Spaces:
Configuration error

Configuration error
Add files
Browse files- LICENSE +107 -0
- README.md +84 -13
- checkpoints/.gitattributes +35 -0
- checkpoints/README.md +5 -0
- checkpoints/ckpt.txt +1 -0
- checkpoints/cloth_segm.pth +3 -0
- checkpoints/ipadapter_faceid/ckpt.txt +1 -0
- checkpoints/oms_diffusion_768_200000.safetensors +3 -0
- garment_adapter/__pycache__/attention_processor.cpython-310.pyc +0 -0
- garment_adapter/__pycache__/garment_diffusion.cpython-310.pyc +0 -0
- garment_adapter/attention_processor.py +682 -0
- garment_adapter/garment_diffusion.py +248 -0
- garment_adapter/garment_ipadapter_faceid.py +673 -0
- garment_seg/__pycache__/network.cpython-310.pyc +0 -0
- garment_seg/__pycache__/process.cpython-310.pyc +0 -0
- garment_seg/network.py +560 -0
- garment_seg/process.py +99 -0
- gradio_animatediff.py +38 -0
- gradio_controlnet_inpainting.py +76 -0
- gradio_controlnet_openpose.py +72 -0
- gradio_generate.py +61 -0
- gradio_ipadapter_faceid.py +97 -0
- gradio_ipadapter_openpose.py +109 -0
- gradio_sd_inpainting.py +62 -0
- images/workflow.png +0 -0
- inference.py +41 -0
- nohup.out +1 -0
- output_img/out_0.png +0 -0
- output_img/out_1.png +0 -0
- output_img/out_2.png +0 -0
- output_img/out_3.png +0 -0
- pipelines/OmsAnimateDiffusionPipeline.py +306 -0
- pipelines/OmsDiffusionControlNetPipeline.py +437 -0
- pipelines/OmsDiffusionInpaintPipeline.py +502 -0
- pipelines/OmsDiffusionPipeline.py +294 -0
- pipelines/__pycache__/OmsDiffusionPipeline.cpython-310.pyc +0 -0
- run.log +2 -0
- utils/__pycache__/utils.cpython-310.pyc +0 -0
- utils/resampler.py +158 -0
- utils/utils.py +72 -0
- valid_cloth/t1.png +0 -0
- valid_cloth/t2.jpg +0 -0
- valid_cloth/t3.jpg +0 -0
- valid_cloth/t4.jpg +0 -0
LICENSE
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
|
| 2 |
+
|
| 3 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and does not provide legal services or legal advice. Distribution of Creative Commons public licenses does not create a lawyer-client or other relationship. Creative Commons makes its licenses and related information available on an "as-is" basis. Creative Commons gives no warranties regarding its licenses, any material licensed under their terms and conditions, or any related information. Creative Commons disclaims all liability for damages resulting from their use to the fullest extent possible.
|
| 4 |
+
|
| 5 |
+
Using Creative Commons Public Licenses
|
| 6 |
+
|
| 7 |
+
Creative Commons public licenses provide a standard set of terms and conditions that creators and other rights holders may use to share original works of authorship and other material subject to copyright and certain other rights specified in the public license below. The following considerations are for informational purposes only, are not exhaustive, and do not form part of our licenses.
|
| 8 |
+
|
| 9 |
+
Considerations for licensors: Our public licenses are intended for use by those authorized to give the public permission to use material in ways otherwise restricted by copyright and certain other rights. Our licenses are irrevocable. Licensors should read and understand the terms and conditions of the license they choose before applying it. Licensors should also secure all rights necessary before applying our licenses so that the public can reuse the material as expected. Licensors should clearly mark any material not subject to the license. This includes other CC-licensed material, or material used under an exception or limitation to copyright. More considerations for licensors : wiki.creativecommons.org/Considerations_for_licensors
|
| 10 |
+
|
| 11 |
+
Considerations for the public: By using one of our public licenses, a licensor grants the public permission to use the licensed material under specified terms and conditions. If the licensor's permission is not necessary for any reason–for example, because of any applicable exception or limitation to copyright–then that use is not regulated by the license. Our licenses grant only permissions under copyright and certain other rights that a licensor has authority to grant. Use of the licensed material may still be restricted for other reasons, including because others have copyright or other rights in the material. A licensor may make special requests, such as asking that all changes be marked or described. Although not required by our licenses, you are encouraged to respect those requests where reasonable. More considerations for the public : wiki.creativecommons.org/Considerations_for_licensees
|
| 12 |
+
|
| 13 |
+
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License
|
| 14 |
+
|
| 15 |
+
By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms and conditions of this Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License ("Public License"). To the extent this Public License may be interpreted as a contract, You are granted the Licensed Rights in consideration of Your acceptance of these terms and conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.
|
| 16 |
+
|
| 17 |
+
Section 1 – Definitions.
|
| 18 |
+
|
| 19 |
+
a. Adapted Material means material subject to Copyright and Similar Rights that is derived from or based upon the Licensed Material and in which the Licensed Material is translated, altered, arranged, transformed, or otherwise modified in a manner requiring permission under the Copyright and Similar Rights held by the Licensor. For purposes of this Public License, where the Licensed Material is a musical work, performance, or sound recording, Adapted Material is always produced where the Licensed Material is synched in timed relation with a moving image.
|
| 20 |
+
b. Adapter's License means the license You apply to Your Copyright and Similar Rights in Your contributions to Adapted Material in accordance with the terms and conditions of this Public License.
|
| 21 |
+
c. BY-NC-SA Compatible License means a license listed at creativecommons.org/compatiblelicenses, approved by Creative Commons as essentially the equivalent of this Public License.
|
| 22 |
+
d. Copyright and Similar Rights means copyright and/or similar rights closely related to copyright including, without limitation, performance, broadcast, sound recording, and Sui Generis Database Rights, without regard to how the rights are labeled or categorized. For purposes of this Public License, the rights specified in Section 2(b)(1)-(2) are not Copyright and Similar Rights.
|
| 23 |
+
e. Effective Technological Measures means those measures that, in the absence of proper authority, may not be circumvented under laws fulfilling obligations under Article 11 of the WIPO Copyright Treaty adopted on December 20, 1996, and/or similar international agreements.
|
| 24 |
+
f. Exceptions and Limitations means fair use, fair dealing, and/or any other exception or limitation to Copyright and Similar Rights that applies to Your use of the Licensed Material.
|
| 25 |
+
g. License Elements means the license attributes listed in the name of a Creative Commons Public License. The License Elements of this Public License are Attribution, NonCommercial, and ShareAlike.
|
| 26 |
+
h. Licensed Material means the artistic or literary work, database, or other material to which the Licensor applied this Public License.
|
| 27 |
+
i. Licensed Rights means the rights granted to You subject to the terms and conditions of this Public License, which are limited to all Copyright and Similar Rights that apply to Your use of the Licensed Material and that the Licensor has authority to license.
|
| 28 |
+
j. Licensor means the individual(s) or entity(ies) granting rights under this Public License.
|
| 29 |
+
k. NonCommercial means not primarily intended for or directed towards commercial advantage or monetary compensation. For purposes of this Public License, the exchange of the Licensed Material for other material subject to Copyright and Similar Rights by digital file-sharing or similar means is NonCommercial provided there is no payment of monetary compensation in connection with the exchange.
|
| 30 |
+
l. Share means to provide material to the public by any means or process that requires permission under the Licensed Rights, such as reproduction, public display, public performance, distribution, dissemination, communication, or importation, and to make material available to the public including in ways that members of the public may access the material from a place and at a time individually chosen by them.
|
| 31 |
+
m. Sui Generis Database Rights means rights other than copyright resulting from Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases, as amended and/or succeeded, as well as other essentially equivalent rights anywhere in the world.
|
| 32 |
+
n. You means the individual or entity exercising the Licensed Rights under this Public License. Your has a corresponding meaning.
|
| 33 |
+
Section 2 – Scope.
|
| 34 |
+
|
| 35 |
+
a. License grant.
|
| 36 |
+
1. Subject to the terms and conditions of this Public License, the Licensor hereby grants You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license to exercise the Licensed Rights in the Licensed Material to:
|
| 37 |
+
A. reproduce and Share the Licensed Material, in whole or in part, for NonCommercial purposes only; and
|
| 38 |
+
B. produce, reproduce, and Share Adapted Material for NonCommercial purposes only.
|
| 39 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where Exceptions and Limitations apply to Your use, this Public License does not apply, and You do not need to comply with its terms and conditions.
|
| 40 |
+
3. Term. The term of this Public License is specified in Section 6(a).
|
| 41 |
+
4. Media and formats; technical modifications allowed. The Licensor authorizes You to exercise the Licensed Rights in all media and formats whether now known or hereafter created, and to make technical modifications necessary to do so. The Licensor waives and/or agrees not to assert any right or authority to forbid You from making technical modifications necessary to exercise the Licensed Rights, including technical modifications necessary to circumvent Effective Technological Measures. For purposes of this Public License, simply making modifications authorized by this Section 2(a)(4) never produces Adapted Material.
|
| 42 |
+
5. Downstream recipients.
|
| 43 |
+
A. Offer from the Licensor – Licensed Material. Every recipient of the Licensed Material automatically receives an offer from the Licensor to exercise the Licensed Rights under the terms and conditions of this Public License.
|
| 44 |
+
B. Additional offer from the Licensor – Adapted Material. Every recipient of Adapted Material from You automatically receives an offer from the Licensor to exercise the Licensed Rights in the Adapted Material under the conditions of the Adapter's License You apply.
|
| 45 |
+
C. No downstream restrictions. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, the Licensed Material if doing so restricts exercise of the Licensed Rights by any recipient of the Licensed Material.
|
| 46 |
+
6. No endorsement. Nothing in this Public License constitutes or may be construed as permission to assert or imply that You are, or that Your use of the Licensed Material is, connected with, or sponsored, endorsed, or granted official status by, the Licensor or others designated to receive attribution as provided in Section 3(a)(1)(A)(i).
|
| 47 |
+
b. Other rights.
|
| 48 |
+
1. Moral rights, such as the right of integrity, are not licensed under this Public License, nor are publicity, privacy, and/or other similar personality rights; however, to the extent possible, the Licensor waives and/or agrees not to assert any such rights held by the Licensor to the limited extent necessary to allow You to exercise the Licensed Rights, but not otherwise.
|
| 49 |
+
2. Patent and trademark rights are not licensed under this Public License.
|
| 50 |
+
3. To the extent possible, the Licensor waives any right to collect royalties from You for the exercise of the Licensed Rights, whether directly or through a collecting society under any voluntary or waivable statutory or compulsory licensing scheme. In all other cases the Licensor expressly reserves any right to collect such royalties, including when the Licensed Material is used other than for NonCommercial purposes.
|
| 51 |
+
Section 3 – License Conditions.
|
| 52 |
+
|
| 53 |
+
Your exercise of the Licensed Rights is expressly made subject to the following conditions.
|
| 54 |
+
|
| 55 |
+
a. Attribution.
|
| 56 |
+
1. If You Share the Licensed Material (including in modified form), You must:
|
| 57 |
+
A. retain the following if it is supplied by the Licensor with the Licensed Material:
|
| 58 |
+
i. identification of the creator(s) of the Licensed Material and any others designated to receive attribution, in any reasonable manner requested by the Licensor (including by pseudonym if designated);
|
| 59 |
+
ii. a copyright notice;
|
| 60 |
+
iii. a notice that refers to this Public License;
|
| 61 |
+
iv. a notice that refers to the disclaimer of warranties;
|
| 62 |
+
v. a URI or hyperlink to the Licensed Material to the extent reasonably practicable;
|
| 63 |
+
|
| 64 |
+
B. indicate if You modified the Licensed Material and retain an indication of any previous modifications; and
|
| 65 |
+
C. indicate the Licensed Material is licensed under this Public License, and include the text of, or the URI or hyperlink to, this Public License.
|
| 66 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any reasonable manner based on the medium, means, and context in which You Share the Licensed Material. For example, it may be reasonable to satisfy the conditions by providing a URI or hyperlink to a resource that includes the required information.
|
| 67 |
+
3. If requested by the Licensor, You must remove any of the information required by Section 3(a)(1)(A) to the extent reasonably practicable.
|
| 68 |
+
b. ShareAlike.In addition to the conditions in Section 3(a), if You Share Adapted Material You produce, the following conditions also apply.
|
| 69 |
+
1. The Adapter's License You apply must be a Creative Commons license with the same License Elements, this version or later, or a BY-NC-SA Compatible License.
|
| 70 |
+
2. You must include the text of, or the URI or hyperlink to, the Adapter's License You apply. You may satisfy this condition in any reasonable manner based on the medium, means, and context in which You Share Adapted Material.
|
| 71 |
+
3. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, Adapted Material that restrict exercise of the rights granted under the Adapter's License You apply.
|
| 72 |
+
Section 4 – Sui Generis Database Rights.
|
| 73 |
+
|
| 74 |
+
Where the Licensed Rights include Sui Generis Database Rights that apply to Your use of the Licensed Material:
|
| 75 |
+
|
| 76 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right to extract, reuse, reproduce, and Share all or a substantial portion of the contents of the database for NonCommercial purposes only;
|
| 77 |
+
b. if You include all or a substantial portion of the database contents in a database in which You have Sui Generis Database Rights, then the database in which You have Sui Generis Database Rights (but not its individual contents) is Adapted Material, including for purposes of Section 3(b); and
|
| 78 |
+
c. You must comply with the conditions in Section 3(a) if You Share all or a substantial portion of the contents of the database.
|
| 79 |
+
For the avoidance of doubt, this Section 4 supplements and does not replace Your obligations under this Public License where the Licensed Rights include other Copyright and Similar Rights.
|
| 80 |
+
Section 5 – Disclaimer of Warranties and Limitation of Liability.
|
| 81 |
+
|
| 82 |
+
a. Unless otherwise separately undertaken by the Licensor, to the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.
|
| 83 |
+
b. To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.
|
| 84 |
+
c. The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
|
| 85 |
+
Section 6 – Term and Termination.
|
| 86 |
+
|
| 87 |
+
a. This Public License applies for the term of the Copyright and Similar Rights licensed here. However, if You fail to comply with this Public License, then Your rights under this Public License terminate automatically.
|
| 88 |
+
b. Where Your right to use the Licensed Material has terminated under Section 6(a), it reinstates:
|
| 89 |
+
1. automatically as of the date the violation is cured, provided it is cured within 30 days of Your discovery of the violation; or
|
| 90 |
+
2. upon express reinstatement by the Licensor.
|
| 91 |
+
For the avoidance of doubt, this Section 6(b) does not affect any right the Licensor may have to seek remedies for Your violations of this Public License.
|
| 92 |
+
|
| 93 |
+
c. For the avoidance of doubt, the Licensor may also offer the Licensed Material under separate terms or conditions or stop distributing the Licensed Material at any time; however, doing so will not terminate this Public License.
|
| 94 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public License.
|
| 95 |
+
Section 7 – Other Terms and Conditions.
|
| 96 |
+
|
| 97 |
+
a. The Licensor shall not be bound by any additional or different terms or conditions communicated by You unless expressly agreed.
|
| 98 |
+
b. Any arrangements, understandings, or agreements regarding the Licensed Material not stated herein are separate from and independent of the terms and conditions of this Public License.
|
| 99 |
+
Section 8 – Interpretation.
|
| 100 |
+
|
| 101 |
+
a. For the avoidance of doubt, this Public License does not, and shall not be interpreted to, reduce, limit, restrict, or impose conditions on any use of the Licensed Material that could lawfully be made without permission under this Public License.
|
| 102 |
+
b. To the extent possible, if any provision of this Public License is deemed unenforceable, it shall be automatically reformed to the minimum extent necessary to make it enforceable. If the provision cannot be reformed, it shall be severed from this Public License without affecting the enforceability of the remaining terms and conditions.
|
| 103 |
+
c. No term or condition of this Public License will be waived and no failure to comply consented to unless expressly agreed to by the Licensor.
|
| 104 |
+
d. Nothing in this Public License constitutes or may be interpreted as a limitation upon, or waiver of, any privileges and immunities that apply to the Licensor or You, including from the legal processes of any jurisdiction or authority.
|
| 105 |
+
Creative Commons is not a party to its public licenses. Notwithstanding, Creative Commons may elect to apply one of its public licenses to material it publishes and in those instances will be considered the "Licensor." The text of the Creative Commons public licenses is dedicated to the public domain under the CC0 Public Domain Dedication. Except for the limited purpose of indicating that material is shared under a Creative Commons public license or as otherwise permitted by the Creative Commons policies published at creativecommons.org/policies, Creative Commons does not authorize the use of the trademark "Creative Commons" or any other trademark or logo of Creative Commons without its prior written consent including, without limitation, in connection with any unauthorized modifications to any of its public licenses or any other arrangements, understandings, or agreements concerning use of licensed material. For the avoidance of doubt, this paragraph does not form part of the public licenses.
|
| 106 |
+
|
| 107 |
+
Creative Commons may be contacted at creativecommons.org.
|
README.md
CHANGED
|
@@ -1,13 +1,84 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Magic Clothing
|
| 2 |
+
This repository is the official implementation of Magic Clothing
|
| 3 |
+
|
| 4 |
+
Magic Clothing is a branch version of [OOTDiffusion](https://github.com/levihsu/OOTDiffusion), focusing on controllable garment-driven image synthesis
|
| 5 |
+
|
| 6 |
+
Please refer to our [previous paper](https://arxiv.org/abs/2403.01779) for more details
|
| 7 |
+
|
| 8 |
+
> **Magic Clothing: Controllable Garment-Driven Image Synthesis** (coming soon)<br>
|
| 9 |
+
> [Weifeng Chen](https://github.com/ShineChen1024)\*, [Tao Gu](https://github.com/T-Gu)\*, [Yuhao Xu](http://levihsu.github.io/), [Chengcai Chen](https://www.researchgate.net/profile/Chengcai-Chen)<br>
|
| 10 |
+
> \* Equal contribution<br>
|
| 11 |
+
> Xiao-i Research
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## News
|
| 15 |
+
|
| 16 |
+
🔥 [2024/3/8] We released the model weights trained on the 768 resolution. The strength of clothing and text prompts can be independently adjusted.
|
| 17 |
+
|
| 18 |
+
🤗 [Hugging Face link](https://huggingface.co/ShineChen1024/MagicClothing)
|
| 19 |
+
|
| 20 |
+
🔥 [2024/2/28] We support [IP-Adapter-FaceID](https://huggingface.co/h94/IP-Adapter-FaceID) with [ControlNet-Openpose](https://github.com/lllyasviel/ControlNet-v1-1-nightly)! A portrait and a reference pose image can be used as additional conditions.
|
| 21 |
+
|
| 22 |
+
Have fun with **gradio_ipadapter_openpose.py**
|
| 23 |
+
|
| 24 |
+
🔥 [2024/2/23] We support [IP-Adapter-FaceID](https://huggingface.co/h94/IP-Adapter-FaceID) now! A portrait image can be used as an additional condition.
