Spaces:
Build error

Build error

Commit
·
4ba35bc
1
Parent(s):
f9c7b49
add script for speaker diarization demo
Browse files- README.md +4 -5
- __pycache__/configs.cpython-38.pyc +0 -0
- app.py +167 -0
- blog_samples/4092.wav +0 -0
- computed_diarization_plots/recording_1_NeMo.png +0 -0
- computed_diarization_plots/recording_1_PyAnnote.png +0 -0
- computed_diarization_plots/recording_2_NeMo.png +0 -0
- computed_diarization_plots/recording_2_PyAnnote.png +0 -0
- computed_diarization_plots/recording_3_NeMo.png +0 -0
- computed_diarization_plots/recording_3_PyAnnote.png +0 -0
- configs.py +5 -0
- diarizers/__pycache__/diarizer.cpython-38.pyc +0 -0
- diarizers/__pycache__/nemo_diarizer.cpython-38.pyc +0 -0
- diarizers/__pycache__/pyannote_diarizer.cpython-38.pyc +0 -0
- diarizers/diarizer.py +21 -0
- diarizers/input_manifest.json +1 -0
- diarizers/nemo_diarizer.py +114 -0
- diarizers/pyannote_diarizer.py +35 -0
- docs/asr+diar.png +0 -0
- docs/flow_chart_diarization.png +0 -0
- docs/flow_chart_diarization_tree.png +0 -0
- docs/speech_embedding.png +0 -0
- manifest_vad_input.json +1 -0
- packages.txt +3 -0
- requirements.txt +15 -0
- samples/recording_1.wav +0 -0
- samples/recording_2.wav +0 -0
- samples/recording_3.wav +0 -0
- utils/__pycache__/audio_utils.cpython-38.pyc +0 -0
- utils/__pycache__/general_utils.cpython-38.pyc +0 -0
- utils/__pycache__/streamlit_utils.cpython-38.pyc +0 -0
- utils/__pycache__/text_utils.cpython-38.pyc +0 -0
- utils/audio_utils.py +46 -0
- utils/general_utils.py +23 -0
- utils/streamlit_utils.py +11 -0
- utils/text_utils.py +282 -0
README.md
CHANGED
|
@@ -1,13 +1,12 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
-
license: apache-2.0
|
| 11 |
---
|
| 12 |
|
| 13 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Diarization
|
| 3 |
+
emoji: 🐠
|
| 4 |
+
colorFrom: red
|
| 5 |
+
colorTo: green
|
| 6 |
sdk: streamlit
|
| 7 |
sdk_version: 1.10.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
__pycache__/configs.cpython-38.pyc
ADDED
|
Binary file (364 Bytes). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
General streamlit diarization application
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import shutil
|
| 6 |
+
from io import BytesIO
|
| 7 |
+
from typing import Dict, Union
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
|
| 10 |
+
import librosa
|
| 11 |
+
import librosa.display
|
| 12 |
+
import matplotlib.figure
|
| 13 |
+
import numpy as np
|
| 14 |
+
import streamlit as st
|
| 15 |
+
import streamlit.uploaded_file_manager
|
| 16 |
+
from PIL import Image
|
| 17 |
+
from pydub import AudioSegment
|
| 18 |
+
from matplotlib import pyplot as plt
|
| 19 |
+
|
| 20 |
+
import configs
|
| 21 |
+
from utils import audio_utils, text_utils, general_utils, streamlit_utils
|
| 22 |
+
from diarizers import pyannote_diarizer, nemo_diarizer
|
| 23 |
+
|
| 24 |
+
plt.rcParams["figure.figsize"] = (10, 5)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def plot_audio_diarization(diarization_figure: Union[plt.gcf, np.array], diarization_name: str,
|
| 28 |
+
audio_data: np.array,
|
| 29 |
+
sampling_frequency: int):
|
| 30 |
+
"""
|
| 31 |
+
Function that plots the audio along with the different applied diarization techniques
|
| 32 |
+
Args:
|
| 33 |
+
diarization_figure (plt.gcf): the diarization figure to plot
|
| 34 |
+
diarization_name (str): the name of the diarization technique
|
| 35 |
+
audio_data (np.array): the audio numpy array
|
| 36 |
+
sampling_frequency (int): the audio sampling frequency
|
| 37 |
+
"""
|
| 38 |
+
col1, col2 = st.columns([3, 5])
|
| 39 |
+
with col1:
|
| 40 |
+
st.markdown(
|
| 41 |
+
f"<h4 style='text-align: center; color: black;'>Original</h5>",
|
| 42 |
+
unsafe_allow_html=True,
|
| 43 |
+
)
|
| 44 |
+
st.markdown("<br></br>", unsafe_allow_html=True)
|
| 45 |
+
|
| 46 |
+
st.audio(audio_utils.create_st_audio_virtualfile(audio_data, sampling_frequency))
|
| 47 |
+
with col2:
|
| 48 |
+
st.markdown(
|
| 49 |
+
f"<h4 style='text-align: center; color: black;'>{diarization_name}</h5>",
|
| 50 |
+
unsafe_allow_html=True,
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
if type(diarization_figure) == matplotlib.figure.Figure:
|
| 54 |
+
buf = BytesIO()
|
| 55 |
+
diarization_figure.savefig(buf, format="png")
|
| 56 |
+
st.image(buf)
|
| 57 |
+
else:
|
| 58 |
+
st.image(diarization_figure)
|
| 59 |
+
st.markdown("---")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def execute_diarization(file_uploader: st.uploaded_file_manager.UploadedFile, selected_option: any,
|
| 63 |
+
sample_option_dict: Dict[str, str],
|
| 64 |
+
diarization_checkbox_dict: Dict[str, bool],
|
| 65 |
+
session_id: str):
|
| 66 |
+
"""
|
| 67 |
+
Function that exectutes the diarization based on the specified files and pipelines
|
| 68 |
+
Args:
|
| 69 |
+
file_uploader (st.uploaded_file_manager.UploadedFile): the uploaded streamlit audio file
|
| 70 |
+
selected_option (any): the selected option of samples
|
| 71 |
+
Dict[str, str]: a dictionary where the name is the file name (without extension to be listed
|
| 72 |
+
as an option for the user) and the value is the original file name
|
| 73 |
+
diarization_checkbox_dict (Dict[str, bool]): dictionary where the key is the Diarization
|
| 74 |
+
technique name and the value is a boolean indicating whether to apply that technique
|
| 75 |
+
session_id (str): unique id of the user session
|
| 76 |
+
"""
|
| 77 |
+
user_folder = os.path.join(configs.UPLOADED_AUDIO_SAMPLES_DIR, session_id)
|
| 78 |
+
Path(user_folder).mkdir(parents=True, exist_ok=True)
|
| 79 |
+
|
| 80 |
+
if file_uploader is not None:
|
| 81 |
+
file_name = file_uploader.name
|
| 82 |
+
file_path = os.path.join(user_folder, file_name)
|
| 83 |
+
audio = AudioSegment.from_wav(file_uploader).set_channels(1)
|
| 84 |
+
# slice first 30 seconds (slicing is done by ms)
|
| 85 |
+
audio = audio[0:1000 * 30]
|
| 86 |
+
audio.export(file_path, format='wav')
|
| 87 |
+
else:
|
| 88 |
+
file_name = sample_option_dict[selected_option]
