Spaces:
Configuration error

Configuration error
pengsida
commited on
Commit
•
1ba539f
1
Parent(s):
6b5c61d
initial commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- INSTALL.md +46 -0
- LICENSE +18 -0
- README.md +202 -12
- configs/default.yaml +0 -0
- configs/h36m_exp/latent_xyzc_s11g.yaml +28 -0
- configs/h36m_exp/latent_xyzc_s9p.yaml +28 -0
- configs/monocular_custom.yaml +25 -0
- configs/multi_view_custom.yaml +25 -0
- configs/nerf/nerf_313.yaml +145 -0
- configs/nerf/nerf_315.yaml +18 -0
- configs/nerf/nerf_377.yaml +18 -0
- configs/nerf/nerf_386.yaml +18 -0
- configs/nerf/nerf_387.yaml +18 -0
- configs/nerf/nerf_390.yaml +18 -0
- configs/nerf/nerf_392.yaml +18 -0
- configs/nerf/nerf_393.yaml +18 -0
- configs/nerf/nerf_394.yaml +18 -0
- configs/neural_volumes/neural_volumes_313.yaml +94 -0
- configs/neural_volumes/neural_volumes_315.yaml +94 -0
- configs/neural_volumes/neural_volumes_377.yaml +94 -0
- configs/neural_volumes/neural_volumes_386.yaml +94 -0
- configs/neural_volumes/neural_volumes_387.yaml +94 -0
- configs/neural_volumes/neural_volumes_390.yaml +95 -0
- configs/neural_volumes/neural_volumes_392.yaml +94 -0
- configs/neural_volumes/neural_volumes_393.yaml +94 -0
- configs/neural_volumes/neural_volumes_394.yaml +94 -0
- configs/snapshot_exp/snapshot_f1c.yaml +20 -0
- configs/snapshot_exp/snapshot_f3c.yaml +134 -0
- configs/snapshot_exp/snapshot_f4c.yaml +21 -0
- configs/snapshot_exp/snapshot_f6p.yaml +20 -0
- configs/snapshot_exp/snapshot_f7p.yaml +20 -0
- configs/snapshot_exp/snapshot_f8p.yaml +20 -0
- configs/snapshot_exp/snapshot_m2c.yaml +20 -0
- configs/snapshot_exp/snapshot_m2o.yaml +20 -0
- configs/snapshot_exp/snapshot_m3c.yaml +20 -0
- configs/snapshot_exp/snapshot_m5o.yaml +20 -0
- configs/zju_mocap_exp/latent_xyzc_313.yaml +152 -0
- configs/zju_mocap_exp/latent_xyzc_315.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_377.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_386.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_387.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_390.yaml +23 -0
- configs/zju_mocap_exp/latent_xyzc_392.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_393.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_394.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_395.yaml +21 -0
- configs/zju_mocap_exp/latent_xyzc_396.yaml +22 -0
- configs/zju_mocap_exp/xyzc_rotate_demo_313.yaml +93 -0
- configs/zju_mocap_frame1_exp/latent_xyzc_313_ni1.yaml +21 -0
- configs/zju_mocap_frame1_exp/latent_xyzc_315_ni1.yaml +21 -0
INSTALL.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Set up the python environment
|
| 2 |
+
|
| 3 |
+
```
|
| 4 |
+
conda create -n neuralbody python=3.7
|
| 5 |
+
conda activate neuralbody
|
| 6 |
+
|
| 7 |
+
# make sure that the pytorch cuda is consistent with the system cuda
|
| 8 |
+
# e.g., if your system cuda is 10.0, install torch 1.4 built from cuda 10.0
|
| 9 |
+
pip install torch==1.4.0+cu100 -f https://download.pytorch.org/whl/torch_stable.html
|
| 10 |
+
|
| 11 |
+
pip install -r requirements.txt
|
| 12 |
+
|
| 13 |
+
# install spconv
|
| 14 |
+
cd
|
| 15 |
+
git clone https://github.com/traveller59/spconv --recursive
|
| 16 |
+
cd spconv
|
| 17 |
+
git checkout abf0acf30f5526ea93e687e3f424f62d9cd8313a
|
| 18 |
+
git submodule update --init --recursive
|
| 19 |
+
export CUDA_HOME="/usr/local/cuda-10.0"
|
| 20 |
+
python setup.py bdist_wheel
|
| 21 |
+
cd dist
|
| 22 |
+
pip install spconv-1.2.1-cp36-cp36m-linux_x86_64.whl
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
### Set up datasets
|
| 26 |
+
|
| 27 |
+
#### People-Snapshot dataset
|
| 28 |
+
|
| 29 |
+
1. Download the People-Snapshot dataset [here](https://graphics.tu-bs.de/people-snapshot).
|
| 30 |
+
2. Process the People-Snapshot dataset using the [script](https://github.com/zju3dv/neuralbody#process-people-snapshot).
|
| 31 |
+
3. Create a soft link:
|
| 32 |
+
```
|
| 33 |
+
ROOT=/path/to/neuralbody
|
| 34 |
+
cd $ROOT/data
|
| 35 |
+
ln -s /path/to/people_snapshot people_snapshot
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
#### ZJU-Mocap dataset
|
| 39 |
+
|
| 40 |
+
1. If someone wants to download the ZJU-Mocap dataset, please fill in the [agreement](https://zjueducn-my.sharepoint.com/:b:/g/personal/pengsida_zju_edu_cn/EUPiybrcFeNEhdQROx4-LNEBm4lzLxDwkk1SBcNWFgeplA?e=BGDiQh), and email me (pengsida@zju.edu.cn) and cc Xiaowei Zhou (xwzhou@zju.edu.cn) to request the download link.
|
| 41 |
+
2. Create a soft link:
|
| 42 |
+
```
|
| 43 |
+
ROOT=/path/to/neuralbody
|
| 44 |
+
cd $ROOT/data
|
| 45 |
+
ln -s /path/to/zju_mocap zju_mocap
|
| 46 |
+
```
|
LICENSE
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
////////////////////////////////////////////////////////////////////////////
|
| 2 |
+
// Copyright 2020-2021 the 3D Vision Group at the State Key Lab of CAD&CG,
|
| 3 |
+
// Zhejiang University. All Rights Reserved.
|
| 4 |
+
//
|
| 5 |
+
// For more information see <https://github.com/zju3dv/neuralbody>
|
| 6 |
+
// If you use this code, please cite the corresponding publications as
|
| 7 |
+
// listed on the above website.
|
| 8 |
+
//
|
| 9 |
+
// Permission to use, copy, modify and distribute this software and its
|
| 10 |
+
// documentation for educational, research and non-profit purposes only.
|
| 11 |
+
// Any modification based on this work must be open source and prohibited
|
| 12 |
+
// for commercial use.
|
| 13 |
+
// You must retain, in the source form of any derivative works that you
|
| 14 |
+
// distribute, all copyright, patent, trademark, and attribution notices
|
| 15 |
+
// from the source form of this work.
|
| 16 |
+
//
|
| 17 |
+
//
|
| 18 |
+
////////////////////////////////////////////////////////////////////////////
|
README.md
CHANGED
|
@@ -1,12 +1,202 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
**News**
|
| 2 |
+
|
| 3 |
+
* `05/17/2021` To make the comparison on ZJU-MoCap easier, we save quantitative and qualitative results of other methods at [here](https://github.com/zju3dv/neuralbody/blob/master/supplementary_material.md#results-of-other-methods-on-zju-mocap), including Neural Volumes, Multi-view Neural Human Rendering, and Deferred Neural Human Rendering.
