Spaces:
Configuration error

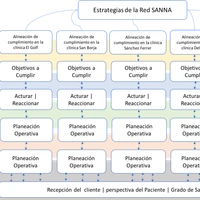
Configuration error
| import gc | |
| import hashlib | |
| import os | |
| import queue | |
| import threading | |
| import json | |
| import shlex | |
| import sys | |
| import subprocess | |
| import librosa | |
| import numpy as np | |
| import soundfile as sf | |
| import torch | |
| from tqdm import tqdm | |
| try: | |
| from .utils import ( | |
| remove_directory_contents, | |
| create_directories, | |
| ) | |
| except: # noqa | |
| from utils import ( | |
| remove_directory_contents, | |
| create_directories, | |
| ) | |
| from .logging_setup import logger | |
| try: | |
| import onnxruntime as ort | |
| except Exception as error: | |
| logger.error(str(error)) | |
| # import warnings | |
| # warnings.filterwarnings("ignore") | |
| stem_naming = { | |
| "Vocals": "Instrumental", | |
| "Other": "Instruments", | |
| "Instrumental": "Vocals", | |
| "Drums": "Drumless", | |
| "Bass": "Bassless", | |
| } | |
| class MDXModel: | |
| def __init__( | |
| self, | |
| device, | |
| dim_f, | |
| dim_t, | |
| n_fft, | |
| hop=1024, | |
| stem_name=None, | |
| compensation=1.000, | |
| ): | |
| self.dim_f = dim_f | |
| self.dim_t = dim_t | |
| self.dim_c = 4 | |
| self.n_fft = n_fft | |
| self.hop = hop | |
| self.stem_name = stem_name | |
| self.compensation = compensation | |
| self.n_bins = self.n_fft // 2 + 1 | |
| self.chunk_size = hop * (self.dim_t - 1) | |
| self.window = torch.hann_window( | |
| window_length=self.n_fft, periodic=True | |
| ).to(device) | |
| out_c = self.dim_c | |
| self.freq_pad = torch.zeros( | |
| [1, out_c, self.n_bins - self.dim_f, self.dim_t] | |
| ).to(device) | |
| def stft(self, x): | |
| x = x.reshape([-1, self.chunk_size]) | |
| x = torch.stft( | |
| x, | |
| n_fft=self.n_fft, | |
| hop_length=self.hop, | |
| window=self.window, | |
| center=True, | |
| return_complex=True, | |
| ) | |
| x = torch.view_as_real(x) | |
| x = x.permute([0, 3, 1, 2]) | |
| x = x.reshape([-1, 2, 2, self.n_bins, self.dim_t]).reshape( | |
| [-1, 4, self.n_bins, self.dim_t] | |
| ) | |
| return x[:, :, : self.dim_f] | |
| def istft(self, x, freq_pad=None): | |
| freq_pad = ( | |
| self.freq_pad.repeat([x.shape[0], 1, 1, 1]) | |
| if freq_pad is None | |
| else freq_pad | |
| ) | |
| x = torch.cat([x, freq_pad], -2) | |
| # c = 4*2 if self.target_name=='*' else 2 | |
| x = x.reshape([-1, 2, 2, self.n_bins, self.dim_t]).reshape( | |
| [-1, 2, self.n_bins, self.dim_t] | |
| ) | |
| x = x.permute([0, 2, 3, 1]) | |
| x = x.contiguous() | |
| x = torch.view_as_complex(x) | |
| x = torch.istft( | |
| x, | |
| n_fft=self.n_fft, | |
| hop_length=self.hop, | |
| window=self.window, | |
| center=True, | |
| ) | |
| return x.reshape([-1, 2, self.chunk_size]) | |
| class MDX: | |
| DEFAULT_SR = 44100 | |
| # Unit: seconds | |
| DEFAULT_CHUNK_SIZE = 0 * DEFAULT_SR | |
| DEFAULT_MARGIN_SIZE = 1 * DEFAULT_SR | |
| def __init__( | |
| self, model_path: str, params: MDXModel, processor=0 | |
| ): | |
| # Set the device and the provider (CPU or CUDA) | |
| self.device = ( | |
| torch.device(f"cuda:{processor}") | |
| if processor >= 0 | |
| else torch.device("cpu") | |
| ) | |
| self.provider = ( | |
| ["CUDAExecutionProvider"] | |
| if processor >= 0 | |
