| 585 |
+
block_size_N=64,
|
| 586 |
+
):
|
| 587 |
+
print('========================================')
|
| 588 |
+
if query is None and key is None and value is None:
|
| 589 |
+
q = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 590 |
+
k = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 591 |
+
v = torch.randn((batch_size, num_heads, context_size, head_dim), dtype=dtype, device=device)
|
| 592 |
+
else:
|
| 593 |
+
q = torch.tensor(query, dtype=dtype, device=device)
|
| 594 |
+
k = torch.tensor(key, dtype=dtype, device=device)
|
| 595 |
+
v = torch.tensor(value, dtype=dtype, device=device)
|
| 596 |
+
batch_size, num_heads, context_size, head_dim = q.shape
|
| 597 |
+
print(f'BATCH={batch_size}, N_CTX={context_size}, N_HEADS={num_heads}, D_HEAD={head_dim}')
|
| 598 |
+
if seqlens is None:
|
| 599 |
+
seqlens = torch.randint(context_size // 2, context_size, (batch_size, ), dtype=torch.int32, device=device)
|
| 600 |
+
else:
|
| 601 |
+
seqlens = torch.tensor(seqlens, dtype=torch.int32, device=device)
|
| 602 |
+
print(seqlens)
|
| 603 |
+
dense_mask_nnz = seqlens.to(torch.float32).square().sum().item() * num_heads / 2
|
| 604 |
+
sm_scale = head_dim ** -0.5
|
| 605 |
+
|
| 606 |
+
if torch_test:
|
| 607 |
+
causal_mask = make_causal_mask(seqlens, device, context_size)
|
| 608 |
+
ref_o_dense = torch_forward(q, k, v, causal_mask, sm_scale)
|
| 609 |
+
|
| 610 |
+
if vertical_indexes is None or slash_indexes is None:
|
| 611 |
+
vertical_indexes = torch.stack([
|
| 612 |
+
torch.stack([
|
| 613 |
+
torch.randperm(seqlen, dtype=torch.int32, device=device)[:nnz_v].sort(descending=False)[0]
|
| 614 |
+
for _ in range(num_heads)
|
| 615 |
+
])
|
| 616 |
+
for seqlen in seqlens
|
| 617 |
+
])
|
| 618 |
+
slash_indexes = torch.concatenate([
|
| 619 |
+
torch.stack([
|
| 620 |
+
torch.stack([
|
| 621 |
+
torch.randperm(seqlen - 1, dtype=torch.int32, device=device)[:nnz_s - 1].sort(descending=True)[0] + 1
|
| 622 |
+
for _ in range(num_heads)
|
| 623 |
+
])
|
| 624 |
+
for seqlen in seqlens
|
| 625 |
+
]),
|
| 626 |
+
torch.zeros((batch_size, num_heads, 1), dtype=torch.int32, device=device)
|
| 627 |
+
], dim=-1)
|
| 628 |
+
pycuda_build_index_fn = lambda: pycuda_build_index(
|
| 629 |
+
seqlens, vertical_indexes, slash_indexes, context_size, block_size_M, block_size_N
|
| 630 |
+
)
|
| 631 |
+
indexes = pycuda_build_index_fn()
|
| 632 |
+
block_count, block_offset, column_count, column_index = indexes
|
| 633 |
+
if torch_test:
|
| 634 |
+
block_count_ref, block_offset_ref, column_count_ref, column_index_ref = torch_build_index(
|
| 635 |
+
seqlens, vertical_indexes, slash_indexes, context_size, block_size_M, block_size_N
|
| 636 |
+
)
|
| 637 |
+
torch.testing.assert_close(block_count_ref, block_count)
|
| 638 |
+
torch.testing.assert_close(block_offset_ref, block_offset)
|
| 639 |
+
torch.testing.assert_close(column_count_ref, column_count)
|
| 640 |
+
torch.testing.assert_close(column_index_ref, column_index)
|
| 641 |
+
sparse_mask_nnz = column_count.to(torch.float64).sum().item() * block_size_M + \
|
| 642 |
+
block_count.to(torch.float64).sum().item() * block_size_M * block_size_N
|
| 643 |
+
print(f'block mask sparsity: {1 - sparse_mask_nnz / dense_mask_nnz}')
|
| 644 |
+
|
| 645 |
+
pycuda_build_index_fn = lambda: pycuda_build_index(
|
| 646 |
+
seqlens, vertical_indexes, slash_indexes, context_size, block_size_M, block_size_N
|
| 647 |
+
)
|
| 648 |
+
profile(pycuda_build_index_fn, 0., 'pycuda-index')
|
| 649 |
+
|
| 650 |
+
if torch_test:
|
| 651 |
+
finegrained_mask = make_finegrained_mask(vertical_indexes, slash_indexes, causal_mask, device)
|
| 652 |
+
block_mask = make_block_mask(*indexes, seqlens, causal_mask, device, block_size_M, block_size_N)
|
| 653 |
+
plot_mask(finegrained_mask, 'mask.png', 0, 0)
|
| 654 |
+
plot_mask(block_mask, 'mask-1.png', 0, 0)
|
| 655 |
+
ref_o_sparse = torch_forward(q, k, v, block_mask, sm_scale)
|
| 656 |
+
|
| 657 |
+
triton_dense_fn = lambda: triton_dense_forward(q, k, v, seqlens, sm_scale)
|
| 658 |
+
output_triton_dense = triton_dense_fn()
|
| 659 |
+
if torch_test:
|
| 660 |
+
# Note: not correct for context_size % block_size_M != 0
|
| 661 |
+
torch.testing.assert_close(output_triton_dense, ref_o_dense, atol=1e-2, rtol=0)
|
| 662 |
+
profile(triton_dense_fn, 2. * head_dim * dense_mask_nnz, 'triton-dense')
|
| 663 |
+
|
| 664 |
+
triton_sparse_fn = lambda: triton_sparse_forward(q, k, v, seqlens, *indexes, sm_scale, block_size_M, block_size_N)
|
| 665 |
+
output_triton_sparse = triton_sparse_fn()
|
| 666 |
+
if torch_test:
|
| 667 |
+
torch.testing.assert_close(output_triton_sparse, ref_o_sparse, atol=1e-2, rtol=0)
|
| 668 |
+
profile(triton_sparse_fn, 2. * head_dim * sparse_mask_nnz, 'triton-sparse')
|
| 669 |
+
|
| 670 |
+
q = q.swapaxes(1, 2).contiguous()
|
| 671 |
+
k = k.swapaxes(1, 2).contiguous()
|
| 672 |
+
v = v.swapaxes(1, 2).contiguous()
|
| 673 |
+
q = torch.concatenate([q[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 674 |
+
k = torch.concatenate([k[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 675 |
+
v = torch.concatenate([v[i, :seqlen, :, :] for i, seqlen in enumerate(seqlens)])
|
| 676 |
+
seqlens = torch.nn.functional.pad(torch.cumsum(seqlens, dim=0, dtype=torch.int32), (1, 0))
|
| 677 |
+
|
| 678 |
+
flash_fn = lambda: flash_attn_forward(q, k, v, seqlens, sm_scale, context_size)
|
| 679 |
+
output_flash = flash_fn()
|
| 680 |
+
output_flash = torch.stack([
|
| 681 |
+
torch.nn.functional.pad(
|
| 682 |
+
output_flash[seqlens[i]:seqlens[i + 1], :, :],
|
| 683 |
+
(0, 0, 0, 0, 0, context_size + seqlens[i] - seqlens[i + 1])
|
| 684 |
+
)
|
| 685 |
+
for i in range(batch_size)
|
| 686 |
+
]).swapaxes(1, 2).contiguous()
|
| 687 |
+
if torch_test:
|
| 688 |
+
torch.testing.assert_close(output_flash, ref_o_dense, atol=1e-2, rtol=0)
|
| 689 |
+
profile(flash_fn, 2. * head_dim * dense_mask_nnz, 'flash-dense')
|
| 690 |
+
print('========================================\n')
|
| 691 |
+
|
| 692 |
+
if torch_test and sparse_mask_nnz >= dense_mask_nnz:
|
| 693 |
+
torch.testing.assert_close(output_flash, output_triton_sparse, atol=1e-2, rtol=0)
|
| 694 |
+
|
| 695 |
+
|
| 696 |
+
def pit_sparse_flash_attention_forward(
|
| 697 |
+
query: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 698 |
+
key: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 699 |
+
value: torch.Tensor, # [BATCH, N_HEADS, N_CTX, D_HEAD]
|
| 700 |
+
v_idx: torch.Tensor, # [BATCH, N_HEADS, NNZ_V]
|
| 701 |
+
s_idx: torch.Tensor, # [BATCH, N_HEADS, NNZ_S]
|
| 702 |
+
block_size_M: int = 64,
|
| 703 |
+
block_size_N: int = 64,
|
| 704 |
+
):
|
| 705 |
+
batch_size, num_heads, context_size, head_dim = query.shape
|
| 706 |
+
pad = block_size_M - (context_size & (block_size_M - 1))
|
| 707 |
+
query = torch.nn.functional.pad(query, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 708 |
+
key = torch.nn.functional.pad(key, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 709 |
+
value = torch.nn.functional.pad(value, [0, 0, 0, pad, 0, 0, 0, 0])
|
| 710 |
+
|
| 711 |
+
if head_dim not in [16, 32, 64, 128, 256, 512]:
|
| 712 |
+
target_dim = 2 ** math.ceil(math.log2(head_dim)) - head_dim
|
| 713 |
+
query = torch.nn.functional.pad(query, [0, target_dim, 0, 0, 0, 0, 0, 0])
|
| 714 |
+
key = torch.nn.functional.pad(key, [0, target_dim, 0, 0, 0, 0, 0, 0])
|
| 715 |
+
value = torch.nn.functional.pad(value, [0, target_dim, 0, 0, 0, 0, 0, 0])
|
| 716 |
+
|
| 717 |
+
v_idx = v_idx.to(torch.int32).reshape((batch_size, num_heads, -1)).sort(dim=-1, descending=False)[0]
|
| 718 |
+
s_idx = s_idx.to(torch.int32).reshape((batch_size, num_heads, -1)).sort(dim=-1, descending=True)[0]
|
| 719 |
+
seqlens = torch.tensor([context_size], dtype=torch.int32, device=query.device)
|
| 720 |
+
sm_scale = head_dim ** -0.5
|
| 721 |
+
block_count, block_offset, column_count, column_index = pycuda_build_index(
|
| 722 |
+
seqlens, v_idx, s_idx, context_size, block_size_M, block_size_N,
|
| 723 |
+
)
|
| 724 |
+
# if context_size > 700000:
|
| 725 |
+
# import ipdb; ipdb.set_trace()
|
| 726 |
+
# dense_mask_nnz = seqlens.to(torch.float32).square().sum().item() * num_heads / 2
|
| 727 |
+
# sparse_mask_nnz = column_count.to(torch.float64).sum().item() * block_size_M + \
|
| 728 |
+
# block_count.to(torch.float64).sum().item() * block_size_M * block_size_N
|
| 729 |
+
# print(f'block mask sparsity: {1 - sparse_mask_nnz / dense_mask_nnz}')
|
| 730 |
+
out = triton_sparse_forward(
|
| 731 |
+
query, key, value, seqlens,
|
| 732 |
+
block_count, block_offset, column_count, column_index,
|
| 733 |
+
sm_scale, block_size_M, block_size_N,
|
| 734 |
+
)
|
| 735 |
+
return out[..., :context_size, :head_dim]
|
minference/ops/streaming_kernel.py
ADDED
|
@@ -0,0 +1,763 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Fused Attention
|
| 3 |
+
===============
|
| 4 |
+
|
| 5 |
+
This is a Triton implementation of the Flash Attention v2 algorithm from Tri Dao (https://tridao.me/publications/flash2/flash2.pdf)
|
| 6 |
+
Credits: OpenAI kernel team
|
| 7 |
+
|
| 8 |
+
Extra Credits:
|
| 9 |
+
- Original flash attention paper (https://arxiv.org/abs/2205.14135)
|
| 10 |
+
- Rabe and Staats (https://arxiv.org/pdf/2112.05682v2.pdf)
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import math
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import triton
|
| 18 |
+
import triton.language as tl
|
| 19 |
+
|
| 20 |
+
_BLOCK_N=64
|
| 21 |
+
_BLOCK_M=64
|
| 22 |
+
|
| 23 |
+
@triton.jit
|
| 24 |
+
def _attn_fwd_inner(acc, l_i, m_i, q,
|
| 25 |
+
K_block_ptr, V_block_ptr,
|
| 26 |
+
start_m, qk_scale, N_CTX,
|
| 27 |
+
sliding_window_offset, sliding_window_size,
|
| 28 |
+
BLOCK_M: tl.constexpr, BLOCK_DMODEL: tl.constexpr, BLOCK_N: tl.constexpr, SLIDING_WINDOW: tl.constexpr,
|
| 29 |
+
IS_EVEN_M: tl.constexpr, IS_EVEN_N: tl.constexpr, COMPLEMENT_SLIDING_WINDOW: tl.constexpr
|
| 30 |
+
):
