# (NeurIPS 2024) Compact and Mighty - Image Tokenization with Only 32 Tokens for both Reconstruction and Generation!
[](https://huggingface.co/spaces/fun-research/TiTok)
[](https://yucornetto.github.io/projects/titok.html)
[](https://arxiv.org/abs/2406.07550)
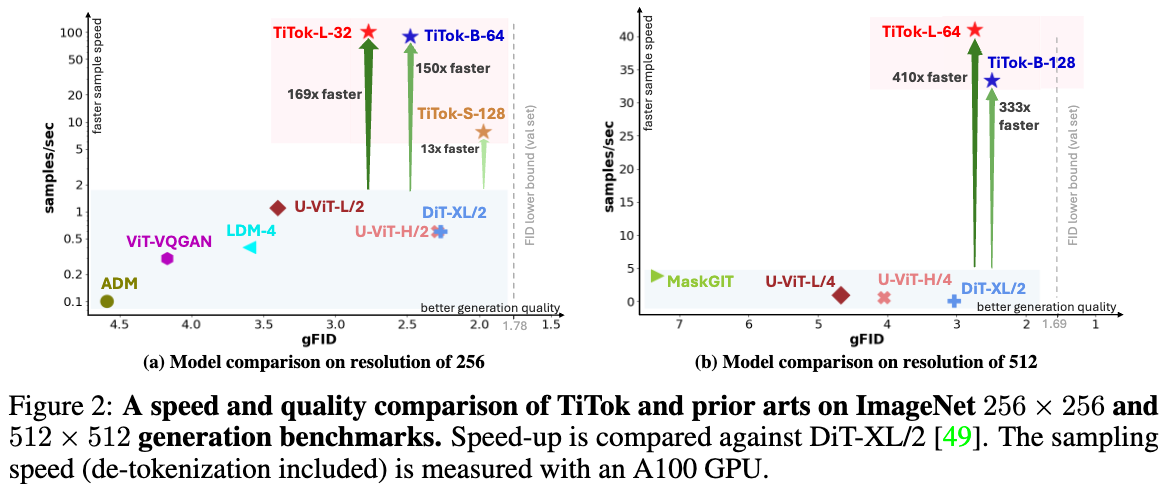
We present a compact 1D tokenizer which can represent an image with as few as 32 discrete tokens. As a result, it leads to a substantial speed-up on the sampling process (e.g., **410 × faster** than DiT-XL/2) while obtaining a competitive generation quality.

## 🚀 Contributions
#### We introduce a novel 1D image tokenization framework that breaks grid constraints existing in 2D tokenization methods, leading to a much more flexible and compact image latent representation.
#### The proposed 1D tokenizer can tokenize a 256 × 256 image into as few as 32 discrete tokens, leading to a significant speed-up (hundreds times faster than diffusion models) in generation process, while maintaining state-of-the-art generation quality.
#### We conduct a series of experiments to probe the properties of rarely studied 1D image tokenization, paving the path towards compact latent space for efficient and effective image representation.
## Model Zoo
| Model | Link | FID |
| ------------- | ------------- | ------------- |
| TiTok-L-32 Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_l32_imagenet)| 2.21 (reconstruction) |
| TiTok-B-64 Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_b64_imagenet) | 1.70 (reconstruction) |
| TiTok-S-128 Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_s128_imagenet) | 1.71 (reconstruction) |
| TiTok-L-32 Generator | [checkpoint](https://huggingface.co/yucornetto/generator_titok_l32_imagenet) | 2.77 (generation) |
| TiTok-B-64 Generator | [checkpoint](https://huggingface.co/yucornetto/generator_titok_b64_imagenet) | 2.48 (generation) |
| TiTok-S-128 Generator | [checkpoint](https://huggingface.co/yucornetto/generator_titok_s128_imagenet) | 1.97 (generation) |
| TiTok-BL-64 VQ Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_bl64_vq8k_imagenet)| 2.06 (reconstruction) |
| TiTok-BL-128 VQ Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_bl128_vq8k_imagenet)| 1.49 (reconstruction) |
| TiTok-SL-256 VQ Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_sl256_vq8k_imagenet)| 1.03 (reconstruction) |
| TiTok-LL-32 VAE Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_ll32_vae_c16_imagenet)| 1.61 (reconstruction) |
| TiTok-BL-64 VAE Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_bl64_vae_c16_imagenet)| 1.25 (reconstruction) |
| TiTok-BL-128 VAE Tokenizer | [checkpoint](https://huggingface.co/yucornetto/tokenizer_titok_bl128_vae_c16_imagenet)| 0.84 (reconstruction) |
Please note that these models are trained only on limited academic dataset ImageNet, and they are only for research purposes.