|
| 25 |
+
|
| 26 |
+
Have fun with **gradio_ipadapter_faceid.py**
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Installation
|
| 34 |
+
|
| 35 |
+
1. Clone the repository
|
| 36 |
+
|
| 37 |
+
```sh
|
| 38 |
+
git clone https://github.com/ShineChen1024/MagicClothing.git
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
2. Create a conda environment and install the required packages
|
| 42 |
+
|
| 43 |
+
```sh
|
| 44 |
+
conda create -n magicloth python==3.10
|
| 45 |
+
conda activate magicloth
|
| 46 |
+
pip install torch==2.0.1 torchvision==0.15.2 numpy==1.25.1 diffusers==0.25.1 opencv-python==4.9.0.80 transformers==4.31.0 gradio==4.16.0 safetensors==0.3.1 controlnet-aux==0.0.6 accelerate==0.21.0
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
## Inference
|
| 50 |
+
|
| 51 |
+
1. Python demo
|
| 52 |
+
|
| 53 |
+
> 512 weights
|
| 54 |
+
|
| 55 |
+
```sh
|
| 56 |
+
python inference.py --cloth_path [your cloth path] --model_path [your model path]
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
> 768 weights
|
| 60 |
+
|
| 61 |
+
```sh
|
| 62 |
+
python inference.py --cloth_path [your cloth path] --model_path [your model path] --enable_cloth_guidance
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
2. Gradio demo
|
| 66 |
+
|
| 67 |
+
> 512 weights
|
| 68 |
+
|
| 69 |
+
```sh
|
| 70 |
+
python gradio_generate.py --model_path [your model path]
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
> 768 weights
|
| 74 |
+
|
| 75 |
+
```sh
|
| 76 |
+
python gradio_generate.py --model_path [your model path] --enable_cloth_guidance
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
## TODO List
|
| 80 |
+
- [ ] Paper
|
| 81 |
+
- [x] Gradio demo
|
| 82 |
+
- [x] Inference code
|
| 83 |
+
- [x] Model weights
|
| 84 |
+
- [ ] Training code
|
checkpoints/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
checkpoints/README.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-nc-sa-4.0
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
+
Model weights of [Magic Clothing](https://github.com/ShineChen1024/MagicClothing)
|
checkpoints/ckpt.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# put cloth_segm.pth here
|
checkpoints/cloth_segm.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f71fad2bc11789a996acc507d1a5a1602ae0edefc2b9aba1cd198be5cc9c1a44
|
| 3 |
+
size 176625341
|
checkpoints/ipadapter_faceid/ckpt.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
download ckpt from https://huggingface.co/h94/IP-Adapter-FaceID, put the weights here
|
checkpoints/oms_diffusion_768_200000.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:763bf6f0c2484162901c523dbb0cb310b301535594f05e64c173238b24034191
|
| 3 |
+
size 3438118560
|
garment_adapter/__pycache__/attention_processor.cpython-310.pyc
ADDED
|
Binary file (12.8 kB). View file
|
|
|
garment_adapter/__pycache__/garment_diffusion.cpython-310.pyc
ADDED
|
Binary file (6.86 kB). View file
|
|
|
garment_adapter/attention_processor.py
ADDED
|
@@ -0,0 +1,682 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from typing import Optional
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from diffusers.utils import USE_PEFT_BACKEND
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from diffusers.models.attention_processor import Attention
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class AttnProcessor(nn.Module):
|
| 12 |
+
r"""
|
| 13 |
+
Default processor for performing attention-related computations.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self):
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
def __call__(
|
| 20 |
+
self,
|
| 21 |
+
attn: Attention,
|
| 22 |
+
hidden_states: torch.FloatTensor,
|
| 23 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 24 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 25 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 26 |
+
scale: float = 1.0,
|
| 27 |
+
attn_store=None,
|
| 28 |
+
do_classifier_free_guidance=None,
|
| 29 |
+
enable_cloth_guidance=None
|
| 30 |
+
) -> torch.Tensor:
|
| 31 |
+
residual = hidden_states
|
| 32 |
+
|
| 33 |
+
args = () if USE_PEFT_BACKEND else (scale,)
|
| 34 |
+
|
| 35 |
+
if attn.spatial_norm is not None:
|
| 36 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 37 |
+
|
| 38 |
+
input_ndim = hidden_states.ndim
|
| 39 |
+
|
| 40 |
+
if input_ndim == 4:
|
| 41 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 42 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 43 |
+
|
| 44 |
+
batch_size, sequence_length, _ = (
|
| 45 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 46 |
+
)
|
| 47 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 48 |
+
|
| 49 |
+
if attn.group_norm is not None:
|
| 50 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 51 |
+
|
| 52 |
+
query = attn.to_q(hidden_states, *args)
|
| 53 |
+
|
| 54 |
+
if encoder_hidden_states is None:
|
| 55 |
+
encoder_hidden_states = hidden_states
|
| 56 |
+
elif attn.norm_cross:
|
| 57 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 58 |
+
|
| 59 |
+
key = attn.to_k(encoder_hidden_states, *args)
|
| 60 |
+
value = attn.to_v(encoder_hidden_states, *args)
|
| 61 |
+
|
| 62 |
+
query = attn.head_to_batch_dim(query)
|
| 63 |
+
key = attn.head_to_batch_dim(key)
|
| 64 |
+
value = attn.head_to_batch_dim(value)
|
| 65 |
+
|
| 66 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 67 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 68 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 69 |
+
|
| 70 |
+
# linear proj
|
| 71 |
+
hidden_states = attn.to_out[0](hidden_states, *args)
|
| 72 |
+
# dropout
|
| 73 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 74 |
+
|
| 75 |
+
if input_ndim == 4:
|
| 76 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 77 |
+
|
| 78 |
+
if attn.residual_connection:
|
| 79 |
+
hidden_states = hidden_states + residual
|
| 80 |
+
|
| 81 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 82 |
+
|
| 83 |
+
return hidden_states
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class REFAttnProcessor(nn.Module):
|
| 87 |
+
def __init__(self, name, type="read"):
|
| 88 |
+
super().__init__()
|
| 89 |
+
self.name = name
|
| 90 |
+
self.type = type
|
| 91 |
+
|
| 92 |
+
def __call__(
|
| 93 |
+
self,
|
| 94 |
+
attn: Attention,
|
| 95 |
+
hidden_states: torch.FloatTensor,
|
| 96 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 97 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 98 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 99 |
+
scale: float = 1.0,
|
| 100 |
+
attn_store=None,
|
| 101 |
+
do_classifier_free_guidance=None,
|
| 102 |
+
enable_cloth_guidance=None
|
| 103 |
+
) -> torch.Tensor:
|
| 104 |
+
if self.type == "read":
|
| 105 |
+
attn_store[self.name] = hidden_states
|
| 106 |
+
elif self.type == "write":
|
| 107 |
+
ref_hidden_states = attn_store[self.name]
|
| 108 |
+
if do_classifier_free_guidance:
|
| 109 |
+
empty_copy = torch.zeros_like(ref_hidden_states)
|
| 110 |
+
if enable_cloth_guidance:
|
| 111 |
+
ref_hidden_states = torch.cat([empty_copy, ref_hidden_states, ref_hidden_states])
|
| 112 |
+
else:
|
| 113 |
+
ref_hidden_states = torch.cat([empty_copy, ref_hidden_states])
|
| 114 |
+
hidden_states = torch.cat([hidden_states, ref_hidden_states], dim=1)
|
| 115 |
+
else:
|
| 116 |
+
raise ValueError("unsupport type")
|
| 117 |
+
residual = hidden_states
|
| 118 |
+
|
| 119 |
+
args = () if USE_PEFT_BACKEND else (scale,)
|
| 120 |
+
|
| 121 |
+
if attn.spatial_norm is not None:
|
| 122 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 123 |
+
|
| 124 |
+
input_ndim = hidden_states.ndim
|
| 125 |
+
|
| 126 |
+
if input_ndim == 4:
|
| 127 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 128 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 129 |
+
|
| 130 |
+
batch_size, sequence_length, _ = (
|
| 131 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 132 |
+
)
|
| 133 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 134 |
+
|
| 135 |
+
if attn.group_norm is not None:
|
| 136 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 137 |
+
|
| 138 |
+
query = attn.to_q(hidden_states, *args)
|
| 139 |
+
|
| 140 |
+
if encoder_hidden_states is None:
|
| 141 |
+
encoder_hidden_states = hidden_states
|
| 142 |
+
elif attn.norm_cross:
|
| 143 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 144 |
+
|
| 145 |
+
key = attn.to_k(encoder_hidden_states, *args)
|
| 146 |
+
value = attn.to_v(encoder_hidden_states, *args)
|
| 147 |
+
|
| 148 |
+
query = attn.head_to_batch_dim(query)
|
| 149 |
+
key = attn.head_to_batch_dim(key)
|
| 150 |
+
value = attn.head_to_batch_dim(value)
|
| 151 |
+
|
| 152 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 153 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 154 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 155 |
+
|
| 156 |
+
if self.type == "write":
|
| 157 |
+
hidden_states, _ = torch.chunk(hidden_states, 2, dim=1)
|
| 158 |
+
|
| 159 |
+
# linear proj
|
| 160 |
+
hidden_states = attn.to_out[0](hidden_states, *args)
|
| 161 |
+
# dropout
|
| 162 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 163 |
+
|
| 164 |
+
if input_ndim == 4:
|
| 165 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 166 |
+
|
| 167 |
+
if attn.residual_connection:
|
| 168 |
+
hidden_states = hidden_states + residual
|
| 169 |
+
|
| 170 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 171 |
+
|
| 172 |
+
return hidden_states
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
class AttnProcessor2_0(nn.Module):
|
| 176 |
+
r"""
|
| 177 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 178 |
+
"""
|
| 179 |
+
|
| 180 |
+
def __init__(self):
|
| 181 |
+
super().__init__()
|
| 182 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 183 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 184 |
+
|
| 185 |
+
def __call__(
|
| 186 |
+
self,
|
| 187 |
+
attn: Attention,
|
| 188 |
+
hidden_states: torch.FloatTensor,
|
| 189 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 190 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 191 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 192 |
+
scale: float = 1.0,
|
| 193 |
+
attn_store=None,
|
| 194 |
+
do_classifier_free_guidance=None,
|
| 195 |
+
enable_cloth_guidance=None
|
| 196 |
+
) -> torch.FloatTensor:
|
| 197 |
+
residual = hidden_states
|
| 198 |
+
if attn.spatial_norm is not None:
|
| 199 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 200 |
+
|
| 201 |
+
input_ndim = hidden_states.ndim
|
| 202 |
+
|
| 203 |
+
if input_ndim == 4:
|
| 204 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 205 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 206 |
+
|
| 207 |
+
batch_size, sequence_length, _ = (
|
| 208 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
if attention_mask is not None:
|
| 212 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 213 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 214 |
+
# (batch, heads, source_length, target_length)
|
| 215 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 216 |
+
|
| 217 |
+
if attn.group_norm is not None:
|
| 218 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 219 |
+
|
| 220 |
+
args = () if USE_PEFT_BACKEND else (scale,)
|
| 221 |
+
query = attn.to_q(hidden_states, *args)
|
| 222 |
+
|
| 223 |
+
if encoder_hidden_states is None:
|
| 224 |
+
encoder_hidden_states = hidden_states
|
| 225 |
+
elif attn.norm_cross:
|
| 226 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 227 |
+
|
| 228 |
+
key = attn.to_k(encoder_hidden_states, *args)
|
| 229 |
+
value = attn.to_v(encoder_hidden_states, *args)
|
| 230 |
+
|
| 231 |
+
inner_dim = key.shape[-1]
|
| 232 |
+
head_dim = inner_dim // attn.heads
|
| 233 |
+
|
| 234 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 235 |
+
|
| 236 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 237 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 238 |
+
|
| 239 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 240 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 241 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 242 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 246 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 247 |
+
|
| 248 |
+
# linear proj
|
| 249 |
+
hidden_states = attn.to_out[0](hidden_states, *args)
|
| 250 |
+
# dropout
|
| 251 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 252 |
+
|
| 253 |
+
if input_ndim == 4:
|
| 254 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 255 |
+
|
| 256 |
+
if attn.residual_connection:
|
| 257 |
+
hidden_states = hidden_states + residual
|
| 258 |
+
|
| 259 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 260 |
+
|
| 261 |
+
return hidden_states
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class REFAttnProcessor2_0(nn.Module):
|
| 265 |
+
def __init__(self, name, type="read"):
|
| 266 |
+
super().__init__()
|
| 267 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 268 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 269 |
+
self.name = name
|
| 270 |
+
self.type = type
|
| 271 |
+
|
| 272 |
+
def __call__(
|
| 273 |
+
self,
|
| 274 |
+
attn: Attention,
|
| 275 |
+
hidden_states: torch.FloatTensor,
|
| 276 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 277 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 278 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 279 |
+
scale: float = 1.0,
|
| 280 |
+
attn_store=None,
|
| 281 |
+
do_classifier_free_guidance=False,
|
| 282 |
+
enable_cloth_guidance=True
|
| 283 |
+
) -> torch.FloatTensor:
|
| 284 |
+
if self.type == "read":
|
| 285 |
+
attn_store[self.name] = hidden_states
|
| 286 |
+
elif self.type == "write":
|
| 287 |
+
ref_hidden_states = attn_store[self.name]
|
| 288 |
+
if do_classifier_free_guidance:
|
| 289 |
+
empty_copy = torch.zeros_like(ref_hidden_states)
|
| 290 |
+
if enable_cloth_guidance:
|
| 291 |
+
ref_hidden_states = torch.cat([empty_copy, ref_hidden_states, ref_hidden_states])
|
| 292 |
+
else:
|
| 293 |
+
ref_hidden_states = torch.cat([empty_copy, ref_hidden_states])
|
| 294 |
+
hidden_states = torch.cat([hidden_states, ref_hidden_states], dim=1)
|
| 295 |
+
else:
|
| 296 |
+
raise ValueError("unsupport type")
|
| 297 |
+
residual = hidden_states
|
| 298 |
+
if attn.spatial_norm is not None:
|
| 299 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 300 |
+
|
| 301 |
+
input_ndim = hidden_states.ndim
|
| 302 |
+
|
| 303 |
+
if input_ndim == 4:
|
| 304 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 305 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 306 |
+
|
| 307 |
+
batch_size, sequence_length, _ = (
|
| 308 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
if attention_mask is not None:
|
| 312 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 313 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 314 |
+
# (batch, heads, source_length, target_length)
|
| 315 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 316 |
+
|
| 317 |
+
if attn.group_norm is not None:
|
| 318 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 319 |
+
|
| 320 |
+
args = () if USE_PEFT_BACKEND else (scale,)
|
| 321 |
+
query = attn.to_q(hidden_states, *args)
|
| 322 |
+
|
| 323 |
+
if encoder_hidden_states is None:
|
| 324 |
+
encoder_hidden_states = hidden_states
|
| 325 |
+
elif attn.norm_cross:
|
| 326 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 327 |
+
|
| 328 |
+
key = attn.to_k(encoder_hidden_states, *args)
|
| 329 |
+
value = attn.to_v(encoder_hidden_states, *args)
|
| 330 |
+
|
| 331 |
+
inner_dim = key.shape[-1]
|
| 332 |
+
head_dim = inner_dim // attn.heads
|
| 333 |
+
|
| 334 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 335 |
+
|
| 336 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 337 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 338 |
+
|
| 339 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 340 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 341 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 342 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 346 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 347 |
+
|
| 348 |
+
if self.type == "write":
|
| 349 |
+
hidden_states, _ = torch.chunk(hidden_states, 2, dim=1)
|
| 350 |
+
# linear proj
|
| 351 |
+
hidden_states = attn.to_out[0](hidden_states, *args)
|
| 352 |
+
# dropout
|
| 353 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 354 |
+
|
| 355 |
+
if input_ndim == 4:
|
| 356 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 357 |
+
|
| 358 |
+
if attn.residual_connection:
|
| 359 |
+
hidden_states = hidden_states + residual
|
| 360 |
+
|
| 361 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 362 |
+
return hidden_states
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class REFAnimateDiffAttnProcessor2_0(nn.Module):
|
| 366 |
+
def __init__(self, name, type="read"):
|
| 367 |
+
super().__init__()
|
| 368 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 369 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 370 |
+
self.name = name
|
| 371 |
+
self.type = type
|
| 372 |
+
|
| 373 |
+
def __call__(
|
| 374 |
+
self,
|
| 375 |
+
attn: Attention,
|
| 376 |
+
hidden_states: torch.FloatTensor,
|
| 377 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 378 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 379 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 380 |
+
scale: float = 1.0,
|
| 381 |
+
attn_store=None,
|
| 382 |
+
do_classifier_free_guidance=False,
|
| 383 |
+
) -> torch.FloatTensor:
|
| 384 |
+
if self.type == "read":
|
| 385 |
+
attn_store[self.name] = hidden_states
|
| 386 |
+
elif self.type == "write":
|
| 387 |
+
ref_hidden_states = attn_store[self.name]
|
| 388 |
+
if do_classifier_free_guidance:
|
| 389 |
+
empty_copy = torch.zeros_like(ref_hidden_states)
|
| 390 |
+
ref_hidden_states = torch.cat([empty_copy, ref_hidden_states, ref_hidden_states])
|
| 391 |
+
if hidden_states.shape[0] % ref_hidden_states.shape[0] != 0:
|
| 392 |
+
raise ValueError("not evenly divisible")
|
| 393 |
+
# ref_hidden_states = ref_hidden_states*1.05
|
| 394 |
+
hidden_states = torch.cat([hidden_states, ref_hidden_states.repeat(hidden_states.shape[0] // ref_hidden_states.shape[0], 1, 1)], dim=1)
|
| 395 |
+
else:
|
| 396 |
+
raise ValueError("unsupport type")
|
| 397 |
+
residual = hidden_states
|
| 398 |
+
if attn.spatial_norm is not None:
|
| 399 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 400 |
+
|
| 401 |
+
input_ndim = hidden_states.ndim
|
| 402 |
+
|
| 403 |
+
if input_ndim == 4:
|
| 404 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 405 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 406 |
+
|
| 407 |
+
batch_size, sequence_length, _ = (
|
| 408 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 409 |
+
)
|
| 410 |
+
|
| 411 |
+
if attention_mask is not None:
|
| 412 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 413 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 414 |
+
# (batch, heads, source_length, target_length)
|
| 415 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 416 |