|
| 31 |
+
# range of values handled by this stage
|
| 32 |
+
if SLIDING_WINDOW and not COMPLEMENT_SLIDING_WINDOW:
|
| 33 |
+
if COMPLEMENT_SLIDING_WINDOW:
|
| 34 |
+
lo = 0
|
| 35 |
+
hi = (((start_m + 1) * BLOCK_M + sliding_window_offset - sliding_window_size + BLOCK_N - 1) // BLOCK_N) * BLOCK_N
|
| 36 |
+
else:
|
| 37 |
+
lo = ((start_m * BLOCK_M + sliding_window_offset - sliding_window_size + 1) // BLOCK_N) * BLOCK_N
|
| 38 |
+
hi = ((((start_m + 1) * BLOCK_M - 1) + sliding_window_offset + BLOCK_N) // BLOCK_N) * BLOCK_N
|
| 39 |
+
if lo < 0:
|
| 40 |
+
lo = 0
|
| 41 |
+
if hi > N_CTX:
|
| 42 |
+
hi = N_CTX
|
| 43 |
+
|
| 44 |
+
# lo = 0
|
| 45 |
+
# hi = N_CTX
|
| 46 |
+
lo = tl.multiple_of(lo, BLOCK_N)
|
| 47 |
+
K_block_ptr = tl.advance(K_block_ptr, (0, lo))
|
| 48 |
+
V_block_ptr = tl.advance(V_block_ptr, (lo, 0))
|
| 49 |
+
else:
|
| 50 |
+
lo, hi = 0, N_CTX
|
| 51 |
+
|
| 52 |
+
# loop over k, v and update accumulator
|
| 53 |
+
for start_n in range(lo, hi, BLOCK_N):
|
| 54 |
+
start_n = tl.multiple_of(start_n, BLOCK_N)
|
| 55 |
+
# -- compute qk ----
|
| 56 |
+
if IS_EVEN_N:
|
| 57 |
+
k = tl.load(K_block_ptr)
|
| 58 |
+
else:
|
| 59 |
+
k = tl.load(K_block_ptr, boundary_check=(0, 1), padding_option="zero")
|
| 60 |
+
|
| 61 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 62 |
+
qk += tl.dot(q, k)
|
| 63 |
+
qk = qk * qk_scale
|
| 64 |
+
|
| 65 |
+
if SLIDING_WINDOW:
|
| 66 |
+
dist = tl.arange(0, BLOCK_M)[:, None] - tl.arange(0, BLOCK_N)[None, :] \
|
| 67 |
+
+ start_m * BLOCK_M - start_n + sliding_window_offset
|
| 68 |
+
|
| 69 |
+
if COMPLEMENT_SLIDING_WINDOW:
|
| 70 |
+
mask = (dist >= sliding_window_size)
|
| 71 |
+
else:
|
| 72 |
+
mask = (dist >= 0) & (dist < sliding_window_size)
|
| 73 |
+
|
| 74 |
+
qk = tl.where(mask, qk, float("-inf"))
|
| 75 |
+
|
| 76 |
+
if not IS_EVEN_N:
|
| 77 |
+
qk = tl.where(((tl.arange(0, BLOCK_N) + start_n) < N_CTX)[None, :], qk, float("-inf"))
|
| 78 |
+
|
| 79 |
+
m_ij = tl.maximum(m_i, tl.max(qk, 1))
|
| 80 |
+
qk = qk - m_ij[:, None]
|
| 81 |
+
p = tl.math.exp2(qk)
|
| 82 |
+
|
| 83 |
+
if SLIDING_WINDOW:
|
| 84 |
+
p = tl.where(mask, p, 0)
|
| 85 |
+
|
| 86 |
+
if not IS_EVEN_N:
|
| 87 |
+
p = tl.where(((tl.arange(0, BLOCK_N) + start_n) < N_CTX)[None, :], p, 0)
|
| 88 |
+
|
| 89 |
+
l_ij = tl.sum(p, 1)
|
| 90 |
+
# -- update m_i and l_i
|
| 91 |
+
tmp = m_i - m_ij
|
| 92 |
+
alpha_mask = (tmp != tmp) # check nan
|
| 93 |
+
alpha = tl.math.exp2(tmp)
|
| 94 |
+
alpha = tl.where(alpha_mask, 1., alpha)
|
| 95 |
+
l_i = l_i * alpha + l_ij
|
| 96 |
+
# -- update output accumulator --
|
| 97 |
+
acc = acc * alpha[:, None]
|
| 98 |
+
# update acc
|
| 99 |
+
if IS_EVEN_N:
|
| 100 |
+
v = tl.load(V_block_ptr)
|
| 101 |
+
else:
|
| 102 |
+
v = tl.load(V_block_ptr, boundary_check=(0, 1), padding_option="zero")
|
| 103 |
+
|
| 104 |
+
acc += tl.dot(p.to(v.dtype), v)
|
| 105 |
+
# update m_i and l_i
|
| 106 |
+
m_i = m_ij
|
| 107 |
+
V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
|
| 108 |
+
K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
|
| 109 |
+
|
| 110 |
+
return acc, l_i, m_i
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
@triton.heuristics(
|
| 114 |
+
{
|
| 115 |
+
"IS_EVEN_M": lambda args: args["N_CTX"] % args["BLOCK_M"] == 0,
|
| 116 |
+
"IS_EVEN_N": lambda args: args["NKV_CTX"] % args["BLOCK_N"] == 0,
|
| 117 |
+
}
|
| 118 |
+
)
|
| 119 |
+
@triton.jit
|
| 120 |
+
def _attn_fwd(Q, K, V, sm_scale, M, Out, L,#
|
| 121 |
+
stride_qz, stride_qh, stride_qm, stride_qk, #
|
| 122 |
+
stride_kz, stride_kh, stride_kn, stride_kk, #
|
| 123 |
+
stride_vz, stride_vh, stride_vk, stride_vn, #
|
| 124 |
+
stride_oz, stride_oh, stride_om, stride_on, #
|
| 125 |
+
Z, H, H_KV, #
|
| 126 |
+
N_CTX, #
|
| 127 |
+
ROUND_CTX,
|
| 128 |
+
NKV_CTX,
|
| 129 |
+
sliding_window_offset,
|
| 130 |
+
sliding_window_size,
|
| 131 |
+
IS_EVEN_M: tl.constexpr,
|
| 132 |
+
IS_EVEN_N: tl.constexpr,
|
| 133 |
+
BLOCK_M: tl.constexpr, #
|
| 134 |
+
BLOCK_DMODEL: tl.constexpr, #
|
| 135 |
+
BLOCK_N: tl.constexpr, #
|
| 136 |
+
END: tl.constexpr,
|
| 137 |
+
INIT: tl.constexpr,
|
| 138 |
+
SLIDING_WINDOW: tl.constexpr,
|
| 139 |
+
COMPLEMENT_SLIDING_WINDOW: tl.constexpr
|
| 140 |
+
):
|
| 141 |
+
|
| 142 |
+
start_m = tl.program_id(0)
|
| 143 |
+
off_hz = tl.program_id(1)
|
| 144 |
+
off_z = off_hz // H
|
| 145 |
+
off_h = off_hz % H
|
| 146 |
+
off_hkv = off_h // (H//H_KV)
|
| 147 |
+
q_offset = off_z.to(tl.int64) * stride_qz + off_h.to(tl.int64) * stride_qh
|
| 148 |
+
k_offset = off_z.to(tl.int64) * stride_kz + off_hkv.to(tl.int64) * stride_kh
|
| 149 |
+
v_offset = off_z.to(tl.int64) * stride_vz + off_hkv.to(tl.int64) * stride_vh
|
| 150 |
+
o_offset = off_z.to(tl.int64) * stride_oz + off_h.to(tl.int64) * stride_oh
|
| 151 |
+
|
| 152 |
+
# block pointers
|
| 153 |
+
Q_block_ptr = tl.make_block_ptr(
|
| 154 |
+
base=Q + q_offset,
|
| 155 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 156 |
+
strides=(stride_qm, stride_qk),
|
| 157 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 158 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 159 |
+
order=(1, 0),
|
| 160 |
+
)
|
| 161 |
+
V_block_ptr = tl.make_block_ptr(
|
| 162 |
+
base=V + v_offset,
|
| 163 |
+
shape=(NKV_CTX, BLOCK_DMODEL),
|
| 164 |
+
strides=(stride_vk, stride_vn),
|
| 165 |
+
offsets=(0, 0),
|
| 166 |
+
block_shape=(BLOCK_N, BLOCK_DMODEL),
|
| 167 |
+
order=(1, 0),
|
| 168 |
+
)
|
| 169 |
+
K_block_ptr = tl.make_block_ptr(
|
| 170 |
+
base=K + k_offset,
|
| 171 |
+
shape=(BLOCK_DMODEL, NKV_CTX),
|
| 172 |
+
strides=(stride_kk, stride_kn),
|
| 173 |
+
offsets=(0, 0),
|
| 174 |
+
block_shape=(BLOCK_DMODEL, BLOCK_N),
|
| 175 |
+
order=(0, 1),
|
| 176 |
+
)
|
| 177 |
+
O_block_ptr = tl.make_block_ptr(
|
| 178 |
+
base=Out + o_offset,
|
| 179 |
+
shape=(ROUND_CTX, BLOCK_DMODEL),
|
| 180 |
+
strides=(stride_om, stride_on),
|
| 181 |
+
offsets=(start_m * BLOCK_M, 0),
|
| 182 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 183 |
+
order=(1, 0),
|
| 184 |
+
)
|
| 185 |
+
# initialize offsets
|
| 186 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 187 |
+
# initialize pointer to m and l
|
| 188 |
+
m_ptrs = M + off_hz * ROUND_CTX + offs_m
|
| 189 |
+
l_ptrs = L + off_hz * ROUND_CTX + offs_m
|
| 190 |
+
if INIT:
|
| 191 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
| 192 |
+
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0
|
| 193 |
+
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
| 194 |
+
else:
|
| 195 |
+
# don't have to check boundary for q len
|
| 196 |
+
m_i = tl.load(m_ptrs).to(tl.float32)
|
| 197 |
+
l_i = tl.load(l_ptrs).to(tl.float32)
|
| 198 |
+
acc = tl.load(O_block_ptr).to(tl.float32)
|
| 199 |
+
|
| 200 |
+
qk_scale = sm_scale
|
| 201 |
+
qk_scale *= 1.4426950408889634 # 1/log(2)
|
| 202 |
+
# load q: it will stay in SRAM throughout
|
| 203 |
+
if IS_EVEN_M:
|
| 204 |
+
q = tl.load(Q_block_ptr)
|
| 205 |
+
else:
|
| 206 |
+
q = tl.load(Q_block_ptr, boundary_check=(0, 1), padding_option="zero")
|
| 207 |
+
|
| 208 |
+
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
|
| 209 |
+
start_m, qk_scale, NKV_CTX, #
|
| 210 |
+
sliding_window_offset, sliding_window_size,
|
| 211 |
+
BLOCK_M, BLOCK_DMODEL, BLOCK_N, SLIDING_WINDOW, IS_EVEN_M, IS_EVEN_N,
|
| 212 |
+
COMPLEMENT_SLIDING_WINDOW)
|
| 213 |
+
# epilogue
|
| 214 |
+
if (END):
|
| 215 |
+
m_i += tl.math.log2(l_i)
|
| 216 |
+
acc = acc / l_i[:, None]
|
| 217 |
+
else:
|
| 218 |
+
tl.store(l_ptrs, l_i)
|
| 219 |
+
|
| 220 |
+
tl.store(m_ptrs, m_i)
|
| 221 |
+
tl.store(O_block_ptr, acc.to(Out.type.element_ty))
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
@triton.heuristics(
|
| 225 |
+
{
|
| 226 |
+
"IS_EVEN_M": lambda args: args["N_CTX"] % args["BLOCK_M"] == 0,
|
| 227 |
+
"IS_EVEN_N": lambda args: args["NKV_CTX"] % args["BLOCK_N"] == 0,
|
| 228 |
+
}
|
| 229 |
+
)
|
| 230 |
+
@triton.jit
|
| 231 |
+
def _score_kernel(
|
| 232 |
+
Q, K, M, sm_scale, Out,
|
| 233 |
+
stride_qz, stride_qh, stride_qm, stride_qk, #
|
| 234 |
+
stride_kz, stride_kh, stride_kn, stride_kk, #
|
| 235 |
+
stride_oz, stride_oh, stride_on,
|
| 236 |
+
Z, H, H_KV, #
|
| 237 |
+
N_CTX, #
|
| 238 |
+
ROUND_CTX,
|
| 239 |
+
NKV_CTX,
|
| 240 |
+
sliding_window_offset,
|
| 241 |
+
sliding_window_size,
|
| 242 |
+
SLIDING_WINDOW: tl.constexpr,
|
| 243 |
+
COMPLEMENT_SLIDING_WINDOW: tl.constexpr,
|
| 244 |
+
IS_EVEN_M: tl.constexpr,
|
| 245 |
+
IS_EVEN_N: tl.constexpr,
|
| 246 |
+
BLOCK_M: tl.constexpr, #
|
| 247 |
+
BLOCK_DMODEL: tl.constexpr, #
|
| 248 |
+
BLOCK_N: tl.constexpr, #
|
| 249 |
+
):
|
| 250 |
+
start_n = tl.program_id(0)
|
| 251 |
+
off_hz = tl.program_id(1)
|
| 252 |
+
off_z = off_hz // H
|
| 253 |
+
off_h = off_hz % H
|
| 254 |
+
off_hkv = off_h // (H//H_KV)
|
| 255 |
+
q_offset = off_z.to(tl.int64) * stride_qz + off_h.to(tl.int64) * stride_qh
|
| 256 |
+
k_offset = off_z.to(tl.int64) * stride_kz + off_hkv.to(tl.int64) * stride_kh
|
| 257 |
+
m_ptrs = M + off_hz * ROUND_CTX + tl.arange(0, BLOCK_M)
|
| 258 |
+
o = tl.zeros([BLOCK_M], dtype=tl.float32)
|
| 259 |
+
|
| 260 |
+
Q_block_ptr = tl.make_block_ptr(
|
| 261 |
+
base=Q + q_offset,
|
| 262 |
+
shape=(N_CTX, BLOCK_DMODEL),
|
| 263 |
+
strides=(stride_qm, stride_qk),
|
| 264 |
+
offsets=(0, 0),
|
| 265 |
+
block_shape=(BLOCK_M, BLOCK_DMODEL),
|
| 266 |
+
order=(1, 0),
|
| 267 |
+
)
|
| 268 |
+
K_block_ptr = tl.make_block_ptr(
|
| 269 |
+
base=K + k_offset,
|
| 270 |
+
shape=(BLOCK_DMODEL, NKV_CTX),
|
| 271 |
+
strides=(stride_kk, stride_kn),
|
| 272 |
+
offsets=(0, start_n * BLOCK_N),
|
| 273 |
+
block_shape=(BLOCK_DMODEL, BLOCK_N),
|
| 274 |
+
order=(0, 1),
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
if IS_EVEN_N:
|
| 278 |
+
k = tl.load(K_block_ptr)
|
| 279 |
+
else:
|
| 280 |
+
k = tl.load(K_block_ptr, boundary_check=(0, 1), padding_option="zero")
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
lo = 0
|
| 284 |
+
hi = ROUND_CTX