|
| 4 |
+
* `05/13/2021` To make the following works easier compare with our model, we save our rendering results of ZJU-MoCap at [here](https://zjueducn-my.sharepoint.com/:u:/g/personal/pengsida_zju_edu_cn/Ea3VOUy204VAiVJ-V-OGd9YBxdhbtfpS-U6icD_rDq0mUQ?e=cAcylK) and write a [document](supplementary_material.md) that describes the training and test protocols.
|
| 5 |
+
* `05/12/2021` The code supports the test and visualization on unseen human poses.
|
| 6 |
+
* `05/12/2021` We update the ZJU-MoCap dataset with better fitted SMPL using [EasyMocap](https://github.com/zju3dv/EasyMocap). We also release a [website](https://zju3dv.github.io/zju_mocap/) for visualization. Please see [here](https://github.com/zju3dv/neuralbody#potential-problems-of-provided-smpl-parameters) for the usage of provided smpl parameters.
|
| 7 |
+
|
| 8 |
+
# Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
|
| 9 |
+
### [Project Page](https://zju3dv.github.io/neuralbody) | [Video](https://www.youtube.com/watch?v=BPCAMeBCE-8) | [Paper](https://arxiv.org/pdf/2012.15838.pdf) | [Data](https://github.com/zju3dv/neuralbody/blob/master/INSTALL.md#zju-mocap-dataset)
|
| 10 |
+
|
| 11 |
+
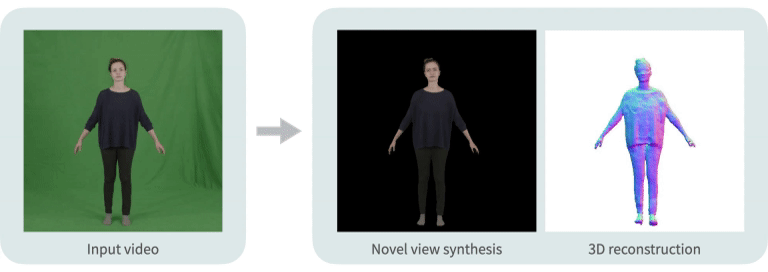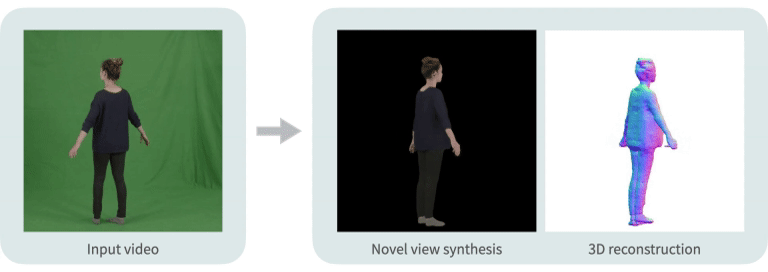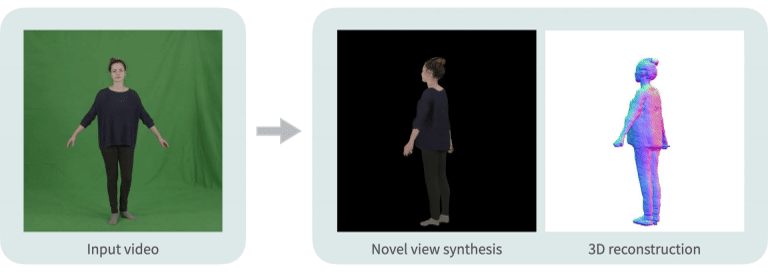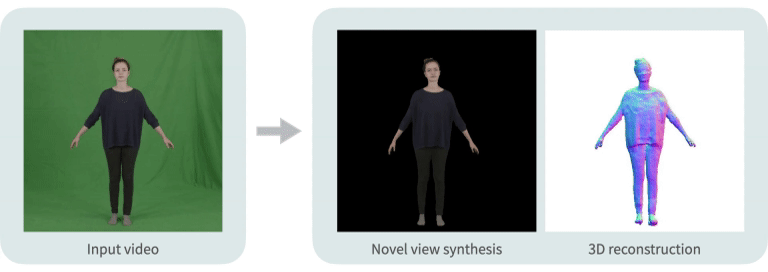
|
| 12 |
+
|
| 13 |
+
> [Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans](https://arxiv.org/pdf/2012.15838.pdf)
|
| 14 |
+
> Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, Xiaowei Zhou
|
| 15 |
+
> CVPR 2021
|
| 16 |
+
|
| 17 |
+
Any questions or discussions are welcomed!
|
| 18 |
+
|
| 19 |
+
## Installation
|
| 20 |
+
|
| 21 |
+
Please see [INSTALL.md](INSTALL.md) for manual installation.
|
| 22 |
+
|
| 23 |
+
### Installation using docker
|
| 24 |
+
|
| 25 |
+
Please see [docker/README.md](docker/README.md).
|
| 26 |
+
|
| 27 |
+
Thanks to [Zhaoyi Wan](https://github.com/wanzysky) for providing the docker implementation.
|
| 28 |
+
|
| 29 |
+
## Run the code on the custom dataset
|
| 30 |
+
|
| 31 |
+
Please see [CUSTOM](tools/custom).
|
| 32 |
+
|
| 33 |
+
## Run the code on People-Snapshot
|
| 34 |
+
|
| 35 |
+
Please see [INSTALL.md](INSTALL.md) to download the dataset.
|
| 36 |
+
|
| 37 |
+
We provide the pretrained models at [here](https://zjueducn-my.sharepoint.com/:f:/g/personal/pengsida_zju_edu_cn/Enn43YWDHwBEg-XBqnetFYcBLr3cItZ0qUFU-oKUpDHKXw?e=FObjE9).
|
| 38 |
+
|
| 39 |
+
### Process People-Snapshot
|
| 40 |
+
|
| 41 |
+
We already provide some processed data. If you want to process more videos of People-Snapshot, you could use [tools/process_snapshot.py](tools/process_snapshot.py).
|
| 42 |
+
|
| 43 |
+
You can also visualize smpl parameters of People-Snapshot with [tools/vis_snapshot.py](tools/vis_snapshot.py).
|
| 44 |
+
|
| 45 |
+
### Visualization on People-Snapshot
|
| 46 |
+
|
| 47 |
+
Take the visualization on `female-3-casual` as an example. The command lines for visualization are recorded in [visualize.sh](visualize.sh).
|
| 48 |
+
|
| 49 |
+
1. Download the corresponding pretrained model and put it to `$ROOT/data/trained_model/if_nerf/female3c/latest.pth`.
|
| 50 |
+
2. Visualization:
|
| 51 |
+
* Visualize novel views of single frame
|
| 52 |
+
```
|
| 53 |
+
python run.py --type visualize --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c vis_novel_view True num_render_views 144
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
* Visualize views of dynamic humans with fixed camera
|
| 59 |
+
```
|
| 60 |
+
python run.py --type visualize --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c vis_novel_pose True
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+

|
| 64 |
+
|
| 65 |
+
* Visualize mesh
|
| 66 |
+
```
|
| 67 |
+
# generate meshes
|
| 68 |
+
python run.py --type visualize --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c vis_mesh True train.num_workers 0
|
| 69 |
+
# visualize a specific mesh
|
| 70 |
+
python tools/render_mesh.py --exp_name female3c --dataset people_snapshot --mesh_ind 226
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
3. The results of visualization are located at `$ROOT/data/render/female3c` and `$ROOT/data/perform/female3c`.
|
| 76 |
+
|
| 77 |
+
### Training on People-Snapshot
|
| 78 |
+
|
| 79 |
+
Take the training on `female-3-casual` as an example. The command lines for training are recorded in [train.sh](train.sh).
