Spaces:
Running

Running
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +18 -0
- .gitignore +139 -0
- .gradio/certificate.pem +31 -0
- LICENSE +21 -0
- NOTICE +213 -0
- README.md +243 -7
- app.py +26 -0
- config/train_booking.yaml +22 -0
- config/train_cord.yaml +22 -0
- config/train_docvqa.yaml +23 -0
- config/train_invoices.yaml +22 -0
- config/train_rvlcdip.yaml +23 -0
- config/train_zhtrainticket.yaml +22 -0
- dataset/.gitkeep +1 -0
- donut/__init__.py +16 -0
- donut/_version.py +6 -0
- donut/model.py +613 -0
- donut/util.py +340 -0
- lightning_module.py +198 -0
- misc/overview.png +0 -0
- misc/sample_image_cord_test_receipt_00004.png +3 -0
- misc/sample_image_donut_document.png +0 -0
- misc/sample_synthdog.png +3 -0
- misc/screenshot_gradio_demos.png +3 -0
- result/.gitkeep +1 -0
- setup.py +77 -0
- synthdog/README.md +63 -0
- synthdog/config_en.yaml +119 -0
- synthdog/config_ja.yaml +119 -0
- synthdog/config_ko.yaml +119 -0
- synthdog/config_zh.yaml +119 -0
- synthdog/elements/__init__.py +12 -0
- synthdog/elements/background.py +24 -0
- synthdog/elements/content.py +118 -0
- synthdog/elements/document.py +65 -0
- synthdog/elements/paper.py +17 -0
- synthdog/elements/textbox.py +43 -0
- synthdog/layouts/__init__.py +9 -0
- synthdog/layouts/grid.py +68 -0
- synthdog/layouts/grid_stack.py +74 -0
- synthdog/resources/background/bedroom_83.jpg +0 -0
- synthdog/resources/background/bob+dylan_83.jpg +0 -0
- synthdog/resources/background/coffee_122.jpg +0 -0
- synthdog/resources/background/coffee_18.jpeg +3 -0
- synthdog/resources/background/crater_141.jpg +3 -0
- synthdog/resources/background/cream_124.jpg +3 -0
- synthdog/resources/background/eagle_110.jpg +0 -0
- synthdog/resources/background/farm_25.jpg +0 -0
- synthdog/resources/background/hiking_18.jpg +0 -0
- synthdog/resources/corpus/enwiki.txt +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,21 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
misc/sample_image_cord_test_receipt_00004.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
misc/sample_synthdog.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
misc/screenshot_gradio_demos.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
synthdog/resources/background/coffee_18.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
synthdog/resources/background/crater_141.jpg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
synthdog/resources/background/cream_124.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
synthdog/resources/font/ja/NotoSansJP-Regular.otf filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
synthdog/resources/font/ja/NotoSerifJP-Regular.otf filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
synthdog/resources/font/ko/NotoSansKR-Regular.otf filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
synthdog/resources/font/ko/NotoSerifKR-Regular.otf filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
synthdog/resources/font/zh/NotoSansSC-Regular.otf filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
synthdog/resources/font/zh/NotoSerifSC-Regular.otf filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
synthdog/resources/paper/paper_1.jpg filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
synthdog/resources/paper/paper_2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
synthdog/resources/paper/paper_3.jpg filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
synthdog/resources/paper/paper_4.jpg filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
synthdog/resources/paper/paper_5.jpg filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
synthdog/resources/paper/paper_6.jpg filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
core.*
|
| 2 |
+
*.bin
|
| 3 |
+
.nfs*
|
| 4 |
+
.vscode/*
|
| 5 |
+
dataset/*
|
| 6 |
+
result/*
|
| 7 |
+
misc/*
|
| 8 |
+
!misc/*.png
|
| 9 |
+
!dataset/.gitkeep
|
| 10 |
+
!result/.gitkeep
|
| 11 |
+
# Byte-compiled / optimized / DLL files
|
| 12 |
+
__pycache__/
|
| 13 |
+
*.py[cod]
|
| 14 |
+
*$py.class
|
| 15 |
+
|
| 16 |
+
# C extensions
|
| 17 |
+
*.so
|
| 18 |
+
|
| 19 |
+
# Distribution / packaging
|
| 20 |
+
.Python
|
| 21 |
+
build/
|
| 22 |
+
develop-eggs/
|
| 23 |
+
dist/
|
| 24 |
+
downloads/
|
| 25 |
+
eggs/
|
| 26 |
+
.eggs/
|
| 27 |
+
lib/
|
| 28 |
+
lib64/
|
| 29 |
+
parts/
|
| 30 |
+
sdist/
|
| 31 |
+
var/
|
| 32 |
+
wheels/
|
| 33 |
+
pip-wheel-metadata/
|
| 34 |
+
share/python-wheels/
|
| 35 |
+
*.egg-info/
|
| 36 |
+
.installed.cfg
|
| 37 |
+
*.egg
|
| 38 |
+
MANIFEST
|
| 39 |
+
|
| 40 |
+
# PyInstaller
|
| 41 |
+
# Usually these files are written by a python script from a template
|
| 42 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 43 |
+
*.manifest
|
| 44 |
+
*.spec
|
| 45 |
+
|
| 46 |
+
# Installer logs
|
| 47 |
+
pip-log.txt
|
| 48 |
+
pip-delete-this-directory.txt
|
| 49 |
+
|
| 50 |
+
# Unit test / coverage reports
|
| 51 |
+
htmlcov/
|
| 52 |
+
.tox/
|
| 53 |
+
.nox/
|
| 54 |
+
.coverage
|
| 55 |
+
.coverage.*
|
| 56 |
+
.cache
|
| 57 |
+
nosetests.xml
|
| 58 |
+
coverage.xml
|
| 59 |
+
*.cover
|
| 60 |
+
*.py,cover
|
| 61 |
+
.hypothesis/
|
| 62 |
+
.pytest_cache/
|
| 63 |
+
|
| 64 |
+
# Translations
|
| 65 |
+
*.mo
|
| 66 |
+
*.pot
|
| 67 |
+
|
| 68 |
+
# Django stuff:
|
| 69 |
+
*.log
|
| 70 |
+
local_settings.py
|
| 71 |
+
db.sqlite3
|
| 72 |
+
db.sqlite3-journal
|
| 73 |
+
|
| 74 |
+
# Flask stuff:
|
| 75 |
+
instance/
|
| 76 |
+
.webassets-cache
|
| 77 |
+
|
| 78 |
+
# Scrapy stuff:
|
| 79 |
+
.scrapy
|
| 80 |
+
|
| 81 |
+
# Sphinx documentation
|
| 82 |
+
docs/_build/
|
| 83 |
+
|
| 84 |
+
# PyBuilder
|
| 85 |
+
target/
|
| 86 |
+
|
| 87 |
+
# Jupyter Notebook
|
| 88 |
+
.ipynb_checkpoints
|
| 89 |
+
|
| 90 |
+
# IPython
|
| 91 |
+
profile_default/
|
| 92 |
+
ipython_config.py
|
| 93 |
+
|
| 94 |
+
# pyenv
|
| 95 |
+
.python-version
|
| 96 |
+
|
| 97 |
+
# pipenv
|
| 98 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 99 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 100 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 101 |
+
# install all needed dependencies.
|
| 102 |
+
#Pipfile.lock
|
| 103 |
+
|
| 104 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 105 |
+
__pypackages__/
|
| 106 |
+
|
| 107 |
+
# Celery stuff
|
| 108 |
+
celerybeat-schedule
|
| 109 |
+
celerybeat.pid
|
| 110 |
+
|
| 111 |
+
# SageMath parsed files
|
| 112 |
+
*.sage.py
|
| 113 |
+
|
| 114 |
+
# Environments
|
| 115 |
+
.env
|
| 116 |
+
.venv
|
| 117 |
+
env/
|
| 118 |
+
venv/
|
| 119 |
+
ENV/
|
| 120 |
+
env.bak/
|
| 121 |
+
venv.bak/
|
| 122 |
+
|
| 123 |
+
# Spyder project settings
|
| 124 |
+
.spyderproject
|
| 125 |
+
.spyproject
|
| 126 |
+
|
| 127 |
+
# Rope project settings
|
| 128 |
+
.ropeproject
|
| 129 |
+
|
| 130 |
+
# mkdocs documentation
|
| 131 |
+
/site
|
| 132 |
+
|
| 133 |
+
# mypy
|
| 134 |
+
.mypy_cache/
|
| 135 |
+
.dmypy.json
|
| 136 |
+
dmypy.json
|
| 137 |
+
|
| 138 |
+
# Pyre type checker
|
| 139 |
+
.pyre/
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT license
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in
|
| 13 |
+
all copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 21 |
+
THE SOFTWARE.
|
NOTICE
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Donut
|
| 2 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 3 |
+
|
| 4 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 5 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 6 |
+
in the Software without restriction, including without limitation the rights
|
| 7 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 8 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 9 |
+
furnished to do so, subject to the following conditions:
|
| 10 |
+
|
| 11 |
+
The above copyright notice and this permission notice shall be included in
|
| 12 |
+
all copies or substantial portions of the Software.
|
| 13 |
+
|
| 14 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 15 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 16 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 17 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 18 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 19 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 20 |
+
THE SOFTWARE.
|
| 21 |
+
|
| 22 |
+
--------------------------------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
This project contains subcomponents with separate copyright notices and license terms.
|
| 25 |
+
Your use of the source code for these subcomponents is subject to the terms and conditions of the following licenses.
|
| 26 |
+
|
| 27 |
+
=====
|
| 28 |
+
|
| 29 |
+
googlefonts/noto-fonts
|
| 30 |
+
https://fonts.google.com/specimen/Noto+Sans
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
Copyright 2018 The Noto Project Authors (github.com/googlei18n/noto-fonts)
|
| 34 |
+
|
| 35 |
+
This Font Software is licensed under the SIL Open Font License,
|
| 36 |
+
Version 1.1.
|
| 37 |
+
|
| 38 |
+
This license is copied below, and is also available with a FAQ at:
|
| 39 |
+
http://scripts.sil.org/OFL
|
| 40 |
+
|
| 41 |
+
-----------------------------------------------------------
|
| 42 |
+
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
|
| 43 |
+
-----------------------------------------------------------
|
| 44 |
+
|
| 45 |
+
PREAMBLE
|
| 46 |
+
The goals of the Open Font License (OFL) are to stimulate worldwide
|
| 47 |
+
development of collaborative font projects, to support the font
|
| 48 |
+
creation efforts of academic and linguistic communities, and to
|
| 49 |
+
provide a free and open framework in which fonts may be shared and
|
| 50 |
+
improved in partnership with others.
|
| 51 |
+
|
| 52 |
+
The OFL allows the licensed fonts to be used, studied, modified and
|
| 53 |
+
redistributed freely as long as they are not sold by themselves. The
|
| 54 |
+
fonts, including any derivative works, can be bundled, embedded,
|
| 55 |
+
redistributed and/or sold with any software provided that any reserved
|
| 56 |
+
names are not used by derivative works. The fonts and derivatives,
|
| 57 |
+
however, cannot be released under any other type of license. The
|
| 58 |
+
requirement for fonts to remain under this license does not apply to
|
| 59 |
+
any document created using the fonts or their derivatives.
|
| 60 |
+
|
| 61 |
+
DEFINITIONS
|
| 62 |
+
"Font Software" refers to the set of files released by the Copyright
|
| 63 |
+
Holder(s) under this license and clearly marked as such. This may
|
| 64 |
+
include source files, build scripts and documentation.
|
| 65 |
+
|
| 66 |
+
"Reserved Font Name" refers to any names specified as such after the
|
| 67 |
+
copyright statement(s).
|
| 68 |
+
|
| 69 |
+
"Original Version" refers to the collection of Font Software
|
| 70 |
+
components as distributed by the Copyright Holder(s).
|
| 71 |
+
|
| 72 |
+
"Modified Version" refers to any derivative made by adding to,
|
| 73 |
+
deleting, or substituting -- in part or in whole -- any of the
|
| 74 |
+
components of the Original Version, by changing formats or by porting
|
| 75 |
+
the Font Software to a new environment.
|
| 76 |
+
|
| 77 |
+
"Author" refers to any designer, engineer, programmer, technical
|
| 78 |
+
writer or other person who contributed to the Font Software.
|
| 79 |
+
|
| 80 |
+
PERMISSION & CONDITIONS
|
| 81 |
+
Permission is hereby granted, free of charge, to any person obtaining
|
| 82 |
+
a copy of the Font Software, to use, study, copy, merge, embed,
|
| 83 |
+
modify, redistribute, and sell modified and unmodified copies of the
|
| 84 |
+
Font Software, subject to the following conditions:
|
| 85 |
+
|
| 86 |
+
1) Neither the Font Software nor any of its individual components, in
|
| 87 |
+
Original or Modified Versions, may be sold by itself.
|
| 88 |
+
|
| 89 |
+
2) Original or Modified Versions of the Font Software may be bundled,
|
| 90 |
+
redistributed and/or sold with any software, provided that each copy
|
| 91 |
+
contains the above copyright notice and this license. These can be
|
| 92 |
+
included either as stand-alone text files, human-readable headers or
|
| 93 |
+
in the appropriate machine-readable metadata fields within text or
|
| 94 |
+
binary files as long as those fields can be easily viewed by the user.
|
| 95 |
+
|
| 96 |
+
3) No Modified Version of the Font Software may use the Reserved Font
|
| 97 |
+
Name(s) unless explicit written permission is granted by the
|
| 98 |
+
corresponding Copyright Holder. This restriction only applies to the
|
| 99 |
+
primary font name as presented to the users.
|
| 100 |
+
|
| 101 |
+
4) The name(s) of the Copyright Holder(s) or the Author(s) of the Font
|
| 102 |
+
Software shall not be used to promote, endorse or advertise any
|
| 103 |
+
Modified Version, except to acknowledge the contribution(s) of the
|
| 104 |
+
Copyright Holder(s) and the Author(s) or with their explicit written
|
| 105 |
+
permission.
|
| 106 |
+
|
| 107 |
+
5) The Font Software, modified or unmodified, in part or in whole,
|
| 108 |
+
must be distributed entirely under this license, and must not be
|
| 109 |
+
distributed under any other license. The requirement for fonts to
|
| 110 |
+
remain under this license does not apply to any document created using
|
| 111 |
+
the Font Software.
|
| 112 |
+
|
| 113 |
+
TERMINATION
|
| 114 |
+
This license becomes null and void if any of the above conditions are
|
| 115 |
+
not met.
|
| 116 |
+
|
| 117 |
+
DISCLAIMER
|
| 118 |
+
THE FONT SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
| 119 |
+
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTIES OF
|
| 120 |
+
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT
|
| 121 |
+
OF COPYRIGHT, PATENT, TRADEMARK, OR OTHER RIGHT. IN NO EVENT SHALL THE
|
| 122 |
+
COPYRIGHT HOLDER BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
|
| 123 |
+
INCLUDING ANY GENERAL, SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL
|
| 124 |
+
DAMAGES, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
| 125 |
+
FROM, OUT OF THE USE OR INABILITY TO USE THE FONT SOFTWARE OR FROM
|
| 126 |
+
OTHER DEALINGS IN THE FONT SOFTWARE.
|
| 127 |
+
|
| 128 |
+
=====
|
| 129 |
+
|
| 130 |
+
huggingface/transformers
|
| 131 |
+
https://github.com/huggingface/transformers
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
Copyright [yyyy] [name of copyright owner]
|
| 135 |
+
|
| 136 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 137 |
+
you may not use this file except in compliance with the License.
|
| 138 |
+
You may obtain a copy of the License at
|
| 139 |
+
|
| 140 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 141 |
+
|
| 142 |
+
Unless required by applicable law or agreed to in writing, software
|
| 143 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 144 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 145 |
+
See the License for the specific language governing permissions and limitations under the License.
|
| 146 |
+
|
| 147 |
+
=====
|
| 148 |
+
|
| 149 |
+
clovaai/synthtiger
|
| 150 |
+
https://github.com/clovaai/synthtiger
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
Copyright (c) 2021-present NAVER Corp.
|
| 154 |
+
|
| 155 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 156 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 157 |
+
in the Software without restriction, including without limitation the rights
|
| 158 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 159 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 160 |
+
furnished to do so, subject to the following conditions:
|
| 161 |
+
|
| 162 |
+
The above copyright notice and this permission notice shall be included in
|
| 163 |
+
all copies or substantial portions of the Software.
|
| 164 |
+
|
| 165 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 166 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 167 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 168 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 169 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 170 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 171 |
+
THE SOFTWARE.
|
| 172 |
+
|
| 173 |
+
=====
|
| 174 |
+
|
| 175 |
+
rwightman/pytorch-image-models
|
| 176 |
+
https://github.com/rwightman/pytorch-image-models
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
Copyright 2019 Ross Wightman
|
| 180 |
+
|
| 181 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 182 |
+
you may not use this file except in compliance with the License.
|
| 183 |
+
You may obtain a copy of the License at
|
| 184 |
+
|
| 185 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 186 |
+
|
| 187 |
+
Unless required by applicable law or agreed to in writing, software
|
| 188 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 189 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 190 |
+
See the License for the specific language governing permissions and
|
| 191 |
+
limitations under the License.
|
| 192 |
+
|
| 193 |
+
=====
|
| 194 |
+
|
| 195 |
+
ankush-me/SynthText
|
| 196 |
+
https://github.com/ankush-me/SynthText
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
Copyright 2017, Ankush Gupta.
|
| 200 |
+
|
| 201 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 202 |
+
you may not use this file except in compliance with the License.
|
| 203 |
+
You may obtain a copy of the License at
|
| 204 |
+
|
| 205 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 206 |
+
|
| 207 |
+
Unless required by applicable law or agreed to in writing, software
|
| 208 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 209 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 210 |
+
See the License for the specific language governing permissions and
|
| 211 |
+
limitations under the License.
|
| 212 |
+
|
| 213 |
+
=====
|
README.md
CHANGED
|
@@ -1,12 +1,248 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: gray
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 5.5.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: donut-booking-gradio
|
| 3 |
+
app_file: app.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.5.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
<div align="center">
|
| 8 |
+
|
| 9 |
+
# Donut 🍩 : Document Understanding Transformer
|
| 10 |
+
|
| 11 |
+
[](https://arxiv.org/abs/2111.15664)
|
| 12 |
+
[](#how-to-cite)
|
| 13 |
+
[](#demo)
|
| 14 |
+
[](#demo)
|
| 15 |
+
[](https://pypi.org/project/donut-python)
|
| 16 |
+
[](https://pepy.tech/project/donut-python)
|
| 17 |
+
|
| 18 |
+
Official Implementation of Donut and SynthDoG | [Paper](https://arxiv.org/abs/2111.15664) | [Slide](https://docs.google.com/presentation/d/1gv3A7t4xpwwNdpxV_yeHzEOMy-exJCAz6AlAI9O5fS8/edit?usp=sharing) | [Poster](https://docs.google.com/presentation/d/1m1f8BbAm5vxPcqynn_MbFfmQAlHQIR5G72-hQUFS2sk/edit?usp=sharing)
|
| 19 |
+
|
| 20 |
+
</div>
|
| 21 |
+
|
| 22 |
+
## Introduction
|
| 23 |
+
|
| 24 |
+
**Donut** 🍩, **Do**cume**n**t **u**nderstanding **t**ransformer, is a new method of document understanding that utilizes an OCR-free end-to-end Transformer model. Donut does not require off-the-shelf OCR engines/APIs, yet it shows state-of-the-art performances on various visual document understanding tasks, such as visual document classification or information extraction (a.k.a. document parsing).
|
| 25 |
+
In addition, we present **SynthDoG** 🐶, **Synth**etic **Do**cument **G**enerator, that helps the model pre-training to be flexible on various languages and domains.
|
| 26 |
+
|
| 27 |
+
Our academic paper, which describes our method in detail and provides full experimental results and analyses, can be found here:<br>
|
| 28 |
+
> [**OCR-free Document Understanding Transformer**](https://arxiv.org/abs/2111.15664).<br>
|
| 29 |
+
> [Geewook Kim](https://geewook.kim), [Teakgyu Hong](https://dblp.org/pid/183/0952.html), [Moonbin Yim](https://github.com/moonbings), [JeongYeon Nam](https://github.com/long8v), [Jinyoung Park](https://github.com/jyp1111), [Jinyeong Yim](https://jinyeong.github.io), [Wonseok Hwang](https://scholar.google.com/citations?user=M13_WdcAAAAJ), [Sangdoo Yun](https://sangdooyun.github.io), [Dongyoon Han](https://dongyoonhan.github.io), [Seunghyun Park](https://scholar.google.com/citations?user=iowjmTwAAAAJ). In ECCV 2022.
|
| 30 |
+
|
| 31 |
+
<img width="946" alt="image" src="misc/overview.png">
|
| 32 |
+
|
| 33 |
+
## Pre-trained Models and Web Demos
|
| 34 |
+
|
| 35 |
+
Gradio web demos are available! [](#demo) [](#demo)
|
| 36 |
+
|:--:|
|
| 37 |
+
||
|
| 38 |
+
- You can run the demo with `./app.py` file.
|
| 39 |
+
- Sample images are available at `./misc` and more receipt images are available at [CORD dataset link](https://huggingface.co/datasets/naver-clova-ix/cord-v2).
|
| 40 |
+
- Web demos are available from the links in the following table.
|
| 41 |
+
- Note: We have updated the Google Colab demo (as of June 15, 2023) to ensure its proper working.
|
| 42 |
+
|
| 43 |
+
|Task|Sec/Img|Score|Trained Model|<div id="demo">Demo</div>|
|
| 44 |
+
|---|---|---|---|---|
|
| 45 |
+
| [CORD](https://github.com/clovaai/cord) (Document Parsing) | 0.7 /<br> 0.7 /<br> 1.2 | 91.3 /<br> 91.1 /<br> 90.9 | [donut-base-finetuned-cord-v2](https://huggingface.co/naver-clova-ix/donut-base-finetuned-cord-v2/tree/official) (1280) /<br> [donut-base-finetuned-cord-v1](https://huggingface.co/naver-clova-ix/donut-base-finetuned-cord-v1/tree/official) (1280) /<br> [donut-base-finetuned-cord-v1-2560](https://huggingface.co/naver-clova-ix/donut-base-finetuned-cord-v1-2560/tree/official) | [gradio space web demo](https://huggingface.co/spaces/naver-clova-ix/donut-base-finetuned-cord-v2),<br>[google colab demo (updated at 23.06.15)](https://colab.research.google.com/drive/1NMSqoIZ_l39wyRD7yVjw2FIuU2aglzJi?usp=sharing) |
|
| 46 |
+
| [Train Ticket](https://github.com/beacandler/EATEN) (Document Parsing) | 0.6 | 98.7 | [donut-base-finetuned-zhtrainticket](https://huggingface.co/naver-clova-ix/donut-base-finetuned-zhtrainticket/tree/official) | [google colab demo (updated at 23.06.15)](https://colab.research.google.com/drive/1YJBjllahdqNktXaBlq5ugPh1BCm8OsxI?usp=sharing) |
|
| 47 |
+
| [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip) (Document Classification) | 0.75 | 95.3 | [donut-base-finetuned-rvlcdip](https://huggingface.co/naver-clova-ix/donut-base-finetuned-rvlcdip/tree/official) | [gradio space web demo](https://huggingface.co/spaces/nielsr/donut-rvlcdip),<br>[google colab demo (updated at 23.06.15)](https://colab.research.google.com/drive/1iWOZHvao1W5xva53upcri5V6oaWT-P0O?usp=sharing) |
|
| 48 |
+
| [DocVQA Task1](https://rrc.cvc.uab.es/?ch=17) (Document VQA) | 0.78 | 67.5 | [donut-base-finetuned-docvqa](https://huggingface.co/naver-clova-ix/donut-base-finetuned-docvqa/tree/official) | [gradio space web demo](https://huggingface.co/spaces/nielsr/donut-docvqa),<br>[google colab demo (updated at 23.06.15)](https://colab.research.google.com/drive/1oKieslZCulFiquequ62eMGc-ZWgay4X3?usp=sharing) |
|
| 49 |
+
|
| 50 |
+
The links to the pre-trained backbones are here:
|
| 51 |
+
- [`donut-base`](https://huggingface.co/naver-clova-ix/donut-base/tree/official): trained with 64 A100 GPUs (~2.5 days), number of layers (encoder: {2,2,14,2}, decoder: 4), input size 2560x1920, swin window size 10, IIT-CDIP (11M) and SynthDoG (English, Chinese, Japanese, Korean, 0.5M x 4).
|
| 52 |
+
- [`donut-proto`](https://huggingface.co/naver-clova-ix/donut-proto/tree/official): (preliminary model) trained with 8 V100 GPUs (~5 days), number of layers (encoder: {2,2,18,2}, decoder: 4), input size 2048x1536, swin window size 8, and SynthDoG (English, Japanese, Korean, 0.4M x 3).
|
| 53 |
+
|
| 54 |
+
Please see [our paper](#how-to-cite) for more details.
|
| 55 |
+
|
| 56 |
+
## SynthDoG datasets
|
| 57 |
+
|
| 58 |
+

