from enum import Enum
from functools import partial
from pathlib import Path
from typing import Optional, Tuple
import gradio as gr
from gradio_huggingfacehub_search import HuggingfaceHubSearch
import huggingface_hub
from sentence_transformers import SentenceTransformer
from sentence_transformers import (
export_dynamic_quantized_onnx_model as st_export_dynamic_quantized_onnx_model,
export_optimized_onnx_model as st_export_optimized_onnx_model,
export_static_quantized_openvino_model as st_export_static_quantized_openvino_model,
)
from huggingface_hub import model_info, upload_folder, get_repo_discussions, list_repo_commits, HfFileSystem
from huggingface_hub.errors import RepositoryNotFoundError
from optimum.intel import OVQuantizationConfig
from tempfile import TemporaryDirectory
class Backend(Enum):
# TORCH = "PyTorch"
ONNX = "ONNX"
ONNX_DYNAMIC_QUANTIZATION = "ONNX (Dynamic Quantization)"
ONNX_OPTIMIZATION = "ONNX (Optimization)"
OPENVINO = "OpenVINO"
OPENVINO_STATIC_QUANTIZATION = "OpenVINO (Static Quantization)"
def __str__(self):
return self.value
backends = [str(backend) for backend in Backend]
FILE_SYSTEM = HfFileSystem()
def is_new_model(model_id: str) -> bool:
"""
Check if the model ID exists on the Hugging Face Hub. If we get a request error, then we
assume the model *does* exist.
"""
try:
model_info(model_id)
except RepositoryNotFoundError:
return True
except Exception:
pass
return False
def is_sentence_transformer_model(model_id: str) -> bool:
return "sentence-transformers" in model_info(model_id).tags
def get_last_commit(model_id: str) -> str:
"""
Get the last commit hash of the model ID.
"""
return f"https://huggingface.co/{model_id}/commit/{list_repo_commits(model_id)[0].commit_id}"
def get_last_pr(model_id: str) -> Tuple[str, int]:
last_pr = next(get_repo_discussions(model_id))
return last_pr.url, last_pr.num
def does_file_glob_exist(repo_id: str, glob: str) -> bool:
"""
Check if a file glob exists in the repository.
"""
try:
return bool(FILE_SYSTEM.glob(f"{repo_id}/{glob}", detail=False))
except FileNotFoundError:
return False
def export_to_torch(model_id, create_pr, output_model_id):
model = SentenceTransformer(model_id, backend="torch")
model.push_to_hub(
repo_id=output_model_id,
create_pr=create_pr,
exist_ok=True,
)
def export_to_onnx(model_id: str, create_pr: bool, output_model_id: str, token: Optional[str] = None) -> None:
if does_file_glob_exist(output_model_id, "**/model.onnx"):
raise FileExistsError("An ONNX model already exists in the repository")
model = SentenceTransformer(model_id, backend="onnx")
commit_message = "Add exported onnx model 'model.onnx'"
if is_new_model(output_model_id):
model.push_to_hub(
repo_id=output_model_id,
commit_message=commit_message,
create_pr=create_pr,
token=token,
)
else:
with TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir)
commit_description = f"""
Hello!
*This pull request has been automatically generated from the [Sentence Transformers backend-export](https://huggingface.co/spaces/sentence-transformers/backend-export) Space.*
## Pull Request overview
* Add exported ONNX model `model.onnx`.
