Spaces:
Build error

Build error
Add application
Browse files- README.md +26 -5
- app.py +126 -0
- invoice.png +0 -0
- packages.txt +1 -0
- requirements.txt +6 -0
README.md
CHANGED
|
@@ -1,12 +1,33 @@
|
|
| 1 |
---
|
| 2 |
title: LayoutLMv3 FUNSD
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.0.24
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: LayoutLMv3 FUNSD
|
| 3 |
+
emoji: 📑
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: gradio
|
|
|
|
| 7 |
app_file: app.py
|
| 8 |
pinned: false
|
| 9 |
---
|
| 10 |
|
| 11 |
+
# Configuration
|
| 12 |
+
|
| 13 |
+
`title`: _string_
|
| 14 |
+
Display title for the Space
|
| 15 |
+
|
| 16 |
+
`emoji`: _string_
|
| 17 |
+
Space emoji (emoji-only character allowed)
|
| 18 |
+
|
| 19 |
+
`colorFrom`: _string_
|
| 20 |
+
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 21 |
+
|
| 22 |
+
`colorTo`: _string_
|
| 23 |
+
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
|
| 24 |
+
|
| 25 |
+
`sdk`: _string_
|
| 26 |
+
Can be either `gradio` or `streamlit`
|
| 27 |
+
|
| 28 |
+
`app_file`: _string_
|
| 29 |
+
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
|
| 30 |
+
Path is relative to the root of the repository.
|
| 31 |
+
|
| 32 |
+
`pinned`: _boolean_
|
| 33 |
+
Whether the Space stays on top of your list.
|
app.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
os.system("pip install pyyaml==5.1")
|
| 4 |
+
# workaround: install old version of pytorch since detectron2 hasn't released packages for pytorch 1.9 (issue: https://github.com/facebookresearch/detectron2/issues/3158)
|
| 5 |
+
os.system(
|
| 6 |
+
"pip install torch==1.8.0+cu101 torchvision==0.9.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html"
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
# install detectron2 that matches pytorch 1.8
|
| 10 |
+
# See https://detectron2.readthedocs.io/tutorials/install.html for instructions
|
| 11 |
+
os.system(
|
| 12 |
+
"pip install -q detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu101/torch1.8/index.html"
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
## install PyTesseract
|
| 16 |
+
os.system("pip install -q pytesseract")
|
| 17 |
+
|
| 18 |
+
import gradio as gr
|
| 19 |
+
import numpy as np
|
| 20 |
+
from transformers import LayoutLMv3Processor, LayoutLMv3ForTokenClassification
|
| 21 |
+
from datasets import load_dataset
|
| 22 |
+
from PIL import Image, ImageDraw, ImageFont
|
| 23 |
+
|
| 24 |
+
processor = LayoutLMv3Processor.from_pretrained("microsoft/layoutlmv3-base")
|
| 25 |
+
model = LayoutLMv3ForTokenClassification.from_pretrained(
|
| 26 |
+
"nielsr/layoutlmv3-finetuned-funsd"
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
# load image example
|
| 30 |
+
dataset = load_dataset("nielsr/funsd", split="test")
|
| 31 |
+
image = Image.open(dataset[0]["image_path"]).convert("RGB")
|
| 32 |
+
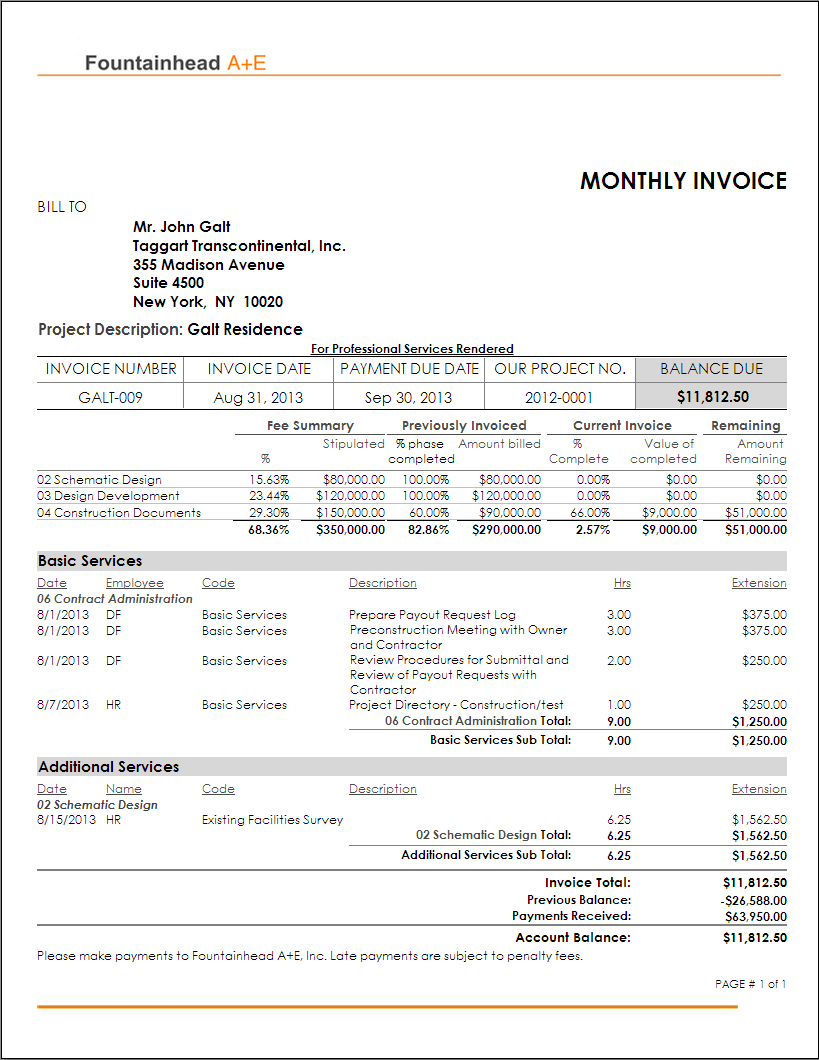
image = Image.open("./invoice.png")
|
| 33 |
+
image.save("document.png")
|
| 34 |
+
|
| 35 |
+
labels = dataset.features["ner_tags"].feature.names
|
| 36 |
+
id2label = {v: k for v, k in enumerate(labels)}
|
| 37 |
+
label2color = {
|
| 38 |
+
"question": "blue",
|
| 39 |
+
"answer": "green",
|
| 40 |
+
"header": "orange",
|
| 41 |
+
"other": "violet",
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def unnormalize_box(bbox, width, height):
|
| 46 |
+
return [
|
| 47 |
+
width * (bbox[0] / 1000),
|
| 48 |
+
height * (bbox[1] / 1000),
|
| 49 |
+
width * (bbox[2] / 1000),
|
| 50 |
+
height * (bbox[3] / 1000),
|
| 51 |
+
]
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def iob_to_label(label):
|
| 55 |
+
label = label[2:]
|