|
| 285 |
+
qk_scale = sm_scale
|
| 286 |
+
qk_scale *= 1.4426950408889634 # 1/log(2)
|
| 287 |
+
|
| 288 |
+
for start_m in range(lo, hi, BLOCK_M):
|
| 289 |
+
start_m = tl.multiple_of(start_m, BLOCK_M)
|
| 290 |
+
if IS_EVEN_M:
|
| 291 |
+
q = tl.load(Q_block_ptr)
|
| 292 |
+
else:
|
| 293 |
+
q = tl.load(Q_block_ptr, boundary_check=(0,1), padding_option="zero")
|
| 294 |
+
|
| 295 |
+
m = tl.load(m_ptrs)
|
| 296 |
+
|
| 297 |
+
# calc qk
|
| 298 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 299 |
+
qk += tl.dot(q, k)
|
| 300 |
+
qk = qk * qk_scale
|
| 301 |
+
|
| 302 |
+
if SLIDING_WINDOW:
|
| 303 |
+
# dist = tl.arange(start_m, start_m + BLOCK_M)[:, None] \
|
| 304 |
+
# - tl.arange(start_n * BLOCK_N, (start_n + 1) + BLOCK_N)[None, :] + sliding_window_offset
|
| 305 |
+
dist = tl.arange(0, BLOCK_M)[:, None] - tl.arange(0, BLOCK_N)[None, :] \
|
| 306 |
+
+ start_m - start_n * BLOCK_N + sliding_window_offset
|
| 307 |
+
|
| 308 |
+
if COMPLEMENT_SLIDING_WINDOW:
|
| 309 |
+
mask = (dist >= sliding_window_size)
|
| 310 |
+
else:
|
| 311 |
+
mask = (dist >= 0) & (dist < sliding_window_size)
|
| 312 |
+
|
| 313 |
+
qk = qk - m[:, None]
|
| 314 |
+
p = tl.math.exp2(qk) # (BLOCK_M, BLOCK_N)
|
| 315 |
+
|
| 316 |
+
if SLIDING_WINDOW:
|
| 317 |
+
p = tl.where(mask, p, 0)
|
| 318 |
+
|
| 319 |
+
if not IS_EVEN_N:
|
| 320 |
+
p = tl.where(
|
| 321 |
+
((tl.arange(0, BLOCK_M) + start_m) < N_CTX)[:, None],
|
| 322 |
+
p, 0
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
o += tl.sum(p, axis=0)
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
Q_block_ptr = tl.advance(Q_block_ptr, offsets=(BLOCK_M, 0))
|
| 329 |
+
m_ptrs = m_ptrs + BLOCK_M
|
| 330 |
+
|
| 331 |
+
o_offset = off_z.to(tl.int64) * stride_oz + off_h.to(tl.int64) * stride_oh
|
| 332 |
+
o_range = tl.arange(0, BLOCK_N) + start_n * BLOCK_N # orange
|
| 333 |
+
o_ptrs = Out + o_offset + o_range
|
| 334 |
+
tl.store(o_ptrs, o.to(Out.type.element_ty), mask = o_range < NKV_CTX)
|
| 335 |
+
|
| 336 |
+
def get_score(q, k, m, sliding_window, complement_sliding_window):
|
| 337 |
+
assert q.dim() == 4
|
| 338 |
+
assert k.dim() == 4
|
| 339 |
+
assert m.dim() == 3
|
| 340 |
+
assert q.shape[:2] == m.shape[:2]
|
| 341 |
+
N_CTX = q.size(-2)
|
| 342 |
+
NKV_CTX = k.size(-2)
|
| 343 |
+
ROUND_CTX = m.size(-1)
|
| 344 |
+
ret = torch.zeros(
|
| 345 |
+
(q.size(0), q.size(1), k.size(2)),
|
| 346 |
+
dtype=k.dtype, device=k.device
|
| 347 |
+
)
|
| 348 |
+
if sliding_window is not None:
|
| 349 |
+
sliding_window_offset, sliding_window_size = sliding_window
|
| 350 |
+
else:
|
| 351 |
+
sliding_window_offset, sliding_window_size = None, None
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
grid = lambda META: (
|
| 355 |
+
triton.cdiv(k.shape[2], META["BLOCK_N"]),
|
| 356 |
+
q.shape[0] * q.shape[1]
|
| 357 |
+
)
|
| 358 |
+
sm_scale = 1 / math.sqrt(q.size(-1))
|
| 359 |
+
|
| 360 |
+
global _BLOCK_N
|
| 361 |
+
global _BLOCK_M
|
| 362 |
+
|
| 363 |
+
try:
|
| 364 |
+
_score_kernel[grid](
|
| 365 |
+
q, k, m, sm_scale, ret,
|
| 366 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 367 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 368 |
+
ret.stride(0), ret.stride(1), ret.stride(2),
|
| 369 |
+
q.size(0), q.size(1), k.size(1),
|
| 370 |
+
N_CTX, ROUND_CTX, NKV_CTX,
|
| 371 |
+
sliding_window_offset,
|
| 372 |
+
sliding_window_size,
|
| 373 |
+
SLIDING_WINDOW=(sliding_window is not None),
|
| 374 |
+
COMPLEMENT_SLIDING_WINDOW=complement_sliding_window,
|
| 375 |
+
BLOCK_M=_BLOCK_M,
|
| 376 |
+
BLOCK_N=_BLOCK_N,
|
| 377 |
+
BLOCK_DMODEL=q.size(-1)
|
| 378 |
+
)
|
| 379 |
+
except triton.OutOfResources as E:
|
| 380 |
+
from warnings import warn
|
| 381 |
+
_BLOCK_N = _BLOCK_N // 2
|
| 382 |
+
_BLOCK_M = _BLOCK_M // 2
|
| 383 |
+
warn(f"Triton Attention Output Resources. {E}\nUse smaller block size {_BLOCK_N}.")
|
| 384 |
+
_score_kernel[grid](
|
| 385 |
+
q, k, m, sm_scale, ret,
|
| 386 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3),
|
| 387 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3),
|
| 388 |
+
ret.stride(0), ret.stride(1), ret.stride(2),
|
| 389 |
+
q.size(0), q.size(1), k.size(1),
|
| 390 |
+
N_CTX, ROUND_CTX, NKV_CTX,
|
| 391 |
+
sliding_window_offset,
|
| 392 |
+
sliding_window_size,
|
| 393 |
+
SLIDING_WINDOW=(sliding_window is not None),
|
| 394 |
+
COMPLEMENT_SLIDING_WINDOW=complement_sliding_window,
|
| 395 |
+
BLOCK_M=_BLOCK_M,
|
| 396 |
+
BLOCK_N=_BLOCK_N,
|
| 397 |
+
BLOCK_DMODEL=q.size(-1)
|
| 398 |
+
)
|
| 399 |
+
|
| 400 |
+
return ret
|
| 401 |
+
|
| 402 |
+
def _forward(
|
| 403 |
+
q, k, v, sm_scale,
|
| 404 |
+
o = None, m = None, l = None, end = False,
|
| 405 |
+
sliding_window=None, init=False,
|
| 406 |
+
complement_sliding_window=False
|
| 407 |
+
):
|
| 408 |
+
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
| 409 |
+
|
| 410 |
+
assert Lq == Lk and Lk == Lv
|
| 411 |
+
assert Lk in {16, 32, 64, 128}
|
| 412 |
+
|
| 413 |
+
q_round_len = math.ceil(q.shape[2] / 64) * 64
|
| 414 |
+
|
| 415 |
+
if sliding_window is not None:
|
| 416 |
+
sliding_window_offset, sliding_window_size = sliding_window
|
| 417 |
+
else:
|
| 418 |
+
sliding_window_offset, sliding_window_size = None, None
|
| 419 |
+
|
| 420 |
+
grid = lambda META: (
|
| 421 |
+
triton.cdiv(q.shape[2], META["BLOCK_M"]),
|
| 422 |
+
q.shape[0] * q.shape[1],
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
global _BLOCK_N
|
| 426 |
+
global _BLOCK_M
|
| 427 |
+
|
| 428 |
+
try:
|
| 429 |
+
_attn_fwd[grid](
|
| 430 |
+
q, k, v, sm_scale, m, o, l, #
|
| 431 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3), #
|
| 432 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3), #
|
| 433 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3), #
|
| 434 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3), #
|
| 435 |
+
q.shape[0], q.shape[1], k.shape[1], #
|
| 436 |
+
q.shape[2], #
|
| 437 |
+
q_round_len,
|
| 438 |
+
k.shape[2],
|
| 439 |
+
sliding_window_offset,
|
| 440 |
+
sliding_window_size,
|
| 441 |
+
BLOCK_DMODEL=Lk, #
|
| 442 |
+
END=end,
|
| 443 |
+
INIT=init,
|
| 444 |
+
BLOCK_M=_BLOCK_M,
|
| 445 |
+
BLOCK_N=_BLOCK_N,
|
| 446 |
+
SLIDING_WINDOW=(sliding_window is not None),
|
| 447 |
+
COMPLEMENT_SLIDING_WINDOW=complement_sliding_window,
|
| 448 |
+
num_warps=4,
|
| 449 |
+
num_stages=4
|
| 450 |
+
)
|
| 451 |
+
except triton.OutOfResources as E:
|
| 452 |
+
_BLOCK_N = _BLOCK_N // 2
|
| 453 |
+
_BLOCK_M = _BLOCK_M // 2
|
| 454 |
+
from warnings import warn
|
| 455 |
+
warn(f"Triton Attention Output Resources. {E}\nUse smaller block size {_BLOCK_N}.")
|
| 456 |
+
_attn_fwd[grid](
|
| 457 |
+
q, k, v, sm_scale, m, o, l, #
|
| 458 |
+
q.stride(0), q.stride(1), q.stride(2), q.stride(3), #
|
| 459 |
+
k.stride(0), k.stride(1), k.stride(2), k.stride(3), #
|
| 460 |
+
v.stride(0), v.stride(1), v.stride(2), v.stride(3), #
|
| 461 |
+
o.stride(0), o.stride(1), o.stride(2), o.stride(3), #
|
| 462 |
+
q.shape[0], q.shape[1], k.shape[1], #
|
| 463 |
+
q.shape[2], #
|
| 464 |
+
q_round_len,
|
| 465 |
+
k.shape[2],
|
| 466 |
+
sliding_window_offset,
|
| 467 |
+
sliding_window_size,
|
| 468 |
+
BLOCK_DMODEL=Lk, #
|
| 469 |
+
END=end,
|
| 470 |
+
INIT=init,
|
| 471 |
+
BLOCK_M=_BLOCK_M,
|
| 472 |
+
BLOCK_N=_BLOCK_N,
|
| 473 |
+
SLIDING_WINDOW=(sliding_window is not None),
|
| 474 |
+
COMPLEMENT_SLIDING_WINDOW=complement_sliding_window,
|
| 475 |
+
num_warps=4,
|
| 476 |
+
num_stages=4
|
| 477 |
+
)
|
| 478 |
+
|
| 479 |
+
|
| 480 |
+
if end:
|
| 481 |
+
o = o[:, :, :q.shape[2], :].contiguous().to(q.dtype)
|
| 482 |
+
|
| 483 |
+
return o, m, l
|
| 484 |
+
|
| 485 |
+
class MultiStageDotProductionAttention:
|
| 486 |
+
def __init__(
|
| 487 |
+
self,
|
| 488 |
+
q_shape,
|
| 489 |
+
dtype,
|
| 490 |
+
device,
|
| 491 |
+
):
|
| 492 |
+
self.q_shape = q_shape
|
| 493 |
+
self.dtype = dtype
|
| 494 |
+
self.device = device
|
| 495 |
+
self.end = False
|
| 496 |
+
self.ret = torch.zeros(
|
| 497 |
+
q_shape, dtype=dtype, device=device
|
| 498 |
+
)
|
| 499 |
+
self.score_list = []
|
| 500 |
+
|
| 501 |
+
def append(
|
| 502 |
+
self,
|
| 503 |
+
q: torch.Tensor, k: torch.Tensor, v: torch.Tensor,
|
| 504 |
+
sliding_window=None, complement_sliding_window: bool = False,
|
| 505 |
+
end=False, get_score=False,
|
| 506 |
+
*args, **kwargs
|
| 507 |
+
):
|
| 508 |
+
raise NotImplementedError
|
| 509 |
+
|
| 510 |
+
|
| 511 |
+
def get_result(self):
|
| 512 |
+
return self.ret, self.score_list
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
class TritonMultiStageDotProductionAttention(MultiStageDotProductionAttention):
|
| 516 |
+
def __init__(self, q_shape, dtype, device):
|
| 517 |
+
self.q_shape = q_shape
|
| 518 |
+
self.dtype = dtype
|
| 519 |
+
self.device = device
|
| 520 |
+
q_round_len = math.ceil(q_shape[2] / 64) * 64
|
| 521 |
+
o_shape = (q_shape[0], q_shape[1], q_round_len, q_shape[3])
|
| 522 |
+
m_shape = (q_shape[0], q_shape[1], q_round_len)
|
| 523 |
+
l_shape = (q_shape[0], q_shape[1], q_round_len)
|
| 524 |
+
|
| 525 |
+
self.o = torch.empty(o_shape, device=device, dtype=torch.float32)
|
| 526 |
+
self.m = torch.empty(m_shape, device=device, dtype=torch.float32)
|
| 527 |
+
self.l = torch.empty(l_shape, device=device, dtype=torch.float32)
|
| 528 |
+
self.q_list = []
|
| 529 |
+
self.k_list = []
|
| 530 |
+
self.sliding_window_list = []
|
| 531 |
+
self.complement_sliding_window_list = []
|
| 532 |
+
self.score_list = []
|
| 533 |
+
self.end = False
|
| 534 |
+
self.init = False
|
| 535 |
+
|
| 536 |
+
def finalize(self):
|
| 537 |
+
self.end = True
|
| 538 |
+
for q, k, sliding_window, comp in zip(self.q_list, self.k_list, self.sliding_window_list, self.complement_sliding_window_list):
|
| 539 |
+
if q is not None:
|
| 540 |
+
score = get_score(q, k, self.m, sliding_window, comp)
|
| 541 |
+
self.score_list.append(score)
|
| 542 |
+
else:
|
| 543 |
+
self.score_list.append(None)
|
| 544 |
+
|
| 545 |
+
