Spaces:
Running

Running
Remove large file train_info.txt
Browse files- app.py +76 -22
- new_test_saved_finetuned_model.py +2 -2
- plot.png +0 -0
- result.txt +7 -7
- roc_data.pkl +2 -2
- school_grduation_rate.pkl +3 -0
- selected_rows.txt +0 -0
- train.txt +0 -0
- train_info.txt +0 -1
- train_label.txt +0 -0
app.py
CHANGED
|
@@ -7,9 +7,10 @@ import subprocess
|
|
| 7 |
import shutil
|
| 8 |
import matplotlib.pyplot as plt
|
| 9 |
from sklearn.metrics import roc_curve, auc
|
|
|
|
| 10 |
# Define the function to process the input file and model selection
|
| 11 |
|
| 12 |
-
def process_file(file,label,info,
|
| 13 |
# progress = gr.Progress(track_tqdm=True)
|
| 14 |
progress(0, desc="Starting the processing")
|
| 15 |
with open(file.name, 'r') as f:
|
|
@@ -21,27 +22,66 @@ def process_file(file,label,info,inc_val,progress=Progress(track_tqdm=True)):
|
|
| 21 |
shutil.copyfile(file.name, saved_test_dataset)
|
| 22 |
shutil.copyfile(label.name, saved_test_label)
|
| 23 |
shutil.copyfile(info.name, saved_train_info)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
# For demonstration purposes, we'll just return the content with the selected model name
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
# else:
|
| 32 |
-
# checkpoint=None
|
| 33 |
-
# print(checkpoint)
|
| 34 |
-
if (inc_val<5):
|
| 35 |
-
model_name="highGRschool10"
|
| 36 |
-
elif(inc_val>=5 & inc_val<10):
|
| 37 |
-
model_name="highGRschool10"
|
| 38 |
else:
|
| 39 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 40 |
subprocess.run([
|
| 41 |
"python", "new_test_saved_finetuned_model.py",
|
| 42 |
"-workspace_name", "ratio_proportion_change3_2223/sch_largest_100-coded",
|
| 43 |
-
"-finetune_task",
|
| 44 |
-
|
| 45 |
# "-test_label_path","../../../../train_label.txt",
|
| 46 |
"-finetuned_bert_classifier_checkpoint",
|
| 47 |
"ratio_proportion_change3_2223/sch_largest_100-coded/output/highGRschool10/bert_fine_tuned.model.ep42",
|
|
@@ -77,12 +117,26 @@ def process_file(file,label,info,inc_val,progress=Progress(track_tqdm=True)):
|
|
| 77 |
progress(1.0)
|
| 78 |
# Prepare text output
|
| 79 |
text_output = f"Model: {model_name}\nResult:\n{result}"
|
| 80 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 81 |
return text_output,plot_path
|
| 82 |
|
| 83 |
# List of models for the dropdown menu
|
| 84 |
|
| 85 |
-
models = ["
|
| 86 |
|
| 87 |
# Create the Gradio interface
|
| 88 |
with gr.Blocks(css="""
|
|
@@ -275,10 +329,10 @@ tbody.svelte-18wv37q>tr.svelte-18wv37q:nth-child(odd) {
|
|
| 275 |
|
| 276 |
info_input = gr.File(label="Upload test info", file_types=['.txt'], elem_classes="file-box")
|
| 277 |
|
| 278 |
-
|
| 279 |
|
| 280 |
|
| 281 |
-
increment_slider = gr.Slider(minimum=
|
| 282 |
|
| 283 |
with gr.Row():
|
| 284 |
output_text = gr.Textbox(label="Output Text")
|
|
@@ -286,7 +340,7 @@ tbody.svelte-18wv37q>tr.svelte-18wv37q:nth-child(odd) {
|
|
| 286 |
|
| 287 |
btn = gr.Button("Submit")
|
| 288 |
|
| 289 |
-
btn.click(fn=process_file, inputs=[file_input,label_input,info_input,increment_slider], outputs=[output_text,output_image])
|
| 290 |
|
| 291 |
|
| 292 |
# Launch the app
|
|
|
|
| 7 |
import shutil
|
| 8 |
import matplotlib.pyplot as plt
|
| 9 |