|
| 59 |
+
|
| 60 |
+
The links to the SynthDoG-generated datasets are here:
|
| 61 |
+
|
| 62 |
+
- [`synthdog-en`](https://huggingface.co/datasets/naver-clova-ix/synthdog-en): English, 0.5M.
|
| 63 |
+
- [`synthdog-zh`](https://huggingface.co/datasets/naver-clova-ix/synthdog-zh): Chinese, 0.5M.
|
| 64 |
+
- [`synthdog-ja`](https://huggingface.co/datasets/naver-clova-ix/synthdog-ja): Japanese, 0.5M.
|
| 65 |
+
- [`synthdog-ko`](https://huggingface.co/datasets/naver-clova-ix/synthdog-ko): Korean, 0.5M.
|
| 66 |
+
|
| 67 |
+
To generate synthetic datasets with our SynthDoG, please see `./synthdog/README.md` and [our paper](#how-to-cite) for details.
|
| 68 |
+
|
| 69 |
+
## Updates
|
| 70 |
+
|
| 71 |
+
**_2023-06-15_** We have updated all Google Colab demos to ensure its proper working.<br>
|
| 72 |
+
**_2022-11-14_** New version 1.0.9 is released (`pip install donut-python --upgrade`). See [1.0.9 Release Notes](https://github.com/clovaai/donut/releases/tag/1.0.9).<br>
|
| 73 |
+
**_2022-08-12_** Donut 🍩 is also available at [huggingface/transformers 🤗](https://huggingface.co/docs/transformers/main/en/model_doc/donut) (contributed by [@NielsRogge](https://github.com/NielsRogge)). `donut-python` loads the pre-trained weights from the `official` branch of the model repositories. See [1.0.5 Release Notes](https://github.com/clovaai/donut/releases/tag/1.0.5).<br>
|
| 74 |
+
**_2022-08-05_** A well-executed hands-on tutorial on donut 🍩 is published at [Towards Data Science](https://towardsdatascience.com/ocr-free-document-understanding-with-donut-1acfbdf099be) (written by [@estaudere](https://github.com/estaudere)).<br>
|
| 75 |
+
**_2022-07-20_** First Commit, We release our code, model weights, synthetic data and generator.
|
| 76 |
+
|
| 77 |
+
## Software installation
|
| 78 |
+
|
| 79 |
+
[](https://pypi.org/project/donut-python)
|
| 80 |
+
[](https://pepy.tech/project/donut-python)
|
| 81 |
+
|
| 82 |
+
```bash
|
| 83 |
+
pip install donut-python
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
or clone this repository and install the dependencies:
|
| 87 |
+
```bash
|
| 88 |
+
git clone https://github.com/clovaai/donut.git
|
| 89 |
+
cd donut/
|
| 90 |
+
conda create -n donut_official python=3.7
|
| 91 |
+
conda activate donut_official
|
| 92 |
+
pip install .
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
We tested [donut-python](https://pypi.org/project/donut-python/1.0.1) == 1.0.1 with:
|
| 96 |
+
- [torch](https://github.com/pytorch/pytorch) == 1.11.0+cu113
|
| 97 |
+
- [torchvision](https://github.com/pytorch/vision) == 0.12.0+cu113
|
| 98 |
+
- [pytorch-lightning](https://github.com/Lightning-AI/lightning) == 1.6.4
|
| 99 |
+
- [transformers](https://github.com/huggingface/transformers) == 4.11.3
|
| 100 |
+
- [timm](https://github.com/rwightman/pytorch-image-models) == 0.5.4
|
| 101 |
+
|
| 102 |
+
**Note**: From several reported issues, we have noticed increased challenges in configuring the testing environment for `donut-python` due to recent updates in key dependency libraries. While we are actively working on a solution, we have updated the Google Colab demo (as of June 15, 2023) to ensure its proper working. For assistance, we encourage you to refer to the following demo links: [CORD Colab Demo](https://colab.research.google.com/drive/1NMSqoIZ_l39wyRD7yVjw2FIuU2aglzJi?usp=sharing), [Train Ticket Colab Demo](https://colab.research.google.com/drive/1YJBjllahdqNktXaBlq5ugPh1BCm8OsxI?usp=sharing), [RVL-CDIP Colab Demo](https://colab.research.google.com/drive/1iWOZHvao1W5xva53upcri5V6oaWT-P0O?usp=sharing), [DocVQA Colab Demo](https://colab.research.google.com/drive/1oKieslZCulFiquequ62eMGc-ZWgay4X3?usp=sharing).
|
| 103 |
+
|
| 104 |
+
## Getting Started
|
| 105 |
+
|
| 106 |
+
### Data
|
| 107 |
+
|
| 108 |
+
This repository assumes the following structure of dataset:
|
| 109 |
+
```bash
|
| 110 |
+
> tree dataset_name
|
| 111 |
+
dataset_name
|
| 112 |
+
├── test
|
| 113 |
+
│ ├── metadata.jsonl
|
| 114 |
+
│ ├── {image_path0}
|
| 115 |
+
│ ├── {image_path1}
|
| 116 |
+
│ .
|
| 117 |
+
│ .
|
| 118 |
+
├── train
|
| 119 |
+
│ ├── metadata.jsonl
|
| 120 |
+
│ ├── {image_path0}
|
| 121 |
+
│ ├── {image_path1}
|
| 122 |
+
│ .
|
| 123 |
+
│ .
|
| 124 |
+
└── validation
|
| 125 |
+
├── metadata.jsonl
|
| 126 |
+
├── {image_path0}
|
| 127 |
+
├── {image_path1}
|
| 128 |
+
.
|
| 129 |
+
.
|
| 130 |
+
|
| 131 |
+
> cat dataset_name/test/metadata.jsonl
|
| 132 |
+
{"file_name": {image_path0}, "ground_truth": "{\"gt_parse\": {ground_truth_parse}, ... {other_metadata_not_used} ... }"}
|
| 133 |
+
{"file_name": {image_path1}, "ground_truth": "{\"gt_parse\": {ground_truth_parse}, ... {other_metadata_not_used} ... }"}
|
| 134 |
+
.
|
| 135 |
+
.
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
- The structure of `metadata.jsonl` file is in [JSON Lines text format](https://jsonlines.org), i.e., `.jsonl`. Each line consists of
|
| 139 |
+
- `file_name` : relative path to the image file.
|
| 140 |
+
- `ground_truth` : string format (json dumped), the dictionary contains either `gt_parse` or `gt_parses`. Other fields (metadata) can be added to the dictionary but will not be used.
|
| 141 |
+
- `donut` interprets all tasks as a JSON prediction problem. As a result, all `donut` model training share a same pipeline. For training and inference, the only thing to do is preparing `gt_parse` or `gt_parses` for the task in format described below.
|
| 142 |
+
|
| 143 |
+
#### For Document Classification
|
| 144 |
+
The `gt_parse` follows the format of `{"class" : {class_name}}`, for example, `{"class" : "scientific_report"}` or `{"class" : "presentation"}`.
|
| 145 |
+
- Google colab demo is available [here](https://colab.research.google.com/drive/1xUDmLqlthx8A8rWKLMSLThZ7oeRJkDuU?usp=sharing).
|
| 146 |
+
- Gradio web demo is available [here](https://huggingface.co/spaces/nielsr/donut-rvlcdip).
|
| 147 |
+
|
| 148 |
+
#### For Document Information Extraction
|
| 149 |
+
The `gt_parse` is a JSON object that contains full information of the document image, for example, the JSON object for a receipt may look like `{"menu" : [{"nm": "ICE BLACKCOFFEE", "cnt": "2", ...}, ...], ...}`.
|
| 150 |
+
- More examples are available at [CORD dataset](https://huggingface.co/datasets/naver-clova-ix/cord-v2).
|
| 151 |
+
- Google colab demo is available [here](https://colab.research.google.com/drive/1o07hty-3OQTvGnc_7lgQFLvvKQuLjqiw?usp=sharing).
|
| 152 |
+
- Gradio web demo is available [here](https://huggingface.co/spaces/naver-clova-ix/donut-base-finetuned-cord-v2).
|
| 153 |
+
|
| 154 |
+
#### For Document Visual Question Answering
|
| 155 |
+
The `gt_parses` follows the format of `[{"question" : {question_sentence}, "answer" : {answer_candidate_1}}, {"question" : {question_sentence}, "answer" : {answer_candidate_2}}, ...]`, for example, `[{"question" : "what is the model name?", "answer" : "donut"}, {"question" : "what is the model name?", "answer" : "document understanding transformer"}]`.
|
| 156 |
+
- DocVQA Task1 has multiple answers, hence `gt_parses` should be a list of dictionary that contains a pair of question and answer.
|
| 157 |
+
- Google colab demo is available [here](https://colab.research.google.com/drive/1Z4WG8Wunj3HE0CERjt608ALSgSzRC9ig?usp=sharing).
|
| 158 |
+
- Gradio web demo is available [here](https://huggingface.co/spaces/nielsr/donut-docvqa).
|
| 159 |
+
|
| 160 |
+
#### For (Pseudo) Text Reading Task
|
| 161 |
+
The `gt_parse` looks like `{"text_sequence" : "word1 word2 word3 ... "}`
|
| 162 |
+
- This task is also a pre-training task of Donut model.
|
| 163 |
+
- You can use our **SynthDoG** 🐶 to generate synthetic images for the text reading task with proper `gt_parse`. See `./synthdog/README.md` for details.
|
| 164 |
+
|
| 165 |
+
### Training
|
| 166 |
+
|
| 167 |
+
This is the configuration of Donut model training on [CORD](https://github.com/clovaai/cord) dataset used in our experiment.
|
| 168 |
+
We ran this with a single NVIDIA A100 GPU.
|
| 169 |
+
|
| 170 |
+
```bash
|
| 171 |
+
python train.py --config config/train_cord.yaml \
|
| 172 |
+
--pretrained_model_name_or_path "naver-clova-ix/donut-base" \
|
| 173 |
+
--dataset_name_or_paths '["naver-clova-ix/cord-v2"]' \
|
| 174 |
+
--exp_version "test_experiment"
|
| 175 |
+
.
|
| 176 |
+
.
|
| 177 |
+
Prediction: <s_menu><s_nm>Lemon Tea (L)</s_nm><s_cnt>1</s_cnt><s_price>25.000</s_price></s_menu><s_total><s_total_price>25.000</s_total_price><s_cashprice>30.000</s_cashprice><s_changeprice>5.000</s_changeprice></s_total>
|
| 178 |
+
Answer: <s_menu><s_nm>Lemon Tea (L)</s_nm><s_cnt>1</s_cnt><s_price>25.000</s_price></s_menu><s_total><s_total_price>25.000</s_total_price><s_cashprice>30.000</s_cashprice><s_changeprice>5.000</s_changeprice></s_total>
|
| 179 |
+
Normed ED: 0.0
|
| 180 |
+
Prediction: <s_menu><s_nm>Hulk Topper Package</s_nm><s_cnt>1</s_cnt><s_price>100.000</s_price></s_menu><s_total><s_total_price>100.000</s_total_price><s_cashprice>100.000</s_cashprice><s_changeprice>0</s_changeprice></s_total>
|
| 181 |
+
Answer: <s_menu><s_nm>Hulk Topper Package</s_nm><s_cnt>1</s_cnt><s_price>100.000</s_price></s_menu><s_total><s_total_price>100.000</s_total_price><s_cashprice>100.000</s_cashprice><s_changeprice>0</s_changeprice></s_total>
|
| 182 |
+
Normed ED: 0.0
|
| 183 |
+
Prediction: <s_menu><s_nm>Giant Squid</s_nm><s_cnt>x 1</s_cnt><s_price>Rp. 39.000</s_price><s_sub><s_nm>C.Finishing - Cut</s_nm><s_price>Rp. 0</s_price><sep/><s_nm>B.Spicy Level - Extreme Hot Rp. 0</s_price></s_sub><sep/><s_nm>A.Flavour - Salt & Pepper</s_nm><s_price>Rp. 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price>Rp. 39.000</s_subtotal_price></s_sub_total><s_total><s_total_price>Rp. 39.000</s_total_price><s_cashprice>Rp. 50.000</s_cashprice><s_changeprice>Rp. 11.000</s_changeprice></s_total>
|
| 184 |
+
Answer: <s_menu><s_nm>Giant Squid</s_nm><s_cnt>x1</s_cnt><s_price>Rp. 39.000</s_price><s_sub><s_nm>C.Finishing - Cut</s_nm><s_price>Rp. 0</s_price><sep/><s_nm>B.Spicy Level - Extreme Hot</s_nm><s_price>Rp. 0</s_price><sep/><s_nm>A.Flavour- Salt & Pepper</s_nm><s_price>Rp. 0</s_price></s_sub></s_menu><s_sub_total><s_subtotal_price>Rp. 39.000</s_subtotal_price></s_sub_total><s_total><s_total_price>Rp. 39.000</s_total_price><s_cashprice>Rp. 50.000</s_cashprice><s_changeprice>Rp. 11.000</s_changeprice></s_total>
|
| 185 |
+
Normed ED: 0.039603960396039604
|
| 186 |
+
Epoch 29: 100%|█████████████| 200/200 [01:49<00:00, 1.82it/s, loss=0.00327, exp_name=train_cord, exp_version=test_experiment]
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
Some important arguments:
|
| 190 |
+
|
| 191 |
+
- `--config` : config file path for model training.
|
| 192 |
+
- `--pretrained_model_name_or_path` : string format, model name in Hugging Face modelhub or local path.
|
| 193 |
+
- `--dataset_name_or_paths` : string format (json dumped), list of dataset names in Hugging Face datasets or local paths.
|
| 194 |
+
- `--result_path` : file path to save model outputs/artifacts.
|
| 195 |
+
- `--exp_version` : used for experiment versioning. The output files are saved at `{result_path}/{exp_version}/*`
|
| 196 |
+
|
| 197 |
+
### Test
|
| 198 |
+
|
| 199 |
+
With the trained model, test images and ground truth parses, you can get inference results and accuracy scores.
|
| 200 |
+
|
| 201 |
+
```bash
|
| 202 |
+
python test.py --dataset_name_or_path naver-clova-ix/cord-v2 --pretrained_model_name_or_path ./result/train_cord/test_experiment --save_path ./result/output.json
|
| 203 |
+
100%|█████████████| 100/100 [00:35<00:00, 2.80it/s]
|
| 204 |
+
Total number of samples: 100, Tree Edit Distance (TED) based accuracy score: 0.9129639764131697, F1 accuracy score: 0.8406020841373987
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
Some important arguments:
|
| 208 |
+
|
| 209 |
+
- `--dataset_name_or_path` : string format, the target dataset name in Hugging Face datasets or local path.
|
| 210 |
+
- `--pretrained_model_name_or_path` : string format, the model name in Hugging Face modelhub or local path.
|
| 211 |
+
- `--save_path`: file path to save predictions and scores.
|
| 212 |
+
|
| 213 |
+
## How to Cite
|
| 214 |
+
If you find this work useful to you, please cite:
|
| 215 |
+
```bibtex
|
| 216 |
+
@inproceedings{kim2022donut,
|
| 217 |
+
title = {OCR-Free Document Understanding Transformer},
|
| 218 |
+
author = {Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, JeongYeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun},
|
| 219 |
+
booktitle = {European Conference on Computer Vision (ECCV)},
|
| 220 |
+
year = {2022}
|
| 221 |
+
}
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
## License
|
| 225 |
+
|
| 226 |
+
```
|
| 227 |
+
MIT license
|
| 228 |
+
|
| 229 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 230 |
+
|
| 231 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 232 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 233 |
+
in the Software without restriction, including without limitation the rights
|
| 234 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 235 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 236 |
+
furnished to do so, subject to the following conditions:
|
| 237 |
+
|
| 238 |
+
The above copyright notice and this permission notice shall be included in
|
| 239 |
+
all copies or substantial portions of the Software.
|
| 240 |
|
| 241 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 242 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 243 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 244 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 245 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 246 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 247 |
+
THE SOFTWARE.
|
| 248 |
+
```
|
app.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import argparse
|
| 3 |
+
import torch
|
| 4 |
+
from PIL import Image
|
| 5 |
+
from donut import DonutModel
|
| 6 |
+
def demo_process(input_img):
|
| 7 |
+
global model, task_prompt, task_name
|
| 8 |
+
input_img = Image.fromarray(input_img)
|
| 9 |
+
output = model.inference(image=input_img, prompt=task_prompt)["predictions"][0]