self.ret = self.o
|
| 546 |
+
|
| 547 |
+
def append(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, end=False, get_score=False, sliding_window = None, complement_sliding_window: bool = False):
|
| 548 |
+
assert q.shape == self.q_shape
|
| 549 |
+
|
| 550 |
+
if isinstance(sliding_window, int):
|
| 551 |
+
sliding_window = (
|
| 552 |
+
k.shape[2] - q.shape[2], sliding_window
|
| 553 |
+
)
|
| 554 |
+
|
| 555 |
+
q = q.contiguous()
|
| 556 |
+
k = k.contiguous()
|
| 557 |
+
v = v.contiguous()
|
| 558 |
+
|
| 559 |
+
sm_scale = 1 / math.sqrt(q.shape[-1])
|
| 560 |
+
o, m, l = _forward(
|
| 561 |
+
q, k, v, sm_scale, self.o, self.m, self.l,
|
| 562 |
+
sliding_window=sliding_window, end=end, init=not self.init,
|
| 563 |
+
complement_sliding_window=complement_sliding_window
|
| 564 |
+
)
|
| 565 |
+
self.init = True
|
| 566 |
+
self.o = o
|
| 567 |
+
self.m = m
|
| 568 |
+
self.l = l
|
| 569 |
+
if get_score:
|
| 570 |
+
self.q_list.append(q)
|
| 571 |
+
self.k_list.append(k)
|
| 572 |
+
self.sliding_window_list.append(sliding_window)
|
| 573 |
+
self.complement_sliding_window_list.append(complement_sliding_window)
|
| 574 |
+
else:
|
| 575 |
+
self.q_list.append(None)
|
| 576 |
+
self.k_list.append(None)
|
| 577 |
+
self.sliding_window_list.append(None)
|
| 578 |
+
self.complement_sliding_window_list.append(None)
|
| 579 |
+
|
| 580 |
+
if end:
|
| 581 |
+
assert not self.end
|
| 582 |
+
self.finalize()
|
| 583 |
+
|
| 584 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 585 |
+
"""
|
| 586 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 587 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 588 |
+
"""
|
| 589 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 590 |
+
if n_rep == 1:
|
| 591 |
+
return hidden_states
|
| 592 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 593 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 594 |
+
|
| 595 |
+
def streaming_forward(
|
| 596 |
+
q, k, v,
|
| 597 |
+
n_init, n_local,
|
| 598 |
+
):
|
| 599 |
+
# q,k,v should be tensors already equipped with RoPE
|
| 600 |
+
# k,v should already repeated to align with q.shape
|
| 601 |
+
|
| 602 |
+
assert q.dim() == 4 # (bsz, num_heads, seqlen, head_dim)
|
| 603 |
+
assert q.shape == k.shape == v.shape
|
| 604 |
+
|
| 605 |
+
head_dim = q.shape[-1]
|
| 606 |
+
if head_dim not in [16, 32, 64, 128, 256, 512]:
|
| 607 |
+
target_dim = 2 ** math.ceil(math.log2(head_dim)) - head_dim
|
| 608 |
+
q = torch.nn.functional.pad(q, [0, target_dim, 0, 0, 0, 0, 0, 0])
|
| 609 |
+
k = torch.nn.functional.pad(k, [0, target_dim, 0, 0, 0, 0, 0, 0])
|
| 610 |
+
v = torch.nn.functional.pad(v, [0, target_dim, 0, 0, 0, 0, 0, 0])
|
| 611 |
+
|
| 612 |
+
q_len = q.size(2)
|
| 613 |
+
k_len = k.size(2)
|
| 614 |
+
|
| 615 |
+
attn = TritonMultiStageDotProductionAttention(q.shape, q.dtype, q.device)
|
| 616 |
+
|
| 617 |
+
if k_len > n_local:
|
| 618 |
+
init_k = k[:, :, :n_init, :].contiguous()
|
| 619 |
+
init_v = v[:, :, :n_init, :].contiguous()
|
| 620 |
+
|
| 621 |
+
attn.append(q, k, v, sliding_window=n_local)
|
| 622 |
+
attn.append(
|
| 623 |
+
q, init_k, init_v, end=True,
|
| 624 |
+
sliding_window=(k_len - q_len, n_local), complement_sliding_window=True
|
| 625 |
+
)
|
| 626 |
+
else:
|
| 627 |
+
attn.append(q, k, v, sliding_window=n_local, end=True)
|
| 628 |
+
|
| 629 |
+
score, _ = attn.get_result()
|
| 630 |
+
return score[...,:head_dim]
|
| 631 |
+
|
| 632 |
+
def streaming_forward2(
|
| 633 |
+
q, k, v,
|
| 634 |
+
n_init, n_local,
|
| 635 |
+
):
|
| 636 |
+
q_len = q.size(2)
|
| 637 |
+
k_len = k.size(2)
|
| 638 |
+
|
| 639 |
+
attn = TritonMultiStageDotProductionAttention(q.shape, q.dtype, q.device)
|
| 640 |
+
|
| 641 |
+
if k_len > n_local:
|
| 642 |
+
init_k = k[:, :, :n_init, :].contiguous()
|
| 643 |
+
init_v = v[:, :, :n_init, :].contiguous()
|
| 644 |
+
|
| 645 |
+
else:
|
| 646 |
+
init_k = torch.empty(
|
| 647 |
+
(k.size(0), k.size(1), 0, k.size(3)),
|
| 648 |
+
dtype=k.dtype, device=k.device
|
| 649 |
+
)
|
| 650 |
+
init_v = torch.empty(
|
| 651 |
+
(v.size(0), v.size(1), 0, v.size(3)),
|
| 652 |
+
dtype=v.dtype, device=v.device
|
| 653 |
+
)
|
| 654 |
+
|
| 655 |
+
attn.append(q, k, v, sliding_window=n_local)
|
| 656 |
+
attn.append(
|
| 657 |
+
q, init_k, init_v, end=True,
|
| 658 |
+
sliding_window=(k_len - q_len, n_local), complement_sliding_window=True
|
| 659 |
+
)
|
| 660 |
+
|
| 661 |
+
score, _ = attn.get_result()
|
| 662 |
+
return score
|
| 663 |
+
|
| 664 |
+
def stream_llm_forward(n_local, n_init, *args, **kwargs):
|
| 665 |
+
Attn = TritonMultiStageDotProductionAttention
|
| 666 |
+
def forward(self, query : torch.Tensor,
|
| 667 |
+
key_value : torch.Tensor,
|
| 668 |
+
position_bias : torch.Tensor,
|
| 669 |
+
use_cache: bool,
|
| 670 |
+
past_key_value,
|
| 671 |
+
project_q, project_k, project_v, attention_out,
|
| 672 |
+
dim_head, num_heads, num_heads_kv
|
| 673 |
+
):
|
| 674 |
+
|
| 675 |
+
batch_size = query.size(0)
|
| 676 |
+
len_q = query.size(1)
|
| 677 |
+
len_k = key_value.size(1)
|
| 678 |
+
|
| 679 |
+
h_q = project_q(query) # (batch, len_q, num_heads * dim_head)
|
| 680 |
+
h_k = project_k(key_value) # (batch, len_k, num_heads * dim_head)
|
| 681 |
+
h_v = project_v(key_value) # (batch, len_k, num_heads * dim_head)
|
| 682 |
+
|
| 683 |
+
h_q = h_q.view(batch_size, len_q, num_heads, dim_head).permute(0, 2, 1, 3) # (batch, num_heads, len_q, dim_head)
|
| 684 |
+
h_k = h_k.view(batch_size, len_k, num_heads_kv, dim_head).permute(0, 2, 1, 3) # (batch, num_heads_kv, len_k, dim_head)
|
| 685 |
+
h_v = h_v.view(batch_size, len_k, num_heads_kv, dim_head).permute(0, 2, 1, 3) # (batch, num_heads_kv, len_k, dim_head)
|
| 686 |
+
|
| 687 |
+
h_q = h_q.contiguous() # (batch * num_heads, len_q, dim_head)
|
| 688 |
+
h_k = h_k.contiguous() # (batch * num_heads, len_k, dim_head)
|
| 689 |
+
h_v = h_v.contiguous() # (batch * num_heads, len_k, dim_head)
|
| 690 |
+
|
| 691 |
+
if past_key_value is not None:
|
| 692 |
+
h_k = torch.cat([past_key_value[0], h_k], dim=-2)
|
| 693 |
+
h_v = torch.cat([past_key_value[1], h_v], dim=-2)
|
| 694 |
+
|
| 695 |
+
len_k += past_key_value[2]
|
| 696 |
+
|
| 697 |
+
if use_cache:
|
| 698 |
+
if len_k <= n_local + n_init:
|
| 699 |
+
h_k_cache = h_k
|
| 700 |
+
h_v_cache = h_v
|
| 701 |
+
else:
|
| 702 |
+
h_k_cache = torch.cat([h_k[:,:, :n_init, :], h_k[:, :, max(0, h_k.size(-2) - n_local):, :]], dim=2)
|
| 703 |
+
h_v_cache = torch.cat([h_v[:,:, :n_init, :], h_v[:, :, max(0, h_k.size(-2) - n_local):, :]], dim=2)
|
| 704 |
+
|
| 705 |
+
current_key_value = (h_k_cache, h_v_cache, len_k)
|
| 706 |
+
|
| 707 |
+
else:
|
| 708 |
+
current_key_value = None
|
| 709 |
+
|
| 710 |
+
h_q_ = h_q
|
| 711 |
+
h_k_ = h_k
|
| 712 |
+
h_v_ = h_v
|
| 713 |
+
|
| 714 |
+
if len_q + n_local < h_k_.size(-2):
|
| 715 |
+
h_k_ = h_k_[:, :, h_k_.size(-2) - len_q - n_local:, :].contiguous().clone()
|
| 716 |
+
h_v_ = h_v_[:, :, h_v_.size(-2) - len_q - n_local:, :].contiguous().clone()
|
| 717 |
+
|
| 718 |
+
local_h_q, local_h_k = position_bias(h_q_, h_k_)
|
| 719 |
+
local_h_v = h_v_
|
| 720 |
+
|
| 721 |
+
if len_k > n_local:
|
| 722 |
+
init_h_q = position_bias.apply_rotary_pos_emb_one_angle(
|
| 723 |
+
h_q, n_local + n_init
|
| 724 |
+
)
|
| 725 |
+
init_h_k = position_bias.apply_rotary_pos_emb(
|
| 726 |
+
h_k[:, :, :n_init, :].contiguous(),
|
| 727 |
+
n_init, n_init, position_bias._cos_cached, position_bias._sin_cached
|
| 728 |
+
)
|
| 729 |
+
init_h_v = h_v[:, :, :n_init, :].contiguous()
|
| 730 |
+
|
| 731 |
+
else:
|
| 732 |
+
init_h_q = h_q
|
| 733 |
+
init_h_k = torch.empty(
|
| 734 |
+
(batch_size, num_heads_kv, 0, dim_head),
|
| 735 |
+
device=h_k.device,
|
| 736 |
+
dtype=h_k.dtype
|
| 737 |
+
)
|
| 738 |
+
init_h_v = torch.empty(
|
| 739 |
+
(batch_size, num_heads_kv, 0, dim_head),
|
| 740 |
+
device=h_v.device,
|
| 741 |
+
dtype=h_v.dtype
|
| 742 |
+
)
|
| 743 |
+
|
| 744 |
+
attn = Attn(local_h_q.shape, local_h_q.dtype, local_h_q.device)
|
| 745 |
+
attn.append(local_h_q, local_h_k, local_h_v, sliding_window=n_local)
|
| 746 |
+
attn.append(
|
| 747 |
+
init_h_q, init_h_k, init_h_v, end=True,
|
| 748 |
+
sliding_window=(len_k - len_q, n_local),
|
| 749 |
+
complement_sliding_window=True
|
| 750 |
+
)
|
| 751 |
+
score, _ = attn.get_result()
|
| 752 |
+
|
| 753 |
+
score = score.view(batch_size, num_heads, len_q, dim_head).permute(0, 2, 1, 3).contiguous() # (batch, len_q, num_heads, dim_head)
|
| 754 |
+
score = score.reshape(batch_size, len_q, num_heads * dim_head) # (batch, len_q, num_heads * dim_head)
|
| 755 |
+
|
| 756 |
+
score = attention_out(score)
|
| 757 |
+
|
| 758 |
+
if use_cache:
|
| 759 |
+
return score, current_key_value
|
| 760 |
+
else:
|
| 761 |
+
return score
|
| 762 |
+
|
| 763 |
+
return forward
|
minference/patch.py
ADDED
|
@@ -0,0 +1,1279 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import transformers
|
| 5 |
+
from transformers.cache_utils import *
|
| 6 |
+
from transformers.models.llama.modeling_llama import *
|
| 7 |
+
|
| 8 |
+
from .modules.inf_llm import InfLLMGenerator, inf_llm_forward
|
| 9 |
+
from .modules.minference_forward import (
|
| 10 |
+
gather_last_q_vertical_slash_topk_v4,
|
| 11 |
+
gather_last_q_vertical_slash_topk_vllm,
|
| 12 |
+
init_minference_parameters,
|
| 13 |
+
minference_forward,
|
| 14 |
+
minference_kv_cache_cpu_forward,
|
| 15 |
+
minference_vllm_forward,
|
| 16 |
+
minference_with_snapkv_forward,
|
| 17 |
+
search_pattern,
|
| 18 |
+
sum_all_diagonal_matrix,
|
| 19 |
+
)
|
| 20 |
+
from .ops.streaming_kernel import stream_llm_forward
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class RotaryEmbeddingESM(torch.nn.Module):
|
| 24 |
+
"""
|
| 25 |
+
Rotary position embeddings based on those in
|
| 26 |
+
[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer). Query and keys are transformed by rotation
|
| 27 |
+
matrices which depend on their relative positions.