|
| 80 |
+
|
| 81 |
+
1. Train:
|
| 82 |
+
```
|
| 83 |
+
# training
|
| 84 |
+
python train_net.py --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c resume False
|
| 85 |
+
# distributed training
|
| 86 |
+
python -m torch.distributed.launch --nproc_per_node=4 train_net.py --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c resume False gpus "0, 1, 2, 3" distributed True
|
| 87 |
+
```
|
| 88 |
+
2. Train with white background:
|
| 89 |
+
```
|
| 90 |
+
# training
|
| 91 |
+
python train_net.py --cfg_file configs/snapshot_exp/snapshot_f3c.yaml exp_name female3c resume False white_bkgd True
|
| 92 |
+
```
|
| 93 |
+
3. Tensorboard:
|
| 94 |
+
```
|
| 95 |
+
tensorboard --logdir data/record/if_nerf
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
## Run the code on ZJU-MoCap
|
| 99 |
+
|
| 100 |
+
Please see [INSTALL.md](INSTALL.md) to download the dataset.
|
| 101 |
+
|
| 102 |
+
We provide the pretrained models at [here](https://zjueducn-my.sharepoint.com/:f:/g/personal/pengsida_zju_edu_cn/Enn43YWDHwBEg-XBqnetFYcBLr3cItZ0qUFU-oKUpDHKXw?e=FObjE9).
|
| 103 |
+
|
| 104 |
+
### Potential problems of provided smpl parameters
|
| 105 |
+
|
| 106 |
+
1. The newly fitted parameters locate in `new_params`. Currently, the released pretrained models are trained on previously fitted parameters, which locate in `params`.
|
| 107 |
+
2. The smpl parameters of ZJU-MoCap have different definition from the one of MPI's smplx.
|
| 108 |
+
* If you want to extract vertices from the provided smpl parameters, please use `zju_smpl/extract_vertices.py`.
|
| 109 |
+
* The reason that we use the current definition is described at [here](https://github.com/zju3dv/EasyMocap/blob/master/doc/02_output.md#attention-for-smplsmpl-x-users).
|
| 110 |
+
|
| 111 |
+
It is okay to train Neural Body with smpl parameters fitted by smplx.
|
| 112 |
+
|
| 113 |
+
### Test on ZJU-MoCap
|
| 114 |
+
|
| 115 |
+
The command lines for test are recorded in [test.sh](test.sh).
|
| 116 |
+
|
| 117 |
+
Take the test on `sequence 313` as an example.
|
| 118 |
+
|
| 119 |
+
1. Download the corresponding pretrained model and put it to `$ROOT/data/trained_model/if_nerf/xyzc_313/latest.pth`.
|
| 120 |
+
2. Test on training human poses:
|
| 121 |
+
```
|
| 122 |
+
python run.py --type evaluate --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313
|
| 123 |
+
```
|
| 124 |
+
3. Test on unseen human poses:
|
| 125 |
+
```
|
| 126 |
+
python run.py --type evaluate --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 test_novel_pose True
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
### Visualization on ZJU-MoCap
|
| 130 |
+
|
| 131 |
+
Take the visualization on `sequence 313` as an example. The command lines for visualization are recorded in [visualize.sh](visualize.sh).
|
| 132 |
+
|
| 133 |
+
1. Download the corresponding pretrained model and put it to `$ROOT/data/trained_model/if_nerf/xyzc_313/latest.pth`.
|
| 134 |
+
2. Visualization:
|
| 135 |
+
* Visualize novel views of single frame
|
| 136 |
+
```
|
| 137 |
+
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_view True
|
| 138 |
+
```
|
| 139 |
+
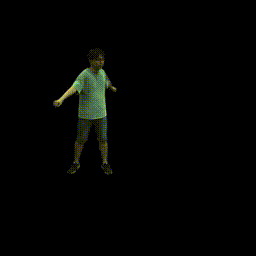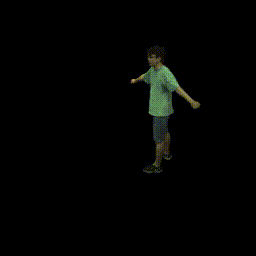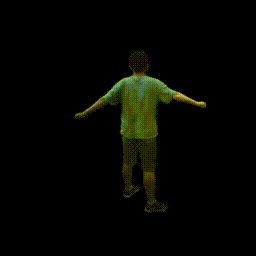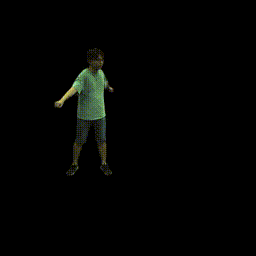
|
| 140 |
+
|
| 141 |
+
* Visualize novel views of single frame by rotating the SMPL model
|
| 142 |
+
```
|
| 143 |
+
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_view True num_render_views 100
|
| 144 |
+
```
|
| 145 |
+
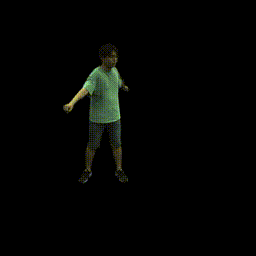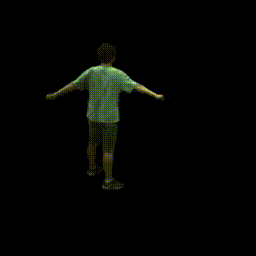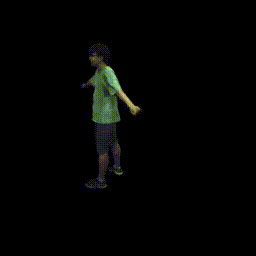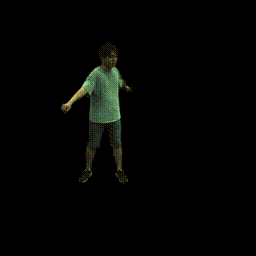
|
| 146 |
+
|
| 147 |
+
* Visualize views of dynamic humans with fixed camera
|
| 148 |
+
```
|
| 149 |
+
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_pose True num_render_frame 1000 num_render_views 1
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
* Visualize views of dynamic humans with rotated camera
|
| 154 |
+
```
|
| 155 |
+
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_novel_pose True num_render_frame 1000
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
* Visualize mesh
|
| 160 |
+
```
|
| 161 |
+
# generate meshes
|
| 162 |
+
python run.py --type visualize --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 vis_mesh True train.num_workers 0
|
| 163 |
+
# visualize a specific mesh
|
| 164 |
+
python tools/render_mesh.py --exp_name xyzc_313 --dataset zju_mocap --mesh_ind 0
|
| 165 |
+
```
|
| 166 |
+

|
| 167 |
+
|
| 168 |
+
4. The results of visualization are located at `$ROOT/data/render/xyzc_313` and `$ROOT/data/perform/xyzc_313`.
|
| 169 |
+
|
| 170 |
+
### Training on ZJU-MoCap
|
| 171 |
+
|
| 172 |
+
Take the training on `sequence 313` as an example. The command lines for training are recorded in [train.sh](train.sh).
|
| 173 |
+
|
| 174 |
+
1. Train:
|
| 175 |
+
```
|
| 176 |
+
# training
|
| 177 |
+
python train_net.py --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 resume False
|
| 178 |
+
# distributed training
|
| 179 |
+
python -m torch.distributed.launch --nproc_per_node=4 train_net.py --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 resume False gpus "0, 1, 2, 3" distributed True
|
| 180 |
+
```
|
| 181 |
+
2. Train with white background:
|
| 182 |
+
```
|
| 183 |
+
# training
|
| 184 |
+
python train_net.py --cfg_file configs/zju_mocap_exp/latent_xyzc_313.yaml exp_name xyzc_313 resume False white_bkgd True
|
| 185 |
+
```
|
| 186 |
+
3. Tensorboard:
|
| 187 |
+
```
|
| 188 |
+
tensorboard --logdir data/record/if_nerf
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
## Citation
|
| 192 |
+
|
| 193 |
+
If you find this code useful for your research, please use the following BibTeX entry.