|
| 89 |
+
file_path = os.path.join(configs.AUDIO_SAMPLES_DIR, file_name)
|
| 90 |
+
|
| 91 |
+
audio_data, sampling_frequency = librosa.load(file_path)
|
| 92 |
+
|
| 93 |
+
nb_pipelines_to_run = sum(pipeline_bool for pipeline_bool in diarization_checkbox_dict.values())
|
| 94 |
+
pipeline_count = 0
|
| 95 |
+
for diarization_idx, (diarization_name, diarization_bool) in \
|
| 96 |
+
enumerate(diarization_checkbox_dict.items()):
|
| 97 |
+
|
| 98 |
+
if diarization_bool:
|
| 99 |
+
pipeline_count += 1
|
| 100 |
+
if diarization_name == 'PyAnnote':
|
| 101 |
+
diarizer = pyannote_diarizer.PyannoteDiarizer(file_path)
|
| 102 |
+
elif diarization_name == 'NeMo':
|
| 103 |
+
diarizer = nemo_diarizer.NemoDiarizer(file_path, user_folder)
|
| 104 |
+
else:
|
| 105 |
+
raise NotImplementedError('Framework not recognized')
|
| 106 |
+
|
| 107 |
+
if file_uploader is not None:
|
| 108 |
+
with st.spinner(
|
| 109 |
+
f"Executing {pipeline_count}/{nb_pipelines_to_run} diarization pipelines "
|
| 110 |
+
f"({diarization_name}). This might take 1-2 minutes..."):
|
| 111 |
+
diarizer_figure = diarizer.get_diarization_figure()
|
| 112 |
+
else:
|
| 113 |
+
diarizer_figure = Image.open(f"{configs.PRECOMPUTED_DIARIZATION_FIGURE}/"
|
| 114 |
+
f"{file_name.rsplit('.')[0]}_{diarization_name}.png")
|
| 115 |
+
|
| 116 |
+
plot_audio_diarization(diarizer_figure, diarization_name, audio_data,
|
| 117 |
+
sampling_frequency)
|
| 118 |
+
|
| 119 |
+
shutil.rmtree(user_folder)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def main():
|
| 123 |
+
# 1) Write input text
|
| 124 |
+
text_utils.intro_container()
|
| 125 |
+
diarization_container = st.container()
|
| 126 |
+
|
| 127 |
+
# 2)Create the diarization container
|
| 128 |
+
diarization_container.markdown("---")
|
| 129 |
+
|
| 130 |
+
# 2.1) Diarization method
|
| 131 |
+
text_utils.demo_container(diarization_container)
|
| 132 |
+
diarization_container.markdown("Choose the Diarization method here:")
|
| 133 |
+
|
| 134 |
+
diarization_checkbox_dict = {}
|
| 135 |
+
for diarization_method in configs.DIARIZATION_METHODS:
|
| 136 |
+
diarization_checkbox_dict[diarization_method] = diarization_container.checkbox(
|
| 137 |
+
diarization_method)
|
| 138 |
+
|
| 139 |
+
# 2.2) Diarization upload/sample select
|
| 140 |
+
diarization_container.markdown("(Optional) Upload an audio file here:")
|
| 141 |
+
file_uploader = diarization_container.file_uploader(
|
| 142 |
+
label="", type=[".wav", ".wave"]
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
sample_option_dict = general_utils.get_dict_of_audio_samples(configs.AUDIO_SAMPLES_DIR)
|
| 146 |
+
diarization_container.markdown("Or select a sample file here:")
|
| 147 |
+
selected_option = diarization_container.selectbox(
|
| 148 |
+
label="", options=list(sample_option_dict.keys())
|
| 149 |
+
)
|
| 150 |
+
diarization_container.markdown("---")
|
| 151 |
+
|
| 152 |
+
## 2.3) Apply specified diarization pipeline
|
| 153 |
+
if diarization_container.button("Apply"):
|
| 154 |
+
session_id = streamlit_utils.get_session()
|
| 155 |
+
execute_diarization(
|
| 156 |
+
file_uploader=file_uploader,
|
| 157 |
+
selected_option=selected_option,
|
| 158 |
+
sample_option_dict=sample_option_dict,
|
| 159 |
+
diarization_checkbox_dict=diarization_checkbox_dict,
|
| 160 |
+
session_id=session_id
|
| 161 |
+
)
|
| 162 |
+
text_utils.conlusion_container()
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
if __name__ == "__main__":
|
| 166 |
+
st.set_page_config(layout="wide", page_title="Audio diarization visualization")
|
| 167 |
+
main()
|
blog_samples/4092.wav
ADDED
|
Binary file (241 kB). View file
|
|
|
computed_diarization_plots/recording_1_NeMo.png
ADDED

|
computed_diarization_plots/recording_1_PyAnnote.png
ADDED

|
computed_diarization_plots/recording_2_NeMo.png
ADDED

|
computed_diarization_plots/recording_2_PyAnnote.png
ADDED

|
computed_diarization_plots/recording_3_NeMo.png
ADDED

|
computed_diarization_plots/recording_3_PyAnnote.png
ADDED

|
configs.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""General configs"""
|
| 2 |
+
DIARIZATION_METHODS = ['PyAnnote', 'NeMo']
|
| 3 |
+
AUDIO_SAMPLES_DIR = 'samples'
|
| 4 |
+
UPLOADED_AUDIO_SAMPLES_DIR = 'uploaded_samples'
|
| 5 |
+
PRECOMPUTED_DIARIZATION_FIGURE = 'computed_diarization_plots'
|
diarizers/__pycache__/diarizer.cpython-38.pyc
ADDED
|
Binary file (830 Bytes). View file
|
|
|
diarizers/__pycache__/nemo_diarizer.cpython-38.pyc
ADDED
|
Binary file (4.38 kB). View file
|
|
|
diarizers/__pycache__/pyannote_diarizer.cpython-38.pyc
ADDED
|
Binary file (1.66 kB). View file
|
|
|
diarizers/diarizer.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Abstract class for diarization
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
|
| 7 |
+
from abc import ABC, abstractmethod
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Diarizer(ABC):
|
| 11 |
+
"""
|
| 12 |
+
Diarizer base class
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
@abstractmethod
|
| 16 |
+
def get_diarization_figure(self) -> plt.gcf:
|
| 17 |
+
"""
|
| 18 |
+
Function that returns the audio plot with diarization segmentations
|
| 19 |
+
Returns:
|
| 20 |
+
plt.gcf: the diarization plot
|
| 21 |
+
"""
|
diarizers/input_manifest.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"audio_filepath": "uploaded_samples/0217b861_28cd_4326_a5ea_ffa48f26d5bb/ES2004a.Mix-Headset_cut_2.wav", "offset": 0, "duration": null, "label": "infer", "text": "-", "num_speakers": null, "rttm_filepath": null, "uem_filepath": null}
|
diarizers/nemo_diarizer.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Nemo diarizer
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
|
| 7 |
+
import wget
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
from omegaconf import OmegaConf
|
| 10 |
+
from nemo.collections.asr.models import ClusteringDiarizer
|
| 11 |
+
from nemo.collections.asr.parts.utils.speaker_utils import rttm_to_labels, labels_to_pyannote_object
|
| 12 |