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def __init__(
|
| 31 |
+
self,
|
| 32 |
+
dim: int,
|
| 33 |
+
base: Union[int, float] = 10000,
|
| 34 |
+
distance_scale: Union[int, float] = 1,
|
| 35 |
+
):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.base = base
|
| 38 |
+
self.distance_scale = distance_scale
|
| 39 |
+
|
| 40 |
+
# Generate and save the inverse frequency buffer (non trainable)
|
| 41 |
+
inv_freq = 1.0 / (
|
| 42 |
+
base ** (torch.arange(0, dim, 2, device="cuda", dtype=torch.float32) / dim)
|
| 43 |
+
)
|
| 44 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 45 |
+
|
| 46 |
+
self._seq_len_cached = -1
|
| 47 |
+
self._cos_cached = None
|
| 48 |
+
self._sin_cached = None
|
| 49 |
+
|
| 50 |
+
def rotate_half(self, x):
|
| 51 |
+
x1, x2 = x.chunk(2, dim=-1)
|
| 52 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 53 |
+
|
| 54 |
+
def apply_rotary_pos_emb(self, x, length, right, cos, sin):
|
| 55 |
+
dtype = x.dtype
|
| 56 |
+
if cos.dim() == 2:
|
| 57 |
+
cos = cos[right - length : right, :]
|
| 58 |
+
sin = sin[right - length : right, :]
|
| 59 |
+
elif cos.dim() == 3:
|
| 60 |
+
cos = cos[:, right - length : right, :]
|
| 61 |
+
sin = sin[:, right - length : right, :]
|
| 62 |
+
elif cos.dim() == 4:
|
| 63 |
+
cos = cos[:, :, right - length : right, :]
|
| 64 |
+
sin = sin[:, :, right - length : right, :]
|
| 65 |
+
|
| 66 |
+
return ((x.float() * cos) + (self.rotate_half(x).float() * sin)).to(dtype)
|
| 67 |
+
|
| 68 |
+
def _update_cos_sin_tables(self, x, seq_dim):
|
| 69 |
+
seq_len = x.size(seq_dim)
|
| 70 |
+
if seq_len > self._seq_len_cached:
|
| 71 |
+
self._seq_len_cached = seq_len
|
| 72 |
+
t = torch.arange(seq_len, device=x.device).type_as(self.inv_freq)
|
| 73 |
+
freqs = torch.outer(t * self.distance_scale, self.inv_freq)
|
| 74 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 75 |
+
if x.dim() == 2:
|
| 76 |
+
self._cos_cached = emb.cos()
|
| 77 |
+
self._sin_cached = emb.sin()
|
| 78 |
+
elif x.dim() == 3:
|
| 79 |
+
self._cos_cached = emb.cos()[None, :, :]
|
| 80 |
+
self._sin_cached = emb.sin()[None, :, :]
|
| 81 |
+
elif x.dim() == 4:
|
| 82 |
+
self._cos_cached = emb.cos()[None, None, :, :]
|
| 83 |
+
self._sin_cached = emb.sin()[None, None, :, :]
|
| 84 |
+
return self._cos_cached, self._sin_cached
|
| 85 |
+
|
| 86 |
+
def _update_cos_sin_tables_len(self, seq_len, device, dim=None):
|
| 87 |
+
if seq_len > self._seq_len_cached:
|
| 88 |
+
if dim is None:
|
| 89 |
+
assert self._cos_cached is not None
|
| 90 |
+
dim = self._cos_cached.dim()
|
| 91 |
+
|
| 92 |
+
self._seq_len_cached = seq_len
|
| 93 |
+
t = torch.arange(seq_len, device=device).type_as(self.inv_freq)
|
| 94 |
+
freqs = torch.outer(t * self.distance_scale, self.inv_freq)
|
| 95 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 96 |
+
if dim == 2:
|
| 97 |
+
self._cos_cached = emb.cos()
|
| 98 |
+
self._sin_cached = emb.sin()
|
| 99 |
+
elif dim == 3:
|
| 100 |
+
self._cos_cached = emb.cos()[None, :, :]
|
| 101 |
+
self._sin_cached = emb.sin()[None, :, :]
|
| 102 |
+
elif dim == 4:
|
| 103 |
+
self._cos_cached = emb.cos()[None, None, :, :]
|
| 104 |
+
self._sin_cached = emb.sin()[None, None, :, :]
|
| 105 |
+
|
| 106 |
+
return self._cos_cached, self._sin_cached
|
| 107 |
+
|
| 108 |
+
def apply_rotary_pos_emb_one_angle(self, x: torch.Tensor, index):
|
| 109 |
+
dtype = x.dtype
|
| 110 |
+
cos, sin = self._update_cos_sin_tables_len(index, x.device)
|
| 111 |
+
if cos.dim() == 2:
|
| 112 |
+
cos = cos[index - 1 : index, :]
|
| 113 |
+
sin = sin[index - 1 : index, :]
|
| 114 |
+
elif cos.dim() == 3:
|
| 115 |
+
cos = cos[:, index - 1 : index, :]
|
| 116 |
+
sin = sin[:, index - 1 : index, :]
|
| 117 |
+
elif cos.dim() == 4:
|
| 118 |
+
cos = cos[:, :, index - 1 : index, :]
|
| 119 |
+
sin = sin[:, :, index - 1 : index, :]
|
| 120 |
+
|
| 121 |
+
return ((x.float() * cos) + (self.rotate_half(x).float() * sin)).to(dtype)
|
| 122 |
+
|
| 123 |
+
def forward(
|
| 124 |
+
self, q: torch.Tensor, k: torch.Tensor, seq_dim=-2
|
| 125 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 126 |
+
self._cos_cached, self._sin_cached = self._update_cos_sin_tables(
|
| 127 |
+
k, seq_dim=seq_dim
|
| 128 |
+
)
|
| 129 |
+
return (
|
| 130 |
+
self.apply_rotary_pos_emb(
|
| 131 |
+
q, q.size(seq_dim), k.size(seq_dim), self._cos_cached, self._sin_cached
|
| 132 |
+
),
|
| 133 |
+
self.apply_rotary_pos_emb(
|
| 134 |
+
k, k.size(seq_dim), k.size(seq_dim), self._cos_cached, self._sin_cached
|
| 135 |
+
),
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
ATTN_FORWRAD = {
|
| 140 |
+
"streaming": stream_llm_forward,
|
| 141 |
+
"minference": minference_forward,
|
| 142 |
+
"inf_llm": inf_llm_forward,
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def huggingface_forward(forward):
|
| 147 |
+
def hf_forward(
|
| 148 |
+
self,
|
| 149 |
+
hidden_states: torch.Tensor,
|
| 150 |
+
attention_mask=None,
|
| 151 |
+
position_ids=None,
|
| 152 |
+
past_key_value=None,
|
| 153 |
+
output_attentions: bool = False,
|
| 154 |
+
use_cache: bool = False,
|
| 155 |
+
**kwargs,
|
| 156 |
+
):
|
| 157 |
+
assert not output_attentions
|
| 158 |
+
ret = forward(
|
| 159 |
+
self,
|
| 160 |
+
hidden_states,
|
| 161 |
+
hidden_states,
|
| 162 |
+
position_ids,
|
| 163 |
+
use_cache,
|
| 164 |
+
past_key_value,
|
| 165 |
+
self.q_proj,
|
| 166 |
+
self.k_proj,
|
| 167 |
+
self.v_proj,
|
| 168 |
+
self.o_proj,
|
| 169 |
+
self.head_dim,
|
| 170 |
+
self.num_heads,
|
| 171 |
+
self.num_key_value_heads,
|
| 172 |
+
)
|
| 173 |
+
if use_cache:
|
| 174 |
+
o, pkv = ret
|
| 175 |
+
else:
|
| 176 |
+
o = ret
|
| 177 |
+
pkv = None
|
| 178 |
+
|
| 179 |
+
return o, None, pkv
|
| 180 |
+
|
| 181 |
+
return hf_forward
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def hf_437_prepare_inputs_for_generation(
|
| 185 |
+
self,
|
| 186 |
+
input_ids,
|
| 187 |
+
past_key_values=None,
|
| 188 |
+
attention_mask=None,
|
| 189 |
+
inputs_embeds=None,
|
| 190 |
+
**kwargs,
|
| 191 |
+
):
|
| 192 |
+
if past_key_values is not None:
|
| 193 |
+
if isinstance(past_key_values, transformers.cache_utils.Cache):
|
| 194 |
+
cache_length = past_key_values.get_seq_length()
|
| 195 |
+
past_length = past_key_values.seen_tokens
|
| 196 |
+
max_cache_length = past_key_values.get_max_length()
|
| 197 |
+
else:
|
| 198 |
+
cache_length = past_length = past_key_values[0][0].shape[2]
|
| 199 |
+
max_cache_length = None
|
| 200 |
+
|
| 201 |
+
# Keep only the unprocessed tokens:
|
| 202 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 203 |
+
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
| 204 |
+
# input)
|
| 205 |
+
if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
|
| 206 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 207 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 208 |
+
# input_ids based on the past_length.
|
| 209 |
+
elif past_length < input_ids.shape[1]:
|
| 210 |
+
input_ids = input_ids[:, past_length:]
|
| 211 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 212 |
+
|
| 213 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 214 |
+
if (
|
| 215 |
+
max_cache_length is not None
|
| 216 |
+
and attention_mask is not None
|
| 217 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 218 |
+
):
|
| 219 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 220 |
+
|
| 221 |
+
position_ids = kwargs.get("position_ids", None)
|
| 222 |
+
if attention_mask is not None and position_ids is None:
|
| 223 |
+
# create position_ids on the fly for batch generation
|
| 224 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 225 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 226 |
+
if past_key_values:
|
| 227 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 228 |
+
|
| 229 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 230 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 231 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 232 |
+
else:
|
| 233 |
+
model_inputs = {"input_ids": input_ids}
|
| 234 |
+
|
| 235 |
+
model_inputs.update(
|
| 236 |
+
{
|
| 237 |
+
"position_ids": position_ids,
|
| 238 |
+
"past_key_values": past_key_values,
|
| 239 |
+
"use_cache": kwargs.get("use_cache"),
|
| 240 |
+
"attention_mask": attention_mask,
|
| 241 |
+
}
|
| 242 |
+
)
|
| 243 |
+
return model_inputs
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def prepare_inputs_for_generation(
|
| 247 |
+
self,
|
| 248 |
+
input_ids,
|
| 249 |
+
past_key_values=None,
|
| 250 |
+
attention_mask=None,
|
| 251 |
+
inputs_embeds=None,
|
| 252 |
+
cache_position=None,
|
| 253 |
+
**kwargs,
|
| 254 |
+
):
|
| 255 |
+
# With static cache, the `past_key_values` is None
|
| 256 |
+
# TODO joao: standardize interface for the different Cache classes and remove of this if
|
| 257 |
+
has_static_cache = False
|
| 258 |
+
if past_key_values is None:
|
| 259 |
+
past_key_values = getattr(
|
| 260 |
+
getattr(self.model.layers[0], "self_attn", {}), "past_key_value", None
|
| 261 |
+
)
|
| 262 |
+
has_static_cache = past_key_values is not None
|
| 263 |
+
|
| 264 |
+
past_length = 0
|
| 265 |
+
if past_key_values is not None:
|
| 266 |
+
if isinstance(past_key_values, transformers.cache_utils.Cache):
|
| 267 |
+
past_length = (
|
| 268 |
+
cache_position[0]
|
| 269 |
+
if cache_position is not None
|
| 270 |
+
else past_key_values.get_seq_length()
|
| 271 |
+
)
|
| 272 |
+
max_cache_length = (
|
| 273 |
+
torch.tensor(past_key_values.get_max_length(), device=input_ids.device)
|
| 274 |
+
if past_key_values.get_max_length() is not None
|
| 275 |
+
else None
|
| 276 |
+
)
|
| 277 |
+
cache_length = (
|
| 278 |
+
past_length
|
| 279 |
+
if max_cache_length is None
|
| 280 |
+
else torch.min(max_cache_length, past_length)
|
| 281 |
+
)
|
| 282 |
+
# TODO joao: remove this `else` after `generate` prioritizes `Cache` objects
|
| 283 |
+
else:
|
| 284 |
+
# cache_length = past_length = past_key_values[0][0].shape[2]
|
| 285 |
+
cache_length = past_length = cache_position[0]
|
| 286 |
+
max_cache_length = None
|
| 287 |
+
|
| 288 |
+
# Keep only the unprocessed tokens:
|
| 289 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 290 |
+
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
| 291 |
+
# input)
|
| 292 |
+
if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
|
| 293 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 294 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 295 |
+
# input_ids based on the past_length.
|
| 296 |
+
elif past_length < input_ids.shape[1]:
|
| 297 |
+
input_ids = input_ids[:, past_length:]
|
| 298 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 299 |
+
|
| 300 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 301 |
+
if (
|
| 302 |
+
max_cache_length is not None
|
| 303 |
+
and attention_mask is not None
|
| 304 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 305 |
+
):
|
| 306 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 307 |
+
|
| 308 |
+
position_ids = kwargs.get("position_ids", None)
|
| 309 |
+
if attention_mask is not None and position_ids is None:
|
| 310 |
+
# create position_ids on the fly for batch generation
|
| 311 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 312 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 313 |
+
if past_key_values:
|
| 314 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 315 |
+
|
| 316 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 317 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 318 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 319 |
+
else:
|
| 320 |
+
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
| 321 |
+
# recompiles graphs as the stride of the inputs is a guard. Ref: https://github.com/huggingface/transformers/pull/29114
|
| 322 |
+
# TODO: use `next_tokens` directly instead.
|
| 323 |
+
model_inputs = {"input_ids": input_ids.contiguous()}
|
| 324 |
+
|
| 325 |
+
input_length = (
|
| 326 |
+
position_ids.shape[-1] if position_ids is not None else input_ids.shape[-1]
|
| 327 |
+
)
|
| 328 |
+
if cache_position is None:
|
| 329 |
+
cache_position = torch.arange(
|
| 330 |
+
past_length, past_length + input_length, device=input_ids.device
|
| 331 |
+
)
|
| 332 |
+
else:
|
| 333 |
+
cache_position = cache_position[-input_length:]
|
| 334 |
+
|
| 335 |
+
if has_static_cache:
|
| 336 |
+
past_key_values = None
|
| 337 |
+
|
| 338 |
+
model_inputs.update(
|
| 339 |
+
{
|
| 340 |
+
"position_ids": position_ids,
|
| 341 |
+
"cache_position": cache_position,
|
| 342 |
+
"past_key_values": past_key_values,
|
| 343 |
+
"use_cache": kwargs.get("use_cache"),
|
| 344 |
+
"attention_mask": attention_mask,
|
| 345 |
+
}
|
| 346 |
+
)
|
| 347 |
+
return model_inputs
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
def prepare_inputs_for_generation_snapkv(
|
| 351 |
+
self,
|
| 352 |
+
input_ids,
|
| 353 |
+
past_key_values=None,
|
| 354 |
+
attention_mask=None,
|
| 355 |
+
inputs_embeds=None,
|
| 356 |
+
**kwargs,
|
| 357 |
+
):
|
| 358 |
+
if past_key_values is None: # [SnapKV]
|
| 359 |
+
for layer in self.model.layers:
|
| 360 |
+
layer.self_attn.kv_seq_len = 0
|
| 361 |
+
if past_key_values is not None:
|
| 362 |
+
if isinstance(past_key_values, Cache):
|
| 363 |
+
cache_length = past_key_values.get_seq_length()
|
| 364 |
+
past_length = past_key_values.seen_tokens
|
| 365 |
+
max_cache_length = past_key_values.get_max_length()
|
| 366 |
+
else:
|
| 367 |
+
# cache_length = past_length = past_key_values[0][0].shape[2]
|
| 368 |
+
# max_cache_length = None
|
| 369 |
+
cache_length = past_length = self.model.layers[0].self_attn.kv_seq_len
|
| 370 |
+
max_cache_length = None
|
| 371 |
+
# Keep only the unprocessed tokens:
|
| 372 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 373 |
+
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
| 374 |
+
# input)
|
| 375 |
+
if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
|
| 376 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 377 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 378 |
+
# input_ids based on the past_length.
|
| 379 |
+
elif past_length < input_ids.shape[1]:
|
| 380 |
+
input_ids = input_ids[:, past_length:]
|
| 381 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 382 |
+
|
| 383 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 384 |
+
if (
|
| 385 |
+
max_cache_length is not None
|
| 386 |
+
and attention_mask is not None
|
| 387 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 388 |
+
):
|
| 389 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 390 |
+
|
| 391 |
+
position_ids = kwargs.get("position_ids", None)
|
| 392 |
+
if attention_mask is not None and position_ids is None:
|
| 393 |
+
# create position_ids on the fly for batch generation
|
| 394 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 395 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 396 |
+
if past_key_values:
|
| 397 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 398 |
+
|
| 399 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 400 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 401 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 402 |
+
else:
|
| 403 |
+
model_inputs = {"input_ids": input_ids}
|
| 404 |
+
|
| 405 |
+
model_inputs.update(
|
| 406 |
+
{
|
| 407 |
+
"position_ids": position_ids,
|
| 408 |
+
"past_key_values": past_key_values,
|
| 409 |
+
"use_cache": kwargs.get("use_cache"),
|
| 410 |
+
"attention_mask": attention_mask,
|
| 411 |
+
}
|
| 412 |
+
)
|
| 413 |
+
return model_inputs
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
def _prepare_decoder_attention_mask_inference(
|
| 417 |
+
self, attention_mask, input_shape, inputs_embeds, past_key_values_length
|
| 418 |
+
):
|
| 419 |
+
# [bsz, seq_len]
|
| 420 |
+
if past_key_values_length > 0 and attention_mask is not None:
|
| 421 |
+
attention_mask = torch.cat(
|
| 422 |
+
(
|
| 423 |
+
torch.full(
|
| 424 |
+
(input_shape[0], past_key_values_length),
|
| 425 |
+
True,
|
| 426 |
+
dtype=attention_mask.dtype,
|
| 427 |
+
device=attention_mask.device,
|
| 428 |
+
),
|
| 429 |
+
attention_mask,
|
| 430 |
+
),
|
| 431 |
+
dim=-1,
|
| 432 |
+
)
|
| 433 |
+
|
| 434 |
+
if attention_mask is not None and torch.all(attention_mask):
|
| 435 |
+
return None # This uses the faster call when training with full samples
|
| 436 |
+
|
| 437 |
+
return attention_mask
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
def forward_llama_decoder_layer(
|
| 441 |
+
self,
|
| 442 |
+
hidden_states: torch.Tensor,
|
| 443 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 444 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 445 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 446 |
+
output_attentions: Optional[bool] = False,
|
| 447 |
+
use_cache: Optional[bool] = False,
|
| 448 |
+
padding_mask: Optional[torch.LongTensor] = None,
|
| 449 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 450 |
+
"""
|
| 451 |
+
Args:
|
| 452 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 453 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 454 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 455 |
+
output_attentions (`bool`, *optional*):
|
| 456 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 457 |
+
returned tensors for more detail.
