'
+ image_html = ""
+
+ for path in [Path(f"characters/{character}.{extension}") for extension in ['png', 'jpg', 'jpeg']]:
+ if path.exists():
+ image_html = f'}) '
+ break
+
+ container_html += f'{image_html} {character}'
+ container_html += "
'
+ break
+
+ container_html += f'{image_html} {character}'
+ container_html += "
"
+ cards.append([container_html, character])
+
+ return cards
+
+
+def select_character(evt: gr.SelectData):
+ return (evt.value[1])
+
+
+def ui():
+ with gr.Accordion("Character gallery", open=False):
+ update = gr.Button("Refresh")
+ gr.HTML(value="")
+ gallery = gr.Dataset(components=[gr.HTML(visible=False)],
+ label="",
+ samples=generate_html(),
+ elem_classes=["character-gallery"],
+ samples_per_page=50
+ )
+ update.click(generate_html, [], gallery)
+ gallery.select(select_character, None, gradio['character_menu'])
diff --git a/extensions/google_translate/requirements.txt b/extensions/google_translate/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..554a00df62818f96ba7d396ae39d8e58efbe9bfe
--- /dev/null
+++ b/extensions/google_translate/requirements.txt
@@ -0,0 +1 @@
+deep-translator==1.9.2
diff --git a/extensions/google_translate/script.py b/extensions/google_translate/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dfdbcd0c0a9b889497dc2a147007e997c3cda80
--- /dev/null
+++ b/extensions/google_translate/script.py
@@ -0,0 +1,56 @@
+import gradio as gr
+from deep_translator import GoogleTranslator
+
+params = {
+ "activate": True,
+ "language string": "ja",
+}
+
+language_codes = {'Afrikaans': 'af', 'Albanian': 'sq', 'Amharic': 'am', 'Arabic': 'ar', 'Armenian': 'hy', 'Azerbaijani': 'az', 'Basque': 'eu', 'Belarusian': 'be', 'Bengali': 'bn', 'Bosnian': 'bs', 'Bulgarian': 'bg', 'Catalan': 'ca', 'Cebuano': 'ceb', 'Chinese (Simplified)': 'zh-CN', 'Chinese (Traditional)': 'zh-TW', 'Corsican': 'co', 'Croatian': 'hr', 'Czech': 'cs', 'Danish': 'da', 'Dutch': 'nl', 'English': 'en', 'Esperanto': 'eo', 'Estonian': 'et', 'Finnish': 'fi', 'French': 'fr', 'Frisian': 'fy', 'Galician': 'gl', 'Georgian': 'ka', 'German': 'de', 'Greek': 'el', 'Gujarati': 'gu', 'Haitian Creole': 'ht', 'Hausa': 'ha', 'Hawaiian': 'haw', 'Hebrew': 'iw', 'Hindi': 'hi', 'Hmong': 'hmn', 'Hungarian': 'hu', 'Icelandic': 'is', 'Igbo': 'ig', 'Indonesian': 'id', 'Irish': 'ga', 'Italian': 'it', 'Japanese': 'ja', 'Javanese': 'jw', 'Kannada': 'kn', 'Kazakh': 'kk', 'Khmer': 'km', 'Korean': 'ko', 'Kurdish': 'ku', 'Kyrgyz': 'ky', 'Lao': 'lo', 'Latin': 'la', 'Latvian': 'lv', 'Lithuanian': 'lt', 'Luxembourgish': 'lb', 'Macedonian': 'mk', 'Malagasy': 'mg', 'Malay': 'ms', 'Malayalam': 'ml', 'Maltese': 'mt', 'Maori': 'mi', 'Marathi': 'mr', 'Mongolian': 'mn', 'Myanmar (Burmese)': 'my', 'Nepali': 'ne', 'Norwegian': 'no', 'Nyanja (Chichewa)': 'ny', 'Pashto': 'ps', 'Persian': 'fa', 'Polish': 'pl', 'Portuguese (Portugal, Brazil)': 'pt', 'Punjabi': 'pa', 'Romanian': 'ro', 'Russian': 'ru', 'Samoan': 'sm', 'Scots Gaelic': 'gd', 'Serbian': 'sr', 'Sesotho': 'st', 'Shona': 'sn', 'Sindhi': 'sd', 'Sinhala (Sinhalese)': 'si', 'Slovak': 'sk', 'Slovenian': 'sl', 'Somali': 'so', 'Spanish': 'es', 'Sundanese': 'su', 'Swahili': 'sw', 'Swedish': 'sv', 'Tagalog (Filipino)': 'tl', 'Tajik': 'tg', 'Tamil': 'ta', 'Telugu': 'te', 'Thai': 'th', 'Turkish': 'tr', 'Ukrainian': 'uk', 'Urdu': 'ur', 'Uzbek': 'uz', 'Vietnamese': 'vi', 'Welsh': 'cy', 'Xhosa': 'xh', 'Yiddish': 'yi', 'Yoruba': 'yo', 'Zulu': 'zu'}
+
+
+def input_modifier(string):
+ """
+ This function is applied to your text inputs before
+ they are fed into the model.
+ """
+ if not params['activate']:
+ return string
+
+ return GoogleTranslator(source=params['language string'], target='en').translate(string)
+
+
+def output_modifier(string):
+ """
+ This function is applied to the model outputs.
+ """
+ if not params['activate']:
+ return string
+
+ return GoogleTranslator(source='en', target=params['language string']).translate(string)
+
+
+def bot_prefix_modifier(string):
+ """
+ This function is only applied in chat mode. It modifies
+ the prefix text for the Bot and can be used to bias its
+ behavior.
+ """
+
+ return string
+
+
+def ui():
+ # Finding the language name from the language code to use as the default value
+ language_name = list(language_codes.keys())[list(language_codes.values()).index(params['language string'])]
+
+ # Gradio elements
+ with gr.Row():
+ activate = gr.Checkbox(value=params['activate'], label='Activate translation')
+
+ with gr.Row():
+ language = gr.Dropdown(value=language_name, choices=[k for k in language_codes], label='Language')
+
+ # Event functions to update the parameters in the backend
+ activate.change(lambda x: params.update({"activate": x}), activate, None)
+ language.change(lambda x: params.update({"language string": language_codes[x]}), language, None)
diff --git a/extensions/llava/script.py b/extensions/llava/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..781d584b78ebf8e7c0c87e4203665286b92cf81c
--- /dev/null
+++ b/extensions/llava/script.py
@@ -0,0 +1,8 @@
+import gradio as gr
+
+from modules.logging_colors import logger
+
+
+def ui():
+ gr.Markdown("### This extension is deprecated, use \"multimodal\" extension instead")
+ logger.error("LLaVA extension is deprecated, use \"multimodal\" extension instead")
diff --git a/extensions/multimodal/DOCS.md b/extensions/multimodal/DOCS.md
new file mode 100644
index 0000000000000000000000000000000000000000..eaa4365e9a304a14ebbdb1d4d435f3a2a1f7a7d2
--- /dev/null
+++ b/extensions/multimodal/DOCS.md
@@ -0,0 +1,85 @@
+# Technical description of multimodal extension
+
+## Working principle
+Multimodality extension does most of the stuff which is required for any image input:
+
+- adds the UI
+- saves the images as base64 JPEGs to history
+- provides the hooks to the UI
+- if there are images in the prompt, it:
+ - splits the prompt to text and image parts
+ - adds image start/end markers to text parts, then encodes and embeds the text parts
+ - calls the vision pipeline to embed the images
+ - stitches the embeddings together, and returns them to text generation
+- loads the appropriate vision pipeline, selected either from model name, or by specifying --multimodal-pipeline parameter
+
+Now, for the pipelines, they:
+
+- load the required vision models
+- return some consts, for example the number of tokens taken up by image
+- and most importantly: return the embeddings for LLM, given a list of images
+
+## Prompts/history
+
+To save images in prompt/history, this extension is using a base64 JPEG, wrapped in a HTML tag, like so:
+```
+ +```
+where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `
+```
+where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `) `.
+
+## LLM input
+To describe the input, let's see it on an example prompt:
+```
+text1'`, where `img_str` is base-64 jpeg data. Note that you will need to launch `server.py` with the arguments `--api --extensions multimodal`.
