Spaces:
Runtime error

Runtime error
Upload 21 files
Browse files- .gitattributes +5 -0
- open_oasis_master/.gitattributes +1 -0
- open_oasis_master/LICENSE +21 -0
- open_oasis_master/README.md +37 -0
- open_oasis_master/attention.py +137 -0
- open_oasis_master/dit.py +310 -0
- open_oasis_master/embeddings.py +103 -0
- open_oasis_master/generate.py +119 -0
- open_oasis_master/media/arch.png +0 -0
- open_oasis_master/media/sample_0.gif +3 -0
- open_oasis_master/media/sample_1.gif +3 -0
- open_oasis_master/media/thumb.png +0 -0
- open_oasis_master/requirements.txt +31 -0
- open_oasis_master/rotary_embedding_torch.py +316 -0
- open_oasis_master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.actions.pt +3 -0
- open_oasis_master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.mp4 +3 -0
- open_oasis_master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.actions.pt +3 -0
- open_oasis_master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.mp4 +3 -0
- open_oasis_master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.actions.pt +3 -0
- open_oasis_master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.mp4 +3 -0
- open_oasis_master/utils.py +82 -0
- open_oasis_master/vae.py +381 -0
.gitattributes
CHANGED
|
@@ -38,3 +38,8 @@ open-oasis-master/media/sample_1.gif filter=lfs diff=lfs merge=lfs -text
|
|
| 38 |
open-oasis-master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
open-oasis-master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
open-oasis-master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.mp4 filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
open-oasis-master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
open-oasis-master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
open-oasis-master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
open_oasis_master/media/sample_0.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
open_oasis_master/media/sample_1.gif filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
open_oasis_master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
open_oasis_master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
open_oasis_master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.mp4 filter=lfs diff=lfs merge=lfs -text
|
open_oasis_master/.gitattributes
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
video.mp4 filter=lfs diff=lfs merge=lfs -text
|
open_oasis_master/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Etched & Decart
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
open_oasis_master/README.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Oasis 500M
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
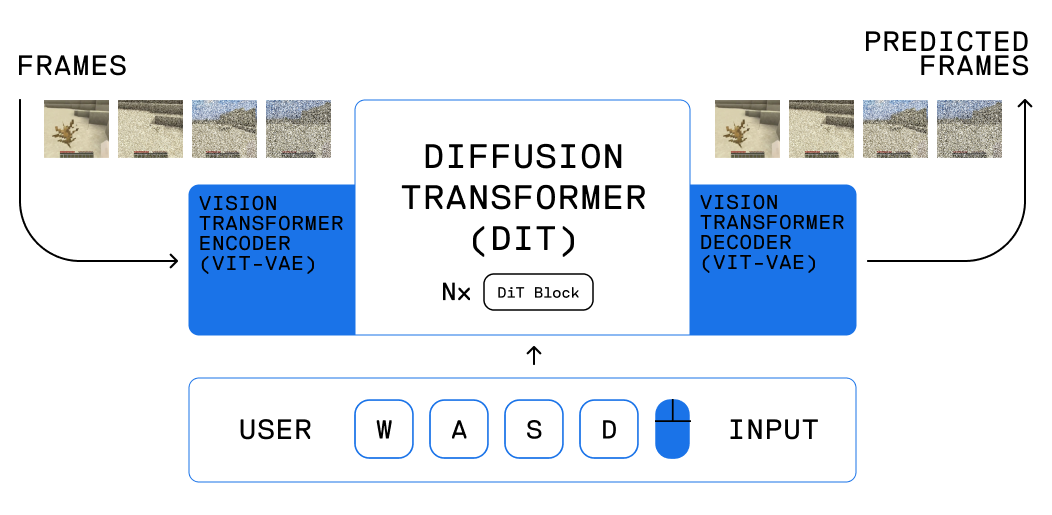
Oasis is an interactive world model developed by [Decart](https://www.decart.ai/) and [Etched](https://www.etched.com/). Based on diffusion transformers, Oasis takes in user keyboard input and generates gameplay in an autoregressive manner. We release the weights for Oasis 500M, a downscaled version of the model, along with inference code for action-conditional frame generation.
|
| 8 |
+
|
| 9 |
+
For more details, see our [joint blog post](https://oasis-model.github.io/) to learn more.
|
| 10 |
+
|
| 11 |
+
And to use the most powerful version of the model, be sure to check out the [live demo](https://oasis.us.decart.ai/) as well!
|
| 12 |
+
|
| 13 |
+
## Setup
|
| 14 |
+
```
|
| 15 |
+
git clone https://github.com/etched-ai/open-oasis.git
|
| 16 |
+
cd open-oasis
|
| 17 |
+
pip install -r requirements.txt
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
## Download the model weights
|
| 21 |
+
```
|
| 22 |
+
huggingface-cli login
|
| 23 |
+
huggingface-cli download Etched/oasis-500m oasis500m.pt # DiT checkpoint
|
| 24 |
+
huggingface-cli download Etched/oasis-500m vit-l-20.pt # ViT VAE checkpoint
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
## Basic Usage
|
| 28 |
+
We include a basic inference script that loads a prompt frame from a video and generates additional frames conditioned on actions.
|
| 29 |
+
```
|
| 30 |
+
python generate.py
|
| 31 |
+
```
|
| 32 |
+
The resulting video will be saved to `video.mp4`. Here's are some examples of a generation from this 500M model!
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
> Hint: try swapping out the `.mp4` input file in the script to try different environments!
|
open_oasis_master/attention.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Based on https://github.com/buoyancy99/diffusion-forcing/blob/main/algorithms/diffusion_forcing/models/attention.py
|
| 3 |
+
"""
|
| 4 |
+
from typing import Optional
|
| 5 |
+
from collections import namedtuple
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
from einops import rearrange
|
| 10 |
+
from rotary_embedding_torch import RotaryEmbedding, apply_rotary_emb
|
| 11 |
+
from embeddings import TimestepEmbedding, Timesteps, Positions2d
|
| 12 |
+
|
| 13 |
+
class TemporalAxialAttention(nn.Module):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
dim: int,
|
| 17 |
+
heads: int = 4,
|
| 18 |
+
dim_head: int = 32,
|
| 19 |
+
is_causal: bool = True,
|
| 20 |
+
rotary_emb: Optional[RotaryEmbedding] = None,
|
| 21 |
+
):
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.inner_dim = dim_head * heads
|
| 24 |
+
self.heads = heads
|
| 25 |
+
self.head_dim = dim_head
|
| 26 |
+
self.inner_dim = dim_head * heads
|
| 27 |
+
self.to_qkv = nn.Linear(dim, self.inner_dim * 3, bias=False)
|
| 28 |
+
self.to_out = nn.Linear(self.inner_dim, dim)
|
| 29 |
+
|
| 30 |
+
self.rotary_emb = rotary_emb
|
| 31 |
+
self.time_pos_embedding = (
|
| 32 |
+
nn.Sequential(
|
| 33 |
+
Timesteps(dim),
|
| 34 |
+
TimestepEmbedding(in_channels=dim, time_embed_dim=dim * 4, out_dim=dim),
|
| 35 |
+
)
|
| 36 |
+
if rotary_emb is None
|
| 37 |
+
else None
|
| 38 |
+
)
|
| 39 |
+
self.is_causal = is_causal
|
| 40 |
+
|
| 41 |
+
def forward(self, x: torch.Tensor):
|
| 42 |
+
B, T, H, W, D = x.shape
|
| 43 |
+
|
| 44 |
+
if self.time_pos_embedding is not None:
|
| 45 |
+
time_emb = self.time_pos_embedding(
|
| 46 |
+
torch.arange(T, device=x.device)
|
| 47 |
+
)
|
| 48 |
+
x = x + rearrange(time_emb, "t d -> 1 t 1 1 d")
|
| 49 |
+
|
| 50 |
+
q, k, v = self.to_qkv(x).chunk(3, dim=-1)
|
| 51 |
+
|
| 52 |
+
q = rearrange(q, "B T H W (h d) -> (B H W) h T d", h=self.heads)
|
| 53 |
+
k = rearrange(k, "B T H W (h d) -> (B H W) h T d", h=self.heads)
|
| 54 |
+
v = rearrange(v, "B T H W (h d) -> (B H W) h T d", h=self.heads)
|
| 55 |
+
|
| 56 |
+
if self.rotary_emb is not None:
|
| 57 |
+
q = self.rotary_emb.rotate_queries_or_keys(q, self.rotary_emb.freqs)
|
| 58 |
+
k = self.rotary_emb.rotate_queries_or_keys(k, self.rotary_emb.freqs)
|
| 59 |
+
|
| 60 |
+
q, k, v = map(lambda t: t.contiguous(), (q, k, v))
|
| 61 |
+
|
| 62 |
+
x = F.scaled_dot_product_attention(
|
| 63 |
+
query=q, key=k, value=v, is_causal=self.is_causal
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
x = rearrange(x, "(B H W) h T d -> B T H W (h d)", B=B, H=H, W=W)
|
| 67 |
+
x = x.to(q.dtype)
|
| 68 |
+
|
| 69 |
+
# linear proj
|
| 70 |
+
x = self.to_out(x)
|
| 71 |
+
return x
|
| 72 |
+
|
| 73 |
+
class SpatialAxialAttention(nn.Module):
|
| 74 |
+
def __init__(
|
| 75 |
+
self,
|
| 76 |
+
dim: int,
|
| 77 |
+
heads: int = 4,
|
| 78 |
+
dim_head: int = 32,
|
| 79 |
+
rotary_emb: Optional[RotaryEmbedding] = None,
|
| 80 |
+
):
|
| 81 |
+
super().__init__()
|
| 82 |
+
self.inner_dim = dim_head * heads
|
| 83 |
+
self.heads = heads
|
| 84 |
+
self.head_dim = dim_head
|
| 85 |
+
self.inner_dim = dim_head * heads
|
| 86 |
+
self.to_qkv = nn.Linear(dim, self.inner_dim * 3, bias=False)
|
| 87 |
+
self.to_out = nn.Linear(self.inner_dim, dim)
|
| 88 |
+
|
| 89 |
+
self.rotary_emb = rotary_emb
|
| 90 |
+
self.space_pos_embedding = (
|
| 91 |
+
nn.Sequential(
|
| 92 |
+
Positions2d(dim),
|
| 93 |
+
TimestepEmbedding(in_channels=dim, time_embed_dim=dim * 4, out_dim=dim),
|
| 94 |
+
)
|
| 95 |
+
if rotary_emb is None
|
| 96 |
+
else None
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
def forward(self, x: torch.Tensor):
|
| 100 |
+
B, T, H, W, D = x.shape
|
| 101 |
+
|
| 102 |
+
if self.space_pos_embedding is not None:
|
| 103 |
+
h_steps = torch.arange(H, device=x.device)
|
| 104 |
+
w_steps = torch.arange(W, device=x.device)
|
| 105 |
+
grid = torch.meshgrid(h_steps, w_steps, indexing="ij")
|
| 106 |
+
space_emb = self.space_pos_embedding(grid)
|
| 107 |
+
x = x + rearrange(space_emb, "h w d -> 1 1 h w d")
|
| 108 |
+
|
| 109 |
+
q, k, v = self.to_qkv(x).chunk(3, dim=-1)
|
| 110 |
+
|
| 111 |
+
q = rearrange(q, "B T H W (h d) -> (B T) h H W d", h=self.heads)
|
| 112 |
+
k = rearrange(k, "B T H W (h d) -> (B T) h H W d", h=self.heads)
|
| 113 |
+
v = rearrange(v, "B T H W (h d) -> (B T) h H W d", h=self.heads)