|
| 10 |
+
return output
|
| 11 |
+
parser = argparse.ArgumentParser()
|
| 12 |
+
parser.add_argument("--task", type=str, default="Booking")
|
| 13 |
+
parser.add_argument("--pretrained_path", type=str, default="result/train_booking/20241112_150925")
|
| 14 |
+
args, left_argv = parser.parse_known_args()
|
| 15 |
+
task_name = args.task
|
| 16 |
+
task_prompt = f"<s_{task_name}>"
|
| 17 |
+
model = DonutModel.from_pretrained("./result/train_booking/20241112_150925")
|
| 18 |
+
if torch.cuda.is_available():
|
| 19 |
+
model.half()
|
| 20 |
+
device = torch.device("cuda")
|
| 21 |
+
model.to(device)
|
| 22 |
+
else:
|
| 23 |
+
model.encoder.to(torch.bfloat16)
|
| 24 |
+
model.eval()
|
| 25 |
+
demo = gr.Interface(fn=demo_process,inputs="image",outputs="json", title=f"Donut 🍩 demonstration for `{task_name}` task",)
|
| 26 |
+
demo.launch(debug=True)
|
config/train_booking.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: null # only used for resume_from_checkpoint option in PL
|
| 2 |
+
result_path: "./result"
|
| 3 |
+
pretrained_model_name_or_path: "naver-clova-ix/donut-base" # loading a pre-trained model (from moldehub or path)
|
| 4 |
+
dataset_name_or_paths: ["./dataset/Booking"] # loading datasets (from moldehub or path)
|
| 5 |
+
sort_json_key: False # cord dataset is preprocessed, and publicly available at https://huggingface.co/datasets/naver-clova-ix/cord-v2
|
| 6 |
+
train_batch_sizes: [2]
|
| 7 |
+
val_batch_sizes: [1]
|
| 8 |
+
input_size: [1280, 960] # when the input resolution differs from the pre-training setting, some weights will be newly initialized (but the model training would be okay)
|
| 9 |
+
max_length: 768
|
| 10 |
+
align_long_axis: False
|
| 11 |
+
num_nodes: 1
|
| 12 |
+
seed: 2022
|
| 13 |
+
lr: 3e-5
|
| 14 |
+
warmup_steps: 400 # 800/2*10/10, 10%
|
| 15 |
+
num_training_samples_per_epoch: 800
|
| 16 |
+
max_epochs: 10
|
| 17 |
+
max_steps: -1
|
| 18 |
+
num_workers: 8
|
| 19 |
+
val_check_interval: 1.0
|
| 20 |
+
check_val_every_n_epoch: 3
|
| 21 |
+
gradient_clip_val: 1.0
|
| 22 |
+
verbose: True
|
config/train_cord.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: null # only used for resume_from_checkpoint option in PL
|
| 2 |
+
result_path: "./result"
|
| 3 |
+
pretrained_model_name_or_path: "naver-clova-ix/donut-base" # loading a pre-trained model (from moldehub or path)
|
| 4 |
+
dataset_name_or_paths: ["naver-clova-ix/cord-v2"] # loading datasets (from moldehub or path)
|
| 5 |
+
sort_json_key: False # cord dataset is preprocessed, and publicly available at https://huggingface.co/datasets/naver-clova-ix/cord-v2
|
| 6 |
+
train_batch_sizes: [8]
|
| 7 |
+
val_batch_sizes: [1]
|
| 8 |
+
input_size: [1280, 960] # when the input resolution differs from the pre-training setting, some weights will be newly initialized (but the model training would be okay)
|
| 9 |
+
max_length: 768
|
| 10 |
+
align_long_axis: False
|
| 11 |
+
num_nodes: 1
|
| 12 |
+
seed: 2022
|
| 13 |
+
lr: 3e-5
|
| 14 |
+
warmup_steps: 300 # 800/8*30/10, 10%
|
| 15 |
+
num_training_samples_per_epoch: 800
|
| 16 |
+
max_epochs: 30
|
| 17 |
+
max_steps: -1
|
| 18 |
+
num_workers: 8
|
| 19 |
+
val_check_interval: 1.0
|
| 20 |
+
check_val_every_n_epoch: 3
|
| 21 |
+
gradient_clip_val: 1.0
|
| 22 |
+
verbose: True
|
config/train_docvqa.yaml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: null
|
| 2 |
+
result_path: "./result"
|
| 3 |
+
pretrained_model_name_or_path: "naver-clova-ix/donut-base"
|
| 4 |
+
dataset_name_or_paths: ["./dataset/docvqa"] # should be prepared from https://rrc.cvc.uab.es/?ch=17
|
| 5 |
+
sort_json_key: True
|
| 6 |
+
train_batch_sizes: [2]
|
| 7 |
+
val_batch_sizes: [4]
|
| 8 |
+
input_size: [2560, 1920]
|
| 9 |
+
max_length: 128
|
| 10 |
+
align_long_axis: False
|
| 11 |
+
# num_nodes: 8 # memo: donut-base-finetuned-docvqa was trained with 8 nodes
|
| 12 |
+
num_nodes: 1
|
| 13 |
+
seed: 2022
|
| 14 |
+
lr: 3e-5
|
| 15 |
+
warmup_steps: 10000
|
| 16 |
+
num_training_samples_per_epoch: 39463
|
| 17 |
+
max_epochs: 300
|
| 18 |
+
max_steps: -1
|
| 19 |
+
num_workers: 8
|
| 20 |
+
val_check_interval: 1.0
|
| 21 |
+
check_val_every_n_epoch: 1
|
| 22 |
+
gradient_clip_val: 0.25
|
| 23 |
+
verbose: True
|
config/train_invoices.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: null # only used for resume_from_checkpoint option in PL
|
| 2 |
+
result_path: "./result"
|
| 3 |
+
pretrained_model_name_or_path: "naver-clova-ix/donut-base" # loading a pre-trained model (from moldehub or path)
|
| 4 |
+
dataset_name_or_paths: ["naver-clova-ix/cord-v2"] # loading datasets (from moldehub or path)
|
| 5 |
+
sort_json_key: False # cord dataset is preprocessed, and publicly available at https://huggingface.co/datasets/naver-clova-ix/cord-v2
|
| 6 |
+
train_batch_sizes: [8]
|
| 7 |
+
val_batch_sizes: [1]
|
| 8 |
+
input_size: [1280, 960] # when the input resolution differs from the pre-training setting, some weights will be newly initialized (but the model training would be okay)
|
| 9 |
+
max_length: 768
|
| 10 |
+
align_long_axis: False
|
| 11 |
+
num_nodes: 1
|
| 12 |
+
seed: 2022
|
| 13 |
+
lr: 3e-5
|
| 14 |
+
warmup_steps: 300 # 800/8*30/10, 10%
|
| 15 |
+
num_training_samples_per_epoch: 800
|
| 16 |
+
max_epochs: 30
|
| 17 |
+
max_steps: -1
|
| 18 |
+
num_workers: 8
|
| 19 |
+
val_check_interval: 1.0
|
| 20 |
+
check_val_every_n_epoch: 3
|
| 21 |
+
gradient_clip_val: 1.0
|
| 22 |
+
verbose: True
|
config/train_rvlcdip.yaml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: null
|
| 2 |
+
result_path: "./result"
|
| 3 |
+
pretrained_model_name_or_path: "naver-clova-ix/donut-base"
|
| 4 |
+
dataset_name_or_paths: ["./dataset/rvlcdip"] # should be prepared from https://www.cs.cmu.edu/~aharley/rvl-cdip/
|
| 5 |
+
sort_json_key: True
|
| 6 |
+
train_batch_sizes: [2]
|
| 7 |
+
val_batch_sizes: [4]
|
| 8 |
+
input_size: [2560, 1920]
|
| 9 |
+
max_length: 8
|
| 10 |
+
align_long_axis: False
|
| 11 |
+
# num_nodes: 8 # memo: donut-base-finetuned-rvlcdip was trained with 8 nodes
|
| 12 |
+
num_nodes: 1
|
| 13 |
+
seed: 2022
|
| 14 |
+
lr: 2e-5
|
| 15 |
+
warmup_steps: 10000
|
| 16 |
+
num_training_samples_per_epoch: 320000
|
| 17 |
+
max_epochs: 100
|
| 18 |
+
max_steps: -1
|
| 19 |
+
num_workers: 8
|
| 20 |
+
val_check_interval: 1.0
|
| 21 |
+
check_val_every_n_epoch: 1
|
| 22 |
+
gradient_clip_val: 1.0
|
| 23 |
+
verbose: True
|
config/train_zhtrainticket.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
resume_from_checkpoint_path: null
|
| 2 |
+
result_path: "./result"
|
| 3 |
+
pretrained_model_name_or_path: "naver-clova-ix/donut-base"
|
| 4 |
+
dataset_name_or_paths: ["./dataset/zhtrainticket"] # should be prepared from https://github.com/beacandler/EATEN
|
| 5 |
+
sort_json_key: True
|
| 6 |
+
train_batch_sizes: [8]
|
| 7 |
+
val_batch_sizes: [1]
|
| 8 |
+
input_size: [960, 1280]
|
| 9 |
+
max_length: 256
|
| 10 |
+
align_long_axis: False
|
| 11 |
+
num_nodes: 1
|
| 12 |
+
seed: 2022
|
| 13 |
+
lr: 3e-5
|
| 14 |
+
warmup_steps: 300
|
| 15 |
+
num_training_samples_per_epoch: 1368
|
| 16 |
+
max_epochs: 10
|
| 17 |
+
max_steps: -1
|
| 18 |
+
num_workers: 8
|
| 19 |
+
val_check_interval: 1.0
|
| 20 |
+
check_val_every_n_epoch: 1
|
| 21 |
+
gradient_clip_val: 1.0
|
| 22 |
+
verbose: True
|
dataset/.gitkeep
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
donut/__init__.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
from .model import DonutConfig, DonutModel
|
| 7 |
+
from .util import DonutDataset, JSONParseEvaluator, load_json, save_json
|
| 8 |
+
|
| 9 |
+
__all__ = [
|
| 10 |
+
"DonutConfig",
|
| 11 |
+
"DonutModel",
|
| 12 |
+
"DonutDataset",
|
| 13 |
+
"JSONParseEvaluator",
|
| 14 |
+
"load_json",
|
| 15 |
+
"save_json",
|
| 16 |
+
]
|
donut/_version.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
__version__ = "1.0.9"
|
donut/model.py
ADDED
|
@@ -0,0 +1,613 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import math
|
| 7 |
+
import os
|
| 8 |
+
import re
|
| 9 |
+
from typing import Any, List, Optional, Union
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import PIL
|
| 13 |
+
import timm
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
from PIL import ImageOps
|
| 18 |
+
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
|
| 19 |
+
from timm.models.swin_transformer import SwinTransformer
|
| 20 |
+
from torchvision import transforms
|
| 21 |
+
from torchvision.transforms.functional import resize, rotate
|
| 22 |
+
from transformers import MBartConfig, MBartForCausalLM, XLMRobertaTokenizer
|
| 23 |
+
from transformers.file_utils import ModelOutput
|
| 24 |
+
from transformers.modeling_utils import PretrainedConfig, PreTrainedModel
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class SwinEncoder(nn.Module):
|
| 28 |
+
r"""
|
| 29 |
+
Donut encoder based on SwinTransformer
|
| 30 |
+
Set the initial weights and configuration with a pretrained SwinTransformer and then
|
| 31 |
+
modify the detailed configurations as a Donut Encoder
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
input_size: Input image size (width, height)
|
| 35 |
+
align_long_axis: Whether to rotate image if height is greater than width
|
| 36 |
+
window_size: Window size(=patch size) of SwinTransformer
|
| 37 |
+
encoder_layer: Number of layers of SwinTransformer encoder
|
| 38 |
+
name_or_path: Name of a pretrained model name either registered in huggingface.co. or saved in local.
|
| 39 |
+
otherwise, `swin_base_patch4_window12_384` will be set (using `timm`).
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
def __init__(
|
| 43 |
+
self,
|
| 44 |
+
input_size: List[int],
|
| 45 |
+
align_long_axis: bool,
|
| 46 |
+
window_size: int,
|
| 47 |
+
encoder_layer: List[int],
|
| 48 |
+
name_or_path: Union[str, bytes, os.PathLike] = None,
|
| 49 |
+
):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.input_size = input_size
|
| 52 |
+
self.align_long_axis = align_long_axis
|
| 53 |
+
self.window_size = window_size
|
| 54 |
+
self.encoder_layer = encoder_layer
|
| 55 |
+
|
| 56 |
+
self.to_tensor = transforms.Compose(
|
| 57 |
+
[
|
| 58 |
+
transforms.ToTensor(),
|
| 59 |
+
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
|
| 60 |
+
]
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
self.model = SwinTransformer(
|
| 64 |
+
img_size=self.input_size,
|
| 65 |
+
depths=self.encoder_layer,
|
| 66 |
+
window_size=self.window_size,
|
| 67 |
+
patch_size=4,
|
| 68 |
+
embed_dim=128,
|
| 69 |
+
num_heads=[4, 8, 16, 32],
|
| 70 |
+
num_classes=0,
|
| 71 |
+
)
|
| 72 |
+
self.model.norm = None
|
| 73 |
+
|
| 74 |
+
# weight init with swin
|
| 75 |
+
if not name_or_path:
|
| 76 |
+
swin_state_dict = timm.create_model("swin_base_patch4_window12_384", pretrained=True).state_dict()
|
| 77 |
+
new_swin_state_dict = self.model.state_dict()
|
| 78 |
+
for x in new_swin_state_dict:
|
| 79 |
+
if x.endswith("relative_position_index") or x.endswith("attn_mask"):
|
| 80 |
+
pass
|
| 81 |
+
elif (
|
| 82 |
+
x.endswith("relative_position_bias_table")
|
| 83 |
+
and self.model.layers[0].blocks[0].attn.window_size[0] != 12
|
| 84 |
+
):
|
| 85 |
+
pos_bias = swin_state_dict[x].unsqueeze(0)[0]
|
| 86 |
+
old_len = int(math.sqrt(len(pos_bias)))
|
| 87 |
+
new_len = int(2 * window_size - 1)
|
| 88 |
+
pos_bias = pos_bias.reshape(1, old_len, old_len, -1).permute(0, 3, 1, 2)
|
| 89 |
+
pos_bias = F.interpolate(pos_bias, size=(new_len, new_len), mode="bicubic", align_corners=False)
|
| 90 |
+
new_swin_state_dict[x] = pos_bias.permute(0, 2, 3, 1).reshape(1, new_len ** 2, -1).squeeze(0)
|
| 91 |
+
else:
|
| 92 |
+
new_swin_state_dict[x] = swin_state_dict[x]
|
| 93 |
+
self.model.load_state_dict(new_swin_state_dict)
|
| 94 |
+
|
| 95 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 96 |
+
"""
|
| 97 |
+
Args:
|
| 98 |
+
x: (batch_size, num_channels, height, width)
|
| 99 |
+
"""
|
| 100 |
+
x = self.model.patch_embed(x)
|
| 101 |
+
x = self.model.pos_drop(x)
|
| 102 |
+
x = self.model.layers(x)
|
| 103 |
+
return x
|
| 104 |
+
|
| 105 |
+
def prepare_input(self, img: PIL.Image.Image, random_padding: bool = False) -> torch.Tensor:
|
| 106 |
+
"""
|
| 107 |
+
Convert PIL Image to tensor according to specified input_size after following steps below:
|
| 108 |
+
- resize
|
| 109 |
+
- rotate (if align_long_axis is True and image is not aligned longer axis with canvas)
|
| 110 |
+
- pad
|
| 111 |
+
"""
|
| 112 |
+
img = img.convert("RGB")
|
| 113 |
+
if self.align_long_axis and (
|
| 114 |
+
(self.input_size[0] > self.input_size[1] and img.width > img.height)
|
| 115 |
+
or (self.input_size[0] < self.input_size[1] and img.width < img.height)
|
| 116 |
+
):
|
| 117 |
+
img = rotate(img, angle=-90, expand=True)
|
| 118 |
+
img = resize(img, min(self.input_size))
|
| 119 |
+
img.thumbnail((self.input_size[1], self.input_size[0]))
|
| 120 |
+
delta_width = self.input_size[1] - img.width
|
| 121 |
+
delta_height = self.input_size[0] - img.height
|
| 122 |
+
if random_padding:
|
| 123 |
+
pad_width = np.random.randint(low=0, high=delta_width + 1)
|
| 124 |
+
pad_height = np.random.randint(low=0, high=delta_height + 1)
|
| 125 |
+
else:
|
| 126 |
+
pad_width = delta_width // 2
|
| 127 |
+
pad_height = delta_height // 2
|
| 128 |
+
padding = (
|
| 129 |
+
pad_width,
|
| 130 |
+
pad_height,
|
| 131 |
+
delta_width - pad_width,
|
| 132 |
+
delta_height - pad_height,
|
| 133 |
+
)
|
| 134 |
+
return self.to_tensor(ImageOps.expand(img, padding))
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class BARTDecoder(nn.Module):
|
| 138 |
+
"""
|
| 139 |
+
Donut Decoder based on Multilingual BART
|
| 140 |
+
Set the initial weights and configuration with a pretrained multilingual BART model,
|
| 141 |
+
and modify the detailed configurations as a Donut decoder
|
| 142 |
+
|
| 143 |
+
Args:
|
| 144 |
+
decoder_layer:
|
| 145 |
+
Number of layers of BARTDecoder
|
| 146 |
+
max_position_embeddings:
|
| 147 |
+
The maximum sequence length to be trained
|
| 148 |
+
name_or_path:
|
| 149 |
+
Name of a pretrained model name either registered in huggingface.co. or saved in local,
|
| 150 |
+
otherwise, `hyunwoongko/asian-bart-ecjk` will be set (using `transformers`)
