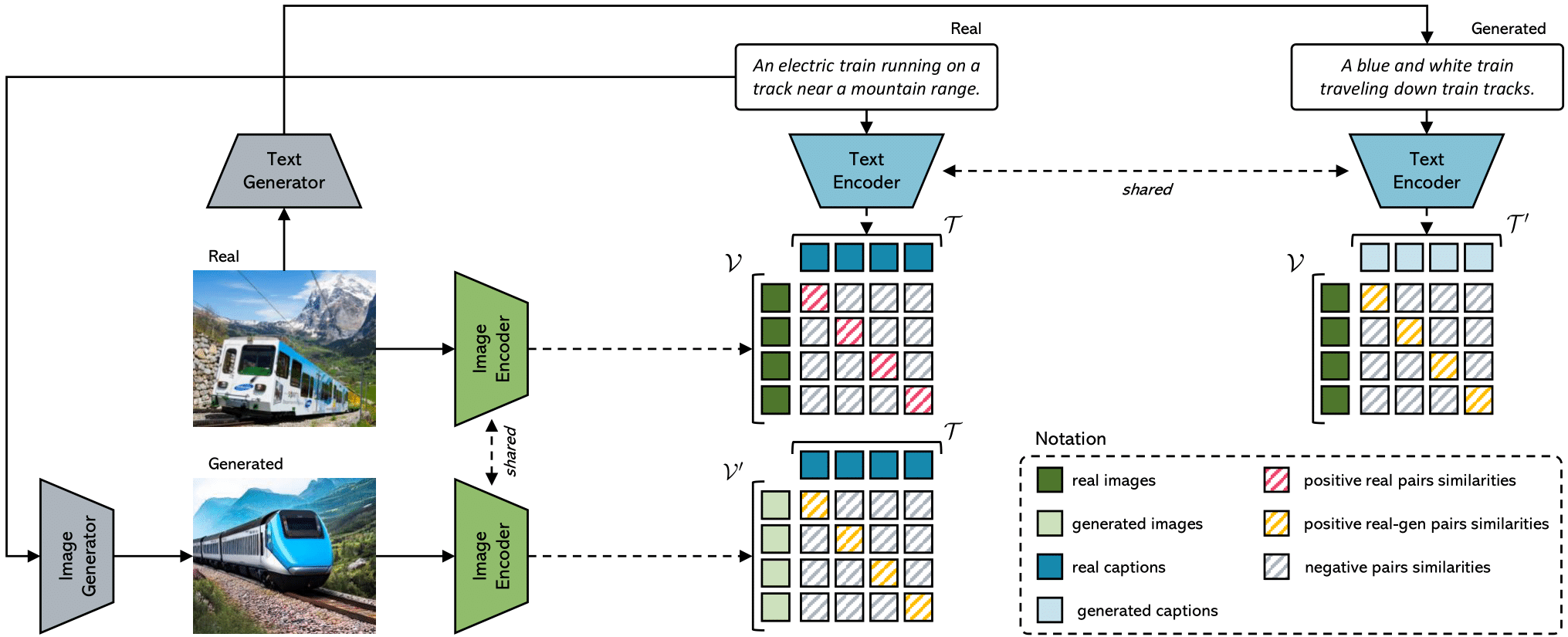
PAC-Score: Positive-Augmented Contrastive Learning for Image and Video Captioning Evaluation (CVPR 2023)

[-f9f107.svg)](https://openaccess.thecvf.com/content/CVPR2023/html/Sarto_Positive-Augmented_Contrastive_Learning_for_Image_and_Video_Captioning_Evaluation_CVPR_2023_paper.html)
[](https://arxiv.org/abs/2303.12112)
This repository contains the reference code for the paper [Positive-Augmented Contrastive Learning for Image and Video Captioning Evaluation](https://arxiv.org/abs/2303.12112), **CVPR 2023 Highlight✨** (top 2.5% of initial submissions and top 10% of accepted papers).
Please cite with the following BibTeX:
```
@inproceedings{sarto2023positive,
title={{Positive-Augmented Contrastive Learning for Image and Video Captioning Evaluation}},
author={Sarto, Sara and Barraco, Manuele and Cornia, Marcella and Baraldi, Lorenzo and Cucchiara, Rita},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
```