|
| 114 |
+
|
| 115 |
+
if self.rotary_emb is not None:
|
| 116 |
+
freqs = self.rotary_emb.get_axial_freqs(H, W)
|
| 117 |
+
q = apply_rotary_emb(freqs, q)
|
| 118 |
+
k = apply_rotary_emb(freqs, k)
|
| 119 |
+
|
| 120 |
+
# prepare for attn
|
| 121 |
+
q = rearrange(q, "(B T) h H W d -> (B T) h (H W) d", B=B, T=T, h=self.heads)
|
| 122 |
+
k = rearrange(k, "(B T) h H W d -> (B T) h (H W) d", B=B, T=T, h=self.heads)
|
| 123 |
+
v = rearrange(v, "(B T) h H W d -> (B T) h (H W) d", B=B, T=T, h=self.heads)
|
| 124 |
+
|
| 125 |
+
q, k, v = map(lambda t: t.contiguous(), (q, k, v))
|
| 126 |
+
|
| 127 |
+
x = F.scaled_dot_product_attention(
|
| 128 |
+
query=q, key=k, value=v, is_causal=False
|
| 129 |
+
)
|
| 130 |
+
|
| 131 |
+
x = rearrange(x, "(B T) h (H W) d -> B T H W (h d)", B=B, H=H, W=W)
|
| 132 |
+
x = x.to(q.dtype)
|
| 133 |
+
|
| 134 |
+
# linear proj
|
| 135 |
+
x = self.to_out(x)
|
| 136 |
+
return x
|
| 137 |
+
|
open_oasis_master/dit.py
ADDED
|
@@ -0,0 +1,310 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
References:
|
| 3 |
+
- DiT: https://github.com/facebookresearch/DiT/blob/main/models.py
|
| 4 |
+
- Diffusion Forcing: https://github.com/buoyancy99/diffusion-forcing/blob/main/algorithms/diffusion_forcing/models/unet3d.py
|
| 5 |
+
- Latte: https://github.com/Vchitect/Latte/blob/main/models/latte.py
|
| 6 |
+
"""
|
| 7 |
+
from typing import Optional, Literal
|
| 8 |
+
import torch
|
| 9 |
+
from torch import nn
|
| 10 |
+
from rotary_embedding_torch import RotaryEmbedding
|
| 11 |
+
from einops import rearrange
|
| 12 |
+
from embeddings import Timesteps, TimestepEmbedding
|
| 13 |
+
from attention import SpatialAxialAttention, TemporalAxialAttention
|
| 14 |
+
from timm.models.vision_transformer import Mlp
|
| 15 |
+
from timm.layers.helpers import to_2tuple
|
| 16 |
+
import math
|
| 17 |
+
|
| 18 |
+
def modulate(x, shift, scale):
|
| 19 |
+
fixed_dims = [1] * len(shift.shape[1:])
|
| 20 |
+
shift = shift.repeat(x.shape[0] // shift.shape[0], *fixed_dims)
|
| 21 |
+
scale = scale.repeat(x.shape[0] // scale.shape[0], *fixed_dims)
|
| 22 |
+
while shift.dim() < x.dim():
|
| 23 |
+
shift = shift.unsqueeze(-2)
|
| 24 |
+
scale = scale.unsqueeze(-2)
|
| 25 |
+
return x * (1 + scale) + shift
|
| 26 |
+
|
| 27 |
+
def gate(x, g):
|
| 28 |
+
fixed_dims = [1] * len(g.shape[1:])
|
| 29 |
+
g = g.repeat(x.shape[0] // g.shape[0], *fixed_dims)
|
| 30 |
+
while g.dim() < x.dim():
|
| 31 |
+
g = g.unsqueeze(-2)
|
| 32 |
+
return g * x
|
| 33 |
+
|
| 34 |
+
class PatchEmbed(nn.Module):
|
| 35 |
+
"""2D Image to Patch Embedding"""
|
| 36 |
+
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
img_height=256,
|
| 40 |
+
img_width=256,
|
| 41 |
+
patch_size=16,
|
| 42 |
+
in_chans=3,
|
| 43 |
+
embed_dim=768,
|
| 44 |
+
norm_layer=None,
|
| 45 |
+
flatten=True,
|
| 46 |
+
):
|
| 47 |
+
super().__init__()
|
| 48 |
+
img_size = (img_height, img_width)
|
| 49 |
+
patch_size = to_2tuple(patch_size)
|
| 50 |
+
self.img_size = img_size
|
| 51 |
+
self.patch_size = patch_size
|
| 52 |
+
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
|
| 53 |
+
self.num_patches = self.grid_size[0] * self.grid_size[1]
|
| 54 |
+
self.flatten = flatten
|
| 55 |
+
|
| 56 |
+
self.proj = nn.Conv2d(
|
| 57 |
+
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size
|
| 58 |
+
)
|
| 59 |
+
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
|
| 60 |
+
|
| 61 |
+
def forward(self, x, random_sample=False):
|
| 62 |
+
B, C, H, W = x.shape
|
| 63 |
+
assert random_sample or (
|
| 64 |
+
H == self.img_size[0] and W == self.img_size[1]
|
| 65 |
+
), f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
|
| 66 |
+
x = self.proj(x)
|
| 67 |
+
if self.flatten:
|
| 68 |
+
x = rearrange(x, "B C H W -> B (H W) C")
|
| 69 |
+
else:
|
| 70 |
+
x = rearrange(x, "B C H W -> B H W C")
|
| 71 |
+
x = self.norm(x)
|
| 72 |
+
return x
|
| 73 |
+
|
| 74 |
+
class TimestepEmbedder(nn.Module):
|
| 75 |
+
"""
|
| 76 |
+
Embeds scalar timesteps into vector representations.
|
| 77 |
+
"""
|
| 78 |
+
def __init__(self, hidden_size, frequency_embedding_size=256):
|
| 79 |
+
super().__init__()
|
| 80 |
+
self.mlp = nn.Sequential(
|
| 81 |
+
nn.Linear(frequency_embedding_size, hidden_size, bias=True), # hidden_size is diffusion model hidden size
|
| 82 |
+
nn.SiLU(),
|
| 83 |
+
nn.Linear(hidden_size, hidden_size, bias=True),
|
| 84 |
+
)
|
| 85 |
+
self.frequency_embedding_size = frequency_embedding_size
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def timestep_embedding(t, dim, max_period=10000):
|
| 89 |
+
"""
|
| 90 |
+
Create sinusoidal timestep embeddings.
|
| 91 |
+
:param t: a 1-D Tensor of N indices, one per batch element.
|
| 92 |
+
These may be fractional.
|
| 93 |
+
:param dim: the dimension of the output.
|
| 94 |
+
:param max_period: controls the minimum frequency of the embeddings.
|
| 95 |
+
:return: an (N, D) Tensor of positional embeddings.
|
| 96 |
+
"""
|
| 97 |
+
# https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py
|
| 98 |
+
half = dim // 2
|
| 99 |
+
freqs = torch.exp(
|
| 100 |
+
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
|
| 101 |
+
).to(device=t.device)
|
| 102 |
+
args = t[:, None].float() * freqs[None]
|
| 103 |
+
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
| 104 |
+
if dim % 2:
|
| 105 |
+
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
| 106 |
+
return embedding
|
| 107 |
+
|
| 108 |
+
def forward(self, t):
|
| 109 |
+
t_freq = self.timestep_embedding(t, self.frequency_embedding_size)
|
| 110 |
+
t_emb = self.mlp(t_freq)
|
| 111 |
+
return t_emb
|
| 112 |
+
|
| 113 |
+
class FinalLayer(nn.Module):
|
| 114 |
+
"""
|
| 115 |
+
The final layer of DiT.
|
| 116 |
+
"""
|
| 117 |
+
def __init__(self, hidden_size, patch_size, out_channels):
|
| 118 |
+
super().__init__()
|
| 119 |
+
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 120 |
+
self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)
|
| 121 |
+
self.adaLN_modulation = nn.Sequential(
|
| 122 |
+
nn.SiLU(),
|
| 123 |
+
nn.Linear(hidden_size, 2 * hidden_size, bias=True)
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
def forward(self, x, c):
|
| 127 |
+
shift, scale = self.adaLN_modulation(c).chunk(2, dim=-1)
|
| 128 |
+
x = modulate(self.norm_final(x), shift, scale)
|
| 129 |
+
x = self.linear(x)
|
| 130 |
+
return x
|
| 131 |
+
|
| 132 |
+
class SpatioTemporalDiTBlock(nn.Module):
|
| 133 |
+
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, is_causal=True, spatial_rotary_emb: Optional[RotaryEmbedding] = None, temporal_rotary_emb: Optional[RotaryEmbedding] = None):
|
| 134 |
+
super().__init__()
|
| 135 |
+
self.is_causal = is_causal
|
| 136 |
+
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
| 137 |
+
approx_gelu = lambda: nn.GELU(approximate="tanh")
|
| 138 |
+
|
| 139 |
+
self.s_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 140 |
+
self.s_attn = SpatialAxialAttention(hidden_size, heads=num_heads, dim_head=hidden_size // num_heads, rotary_emb=spatial_rotary_emb)
|
| 141 |
+
self.s_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 142 |
+
self.s_mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
|
| 143 |
+
self.s_adaLN_modulation = nn.Sequential(
|
| 144 |
+
nn.SiLU(),
|
| 145 |
+
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
self.t_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 149 |
+
self.t_attn = TemporalAxialAttention(hidden_size, heads=num_heads, dim_head=hidden_size // num_heads, is_causal=is_causal, rotary_emb=temporal_rotary_emb)
|
| 150 |
+
self.t_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
| 151 |
+
self.t_mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
|
| 152 |
+
self.t_adaLN_modulation = nn.Sequential(
|
| 153 |
+
nn.SiLU(),
|
| 154 |
+
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
def forward(self, x, c):
|
| 158 |
+
B, T, H, W, D = x.shape
|
| 159 |
+
|
| 160 |
+
# spatial block
|
| 161 |
+
s_shift_msa, s_scale_msa, s_gate_msa, s_shift_mlp, s_scale_mlp, s_gate_mlp = self.s_adaLN_modulation(c).chunk(6, dim=-1)
|
| 162 |
+
x = x + gate(self.s_attn(modulate(self.s_norm1(x), s_shift_msa, s_scale_msa)), s_gate_msa)
|
| 163 |
+
x = x + gate(self.s_mlp(modulate(self.s_norm2(x), s_shift_mlp, s_scale_mlp)), s_gate_mlp)
|
| 164 |
+
|
| 165 |
+
# temporal block
|
| 166 |
+
t_shift_msa, t_scale_msa, t_gate_msa, t_shift_mlp, t_scale_mlp, t_gate_mlp = self.t_adaLN_modulation(c).chunk(6, dim=-1)
|
| 167 |
+
x = x + gate(self.t_attn(modulate(self.t_norm1(x), t_shift_msa, t_scale_msa)), t_gate_msa)
|
| 168 |
+
x = x + gate(self.t_mlp(modulate(self.t_norm2(x), t_shift_mlp, t_scale_mlp)), t_gate_mlp)
|
| 169 |
+
|
| 170 |
+
return x
|
| 171 |
+
|
| 172 |
+
class DiT(nn.Module):
|
| 173 |
+
"""
|
| 174 |
+
Diffusion model with a Transformer backbone.