+
from pyannote.core import notebook
|
| 13 |
+
|
| 14 |
+
from diarizers.diarizer import Diarizer
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class NemoDiarizer(Diarizer):
|
| 18 |
+
"""Class for Nemo Diarizer"""
|
| 19 |
+
|
| 20 |
+
def __init__(self, audio_path: str, data_dir: str):
|
| 21 |
+
"""
|
| 22 |
+
Nemo diarizer class
|
| 23 |
+
Args:
|
| 24 |
+
audio_path (str): the path to the audio file
|
| 25 |
+
"""
|
| 26 |
+
self.audio_path = audio_path
|
| 27 |
+
self.data_dir = data_dir
|
| 28 |
+
self.diarization = None
|
| 29 |
+
self.manifest_dir = os.path.join(self.data_dir, 'input_manifest.json')
|
| 30 |
+
self.model_config = os.path.join(self.data_dir, 'offline_diarization.yaml')
|
| 31 |
+
if not os.path.exists(self.model_config):
|
| 32 |
+
config_url = "https://raw.githubusercontent.com/NVIDIA/NeMo/main/examples/" \
|
| 33 |
+
"speaker_tasks/diarization/conf/offline_diarization.yaml"
|
| 34 |
+
self.model_config = wget.download(config_url, self.data_dir)
|
| 35 |
+
self.config = OmegaConf.load(self.model_config)
|
| 36 |
+
|
| 37 |
+
def _create_manifest_file(self):
|
| 38 |
+
"""
|
| 39 |
+
Function that creates inference manifest file
|
| 40 |
+
"""
|
| 41 |
+
meta = {
|
| 42 |
+
'audio_filepath': self.audio_path,
|
| 43 |
+
'offset': 0,
|
| 44 |
+
'duration': None,
|
| 45 |
+
'label': 'infer',
|
| 46 |
+
'text': '-',
|
| 47 |
+
'num_speakers': None,
|
| 48 |
+
'rttm_filepath': None,
|
| 49 |
+
'uem_filepath': None
|
| 50 |
+
}
|
| 51 |
+
with open(self.manifest_dir, 'w') as fp:
|
| 52 |
+
json.dump(meta, fp)
|
| 53 |
+
fp.write('\n')
|
| 54 |
+
|
| 55 |
+
def _apply_config(self, pretrained_speaker_model: str = 'ecapa_tdnn'):
|
| 56 |
+
"""
|
| 57 |
+
Function that edits the inference configuration file
|
| 58 |
+
Args:
|
| 59 |
+
pretrained_speaker_model (str): the pre-trained embedding model options are
|
| 60 |
+
('escapa_tdnn', vad_telephony_marblenet, titanet_large, ecapa_tdnn)
|
| 61 |
+
https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/asr/
|
| 62 |
+
speaker_diarization/results.html
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
pretrained_vad = 'vad_marblenet'
|
| 66 |
+
|
| 67 |
+
output_dir = os.path.join(self.data_dir, 'outputs')
|
| 68 |
+
self.config.diarizer.manifest_filepath = self.manifest_dir
|
| 69 |
+
self.config.diarizer.out_dir = output_dir
|
| 70 |
+
self.config.diarizer.ignore_overlap = False
|
| 71 |
+
|
| 72 |
+
self.config.diarizer.speaker_embeddings.model_path = pretrained_speaker_model
|
| 73 |
+
self.config.diarizer.speaker_embeddings.parameters.window_length_in_sec = 1.5
|
| 74 |
+
self.config.diarizer.speaker_embeddings.parameters.shift_length_in_sec = 0.75
|
| 75 |
+
self.config.diarizer.oracle_vad = False
|
| 76 |
+
self.config.diarizer.clustering.parameters.oracle_num_speakers = False
|
| 77 |
+
|
| 78 |
+
# Here we use our inhouse pretrained NeMo VAD
|
| 79 |
+
self.config.diarizer.vad.model_path = pretrained_vad
|
| 80 |
+
self.config.diarizer.vad.window_length_in_sec = 0.15
|
| 81 |
+
self.config.diarizer.vad.shift_length_in_sec = 0.01
|
| 82 |
+
self.config.diarizer.vad.parameters.onset = 0.8
|
| 83 |
+
self.config.diarizer.vad.parameters.offset = 0.6
|
| 84 |
+
self.config.diarizer.vad.parameters.min_duration_on = 0.1
|
| 85 |
+
self.config.diarizer.vad.parameters.min_duration_off = 0.4
|
| 86 |
+
|
| 87 |
+
def diarize_audio(self, pretrained_speaker_model: str = 'ecapa_tdnn'):
|
| 88 |
+
"""
|
| 89 |
+
function that diarizes the audio
|
| 90 |
+
Args:
|
| 91 |
+
pretrained_speaker_model (str): the pre-trained embedding model options are
|
| 92 |
+
('escapa_tdnn', vad_telephony_marblenet, titanet_large, ecapa_tdnn)
|
| 93 |
+
https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/asr/
|
| 94 |
+
speaker_diarization/results.html
|
| 95 |
+
"""
|
| 96 |
+
self._create_manifest_file()
|
| 97 |
+
self._apply_config(pretrained_speaker_model)
|
| 98 |
+
sd_model = ClusteringDiarizer(cfg=self.config)
|
| 99 |
+
sd_model.diarize()
|
| 100 |
+
audio_file_name_without_extension = os.path.basename(self.audio_path).rsplit('.', 1)[0]
|
| 101 |
+
output_diarization_pred = f'{self.data_dir}/outputs/pred_rttms/' \
|
| 102 |
+
f'{audio_file_name_without_extension}.rttm'
|
| 103 |
+
pred_labels = rttm_to_labels(output_diarization_pred)
|
| 104 |
+
self.diarization = labels_to_pyannote_object(pred_labels)
|
| 105 |
+
|
| 106 |
+
def get_diarization_figure(self) -> plt.gcf:
|
| 107 |
+
"""
|
| 108 |
+
Function that return the diarization figure
|
| 109 |
+
"""
|
| 110 |
+
if not self.diarization:
|
| 111 |
+
self.diarize_audio()
|
| 112 |
+
figure, ax = plt.subplots()
|
| 113 |
+
notebook.plot_annotation(self.diarization, ax=ax, time=True, legend=True)
|
| 114 |
+
return plt.gcf()
|
diarizers/pyannote_diarizer.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
pyannote diarizer
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
|
| 7 |
+
from pyannote.audio import Pipeline
|
| 8 |
+
from pyannote.core import notebook
|
| 9 |
+
from diarizers.diarizer import Diarizer
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class PyannoteDiarizer(Diarizer):
|
| 13 |
+
def __init__(self, audio_path: str):
|
| 14 |
+
"""
|
| 15 |
+
Pyannote diarizer class
|
| 16 |
+
Note: pyannote does not currently support defining the number of speakers, this
|
| 17 |
+
functionality might be supported later in the future
|
| 18 |
+
Args:
|
| 19 |
+
audio_path (str): the path to the audio file
|
| 20 |
+
Params:
|
| 21 |
+
diarization (Annotations): the output of the diarization algorithm
|
| 22 |
+
"""
|
| 23 |
+
self.audio_path = audio_path
|
| 24 |
+
self.diarization = None
|
| 25 |
+
|
| 26 |
+
def diarize_audio(self):
|
| 27 |
+
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization")
|
| 28 |
+
self.diarization = pipeline({'audio': self.audio_path})
|
| 29 |
+
|
| 30 |
+
def get_diarization_figure(self) -> plt.gcf:
|
| 31 |
+
if not self.diarization:
|
| 32 |
+
self.diarize_audio()
|
| 33 |
+
figure, ax = plt.subplots()