from sklearn.metrics import roc_curve, auc
|
| 10 |
+
import pandas as pd
|
| 11 |
# Define the function to process the input file and model selection
|
| 12 |
|
| 13 |
+
def process_file(file,label,info,model_name,inc_slider,progress=Progress(track_tqdm=True)):
|
| 14 |
# progress = gr.Progress(track_tqdm=True)
|
| 15 |
progress(0, desc="Starting the processing")
|
| 16 |
with open(file.name, 'r') as f:
|
|
|
|
| 22 |
shutil.copyfile(file.name, saved_test_dataset)
|
| 23 |
shutil.copyfile(label.name, saved_test_label)
|
| 24 |
shutil.copyfile(info.name, saved_train_info)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# Load the test_info file and the graduation rate file
|
| 28 |
+
test_info = pd.read_csv('train_info.txt', sep=',', header=None, engine='python')
|
| 29 |
+
grad_rate_data = pd.DataFrame(pd.read_pickle('school_grduation_rate.pkl'),columns=['school_number','grad_rate']) # Load the grad_rate data
|
| 30 |
+
|
| 31 |
+
# Step 1: Extract unique school numbers from test_info
|
| 32 |
+
unique_schools = test_info[0].unique()
|
| 33 |
+
|
| 34 |
+
# Step 2: Filter the grad_rate_data using the unique school numbers
|
| 35 |
+
schools = grad_rate_data[grad_rate_data['school_number'].isin(unique_schools)]
|
| 36 |
+
|
| 37 |
+
# Define a threshold for high and low graduation rates (adjust as needed)
|
| 38 |
+
grad_rate_threshold = 0.9
|
| 39 |
+
|
| 40 |
+
# Step 4: Divide schools into high and low graduation rate groups
|
| 41 |
+
high_grad_schools = schools[schools['grad_rate'] >= grad_rate_threshold]['school_number'].unique()
|
| 42 |
+
low_grad_schools = schools[schools['grad_rate'] < grad_rate_threshold]['school_number'].unique()
|
| 43 |
+
|
| 44 |
+
# Step 5: Sample percentage of schools from each group
|
| 45 |
+
high_sample = pd.Series(high_grad_schools).sample(frac=inc_slider/100, random_state=1).tolist()
|
| 46 |
+
low_sample = pd.Series(low_grad_schools).sample(frac=inc_slider/100, random_state=1).tolist()
|
| 47 |
+
|
| 48 |
+
# Step 6: Combine the sampled schools
|
| 49 |
+
random_schools = high_sample + low_sample
|
| 50 |
+
|
| 51 |
+
# Step 7: Get indices for the sampled schools
|
| 52 |
+
indices = test_info[test_info[0].isin(random_schools)].index.tolist()
|
| 53 |
+
|
| 54 |
+
# Load the test file and select rows based on indices
|
| 55 |
+
test = pd.read_csv('train.txt', sep=',', header=None, engine='python')
|
| 56 |
+
selected_rows_df2 = test.loc[indices]
|
| 57 |
+
|
| 58 |
+
# Save the selected rows to a file
|
| 59 |
+
selected_rows_df2.to_csv('selected_rows.txt', sep='\t', index=False, header=False, quoting=3, escapechar=' ')
|
| 60 |
+
|
| 61 |
+
|
| 62 |
# For demonstration purposes, we'll just return the content with the selected model name
|
| 63 |
+
if(model_name=="High Graduated Schools"):
|
| 64 |
+
finetune_task="highGRschool10"
|
| 65 |
+
elif(model_name== "Low Graduated Schools" ):
|
| 66 |
+
finetune_task="highGRschool10"
|
| 67 |
+
elif(model_name=="Full Set"):
|
| 68 |
+
finetune_task="highGRschool10"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
else:
|
| 70 |
+
finetune_task=None
|
| 71 |
+
# print(checkpoint)
|
| 72 |
+
progress(0.1, desc="Files created and saved")
|
| 73 |
+
# if (inc_val<5):
|
| 74 |
+