|
| 175 |
+
"""
|
| 176 |
+
def __init__(
|
| 177 |
+
self,
|
| 178 |
+
input_h=18,
|
| 179 |
+
input_w=32,
|
| 180 |
+
patch_size=2,
|
| 181 |
+
in_channels=16,
|
| 182 |
+
hidden_size=1024,
|
| 183 |
+
depth=12,
|
| 184 |
+
num_heads=16,
|
| 185 |
+
mlp_ratio=4.0,
|
| 186 |
+
external_cond_dim=25,
|
| 187 |
+
max_frames=32,
|
| 188 |
+
):
|
| 189 |
+
super().__init__()
|
| 190 |
+
self.in_channels = in_channels
|
| 191 |
+
self.out_channels = in_channels
|
| 192 |
+
self.patch_size = patch_size
|
| 193 |
+
self.num_heads = num_heads
|
| 194 |
+
self.max_frames = max_frames
|
| 195 |
+
|
| 196 |
+
self.x_embedder = PatchEmbed(input_h, input_w, patch_size, in_channels, hidden_size, flatten=False)
|
| 197 |
+
self.t_embedder = TimestepEmbedder(hidden_size)
|
| 198 |
+
frame_h, frame_w = self.x_embedder.grid_size
|
| 199 |
+
|
| 200 |
+
self.spatial_rotary_emb = RotaryEmbedding(dim=hidden_size // num_heads // 2, freqs_for="pixel", max_freq=256)
|
| 201 |
+
self.temporal_rotary_emb = RotaryEmbedding(dim=hidden_size // num_heads)
|
| 202 |
+
self.external_cond = nn.Linear(external_cond_dim, hidden_size) if external_cond_dim > 0 else nn.Identity()
|
| 203 |
+
|
| 204 |
+
self.blocks = nn.ModuleList(
|
| 205 |
+
[
|
| 206 |
+
SpatioTemporalDiTBlock(
|
| 207 |
+
hidden_size,
|
| 208 |
+
num_heads,
|
| 209 |
+
mlp_ratio=mlp_ratio,
|
| 210 |
+
is_causal=True,
|
| 211 |
+
spatial_rotary_emb=self.spatial_rotary_emb,
|
| 212 |
+
temporal_rotary_emb=self.temporal_rotary_emb,
|
| 213 |
+
)
|
| 214 |
+
for _ in range(depth)
|
| 215 |
+
]
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
self.final_layer = FinalLayer(hidden_size, patch_size, self.out_channels)
|
| 219 |
+
self.initialize_weights()
|
| 220 |
+
|
| 221 |
+
def initialize_weights(self):
|
| 222 |
+
# Initialize transformer layers:
|
| 223 |
+
def _basic_init(module):
|
| 224 |
+
if isinstance(module, nn.Linear):
|
| 225 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 226 |
+
if module.bias is not None:
|
| 227 |
+
nn.init.constant_(module.bias, 0)
|
| 228 |
+
self.apply(_basic_init)
|
| 229 |
+
|
| 230 |
+
# Initialize patch_embed like nn.Linear (instead of nn.Conv2d):
|
| 231 |
+
w = self.x_embedder.proj.weight.data
|
| 232 |
+
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 233 |
+
nn.init.constant_(self.x_embedder.proj.bias, 0)
|
| 234 |
+
|
| 235 |
+
# Initialize timestep embedding MLP:
|
| 236 |
+
nn.init.normal_(self.t_embedder.mlp[0].weight, std=0.02)
|
| 237 |
+
nn.init.normal_(self.t_embedder.mlp[2].weight, std=0.02)
|
| 238 |
+
|
| 239 |
+
# Zero-out adaLN modulation layers in DiT blocks:
|
| 240 |
+
for block in self.blocks:
|
| 241 |
+
nn.init.constant_(block.s_adaLN_modulation[-1].weight, 0)
|
| 242 |
+
nn.init.constant_(block.s_adaLN_modulation[-1].bias, 0)
|
| 243 |
+
nn.init.constant_(block.t_adaLN_modulation[-1].weight, 0)
|
| 244 |
+
nn.init.constant_(block.t_adaLN_modulation[-1].bias, 0)
|
| 245 |
+
|
| 246 |
+
# Zero-out output layers:
|
| 247 |
+
nn.init.constant_(self.final_layer.adaLN_modulation[-1].weight, 0)
|
| 248 |
+
nn.init.constant_(self.final_layer.adaLN_modulation[-1].bias, 0)
|
| 249 |
+
nn.init.constant_(self.final_layer.linear.weight, 0)
|
| 250 |
+
nn.init.constant_(self.final_layer.linear.bias, 0)
|
| 251 |
+
|
| 252 |
+
def unpatchify(self, x):
|
| 253 |
+
"""
|
| 254 |
+
x: (N, H, W, patch_size**2 * C)
|
| 255 |
+
imgs: (N, H, W, C)
|
| 256 |
+
"""
|
| 257 |
+
c = self.out_channels
|
| 258 |
+
p = self.x_embedder.patch_size[0]
|
| 259 |
+
h = x.shape[1]
|
| 260 |
+
w = x.shape[2]
|
| 261 |
+
|
| 262 |
+
x = x.reshape(shape=(x.shape[0], h, w, p, p, c))
|
| 263 |
+
x = torch.einsum('nhwpqc->nchpwq', x)
|
| 264 |
+
imgs = x.reshape(shape=(x.shape[0], c, h * p, w * p))
|
| 265 |
+
return imgs
|
| 266 |
+
|
| 267 |
+
def forward(self, x, t, external_cond=None):
|
| 268 |
+
"""
|
| 269 |
+
Forward pass of DiT.
|
| 270 |
+
x: (B, T, C, H, W) tensor of spatial inputs (images or latent representations of images)
|
| 271 |
+
t: (B, T,) tensor of diffusion timesteps
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
B, T, C, H, W = x.shape
|
| 275 |
+
|
| 276 |
+
# add spatial embeddings
|
| 277 |
+
x = rearrange(x, "b t c h w -> (b t) c h w")
|
| 278 |
+
x = self.x_embedder(x) # (B*T, C, H, W) -> (B*T, H/2, W/2, D) , C = 16, D = d_model
|
| 279 |
+
# restore shape
|
| 280 |
+
x = rearrange(x, "(b t) h w d -> b t h w d", t = T)
|
| 281 |
+
# embed noise steps
|
| 282 |
+
t = rearrange(t, "b t -> (b t)")
|
| 283 |
+
c = self.t_embedder(t) # (N, D)
|
| 284 |
+
c = rearrange(c, "(b t) d -> b t d", t = T)
|
| 285 |
+
if torch.is_tensor(external_cond):
|
| 286 |
+
c += self.external_cond(external_cond)
|
| 287 |
+
for block in self.blocks:
|
| 288 |
+
x = block(x, c) # (N, T, H, W, D)
|
| 289 |
+
x = self.final_layer(x, c) # (N, T, H, W, patch_size ** 2 * out_channels)
|
| 290 |
+
# unpatchify
|
| 291 |
+
x = rearrange(x, "b t h w d -> (b t) h w d")
|
| 292 |
+
x = self.unpatchify(x) # (N, out_channels, H, W)
|
| 293 |
+
x = rearrange(x, "(b t) c h w -> b t c h w", t = T)
|
| 294 |
+
|
| 295 |
+
return x
|
| 296 |
+
|
| 297 |
+
def DiT_S_2():
|
| 298 |
+
return DiT(
|
| 299 |
+
patch_size=2,
|
| 300 |
+
hidden_size=1024,
|
| 301 |
+
depth=16,
|
| 302 |
+
num_heads=16,
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
DiT_models = {
|
| 306 |
+
"DiT-S/2": DiT_S_2
|
| 307 |
+
}
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
|
open_oasis_master/embeddings.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
from typing import Optional
|
| 6 |
+
import math
|
| 7 |
+
import torch
|
| 8 |
+
from torch import nn
|
| 9 |
+
|
| 10 |
+
# pylint: disable=unused-import
|
| 11 |
+
from diffusers.models.embeddings import TimestepEmbedding
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class Timesteps(nn.Module):
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
num_channels: int,
|
| 18 |
+
flip_sin_to_cos: bool = True,
|
| 19 |
+
downscale_freq_shift: float = 0,
|
| 20 |
+
):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.num_channels = num_channels
|
| 23 |
+
self.flip_sin_to_cos = flip_sin_to_cos
|
| 24 |
+
self.downscale_freq_shift = downscale_freq_shift
|
| 25 |
+
|
| 26 |
+
def forward(self, timesteps):
|
| 27 |
+
t_emb = get_timestep_embedding(
|
| 28 |
+
timesteps,
|
| 29 |
+
self.num_channels,
|
| 30 |
+
flip_sin_to_cos=self.flip_sin_to_cos,
|
| 31 |
+
downscale_freq_shift=self.downscale_freq_shift,
|
| 32 |
+
)
|
| 33 |
+
return t_emb
|
| 34 |
+
|
| 35 |
+
class Positions2d(nn.Module):
|
| 36 |
+
def __init__(
|
| 37 |
+
self,
|
| 38 |
+
num_channels: int,
|
| 39 |
+
flip_sin_to_cos: bool = True,
|
| 40 |
+
downscale_freq_shift: float = 0,
|
| 41 |
+
):
|
| 42 |
+
super().__init__()
|
| 43 |
+
self.num_channels = num_channels
|
| 44 |
+
self.flip_sin_to_cos = flip_sin_to_cos
|
| 45 |
+
self.downscale_freq_shift = downscale_freq_shift
|
| 46 |
+
|
| 47 |
+
def forward(self, grid):
|
| 48 |
+
h_emb = get_timestep_embedding(
|
| 49 |
+
grid[0],
|
| 50 |
+
self.num_channels // 2,
|
| 51 |
+
flip_sin_to_cos=self.flip_sin_to_cos,
|
| 52 |
+
downscale_freq_shift=self.downscale_freq_shift,
|
| 53 |
+
)
|
| 54 |
+
w_emb = get_timestep_embedding(
|
| 55 |
+
grid[1],
|
| 56 |
+
self.num_channels // 2,
|
| 57 |
+
flip_sin_to_cos=self.flip_sin_to_cos,
|
| 58 |
+
downscale_freq_shift=self.downscale_freq_shift,
|
| 59 |
+
)
|
| 60 |
+
emb = torch.cat((h_emb, w_emb), dim=-1)
|
| 61 |
+
return emb
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def get_timestep_embedding(
|
| 65 |
+
timesteps: torch.Tensor,
|
| 66 |
+
embedding_dim: int,
|
| 67 |
+
flip_sin_to_cos: bool = False,
|
| 68 |
+
downscale_freq_shift: float = 1,
|
| 69 |
+
scale: float = 1,
|
| 70 |
+
max_period: int = 10000,
|
| 71 |
+
):
|
| 72 |
+
"""
|
| 73 |
+
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
| 74 |
+
|
| 75 |
+
:param timesteps: a 1-D or 2-D Tensor of N indices, one per batch element.