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
def __init__(
|
| 154 |
+
self, decoder_layer: int, max_position_embeddings: int, name_or_path: Union[str, bytes, os.PathLike] = None
|
| 155 |
+
):
|
| 156 |
+
super().__init__()
|
| 157 |
+
self.decoder_layer = decoder_layer
|
| 158 |
+
self.max_position_embeddings = max_position_embeddings
|
| 159 |
+
|
| 160 |
+
self.tokenizer = XLMRobertaTokenizer.from_pretrained(
|
| 161 |
+
"hyunwoongko/asian-bart-ecjk" if not name_or_path else name_or_path
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
self.model = MBartForCausalLM(
|
| 165 |
+
config=MBartConfig(
|
| 166 |
+
is_decoder=True,
|
| 167 |
+
is_encoder_decoder=False,
|
| 168 |
+
add_cross_attention=True,
|
| 169 |
+
decoder_layers=self.decoder_layer,
|
| 170 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 171 |
+
vocab_size=len(self.tokenizer),
|
| 172 |
+
scale_embedding=True,
|
| 173 |
+
add_final_layer_norm=True,
|
| 174 |
+
)
|
| 175 |
+
)
|
| 176 |
+
self.model.forward = self.forward # to get cross attentions and utilize `generate` function
|
| 177 |
+
|
| 178 |
+
self.model.config.is_encoder_decoder = True # to get cross-attention
|
| 179 |
+
self.add_special_tokens(["<sep/>"]) # <sep/> is used for representing a list in a JSON
|
| 180 |
+
self.model.model.decoder.embed_tokens.padding_idx = self.tokenizer.pad_token_id
|
| 181 |
+
self.model.prepare_inputs_for_generation = self.prepare_inputs_for_inference
|
| 182 |
+
|
| 183 |
+
# weight init with asian-bart
|
| 184 |
+
if not name_or_path:
|
| 185 |
+
bart_state_dict = MBartForCausalLM.from_pretrained("hyunwoongko/asian-bart-ecjk").state_dict()
|
| 186 |
+
new_bart_state_dict = self.model.state_dict()
|
| 187 |
+
for x in new_bart_state_dict:
|
| 188 |
+
if x.endswith("embed_positions.weight") and self.max_position_embeddings != 1024:
|
| 189 |
+
new_bart_state_dict[x] = torch.nn.Parameter(
|
| 190 |
+
self.resize_bart_abs_pos_emb(
|
| 191 |
+
bart_state_dict[x],
|
| 192 |
+
self.max_position_embeddings
|
| 193 |
+
+ 2, # https://github.com/huggingface/transformers/blob/v4.11.3/src/transformers/models/mbart/modeling_mbart.py#L118-L119
|
| 194 |
+
)
|
| 195 |
+
)
|
| 196 |
+
elif x.endswith("embed_tokens.weight") or x.endswith("lm_head.weight"):
|
| 197 |
+
new_bart_state_dict[x] = bart_state_dict[x][: len(self.tokenizer), :]
|
| 198 |
+
else:
|
| 199 |
+
new_bart_state_dict[x] = bart_state_dict[x]
|
| 200 |
+
self.model.load_state_dict(new_bart_state_dict)
|
| 201 |
+
|
| 202 |
+
def add_special_tokens(self, list_of_tokens: List[str]):
|
| 203 |
+
"""
|
| 204 |
+
Add special tokens to tokenizer and resize the token embeddings
|
| 205 |
+
"""
|
| 206 |
+
newly_added_num = self.tokenizer.add_special_tokens({"additional_special_tokens": sorted(set(list_of_tokens))})
|
| 207 |
+
if newly_added_num > 0:
|
| 208 |
+
self.model.resize_token_embeddings(len(self.tokenizer))
|
| 209 |
+
|
| 210 |
+
def prepare_inputs_for_inference(self, input_ids: torch.Tensor, encoder_outputs: torch.Tensor, past_key_values=None, past=None, use_cache: bool = None, attention_mask: torch.Tensor = None):
|
| 211 |
+
"""
|
| 212 |
+
Args:
|
| 213 |
+
input_ids: (batch_size, sequence_lenth)
|
| 214 |
+
Returns:
|
| 215 |
+
input_ids: (batch_size, sequence_length)
|
| 216 |
+
attention_mask: (batch_size, sequence_length)
|
| 217 |
+
encoder_hidden_states: (batch_size, sequence_length, embedding_dim)
|
| 218 |
+
"""
|
| 219 |
+
# for compatibility with transformers==4.11.x
|
| 220 |
+
if past is not None:
|
| 221 |
+
past_key_values = past
|
| 222 |
+
attention_mask = input_ids.ne(self.tokenizer.pad_token_id).long()
|
| 223 |
+
if past_key_values is not None:
|
| 224 |
+
input_ids = input_ids[:, -1:]
|
| 225 |
+
output = {
|
| 226 |
+
"input_ids": input_ids,
|
| 227 |
+
"attention_mask": attention_mask,
|
| 228 |
+
"past_key_values": past_key_values,
|
| 229 |
+
"use_cache": use_cache,
|
| 230 |
+
"encoder_hidden_states": encoder_outputs.last_hidden_state,
|
| 231 |
+
}
|
| 232 |
+
return output
|
| 233 |
+
|
| 234 |
+
def forward(
|
| 235 |
+
self,
|
| 236 |
+
input_ids,
|
| 237 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 238 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 239 |
+
past_key_values: Optional[torch.Tensor] = None,
|
| 240 |
+
labels: Optional[torch.Tensor] = None,
|
| 241 |
+
use_cache: bool = None,
|
| 242 |
+
output_attentions: Optional[torch.Tensor] = None,
|
| 243 |
+
output_hidden_states: Optional[torch.Tensor] = None,
|
| 244 |
+
return_dict: bool = None,
|
| 245 |
+
):
|
| 246 |
+
"""
|
| 247 |
+
A forward fucntion to get cross attentions and utilize `generate` function
|
| 248 |
+
|
| 249 |
+
Source:
|
| 250 |
+
https://github.com/huggingface/transformers/blob/v4.11.3/src/transformers/models/mbart/modeling_mbart.py#L1669-L1810
|
| 251 |
+
|
| 252 |
+
Args:
|
| 253 |
+
input_ids: (batch_size, sequence_length)
|
| 254 |
+
attention_mask: (batch_size, sequence_length)
|
| 255 |
+
encoder_hidden_states: (batch_size, sequence_length, hidden_size)
|
| 256 |
+
|
| 257 |
+
Returns:
|
| 258 |
+
loss: (1, )
|
| 259 |
+
logits: (batch_size, sequence_length, hidden_dim)
|
| 260 |
+
hidden_states: (batch_size, sequence_length, hidden_size)
|
| 261 |
+
decoder_attentions: (batch_size, num_heads, sequence_length, sequence_length)
|
| 262 |
+
cross_attentions: (batch_size, num_heads, sequence_length, sequence_length)
|
| 263 |
+
"""
|
| 264 |
+
output_attentions = output_attentions if output_attentions is not None else self.model.config.output_attentions
|
| 265 |
+
output_hidden_states = (
|
| 266 |
+
output_hidden_states if output_hidden_states is not None else self.model.config.output_hidden_states
|
| 267 |
+
)
|
| 268 |
+
return_dict = return_dict if return_dict is not None else self.model.config.use_return_dict
|
| 269 |
+
outputs = self.model.model.decoder(
|
| 270 |
+
input_ids=input_ids,
|
| 271 |
+
attention_mask=attention_mask,
|
| 272 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 273 |
+
past_key_values=past_key_values,
|
| 274 |
+
use_cache=use_cache,
|
| 275 |
+
output_attentions=output_attentions,
|
| 276 |
+
output_hidden_states=output_hidden_states,
|
| 277 |
+
return_dict=return_dict,
|
| 278 |
+
)
|
| 279 |
+
|
| 280 |
+
logits = self.model.lm_head(outputs[0])
|
| 281 |
+
|
| 282 |
+
loss = None
|
| 283 |
+
if labels is not None:
|
| 284 |
+
loss_fct = nn.CrossEntropyLoss(ignore_index=-100)
|
| 285 |
+
loss = loss_fct(logits.view(-1, self.model.config.vocab_size), labels.view(-1))
|
| 286 |
+
|
| 287 |
+
if not return_dict:
|
| 288 |
+
output = (logits,) + outputs[1:]
|
| 289 |
+
return (loss,) + output if loss is not None else output
|
| 290 |
+
|
| 291 |
+
return ModelOutput(
|
| 292 |
+
loss=loss,
|
| 293 |
+
logits=logits,
|
| 294 |
+
past_key_values=outputs.past_key_values,
|
| 295 |
+
hidden_states=outputs.hidden_states,
|
| 296 |
+
decoder_attentions=outputs.attentions,
|
| 297 |
+
cross_attentions=outputs.cross_attentions,
|
| 298 |
+
)
|
| 299 |
+
|
| 300 |
+
@staticmethod
|
| 301 |
+
def resize_bart_abs_pos_emb(weight: torch.Tensor, max_length: int) -> torch.Tensor:
|
| 302 |
+
"""
|
| 303 |
+
Resize position embeddings
|
| 304 |
+
Truncate if sequence length of Bart backbone is greater than given max_length,
|
| 305 |
+
else interpolate to max_length
|
| 306 |
+
"""
|
| 307 |
+
if weight.shape[0] > max_length:
|
| 308 |
+
weight = weight[:max_length, ...]
|
| 309 |
+
else:
|
| 310 |
+
weight = (
|
| 311 |
+
F.interpolate(
|
| 312 |
+
weight.permute(1, 0).unsqueeze(0),
|
| 313 |
+
size=max_length,
|
| 314 |
+
mode="linear",
|
| 315 |
+
align_corners=False,
|
| 316 |
+
)
|
| 317 |
+
.squeeze(0)
|
| 318 |
+
.permute(1, 0)
|
| 319 |
+
)
|
| 320 |
+
return weight
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
class DonutConfig(PretrainedConfig):
|
| 324 |
+
r"""
|
| 325 |
+
This is the configuration class to store the configuration of a [`DonutModel`]. It is used to
|
| 326 |
+
instantiate a Donut model according to the specified arguments, defining the model architecture
|
| 327 |
+
|
| 328 |
+
Args:
|
| 329 |
+
input_size:
|
| 330 |
+
Input image size (canvas size) of Donut.encoder, SwinTransformer in this codebase
|
| 331 |
+
align_long_axis:
|
| 332 |
+
Whether to rotate image if height is greater than width
|
| 333 |
+
window_size:
|
| 334 |
+
Window size of Donut.encoder, SwinTransformer in this codebase
|
| 335 |
+
encoder_layer:
|
| 336 |
+
Depth of each Donut.encoder Encoder layer, SwinTransformer in this codebase
|
| 337 |
+
decoder_layer:
|
| 338 |
+
Number of hidden layers in the Donut.decoder, such as BART
|
| 339 |
+
max_position_embeddings
|
| 340 |
+
Trained max position embeddings in the Donut decoder,
|
| 341 |
+
if not specified, it will have same value with max_length
|
| 342 |
+
max_length:
|
| 343 |
+
Max position embeddings(=maximum sequence length) you want to train
|
| 344 |
+
name_or_path:
|
| 345 |
+
Name of a pretrained model name either registered in huggingface.co. or saved in local
|
| 346 |
+
"""
|
| 347 |
+
|
| 348 |
+
model_type = "donut"
|
| 349 |
+
|
| 350 |
+
def __init__(
|
| 351 |
+
self,
|
| 352 |
+
input_size: List[int] = [2560, 1920],
|
| 353 |
+
align_long_axis: bool = False,
|
| 354 |
+
window_size: int = 10,
|
| 355 |
+
encoder_layer: List[int] = [2, 2, 14, 2],
|
| 356 |
+
decoder_layer: int = 4,
|
| 357 |
+
max_position_embeddings: int = None,
|
| 358 |
+
max_length: int = 1536,
|
| 359 |
+
name_or_path: Union[str, bytes, os.PathLike] = "",
|
| 360 |
+
**kwargs,
|
| 361 |
+
):
|
| 362 |
+
super().__init__()
|
| 363 |
+
self.input_size = input_size
|
| 364 |
+
self.align_long_axis = align_long_axis
|
| 365 |
+
self.window_size = window_size
|
| 366 |
+
self.encoder_layer = encoder_layer
|
| 367 |
+
self.decoder_layer = decoder_layer
|
| 368 |
+
self.max_position_embeddings = max_length if max_position_embeddings is None else max_position_embeddings
|
| 369 |
+
self.max_length = max_length
|
| 370 |
+
self.name_or_path = name_or_path
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
class DonutModel(PreTrainedModel):
|
| 374 |
+
r"""
|
| 375 |
+
Donut: an E2E OCR-free Document Understanding Transformer.
|
| 376 |
+
The encoder maps an input document image into a set of embeddings,
|
| 377 |
+
the decoder predicts a desired token sequence, that can be converted to a structured format,
|
| 378 |
+
given a prompt and the encoder output embeddings
|
| 379 |
+
"""
|
| 380 |
+
config_class = DonutConfig
|
| 381 |
+
base_model_prefix = "donut"
|
| 382 |
+
|
| 383 |
+
def __init__(self, config: DonutConfig):
|
| 384 |
+
super().__init__(config)
|
| 385 |
+
self.config = config
|
| 386 |
+
self.encoder = SwinEncoder(
|
| 387 |
+
input_size=self.config.input_size,
|
| 388 |
+
align_long_axis=self.config.align_long_axis,
|
| 389 |
+
window_size=self.config.window_size,
|
| 390 |
+
encoder_layer=self.config.encoder_layer,
|
| 391 |
+
name_or_path=self.config.name_or_path,
|
| 392 |
+
)
|
| 393 |
+
self.decoder = BARTDecoder(
|
| 394 |
+
max_position_embeddings=self.config.max_position_embeddings,
|
| 395 |
+
decoder_layer=self.config.decoder_layer,
|
| 396 |
+
name_or_path=self.config.name_or_path,
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
def forward(self, image_tensors: torch.Tensor, decoder_input_ids: torch.Tensor, decoder_labels: torch.Tensor):
|
| 400 |
+
"""
|
| 401 |
+
Calculate a loss given an input image and a desired token sequence,
|
| 402 |
+
the model will be trained in a teacher-forcing manner
|
| 403 |
+
|
| 404 |
+
Args:
|
| 405 |
+
image_tensors: (batch_size, num_channels, height, width)
|
| 406 |
+
decoder_input_ids: (batch_size, sequence_length, embedding_dim)
|
| 407 |
+
decode_labels: (batch_size, sequence_length)
|
| 408 |
+
"""
|
| 409 |
+
encoder_outputs = self.encoder(image_tensors)
|
| 410 |
+
decoder_outputs = self.decoder(
|
| 411 |
+
input_ids=decoder_input_ids,
|
| 412 |
+
encoder_hidden_states=encoder_outputs,
|
| 413 |
+
labels=decoder_labels,
|
| 414 |
+
)
|
| 415 |
+
return decoder_outputs
|
| 416 |
+
|
| 417 |
+
def inference(
|
| 418 |
+
self,
|
| 419 |
+
image: PIL.Image = None,
|
| 420 |
+
prompt: str = None,
|
| 421 |
+
image_tensors: Optional[torch.Tensor] = None,
|
| 422 |
+
prompt_tensors: Optional[torch.Tensor] = None,
|
| 423 |
+
return_json: bool = True,
|
| 424 |
+
return_attentions: bool = False,
|
| 425 |
+
):
|
| 426 |
+
"""
|
| 427 |
+
Generate a token sequence in an auto-regressive manner,
|
| 428 |
+
the generated token sequence is convereted into an ordered JSON format
|
| 429 |
+
|
| 430 |
+
Args:
|
| 431 |
+
image: input document image (PIL.Image)
|
| 432 |
+
prompt: task prompt (string) to guide Donut Decoder generation
|
| 433 |
+
image_tensors: (1, num_channels, height, width)
|
| 434 |
+
convert prompt to tensor if image_tensor is not fed
|
| 435 |
+
prompt_tensors: (1, sequence_length)
|
| 436 |
+
convert image to tensor if prompt_tensor is not fed
|
| 437 |
+
"""
|
| 438 |
+
# prepare backbone inputs (image and prompt)
|
| 439 |
+
if image is None and image_tensors is None:
|
| 440 |
+
raise ValueError("Expected either image or image_tensors")
|
| 441 |
+
if all(v is None for v in {prompt, prompt_tensors}):
|
| 442 |
+
raise ValueError("Expected either prompt or prompt_tensors")
|
| 443 |
+
|
| 444 |
+
if image_tensors is None:
|
| 445 |
+
image_tensors = self.encoder.prepare_input(image).unsqueeze(0)
|
| 446 |
+
|
| 447 |
+
if self.device.type == "cuda": # half is not compatible in cpu implementation.
|
| 448 |
+
image_tensors = image_tensors.half()
|
| 449 |
+
image_tensors = image_tensors.to(self.device)
|
| 450 |
+
|
| 451 |
+
if prompt_tensors is None:
|
| 452 |
+
prompt_tensors = self.decoder.tokenizer(prompt, add_special_tokens=False, return_tensors="pt")["input_ids"]
|
| 453 |
+
|
| 454 |
+
prompt_tensors = prompt_tensors.to(self.device)
|
| 455 |
+
|
| 456 |
+
last_hidden_state = self.encoder(image_tensors)
|
| 457 |
+
if self.device.type != "cuda":
|
| 458 |
+
last_hidden_state = last_hidden_state.to(torch.float32)
|
| 459 |
+
|
| 460 |
+
encoder_outputs = ModelOutput(last_hidden_state=last_hidden_state, attentions=None)