|
| 458 |
+
use_cache (`bool`, *optional*):
|
| 459 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 460 |
+
(see `past_key_values`).
|
| 461 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 462 |
+
"""
|
| 463 |
+
|
| 464 |
+
residual = hidden_states.clone()
|
| 465 |
+
batch, seq_len, embed_dim = hidden_states.shape
|
| 466 |
+
|
| 467 |
+
for start_idx in range(0, seq_len, 32000):
|
| 468 |
+
end_idx = min(seq_len, start_idx + 32000)
|
| 469 |
+
hidden_states[:, start_idx:end_idx, :] = self.input_layernorm(
|
| 470 |
+
hidden_states[:, start_idx:end_idx, :]
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
# Self Attention
|
| 474 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 475 |
+
hidden_states=hidden_states,
|
| 476 |
+
attention_mask=attention_mask,
|
| 477 |
+
position_ids=position_ids,
|
| 478 |
+
past_key_value=past_key_value,
|
| 479 |
+
output_attentions=output_attentions,
|
| 480 |
+
use_cache=use_cache,
|
| 481 |
+
padding_mask=padding_mask,
|
| 482 |
+
)
|
| 483 |
+
hidden_states = residual + hidden_states
|
| 484 |
+
|
| 485 |
+
# Fully Connected
|
| 486 |
+
for start_idx in range(0, seq_len, 32000):
|
| 487 |
+
end_idx = min(seq_len, start_idx + 32000)
|
| 488 |
+
part_hidden_states = hidden_states[:, start_idx:end_idx, :].clone()
|
| 489 |
+
part_hidden_states = self.post_attention_layernorm(part_hidden_states)
|
| 490 |
+
part_hidden_states = self.mlp(part_hidden_states)
|
| 491 |
+
hidden_states[:, start_idx:end_idx, :] += part_hidden_states
|
| 492 |
+
|
| 493 |
+
outputs = (hidden_states,)
|
| 494 |
+
|
| 495 |
+
if output_attentions:
|
| 496 |
+
outputs += (self_attn_weights,)
|
| 497 |
+
|
| 498 |
+
if use_cache:
|
| 499 |
+
outputs += (present_key_value,)
|
| 500 |
+
|
| 501 |
+
return outputs
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
def forward_llama_model(
|
| 505 |
+
self,
|
| 506 |
+
input_ids: torch.LongTensor = None,
|
| 507 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 508 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 509 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 510 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 511 |
+
use_cache: Optional[bool] = None,
|
| 512 |
+
output_attentions: Optional[bool] = None,
|
| 513 |
+
output_hidden_states: Optional[bool] = None,
|
| 514 |
+
return_dict: Optional[bool] = None,
|
| 515 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 516 |
+
output_attentions = (
|
| 517 |
+
output_attentions
|
| 518 |
+
if output_attentions is not None
|
| 519 |
+
else self.config.output_attentions
|
| 520 |
+
)
|
| 521 |
+
output_hidden_states = (
|
| 522 |
+
output_hidden_states
|
| 523 |
+
if output_hidden_states is not None
|
| 524 |
+
else self.config.output_hidden_states
|
| 525 |
+
)
|
| 526 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 527 |
+
|
| 528 |
+
return_dict = (
|
| 529 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 530 |
+
)
|
| 531 |
+
|
| 532 |
+
# retrieve input_ids and inputs_embeds
|
| 533 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 534 |
+
raise ValueError(
|
| 535 |
+
"You cannot specify both input_ids and inputs_embeds at the same time"
|
| 536 |
+
)
|
| 537 |
+
elif input_ids is not None:
|
| 538 |
+
batch_size, seq_length = input_ids.shape[:2]
|
| 539 |
+
elif inputs_embeds is not None:
|
| 540 |
+
batch_size, seq_length = inputs_embeds.shape[:2]
|
| 541 |
+
else:
|
| 542 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 543 |
+
|
| 544 |
+
if self.gradient_checkpointing and self.training:
|
| 545 |
+
if use_cache:
|
| 546 |
+
logger.warning_once(
|
| 547 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 548 |
+
)
|
| 549 |
+
use_cache = False
|
| 550 |
+
|
| 551 |
+
seq_length_with_past = seq_length
|
| 552 |
+
past_key_values_length = 0
|
| 553 |
+
|
| 554 |
+
if use_cache:
|
| 555 |
+
use_legacy_cache = not isinstance(past_key_values, Cache)
|
| 556 |
+
if use_legacy_cache:
|
| 557 |
+
past_key_values = DynamicCache.from_legacy_cache(past_key_values)
|
| 558 |
+
past_key_values_length = past_key_values.get_usable_length(seq_length)
|
| 559 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 560 |
+
|
| 561 |
+
if position_ids is None:
|
| 562 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 563 |
+
position_ids = torch.arange(
|
| 564 |
+
past_key_values_length,
|
| 565 |
+
seq_length + past_key_values_length,
|
| 566 |
+
dtype=torch.long,
|
| 567 |
+
device=device,
|
| 568 |
+
)
|
| 569 |
+
position_ids = position_ids.unsqueeze(0)
|
| 570 |
+
|
| 571 |
+
if inputs_embeds is None:
|
| 572 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 573 |
+
|
| 574 |
+
if attention_mask is None:
|
| 575 |
+
attention_mask = torch.ones(
|
| 576 |
+
(batch_size, seq_length_with_past),
|
| 577 |
+
dtype=torch.bool,
|
| 578 |
+
device=inputs_embeds.device,
|
| 579 |
+
)
|
| 580 |
+
padding_mask = None
|
| 581 |
+
else:
|
| 582 |
+
if 0 in attention_mask:
|
| 583 |
+
padding_mask = attention_mask
|
| 584 |
+
else:
|
| 585 |
+
padding_mask = None
|
| 586 |
+
|
| 587 |
+
attention_mask = self._prepare_decoder_attention_mask(
|
| 588 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 589 |
+
)
|
| 590 |
+
|
| 591 |
+
# embed positions
|
| 592 |
+
hidden_states = inputs_embeds
|
| 593 |
+
|
| 594 |
+
# decoder layers
|
| 595 |
+
all_hidden_states = () if output_hidden_states else None
|
| 596 |
+
all_self_attns = () if output_attentions else None
|
| 597 |
+
next_decoder_cache = None
|
| 598 |
+
|
| 599 |
+
for decoder_layer in self.layers:
|
| 600 |
+
if output_hidden_states:
|
| 601 |
+
all_hidden_states += (hidden_states,)
|
| 602 |
+
|
| 603 |
+
if self.gradient_checkpointing and self.training:
|
| 604 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 605 |
+
decoder_layer.__call__,
|
| 606 |
+
hidden_states,
|
| 607 |
+
attention_mask,
|
| 608 |
+
position_ids,
|
| 609 |
+
past_key_values,
|
| 610 |
+
output_attentions,
|
| 611 |
+
use_cache,
|
| 612 |
+
)
|
| 613 |
+
else:
|
| 614 |
+
layer_outputs = decoder_layer(
|
| 615 |
+
hidden_states,
|
| 616 |
+
attention_mask=attention_mask,
|
| 617 |
+
position_ids=position_ids,
|
| 618 |
+
past_key_value=past_key_values,
|
| 619 |
+
output_attentions=output_attentions,
|
| 620 |
+
use_cache=use_cache,
|
| 621 |
+
)
|
| 622 |
+
|
| 623 |
+
hidden_states = layer_outputs[0]
|
| 624 |
+
|
| 625 |
+
if use_cache:
|
| 626 |
+
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
|
| 627 |
+
|
| 628 |
+
if output_attentions:
|
| 629 |
+
all_self_attns += (layer_outputs[1],)
|
| 630 |
+
|
| 631 |
+
batch, seq_len, embed_dim = hidden_states.shape
|
| 632 |
+
for start_idx in range(0, seq_len, 32000):
|
| 633 |
+
end_idx = min(seq_len, start_idx + 32000)
|
| 634 |
+
hidden_states[:, start_idx:end_idx, :] = self.norm(
|
| 635 |
+
hidden_states[:, start_idx:end_idx, :]
|
| 636 |
+
)
|
| 637 |
+
|
| 638 |
+
# add hidden states from the last decoder layer
|
| 639 |
+
if output_hidden_states:
|
| 640 |
+
all_hidden_states += (hidden_states,)
|
| 641 |
+
|
| 642 |
+
next_cache = None
|
| 643 |
+
if use_cache:
|
| 644 |
+
next_cache = (
|
| 645 |
+
next_decoder_cache.to_legacy_cache()
|
| 646 |
+
if use_legacy_cache
|
| 647 |
+
else next_decoder_cache
|
| 648 |
+
)
|
| 649 |
+
if not return_dict:
|
| 650 |
+
return tuple(
|
| 651 |
+
v
|
| 652 |
+
for v in [hidden_states, next_cache, all_hidden_states, all_self_attns]
|
| 653 |
+
if v is not None
|
| 654 |
+
)
|
| 655 |
+
return BaseModelOutputWithPast(
|
| 656 |
+
last_hidden_state=hidden_states,
|
| 657 |
+
past_key_values=next_cache,
|
| 658 |
+
hidden_states=all_hidden_states,
|
| 659 |
+
attentions=all_self_attns,
|
| 660 |
+
)
|
| 661 |
+
|
| 662 |
+
|
| 663 |
+
def forward_llama_for_causal_lm(
|
| 664 |
+
self,
|
| 665 |
+
input_ids: torch.LongTensor = None,
|
| 666 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 667 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 668 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 669 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 670 |
+
labels: Optional[torch.LongTensor] = None,
|
| 671 |
+
use_cache: Optional[bool] = None,
|
| 672 |
+
output_attentions: Optional[bool] = None,
|
| 673 |
+
output_hidden_states: Optional[bool] = None,
|
| 674 |
+
return_dict: Optional[bool] = None,
|
| 675 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 676 |
+
# assert labels is not None
|
| 677 |
+
output_attentions = (
|
| 678 |
+
output_attentions
|
| 679 |
+
if output_attentions is not None
|
| 680 |
+
else self.config.output_attentions
|
| 681 |
+
)
|
| 682 |
+
output_hidden_states = (
|
| 683 |
+
output_hidden_states
|
| 684 |
+
if output_hidden_states is not None
|
| 685 |
+
else self.config.output_hidden_states
|
| 686 |
+
)
|
| 687 |
+
return_dict = (
|
| 688 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 689 |
+
)
|
| 690 |
+
|
| 691 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 692 |
+
outputs = self.model(
|
| 693 |
+
input_ids=input_ids,
|
| 694 |
+
attention_mask=attention_mask,
|
| 695 |
+
position_ids=position_ids,
|
| 696 |
+
past_key_values=past_key_values,
|
| 697 |
+
inputs_embeds=inputs_embeds,
|
| 698 |
+
use_cache=use_cache,
|
| 699 |
+
output_attentions=output_attentions,
|
| 700 |
+
output_hidden_states=output_hidden_states,
|
| 701 |
+
return_dict=return_dict,
|
| 702 |
+
)
|
| 703 |
+
torch.cuda.empty_cache()
|
| 704 |
+
|
| 705 |
+
hidden_states = outputs[0]
|
| 706 |
+
if labels is not None:
|
| 707 |
+
loss_fct = CrossEntropyLoss(reduction="sum")
|
| 708 |
+
valid_seq_len = input_ids.shape[-1] - 1
|
| 709 |
+
valid_seq_len_slide_win = torch.sum(labels[:, 1:] >= 0).item()
|
| 710 |
+
# print("valid_seq_len_slide_win", valid_seq_len)
|
| 711 |
+
loss = 0.0
|
| 712 |
+
|
| 713 |
+
for start_idx in range(0, valid_seq_len, 32000):
|
| 714 |
+
end_idx = min(start_idx + 32000, valid_seq_len)
|
| 715 |
+
shift_logits = self.lm_head(
|
| 716 |
+
hidden_states[..., start_idx:end_idx, :]
|
| 717 |
+
).float()
|
| 718 |
+
shift_labels = labels[..., start_idx + 1 : end_idx + 1].contiguous()
|
| 719 |
+
# Flatten the tokens
|
| 720 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 721 |
+
shift_labels = shift_labels.view(-1)
|
| 722 |
+
# Enable model parallelism
|
| 723 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 724 |
+
loss += loss_fct(shift_logits, shift_labels)
|
| 725 |
+
|
| 726 |
+
loss /= valid_seq_len_slide_win
|
| 727 |
+
logits = None
|
| 728 |
+
else:
|
| 729 |
+
if self.config.to_dict().get("is_ppl", False):
|
| 730 |
+
logits = self.lm_head(hidden_states)
|
| 731 |
+
else:
|
| 732 |
+
logits = self.lm_head(hidden_states[:, -1:]).float()
|
| 733 |
+
loss = None
|
| 734 |
+
|
| 735 |
+
return CausalLMOutputWithPast(
|
| 736 |
+
loss=loss,
|
| 737 |
+
logits=logits,
|
| 738 |
+
past_key_values=outputs.past_key_values,
|
| 739 |
+
)
|
| 740 |
+
|
| 741 |
+
|
| 742 |
+
def minference_patch(model, config):
|
| 743 |
+
from transformers import LlamaForCausalLM
|
| 744 |
+
|
| 745 |
+
if config.kv_cache_cpu:
|
| 746 |
+
return minference_patch_kv_cache_cpu(model)
|
| 747 |
+
if config.use_snapkv:
|
| 748 |
+
return minference_patch_with_snapkv(model)
|
| 749 |
+
|
| 750 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 751 |
+
Model = model.model.__class__
|
| 752 |
+
DecoderLayer = model.model.layers[0].__class__
|
| 753 |
+
|
| 754 |
+
forward = minference_forward()
|
| 755 |
+
|
| 756 |
+
def update_module(m):
|
| 757 |
+
if isinstance(m, Attention):
|
| 758 |
+
m.init_minference_parameters = init_minference_parameters.__get__(
|
| 759 |
+
m, Attention
|
| 760 |
+
)
|
| 761 |
+
m.gather_last_q_vertical_slash_topk_v4 = (
|
| 762 |
+
gather_last_q_vertical_slash_topk_v4.__get__(m, Attention)
|
| 763 |
+
)
|
| 764 |
+
m.forward = forward.__get__(m, Attention)
|
| 765 |
+
if isinstance(m, DecoderLayer):
|
| 766 |
+
m.forward = forward_llama_decoder_layer.__get__(m, DecoderLayer)
|
| 767 |
+
|
| 768 |
+
model.apply(update_module)
|
| 769 |
+
model.prepare_inputs_for_generation = hf_437_prepare_inputs_for_generation.__get__(
|
| 770 |
+
model, model.__class__
|
| 771 |
+
)
|
| 772 |
+
model.model._use_sdpa = False
|
| 773 |
+
|
| 774 |
+
model.model._prepare_decoder_attention_mask = (
|
| 775 |
+
_prepare_decoder_attention_mask_inference.__get__(
|
| 776 |
+
model.model, model.model.__class__
|
| 777 |
+
)
|
| 778 |
+
)
|
| 779 |
+
model.model.forward = forward_llama_model.__get__(
|
| 780 |
+
model.model, model.model.__class__
|
| 781 |
+
)
|
| 782 |
+
model.forward = forward_llama_for_causal_lm.__get__(model, model.__class__)
|
| 783 |
+
|
| 784 |
+
print("Patched model for minference..")