|
| 76 |
+
These may be fractional.
|
| 77 |
+
:param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
|
| 78 |
+
embeddings. :return: an [N x dim] or [N x M x dim] Tensor of positional embeddings.
|
| 79 |
+
"""
|
| 80 |
+
if len(timesteps.shape) not in [1, 2]:
|
| 81 |
+
raise ValueError("Timesteps should be a 1D or 2D tensor")
|
| 82 |
+
|
| 83 |
+
half_dim = embedding_dim // 2
|
| 84 |
+
exponent = -math.log(max_period) * torch.arange(start=0, end=half_dim, dtype=torch.float32, device=timesteps.device)
|
| 85 |
+
exponent = exponent / (half_dim - downscale_freq_shift)
|
| 86 |
+
|
| 87 |
+
emb = torch.exp(exponent)
|
| 88 |
+
emb = timesteps[..., None].float() * emb
|
| 89 |
+
|
| 90 |
+
# scale embeddings
|
| 91 |
+
emb = scale * emb
|
| 92 |
+
|
| 93 |
+
# concat sine and cosine embeddings
|
| 94 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
| 95 |
+
|
| 96 |
+
# flip sine and cosine embeddings
|
| 97 |
+
if flip_sin_to_cos:
|
| 98 |
+
emb = torch.cat([emb[..., half_dim:], emb[..., :half_dim]], dim=-1)
|
| 99 |
+
|
| 100 |
+
# zero pad
|
| 101 |
+
if embedding_dim % 2 == 1:
|
| 102 |
+
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
| 103 |
+
return emb
|
open_oasis_master/generate.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
References:
|
| 3 |
+
- Diffusion Forcing: https://github.com/buoyancy99/diffusion-forcing
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
from dit import DiT_models
|
| 7 |
+
from vae import VAE_models
|
| 8 |
+
from torchvision.io import read_video, write_video
|
| 9 |
+
from utils import one_hot_actions, sigmoid_beta_schedule
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from einops import rearrange
|
| 12 |
+
from torch import autocast
|
| 13 |
+
assert torch.cuda.is_available()
|
| 14 |
+
device = "cuda:0"
|
| 15 |
+
|
| 16 |
+
# load DiT checkpoint
|
| 17 |
+
ckpt = torch.load("oasis500m.pt")
|
| 18 |
+
model = DiT_models["DiT-S/2"]()
|
| 19 |
+
model.load_state_dict(ckpt, strict=False)
|
| 20 |
+
model = model.to(device).eval()
|
| 21 |
+
|
| 22 |
+
# load VAE checkpoint
|
| 23 |
+
vae_ckpt = torch.load("vit-l-20.pt")
|
| 24 |
+
vae = VAE_models["vit-l-20-shallow-encoder"]()
|
| 25 |
+
vae.load_state_dict(vae_ckpt)
|
| 26 |
+
vae = vae.to(device).eval()
|
| 27 |
+
|
| 28 |
+
# sampling params
|
| 29 |
+
B = 1
|
| 30 |
+
total_frames = 32
|
| 31 |
+
max_noise_level = 1000
|
| 32 |
+
ddim_noise_steps = 100
|
| 33 |
+
noise_range = torch.linspace(-1, max_noise_level - 1, ddim_noise_steps + 1)
|
| 34 |
+
noise_abs_max = 20
|
| 35 |
+
ctx_max_noise_idx = ddim_noise_steps // 10 * 3
|
| 36 |
+
|
| 37 |
+
# get input video
|
| 38 |
+
video_id = "snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001"
|
| 39 |
+
mp4_path = f"sample_data/{video_id}.mp4"
|
| 40 |
+
actions_path = f"sample_data/{video_id}.actions.pt"
|
| 41 |
+
video = read_video(mp4_path, pts_unit="sec")[0].float() / 255
|
| 42 |
+
actions = one_hot_actions(torch.load(actions_path))
|
| 43 |
+
offset = 100
|
| 44 |
+
video = video[offset:offset+total_frames].unsqueeze(0)
|
| 45 |
+
actions = actions[offset:offset+total_frames].unsqueeze(0)
|
| 46 |
+
|
| 47 |
+
# sampling inputs
|
| 48 |
+
n_prompt_frames = 1
|
| 49 |
+
x = video[:, :n_prompt_frames]
|
| 50 |
+
x = x.to(device)
|
| 51 |
+
actions = actions.to(device)
|
| 52 |
+
|
| 53 |
+
# vae encoding
|
| 54 |
+
scaling_factor = 0.07843137255
|
| 55 |
+
x = rearrange(x, "b t h w c -> (b t) c h w")
|
| 56 |
+
H, W = x.shape[-2:]
|
| 57 |
+
with torch.no_grad():
|
| 58 |
+
x = vae.encode(x * 2 - 1).mean * scaling_factor
|
| 59 |
+
x = rearrange(x, "(b t) (h w) c -> b t c h w", t=n_prompt_frames, h=H//vae.patch_size, w=W//vae.patch_size)
|
| 60 |
+
|
| 61 |
+
# get alphas
|
| 62 |
+
betas = sigmoid_beta_schedule(max_noise_level).to(device)
|
| 63 |
+
alphas = 1.0 - betas
|
| 64 |
+
alphas_cumprod = torch.cumprod(alphas, dim=0)
|
| 65 |
+
alphas_cumprod = rearrange(alphas_cumprod, "T -> T 1 1 1")
|
| 66 |
+
|
| 67 |
+
# sampling loop
|
| 68 |
+
for i in tqdm(range(n_prompt_frames, total_frames)):
|
| 69 |
+
chunk = torch.randn((B, 1, *x.shape[-3:]), device=device)
|
| 70 |
+
chunk = torch.clamp(chunk, -noise_abs_max, +noise_abs_max)
|
| 71 |
+
x = torch.cat([x, chunk], dim=1)
|
| 72 |
+
start_frame = max(0, i + 1 - model.max_frames)
|
| 73 |
+
|
| 74 |
+
for noise_idx in reversed(range(1, ddim_noise_steps + 1)):
|
| 75 |
+
# set up noise values
|
| 76 |
+
ctx_noise_idx = min(noise_idx, ctx_max_noise_idx)
|
| 77 |
+
t_ctx = torch.full((B, i), noise_range[ctx_noise_idx], dtype=torch.long, device=device)
|
| 78 |
+
t = torch.full((B, 1), noise_range[noise_idx], dtype=torch.long, device=device)
|
| 79 |
+
t_next = torch.full((B, 1), noise_range[noise_idx - 1], dtype=torch.long, device=device)
|
| 80 |
+
t_next = torch.where(t_next < 0, t, t_next)
|
| 81 |
+
t = torch.cat([t_ctx, t], dim=1)
|
| 82 |
+
t_next = torch.cat([t_ctx, t_next], dim=1)
|
| 83 |
+
|
| 84 |
+
# sliding window
|
| 85 |
+
x_curr = x.clone()
|
| 86 |
+
x_curr = x_curr[:, start_frame:]
|
| 87 |
+
t = t[:, start_frame:]
|
| 88 |
+
t_next = t_next[:, start_frame:]
|
| 89 |
+
|
| 90 |
+
# add some noise to the context
|
| 91 |
+
ctx_noise = torch.randn_like(x_curr[:, :-1])
|
| 92 |
+
ctx_noise = torch.clamp(ctx_noise, -noise_abs_max, +noise_abs_max)
|
| 93 |
+
x_curr[:, :-1] = alphas_cumprod[t[:, :-1]].sqrt() * x_curr[:, :-1] + (1 - alphas_cumprod[t[:, :-1]]).sqrt() * ctx_noise
|
| 94 |
+
|
| 95 |
+
# get model predictions
|
| 96 |
+
with torch.no_grad():
|
| 97 |
+
with autocast("cuda", dtype=torch.half):
|
| 98 |
+
v = model(x_curr, t, actions[:, start_frame : i + 1])
|
| 99 |
+
|
| 100 |
+
x_start = alphas_cumprod[t].sqrt() * x_curr - (1 - alphas_cumprod[t]).sqrt() * v
|
| 101 |
+
x_noise = ((1 / alphas_cumprod[t]).sqrt() * x_curr - x_start) \
|
| 102 |
+
/ (1 / alphas_cumprod[t] - 1).sqrt()
|
| 103 |
+
|
| 104 |
+
# get frame prediction
|
| 105 |
+
x_pred = alphas_cumprod[t_next].sqrt() * x_start + x_noise * (1 - alphas_cumprod[t_next]).sqrt()
|
| 106 |
+
x[:, -1:] = x_pred[:, -1:]
|
| 107 |
+
|
| 108 |
+
# vae decoding
|
| 109 |
+
x = rearrange(x, "b t c h w -> (b t) (h w) c")
|
| 110 |
+
with torch.no_grad():
|
| 111 |
+
x = (vae.decode(x / scaling_factor) + 1) / 2
|
| 112 |
+
x = rearrange(x, "(b t) c h w -> b t h w c", t=total_frames)
|
| 113 |
+
|
| 114 |
+
# save video
|
| 115 |
+
x = torch.clamp(x, 0, 1)
|
| 116 |
+
x = (x * 255).byte()
|
| 117 |
+
write_video("video.mp4", x[0], fps=20)
|
| 118 |
+
print("generation saved to video.mp4.")