|
| 461 |
+
|
| 462 |
+
if len(encoder_outputs.last_hidden_state.size()) == 1:
|
| 463 |
+
encoder_outputs.last_hidden_state = encoder_outputs.last_hidden_state.unsqueeze(0)
|
| 464 |
+
if len(prompt_tensors.size()) == 1:
|
| 465 |
+
prompt_tensors = prompt_tensors.unsqueeze(0)
|
| 466 |
+
|
| 467 |
+
# get decoder output
|
| 468 |
+
decoder_output = self.decoder.model.generate(
|
| 469 |
+
decoder_input_ids=prompt_tensors,
|
| 470 |
+
encoder_outputs=encoder_outputs,
|
| 471 |
+
max_length=self.config.max_length,
|
| 472 |
+
early_stopping=True,
|
| 473 |
+
pad_token_id=self.decoder.tokenizer.pad_token_id,
|
| 474 |
+
eos_token_id=self.decoder.tokenizer.eos_token_id,
|
| 475 |
+
use_cache=True,
|
| 476 |
+
num_beams=1,
|
| 477 |
+
bad_words_ids=[[self.decoder.tokenizer.unk_token_id]],
|
| 478 |
+
return_dict_in_generate=True,
|
| 479 |
+
output_attentions=return_attentions,
|
| 480 |
+
)
|
| 481 |
+
|
| 482 |
+
output = {"predictions": list()}
|
| 483 |
+
for seq in self.decoder.tokenizer.batch_decode(decoder_output.sequences):
|
| 484 |
+
seq = seq.replace(self.decoder.tokenizer.eos_token, "").replace(self.decoder.tokenizer.pad_token, "")
|
| 485 |
+
seq = re.sub(r"<.*?>", "", seq, count=1).strip() # remove first task start token
|
| 486 |
+
if return_json:
|
| 487 |
+
output["predictions"].append(self.token2json(seq))
|
| 488 |
+
else:
|
| 489 |
+
output["predictions"].append(seq)
|
| 490 |
+
|
| 491 |
+
if return_attentions:
|
| 492 |
+
output["attentions"] = {
|
| 493 |
+
"self_attentions": decoder_output.decoder_attentions,
|
| 494 |
+
"cross_attentions": decoder_output.cross_attentions,
|
| 495 |
+
}
|
| 496 |
+
|
| 497 |
+
return output
|
| 498 |
+
|
| 499 |
+
def json2token(self, obj: Any, update_special_tokens_for_json_key: bool = True, sort_json_key: bool = True):
|
| 500 |
+
"""
|
| 501 |
+
Convert an ordered JSON object into a token sequence
|
| 502 |
+
"""
|
| 503 |
+
if type(obj) == dict:
|
| 504 |
+
if len(obj) == 1 and "text_sequence" in obj:
|
| 505 |
+
return obj["text_sequence"]
|
| 506 |
+
else:
|
| 507 |
+
output = ""
|
| 508 |
+
if sort_json_key:
|
| 509 |
+
keys = sorted(obj.keys(), reverse=True)
|
| 510 |
+
else:
|
| 511 |
+
keys = obj.keys()
|
| 512 |
+
for k in keys:
|
| 513 |
+
if update_special_tokens_for_json_key:
|
| 514 |
+
self.decoder.add_special_tokens([fr"<s_{k}>", fr"</s_{k}>"])
|
| 515 |
+
output += (
|
| 516 |
+
fr"<s_{k}>"
|
| 517 |
+
+ self.json2token(obj[k], update_special_tokens_for_json_key, sort_json_key)
|
| 518 |
+
+ fr"</s_{k}>"
|
| 519 |
+
)
|
| 520 |
+
return output
|
| 521 |
+
elif type(obj) == list:
|
| 522 |
+
return r"<sep/>".join(
|
| 523 |
+
[self.json2token(item, update_special_tokens_for_json_key, sort_json_key) for item in obj]
|
| 524 |
+
)
|
| 525 |
+
else:
|
| 526 |
+
obj = str(obj)
|
| 527 |
+
if f"<{obj}/>" in self.decoder.tokenizer.all_special_tokens:
|
| 528 |
+
obj = f"<{obj}/>" # for categorical special tokens
|
| 529 |
+
return obj
|
| 530 |
+
|
| 531 |
+
def token2json(self, tokens, is_inner_value=False):
|
| 532 |
+
"""
|
| 533 |
+
Convert a (generated) token seuqnce into an ordered JSON format
|
| 534 |
+
"""
|
| 535 |
+
output = dict()
|
| 536 |
+
|
| 537 |
+
while tokens:
|
| 538 |
+
start_token = re.search(r"<s_(.*?)>", tokens, re.IGNORECASE)
|
| 539 |
+
if start_token is None:
|
| 540 |
+
break
|
| 541 |
+
key = start_token.group(1)
|
| 542 |
+
end_token = re.search(fr"</s_{key}>", tokens, re.IGNORECASE)
|
| 543 |
+
start_token = start_token.group()
|
| 544 |
+
if end_token is None:
|
| 545 |
+
tokens = tokens.replace(start_token, "")
|
| 546 |
+
else:
|
| 547 |
+
end_token = end_token.group()
|
| 548 |
+
start_token_escaped = re.escape(start_token)
|
| 549 |
+
end_token_escaped = re.escape(end_token)
|
| 550 |
+
content = re.search(f"{start_token_escaped}(.*?){end_token_escaped}", tokens, re.IGNORECASE)
|
| 551 |
+
if content is not None:
|
| 552 |
+
content = content.group(1).strip()
|
| 553 |
+
if r"<s_" in content and r"</s_" in content: # non-leaf node
|
| 554 |
+
value = self.token2json(content, is_inner_value=True)
|
| 555 |
+
if value:
|
| 556 |
+
if len(value) == 1:
|
| 557 |
+
value = value[0]
|
| 558 |
+
output[key] = value
|
| 559 |
+
else: # leaf nodes
|
| 560 |
+
output[key] = []
|
| 561 |
+
for leaf in content.split(r"<sep/>"):
|
| 562 |
+
leaf = leaf.strip()
|
| 563 |
+
if (
|
| 564 |
+
leaf in self.decoder.tokenizer.get_added_vocab()
|
| 565 |
+
and leaf[0] == "<"
|
| 566 |
+
and leaf[-2:] == "/>"
|
| 567 |
+
):
|
| 568 |
+
leaf = leaf[1:-2] # for categorical special tokens
|
| 569 |
+
output[key].append(leaf)
|
| 570 |
+
if len(output[key]) == 1:
|
| 571 |
+
output[key] = output[key][0]
|
| 572 |
+
|
| 573 |
+
tokens = tokens[tokens.find(end_token) + len(end_token) :].strip()
|
| 574 |
+
if tokens[:6] == r"<sep/>": # non-leaf nodes
|
| 575 |
+
return [output] + self.token2json(tokens[6:], is_inner_value=True)
|
| 576 |
+
|
| 577 |
+
if len(output):
|
| 578 |
+
return [output] if is_inner_value else output
|
| 579 |
+
else:
|
| 580 |
+
return [] if is_inner_value else {"text_sequence": tokens}
|
| 581 |
+
|
| 582 |
+
@classmethod
|
| 583 |
+
def from_pretrained(
|
| 584 |
+
cls,
|
| 585 |
+
pretrained_model_name_or_path: Union[str, bytes, os.PathLike],
|
| 586 |
+
*model_args,
|
| 587 |
+
**kwargs,
|
| 588 |
+
):
|
| 589 |
+
r"""
|
| 590 |
+
Instantiate a pretrained donut model from a pre-trained model configuration
|
| 591 |
+
|
| 592 |
+
Args:
|
| 593 |
+
pretrained_model_name_or_path:
|
| 594 |
+
Name of a pretrained model name either registered in huggingface.co. or saved in local,
|
| 595 |
+
e.g., `naver-clova-ix/donut-base`, or `naver-clova-ix/donut-base-finetuned-rvlcdip`
|
| 596 |
+
"""
|
| 597 |
+
model = super(DonutModel, cls).from_pretrained(pretrained_model_name_or_path, revision="official", *model_args, **kwargs)
|
| 598 |
+
|
| 599 |
+
# truncate or interplolate position embeddings of donut decoder
|
| 600 |
+
max_length = kwargs.get("max_length", model.config.max_position_embeddings)
|
| 601 |
+
if (
|
| 602 |
+
max_length != model.config.max_position_embeddings
|
| 603 |
+
): # if max_length of trained model differs max_length you want to train
|
| 604 |
+
model.decoder.model.model.decoder.embed_positions.weight = torch.nn.Parameter(
|
| 605 |
+
model.decoder.resize_bart_abs_pos_emb(
|
| 606 |
+
model.decoder.model.model.decoder.embed_positions.weight,
|
| 607 |
+
max_length
|
| 608 |
+
+ 2, # https://github.com/huggingface/transformers/blob/v4.11.3/src/transformers/models/mbart/modeling_mbart.py#L118-L119
|
| 609 |
+
)
|
| 610 |
+
)
|
| 611 |
+
model.config.max_position_embeddings = max_length
|
| 612 |
+
|
| 613 |
+
return model
|
donut/util.py
ADDED
|
@@ -0,0 +1,340 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import json
|
| 7 |
+
import os
|
| 8 |
+
import random
|
| 9 |
+
from collections import defaultdict
|
| 10 |
+
from typing import Any, Dict, List, Tuple, Union
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import zss
|
| 14 |
+
from datasets import load_dataset
|
| 15 |
+
from nltk import edit_distance
|
| 16 |
+
from torch.utils.data import Dataset
|
| 17 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 18 |
+
from zss import Node
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def save_json(write_path: Union[str, bytes, os.PathLike], save_obj: Any):
|
| 22 |
+
with open(write_path, "w") as f:
|
| 23 |
+
json.dump(save_obj, f)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def load_json(json_path: Union[str, bytes, os.PathLike]):
|
| 27 |
+
with open(json_path, "r") as f:
|
| 28 |
+
return json.load(f)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class DonutDataset(Dataset):
|
| 32 |
+
"""
|
| 33 |
+
DonutDataset which is saved in huggingface datasets format. (see details in https://huggingface.co/docs/datasets)
|
| 34 |
+
Each row, consists of image path(png/jpg/jpeg) and gt data (json/jsonl/txt),
|
| 35 |
+
and it will be converted into input_tensor(vectorized image) and input_ids(tokenized string)
|
| 36 |
+
|
| 37 |
+
Args:
|
| 38 |
+
dataset_name_or_path: name of dataset (available at huggingface.co/datasets) or the path containing image files and metadata.jsonl
|
| 39 |
+
ignore_id: ignore_index for torch.nn.CrossEntropyLoss
|
| 40 |
+
task_start_token: the special token to be fed to the decoder to conduct the target task
|
| 41 |
+
"""
|
| 42 |
+
|
| 43 |
+
def __init__(
|
| 44 |
+
self,
|
| 45 |
+
dataset_name_or_path: str,
|
| 46 |
+
donut_model: PreTrainedModel,
|
| 47 |
+
max_length: int,
|
| 48 |
+
split: str = "train",
|
| 49 |
+
ignore_id: int = -100,
|
| 50 |
+
task_start_token: str = "<s>",
|
| 51 |
+
prompt_end_token: str = None,
|
| 52 |
+
sort_json_key: bool = True,
|
| 53 |
+
):
|
| 54 |
+
super().__init__()
|
| 55 |
+
|
| 56 |
+
self.donut_model = donut_model
|
| 57 |
+
self.max_length = max_length
|
| 58 |
+
self.split = split
|
| 59 |
+
self.ignore_id = ignore_id
|
| 60 |
+
self.task_start_token = task_start_token
|
| 61 |
+
self.prompt_end_token = prompt_end_token if prompt_end_token else task_start_token
|
| 62 |
+
self.sort_json_key = sort_json_key
|
| 63 |
+
|
| 64 |
+
self.dataset = load_dataset(dataset_name_or_path, split=self.split)
|
| 65 |
+
self.dataset_length = len(self.dataset)
|
| 66 |
+
|
| 67 |
+
self.gt_token_sequences = []
|
| 68 |
+
for sample in self.dataset:
|
| 69 |
+
ground_truth = json.loads(sample["ground_truth"])
|
| 70 |
+
if "gt_parses" in ground_truth: # when multiple ground truths are available, e.g., docvqa
|
| 71 |
+
assert isinstance(ground_truth["gt_parses"], list)
|
| 72 |
+
gt_jsons = ground_truth["gt_parses"]
|
| 73 |
+
else:
|
| 74 |
+
assert "gt_parse" in ground_truth and isinstance(ground_truth["gt_parse"], dict)
|
| 75 |
+
gt_jsons = [ground_truth["gt_parse"]]
|
| 76 |
+
|
| 77 |
+
self.gt_token_sequences.append(
|
| 78 |
+
[
|
| 79 |
+
task_start_token
|
| 80 |
+
+ self.donut_model.json2token(
|
| 81 |
+
gt_json,
|
| 82 |
+
update_special_tokens_for_json_key=self.split == "train",
|
| 83 |
+
sort_json_key=self.sort_json_key,
|
| 84 |
+
)
|
| 85 |
+
+ self.donut_model.decoder.tokenizer.eos_token
|
| 86 |
+
for gt_json in gt_jsons # load json from list of json
|
| 87 |
+
]
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
self.donut_model.decoder.add_special_tokens([self.task_start_token, self.prompt_end_token])
|
| 91 |
+
self.prompt_end_token_id = self.donut_model.decoder.tokenizer.convert_tokens_to_ids(self.prompt_end_token)
|
| 92 |
+
|
| 93 |
+
def __len__(self) -> int:
|
| 94 |
+
return self.dataset_length
|
| 95 |
+
|
| 96 |
+
def __getitem__(self, idx: int) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 97 |
+
"""
|
| 98 |
+
Load image from image_path of given dataset_path and convert into input_tensor and labels.
|
| 99 |
+
Convert gt data into input_ids (tokenized string)
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
input_tensor : preprocessed image
|
| 103 |
+
input_ids : tokenized gt_data
|
| 104 |
+
labels : masked labels (model doesn't need to predict prompt and pad token)
|
| 105 |
+
"""
|
| 106 |
+
sample = self.dataset[idx]
|
| 107 |
+
|
| 108 |
+
# input_tensor
|
| 109 |
+
input_tensor = self.donut_model.encoder.prepare_input(sample["image"], random_padding=self.split == "train")
|
| 110 |
+
|
| 111 |
+
# input_ids
|
| 112 |
+
processed_parse = random.choice(self.gt_token_sequences[idx]) # can be more than one, e.g., DocVQA Task 1
|
| 113 |
+
input_ids = self.donut_model.decoder.tokenizer(
|
| 114 |
+
processed_parse,
|
| 115 |
+
add_special_tokens=False,
|
| 116 |
+
max_length=self.max_length,
|
| 117 |
+
padding="max_length",
|
| 118 |
+
truncation=True,
|
| 119 |
+
return_tensors="pt",
|
| 120 |
+
)["input_ids"].squeeze(0)
|
| 121 |
+
|
| 122 |
+
if self.split == "train":
|
| 123 |
+
labels = input_ids.clone()
|
| 124 |
+
labels[
|
| 125 |
+
labels == self.donut_model.decoder.tokenizer.pad_token_id
|
| 126 |
+
] = self.ignore_id # model doesn't need to predict pad token
|
| 127 |
+
labels[
|
| 128 |
+
: torch.nonzero(labels == self.prompt_end_token_id).sum() + 1
|
| 129 |
+
] = self.ignore_id # model doesn't need to predict prompt (for VQA)
|
| 130 |
+
return input_tensor, input_ids, labels
|
| 131 |
+
else:
|
| 132 |
+
prompt_end_index = torch.nonzero(
|
| 133 |
+
input_ids == self.prompt_end_token_id
|
| 134 |
+
).sum() # return prompt end index instead of target output labels
|
| 135 |
+
return input_tensor, input_ids, prompt_end_index, processed_parse
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class JSONParseEvaluator:
|
| 139 |
+
"""
|
| 140 |
+
Calculate n-TED(Normalized Tree Edit Distance) based accuracy and F1 accuracy score
|
| 141 |
+
"""
|
| 142 |
+
|
| 143 |
+
@staticmethod
|
| 144 |
+
def flatten(data: dict):
|
| 145 |
+
"""
|
| 146 |
+
Convert Dictionary into Non-nested Dictionary
|
| 147 |
+
Example:
|
| 148 |
+
input(dict)
|
| 149 |
+
{
|
| 150 |
+
"menu": [
|
| 151 |
+
{"name" : ["cake"], "count" : ["2"]},
|
| 152 |
+
{"name" : ["juice"], "count" : ["1"]},
|
| 153 |
+
]
|
| 154 |
+
}
|
| 155 |
+
output(list)
|
| 156 |
+
[
|
| 157 |
+
("menu.name", "cake"),
|
| 158 |
+
("menu.count", "2"),
|
| 159 |
+
("menu.name", "juice"),
|
| 160 |
+
("menu.count", "1"),
|
| 161 |
+
]
|
| 162 |
+
"""
|
| 163 |
+
flatten_data = list()
|
| 164 |
+
|
| 165 |
+
def _flatten(value, key=""):
|
| 166 |
+
if type(value) is dict:
|
| 167 |
+
for child_key, child_value in value.items():
|
| 168 |
+
_flatten(child_value, f"{key}.{child_key}" if key else child_key)
|
| 169 |
+
elif type(value) is list:
|
| 170 |
+
for value_item in value:
|
| 171 |
+
_flatten(value_item, key)
|
| 172 |
+
else:
|
| 173 |
+
flatten_data.append((key, value))
|
| 174 |
+
|
| 175 |
+
_flatten(data)
|
| 176 |
+
return flatten_data
|
| 177 |
+
|
| 178 |
+
@staticmethod
|
| 179 |
+
def update_cost(node1: Node, node2: Node):
|
| 180 |
+
"""
|
| 181 |
+
Update cost for tree edit distance.
|
| 182 |
+
If both are leaf node, calculate string edit distance between two labels (special token '<leaf>' will be ignored).
|
| 183 |
+
If one of them is leaf node, cost is length of string in leaf node + 1.
|
| 184 |
+
