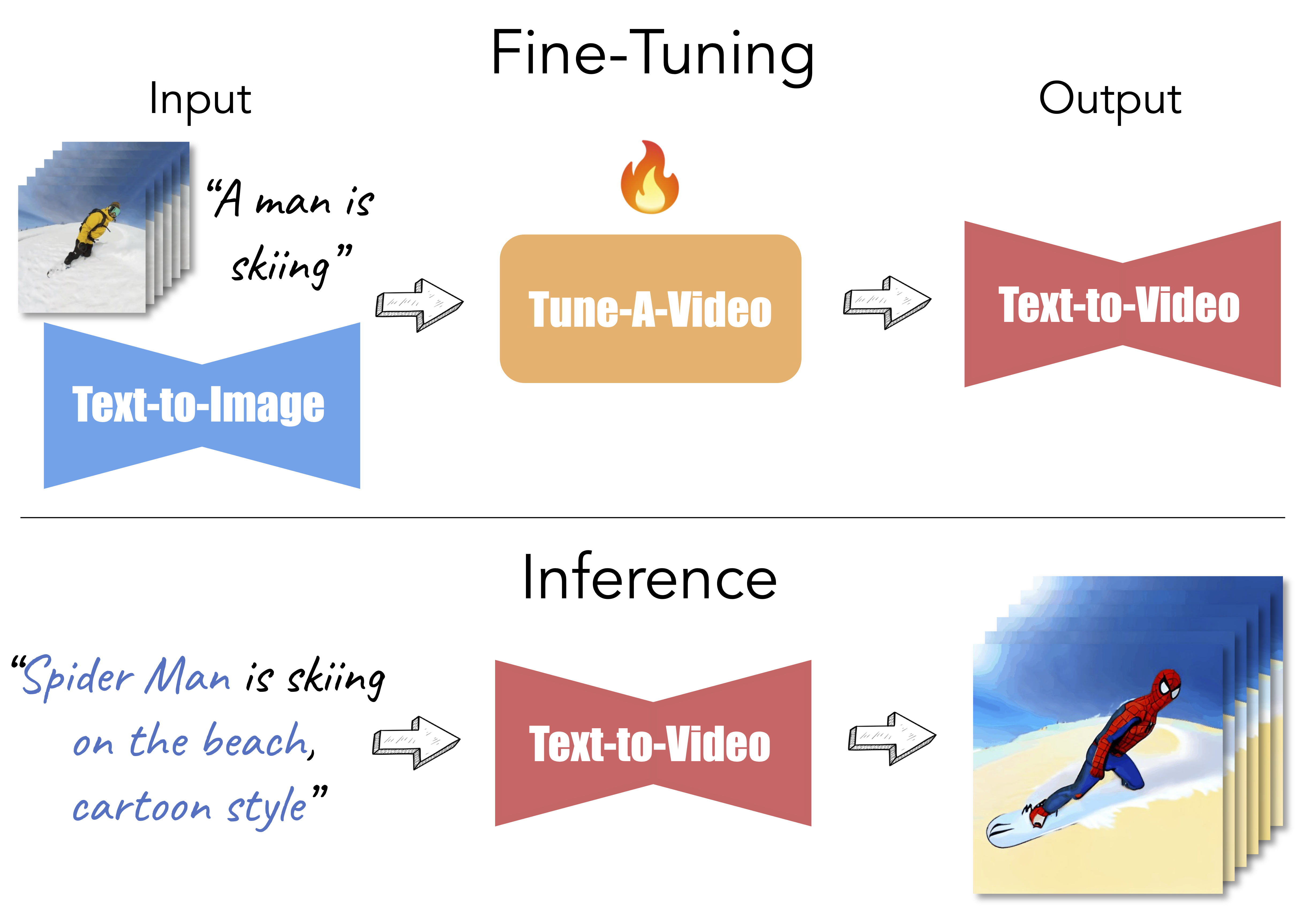
Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.
Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.
| Input Video | Output Video | ||
 |
 |
 |
 |
| "A man is skiing" | "Spider Man is skiing on the beach, cartoon style” | "Wonder Woman, wearing a cowboy hat, is skiing" | "A man, wearing pink clothes, is skiing at sunset" |
 |
 |
 |
 |
| "A rabbit is eating a watermelon" | "A rabbit is |
"A cat with sunglasses is eating a watermelon on the beach" | "A puppy is eating a cheeseburger on the table, comic style" |
 |
 |
 |
 |
| "A jeep car is moving on the road" | "A Porsche car is moving on the beach" | "A car is moving on the road, cartoon style" | "A car is moving on the snow" |
 |
 |
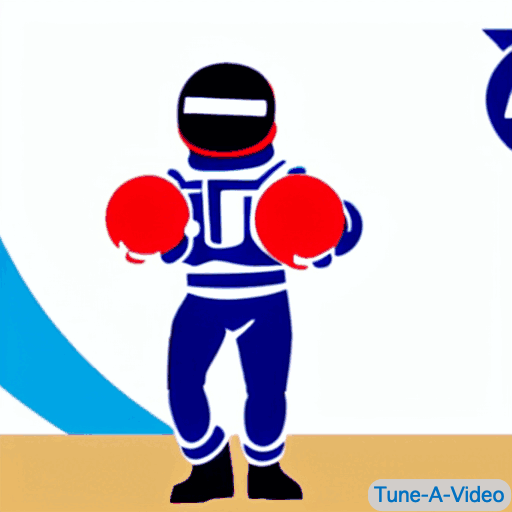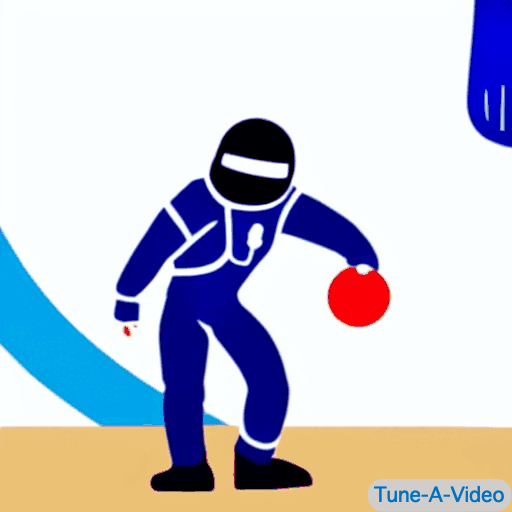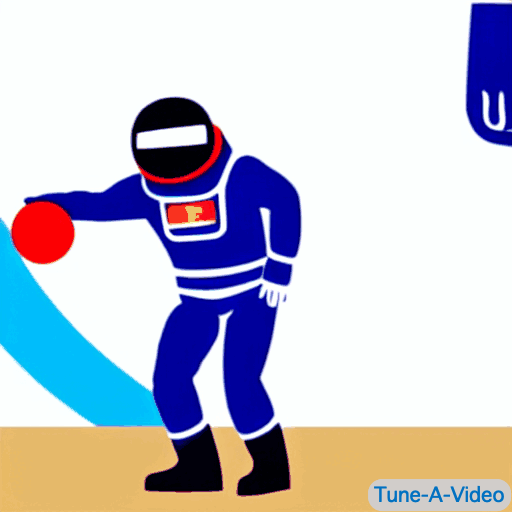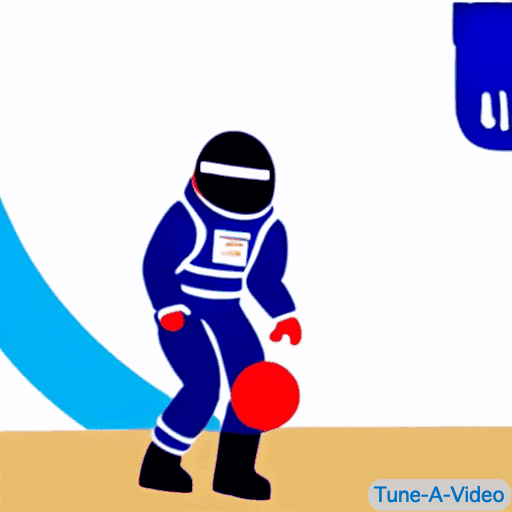 |
 |
| "A man is dribbling a basketball" | "Trump is dribbling a basketball" | "An astronaut is dribbling a basketball, cartoon style" | "A lego man in a black suit is dribbling a basketball" |

| Input Video | Output Video | ||
 |
 |
 |
 |
| "A bear is playing guitar" | "A rabbit is playing guitar, modern disney style" | "A handsome prince is playing guitar, modern disney style" | "A magic princess with sunglasses is playing guitar on the stage, modern disney style" |

| Input Video | Output Video | ||
|
 |
 |
 |
| "A bear is playing guitar" | "Mr Potato Head, made of lego, is playing guitar on the snow" | "Mr Potato Head, wearing sunglasses, is playing guitar on the beach" | "Mr Potato Head is playing guitar in the starry night, Van Gogh style" |