| else ["CPUExecutionProvider"] | |
| ) | |
| self.model = params | |
| # Load the ONNX model using ONNX Runtime | |
| self.ort = ort.InferenceSession(model_path, providers=self.provider) | |
| # Preload the model for faster performance | |
| self.ort.run( | |
| None, | |
| {"input": torch.rand(1, 4, params.dim_f, params.dim_t).numpy()}, | |
| ) | |
| self.process = lambda spec: self.ort.run( | |
| None, {"input": spec.cpu().numpy()} | |
| )[0] | |
| self.prog = None | |
| def get_hash(model_path): | |
| try: | |
| with open(model_path, "rb") as f: | |
| f.seek(-10000 * 1024, 2) | |
| model_hash = hashlib.md5(f.read()).hexdigest() | |
| except: # noqa | |
| model_hash = hashlib.md5(open(model_path, "rb").read()).hexdigest() | |
| return model_hash | |
| def segment( | |
| wave, | |
| combine=True, | |
| chunk_size=DEFAULT_CHUNK_SIZE, | |
| margin_size=DEFAULT_MARGIN_SIZE, | |
| ): | |
| """ | |
| Segment or join segmented wave array | |
| Args: | |
| wave: (np.array) Wave array to be segmented or joined | |
| combine: (bool) If True, combines segmented wave array. | |
| If False, segments wave array. | |
| chunk_size: (int) Size of each segment (in samples) | |
| margin_size: (int) Size of margin between segments (in samples) | |
| Returns: | |
| numpy array: Segmented or joined wave array | |
| """ | |
| if combine: | |
| # Initializing as None instead of [] for later numpy array concatenation | |
| processed_wave = None | |
| for segment_count, segment in enumerate(wave): | |
| start = 0 if segment_count == 0 else margin_size | |
| end = None if segment_count == len(wave) - 1 else -margin_size | |
| if margin_size == 0: | |
| end = None | |
| if processed_wave is None: # Create array for first segment | |
| processed_wave = segment[:, start:end] | |
| else: # Concatenate to existing array for subsequent segments | |
| processed_wave = np.concatenate( | |
| (processed_wave, segment[:, start:end]), axis=-1 | |
| ) | |
| else: | |
| processed_wave = [] | |
| sample_count = wave.shape[-1] | |
| if chunk_size <= 0 or chunk_size > sample_count: | |
| chunk_size = sample_count | |
| if margin_size > chunk_size: | |
| margin_size = chunk_size | |
| for segment_count, skip in enumerate( | |
| range(0, sample_count, chunk_size) | |
| ): | |
| margin = 0 if segment_count == 0 else margin_size | |
| end = min(skip + chunk_size + margin_size, sample_count) | |
| start = skip - margin | |
| cut = wave[:, start:end].copy() | |
| processed_wave.append(cut) | |
| if end == sample_count: | |
| break | |
| return processed_wave | |
| def pad_wave(self, wave): | |
| """ | |
| Pad the wave array to match the required chunk size | |
| Args: | |
| wave: (np.array) Wave array to be padded | |
| Returns: | |
| tuple: (padded_wave, pad, trim) | |
| - padded_wave: Padded wave array | |
| - pad: Number of samples that were padded | |
| - trim: Number of samples that were trimmed | |
| """ | |
| n_sample = wave.shape[1] | |
| trim = self.model.n_fft // 2 | |
| gen_size = self.model.chunk_size - 2 * trim | |
| pad = gen_size - n_sample % gen_size | |
| # Padded wave | |
| wave_p = np.concatenate( | |
| ( | |
| np.zeros((2, trim)), | |
| wave, | |
| np.zeros((2, pad)), | |
| np.zeros((2, trim)), | |
| ), | |
| 1, | |
| ) | |
| mix_waves = [] | |
| for i in range(0, n_sample + pad, gen_size): | |