## Installation
```shell
pip3 install -r requirements.txt
```
## Get Started
```python
import torch
from PIL import Image
import numpy as np
import demo_util
from huggingface_hub import hf_hub_download
from modeling.maskgit import ImageBert
from modeling.titok import TiTok
# Choose one from ["tokenizer_titok_l32_imagenet", "tokenizer_titok_b64_imagenet",
# "tokenizer_titok_s128_imagenet", "tokenizer_titok_bl128_vae_c16_imagenet", tokenizer_titok_bl64_vae_c16_imagenet",
# "tokenizer_titok_ll32_vae_c16_imagenet", "tokenizer_titok_sl256_vq8k_imagenet", "tokenizer_titok_bl128_vq8k_imagenet",
# "tokenizer_titok_bl64_vq8k_imagenet",]
titok_tokenizer = TiTok.from_pretrained("yucornetto/tokenizer_titok_l32_imagenet")
titok_tokenizer.eval()
titok_tokenizer.requires_grad_(False)
titok_generator = ImageBert.from_pretrained("yucornetto/generator_titok_l32_imagenet")
titok_generator.eval()
titok_generator.requires_grad_(False)
# or alternatively, downloads from hf
# hf_hub_download(repo_id="fun-research/TiTok", filename="tokenizer_titok_l32.bin", local_dir="./")
# hf_hub_download(repo_id="fun-research/TiTok", filename="generator_titok_l32.bin", local_dir="./")
# load config
# config = demo_util.get_config("configs/infer/titok_l32.yaml")
# titok_tokenizer = demo_util.get_titok_tokenizer(config)
# titok_generator = demo_util.get_titok_generator(config)
device = "cuda"
titok_tokenizer = titok_tokenizer.to(device)
titok_generator = titok_generator.to(device)
# reconstruct an image. I.e., image -> 32 tokens -> image
img_path = "assets/ILSVRC2012_val_00010240.png"
image = torch.from_numpy(np.array(Image.open(img_path)).astype(np.float32)).permute(2, 0, 1).unsqueeze(0) / 255.0
# tokenization
if titok_tokenizer.quantize_mode == "vq":
encoded_tokens = titok_tokenizer.encode(image.to(device))[1]["min_encoding_indices"]
elif titok_tokenizer.quantize_mode == "vae":
posteriors = titok_tokenizer.encode(image.to(device))[1]
encoded_tokens = posteriors.sample()
else:
raise NotImplementedError
# image assets/ILSVRC2012_val_00010240.png is encoded into tokens tensor([[[ 887, 3979, 349, 720, 2809, 2743, 2101, 603, 2205, 1508, 1891, 4015, 1317, 2956, 3774, 2296, 484, 2612, 3472, 2330, 3140, 3113, 1056, 3779, 654, 2360, 1901, 2908, 2169, 953, 1326, 2598]]], device='cuda:0'), with shape torch.Size([1, 1, 32])
print(f"image {img_path} is encoded into tokens {encoded_tokens}, with shape {encoded_tokens.shape}")
# de-tokenization
reconstructed_image = titok_tokenizer.decode_tokens(encoded_tokens)
reconstructed_image = torch.clamp(reconstructed_image, 0.0, 1.0)
reconstructed_image = (reconstructed_image * 255.0).permute(0, 2, 3, 1).to("cpu", dtype=torch.uint8).numpy()[0]
reconstructed_image = Image.fromarray(reconstructed_image).save("assets/ILSVRC2012_val_00010240_recon.png")
# generate an image
sample_labels = [torch.randint(0, 999, size=(1,)).item()] # random IN-1k class
generated_image = demo_util.sample_fn(
generator=titok_generator,
tokenizer=titok_tokenizer,
labels=sample_labels,
guidance_scale=4.5,
randomize_temperature=1.0,
num_sample_steps=8,
device=device
)
Image.fromarray(generated_image[0]).save(f"assets/generated_{sample_labels[0]}.png")
```
We also provide a [jupyter notebook](demo.ipynb) for a quick tutorial on reconstructing and generating images with TiTok-L-32.
We also support TiTok with [HuggingFace 🤗 Demo](https://huggingface.co/spaces/fun-research/TiTok)!
## Testing on ImageNet-1K Benchmark
We provide a [sampling script](./sample_imagenet_titok.py) for reproducing the generation results on ImageNet-1K benchmark.