+
|
| 417 |
+
if attn.group_norm is not None:
|
| 418 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 419 |
+
|
| 420 |
+
args = () if USE_PEFT_BACKEND else (scale,)
|
| 421 |
+
query = attn.to_q(hidden_states, *args)
|
| 422 |
+
|
| 423 |
+
if encoder_hidden_states is None:
|
| 424 |
+
encoder_hidden_states = hidden_states
|
| 425 |
+
elif attn.norm_cross:
|
| 426 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 427 |
+
|
| 428 |
+
key = attn.to_k(encoder_hidden_states, *args)
|
| 429 |
+
value = attn.to_v(encoder_hidden_states, *args)
|
| 430 |
+
|
| 431 |
+
inner_dim = key.shape[-1]
|
| 432 |
+
head_dim = inner_dim // attn.heads
|
| 433 |
+
|
| 434 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 435 |
+
|
| 436 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 437 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 438 |
+
|
| 439 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 440 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 441 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 442 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 443 |
+
)
|
| 444 |
+
|
| 445 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 446 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 447 |
+
|
| 448 |
+
if self.type == "write":
|
| 449 |
+
hidden_states, _ = torch.chunk(hidden_states, 2, dim=1)
|
| 450 |
+
# linear proj
|
| 451 |
+
hidden_states = attn.to_out[0](hidden_states, *args)
|
| 452 |
+
# dropout
|
| 453 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 454 |
+
|
| 455 |
+
if input_ndim == 4:
|
| 456 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 457 |
+
|
| 458 |
+
if attn.residual_connection:
|
| 459 |
+
hidden_states = hidden_states + residual
|
| 460 |
+
|
| 461 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 462 |
+
return hidden_states
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
class IPAttnProcessor(nn.Module):
|
| 466 |
+
|
| 467 |
+
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
|
| 468 |
+
super().__init__()
|
| 469 |
+
|
| 470 |
+
self.hidden_size = hidden_size
|
| 471 |
+
self.cross_attention_dim = cross_attention_dim
|
| 472 |
+
self.scale = scale
|
| 473 |
+
self.num_tokens = num_tokens
|
| 474 |
+
|
| 475 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 476 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 477 |
+
|
| 478 |
+
def __call__(
|
| 479 |
+
self,
|
| 480 |
+
attn,
|
| 481 |
+
hidden_states,
|
| 482 |
+
encoder_hidden_states=None,
|
| 483 |
+
attention_mask=None,
|
| 484 |
+
temb=None,
|
| 485 |
+
attn_store=None,
|
| 486 |
+
do_classifier_free_guidance=None,
|
| 487 |
+
enable_cloth_guidance=None
|
| 488 |
+
):
|
| 489 |
+
residual = hidden_states
|
| 490 |
+
|
| 491 |
+
if attn.spatial_norm is not None:
|
| 492 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 493 |
+
|
| 494 |
+
input_ndim = hidden_states.ndim
|
| 495 |
+
|
| 496 |
+
if input_ndim == 4:
|
| 497 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 498 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 499 |
+
|
| 500 |
+
batch_size, sequence_length, _ = (
|
| 501 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 502 |
+
)
|
| 503 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 504 |
+
|
| 505 |
+
if attn.group_norm is not None:
|
| 506 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 507 |
+
|
| 508 |
+
query = attn.to_q(hidden_states)
|
| 509 |
+
|
| 510 |
+
if encoder_hidden_states is None:
|
| 511 |
+
encoder_hidden_states = hidden_states
|
| 512 |
+
else:
|
| 513 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 514 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 515 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 516 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 517 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 518 |
+
)
|
| 519 |
+
if attn.norm_cross:
|
| 520 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 521 |
+
|
| 522 |
+
key = attn.to_k(encoder_hidden_states)
|
| 523 |
+
value = attn.to_v(encoder_hidden_states)
|
| 524 |
+
|
| 525 |
+
query = attn.head_to_batch_dim(query)
|
| 526 |
+
key = attn.head_to_batch_dim(key)
|
| 527 |
+
value = attn.head_to_batch_dim(value)
|
| 528 |
+
|
| 529 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 530 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 531 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 532 |
+
|
| 533 |
+
# for ip-adapter
|
| 534 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 535 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 536 |
+
|
| 537 |
+
ip_key = attn.head_to_batch_dim(ip_key)
|
| 538 |
+
ip_value = attn.head_to_batch_dim(ip_value)
|
| 539 |
+
|
| 540 |
+
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
|
| 541 |
+
self.attn_map = ip_attention_probs
|
| 542 |
+
ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
|
| 543 |
+
ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
|
| 544 |
+
|
| 545 |
+
hidden_states = hidden_states + self.scale * ip_hidden_states
|
| 546 |
+
|
| 547 |
+
# linear proj
|
| 548 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 549 |
+
# dropout
|
| 550 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 551 |
+
|
| 552 |
+
if input_ndim == 4:
|
| 553 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 554 |
+
|
| 555 |
+
if attn.residual_connection:
|
| 556 |
+
hidden_states = hidden_states + residual
|
| 557 |
+
|
| 558 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 559 |
+
|
| 560 |
+
return hidden_states
|
| 561 |
+
|
| 562 |
+
|
| 563 |
+
class IPAttnProcessor2_0(torch.nn.Module):
|
| 564 |
+
|
| 565 |
+
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4):
|
| 566 |
+
super().__init__()
|
| 567 |
+
|
| 568 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 569 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 570 |
+
|
| 571 |
+
self.hidden_size = hidden_size
|
| 572 |
+
self.cross_attention_dim = cross_attention_dim
|
| 573 |
+
self.scale = scale
|
| 574 |
+
self.num_tokens = num_tokens
|
| 575 |
+
|
| 576 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 577 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 578 |
+
|
| 579 |
+
def __call__(
|
| 580 |
+
self,
|
| 581 |
+
attn,
|
| 582 |
+
hidden_states,
|
| 583 |
+
encoder_hidden_states=None,
|
| 584 |
+
attention_mask=None,
|
| 585 |
+
temb=None,
|
| 586 |
+
attn_store=None,
|
| 587 |
+
do_classifier_free_guidance=None,
|
| 588 |
+
enable_cloth_guidance=None
|
| 589 |
+
):
|
| 590 |
+
residual = hidden_states
|
| 591 |
+
|
| 592 |
+
if attn.spatial_norm is not None:
|
| 593 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 594 |
+
|
| 595 |
+
input_ndim = hidden_states.ndim
|
| 596 |
+
|
| 597 |
+
if input_ndim == 4:
|
| 598 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 599 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 600 |
+
|
| 601 |
+
batch_size, sequence_length, _ = (
|
| 602 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 603 |
+
)
|
| 604 |
+
|
| 605 |
+
if attention_mask is not None:
|
| 606 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 607 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 608 |
+
# (batch, heads, source_length, target_length)
|
| 609 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 610 |
+
|
| 611 |
+
if attn.group_norm is not None:
|
| 612 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 613 |
+
|
| 614 |
+
query = attn.to_q(hidden_states)
|
| 615 |
+
|
| 616 |
+
if encoder_hidden_states is None:
|
| 617 |
+
encoder_hidden_states = hidden_states
|
| 618 |
+
else:
|
| 619 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 620 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 621 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 622 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 623 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 624 |
+
)
|
| 625 |
+
if attn.norm_cross:
|
| 626 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 627 |
+
|
| 628 |
+
key = attn.to_k(encoder_hidden_states)
|
| 629 |
+
value = attn.to_v(encoder_hidden_states)
|
| 630 |
+
|
| 631 |
+
inner_dim = key.shape[-1]
|
| 632 |
+
head_dim = inner_dim // attn.heads
|
| 633 |
+
|
| 634 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 635 |
+
|
| 636 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 637 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 638 |
+
|
| 639 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 640 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 641 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 642 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 643 |
+
)
|
| 644 |
+
|
| 645 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 646 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 647 |
+
|
| 648 |
+
# for ip-adapter
|
| 649 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 650 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 651 |
+
|
| 652 |
+
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 653 |
+
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 654 |
+
|
| 655 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 656 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 657 |
+
ip_hidden_states = F.scaled_dot_product_attention(
|
| 658 |
+
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
| 659 |
+
)
|
| 660 |
+
with torch.no_grad():
|
| 661 |
+
self.attn_map = query @ ip_key.transpose(-2, -1).softmax(dim=-1)
|
| 662 |
+
# print(self.attn_map.shape)
|
| 663 |
+
|
| 664 |
+
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 665 |
+
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
| 666 |
+
|
| 667 |
+
hidden_states = hidden_states + self.scale * ip_hidden_states
|
| 668 |
+
|
| 669 |
+
# linear proj
|
| 670 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 671 |
+
# dropout
|
| 672 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 673 |
+
|
| 674 |
+
if input_ndim == 4:
|
| 675 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 676 |
+
|
| 677 |
+
if attn.residual_connection:
|
| 678 |
+
hidden_states = hidden_states + residual
|
| 679 |
+
|
| 680 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 681 |
+
|
| 682 |
+
return hidden_states
|
garment_adapter/garment_diffusion.py
ADDED
|
@@ -0,0 +1,248 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import torch
|
| 3 |
+
from safetensors import safe_open
|
| 4 |
+
from garment_seg.process import load_seg_model, generate_mask
|
| 5 |
+
from utils.utils import is_torch2_available, prepare_image, prepare_mask
|
| 6 |
+
from diffusers import UNet2DConditionModel
|
| 7 |
+
|
| 8 |
+
if is_torch2_available():
|
| 9 |
+
from .attention_processor import REFAttnProcessor2_0 as REFAttnProcessor
|
| 10 |
+
from .attention_processor import AttnProcessor2_0 as AttnProcessor
|
| 11 |
+
from .attention_processor import REFAnimateDiffAttnProcessor2_0 as REFAnimateDiffAttnProcessor
|
| 12 |
+
else:
|
| 13 |
+
from .attention_processor import REFAttnProcessor, AttnProcessor
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class ClothAdapter:
|
| 17 |
+
def __init__(self, sd_pipe, ref_path, device, enable_cloth_guidance, set_seg_model=True):
|
| 18 |
+
self.enable_cloth_guidance = enable_cloth_guidance
|
| 19 |
+
self.device = device
|
| 20 |
+
self.pipe = sd_pipe.to(self.device)
|
| 21 |
+
self.set_adapter(self.pipe.unet, "write")
|
| 22 |
+
print(ref_path)
|
| 23 |
+
ref_unet = copy.deepcopy(sd_pipe.unet)
|
| 24 |
+
if ref_unet.config.in_channels == 9:
|
| 25 |
+
ref_unet.conv_in = torch.nn.Conv2d(4, 320, ref_unet.conv_in.kernel_size, ref_unet.conv_in.stride, ref_unet.conv_in.padding)
|
| 26 |
+
ref_unet.register_to_config(in_channels=4)
|
| 27 |
+
state_dict = {}
|
| 28 |
+
with safe_open(ref_path, framework="pt", device="cpu") as f:
|
| 29 |
+
for key in f.keys():
|
| 30 |
+
state_dict[key] = f.get_tensor(key)
|
| 31 |
+
ref_unet.load_state_dict(state_dict, strict=False)
|
| 32 |
+
|
| 33 |
+
self.ref_unet = ref_unet.to(self.device, dtype=self.pipe.dtype)
|
| 34 |
+
self.set_adapter(self.ref_unet, "read")
|
| 35 |
+
if set_seg_model:
|
| 36 |
+
self.set_seg_model()
|
| 37 |
+
self.attn_store = {}
|
| 38 |
+
|
| 39 |
+
def set_seg_model(self, ):
|
| 40 |
+
checkpoint_path = 'checkpoints/cloth_segm.pth'
|
| 41 |
+
self.seg_net = load_seg_model(checkpoint_path, device=self.device)
|
| 42 |
+
|
| 43 |
+
def set_adapter(self, unet, type):
|
| 44 |
+
attn_procs = {}
|
| 45 |
+
for name in unet.attn_processors.keys():
|
| 46 |
+
if "attn1" in name:
|
| 47 |
+
attn_procs[name] = REFAttnProcessor(name=name, type=type)
|
| 48 |
+
else:
|
| 49 |
+
attn_procs[name] = AttnProcessor()
|
| 50 |
+
unet.set_attn_processor(attn_procs)
|
| 51 |
+
|
| 52 |
+
def generate(
|
| 53 |
+
self,
|
| 54 |
+
cloth_image,
|
| 55 |
+
cloth_mask_image=None,
|
| 56 |
+
prompt=None,
|
| 57 |
+
a_prompt="best quality, high quality",
|
| 58 |
+
num_images_per_prompt=4,
|
| 59 |
+
negative_prompt=None,
|
| 60 |
+
seed=-1,
|
| 61 |
+
guidance_scale=7.5,
|
| 62 |
+
cloth_guidance_scale=2.5,
|
| 63 |
+
num_inference_steps=20,
|
| 64 |
+
height=512,
|
| 65 |
+
width=384,
|
| 66 |
+
**kwargs,
|
| 67 |
+
):
|
| 68 |
+
if cloth_mask_image is None:
|
| 69 |
+
cloth_mask_image = generate_mask(cloth_image, net=self.seg_net, device=self.device)
|
| 70 |
+
|
| 71 |
+
cloth = prepare_image(cloth_image, height, width)
|
| 72 |
+
cloth_mask = prepare_mask(cloth_mask_image, height, width)
|
| 73 |
+
cloth = (cloth * cloth_mask).to(self.device, dtype=torch.float16)
|
| 74 |
+
|
| 75 |
+
if prompt is None:
|
| 76 |
+
prompt = "a photography of a model"
|
| 77 |
+
prompt = prompt + ", " + a_prompt
|
| 78 |
+
if negative_prompt is None:
|
| 79 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 80 |
+
|
| 81 |
+
with torch.inference_mode():
|
| 82 |
+
prompt_embeds, negative_prompt_embeds = self.pipe.encode_prompt(
|
| 83 |
+
prompt,
|
| 84 |
+
device=self.device,
|
| 85 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 86 |
+
do_classifier_free_guidance=True,
|
| 87 |
+
negative_prompt=negative_prompt,
|
| 88 |
+
)
|
| 89 |
+
prompt_embeds_null = self.pipe.encode_prompt([""], device=self.device, num_images_per_prompt=num_images_per_prompt, do_classifier_free_guidance=False)[0]
|
| 90 |
+
cloth_embeds = self.pipe.vae.encode(cloth).latent_dist.mode() * self.pipe.vae.config.scaling_factor
|
| 91 |
+
self.ref_unet(torch.cat([cloth_embeds] * num_images_per_prompt), 0, prompt_embeds_null, cross_attention_kwargs={"attn_store": self.attn_store})
|
| 92 |
+
|
| 93 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 94 |
+
if self.enable_cloth_guidance:
|
| 95 |
+
images = self.pipe(
|
| 96 |
+
prompt_embeds=prompt_embeds,
|
| 97 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 98 |
+
guidance_scale=guidance_scale,
|
| 99 |
+
cloth_guidance_scale=cloth_guidance_scale,
|
| 100 |
+
num_inference_steps=num_inference_steps,
|
| 101 |
+
generator=generator,
|
| 102 |
+
height=height,
|
| 103 |
+
width=width,
|
| 104 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": guidance_scale > 1.0, "enable_cloth_guidance": self.enable_cloth_guidance},
|
| 105 |
+
**kwargs,
|
| 106 |
+
).images
|
| 107 |
+
else:
|
| 108 |
+
images = self.pipe(
|
| 109 |
+
prompt_embeds=prompt_embeds,
|
| 110 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 111 |
+
guidance_scale=guidance_scale,
|
| 112 |
+
num_inference_steps=num_inference_steps,
|
| 113 |
+
generator=generator,
|
| 114 |
+
height=height,
|
| 115 |
+
width=width,
|
| 116 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": guidance_scale > 1.0, "enable_cloth_guidance": self.enable_cloth_guidance},
|
| 117 |
+
**kwargs,
|
| 118 |
+
).images
|
| 119 |
+
|
| 120 |
+
return images, cloth_mask_image
|
| 121 |
+
|
| 122 |
+
def generate_inpainting(
|
| 123 |
+
self,
|
| 124 |
+
cloth_image,
|
| 125 |
+
cloth_mask_image=None,
|
| 126 |
+
num_images_per_prompt=4,
|
| 127 |
+
seed=-1,
|
| 128 |
+
cloth_guidance_scale=2.5,
|
| 129 |
+
num_inference_steps=20,
|
| 130 |
+
height=512,
|
| 131 |
+
width=384,
|
| 132 |
+
**kwargs,
|
| 133 |
+
):
|
| 134 |
+
if cloth_mask_image is None:
|
| 135 |
+
cloth_mask_image = generate_mask(cloth_image, net=self.seg_net, device=self.device)
|
| 136 |
+
|
| 137 |
+
cloth = prepare_image(cloth_image, height, width)
|
| 138 |
+
cloth_mask = prepare_mask(cloth_mask_image, height, width)
|
| 139 |
+
cloth = (cloth * cloth_mask).to(self.device, dtype=torch.float16)
|
| 140 |
+
|
| 141 |
+
with torch.inference_mode():
|
| 142 |
+
prompt_embeds_null = self.pipe.encode_prompt([""], device=self.device, num_images_per_prompt=num_images_per_prompt, do_classifier_free_guidance=False)[0]
|
| 143 |
+
cloth_embeds = self.pipe.vae.encode(cloth).latent_dist.mode() * self.pipe.vae.config.scaling_factor
|
| 144 |
+
self.ref_unet(torch.cat([cloth_embeds] * num_images_per_prompt), 0, prompt_embeds_null, cross_attention_kwargs={"attn_store": self.attn_store})
|
| 145 |
+
|
| 146 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 147 |
+
images = self.pipe(
|
| 148 |
+
prompt_embeds=prompt_embeds_null,
|
| 149 |
+
cloth_guidance_scale=cloth_guidance_scale,
|
| 150 |
+
num_inference_steps=num_inference_steps,
|
| 151 |
+
generator=generator,
|
| 152 |
+
height=height,
|
| 153 |
+
width=width,
|
| 154 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": cloth_guidance_scale > 1.0, "enable_cloth_guidance": False},
|
| 155 |
+
**kwargs,
|
| 156 |
+
).images
|
| 157 |
+
|
| 158 |
+
return images, cloth_mask_image
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class ClothAdapter_AnimateDiff:
|
| 162 |
+
def __init__(self, sd_pipe, pipe_path, ref_path, device, set_seg_model=True):
|
| 163 |
+
self.device = device
|
| 164 |
+
self.pipe = sd_pipe.to(self.device)
|
| 165 |
+
self.set_adapter(self.pipe.unet, "write")
|
| 166 |
+
|
| 167 |
+
ref_unet = UNet2DConditionModel.from_pretrained(pipe_path, subfolder='unet', torch_dtype=sd_pipe.dtype)
|
| 168 |
+
state_dict = {}
|
| 169 |
+
with safe_open(ref_path, framework="pt", device="cpu") as f:
|
| 170 |
+
for key in f.keys():
|
| 171 |
+
state_dict[key] = f.get_tensor(key)
|
| 172 |
+
ref_unet.load_state_dict(state_dict, strict=False)
|
| 173 |
+
|
| 174 |
+
self.ref_unet = ref_unet.to(self.device)
|
| 175 |
+
self.set_adapter(self.ref_unet, "read")
|
| 176 |
+
if set_seg_model:
|
| 177 |
+
self.set_seg_model()
|
| 178 |
+
self.attn_store = {}
|
| 179 |
+
|
| 180 |
+
def set_seg_model(self, ):
|
| 181 |
+
checkpoint_path = 'checkpoints/cloth_segm.pth'
|
| 182 |
+
self.seg_net = load_seg_model(checkpoint_path, device=self.device)
|
| 183 |
+
|
| 184 |
+
def set_adapter(self, unet, type):
|
| 185 |
+
attn_procs = {}
|
| 186 |
+
for name in unet.attn_processors.keys():
|
| 187 |
+
if "attn1" in name and "motion_modules" not in name:
|
| 188 |
+
attn_procs[name] = REFAnimateDiffAttnProcessor(name=name, type=type)
|
| 189 |
+
else:
|
| 190 |
+
attn_procs[name] = AttnProcessor()
|
| 191 |
+
unet.set_attn_processor(attn_procs)
|
| 192 |
+
|
| 193 |
+
def generate(
|
| 194 |
+
self,
|
| 195 |
+
cloth_image,
|
| 196 |
+
