

File size: 14,198 Bytes
fcdd7fc 5725f49 fcdd7fc 5725f49 5b3d3f2 5725f49 fcdd7fc 5725f49 fcdd7fc 93e2686 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 a389ec3 fcdd7fc 5725f49 fcdd7fc 5725f49 a389ec3 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc a389ec3 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc 5725f49 fcdd7fc |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 |
#!/usr/bin/env python
from __future__ import annotations
import argparse
import pathlib
import torch
import gradio as gr
from vtoonify_model import Model
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument('--theme', type=str)
parser.add_argument('--share', action='store_true')
parser.add_argument('--port', type=int)
parser.add_argument('--disable-queue',
dest='enable_queue',
action='store_false')
return parser.parse_args()
DESCRIPTION = '''
<div align=center>
<h1 style="font-weight: 900; margin-bottom: 7px;">
使用<a href="https://github.com/williamyang1991/VToonify">VToonify</a>将视频人物卡通化
</h1>
<font color=red><h2 style="font-weight: 900; margin-bottom: 7px;">
本页面是为方便英语不太好朋友了解如何使用,采用的是CPU,运算时间较长,请稳步<a href="https://huggingface.co/spaces/PKUWilliamYang/VToonify">原VToonify</a>,速度将提升数十倍
</h2></font>
</div>
'''
FOOTER = '<div align=center><img id="visitor-badge" alt="visitor badge" src="https://visitor-badge.laobi.icu/badge?page_id=williamyang1991/VToonify" /></div>'
ARTICLE = r"""
如果VToonify对你有帮助请在<a href='https://github.com/williamyang1991/VToonify' target='_blank'>Github Repo</a>上为它点亮⭐.谢谢!
[](https://github.com/williamyang1991/VToonify)
---
<h2 style="font-weight: 900; margin-bottom: 7px;">点击<a href='https://www.toolchest.cn' target='_blank'>返回智能工具箱</a>查看更多好玩的人工智能项目</h2>
📝 **Citation**
If our work is useful for your research, please consider citing:
```bibtex
@article{yang2022Vtoonify,
title={VToonify: Controllable High-Resolution Portrait Video Style Transfer},
author={Yang, Shuai and Jiang, Liming and Liu, Ziwei and Loy, Chen Change},
journal={ACM Transactions on Graphics (TOG)},
volume={41},
number={6},
articleno={203},
pages={1--15},
year={2022},
publisher={ACM New York, NY, USA},
doi={10.1145/3550454.3555437},
}
```
📋 **License**
This project is licensed under <a rel="license" href="https://github.com/williamyang1991/VToonify/blob/main/LICENSE.md">S-Lab License 1.0</a>.
Redistribution and use for non-commercial purposes should follow this license.
📧 **Contact**
If you have any questions, please feel free to reach me out at <b>williamyang@pku.edu.cn</b>.
"""
def update_slider(choice: str) -> dict:
if type(choice) == str and choice.endswith('-d'):
return gr.Slider.update(maximum=1, minimum=0, value=0.5)
else:
return gr.Slider.update(maximum=0.5, minimum=0.5, value=0.5)
def set_example_image(example: list) -> dict:
return gr.Image.update(value=example[0])
def set_example_video(example: list) -> dict:
return gr.Video.update(value=example[0]),
sample_video = ['./vtoonify/data/529_2.mp4','./vtoonify/data/7154235.mp4','./vtoonify/data/651.mp4','./vtoonify/data/908.mp4']
sample_vid = gr.Video(label='Video file') #for displaying the example
example_videos = gr.components.Dataset(components=[sample_vid], samples=[[path] for path in sample_video], type='values', label='Video Examples')
def main():
args = parse_args()
args.device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('*** Now using %s.'%(args.device))
model = Model(device=args.device)
with gr.Blocks(theme=args.theme, css='style.css') as demo:
gr.Markdown(DESCRIPTION)
with gr.Box():
gr.Markdown('''## 第1步(选择卡通类型)
- 选择 **卡通类型**.
- 带有 `-d` 表示它可以调整卡通化的程度.
- 不带 `-d` 通常会有更好的卡通效果.