|
| 34 |
+
notebook.plot_annotation(self.diarization, ax=ax, time=True, legend=True)
|
| 35 |
+
return plt.gcf()
|
docs/asr+diar.png
ADDED
|
docs/flow_chart_diarization.png
ADDED

|
docs/flow_chart_diarization_tree.png
ADDED
|
docs/speech_embedding.png
ADDED

|
manifest_vad_input.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"audio_filepath": "uploaded_samples/6f1f8cbc_f8bb_4a6a_9ce5_8c182df3e886/ES2004a.Mix-Headset_cut_2.wav", "duration": 30.0, "label": "infer", "text": "_", "offset": 0}
|
packages.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
libsndfile1
|
| 2 |
+
ffmpeg
|
| 3 |
+
sox
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
librosa==0.9.1
|
| 2 |
+
Pillow==9.1.1
|
| 3 |
+
numpy==1.22
|
| 4 |
+
streamlit==1.10.0
|
| 5 |
+
matplotlib==3.5.2
|
| 6 |
+
scipy==1.8.1
|
| 7 |
+
audiomentations==0.25.1
|
| 8 |
+
pydub==0.25.1
|
| 9 |
+
https://github.com/pyannote/pyannote-audio/archive/develop.zip
|
| 10 |
+
speechbrain==0.5.11
|
| 11 |
+
wget==3.2
|
| 12 |
+
unidecode==1.3.4
|
| 13 |
+
huggingface_hub==0.7
|
| 14 |
+
torchaudio -f https://download.pytorch.org/whl/torch_stable.html
|
| 15 |
+
git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
|
samples/recording_1.wav
ADDED
|
Binary file (480 kB). View file
|
|
|
samples/recording_2.wav
ADDED
|
Binary file (480 kB). View file
|
|
|
samples/recording_3.wav
ADDED
|
Binary file (480 kB). View file
|
|
|
utils/__pycache__/audio_utils.cpython-38.pyc
ADDED
|
Binary file (1.85 kB). View file
|
|
|
utils/__pycache__/general_utils.cpython-38.pyc
ADDED
|
Binary file (921 Bytes). View file
|
|
|
utils/__pycache__/streamlit_utils.cpython-38.pyc
ADDED
|
Binary file (478 Bytes). View file
|
|
|
utils/__pycache__/text_utils.cpython-38.pyc
ADDED
|
Binary file (15.9 kB). View file
|
|
|
utils/audio_utils.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""General helper functions for audio processing"""
|
| 2 |
+
|
| 3 |
+
import io
|
| 4 |
+
|
| 5 |
+
import streamlit as st
|
| 6 |
+
import streamlit.uploaded_file_manager
|
| 7 |
+
import numpy as np
|
| 8 |
+
import pydub
|
| 9 |
+
from scipy.io import wavfile
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def create_st_audio_virtualfile(audio_data: np.array, sample_rate: int) -> io.BytesIO:
|
| 13 |
+
"""
|
| 14 |
+
Function that creates the audi virtual file needed to run the audio player
|
| 15 |
+
Args:
|
| 16 |
+
audio_data (np.array): the audio data array
|
| 17 |
+
sample_rate (int): the sampling frequency fo the audio
|
| 18 |
+
Returns:
|
| 19 |
+
io.Bytesio: the audio virtual file stored in temporary memory
|
| 20 |
+
"""
|
| 21 |
+
virtual_audio_file = io.BytesIO()
|
| 22 |
+
wavfile.write(virtual_audio_file, rate=sample_rate, data=audio_data)
|
| 23 |
+
|
| 24 |
+
return virtual_audio_file
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def parse_uploaded_audio_file(uploaded_file: st.uploaded_file_manager.UploadedFile):
|
| 28 |
+
"""
|
| 29 |
+
Function that parses the uploaded file into it's a numpy array representation and sampling
|
| 30 |
+
frequency
|
| 31 |
+
Args:
|
| 32 |
+
uploaded_file (st.uploaded_file_manager.UploadedFile): the uploaded streamlit audio file
|
| 33 |
+
"""
|
| 34 |
+
audio_data = pydub.AudioSegment.from_file(
|
| 35 |
+
file=uploaded_file, format=uploaded_file.name.split(".")[-1]
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
channel_sounds = audio_data.split_to_mono()
|
| 39 |
+
samples = [channel.get_array_of_samples() for channel in channel_sounds]
|
| 40 |
+
|
| 41 |
+
fp_arr = np.array(samples).T.astype(np.float32)
|
| 42 |
+
fp_arr /= np.iinfo(samples[0].typecode).max
|
| 43 |
+
|
| 44 |
+
return fp_arr[:, 0], audio_data.frame_rate
|
| 45 |
+
|
| 46 |
+
|
utils/general_utils.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
General utility functions
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
from typing import List, Dict
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def get_dict_of_audio_samples(audio_sample_path: str) -> Dict[str, str]:
|
| 9 |
+
"""
|
| 10 |
+
Function that returns the list of available audio samples
|
| 11 |
+
Args:
|
| 12 |
+
audio_sample_path (str): The path to the directory with the audio samples
|
| 13 |
+
Returns:
|
| 14 |
+
Dict[str, str]: a dictionary where the name is the file name (without extension to be listed
|
| 15 |
+
as an option for the user) and the value is the original file name
|
| 16 |
+
"""
|
| 17 |
+
audio_sample_dict = {}
|
| 18 |
+
|
| 19 |
+
for file in os.listdir(audio_sample_path):
|
| 20 |
+
file_option = os.path.basename(file).rsplit('.')[0]
|
| 21 |
+
audio_sample_dict[file_option] = file
|
| 22 |
+
|
| 23 |
+
return audio_sample_dict
|
utils/streamlit_utils.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from streamlit.scriptrunner import get_script_run_ctx as get_report_ctx
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def get_session() -> str:
|
| 5 |
+
"""
|
| 6 |
+
Function that returns a unique identifier per user session
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
session_id = get_report_ctx().session_id.replace('-', '_')
|
| 10 |
+
|
| 11 |
+
return session_id
|
utils/text_utils.py
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Utils for generating text in streamlit
|
| 3 |
+
"""
|
| 4 |
+
import librosa
|
| 5 |
+
import streamlit as st
|
| 6 |
+
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
from utils import audio_utils
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def intro_container():
|
| 13 |
+
container = st.container()
|
| 14 |
+
container.title(
|
| 15 |
+
'Who spoke when: Choosing the right speaker diarization tool')
|
| 16 |
+
container.markdown(
|
| 17 |
+
'With the increase in applications of automated ***speech recognition systems (ASR)***, '
|
| 18 |
+
'the ability to partition a speech audio stream with multiple speakers into individual'
|
| 19 |
+
' segments associated with each individual has become a crucial part of understanding '
|
| 20 |
+
'speech data.')