```bash
# Prepare ADM evaluation script
git clone https://github.com/openai/guided-diffusion.git
wget https://openaipublic.blob.core.windows.net/diffusion/jul-2021/ref_batches/imagenet/256/VIRTUAL_imagenet256_labeled.npz
```
```python
# Reproducing TiTok-L-32
torchrun --nnodes=1 --nproc_per_node=8 --rdzv-endpoint=localhost:9999 sample_imagenet_titok.py config=configs/infer/titok_l32.yaml experiment.output_dir="titok_l_32"
# Run eval script. The result FID should be ~2.77
python3 guided-diffusion/evaluations/evaluator.py VIRTUAL_imagenet256_labeled.npz titok_l_32.npz
# Reproducing TiTok-B-64
torchrun --nnodes=1 --nproc_per_node=8 --rdzv-endpoint=localhost:9999 sample_imagenet_titok.py config=configs/infer/titok_b64.yaml experiment.output_dir="titok_b_64"
# Run eval script. The result FID should be ~2.48
python3 guided-diffusion/evaluations/evaluator.py VIRTUAL_imagenet256_labeled.npz titok_b_64.npz
# Reproducing TiTok-S-128
torchrun --nnodes=1 --nproc_per_node=8 --rdzv-endpoint=localhost:9999 sample_imagenet_titok.py config=configs/infer/titok_s128.yaml experiment.output_dir="titok_s_128"
# Run eval script. The result FID should be ~1.97
python3 guided-diffusion/evaluations/evaluator.py VIRTUAL_imagenet256_labeled.npz titok_s_128.npz
```
## Training Preparation
We use [webdataset](https://github.com/webdataset/webdataset) format for data loading. To begin with, it is needed to convert the dataset into webdataset format. An example script to convert ImageNet to wds format is provided [here](./data/convert_imagenet_to_wds.py).
Furthermore, the stage1 training relies on a pre-trained MaskGIT-VQGAN to generate proxy codes as learning targets. You can convert the [official Jax weight](https://github.com/google-research/maskgit) to PyTorch version using [this script](https://github.com/huggingface/open-muse/blob/main/scripts/convert_maskgit_vqgan.py). Alternatively, we provided a converted version at [HuggingFace](https://huggingface.co/fun-research/TiTok/blob/main/maskgit-vqgan-imagenet-f16-256.bin) and [Google Drive](https://drive.google.com/file/d/1DjZqzJrUt2hwpmUPkjGSBTFEJcOkLY-Q/view?usp=sharing). The MaskGIT-VQGAN's weight will be automatically downloaded when you run the training script.
## Training
We provide example commands to train TiTok as follows:
```bash
# Training for TiTok-B64
# Stage 1
WANDB_MODE=offline accelerate launch --num_machines=1 --num_processes=8 --machine_rank=0 --main_process_ip=127.0.0.1 --main_process_port=9999 --same_network scripts/train_titok.py config=configs/training/stage1/titok_b64.yaml \
experiment.project="titok_b64_stage1" \
experiment.name="titok_b64_stage1_run1" \
experiment.output_dir="titok_b64_stage1_run1" \
training.per_gpu_batch_size=32
# Stage 2
WANDB_MODE=offline accelerate launch --num_machines=1 --num_processes=8 --machine_rank=0 --main_process_ip=127.0.0.1 --main_process_port=9999 --same_network scripts/train_titok.py config=configs/training/stage2/titok_b64.yaml \
experiment.project="titok_b64_stage2" \
experiment.name="titok_b64_stage2_run1" \
experiment.output_dir="titok_b64_stage2_run1" \
training.per_gpu_batch_size=32 \
experiment.init_weight=${PATH_TO_STAGE1_WEIGHT}
# Train Generator (TiTok-B64 as example)
WANDB_MODE=offline accelerate launch --num_machines=4 --num_processes=32 --machine_rank=${MACHINE_RANK} --main_process_ip=${ROOT_IP}--main_process_port=${ROOT_PORT} --same_network scripts/train_maskgit.py config=configs/training/generator/maskgit.yaml \
experiment.project="titok_generation" \
experiment.name="titok_b64_maskgit" \
experiment.output_dir="titok_b64_maskgit" \
experiment.tokenizer_checkpoint=${PATH_TO_STAGE1_or_STAGE2_WEIGHT}
```
You may remove the flag "WANDB_MODE=offline" to support online wandb logging, if you have configured it.
The config _titok_b64.yaml_ can be replaced with _titok_s128.yaml_ or _titok_l32.yaml_ for other TiTok variants.
## Visualizations


## Citing
If you use our work in your research, please use the following BibTeX entry.
```BibTeX
@inproceedings{yu2024an,
author = {Qihang Yu and Mark Weber and Xueqing Deng and Xiaohui Shen and Daniel Cremers and Liang-Chieh Chen},
title = {An Image is Worth 32 Tokens for Reconstruction and Generation},
journal = {NeurIPS},
year = {2024}
}
```
## Acknowledgement
[MaskGIT](https://github.com/google-research/maskgit)
[Taming-Transformers](https://github.com/CompVis/taming-transformers)
[Open-MUSE](https://github.com/huggingface/open-muse)
[MUSE-Pytorch](https://github.com/baaivision/MUSE-Pytorch)