## Tip:
Consider testing this pull request before merging by loading the model from this PR with the `revision` argument:
```python
from sentence_transformers import SentenceTransformer
# TODO: Fill in the PR number
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="onnx",
)
# Verify that everything works as expected
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
```
"""
upload_folder(
repo_id=output_model_id,
folder_path=Path(tmp_dir) / "onnx",
path_in_repo="onnx",
commit_message=commit_message,
commit_description=commit_description if create_pr else None,
create_pr=create_pr,
token=token,
)
def export_to_onnx_snippet(model_id: str, create_pr: bool, output_model_id: str) -> str:
return """\
pip install sentence_transformers[onnx-gpu]
# or
pip install sentence_transformers[onnx]
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model to be exported with the ONNX backend
model = SentenceTransformer(
"{model_id}",
backend="onnx",
)
# 2. Push the model to the Hugging Face Hub
{f'model.push_to_hub("{output_model_id}")'
if not create_pr
else f'''model.push_to_hub(
"{output_model_id}",
create_pr=True,
)'''}
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model from the Hugging Face Hub
# (until merged) Use the `revision` argument to load the model from the PR
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="onnx",
)
# 2. Inference works as normal
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
similarities = model.similarity(embeddings, embeddings)
"""
def export_to_onnx_dynamic_quantization(
model_id: str, create_pr: bool, output_model_id: str, onnx_quantization_config: str, token: Optional[str] = None
) -> None:
if does_file_glob_exist(output_model_id, f"onnx/model_qint8_{onnx_quantization_config}.onnx"):
raise FileExistsError("The quantized ONNX model already exists in the repository")
model = SentenceTransformer(model_id, backend="onnx")
if not create_pr and is_new_model(output_model_id):
model.push_to_hub(repo_id=output_model_id, token=token)
# Monkey-patch the upload_folder function to include the token, as it's not used in export_dynamic_quantized_onnx_model
original_upload_folder = huggingface_hub.upload_folder
huggingface_hub.upload_folder = partial(original_upload_folder, token=token)
try:
st_export_dynamic_quantized_onnx_model(
model,
quantization_config=onnx_quantization_config,
model_name_or_path=output_model_id,
push_to_hub=True,
create_pr=create_pr,
)
except ValueError:
# Currently, quantization with optimum has some issues if there's already an ONNX model in a subfolder
model = SentenceTransformer(model_id, backend="onnx", model_kwargs={"export": True})
st_export_dynamic_quantized_onnx_model(
model,
quantization_config=onnx_quantization_config,
model_name_or_path=output_model_id,
push_to_hub=True,
create_pr=create_pr,
)
finally:
huggingface_hub.upload_folder = original_upload_folder
def export_to_onnx_dynamic_quantization_snippet(
model_id: str, create_pr: bool, output_model_id: str, onnx_quantization_config: str
) -> str:
return """\
pip install sentence_transformers[onnx-gpu]
# or
pip install sentence_transformers[onnx]
""", f"""\
from sentence_transformers import (
SentenceTransformer,
export_dynamic_quantized_onnx_model,
)
# 1. Load the model to be quantized with the ONNX backend
model = SentenceTransformer(
"{model_id}",
backend="onnx",
)
# 2. Export the model with {onnx_quantization_config} dynamic quantization
export_dynamic_quantized_onnx_model(
model,
quantization_config="{onnx_quantization_config}",
model_name_or_path="{output_model_id}",
push_to_hub=True,
{''' create_pr=True,
''' if create_pr else ''})
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model from the Hugging Face Hub
# (until merged) Use the `revision` argument to load the model from the PR
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="onnx",
model_kwargs={{"file_name": "model_qint8_{onnx_quantization_config}.onnx"}},
)
# 2. Inference works as normal
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
similarities = model.similarity(embeddings, embeddings)
"""
def export_to_onnx_optimization(model_id: str, create_pr: bool, output_model_id: str, onnx_optimization_config: str, token: Optional[str] = None) -> None:
if does_file_glob_exist(output_model_id, f"onnx/model_{onnx_optimization_config}.onnx"):
raise FileExistsError("The optimized ONNX model already exists in the repository")
model = SentenceTransformer(model_id, backend="onnx")
if not create_pr and is_new_model(output_model_id):
model.push_to_hub(repo_id=output_model_id, token=token)
# Monkey-patch the upload_folder function to include the token, as it's not used in export_optimized_onnx_model
original_upload_folder = huggingface_hub.upload_folder
huggingface_hub.upload_folder = partial(original_upload_folder, token=token)
try:
st_export_optimized_onnx_model(
model,
optimization_config=onnx_optimization_config,
model_name_or_path=output_model_id,
push_to_hub=True,
create_pr=create_pr,
)
finally:
huggingface_hub.upload_folder = original_upload_folder
def export_to_onnx_optimization_snippet(model_id: str, create_pr: bool, output_model_id: str, onnx_optimization_config: str) -> str:
return """\
pip install sentence_transformers[onnx-gpu]
# or
pip install sentence_transformers[onnx]
""", f"""\
from sentence_transformers import (
SentenceTransformer,
export_optimized_onnx_model,
)
# 1. Load the model to be optimized with the ONNX backend
model = SentenceTransformer(
"{model_id}",
backend="onnx",
)
# 2. Export the model with {onnx_optimization_config} optimization level
export_optimized_onnx_model(
model,
optimization_config="{onnx_optimization_config}",
model_name_or_path="{output_model_id}",
push_to_hub=True,
{''' create_pr=True,
''' if create_pr else ''})
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model from the Hugging Face Hub
# (until merged) Use the `revision` argument to load the model from the PR
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="onnx",
model_kwargs={{"file_name": "model_{onnx_optimization_config}.onnx"}},
)
# 2. Inference works as normal
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
similarities = model.similarity(embeddings, embeddings)
"""
def export_to_openvino(model_id: str, create_pr: bool, output_model_id: str, token: Optional[str] = None) -> None:
if does_file_glob_exist(output_model_id, "**/openvino_model.xml"):
raise FileExistsError("The OpenVINO model already exists in the repository")
model = SentenceTransformer(model_id, backend="openvino")
commit_message = "Add exported openvino model 'openvino_model.xml'"
if is_new_model(output_model_id):
model.push_to_hub(
repo_id=output_model_id,
commit_message=commit_message,
create_pr=create_pr,
token=token,
)
else:
with TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir)
commit_description = f"""
Hello!