+
+Python example:
+
+```Python
+import base64
+import requests
+
+CONTEXT = "You are LLaVA, a large language and vision assistant trained by UW Madison WAIV Lab. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. Follow the instructions carefully and explain your answers in detail.### Human: Hi!### Assistant: Hi there! How can I help you today?\n"
+
+with open('extreme_ironing.jpg', 'rb') as f:
+ img_str = base64.b64encode(f.read()).decode('utf-8')
+ prompt = CONTEXT + f'### Human: What is unusual about this image: \n### Assistant: '
+ print(requests.post('http://127.0.0.1:5000/api/v1/generate', json={'prompt': prompt, 'stopping_strings': ['\n###']}).json())
+```
+script output:
+```Python
+{'results': [{'text': "The unusual aspect of this image is that a man is standing on top of a yellow minivan while doing his laundry. He has set up a makeshift clothes line using the car's rooftop as an outdoor drying area. This scene is uncommon because people typically do their laundry indoors, in a dedicated space like a laundromat or a room in their home, rather than on top of a moving vehicle. Additionally, hanging clothes on the car could be potentially hazardous or illegal in some jurisdictions due to the risk of damaging the vehicle or causing accidents on the road.\n##"}]}
+```
+
+## For pipeline developers/technical description
+see [DOCS.md](https://github.com/oobabooga/text-generation-webui/blob/main/extensions/multimodal/DOCS.md)
diff --git a/extensions/multimodal/abstract_pipeline.py b/extensions/multimodal/abstract_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..584219419d256e7743fd4d5120c56bcfa8f2a9f9
--- /dev/null
+++ b/extensions/multimodal/abstract_pipeline.py
@@ -0,0 +1,62 @@
+from abc import ABC, abstractmethod
+from typing import List, Optional
+
+import torch
+from PIL import Image
+
+
+class AbstractMultimodalPipeline(ABC):
+ @staticmethod
+ @abstractmethod
+ def name() -> str:
+ 'name of the pipeline, should be same as in --multimodal-pipeline'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_start() -> Optional[str]:
+ 'return image start string, string representation of image start token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_end() -> Optional[str]:
+ 'return image end string, string representation of image end token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_token_id() -> int:
+ 'return placeholder token id'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def num_image_embeds() -> int:
+ 'return the number of embeds used by a single image (for example: 256 for LLaVA)'
+ pass
+
+ @abstractmethod
+ def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
+ 'forward the images through vision pipeline, and return their embeddings'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def embed_tokens(input_ids: torch.Tensor) -> torch.Tensor:
+ 'embed tokens, the exact function varies by LLM, for LLaMA it is `shared.model.model.embed_tokens`'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_embeddings() -> torch.Tensor:
+ 'get placeholder embeddings if there are multiple images, and `add_all_images_to_prompt` is False'
+ pass
+
+ def _get_device(self, setting_name: str, params: dict):
+ if params[setting_name] is None:
+ return torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
+ return torch.device(params[setting_name])
+
+ def _get_dtype(self, setting_name: str, params: dict):
+ return torch.float32 if int(params[setting_name]) == 32 else torch.float16
diff --git a/extensions/multimodal/multimodal_embedder.py b/extensions/multimodal/multimodal_embedder.py
new file mode 100644
index 0000000000000000000000000000000000000000..626077cb80987d66af90f390e31aa2f2def76fec
--- /dev/null
+++ b/extensions/multimodal/multimodal_embedder.py
@@ -0,0 +1,178 @@
+import base64
+import re
+from dataclasses import dataclass
+from io import BytesIO
+from typing import Any, List, Optional
+
+import torch
+from PIL import Image
+
+from extensions.multimodal.pipeline_loader import load_pipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode, get_max_prompt_length
+
+
+@dataclass
+class PromptPart:
+ text: str
+ image: Optional[Image.Image] = None
+ is_image: bool = False
+ input_ids: Optional[torch.Tensor] = None
+ embedding: Optional[torch.Tensor] = None
+
+
+class MultimodalEmbedder:
+ def __init__(self, params: dict):
+ pipeline, source = load_pipeline(params)
+ self.pipeline = pipeline
+ logger.info(f'Multimodal: loaded pipeline {self.pipeline.name()} from pipelines/{source} ({self.pipeline.__class__.__name__})')
+
+ def _split_prompt(self, prompt: str, load_images: bool = False) -> List[PromptPart]:
+ """Splits a prompt into a list of `PromptParts` to separate image data from text.
+ It will also append `image_start` and `image_end` before and after the image, and optionally parse and load the images,
+ if `load_images` is `True`.
+ """
+ parts: List[PromptPart] = []
+ curr = 0
+ while True:
+ match = re.search(r'', prompt[curr:])
+ if match is None:
+ # no more image tokens, append the rest of the prompt
+ if curr > 0:
+ # add image end token after last image
+ parts.append(PromptPart(text=self.pipeline.image_end() + prompt[curr:]))
+ else:
+ parts.append(PromptPart(text=prompt))
+ break
+ # found an image, append image start token to the text
+ if match.start() > 0:
+ parts.append(PromptPart(text=prompt[curr:curr + match.start()] + self.pipeline.image_start()))
+ else:
+ parts.append(PromptPart(text=self.pipeline.image_start()))
+ # append the image
+ parts.append(PromptPart(
+ text=match.group(0),
+ image=Image.open(BytesIO(base64.b64decode(match.group(1)))) if load_images else None,
+ is_image=True
+ ))
+ curr += match.end()
+ return parts
+
+ def _len_in_tokens_prompt_parts(self, parts: List[PromptPart]) -> int:
+ """Total length in tokens of all `parts`"""
+ tokens = 0
+ for part in parts:
+ if part.is_image:
+ tokens += self.pipeline.num_image_embeds()
+ elif part.input_ids is not None:
+ tokens += len(part.input_ids)
+ else:
+ tokens += len(encode(part.text)[0])
+ return tokens
+
+ def len_in_tokens(self, prompt: str) -> int:
+ """Total length in tokens for a given text `prompt`"""
+ parts = self._split_prompt(prompt, False)
+ return self._len_in_tokens_prompt_parts(parts)
+
+ def _encode_single_text(self, part: PromptPart, add_bos_token: bool) -> PromptPart:
+ """Encode a single prompt `part` to `input_ids`. Returns a `PromptPart`"""
+ if part.is_image:
+ placeholders = torch.ones((self.pipeline.num_image_embeds())) * self.pipeline.placeholder_token_id()
+ part.input_ids = placeholders.to(shared.model.device, dtype=torch.int64)
+ else:
+ part.input_ids = encode(part.text, add_bos_token=add_bos_token)[0].to(shared.model.device, dtype=torch.int64)
+ return part
+
+ @staticmethod
+ def _num_images(parts: List[PromptPart]) -> int:
+ count = 0
+ for part in parts:
+ if part.is_image:
+ count += 1
+ return count
+
+ def _encode_text(self, state, parts: List[PromptPart]) -> List[PromptPart]:
+ """Encode text to token_ids, also truncate the prompt, if necessary.
+
+ The chat/instruct mode should make prompts that fit in get_max_prompt_length, but if max_new_tokens are set
+ such that the context + min_rows don't fit, we can get a prompt which is too long.