|
| 21 |
+
container.markdown(
|
| 22 |
+
'In this blog post, we will take a look at different open source frameworks for'
|
| 23 |
+
'speaker diarization and provide you with a guide to pick the most suited '
|
| 24 |
+
'one for your use case.')
|
| 25 |
+
|
| 26 |
+
container.markdown(
|
| 27 |
+
"Before we get into the technical details, libraries and tools, let's first understand what"
|
| 28 |
+
" speaker diarization is and how it works!")
|
| 29 |
+
container.markdown("---")
|
| 30 |
+
container.header("🗣️ What is speaker diarization?️")
|
| 31 |
+
|
| 32 |
+
container.markdown('\n')
|
| 33 |
+
container.markdown(
|
| 34 |
+
'Speaker diarization aims to answer the question of ***"who spoke when"***. In short: diariziation algorithms '
|
| 35 |
+
'break down an audio stream of multiple speakers into segments corresponding to the individual speakers. '
|
| 36 |
+
'By combining the information that we get from diarization with ASR transcriptions, we can '
|
| 37 |
+
'transform the generated transcript into a format which is more readable and interpretable for humans '
|
| 38 |
+
'and that can be used for other downstream NLP tasks.')
|
| 39 |
+
col1_im1, col2_im1, col3_im1 = container.columns([2, 5, 2])
|
| 40 |
+
|
| 41 |
+
with col1_im1:
|
| 42 |
+
st.write(' ')
|
| 43 |
+
|
| 44 |
+
with col2_im1:
|
| 45 |
+
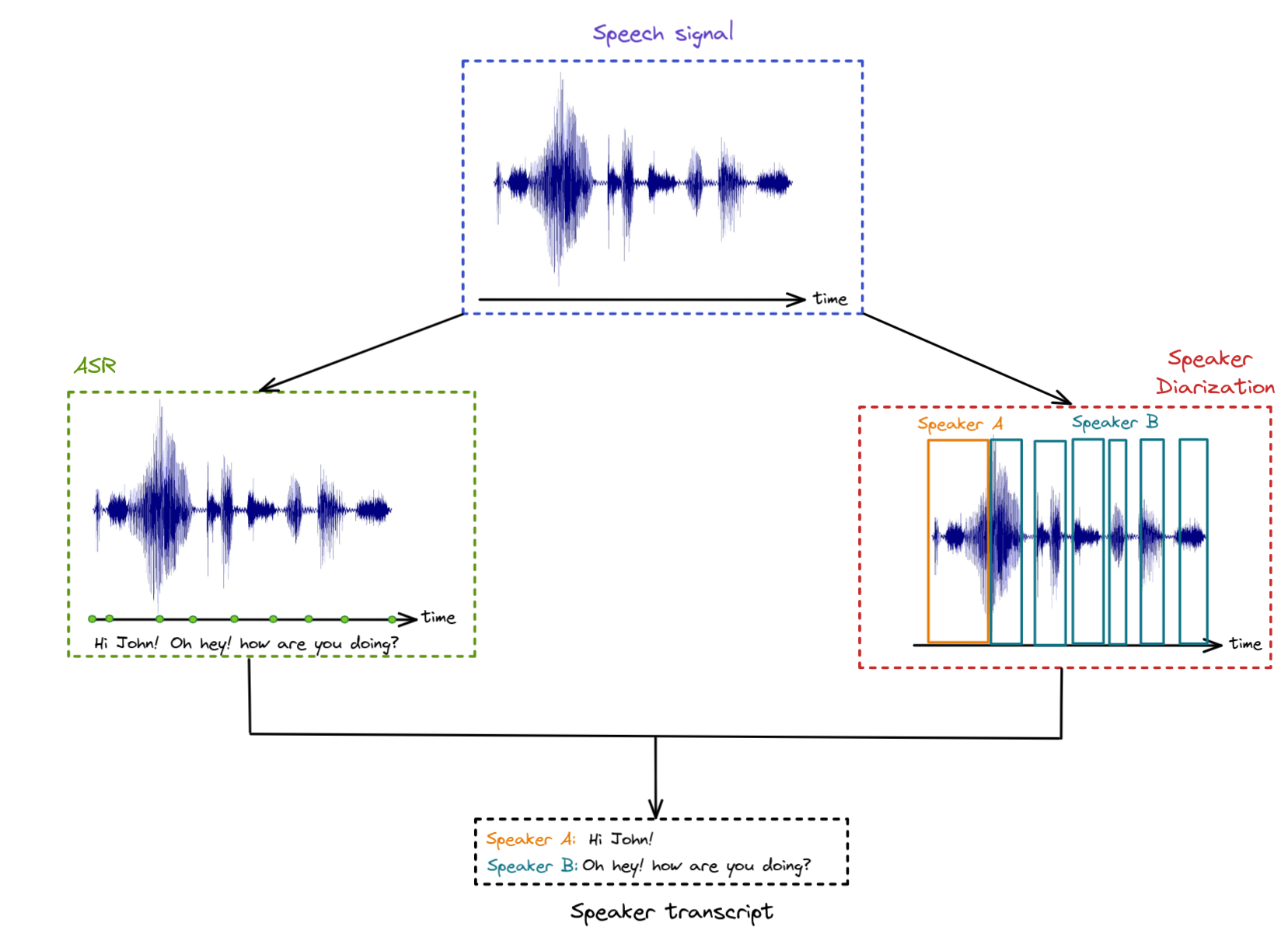
st.image(Image.open('docs/asr+diar.png'),
|
| 46 |
+
caption='Workflow of combining the output of both ASR and speaker '
|
| 47 |
+
'diarization on a speech signal to generate a speaker transcript.',
|
| 48 |
+
use_column_width=True)
|
| 49 |
+
|
| 50 |
+
with col3_im1:
|
| 51 |
+
st.write(' ')
|
| 52 |
+
|
| 53 |
+
container.markdown(
|
| 54 |
+
"Let's illustrate this with an example. We have a recording of a casual phone conversation "
|
| 55 |
+
"between two people. You can see what the different transcriptions look like when we "
|
| 56 |
+
"transcribe the conversation with and without diarization.")