# model_name="highGRschool10"
|
| 75 |
+
# elif(inc_val>=5 & inc_val<10):
|
| 76 |
+
# model_name="highGRschool10"
|
| 77 |
+
# else:
|
| 78 |
+
# model_name="highGRschool10"
|
| 79 |
+
progress(0.2, desc="Executing models")
|
| 80 |
subprocess.run([
|
| 81 |
"python", "new_test_saved_finetuned_model.py",
|
| 82 |
"-workspace_name", "ratio_proportion_change3_2223/sch_largest_100-coded",
|
| 83 |
+
"-finetune_task", "highGRschool10",
|
| 84 |
+
"-test_dataset_path","../../../../selected_rows.txt",
|
| 85 |
# "-test_label_path","../../../../train_label.txt",
|
| 86 |
"-finetuned_bert_classifier_checkpoint",
|
| 87 |
"ratio_proportion_change3_2223/sch_largest_100-coded/output/highGRschool10/bert_fine_tuned.model.ep42",
|
|
|
|
| 117 |
progress(1.0)
|
| 118 |
# Prepare text output
|
| 119 |
text_output = f"Model: {model_name}\nResult:\n{result}"
|
| 120 |
+
# Prepare text output with HTML formatting
|
| 121 |
+
text_output = f"""
|
| 122 |
+
Model: {model_name}\n
|
| 123 |
+
Result Summary:\n
|
| 124 |
+
-----------------\n
|
| 125 |
+
Average Loss: {result['avg_loss']:.4f}\n
|
| 126 |
+
Total Accuracy: {result['total_acc']:.2f}%\n
|
| 127 |
+
Precision: {result['precisions']:.2f}\n
|
| 128 |
+
Recall: {result['recalls']:.2f}\n
|
| 129 |
+
F1-Score: {result['f1_scores']:.2f}\n
|
| 130 |
+
Time Taken: {result['time_taken_from_start']:.2f} seconds\n
|
| 131 |
+
AUC Score: {result['auc_score']:.4f}\n
|
| 132 |
+
-----------------\n
|
| 133 |
+
Note: The ROC Curve is also displayed for the evaluation.
|
| 134 |
+
"""
|
| 135 |
return text_output,plot_path
|
| 136 |
|
| 137 |
# List of models for the dropdown menu
|
| 138 |
|
| 139 |
+
models = ["High Graduated Schools", "Low Graduated Schools", "Full Set"]
|
| 140 |
|
| 141 |
# Create the Gradio interface
|
| 142 |
with gr.Blocks(css="""
|
|
|
|
| 329 |
|
| 330 |
info_input = gr.File(label="Upload test info", file_types=['.txt'], elem_classes="file-box")
|
| 331 |
|
| 332 |
+
model_dropdown = gr.Dropdown(choices=models, label="Select Finetune Task", elem_classes="dropdown-menu")
|
| 333 |
|
| 334 |
|
| 335 |
+
increment_slider = gr.Slider(minimum=5, maximum=100, step=5, label="Schools Percentage", value=5)
|
| 336 |
|
| 337 |
with gr.Row():
|
| 338 |
output_text = gr.Textbox(label="Output Text")
|
|
|
|
| 340 |
|
| 341 |
btn = gr.Button("Submit")
|
| 342 |
|
| 343 |
+
btn.click(fn=process_file, inputs=[file_input,label_input,info_input,model_dropdown,increment_slider], outputs=[output_text,output_image])
|
| 344 |
|
| 345 |
|
| 346 |
# Launch the app
|
new_test_saved_finetuned_model.py
CHANGED
|
@@ -495,7 +495,7 @@ def train():
|
|
| 495 |
parser.add_argument("-hs", "--hidden", type=int, default=64, help="hidden size of transformer model") #64
|
| 496 |
parser.add_argument("-l", "--layers", type=int, default=4, help="number of layers") #4
|
| 497 |
parser.add_argument("-a", "--attn_heads", type=int, default=4, help="number of attention heads") #8
|
| 498 |
-
parser.add_argument("-s", "--seq_len", type=int, default=
|
| 499 |
|
| 500 |
parser.add_argument("-b", "--batch_size", type=int, default=500, help="number of batch_size") #64
|
| 501 |
parser.add_argument("-e", "--epochs", type=int, default=1)#1501, help="number of epochs") #501