cloth_mask_image=None,
|
| 197 |
+
prompt=None,
|
| 198 |
+
a_prompt="best quality, high quality",
|
| 199 |
+
num_images_per_prompt=4,
|
| 200 |
+
negative_prompt=None,
|
| 201 |
+
seed=-1,
|
| 202 |
+
guidance_scale=7.5,
|
| 203 |
+
cloth_guidance_scale=3.,
|
| 204 |
+
num_inference_steps=20,
|
| 205 |
+
height=512,
|
| 206 |
+
width=384,
|
| 207 |
+
**kwargs,
|
| 208 |
+
):
|
| 209 |
+
if cloth_mask_image is None:
|
| 210 |
+
cloth_mask_image = generate_mask(cloth_image, net=self.seg_net, device=self.device)
|
| 211 |
+
|
| 212 |
+
cloth = prepare_image(cloth_image, height, width)
|
| 213 |
+
cloth_mask = prepare_mask(cloth_mask_image, height, width)
|
| 214 |
+
cloth = (cloth * cloth_mask).to(self.device, dtype=torch.float16)
|
| 215 |
+
|
| 216 |
+
if prompt is None:
|
| 217 |
+
prompt = "a photography of a model"
|
| 218 |
+
prompt = prompt + ", " + a_prompt
|
| 219 |
+
if negative_prompt is None:
|
| 220 |
+
negative_prompt = "bare, naked, nude, undressed, monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 221 |
+
|
| 222 |
+
with torch.inference_mode():
|
| 223 |
+
prompt_embeds, negative_prompt_embeds = self.pipe.encode_prompt(
|
| 224 |
+
prompt,
|
| 225 |
+
device=self.device,
|
| 226 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 227 |
+
do_classifier_free_guidance=True,
|
| 228 |
+
negative_prompt=negative_prompt,
|
| 229 |
+
)
|
| 230 |
+
prompt_embeds_null = self.pipe.encode_prompt([""], device=self.device, num_images_per_prompt=num_images_per_prompt, do_classifier_free_guidance=False)[0]
|
| 231 |
+
cloth_embeds = self.pipe.vae.encode(cloth).latent_dist.mode() * self.pipe.vae.config.scaling_factor
|
| 232 |
+
self.ref_unet(torch.cat([cloth_embeds] * num_images_per_prompt), 0, prompt_embeds_null, cross_attention_kwargs={"attn_store": self.attn_store})
|
| 233 |
+
|
| 234 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 235 |
+
frames = self.pipe(
|
| 236 |
+
prompt_embeds=prompt_embeds,
|
| 237 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 238 |
+
guidance_scale=guidance_scale,
|
| 239 |
+
cloth_guidance_scale=cloth_guidance_scale,
|
| 240 |
+
num_inference_steps=num_inference_steps,
|
| 241 |
+
generator=generator,
|
| 242 |
+
height=height,
|
| 243 |
+
width=width,
|
| 244 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": guidance_scale > 1.0},
|
| 245 |
+
**kwargs,
|
| 246 |
+
).frames
|
| 247 |
+
|
| 248 |
+
return frames, cloth_mask_image
|
garment_adapter/garment_ipadapter_faceid.py
ADDED
|
@@ -0,0 +1,673 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pdb
|
| 3 |
+
from typing import List
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
from safetensors import safe_open
|
| 8 |
+
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
| 9 |
+
from garment_seg.process import load_seg_model, generate_mask
|
| 10 |
+
|
| 11 |
+
from utils.utils import is_torch2_available, prepare_image, prepare_mask
|
| 12 |
+
import copy
|
| 13 |
+
from utils.resampler import PerceiverAttention, FeedForward
|
| 14 |
+
from insightface.utils import face_align
|
| 15 |
+
from insightface.app import FaceAnalysis
|
| 16 |
+
import cv2
|
| 17 |
+
|
| 18 |
+
USE_DAFAULT_ATTN = False # should be True for visualization_attnmap
|
| 19 |
+
if is_torch2_available() and (not USE_DAFAULT_ATTN):
|
| 20 |
+
from .attention_processor import AttnProcessor2_0 as AttnProcessor
|
| 21 |
+
from .attention_processor import IPAttnProcessor2_0 as IPAttnProcessor
|
| 22 |
+
from .attention_processor import REFAttnProcessor2_0 as REFAttnProcessor
|
| 23 |
+
else:
|
| 24 |
+
from .attention_processor import AttnProcessor, IPAttnProcessor, REFAttnProcessor
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class FacePerceiverResampler(torch.nn.Module):
|
| 28 |
+
def __init__(
|
| 29 |
+
self,
|
| 30 |
+
*,
|
| 31 |
+
dim=768,
|
| 32 |
+
depth=4,
|
| 33 |
+
dim_head=64,
|
| 34 |
+
heads=16,
|
| 35 |
+
embedding_dim=1280,
|
| 36 |
+
output_dim=768,
|
| 37 |
+
ff_mult=4,
|
| 38 |
+
):
|
| 39 |
+
super().__init__()
|
| 40 |
+
|
| 41 |
+
self.proj_in = torch.nn.Linear(embedding_dim, dim)
|
| 42 |
+
self.proj_out = torch.nn.Linear(dim, output_dim)
|
| 43 |
+
self.norm_out = torch.nn.LayerNorm(output_dim)
|
| 44 |
+
self.layers = torch.nn.ModuleList([])
|
| 45 |
+
for _ in range(depth):
|
| 46 |
+
self.layers.append(
|
| 47 |
+
torch.nn.ModuleList(
|
| 48 |
+
[
|
| 49 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 50 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 51 |
+
]
|
| 52 |
+
)
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
def forward(self, latents, x):
|
| 56 |
+
x = self.proj_in(x)
|
| 57 |
+
for attn, ff in self.layers:
|
| 58 |
+
latents = attn(x, latents) + latents
|
| 59 |
+
latents = ff(latents) + latents
|
| 60 |
+
latents = self.proj_out(latents)
|
| 61 |
+
return self.norm_out(latents)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class MLPProjModel(torch.nn.Module):
|
| 65 |
+
def __init__(self, cross_attention_dim=768, id_embeddings_dim=512, num_tokens=4):
|
| 66 |
+
super().__init__()
|
| 67 |
+
|
| 68 |
+
self.cross_attention_dim = cross_attention_dim
|
| 69 |
+
self.num_tokens = num_tokens
|
| 70 |
+
|
| 71 |
+
self.proj = torch.nn.Sequential(
|
| 72 |
+
torch.nn.Linear(id_embeddings_dim, id_embeddings_dim * 2),
|
| 73 |
+
torch.nn.GELU(),
|
| 74 |
+
torch.nn.Linear(id_embeddings_dim * 2, cross_attention_dim * num_tokens),
|
| 75 |
+
)
|
| 76 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 77 |
+
|
| 78 |
+
def forward(self, id_embeds):
|
| 79 |
+
x = self.proj(id_embeds)
|
| 80 |
+
x = x.reshape(-1, self.num_tokens, self.cross_attention_dim)
|
| 81 |
+
x = self.norm(x)
|
| 82 |
+
return x
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class ProjPlusModel(torch.nn.Module):
|
| 86 |
+
def __init__(self, cross_attention_dim=768, id_embeddings_dim=512, clip_embeddings_dim=1280, num_tokens=4):
|
| 87 |
+
super().__init__()
|
| 88 |
+
|
| 89 |
+
self.cross_attention_dim = cross_attention_dim
|
| 90 |
+
self.num_tokens = num_tokens
|
| 91 |
+
|
| 92 |
+
self.proj = torch.nn.Sequential(
|
| 93 |
+
torch.nn.Linear(id_embeddings_dim, id_embeddings_dim * 2),
|
| 94 |
+
torch.nn.GELU(),
|
| 95 |
+
torch.nn.Linear(id_embeddings_dim * 2, cross_attention_dim * num_tokens),
|
| 96 |
+
)
|
| 97 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 98 |
+
|
| 99 |
+
self.perceiver_resampler = FacePerceiverResampler(
|
| 100 |
+
dim=cross_attention_dim,
|
| 101 |
+
depth=4,
|
| 102 |
+
dim_head=64,
|
| 103 |
+
heads=cross_attention_dim // 64,
|
| 104 |
+
embedding_dim=clip_embeddings_dim,
|
| 105 |
+
output_dim=cross_attention_dim,
|
| 106 |
+
ff_mult=4,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
def forward(self, id_embeds, clip_embeds, shortcut=False, scale=1.0):
|
| 110 |
+
x = self.proj(id_embeds)
|
| 111 |
+
x = x.reshape(-1, self.num_tokens, self.cross_attention_dim)
|
| 112 |
+
x = self.norm(x)
|
| 113 |
+
out = self.perceiver_resampler(x, clip_embeds)
|
| 114 |
+
if shortcut:
|
| 115 |
+
out = x + scale * out
|
| 116 |
+
return out
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
class IPAdapterFaceID:
|
| 120 |
+
def __init__(self, sd_pipe, ref_path, ip_ckpt, device, enable_cloth_guidance, num_tokens=4, n_cond=1, torch_dtype=torch.float16, set_seg_model=True):
|
| 121 |
+
self.enable_cloth_guidance = enable_cloth_guidance
|
| 122 |
+
self.device = device
|
| 123 |
+
self.ip_ckpt = ip_ckpt
|
| 124 |
+
self.num_tokens = num_tokens
|
| 125 |
+
self.n_cond = n_cond
|
| 126 |
+
self.torch_dtype = torch_dtype
|
| 127 |
+
|
| 128 |
+
self.pipe = sd_pipe.to(self.device)
|
| 129 |
+
self.set_ip_adapter()
|
| 130 |
+
|
| 131 |
+
# image proj model
|
| 132 |
+
self.image_proj_model = self.init_proj()
|
| 133 |
+
|
| 134 |
+
self.load_ip_adapter()
|
| 135 |
+
|
| 136 |
+
self.set_insightface()
|
| 137 |
+
|
| 138 |
+
ref_unet = copy.deepcopy(sd_pipe.unet)
|
| 139 |
+
state_dict = {}
|
| 140 |
+
with safe_open(ref_path, framework="pt", device="cpu") as f:
|
| 141 |
+
for key in f.keys():
|
| 142 |
+
state_dict[key] = f.get_tensor(key)
|
| 143 |
+
ref_unet.load_state_dict(state_dict, strict=False)
|
| 144 |
+
|
| 145 |
+
self.ref_unet = ref_unet.to(self.device)
|
| 146 |
+
self.set_ref_adapter()
|
| 147 |
+
if set_seg_model:
|
| 148 |
+
self.set_seg_model()
|
| 149 |
+
self.attn_store = {}
|
| 150 |
+
|
| 151 |
+
def set_insightface(self):
|
| 152 |
+
self.app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
|
| 153 |
+
self.app.prepare(ctx_id=0, det_size=(640, 640))
|
| 154 |
+
|
| 155 |
+
def set_seg_model(self, ):
|
| 156 |
+
checkpoint_path = 'checkpoints/cloth_segm.pth'
|
| 157 |
+
self.seg_net = load_seg_model(checkpoint_path, device=self.device)
|
| 158 |
+
|
| 159 |
+
def init_proj(self):
|
| 160 |
+
image_proj_model = MLPProjModel(
|
| 161 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 162 |
+
id_embeddings_dim=512,
|
| 163 |
+
num_tokens=self.num_tokens,
|
| 164 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 165 |
+
return image_proj_model
|
| 166 |
+
|
| 167 |
+
def set_ref_adapter(self):
|
| 168 |
+
attn_procs = {}
|
| 169 |
+
for name in self.ref_unet.attn_processors.keys():
|
| 170 |
+
if "attn1" in name:
|
| 171 |
+
attn_procs[name] = REFAttnProcessor(name=name, type="read")
|
| 172 |
+
else:
|
| 173 |
+
attn_procs[name] = AttnProcessor()
|
| 174 |
+
self.ref_unet.set_attn_processor(attn_procs)
|
| 175 |
+
|
| 176 |
+
def set_ip_adapter(self):
|
| 177 |
+
unet = self.pipe.unet
|
| 178 |
+
attn_procs = {}
|
| 179 |
+
for name in unet.attn_processors.keys():
|
| 180 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 181 |
+
if name.startswith("mid_block"):
|
| 182 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 183 |
+
elif name.startswith("up_blocks"):
|
| 184 |
+
block_id = int(name[len("up_blocks.")])
|
| 185 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 186 |
+
elif name.startswith("down_blocks"):
|
| 187 |
+
block_id = int(name[len("down_blocks.")])
|
| 188 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 189 |
+
if cross_attention_dim is None:
|
| 190 |
+
attn_procs[name] = REFAttnProcessor(name=name, type="write")
|
| 191 |
+
else:
|
| 192 |
+
attn_procs[name] = IPAttnProcessor(
|
| 193 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, scale=1.0, num_tokens=self.num_tokens * self.n_cond,
|
| 194 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 195 |
+
unet.set_attn_processor(attn_procs)
|
| 196 |
+
|
| 197 |
+
def load_ip_adapter(self):
|
| 198 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 199 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 200 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 201 |
+
for key in f.keys():
|
| 202 |
+
if key.startswith("image_proj."):
|
| 203 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 204 |
+
elif key.startswith("ip_adapter."):
|
| 205 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 206 |
+
else:
|
| 207 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 208 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 209 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 210 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"], strict=False)
|
| 211 |
+
|
| 212 |
+
@torch.inference_mode()
|
| 213 |
+
def get_image_embeds(self, faceid_embeds):
|
| 214 |
+
|
| 215 |
+
multi_face = False
|
| 216 |
+
if faceid_embeds.dim() == 3:
|
| 217 |
+
multi_face = True
|
| 218 |
+
b, n, c = faceid_embeds.shape
|
| 219 |
+
faceid_embeds = faceid_embeds.reshape(b * n, c)
|
| 220 |
+
|
| 221 |
+
faceid_embeds = faceid_embeds.to(self.device, dtype=self.torch_dtype)
|
| 222 |
+
image_prompt_embeds = self.image_proj_model(faceid_embeds)
|
| 223 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(faceid_embeds))
|
| 224 |
+
if multi_face:
|
| 225 |
+
c = image_prompt_embeds.size(-1)
|
| 226 |
+
image_prompt_embeds = image_prompt_embeds.reshape(b, -1, c)
|
| 227 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.reshape(b, -1, c)
|
| 228 |
+
|
| 229 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 230 |
+
|
| 231 |
+
def set_scale(self, scale):
|
| 232 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 233 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 234 |
+
attn_processor.scale = scale
|
| 235 |
+
|
| 236 |
+
def generate(
|
| 237 |
+
self,
|
| 238 |
+
cloth_image,
|
| 239 |
+
face_image,
|
| 240 |
+
cloth_mask=None,
|
| 241 |
+
prompt=None,
|
| 242 |
+
a_prompt="best quality, high quality",
|
| 243 |
+
negative_prompt=None,
|
| 244 |
+
num_samples=4,
|
| 245 |
+
seed=None,
|
| 246 |
+
guidance_scale=3.,
|
| 247 |
+
cloth_guidance_scale=3.,
|
| 248 |
+
num_inference_steps=30,
|
| 249 |
+
height=512,
|
| 250 |
+
width=384,
|
| 251 |
+
scale=1.0,
|
| 252 |
+
**kwargs,
|
| 253 |
+
):
|
| 254 |
+
faces = self.app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
|
| 255 |
+
try:
|
| 256 |
+
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
|
| 257 |
+
except:
|
| 258 |
+
return None
|
| 259 |
+
|
| 260 |
+
if cloth_mask is None:
|
| 261 |
+
cloth_mask_image = generate_mask(cloth_image, net=self.seg_net, device=self.device)
|
| 262 |
+
|
| 263 |
+
cloth = prepare_image(cloth_image, height, width)
|
| 264 |
+
cloth_mask = prepare_mask(cloth_mask_image, height, width)
|
| 265 |
+
cloth = (cloth * cloth_mask).to(self.device, dtype=torch.float16)
|
| 266 |
+
|
| 267 |
+
self.set_scale(scale)
|
| 268 |
+
|
| 269 |
+
num_prompts = faceid_embeds.size(0)
|
| 270 |
+
|
| 271 |
+
if prompt is None:
|
| 272 |
+
prompt = "a photography of a model"
|
| 273 |
+
prompt = prompt + ", " + a_prompt
|
| 274 |
+
if negative_prompt is None:
|
| 275 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 276 |
+
|
| 277 |
+
if not isinstance(prompt, List):
|
| 278 |
+
prompt = [prompt] * num_prompts
|
| 279 |
+
if not isinstance(negative_prompt, List):
|
| 280 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 281 |
+
|
| 282 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds)
|
| 283 |
+
|
| 284 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 285 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 286 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 287 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 288 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 289 |
+
|
| 290 |
+
with torch.inference_mode():
|
| 291 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 292 |
+
prompt,
|
| 293 |
+
device=self.device,
|
| 294 |
+
num_images_per_prompt=num_samples,
|
| 295 |
+
do_classifier_free_guidance=True,
|
| 296 |
+
negative_prompt=negative_prompt,
|
| 297 |
+
)
|
| 298 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 299 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 300 |
+
|
| 301 |
+
prompt_embeds_null = self.pipe.encode_prompt([""], device=self.device, num_images_per_prompt=num_samples, do_classifier_free_guidance=False)[0]
|
| 302 |
+
cloth_embeds = self.pipe.vae.encode(cloth).latent_dist.mode() * self.pipe.vae.config.scaling_factor
|
| 303 |
+
self.ref_unet(torch.cat([cloth_embeds] * num_samples), 0, prompt_embeds_null, cross_attention_kwargs={"attn_store": self.attn_store})
|
| 304 |
+
|
| 305 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 306 |
+
images = self.pipe(
|
| 307 |
+
prompt_embeds=prompt_embeds,
|
| 308 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 309 |
+
guidance_scale=guidance_scale,
|
| 310 |
+
num_inference_steps=num_inference_steps,
|
| 311 |
+
generator=generator,
|
| 312 |
+
height=height,
|
| 313 |
+
width=width,
|
| 314 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": guidance_scale > 1.0, "enable_cloth_guidance": self.enable_cloth_guidance},
|
| 315 |
+
**kwargs,
|
| 316 |
+
).images
|
| 317 |
+
|
| 318 |
+
return images, cloth_mask_image
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
class IPAdapterFaceIDPlus:
|
| 322 |
+
def __init__(self, sd_pipe, ref_path, image_encoder_path, ip_ckpt, device, enable_cloth_guidance, num_tokens=4, torch_dtype=torch.float16, set_seg_model=True):
|
| 323 |
+
self.enable_cloth_guidance = enable_cloth_guidance
|
| 324 |
+
self.device = device
|
| 325 |
+
self.image_encoder_path = image_encoder_path
|
| 326 |
+
self.ip_ckpt = ip_ckpt
|
| 327 |
+
self.num_tokens = num_tokens
|
| 328 |
+
self.torch_dtype = torch_dtype
|
| 329 |
+
|
| 330 |
+
self.pipe = sd_pipe.to(self.device)
|
| 331 |
+
self.set_ip_adapter()
|
| 332 |
+
|
| 333 |
+
# load image encoder
|
| 334 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(self.image_encoder_path).to(
|
| 335 |
+
self.device, dtype=self.torch_dtype
|
| 336 |
+
)
|
| 337 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 338 |
+
# image proj model
|
| 339 |
+
self.image_proj_model = self.init_proj()
|
| 340 |
+
|
| 341 |
+
self.load_ip_adapter()
|
| 342 |
+
|
| 343 |
+
self.set_insightface()
|
| 344 |
+
|
| 345 |
+
ref_unet = copy.deepcopy(sd_pipe.unet)
|
| 346 |
+
state_dict = {}
|
| 347 |
+
with safe_open(ref_path, framework="pt", device="cpu") as f:
|
| 348 |
+
for key in f.keys():
|
| 349 |
+
state_dict[key] = f.get_tensor(key)
|
| 350 |
+
ref_unet.load_state_dict(state_dict, strict=False)
|
| 351 |
+
|
| 352 |
+
self.ref_unet = ref_unet.to(self.device)
|
| 353 |
+
self.set_ref_adapter()
|
| 354 |
+
if set_seg_model:
|
| 355 |
+
self.set_seg_model()
|
| 356 |
+
self.attn_store = {}
|
| 357 |
+
|
| 358 |
+
def set_insightface(self):
|
| 359 |
+
self.app = FaceAnalysis(name="buffalo_l", providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
|
| 360 |
+
self.app.prepare(ctx_id=0, det_size=(640, 640))
|
| 361 |
+
|
| 362 |
+
def set_seg_model(self, ):
|
| 363 |
+
checkpoint_path = 'checkpoints/cloth_segm.pth'
|
| 364 |
+
self.seg_net = load_seg_model(checkpoint_path, device=self.device)
|
| 365 |
+
|
| 366 |
+
def init_proj(self):
|
| 367 |
+
image_proj_model = ProjPlusModel(
|
| 368 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 369 |
+
id_embeddings_dim=512,
|
| 370 |
+
clip_embeddings_dim=self.image_encoder.config.hidden_size,
|
| 371 |
+
num_tokens=self.num_tokens,
|
| 372 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 373 |
+
return image_proj_model
|
| 374 |
+
|
| 375 |
+
def set_ref_adapter(self):
|
| 376 |
+
attn_procs = {}
|
| 377 |
+
for name in self.ref_unet.attn_processors.keys():
|
| 378 |
+
if "attn1" in name:
|
| 379 |
+
attn_procs[name] = REFAttnProcessor(name=name, type="read")
|
| 380 |
+
else:
|
| 381 |
+
attn_procs[name] = AttnProcessor()
|
| 382 |
+
self.ref_unet.set_attn_processor(attn_procs)
|
| 383 |
+
|
| 384 |
+
def set_ip_adapter(self):
|
| 385 |
+
unet = self.pipe.unet
|
| 386 |
+
attn_procs = {}
|
| 387 |
+
for name in unet.attn_processors.keys():
|
| 388 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 389 |
+
if name.startswith("mid_block"):
|
| 390 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 391 |
+
elif name.startswith("up_blocks"):
|
| 392 |
+
block_id = int(name[len("up_blocks.")])
|
| 393 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 394 |
+
elif name.startswith("down_blocks"):
|
| 395 |
+
block_id = int(name[len("down_blocks.")])