| waves = np.array(wave_p[:, i:i + self.model.chunk_size]) | |
| mix_waves.append(waves) | |
| mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to( | |
| self.device | |
| ) | |
| return mix_waves, pad, trim | |
| def _process_wave(self, mix_waves, trim, pad, q: queue.Queue, _id: int): | |
| """ | |
| Process each wave segment in a multi-threaded environment | |
| Args: | |
| mix_waves: (torch.Tensor) Wave segments to be processed | |
| trim: (int) Number of samples trimmed during padding | |
| pad: (int) Number of samples padded during padding | |
| q: (queue.Queue) Queue to hold the processed wave segments | |
| _id: (int) Identifier of the processed wave segment | |
| Returns: | |
| numpy array: Processed wave segment | |
| """ | |
| mix_waves = mix_waves.split(1) | |
| with torch.no_grad(): | |
| pw = [] | |
| for mix_wave in mix_waves: | |
| self.prog.update() | |
| spec = self.model.stft(mix_wave) | |
| processed_spec = torch.tensor(self.process(spec)) | |
| processed_wav = self.model.istft( | |
| processed_spec.to(self.device) | |
| ) | |
| processed_wav = ( | |
| processed_wav[:, :, trim:-trim] | |
| .transpose(0, 1) | |
| .reshape(2, -1) | |
| .cpu() | |
| .numpy() | |
| ) | |
| pw.append(processed_wav) | |
| processed_signal = np.concatenate(pw, axis=-1)[:, :-pad] | |
| q.put({_id: processed_signal}) | |
| return processed_signal | |
| def process_wave(self, wave: np.array, mt_threads=1): | |
| """ | |
| Process the wave array in a multi-threaded environment | |
| Args: | |
| wave: (np.array) Wave array to be processed | |
| mt_threads: (int) Number of threads to be used for processing | |
| Returns: | |
| numpy array: Processed wave array | |
| """ | |
| self.prog = tqdm(total=0) | |
| chunk = wave.shape[-1] // mt_threads | |
| waves = self.segment(wave, False, chunk) | |
| # Create a queue to hold the processed wave segments | |
| q = queue.Queue() | |
| threads = [] | |
| for c, batch in enumerate(waves): | |
| mix_waves, pad, trim = self.pad_wave(batch) | |
| self.prog.total = len(mix_waves) * mt_threads | |
| thread = threading.Thread( | |
| target=self._process_wave, args=(mix_waves, trim, pad, q, c) | |
| ) | |
| thread.start() | |
| threads.append(thread) | |
| for thread in threads: | |
| thread.join() | |
| self.prog.close() | |
| processed_batches = [] | |
| while not q.empty(): | |
| processed_batches.append(q.get()) | |
| processed_batches = [ | |
| list(wave.values())[0] | |
| for wave in sorted( | |
| processed_batches, key=lambda d: list(d.keys())[0] | |
| ) | |
| ] | |
| assert len(processed_batches) == len( | |
| waves | |
| ), "Incomplete processed batches, please reduce batch size!" | |
| return self.segment(processed_batches, True, chunk) | |
| def run_mdx( | |
| model_params, | |
| output_dir, | |
| model_path, | |
| filename, | |
| exclude_main=False, | |
| exclude_inversion=False, | |
| suffix=None, | |
| invert_suffix=None, | |
| denoise=False, | |
| keep_orig=True, | |
| m_threads=2, | |
| device_base="cuda", | |
| ): | |
| if device_base == "cuda": | |
| device = torch.device("cuda:0") | |
| processor_num = 0 | |
| device_properties = torch.cuda.get_device_properties(device) | |
| vram_gb = device_properties.total_memory / 1024**3 | |
| m_threads = 1 if vram_gb < 8 else 2 | |
