from pathlib import Path
from functools import partial
from joeynmt.prediction import predict
from joeynmt.helpers import (
check_version,
load_checkpoint,
load_config,
parse_train_args,
resolve_ckpt_path,
)
from joeynmt.model import build_model
from joeynmt.tokenizers import build_tokenizer
from joeynmt.vocabulary import build_vocab
from joeynmt.datasets import build_dataset
import gradio as gr
languages_scripts = {
"Azeri Turkish in Persian": "AzeriTurkish-Persian",
"Central Kurdish in Arabic": "Sorani-Arabic",
"Central Kurdish in Persian": "Sorani-Persian",
"Gilaki in Persian": "Gilaki-Persian",
"Gorani in Arabic": "Gorani-Arabic",
"Gorani in Central Kurdish": "Gorani-Sorani",
"Gorani in Persian": "Gorani-Persian",
"Kashmiri in Urdu": "Kashmiri-Urdu",
"Mazandarani in Persian": "Mazandarani-Persian",
"Northern Kurdish in Arabic": "Kurmanji-Arabic",
"Northern Kurdish in Persian": "Kurmanji-Persian",
"Sindhi in Urdu": "Sindhi-Urdu"
}
def normalize(text, language_script):
cfg_file = "./models/%s/config.yaml"%languages_scripts[language_script]
ckpt = "./models/%s/best.ckpt"%languages_scripts[language_script]
cfg = load_config(Path(cfg_file))
# parse and validate cfg
model_dir, load_model, device, n_gpu, num_workers, _, fp16 = parse_train_args(
cfg["training"], mode="prediction")
test_cfg = cfg["testing"]
src_cfg = cfg["data"]["src"]
trg_cfg = cfg["data"]["trg"]
load_model = load_model if ckpt is None else Path(ckpt)
ckpt = resolve_ckpt_path(load_model, model_dir)
src_vocab, trg_vocab = build_vocab(cfg["data"], model_dir=model_dir)
model = build_model(cfg["model"], src_vocab=src_vocab, trg_vocab=trg_vocab)
# load model state from disk
model_checkpoint = load_checkpoint(ckpt, device=device)
model.load_state_dict(model_checkpoint["model_state"])
if device.type == "cuda":
model.to(device)
tokenizer = build_tokenizer(cfg["data"])
sequence_encoder = {
src_cfg["lang"]: partial(src_vocab.sentences_to_ids, bos=False, eos=True),
trg_cfg["lang"]: None,
}
test_cfg["batch_size"] = 1 # CAUTION: this will raise an error if n_gpus > 1
test_cfg["batch_type"] = "sentence"
test_data = build_dataset(
dataset_type="stream",
path=None,
src_lang=src_cfg["lang"],
trg_lang=trg_cfg["lang"],
split="test",
tokenizer=tokenizer,
sequence_encoder=sequence_encoder,
)
test_data.set_item(text)
# test_data.set_item(INPUT.rstrip())
cfg=test_cfg
_, _, hypotheses, trg_tokens, trg_scores, _ = predict(
model=model,
data=test_data,
compute_loss=False,
device=device,
n_gpu=n_gpu,
normalization="none",
num_workers=num_workers,
cfg=cfg,
fp16=fp16,
)
return hypotheses[0]
title = """
Script Normalization for Unconventional Writing
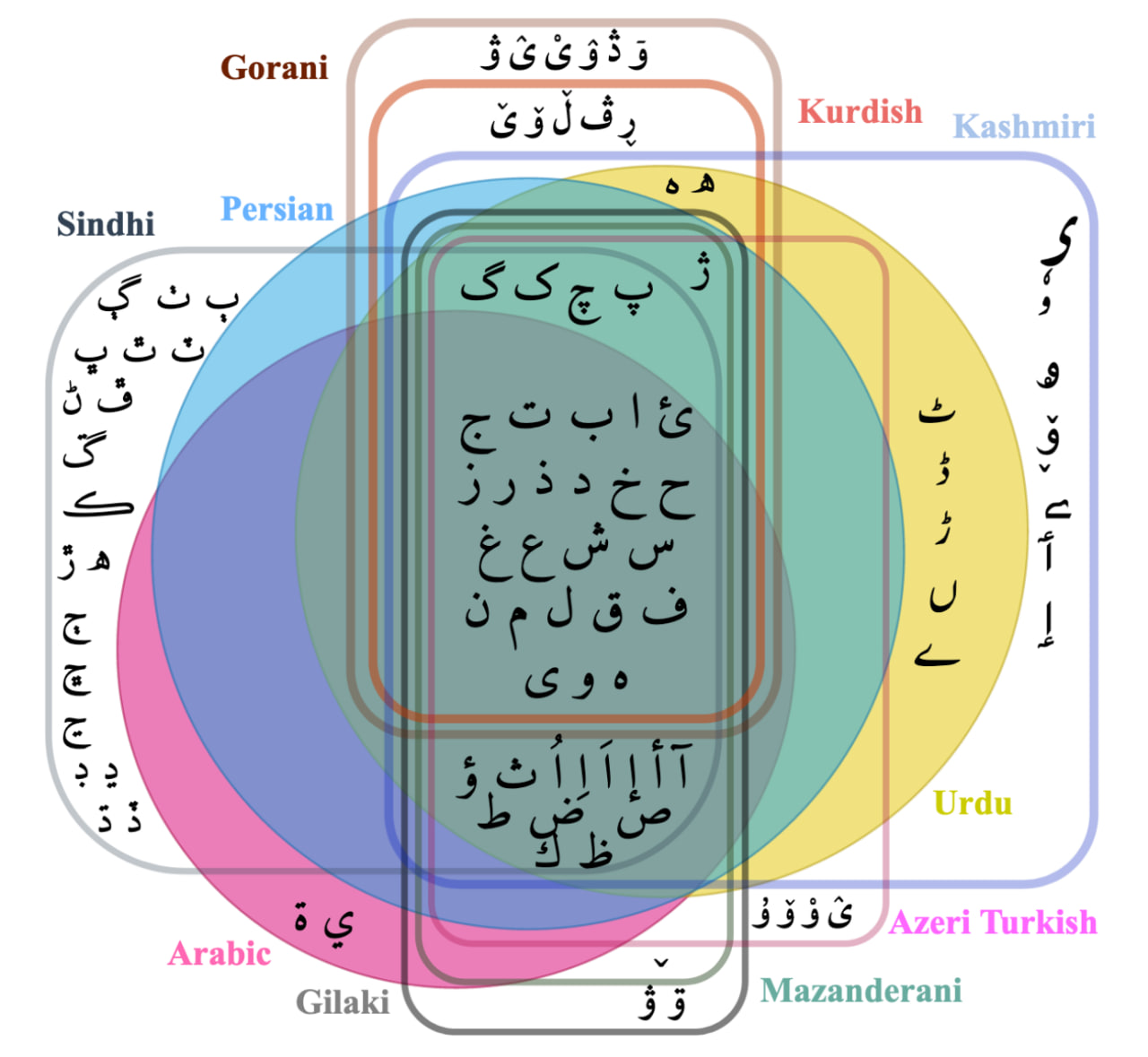
"""
description = """
- "mar7aba!"