+ We can't truncate image embeddings, as it leads to broken generation, so remove the images instead and warn the user
+ """
+ encoded: List[PromptPart] = []
+ for i, part in enumerate(parts):
+ encoded.append(self._encode_single_text(part, i == 0 and state['add_bos_token']))
+
+ # truncation:
+ max_len = get_max_prompt_length(state)
+ removed_images = 0
+
+ # 1. remove entire text/image blocks
+ while self._len_in_tokens_prompt_parts(encoded[1:]) > max_len:
+ if encoded[0].is_image:
+ removed_images += 1
+ encoded = encoded[1:]
+
+ # 2. check if the last prompt part doesn't need to get truncated
+ if self._len_in_tokens_prompt_parts(encoded) > max_len:
+ if encoded[0].is_image:
+ # don't truncate image embeddings, just remove the image, otherwise generation will be broken
+ removed_images += 1
+ encoded = encoded[1:]
+ elif len(encoded) > 1 and encoded[0].text.endswith(self.pipeline.image_start()):
+ # see if we can keep image_start token
+ len_image_start = len(encode(self.pipeline.image_start(), add_bos_token=state['add_bos_token'])[0])
+ if self._len_in_tokens_prompt_parts(encoded[1:]) + len_image_start > max_len:
+ # we can't -> remove this text, and the image
+ encoded = encoded[2:]
+ removed_images += 1
+ else:
+ # we can -> just truncate the text
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+ elif len(encoded) > 0:
+ # only one text left, truncate it normally
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+
+ # notify user if we truncated an image
+ if removed_images > 0:
+ logger.warning(f"Multimodal: removed {removed_images} image(s) from prompt. Try decreasing max_new_tokens if generation is broken")
+
+ return encoded
+
+ def _embed(self, parts: List[PromptPart]) -> List[PromptPart]:
+ # batch images
+ image_indicies = [i for i, part in enumerate(parts) if part.is_image]
+ embedded = self.pipeline.embed_images([parts[i].image for i in image_indicies])
+ for i, embeds in zip(image_indicies, embedded):
+ parts[i].embedding = embeds
+ # embed text
+ for (i, part) in enumerate(parts):
+ if not part.is_image:
+ parts[i].embedding = self.pipeline.embed_tokens(part.input_ids)
+ return parts
+
+ def _remove_old_images(self, parts: List[PromptPart], params: dict) -> List[PromptPart]:
+ if params['add_all_images_to_prompt']:
+ return parts
+ already_added = False
+ for i, part in reversed(list(enumerate(parts))):
+ if part.is_image:
+ if already_added:
+ parts[i].embedding = self.pipeline.placeholder_embeddings()
+ else:
+ already_added = True
+ return parts
+
+ def forward(self, prompt: str, state: Any, params: dict):
+ prompt_parts = self._split_prompt(prompt, True)
+ prompt_parts = self._encode_text(state, prompt_parts)
+ prompt_parts = self._embed(prompt_parts)
+ prompt_parts = self._remove_old_images(prompt_parts, params)
+ embeds = tuple(part.embedding for part in prompt_parts)
+ ids = tuple(part.input_ids for part in prompt_parts)
+ input_embeds = torch.cat(embeds, dim=0)
+ input_ids = torch.cat(ids, dim=0)
+ return prompt, input_ids, input_embeds, self._num_images(prompt_parts)
diff --git a/extensions/multimodal/pipeline_loader.py b/extensions/multimodal/pipeline_loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fcd0a9b410fbc44a51941e0a87b294de871ef8b
--- /dev/null
+++ b/extensions/multimodal/pipeline_loader.py
@@ -0,0 +1,52 @@
+import traceback
+from importlib import import_module
+from pathlib import Path
+from typing import Tuple
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+
+
+def _get_available_pipeline_modules():
+ pipeline_path = Path(__file__).parent / 'pipelines'
+ modules = [p for p in pipeline_path.iterdir() if p.is_dir()]
+ return [m.name for m in modules if (m / 'pipelines.py').exists()]
+
+
+def load_pipeline(params: dict) -> Tuple[AbstractMultimodalPipeline, str]:
+ pipeline_modules = {}
+ available_pipeline_modules = _get_available_pipeline_modules()
+ for name in available_pipeline_modules:
+ try:
+ pipeline_modules[name] = import_module(f'extensions.multimodal.pipelines.{name}.pipelines')
+ except:
+ logger.warning(f'Failed to get multimodal pipelines from {name}')
+ logger.warning(traceback.format_exc())
+
+ if shared.args.multimodal_pipeline is not None:
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline')(shared.args.multimodal_pipeline, params)
+ if pipeline is not None:
+ return (pipeline, k)
+ else:
+ model_name = shared.args.model.lower()
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline_from_model_name'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline_from_model_name')(model_name, params)
+ if pipeline is not None:
+ return (pipeline, k)
+
+ available = []
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'available_pipelines'):
+ pipelines = getattr(pipeline_modules[k], 'available_pipelines')
+ available += pipelines
+
+ if shared.args.multimodal_pipeline is not None:
+ log = f'Multimodal - ERROR: Failed to load multimodal pipeline "{shared.args.multimodal_pipeline}", available pipelines are: {available}.'
+ else:
+ log = f'Multimodal - ERROR: Failed to determine multimodal pipeline for model {shared.args.model}, please select one manually using --multimodal-pipeline [PIPELINE]. Available pipelines are: {available}.'
+ logger.critical(f'{log} Please specify a correct pipeline, or disable the extension')
+ raise RuntimeError(f'{log} Please specify a correct pipeline, or disable the extension')
diff --git a/extensions/multimodal/pipelines/llava/README.md b/extensions/multimodal/pipelines/llava/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..aff64faaae07d2f4da6c24e8ea03693326313139
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/README.md
@@ -0,0 +1,9 @@
+## LLaVA pipeline
+
+This module provides 2 pipelines:
+- `llava-7b` - for use with LLaVA v0 7B model (finetuned LLaMa 7B)
+- `llava-13b` - for use with LLaVA v0 13B model (finetuned LLaMa 13B)
+
+[LLaVA](https://github.com/haotian-liu/LLaVA) uses CLIP `openai/clip-vit-large-patch14` as the vision model, and then a single linear layer. For 13B the projector weights are in `liuhaotian/LLaVA-13b-delta-v0`, and for 7B they are in `liuhaotian/LLaVA-7b-delta-v0`.
+
+The supported parameter combinations for both the vision model, and the projector are: CUDA/32bit, CUDA/16bit, CPU/32bit
diff --git a/extensions/multimodal/pipelines/llava/llava.py b/extensions/multimodal/pipelines/llava/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..eca2be50bbcfce3f4b7c1f1bee89c80581a6b517
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/llava.py
@@ -0,0 +1,145 @@
+import time
+from abc import abstractmethod
+from typing import List, Tuple
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPVisionModel
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode
+
+
+class LLaVA_v0_Pipeline(AbstractMultimodalPipeline):
+ CLIP_REPO = "openai/clip-vit-large-patch14"
+
+ def __init__(self, params: dict) -> None:
+ super().__init__()
+ self.clip_device = self._get_device("vision_device", params)
+ self.clip_dtype = self._get_dtype("vision_bits", params)
+ self.projector_device = self._get_device("projector_device", params)
+ self.projector_dtype = self._get_dtype("projector_bits", params)
+ self.image_processor, self.vision_tower, self.mm_projector = self._load_models()
+
+ def _load_models(self):
+ start_ts = time.time()
+
+ logger.info(f"LLaVA - Loading CLIP from {LLaVA_v0_Pipeline.CLIP_REPO} as {self.clip_dtype} on {self.clip_device}...")
+ image_processor = CLIPImageProcessor.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype)
+ vision_tower = CLIPVisionModel.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype).to(self.clip_device)
+
+ logger.info(f"LLaVA - Loading projector from {self.llava_projector_repo()} as {self.projector_dtype} on {self.projector_device}...")
+ projector_path = hf_hub_download(self.llava_projector_repo(), self.llava_projector_filename())
+ mm_projector = torch.nn.Linear(*self.llava_projector_shape())
+ projector_data = torch.load(projector_path)
+ mm_projector.weight = torch.nn.Parameter(projector_data['model.mm_projector.weight'].to(dtype=self.projector_dtype), False)
+ mm_projector.bias = torch.nn.Parameter(projector_data['model.mm_projector.bias'].to(dtype=self.projector_dtype), False)
+ mm_projector = mm_projector.to(self.projector_device)
+
+ logger.info(f"LLaVA supporting models loaded, took {time.time() - start_ts:.2f} seconds")
+ return image_processor, vision_tower, mm_projector
+
+ @staticmethod
+ def image_start() -> str:
+ return "'
+
+ if '
`.
+
+## LLM input
+To describe the input, let's see it on an example prompt:
+```
+text1'`, where `img_str` is base-64 jpeg data. Note that you will need to launch `server.py` with the arguments `--api --extensions multimodal`.