|
| 194 |
+
|
| 195 |
+
```
|
| 196 |
+
@inproceedings{peng2021neural,
|
| 197 |
+
title={Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans},
|
| 198 |
+
author={Peng, Sida and Zhang, Yuanqing and Xu, Yinghao and Wang, Qianqian and Shuai, Qing and Bao, Hujun and Zhou, Xiaowei},
|
| 199 |
+
booktitle={CVPR},
|
| 200 |
+
year={2021}
|
| 201 |
+
}
|
| 202 |
+
```
|
configs/default.yaml
ADDED
|
File without changes
|
configs/h36m_exp/latent_xyzc_s11g.yaml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/h36m/S11/Greeting'
|
| 8 |
+
human: 'S11'
|
| 9 |
+
ann_file: 'data/h36m/S11/Greeting/annots.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/h36m/S11/Greeting'
|
| 14 |
+
human: 'S11'
|
| 15 |
+
ann_file: 'data/h36m/S11/Greeting/annots.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
H: 1002
|
| 20 |
+
W: 1000
|
| 21 |
+
ratio: 1.
|
| 22 |
+
training_view: [0, 1, 2, 3]
|
| 23 |
+
begin_ith_frame: 1200
|
| 24 |
+
num_train_frame: 400
|
| 25 |
+
smpl: 'smpl'
|
| 26 |
+
vertices: 'vertices'
|
| 27 |
+
params: 'params'
|
| 28 |
+
big_box: True
|
configs/h36m_exp/latent_xyzc_s9p.yaml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/h36m/S9/Posing'
|
| 8 |
+
human: 'S9'
|
| 9 |
+
ann_file: 'data/h36m/S9/Posing/annots.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/h36m/S9/Posing'
|
| 14 |
+
human: 'S9'
|
| 15 |
+
ann_file: 'data/h36m/S9/Posing/annots.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
H: 1002
|
| 20 |
+
W: 1000
|
| 21 |
+
ratio: 1.
|
| 22 |
+
training_view: [0, 1, 2, 3]
|
| 23 |
+
begin_ith_frame: 1000
|
| 24 |
+
num_train_frame: 300
|
| 25 |
+
smpl: 'smpl'
|
| 26 |
+
vertices: 'vertices'
|
| 27 |
+
params: 'params'
|
| 28 |
+
big_box: True
|
configs/monocular_custom.yaml
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'path/to/custom_data',
|
| 8 |
+
human: 'custom',
|
| 9 |
+
ann_file: 'path/to/custom_data/params.npy',
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'path/to/custom_data',
|
| 14 |
+
human: 'custom',
|
| 15 |
+
ann_file: 'path/to/custom_data/params.npy',
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
training_view: [0, 6, 12, 18]
|
| 21 |
+
num_train_frame: 300
|
| 22 |
+
smpl: 'smpl'
|
| 23 |
+
vertices: 'vertices'
|
| 24 |
+
params: 'params'
|
| 25 |
+
big_box: True
|
configs/multi_view_custom.yaml
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'path/to/custom_data',
|
| 8 |
+
human: 'custom',
|
| 9 |
+
ann_file: 'path/to/custom_data/annots.npy',
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'path/to/custom_data',
|
| 14 |
+
human: 'custom',
|
| 15 |
+
ann_file: 'path/to/custom_data/annots.npy',
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
training_view: [0, 6, 12, 18]
|
| 21 |
+
num_train_frame: 300
|
| 22 |
+
smpl: 'smpl'
|
| 23 |
+
vertices: 'vertices'
|
| 24 |
+
params: 'params'
|
| 25 |
+
big_box: True
|
configs/nerf/nerf_313.yaml
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_dataset'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_dataset.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_dataset'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_dataset.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.nerf'
|
| 10 |
+
network_path: 'lib/networks/nerf.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.volume_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/volume_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.nerf.py'
|
| 15 |
+
trainer_path: 'lib/train/trainers/nerf.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.if_nerf'
|
| 18 |
+
evaluator_path: 'lib/evaluators/if_nerf.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 313
|
| 24 |
+
|
| 25 |
+
train_dataset:
|
| 26 |
+
data_root: 'data/zju_mocap/CoreView_313'
|
| 27 |
+
human: 'CoreView_313'
|
| 28 |
+
ann_file: 'data/zju_mocap/CoreView_313/annots.npy'
|
| 29 |
+
split: 'train'
|
| 30 |
+
|
| 31 |
+
test_dataset:
|
| 32 |
+
data_root: 'data/zju_mocap/CoreView_313'
|
| 33 |
+
human: 'CoreView_313'
|
| 34 |
+
ann_file: 'data/zju_mocap/CoreView_313/annots.npy'
|
| 35 |
+
split: 'test'
|
| 36 |
+
|
| 37 |
+
train:
|
| 38 |
+
batch_size: 1
|
| 39 |
+
collator: ''
|
| 40 |
+
lr: 5e-4
|
| 41 |
+
weight_decay: 0
|
| 42 |
+
epoch: 400
|
| 43 |
+
scheduler:
|
| 44 |
+
type: 'exponential'
|
| 45 |
+
gamma: 0.1
|
| 46 |
+
decay_epochs: 1000
|
| 47 |
+
num_workers: 16
|
| 48 |
+
|
| 49 |
+
test:
|
| 50 |
+
sampler: 'FrameSampler'
|
| 51 |
+
batch_size: 1
|
| 52 |
+
collator: ''
|
| 53 |
+
|
| 54 |
+
ep_iter: 500
|
| 55 |
+
save_ep: 1000
|
| 56 |
+
eval_ep: 1000
|
| 57 |
+
|
| 58 |
+
# training options
|
| 59 |
+
netdepth: 8
|
| 60 |
+
netwidth: 256
|
| 61 |
+
netdepth_fine: 8
|
| 62 |
+
netwidth_fine: 256
|
| 63 |
+
netchunk: 65536
|
| 64 |
+
chunk: 32768
|
| 65 |
+
|
| 66 |
+
no_batching: True
|
| 67 |
+
|
| 68 |
+
# rendering options
|
| 69 |
+
use_viewdirs: True
|
| 70 |
+
i_embed: 0
|
| 71 |
+
xyz_res: 10
|
| 72 |
+
view_res: 4
|
| 73 |
+
raw_noise_std: 0
|
| 74 |
+
lindisp: False
|
| 75 |
+
|
| 76 |
+
N_samples: 64
|
| 77 |
+
N_importance: 128
|
| 78 |
+
N_rand: 1024
|
| 79 |
+
|
| 80 |
+
perturb: 1
|
| 81 |
+
white_bkgd: False
|
| 82 |
+
|
| 83 |
+
num_render_views: 50
|
| 84 |
+
|
| 85 |
+
# data options
|
| 86 |
+
ratio: 0.5
|
| 87 |
+
num_train_frame: 1
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
novel_view_cfg:
|
| 98 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_demo_dataset'
|
| 99 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_demo_dataset.py'
|
| 100 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_demo_dataset'
|
| 101 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_demo_dataset.py'
|
| 102 |
+
|
| 103 |
+
renderer_module: 'lib.networks.renderer.volume_renderer'
|
| 104 |
+
renderer_path: 'lib/networks/renderer/volume_renderer.py'
|
| 105 |
+
|
| 106 |
+
visualizer_module: 'lib.visualizers.if_nerf_demo'
|
| 107 |
+
visualizer_path: 'lib/visualizers/if_nerf_demo.py'
|
| 108 |
+
|
| 109 |
+
test:
|
| 110 |
+
sampler: ''
|
| 111 |
+
|
| 112 |
+
novel_pose_cfg:
|
| 113 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_perform_dataset'
|
| 114 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_perform_dataset.py'
|
| 115 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_perform_dataset'
|
| 116 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_perform_dataset.py'
|
| 117 |
+
|
| 118 |
+
renderer_module: 'lib.networks.renderer.volume_renderer'
|
| 119 |
+
renderer_path: 'lib/networks/renderer/volume_renderer.py'
|
| 120 |
+
|
| 121 |
+
visualizer_module: 'lib.visualizers.if_nerf_perform'
|
| 122 |
+
visualizer_path: 'lib/visualizers/if_nerf_perform.py'
|
| 123 |
+
|
| 124 |
+
test:
|
| 125 |
+
sampler: ''
|
| 126 |
+
|
| 127 |
+
mesh_cfg:
|
| 128 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_mesh_dataset'
|
| 129 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_mesh_dataset.py'
|
| 130 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_mesh_dataset'
|
| 131 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_mesh_dataset.py'
|
| 132 |
+
|
| 133 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 134 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 135 |
+
renderer_module: 'lib.networks.renderer.volume_mesh_renderer'
|
| 136 |
+
renderer_path: 'lib/networks/renderer/volume_mesh_renderer.py'
|
| 137 |
+
|
| 138 |
+
visualizer_module: 'lib.visualizers.if_nerf_mesh'
|
| 139 |
+
visualizer_path: 'lib/visualizers/if_nerf_mesh.py'
|
| 140 |
+
|
| 141 |
+
mesh_th: 5
|
| 142 |
+
|
| 143 |
+
test:
|
| 144 |
+
sampler: 'FrameSampler'
|
| 145 |
+
frame_sampler_interval: 1
|
configs/nerf/nerf_315.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 315
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_315'
|
| 10 |
+
human: 'CoreView_315'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_315/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_315'
|
| 16 |
+
human: 'CoreView_315'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_315/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_377.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 377
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_377'
|
| 10 |
+
human: 'CoreView_377'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_377/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_377'
|
| 16 |
+
human: 'CoreView_377'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_377/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_386.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 386
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_386'
|
| 10 |
+
human: 'CoreView_386'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_386/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_386'
|
| 16 |
+