|
| 119 |
+
|
open_oasis_master/media/arch.png
ADDED
|
open_oasis_master/media/sample_0.gif
ADDED

|
Git LFS Details
|
open_oasis_master/media/sample_1.gif
ADDED

|
Git LFS Details
|
open_oasis_master/media/thumb.png
ADDED
|
open_oasis_master/requirements.txt
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
av==13.1.0
|
| 2 |
+
certifi==2024.8.30
|
| 3 |
+
charset-normalizer==3.4.0
|
| 4 |
+
diffusers==0.31.0
|
| 5 |
+
einops==0.8.0
|
| 6 |
+
filelock==3.13.1
|
| 7 |
+
fsspec==2024.2.0
|
| 8 |
+
huggingface-hub==0.26.2
|
| 9 |
+
idna==3.10
|
| 10 |
+
importlib_metadata==8.5.0
|
| 11 |
+
Jinja2==3.1.3
|
| 12 |
+
MarkupSafe==2.1.5
|
| 13 |
+
mpmath==1.3.0
|
| 14 |
+
networkx==3.2.1
|
| 15 |
+
numpy==1.26.3
|
| 16 |
+
packaging==24.1
|
| 17 |
+
pillow==10.2.0
|
| 18 |
+
PyYAML==6.0.2
|
| 19 |
+
regex==2024.9.11
|
| 20 |
+
requests==2.32.3
|
| 21 |
+
safetensors==0.4.5
|
| 22 |
+
sympy==1.13.1
|
| 23 |
+
timm==1.0.11
|
| 24 |
+
torch==2.5.1
|
| 25 |
+
torchaudio==2.5.1
|
| 26 |
+
torchvision==0.20.1
|
| 27 |
+
tqdm==4.66.6
|
| 28 |
+
triton==3.1.0
|
| 29 |
+
typing_extensions==4.9.0
|
| 30 |
+
urllib3==2.2.3
|
| 31 |
+
zipp==3.20.2
|
open_oasis_master/rotary_embedding_torch.py
ADDED
|
@@ -0,0 +1,316 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from https://github.com/lucidrains/rotary-embedding-torch/blob/main/rotary_embedding_torch/rotary_embedding_torch.py
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
from __future__ import annotations
|
| 6 |
+
from math import pi, log
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from torch.nn import Module, ModuleList
|
| 10 |
+
from torch.amp import autocast
|
| 11 |
+
from torch import nn, einsum, broadcast_tensors, Tensor
|
| 12 |
+
|
| 13 |
+
from einops import rearrange, repeat
|
| 14 |
+
|
| 15 |
+
from typing import Literal
|
| 16 |
+
|
| 17 |
+
# helper functions
|
| 18 |
+
|
| 19 |
+
def exists(val):
|
| 20 |
+
return val is not None
|
| 21 |
+
|
| 22 |
+
def default(val, d):
|
| 23 |
+
return val if exists(val) else d
|
| 24 |
+
|
| 25 |
+
# broadcat, as tortoise-tts was using it
|
| 26 |
+
|
| 27 |
+
def broadcat(tensors, dim = -1):
|
| 28 |
+
broadcasted_tensors = broadcast_tensors(*tensors)
|
| 29 |
+
return torch.cat(broadcasted_tensors, dim = dim)
|
| 30 |
+
|
| 31 |
+
# rotary embedding helper functions
|
| 32 |
+
|
| 33 |
+
def rotate_half(x):
|
| 34 |
+
x = rearrange(x, '... (d r) -> ... d r', r = 2)
|
| 35 |
+
x1, x2 = x.unbind(dim = -1)
|
| 36 |
+
x = torch.stack((-x2, x1), dim = -1)
|
| 37 |
+
return rearrange(x, '... d r -> ... (d r)')
|
| 38 |
+
|
| 39 |
+
@autocast('cuda', enabled = False)
|
| 40 |
+
def apply_rotary_emb(freqs, t, start_index = 0, scale = 1., seq_dim = -2):
|
| 41 |
+
dtype = t.dtype
|
| 42 |
+
|
| 43 |
+
if t.ndim == 3:
|
| 44 |
+
seq_len = t.shape[seq_dim]
|
| 45 |
+
freqs = freqs[-seq_len:]
|
| 46 |
+
|
| 47 |
+
rot_dim = freqs.shape[-1]
|
| 48 |
+
end_index = start_index + rot_dim
|
| 49 |
+
|
| 50 |
+
assert rot_dim <= t.shape[-1], f'feature dimension {t.shape[-1]} is not of sufficient size to rotate in all the positions {rot_dim}'
|
| 51 |
+
|
| 52 |
+
# Split t into three parts: left, middle (to be transformed), and right
|
| 53 |
+
t_left = t[..., :start_index]
|
| 54 |
+
t_middle = t[..., start_index:end_index]
|
| 55 |
+
t_right = t[..., end_index:]
|
| 56 |
+
|
| 57 |
+
# Apply rotary embeddings without modifying t in place
|
| 58 |
+
t_transformed = (t_middle * freqs.cos() * scale) + (rotate_half(t_middle) * freqs.sin() * scale)
|
| 59 |
+
|
| 60 |
+
out = torch.cat((t_left, t_transformed, t_right), dim=-1)
|
| 61 |
+
|
| 62 |
+
return out.type(dtype)
|
| 63 |
+
|
| 64 |
+
# learned rotation helpers
|
| 65 |
+
|
| 66 |
+
def apply_learned_rotations(rotations, t, start_index = 0, freq_ranges = None):
|
| 67 |
+
if exists(freq_ranges):
|
| 68 |
+
rotations = einsum('..., f -> ... f', rotations, freq_ranges)
|
| 69 |
+
rotations = rearrange(rotations, '... r f -> ... (r f)')
|
| 70 |
+
|
| 71 |
+
rotations = repeat(rotations, '... n -> ... (n r)', r = 2)
|
| 72 |
+
return apply_rotary_emb(rotations, t, start_index = start_index)
|
| 73 |
+
|
| 74 |
+
# classes
|
| 75 |
+
|
| 76 |
+
class RotaryEmbedding(Module):
|
| 77 |
+
def __init__(
|
| 78 |
+
self,
|
| 79 |
+
dim,
|
| 80 |
+
custom_freqs: Tensor | None = None,
|
| 81 |
+
freqs_for: Literal['lang', 'pixel', 'constant'] = 'lang',
|
| 82 |
+
theta = 10000,
|
| 83 |
+
max_freq = 10,
|
| 84 |
+
num_freqs = 1,
|
| 85 |
+
learned_freq = False,
|
| 86 |
+
use_xpos = False,
|
| 87 |
+
xpos_scale_base = 512,
|
| 88 |
+
interpolate_factor = 1.,
|
| 89 |
+
theta_rescale_factor = 1.,
|
| 90 |
+
seq_before_head_dim = False,
|
| 91 |
+
cache_if_possible = True,
|
| 92 |
+
cache_max_seq_len = 8192
|
| 93 |
+
):
|
| 94 |
+
super().__init__()
|
| 95 |
+
# proposed by reddit user bloc97, to rescale rotary embeddings to longer sequence length without fine-tuning
|
| 96 |
+
# has some connection to NTK literature
|
| 97 |
+
# https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
|
| 98 |
+
|
| 99 |
+
theta *= theta_rescale_factor ** (dim / (dim - 2))
|
| 100 |
+
|
| 101 |
+
self.freqs_for = freqs_for
|
| 102 |
+
|
| 103 |
+
if exists(custom_freqs):
|
| 104 |
+
freqs = custom_freqs
|
| 105 |
+
elif freqs_for == 'lang':
|
| 106 |
+
freqs = 1. / (theta ** (torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 107 |
+
elif freqs_for == 'pixel':
|
| 108 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 109 |
+
elif freqs_for == 'spacetime':
|
| 110 |
+
time_freqs = 1. / (theta ** (torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 111 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 112 |
+
elif freqs_for == 'constant':
|
| 113 |
+
freqs = torch.ones(num_freqs).float()
|
| 114 |
+
|
| 115 |
+
if freqs_for == 'spacetime':
|
| 116 |
+
self.time_freqs = nn.Parameter(time_freqs, requires_grad = learned_freq)
|
| 117 |
+
self.freqs = nn.Parameter(freqs, requires_grad = learned_freq)
|
| 118 |
+
|
| 119 |
+
self.cache_if_possible = cache_if_possible
|
| 120 |
+
self.cache_max_seq_len = cache_max_seq_len
|
| 121 |
+
|
| 122 |
+
self.register_buffer('cached_freqs', torch.zeros(cache_max_seq_len, dim), persistent = False)
|
| 123 |
+
self.register_buffer('cached_freqs_seq_len', torch.tensor(0), persistent = False)
|
| 124 |
+
|
| 125 |
+
self.learned_freq = learned_freq
|
| 126 |
+
|
| 127 |
+
# dummy for device
|
| 128 |
+
|
| 129 |
+
self.register_buffer('dummy', torch.tensor(0), persistent = False)
|
| 130 |
+
|
| 131 |
+
# default sequence dimension
|
| 132 |
+
|
| 133 |
+
self.seq_before_head_dim = seq_before_head_dim
|
| 134 |
+
self.default_seq_dim = -3 if seq_before_head_dim else -2
|
| 135 |
+
|
| 136 |
+
# interpolation factors
|
| 137 |
+
|
| 138 |
+
assert interpolate_factor >= 1.
|
| 139 |
+
self.interpolate_factor = interpolate_factor
|
| 140 |
+
|
| 141 |
+
# xpos
|
| 142 |
+
|
| 143 |
+
self.use_xpos = use_xpos
|
| 144 |
+
|
| 145 |
+
if not use_xpos:
|
| 146 |
+
return
|
| 147 |
+
|
| 148 |
+
scale = (torch.arange(0, dim, 2) + 0.4 * dim) / (1.4 * dim)
|
| 149 |
+
self.scale_base = xpos_scale_base
|
| 150 |
+
|
| 151 |
+
self.register_buffer('scale', scale, persistent = False)
|
| 152 |
+
self.register_buffer('cached_scales', torch.zeros(cache_max_seq_len, dim), persistent = False)
|
| 153 |
+
self.register_buffer('cached_scales_seq_len', torch.tensor(0), persistent = False)
|
| 154 |
+
|
| 155 |
+
# add apply_rotary_emb as static method
|
| 156 |
+
|
| 157 |
+
self.apply_rotary_emb = staticmethod(apply_rotary_emb)
|
| 158 |
+
|
| 159 |
+
@property
|
| 160 |
+
def device(self):
|
| 161 |
+
return self.dummy.device
|
| 162 |
+
|
| 163 |
+
def get_seq_pos(self, seq_len, device, dtype, offset = 0):
|
| 164 |
+
return (torch.arange(seq_len, device = device, dtype = dtype) + offset) / self.interpolate_factor
|
| 165 |
+
|
| 166 |
+
def rotate_queries_or_keys(self, t, freqs, seq_dim = None, offset = 0, scale = None):
|
| 167 |
+
seq_dim = default(seq_dim, self.default_seq_dim)
|
| 168 |
+
|
| 169 |
+
assert not self.use_xpos or exists(scale), 'you must use `.rotate_queries_and_keys` method instead and pass in both queries and keys, for length extrapolatable rotary embeddings'
|
| 170 |
+
|
| 171 |
+
device, dtype, seq_len = t.device, t.dtype, t.shape[seq_dim]
|
| 172 |
+
|
| 173 |
+
seq = self.get_seq_pos(seq_len, device = device, dtype = dtype, offset = offset)
|
| 174 |
+
|
| 175 |
+
seq_freqs = self.forward(seq, freqs, seq_len = seq_len, offset = offset)
|
| 176 |
+
|
| 177 |
+
if seq_dim == -3:
|
| 178 |
+
seq_freqs = rearrange(seq_freqs, 'n d -> n 1 d')
|
| 179 |
+
|
| 180 |
+
return apply_rotary_emb(seq_freqs, t, scale = default(scale, 1.), seq_dim = seq_dim)
|
| 181 |
+
|
| 182 |
+
def rotate_queries_with_cached_keys(self, q, k, seq_dim = None, offset = 0):
|
| 183 |
+
dtype, device, seq_dim = q.dtype, q.device, default(seq_dim, self.default_seq_dim)
|
| 184 |
+
|
| 185 |
+
q_len, k_len = q.shape[seq_dim], k.shape[seq_dim]
|
| 186 |
+
assert q_len <= k_len
|
| 187 |
+
|
| 188 |
+
q_scale = k_scale = 1.