+
+Python example:
+
+```Python
+import base64
+import requests
+
+CONTEXT = "You are LLaVA, a large language and vision assistant trained by UW Madison WAIV Lab. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. Follow the instructions carefully and explain your answers in detail.### Human: Hi!### Assistant: Hi there! How can I help you today?\n"
+
+with open('extreme_ironing.jpg', 'rb') as f:
+ img_str = base64.b64encode(f.read()).decode('utf-8')
+ prompt = CONTEXT + f'### Human: What is unusual about this image: \n### Assistant: '
+ print(requests.post('http://127.0.0.1:5000/api/v1/generate', json={'prompt': prompt, 'stopping_strings': ['\n###']}).json())
+```
+script output:
+```Python
+{'results': [{'text': "The unusual aspect of this image is that a man is standing on top of a yellow minivan while doing his laundry. He has set up a makeshift clothes line using the car's rooftop as an outdoor drying area. This scene is uncommon because people typically do their laundry indoors, in a dedicated space like a laundromat or a room in their home, rather than on top of a moving vehicle. Additionally, hanging clothes on the car could be potentially hazardous or illegal in some jurisdictions due to the risk of damaging the vehicle or causing accidents on the road.\n##"}]}
+```
+
+## For pipeline developers/technical description
+see [DOCS.md](https://github.com/oobabooga/text-generation-webui/blob/main/extensions/multimodal/DOCS.md)
diff --git a/extensions/multimodal/abstract_pipeline.py b/extensions/multimodal/abstract_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..584219419d256e7743fd4d5120c56bcfa8f2a9f9
--- /dev/null
+++ b/extensions/multimodal/abstract_pipeline.py
@@ -0,0 +1,62 @@
+from abc import ABC, abstractmethod
+from typing import List, Optional
+
+import torch
+from PIL import Image
+
+
+class AbstractMultimodalPipeline(ABC):
+ @staticmethod
+ @abstractmethod
+ def name() -> str:
+ 'name of the pipeline, should be same as in --multimodal-pipeline'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_start() -> Optional[str]:
+ 'return image start string, string representation of image start token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_end() -> Optional[str]:
+ 'return image end string, string representation of image end token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_token_id() -> int:
+ 'return placeholder token id'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def num_image_embeds() -> int:
+ 'return the number of embeds used by a single image (for example: 256 for LLaVA)'
+ pass
+
+ @abstractmethod
+ def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
+ 'forward the images through vision pipeline, and return their embeddings'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def embed_tokens(input_ids: torch.Tensor) -> torch.Tensor:
+ 'embed tokens, the exact function varies by LLM, for LLaMA it is `shared.model.model.embed_tokens`'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_embeddings() -> torch.Tensor:
+ 'get placeholder embeddings if there are multiple images, and `add_all_images_to_prompt` is False'
+ pass
+
+ def _get_device(self, setting_name: str, params: dict):
+ if params[setting_name] is None:
+ return torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
+ return torch.device(params[setting_name])
+
+ def _get_dtype(self, setting_name: str, params: dict):
+ return torch.float32 if int(params[setting_name]) == 32 else torch.float16
diff --git a/extensions/multimodal/multimodal_embedder.py b/extensions/multimodal/multimodal_embedder.py
new file mode 100644
index 0000000000000000000000000000000000000000..626077cb80987d66af90f390e31aa2f2def76fec
--- /dev/null
+++ b/extensions/multimodal/multimodal_embedder.py
@@ -0,0 +1,178 @@
+import base64
+import re
+from dataclasses import dataclass
+from io import BytesIO
+from typing import Any, List, Optional
+
+import torch
+from PIL import Image
+
+from extensions.multimodal.pipeline_loader import load_pipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode, get_max_prompt_length
+
+
+@dataclass
+class PromptPart:
+ text: str
+ image: Optional[Image.Image] = None
+ is_image: bool = False
+ input_ids: Optional[torch.Tensor] = None
+ embedding: Optional[torch.Tensor] = None
+
+
+class MultimodalEmbedder:
+ def __init__(self, params: dict):
+ pipeline, source = load_pipeline(params)
+ self.pipeline = pipeline
+ logger.info(f'Multimodal: loaded pipeline {self.pipeline.name()} from pipelines/{source} ({self.pipeline.__class__.__name__})')
+
+ def _split_prompt(self, prompt: str, load_images: bool = False) -> List[PromptPart]:
+ """Splits a prompt into a list of `PromptParts` to separate image data from text.
+ It will also append `image_start` and `image_end` before and after the image, and optionally parse and load the images,
+ if `load_images` is `True`.
+ """
+ parts: List[PromptPart] = []
+ curr = 0
+ while True:
+ match = re.search(r'', prompt[curr:])
+ if match is None:
+ # no more image tokens, append the rest of the prompt
+ if curr > 0:
+ # add image end token after last image
+ parts.append(PromptPart(text=self.pipeline.image_end() + prompt[curr:]))
+ else:
+ parts.append(PromptPart(text=prompt))
+ break
+ # found an image, append image start token to the text
+ if match.start() > 0:
+ parts.append(PromptPart(text=prompt[curr:curr + match.start()] + self.pipeline.image_start()))
+ else:
+ parts.append(PromptPart(text=self.pipeline.image_start()))
+ # append the image
+ parts.append(PromptPart(
+ text=match.group(0),
+ image=Image.open(BytesIO(base64.b64decode(match.group(1)))) if load_images else None,
+ is_image=True
+ ))
+ curr += match.end()
+ return parts
+
+ def _len_in_tokens_prompt_parts(self, parts: List[PromptPart]) -> int:
+ """Total length in tokens of all `parts`"""
+ tokens = 0
+ for part in parts:
+ if part.is_image:
+ tokens += self.pipeline.num_image_embeds()
+ elif part.input_ids is not None:
+ tokens += len(part.input_ids)
+ else:
+ tokens += len(encode(part.text)[0])
+ return tokens
+
+ def len_in_tokens(self, prompt: str) -> int:
+ """Total length in tokens for a given text `prompt`"""
+ parts = self._split_prompt(prompt, False)
+ return self._len_in_tokens_prompt_parts(parts)
+
+ def _encode_single_text(self, part: PromptPart, add_bos_token: bool) -> PromptPart:
+ """Encode a single prompt `part` to `input_ids`. Returns a `PromptPart`"""
+ if part.is_image:
+ placeholders = torch.ones((self.pipeline.num_image_embeds())) * self.pipeline.placeholder_token_id()
+ part.input_ids = placeholders.to(shared.model.device, dtype=torch.int64)
+ else:
+ part.input_ids = encode(part.text, add_bos_token=add_bos_token)[0].to(shared.model.device, dtype=torch.int64)
+ return part
+
+ @staticmethod
+ def _num_images(parts: List[PromptPart]) -> int:
+ count = 0
+ for part in parts:
+ if part.is_image:
+ count += 1
+ return count
+
+ def _encode_text(self, state, parts: List[PromptPart]) -> List[PromptPart]:
+ """Encode text to token_ids, also truncate the prompt, if necessary.
+
+ The chat/instruct mode should make prompts that fit in get_max_prompt_length, but if max_new_tokens are set
+ such that the context + min_rows don't fit, we can get a prompt which is too long.
+ We can't truncate image embeddings, as it leads to broken generation, so remove the images instead and warn the user
+ """
+ encoded: List[PromptPart] = []
+ for i, part in enumerate(parts):
+ encoded.append(self._encode_single_text(part, i == 0 and state['add_bos_token']))
+
+ # truncation:
+ max_len = get_max_prompt_length(state)
+ removed_images = 0
+
+ # 1. remove entire text/image blocks
+ while self._len_in_tokens_prompt_parts(encoded[1:]) > max_len:
+ if encoded[0].is_image:
+ removed_images += 1
+ encoded = encoded[1:]
+
+ # 2. check if the last prompt part doesn't need to get truncated
+ if self._len_in_tokens_prompt_parts(encoded) > max_len:
+ if encoded[0].is_image:
+ # don't truncate image embeddings, just remove the image, otherwise generation will be broken
+ removed_images += 1
+ encoded = encoded[1:]
+ elif len(encoded) > 1 and encoded[0].text.endswith(self.pipeline.image_start()):
+ # see if we can keep image_start token
+ len_image_start = len(encode(self.pipeline.image_start(), add_bos_token=state['add_bos_token'])[0])
+ if self._len_in_tokens_prompt_parts(encoded[1:]) + len_image_start > max_len:
+ # we can't -> remove this text, and the image
+ encoded = encoded[2:]
+ removed_images += 1
+ else:
+ # we can -> just truncate the text
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+ elif len(encoded) > 0:
+ # only one text left, truncate it normally
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+
+ # notify user if we truncated an image
+ if removed_images > 0:
+ logger.warning(f"Multimodal: removed {removed_images} image(s) from prompt. Try decreasing max_new_tokens if generation is broken")
+
+ return encoded
+
+ def _embed(self, parts: List[PromptPart]) -> List[PromptPart]:
+ # batch images
+ image_indicies = [i for i, part in enumerate(parts) if part.is_image]
+ embedded = self.pipeline.embed_images([parts[i].image for i in image_indicies])
+ for i, embeds in zip(image_indicies, embedded):
+ parts[i].embedding = embeds
+ # embed text
+ for (i, part) in enumerate(parts):
+ if not part.is_image:
+ parts[i].embedding = self.pipeline.embed_tokens(part.input_ids)
+ return parts
+
+ def _remove_old_images(self, parts: List[PromptPart], params: dict) -> List[PromptPart]:
+ if params['add_all_images_to_prompt']:
+ return parts
+ already_added = False
+ for i, part in reversed(list(enumerate(parts))):
+ if part.is_image:
+ if already_added:
+ parts[i].embedding = self.pipeline.placeholder_embeddings()
+ else:
+ already_added = True
+ return parts
+
+ def forward(self, prompt: str, state: Any, params: dict):
+ prompt_parts = self._split_prompt(prompt, True)
+ prompt_parts = self._encode_text(state, prompt_parts)
+ prompt_parts = self._embed(prompt_parts)
+ prompt_parts = self._remove_old_images(prompt_parts, params)
+ embeds = tuple(part.embedding for part in prompt_parts)
+ ids = tuple(part.input_ids for part in prompt_parts)
+ input_embeds = torch.cat(embeds, dim=0)
+ input_ids = torch.cat(ids, dim=0)
+ return prompt, input_ids, input_embeds, self._num_images(prompt_parts)
diff --git a/extensions/multimodal/pipeline_loader.py b/extensions/multimodal/pipeline_loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fcd0a9b410fbc44a51941e0a87b294de871ef8b
--- /dev/null
+++ b/extensions/multimodal/pipeline_loader.py
@@ -0,0 +1,52 @@
+import traceback
+from importlib import import_module
+from pathlib import Path
+from typing import Tuple
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+
+
+def _get_available_pipeline_modules():
+ pipeline_path = Path(__file__).parent / 'pipelines'
+ modules = [p for p in pipeline_path.iterdir() if p.is_dir()]
+ return [m.name for m in modules if (m / 'pipelines.py').exists()]
+
+
+def load_pipeline(params: dict) -> Tuple[AbstractMultimodalPipeline, str]:
+ pipeline_modules = {}
+ available_pipeline_modules = _get_available_pipeline_modules()
+ for name in available_pipeline_modules:
+ try:
+ pipeline_modules[name] = import_module(f'extensions.multimodal.pipelines.{name}.pipelines')
+ except:
+ logger.warning(f'Failed to get multimodal pipelines from {name}')
+ logger.warning(traceback.format_exc())
+
+ if shared.args.multimodal_pipeline is not None:
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline')(shared.args.multimodal_pipeline, params)
+ if pipeline is not None:
+ return (pipeline, k)
+ else:
+ model_name = shared.args.model.lower()
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline_from_model_name'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline_from_model_name')(model_name, params)
+ if pipeline is not None:
+ return (pipeline, k)
+
+ available = []
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'available_pipelines'):
+ pipelines = getattr(pipeline_modules[k], 'available_pipelines')
+ available += pipelines
+
+ if shared.args.multimodal_pipeline is not None:
+ log = f'Multimodal - ERROR: Failed to load multimodal pipeline "{shared.args.multimodal_pipeline}", available pipelines are: {available}.'
