
File size: 10,814 Bytes
641ff3e cf9d95c 641ff3e cf9d95c 641ff3e 339a165 641ff3e 8652429 641ff3e 8235bbb 04d80a1 21d060c 8652429 21d060c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
---
title: Document redaction
emoji: 😎
colorFrom: blue
colorTo: green
sdk: docker
app_file: app.py
pinned: false
license: agpl-3.0
---
# Document redaction
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Documents/images can be redacted using 'Quick' image analysis that works fine for typed text, but not handwriting/signatures. On the Redaction settings tab, choose 'Complex image analysis' OCR using AWS Textract (if you are using AWS) to redact these more complex elements (this service has a cost). Addtionally you can choose the method for PII identification. 'Local' gives quick, lower quality results, AWS Comprehend gives better results but has a cost.
Review suggested redactions on the 'Review redactions' tab using a point and click visual interface. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or terms to exclude from redaction. Please see the [User Guide](https://github.com/seanpedrick-case/doc_redaction/blob/main/README.md) for a walkthrough on how to use this and all other features in the app. The app accepts a maximum file size of 100mb. Please consider giving feedback for the quality of the answers underneath the redact buttons when the option appears, this will help to improve the app in future.
NOTE: In testing the app seems to find about 60% of personal information on a given (typed) page of text. It is essential that all outputs are checked **by a human** to ensure that all personal information has been removed.
# USER GUIDE
Please refer to these example files to follow this guide:
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
- [Partnership Agreement Toolkit (for signatures)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
## Quick start
Download the files above to your computer. Open up the redaction app at [Hugging Face](https://huggingface.co/spaces/seanpedrickcase/document_redaction) to use the public version (not for use with private documents), or the link provided by email if using with secure documents.
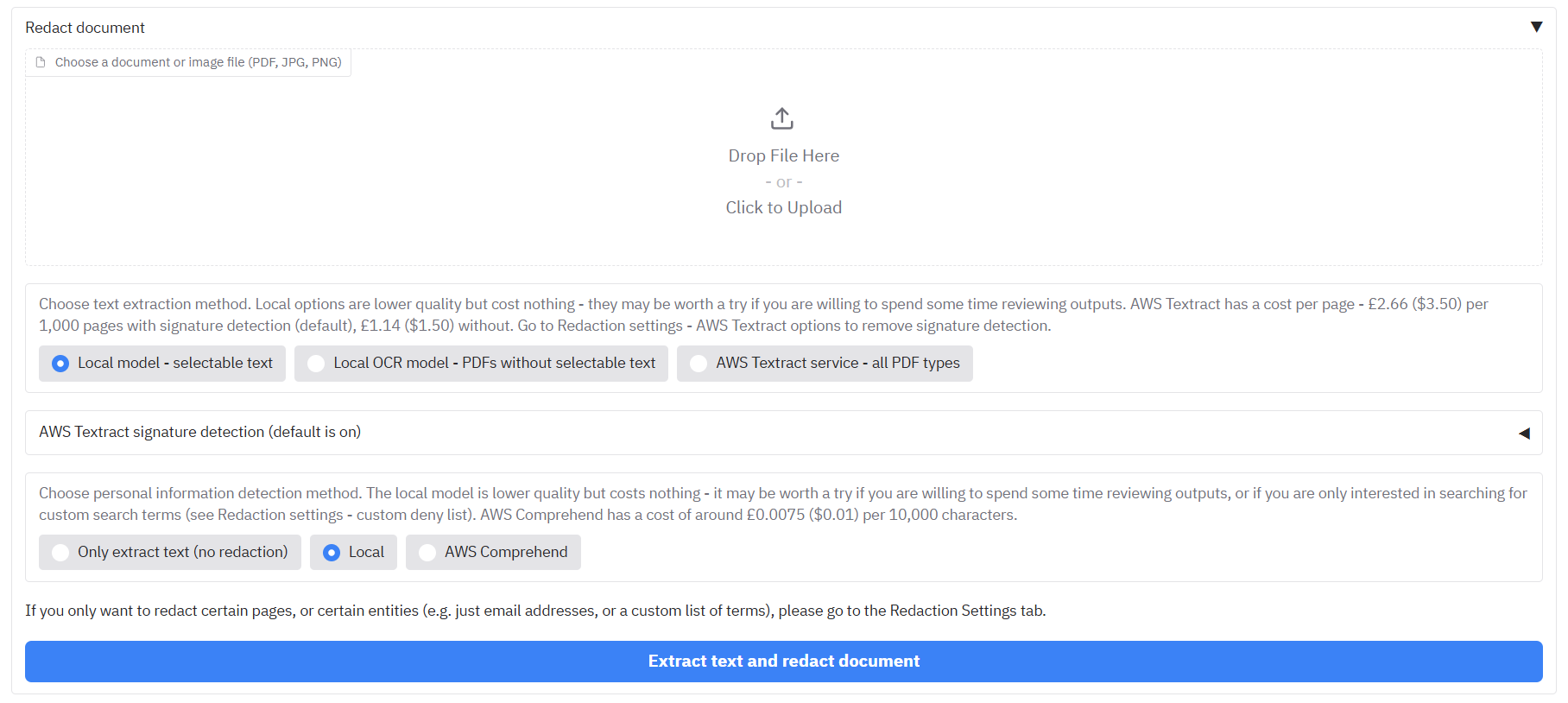
Click on the upload files area, and select the three different files (they should all be stored in the same folder if you want them to be redacted at the same time).