human: 'CoreView_386'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_386/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_387.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 387
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_387'
|
| 10 |
+
human: 'CoreView_387'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_387/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_387'
|
| 16 |
+
human: 'CoreView_387'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_387/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_390.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 390
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_390'
|
| 10 |
+
human: 'CoreView_390'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_390/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_390'
|
| 16 |
+
human: 'CoreView_390'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_390/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_392.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 392
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_392'
|
| 10 |
+
human: 'CoreView_392'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_392/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_392'
|
| 16 |
+
human: 'CoreView_392'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_392/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_393.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 393
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_393'
|
| 10 |
+
human: 'CoreView_393'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_393/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_393'
|
| 16 |
+
human: 'CoreView_393'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_393/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/nerf/nerf_394.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/nerf/nerf_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 394
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_394'
|
| 10 |
+
human: 'CoreView_394'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_394/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_394'
|
| 16 |
+
human: 'CoreView_394'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_394/annots.npy'
|
| 18 |
+
split: 'test'
|
configs/neural_volumes/neural_volumes_313.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 313
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human313_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human313_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 60
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_315.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 315
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human315_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human315_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 400
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_377.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 377
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human377_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human377_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 300
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_386.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 386
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human386_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human386_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 300
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_387.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 387
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human387_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human387_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 300
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_390.yaml
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 390
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human390_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human390_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
begin_i: 700
|
| 88 |
+
ni: 300
|
| 89 |
+
smpl: 'smpl'
|
| 90 |
+
params: 'params'
|
| 91 |
+
|
| 92 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 93 |
+
|
| 94 |
+
# record options
|
| 95 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_392.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 392
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human392_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human392_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 300
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_393.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 393
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human393_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human393_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 300
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/neural_volumes/neural_volumes_394.yaml
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.can_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/can_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.neural_volume'
|
| 18 |
+
evaluator_path: 'lib/evaluators/neural_volume.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 394
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human394_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human394_0001_Test
|
| 40 |
+
sampler: 'FrameSampler'
|
| 41 |
+
batch_size: 1
|
| 42 |
+
collator: ''
|
| 43 |
+
|
| 44 |
+
ep_iter: 500
|
| 45 |
+
save_ep: 1000
|
| 46 |
+
eval_ep: 1000
|
| 47 |
+
|
| 48 |
+
# training options
|
| 49 |
+
netdepth: 8
|
| 50 |
+
netwidth: 256
|
| 51 |
+
netdepth_fine: 8
|
| 52 |
+
netwidth_fine: 256
|
| 53 |
+
netchunk: 65536
|
| 54 |
+
chunk: 32768
|
| 55 |
+
|
| 56 |
+
no_batching: True
|
| 57 |
+
|
| 58 |
+
precrop_iters: 500
|
| 59 |
+
precrop_frac: 0.5
|
| 60 |
+
|
| 61 |
+
# network options
|
| 62 |
+
point_feature: 6
|
| 63 |
+
|
| 64 |
+
# rendering options
|
| 65 |
+
use_viewdirs: True
|
| 66 |
+
i_embed: 0
|
| 67 |
+
xyz_res: 10
|
| 68 |
+
view_res: 4
|
| 69 |
+
raw_noise_std: 0
|
| 70 |
+
|
| 71 |
+
N_samples: 64
|
| 72 |
+
N_importance: 128
|
| 73 |
+
N_rand: 1024
|
| 74 |
+
|
| 75 |
+
near: 1
|
| 76 |
+
far: 3
|
| 77 |
+
|
| 78 |
+
perturb: 1
|
| 79 |
+
white_bkgd: False
|
| 80 |
+
|
| 81 |
+
render_views: 50
|
| 82 |
+
|
| 83 |
+
# data options
|
| 84 |
+
res: 256
|
| 85 |
+
ratio: 0.5
|
| 86 |
+
intv: 6
|
| 87 |
+
ni: 300
|
| 88 |
+
smpl: 'smpl'
|
| 89 |
+
params: 'params'
|
| 90 |
+
|
| 91 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 92 |
+
|
| 93 |
+
# record options
|
| 94 |
+
log_interval: 1
|
configs/snapshot_exp/snapshot_f1c.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/female-1-casual'
|
| 8 |
+
human: 'female-1-casual'
|
| 9 |
+
ann_file: 'data/people_snapshot/female-1-casual/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/female-1-casual'
|
| 14 |
+
human: 'female-1-casual'
|
| 15 |
+
ann_file: 'data/people_snapshot/female-1-casual/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 250
|
configs/snapshot_exp/snapshot_f3c.yaml
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.monocular_dataset'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/monocular_dataset.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.monocular_dataset'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/monocular_dataset.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.if_nerf'
|
| 18 |
+
evaluator_path: 'lib/evaluators/if_nerf.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
train_dataset:
|
| 24 |
+
data_root: 'data/people_snapshot/female-3-casual'
|
| 25 |
+
human: 'female-3-casual'
|
| 26 |
+
ann_file: 'data/people_snapshot/female-3-casual/params.npy'
|
| 27 |
+
split: 'train'
|
| 28 |
+
|
| 29 |
+
test_dataset:
|
| 30 |
+
data_root: 'data/people_snapshot/female-3-casual'
|
| 31 |
+
human: 'female-3-casual'
|
| 32 |
+
ann_file: 'data/people_snapshot/female-3-casual/params.npy'
|
| 33 |
+
split: 'test'
|
| 34 |
+
|
| 35 |
+
train:
|
| 36 |
+
batch_size: 1
|
| 37 |
+
collator: ''
|
| 38 |
+
lr: 5e-4
|
| 39 |
+
weight_decay: 0
|
| 40 |
+
epoch: 400
|
| 41 |
+
scheduler:
|
| 42 |
+
type: 'exponential'
|
| 43 |
+
gamma: 0.1
|
| 44 |
+
decay_epochs: 1000
|
| 45 |
+
num_workers: 16
|
| 46 |
+
|
| 47 |
+
test:
|
| 48 |
+
batch_size: 1
|
| 49 |
+
collator: ''
|
| 50 |
+
|
| 51 |
+
ep_iter: 500
|
| 52 |
+
save_ep: 100
|
| 53 |
+
eval_ep: 1000
|
| 54 |
+
|
| 55 |
+
# rendering options
|
| 56 |
+
i_embed: 0
|
| 57 |
+
xyz_res: 10
|
| 58 |
+
view_res: 4
|
| 59 |
+
raw_noise_std: 0
|
| 60 |
+
|
| 61 |
+
N_samples: 64
|
| 62 |
+
N_importance: 128
|
| 63 |
+
N_rand: 1024
|
| 64 |
+
|
| 65 |
+
perturb: 1
|
| 66 |
+
white_bkgd: False
|
| 67 |
+
|
| 68 |
+
num_render_views: 50
|
| 69 |
+
|
| 70 |
+
# data options
|
| 71 |
+
H: 1080
|
| 72 |
+
W: 1080
|
| 73 |
+
ratio: 1.