''')
with gr.Row():
with gr.Column():
gr.Markdown('''选择类型''')
with gr.Row():
style_type = gr.Radio(label='Style Type',
choices=['cartoon1','cartoon1-d','cartoon2-d','cartoon3-d',
'cartoon4','cartoon4-d','cartoon5-d','comic1-d',
'comic2-d','arcane1','arcane1-d','arcane2', 'arcane2-d',
'caricature1','caricature2','pixar','pixar-d',
'illustration1-d', 'illustration2-d', 'illustration3-d', 'illustration4-d', 'illustration5-d',
]
)
exstyle = gr.Variable()
with gr.Row():
loadmodel_button = gr.Button('加载模型')
with gr.Row():
load_info = gr.Textbox(label='Process Information', interactive=False, value='No model loaded.')
with gr.Column():
gr.Markdown('''类型参考
''')
with gr.Box():
gr.Markdown('''## 第2步 (对图片或视频进行预处理)
- 拖动1个含有人脸的图片或视频到 **输入图像**/**输入视频**.
- 点击 **缩放图像**/**缩放第1帧** 按钮.
- 缩放输入使它更好的适用模型.
- 最后的图像结果将是基于 **缩放后的脸**. 使用边框距离参数调整背景.
- **<font color=red>若出现[Error: no face detected!]错误</font>**: 是因为vtoonify没有检测到人脸,请调整后再试,或者更换原始图像.
- 对于视频输入, 则点击 **缩放视频** 按钮.
- 最后的视频结果将是基于 **缩放后的视频**. 为了避免超出硬件处理能力, 视频将被裁剪成 **100/300** 帧来适应 CPU/GPU.
''')
with gr.Row():
with gr.Box():
with gr.Column():
gr.Markdown('''调整边框距离参数.
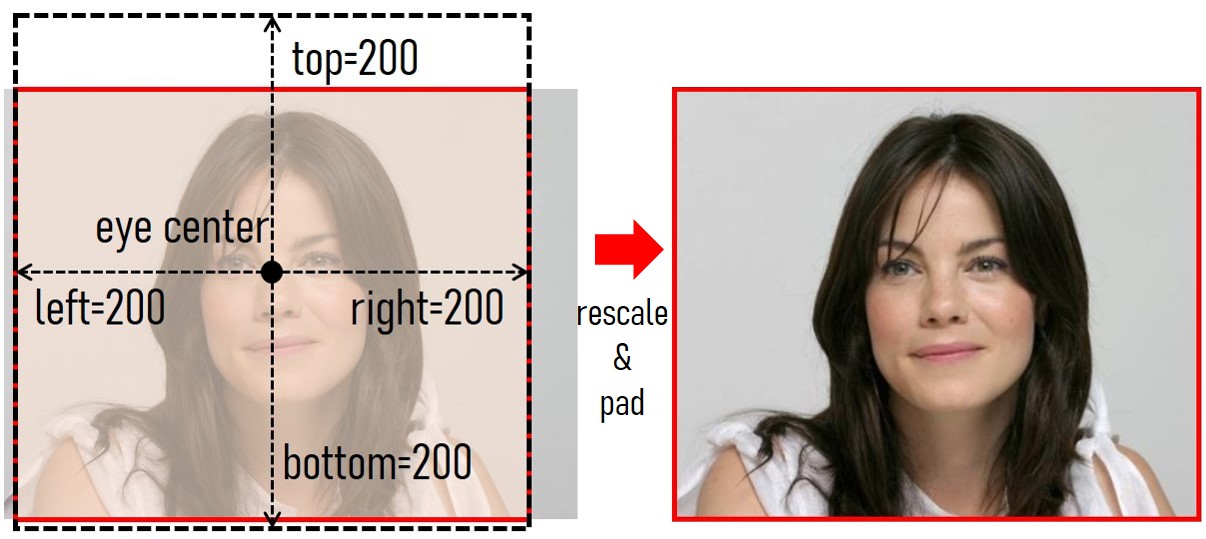''')
with gr.Row():
top = gr.Slider(128,
256,
value=200,
step=8,
label='上')
with gr.Row():
bottom = gr.Slider(128,
256,
value=200,
step=8,
label='下')
with gr.Row():
left = gr.Slider(128,
256,
value=200,
step=8,
label='左')
with gr.Row():
right = gr.Slider(128,
256,
value=200,
step=8,
label='右')
with gr.Box():
with gr.Column():
gr.Markdown('''输入''')
with gr.Row():
input_image = gr.Image(label='输入图像',
type='filepath')
with gr.Row():
preprocess_image_button = gr.Button('缩放图像')
with gr.Row():
input_video = gr.Video(label='输入视频',
mirror_webcam=False,
type='filepath')
with gr.Row():
preprocess_video0_button = gr.Button('缩放第一帧')
preprocess_video1_button = gr.Button('绽放视频')
with gr.Box():
with gr.Column():
gr.Markdown('''View''')
with gr.Row():
input_info = gr.Textbox(label='处理信息', interactive=False, value='n.a.')
