Spaces:
Sleeping

Sleeping
Upload 10 files
Browse files- .gitattributes +4 -0
- README.md +188 -11
- credentialsample.json +14 -0
- screenshots/ans.png +3 -0
- screenshots/ans2.png +0 -0
- screenshots/define_query.png +0 -0
- screenshots/extractinfo.png +0 -0
- screenshots/home.png +0 -0
- screenshots/running.png +3 -0
- screenshots/upload_data.png +3 -0
- screenshots/viewdown.png +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
screenshots/ans.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
screenshots/running.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
screenshots/upload_data.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
screenshots/viewdown.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,14 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
---
|
| 13 |
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# **DataScribe: AI-Powered Information Extraction**
|
| 3 |
+
|
| 4 |
+
DataScribe is an intelligent AI agent designed to streamline data retrieval, extraction, and structuring. By harnessing the power of Large Language Models (LLMs) and automated web search capabilities, it enables users to extract actionable insights from datasets with minimal effort. Designed for efficiency, scalability, and user-friendliness, DataScribe is ideal for professionals handling large datasets or requiring quick access to structured information.
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## 🚀 **Key Features**
|
| 9 |
+
|
| 10 |
+
### Core Functionalities
|
| 11 |
+
1. **File Upload & Integration**
|
| 12 |
+
- Upload datasets directly from CSV files.
|
| 13 |
+
- **Google Sheets Integration**: Seamlessly connect and interact with Google Sheets.
|
| 14 |
+
|
| 15 |
+
2. **Custom Query Definition**
|
| 16 |
+
- Define intuitive query templates for extracting data.
|
| 17 |
+
- **Advanced Query Templates**: Extract multiple fields simultaneously, e.g., "Find the email and address for {company}."
|
| 18 |
+
|
| 19 |
+
3. **Automated Information Retrieval**
|
| 20 |
+
- **LLM-Powered Extraction**: Uses ChatGroq for LLM processing and Serper API for web searches.
|
| 21 |
+
- **Retry Mechanism**: Handles failed queries with robust retries for accurate results.
|
| 22 |
+
|
| 23 |
+
4. **Interactive Results Dashboard**
|
| 24 |
+
- View extracted data in a clean, dynamic, and filterable table view.
|
| 25 |
+
|
| 26 |
+
5. **Export & Update Options**
|
| 27 |
+
- Download results as CSV or directly update Google Sheets.
|
| 28 |
+
|
| 29 |
+
---
|
| 30 |
+
|
| 31 |
+
## 🛠️ **Technology Stack**
|
| 32 |
+
|
| 33 |
+
| **Component** | **Technologies** |
|
| 34 |
+
|----------------------|-------------------------------------------|
|
| 35 |
+
| **Dashboard/UI** | Streamlit |
|
| 36 |
+
| **Data Handling** | pandas, Google Sheets API (Auth0, gspread)|
|
| 37 |
+
| **Search API** | Serper API, ScraperAPI |
|
| 38 |
+
| **LLM API** | Groq API |
|
| 39 |
+
| **Backend** | Python |
|
| 40 |
+
| **Agents** | LangChain |
|
| 41 |
+
|
| 42 |
+
---
|
| 43 |
+
|
| 44 |
+
## 📂 **Repository Structure**
|
| 45 |
+
|
| 46 |
+
```
|
| 47 |
+
DataScribe/
|
| 48 |
+
├── app.py # Main application entry point
|
| 49 |
+
├── funcs/ # Core functionalities
|
| 50 |
+
│ ├── googlesheet.py # Google Sheets integration
|
| 51 |
+
│ ├── llm.py # LLM-based extraction and search
|
| 52 |
+
├── views/ # UI components and layout
|
| 53 |
+
│ ├── home.py # Home page and navigation
|
| 54 |
+
│ ├── upload_data.py # File upload and data preprocessing
|
| 55 |
+
│ ├── define_query.py # Query definition logic
|
| 56 |
+
│ ├── extract_information.py # Information extraction workflows
|
| 57 |
+
│ ├── view_and_download.py # Result viewing and export functionalities
|
| 58 |
+
├── requirements.txt # Dependency list
|
| 59 |
+
├── .env.sample # Environment variable template
|
| 60 |
+
├── credentialsample.json # Google API credentials template
|
| 61 |
+
├── README.md # Documentation
|
| 62 |
+
├── LICENSE # License information
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
---
|
| 66 |
+
|
| 67 |
+
## 📖 **Setup Instructions**
|
| 68 |
+
|
| 69 |
+
### Prerequisites
|
| 70 |
+
- Python 3.9 or higher.
|
| 71 |
+
- Google API credentials for Sheets integration.