|
| 74 |
+
num_train_frame: 230
|
| 75 |
+
|
| 76 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 77 |
+
|
| 78 |
+
# record options
|
| 79 |
+
log_interval: 1
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
novel_view_cfg:
|
| 83 |
+
train_dataset_module: 'lib.datasets.light_stage.monocular_demo_dataset'
|
| 84 |
+
train_dataset_path: 'lib/datasets/light_stage/monocular_demo_dataset.py'
|
| 85 |
+
test_dataset_module: 'lib.datasets.light_stage.monocular_demo_dataset'
|
| 86 |
+
test_dataset_path: 'lib/datasets/light_stage/monocular_demo_dataset.py'
|
| 87 |
+
|
| 88 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer_msk'
|
| 89 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer_msk.py'
|
| 90 |
+
|
| 91 |
+
visualizer_module: 'lib.visualizers.if_nerf_demo'
|
| 92 |
+
visualizer_path: 'lib/visualizers/if_nerf_demo.py'
|
| 93 |
+
|
| 94 |
+
ratio: 0.5
|
| 95 |
+
|
| 96 |
+
test:
|
| 97 |
+
sampler: ''
|
| 98 |
+
|
| 99 |
+
novel_pose_cfg:
|
| 100 |
+
train_dataset_module: 'lib.datasets.light_stage.monocular_dataset'
|
| 101 |
+
train_dataset_path: 'lib/datasets/light_stage/monocular_dataset.py'
|
| 102 |
+
test_dataset_module: 'lib.datasets.light_stage.monocular_dataset'
|
| 103 |
+
test_dataset_path: 'lib/datasets/light_stage/monocular_dataset.py'
|
| 104 |
+
|
| 105 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer_msk'
|
| 106 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer_msk.py'
|
| 107 |
+
|
| 108 |
+
visualizer_module: 'lib.visualizers.if_nerf_perform'
|
| 109 |
+
visualizer_path: 'lib/visualizers/if_nerf_perform.py'
|
| 110 |
+
|
| 111 |
+
ratio: 0.5
|
| 112 |
+
|
| 113 |
+
test:
|
| 114 |
+
sampler: ''
|
| 115 |
+
|
| 116 |
+
mesh_cfg:
|
| 117 |
+
train_dataset_module: 'lib.datasets.light_stage.monocular_mesh_dataset'
|
| 118 |
+
train_dataset_path: 'lib/datasets/light_stage/monocular_mesh_dataset.py'
|
| 119 |
+
test_dataset_module: 'lib.datasets.light_stage.monocular_mesh_dataset'
|
| 120 |
+
test_dataset_path: 'lib/datasets/light_stage/monocular_mesh_dataset.py'
|
| 121 |
+
|
| 122 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 123 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 124 |
+
renderer_module: 'lib.networks.renderer.if_mesh_renderer'
|
| 125 |
+
renderer_path: 'lib/networks/renderer/if_mesh_renderer.py'
|
| 126 |
+
|
| 127 |
+
visualizer_module: 'lib.visualizers.if_nerf_mesh'
|
| 128 |
+
visualizer_path: 'lib/visualizers/if_nerf_mesh.py'
|
| 129 |
+
|
| 130 |
+
mesh_th: 5
|
| 131 |
+
|
| 132 |
+
test:
|
| 133 |
+
sampler: 'FrameSampler'
|
| 134 |
+
frame_sampler_interval: 1
|
configs/snapshot_exp/snapshot_f4c.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/female-4-casual'
|
| 8 |
+
human: 'female-4-casual'
|
| 9 |
+
ann_file: 'data/people_snapshot/female-4-casual/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/female-4-casual'
|
| 14 |
+
human: 'female-4-casual'
|
| 15 |
+
ann_file: 'data/people_snapshot/female-4-casual/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 200
|
| 21 |
+
begin_ith_frame: 10
|
configs/snapshot_exp/snapshot_f6p.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/female-6-plaza'
|
| 8 |
+
human: 'female-6-plaza'
|
| 9 |
+
ann_file: 'data/people_snapshot/female-6-plaza/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/female-6-plaza'
|
| 14 |
+
human: 'female-6-plaza'
|
| 15 |
+
ann_file: 'data/people_snapshot/female-6-plaza/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 240
|
configs/snapshot_exp/snapshot_f7p.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/female-7-plaza'
|
| 8 |
+
human: 'female-7-plaza'
|
| 9 |
+
ann_file: 'data/people_snapshot/female-7-plaza/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/female-7-plaza'
|
| 14 |
+
human: 'female-7-plaza'
|
| 15 |
+
ann_file: 'data/people_snapshot/female-7-plaza/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 185
|
configs/snapshot_exp/snapshot_f8p.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/female-8-plaza'
|
| 8 |
+
human: 'female-8-plaza'
|
| 9 |
+
ann_file: 'data/people_snapshot/female-8-plaza/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/female-8-plaza'
|
| 14 |
+
human: 'female-8-plaza'
|
| 15 |
+
ann_file: 'data/people_snapshot/female-8-plaza/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 200
|
configs/snapshot_exp/snapshot_m2c.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/male-2-casual'
|
| 8 |
+
human: 'male-2-casual'
|
| 9 |
+
ann_file: 'data/people_snapshot/male-2-casual/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/male-2-casual'
|
| 14 |
+
human: 'male-2-casual'
|
| 15 |
+
ann_file: 'data/people_snapshot/male-2-casual/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 180
|
configs/snapshot_exp/snapshot_m2o.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/male-2-outdoor'
|
| 8 |
+
human: 'male-2-outdoor'
|
| 9 |
+
ann_file: 'data/people_snapshot/male-2-outdoor/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/male-2-outdoor'
|
| 14 |
+
human: 'male-2-outdoor'
|
| 15 |
+
ann_file: 'data/people_snapshot/male-2-outdoor/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 150
|
configs/snapshot_exp/snapshot_m3c.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/male-3-casual'
|
| 8 |
+
human: 'male-3-casual'
|
| 9 |
+
ann_file: 'data/people_snapshot/male-3-casual/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/male-3-casual'
|
| 14 |
+
human: 'male-3-casual'
|
| 15 |
+
ann_file: 'data/people_snapshot/male-3-casual/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 235
|
configs/snapshot_exp/snapshot_m5o.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/snapshot_exp/snapshot_f3c.yaml'
|
| 5 |
+
|
| 6 |
+
train_dataset:
|
| 7 |
+
data_root: 'data/people_snapshot/male-5-outdoor'
|
| 8 |
+
human: 'male-5-outdoor'
|
| 9 |
+
ann_file: 'data/people_snapshot/male-5-outdoor/params.npy'
|
| 10 |
+
split: 'train'
|
| 11 |
+
|
| 12 |
+
test_dataset:
|
| 13 |
+
data_root: 'data/people_snapshot/male-5-outdoor'
|
| 14 |
+
human: 'male-5-outdoor'
|
| 15 |
+
ann_file: 'data/people_snapshot/male-5-outdoor/params.npy'
|
| 16 |
+
split: 'test'
|
| 17 |
+
|
| 18 |
+
# data options
|
| 19 |
+
ratio: 1.