If neither are leaf node, cost is 0 if label1 is same with label2 othewise 1
|
| 185 |
+
"""
|
| 186 |
+
label1 = node1.label
|
| 187 |
+
label2 = node2.label
|
| 188 |
+
label1_leaf = "<leaf>" in label1
|
| 189 |
+
label2_leaf = "<leaf>" in label2
|
| 190 |
+
if label1_leaf == True and label2_leaf == True:
|
| 191 |
+
return edit_distance(label1.replace("<leaf>", ""), label2.replace("<leaf>", ""))
|
| 192 |
+
elif label1_leaf == False and label2_leaf == True:
|
| 193 |
+
return 1 + len(label2.replace("<leaf>", ""))
|
| 194 |
+
elif label1_leaf == True and label2_leaf == False:
|
| 195 |
+
return 1 + len(label1.replace("<leaf>", ""))
|
| 196 |
+
else:
|
| 197 |
+
return int(label1 != label2)
|
| 198 |
+
|
| 199 |
+
@staticmethod
|
| 200 |
+
def insert_and_remove_cost(node: Node):
|
| 201 |
+
"""
|
| 202 |
+
Insert and remove cost for tree edit distance.
|
| 203 |
+
If leaf node, cost is length of label name.
|
| 204 |
+
Otherwise, 1
|
| 205 |
+
"""
|
| 206 |
+
label = node.label
|
| 207 |
+
if "<leaf>" in label:
|
| 208 |
+
return len(label.replace("<leaf>", ""))
|
| 209 |
+
else:
|
| 210 |
+
return 1
|
| 211 |
+
|
| 212 |
+
def normalize_dict(self, data: Union[Dict, List, Any]):
|
| 213 |
+
"""
|
| 214 |
+
Sort by value, while iterate over element if data is list
|
| 215 |
+
"""
|
| 216 |
+
if not data:
|
| 217 |
+
return {}
|
| 218 |
+
|
| 219 |
+
if isinstance(data, dict):
|
| 220 |
+
new_data = dict()
|
| 221 |
+
for key in sorted(data.keys(), key=lambda k: (len(k), k)):
|
| 222 |
+
value = self.normalize_dict(data[key])
|
| 223 |
+
if value:
|
| 224 |
+
if not isinstance(value, list):
|
| 225 |
+
value = [value]
|
| 226 |
+
new_data[key] = value
|
| 227 |
+
|
| 228 |
+
elif isinstance(data, list):
|
| 229 |
+
if all(isinstance(item, dict) for item in data):
|
| 230 |
+
new_data = []
|
| 231 |
+
for item in data:
|
| 232 |
+
item = self.normalize_dict(item)
|
| 233 |
+
if item:
|
| 234 |
+
new_data.append(item)
|
| 235 |
+
else:
|
| 236 |
+
new_data = [str(item).strip() for item in data if type(item) in {str, int, float} and str(item).strip()]
|
| 237 |
+
else:
|
| 238 |
+
new_data = [str(data).strip()]
|
| 239 |
+
|
| 240 |
+
return new_data
|
| 241 |
+
|
| 242 |
+
def cal_f1(self, preds: List[dict], answers: List[dict]):
|
| 243 |
+
"""
|
| 244 |
+
Calculate global F1 accuracy score (field-level, micro-averaged) by counting all true positives, false negatives and false positives
|
| 245 |
+
"""
|
| 246 |
+
total_tp, total_fn_or_fp = 0, 0
|
| 247 |
+
for pred, answer in zip(preds, answers):
|
| 248 |
+
pred, answer = self.flatten(self.normalize_dict(pred)), self.flatten(self.normalize_dict(answer))
|
| 249 |
+
for field in pred:
|
| 250 |
+
if field in answer:
|
| 251 |
+
total_tp += 1
|
| 252 |
+
answer.remove(field)
|
| 253 |
+
else:
|
| 254 |
+
total_fn_or_fp += 1
|
| 255 |
+
total_fn_or_fp += len(answer)
|
| 256 |
+
return total_tp / (total_tp + total_fn_or_fp / 2)
|
| 257 |
+
|
| 258 |
+
def construct_tree_from_dict(self, data: Union[Dict, List], node_name: str = None):
|
| 259 |
+
"""
|
| 260 |
+
Convert Dictionary into Tree
|
| 261 |
+
|
| 262 |
+
Example:
|
| 263 |
+
input(dict)
|
| 264 |
+
|
| 265 |
+
{
|
| 266 |
+
"menu": [
|
| 267 |
+
{"name" : ["cake"], "count" : ["2"]},
|
| 268 |
+
{"name" : ["juice"], "count" : ["1"]},
|
| 269 |
+
]
|
| 270 |
+
}
|
| 271 |
+
|
| 272 |
+
output(tree)
|
| 273 |
+
<root>
|
| 274 |
+
|
|
| 275 |
+
menu
|
| 276 |
+
/ \
|
| 277 |
+
<subtree> <subtree>
|
| 278 |
+
/ | | \
|
| 279 |
+
name count name count
|
| 280 |
+
/ | | \
|
| 281 |
+
<leaf>cake <leaf>2 <leaf>juice <leaf>1
|
| 282 |
+
"""
|
| 283 |
+
if node_name is None:
|
| 284 |
+
node_name = "<root>"
|
| 285 |
+
|
| 286 |
+
node = Node(node_name)
|
| 287 |
+
|
| 288 |
+
if isinstance(data, dict):
|
| 289 |
+
for key, value in data.items():
|
| 290 |
+
kid_node = self.construct_tree_from_dict(value, key)
|
| 291 |
+
node.addkid(kid_node)
|
| 292 |
+
elif isinstance(data, list):
|
| 293 |
+
if all(isinstance(item, dict) for item in data):
|
| 294 |
+
for item in data:
|
| 295 |
+
kid_node = self.construct_tree_from_dict(
|
| 296 |
+
item,
|
| 297 |
+
"<subtree>",
|
| 298 |
+
)
|
| 299 |
+
node.addkid(kid_node)
|
| 300 |
+
else:
|
| 301 |
+
for item in data:
|
| 302 |
+
node.addkid(Node(f"<leaf>{item}"))
|
| 303 |
+
else:
|
| 304 |
+
raise Exception(data, node_name)
|
| 305 |
+
return node
|
| 306 |
+
|
| 307 |
+
def cal_acc(self, pred: dict, answer: dict):
|
| 308 |
+
"""
|
| 309 |
+
Calculate normalized tree edit distance(nTED) based accuracy.
|
| 310 |
+
1) Construct tree from dict,
|
| 311 |
+
2) Get tree distance with insert/remove/update cost,
|
| 312 |
+
3) Divide distance with GT tree size (i.e., nTED),
|
| 313 |
+
4) Calculate nTED based accuracy. (= max(1 - nTED, 0 ).
|
| 314 |
+
"""
|
| 315 |
+
pred = self.construct_tree_from_dict(self.normalize_dict(pred))
|
| 316 |
+
answer = self.construct_tree_from_dict(self.normalize_dict(answer))
|
| 317 |
+
return max(
|
| 318 |
+
0,
|
| 319 |
+
1
|
| 320 |
+
- (
|
| 321 |
+
zss.distance(
|
| 322 |
+
pred,
|
| 323 |
+
answer,
|
| 324 |
+
get_children=zss.Node.get_children,
|
| 325 |
+
insert_cost=self.insert_and_remove_cost,
|
| 326 |
+
remove_cost=self.insert_and_remove_cost,
|
| 327 |
+
update_cost=self.update_cost,
|
| 328 |
+
return_operations=False,
|
| 329 |
+
)
|
| 330 |
+
/ zss.distance(
|
| 331 |
+
self.construct_tree_from_dict(self.normalize_dict({})),
|
| 332 |
+
answer,
|
| 333 |
+
get_children=zss.Node.get_children,
|
| 334 |
+
insert_cost=self.insert_and_remove_cost,
|
| 335 |
+
remove_cost=self.insert_and_remove_cost,
|
| 336 |
+
update_cost=self.update_cost,
|
| 337 |
+
return_operations=False,
|
| 338 |
+
)
|
| 339 |
+
),
|
| 340 |
+
)
|
lightning_module.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import math
|
| 7 |
+
import random
|
| 8 |
+
import re
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import pytorch_lightning as pl
|
| 13 |
+
import torch
|
| 14 |
+
from nltk import edit_distance
|
| 15 |
+
from pytorch_lightning.utilities import rank_zero_only
|
| 16 |
+
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
|
| 17 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 18 |
+
from torch.optim.lr_scheduler import LambdaLR
|
| 19 |
+
from torch.utils.data import DataLoader
|
| 20 |
+
|
| 21 |
+
from donut import DonutConfig, DonutModel
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class DonutModelPLModule(pl.LightningModule):
|
| 25 |
+
def __init__(self, config):
|
| 26 |
+
super().__init__()
|
| 27 |
+
self.config = config
|
| 28 |
+
|
| 29 |
+
if self.config.get("pretrained_model_name_or_path", False):
|
| 30 |
+
self.model = DonutModel.from_pretrained(
|
| 31 |
+
self.config.pretrained_model_name_or_path,
|
| 32 |
+
input_size=self.config.input_size,
|
| 33 |
+
max_length=self.config.max_length,
|
| 34 |
+
align_long_axis=self.config.align_long_axis,
|
| 35 |
+
ignore_mismatched_sizes=True,
|
| 36 |
+
)
|
| 37 |
+
else:
|
| 38 |
+
self.model = DonutModel(
|
| 39 |
+
config=DonutConfig(
|
| 40 |
+
input_size=self.config.input_size,
|
| 41 |
+
max_length=self.config.max_length,
|
| 42 |
+
align_long_axis=self.config.align_long_axis,
|
| 43 |
+
# with DonutConfig, the architecture customization is available, e.g.,
|
| 44 |
+
# encoder_layer=[2,2,14,2], decoder_layer=4, ...
|
| 45 |
+
)
|
| 46 |
+
)
|
| 47 |
+
self.pytorch_lightning_version_is_1 = int(pl.__version__[0]) < 2
|
| 48 |
+
self.num_of_loaders = len(self.config.dataset_name_or_paths)
|
| 49 |
+
|
| 50 |
+
def training_step(self, batch, batch_idx):
|
| 51 |
+
image_tensors, decoder_input_ids, decoder_labels = list(), list(), list()
|
| 52 |
+
for batch_data in batch:
|
| 53 |
+
image_tensors.append(batch_data[0])
|
| 54 |
+
decoder_input_ids.append(batch_data[1][:, :-1])
|
| 55 |
+
decoder_labels.append(batch_data[2][:, 1:])
|
| 56 |
+
image_tensors = torch.cat(image_tensors)
|
| 57 |
+
decoder_input_ids = torch.cat(decoder_input_ids)
|
| 58 |
+
decoder_labels = torch.cat(decoder_labels)
|
| 59 |
+
loss = self.model(image_tensors, decoder_input_ids, decoder_labels)[0]
|
| 60 |
+
self.log_dict({"train_loss": loss}, sync_dist=True)
|
| 61 |
+
if not self.pytorch_lightning_version_is_1:
|
| 62 |
+
self.log('loss', loss, prog_bar=True)
|
| 63 |
+
return loss
|
| 64 |
+
|
| 65 |
+
def on_validation_epoch_start(self) -> None:
|
| 66 |
+
super().on_validation_epoch_start()
|
| 67 |
+
self.validation_step_outputs = [[] for _ in range(self.num_of_loaders)]
|
| 68 |
+
return
|
| 69 |
+
|
| 70 |
+
def validation_step(self, batch, batch_idx, dataloader_idx=0):
|
| 71 |
+
image_tensors, decoder_input_ids, prompt_end_idxs, answers = batch
|
| 72 |
+
decoder_prompts = pad_sequence(
|
| 73 |
+
[input_id[: end_idx + 1] for input_id, end_idx in zip(decoder_input_ids, prompt_end_idxs)],
|
| 74 |
+
batch_first=True,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
preds = self.model.inference(
|
| 78 |
+
image_tensors=image_tensors,
|
| 79 |
+
prompt_tensors=decoder_prompts,
|
| 80 |
+
return_json=False,
|
| 81 |
+
return_attentions=False,
|
| 82 |
+
)["predictions"]
|
| 83 |
+
|
| 84 |
+
scores = list()
|
| 85 |
+
for pred, answer in zip(preds, answers):
|
| 86 |
+
pred = re.sub(r"(?:(?<=>) | (?=</s_))", "", pred)
|
| 87 |
+
answer = re.sub(r"<.*?>", "", answer, count=1)
|
| 88 |
+
answer = answer.replace(self.model.decoder.tokenizer.eos_token, "")
|
| 89 |
+
scores.append(edit_distance(pred, answer) / max(len(pred), len(answer)))
|
| 90 |
+
|
| 91 |
+
if self.config.get("verbose", False) and len(scores) == 1:
|
| 92 |
+
self.print(f"Prediction: {pred}")
|
| 93 |
+
self.print(f" Answer: {answer}")
|
| 94 |
+
self.print(f" Normed ED: {scores[0]}")
|
| 95 |
+
|
| 96 |
+
self.validation_step_outputs[dataloader_idx].append(scores)
|
| 97 |
+
|
| 98 |
+
return scores
|
| 99 |
+
|
| 100 |
+
def on_validation_epoch_end(self):
|
| 101 |
+
assert len(self.validation_step_outputs) == self.num_of_loaders
|
| 102 |
+
cnt = [0] * self.num_of_loaders
|
| 103 |
+
total_metric = [0] * self.num_of_loaders
|
| 104 |
+
val_metric = [0] * self.num_of_loaders
|
| 105 |
+
for i, results in enumerate(self.validation_step_outputs):
|
| 106 |
+
for scores in results:
|
| 107 |
+
cnt[i] += len(scores)
|
| 108 |
+
total_metric[i] += np.sum(scores)
|
| 109 |
+
val_metric[i] = total_metric[i] / cnt[i]
|
| 110 |
+
val_metric_name = f"val_metric_{i}th_dataset"
|
| 111 |
+
self.log_dict({val_metric_name: val_metric[i]}, sync_dist=True)
|
| 112 |
+
self.log_dict({"val_metric": np.sum(total_metric) / np.sum(cnt)}, sync_dist=True)
|
| 113 |
+
|
| 114 |
+
def configure_optimizers(self):
|
| 115 |
+
|
| 116 |
+
max_iter = None
|
| 117 |
+
|
| 118 |
+
if int(self.config.get("max_epochs", -1)) > 0:
|
| 119 |
+
assert len(self.config.train_batch_sizes) == 1, "Set max_epochs only if the number of datasets is 1"
|
| 120 |
+
max_iter = (self.config.max_epochs * self.config.num_training_samples_per_epoch) / (
|
| 121 |
+
self.config.train_batch_sizes[0] * torch.cuda.device_count() * self.config.get("num_nodes", 1)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
if int(self.config.get("max_steps", -1)) > 0:
|
| 125 |
+
max_iter = min(self.config.max_steps, max_iter) if max_iter is not None else self.config.max_steps
|
| 126 |
+
|
| 127 |
+
assert max_iter is not None
|
| 128 |
+
optimizer = torch.optim.Adam(self.parameters(), lr=self.config.lr)
|
| 129 |
+
scheduler = {
|
| 130 |
+
"scheduler": self.cosine_scheduler(optimizer, max_iter, self.config.warmup_steps),
|
| 131 |
+
"name": "learning_rate",
|
| 132 |
+
"interval": "step",
|
| 133 |
+
}
|
| 134 |
+
return [optimizer], [scheduler]
|
| 135 |
+
|
| 136 |
+
@staticmethod
|
| 137 |
+
def cosine_scheduler(optimizer, training_steps, warmup_steps):
|
| 138 |
+
def lr_lambda(current_step):
|
| 139 |
+
if current_step < warmup_steps:
|
| 140 |
+
return current_step / max(1, warmup_steps)
|
| 141 |
+
progress = current_step - warmup_steps
|
| 142 |
+
progress /= max(1, training_steps - warmup_steps)
|
| 143 |
+
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * progress)))
|
| 144 |
+
|
| 145 |
+
return LambdaLR(optimizer, lr_lambda)
|
| 146 |
+
|
| 147 |
+
@rank_zero_only
|
| 148 |
+
def on_save_checkpoint(self, checkpoint):
|
| 149 |
+
save_path = Path(self.config.result_path) / self.config.exp_name / self.config.exp_version
|
| 150 |
+
self.model.save_pretrained(save_path)
|
| 151 |
+
self.model.decoder.tokenizer.save_pretrained(save_path)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class DonutDataPLModule(pl.LightningDataModule):
|
| 155 |
+
def __init__(self, config):
|
| 156 |
+
super().__init__()
|
| 157 |
+
self.config = config
|
| 158 |
+
self.train_batch_sizes = self.config.train_batch_sizes
|
| 159 |
+
self.val_batch_sizes = self.config.val_batch_sizes
|
| 160 |
+
self.train_datasets = []
|
| 161 |
+
self.val_datasets = []
|
| 162 |
+
self.g = torch.Generator()
|
| 163 |
+
self.g.manual_seed(self.config.seed)
|
| 164 |
+
|
| 165 |
+
def train_dataloader(self):
|
| 166 |
+
loaders = list()
|
| 167 |
+
for train_dataset, batch_size in zip(self.train_datasets, self.train_batch_sizes):
|
| 168 |
+
loaders.append(
|
| 169 |
+
DataLoader(
|
| 170 |
+
train_dataset,
|
| 171 |
+
batch_size=batch_size,
|
| 172 |
+
num_workers=self.config.num_workers,
|
| 173 |
+
pin_memory=True,
|
| 174 |
+
worker_init_fn=self.seed_worker,
|
| 175 |
+
generator=self.g,
|
| 176 |
+
shuffle=True,
|
| 177 |
+
)
|
| 178 |
+
)
|
| 179 |
+
return loaders
|
| 180 |
+
|
| 181 |
+
def val_dataloader(self):
|
| 182 |
+
loaders = list()
|
| 183 |
+
for val_dataset, batch_size in zip(self.val_datasets, self.val_batch_sizes):
|
| 184 |
+
loaders.append(
|
| 185 |
+
DataLoader(
|
| 186 |
+
val_dataset,
|
| 187 |
+
batch_size=batch_size,
|
| 188 |
+
pin_memory=True,
|
| 189 |
+
shuffle=False,
|
| 190 |
+
)
|
| 191 |
+
)
|
| 192 |
+
return loaders
|
| 193 |
+
|
| 194 |
+
@staticmethod
|
| 195 |
+
def seed_worker(wordker_id):
|
| 196 |
+
worker_seed = torch.initial_seed() % 2 ** 32
|
| 197 |
+
np.random.seed(worker_seed)
|
| 198 |
+
random.seed(worker_seed)
|
misc/overview.png
ADDED
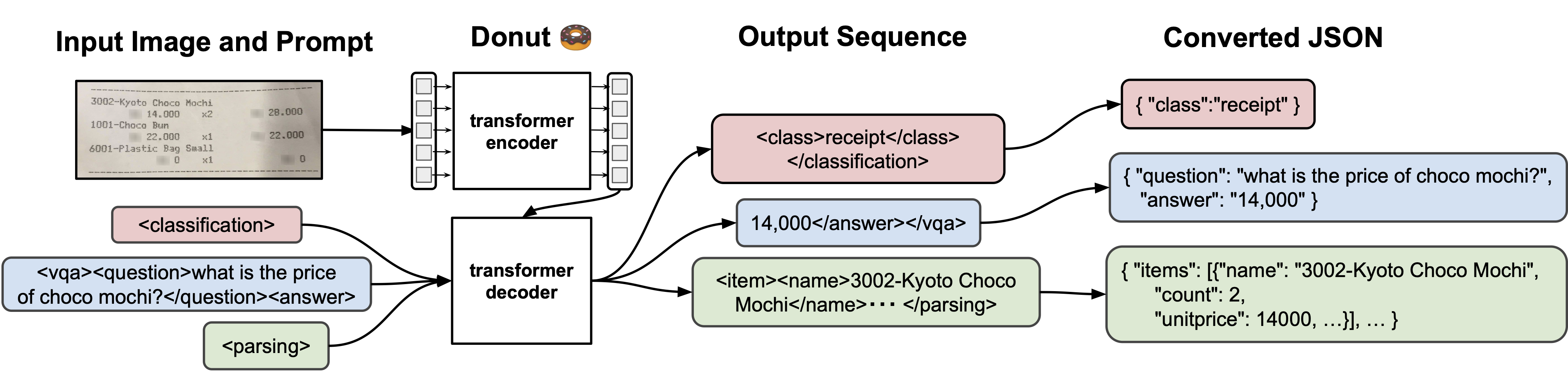
|
misc/sample_image_cord_test_receipt_00004.png
ADDED