|
|
@@ -508,7 +508,7 @@ def train():
|
|
| 508 |
# parser.add_argument("--corpus_lines", type=int, default=None, help="total number of lines in corpus")
|
| 509 |
parser.add_argument("--cuda_devices", type=int, nargs='+', default=None, help="CUDA device ids")
|
| 510 |
# parser.add_argument("--on_memory", type=bool, default=False, help="Loading on memory: true or false")
|
| 511 |
-
|
| 512 |
parser.add_argument("--dropout", type=float, default=0.1, help="dropout of network")
|
| 513 |
parser.add_argument("--lr", type=float, default=1e-05, help="learning rate of adam") #1e-3
|
| 514 |
parser.add_argument("--adam_weight_decay", type=float, default=0.01, help="weight_decay of adam")
|
|
|
|
| 495 |
parser.add_argument("-hs", "--hidden", type=int, default=64, help="hidden size of transformer model") #64
|
| 496 |
parser.add_argument("-l", "--layers", type=int, default=4, help="number of layers") #4
|
| 497 |
parser.add_argument("-a", "--attn_heads", type=int, default=4, help="number of attention heads") #8
|
| 498 |
+
parser.add_argument("-s", "--seq_len", type=int, default=128, help="maximum sequence length")
|
| 499 |
|
| 500 |
parser.add_argument("-b", "--batch_size", type=int, default=500, help="number of batch_size") #64
|
| 501 |
parser.add_argument("-e", "--epochs", type=int, default=1)#1501, help="number of epochs") #501
|
|
|
|
| 508 |
# parser.add_argument("--corpus_lines", type=int, default=None, help="total number of lines in corpus")
|
| 509 |
parser.add_argument("--cuda_devices", type=int, nargs='+', default=None, help="CUDA device ids")
|
| 510 |
# parser.add_argument("--on_memory", type=bool, default=False, help="Loading on memory: true or false")
|
| 511 |
+
|
| 512 |
parser.add_argument("--dropout", type=float, default=0.1, help="dropout of network")
|
| 513 |
parser.add_argument("--lr", type=float, default=1e-05, help="learning rate of adam") #1e-3
|
| 514 |
parser.add_argument("--adam_weight_decay", type=float, default=0.01, help="weight_decay of adam")
|
plot.png
CHANGED
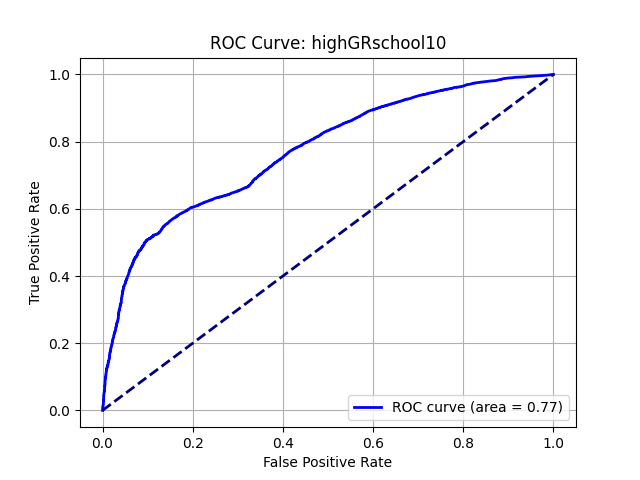
|

|
result.txt
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
-
avg_loss: 0.
|
| 2 |
-
total_acc:
|
| 3 |
-
precisions: 0.
|
| 4 |
-
recalls: 0.
|
| 5 |
-
f1_scores: 0.
|
| 6 |
-
time_taken_from_start:
|
| 7 |
-
auc_score: 0.
|
|
|
|
| 1 |
+
avg_loss: 0.5631513595581055
|
| 2 |
+
total_acc: 69.7320542507443
|
| 3 |
+
precisions: 0.7236992960620143
|
| 4 |
+
recalls: 0.6973205425074429
|
| 5 |
+
f1_scores: 0.6879225873063946
|
| 6 |
+
time_taken_from_start: 73.04951095581055
|
| 7 |
+
auc_score: 0.7452296224317393
|
roc_data.pkl
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f4beb5de79dfb3592402832ced8db0c87f3264e46c0813553c40728c7ddafed5
|
| 3 |
+
size 29285
|
school_grduation_rate.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6c0c99dd8fc601de1fc8f4af5880bf71b7198c09bf0d016a880b02043e0b3d03
|
| 3 |
+
size 18356
|
selected_rows.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train.txt
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train_info.txt
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
test
|
|
|
|
|
|
train_label.txt
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|