Then select one of the three redaction options below:
- 'Simple text analysis - PDFs with selectable text' - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
- 'Quick image analysis - typed text' - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles a lot with handwriting/signatures. If you are interested in the latter, then you should use the third option.
- 'Complex image analysis - docs with handwriting/signatures (AWS Textract)' - Only available for instances of the app running on AWS, or for those with AWS accounts running this app locally (through boto3). AWS Textract is a service that performs OCR on the document on their systems, which requires sending the relevant pages to their (secure) service. This is a more advanced version of OCR than the second option above, but it does carry a (relatively small) cost, so should be used on documents/pages where the other options struggle. It excels also in identifying handwriting and signatures.
Hit 'Redact document(s)'. The app will then run through the documents one by one, and after a minute or so, you should see a message saying that processing is complete, with some files appearing in the bottom right.

Additional processing outputs are available under the 'Redaction settings' tab. Scroll to the bottom, and you will see two types of file for each input file. 'ocr_results...' or '...all_text_output' csv files are files containing the text identified by the OCR model (for images/image-based PDFs), or the text extraction tool (PikePDF). If you are using AWS Textract, you should also get a .json file with the Textract outputs.

## Redacting additional types of information
You may want to redact additional types of information beyond the defaults. There are dates in the example complaint letter. Say we wanted to redact those dates also?
Under the 'Redaction settings' tab, go to 'Entities to redact (click close to down arrow for full list)'. Click close to the dropdown arrow and you should see a list of possible 'entities' to redact. Select 'DATE_TIME' and it should appear in the main list. To remove items, click on the 'x' next to their name.
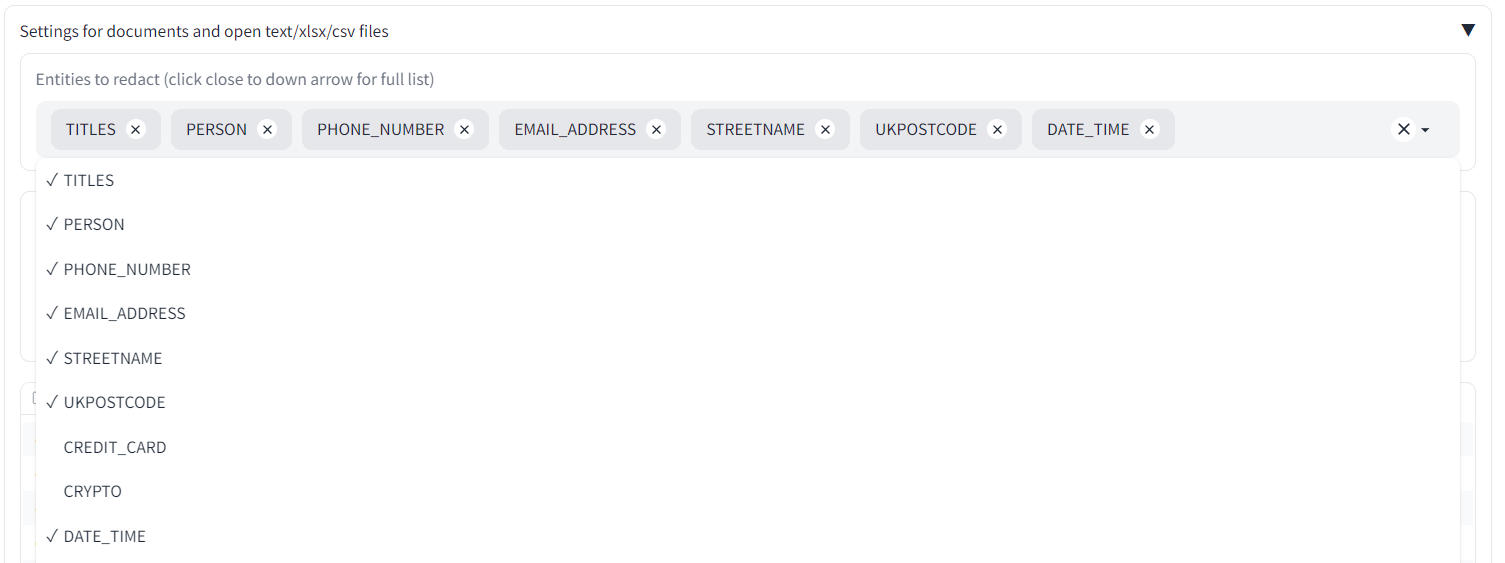
Now, go back to the main screen and click 'Redact Document(s)' again. You should now get a redacted version of 'Example complaint letter' that has the dates and times removed.