*This pull request has been automatically generated from the [Sentence Transformers backend-export](https://huggingface.co/spaces/sentence-transformers/backend-export) Space.*
## Pull Request overview
* Add exported OpenVINO model `openvino_model.xml`.
## Tip:
Consider testing this pull request before merging by loading the model from this PR with the `revision` argument:
```python
from sentence_transformers import SentenceTransformer
# TODO: Fill in the PR number
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="openvino",
)
# Verify that everything works as expected
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
```
"""
upload_folder(
repo_id=output_model_id,
folder_path=Path(tmp_dir) / "openvino",
path_in_repo="openvino",
commit_message=commit_message,
commit_description=commit_description if create_pr else None,
create_pr=create_pr,
token=token,
)
def export_to_openvino_snippet(model_id: str, create_pr: bool, output_model_id: str) -> str:
return """\
pip install sentence_transformers[openvino]
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model to be exported with the OpenVINO backend
model = SentenceTransformer(
"{model_id}",
backend="openvino",
)
# 2. Push the model to the Hugging Face Hub
{f'model.push_to_hub("{output_model_id}")'
if not create_pr
else f'''model.push_to_hub(
"{output_model_id}",
create_pr=True,
)'''}
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model from the Hugging Face Hub
# (until merged) Use the `revision` argument to load the model from the PR
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="openvino",
)
# 2. Inference works as normal
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
similarities = model.similarity(embeddings, embeddings)
"""
def export_to_openvino_static_quantization(
model_id: str,
create_pr: bool,
output_model_id: str,
ov_quant_dataset_name: str,
ov_quant_dataset_subset: str,
ov_quant_dataset_split: str,
ov_quant_dataset_column_name: str,
ov_quant_dataset_num_samples: int,
token: Optional[str] = None,
) -> None:
if does_file_glob_exist(output_model_id, "openvino/openvino_model_qint8_quantized.xml"):
raise FileExistsError("The quantized OpenVINO model already exists in the repository")
model = SentenceTransformer(model_id, backend="openvino")
if not create_pr and is_new_model(output_model_id):
model.push_to_hub(repo_id=output_model_id, token=token)
# Monkey-patch the upload_folder function to include the token, as it's not used in export_static_quantized_openvino_model
original_upload_folder = huggingface_hub.upload_folder
huggingface_hub.upload_folder = partial(original_upload_folder, token=token)
try:
st_export_static_quantized_openvino_model(
model,
quantization_config=OVQuantizationConfig(
num_samples=ov_quant_dataset_num_samples,
),
model_name_or_path=output_model_id,
dataset_name=ov_quant_dataset_name,
dataset_config_name=ov_quant_dataset_subset,
dataset_split=ov_quant_dataset_split,
column_name=ov_quant_dataset_column_name,
push_to_hub=True,
create_pr=create_pr,
)
finally:
huggingface_hub.upload_folder = original_upload_folder
def export_to_openvino_static_quantization_snippet(
model_id: str,
create_pr: bool,
output_model_id: str,
ov_quant_dataset_name: str,
ov_quant_dataset_subset: str,
ov_quant_dataset_split: str,
ov_quant_dataset_column_name: str,
ov_quant_dataset_num_samples: int,
) -> str:
return """\
pip install sentence_transformers[openvino]
""", f"""\
from sentence_transformers import (
SentenceTransformer,
export_static_quantized_openvino_model,
)
from optimum.intel import OVQuantizationConfig
# 1. Load the model to be quantized with the OpenVINO backend
model = SentenceTransformer(
"{model_id}",
backend="openvino",
)
# 2. Export the model with int8 static quantization
export_static_quantized_openvino_model(
model,
quantization_config=OVQuantizationConfig(
num_samples={ov_quant_dataset_num_samples},
),
model_name_or_path="{output_model_id}",
dataset_name="{ov_quant_dataset_name}",
dataset_config_name="{ov_quant_dataset_subset}",
dataset_split="{ov_quant_dataset_split}",
column_name="{ov_quant_dataset_column_name}",
push_to_hub=True,
{''' create_pr=True,
''' if create_pr else ''})
""", f"""\
from sentence_transformers import SentenceTransformer
# 1. Load the model from the Hugging Face Hub
# (until merged) Use the `revision` argument to load the model from the PR
pr_number = 2
model = SentenceTransformer(
"{output_model_id}",
revision=f"refs/pr/{{pr_number}}",
backend="openvino",
model_kwargs={{"file_name": "openvino_model_qint8_quantized.xml"}},
)
# 2. Inference works as normal
embeddings = model.encode(["The weather is lovely today.", "It's so sunny outside!", "He drove to the stadium."])