|
| 57 |
+
|
| 58 |
+
container.markdown('\n')
|
| 59 |
+
|
| 60 |
+
col1, col2, col3 = container.columns(3)
|
| 61 |
+
with col1:
|
| 62 |
+
st.subheader("🎧 Audio recording ")
|
| 63 |
+
st.markdown("<br></br>", unsafe_allow_html=True)
|
| 64 |
+
st.markdown("<br></br>", unsafe_allow_html=True)
|
| 65 |
+
st.markdown("<br></br>", unsafe_allow_html=True)
|
| 66 |
+
audio_data, sampling_frequency = librosa.load('blog_samples/4092.wav')
|
| 67 |
+
st.audio(audio_utils.create_st_audio_virtualfile(audio_data, sampling_frequency))
|
| 68 |
+
|
| 69 |
+
with col2:
|
| 70 |
+
st.subheader("❌ Without diarization")
|
| 71 |
+
st.text("I just got back from the gym. oh good.\n"
|
| 72 |
+
"uhuh. How's it going? oh pretty well. It was\n"
|
| 73 |
+
"really crowded today yeah. I kind of\n"
|
| 74 |
+
"assumed everyone would be at the shore.\n"
|
| 75 |
+
"uhhuh. I was wrong. Well it's the\n"
|
| 76 |
+
"middle of the week or whatever so. But\n"
|
| 77 |
+
"it's the fourth of July. mm. So. yeah.\n"
|
| 78 |
+
"People have to work tomorrow. Do you\n"
|
| 79 |
+
"have to work tomorrow? yeah. Did you\n"
|
| 80 |
+
"have off yesterday? Yes. oh that's good.\n"
|
| 81 |
+
"And I was paid too. oh. Is it paid today?\n"
|
| 82 |
+
"No. oh.\n")
|
| 83 |
+
|
| 84 |
+
with col3:
|
| 85 |
+
st.subheader('✅ With diarization')
|
| 86 |
+
st.text("A: I just got back from the gym.\n"
|
| 87 |
+
"B: oh good.\n"
|
| 88 |
+
"A: uhhuh.\n"
|
| 89 |
+
"B: How's it going?\n"
|
| 90 |
+
"A: oh pretty well.\n"
|
| 91 |
+
"A: It was really crowded today.\n"
|
| 92 |
+
"B: yeah.\n"
|
| 93 |
+
"A: I kind of assumed everyone would be at \n"
|
| 94 |
+
"the shore.\n"
|
| 95 |
+
"B: uhhuh.\n"
|
| 96 |
+
"A: I was wrong.\n"
|
| 97 |
+
"B: Well it's the middle of the week or\n"
|
| 98 |
+
" whatever so.\n"
|
| 99 |
+
"A: But it's the fourth of July.\n"
|
| 100 |
+
"B: mm.\n"
|
| 101 |
+
"A: So.\n"
|
| 102 |
+
"B: yeah.\n"
|
| 103 |
+
"B: People have to work tomorrow.\n"
|
| 104 |
+
"B: Do you have to work tomorrow?\n"
|
| 105 |
+
"A: yeah.\n"
|
| 106 |
+
"B: Did you have off yesterday?\n"
|
| 107 |
+
"A: Yes.\n"
|
| 108 |
+
"B: oh that's good.\n"
|
| 109 |
+
"A: And I was paid too.\n"
|
| 110 |
+
"B: oh.\n"
|
| 111 |
+
"B: Is it paid today?\n"
|
| 112 |
+
"A: No.\n"
|
| 113 |
+
"B: oh.\n")
|
| 114 |
+
|
| 115 |
+
container.markdown(
|
| 116 |
+
"By generating a **speaker-aware transcript**, we can more easily interpret the generated"
|
| 117 |
+
" conversation compared to a generated transcript without diarization. Much neater no? ✨")
|
| 118 |
+
container.caption(
|
| 119 |
+
"Alright, that's more interpretable for human readers, but what can I do with "
|
| 120 |
+
"those speaker-aware transcripts? 🤔")
|
| 121 |
+
container.markdown(
|
| 122 |
+
"Speaker-aware transcripts can be a powerful tool for analyzing speech data:")
|
| 123 |
+
container.markdown("""
|
| 124 |
+
* We can use the transcripts to analyze individual speaker's sentiment by using **sentiment analysis** on both audio and text transcripts.
|
| 125 |
+
* Another use case is telemedicine where we might identify the **<doctor>** and **<patient>** tags on the transcription to create an accurate transcript and attach it to the patient file or EHR system.
|
| 126 |
+
* Speaker Diarization can be used by hiring platforms to analyze phone and video recruitment calls. This allows them to split and categorize candidates depending on their response to certain questions without having to listen again to the recordings.
|
| 127 |
+
""")
|
| 128 |
+
container.markdown(
|
| 129 |
+
"Now that we've seen the importance of speaker diarization and some of its applications,"
|
| 130 |
+
" it's time to find out we can implement diarization algorithms.")
|
| 131 |
+
|
| 132 |
+
container.markdown("---")
|
| 133 |
+
container.header('📝 The workflow of a speaker diarization system')
|
| 134 |
+
container.markdown(
|
| 135 |
+
"Building robust and accurate speaker diarization is not as a trivial task."
|
| 136 |
+
" Real world audio data is messy and complex due to many factors, such"
|
| 137 |
+
" as having a noisy background, multiple speakers talking at the same time and "
|
| 138 |
+
"subtle differences between the speakers' voices in pitch and tone. Moreover, speaker diarization systems often suffer "
|
| 139 |
+
"from **domain mismatch** where a model on data from a specific domain works poorly when applied to another domain.")
|
| 140 |
+
|
| 141 |
+
container.markdown(
|
| 142 |
+
"All in all, tackling speaker diarization is no easy feat. Current speaker diarization systems can be divided into two categories: **Traditional systems** and **End-to-End systems**. Let's look at how they work:")
|
| 143 |
+
container.subheader('Traditional diarization systems')
|
| 144 |
+
container.markdown(
|
| 145 |
+
"Those consist of many independent submodules that are optimized individually, namely being:")
|
| 146 |
+
container.markdown("""
|
| 147 |
+
* **Speech detection**: The first step is to identify speech and remove non-speech signals with a voice activity detector (VAD) algorithm.
|
| 148 |
+
* **Speech segmentation**: The output of the VAD is then segmented into small segments consisting of a few seconds (usually 1-2 seconds).
|
| 149 |
+
* **Speech embedder**: A neural network pre-trained on speaker recognition is used to derive a high-level representation of the speech segments. Those embeddings are vector representations that summarize the voice characteristics (a.k.a voice print).
|
| 150 |
+
* **Clustering**: After extracting segment embeddings, we need to cluster the speech embeddings with a clustering algorithm (for example K-Means or spectral clustering). The clustering produces our desired diarization results, which consists of identifying the number of unique speakers (derived from the number of unique clusters) and assigning a speaker label to each embedding (or speech segment).