If you want to redact different files, I suggest you refresh your browser page to start a new session and unload all previous data.
## Excluding terms from redaction and redacting specified pages
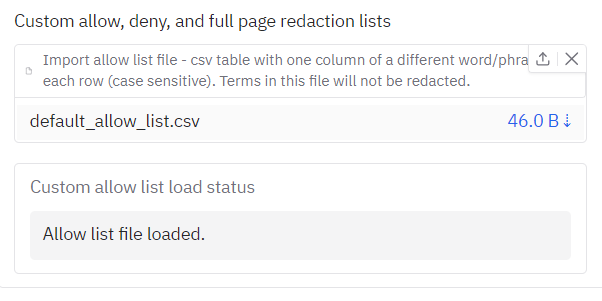
In the redacted outputs of the 'Example of files sent to a professor before applying' PDF, you can see that it is frequently redacting references to Dr Hyde's lab in the main body of the text. Let's say that references to Dr Hyde were not considered personal information in this context. You can exclude this term from redaction (and others) by providing an 'allow list' file. This is simply a csv that contains the case sensitive terms to exclude in the first column, in our example, 'Hyde' and 'Muller glia'. The example file is provided [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/allow_list.csv). Go to the 'Redaction settings' tab, click on the 'Import allow list file' button halfway down, and select the csv file you have created. It should be loaded for next time you hit the redact button. Go back to the first tab and do this.
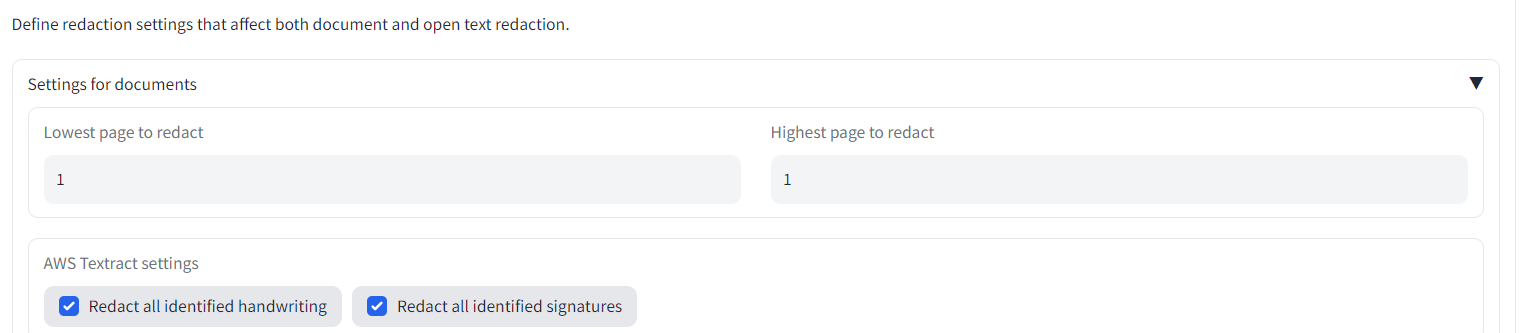
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
## Reviewing suggested redactions and modifying
Quite often there are certain terms suggested for redaction by the model that don't match quite what you intended. The app allows you to review and modify suggested redactions for the last file redacted. Refresh your browser tab. On the first tab 'PDFs/images' upload the 'Example of files sent to a professor before applying.pdf' file. Let's stick with the 'Simple text analysis - PDFs with selectable text' option, and hit 'Redact document(s)'. Once the outputs are created, go to the 'Review redactions' tab.
On this tab you have a visual interface that allows you to inspect and modify redactions suggested by the app.