|
| 396 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 397 |
+
if cross_attention_dim is None:
|
| 398 |
+
attn_procs[name] = REFAttnProcessor(name=name, type="write")
|
| 399 |
+
else:
|
| 400 |
+
attn_procs[name] = IPAttnProcessor(
|
| 401 |
+
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, scale=1.0, num_tokens=self.num_tokens,
|
| 402 |
+
).to(self.device, dtype=self.torch_dtype)
|
| 403 |
+
unet.set_attn_processor(attn_procs)
|
| 404 |
+
|
| 405 |
+
def load_ip_adapter(self):
|
| 406 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 407 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 408 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 409 |
+
for key in f.keys():
|
| 410 |
+
if key.startswith("image_proj."):
|
| 411 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 412 |
+
elif key.startswith("ip_adapter."):
|
| 413 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 414 |
+
else:
|
| 415 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 416 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 417 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 418 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"], strict=False)
|
| 419 |
+
|
| 420 |
+
@torch.inference_mode()
|
| 421 |
+
def get_image_embeds(self, faceid_embeds, face_image, s_scale, shortcut):
|
| 422 |
+
clip_image = self.clip_image_processor(images=face_image, return_tensors="pt").pixel_values
|
| 423 |
+
clip_image = clip_image.to(self.device, dtype=self.torch_dtype)
|
| 424 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 425 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 426 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 427 |
+
).hidden_states[-2]
|
| 428 |
+
|
| 429 |
+
faceid_embeds = faceid_embeds.to(self.device, dtype=self.torch_dtype)
|
| 430 |
+
image_prompt_embeds = self.image_proj_model(faceid_embeds, clip_image_embeds, shortcut=shortcut, scale=s_scale)
|
| 431 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(faceid_embeds), uncond_clip_image_embeds, shortcut=shortcut, scale=s_scale)
|
| 432 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 433 |
+
|
| 434 |
+
def set_scale(self, scale):
|
| 435 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 436 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 437 |
+
attn_processor.scale = scale
|
| 438 |
+
|
| 439 |
+
def generate(
|
| 440 |
+
self,
|
| 441 |
+
cloth_image,
|
| 442 |
+
face_image,
|
| 443 |
+
cloth_mask=None,
|
| 444 |
+
prompt=None,
|
| 445 |
+
a_prompt="best quality, high quality",
|
| 446 |
+
negative_prompt=None,
|
| 447 |
+
num_samples=4,
|
| 448 |
+
seed=None,
|
| 449 |
+
guidance_scale=2.5,
|
| 450 |
+
cloth_guidance_scale=2.5,
|
| 451 |
+
num_inference_steps=20,
|
| 452 |
+
height=512,
|
| 453 |
+
width=384,
|
| 454 |
+
scale=1.0,
|
| 455 |
+
s_scale=1.,
|
| 456 |
+
shortcut=False,
|
| 457 |
+
**kwargs,
|
| 458 |
+
):
|
| 459 |
+
face_image = cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR)
|
| 460 |
+
faces = self.app.get(face_image)
|
| 461 |
+
try:
|
| 462 |
+
faceid_embeds = torch.from_numpy(faces[0].normed_embedding).unsqueeze(0)
|
| 463 |
+
face_image = face_align.norm_crop(face_image, landmark=faces[0].kps, image_size=224)
|
| 464 |
+
except:
|
| 465 |
+
return None
|
| 466 |
+
|
| 467 |
+
if cloth_mask is None:
|
| 468 |
+
cloth_mask_image = generate_mask(cloth_image, net=self.seg_net, device=self.device)
|
| 469 |
+
|
| 470 |
+
cloth = prepare_image(cloth_image, height, width)
|
| 471 |
+
cloth_mask = prepare_mask(cloth_mask_image, height, width)
|
| 472 |
+
cloth = (cloth * cloth_mask).to(self.device, dtype=torch.float16)
|
| 473 |
+
self.set_scale(scale)
|
| 474 |
+
|
| 475 |
+
num_prompts = faceid_embeds.size(0)
|
| 476 |
+
|
| 477 |
+
if prompt is None:
|
| 478 |
+
prompt = "a photography of a model"
|
| 479 |
+
prompt = prompt + ", " + a_prompt
|
| 480 |
+
if negative_prompt is None:
|
| 481 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 482 |
+
|
| 483 |
+
if not isinstance(prompt, List):
|
| 484 |
+
prompt = [prompt] * num_prompts
|
| 485 |
+
if not isinstance(negative_prompt, List):
|
| 486 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 487 |
+
|
| 488 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds, face_image, s_scale, shortcut)
|
| 489 |
+
|
| 490 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 491 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 492 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 493 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 494 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 495 |
+
|
| 496 |
+
with torch.inference_mode():
|
| 497 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 498 |
+
prompt,
|
| 499 |
+
device=self.device,
|
| 500 |
+
num_images_per_prompt=num_samples,
|
| 501 |
+
do_classifier_free_guidance=True,
|
| 502 |
+
negative_prompt=negative_prompt,
|
| 503 |
+
)
|
| 504 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 505 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 506 |
+
|
| 507 |
+
prompt_embeds_null = self.pipe.encode_prompt([""], device=self.device, num_images_per_prompt=num_samples, do_classifier_free_guidance=False)[0]
|
| 508 |
+
cloth_embeds = self.pipe.vae.encode(cloth).latent_dist.mode() * self.pipe.vae.config.scaling_factor
|
| 509 |
+
self.ref_unet(torch.cat([cloth_embeds] * num_samples), 0, prompt_embeds_null, cross_attention_kwargs={"attn_store": self.attn_store})
|
| 510 |
+
|
| 511 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 512 |
+
if self.enable_cloth_guidance:
|
| 513 |
+
images = self.pipe(
|
| 514 |
+
prompt_embeds=prompt_embeds,
|
| 515 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 516 |
+
guidance_scale=guidance_scale,
|
| 517 |
+
cloth_guidance_scale=cloth_guidance_scale,
|
| 518 |
+
num_inference_steps=num_inference_steps,
|
| 519 |
+
generator=generator,
|
| 520 |
+
height=height,
|
| 521 |
+
width=width,
|
| 522 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": guidance_scale > 1.0, "enable_cloth_guidance": self.enable_cloth_guidance},
|
| 523 |
+
**kwargs,
|
| 524 |
+
).images
|
| 525 |
+
else:
|
| 526 |
+
images = self.pipe(
|
| 527 |
+
prompt_embeds=prompt_embeds,
|
| 528 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 529 |
+
guidance_scale=guidance_scale,
|
| 530 |
+
num_inference_steps=num_inference_steps,
|
| 531 |
+
generator=generator,
|
| 532 |
+
height=height,
|
| 533 |
+
width=width,
|
| 534 |
+
cross_attention_kwargs={"attn_store": self.attn_store, "do_classifier_free_guidance": guidance_scale > 1.0, "enable_cloth_guidance": self.enable_cloth_guidance},
|
| 535 |
+
**kwargs,
|
| 536 |
+
).images
|
| 537 |
+
|
| 538 |
+
return images, cloth_mask_image
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
class IPAdapterFaceIDXL(IPAdapterFaceID):
|
| 542 |
+
"""SDXL"""
|
| 543 |
+
|
| 544 |
+
def generate(
|
| 545 |
+
self,
|
| 546 |
+
faceid_embeds=None,
|
| 547 |
+
prompt=None,
|
| 548 |
+
negative_prompt=None,
|
| 549 |
+
scale=1.0,
|
| 550 |
+
num_samples=4,
|
| 551 |
+
seed=None,
|
| 552 |
+
num_inference_steps=30,
|
| 553 |
+
**kwargs,
|
| 554 |
+
):
|
| 555 |
+
self.set_scale(scale)
|
| 556 |
+
|
| 557 |
+
num_prompts = faceid_embeds.size(0)
|
| 558 |
+
|
| 559 |
+
if prompt is None:
|
| 560 |
+
prompt = "best quality, high quality"
|
| 561 |
+
if negative_prompt is None:
|
| 562 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 563 |
+
|
| 564 |
+
if not isinstance(prompt, List):
|
| 565 |
+
prompt = [prompt] * num_prompts
|
| 566 |
+
if not isinstance(negative_prompt, List):
|
| 567 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 568 |
+
|
| 569 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds)
|
| 570 |
+
|
| 571 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 572 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 573 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 574 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 575 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 576 |
+
|
| 577 |
+
with torch.inference_mode():
|
| 578 |
+
(
|
| 579 |
+
prompt_embeds,
|
| 580 |
+
negative_prompt_embeds,
|
| 581 |
+
pooled_prompt_embeds,
|
| 582 |
+
negative_pooled_prompt_embeds,
|
| 583 |
+
) = self.pipe.encode_prompt(
|
| 584 |
+
prompt,
|
| 585 |
+
num_images_per_prompt=num_samples,
|
| 586 |
+
do_classifier_free_guidance=True,
|
| 587 |
+
negative_prompt=negative_prompt,
|
| 588 |
+
)
|
| 589 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 590 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 591 |
+
|
| 592 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 593 |
+
images = self.pipe(
|
| 594 |
+
prompt_embeds=prompt_embeds,
|
| 595 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 596 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 597 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 598 |
+
num_inference_steps=num_inference_steps,
|
| 599 |
+
generator=generator,
|
| 600 |
+
**kwargs,
|
| 601 |
+
).images
|
| 602 |
+
|
| 603 |
+
return images
|
| 604 |
+
|
| 605 |
+
|
| 606 |
+
class IPAdapterFaceIDPlusXL(IPAdapterFaceIDPlus):
|
| 607 |
+
"""SDXL"""
|
| 608 |
+
|
| 609 |
+
def generate(
|
| 610 |
+
self,
|
| 611 |
+
face_image=None,
|
| 612 |
+
faceid_embeds=None,
|
| 613 |
+
prompt=None,
|
| 614 |
+
negative_prompt=None,
|
| 615 |
+
scale=1.0,
|
| 616 |
+
num_samples=4,
|
| 617 |
+
seed=None,
|
| 618 |
+
guidance_scale=7.5,
|
| 619 |
+
num_inference_steps=30,
|
| 620 |
+
s_scale=1.0,
|
| 621 |
+
shortcut=True,
|
| 622 |
+
**kwargs,
|
| 623 |
+
):
|
| 624 |
+
self.set_scale(scale)
|
| 625 |
+
|
| 626 |
+
num_prompts = faceid_embeds.size(0)
|
| 627 |
+
|
| 628 |
+
if prompt is None:
|
| 629 |
+
prompt = "best quality, high quality"
|
| 630 |
+
if negative_prompt is None:
|
| 631 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 632 |
+
|
| 633 |
+
if not isinstance(prompt, List):
|
| 634 |
+
prompt = [prompt] * num_prompts
|
| 635 |
+
if not isinstance(negative_prompt, List):
|
| 636 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 637 |
+
|
| 638 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(faceid_embeds, face_image, s_scale, shortcut)
|
| 639 |
+
|
| 640 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 641 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 642 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 643 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 644 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 645 |
+
|
| 646 |
+
with torch.inference_mode():
|
| 647 |
+
(
|
| 648 |
+
prompt_embeds,
|
| 649 |
+
negative_prompt_embeds,
|
| 650 |
+
pooled_prompt_embeds,
|
| 651 |
+
negative_pooled_prompt_embeds,
|
| 652 |
+
) = self.pipe.encode_prompt(
|
| 653 |
+
prompt,
|
| 654 |
+
num_images_per_prompt=num_samples,
|
| 655 |
+
do_classifier_free_guidance=True,
|
| 656 |
+
negative_prompt=negative_prompt,
|
| 657 |
+
)
|
| 658 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 659 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 660 |
+
|
| 661 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 662 |
+
images = self.pipe(
|
| 663 |
+
prompt_embeds=prompt_embeds,
|
| 664 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 665 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 666 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 667 |
+
num_inference_steps=num_inference_steps,
|
| 668 |
+
generator=generator,
|
| 669 |
+
guidance_scale=guidance_scale,
|
| 670 |
+
**kwargs,
|
| 671 |
+
).images
|
| 672 |
+
|
| 673 |
+
return images
|
garment_seg/__pycache__/network.cpython-310.pyc
ADDED
|
Binary file (10.1 kB). View file
|
|
|
garment_seg/__pycache__/process.cpython-310.pyc
ADDED
|
Binary file (3.12 kB). View file
|
|
|
garment_seg/network.py
ADDED
|
@@ -0,0 +1,560 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class REBNCONV(nn.Module):
|
| 7 |
+
def __init__(self, in_ch=3, out_ch=3, dirate=1):
|
| 8 |
+
super(REBNCONV, self).__init__()
|
| 9 |
+
|
| 10 |
+
self.conv_s1 = nn.Conv2d(
|
| 11 |
+
in_ch, out_ch, 3, padding=1 * dirate, dilation=1 * dirate
|
| 12 |
+
)
|
| 13 |
+
self.bn_s1 = nn.BatchNorm2d(out_ch)
|
| 14 |
+
self.relu_s1 = nn.ReLU(inplace=True)
|
| 15 |
+
|
| 16 |
+
def forward(self, x):
|
| 17 |
+
|
| 18 |
+
hx = x
|
| 19 |
+
xout = self.relu_s1(self.bn_s1(self.conv_s1(hx)))
|
| 20 |
+
|
| 21 |
+
return xout
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## upsample tensor 'src' to have the same spatial size with tensor 'tar'
|
| 25 |
+
def _upsample_like(src, tar):
|
| 26 |
+
|
| 27 |
+
src = F.upsample(src, size=tar.shape[2:], mode="bilinear")
|
| 28 |
+
|
| 29 |
+
return src
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
### RSU-7 ###
|
| 33 |
+
class RSU7(nn.Module): # UNet07DRES(nn.Module):
|
| 34 |
+
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
|
| 35 |
+
super(RSU7, self).__init__()
|
| 36 |
+
|
| 37 |
+
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
|
| 38 |
+
|
| 39 |
+
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
|
| 40 |
+
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 41 |
+
|
| 42 |
+
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 43 |
+
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 44 |
+
|
| 45 |
+
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 46 |
+
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 47 |
+
|
| 48 |
+
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 49 |
+
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 50 |
+
|
| 51 |
+
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 52 |
+
self.pool5 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 53 |
+
|
| 54 |
+
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 55 |
+
|
| 56 |
+
self.rebnconv7 = REBNCONV(mid_ch, mid_ch, dirate=2)
|
| 57 |
+
|
| 58 |
+
self.rebnconv6d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 59 |
+
self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 60 |
+
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 61 |
+
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 62 |
+
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 63 |
+
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
|
| 64 |
+
|
| 65 |
+
def forward(self, x):
|
| 66 |
+
|
| 67 |
+
hx = x
|
| 68 |
+
hxin = self.rebnconvin(hx)
|
| 69 |
+
|
| 70 |
+
hx1 = self.rebnconv1(hxin)
|
| 71 |
+
hx = self.pool1(hx1)
|
| 72 |
+
|
| 73 |
+
hx2 = self.rebnconv2(hx)
|
| 74 |
+
hx = self.pool2(hx2)
|
| 75 |
+
|
| 76 |
+
hx3 = self.rebnconv3(hx)
|
| 77 |
+
hx = self.pool3(hx3)
|
| 78 |
+
|
| 79 |
+
hx4 = self.rebnconv4(hx)
|
| 80 |
+
hx = self.pool4(hx4)
|
| 81 |
+
|
| 82 |
+
hx5 = self.rebnconv5(hx)
|
| 83 |
+
hx = self.pool5(hx5)
|
| 84 |
+
|
| 85 |
+
hx6 = self.rebnconv6(hx)
|
| 86 |
+
|
| 87 |
+
hx7 = self.rebnconv7(hx6)
|
| 88 |
+
|
| 89 |
+
hx6d = self.rebnconv6d(torch.cat((hx7, hx6), 1))
|
| 90 |
+
hx6dup = _upsample_like(hx6d, hx5)
|
| 91 |
+
|
| 92 |
+
hx5d = self.rebnconv5d(torch.cat((hx6dup, hx5), 1))
|
| 93 |
+
hx5dup = _upsample_like(hx5d, hx4)
|
| 94 |
+
|
| 95 |
+
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
|
| 96 |
+
hx4dup = _upsample_like(hx4d, hx3)
|
| 97 |
+
|
| 98 |
+
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
|
| 99 |
+
hx3dup = _upsample_like(hx3d, hx2)
|
| 100 |
+
|
| 101 |
+
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
|
| 102 |
+
hx2dup = _upsample_like(hx2d, hx1)
|
| 103 |
+
|
| 104 |
+
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
|
| 105 |
+
|
| 106 |
+
"""
|
| 107 |
+
del hx1, hx2, hx3, hx4, hx5, hx6, hx7
|
| 108 |
+
del hx6d, hx5d, hx3d, hx2d
|
| 109 |
+
del hx2dup, hx3dup, hx4dup, hx5dup, hx6dup
|
| 110 |
+
"""
|
| 111 |
+
|
| 112 |
+
return hx1d + hxin
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
### RSU-6 ###
|
| 116 |
+
class RSU6(nn.Module): # UNet06DRES(nn.Module):
|
| 117 |
+
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
|
| 118 |
+
super(RSU6, self).__init__()
|
| 119 |
+
|
| 120 |
+
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
|
| 121 |
+
|
| 122 |
+
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
|
| 123 |
+
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 124 |
+
|
| 125 |
+
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 126 |
+
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 127 |
+
|
| 128 |
+
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 129 |
+
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 130 |
+
|
| 131 |
+
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 132 |
+
self.pool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 133 |
+
|
| 134 |
+
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 135 |
+
|
| 136 |
+
self.rebnconv6 = REBNCONV(mid_ch, mid_ch, dirate=2)
|
| 137 |
+
|
| 138 |
+
self.rebnconv5d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 139 |
+
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 140 |
+
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 141 |
+
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 142 |
+
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
|
| 143 |
+
|
| 144 |
+
def forward(self, x):
|
| 145 |
+
|
| 146 |
+
hx = x
|
| 147 |
+
|
| 148 |
+
hxin = self.rebnconvin(hx)
|
| 149 |
+
|
| 150 |
+
hx1 = self.rebnconv1(hxin)
|
| 151 |
+
hx = self.pool1(hx1)
|
| 152 |
+
|
| 153 |
+
hx2 = self.rebnconv2(hx)
|
| 154 |
+
hx = self.pool2(hx2)
|
| 155 |
+
|
| 156 |
+
hx3 = self.rebnconv3(hx)
|
| 157 |
+
hx = self.pool3(hx3)
|
| 158 |
+
|
| 159 |
+
hx4 = self.rebnconv4(hx)
|
| 160 |
+
hx = self.pool4(hx4)
|
| 161 |
+
|
| 162 |
+
hx5 = self.rebnconv5(hx)
|
| 163 |
+
|
| 164 |
+
hx6 = self.rebnconv6(hx5)
|
| 165 |
+
|
| 166 |
+
hx5d = self.rebnconv5d(torch.cat((hx6, hx5), 1))
|
| 167 |
+
hx5dup = _upsample_like(hx5d, hx4)
|
| 168 |
+
|
| 169 |
+
hx4d = self.rebnconv4d(torch.cat((hx5dup, hx4), 1))
|
| 170 |
+
hx4dup = _upsample_like(hx4d, hx3)
|
| 171 |
+
|
| 172 |
+
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
|
| 173 |
+
hx3dup = _upsample_like(hx3d, hx2)
|
| 174 |
+
|
| 175 |
+
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
|
| 176 |
+
hx2dup = _upsample_like(hx2d, hx1)
|
| 177 |
+
|
| 178 |
+
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
|
| 179 |
+
|
| 180 |
+
"""
|
| 181 |
+
del hx1, hx2, hx3, hx4, hx5, hx6
|
| 182 |
+
del hx5d, hx4d, hx3d, hx2d
|
| 183 |
+
del hx2dup, hx3dup, hx4dup, hx5dup
|
| 184 |
+
"""
|
| 185 |
+
|
| 186 |
+
return hx1d + hxin
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
### RSU-5 ###
|
| 190 |
+
class RSU5(nn.Module): # UNet05DRES(nn.Module):
|
| 191 |
+
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
|
| 192 |
+
super(RSU5, self).__init__()
|
| 193 |
+
|
| 194 |
+
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
|
| 195 |
+
|
| 196 |
+
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
|
| 197 |
+
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 198 |
+
|
| 199 |
+
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 200 |
+
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 201 |
+
|
| 202 |
+
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 203 |
+
self.pool3 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 204 |
+
|
| 205 |
+
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 206 |
+
|
| 207 |
+
self.rebnconv5 = REBNCONV(mid_ch, mid_ch, dirate=2)
|
| 208 |
+
|
| 209 |
+
self.rebnconv4d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 210 |