|
| 151 |
+
""")
|
| 152 |
+
col1_im1, col2_im1, col3_im1 = container.columns([2, 5, 2])
|
| 153 |
+
|
| 154 |
+
with col1_im1:
|
| 155 |
+
st.write(' ')
|
| 156 |
+
|
| 157 |
+
with col2_im1:
|
| 158 |
+
st.image(Image.open('docs/speech_embedding.png'),
|
| 159 |
+
caption="Process of identifying speaker segments from speech activity embeddings.",
|
| 160 |
+
|
| 161 |
+
use_column_width=True)
|
| 162 |
+
|
| 163 |
+
with col3_im1:
|
| 164 |
+
st.write(' ')
|
| 165 |
+
|
| 166 |
+
container.subheader('End-to-end diarization systems')
|
| 167 |
+
container.markdown(
|
| 168 |
+
"Here the individual submodules of the traditional speaker diarization system can be replaced by one neural network that is trained end-to-end on speaker diarization.")
|
| 169 |
+
|
| 170 |
+
container.markdown('**Advantages**')
|
| 171 |
+
container.markdown(
|
| 172 |
+
'➕ Direct optimization of the network towards maximizing the accuracy for the diarization task. This is in contrast with traditional systems where submodules are optimized individually but not as a whole.')
|
| 173 |
+
container.markdown(
|
| 174 |
+
'➕ Less need to come up with useful pre-processing and post-processing transformation on the input data.')
|
| 175 |
+
container.markdown(' **Disadvantages**')
|
| 176 |
+
container.markdown(
|
| 177 |
+
'➖ More effort needed for data collection and labelling. This is because this type of approach requires speaker-aware transcripts for training. This differs from traditional systems where only labels consisting of the speaker tag along with the audio timestamp are needed (without transcription efforts).')
|
| 178 |
+
container.markdown('➖ These systems have the tendency to overfit on the training data.')
|
| 179 |
+
|
| 180 |
+
container.markdown("---")
|
| 181 |
+
container.header('📚 Speaker diarization frameworks')
|
| 182 |
+
container.markdown(
|
| 183 |
+
"As you can see, there are advantages and disadvantages to both traditional and end-to-end diarization systems."
|
| 184 |
+
"Building a speaker diarization system also involves aggregating quite a few "
|
| 185 |
+
"building blocks and the implementation can seem daunting at first glance. Luckily, there exists a plethora "
|
| 186 |
+
"of libraries and packages that have all those steps implemented and are ready for you to use out of the box 🔥.")
|
| 187 |
+
container.markdown(
|
| 188 |
+
"I will focus on the most popular **open-source** speaker diarization libraries. Make sure to check out"
|
| 189 |
+
" [this link](https://wq2012.github.io/awesome-diarization/) for a more exhaustive list on different diarization libraries.")
|
| 190 |
+
|
| 191 |
+
container.markdown("### 1. [PyAnnote](https://github.com/pyannote/pyannote-audio)")
|
| 192 |
+
container.markdown(
|
| 193 |
+
"Arguably one of the most popular libraries out there for speaker diarization.\n"
|
| 194 |
+
"* Comes with a set of available pre-trained models for the VAD, embedder and segmentation model.\n"
|
| 195 |
+
"* The inference pipeline can identify multiple speakers speaking at the same time (multi-label diarization).\n"
|
| 196 |
+
|
| 197 |
+
"* It is not possible to define the number of speakers for the clustering algorithm. This could lead to an over-estimation or under-estimation of the number of speakers if they are known beforehand.")
|
| 198 |
+
"* Note that the pre-trained models are based on the [VoxCeleb datasets](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/) which consists of recording of celebrities extracted from YouTube. The audio quality of those recordings are crisp and clear, so you might need to retrain your model if you want to tackle other types of data like recorded phone calls.\n"
|
| 199 |
+
|
| 200 |
+
container.markdown("### 2. [NVIDIA NeMo](https://developer.nvidia.com/nvidia-nemo)")
|
| 201 |
+
container.markdown(
|
| 202 |
+
"The Nvidia NeMo toolkit has separate collections for Automatic Speech Recognition (ASR), Natural Language Processing (NLP), and Text-to-Speech (TTS) models.\n"
|
| 203 |
+
"* Diarization results can be combined easily with ASR outputs to generate speaker-aware transcripts.\n"
|
| 204 |
+
"* Possibility to define the number of speakers beforehand if they are known, resulting in a more accurate diarization output.\n"
|
| 205 |
+
"* The fact that the NeMo toolkit also includes NLP related frameworks makes it easy to integrate the diarization outcome with downstream NLP tasks.\n"
|
| 206 |
+
"* The models that the pre-trained networks were trained on were trained on [VoxCeleb datasets](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/) as well as the [Fisher](https://catalog.ldc.upenn.edu/LDC2004T19) and [SwitchBoard](https://catalog.ldc.upenn.edu/LDC97S62) dataset, which consists of telephone conversations in English. This makes it more suitable as a starting point for fine-tuning a model for call-center use cases compared to the pre-trained models used in PyAnnote. More information about the pre-trained models can be found [here](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/asr/speaker_diarization/results.html).\n"
|
| 207 |
+
)
|
| 208 |
+
container.markdown("### 3. [Simple Diarizer](https://github.com/cvqluu/simple_diarizer)")
|
| 209 |
+
container.markdown(
|
| 210 |
+
"A simplified diarization pipeline that can be used for quick testing.\n"
|
| 211 |
+
"* Uses the same pre-trained models as PyAnnote.\n"
|
| 212 |
+
"* Unlike PyAnnote, this library does not include the option to fine tune the pre-trained models, making it less suitable for specialized use cases.\n"
|
| 213 |
+
"* Similarly to Nvidia NeMo, there's the option to define the number of speakers beforehand.\n")
|
| 214 |
+
container.markdown(
|
| 215 |
+
"### 4. [SpeechBrain](https://github.com/speechbrain/speechbrain)")
|
| 216 |
+
container.markdown(
|
| 217 |
+
"All-in-one conversational AI toolkit based on PyTorch.\n"
|
| 218 |
+
"* The SpeechBrain Ecosystem makes it easy to develop integrated speech solutions with systems such ASR, speaker identification, speech enhancement, speech separation and language identification.\n"
|
| 219 |
+
"* Large amount of pre-trained models for various tasks. Checkout their [HuggingFace page](https://huggingface.co/speechbrain) for more information.\n"
|
| 220 |
+
"* Contains [comprehensible tutorials](https://speechbrain.github.io/tutorial_basics.html) for various speech building blocks to easily get started.\n"
|
| 221 |
+
"* Diarization pipeline is still not fully implemented yet but this [might change in the future](https://github.com/speechbrain/speechbrain/issues/1208).")