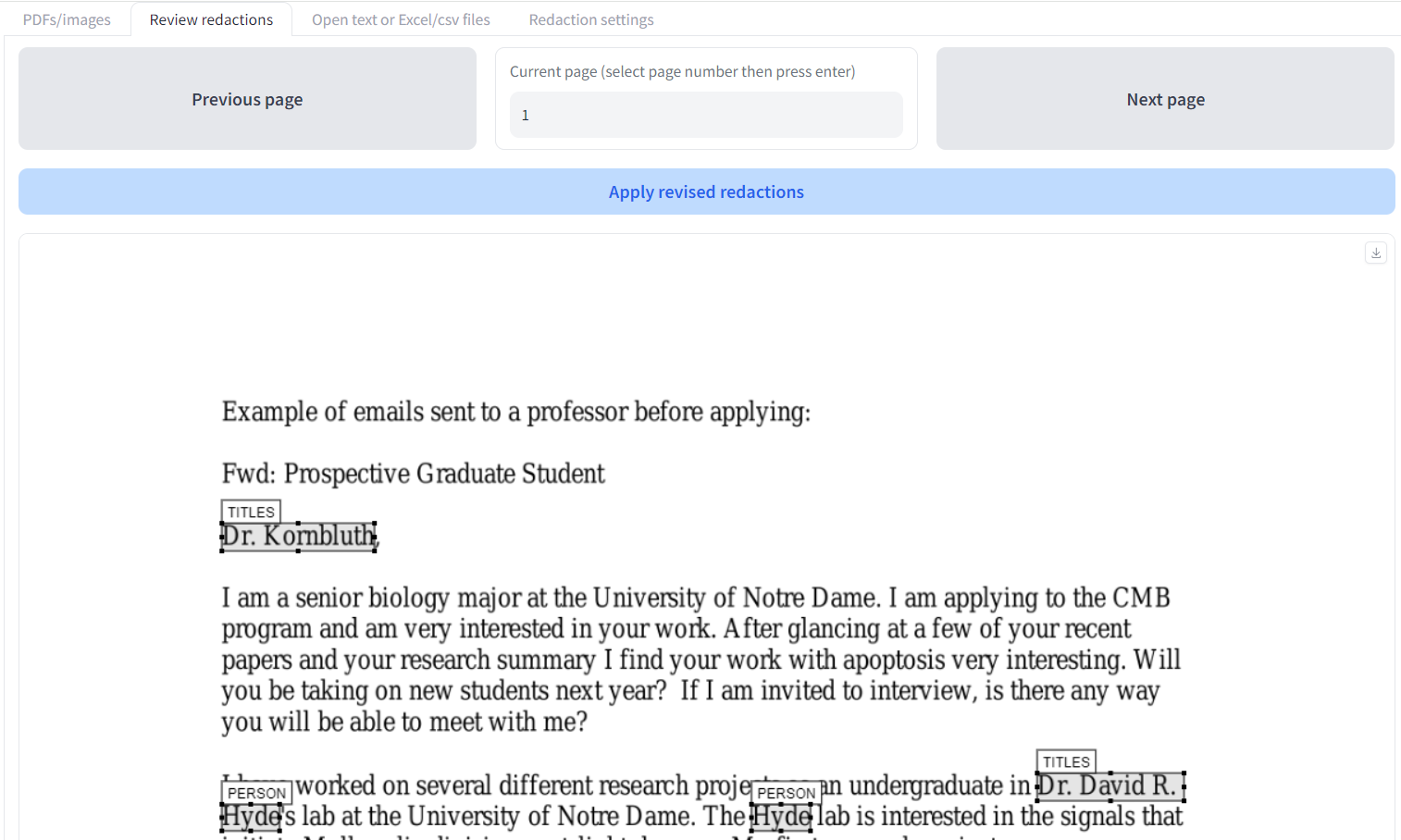
You can change the page viewed either by clicking 'Previous page' or 'Next page', or by typing a specific page number in the 'Current page' box and pressing Enter on your keyboard. Each time you switch page, it will save redactions you have made on the page you are moving from, so you will not lose changes you have made.
On your selected page, each redaction is highlighted with a box next to its suggested entity type. By default the interface allows you to modify existing redaction boxes. Click and hold on an existing box to move it. Click on one of the small boxes at the edges to change the size of the box. To delete a box, click on it to highlight it, then press delete on your keyboard. Alternatively, double click on a box and click 'Remove' on the box that appears.
To change to 'add new redactions' mode, scroll to the bottom of the page. Click on the box icon, and your cursor will change into a crosshair. Now you can add new redaction boxes where you wish.
Once you happy with your modified changes throughout the document, click 'Apply revised redactions' at the top of the page. The app will then run through all the pages in the document to update the redactions, and will output a modified PDF file. The modified PDF will appear at the bottom of the page.

## Handwriting and signatures
The file 'Partnership-Agreement-Toolkit_0_0.pdf' is provided as an example document to test AWS Textract + redaction with a document that has signatures in. If you have access to AWS Textract in the app, try removing all entity types from redaction on the Redaction settings and clicking the big X to the right of 'Entities to redact'. Then set the lowest and highest pages to redact to 5 and 7 respectively. On the first tab, select 'Complex image analysis - docs with handwriting/signatures (AWS Textract)'. The outputs should show pages 5 - 7 with handwriting/signatures redacted, which you can inspect and modify on the 'Review redactions' tab.
Any feedback or comments on the app, please get in touch!
|