|
Git LFS Details
|
misc/sample_image_donut_document.png
ADDED

|
misc/sample_synthdog.png
ADDED

|
Git LFS Details
|
misc/screenshot_gradio_demos.png
ADDED

|
Git LFS Details
|
result/.gitkeep
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
setup.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import os
|
| 7 |
+
from setuptools import find_packages, setup
|
| 8 |
+
|
| 9 |
+
ROOT = os.path.abspath(os.path.dirname(__file__))
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def read_version():
|
| 13 |
+
data = {}
|
| 14 |
+
path = os.path.join(ROOT, "donut", "_version.py")
|
| 15 |
+
with open(path, "r", encoding="utf-8") as f:
|
| 16 |
+
exec(f.read(), data)
|
| 17 |
+
return data["__version__"]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def read_long_description():
|
| 21 |
+
path = os.path.join(ROOT, "README.md")
|
| 22 |
+
with open(path, "r", encoding="utf-8") as f:
|
| 23 |
+
text = f.read()
|
| 24 |
+
return text
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
setup(
|
| 28 |
+
name="donut-python",
|
| 29 |
+
version=read_version(),
|
| 30 |
+
description="OCR-free Document Understanding Transformer",
|
| 31 |
+
long_description=read_long_description(),
|
| 32 |
+
long_description_content_type="text/markdown",
|
| 33 |
+
author="Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park",
|
| 34 |
+
author_email="gwkim.rsrch@gmail.com",
|
| 35 |
+
url="https://github.com/clovaai/donut",
|
| 36 |
+
license="MIT",
|
| 37 |
+
packages=find_packages(
|
| 38 |
+
exclude=[
|
| 39 |
+
"config",
|
| 40 |
+
"dataset",
|
| 41 |
+
"misc",
|
| 42 |
+
"result",
|
| 43 |
+
"synthdog",
|
| 44 |
+
"app.py",
|
| 45 |
+
"lightning_module.py",
|
| 46 |
+
"README.md",
|
| 47 |
+
"train.py",
|
| 48 |
+
"test.py",
|
| 49 |
+
]
|
| 50 |
+
),
|
| 51 |
+
python_requires=">=3.7",
|
| 52 |
+
install_requires=[
|
| 53 |
+
"transformers>=4.11.3",
|
| 54 |
+
"timm",
|
| 55 |
+
"datasets[vision]",
|
| 56 |
+
"pytorch-lightning>=1.6.4",
|
| 57 |
+
"nltk",
|
| 58 |
+
"sentencepiece",
|
| 59 |
+
"zss",
|
| 60 |
+
"sconf>=0.2.3",
|
| 61 |
+
],
|
| 62 |
+
classifiers=[
|
| 63 |
+
"Intended Audience :: Developers",
|
| 64 |
+
"Intended Audience :: Information Technology",
|
| 65 |
+
"Intended Audience :: Science/Research",
|
| 66 |
+
"License :: OSI Approved :: MIT License",
|
| 67 |
+
"Programming Language :: Python",
|
| 68 |
+
"Programming Language :: Python :: 3",
|
| 69 |
+
"Programming Language :: Python :: 3.7",
|
| 70 |
+
"Programming Language :: Python :: 3.8",
|
| 71 |
+
"Programming Language :: Python :: 3.9",
|
| 72 |
+
"Programming Language :: Python :: 3.10",
|
| 73 |
+
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
| 74 |
+
"Topic :: Software Development :: Libraries",
|
| 75 |
+
"Topic :: Software Development :: Libraries :: Python Modules",
|
| 76 |
+
],
|
| 77 |
+
)
|
synthdog/README.md
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SynthDoG 🐶: Synthetic Document Generator
|
| 2 |
+
|
| 3 |
+
SynthDoG is synthetic document generator for visual document understanding (VDU).
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
## Prerequisites
|
| 8 |
+
|
| 9 |
+
- python>=3.6
|
| 10 |
+
- [synthtiger](https://github.com/clovaai/synthtiger) (`pip install synthtiger`)
|
| 11 |
+
|
| 12 |
+
## Usage
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
# Set environment variable (for macOS)
|
| 16 |
+
$ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES
|
| 17 |
+
|
| 18 |
+
synthtiger -o ./outputs/SynthDoG_en -c 50 -w 4 -v template.py SynthDoG config_en.yaml
|
| 19 |
+
|
| 20 |
+
{'config': 'config_en.yaml',
|
| 21 |
+
'count': 50,
|
| 22 |
+
'name': 'SynthDoG',
|
| 23 |
+
'output': './outputs/SynthDoG_en',
|
| 24 |
+
'script': 'template.py',
|
| 25 |
+
'verbose': True,
|
| 26 |
+
'worker': 4}
|
| 27 |
+
{'aspect_ratio': [1, 2],
|
| 28 |
+
.
|
| 29 |
+
.
|
| 30 |
+
'quality': [50, 95],
|
| 31 |
+
'short_size': [720, 1024]}
|
| 32 |
+
Generated 1 data (task 3)
|
| 33 |
+
Generated 2 data (task 0)
|
| 34 |
+
Generated 3 data (task 1)
|
| 35 |
+
.
|
| 36 |
+
.
|
| 37 |
+
Generated 49 data (task 48)
|
| 38 |
+
Generated 50 data (task 49)
|
| 39 |
+
46.32 seconds elapsed
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
Some important arguments:
|
| 43 |
+
|
| 44 |
+
- `-o` : directory path to save data.
|
| 45 |
+
- `-c` : number of data to generate.
|
| 46 |
+
- `-w` : number of workers.
|
| 47 |
+
- `-s` : random seed.
|
| 48 |
+
- `-v` : print error messages.
|
| 49 |
+
|
| 50 |
+
To generate ECJK samples:
|
| 51 |
+
```bash
|
| 52 |
+
# english
|
| 53 |
+
synthtiger -o {dataset_path} -c {num_of_data} -w {num_of_workers} -v template.py SynthDoG config_en.yaml
|
| 54 |
+
|
| 55 |
+
# chinese
|
| 56 |
+
synthtiger -o {dataset_path} -c {num_of_data} -w {num_of_workers} -v template.py SynthDoG config_zh.yaml
|
| 57 |
+
|
| 58 |
+
# japanese
|
| 59 |
+
synthtiger -o {dataset_path} -c {num_of_data} -w {num_of_workers} -v template.py SynthDoG config_ja.yaml
|
| 60 |
+
|
| 61 |
+
# korean
|
| 62 |
+
synthtiger -o {dataset_path} -c {num_of_data} -w {num_of_workers} -v template.py SynthDoG config_ko.yaml
|
| 63 |
+
```
|
synthdog/config_en.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
quality: [50, 95]
|
| 2 |
+
landscape: 0.5
|
| 3 |
+
short_size: [720, 1024]
|
| 4 |
+
aspect_ratio: [1, 2]
|
| 5 |
+
|
| 6 |
+
background:
|
| 7 |
+
image:
|
| 8 |
+
paths: [resources/background]
|
| 9 |
+
weights: [1]
|
| 10 |
+
|
| 11 |
+
effect:
|
| 12 |
+
args:
|
| 13 |
+
# gaussian blur
|
| 14 |
+
- prob: 1
|
| 15 |
+
args:
|
| 16 |
+
sigma: [0, 10]
|
| 17 |
+
|
| 18 |
+
document:
|
| 19 |
+
fullscreen: 0.5
|
| 20 |
+
landscape: 0.5
|
| 21 |
+
short_size: [480, 1024]
|
| 22 |
+
aspect_ratio: [1, 2]
|
| 23 |
+
|
| 24 |
+
paper:
|
| 25 |
+
image:
|
| 26 |
+
paths: [resources/paper]
|
| 27 |
+
weights: [1]
|
| 28 |
+
alpha: [0, 0.2]
|
| 29 |
+
grayscale: 1
|
| 30 |
+
crop: 1
|
| 31 |
+
|
| 32 |
+
content:
|
| 33 |
+
margin: [0, 0.1]
|
| 34 |
+
text:
|
| 35 |
+
path: resources/corpus/enwiki.txt
|
| 36 |
+
font:
|
| 37 |
+
paths: [resources/font/en]
|
| 38 |
+
weights: [1]
|
| 39 |
+
bold: 0
|
| 40 |
+
layout:
|
| 41 |
+
text_scale: [0.0334, 0.1]
|
| 42 |
+
max_row: 10
|
| 43 |
+
max_col: 3
|
| 44 |
+
fill: [0.5, 1]
|
| 45 |
+
full: 0.1
|
| 46 |
+
align: [left, right, center]
|
| 47 |
+
stack_spacing: [0.0334, 0.0334]
|
| 48 |
+
stack_fill: [0.5, 1]
|
| 49 |
+
stack_full: 0.1
|
| 50 |
+
textbox:
|
| 51 |
+
fill: [0.5, 1]
|
| 52 |
+
textbox_color:
|
| 53 |
+
prob: 0.2
|
| 54 |
+
args:
|
| 55 |
+
gray: [0, 64]
|
| 56 |
+
colorize: 1
|
| 57 |
+
content_color:
|
| 58 |
+
prob: 0.2
|
| 59 |
+
args:
|
| 60 |
+
gray: [0, 64]
|
| 61 |
+
colorize: 1
|
| 62 |
+
|
| 63 |
+
effect:
|
| 64 |
+
args:
|
| 65 |
+
# elastic distortion
|
| 66 |
+
- prob: 1
|
| 67 |
+
args:
|
| 68 |
+
alpha: [0, 1]
|
| 69 |
+
sigma: [0, 0.5]
|
| 70 |
+
# gaussian noise
|
| 71 |
+
- prob: 1
|
| 72 |
+
args:
|
| 73 |
+
scale: [0, 8]
|
| 74 |
+
per_channel: 0
|
| 75 |
+
# perspective
|
| 76 |
+
- prob: 1
|
| 77 |
+
args:
|
| 78 |
+
weights: [750, 50, 50, 25, 25, 25, 25, 50]
|
| 79 |
+
args:
|
| 80 |
+
- percents: [[0.75, 1], [0.75, 1], [0.75, 1], [0.75, 1]]
|
| 81 |
+
- percents: [[0.75, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 82 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [0.75, 1]]
|
| 83 |
+
- percents: [[0.75, 1], [1, 1], [1, 1], [1, 1]]
|
| 84 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [1, 1]]
|
| 85 |
+
- percents: [[1, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 86 |
+
- percents: [[1, 1], [1, 1], [1, 1], [0.75, 1]]
|
| 87 |
+
- percents: [[1, 1], [1, 1], [1, 1], [1, 1]]
|
| 88 |
+
|
| 89 |
+
effect:
|
| 90 |
+
args:
|
| 91 |
+
# color
|
| 92 |
+
- prob: 0.2
|
| 93 |
+
args:
|
| 94 |
+
rgb: [[0, 255], [0, 255], [0, 255]]
|
| 95 |
+
alpha: [0, 0.2]
|
| 96 |
+
# shadow
|
| 97 |
+
- prob: 1
|
| 98 |
+
args:
|
| 99 |
+
intensity: [0, 160]
|
| 100 |
+
amount: [0, 1]
|
| 101 |
+
smoothing: [0.5, 1]
|
| 102 |
+
bidirectional: 0
|
| 103 |
+
# contrast
|
| 104 |
+
- prob: 1
|
| 105 |
+
args:
|
| 106 |
+
alpha: [1, 1.5]
|
| 107 |
+
# brightness
|
| 108 |
+
- prob: 1
|
| 109 |
+
args:
|
| 110 |
+
beta: [-48, 0]
|
| 111 |
+
# motion blur
|
| 112 |
+
- prob: 0.5
|
| 113 |
+
args:
|
| 114 |
+
k: [3, 5]
|
| 115 |
+
angle: [0, 360]
|
| 116 |
+
# gaussian blur
|
| 117 |
+
- prob: 1
|
| 118 |
+
args:
|
| 119 |
+
sigma: [0, 1.5]
|
synthdog/config_ja.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
quality: [50, 95]
|
| 2 |
+
landscape: 0.5
|
| 3 |
+
short_size: [720, 1024]
|
| 4 |
+
aspect_ratio: [1, 2]
|
| 5 |
+
|
| 6 |
+
background:
|
| 7 |
+
image:
|
| 8 |
+
paths: [resources/background]
|
| 9 |
+
weights: [1]
|
| 10 |
+
|
| 11 |
+
effect:
|
| 12 |
+
args:
|
| 13 |
+
# gaussian blur
|
| 14 |
+
- prob: 1
|
| 15 |
+
args:
|
| 16 |
+
sigma: [0, 10]
|
| 17 |
+
|
| 18 |
+
document:
|
| 19 |
+
fullscreen: 0.5
|
| 20 |
+
landscape: 0.5
|
| 21 |
+
short_size: [480, 1024]
|
| 22 |
+
aspect_ratio: [1, 2]
|
| 23 |
+
|
| 24 |
+
paper:
|
| 25 |
+
image:
|
| 26 |
+
paths: [resources/paper]
|
| 27 |
+
weights: [1]
|
| 28 |
+
alpha: [0, 0.2]
|
| 29 |
+
grayscale: 1
|
| 30 |
+
crop: 1
|
| 31 |
+
|
| 32 |
+
content:
|
| 33 |
+
margin: [0, 0.1]
|
| 34 |
+
text:
|
| 35 |
+
path: resources/corpus/jawiki.txt
|
| 36 |
+
font:
|
| 37 |
+
paths: [resources/font/ja]
|
| 38 |
+
weights: [1]
|
| 39 |
+
bold: 0
|
| 40 |
+
layout:
|
| 41 |
+
text_scale: [0.0334, 0.1]
|
| 42 |
+
max_row: 10
|
| 43 |
+
max_col: 3
|
| 44 |
+
fill: [0.5, 1]
|
| 45 |
+
full: 0.1
|
| 46 |
+
align: [left, right, center]
|
| 47 |
+
stack_spacing: [0.0334, 0.0334]
|
| 48 |
+
stack_fill: [0.5, 1]
|
| 49 |
+
stack_full: 0.1
|
| 50 |
+
textbox:
|
| 51 |
+
fill: [0.5, 1]
|
| 52 |
+
textbox_color:
|
| 53 |
+
prob: 0.2
|
| 54 |
+
args:
|
| 55 |
+
gray: [0, 64]
|
| 56 |
+
colorize: 1
|
| 57 |
+
content_color:
|
| 58 |
+
prob: 0.2
|
| 59 |
+
args:
|
| 60 |
+
gray: [0, 64]
|
| 61 |
+
colorize: 1
|
| 62 |
+
|
| 63 |
+
effect:
|
| 64 |
+
args:
|
| 65 |
+
# elastic distortion
|
| 66 |
+
- prob: 1
|
| 67 |
+
args:
|
| 68 |
+
alpha: [0, 1]
|
| 69 |
+
sigma: [0, 0.5]
|
| 70 |
+
# gaussian noise
|
| 71 |
+
- prob: 1
|
| 72 |
+
args:
|
| 73 |
+
scale: [0, 8]
|
| 74 |
+
per_channel: 0
|
| 75 |
+
# perspective
|
| 76 |
+
- prob: 1
|
| 77 |
+
args:
|
| 78 |
+
weights: [750, 50, 50, 25, 25, 25, 25, 50]
|
| 79 |
+
args:
|
| 80 |
+
- percents: [[0.75, 1], [0.75, 1], [0.75, 1], [0.75, 1]]
|
| 81 |
+
- percents: [[0.75, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 82 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [0.75, 1]]
|
| 83 |
+
- percents: [[0.75, 1], [1, 1], [1, 1], [1, 1]]
|
| 84 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [1, 1]]
|
| 85 |
+
- percents: [[1, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 86 |
+
- percents: [[1, 1], [1, 1], [1, 1], [0.75, 1]]
|
| 87 |
+
- percents: [[1, 1], [1, 1], [1, 1], [1, 1]]
|
| 88 |
+
|
| 89 |
+
effect:
|
| 90 |
+
args:
|
| 91 |
+
# color
|
| 92 |
+
- prob: 0.2
|
| 93 |
+
args:
|
| 94 |
+
rgb: [[0, 255], [0, 255], [0, 255]]
|
| 95 |
+
alpha: [0, 0.2]
|
| 96 |
+
# shadow
|
| 97 |
+
- prob: 1
|
| 98 |
+
args:
|
| 99 |
+
intensity: [0, 160]
|
| 100 |
+
amount: [0, 1]
|
| 101 |
+
smoothing: [0.5, 1]
|
| 102 |
+
bidirectional: 0
|
| 103 |
+
# contrast
|
| 104 |
+
- prob: 1
|
| 105 |
+
args:
|
| 106 |
+
alpha: [1, 1.5]
|
| 107 |
+
# brightness
|
| 108 |
+
- prob: 1
|
| 109 |
+
args:
|
| 110 |
+
beta: [-48, 0]
|
| 111 |
+
# motion blur
|
| 112 |
+
- prob: 0.5
|
| 113 |
+
args:
|
| 114 |
+
k: [3, 5]
|
| 115 |
+
angle: [0, 360]
|
| 116 |
+
# gaussian blur
|
| 117 |
+
- prob: 1
|
| 118 |
+
args:
|
| 119 |
+
sigma: [0, 1.5]
|
synthdog/config_ko.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
quality: [50, 95]
|
| 2 |
+
landscape: 0.5
|
| 3 |
+
short_size: [720, 1024]
|
| 4 |
+
aspect_ratio: [1, 2]
|
| 5 |
+
|
| 6 |
+
background:
|
| 7 |
+
image:
|
| 8 |
+
paths: [resources/background]
|
| 9 |
+
weights: [1]
|
| 10 |
+
|
| 11 |
+
effect:
|
| 12 |
+
args:
|
| 13 |
+
# gaussian blur
|
| 14 |
+
- prob: 1
|
| 15 |
+
args:
|
| 16 |
+
sigma: [0, 10]
|
| 17 |
+
|
| 18 |
+
document:
|
| 19 |
+
fullscreen: 0.5
|
| 20 |
+
landscape: 0.5
|
| 21 |
+
short_size: [480, 1024]
|
| 22 |
+
aspect_ratio: [1, 2]
|
| 23 |
+
|
| 24 |
+
paper:
|
| 25 |
+
image:
|
| 26 |
+
paths: [resources/paper]
|
| 27 |
+
weights: [1]
|
| 28 |
+
alpha: [0, 0.2]
|
| 29 |
+
grayscale: 1
|
| 30 |
+
crop: 1
|
| 31 |
+
|
| 32 |
+
content:
|
| 33 |
+
margin: [0, 0.1]
|
| 34 |
+
text:
|
| 35 |
+
path: resources/corpus/kowiki.txt
|
| 36 |
+
font:
|
| 37 |
+
paths: [resources/font/ko]
|
| 38 |
+
weights: [1]
|
| 39 |
+
bold: 0
|
| 40 |
+
layout:
|
| 41 |
+
text_scale: [0.0334, 0.1]
|
| 42 |
+
max_row: 10
|
| 43 |
+
max_col: 3
|
| 44 |
+
fill: [0.5, 1]
|
| 45 |
+
full: 0.1
|
| 46 |
+
align: [left, right, center]
|
| 47 |
+
stack_spacing: [0.0334, 0.0334]
|
| 48 |
+
stack_fill: [0.5, 1]
|
| 49 |
+
stack_full: 0.1
|
| 50 |
+
textbox:
|
| 51 |
+
fill: [0.5, 1]
|
| 52 |
+
textbox_color:
|
| 53 |
+
prob: 0.2
|
| 54 |
+
args:
|
| 55 |
+
gray: [0, 64]
|
| 56 |
+
colorize: 1
|
| 57 |
+
content_color:
|
| 58 |
+
prob: 0.2
|
| 59 |
+
args:
|
| 60 |
+
gray: [0, 64]
|
| 61 |
+
colorize: 1
|
| 62 |
+
|
| 63 |
+
effect:
|
| 64 |
+
args:
|
| 65 |
+
# elastic distortion
|
| 66 |
+
- prob: 1
|
| 67 |
+
args:
|
| 68 |
+
alpha: [0, 1]
|
| 69 |
+
sigma: [0, 0.5]
|
| 70 |
+
# gaussian noise
|
| 71 |
+
- prob: 1
|
| 72 |
+
args:
|
| 73 |
+
scale: [0, 8]
|
| 74 |
+
per_channel: 0
|
| 75 |
+
# perspective
|
| 76 |
+
- prob: 1
|
| 77 |
+
args:
|
| 78 |
+
weights: [750, 50, 50, 25, 25, 25, 25, 50]
|
| 79 |
+
args:
|
| 80 |
+
- percents: [[0.75, 1], [0.75, 1], [0.75, 1], [0.75, 1]]
|
| 81 |
+
- percents: [[0.75, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 82 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [0.75, 1]]
|
| 83 |
+
- percents: [[0.75, 1], [1, 1], [1, 1], [1, 1]]
|
| 84 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [1, 1]]
|
| 85 |
+
- percents: [[1, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 86 |
+
- percents: [[1, 1], [1, 1], [1, 1], [0.75, 1]]
|
| 87 |
+
- percents: [[1, 1], [1, 1], [1, 1], [1, 1]]
|
| 88 |
+
|
| 89 |
+
effect:
|
| 90 |
+
args:
|
| 91 |
+
# color
|
| 92 |
+
- prob: 0.2
|
| 93 |
+
args:
|
| 94 |
+
rgb: [[0, 255], [0, 255], [0, 255]]
|
| 95 |
+
alpha: [0, 0.2]
|
| 96 |
+
# shadow
|
| 97 |
+
- prob: 1
|
| 98 |
+
args:
|
| 99 |
+
intensity: [0, 160]
|
| 100 |
+
amount: [0, 1]
|
| 101 |
+
smoothing: [0.5, 1]
|
| 102 |
+
bidirectional: 0
|
| 103 |
+
# contrast
|
| 104 |
+
- prob: 1
|
| 105 |
+
args:
|
| 106 |
+
alpha: [1, 1.5]
|
| 107 |
+
# brightness
|
| 108 |
+
- prob: 1
|
| 109 |
+
args:
|
| 110 |
+
beta: [-48, 0]
|
| 111 |
+
# motion blur
|
| 112 |
+
- prob: 0.5
|
| 113 |
+
args:
|
| 114 |
+
k: [3, 5]
|
| 115 |
+
angle: [0, 360]
|
| 116 |
+
# gaussian blur
|
| 117 |
+
- prob: 1
|
| 118 |
+
args:
|
| 119 |
+
sigma: [0, 1.5]
|
synthdog/config_zh.yaml
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
quality: [50, 95]
|
| 2 |
+
landscape: 0.5
|
| 3 |
+
short_size: [720, 1024]
|
| 4 |
+
aspect_ratio: [1, 2]
|
| 5 |
+
|
| 6 |
+
background:
|
| 7 |
+
image:
|
| 8 |
+
paths: [resources/background]
|
| 9 |
+
weights: [1]
|
| 10 |
+
|
| 11 |
+
effect:
|
| 12 |
+
args:
|
| 13 |
+
# gaussian blur
|
| 14 |
+
- prob: 1
|
| 15 |
+
args:
|
| 16 |
+
sigma: [0, 10]
|
| 17 |
+
|
| 18 |
+
document:
|
| 19 |
+
fullscreen: 0.5
|
| 20 |
+
landscape: 0.5
|
| 21 |
+
short_size: [480, 1024]
|
| 22 |
+
aspect_ratio: [1, 2]
|
| 23 |
+
|
| 24 |
+
paper:
|
| 25 |
+
image:
|
| 26 |
+
paths: [resources/paper]
|
| 27 |
+
weights: [1]
|
| 28 |
+
alpha: [0, 0.2]
|
| 29 |
+
grayscale: 1
|
| 30 |
+
crop: 1
|
| 31 |
+
|
| 32 |
+
content:
|
| 33 |
+
margin: [0, 0.1]
|
| 34 |
+
text:
|
| 35 |
+
path: resources/corpus/zhwiki.txt
|
| 36 |
+
font:
|
| 37 |
+
paths: [resources/font/zh]
|
| 38 |
+
weights: [1]
|
| 39 |
+
bold: 0
|
| 40 |
+
layout:
|
| 41 |
+
text_scale: [0.0334, 0.1]
|
| 42 |
+
max_row: 10
|
| 43 |
+
max_col: 3
|
| 44 |
+
fill: [0.5, 1]
|
| 45 |
+
full: 0.1
|
| 46 |
+
align: [left, right, center]
|
| 47 |
+
stack_spacing: [0.0334, 0.0334]
|
| 48 |
+
stack_fill: [0.5, 1]
|
| 49 |
+
stack_full: 0.1
|
| 50 |
+
textbox:
|
| 51 |
+
fill: [0.5, 1]
|
| 52 |
+
textbox_color:
|
| 53 |
+
prob: 0.2
|
| 54 |
+
args:
|
| 55 |
+
gray: [0, 64]
|
| 56 |
+
colorize: 1
|
| 57 |
+
content_color:
|
| 58 |
+
prob: 0.2
|
| 59 |
+
args:
|
| 60 |
+
gray: [0, 64]
|
| 61 |
+
colorize: 1
|
| 62 |
+
|
| 63 |
+
effect:
|
| 64 |
+
args:
|
| 65 |
+
# elastic distortion
|
| 66 |
+
- prob: 1
|
| 67 |
+
args:
|
| 68 |
+
alpha: [0, 1]
|
| 69 |
+
sigma: [0, 0.5]
|
| 70 |
+
# gaussian noise
|
| 71 |
+
- prob: 1
|
| 72 |
+
args:
|
| 73 |
+
scale: [0, 8]
|
| 74 |
+
per_channel: 0
|
| 75 |
+
# perspective
|
| 76 |
+
- prob: 1
|
| 77 |
+
args:
|
| 78 |
+
weights: [750, 50, 50, 25, 25, 25, 25, 50]
|
| 79 |
+
args:
|
| 80 |
+
- percents: [[0.75, 1], [0.75, 1], [0.75, 1], [0.75, 1]]