similarities = model.similarity(embeddings, embeddings)
"""
def on_submit(
model_id,
create_pr,
output_model_id,
backend,
onnx_quantization_config,
onnx_optimization_config,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
inference_snippet: str,
oauth_token: Optional[gr.OAuthToken] = None,
profile: Optional[gr.OAuthProfile] = None,
):
if oauth_token is None or profile is None:
return "Commit or PR url:
...", inference_snippet, gr.Textbox("Please sign in with Hugging Face to use this Space", visible=True)
if not model_id:
return "Commit or PR url:
...", inference_snippet, gr.Textbox("Please enter a model ID", visible=True)
if not is_sentence_transformer_model(model_id):
return "Commit or PR url:
...", inference_snippet, gr.Textbox("The source model must have a Sentence Transformers tag", visible=True)
if output_model_id and "/" not in output_model_id:
output_model_id = f"{profile.name}/{output_model_id}"
output_model_id = output_model_id if not create_pr else model_id
try:
if backend == Backend.ONNX.value:
export_to_onnx(model_id, create_pr, output_model_id, token=oauth_token.token)
elif backend == Backend.ONNX_DYNAMIC_QUANTIZATION.value:
export_to_onnx_dynamic_quantization(
model_id, create_pr, output_model_id, onnx_quantization_config, token=oauth_token.token
)
elif backend == Backend.ONNX_OPTIMIZATION.value:
export_to_onnx_optimization(
model_id, create_pr, output_model_id, onnx_optimization_config, token=oauth_token.token
)
elif backend == Backend.OPENVINO.value:
export_to_openvino(model_id, create_pr, output_model_id, token=oauth_token.token)
elif backend == Backend.OPENVINO_STATIC_QUANTIZATION.value:
export_to_openvino_static_quantization(
model_id,
create_pr,
output_model_id,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
token=oauth_token.token,
)
except FileExistsError as exc:
return "Commit or PR url:
...", inference_snippet, gr.Textbox(str(exc), visible=True)
if create_pr:
url, num = get_last_pr(output_model_id)
return f"PR url:
{url}", inference_snippet.replace("pr_number = 2", f"pr_number = {num}"), gr.Textbox(visible=False)
# Remove the lines that refer to the revision argument
lines = inference_snippet.splitlines()
del lines[7]
del lines[4]
del lines[3]
inference_snippet = "\n".join(lines)
return f"Commit url:
{get_last_commit(output_model_id)}", inference_snippet, gr.Textbox(visible=False)
def on_change(
model_id,
create_pr,
output_model_id,
backend,
onnx_quantization_config,
onnx_optimization_config,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
oauth_token: Optional[gr.OAuthToken] = None,
profile: Optional[gr.OAuthProfile] = None,
) -> str:
if oauth_token is None or profile is None:
return "", "", "", gr.Textbox("Please sign in with Hugging Face to use this Space", visible=True)
if not model_id:
return "", "", "", gr.Textbox("Please enter a model ID", visible=True)
if output_model_id and "/" not in output_model_id:
output_model_id = f"{profile.username}/{output_model_id}"