|
| 189 |
+
|
| 190 |
+
if self.use_xpos:
|
| 191 |
+
seq = self.get_seq_pos(k_len, dtype = dtype, device = device)
|
| 192 |
+
|
| 193 |
+
q_scale = self.get_scale(seq[-q_len:]).type(dtype)
|
| 194 |
+
k_scale = self.get_scale(seq).type(dtype)
|
| 195 |
+
|
| 196 |
+
rotated_q = self.rotate_queries_or_keys(q, seq_dim = seq_dim, scale = q_scale, offset = k_len - q_len + offset)
|
| 197 |
+
rotated_k = self.rotate_queries_or_keys(k, seq_dim = seq_dim, scale = k_scale ** -1)
|
| 198 |
+
|
| 199 |
+
rotated_q = rotated_q.type(q.dtype)
|
| 200 |
+
rotated_k = rotated_k.type(k.dtype)
|
| 201 |
+
|
| 202 |
+
return rotated_q, rotated_k
|
| 203 |
+
|
| 204 |
+
def rotate_queries_and_keys(self, q, k, freqs, seq_dim = None):
|
| 205 |
+
seq_dim = default(seq_dim, self.default_seq_dim)
|
| 206 |
+
|
| 207 |
+
assert self.use_xpos
|
| 208 |
+
device, dtype, seq_len = q.device, q.dtype, q.shape[seq_dim]
|
| 209 |
+
|
| 210 |
+
seq = self.get_seq_pos(seq_len, dtype = dtype, device = device)
|
| 211 |
+
|
| 212 |
+
seq_freqs = self.forward(seq, freqs, seq_len = seq_len)
|
| 213 |
+
scale = self.get_scale(seq, seq_len = seq_len).to(dtype)
|
| 214 |
+
|
| 215 |
+
if seq_dim == -3:
|
| 216 |
+
seq_freqs = rearrange(seq_freqs, 'n d -> n 1 d')
|
| 217 |
+
scale = rearrange(scale, 'n d -> n 1 d')
|
| 218 |
+
|
| 219 |
+
rotated_q = apply_rotary_emb(seq_freqs, q, scale = scale, seq_dim = seq_dim)
|
| 220 |
+
rotated_k = apply_rotary_emb(seq_freqs, k, scale = scale ** -1, seq_dim = seq_dim)
|
| 221 |
+
|
| 222 |
+
rotated_q = rotated_q.type(q.dtype)
|
| 223 |
+
rotated_k = rotated_k.type(k.dtype)
|
| 224 |
+
|
| 225 |
+
return rotated_q, rotated_k
|
| 226 |
+
|
| 227 |
+
def get_scale(
|
| 228 |
+
self,
|
| 229 |
+
t: Tensor,
|
| 230 |
+
seq_len: int | None = None,
|
| 231 |
+
offset = 0
|
| 232 |
+
):
|
| 233 |
+
assert self.use_xpos
|
| 234 |
+
|
| 235 |
+
should_cache = (
|
| 236 |
+
self.cache_if_possible and
|
| 237 |
+
exists(seq_len) and
|
| 238 |
+
(offset + seq_len) <= self.cache_max_seq_len
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
if (
|
| 242 |
+
should_cache and \
|
| 243 |
+
exists(self.cached_scales) and \
|
| 244 |
+
(seq_len + offset) <= self.cached_scales_seq_len.item()
|
| 245 |
+
):
|
| 246 |
+
return self.cached_scales[offset:(offset + seq_len)]
|
| 247 |
+
|
| 248 |
+
scale = 1.
|
| 249 |
+
if self.use_xpos:
|
| 250 |
+
power = (t - len(t) // 2) / self.scale_base
|
| 251 |
+
scale = self.scale ** rearrange(power, 'n -> n 1')
|
| 252 |
+
scale = repeat(scale, 'n d -> n (d r)', r = 2)
|
| 253 |
+
|
| 254 |
+
if should_cache and offset == 0:
|
| 255 |
+
self.cached_scales[:seq_len] = scale.detach()
|
| 256 |
+
self.cached_scales_seq_len.copy_(seq_len)
|
| 257 |
+
|
| 258 |
+
return scale
|
| 259 |
+
|
| 260 |
+
def get_axial_freqs(self, *dims):
|
| 261 |
+
Colon = slice(None)
|
| 262 |
+
all_freqs = []
|
| 263 |
+
|
| 264 |
+
for ind, dim in enumerate(dims):
|
| 265 |
+
# only allow pixel freqs for last two dimensions
|
| 266 |
+
use_pixel = (self.freqs_for == 'pixel' or self.freqs_for == 'spacetime') and ind >= len(dims) - 2
|
| 267 |
+
if use_pixel:
|
| 268 |
+
pos = torch.linspace(-1, 1, steps = dim, device = self.device)
|
| 269 |
+
else:
|
| 270 |
+
pos = torch.arange(dim, device = self.device)
|
| 271 |
+
|
| 272 |
+
if self.freqs_for == 'spacetime' and not use_pixel:
|
| 273 |
+
seq_freqs = self.forward(pos, self.time_freqs, seq_len = dim)
|
| 274 |
+
else:
|
| 275 |
+
seq_freqs = self.forward(pos, self.freqs, seq_len = dim)
|
| 276 |
+
|
| 277 |
+
all_axis = [None] * len(dims)
|
| 278 |
+
all_axis[ind] = Colon
|
| 279 |
+
|
| 280 |
+
new_axis_slice = (Ellipsis, *all_axis, Colon)
|
| 281 |
+
all_freqs.append(seq_freqs[new_axis_slice])
|
| 282 |
+
|
| 283 |
+
all_freqs = broadcast_tensors(*all_freqs)
|
| 284 |
+
return torch.cat(all_freqs, dim = -1)
|
| 285 |
+
|
| 286 |
+
@autocast('cuda', enabled = False)
|
| 287 |
+
def forward(
|
| 288 |
+
self,
|
| 289 |
+
t: Tensor,
|
| 290 |
+
freqs: Tensor,
|
| 291 |
+
seq_len = None,
|
| 292 |
+
offset = 0
|
| 293 |
+
):
|
| 294 |
+
should_cache = (
|
| 295 |
+
self.cache_if_possible and
|
| 296 |
+
not self.learned_freq and
|
| 297 |
+
exists(seq_len) and
|
| 298 |
+
self.freqs_for != 'pixel' and
|
| 299 |
+
(offset + seq_len) <= self.cache_max_seq_len
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
if (
|
| 303 |
+
should_cache and \
|
| 304 |
+
exists(self.cached_freqs) and \
|
| 305 |
+
(offset + seq_len) <= self.cached_freqs_seq_len.item()
|
| 306 |
+
):
|
| 307 |
+
return self.cached_freqs[offset:(offset + seq_len)].detach()
|
| 308 |
+
|
| 309 |
+
freqs = einsum('..., f -> ... f', t.type(freqs.dtype), freqs)
|
| 310 |
+
freqs = repeat(freqs, '... n -> ... (n r)', r = 2)
|
| 311 |
+
|
| 312 |
+
if should_cache and offset == 0:
|
| 313 |
+
self.cached_freqs[:seq_len] = freqs.detach()
|
| 314 |
+
self.cached_freqs_seq_len.copy_(seq_len)
|
| 315 |
+
|
| 316 |
+
return freqs
|
open_oasis_master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.actions.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cc3ea8894f87e2c2c2387dd32b193f27a8a95009397c32b5fbaf8a6f23608b0c
|
| 3 |
+
size 230180
|
open_oasis_master/sample_data/Player729-f153ac423f61-20210806-224813.chunk_000.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9fb1cf3a87be9deca2fec2e946427521a85026ee607cf9281aa87f6df447e4ea
|
| 3 |
+
size 6818283
|
open_oasis_master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.actions.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:955929d771293156d3f27d295091a978dcd97fdaa78e3a17395ac90c0403004d
|
| 3 |
+
size 230308
|
open_oasis_master/sample_data/snippy-chartreuse-mastiff-f79998db196d-20220401-224517.chunk_001.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:745b0348a014d943f70ccf6ccba17ad260540caba502b312d972235326003ab0
|
| 3 |
+
size 7109171
|
open_oasis_master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.actions.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46ae60cc9d3a02df949923c707df4c5cd3f49d279aa6500c81f0ef00c14f7747
|
| 3 |
+
size 230176
|
open_oasis_master/sample_data/treechop-f153ac423f61-20210916-183423.chunk_000.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a0ad584df52d7b2636fae5d7a3116f596f25a09ba7d28ff5fc42193105605d92
|
| 3 |
+
size 8716515
|
open_oasis_master/utils.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from https://github.com/buoyancy99/diffusion-forcing/blob/main/algorithms/diffusion_forcing/models/utils.py
|
| 3 |
+
Action format derived from VPT https://github.com/openai/Video-Pre-Training
|
| 4 |
+
"""
|
| 5 |
+
import math
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
from einops import rearrange, parse_shape
|
| 9 |
+
from typing import Mapping, Sequence
|
| 10 |
+
import torch
|
| 11 |
+
from einops import rearrange
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def sigmoid_beta_schedule(timesteps, start=-3, end=3, tau=1, clamp_min=1e-5):
|
| 15 |
+
"""
|
| 16 |
+
sigmoid schedule
|
| 17 |
+
proposed in https://arxiv.org/abs/2212.11972 - Figure 8
|
| 18 |
+
better for images > 64x64, when used during training
|
| 19 |
+
"""
|
| 20 |
+
steps = timesteps + 1
|
| 21 |
+
t = torch.linspace(0, timesteps, steps, dtype=torch.float32) / timesteps
|
| 22 |
+
v_start = torch.tensor(start / tau).sigmoid()
|
| 23 |
+
v_end = torch.tensor(end / tau).sigmoid()
|
| 24 |
+
alphas_cumprod = (-((t * (end - start) + start) / tau).sigmoid() + v_end) / (v_end - v_start)