|
| 72 |
+
|
| 73 |
+
### Installation Steps
|
| 74 |
+
|
| 75 |
+
1. **Clone the Repository**
|
| 76 |
+
```bash
|
| 77 |
+
git clone https://github.com/sam22ridhi/DataScribe.git
|
| 78 |
+
cd DataScribe
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
2. **Install Dependencies**
|
| 82 |
+
```bash
|
| 83 |
+
pip install -r requirements.txt
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
3. **Set Up Environment Variables**
|
| 87 |
+
- Copy the `.env.sample` file to `.env`:
|
| 88 |
+
```bash
|
| 89 |
+
cp .env.sample .env
|
| 90 |
+
```
|
| 91 |
+
- Add the required API keys to the `.env` file:
|
| 92 |
+
```plaintext
|
| 93 |
+
GOOGLE_API_KEY=<your_google_api_key>
|
| 94 |
+
SERPER_API_KEY=<your_serper_api_key>
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
4. **Prepare Google API Credentials**
|
| 98 |
+
- Replace the content in `credentialsample.json` with your Google API credentials and save it as `credentials.json`.
|
| 99 |
+
|
| 100 |
+
5. **Run the Application**
|
| 101 |
+
```bash
|
| 102 |
+
streamlit run app.py
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
6. **Access the Application**
|
| 106 |
+
Open [http://localhost:8501](http://localhost:8501) in your browser.
|
| 107 |
+
|
| 108 |
+
---
|
| 109 |
+
|
| 110 |
+
## 🛠️ **Usage Guide**
|
| 111 |
+
|
| 112 |
+
1. **Upload Data**
|
| 113 |
+
Navigate to the **Upload Data** tab to import a CSV file or connect to Google Sheets.
|
| 114 |
+
|
| 115 |
+
2. **Define Query**
|
| 116 |
+
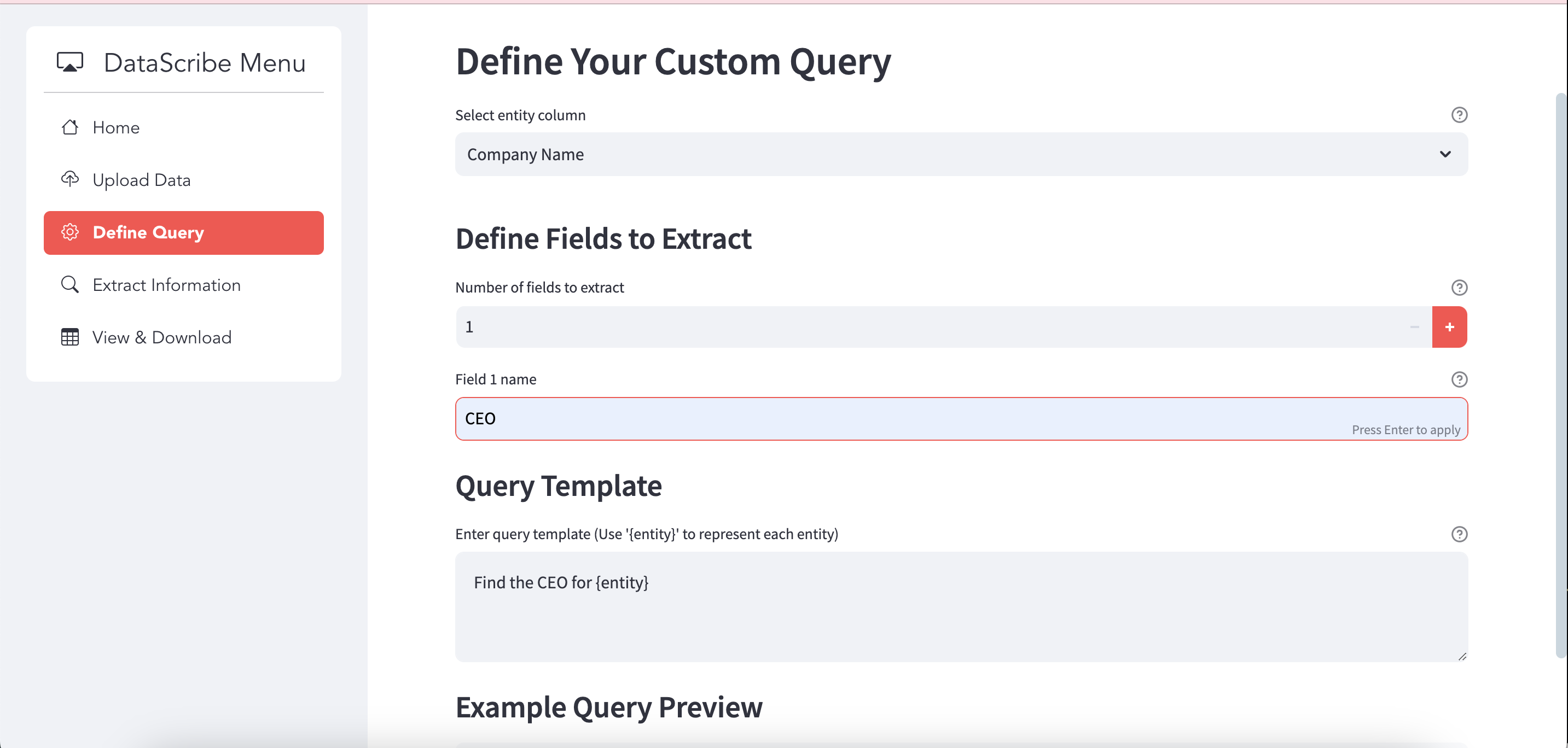
Use the **Define Query** tab to specify search templates. Select the column containing the entities and define fields to extract.
