import spaces
import gradio as gr
from huggingface_hub import hf_hub_download
import json
import torch
import os
from env import AttrDict
from meldataset import get_mel_spectrogram, MAX_WAV_VALUE
from bigvgan import BigVGAN
import librosa
import numpy as np
from utils import plot_spectrogram
import PIL
if torch.cuda.is_available():
device = torch.device('cuda')
torch.backends.cudnn.benchmark = False
print(f"using GPU")
else:
device = torch.device('cpu')
print(f"using CPU")
def load_checkpoint(filepath):
assert os.path.isfile(filepath)
print("Loading '{}'".format(filepath))
checkpoint_dict = torch.load(filepath, map_location='cpu')
print("Complete.")
return checkpoint_dict
def inference_gradio(input, model_choice): # input is audio waveform in [T, channel]
sr, audio = input # unpack input to sampling rate and audio itself
audio = np.transpose(audio) # transpose to [channel, T] for librosa
audio = audio / MAX_WAV_VALUE # convert int16 to float range used by BigVGAN
model = dict_model[model_choice]
if sr != model.h.sampling_rate: # convert audio to model's sampling rate
audio = librosa.resample(audio, orig_sr=sr, target_sr=model.h.sampling_rate)
if len(audio.shape) == 2: # stereo
audio = librosa.to_mono(audio) # convert to mono if stereo
audio = librosa.util.normalize(audio) * 0.95
output, spec_gen = inference_model(
audio, model
) # output is generated audio in ndarray, int16
spec_plot_gen = plot_spectrogram(spec_gen)
output_audio = (model.h.sampling_rate, output) # tuple for gr.Audio output
buffer = spec_plot_gen.canvas.buffer_rgba()
output_image = PIL.Image.frombuffer(
"RGBA",
spec_plot_gen.canvas.get_width_height(),
buffer,
"raw",
"RGBA",
0,
1
)
return output_audio, output_image
@spaces.GPU(duration=120)
def inference_model(audio_input, model):
# load model to device
model.to(device)
with torch.inference_mode():
wav = torch.FloatTensor(audio_input)
# compute mel spectrogram from the ground truth audio
spec_gt = get_mel_spectrogram(wav.unsqueeze(0), model.h).to(device)
y_g_hat = model(spec_gt)
audio_gen = y_g_hat.squeeze().cpu()
spec_gen = get_mel_spectrogram(audio_gen.unsqueeze(0), model.h)
audio_gen = audio_gen.numpy() # [T], float [-1, 1]
audio_gen = (audio_gen * MAX_WAV_VALUE).astype("int16") # [T], int16
spec_gen = spec_gen.squeeze().numpy() # [C, T_frame]
# unload to cpu
model.to("cpu")
# delete gpu tensor
del spec_gt, y_g_hat
return audio_gen, spec_gen
css = """
a {
color: inherit;
text-decoration: underline;
}
.gradio-container {
font-family: 'IBM Plex Sans', sans-serif;
}
.gr-button {
color: white;
border-color: #000000;
background: #000000;
}
input[type='range'] {
accent-color: #000000;
}
.dark input[type='range'] {
accent-color: #dfdfdf;
}
.container {
max-width: 730px;
margin: auto;
padding-top: 1.5rem;
}
#gallery {
min-height: 22rem;
margin-bottom: 15px;
margin-left: auto;
margin-right: auto;
border-bottom-right-radius: .5rem !important;
border-bottom-left-radius: .5rem !important;
}
#gallery>div>.h-full {
min-height: 20rem;
}
.details:hover {
text-decoration: underline;
}
.gr-button {
white-space: nowrap;
}
.gr-button:focus {
border-color: rgb(147 197 253 / var(--tw-border-opacity));
outline: none;
box-shadow: var(--tw-ring-offset-shadow), var(--tw-ring-shadow), var(--tw-shadow, 0 0 #0000);