+
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 211 |
+
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 212 |
+
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
|
| 213 |
+
|
| 214 |
+
def forward(self, x):
|
| 215 |
+
|
| 216 |
+
hx = x
|
| 217 |
+
|
| 218 |
+
hxin = self.rebnconvin(hx)
|
| 219 |
+
|
| 220 |
+
hx1 = self.rebnconv1(hxin)
|
| 221 |
+
hx = self.pool1(hx1)
|
| 222 |
+
|
| 223 |
+
hx2 = self.rebnconv2(hx)
|
| 224 |
+
hx = self.pool2(hx2)
|
| 225 |
+
|
| 226 |
+
hx3 = self.rebnconv3(hx)
|
| 227 |
+
hx = self.pool3(hx3)
|
| 228 |
+
|
| 229 |
+
hx4 = self.rebnconv4(hx)
|
| 230 |
+
|
| 231 |
+
hx5 = self.rebnconv5(hx4)
|
| 232 |
+
|
| 233 |
+
hx4d = self.rebnconv4d(torch.cat((hx5, hx4), 1))
|
| 234 |
+
hx4dup = _upsample_like(hx4d, hx3)
|
| 235 |
+
|
| 236 |
+
hx3d = self.rebnconv3d(torch.cat((hx4dup, hx3), 1))
|
| 237 |
+
hx3dup = _upsample_like(hx3d, hx2)
|
| 238 |
+
|
| 239 |
+
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
|
| 240 |
+
hx2dup = _upsample_like(hx2d, hx1)
|
| 241 |
+
|
| 242 |
+
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
|
| 243 |
+
|
| 244 |
+
"""
|
| 245 |
+
del hx1, hx2, hx3, hx4, hx5
|
| 246 |
+
del hx4d, hx3d, hx2d
|
| 247 |
+
del hx2dup, hx3dup, hx4dup
|
| 248 |
+
"""
|
| 249 |
+
|
| 250 |
+
return hx1d + hxin
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
### RSU-4 ###
|
| 254 |
+
class RSU4(nn.Module): # UNet04DRES(nn.Module):
|
| 255 |
+
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
|
| 256 |
+
super(RSU4, self).__init__()
|
| 257 |
+
|
| 258 |
+
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
|
| 259 |
+
|
| 260 |
+
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
|
| 261 |
+
self.pool1 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 262 |
+
|
| 263 |
+
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 264 |
+
self.pool2 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 265 |
+
|
| 266 |
+
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=1)
|
| 267 |
+
|
| 268 |
+
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=2)
|
| 269 |
+
|
| 270 |
+
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 271 |
+
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=1)
|
| 272 |
+
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
|
| 273 |
+
|
| 274 |
+
def forward(self, x):
|
| 275 |
+
|
| 276 |
+
hx = x
|
| 277 |
+
|
| 278 |
+
hxin = self.rebnconvin(hx)
|
| 279 |
+
|
| 280 |
+
hx1 = self.rebnconv1(hxin)
|
| 281 |
+
hx = self.pool1(hx1)
|
| 282 |
+
|
| 283 |
+
hx2 = self.rebnconv2(hx)
|
| 284 |
+
hx = self.pool2(hx2)
|
| 285 |
+
|
| 286 |
+
hx3 = self.rebnconv3(hx)
|
| 287 |
+
|
| 288 |
+
hx4 = self.rebnconv4(hx3)
|
| 289 |
+
|
| 290 |
+
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
|
| 291 |
+
hx3dup = _upsample_like(hx3d, hx2)
|
| 292 |
+
|
| 293 |
+
hx2d = self.rebnconv2d(torch.cat((hx3dup, hx2), 1))
|
| 294 |
+
hx2dup = _upsample_like(hx2d, hx1)
|
| 295 |
+
|
| 296 |
+
hx1d = self.rebnconv1d(torch.cat((hx2dup, hx1), 1))
|
| 297 |
+
|
| 298 |
+
"""
|
| 299 |
+
del hx1, hx2, hx3, hx4
|
| 300 |
+
del hx3d, hx2d
|
| 301 |
+
del hx2dup, hx3dup
|
| 302 |
+
"""
|
| 303 |
+
|
| 304 |
+
return hx1d + hxin
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
### RSU-4F ###
|
| 308 |
+
class RSU4F(nn.Module): # UNet04FRES(nn.Module):
|
| 309 |
+
def __init__(self, in_ch=3, mid_ch=12, out_ch=3):
|
| 310 |
+
super(RSU4F, self).__init__()
|
| 311 |
+
|
| 312 |
+
self.rebnconvin = REBNCONV(in_ch, out_ch, dirate=1)
|
| 313 |
+
|
| 314 |
+
self.rebnconv1 = REBNCONV(out_ch, mid_ch, dirate=1)
|
| 315 |
+
self.rebnconv2 = REBNCONV(mid_ch, mid_ch, dirate=2)
|
| 316 |
+
self.rebnconv3 = REBNCONV(mid_ch, mid_ch, dirate=4)
|
| 317 |
+
|
| 318 |
+
self.rebnconv4 = REBNCONV(mid_ch, mid_ch, dirate=8)
|
| 319 |
+
|
| 320 |
+
self.rebnconv3d = REBNCONV(mid_ch * 2, mid_ch, dirate=4)
|
| 321 |
+
self.rebnconv2d = REBNCONV(mid_ch * 2, mid_ch, dirate=2)
|
| 322 |
+
self.rebnconv1d = REBNCONV(mid_ch * 2, out_ch, dirate=1)
|
| 323 |
+
|
| 324 |
+
def forward(self, x):
|
| 325 |
+
|
| 326 |
+
hx = x
|
| 327 |
+
|
| 328 |
+
hxin = self.rebnconvin(hx)
|
| 329 |
+
|
| 330 |
+
hx1 = self.rebnconv1(hxin)
|
| 331 |
+
hx2 = self.rebnconv2(hx1)
|
| 332 |
+
hx3 = self.rebnconv3(hx2)
|
| 333 |
+
|
| 334 |
+
hx4 = self.rebnconv4(hx3)
|
| 335 |
+
|
| 336 |
+
hx3d = self.rebnconv3d(torch.cat((hx4, hx3), 1))
|
| 337 |
+
hx2d = self.rebnconv2d(torch.cat((hx3d, hx2), 1))
|
| 338 |
+
hx1d = self.rebnconv1d(torch.cat((hx2d, hx1), 1))
|
| 339 |
+
|
| 340 |
+
"""
|
| 341 |
+
del hx1, hx2, hx3, hx4
|
| 342 |
+
del hx3d, hx2d
|
| 343 |
+
"""
|
| 344 |
+
|
| 345 |
+
return hx1d + hxin
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
##### U^2-Net ####
|
| 349 |
+
class U2NET(nn.Module):
|
| 350 |
+
def __init__(self, in_ch=3, out_ch=1):
|
| 351 |
+
super(U2NET, self).__init__()
|
| 352 |
+
|
| 353 |
+
self.stage1 = RSU7(in_ch, 32, 64)
|
| 354 |
+
self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 355 |
+
|
| 356 |
+
self.stage2 = RSU6(64, 32, 128)
|
| 357 |
+
self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 358 |
+
|
| 359 |
+
self.stage3 = RSU5(128, 64, 256)
|
| 360 |
+
self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 361 |
+
|
| 362 |
+
self.stage4 = RSU4(256, 128, 512)
|
| 363 |
+
self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 364 |
+
|
| 365 |
+
self.stage5 = RSU4F(512, 256, 512)
|
| 366 |
+
self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 367 |
+
|
| 368 |
+
self.stage6 = RSU4F(512, 256, 512)
|
| 369 |
+
|
| 370 |
+
# decoder
|
| 371 |
+
self.stage5d = RSU4F(1024, 256, 512)
|
| 372 |
+
self.stage4d = RSU4(1024, 128, 256)
|
| 373 |
+
self.stage3d = RSU5(512, 64, 128)
|
| 374 |
+
self.stage2d = RSU6(256, 32, 64)
|
| 375 |
+
self.stage1d = RSU7(128, 16, 64)
|
| 376 |
+
|
| 377 |
+
self.side1 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 378 |
+
self.side2 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 379 |
+
self.side3 = nn.Conv2d(128, out_ch, 3, padding=1)
|
| 380 |
+
self.side4 = nn.Conv2d(256, out_ch, 3, padding=1)
|
| 381 |
+
self.side5 = nn.Conv2d(512, out_ch, 3, padding=1)
|
| 382 |
+
self.side6 = nn.Conv2d(512, out_ch, 3, padding=1)
|
| 383 |
+
|
| 384 |
+
self.outconv = nn.Conv2d(6 * out_ch, out_ch, 1)
|
| 385 |
+
|
| 386 |
+
def forward(self, x):
|
| 387 |
+
|
| 388 |
+
hx = x
|
| 389 |
+
|
| 390 |
+
# stage 1
|
| 391 |
+
hx1 = self.stage1(hx)
|
| 392 |
+
hx = self.pool12(hx1)
|
| 393 |
+
|
| 394 |
+
# stage 2
|
| 395 |
+
hx2 = self.stage2(hx)
|
| 396 |
+
hx = self.pool23(hx2)
|
| 397 |
+
|
| 398 |
+
# stage 3
|
| 399 |
+
hx3 = self.stage3(hx)
|
| 400 |
+
hx = self.pool34(hx3)
|
| 401 |
+
|
| 402 |
+
# stage 4
|
| 403 |
+
hx4 = self.stage4(hx)
|
| 404 |
+
hx = self.pool45(hx4)
|
| 405 |
+
|
| 406 |
+
# stage 5
|
| 407 |
+
hx5 = self.stage5(hx)
|
| 408 |
+
hx = self.pool56(hx5)
|
| 409 |
+
|
| 410 |
+
# stage 6
|
| 411 |
+
hx6 = self.stage6(hx)
|
| 412 |
+
hx6up = _upsample_like(hx6, hx5)
|
| 413 |
+
|
| 414 |
+
# -------------------- decoder --------------------
|
| 415 |
+
hx5d = self.stage5d(torch.cat((hx6up, hx5), 1))
|
| 416 |
+
hx5dup = _upsample_like(hx5d, hx4)
|
| 417 |
+
|
| 418 |
+
hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1))
|
| 419 |
+
hx4dup = _upsample_like(hx4d, hx3)
|
| 420 |
+
|
| 421 |
+
hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1))
|
| 422 |
+
hx3dup = _upsample_like(hx3d, hx2)
|
| 423 |
+
|
| 424 |
+
hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1))
|
| 425 |
+
hx2dup = _upsample_like(hx2d, hx1)
|
| 426 |
+
|
| 427 |
+
hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1))
|
| 428 |
+
|
| 429 |
+
# side output
|
| 430 |
+
d1 = self.side1(hx1d)
|
| 431 |
+
|
| 432 |
+
d2 = self.side2(hx2d)
|
| 433 |
+
d2 = _upsample_like(d2, d1)
|
| 434 |
+
|
| 435 |
+
d3 = self.side3(hx3d)
|
| 436 |
+
d3 = _upsample_like(d3, d1)
|
| 437 |
+
|
| 438 |
+
d4 = self.side4(hx4d)
|
| 439 |
+
d4 = _upsample_like(d4, d1)
|
| 440 |
+
|
| 441 |
+
d5 = self.side5(hx5d)
|
| 442 |
+
d5 = _upsample_like(d5, d1)
|
| 443 |
+
|
| 444 |
+
d6 = self.side6(hx6)
|
| 445 |
+
d6 = _upsample_like(d6, d1)
|
| 446 |
+
|
| 447 |
+
d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1))
|
| 448 |
+
|
| 449 |
+
"""
|
| 450 |
+
del hx1, hx2, hx3, hx4, hx5, hx6
|
| 451 |
+
del hx5d, hx4d, hx3d, hx2d, hx1d
|
| 452 |
+
del hx6up, hx5dup, hx4dup, hx3dup, hx2dup
|
| 453 |
+
"""
|
| 454 |
+
|
| 455 |
+
return d0, d1, d2, d3, d4, d5, d6
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
### U^2-Net small ###
|
| 459 |
+
class U2NETP(nn.Module):
|
| 460 |
+
def __init__(self, in_ch=3, out_ch=1):
|
| 461 |
+
super(U2NETP, self).__init__()
|
| 462 |
+
|
| 463 |
+
self.stage1 = RSU7(in_ch, 16, 64)
|
| 464 |
+
self.pool12 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 465 |
+
|
| 466 |
+
self.stage2 = RSU6(64, 16, 64)
|
| 467 |
+
self.pool23 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 468 |
+
|
| 469 |
+
self.stage3 = RSU5(64, 16, 64)
|
| 470 |
+
self.pool34 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 471 |
+
|
| 472 |
+
self.stage4 = RSU4(64, 16, 64)
|
| 473 |
+
self.pool45 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 474 |
+
|
| 475 |
+
self.stage5 = RSU4F(64, 16, 64)
|
| 476 |
+
self.pool56 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
|
| 477 |
+
|
| 478 |
+
self.stage6 = RSU4F(64, 16, 64)
|
| 479 |
+
|
| 480 |
+
# decoder
|
| 481 |
+
self.stage5d = RSU4F(128, 16, 64)
|
| 482 |
+
self.stage4d = RSU4(128, 16, 64)
|
| 483 |
+
self.stage3d = RSU5(128, 16, 64)
|
| 484 |
+
self.stage2d = RSU6(128, 16, 64)
|
| 485 |
+
self.stage1d = RSU7(128, 16, 64)
|
| 486 |
+
|
| 487 |
+
self.side1 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 488 |
+
self.side2 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 489 |
+
self.side3 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 490 |
+
self.side4 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 491 |
+
self.side5 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 492 |
+
self.side6 = nn.Conv2d(64, out_ch, 3, padding=1)
|
| 493 |
+
|
| 494 |
+
self.outconv = nn.Conv2d(6 * out_ch, out_ch, 1)
|
| 495 |
+
|
| 496 |
+
def forward(self, x):
|
| 497 |
+
|
| 498 |
+
hx = x
|
| 499 |
+
|
| 500 |
+
# stage 1
|
| 501 |
+
hx1 = self.stage1(hx)
|
| 502 |
+
hx = self.pool12(hx1)
|
| 503 |
+
|
| 504 |
+
# stage 2
|
| 505 |
+
hx2 = self.stage2(hx)
|
| 506 |
+
hx = self.pool23(hx2)
|
| 507 |
+
|
| 508 |
+
# stage 3
|
| 509 |
+
hx3 = self.stage3(hx)
|
| 510 |
+
hx = self.pool34(hx3)
|
| 511 |
+
|
| 512 |
+
# stage 4
|
| 513 |
+
hx4 = self.stage4(hx)
|
| 514 |
+
hx = self.pool45(hx4)
|
| 515 |
+
|
| 516 |
+
# stage 5
|
| 517 |
+
hx5 = self.stage5(hx)
|
| 518 |
+
hx = self.pool56(hx5)
|
| 519 |
+
|
| 520 |
+
# stage 6
|
| 521 |
+
hx6 = self.stage6(hx)
|
| 522 |
+
hx6up = _upsample_like(hx6, hx5)
|
| 523 |
+
|
| 524 |
+
# decoder
|
| 525 |
+
hx5d = self.stage5d(torch.cat((hx6up, hx5), 1))
|
| 526 |
+
hx5dup = _upsample_like(hx5d, hx4)
|
| 527 |
+
|
| 528 |
+
hx4d = self.stage4d(torch.cat((hx5dup, hx4), 1))
|
| 529 |
+
hx4dup = _upsample_like(hx4d, hx3)
|
| 530 |
+
|
| 531 |
+
hx3d = self.stage3d(torch.cat((hx4dup, hx3), 1))
|
| 532 |
+
hx3dup = _upsample_like(hx3d, hx2)
|
| 533 |
+
|
| 534 |
+
hx2d = self.stage2d(torch.cat((hx3dup, hx2), 1))
|
| 535 |
+
hx2dup = _upsample_like(hx2d, hx1)
|
| 536 |
+
|
| 537 |
+
hx1d = self.stage1d(torch.cat((hx2dup, hx1), 1))
|
| 538 |
+
|
| 539 |
+
# side output
|
| 540 |
+
d1 = self.side1(hx1d)
|
| 541 |
+
|
| 542 |
+
d2 = self.side2(hx2d)
|
| 543 |
+
d2 = _upsample_like(d2, d1)
|
| 544 |
+
|
| 545 |
+
d3 = self.side3(hx3d)
|
| 546 |
+
d3 = _upsample_like(d3, d1)
|
| 547 |
+
|
| 548 |
+
d4 = self.side4(hx4d)
|
| 549 |
+
d4 = _upsample_like(d4, d1)
|
| 550 |
+
|
| 551 |
+
d5 = self.side5(hx5d)
|
| 552 |
+
d5 = _upsample_like(d5, d1)
|
| 553 |
+
|
| 554 |
+
d6 = self.side6(hx6)
|
| 555 |
+
d6 = _upsample_like(d6, d1)
|
| 556 |
+
|
| 557 |
+
d0 = self.outconv(torch.cat((d1, d2, d3, d4, d5, d6), 1))
|
| 558 |
+
|
| 559 |
+
|
| 560 |
+
return d0, d1, d2, d3, d4, d5, d6
|
garment_seg/process.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from .network import U2NET
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
from PIL import Image
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torchvision.transforms as transforms
|
| 11 |
+
|
| 12 |
+
from collections import OrderedDict
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def load_checkpoint(model, checkpoint_path):
|
| 16 |
+
if not os.path.exists(checkpoint_path):
|
| 17 |
+
print("----No checkpoints at given path----")
|
| 18 |
+
return
|
| 19 |
+
model_state_dict = torch.load(checkpoint_path, map_location=torch.device("cpu"))
|
| 20 |
+
new_state_dict = OrderedDict()
|
| 21 |
+
for k, v in model_state_dict.items():
|
| 22 |
+
name = k[7:] # remove `module.`
|
| 23 |
+
new_state_dict[name] = v
|
| 24 |
+
|
| 25 |
+
model.load_state_dict(new_state_dict)
|
| 26 |
+
print("----checkpoints loaded from path: {}----".format(checkpoint_path))
|
| 27 |
+
return model
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class Normalize_image(object):
|
| 31 |
+
"""Normalize given tensor into given mean and standard dev
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
mean (float): Desired mean to substract from tensors
|
| 35 |
+
std (float): Desired std to divide from tensors
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
def __init__(self, mean, std):
|
| 39 |
+
assert isinstance(mean, (float))
|
| 40 |
+
if isinstance(mean, float):
|
| 41 |
+
self.mean = mean
|
| 42 |
+
|
| 43 |
+
if isinstance(std, float):
|
| 44 |
+
self.std = std
|
| 45 |
+
|
| 46 |
+
self.normalize_1 = transforms.Normalize(self.mean, self.std)
|
| 47 |
+
self.normalize_3 = transforms.Normalize([self.mean] * 3, [self.std] * 3)
|
| 48 |
+
self.normalize_18 = transforms.Normalize([self.mean] * 18, [self.std] * 18)
|
| 49 |
+
|
| 50 |
+
def __call__(self, image_tensor):
|
| 51 |
+
if image_tensor.shape[0] == 1:
|
| 52 |
+
return self.normalize_1(image_tensor)
|
| 53 |
+
|
| 54 |
+
elif image_tensor.shape[0] == 3:
|
| 55 |
+
return self.normalize_3(image_tensor)
|
| 56 |
+
|
| 57 |
+
elif image_tensor.shape[0] == 18:
|
| 58 |
+
return self.normalize_18(image_tensor)
|
| 59 |
+
|
| 60 |
+
else:
|
| 61 |
+
assert "Please set proper channels! Normlization implemented only for 1, 3 and 18"
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def apply_transform(img):
|
| 65 |
+
transforms_list = []
|
| 66 |
+
transforms_list += [transforms.ToTensor()]
|
| 67 |
+
transforms_list += [Normalize_image(0.5, 0.5)]
|
| 68 |
+
transform_rgb = transforms.Compose(transforms_list)
|
| 69 |
+
return transform_rgb(img)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def generate_mask(input_image, net, device='cpu'):
|
| 73 |
+
img = input_image
|
| 74 |
+
img_size = img.size
|
| 75 |
+
img = img.resize((768, 768), Image.BICUBIC)
|
| 76 |
+
image_tensor = apply_transform(img)
|
| 77 |
+
image_tensor = torch.unsqueeze(image_tensor, 0)
|
| 78 |
+
|
| 79 |
+
with torch.no_grad():
|
| 80 |
+
output_tensor = net(image_tensor.to(device))
|
| 81 |
+
output_tensor = F.log_softmax(output_tensor[0], dim=1)
|
| 82 |
+
output_tensor = torch.max(output_tensor, dim=1, keepdim=True)[1]
|
| 83 |
+
output_tensor = torch.squeeze(output_tensor, dim=0)
|
| 84 |
+
output_arr = output_tensor.cpu().numpy()
|
| 85 |
+
mask = (output_arr != 0).astype(np.uint8) * 255
|
| 86 |
+
mask = mask[0] # Selecting the first channel to make it 2D
|
| 87 |
+
alpha_mask_img = Image.fromarray(mask, mode='L')
|
| 88 |
+
alpha_mask_img = alpha_mask_img.resize(img_size, Image.BICUBIC)
|
| 89 |
+
|
| 90 |
+
return alpha_mask_img
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def load_seg_model(checkpoint_path, device='cpu'):
|
| 94 |
+
net = U2NET(in_ch=3, out_ch=4)
|
| 95 |
+
net = load_checkpoint(net, checkpoint_path)
|
| 96 |
+
net = net.to(device)
|
| 97 |
+
net = net.eval()
|
| 98 |
+
|
| 99 |
+
return net
|
gradio_animatediff.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os.path
|
| 2 |
+
import pdb
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL, DDIMScheduler, MotionAdapter, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler,StableVideoDiffusionPipeline
|
| 6 |
+
from diffusers.pipelines import AnimateDiffPipeline
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import argparse
|
| 9 |
+
from diffusers.utils import export_to_gif
|
| 10 |
+
from garment_adapter.garment_diffusion import ClothAdapter_AnimateDiff
|
| 11 |
+
from pipelines.OmsAnimateDiffusionPipeline import OmsAnimateDiffusionPipeline
|
| 12 |
+
|
| 13 |
+
if __name__ == "__main__":
|
| 14 |
+
|
| 15 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 16 |
+
parser.add_argument('--cloth_path', type=str, required=True)
|
| 17 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 18 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 19 |
+
parser.add_argument('--output_path', type=str, default="./output_img")
|
| 20 |
+
|
| 21 |
+
args = parser.parse_args()
|
| 22 |
+
|
| 23 |
+
device = "cuda"
|
| 24 |
+
output_path = args.output_path
|
| 25 |
+
if not os.path.exists(output_path):
|
| 26 |
+
os.makedirs(output_path)
|
| 27 |
+
|
| 28 |
+
cloth_image = Image.open(args.cloth_path).convert("RGB")
|
| 29 |
+
|
| 30 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 31 |
+
adapter = MotionAdapter.from_pretrained("guoyww/animatediff-motion-adapter-v1-5-2", torch_dtype=torch.float16)
|
| 32 |
+
|
| 33 |
+
pipe = OmsAnimateDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, motion_adapter=adapter, torch_dtype=torch.float16)
|
| 34 |
+
# pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
|
| 35 |
+
|
| 36 |
+
full_net = ClothAdapter_AnimateDiff(pipe, args.pipe_path, args.model_path, device)
|
| 37 |
+
frames, cloth_mask_image = full_net.generate(cloth_image, num_images_per_prompt=1, seed=6896868)
|
| 38 |
+
export_to_gif(frames[0], "animation0.gif")
|
gradio_controlnet_inpainting.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL, ControlNetModel
|
| 3 |
+
from diffusers.pipelines import StableDiffusionControlNetPipeline
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import argparse
|
| 6 |
+
from garment_adapter.garment_diffusion import ClothAdapter
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
from pipelines.OmsDiffusionControlNetPipeline import OmsDiffusionControlNetPipeline
|
| 10 |
+
|
| 11 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 12 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 13 |
+
parser.add_argument('--enable_cloth_guidance', action="store_true")
|
| 14 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 15 |
+
|
| 16 |
+
args = parser.parse_args()
|
| 17 |
+
|
| 18 |
+
device = "cuda"
|
| 19 |
+
|
| 20 |
+
control_net_openpose = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16)
|
| 21 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 22 |
+
if args.enable_cloth_guidance:
|
| 23 |
+
pipe = OmsDiffusionControlNetPipeline.from_pretrained(args.pipe_path, vae=vae, controlnet=control_net_openpose, torch_dtype=torch.float16)
|
| 24 |
+
else:
|
| 25 |
+
pipe = StableDiffusionControlNetPipeline.from_pretrained(args.pipe_path, vae=vae, controlnet=control_net_openpose, torch_dtype=torch.float16)
|
| 26 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 27 |