- "هاو ئار یوو؟"
- "Μπιάνβενου α σετ ντεμό!"
What do all these sentences have in common? Being greeted in Arabic with "mar7aba" written in the Latin script, then asked how you are ("هاو ئار یوو؟") in English using the Perso-Arabic script of Kurdish and then, welcomed to this demo in French ("Μπιάνβενου α σετ ντεμό!") written in Greek script. All these sentences are written in an unconventional script.
Although you may find these sentences risible, unconventional writing is a common practice among millions of speakers in bilingual communities. In our paper entitled "Script Normalization for Unconventional Writing of Under-Resourced Languages in Bilingual Communities", we shed light on this problem and propose an approach to normalize noisy text written in unconventional writing.
This demo deploys a few models that are trained for the normalization of unconventional writing. Please note that this tool is not a spell-checker and cannot correct errors beyond character normalization. For better performance, you can apply hard-coded rules on the input and then pass it to the models, hence a hybrid system.
For more information, you can check out the project on GitHub too: https://github.com/sinaahmadi/ScriptNormalization
"""
examples = [
["بو شهرین نوفوسو ، 2014 نجی ایلين نوفوس ساییمی اساسيندا 41 نفر ایمیش .", "Azeri Turkish in Persian"],#"بۇ شهرین نۆفوسو ، 2014 نجی ایلين نۆفوس ساییمی اساسيندا 41 نفر ایمیش ."
["ياخوا تةمةن دريژبيت بوئةم ميللةتة", "Central Kurdish in Arabic"],
["یکیک له جوانیکانی ام شاره جوانه", "Central Kurdish in Persian"],
["نمک درهٰ مردوم گيلک ايسن ؤ اوشان زوان ني گيلکي ايسه .", "Gilaki in Persian"],
["شؤنةو اانةيةرة گةشت و گلي ناجارانةو اؤجالاني دةستش پنةكةرد", "Gorani in Arabic"], #شۆنەو ئانەیەرە گەشت و گێڵی ناچارانەو ئۆجالانی دەستش پنەکەرد
["ڕوٙو زوانی ئەذایی چەنی پەیذابی ؟", "Gorani in Central Kurdish"], # ڕوٙو زوانی ئەڎایی چەنی پەیڎابی ؟
["هنگامکان ظميٛ ر چمان ، بپا کريٛلي بيشان :", "Gorani in Persian"], # هەنگامەکان وزمیٛ وەرو چەمان ، بەپاو کریٛڵی بیەشان :
["ربعی بن افکل اُسے اَکھ صُحابی .", "Kashmiri in Urdu"], # ربعی بن افکل ٲسؠ اَکھ صُحابی .
["اینتا زون گنشکرون 85 میلیون نفر هسن", "Mazandarani in Persian"], # اینتا زوون گِنِشکَرون 85 میلیون نفر هسنه
["بة رطكا هة صطئن ژ دل هاطة بة لافكرن", "Northern Kurdish in Arabic"], #پەرتوکا هەستێن ژ دل هاتە بەلافکرن
["ثرکى همرنگ نرميني دويت هندک قوناغين دي ببريت", "Northern Kurdish in Persian"], # سەرەکی هەمەرەنگ نەرمینێ دڤێت هندەک قوناغێن دی ببڕیت
["ہتی کجھ اپ ۽ تمام دائون ترینون بیھندیون آھن .", "Sindhi in Urdu"] # هتي ڪجھ اپ ۽ تمام ڊائون ٽرينون بيھنديون آھن .
]
article = """
"""
demo = gr.Interface(
title=title,
description=description,
fn=normalize,
inputs = [
gr.inputs.Textbox(lines=4, label="Noisy Text \U0001F974"),
gr.Dropdown(label="Language in unconventional script \U0001F642", choices=sorted(list(languages_scripts.keys()))),
],
outputs=gr.outputs.Textbox(label="Normalized Text \U0001F642"),
examples=examples,
article=article,
examples_per_page=20
)
demo.launch()