|
| 222 |
+
container.markdown(
|
| 223 |
+
"### 5. [Kaldi](https://github.com/kaldi-asr/kaldi)")
|
| 224 |
+
container.markdown(
|
| 225 |
+
"Speech recognition toolkit that is mainly targeted towards researchers. It is written in C++ and used to train speech recognition models and decode audio from audio files.\n"
|
| 226 |
+
"* Relatively steep learning curve for beginners who don't have a lot of experience with speech recognition systems.\n"
|
| 227 |
+
"* Pre-trained model is based on the [CALLHOME](https://catalog.ldc.upenn.edu/LDC97S42) dataset which consists of telephone conversation between native English speakers in North America.\n"
|
| 228 |
+
"* Not suitable for a quick implementation of ASR/diarization systems. \n"
|
| 229 |
+
"* Benefits from large community support. However, mainly targeted towards researchers and less suitable for production ready-solutions.\n")
|
| 230 |
+
|
| 231 |
+
container.markdown(
|
| 232 |
+
"### 6. [UIS-RNN](https://github.com/google/uis-rnn)")
|
| 233 |
+
container.markdown(
|
| 234 |
+
"A fully supervised end-to-end diarization model developed by Google.\n"
|
| 235 |
+
"* No-pretrained model is available, so you need to train it from scratch on your custom transcribed data.\n"
|
| 236 |
+
"* Relatively easy to train if you have a large set of pre-labeled data.\n"
|
| 237 |
+
"* Both training and prediction require the usage of a GPU.\n")
|
| 238 |
+
container.markdown(
|
| 239 |
+
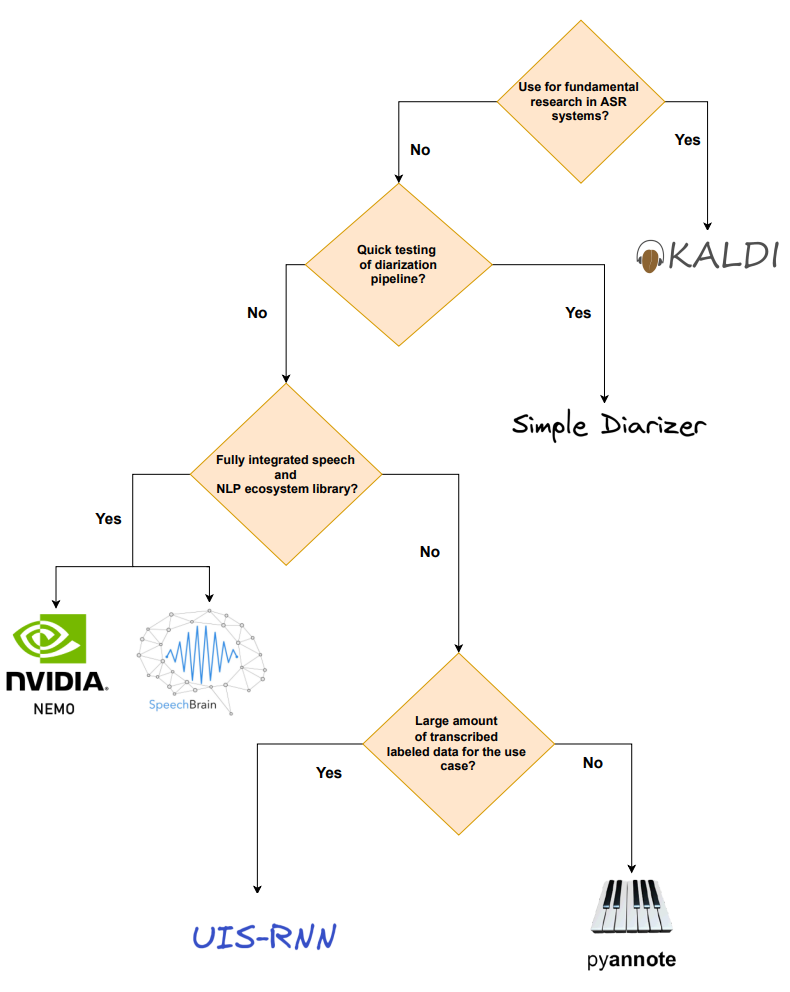
"Phew 😮💨, that's quite some different frameworks! To make it easier to pick the right one for your use case, I've created a simple flowchart that can get you started on picking a suitable library depending on your use case.")
|
| 240 |
+
|
| 241 |
+
col1_im2, col2_im2, col3_im2 = container.columns([4, 5, 4])
|
| 242 |
+
|
| 243 |
+
with col1_im2:
|
| 244 |
+
st.write(' ')
|
| 245 |
+
|
| 246 |
+
with col2_im2:
|
| 247 |
+
st.image(Image.open('docs/flow_chart_diarization_tree.png'),
|
| 248 |
+
caption='Flowchart for choosing a framework suitable for your diarization use case.',
|
| 249 |
+
use_column_width=True)
|
| 250 |
+
|
| 251 |
+
with col3_im2:
|
| 252 |
+
st.write(' ')
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def demo_container(diarization_container):
|
| 256 |
+
diarization_container.header('🤖 Demo')
|
| 257 |
+
diarization_container.markdown(
|
| 258 |
+
"Alright, you're probably very curious at this point to test out a few diarization techniques "
|
| 259 |
+
"yourself. Below is a demo where you can try a few of the libraries that are mentioned above. "
|
| 260 |
+
"You can try running multiple frameworks at the same time and compare their results by ticking multiple "
|
| 261 |
+
"frameworks and clicking **'Apply'**.")
|
| 262 |
+
|
| 263 |
+
diarization_container.caption(
|
| 264 |
+
"Disclaimer: Keep in mind that due to computational constraints, only the first 30 seconds will be used for diarization when uploading your own recordings. "
|
| 265 |
+
"For that reason, the diarization results may not be as accurate compared to diarization computed on longer recordings. This"
|
| 266 |
+
" is simply due to the fact that the diarization algorithms will have much less data to sample from in order to create meaningful clusters of embeddings for "
|
| 267 |
+
"each speaker. On the other hand, the diarization results from the provided samples are pre-computed on the whole recording (length of around ≈10min) and thus "
|
| 268 |
+
"have more accurate diarization results (only the first 30 seconds are shown).")
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
def conlusion_container():
|
| 272 |
+
container = st.container()
|
| 273 |
+
container.title('💬 Conclusions')
|
| 274 |
+
container.markdown("In this blogpost we covered different aspects of speaker diarization.\n")
|
| 275 |
+
container.markdown(
|
| 276 |
+
"👉 First we explained what speaker diarization is and gave a few examples of its different areas of applications.\n")
|
| 277 |
+
container.markdown(
|
| 278 |
+
"👉 We discussed the two main types of systems for implementing diarization system with a solid (high-level) understanding of both **traditional systems** and **end-to-end** systems.")
|
| 279 |
+
container.markdown(
|
| 280 |
+
"👉 Then, we gave a comparison of different diarization frameworks and provided a guide for picking the best one for your use case.")
|
| 281 |
+
container.markdown(
|
| 282 |
+
"👉 Finally, we provided you with an example to quickly try out a few of the diarization libraries.")
|