| else: | |
| device = torch.device("cpu") | |
| processor_num = -1 | |
| m_threads = 1 | |
| model_hash = MDX.get_hash(model_path) | |
| mp = model_params.get(model_hash) | |
| model = MDXModel( | |
| device, | |
| dim_f=mp["mdx_dim_f_set"], | |
| dim_t=2 ** mp["mdx_dim_t_set"], | |
| n_fft=mp["mdx_n_fft_scale_set"], | |
| stem_name=mp["primary_stem"], | |
| compensation=mp["compensate"], | |
| ) | |
| mdx_sess = MDX(model_path, model, processor=processor_num) | |
| wave, sr = librosa.load(filename, mono=False, sr=44100) | |
| # normalizing input wave gives better output | |
| peak = max(np.max(wave), abs(np.min(wave))) | |
| wave /= peak | |
| if denoise: | |
| wave_processed = -(mdx_sess.process_wave(-wave, m_threads)) + ( | |
| mdx_sess.process_wave(wave, m_threads) | |
| ) | |
| wave_processed *= 0.5 | |
| else: | |
| wave_processed = mdx_sess.process_wave(wave, m_threads) | |
| # return to previous peak | |
| wave_processed *= peak | |
| stem_name = model.stem_name if suffix is None else suffix | |
| main_filepath = None | |
| if not exclude_main: | |
| main_filepath = os.path.join( | |
| output_dir, | |
| f"{os.path.basename(os.path.splitext(filename)[0])}_{stem_name}.wav", | |
| ) | |
| sf.write(main_filepath, wave_processed.T, sr) | |
| invert_filepath = None | |
| if not exclude_inversion: | |
| diff_stem_name = ( | |
| stem_naming.get(stem_name) | |
| if invert_suffix is None | |
| else invert_suffix | |
| ) | |
| stem_name = ( | |
| f"{stem_name}_diff" if diff_stem_name is None else diff_stem_name | |
| ) | |
| invert_filepath = os.path.join( | |
| output_dir, | |
| f"{os.path.basename(os.path.splitext(filename)[0])}_{stem_name}.wav", | |
| ) | |
| sf.write( | |
| invert_filepath, | |
| (-wave_processed.T * model.compensation) + wave.T, | |
| sr, | |
| ) | |
| if not keep_orig: | |
| os.remove(filename) | |
| del mdx_sess, wave_processed, wave | |
| gc.collect() | |
| torch.cuda.empty_cache() | |
| return main_filepath, invert_filepath | |
| MDX_DOWNLOAD_LINK = "https://github.com/TRvlvr/model_repo/releases/download/all_public_uvr_models/" | |
| UVR_MODELS = [ | |
| "UVR-MDX-NET-Voc_FT.onnx", | |
| "UVR_MDXNET_KARA_2.onnx", | |
| "Reverb_HQ_By_FoxJoy.onnx", | |
| "UVR-MDX-NET-Inst_HQ_4.onnx", | |
| ] | |
| BASE_DIR = "." # os.path.dirname(os.path.dirname(os.path.abspath(__file__))) | |
| mdxnet_models_dir = os.path.join(BASE_DIR, "mdx_models") | |
| output_dir = os.path.join(BASE_DIR, "clean_song_output") | |
| def convert_to_stereo_and_wav(audio_path): | |
| wave, sr = librosa.load(audio_path, mono=False, sr=44100) | |
| # check if mono | |
| if type(wave[0]) != np.ndarray or audio_path[-4:].lower() != ".wav": # noqa | |
| stereo_path = f"{os.path.splitext(audio_path)[0]}_stereo.wav" | |
| stereo_path = os.path.join(output_dir, stereo_path) | |
| command = shlex.split( | |
| f'ffmpeg -y -loglevel error -i "{audio_path}" -ac 2 -f wav "{stereo_path}"' | |
| ) | |
| sub_params = { | |
| "stdout": subprocess.PIPE, | |
| "stderr": subprocess.PIPE, | |
| "creationflags": subprocess.CREATE_NO_WINDOW | |
| if sys.platform == "win32" | |
| else 0, | |
| } | |
| process_wav = subprocess.Popen(command, **sub_params) | |
| output, errors = process_wav.communicate() | |
| if process_wav.returncode != 0 or not os.path.exists(stereo_path): | |