| 56 |
+
if not label:
|
| 57 |
+
return "other"
|
| 58 |
+
return label
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def process_image(image):
|
| 62 |
+
width, height = image.size
|
| 63 |
+
|
| 64 |
+
# encode
|
| 65 |
+
encoding = processor(
|
| 66 |
+
image, truncation=True, return_offsets_mapping=True, return_tensors="pt"
|
| 67 |
+
)
|
| 68 |
+
offset_mapping = encoding.pop("offset_mapping")
|
| 69 |
+
|
| 70 |
+
# forward pass
|
| 71 |
+
outputs = model(**encoding)
|
| 72 |
+
|
| 73 |
+
# get predictions
|
| 74 |
+
predictions = outputs.logits.argmax(-1).squeeze().tolist()
|
| 75 |
+
token_boxes = encoding.bbox.squeeze().tolist()
|
| 76 |
+
|
| 77 |
+
# only keep non-subword predictions
|
| 78 |
+
is_subword = np.array(offset_mapping.squeeze().tolist())[:, 0] != 0
|
| 79 |
+
true_predictions = [
|
| 80 |
+
id2label[pred] for idx, pred in enumerate(predictions) if not is_subword[idx]
|
| 81 |
+
]
|
| 82 |
+
true_boxes = [
|
| 83 |
+
unnormalize_box(box, width, height)
|
| 84 |
+
for idx, box in enumerate(token_boxes)
|
| 85 |
+
if not is_subword[idx]
|
| 86 |
+
]
|
| 87 |
+
|
| 88 |
+
# draw predictions over the image
|
| 89 |
+
draw = ImageDraw.Draw(image)
|
| 90 |
+
font = ImageFont.load_default()
|
| 91 |
+
for prediction, box in zip(true_predictions, true_boxes):
|
| 92 |
+
predicted_label = iob_to_label(prediction).lower()
|
| 93 |
+
draw.rectangle(box, outline=label2color[predicted_label])
|
| 94 |
+
draw.text(
|
| 95 |
+
(box[0] + 10, box[1] - 10),
|
| 96 |
+
text=predicted_label,
|
| 97 |
+
fill=label2color[predicted_label],
|
| 98 |
+
font=font,
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
return image
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
title = "Interactive demo: LayoutLMv3"
|
| 105 |
+
description = "Demo for Microsoft's LayoutLMv3, a Transformer for state-of-the-art document image understanding tasks. This particular model is fine-tuned on FUNSD, a dataset of manually annotated forms. It annotates the words appearing in the image as QUESTION/ANSWER/HEADER/OTHER. To use it, simply upload an image or use the example image below and click 'Submit'. Results will show up in a few seconds. If you want to make the output bigger, right-click on it and select 'Open image in new tab'."
|
| 106 |
+
article = "<p style='text-align: center'><a href='https://arxiv.org/abs/2204.08387' target='_blank'>LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking</a> | <a href='https://github.com/microsoft/unilm' target='_blank'>Github Repo</a></p>"
|
| 107 |
+
examples = [["document.png"]]
|
| 108 |
+
|
| 109 |
+
css = ".output-image, .input-image {height: 40rem !important; width: 100% !important;}"
|
| 110 |
+
# css = "@media screen and (max-width: 600px) { .output_image, .input_image {height:20rem !important; width: 100% !important;} }"
|
| 111 |
+
# css = ".output_image, .input_image {height: 600px !important}"
|
| 112 |
+
|
| 113 |
+
css = ".image-preview {height: auto !important;}"
|
| 114 |
+
|
| 115 |
+
iface = gr.Interface(
|
| 116 |
+
fn=process_image,
|
| 117 |
+
inputs=gr.inputs.Image(type="pil"),
|
| 118 |
+
outputs=gr.outputs.Image(type="pil", label="annotated image"),
|
| 119 |
+
title=title,
|
| 120 |
+
description=description,
|
| 121 |
+
article=article,
|
| 122 |
+
examples=examples,
|
| 123 |
+
css=css,
|
| 124 |
+
enable_queue=True,
|
| 125 |
+
)
|
| 126 |
+
iface.launch(debug=True)
|
invoice.png
ADDED
|
packages.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
tesseract-ocr
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio
|
| 2 |
+
Pillow
|
| 3 |
+
numpy
|
| 4 |
+
datasets
|
| 5 |
+
torch
|
| 6 |
+
transformers
|