|
| 25 |
+
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
|
| 26 |
+
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])
|
| 27 |
+
return torch.clip(betas, 0, 0.999)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
ACTION_KEYS = [
|
| 31 |
+
"inventory",
|
| 32 |
+
"ESC",
|
| 33 |
+
"hotbar.1",
|
| 34 |
+
"hotbar.2",
|
| 35 |
+
"hotbar.3",
|
| 36 |
+
"hotbar.4",
|
| 37 |
+
"hotbar.5",
|
| 38 |
+
"hotbar.6",
|
| 39 |
+
"hotbar.7",
|
| 40 |
+
"hotbar.8",
|
| 41 |
+
"hotbar.9",
|
| 42 |
+
"forward",
|
| 43 |
+
"back",
|
| 44 |
+
"left",
|
| 45 |
+
"right",
|
| 46 |
+
"cameraX",
|
| 47 |
+
"cameraY",
|
| 48 |
+
"jump",
|
| 49 |
+
"sneak",
|
| 50 |
+
"sprint",
|
| 51 |
+
"swapHands",
|
| 52 |
+
"attack",
|
| 53 |
+
"use",
|
| 54 |
+
"pickItem",
|
| 55 |
+
"drop",
|
| 56 |
+
]
|
| 57 |
+
|
| 58 |
+
def one_hot_actions(actions: Sequence[Mapping[str, int]]) -> torch.Tensor:
|
| 59 |
+
actions_one_hot = torch.zeros(len(actions), len(ACTION_KEYS))
|
| 60 |
+
for i, current_actions in enumerate(actions):
|
| 61 |
+
for j, action_key in enumerate(ACTION_KEYS):
|
| 62 |
+
if action_key.startswith("camera"):
|
| 63 |
+
if action_key == "cameraX":
|
| 64 |
+
value = current_actions["camera"][0]
|
| 65 |
+
elif action_key == "cameraY":
|
| 66 |
+
value = current_actions["camera"][1]
|
| 67 |
+
else:
|
| 68 |
+
raise ValueError(f"Unknown camera action key: {action_key}")
|
| 69 |
+
# NOTE these numbers specific to the camera quantization used in
|
| 70 |
+
# https://github.com/etched-ai/dreamcraft/blob/216e952f795bb3da598639a109bcdba4d2067b69/spark/preprocess_vpt_to_videos_actions.py#L312
|
| 71 |
+
# see method `compress_mouse`
|
| 72 |
+
max_val = 20
|
| 73 |
+
bin_size = 0.5
|
| 74 |
+
num_buckets = int(max_val / bin_size)
|
| 75 |
+
value = (value - num_buckets) / num_buckets
|
| 76 |
+
assert -1 - 1e-3 <= value <= 1 + 1e-3, f"Camera action value must be in [-1, 1], got {value}"
|
| 77 |
+
else:
|
| 78 |
+
value = current_actions[action_key]
|
| 79 |
+
assert 0 <= value <= 1, f"Action value must be in [0, 1] got {value}"
|
| 80 |
+
actions_one_hot[i, j] = value
|
| 81 |
+
|
| 82 |
+
return actions_one_hot
|
open_oasis_master/vae.py
ADDED
|
@@ -0,0 +1,381 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
References:
|
| 3 |
+
- VQGAN: https://github.com/CompVis/taming-transformers
|
| 4 |
+
- MAE: https://github.com/facebookresearch/mae
|
| 5 |
+
"""
|
| 6 |
+
import numpy as np
|
| 7 |
+
import math
|
| 8 |
+
import functools
|
| 9 |
+
from collections import namedtuple
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
from einops import rearrange
|
| 14 |
+
from timm.models.vision_transformer import Mlp
|
| 15 |
+
from timm.layers.helpers import to_2tuple
|
| 16 |
+
from rotary_embedding_torch import RotaryEmbedding, apply_rotary_emb
|
| 17 |
+
from dit import PatchEmbed
|
| 18 |
+
|
| 19 |
+
class DiagonalGaussianDistribution(object):
|
| 20 |
+
def __init__(self, parameters, deterministic=False, dim=1):
|
| 21 |
+
self.parameters = parameters
|
| 22 |
+
self.mean, self.logvar = torch.chunk(parameters, 2, dim=dim)
|
| 23 |
+
if dim == 1:
|
| 24 |
+
self.dims = [1, 2, 3]
|
| 25 |
+
elif dim == 2:
|
| 26 |
+
self.dims = [1, 2]
|
| 27 |
+
else:
|
| 28 |
+
raise NotImplementedError
|
| 29 |
+
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
| 30 |
+
self.deterministic = deterministic
|
| 31 |
+
self.std = torch.exp(0.5 * self.logvar)
|
| 32 |
+
self.var = torch.exp(self.logvar)
|
| 33 |
+
if self.deterministic:
|
| 34 |
+
self.var = self.std = torch.zeros_like(self.mean).to(
|
| 35 |
+
device=self.parameters.device
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
def sample(self):
|
| 39 |
+
x = self.mean + self.std * torch.randn(self.mean.shape).to(
|
| 40 |
+
device=self.parameters.device
|
| 41 |
+
)
|
| 42 |
+
return x
|
| 43 |
+
|
| 44 |
+
def mode(self):
|
| 45 |
+
return self.mean
|
| 46 |
+
|
| 47 |
+
class Attention(nn.Module):
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
dim,
|
| 51 |
+
num_heads,
|
| 52 |
+
frame_height,
|
| 53 |
+
frame_width,
|
| 54 |
+
qkv_bias=False,
|
| 55 |
+
attn_drop=0.0,
|
| 56 |
+
proj_drop=0.0,
|
| 57 |
+
is_causal=False,
|
| 58 |
+
):
|
| 59 |
+
super().__init__()
|
| 60 |
+
self.num_heads = num_heads
|
| 61 |
+
head_dim = dim // num_heads
|
| 62 |
+
self.frame_height = frame_height
|
| 63 |
+
self.frame_width = frame_width
|
| 64 |
+
|
| 65 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 66 |
+
self.attn_drop = attn_drop
|
| 67 |
+
self.proj = nn.Linear(dim, dim)
|
| 68 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 69 |
+
self.is_causal = is_causal
|
| 70 |
+
|
| 71 |
+
rotary_freqs = RotaryEmbedding(
|
| 72 |
+
dim=head_dim // 4,
|
| 73 |
+
freqs_for="pixel",
|
| 74 |
+
max_freq=frame_height*frame_width,
|
| 75 |
+
).get_axial_freqs(frame_height, frame_width)
|
| 76 |
+
self.register_buffer("rotary_freqs", rotary_freqs, persistent=False)
|
| 77 |
+
|
| 78 |
+
def forward(self, x):
|
| 79 |
+
B, N, C = x.shape
|
| 80 |
+
assert N == self.frame_height * self.frame_width
|
| 81 |
+
|
| 82 |
+
qkv = (
|
| 83 |
+
self.qkv(x)
|
| 84 |
+
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
| 85 |
+
.permute(2, 0, 3, 1, 4)
|
| 86 |
+
)
|
| 87 |
+
q, k, v = (
|
| 88 |
+
qkv[0],
|
| 89 |
+
qkv[1],
|
| 90 |
+
qkv[2],
|
| 91 |
+
) # make torchscript happy (cannot use tensor as tuple)
|
| 92 |
+
|
| 93 |
+
if self.rotary_freqs is not None:
|
| 94 |
+
q = rearrange(q, "b h (H W) d -> b h H W d", H=self.frame_height, W=self.frame_width)
|
| 95 |
+
k = rearrange(k, "b h (H W) d -> b h H W d", H=self.frame_height, W=self.frame_width)
|
| 96 |
+
q = apply_rotary_emb(self.rotary_freqs, q)
|
| 97 |
+
k = apply_rotary_emb(self.rotary_freqs, k)
|
| 98 |
+
q = rearrange(q, "b h H W d -> b h (H W) d")
|
| 99 |
+
k = rearrange(k, "b h H W d -> b h (H W) d")
|
| 100 |
+
|
| 101 |
+
attn = F.scaled_dot_product_attention(
|
| 102 |
+
q,
|
| 103 |
+
k,
|
| 104 |
+
v,
|
| 105 |
+
dropout_p=self.attn_drop,
|
| 106 |
+
is_causal=self.is_causal,
|
| 107 |
+
)
|
| 108 |
+
x = attn.transpose(1, 2).reshape(B, N, C)
|
| 109 |
+
|
| 110 |
+
x = self.proj(x)
|
| 111 |
+
x = self.proj_drop(x)
|
| 112 |
+
return x
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
class AttentionBlock(nn.Module):
|
| 116 |
+
def __init__(
|
| 117 |
+
self,
|
| 118 |
+
dim,
|
| 119 |
+
num_heads,
|
| 120 |
+
frame_height,
|
| 121 |
+
frame_width,
|
| 122 |
+
mlp_ratio=4.0,
|
| 123 |
+
qkv_bias=False,
|
| 124 |
+
drop=0.0,
|
| 125 |
+
attn_drop=0.0,
|
| 126 |
+
attn_causal=False,
|
| 127 |
+
drop_path=0.0,
|
| 128 |
+
act_layer=nn.GELU,
|
| 129 |
+
norm_layer=nn.LayerNorm,
|
| 130 |
+
):
|
| 131 |
+
super().__init__()
|
| 132 |
+
self.norm1 = norm_layer(dim)
|
| 133 |
+
self.attn = Attention(
|
| 134 |
+
dim,
|
| 135 |
+
num_heads,
|
| 136 |
+
frame_height,
|
| 137 |
+
frame_width,
|
| 138 |
+
qkv_bias=qkv_bias,
|
| 139 |
+
attn_drop=attn_drop,
|
| 140 |
+
proj_drop=drop,
|
| 141 |
+
is_causal=attn_causal,
|
| 142 |
+
)
|
| 143 |
+
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
|
| 144 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 145 |
+
self.norm2 = norm_layer(dim)
|
| 146 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 147 |
+
self.mlp = Mlp(
|
| 148 |
+
in_features=dim,
|
| 149 |
+
hidden_features=mlp_hidden_dim,
|
| 150 |
+
act_layer=act_layer,
|
| 151 |
+