| raise Exception("Error processing audio to stereo wav") | |
| return stereo_path | |
| else: | |
| return audio_path | |
| def process_uvr_task( | |
| orig_song_path: str = "aud_test.mp3", | |
| main_vocals: bool = False, | |
| dereverb: bool = True, | |
| song_id: str = "mdx", # folder output name | |
| only_voiceless: bool = False, | |
| remove_files_output_dir: bool = False, | |
| ): | |
| if os.environ.get("SONITR_DEVICE") == "cpu": | |
| device_base = "cpu" | |
| else: | |
| device_base = "cuda" if torch.cuda.is_available() else "cpu" | |
| if remove_files_output_dir: | |
| remove_directory_contents(output_dir) | |
| with open(os.path.join(mdxnet_models_dir, "data.json")) as infile: | |
| mdx_model_params = json.load(infile) | |
| song_output_dir = os.path.join(output_dir, song_id) | |
| create_directories(song_output_dir) | |
| orig_song_path = convert_to_stereo_and_wav(orig_song_path) | |
| logger.debug(f"onnxruntime device >> {ort.get_device()}") | |
| if only_voiceless: | |
| logger.info("Voiceless Track Separation...") | |
| return run_mdx( | |
| mdx_model_params, | |
| song_output_dir, | |
| os.path.join(mdxnet_models_dir, "UVR-MDX-NET-Inst_HQ_4.onnx"), | |
| orig_song_path, | |
| suffix="Voiceless", | |
| denoise=False, | |
| keep_orig=True, | |
| exclude_inversion=True, | |
| device_base=device_base, | |
| ) | |
| logger.info("Vocal Track Isolation and Voiceless Track Separation...") | |
| vocals_path, instrumentals_path = run_mdx( | |
| mdx_model_params, | |
| song_output_dir, | |
| os.path.join(mdxnet_models_dir, "UVR-MDX-NET-Voc_FT.onnx"), | |
| orig_song_path, | |
| denoise=True, | |
| keep_orig=True, | |
| device_base=device_base, | |
| ) | |
| if main_vocals: | |
| logger.info("Main Voice Separation from Supporting Vocals...") | |
| backup_vocals_path, main_vocals_path = run_mdx( | |
| mdx_model_params, | |
| song_output_dir, | |
| os.path.join(mdxnet_models_dir, "UVR_MDXNET_KARA_2.onnx"), | |
| vocals_path, | |
| suffix="Backup", | |
| invert_suffix="Main", | |
| denoise=True, | |
| device_base=device_base, | |
| ) | |
| else: | |
| backup_vocals_path, main_vocals_path = None, vocals_path | |
| if dereverb: | |
| logger.info("Vocal Clarity Enhancement through De-Reverberation...") | |
| _, vocals_dereverb_path = run_mdx( | |
| mdx_model_params, | |
| song_output_dir, | |
| os.path.join(mdxnet_models_dir, "Reverb_HQ_By_FoxJoy.onnx"), | |
| main_vocals_path, | |
| invert_suffix="DeReverb", | |
| exclude_main=True, | |
| denoise=True, | |
| device_base=device_base, | |
| ) | |
| else: | |
| vocals_dereverb_path = main_vocals_path | |
| return ( | |
| vocals_path, | |
| instrumentals_path, | |
| backup_vocals_path, | |
| main_vocals_path, | |
| vocals_dereverb_path, | |
| ) | |
| if __name__ == "__main__": | |
| from utils import download_manager | |
| for id_model in UVR_MODELS: | |
| download_manager( | |
| os.path.join(MDX_DOWNLOAD_LINK, id_model), mdxnet_models_dir | |
| ) | |
| ( | |
| vocals_path_, | |
| instrumentals_path_, | |
| backup_vocals_path_, | |
| main_vocals_path_, | |
| vocals_dereverb_path_, | |
| ) = process_uvr_task( | |
| orig_song_path="aud.mp3", | |
| main_vocals=True, | |
| dereverb=True, | |
| song_id="mdx", | |
| remove_files_output_dir=True, | |
| ) | |