+
full_net = ClothAdapter(pipe, args.model_path, device, args.enable_cloth_guidance)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def make_inpaint_condition(image, image_mask):
|
| 31 |
+
image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
|
| 32 |
+
image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
|
| 33 |
+
assert image.shape[0:1] == image_mask.shape[0:1], "image and image_mask must have the same image size"
|
| 34 |
+
image[image_mask > 0.5] = -1.0 # set as masked pixel
|
| 35 |
+
image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
|
| 36 |
+
image = torch.from_numpy(image)
|
| 37 |
+
return image
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def process(cloth_image, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, scale, cloth_guidance_scale, seed, person_image, person_mask):
|
| 41 |
+
inpaint_image = make_inpaint_condition(person_image, person_mask)
|
| 42 |
+
images, cloth_mask_image = full_net.generate(cloth_image, cloth_mask_image, prompt, a_prompt, num_samples, n_prompt, seed, scale,cloth_guidance_scale, sample_steps, height, width, image=inpaint_image)
|
| 43 |
+
return images, cloth_mask_image
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
block = gr.Blocks().queue()
|
| 47 |
+
with block:
|
| 48 |
+
with gr.Row():
|
| 49 |
+
gr.Markdown("##You can enlarge image resolution to get better face, but the cloth maybe lose control, we will release high-resolution checkpoint soon##")
|
| 50 |
+
with gr.Row():
|
| 51 |
+
with gr.Column():
|
| 52 |
+
cloth_image = gr.Image(label="cloth Image", type="pil")
|
| 53 |
+
cloth_mask_image = gr.Image(label="cloth mask Image, if not support, will be produced by inner segment algorithm", type="pil")
|
| 54 |
+
prompt = gr.Textbox(label="Prompt", value='a photography of a model')
|
| 55 |
+
run_button = gr.Button(value="Run")
|
| 56 |
+
with gr.Accordion("Advanced options", open=False):
|
| 57 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 58 |
+
height = gr.Slider(label="Height", minimum=256, maximum=1024, value=768, step=64)
|
| 59 |
+
width = gr.Slider(label="Width", minimum=192, maximum=768, value=576, step=64)
|
| 60 |
+
sample_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
|
| 61 |
+
guidance_scale = gr.Slider(label="Guidance Scale", minimum=1, maximum=10., value=5. if args.enable_cloth_guidance else 2.5, step=0.1)
|
| 62 |
+
cloth_guidance_scale = gr.Slider(label="Cloth guidance Scale", minimum=1, maximum=10., value=2.5, step=0.1, visible=args.enable_cloth_guidance)
|
| 63 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 64 |
+
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, high quality')
|
| 65 |
+
n_prompt = gr.Textbox(label="Negative Prompt", value='bare, monochrome, lowres, bad anatomy, worst quality, low quality')
|
| 66 |
+
with gr.Column():
|
| 67 |
+
person_image = gr.Image(label="person Image", type="pil")
|
| 68 |
+
person_mask = gr.Image(label="person mask", type="pil")
|
| 69 |
+
with gr.Column():
|
| 70 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery", min_width=384)
|
| 71 |
+
cloth_seg_image = gr.Image(label="cloth mask", type="pil", width=192, height=256)
|
| 72 |
+
|
| 73 |
+
ips = [cloth_image, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, guidance_scale, cloth_guidance_scale, seed, person_image, person_mask]
|
| 74 |
+
run_button.click(fn=process, inputs=ips, outputs=[result_gallery, cloth_seg_image])
|
| 75 |
+
|
| 76 |
+
block.launch(server_name="0.0.0.0", server_port=7860)
|
gradio_controlnet_openpose.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL, ControlNetModel
|
| 3 |
+
from diffusers.pipelines import StableDiffusionControlNetPipeline
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import argparse
|
| 6 |
+
from controlnet_aux import OpenposeDetector
|
| 7 |
+
from garment_adapter.garment_diffusion import ClothAdapter
|
| 8 |
+
from pipelines.OmsDiffusionControlNetPipeline import OmsDiffusionControlNetPipeline
|
| 9 |
+
|
| 10 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 11 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 12 |
+
parser.add_argument('--enable_cloth_guidance', action="store_true")
|
| 13 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 14 |
+
|
| 15 |
+
args = parser.parse_args()
|
| 16 |
+
|
| 17 |
+
device = "cuda"
|
| 18 |
+
|
| 19 |
+
openpose_model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet").to(device)
|
| 20 |
+
control_net_openpose = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_openpose", torch_dtype=torch.float16)
|
| 21 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 22 |
+
if args.enable_cloth_guidance:
|
| 23 |
+
pipe = OmsDiffusionControlNetPipeline.from_pretrained(args.pipe_path, vae=vae, controlnet=control_net_openpose, torch_dtype=torch.float16)
|
| 24 |
+
else:
|
| 25 |
+
pipe = StableDiffusionControlNetPipeline.from_pretrained(args.pipe_path, vae=vae, controlnet=control_net_openpose, torch_dtype=torch.float16)
|
| 26 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 27 |
+
full_net = ClothAdapter(pipe, args.model_path, device, args.enable_cloth_guidance)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_pose(image):
|
| 31 |
+
openpose_image = openpose_model(image)
|
| 32 |
+
return openpose_image
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def process(cloth_image, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, scale, cloth_guidance_scale, seed, pose_image):
|
| 36 |
+
images, cloth_mask_image = full_net.generate(cloth_image, cloth_mask_image, prompt, a_prompt, num_samples, n_prompt, seed, scale, cloth_guidance_scale, sample_steps, height, width, image=pose_image)
|
| 37 |
+
return images, cloth_mask_image
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
block = gr.Blocks().queue()
|
| 41 |
+
with block:
|
| 42 |
+
with gr.Row():
|
| 43 |
+
gr.Markdown("##You can enlarge image resolution to get better face, but the cloth maybe lose control, we will release high-resolution checkpoint soon##")
|
| 44 |
+
with gr.Row():
|
| 45 |
+
with gr.Column():
|
| 46 |
+
cloth_image = gr.Image(label="cloth Image", type="pil")
|
| 47 |
+
cloth_mask_image = gr.Image(label="cloth mask Image, if not support, will be produced by inner segment algorithm", type="pil")
|
| 48 |
+
prompt = gr.Textbox(label="Prompt", value='a photography of a model')
|
| 49 |
+
run_button = gr.Button(value="Run")
|
| 50 |
+
with gr.Accordion("Advanced options", open=False):
|
| 51 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 52 |
+
height = gr.Slider(label="Height", minimum=256, maximum=1024, value=768, step=64)
|
| 53 |
+
width = gr.Slider(label="Width", minimum=192, maximum=768, value=576, step=64)
|
| 54 |
+
sample_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
|
| 55 |
+
|
| 56 |
+
guidance_scale = gr.Slider(label="Guidance Scale", minimum=1, maximum=10., value=5. if args.enable_cloth_guidance else 2.5, step=0.1)
|
| 57 |
+
cloth_guidance_scale = gr.Slider(label="Cloth guidance Scale", minimum=1, maximum=10., value=2.5, step=0.1, visible=args.enable_cloth_guidance)
|
| 58 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 59 |
+
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, high quality')
|
| 60 |
+
n_prompt = gr.Textbox(label="Negative Prompt", value='bare, monochrome, lowres, bad anatomy, worst quality, low quality')
|
| 61 |
+
with gr.Column():
|
| 62 |
+
pose_image = gr.Image(label="pose Image", type="pil")
|
| 63 |
+
pose_button = gr.Button(value="get pose")
|
| 64 |
+
with gr.Column():
|
| 65 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery", min_width=384)
|
| 66 |
+
cloth_seg_image = gr.Image(label="cloth mask", type="pil", width=192, height=256)
|
| 67 |
+
|
| 68 |
+
ips = [cloth_image, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, guidance_scale, cloth_guidance_scale, seed, pose_image]
|
| 69 |
+
run_button.click(fn=process, inputs=ips, outputs=[result_gallery, cloth_seg_image])
|
| 70 |
+
pose_button.click(fn=get_pose, inputs=pose_image, outputs=pose_image)
|
| 71 |
+
|
| 72 |
+
block.launch(server_name="0.0.0.0", server_port=7860)
|
gradio_generate.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL
|
| 3 |
+
from diffusers.pipelines import StableDiffusionPipeline
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
from garment_adapter.garment_diffusion import ClothAdapter
|
| 8 |
+
from pipelines.OmsDiffusionPipeline import OmsDiffusionPipeline
|
| 9 |
+
|
| 10 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 11 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 12 |
+
parser.add_argument('--enable_cloth_guidance', action="store_true")
|
| 13 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 14 |
+
|
| 15 |
+
args = parser.parse_args()
|
| 16 |
+
|
| 17 |
+
device = "cuda"
|
| 18 |
+
|
| 19 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 20 |
+
if args.enable_cloth_guidance:
|
| 21 |
+
pipe = OmsDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 22 |
+
else:
|
| 23 |
+
pipe = StableDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 24 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 25 |
+
full_net = ClothAdapter(pipe, args.model_path, device, args.enable_cloth_guidance)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def process(cloth_image, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, scale, cloth_guidance_scale, seed):
|
| 29 |
+
images, cloth_mask_image = full_net.generate(cloth_image, cloth_mask_image, prompt, a_prompt, num_samples, n_prompt, seed, scale, cloth_guidance_scale, sample_steps, height, width)
|
| 30 |
+
return images, cloth_mask_image
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
block = gr.Blocks().queue()
|
| 34 |
+
with block:
|
| 35 |
+
with gr.Row():
|
| 36 |
+
gr.Markdown("##You can enlarge image resolution to get better face, but the cloth maybe lose control, we will release high-resolution checkpoint soon##")
|
| 37 |
+
with gr.Row():
|
| 38 |
+
with gr.Column():
|
| 39 |
+
cloth_image = gr.Image(label="cloth Image", type="pil")
|
| 40 |
+
cloth_mask_image = gr.Image(label="cloth mask Image, if not support, will be produced by inner segment algorithm", type="pil")
|
| 41 |
+
prompt = gr.Textbox(label="Prompt", value='a photography of a model')
|
| 42 |
+
run_button = gr.Button(value="Run")
|
| 43 |
+
with gr.Accordion("Advanced options", open=False):
|
| 44 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 45 |
+
height = gr.Slider(label="Height", minimum=256, maximum=1024, value=768, step=64)
|
| 46 |
+
width = gr.Slider(label="Width", minimum=192, maximum=768, value=576, step=64)
|
| 47 |
+
sample_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
|
| 48 |
+
guidance_scale = gr.Slider(label="Guidance Scale", minimum=1, maximum=10., value=5. if args.enable_cloth_guidance else 2.5, step=0.1)
|
| 49 |
+
cloth_guidance_scale = gr.Slider(label="Cloth guidance Scale", minimum=1, maximum=10., value=2.5, step=0.1, visible=args.enable_cloth_guidance)
|
| 50 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 51 |
+
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, high quality')
|
| 52 |
+
n_prompt = gr.Textbox(label="Negative Prompt", value='bare, monochrome, lowres, bad anatomy, worst quality, low quality')
|
| 53 |
+
|
| 54 |
+
with gr.Column():
|
| 55 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery")
|
| 56 |
+
cloth_seg_image = gr.Image(label="cloth mask", type="pil", width=192, height=256)
|
| 57 |
+
|
| 58 |
+
ips = [cloth_image, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, guidance_scale, cloth_guidance_scale, seed]
|
| 59 |
+
run_button.click(fn=process, inputs=ips, outputs=[result_gallery, cloth_seg_image])
|
| 60 |
+
|
| 61 |
+
block.launch(server_name="0.0.0.0", server_port=7860, share=True)
|
gradio_ipadapter_faceid.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL
|
| 6 |
+
from diffusers.pipelines import StableDiffusionPipeline
|
| 7 |
+
import gradio as gr
|
| 8 |
+
import argparse
|
| 9 |
+
import cv2
|
| 10 |
+
|
| 11 |
+
from pipelines.OmsDiffusionPipeline import OmsDiffusionPipeline
|
| 12 |
+
|
| 13 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 14 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 15 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 16 |
+
parser.add_argument('--enable_cloth_guidance', action="store_true")
|
| 17 |
+
parser.add_argument('--faceid_version', type=str, default="FaceIDPlusV2", choices=['FaceID', 'FaceIDPlus', 'FaceIDPlusV2'])
|
| 18 |
+
|
| 19 |
+
args = parser.parse_args()
|
| 20 |
+
|
| 21 |
+
device = "cuda"
|
| 22 |
+
|
| 23 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 24 |
+
if args.enable_cloth_guidance:
|
| 25 |
+
pipe = OmsDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 26 |
+
else:
|
| 27 |
+
pipe = StableDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 28 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 29 |
+
|
| 30 |
+
if args.faceid_version == "FaceID":
|
| 31 |
+
ip_lora = "./checkpoints/ipadapter_faceid/ip-adapter-faceid_sd15_lora.safetensors"
|
| 32 |
+
ip_ckpt = "./checkpoints/ipadapter_faceid/ip-adapter-faceid_sd15.bin"
|
| 33 |
+
pipe.load_lora_weights(ip_lora)
|
| 34 |
+
pipe.fuse_lora()
|
| 35 |
+
from garment_adapter.garment_ipadapter_faceid import IPAdapterFaceID
|
| 36 |
+
|
| 37 |
+
ip_model = IPAdapterFaceID(pipe, args.model_path, ip_ckpt, device, args.enable_cloth_guidance)
|
| 38 |
+
else:
|
| 39 |
+
if args.faceid_version == "FaceIDPlus":
|
| 40 |
+
ip_ckpt = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plus_sd15.bin"
|
| 41 |
+
ip_lora = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plus_sd15_lora.safetensors"
|
| 42 |
+
v2 = False
|
| 43 |
+
else:
|
| 44 |
+
ip_ckpt = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plusv2_sd15.bin"
|
| 45 |
+
ip_lora = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plusv2_sd15_lora.safetensors"
|
| 46 |
+
v2 = True
|
| 47 |
+
|
| 48 |
+
pipe.load_lora_weights(ip_lora)
|
| 49 |
+
pipe.fuse_lora()
|
| 50 |
+
image_encoder_path = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
|
| 51 |
+
from garment_adapter.garment_ipadapter_faceid import IPAdapterFaceIDPlus as IPAdapterFaceID
|
| 52 |
+
|
| 53 |
+
ip_model = IPAdapterFaceID(pipe, args.model_path, image_encoder_path, ip_ckpt, device, args.enable_cloth_guidance)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def process(cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, scale, cloth_guidance_scale, seed):
|
| 57 |
+
if args.faceid_version == "FaceID":
|
| 58 |
+
result = ip_model.generate(cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, seed, scale, cloth_guidance_scale, sample_steps, height, width)
|
| 59 |
+
else:
|
| 60 |
+
result = ip_model.generate(cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, seed, scale, cloth_guidance_scale, sample_steps, height, width, shortcut=v2)
|
| 61 |
+
if result is None:
|
| 62 |
+
raise gr.Error("人脸检测异常,尝试其他肖像")
|
| 63 |
+
else:
|
| 64 |
+
images, cloth_mask_image = result
|
| 65 |
+
return images, cloth_mask_image
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
block = gr.Blocks().queue()
|
| 69 |
+
with block:
|
| 70 |
+
with gr.Row():
|
| 71 |
+
gr.Markdown("##You can enlarge image resolution to get better face, but the cloth maybe lose control, we will release high-resolution checkpoint soon##")
|
| 72 |
+
with gr.Row():
|
| 73 |
+
with gr.Column():
|
| 74 |
+
face_img = gr.Image(label="face Image", type="pil")
|
| 75 |
+
cloth_image = gr.Image(label="cloth Image", type="pil")
|
| 76 |
+
cloth_mask_image = gr.Image(label="cloth mask Image, if not support, will be produced by inner segment algorithm", type="pil")
|
| 77 |
+
prompt = gr.Textbox(label="Prompt", value='a photography')
|
| 78 |
+
run_button = gr.Button(value="Run")
|
| 79 |
+
with gr.Accordion("Advanced options", open=False):
|
| 80 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 81 |
+
height = gr.Slider(label="Height", minimum=256, maximum=1024, value=768, step=64)
|
| 82 |
+
width = gr.Slider(label="Width", minimum=192, maximum=768, value=576, step=64)
|
| 83 |
+
sample_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
|
| 84 |
+
guidance_scale = gr.Slider(label="Guidance Scale", minimum=1, maximum=10., value=3. if args.enable_cloth_guidance else 2.5, step=0.1)
|
| 85 |
+
cloth_guidance_scale = gr.Slider(label="Cloth guidance Scale", minimum=1, maximum=10., value=3., step=0.1, visible=args.enable_cloth_guidance)
|
| 86 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 87 |
+
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, high quality')
|
| 88 |
+
n_prompt = gr.Textbox(label="Negative Prompt", value='bare, monochrome, lowres, bad anatomy, worst quality, low quality')
|
| 89 |
+
|
| 90 |
+
with gr.Column():
|
| 91 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery")
|
| 92 |
+
cloth_seg_image = gr.Image(label="cloth mask", type="pil", width=192, height=256)
|
| 93 |
+
|
| 94 |
+
ips = [cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, guidance_scale, cloth_guidance_scale, seed]
|
| 95 |
+
run_button.click(fn=process, inputs=ips, outputs=[result_gallery, cloth_seg_image])
|
| 96 |
+
|
| 97 |
+
block.launch(server_name="0.0.0.0", server_port=7860)
|
gradio_ipadapter_openpose.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from controlnet_aux import OpenposeDetector
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL, ControlNetModel
|
| 6 |
+
from diffusers.pipelines import StableDiffusionControlNetPipeline
|
| 7 |
+
import gradio as gr
|
| 8 |
+
import argparse
|
| 9 |
+
import cv2
|
| 10 |
+
|
| 11 |
+
from pipelines.OmsDiffusionControlNetPipeline import OmsDiffusionControlNetPipeline
|
| 12 |
+
|
| 13 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 14 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 15 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 16 |
+
parser.add_argument('--enable_cloth_guidance', action="store_true")
|
| 17 |
+
parser.add_argument('--faceid_version', type=str, default="FaceIDPlus", choices=['FaceID', 'FaceIDPlus', 'FaceIDPlusV2'])
|
| 18 |
+
|
| 19 |
+
args = parser.parse_args()
|
| 20 |
+
|
| 21 |
+
device = "cuda"
|
| 22 |
+
|
| 23 |
+
openpose_model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet").to(device)
|
| 24 |
+
control_net_openpose = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_openpose", torch_dtype=torch.float16)
|
| 25 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 26 |
+
if args.enable_cloth_guidance:
|
| 27 |
+
pipe = OmsDiffusionControlNetPipeline.from_pretrained(args.pipe_path, vae=vae, controlnet=control_net_openpose, torch_dtype=torch.float16)
|
| 28 |
+
else:
|
| 29 |
+
pipe = StableDiffusionControlNetPipeline.from_pretrained(args.pipe_path, vae=vae, controlnet=control_net_openpose, torch_dtype=torch.float16)
|
| 30 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 31 |
+
|
| 32 |
+
if args.faceid_version == "FaceID":
|
| 33 |
+
ip_lora = "./checkpoints/ipadapter_faceid/ip-adapter-faceid_sd15_lora.safetensors"
|
| 34 |
+
ip_ckpt = "./checkpoints/ipadapter_faceid/ip-adapter-faceid_sd15.bin"
|
| 35 |
+
pipe.load_lora_weights(ip_lora)
|
| 36 |
+
|
| 37 |
+
pipe.fuse_lora()
|
| 38 |
+
from garment_adapter.garment_ipadapter_faceid import IPAdapterFaceID
|
| 39 |
+
|
| 40 |
+
ip_model = IPAdapterFaceID(pipe, args.model_path, ip_ckpt, device, args.enable_cloth_guidance)