output_model_id = output_model_id if not create_pr else model_id
if backend == Backend.ONNX.value:
snippets = export_to_onnx_snippet(model_id, create_pr, output_model_id)
elif backend == Backend.ONNX_DYNAMIC_QUANTIZATION.value:
snippets = export_to_onnx_dynamic_quantization_snippet(
model_id, create_pr, output_model_id, onnx_quantization_config
)
elif backend == Backend.ONNX_OPTIMIZATION.value:
snippets = export_to_onnx_optimization_snippet(
model_id, create_pr, output_model_id, onnx_optimization_config
)
elif backend == Backend.OPENVINO.value:
snippets = export_to_openvino_snippet(model_id, create_pr, output_model_id)
elif backend == Backend.OPENVINO_STATIC_QUANTIZATION.value:
snippets = export_to_openvino_static_quantization_snippet(
model_id,
create_pr,
output_model_id,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
)
else:
return "", "", "", gr.Textbox("Unexpected backend!", visible=True)
return *snippets, gr.Textbox(visible=False)
css = """
.container {
padding-left: 0;
}
div:has(> div.text-error) {
border-color: var(--error-border-color);
}
.small-text * {
font-size: var(--block-info-text-size);
}
"""
with gr.Blocks(
css=css,
theme=gr.themes.Base(),
) as demo:
gr.LoginButton(min_width=250)
with gr.Row():
# Left Input Column
with gr.Column(scale=2):
gr.Markdown(
value="""\
### Export a Sentence Transformer model to accelerated backends
Sentence Transformers embedding models can be optimized for **faster inference** on CPU and GPU devices by exporting, quantizing, and optimizing them in ONNX and OpenVINO formats.
Observe the [Speeding up Inference](https://sbert.net/docs/sentence_transformer/usage/efficiency.html) documentation for more information.
""",
label="",
container=True,
)
gr.HTML(value="""\
Click to see performance benchmarks
| GPU |
CPU |

|
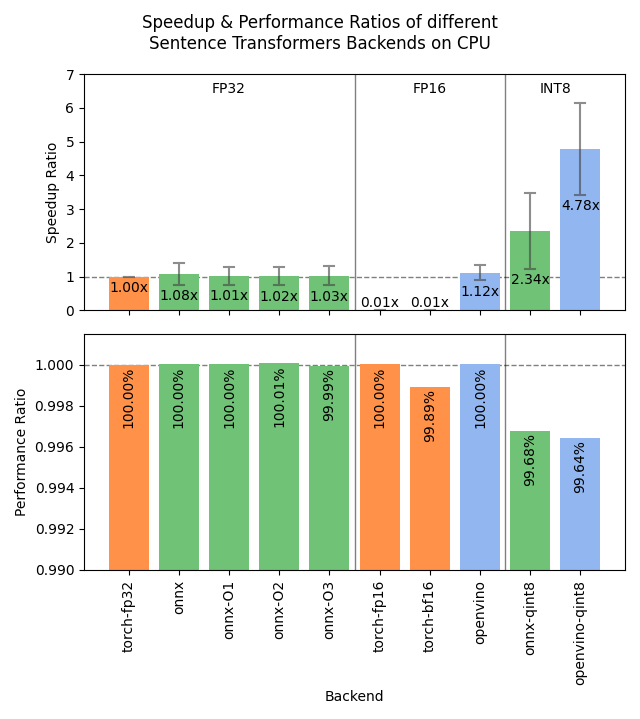
|
onnx refers to the ONNX backendonnx-qint8 refers to ONNX (Dynamic Quantization)onnx-O1 to onnx-O4 refers to ONNX (Optimization)openvino refers to the OpenVINO backendopenvino-qint8 refers to OpenVINO (Static Quantization)
...",
label="",
container=True,
visible=True,
)
submit_button.click(
on_submit,
inputs=[
model_id,
create_pr,
output_model_id,
backend,
onnx_quantization_config,
onnx_optimization_config,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
inference_snippet,
],
outputs=[url, inference_snippet, error],
)
for input_component in [
model_id,
create_pr,
output_model_id,
backend,
onnx_quantization_config,
onnx_optimization_config,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
]:
input_component.change(
on_change,
inputs=[
model_id,
create_pr,
output_model_id,
backend,
onnx_quantization_config,
onnx_optimization_config,
ov_quant_dataset_name,
ov_quant_dataset_subset,
ov_quant_dataset_split,
ov_quant_dataset_column_name,
ov_quant_dataset_num_samples,
],
outputs=[requirements, export_snippet, inference_snippet, error],
)
if __name__ == "__main__":
demo.launch(ssr_mode=False)