Spaces:
Sleeping

Sleeping
Commit
·
0644c3a
1
Parent(s):
9be5835
Upload 3 files
Browse files- Support Chat Bot For Website.PNG +0 -0
- constants.py +6 -0
- utils4.py +72 -0
Support Chat Bot For Website.PNG
ADDED
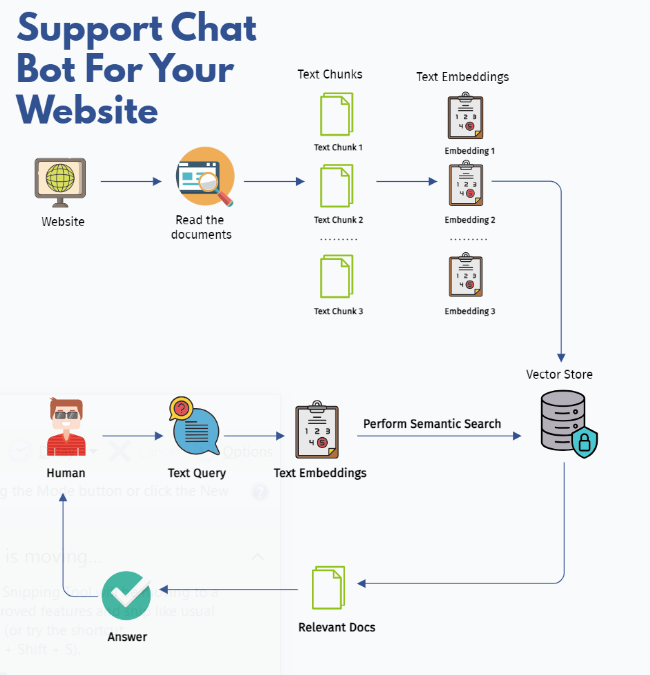
|
constants.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#WEBSITE_URL="https://jobs.excelcult.com/wp-sitemap-posts-post-1.xml"
|
| 2 |
+
#WEBSITE_URL="https://www.naukri.com/jobs-in-kolkata-sitemap-xml"
|
| 3 |
+
|
| 4 |
+
WEBSITE_URL="https://resumes.indeed.com/?co=IN&hl=en&from=gnav-one-host&isid=gnav-gnav-one-host-header-roz/sitemap.xml"
|
| 5 |
+
PINECONE_ENVIRONMENT="gcp-starter"
|
| 6 |
+
PINECONE_INDEX="chatbot"
|
utils4.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 2 |
+
from langchain.vectorstores import Pinecone
|
| 3 |
+
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
|
| 4 |
+
import pinecone
|
| 5 |
+
import asyncio
|
| 6 |
+
from langchain.document_loaders.sitemap import SitemapLoader
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
#Function to fetch data from website
|
| 10 |
+
#https://python.langchain.com/docs/modules/data_connection/document_loaders/integrations/sitemap
|
| 11 |
+
def get_website_data(sitemap_url):
|
| 12 |
+
|
| 13 |
+
loop = asyncio.new_event_loop()
|
| 14 |
+
asyncio.set_event_loop(loop)
|
| 15 |
+
loader = SitemapLoader(
|
| 16 |
+
sitemap_url
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
docs = loader.load()
|
| 20 |
+
|
| 21 |
+
return docs
|
| 22 |
+
|
| 23 |
+
#Function to split data into smaller chunks
|
| 24 |
+
def split_data(docs):
|
| 25 |
+
|
| 26 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 27 |
+
chunk_size = 1000,
|
| 28 |
+
chunk_overlap = 200,
|
| 29 |
+
length_function = len,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
docs_chunks = text_splitter.split_documents(docs)
|
| 33 |
+
return docs_chunks
|
| 34 |
+
|
| 35 |
+
#Function to create embeddings instance
|
| 36 |
+
def create_embeddings():
|
| 37 |
+
|
| 38 |
+
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
|
| 39 |
+
return embeddings
|
| 40 |
+
|
| 41 |
+
#Function to push data to Pinecone
|
| 42 |
+
def push_to_pinecone(pinecone_apikey,pinecone_environment,pinecone_index_name,embeddings,docs):
|
| 43 |
+
|
| 44 |
+
pinecone.init(
|
| 45 |
+
api_key=pinecone_apikey,
|
| 46 |
+
environment=pinecone_environment
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
index_name = pinecone_index_name
|
| 50 |
+
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)
|
| 51 |
+
return index
|
| 52 |
+
|
| 53 |
+
#Function to pull index data from Pinecone
|
| 54 |
+
def pull_from_pinecone(pinecone_apikey,pinecone_environment,pinecone_index_name,embeddings):
|
| 55 |
+
|
| 56 |
+
pinecone.init(
|
| 57 |
+
api_key=pinecone_apikey,
|
| 58 |
+
environment=pinecone_environment
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
index_name = pinecone_index_name
|
| 62 |
+
|
| 63 |
+
index = Pinecone.from_existing_index(index_name, embeddings)
|
| 64 |
+
return index
|
| 65 |
+
|
| 66 |
+
#This function will help us in fetching the top relevent documents from our vector store - Pinecone Index
|
| 67 |
+
def get_similar_docs(index,query,k=2):
|
| 68 |
+
|
| 69 |
+
similar_docs = index.similarity_search(query, k=k)
|
| 70 |
+
return similar_docs
|
| 71 |
+
|
| 72 |
+
|