+ else:
+ log = f'Multimodal - ERROR: Failed to determine multimodal pipeline for model {shared.args.model}, please select one manually using --multimodal-pipeline [PIPELINE]. Available pipelines are: {available}.'
+ logger.critical(f'{log} Please specify a correct pipeline, or disable the extension')
+ raise RuntimeError(f'{log} Please specify a correct pipeline, or disable the extension')
diff --git a/extensions/multimodal/pipelines/llava/README.md b/extensions/multimodal/pipelines/llava/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..aff64faaae07d2f4da6c24e8ea03693326313139
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/README.md
@@ -0,0 +1,9 @@
+## LLaVA pipeline
+
+This module provides 2 pipelines:
+- `llava-7b` - for use with LLaVA v0 7B model (finetuned LLaMa 7B)
+- `llava-13b` - for use with LLaVA v0 13B model (finetuned LLaMa 13B)
+
+[LLaVA](https://github.com/haotian-liu/LLaVA) uses CLIP `openai/clip-vit-large-patch14` as the vision model, and then a single linear layer. For 13B the projector weights are in `liuhaotian/LLaVA-13b-delta-v0`, and for 7B they are in `liuhaotian/LLaVA-7b-delta-v0`.
+
+The supported parameter combinations for both the vision model, and the projector are: CUDA/32bit, CUDA/16bit, CPU/32bit
diff --git a/extensions/multimodal/pipelines/llava/llava.py b/extensions/multimodal/pipelines/llava/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..eca2be50bbcfce3f4b7c1f1bee89c80581a6b517
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/llava.py
@@ -0,0 +1,145 @@
+import time
+from abc import abstractmethod
+from typing import List, Tuple
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPVisionModel
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode
+
+
+class LLaVA_v0_Pipeline(AbstractMultimodalPipeline):
+ CLIP_REPO = "openai/clip-vit-large-patch14"
+
+ def __init__(self, params: dict) -> None:
+ super().__init__()
+ self.clip_device = self._get_device("vision_device", params)
+ self.clip_dtype = self._get_dtype("vision_bits", params)
+ self.projector_device = self._get_device("projector_device", params)
+ self.projector_dtype = self._get_dtype("projector_bits", params)
+ self.image_processor, self.vision_tower, self.mm_projector = self._load_models()
+
+ def _load_models(self):
+ start_ts = time.time()
+
+ logger.info(f"LLaVA - Loading CLIP from {LLaVA_v0_Pipeline.CLIP_REPO} as {self.clip_dtype} on {self.clip_device}...")
+ image_processor = CLIPImageProcessor.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype)
+ vision_tower = CLIPVisionModel.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype).to(self.clip_device)
+
+ logger.info(f"LLaVA - Loading projector from {self.llava_projector_repo()} as {self.projector_dtype} on {self.projector_device}...")
+ projector_path = hf_hub_download(self.llava_projector_repo(), self.llava_projector_filename())
+ mm_projector = torch.nn.Linear(*self.llava_projector_shape())
+ projector_data = torch.load(projector_path)
+ mm_projector.weight = torch.nn.Parameter(projector_data['model.mm_projector.weight'].to(dtype=self.projector_dtype), False)
+ mm_projector.bias = torch.nn.Parameter(projector_data['model.mm_projector.bias'].to(dtype=self.projector_dtype), False)
+ mm_projector = mm_projector.to(self.projector_device)
+
+ logger.info(f"LLaVA supporting models loaded, took {time.time() - start_ts:.2f} seconds")
+ return image_processor, vision_tower, mm_projector
+
+ @staticmethod
+ def image_start() -> str:
+ return "'
+
+ if ' ', prompt)
+
+ if image_match is None:
+ return prompt, input_ids, input_embeds
+
+ prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
+ logger.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
+ return (prompt,
+ input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
+ input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
+
+
+def ui():
+ global multimodal_embedder
+ multimodal_embedder = MultimodalEmbedder(params)
+ with gr.Column():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+ # The models don't seem to deal well with multiple images
+ single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
+ # Prepare the input hijack
+ picture_select.upload(
+ lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
+ [picture_select],
+ None
+ )
+ picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
+ single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
+ shared.gradio['Generate'].click(lambda: None, None, picture_select)
+ shared.gradio['textbox'].submit(lambda: None, None, picture_select)
diff --git a/extensions/ngrok/README.md b/extensions/ngrok/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0324bf9852408d9d2b86cc0165c2d548996f9c94
--- /dev/null
+++ b/extensions/ngrok/README.md
@@ -0,0 +1,69 @@
+# Adding an ingress URL through the ngrok Agent SDK for Python
+
+[ngrok](https://ngrok.com) is a globally distributed reverse proxy commonly used for quickly getting a public URL to a
+service running inside a private network, such as on your local laptop. The ngrok agent is usually
+deployed inside a private network and is used to communicate with the ngrok cloud service.
+
+By default the authtoken in the NGROK_AUTHTOKEN environment variable will be used. Alternatively one may be specified in
+the `settings.json` file, see the Examples below. Retrieve your authtoken on the [Auth Token page of your ngrok dashboard](https://dashboard.ngrok.com/get-started/your-authtoken), signing up is free.
+
+# Documentation
+
+For a list of all available options, see [the configuration documentation](https://ngrok.com/docs/ngrok-agent/config/) or [the connect example](https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py).
+
+The ngrok Python SDK is [on github here](https://github.com/ngrok/ngrok-py). A quickstart guide and a full API reference are included in the [ngrok-py Python API documentation](https://ngrok.github.io/ngrok-py/).
+
+# Running
+
+To enable ngrok install the requirements and then add `--extension ngrok` to the command line options, for instance:
+
+```bash
+pip install -r extensions/ngrok/requirements.txt
+python server.py --extension ngrok
+```
+
+In the output you should then see something like this:
+
+```bash
+INFO:Loading the extension "ngrok"...
+INFO:Session created
+INFO:Created tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" with url "https://d83706cf7be7.ngrok.app"
+INFO:Tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" TCP forwarding to "localhost:7860"
+INFO:Ingress established at https://d83706cf7be7.ngrok.app
+```
+
+You can now access the webui via the url shown, in this case `https://d83706cf7be7.ngrok.app`. It is recommended to add some authentication to the ingress, see below.