|
| 785 |
+
return model
|
| 786 |
+
|
| 787 |
+
|
| 788 |
+
def minference_patch_kv_cache_cpu(model):
|
| 789 |
+
from transformers import LlamaForCausalLM
|
| 790 |
+
|
| 791 |
+
transformers.cache_utils.DynamicCache.update = cpu_cache_update
|
| 792 |
+
transformers.cache_utils.DynamicCache.get = cpu_cache_get
|
| 793 |
+
|
| 794 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 795 |
+
Model = model.model.__class__
|
| 796 |
+
DecoderLayer = model.model.layers[0].__class__
|
| 797 |
+
|
| 798 |
+
forward = minference_kv_cache_cpu_forward()
|
| 799 |
+
|
| 800 |
+
def update_module(m):
|
| 801 |
+
if isinstance(m, Attention):
|
| 802 |
+
m.init_minference_parameters = init_minference_parameters.__get__(
|
| 803 |
+
m, Attention
|
| 804 |
+
)
|
| 805 |
+
m.gather_last_q_vertical_slash_topk_v4 = (
|
| 806 |
+
gather_last_q_vertical_slash_topk_v4.__get__(m, Attention)
|
| 807 |
+
)
|
| 808 |
+
m.forward = forward.__get__(m, Attention)
|
| 809 |
+
if isinstance(m, DecoderLayer):
|
| 810 |
+
m.forward = forward_llama_decoder_layer.__get__(m, DecoderLayer)
|
| 811 |
+
|
| 812 |
+
model.apply(update_module)
|
| 813 |
+
model.prepare_inputs_for_generation = hf_437_prepare_inputs_for_generation.__get__(
|
| 814 |
+
model, model.__class__
|
| 815 |
+
)
|
| 816 |
+
model.model._use_sdpa = False
|
| 817 |
+
|
| 818 |
+
model.model._prepare_decoder_attention_mask = (
|
| 819 |
+
_prepare_decoder_attention_mask_inference.__get__(
|
| 820 |
+
model.model, model.model.__class__
|
| 821 |
+
)
|
| 822 |
+
)
|
| 823 |
+
model.model.forward = forward_llama_model.__get__(
|
| 824 |
+
model.model, model.model.__class__
|
| 825 |
+
)
|
| 826 |
+
model.forward = forward_llama_for_causal_lm.__get__(model, model.__class__)
|
| 827 |
+
|
| 828 |
+
print("Patched model for MInference load KV Cache to CPU.")
|
| 829 |
+
return model
|
| 830 |
+
|
| 831 |
+
|
| 832 |
+
def minference_patch_with_snapkv(model):
|
| 833 |
+
from transformers import LlamaForCausalLM
|
| 834 |
+
|
| 835 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 836 |
+
Model = model.model.__class__
|
| 837 |
+
DecoderLayer = model.model.layers[0].__class__
|
| 838 |
+
|
| 839 |
+
forward = minference_with_snapkv_forward()
|
| 840 |
+
|
| 841 |
+
def update_module(m):
|
| 842 |
+
if isinstance(m, Attention):
|
| 843 |
+
m.init_minference_parameters = init_minference_parameters.__get__(
|
| 844 |
+
m, Attention
|
| 845 |
+
)
|
| 846 |
+
m.gather_last_q_vertical_slash_topk_v4 = (
|
| 847 |
+
gather_last_q_vertical_slash_topk_v4.__get__(m, Attention)
|
| 848 |
+
)
|
| 849 |
+
m.forward = forward.__get__(m, Attention)
|
| 850 |
+
if isinstance(m, DecoderLayer):
|
| 851 |
+
m.forward = forward_llama_decoder_layer.__get__(m, DecoderLayer)
|
| 852 |
+
|
| 853 |
+
model.apply(update_module)
|
| 854 |
+
model.prepare_inputs_for_generation = prepare_inputs_for_generation_snapkv.__get__(
|
| 855 |
+
model, model.__class__
|
| 856 |
+
)
|
| 857 |
+
model.model._use_sdpa = False
|
| 858 |
+
|
| 859 |
+
model.model._prepare_decoder_attention_mask = (
|
| 860 |
+
_prepare_decoder_attention_mask_inference.__get__(
|
| 861 |
+
model.model, model.model.__class__
|
| 862 |
+
)
|
| 863 |
+
)
|
| 864 |
+
model.model.forward = forward_llama_model.__get__(
|
| 865 |
+
model.model, model.model.__class__
|
| 866 |
+
)
|
| 867 |
+
model.forward = forward_llama_for_causal_lm.__get__(model, model.__class__)
|
| 868 |
+
|
| 869 |
+
print("Patched model for minference with SanpKV..")
|
| 870 |
+
return model
|
| 871 |
+
|
| 872 |
+
|
| 873 |
+
def llama_model_forward_vllm(
|
| 874 |
+
self,
|
| 875 |
+
input_ids: Optional[torch.Tensor],
|
| 876 |
+
positions: torch.Tensor,
|
| 877 |
+
kv_caches: List[torch.Tensor],
|
| 878 |
+
attn_metadata,
|
| 879 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 880 |
+
) -> torch.Tensor:
|
| 881 |
+
if inputs_embeds is not None:
|
| 882 |
+
hidden_states = inputs_embeds
|
| 883 |
+
else:
|
| 884 |
+
hidden_states = self.get_input_embeddings(input_ids)
|
| 885 |
+
residual = None
|
| 886 |
+
for i in range(len(self.layers)):
|
| 887 |
+
layer = self.layers[i]
|
| 888 |
+
hidden_states, residual = layer(
|
| 889 |
+
positions,
|
| 890 |
+
hidden_states,
|
| 891 |
+
kv_caches[i],
|
| 892 |
+
attn_metadata,
|
| 893 |
+
residual,
|
| 894 |
+
layer_idx=i,
|
| 895 |
+
)
|
| 896 |
+
hidden_states, _ = self.norm(hidden_states, residual)
|
| 897 |
+
return hidden_states
|
| 898 |
+
|
| 899 |
+
|
| 900 |
+
def llama_layer_forward_vllm(
|
| 901 |
+
self,
|
| 902 |
+
positions: torch.Tensor,
|
| 903 |
+
hidden_states: torch.Tensor,
|
| 904 |
+
kv_cache: torch.Tensor,
|
| 905 |
+
attn_metadata,
|
| 906 |
+
residual: Optional[torch.Tensor],
|
| 907 |
+
layer_idx: int,
|
| 908 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 909 |
+
# Self Attention
|
| 910 |
+
if residual is None:
|
| 911 |
+
residual = hidden_states
|
| 912 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 913 |
+
else:
|
| 914 |
+
hidden_states, residual = self.input_layernorm(hidden_states, residual)
|
| 915 |
+
hidden_states = self.self_attn(
|
| 916 |
+
positions=positions,
|
| 917 |
+
hidden_states=hidden_states,
|
| 918 |
+
kv_cache=kv_cache,
|
| 919 |
+
attn_metadata=attn_metadata,
|
| 920 |
+
layer_idx=layer_idx,
|
| 921 |
+
)
|
| 922 |
+
|
| 923 |
+
# Fully Connected
|
| 924 |
+
hidden_states, residual = self.post_attention_layernorm(hidden_states, residual)
|
| 925 |
+
hidden_states = self.mlp(hidden_states)
|
| 926 |
+
return hidden_states, residual
|
| 927 |
+
|
| 928 |
+
|
| 929 |
+
def llama_attn_forward_vllm(
|
| 930 |
+
self,
|
| 931 |
+
positions: torch.Tensor,
|
| 932 |
+
hidden_states: torch.Tensor,
|
| 933 |
+
kv_cache: torch.Tensor,
|
| 934 |
+
attn_metadata,
|
| 935 |
+
layer_idx: int,
|
| 936 |
+
) -> torch.Tensor:
|
| 937 |
+
qkv, _ = self.qkv_proj(hidden_states)
|
| 938 |
+
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
|
| 939 |
+
q, k = self.rotary_emb(positions, q, k)
|
| 940 |
+
attn_output = self.attn(q, k, v, kv_cache, attn_metadata, self.kv_scale, layer_idx)
|
| 941 |
+
output, _ = self.o_proj(attn_output)
|
| 942 |
+
return output
|
| 943 |
+
|
| 944 |
+
|
| 945 |
+
def vllm_attn_forward(
|
| 946 |
+
self,
|
| 947 |
+
query: torch.Tensor,
|
| 948 |
+
key: torch.Tensor,
|
| 949 |
+
value: torch.Tensor,
|
| 950 |
+
kv_cache: Optional[torch.Tensor],
|
| 951 |
+
attn_metadata,
|
| 952 |
+
kv_scale: float = 1.0,
|
| 953 |
+
layer_idx: int = 0,
|
| 954 |
+
) -> torch.Tensor:
|
| 955 |
+
return self.impl.forward(
|
| 956 |
+
query, key, value, kv_cache, attn_metadata, kv_scale, layer_idx
|
| 957 |
+
)
|
| 958 |
+
|
| 959 |
+
|
| 960 |
+
def minference_patch_vllm(
|
| 961 |
+
llm,
|
| 962 |
+
config_file,
|
| 963 |
+
):
|
| 964 |
+
from vllm.attention import Attention
|
| 965 |
+
from vllm.model_executor.models.llama import (
|
| 966 |
+
LlamaAttention,
|
| 967 |
+
LlamaDecoderLayer,
|
| 968 |
+
LlamaForCausalLM,
|
| 969 |
+
LlamaModel,
|
| 970 |
+
)
|
| 971 |
+
|
| 972 |
+
config = json.load(open(config_file))
|
| 973 |
+
attn_forward = minference_vllm_forward(config)
|
| 974 |
+
|
| 975 |
+
def update_module(m):
|
| 976 |
+
if isinstance(m, Attention):
|
| 977 |
+
m.forward = vllm_attn_forward.__get__(m, Attention)
|
| 978 |
+
|
| 979 |
+
m = m.impl
|
| 980 |
+
m_cls = m.__class__
|
| 981 |
+
m.gather_last_q_vertical_slash_topk_vllm = (
|
| 982 |
+
gather_last_q_vertical_slash_topk_vllm.__get__(m, m_cls)
|
| 983 |
+
)
|
| 984 |
+
m.forward = attn_forward.__get__(m, m_cls)
|
| 985 |
+
if isinstance(m, LlamaDecoderLayer):
|
| 986 |
+
m.forward = llama_layer_forward_vllm.__get__(m, LlamaDecoderLayer)
|
| 987 |
+
if isinstance(m, LlamaModel):
|
| 988 |
+
m.forward = llama_model_forward_vllm.__get__(m, LlamaModel)
|
| 989 |
+
if isinstance(m, LlamaAttention):
|
| 990 |
+
m.forward = llama_attn_forward_vllm.__get__(m, LlamaAttention)
|
| 991 |
+
|
| 992 |
+
llm.llm_engine.model_executor.driver_worker.model_runner.model.apply(update_module)
|
| 993 |
+
|
| 994 |
+
print("Patched model for minference with VLLM..")