--tw-border-opacity: 1;
--tw-ring-offset-shadow: var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color);
--tw-ring-shadow: var(--tw-ring-inset) 0 0 0 calc(3px var(--tw-ring-offset-width)) var(--tw-ring-color);
--tw-ring-color: rgb(191 219 254 / var(--tw-ring-opacity));
--tw-ring-opacity: .5;
}
#advanced-btn {
font-size: .7rem !important;
line-height: 19px;
margin-top: 12px;
margin-bottom: 12px;
padding: 2px 8px;
border-radius: 14px !important;
}
#advanced-options {
margin-bottom: 20px;
}
.footer {
margin-bottom: 45px;
margin-top: 35px;
text-align: center;
border-bottom: 1px solid #e5e5e5;
}
.footer>p {
font-size: .8rem;
display: inline-block;
padding: 0 10px;
transform: translateY(10px);
background: white;
}
.dark .footer {
border-color: #303030;
}
.dark .footer>p {
background: #0b0f19;
}
.acknowledgments h4{
margin: 1.25em 0 .25em 0;
font-weight: bold;
font-size: 115%;
}
#container-advanced-btns{
display: flex;
flex-wrap: wrap;
justify-content: space-between;
align-items: center;
}
.animate-spin {
animation: spin 1s linear infinite;
}
@keyframes spin {
from {
transform: rotate(0deg);
}
to {
transform: rotate(360deg);
}
}
#share-btn-container {
display: flex; padding-left: 0.5rem !important; padding-right: 0.5rem !important; background-color: #000000; justify-content: center; align-items: center; border-radius: 9999px !important; width: 13rem;
margin-top: 10px;
margin-left: auto;
}
#share-btn {
all: initial; color: #ffffff;font-weight: 600; cursor:pointer; font-family: 'IBM Plex Sans', sans-serif; margin-left: 0.5rem !important; padding-top: 0.25rem !important; padding-bottom: 0.25rem !important;right:0;
}
#share-btn * {
all: unset;
}
#share-btn-container div:nth-child(-n+2){
width: auto !important;
min-height: 0px !important;
}
#share-btn-container .wrap {
display: none !important;
}
.gr-form{
flex: 1 1 50%; border-top-right-radius: 0; border-bottom-right-radius: 0;
}
#prompt-container{
gap: 0;
}
#generated_id{
min-height: 700px
}
#setting_id{
margin-bottom: 12px;
text-align: center;
font-weight: 900;
}
"""
######################## script for loading the models ########################
LIST_MODEL_ID = [
"bigvgan_24khz_100band",
"bigvgan_base_24khz_100band",
"bigvgan_22khz_80band",
"bigvgan_base_22khz_80band",
"bigvgan_v2_22khz_80band_256x",
"bigvgan_v2_22khz_80band_fmax8k_256x",
"bigvgan_v2_24khz_100band_256x",
"bigvgan_v2_44khz_128band_256x",
"bigvgan_v2_44khz_128band_512x"
]
dict_model = {}
dict_config = {}
for model_name in LIST_MODEL_ID:
generator = BigVGAN.from_pretrained('nvidia/'+model_name, token=os.environ['TOKEN'])
generator.eval()
generator.remove_weight_norm()
dict_model[model_name] = generator
dict_config[model_name] = generator.h
######################## script for gradio UI ########################
iface = gr.Blocks(css=css)
with iface:
gr.HTML(
"""
"""
)
gr.HTML(
"""
News
[Jul 2024] We release BigVGAN-v2 along with pretrained checkpoints. Below are the highlights:
- Custom CUDA kernel for inference: we provide a fused upsampling + activation kernel written in CUDA for accelerated inference speed. Our test shows 1.5 - 3x faster speed on a single A100 GPU.
- Improved discriminator and loss: BigVGAN-v2 is trained using a multi-scale sub-band CQT discriminator and a multi-scale mel spectrogram loss.