with gr.Row():
aligned_face = gr.Image(label='绽放脸',
type='numpy',
interactive=False)
instyle = gr.Variable()
with gr.Row():
aligned_video = gr.Video(label='绽放视频',
type='mp4',
interactive=False)
with gr.Row():
with gr.Column():
paths = ['./vtoonify/data/pexels-andrea-piacquadio-733872.jpg','./vtoonify/data/i5R8hbZFDdc.jpg','./vtoonify/data/yRpe13BHdKw.jpg','./vtoonify/data/ILip77SbmOE.jpg','./vtoonify/data/077436.jpg','./vtoonify/data/081680.jpg']
example_images = gr.Dataset(components=[input_image],
samples=[[path] for path in paths],
label='示例图像')
with gr.Column():
#example_videos = gr.Dataset(components=[input_video], samples=[['./vtoonify/data/529.mp4']], type='values')
#to render video example on mouse hover/click
example_videos.render()
#to load sample video into input_video upon clicking on it
def load_examples(video):
#print("****** inside load_example() ******")
#print("in_video is : ", video[0])
return video[0]
example_videos.click(load_examples, example_videos, input_video)
with gr.Box():
gr.Markdown('''## 第3步(生成 图像/视频)''')
with gr.Row():
with gr.Column():
gr.Markdown('''
- 调整 **卡通化程度**.
- 点击 **图像卡通化!** 来将第1帧卡通化. 点击 **视频卡通化!** 来让整个视频卡通化.
- 预计时间 对于300帧的1600x1440视频 : 1 小时 (CPU); 2 分钟 (GPU)
''')
style_degree = gr.Slider(0,
1,
value=0.5,
step=0.05,
label='卡通化程度')
with gr.Column():
gr.Markdown('''
''')
with gr.Row():
output_info = gr.Textbox(label='示例信息', interactive=False, value='n.a.')
with gr.Row():
with gr.Column():
with gr.Row():
result_face = gr.Image(label='图像结果',
type='numpy',
interactive=False)
with gr.Row():
toonify_button = gr.Button('图像卡通化!')
with gr.Column():
with gr.Row():
result_video = gr.Video(label='视频结果',
type='mp4',
interactive=False)
with gr.Row():
vtoonify_button = gr.Button('视频卡通化!')
gr.Markdown(ARTICLE)
gr.Markdown(FOOTER)
loadmodel_button.click(fn=model.load_model,
inputs=[style_type],
outputs=[exstyle, load_info])
style_type.change(fn=update_slider,
inputs=style_type,
outputs=style_degree)
preprocess_image_button.click(fn=model.detect_and_align_image,
inputs=[input_image, top, bottom, left, right],
outputs=[aligned_face, instyle, input_info])
preprocess_video0_button.click(fn=model.detect_and_align_video,
inputs=[input_video, top, bottom, left, right],
outputs=[aligned_face, instyle, input_info])
preprocess_video1_button.click(fn=model.detect_and_align_full_video,
inputs=[input_video, top, bottom, left, right],
outputs=[aligned_video, instyle, input_info])
toonify_button.click(fn=model.image_toonify,
inputs=[aligned_face, instyle, exstyle, style_degree, style_type],
outputs=[result_face, output_info])
vtoonify_button.click(fn=model.video_tooniy,
inputs=[aligned_video, instyle, exstyle, style_degree, style_type],
outputs=[result_video, output_info])
example_images.click(fn=set_example_image,
inputs=example_images,
outputs=example_images.components)
demo.launch(
enable_queue=args.enable_queue,
server_port=args.port,
share=args.share,
)
if __name__ == '__main__':
main()
|