|
| 81 |
+
- percents: [[0.75, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 82 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [0.75, 1]]
|
| 83 |
+
- percents: [[0.75, 1], [1, 1], [1, 1], [1, 1]]
|
| 84 |
+
- percents: [[1, 1], [0.75, 1], [1, 1], [1, 1]]
|
| 85 |
+
- percents: [[1, 1], [1, 1], [0.75, 1], [1, 1]]
|
| 86 |
+
- percents: [[1, 1], [1, 1], [1, 1], [0.75, 1]]
|
| 87 |
+
- percents: [[1, 1], [1, 1], [1, 1], [1, 1]]
|
| 88 |
+
|
| 89 |
+
effect:
|
| 90 |
+
args:
|
| 91 |
+
# color
|
| 92 |
+
- prob: 0.2
|
| 93 |
+
args:
|
| 94 |
+
rgb: [[0, 255], [0, 255], [0, 255]]
|
| 95 |
+
alpha: [0, 0.2]
|
| 96 |
+
# shadow
|
| 97 |
+
- prob: 1
|
| 98 |
+
args:
|
| 99 |
+
intensity: [0, 160]
|
| 100 |
+
amount: [0, 1]
|
| 101 |
+
smoothing: [0.5, 1]
|
| 102 |
+
bidirectional: 0
|
| 103 |
+
# contrast
|
| 104 |
+
- prob: 1
|
| 105 |
+
args:
|
| 106 |
+
alpha: [1, 1.5]
|
| 107 |
+
# brightness
|
| 108 |
+
- prob: 1
|
| 109 |
+
args:
|
| 110 |
+
beta: [-48, 0]
|
| 111 |
+
# motion blur
|
| 112 |
+
- prob: 0.5
|
| 113 |
+
args:
|
| 114 |
+
k: [3, 5]
|
| 115 |
+
angle: [0, 360]
|
| 116 |
+
# gaussian blur
|
| 117 |
+
- prob: 1
|
| 118 |
+
args:
|
| 119 |
+
sigma: [0, 1.5]
|
synthdog/elements/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
from elements.background import Background
|
| 7 |
+
from elements.content import Content
|
| 8 |
+
from elements.document import Document
|
| 9 |
+
from elements.paper import Paper
|
| 10 |
+
from elements.textbox import TextBox
|
| 11 |
+
|
| 12 |
+
__all__ = ["Background", "Content", "Document", "Paper", "TextBox"]
|
synthdog/elements/background.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
from synthtiger import components, layers
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Background:
|
| 10 |
+
def __init__(self, config):
|
| 11 |
+
self.image = components.BaseTexture(**config.get("image", {}))
|
| 12 |
+
self.effect = components.Iterator(
|
| 13 |
+
[
|
| 14 |
+
components.Switch(components.GaussianBlur()),
|
| 15 |
+
],
|
| 16 |
+
**config.get("effect", {})
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
def generate(self, size):
|
| 20 |
+
bg_layer = layers.RectLayer(size, (255, 255, 255, 255))
|
| 21 |
+
self.image.apply([bg_layer])
|
| 22 |
+
self.effect.apply([bg_layer])
|
| 23 |
+
|
| 24 |
+
return bg_layer
|
synthdog/elements/content.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
from collections import OrderedDict
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
from synthtiger import components
|
| 10 |
+
|
| 11 |
+
from elements.textbox import TextBox
|
| 12 |
+
from layouts import GridStack
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class TextReader:
|
| 16 |
+
def __init__(self, path, cache_size=2 ** 28, block_size=2 ** 20):
|
| 17 |
+
self.fp = open(path, "r", encoding="utf-8")
|
| 18 |
+
self.length = 0
|
| 19 |
+
self.offsets = [0]
|
| 20 |
+
self.cache = OrderedDict()
|
| 21 |
+
self.cache_size = cache_size
|
| 22 |
+
self.block_size = block_size
|
| 23 |
+
self.bucket_size = cache_size // block_size
|
| 24 |
+
self.idx = 0
|
| 25 |
+
|
| 26 |
+
while True:
|
| 27 |
+
text = self.fp.read(self.block_size)
|
| 28 |
+
if not text:
|
| 29 |
+
break
|
| 30 |
+
self.length += len(text)
|
| 31 |
+
self.offsets.append(self.fp.tell())
|
| 32 |
+
|
| 33 |
+
def __len__(self):
|
| 34 |
+
return self.length
|
| 35 |
+
|
| 36 |
+
def __iter__(self):
|
| 37 |
+
return self
|
| 38 |
+
|
| 39 |
+
def __next__(self):
|
| 40 |
+
char = self.get()
|
| 41 |
+
self.next()
|
| 42 |
+
return char
|
| 43 |
+
|
| 44 |
+
def move(self, idx):
|
| 45 |
+
self.idx = idx
|
| 46 |
+
|
| 47 |
+
def next(self):
|
| 48 |
+
self.idx = (self.idx + 1) % self.length
|
| 49 |
+
|
| 50 |
+
def prev(self):
|
| 51 |
+
self.idx = (self.idx - 1) % self.length
|
| 52 |
+
|
| 53 |
+
def get(self):
|
| 54 |
+
key = self.idx // self.block_size
|
| 55 |
+
|
| 56 |
+
if key in self.cache:
|
| 57 |
+
text = self.cache[key]
|
| 58 |
+
else:
|
| 59 |
+
if len(self.cache) >= self.bucket_size:
|
| 60 |
+
self.cache.popitem(last=False)
|
| 61 |
+
|
| 62 |
+
offset = self.offsets[key]
|
| 63 |
+
self.fp.seek(offset, 0)
|
| 64 |
+
text = self.fp.read(self.block_size)
|
| 65 |
+
self.cache[key] = text
|
| 66 |
+
|
| 67 |
+
self.cache.move_to_end(key)
|
| 68 |
+
char = text[self.idx % self.block_size]
|
| 69 |
+
return char
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class Content:
|
| 73 |
+
def __init__(self, config):
|
| 74 |
+
self.margin = config.get("margin", [0, 0.1])
|
| 75 |
+
self.reader = TextReader(**config.get("text", {}))
|
| 76 |
+
self.font = components.BaseFont(**config.get("font", {}))
|
| 77 |
+
self.layout = GridStack(config.get("layout", {}))
|
| 78 |
+
self.textbox = TextBox(config.get("textbox", {}))
|
| 79 |
+
self.textbox_color = components.Switch(components.Gray(), **config.get("textbox_color", {}))
|
| 80 |
+
self.content_color = components.Switch(components.Gray(), **config.get("content_color", {}))
|
| 81 |
+
|
| 82 |
+
def generate(self, size):
|
| 83 |
+
width, height = size
|
| 84 |
+
|
| 85 |
+
layout_left = width * np.random.uniform(self.margin[0], self.margin[1])
|
| 86 |
+
layout_top = height * np.random.uniform(self.margin[0], self.margin[1])
|
| 87 |
+
layout_width = max(width - layout_left * 2, 0)
|
| 88 |
+
layout_height = max(height - layout_top * 2, 0)
|
| 89 |
+
layout_bbox = [layout_left, layout_top, layout_width, layout_height]
|
| 90 |
+
|
| 91 |
+
text_layers, texts = [], []
|
| 92 |
+
layouts = self.layout.generate(layout_bbox)
|
| 93 |
+
self.reader.move(np.random.randint(len(self.reader)))
|
| 94 |
+
|
| 95 |
+
for layout in layouts:
|
| 96 |
+
font = self.font.sample()
|
| 97 |
+
|
| 98 |
+
for bbox, align in layout:
|
| 99 |
+
x, y, w, h = bbox
|
| 100 |
+
text_layer, text = self.textbox.generate((w, h), self.reader, font)
|
| 101 |
+
self.reader.prev()
|
| 102 |
+
|
| 103 |
+
if text_layer is None:
|
| 104 |
+
continue
|
| 105 |
+
|
| 106 |
+
text_layer.center = (x + w / 2, y + h / 2)
|
| 107 |
+
if align == "left":
|
| 108 |
+
text_layer.left = x
|
| 109 |
+
if align == "right":
|
| 110 |
+
text_layer.right = x + w
|
| 111 |
+
|
| 112 |
+
self.textbox_color.apply([text_layer])
|
| 113 |
+
text_layers.append(text_layer)
|
| 114 |
+
texts.append(text)
|
| 115 |
+
|
| 116 |
+
self.content_color.apply(text_layers)
|
| 117 |
+
|
| 118 |
+
return text_layers, texts
|
synthdog/elements/document.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import numpy as np
|
| 7 |
+
from synthtiger import components
|
| 8 |
+
|
| 9 |
+
from elements.content import Content
|
| 10 |
+
from elements.paper import Paper
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Document:
|
| 14 |
+
def __init__(self, config):
|
| 15 |
+
self.fullscreen = config.get("fullscreen", 0.5)
|
| 16 |
+
self.landscape = config.get("landscape", 0.5)
|
| 17 |
+
self.short_size = config.get("short_size", [480, 1024])
|
| 18 |
+
self.aspect_ratio = config.get("aspect_ratio", [1, 2])
|
| 19 |
+
self.paper = Paper(config.get("paper", {}))
|
| 20 |
+
self.content = Content(config.get("content", {}))
|
| 21 |
+
self.effect = components.Iterator(
|
| 22 |
+
[
|
| 23 |
+
components.Switch(components.ElasticDistortion()),
|
| 24 |
+
components.Switch(components.AdditiveGaussianNoise()),
|
| 25 |
+
components.Switch(
|
| 26 |
+
components.Selector(
|
| 27 |
+
[
|
| 28 |
+
components.Perspective(),
|
| 29 |
+
components.Perspective(),
|
| 30 |
+
components.Perspective(),
|
| 31 |
+
components.Perspective(),
|
| 32 |
+
components.Perspective(),
|
| 33 |
+
components.Perspective(),
|
| 34 |
+
components.Perspective(),
|
| 35 |
+
components.Perspective(),
|
| 36 |
+
]
|
| 37 |
+
)
|
| 38 |
+
),
|
| 39 |
+
],
|
| 40 |
+
**config.get("effect", {}),
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
def generate(self, size):
|
| 44 |
+
width, height = size
|
| 45 |
+
fullscreen = np.random.rand() < self.fullscreen
|
| 46 |
+
|
| 47 |
+
if not fullscreen:
|
| 48 |
+
landscape = np.random.rand() < self.landscape
|
| 49 |
+
max_size = width if landscape else height
|
| 50 |
+
short_size = np.random.randint(
|
| 51 |
+
min(width, height, self.short_size[0]),
|
| 52 |
+
min(width, height, self.short_size[1]) + 1,
|
| 53 |
+
)
|
| 54 |
+
aspect_ratio = np.random.uniform(
|
| 55 |
+
min(max_size / short_size, self.aspect_ratio[0]),
|
| 56 |
+
min(max_size / short_size, self.aspect_ratio[1]),
|
| 57 |
+
)
|
| 58 |
+
long_size = int(short_size * aspect_ratio)
|
| 59 |
+
size = (long_size, short_size) if landscape else (short_size, long_size)
|
| 60 |
+
|
| 61 |
+
text_layers, texts = self.content.generate(size)
|
| 62 |
+
paper_layer = self.paper.generate(size)
|
| 63 |
+
self.effect.apply([*text_layers, paper_layer])
|
| 64 |
+
|
| 65 |
+
return paper_layer, text_layers, texts
|
synthdog/elements/paper.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
from synthtiger import components, layers
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Paper:
|
| 10 |
+
def __init__(self, config):
|
| 11 |
+
self.image = components.BaseTexture(**config.get("image", {}))
|
| 12 |
+
|
| 13 |
+
def generate(self, size):
|
| 14 |
+
paper_layer = layers.RectLayer(size, (255, 255, 255, 255))
|
| 15 |
+
self.image.apply([paper_layer])
|
| 16 |
+
|
| 17 |
+
return paper_layer
|
synthdog/elements/textbox.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import numpy as np
|
| 7 |
+
from synthtiger import layers
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class TextBox:
|
| 11 |
+
def __init__(self, config):
|
| 12 |
+
self.fill = config.get("fill", [1, 1])
|
| 13 |
+
|
| 14 |
+
def generate(self, size, text, font):
|
| 15 |
+
width, height = size
|
| 16 |
+
|
| 17 |
+
char_layers, chars = [], []
|
| 18 |
+
fill = np.random.uniform(self.fill[0], self.fill[1])
|
| 19 |
+
width = np.clip(width * fill, height, width)
|
| 20 |
+
font = {**font, "size": int(height)}
|
| 21 |
+
left, top = 0, 0
|
| 22 |
+
|
| 23 |
+
for char in text:
|
| 24 |
+
if char in "\r\n":
|
| 25 |
+
continue
|
| 26 |
+
|
| 27 |
+
char_layer = layers.TextLayer(char, **font)
|
| 28 |
+
char_scale = height / char_layer.height
|
| 29 |
+
char_layer.bbox = [left, top, *(char_layer.size * char_scale)]
|
| 30 |
+
if char_layer.right > width:
|
| 31 |
+
break
|
| 32 |
+
|
| 33 |
+
char_layers.append(char_layer)
|
| 34 |
+
chars.append(char)
|
| 35 |
+
left = char_layer.right
|
| 36 |
+
|
| 37 |
+
text = "".join(chars).strip()
|
| 38 |
+
if len(char_layers) == 0 or len(text) == 0:
|
| 39 |
+
return None, None
|
| 40 |
+
|
| 41 |
+
text_layer = layers.Group(char_layers).merge()
|
| 42 |
+
|
| 43 |
+
return text_layer, text
|
synthdog/layouts/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
from layouts.grid import Grid
|
| 7 |
+
from layouts.grid_stack import GridStack
|
| 8 |
+
|
| 9 |
+
__all__ = ["Grid", "GridStack"]
|
synthdog/layouts/grid.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Grid:
|
| 10 |
+
def __init__(self, config):
|
| 11 |
+
self.text_scale = config.get("text_scale", [0.05, 0.1])
|
| 12 |
+
self.max_row = config.get("max_row", 5)
|
| 13 |
+
self.max_col = config.get("max_col", 3)
|
| 14 |
+
self.fill = config.get("fill", [0, 1])
|
| 15 |
+
self.full = config.get("full", 0)
|
| 16 |
+
self.align = config.get("align", ["left", "right", "center"])
|
| 17 |
+
|
| 18 |
+
def generate(self, bbox):
|
| 19 |
+
left, top, width, height = bbox
|
| 20 |
+
|
| 21 |
+
text_scale = np.random.uniform(self.text_scale[0], self.text_scale[1])
|
| 22 |
+
text_size = min(width, height) * text_scale
|
| 23 |
+
grids = np.random.permutation(self.max_row * self.max_col)
|
| 24 |
+
|
| 25 |
+
for grid in grids:
|
| 26 |
+
row = grid // self.max_col + 1
|
| 27 |
+
col = grid % self.max_col + 1
|
| 28 |
+
if text_size * (col * 2 - 1) <= width and text_size * row <= height:
|
| 29 |
+
break
|
| 30 |
+
else:
|
| 31 |
+
return None
|
| 32 |
+
|
| 33 |
+
bound = max(1 - text_size / width * (col - 1), 0)
|
| 34 |
+
full = np.random.rand() < self.full
|
| 35 |
+
fill = np.random.uniform(self.fill[0], self.fill[1])
|
| 36 |
+
fill = 1 if full else fill
|
| 37 |
+
fill = np.clip(fill, 0, bound)
|
| 38 |
+
|
| 39 |
+
padding = np.random.randint(4) if col > 1 else np.random.randint(1, 4)
|
| 40 |
+
padding = (bool(padding // 2), bool(padding % 2))
|
| 41 |
+
|
| 42 |
+
weights = np.zeros(col * 2 + 1)
|
| 43 |
+
weights[1:-1] = text_size / width
|
| 44 |
+
probs = 1 - np.random.rand(col * 2 + 1)
|
| 45 |
+
probs[0] = 0 if not padding[0] else probs[0]
|
| 46 |
+
probs[-1] = 0 if not padding[-1] else probs[-1]
|
| 47 |
+
probs[1::2] *= max(fill - sum(weights[1::2]), 0) / sum(probs[1::2])
|
| 48 |
+
probs[::2] *= max(1 - fill - sum(weights[::2]), 0) / sum(probs[::2])
|
| 49 |
+
weights += probs
|
| 50 |
+
|
| 51 |
+
widths = [width * weights[c] for c in range(col * 2 + 1)]
|
| 52 |
+
heights = [text_size for _ in range(row)]
|
| 53 |
+
|
| 54 |
+
xs = np.cumsum([0] + widths)
|
| 55 |
+
ys = np.cumsum([0] + heights)
|
| 56 |
+
|
| 57 |
+
layout = []
|
| 58 |
+
|
| 59 |
+
for c in range(col):
|
| 60 |
+
align = self.align[np.random.randint(len(self.align))]
|
| 61 |
+
|
| 62 |
+
for r in range(row):
|
| 63 |
+
x, y = xs[c * 2 + 1], ys[r]
|
| 64 |
+
w, h = xs[c * 2 + 2] - x, ys[r + 1] - y
|
| 65 |
+
bbox = [left + x, top + y, w, h]
|
| 66 |
+
layout.append((bbox, align))
|
| 67 |
+
|
| 68 |
+
return layout
|
synthdog/layouts/grid_stack.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Donut
|
| 3 |
+
Copyright (c) 2022-present NAVER Corp.
|
| 4 |
+
MIT License
|
| 5 |
+
"""
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
from layouts import Grid
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class GridStack:
|
| 12 |
+
def __init__(self, config):
|
| 13 |
+
self.text_scale = config.get("text_scale", [0.05, 0.1])
|
| 14 |
+
self.max_row = config.get("max_row", 5)
|
| 15 |
+
self.max_col = config.get("max_col", 3)
|
| 16 |
+
self.fill = config.get("fill", [0, 1])
|
| 17 |
+
self.full = config.get("full", 0)
|
| 18 |
+
self.align = config.get("align", ["left", "right", "center"])
|
| 19 |
+
self.stack_spacing = config.get("stack_spacing", [0, 0.05])
|
| 20 |
+
self.stack_fill = config.get("stack_fill", [1, 1])
|
| 21 |
+
self.stack_full = config.get("stack_full", 0)
|
| 22 |
+
self._grid = Grid(
|
| 23 |
+
{
|
| 24 |
+
"text_scale": self.text_scale,
|
| 25 |
+
"max_row": self.max_row,
|
| 26 |
+
"max_col": self.max_col,
|
| 27 |
+
"align": self.align,
|
| 28 |
+
}
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
def generate(self, bbox):
|
| 32 |
+
left, top, width, height = bbox
|
| 33 |
+
|
| 34 |
+
stack_spacing = np.random.uniform(self.stack_spacing[0], self.stack_spacing[1])
|
| 35 |
+
stack_spacing *= min(width, height)
|
| 36 |
+
|
| 37 |
+
stack_full = np.random.rand() < self.stack_full
|
| 38 |
+
stack_fill = np.random.uniform(self.stack_fill[0], self.stack_fill[1])
|
| 39 |
+
stack_fill = 1 if stack_full else stack_fill
|
| 40 |
+
|
| 41 |
+
full = np.random.rand() < self.full
|
| 42 |
+
fill = np.random.uniform(self.fill[0], self.fill[1])
|
| 43 |
+
fill = 1 if full else fill
|
| 44 |
+
self._grid.fill = [fill, fill]
|
| 45 |
+
|
| 46 |
+
layouts = []
|
| 47 |
+
line = 0
|
| 48 |
+
|
| 49 |
+
while True:
|
| 50 |
+
grid_size = (width, height * stack_fill - line)
|
| 51 |
+
text_scale = np.random.uniform(self.text_scale[0], self.text_scale[1])
|
| 52 |
+
text_size = min(width, height) * text_scale
|
| 53 |
+
text_scale = text_size / min(grid_size)
|
| 54 |
+
self._grid.text_scale = [text_scale, text_scale]
|
| 55 |
+
|
| 56 |
+
layout = self._grid.generate([left, top + line, *grid_size])
|
| 57 |
+
if layout is None:
|
| 58 |
+
break
|
| 59 |
+
|
| 60 |
+
line = max(y + h - top for (_, y, _, h), _ in layout) + stack_spacing
|
| 61 |
+
layouts.append(layout)
|
| 62 |
+
|
| 63 |
+
line = max(line - stack_spacing, 0)
|
| 64 |
+
space = max(height - line, 0)
|
| 65 |
+
spaces = np.random.rand(len(layouts) + 1)
|
| 66 |
+
spaces *= space / sum(spaces) if sum(spaces) > 0 else 0
|
| 67 |
+
spaces = np.cumsum(spaces)
|
| 68 |
+
|
| 69 |
+
for layout, space in zip(layouts, spaces):
|
| 70 |
+
for bbox, _ in layout:
|
| 71 |
+
x, y, w, h = bbox
|
| 72 |
+
bbox[:] = [x, y + space, w, h]
|
| 73 |
+
|
| 74 |
+
return layouts
|
synthdog/resources/background/bedroom_83.jpg
ADDED

|
synthdog/resources/background/bob+dylan_83.jpg
ADDED

|
synthdog/resources/background/coffee_122.jpg
ADDED

|
synthdog/resources/background/coffee_18.jpeg
ADDED

|
Git LFS Details
|
synthdog/resources/background/crater_141.jpg
ADDED

|
Git LFS Details
|
synthdog/resources/background/cream_124.jpg
ADDED

|
Git LFS Details
|
synthdog/resources/background/eagle_110.jpg
ADDED

|
synthdog/resources/background/farm_25.jpg
ADDED

|
synthdog/resources/background/hiking_18.jpg
ADDED

|
synthdog/resources/corpus/enwiki.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|