- Larger training data: BigVGAN-v2 is trained using datasets containing diverse audio types, including speech in multiple languages, environmental sounds, and instruments.
- We provide pretrained checkpoints of BigVGAN-v2 using diverse audio configurations, supporting up to 44 kHz sampling rate and 512x upsampling ratio.
"""
)
gr.HTML(
"""
Model Overview
BigVGAN is a neural vocoder model that generates audio waveforms using mel spectrogram as inputs.
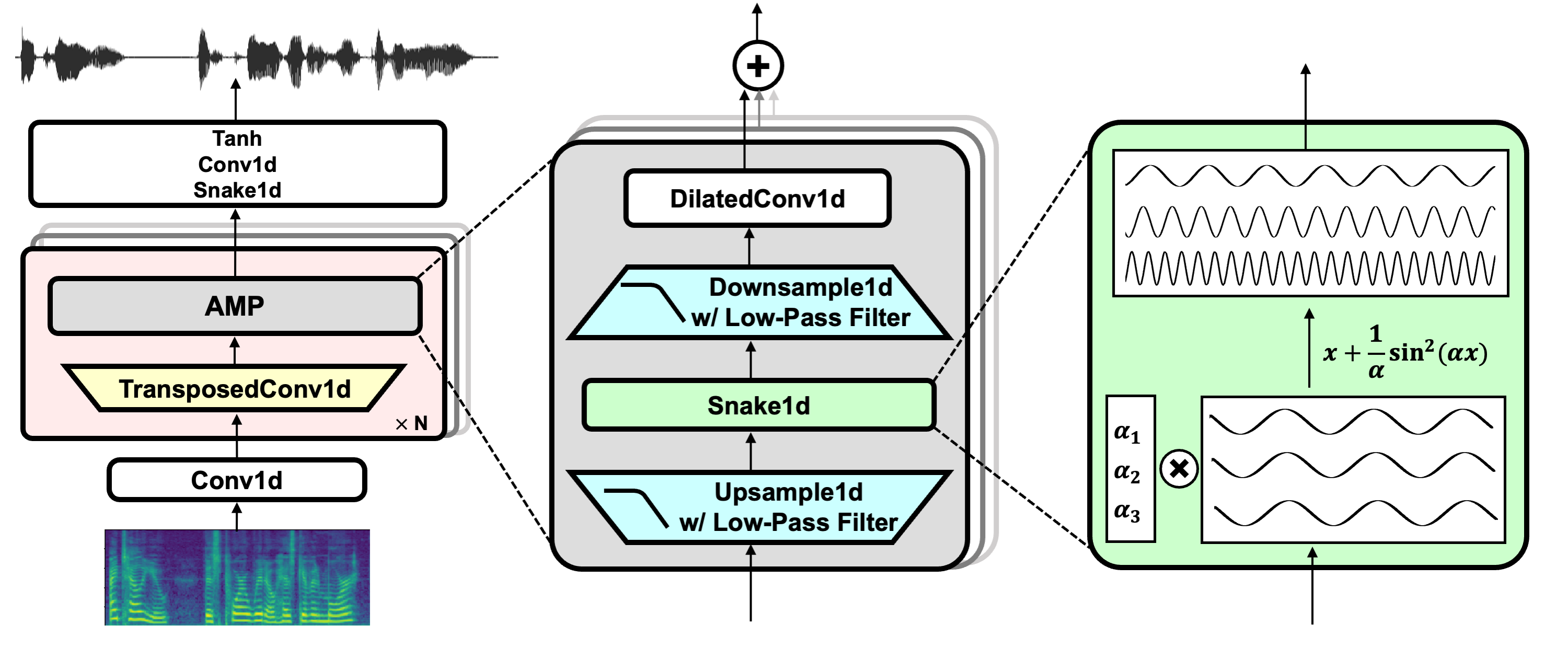
"""
)
with gr.Group():
model_choice = gr.Dropdown(
label="Select the model. Default: bigvgan_v2_24khz_100band_256x",
value="bigvgan_v2_24khz_100band_256x",
choices=[m for m in LIST_MODEL_ID],
interactive=True,
)
audio_input = gr.Audio(
label="Input Audio", elem_id="input-audio", interactive=True
)
button = gr.Button("Submit")
output_audio = gr.Audio(label="Output Audio", elem_id="output-audio")
output_image = gr.Image(label="Output Mel Spectrogram", elem_id="output-image-gen")
button.click(
inference_gradio,
inputs=[audio_input, model_choice],
outputs=[output_audio, output_image],
concurrency_limit=10,
)
gr.Examples(
[
[os.path.join(os.path.dirname(__file__), "examples/jensen_24k.wav"), "bigvgan_v2_24khz_100band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/libritts_24k.wav"), "bigvgan_v2_24khz_100band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/queen_24k.wav"), "bigvgan_v2_24khz_100band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/dance_24k.wav"), "bigvgan_v2_24khz_100band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/megalovania_24k.wav"), "bigvgan_v2_24khz_100band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/hifitts_44k.wav"), "bigvgan_v2_44khz_128band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/musdbhq_44k.wav"), "bigvgan_v2_44khz_128band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/musiccaps1_44k.wav"), "bigvgan_v2_44khz_128band_256x"],
[os.path.join(os.path.dirname(__file__), "examples/musiccaps2_44k.wav"), "bigvgan_v2_44khz_128band_256x"],
],
fn=inference_gradio,
inputs=[audio_input, model_choice],
outputs=[output_audio, output_image]
)
gr.HTML(
"""
| Model Name |
Sampling Rate |
Mel band |
fmax |
Upsampling Ratio |
Parameters |
Dataset |
Fine-Tuned |
| bigvgan_v2_44khz_128band_512x |
44 kHz |
128 |
22050 |
512 |
122M |
Large-scale Compilation |
No |
| bigvgan_v2_44khz_128band_256x |
44 kHz |
128 |
22050 |
256 |
112M |
Large-scale Compilation |
No |
| bigvgan_v2_24khz_100band_256x |
24 kHz |
100 |
12000 |
256 |
112M |
Large-scale Compilation |
No |
| bigvgan_v2_22khz_80band_256x |
22 kHz |
80 |
11025 |
256 |
112M |
Large-scale Compilation |
No |
| bigvgan_v2_22khz_80band_fmax8k_256x |
22 kHz |
80 |
8000 |
256 |
112M |
Large-scale Compilation |
No |
| bigvgan_24khz_100band |
24 kHz |
100 |
12000 |
256 |
112M |
LibriTTS |
No |
| bigvgan_base_24khz_100band |
24 kHz |
100 |
12000 |
256 |
14M |
LibriTTS |
No |
| bigvgan_22khz_80band |
22 kHz |
80 |
8000 |
256 |
112M |
LibriTTS + VCTK + LJSpeech |
No |
| bigvgan_base_22khz_80band |
22 kHz |
80 |
8000 |
256 |
14M |
LibriTTS + VCTK + LJSpeech |
No |
NOTE: The v1 models are trained using speech audio datasets ONLY! (24kHz models: LibriTTS, 22kHz models: LibriTTS + VCTK + LJSpeech).
"""
)
iface.queue()
iface.launch()