|
| 995 |
+
return llm
|
| 996 |
+
|
| 997 |
+
|
| 998 |
+
def patch_hf(
|
| 999 |
+
model,
|
| 1000 |
+
attn_type: str = "inf_llm",
|
| 1001 |
+
attn_kwargs: dict = {},
|
| 1002 |
+
base=None,
|
| 1003 |
+
distance_scale=None,
|
| 1004 |
+
**kwargs,
|
| 1005 |
+
):
|
| 1006 |
+
attn_kwargs.update(kwargs)
|
| 1007 |
+
# This approach lacks scalability and will be refactored.
|
| 1008 |
+
from transformers import LlamaForCausalLM, MistralForCausalLM, Qwen2ForCausalLM
|
| 1009 |
+
from transformers.models.llama.modeling_llama import (
|
| 1010 |
+
BaseModelOutputWithPast,
|
| 1011 |
+
LlamaAttention,
|
| 1012 |
+
LlamaModel,
|
| 1013 |
+
)
|
| 1014 |
+
from transformers.models.mistral.modeling_mistral import (
|
| 1015 |
+
MistralAttention,
|
| 1016 |
+
MistralModel,
|
| 1017 |
+
)
|
| 1018 |
+
from transformers.models.qwen2.modeling_qwen2 import Qwen2Attention, Qwen2Model
|
| 1019 |
+
|
| 1020 |
+
def model_forward(
|
| 1021 |
+
self,
|
| 1022 |
+
input_ids: torch.LongTensor = None,
|
| 1023 |
+
attention_mask=None,
|
| 1024 |
+
position_ids=None,
|
| 1025 |
+
past_key_values=None,
|
| 1026 |
+
inputs_embeds=None,
|
| 1027 |
+
use_cache=None,
|
| 1028 |
+
output_attentions=None,
|
| 1029 |
+
output_hidden_states=None,
|
| 1030 |
+
return_dict=None,
|
| 1031 |
+
*args,
|
| 1032 |
+
**kwargs,
|
| 1033 |
+
):
|
| 1034 |
+
output_attentions = (
|
| 1035 |
+
output_attentions
|
| 1036 |
+
if output_attentions is not None
|
| 1037 |
+
else self.config.output_attentions
|
| 1038 |
+
)
|
| 1039 |
+
output_hidden_states = (
|
| 1040 |
+
output_hidden_states
|
| 1041 |
+
if output_hidden_states is not None
|
| 1042 |
+
else self.config.output_hidden_states
|
| 1043 |
+
)
|
| 1044 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 1045 |
+
|
| 1046 |
+
return_dict = (
|
| 1047 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1048 |
+
)
|
| 1049 |
+
|
| 1050 |
+
# retrieve input_ids and inputs_embeds
|
| 1051 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 1052 |
+
raise ValueError(
|
| 1053 |
+
"You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time"
|
| 1054 |
+
)
|
| 1055 |
+
elif input_ids is not None:
|
| 1056 |
+
batch_size, seq_length = input_ids.shape
|
| 1057 |
+
elif inputs_embeds is not None:
|
| 1058 |
+
batch_size, seq_length, _ = inputs_embeds.shape
|
| 1059 |
+
else:
|
| 1060 |
+
raise ValueError(
|
| 1061 |
+
"You have to specify either decoder_input_ids or decoder_inputs_embeds"
|
| 1062 |
+
)
|
| 1063 |
+
|
| 1064 |
+
if inputs_embeds is None:
|
| 1065 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 1066 |
+
if hasattr(self, "config") and hasattr(self.config, "scale_emb"):
|
| 1067 |
+
inputs_embeds = inputs_embeds * self.config.scale_emb
|
| 1068 |
+
|
| 1069 |
+
if use_cache:
|
| 1070 |
+
pkv = tuple()
|
| 1071 |
+
|
| 1072 |
+
else:
|
| 1073 |
+
pkv = None
|
| 1074 |
+
|
| 1075 |
+
hidden_states = inputs_embeds
|
| 1076 |
+
|
| 1077 |
+
# decoder layers
|
| 1078 |
+
all_hidden_states = () if output_hidden_states else None
|
| 1079 |
+
all_self_attns = () if output_attentions else None
|
| 1080 |
+
|
| 1081 |
+
for i, decoder_layer in enumerate(self.layers):
|
| 1082 |
+
if output_hidden_states:
|
| 1083 |
+
all_hidden_states += (hidden_states,)
|
| 1084 |
+
|
| 1085 |
+
layer_outputs = decoder_layer(
|
| 1086 |
+
hidden_states,
|
| 1087 |
+
attention_mask=attention_mask,
|
| 1088 |
+
position_ids=self.position_bias,
|
| 1089 |
+
past_key_value=(
|
| 1090 |
+
past_key_values[i] if past_key_values is not None else None
|
| 1091 |
+
),
|
| 1092 |
+
output_attentions=output_attentions,
|
| 1093 |
+
use_cache=use_cache,
|
| 1094 |
+
)
|
| 1095 |
+
|
| 1096 |
+
hidden_states = layer_outputs[0]
|
| 1097 |
+
|
| 1098 |
+
if use_cache:
|
| 1099 |
+
_cache = layer_outputs[2 if output_attentions else 1]
|
| 1100 |
+
pkv = pkv + (_cache,)
|
| 1101 |
+
|
| 1102 |
+
if output_attentions:
|
| 1103 |
+
all_self_attns += (layer_outputs[1],)
|
| 1104 |
+
|
| 1105 |
+
# hidden_states = self.norm(hidden_states)
|
| 1106 |
+
for start_idx in range(0, hidden_states.size(1), 32000):
|
| 1107 |
+
end_idx = min(hidden_states.size(1), start_idx + 32000)
|
| 1108 |
+
hidden_states[:, start_idx:end_idx, :] = self.norm(
|
| 1109 |
+
hidden_states[:, start_idx:end_idx, :]
|
| 1110 |
+
)
|
| 1111 |
+
|
| 1112 |
+
# add hidden states from the last decoder layer
|
| 1113 |
+
if output_hidden_states:
|
| 1114 |
+
all_hidden_states += (hidden_states,)
|
| 1115 |
+
|
| 1116 |
+
if not return_dict:
|
| 1117 |
+
return tuple(
|
| 1118 |
+
v
|
| 1119 |
+
for v in [hidden_states, pkv, all_hidden_states, all_self_attns]
|
| 1120 |
+
if v is not None
|
| 1121 |
+
)
|
| 1122 |
+
return BaseModelOutputWithPast(
|
| 1123 |
+
last_hidden_state=hidden_states,
|
| 1124 |
+
past_key_values=pkv,
|
| 1125 |
+
hidden_states=all_hidden_states,
|
| 1126 |
+
attentions=all_self_attns,
|
| 1127 |
+
)
|
| 1128 |
+
|
| 1129 |
+
forward = huggingface_forward(ATTN_FORWRAD[attn_type](**attn_kwargs))
|
| 1130 |
+
|
| 1131 |
+
if isinstance(model, LlamaForCausalLM):
|
| 1132 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 1133 |
+
Model = model.model.__class__
|
| 1134 |
+
elif isinstance(model, MistralForCausalLM):
|
| 1135 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 1136 |
+
Model = model.model.__class__
|
| 1137 |
+
elif isinstance(model, Qwen2ForCausalLM):
|
| 1138 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 1139 |
+
Model = model.model.__class__
|
| 1140 |
+
elif model.__class__.__name__ == "MiniCPMForCausalLM":
|
| 1141 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 1142 |
+
Model = model.model.__class__
|
| 1143 |
+
elif model.__class__.__name__ == "Phi3ForCausalLM":
|
| 1144 |
+
Attention = model.model.layers[0].self_attn.__class__
|
| 1145 |
+
Model = model.model.__class__
|
| 1146 |
+
else:
|
| 1147 |
+
raise ValueError("Only supports llama, mistral and qwen2 models.")
|
| 1148 |
+
|
| 1149 |
+
hf_rope = model.model.layers[0].self_attn.rotary_emb
|
| 1150 |
+
base = base if base is not None else hf_rope.base
|
| 1151 |
+
distance_scale = distance_scale if distance_scale is not None else 1.0
|
| 1152 |
+
rope = RotaryEmbeddingESM(hf_rope.dim, base, distance_scale)
|
| 1153 |
+
model.model.position_bias = rope
|
| 1154 |
+
model.model.hf_position_bias = hf_rope
|
| 1155 |
+
|
| 1156 |
+
def set_forward(m):
|
| 1157 |
+
if isinstance(m, Attention):
|
| 1158 |
+
m._old_forward = m.forward
|
| 1159 |
+
m.forward = forward.__get__(m, Attention)
|
| 1160 |
+
|
| 1161 |
+
model.apply(set_forward)
|
| 1162 |
+
|
| 1163 |
+
model._old_prepare_inputs_for_generation = model.prepare_inputs_for_generation
|
| 1164 |
+
model.prepare_inputs_for_generation = prepare_inputs_for_generation.__get__(
|
| 1165 |
+
model, model.__class__
|
| 1166 |
+
)
|
| 1167 |
+
model.model._old_forward = model.model.forward
|
| 1168 |
+
model.model.forward = model_forward.__get__(model.model, Model)
|
| 1169 |
+
|
| 1170 |
+
if attn_type == "inf_llm":
|
| 1171 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(
|
| 1172 |
+
model.config._name_or_path
|
| 1173 |
+
)
|
| 1174 |
+
model = InfLLMGenerator(model, tokenizer)
|
| 1175 |
+
|
| 1176 |
+
print("Patched model ...")
|
| 1177 |
+
return model
|
| 1178 |
+
|
| 1179 |
+
|
| 1180 |
+
def fp8_cache_update(
|
| 1181 |
+
self,
|
| 1182 |
+
key_states: torch.Tensor,
|
| 1183 |
+
value_states: torch.Tensor,
|
| 1184 |
+
layer_idx: int,
|
| 1185 |
+
cache_kwargs: Optional[Dict[str, Any]] = None,
|
| 1186 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 1187 |
+
"""
|
| 1188 |
+
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
|
| 1189 |
+
|
| 1190 |
+
Parameters:
|
| 1191 |
+
key_states (`torch.Tensor`):
|
| 1192 |
+
The new key states to cache.
|
| 1193 |
+
value_states (`torch.Tensor`):
|
| 1194 |
+
The new value states to cache.
|
| 1195 |
+
layer_idx (`int`):
|
| 1196 |
+
The index of the layer to cache the states for.
|
| 1197 |
+
cache_kwargs (`Dict[str, Any]`, `optional`):
|
| 1198 |
+
Additional arguments for the cache subclass. No additional arguments are used in `DynamicCache`.
|
| 1199 |
+
|
| 1200 |
+
Return:
|
| 1201 |
+
A tuple containing the updated key and value states.
|
| 1202 |
+
"""
|
| 1203 |
+
# Update the number of seen tokens
|
| 1204 |
+
if layer_idx == 0:
|
| 1205 |
+
self.seen_tokens += key_states.shape[-2]
|
| 1206 |
+
|
| 1207 |
+
# Update the cache
|
| 1208 |
+
if len(self.key_cache) <= layer_idx:
|
| 1209 |
+
self.key_cache.append(key_states.to(torch.float8_e5m2))
|
| 1210 |
+
self.value_cache.append(value_states.to(torch.float8_e5m2))
|
| 1211 |
+
else:
|
| 1212 |
+
self.key_cache[layer_idx] = torch.cat(
|
| 1213 |
+
[self.key_cache[layer_idx], key_states.to(torch.float8_e5m2)], dim=-2
|
| 1214 |
+
)
|
| 1215 |
+
self.value_cache[layer_idx] = torch.cat(
|
| 1216 |
+
[self.value_cache[layer_idx], value_states.to(torch.float8_e5m2)], dim=-2
|
| 1217 |
+
)
|
| 1218 |
+
|
| 1219 |
+
return self.key_cache[layer_idx].to(key_states.dtype), self.value_cache[
|
| 1220 |
+
layer_idx
|
| 1221 |
+
].to(key_states.dtype)
|
| 1222 |
+
|
| 1223 |
+
|
| 1224 |
+
def cpu_cache_update(
|
| 1225 |
+
self,
|
| 1226 |
+
key_states: torch.Tensor,
|
| 1227 |
+
value_states: torch.Tensor,
|
| 1228 |
+
layer_idx: int,
|
| 1229 |
+
cache_kwargs: Optional[Dict[str, Any]] = None,
|
| 1230 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 1231 |
+
if layer_idx == 0:
|
| 1232 |
+
if "_seen_tokens" in self.__dict__:
|
| 1233 |
+
self._seen_tokens += key_states.shape[-2]
|
| 1234 |
+
else:
|
| 1235 |
+
self.seen_tokens += key_states.shape[-2]
|
| 1236 |
+
|
| 1237 |
+
# Update the cache
|
| 1238 |
+
if len(self.key_cache) <= layer_idx:
|
| 1239 |
+
self.key_cache.append(key_states.cpu())
|
| 1240 |
+
self.value_cache.append(value_states.cpu())
|
| 1241 |
+
else:
|
| 1242 |
+
self.key_cache[layer_idx] = torch.cat(
|
| 1243 |
+
[self.key_cache[layer_idx], key_states.cpu()], dim=-2
|
| 1244 |
+
)
|
| 1245 |
+
self.value_cache[layer_idx] = torch.cat(
|
| 1246 |
+
[self.value_cache[layer_idx], value_states.cpu()], dim=-2
|
| 1247 |
+
)
|
| 1248 |
+
|
| 1249 |
+
|
| 1250 |
+
def cpu_cache_get(
|
| 1251 |
+
self,
|
| 1252 |
+
key_states: torch.Tensor,
|
| 1253 |
+
value_states: torch.Tensor,
|
| 1254 |
+
layer_idx: int,
|
| 1255 |
+
head_idx: int,
|
| 1256 |
+
cache_kwargs: Optional[Dict[str, Any]] = None,
|
| 1257 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 1258 |
+
if layer_idx == 0:
|
| 1259 |
+
if "_seen_tokens" in self.__dict__:
|
| 1260 |
+
self._seen_tokens += key_states.shape[-2]
|
| 1261 |
+
else:
|
| 1262 |
+
self.seen_tokens += key_states.shape[-2]
|
| 1263 |
+
|
| 1264 |
+
# Update the cache
|
| 1265 |
+
if len(self.key_cache) <= layer_idx:
|
| 1266 |
+
return key_states, value_states
|
| 1267 |
+
else:
|
| 1268 |
+
key_states = torch.cat(
|
| 1269 |
+
[self.key_cache[layer_idx][:, head_idx : head_idx + 1].cuda(), key_states],
|
| 1270 |
+
dim=-2,
|
| 1271 |
+
)
|
| 1272 |
+
value_states = torch.cat(
|
| 1273 |
+
[
|
| 1274 |
+
self.value_cache[layer_idx][:, head_idx : head_idx + 1].cuda(),
|
| 1275 |
+
value_states,
|
| 1276 |
+
],
|
| 1277 |
+
dim=-2,
|
| 1278 |
+
)
|
| 1279 |
+
return key_states, value_states
|
minference/version.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Microsoft
|
| 2 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 3 |
+
|
| 4 |
+
_MAJOR = "0"
|
| 5 |
+
_MINOR = "1"
|
| 6 |
+
# On master and in a nightly release the patch should be one ahead of the last
|
| 7 |
+
# released build.
|
| 8 |
+
_PATCH = "0"
|
| 9 |
+
# This is mainly for nightly builds which have the suffix ".dev$DATE". See
|
| 10 |
+
# https://semver.org/#is-v123-a-semantic-version for the semantics.
|
| 11 |
+
_SUFFIX = "alpha.1"
|
| 12 |
+
|
| 13 |
+
VERSION_SHORT = "{0}.{1}".format(_MAJOR, _MINOR)
|
| 14 |
+
VERSION = "{0}.{1}.{2}{3}".format(_MAJOR, _MINOR, _PATCH, _SUFFIX)
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
flash_attn
|
| 2 |
+
triton==2.1.0
|
| 3 |
+
pycuda==2023.1
|
| 4 |
+
accelerate
|
| 5 |
+
transformers
|