+
+# Example Settings
+
+In `settings.json` add a `ngrok` key with a dictionary of options, for instance:
+
+To enable basic authentication:
+```json
+{
+ "ngrok": {
+ "basic_auth": "user:password"
+ }
+}
+```
+
+To enable OAUTH authentication:
+```json
+{
+ "ngrok": {
+ "oauth_provider": "google",
+ "oauth_allow_domains": "asdf.com",
+ "oauth_allow_emails": "asdf@asdf.com"
+ }
+}
+```
+
+To add an authtoken instead of using the NGROK_AUTHTOKEN environment variable:
+```json
+{
+ "ngrok": {
+ "authtoken": "
', prompt)
+
+ if image_match is None:
+ return prompt, input_ids, input_embeds
+
+ prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
+ logger.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
+ return (prompt,
+ input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
+ input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
+
+
+def ui():
+ global multimodal_embedder
+ multimodal_embedder = MultimodalEmbedder(params)
+ with gr.Column():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+ # The models don't seem to deal well with multiple images
+ single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
+ # Prepare the input hijack
+ picture_select.upload(
+ lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
+ [picture_select],
+ None
+ )
+ picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
+ single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
+ shared.gradio['Generate'].click(lambda: None, None, picture_select)
+ shared.gradio['textbox'].submit(lambda: None, None, picture_select)
diff --git a/extensions/ngrok/README.md b/extensions/ngrok/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0324bf9852408d9d2b86cc0165c2d548996f9c94
--- /dev/null
+++ b/extensions/ngrok/README.md
@@ -0,0 +1,69 @@
+# Adding an ingress URL through the ngrok Agent SDK for Python
+
+[ngrok](https://ngrok.com) is a globally distributed reverse proxy commonly used for quickly getting a public URL to a
+service running inside a private network, such as on your local laptop. The ngrok agent is usually
+deployed inside a private network and is used to communicate with the ngrok cloud service.
+
+By default the authtoken in the NGROK_AUTHTOKEN environment variable will be used. Alternatively one may be specified in
+the `settings.json` file, see the Examples below. Retrieve your authtoken on the [Auth Token page of your ngrok dashboard](https://dashboard.ngrok.com/get-started/your-authtoken), signing up is free.
+
+# Documentation
+
+For a list of all available options, see [the configuration documentation](https://ngrok.com/docs/ngrok-agent/config/) or [the connect example](https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py).
+
+The ngrok Python SDK is [on github here](https://github.com/ngrok/ngrok-py). A quickstart guide and a full API reference are included in the [ngrok-py Python API documentation](https://ngrok.github.io/ngrok-py/).
+
+# Running
+
+To enable ngrok install the requirements and then add `--extension ngrok` to the command line options, for instance:
+
+```bash
+pip install -r extensions/ngrok/requirements.txt
+python server.py --extension ngrok
+```
+
+In the output you should then see something like this:
+
+```bash
+INFO:Loading the extension "ngrok"...
+INFO:Session created
+INFO:Created tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" with url "https://d83706cf7be7.ngrok.app"
+INFO:Tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" TCP forwarding to "localhost:7860"
+INFO:Ingress established at https://d83706cf7be7.ngrok.app
+```
+
+You can now access the webui via the url shown, in this case `https://d83706cf7be7.ngrok.app`. It is recommended to add some authentication to the ingress, see below.
+
+# Example Settings
+
+In `settings.json` add a `ngrok` key with a dictionary of options, for instance:
+
+To enable basic authentication:
+```json
+{
+ "ngrok": {
+ "basic_auth": "user:password"
+ }
+}
+```
+
+To enable OAUTH authentication:
+```json
+{
+ "ngrok": {
+ "oauth_provider": "google",
+ "oauth_allow_domains": "asdf.com",
+ "oauth_allow_emails": "asdf@asdf.com"
+ }
+}
+```
+
+To add an authtoken instead of using the NGROK_AUTHTOKEN environment variable:
+```json
+{
+ "ngrok": {
+ "authtoken": "
+
+
+Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures`
+(it's not really required, but completes the picture, *pun intended*).
+
+
+## History
+
+Consider the version included with [oobabooga's repository](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/sd_api_pictures) to be STABLE, experimental developments and untested features are pushed in [Brawlence/SD_api_pics](https://github.com/Brawlence/SD_api_pics)
+
+Lastest change:
+1.1.0 → 1.1.1 Fixed not having Auto1111's metadata in received images
+
+## Details
+
+The image generation is triggered:
+- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
+- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
+- always on in `Picturebook/Adventure` mode (if not currently suppressed by 'Suppress the picture response')
+
+## Prerequisites
+
+One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
+To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
+
+## Features overview
+- Connection to API check (press enter in the address box)
+- [VRAM management (model shuffling)](https://github.com/Brawlence/SD_api_pics/wiki/VRAM-management-feature)
+- [Three different operation modes](https://github.com/Brawlence/SD_api_pics/wiki/Modes-of-operation) (manual, interactive, always-on)
+- User-defined persistent settings via settings.json
+
+### Connection check
+
+Insert the Automatic1111's WebUI address and press Enter:
+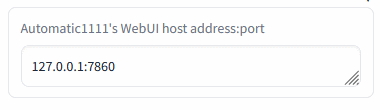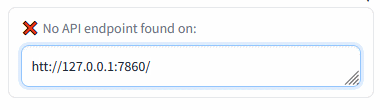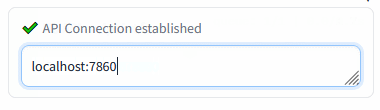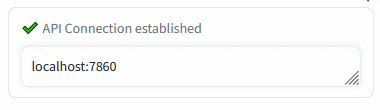
+Green mark confirms the ability to communicate with Auto1111's API on this address. Red cross means something's not right (the ext won't work).
+
+### Persistents settings
+
+Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
+present in script.py, ex:
+
+```json
+{
+ "sd_api_pictures-manage_VRAM": 1,
+ "sd_api_pictures-save_img": 1,
+ "sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
+ "sd_api_pictures-sampler_name": "DPM++ 2M Karras"
+}
+```
+
+will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
+
+---
+
+## Demonstrations:
+
+Those are examples of the version 1.0.0, but the core functionality is still the same
+
+Interface overview
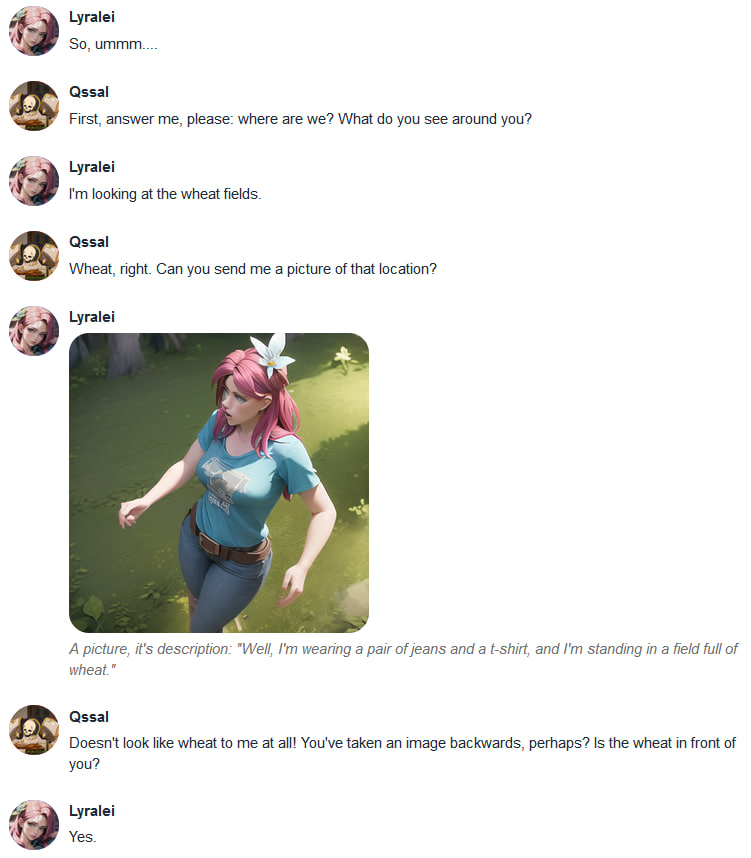
+ +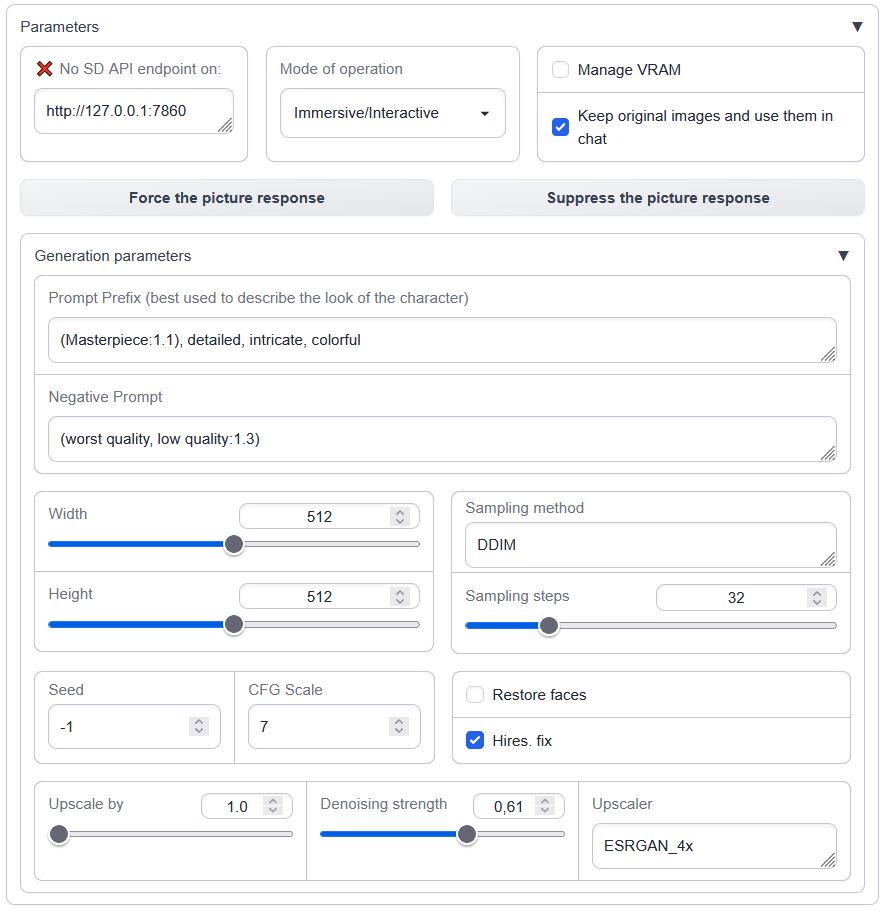 + +
+
+
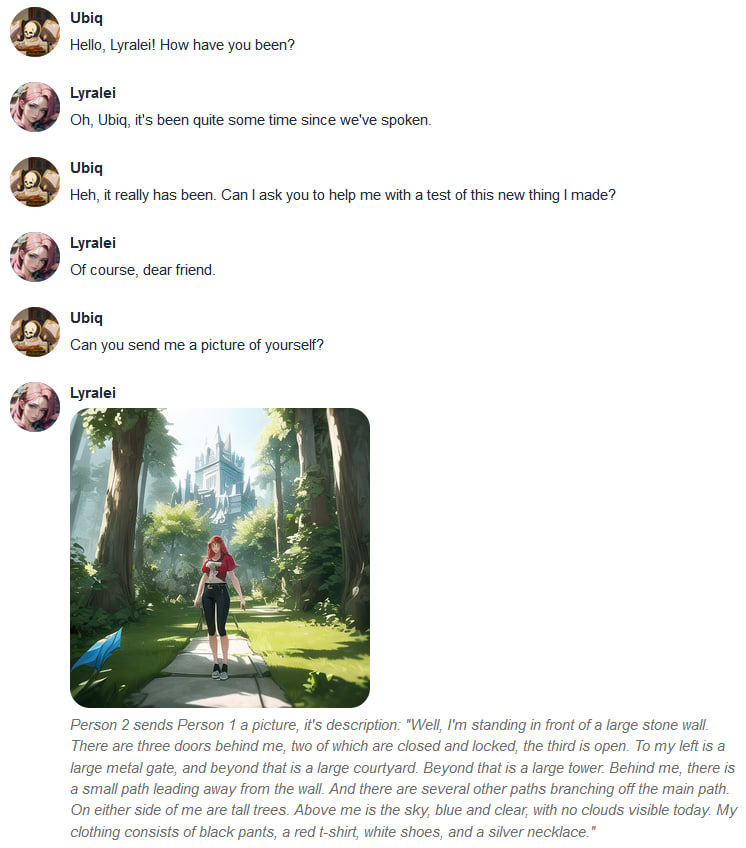
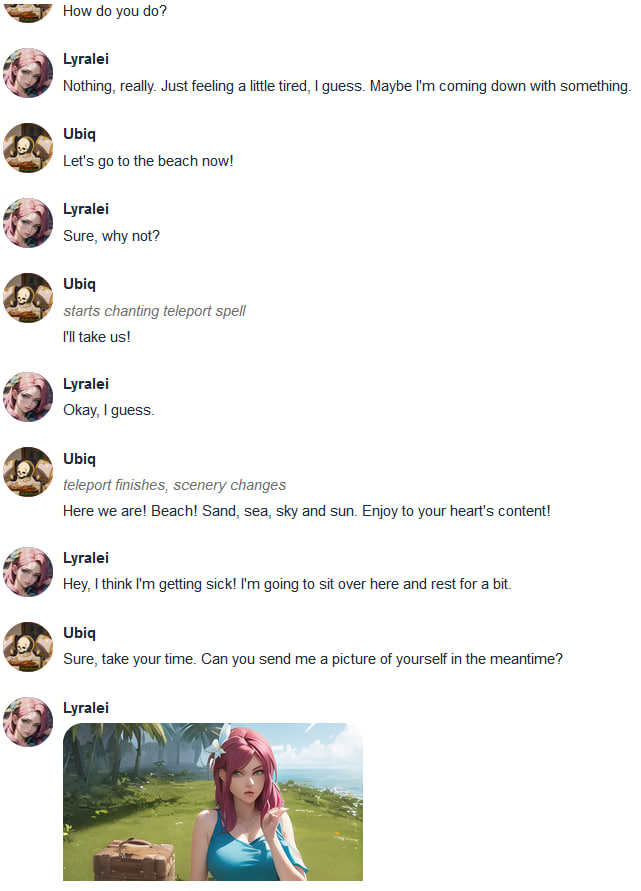
+Conversation 1
+ + + + + + + +
+
+
diff --git a/extensions/sd_api_pictures/script.py b/extensions/sd_api_pictures/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..78488cd022b7a68ad1162fabbc1976662534b24f
--- /dev/null
+++ b/extensions/sd_api_pictures/script.py
@@ -0,0 +1,383 @@
+import base64
+import io
+import re
+import time
+from datetime import date
+from pathlib import Path
+
+import gradio as gr
+import requests
+import torch
+from PIL import Image
+
+from modules import shared
+from modules.models import reload_model, unload_model
+from modules.ui import create_refresh_button
+
+torch._C._jit_set_profiling_mode(False)
+
+# parameters which can be customized in settings.json of webui
+params = {
+ 'address': 'http://127.0.0.1:7860',
+ 'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
+ 'manage_VRAM': False,
+ 'save_img': False,
+ 'SD_model': 'NeverEndingDream', # not used right now
+ 'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
+ 'negative_prompt': '(worst quality, low quality:1.3)',
+ 'width': 512,
+ 'height': 512,
+ 'denoising_strength': 0.61,
+ 'restore_faces': False,
+ 'enable_hr': False,
+ 'hr_upscaler': 'ESRGAN_4x',
+ 'hr_scale': '1.0',
+ 'seed': -1,
+ 'sampler_name': 'DPM++ 2M Karras',
+ 'steps': 32,
+ 'cfg_scale': 7,
+ 'textgen_prefix': 'Please provide a detailed and vivid description of [subject]',
+ 'sd_checkpoint': ' ',
+ 'checkpoint_list': [" "]
+}
+
+
+def give_VRAM_priority(actor):
+ global shared, params
+
+ if actor == 'SD':
+ unload_model()
+ print("Requesting Auto1111 to re-load last checkpoint used...")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
+ response.raise_for_status()
+
+ elif actor == 'LLM':
+ print("Requesting Auto1111 to vacate VRAM...")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
+ response.raise_for_status()
+ reload_model()
+
+ elif actor == 'set':
+ print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
+ response.raise_for_status()
+
+ elif actor == 'reset':
+ print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
+ response.raise_for_status()
+
+ else:
+ raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
+
+ response.raise_for_status()
+ del response
+
+
+if params['manage_VRAM']:
+ give_VRAM_priority('set')
+
+SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
+
+picture_response = False # specifies if the next model response should appear as a picture
+
+
+def remove_surrounded_chars(string):
+ # this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
+ # 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
+ return re.sub('\*[^\*]*?(\*|$)', '', string)
+
+
+def triggers_are_in(string):
+ string = remove_surrounded_chars(string)
+ # regex searches for send|main|message|me (at the end of the word) followed by
+ # a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
+ # (?aims) are regex parser flags
+ return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
+
+
+def state_modifier(state):
+ if picture_response:
+ state['stream'] = False
+
+ return state
+
+
+def input_modifier(string):
+ """
+ This function is applied to your text inputs before
+ they are fed into the model.