|
| 20 |
+
num_train_frame: 295
|
configs/zju_mocap_exp/latent_xyzc_313.yaml
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_dataset'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_dataset.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_dataset'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_dataset.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.if_nerf'
|
| 18 |
+
evaluator_path: 'lib/evaluators/if_nerf.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf.py'
|
| 22 |
+
|
| 23 |
+
human: 313
|
| 24 |
+
|
| 25 |
+
train_dataset:
|
| 26 |
+
data_root: 'data/zju_mocap/CoreView_313'
|
| 27 |
+
human: 'CoreView_313'
|
| 28 |
+
ann_file: 'data/zju_mocap/CoreView_313/annots.npy'
|
| 29 |
+
split: 'train'
|
| 30 |
+
|
| 31 |
+
test_dataset:
|
| 32 |
+
data_root: 'data/zju_mocap/CoreView_313'
|
| 33 |
+
human: 'CoreView_313'
|
| 34 |
+
ann_file: 'data/zju_mocap/CoreView_313/annots.npy'
|
| 35 |
+
split: 'test'
|
| 36 |
+
|
| 37 |
+
train:
|
| 38 |
+
batch_size: 1
|
| 39 |
+
collator: ''
|
| 40 |
+
lr: 5e-4
|
| 41 |
+
weight_decay: 0
|
| 42 |
+
epoch: 400
|
| 43 |
+
scheduler:
|
| 44 |
+
type: 'exponential'
|
| 45 |
+
gamma: 0.1
|
| 46 |
+
decay_epochs: 1000
|
| 47 |
+
num_workers: 16
|
| 48 |
+
|
| 49 |
+
test:
|
| 50 |
+
sampler: 'FrameSampler'
|
| 51 |
+
batch_size: 1
|
| 52 |
+
collator: ''
|
| 53 |
+
|
| 54 |
+
ep_iter: 500
|
| 55 |
+
save_ep: 1000
|
| 56 |
+
eval_ep: 1000
|
| 57 |
+
|
| 58 |
+
# rendering options
|
| 59 |
+
i_embed: 0
|
| 60 |
+
xyz_res: 10
|
| 61 |
+
view_res: 4
|
| 62 |
+
raw_noise_std: 0
|
| 63 |
+
|
| 64 |
+
N_samples: 64
|
| 65 |
+
N_importance: 128
|
| 66 |
+
N_rand: 1024
|
| 67 |
+
|
| 68 |
+
perturb: 1
|
| 69 |
+
white_bkgd: False
|
| 70 |
+
|
| 71 |
+
num_render_views: 50
|
| 72 |
+
|
| 73 |
+
# data options
|
| 74 |
+
H: 1024
|
| 75 |
+
W: 1024
|
| 76 |
+
ratio: 0.5
|
| 77 |
+
training_view: [0, 6, 12, 18]
|
| 78 |
+
num_train_frame: 60
|
| 79 |
+
num_novel_pose_frame: 1000
|
| 80 |
+
smpl: 'smpl'
|
| 81 |
+
params: 'params'
|
| 82 |
+
|
| 83 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 84 |
+
|
| 85 |
+
# record options
|
| 86 |
+
log_interval: 1
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
novel_view_cfg:
|
| 90 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_demo_dataset'
|
| 91 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_demo_dataset.py'
|
| 92 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_demo_dataset'
|
| 93 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_demo_dataset.py'
|
| 94 |
+
|
| 95 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer_mmsk'
|
| 96 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer_mmsk.py'
|
| 97 |
+
|
| 98 |
+
visualizer_module: 'lib.visualizers.if_nerf_demo'
|
| 99 |
+
visualizer_path: 'lib/visualizers/if_nerf_demo.py'
|
| 100 |
+
|
| 101 |
+
test:
|
| 102 |
+
sampler: ''
|
| 103 |
+
|
| 104 |
+
rotate_smpl_cfg:
|
| 105 |
+
train_dataset_module: 'lib.datasets.light_stage.rotate_smpl_dataset'
|
| 106 |
+
train_dataset_path: 'lib/datasets/light_stage/rotate_smpl_dataset.py'
|
| 107 |
+
test_dataset_module: 'lib.datasets.light_stage.rotate_smpl_dataset'
|
| 108 |
+
test_dataset_path: 'lib/datasets/light_stage/rotate_smpl_dataset.py'
|
| 109 |
+
|
| 110 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 111 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 112 |
+
|
| 113 |
+
visualizer_module: 'lib.visualizers.if_nerf_demo'
|
| 114 |
+
visualizer_path: 'lib/visualizers/if_nerf_demo.py'
|
| 115 |
+
|
| 116 |
+
test:
|
| 117 |
+
sampler: ''
|
| 118 |
+
|
| 119 |
+
novel_pose_cfg:
|
| 120 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_perform_dataset'
|
| 121 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_perform_dataset.py'
|
| 122 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_perform_dataset'
|
| 123 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_perform_dataset.py'
|
| 124 |
+
|
| 125 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer_mmsk'
|
| 126 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer_mmsk.py'
|
| 127 |
+
|
| 128 |
+
visualizer_module: 'lib.visualizers.if_nerf_perform'
|
| 129 |
+
visualizer_path: 'lib/visualizers/if_nerf_perform.py'
|
| 130 |
+
|
| 131 |
+
test:
|
| 132 |
+
sampler: ''
|
| 133 |
+
|
| 134 |
+
mesh_cfg:
|
| 135 |
+
train_dataset_module: 'lib.datasets.light_stage.multi_view_mesh_dataset'
|
| 136 |
+
train_dataset_path: 'lib/datasets/light_stage/multi_view_mesh_dataset.py'
|
| 137 |
+
test_dataset_module: 'lib.datasets.light_stage.multi_view_mesh_dataset'
|
| 138 |
+
test_dataset_path: 'lib/datasets/light_stage/multi_view_mesh_dataset.py'
|
| 139 |
+
|
| 140 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 141 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 142 |
+
renderer_module: 'lib.networks.renderer.if_mesh_renderer'
|
| 143 |
+
renderer_path: 'lib/networks/renderer/if_mesh_renderer.py'
|
| 144 |
+
|
| 145 |
+
visualizer_module: 'lib.visualizers.if_nerf_mesh'
|
| 146 |
+
visualizer_path: 'lib/visualizers/if_nerf_mesh.py'
|
| 147 |
+
|
| 148 |
+
mesh_th: 5
|
| 149 |
+
|
| 150 |
+
test:
|
| 151 |
+
sampler: 'FrameSampler'
|
| 152 |
+
frame_sampler_interval: 1
|
configs/zju_mocap_exp/latent_xyzc_315.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 315
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_315'
|
| 10 |
+
human: 'CoreView_315'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_315/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_315'
|
| 16 |
+
human: 'CoreView_315'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_315/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 400
|
configs/zju_mocap_exp/latent_xyzc_377.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 377
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_377'
|
| 10 |
+
human: 'CoreView_377'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_377/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_377'
|
| 16 |
+
human: 'CoreView_377'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_377/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_386.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 386
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_386'
|
| 10 |
+
human: 'CoreView_386'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_386/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_386'
|
| 16 |
+
human: 'CoreView_386'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_386/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_387.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 387
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_387'
|
| 10 |
+
human: 'CoreView_387'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_387/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_387'