|
| 117 |
+
|
| 118 |
+
3. **Extract Information**
|
| 119 |
+
Execute automated searches in the **Extract Information** tab to fetch structured data.
|
| 120 |
+
|
| 121 |
+
4. **View & Download**
|
| 122 |
+
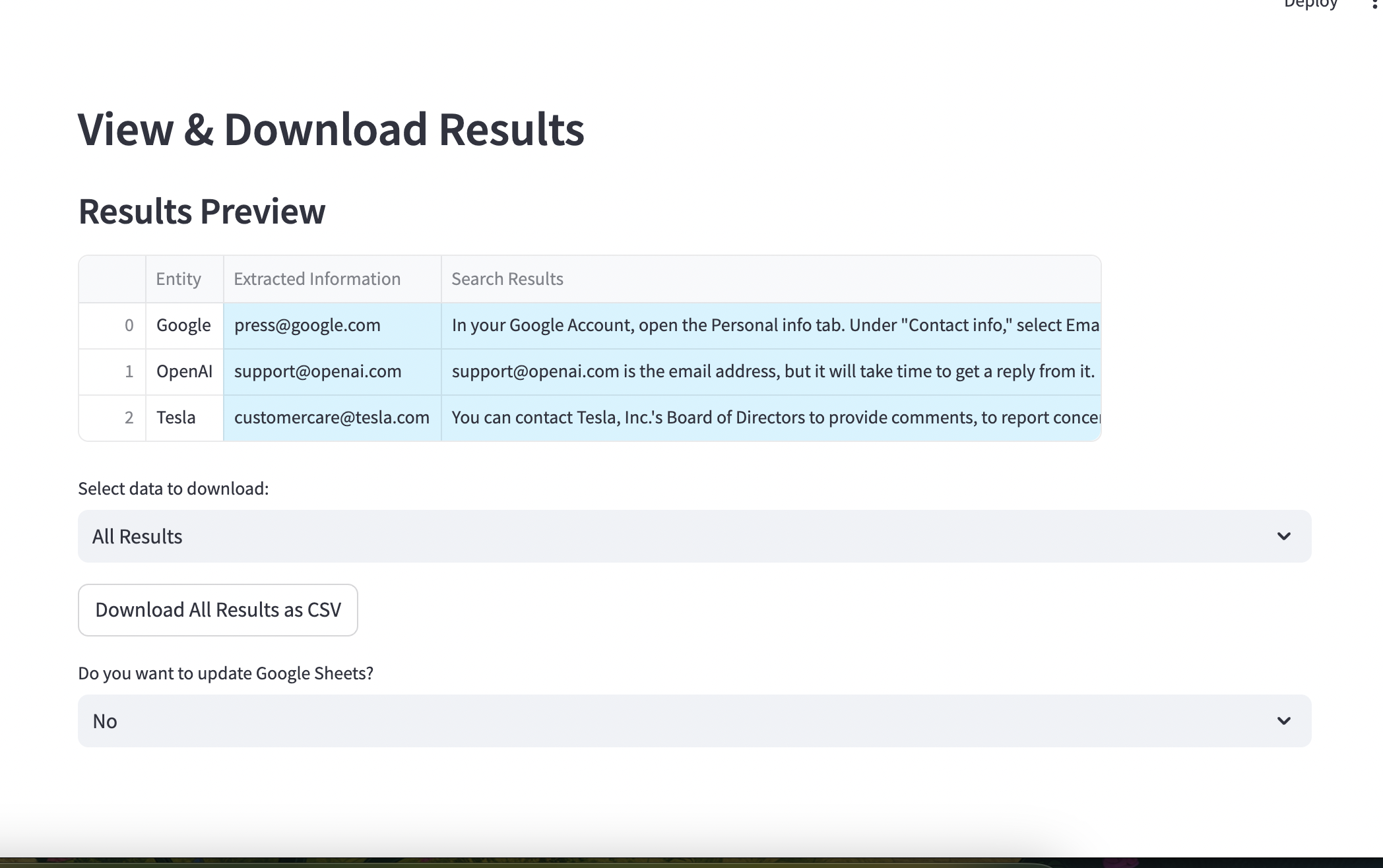
Review the results in the **View & Download** tab, then export as CSV or update Google Sheets directly.