+ """
+
+ global params
+
+ if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
+ return string
+
+ if triggers_are_in(string): # if we're in it, check for trigger words
+ toggle_generation(True)
+ string = string.lower()
+ if "of" in string:
+ subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
+ string = params['textgen_prefix'].replace("[subject]", subject)
+ else:
+ string = params['textgen_prefix'].replace("[subject]", "your appearance, your surroundings and what you are doing right now")
+
+ return string
+
+# Get and save the Stable Diffusion-generated picture
+def get_SD_pictures(description, character):
+
+ global params
+
+ if params['manage_VRAM']:
+ give_VRAM_priority('SD')
+
+ payload = {
+ "prompt": params['prompt_prefix'] + description,
+ "seed": params['seed'],
+ "sampler_name": params['sampler_name'],
+ "enable_hr": params['enable_hr'],
+ "hr_scale": params['hr_scale'],
+ "hr_upscaler": params['hr_upscaler'],
+ "denoising_strength": params['denoising_strength'],
+ "steps": params['steps'],
+ "cfg_scale": params['cfg_scale'],
+ "width": params['width'],
+ "height": params['height'],
+ "restore_faces": params['restore_faces'],
+ "override_settings_restore_afterwards": True,
+ "negative_prompt": params['negative_prompt']
+ }
+
+ print(f'Prompting the image generator via the API on {params["address"]}...')
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
+ response.raise_for_status()
+ r = response.json()
+
+ visible_result = ""
+ for img_str in r['images']:
+ if params['save_img']:
+ img_data = base64.b64decode(img_str)
+
+ variadic = f'{date.today().strftime("%Y_%m_%d")}/{character}_{int(time.time())}'
+ output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
+ output_file.parent.mkdir(parents=True, exist_ok=True)
+
+ with open(output_file.as_posix(), 'wb') as f:
+ f.write(img_data)
+
+ visible_result = visible_result + f'Conversation 2
+ + + + + + \n'
+ else:
+ image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
+ # lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
+ image.thumbnail((300, 300))
+ buffered = io.BytesIO()
+ image.save(buffered, format="JPEG")
+ buffered.seek(0)
+ image_bytes = buffered.getvalue()
+ img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
+ visible_result = visible_result + f''
+ return text, visible_text
+
+
+def ui():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+
+ # Prepare the input hijack, update the interface values, call the generation function, and clear the picture
+ picture_select.upload(
+ lambda picture, name1, name2: input_hijack.update({"state": True, "value": generate_chat_picture(picture, name1, name2)}), [picture_select, shared.gradio['name1'], shared.gradio['name2']], None).then(
+ gather_interface_values, gradio(shared.input_elements), gradio('interface_state')).then(
+ chat.generate_chat_reply_wrapper, shared.input_params, gradio('display', 'history'), show_progress=False).then(
+ lambda: None, None, picture_select, show_progress=False)
diff --git a/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt b/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/extensions/silero_tts/requirements.txt b/extensions/silero_tts/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1017bf0d7accb9930872ededd8a4bc077d393958
--- /dev/null
+++ b/extensions/silero_tts/requirements.txt
@@ -0,0 +1,5 @@
+ipython
+num2words
+omegaconf
+pydub
+PyYAML
diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ecd5bd9537eab81c093745c751b61dbf3c7a325
--- /dev/null
+++ b/extensions/silero_tts/script.py
@@ -0,0 +1,187 @@
+import time
+from pathlib import Path
+
+import gradio as gr
+import torch
+
+from extensions.silero_tts import tts_preprocessor
+from modules import chat, shared
+from modules.utils import gradio
+
+torch._C._jit_set_profiling_mode(False)
+
+
+params = {
+ 'activate': True,
+ 'speaker': 'en_56',
+ 'language': 'en',
+ 'model_id': 'v3_en',
+ 'sample_rate': 48000,
+ 'device': 'cpu',
+ 'show_text': False,
+ 'autoplay': True,
+ 'voice_pitch': 'medium',
+ 'voice_speed': 'medium',
+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json
+}
+
+current_params = params.copy()
+voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
+voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
+voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
+
+# Used for making text xml compatible, needed for voice pitch and speed control
+table = str.maketrans({
+ "<": "<",
+ ">": ">",
+ "&": "&",
+ "'": "'",
+ '"': """,
+})
+
+
+def xmlesc(txt):
+ return txt.translate(table)
+
+
+def load_model():
+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
+ model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
+ if Path(model_path).is_file():
+ print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
+ else:
+ print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
+ model.to(params['device'])
+ return model
+
+
+def remove_tts_from_history(history):
+ for i, entry in enumerate(history['internal']):
+ history['visible'][i] = [history['visible'][i][0], entry[1]]
+
+ return history
+
+
+def toggle_text_in_history(history):
+ for i, entry in enumerate(history['visible']):
+ visible_reply = entry[1]
+ if visible_reply.startswith('
\n'
+ else:
+ image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
+ # lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
+ image.thumbnail((300, 300))
+ buffered = io.BytesIO()
+ image.save(buffered, format="JPEG")
+ buffered.seek(0)
+ image_bytes = buffered.getvalue()
+ img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
+ visible_result = visible_result + f''
+ return text, visible_text
+
+
+def ui():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+
+ # Prepare the input hijack, update the interface values, call the generation function, and clear the picture
+ picture_select.upload(
+ lambda picture, name1, name2: input_hijack.update({"state": True, "value": generate_chat_picture(picture, name1, name2)}), [picture_select, shared.gradio['name1'], shared.gradio['name2']], None).then(
+ gather_interface_values, gradio(shared.input_elements), gradio('interface_state')).then(
+ chat.generate_chat_reply_wrapper, shared.input_params, gradio('display', 'history'), show_progress=False).then(
+ lambda: None, None, picture_select, show_progress=False)
diff --git a/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt b/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/extensions/silero_tts/requirements.txt b/extensions/silero_tts/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1017bf0d7accb9930872ededd8a4bc077d393958
--- /dev/null
+++ b/extensions/silero_tts/requirements.txt
@@ -0,0 +1,5 @@
+ipython
+num2words
+omegaconf
+pydub
+PyYAML
diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ecd5bd9537eab81c093745c751b61dbf3c7a325
--- /dev/null
+++ b/extensions/silero_tts/script.py
@@ -0,0 +1,187 @@
+import time
+from pathlib import Path
+
+import gradio as gr
+import torch
+
+from extensions.silero_tts import tts_preprocessor
+from modules import chat, shared
+from modules.utils import gradio
+
+torch._C._jit_set_profiling_mode(False)
+
+
+params = {
+ 'activate': True,
+ 'speaker': 'en_56',
+ 'language': 'en',
+ 'model_id': 'v3_en',
+ 'sample_rate': 48000,
+ 'device': 'cpu',
+ 'show_text': False,
+ 'autoplay': True,
+ 'voice_pitch': 'medium',
+ 'voice_speed': 'medium',
+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json
+}
+
+current_params = params.copy()
+voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
+voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
+voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
+
+# Used for making text xml compatible, needed for voice pitch and speed control
+table = str.maketrans({
+ "<": "<",
+ ">": ">",
+ "&": "&",
+ "'": "'",
+ '"': """,
+})
+
+
+def xmlesc(txt):
+ return txt.translate(table)
+
+
+def load_model():
+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
+ model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
+ if Path(model_path).is_file():
+ print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
+ else:
+ print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
+ model.to(params['device'])
+ return model
+
+
+def remove_tts_from_history(history):
+ for i, entry in enumerate(history['internal']):
+ history['visible'][i] = [history['visible'][i][0], entry[1]]
+
+ return history
+
+
+def toggle_text_in_history(history):
+ for i, entry in enumerate(history['visible']):
+ visible_reply = entry[1]
+ if visible_reply.startswith('