|
| 16 |
+
human: 'CoreView_387'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_387/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_390.yaml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 390
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_390'
|
| 10 |
+
human: 'CoreView_390'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_390/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_390'
|
| 16 |
+
human: 'CoreView_390'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_390/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
| 22 |
+
begin_ith_frame: 700
|
| 23 |
+
num_novel_pose_frame: 700
|
configs/zju_mocap_exp/latent_xyzc_392.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 392
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_392'
|
| 10 |
+
human: 'CoreView_392'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_392/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_392'
|
| 16 |
+
human: 'CoreView_392'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_392/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_393.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 393
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_393'
|
| 10 |
+
human: 'CoreView_393'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_393/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_393'
|
| 16 |
+
human: 'CoreView_393'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_393/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_394.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 394
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_394'
|
| 10 |
+
human: 'CoreView_394'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_394/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_394'
|
| 16 |
+
human: 'CoreView_394'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_394/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_395.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 395
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_395'
|
| 10 |
+
human: 'CoreView_395'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_395/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_395'
|
| 16 |
+
human: 'CoreView_395'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_395/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 300
|
configs/zju_mocap_exp/latent_xyzc_396.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 396
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_396'
|
| 10 |
+
human: 'CoreView_396'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_396/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_396'
|
| 16 |
+
human: 'CoreView_396'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_396/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 540
|
| 22 |
+
begin_ith_frame: 810
|
configs/zju_mocap_exp/xyzc_rotate_demo_313.yaml
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
train_dataset_module: 'lib.datasets.light_stage.can_smpl_demo'
|
| 5 |
+
train_dataset_path: 'lib/datasets/light_stage/can_smpl_demo.py'
|
| 6 |
+
test_dataset_module: 'lib.datasets.light_stage.rotate_smpl'
|
| 7 |
+
test_dataset_path: 'lib/datasets/light_stage/rotate_smpl.py'
|
| 8 |
+
|
| 9 |
+
network_module: 'lib.networks.latent_xyzc'
|
| 10 |
+
network_path: 'lib/networks/latent_xyzc.py'
|
| 11 |
+
renderer_module: 'lib.networks.renderer.if_clight_renderer'
|
| 12 |
+
renderer_path: 'lib/networks/renderer/if_clight_renderer.py'
|
| 13 |
+
|
| 14 |
+
trainer_module: 'lib.train.trainers.if_nerf_clight'
|
| 15 |
+
trainer_path: 'lib/train/trainers/if_nerf_clight.py'
|
| 16 |
+
|
| 17 |
+
evaluator_module: 'lib.evaluators.if_nerf'
|
| 18 |
+
evaluator_path: 'lib/evaluators/if_nerf.py'
|
| 19 |
+
|
| 20 |
+
visualizer_module: 'lib.visualizers.if_nerf_demo'
|
| 21 |
+
visualizer_path: 'lib/visualizers/if_nerf_demo.py'
|
| 22 |
+
|
| 23 |
+
human: 313
|
| 24 |
+
|
| 25 |
+
train:
|
| 26 |
+
dataset: Human313_0001_Train
|
| 27 |
+
batch_size: 1
|
| 28 |
+
collator: ''
|
| 29 |
+
lr: 5e-4
|
| 30 |
+
weight_decay: 0
|
| 31 |
+
epoch: 400
|
| 32 |
+
scheduler:
|
| 33 |
+
type: 'exponential'
|
| 34 |
+
gamma: 0.1
|
| 35 |
+
decay_epochs: 1000
|
| 36 |
+
num_workers: 16
|
| 37 |
+
|
| 38 |
+
test:
|
| 39 |
+
dataset: Human313_0001_Test
|
| 40 |
+
batch_size: 1
|
| 41 |
+
collator: ''
|
| 42 |
+
|
| 43 |
+
ep_iter: 500
|
| 44 |
+
save_ep: 1000
|
| 45 |
+
eval_ep: 1000
|
| 46 |
+
|
| 47 |
+
# training options
|
| 48 |
+
netdepth: 8
|
| 49 |
+
netwidth: 256
|
| 50 |
+
netdepth_fine: 8
|
| 51 |
+
netwidth_fine: 256
|
| 52 |
+
netchunk: 65536
|
| 53 |
+
chunk: 32768
|
| 54 |
+
|
| 55 |
+
no_batching: True
|
| 56 |
+
|
| 57 |
+
precrop_iters: 500
|
| 58 |
+
precrop_frac: 0.5
|
| 59 |
+
|
| 60 |
+
# network options
|
| 61 |
+
point_feature: 6
|
| 62 |
+
|
| 63 |
+
# rendering options
|
| 64 |
+
use_viewdirs: True
|
| 65 |
+
i_embed: 0
|
| 66 |
+
xyz_res: 10
|
| 67 |
+
view_res: 4
|
| 68 |
+
raw_noise_std: 0
|
| 69 |
+
|
| 70 |
+
N_samples: 64
|
| 71 |
+
N_importance: 128
|
| 72 |
+
N_rand: 1024
|
| 73 |
+
|
| 74 |
+
near: 1
|
| 75 |
+
far: 3
|
| 76 |
+
|
| 77 |
+
perturb: 1
|
| 78 |
+
white_bkgd: False
|
| 79 |
+
|
| 80 |
+
render_views: 50
|
| 81 |
+
|
| 82 |
+
# data options
|
| 83 |
+
res: 256
|
| 84 |
+
ratio: 0.5
|
| 85 |
+
intv: 6
|
| 86 |
+
ni: 60
|
| 87 |
+
smpl: 'smpl'
|
| 88 |
+
params: 'params'
|
| 89 |
+
|
| 90 |
+
voxel_size: [0.005, 0.005, 0.005] # dhw
|
| 91 |
+
|
| 92 |
+
# record options
|
| 93 |
+
log_interval: 1
|
configs/zju_mocap_frame1_exp/latent_xyzc_313_ni1.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 313
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_313'
|
| 10 |
+
human: 'CoreView_313'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_313/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_313'
|
| 16 |
+
human: 'CoreView_313'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_313/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 1
|
configs/zju_mocap_frame1_exp/latent_xyzc_315_ni1.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task: 'if_nerf'
|
| 2 |
+
gpus: [0]
|
| 3 |
+
|
| 4 |
+
parent_cfg: 'configs/zju_mocap_exp/latent_xyzc_313.yaml'
|
| 5 |
+
|
| 6 |
+
human: 315
|
| 7 |
+
|
| 8 |
+
train_dataset:
|
| 9 |
+
data_root: 'data/zju_mocap/CoreView_315'
|
| 10 |
+
human: 'CoreView_315'
|
| 11 |
+
ann_file: 'data/zju_mocap/CoreView_315/annots.npy'
|
| 12 |
+
split: 'train'
|
| 13 |
+
|
| 14 |
+
test_dataset:
|
| 15 |
+
data_root: 'data/zju_mocap/CoreView_315'
|
| 16 |
+
human: 'CoreView_315'
|
| 17 |
+
ann_file: 'data/zju_mocap/CoreView_315/annots.npy'
|
| 18 |
+
split: 'test'
|
| 19 |
+
|
| 20 |
+
# data options
|
| 21 |
+
num_train_frame: 1
|