|
| 123 |
+
|
| 124 |
---
|
| 125 |
+
|
| 126 |
+
## 🌟 **Screenshots**
|
| 127 |
+
|
| 128 |
+
#### **Home Page**
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
#### **File Upload**
|
| 132 |
+

|
| 133 |
+
|
| 134 |
+
#### **Define Query**
|
| 135 |
+

|
| 136 |
+
|
| 137 |
+
#### **Extracted Data**
|
| 138 |
+

|
| 139 |
+
|
| 140 |
+
#### **Running the Application**
|
| 141 |
+

|
| 142 |
+

|
| 143 |
+

|
| 144 |
+
|
| 145 |
+
#### **View & Download Results**
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+
|
| 149 |
---
|
| 150 |
|
| 151 |
+
## 📝 **Loom Video Walkthrough**
|
| 152 |
+
|
| 153 |
+
Watch the [2-minute walkthrough](https://www.loom.com/share/2da6b8a8929b46698b4c61aa57d3b461?sid=ef63cba4-37db-468d-86f1-e52ee08d7e0c) showcasing:
|
| 154 |
+
1. Overview of DataScribe's purpose and features.
|
| 155 |
+
2. Key workflows, including upload, extraction, and export.
|
| 156 |
+
3. Code features
|
| 157 |
+
|
| 158 |
+
## 📝 **Hugging Face Tryout**
|
| 159 |
+
|
| 160 |
+
Try out on [huggin face link](https://huggingface.co/spaces/samiee2213/DataScribe)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
## 🙌 **Acknowledgements**
|
| 164 |
+
|
| 165 |
+
Special thanks to **Breakout AI** and **Kapil Mittal** for their opportunity to demonstrate my skills through this project/assessment.
|
| 166 |
+
|
| 167 |
+
---
|
| 168 |
+
|
| 169 |
+
## 📜 **License**
|
| 170 |
+
|
| 171 |
+
This project is licensed under the [Apache License 2.0](LICENSE).
|
| 172 |
+
|
| 173 |
+
---
|
| 174 |
+
|
| 175 |
+
## 🤝 **Contributing**
|
| 176 |
+
|
| 177 |
+
We welcome contributions!
|
| 178 |
+
1. Fork the repository.
|
| 179 |
+
2. Create a feature branch.
|
| 180 |
+
3. Submit a pull request with a detailed description of changes.
|
| 181 |
+
|
| 182 |
+
---
|
| 183 |
+
|
| 184 |
+
## 📬 **Contact**
|
| 185 |
+
|
| 186 |
+
For feedback or support:
|
| 187 |
+
- [Open an Issue](https://github.com/sam22ridhi/DataScribe/issues)
|
| 188 |
+
- Email: **samridhiraj04@gmail.com**
|
| 189 |
+
|
| 190 |
+
---
|
| 191 |
+
|
credentialsample.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"type": " ",
|
| 3 |
+
"project_id": " ",
|
| 4 |
+
"private_key_id": " ",
|
| 5 |
+
"private_key": "",
|
| 6 |
+
"client_email": "",
|
| 7 |
+
"client_id": "",
|
| 8 |
+
"auth_uri": "",
|
| 9 |
+
"token_uri": "",
|
| 10 |
+
"auth_provider_x509_cert_url": "",
|
| 11 |
+
"client_x509_cert_url": "",
|
| 12 |
+
"universe_domain": ""
|
| 13 |
+
}
|
| 14 |
+
|
screenshots/ans.png
ADDED

|
Git LFS Details
|
screenshots/ans2.png
ADDED
|
screenshots/define_query.png
ADDED
|
screenshots/extractinfo.png
ADDED

|
screenshots/home.png
ADDED

|
screenshots/running.png
ADDED

|
Git LFS Details
|
screenshots/upload_data.png
ADDED

|
Git LFS Details
|
screenshots/viewdown.png
ADDED

|
Git LFS Details
|