drop=drop,
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
def forward(self, x):
|
| 155 |
+
x = x + self.drop_path(self.attn(self.norm1(x)))
|
| 156 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 157 |
+
return x
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
class AutoencoderKL(nn.Module):
|
| 161 |
+
def __init__(
|
| 162 |
+
self,
|
| 163 |
+
latent_dim,
|
| 164 |
+
input_height=256,
|
| 165 |
+
input_width=256,
|
| 166 |
+
patch_size=16,
|
| 167 |
+
enc_dim=768,
|
| 168 |
+
enc_depth=6,
|
| 169 |
+
enc_heads=12,
|
| 170 |
+
dec_dim=768,
|
| 171 |
+
dec_depth=6,
|
| 172 |
+
dec_heads=12,
|
| 173 |
+
mlp_ratio=4.0,
|
| 174 |
+
norm_layer=functools.partial(nn.LayerNorm, eps=1e-6),
|
| 175 |
+
use_variational=True,
|
| 176 |
+
**kwargs,
|
| 177 |
+
):
|
| 178 |
+
super().__init__()
|
| 179 |
+
self.input_height = input_height
|
| 180 |
+
self.input_width = input_width
|
| 181 |
+
self.patch_size = patch_size
|
| 182 |
+
self.seq_h = input_height // patch_size
|
| 183 |
+
self.seq_w = input_width // patch_size
|
| 184 |
+
self.seq_len = self.seq_h * self.seq_w
|
| 185 |
+
self.patch_dim = 3 * patch_size**2
|
| 186 |
+
|
| 187 |
+
self.latent_dim = latent_dim
|
| 188 |
+
self.enc_dim = enc_dim
|
| 189 |
+
self.dec_dim = dec_dim
|
| 190 |
+
|
| 191 |
+
# patch
|
| 192 |
+
self.patch_embed = PatchEmbed(input_height, input_width, patch_size, 3, enc_dim)
|
| 193 |
+
|
| 194 |
+
# encoder
|
| 195 |
+
self.encoder = nn.ModuleList(
|
| 196 |
+
[
|
| 197 |
+
AttentionBlock(
|
| 198 |
+
enc_dim,
|
| 199 |
+
enc_heads,
|
| 200 |
+
self.seq_h,
|
| 201 |
+
self.seq_w,
|
| 202 |
+
mlp_ratio,
|
| 203 |
+
qkv_bias=True,
|
| 204 |
+
norm_layer=norm_layer,
|
| 205 |
+
)
|
| 206 |
+
for i in range(enc_depth)
|
| 207 |
+
]
|
| 208 |
+
)
|
| 209 |
+
self.enc_norm = norm_layer(enc_dim)
|
| 210 |
+
|
| 211 |
+
# bottleneck
|
| 212 |
+
self.use_variational = use_variational
|
| 213 |
+
mult = 2 if self.use_variational else 1
|
| 214 |
+
self.quant_conv = nn.Linear(enc_dim, mult * latent_dim)
|
| 215 |
+
self.post_quant_conv = nn.Linear(latent_dim, dec_dim)
|
| 216 |
+
|
| 217 |
+
# decoder
|
| 218 |
+
self.decoder = nn.ModuleList(
|
| 219 |
+
[
|
| 220 |
+
AttentionBlock(
|
| 221 |
+
dec_dim,
|
| 222 |
+
dec_heads,
|
| 223 |
+
self.seq_h,
|
| 224 |
+
self.seq_w,
|
| 225 |
+
mlp_ratio,
|
| 226 |
+
qkv_bias=True,
|
| 227 |
+
norm_layer=norm_layer,
|
| 228 |
+
)
|
| 229 |
+
for i in range(dec_depth)
|
| 230 |
+
]
|
| 231 |
+
)
|
| 232 |
+
self.dec_norm = norm_layer(dec_dim)
|
| 233 |
+
self.predictor = nn.Linear(dec_dim, self.patch_dim) # decoder to patch
|
| 234 |
+
|
| 235 |
+
# initialize this weight first
|
| 236 |
+
self.initialize_weights()
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
def initialize_weights(self):
|
| 240 |
+
# initialization
|
| 241 |
+
# initialize nn.Linear and nn.LayerNorm
|
| 242 |
+
self.apply(self._init_weights)
|
| 243 |
+
|
| 244 |
+
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
|
| 245 |
+
w = self.patch_embed.proj.weight.data
|
| 246 |
+
nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 247 |
+
|
| 248 |
+
def _init_weights(self, m):
|
| 249 |
+
if isinstance(m, nn.Linear):
|
| 250 |
+
# we use xavier_uniform following official JAX ViT:
|
| 251 |
+
nn.init.xavier_uniform_(m.weight)
|
| 252 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 253 |
+
nn.init.constant_(m.bias, 0.0)
|
| 254 |
+
elif isinstance(m, nn.LayerNorm):
|
| 255 |
+
nn.init.constant_(m.bias, 0.0)
|
| 256 |
+
nn.init.constant_(m.weight, 1.0)
|
| 257 |
+
|
| 258 |
+
def patchify(self, x):
|
| 259 |
+
# patchify
|
| 260 |
+
bsz, _, h, w = x.shape
|
| 261 |
+
x = x.reshape(
|
| 262 |
+
bsz,
|
| 263 |
+
3,
|
| 264 |
+
self.seq_h,
|
| 265 |
+
self.patch_size,
|
| 266 |
+
self.seq_w,
|
| 267 |
+
self.patch_size,
|
| 268 |
+
).permute(
|
| 269 |
+
[0, 1, 3, 5, 2, 4]
|
| 270 |
+
) # [b, c, h, p, w, p] --> [b, c, p, p, h, w]
|
| 271 |
+
x = x.reshape(
|
| 272 |
+
bsz, self.patch_dim, self.seq_h, self.seq_w
|
| 273 |
+
) # --> [b, cxpxp, h, w]
|
| 274 |
+
x = x.permute([0, 2, 3, 1]).reshape(
|
| 275 |
+
bsz, self.seq_len, self.patch_dim
|
| 276 |
+
) # --> [b, hxw, cxpxp]
|
| 277 |
+
return x
|
| 278 |
+
|
| 279 |
+
def unpatchify(self, x):
|
| 280 |
+
bsz = x.shape[0]
|
| 281 |
+
# unpatchify
|
| 282 |
+
x = x.reshape(bsz, self.seq_h, self.seq_w, self.patch_dim).permute(
|
| 283 |
+
[0, 3, 1, 2]
|
| 284 |
+
) # [b, h, w, cxpxp] --> [b, cxpxp, h, w]
|
| 285 |
+
x = x.reshape(
|
| 286 |
+
bsz,
|
| 287 |
+
3,
|
| 288 |
+
self.patch_size,
|
| 289 |
+
self.patch_size,
|
| 290 |
+
self.seq_h,
|
| 291 |
+
self.seq_w,
|
| 292 |
+
).permute(
|
| 293 |
+
[0, 1, 4, 2, 5, 3]
|
| 294 |
+
) # [b, c, p, p, h, w] --> [b, c, h, p, w, p]
|
| 295 |
+
x = x.reshape(
|
| 296 |
+
bsz,
|
| 297 |
+
3,
|
| 298 |
+
self.input_height,
|
| 299 |
+
self.input_width,
|
| 300 |
+
) # [b, c, hxp, wxp]
|
| 301 |
+
return x
|
| 302 |
+
|
| 303 |
+
def encode(self, x):
|
| 304 |
+
# patchify
|
| 305 |
+
x = self.patch_embed(x)
|
| 306 |
+
|
| 307 |
+
# encoder
|
| 308 |
+
for blk in self.encoder:
|
| 309 |
+
x = blk(x)
|
| 310 |
+
x = self.enc_norm(x)
|
| 311 |
+
|
| 312 |
+
# bottleneck
|
| 313 |
+
moments = self.quant_conv(x)
|
| 314 |
+
if not self.use_variational:
|
| 315 |
+
moments = torch.cat((moments, torch.zeros_like(moments)), 2)
|
| 316 |
+
posterior = DiagonalGaussianDistribution(
|
| 317 |
+
moments, deterministic=(not self.use_variational), dim=2
|
| 318 |
+
)
|
| 319 |
+
return posterior
|
| 320 |
+
|
| 321 |
+
def decode(self, z):
|
| 322 |
+
# bottleneck
|
| 323 |
+
z = self.post_quant_conv(z)
|
| 324 |
+
|
| 325 |
+
# decoder
|
| 326 |
+
for blk in self.decoder:
|
| 327 |
+
z = blk(z)
|
| 328 |
+
z = self.dec_norm(z)
|
| 329 |
+
|
| 330 |
+
# predictor
|
| 331 |
+
z = self.predictor(z)
|
| 332 |
+
|
| 333 |
+
# unpatchify
|
| 334 |
+
dec = self.unpatchify(z)
|
| 335 |
+
return dec
|
| 336 |
+
|
| 337 |
+
def autoencode(self, input, sample_posterior=True):
|
| 338 |
+
posterior = self.encode(input)
|
| 339 |
+
if self.use_variational and sample_posterior:
|
| 340 |
+
z = posterior.sample()
|
| 341 |
+
else:
|
| 342 |
+
z = posterior.mode()
|
| 343 |
+
dec = self.decode(z)
|
| 344 |
+
return dec, posterior, z
|
| 345 |
+
|
| 346 |
+
def get_input(self, batch, k):
|
| 347 |
+
x = batch[k]
|
| 348 |
+
if len(x.shape) == 3:
|
| 349 |
+
x = x[..., None]
|
| 350 |
+
x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format).float()
|
| 351 |
+
return x
|
| 352 |
+
|
| 353 |
+
def forward(self, inputs, labels, split="train"):
|
| 354 |
+
rec, post, latent = self.autoencode(inputs)
|
| 355 |
+
return rec, post, latent
|
| 356 |
+
|
| 357 |
+
def get_last_layer(self):
|
| 358 |
+
return self.predictor.weight
|
| 359 |
+
|
| 360 |
+
def ViT_L_20_Shallow_Encoder(**kwargs):
|
| 361 |
+
if "latent_dim" in kwargs:
|
| 362 |
+
latent_dim = kwargs.pop("latent_dim")
|
| 363 |
+
else:
|
| 364 |
+
latent_dim = 16
|
| 365 |
+
return AutoencoderKL(
|
| 366 |
+
latent_dim=latent_dim,
|
| 367 |
+
patch_size=20,
|
| 368 |
+
enc_dim=1024,
|
| 369 |
+
enc_depth=6,
|
| 370 |
+
enc_heads=16,
|
| 371 |
+
dec_dim=1024,
|
| 372 |
+
dec_depth=12,
|
| 373 |
+
dec_heads=16,
|
| 374 |
+
input_height=360,
|
| 375 |
+
input_width=640,
|
| 376 |
+
**kwargs,
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
VAE_models = {
|
| 380 |
+
"vit-l-20-shallow-encoder": ViT_L_20_Shallow_Encoder,
|
| 381 |
+
}
|