|
| 41 |
+
else:
|
| 42 |
+
if args.faceid_version == "FaceIDPlus":
|
| 43 |
+
ip_ckpt = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plus_sd15.bin"
|
| 44 |
+
ip_lora = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plus_sd15_lora.safetensors"
|
| 45 |
+
v2 = False
|
| 46 |
+
else:
|
| 47 |
+
ip_ckpt = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plusv2_sd15.bin"
|
| 48 |
+
ip_lora = "./checkpoints/ipadapter_faceid/ip-adapter-faceid-plusv2_sd15_lora.safetensors"
|
| 49 |
+
v2 = True
|
| 50 |
+
|
| 51 |
+
pipe.load_lora_weights(ip_lora)
|
| 52 |
+
pipe.fuse_lora()
|
| 53 |
+
|
| 54 |
+
image_encoder_path = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
|
| 55 |
+
from garment_adapter.garment_ipadapter_faceid import IPAdapterFaceIDPlus as IPAdapterFaceID
|
| 56 |
+
|
| 57 |
+
ip_model = IPAdapterFaceID(pipe, args.model_path, image_encoder_path, ip_ckpt, device, args.enable_cloth_guidance)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def process(cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, scale, cloth_guidance_scale, seed, pose_image):
|
| 61 |
+
if args.faceid_version == "FaceID":
|
| 62 |
+
result = ip_model.generate(cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, seed, scale, cloth_guidance_scale, sample_steps, height, width, image=pose_image)
|
| 63 |
+
else:
|
| 64 |
+
result = ip_model.generate(cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, seed, scale, cloth_guidance_scale, sample_steps, height, width, shortcut=v2, image=pose_image)
|
| 65 |
+
if result is None:
|
| 66 |
+
raise gr.Error("人脸检测异常,尝试其他肖像")
|
| 67 |
+
else:
|
| 68 |
+
images, cloth_mask_image = result
|
| 69 |
+
return images, cloth_mask_image
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_pose(image):
|
| 73 |
+
openpose_image = openpose_model(image)
|
| 74 |
+
return openpose_image
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
block = gr.Blocks().queue()
|
| 78 |
+
with block:
|
| 79 |
+
with gr.Row():
|
| 80 |
+
gr.Markdown("##You can enlarge image resolution to get better face, but the cloth maybe lose control, we will release high-resolution checkpoint soon##")
|
| 81 |
+
with gr.Row():
|
| 82 |
+
with gr.Column():
|
| 83 |
+
face_img = gr.Image(label="face Image", type="pil")
|
| 84 |
+
cloth_image = gr.Image(label="cloth Image", type="pil")
|
| 85 |
+
cloth_mask_image = gr.Image(label="cloth mask Image, if not support, will be produced by inner segment algorithm", type="pil")
|
| 86 |
+
prompt = gr.Textbox(label="Prompt", value='a photography')
|
| 87 |
+
run_button = gr.Button(value="Run")
|
| 88 |
+
with gr.Accordion("Advanced options", open=False):
|
| 89 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 90 |
+
height = gr.Slider(label="Height", minimum=256, maximum=1024, value=768, step=64)
|
| 91 |
+
width = gr.Slider(label="Width", minimum=192, maximum=768, value=576, step=64)
|
| 92 |
+
sample_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
|
| 93 |
+
guidance_scale = gr.Slider(label="Guidance Scale", minimum=1, maximum=10., value=3. if args.enable_cloth_guidance else 2.5, step=0.1)
|
| 94 |
+
cloth_guidance_scale = gr.Slider(label="Cloth guidance Scale", minimum=1, maximum=10., value=3., step=0.1, visible=args.enable_cloth_guidance)
|
| 95 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 96 |
+
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, high quality')
|
| 97 |
+
n_prompt = gr.Textbox(label="Negative Prompt", value='bare, monochrome, lowres, bad anatomy, worst quality, low quality')
|
| 98 |
+
with gr.Column():
|
| 99 |
+
pose_image = gr.Image(label="pose Image", type="pil")
|
| 100 |
+
pose_button = gr.Button(value="get pose")
|
| 101 |
+
with gr.Column():
|
| 102 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery")
|
| 103 |
+
cloth_seg_image = gr.Image(label="cloth mask", type="pil", width=192, height=256)
|
| 104 |
+
|
| 105 |
+
ips = [cloth_image, face_img, cloth_mask_image, prompt, a_prompt, n_prompt, num_samples, width, height, sample_steps, guidance_scale, cloth_guidance_scale, seed, pose_image]
|
| 106 |
+
run_button.click(fn=process, inputs=ips, outputs=[result_gallery, cloth_seg_image])
|
| 107 |
+
pose_button.click(fn=get_pose, inputs=pose_image, outputs=pose_image)
|
| 108 |
+
|
| 109 |
+
block.launch(server_name="0.0.0.0", server_port=7860)
|
gradio_sd_inpainting.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL
|
| 5 |
+
from diffusers.pipelines import StableDiffusionInpaintPipeline
|
| 6 |
+
import gradio as gr
|
| 7 |
+
import argparse
|
| 8 |
+
|
| 9 |
+
from garment_adapter.garment_diffusion import ClothAdapter
|
| 10 |
+
from pipelines.OmsDiffusionInpaintPipeline import OmsDiffusionInpaintPipeline
|
| 11 |
+
|
| 12 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 13 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 14 |
+
parser.add_argument('--pipe_path', type=str, default="runwayml/stable-diffusion-inpainting")
|
| 15 |
+
|
| 16 |
+
args = parser.parse_args()
|
| 17 |
+
|
| 18 |
+
device = "cuda"
|
| 19 |
+
|
| 20 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 21 |
+
pipe = OmsDiffusionInpaintPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 22 |
+
pipe.safety_checker = None
|
| 23 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 24 |
+
full_net = ClothAdapter(pipe, args.model_path, device, False)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def process(person_image, person_mask, cloth_image, cloth_mask_image, num_samples, width, height, sample_steps, cloth_guidance_scale, seed):
|
| 28 |
+
# person_image = person_image_mask['background'].convert("RGB")
|
| 29 |
+
# person_mask = person_image_mask['layers'][0].split()[-1]
|
| 30 |
+
|
| 31 |
+
images, cloth_mask_image = full_net.generate_inpainting(cloth_image, cloth_mask_image, num_samples, seed, cloth_guidance_scale, sample_steps, height, width, image=person_image, mask_image=person_mask)
|
| 32 |
+
return images, cloth_mask_image
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
block = gr.Blocks().queue()
|
| 36 |
+
with block:
|
| 37 |
+
with gr.Row():
|
| 38 |
+
gr.Markdown("##You can enlarge image resolution to get better face, but the cloth maybe lose control, we will release high-resolution checkpoint soon##")
|
| 39 |
+
with gr.Row():
|
| 40 |
+
with gr.Column():
|
| 41 |
+
cloth_image = gr.Image(label="cloth Image", type="pil")
|
| 42 |
+
cloth_mask_image = gr.Image(label="cloth mask Image, if not support, will be produced by inner segment algorithm", type="pil")
|
| 43 |
+
run_button = gr.Button(value="Run")
|
| 44 |
+
with gr.Accordion("Advanced options", open=False):
|
| 45 |
+
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
|
| 46 |
+
height = gr.Slider(label="Height", minimum=256, maximum=1024, value=1024, step=64)
|
| 47 |
+
width = gr.Slider(label="Width", minimum=192, maximum=768, value=768, step=64)
|
| 48 |
+
sample_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
|
| 49 |
+
cloth_guidance_scale = gr.Slider(label="Cloth guidance Scale", minimum=1, maximum=10., value=2.5, step=0.1)
|
| 50 |
+
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, value=1234)
|
| 51 |
+
with gr.Column():
|
| 52 |
+
person_image = gr.Image(label="person Image", type="pil")
|
| 53 |
+
person_mask = gr.Image(label="person mask", type="pil")
|
| 54 |
+
# person_image_mask = gr.ImageMask(label="person Image", type="pil")
|
| 55 |
+
with gr.Column():
|
| 56 |
+
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery")
|
| 57 |
+
cloth_seg_image = gr.Image(label="cloth mask", type="pil", width=192, height=256)
|
| 58 |
+
|
| 59 |
+
ips = [person_image, person_mask, cloth_image, cloth_mask_image, num_samples, width, height, sample_steps, cloth_guidance_scale, seed]
|
| 60 |
+
run_button.click(fn=process, inputs=ips, outputs=[result_gallery, cloth_seg_image])
|
| 61 |
+
|
| 62 |
+
block.launch(server_name="0.0.0.0", server_port=7860)
|
images/workflow.png
ADDED
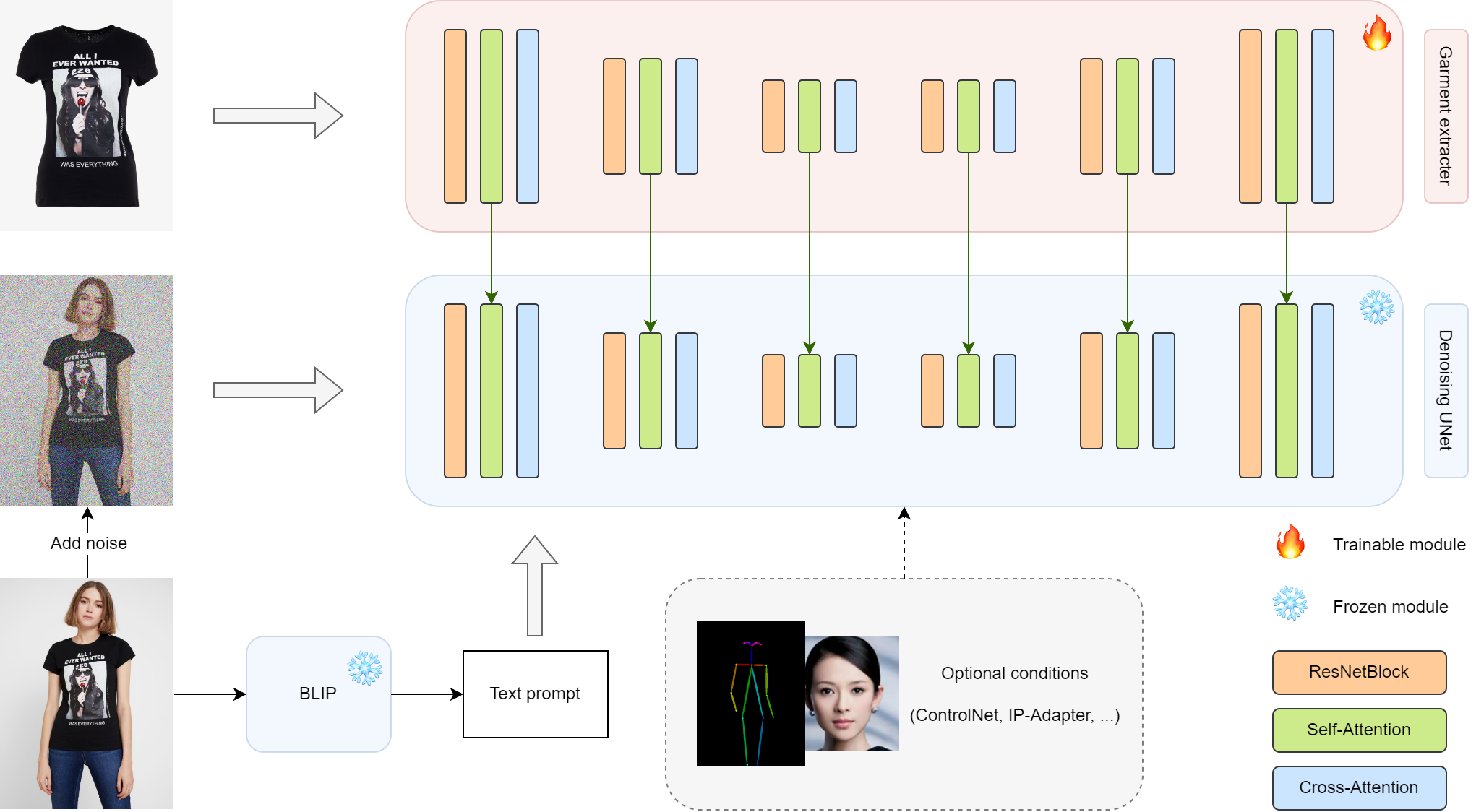
|
inference.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os.path
|
| 2 |
+
import pdb
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from diffusers import UniPCMultistepScheduler, AutoencoderKL
|
| 6 |
+
from diffusers.pipelines import StableDiffusionPipeline
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import argparse
|
| 9 |
+
|
| 10 |
+
from garment_adapter.garment_diffusion import ClothAdapter
|
| 11 |
+
from pipelines.OmsDiffusionPipeline import OmsDiffusionPipeline
|
| 12 |
+
|
| 13 |
+
if __name__ == "__main__":
|
| 14 |
+
|
| 15 |
+
parser = argparse.ArgumentParser(description='oms diffusion')
|
| 16 |
+
parser.add_argument('--cloth_path', type=str, required=True)
|
| 17 |
+
parser.add_argument('--model_path', type=str, required=True)
|
| 18 |
+
parser.add_argument('--enable_cloth_guidance', action="store_true")
|
| 19 |
+
parser.add_argument('--pipe_path', type=str, default="SG161222/Realistic_Vision_V4.0_noVAE")
|
| 20 |
+
parser.add_argument('--output_path', type=str, default="./output_img")
|
| 21 |
+
|
| 22 |
+
args = parser.parse_args()
|
| 23 |
+
|
| 24 |
+
device = "cuda"
|
| 25 |
+
output_path = args.output_path
|
| 26 |
+
if not os.path.exists(output_path):
|
| 27 |
+
os.makedirs(output_path)
|
| 28 |
+
|
| 29 |
+
cloth_image = Image.open(args.cloth_path).convert("RGB")
|
| 30 |
+
|
| 31 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse").to(dtype=torch.float16)
|
| 32 |
+
if args.enable_cloth_guidance:
|
| 33 |
+
pipe = OmsDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 34 |
+
else:
|
| 35 |
+
pipe = StableDiffusionPipeline.from_pretrained(args.pipe_path, vae=vae, torch_dtype=torch.float16)
|
| 36 |
+
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
| 37 |
+
|
| 38 |
+
full_net = ClothAdapter(pipe, args.model_path, device, args.enable_cloth_guidance)
|
| 39 |
+
images = full_net.generate(cloth_image)
|
| 40 |
+
for i, image in enumerate(images[0]):
|
| 41 |
+
image.save(os.path.join(output_path, "out_" + str(i) + ".png"))
|
nohup.out
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
output_img/out_0.png
ADDED

|
output_img/out_1.png
ADDED

|
output_img/out_2.png
ADDED

|
output_img/out_3.png
ADDED

|
pipelines/OmsAnimateDiffusionPipeline.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from diffusers.pipelines.animatediff.pipeline_animatediff import *
|
| 2 |
+
|
| 3 |
+
class OmsAnimateDiffusionPipeline(AnimateDiffPipeline):
|
| 4 |
+
|
| 5 |
+
def _denoise_loop(
|
| 6 |
+
self,
|
| 7 |
+
timesteps,
|
| 8 |
+
num_inference_steps,
|
| 9 |
+
do_classifier_free_guidance,
|
| 10 |
+
guidance_scale,
|
| 11 |
+
cloth_guidance_scale,
|
| 12 |
+
num_warmup_steps,
|
| 13 |
+
prompt_embeds,
|
| 14 |
+
negative_prompt_embeds,
|
| 15 |
+
latents,
|
| 16 |
+
cross_attention_kwargs,
|
| 17 |
+
added_cond_kwargs,
|
| 18 |
+
extra_step_kwargs,
|
| 19 |
+
callback,
|
| 20 |
+
callback_steps,
|
| 21 |
+
callback_on_step_end,
|
| 22 |
+
callback_on_step_end_tensor_inputs,
|
| 23 |
+
):
|
| 24 |
+
"""Denoising loop for AnimateDiff."""
|
| 25 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 26 |
+
for i, t in enumerate(timesteps):
|
| 27 |
+
# expand the latents if we are doing classifier free guidance
|
| 28 |
+
latent_model_input = torch.cat([latents] * 3) if do_classifier_free_guidance else latents
|
| 29 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 30 |
+
|
| 31 |
+
# predict the noise residual
|
| 32 |
+
noise_pred = self.unet(
|
| 33 |
+
latent_model_input,
|
| 34 |
+
t,
|
| 35 |
+
encoder_hidden_states=prompt_embeds,
|
| 36 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 37 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 38 |
+
).sample
|
| 39 |
+
|
| 40 |
+
# perform guidance
|
| 41 |
+
if do_classifier_free_guidance:
|
| 42 |
+
noise_pred_uncond, noise_pred_cloth, noise_pred_text = noise_pred.chunk(3)
|
| 43 |
+
noise_pred = (
|
| 44 |
+
noise_pred_uncond
|
| 45 |
+
+ guidance_scale * (noise_pred_text - noise_pred_cloth)
|
| 46 |
+
+ cloth_guidance_scale * (noise_pred_cloth - noise_pred_uncond)
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 50 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
|
| 51 |
+
|
| 52 |
+
if callback_on_step_end is not None:
|
| 53 |
+
callback_kwargs = {}
|
| 54 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 55 |
+
callback_kwargs[k] = locals()[k]
|
| 56 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 57 |
+
|
| 58 |
+
latents = callback_outputs.pop("latents", latents)
|
| 59 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 60 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 61 |
+
|
| 62 |
+
# call the callback, if provided
|
| 63 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 64 |
+
progress_bar.update()
|
| 65 |
+
if callback is not None and i % callback_steps == 0:
|
| 66 |
+
callback(i, t, latents)
|
| 67 |
+
|
| 68 |
+
return latents
|
| 69 |
+
|
| 70 |
+
@torch.no_grad()
|
| 71 |
+
def __call__(
|
| 72 |
+
self,
|
| 73 |
+
prompt: Union[str, List[str]] = None,
|
| 74 |
+
num_frames: Optional[int] = 16,
|
| 75 |
+
height: Optional[int] = None,
|
| 76 |
+
width: Optional[int] = None,
|
| 77 |
+
num_inference_steps: int = 50,
|
| 78 |
+
guidance_scale: float = 7.5,
|
| 79 |
+
cloth_guidance_scale: float = 7.5,
|
| 80 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 81 |
+
num_videos_per_prompt: Optional[int] = 1,
|
| 82 |
+
eta: float = 0.0,
|
| 83 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 84 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 85 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 86 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 87 |
+
ip_adapter_image: Optional[PipelineImageInput] = None,
|
| 88 |
+
output_type: Optional[str] = "pil",
|
| 89 |
+
return_dict: bool = True,
|
| 90 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 91 |
+
clip_skip: Optional[int] = None,
|
| 92 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 93 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 94 |
+
**kwargs,
|
| 95 |
+
):
|
| 96 |
+
r"""
|
| 97 |
+
The call function to the pipeline for generation.
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 101 |
+
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
|
| 102 |
+
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 103 |
+
The height in pixels of the generated video.
|
| 104 |
+
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 105 |
+
The width in pixels of the generated video.
|
| 106 |
+
num_frames (`int`, *optional*, defaults to 16):
|
| 107 |
+
The number of video frames that are generated. Defaults to 16 frames which at 8 frames per seconds
|
| 108 |
+
amounts to 2 seconds of video.
|
| 109 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 110 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality videos at the
|
| 111 |
+
expense of slower inference.
|
| 112 |
+
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 113 |
+
A higher guidance scale value encourages the model to generate images closely linked to the text
|
| 114 |
+
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
|
| 115 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 116 |
+
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
|
| 117 |
+
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
|
| 118 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 119 |
+
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
|
| 120 |
+
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
|
| 121 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 122 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 123 |
+
generation deterministic.
|
| 124 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 125 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for video
|
| 126 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 127 |
+
tensor is generated by sampling using the supplied random `generator`. Latents should be of shape
|
| 128 |
+
`(batch_size, num_channel, num_frames, height, width)`.
|
| 129 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 130 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
|
| 131 |
+
provided, text embeddings are generated from the `prompt` input argument.
|
| 132 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 133 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
|
| 134 |
+
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
|
| 135 |
+
ip_adapter_image: (`PipelineImageInput`, *optional*):
|
| 136 |
+
Optional image input to work with IP Adapters.
|
| 137 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 138 |
+
The output format of the generated video. Choose between `torch.FloatTensor`, `PIL.Image` or
|
| 139 |
+
`np.array`.
|
| 140 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 141 |
+
Whether or not to return a [`~pipelines.text_to_video_synthesis.TextToVideoSDPipelineOutput`] instead
|
| 142 |
+
of a plain tuple.
|
| 143 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 144 |
+
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
|
| 145 |
+
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 146 |
+
clip_skip (`int`, *optional*):
|
| 147 |
+
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
| 148 |
+
the output of the pre-final layer will be used for computing the prompt embeddings.
|
| 149 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 150 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 151 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 152 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 153 |
+
`callback_on_step_end_tensor_inputs`.
|
| 154 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 155 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 156 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 157 |
+
`._callback_tensor_inputs` attribute of your pipeine class.
|
| 158 |
+
|
| 159 |
+
Examples:
|
| 160 |
+
|
| 161 |
+
Returns:
|
| 162 |
+
[`~pipelines.text_to_video_synthesis.TextToVideoSDPipelineOutput`] or `tuple`:
|
| 163 |
+
If `return_dict` is `True`, [`~pipelines.text_to_video_synthesis.TextToVideoSDPipelineOutput`] is
|
| 164 |
+
returned, otherwise a `tuple` is returned where the first element is a list with the generated frames.
|
| 165 |
+
"""
|
| 166 |
+
|
| 167 |
+
callback = kwargs.pop("callback", None)
|
| 168 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 169 |
+
|
| 170 |
+
if callback is not None:
|
| 171 |
+
deprecate(
|
| 172 |
+
"callback",
|
| 173 |
+
"1.0.0",
|
| 174 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 175 |
+
)
|
| 176 |
+
if callback_steps is not None:
|
| 177 |
+
deprecate(
|
| 178 |
+
"callback_steps",
|
| 179 |
+
"1.0.0",
|
| 180 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
# 0. Default height and width to unet
|
| 184 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 185 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 186 |
+
|
| 187 |
+
num_videos_per_prompt = 1
|
| 188 |
+
|
| 189 |
+
# 1. Check inputs. Raise error if not correct
|
| 190 |
+
self.check_inputs(
|
| 191 |
+
prompt,
|
| 192 |
+
height,
|
| 193 |
+
width,
|
| 194 |
+
callback_steps,
|
| 195 |
+
negative_prompt,
|
| 196 |
+
prompt_embeds,
|
| 197 |
+
negative_prompt_embeds,
|
| 198 |
+
callback_on_step_end_tensor_inputs,
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
self._guidance_scale = guidance_scale
|
| 202 |
+
self._clip_skip = clip_skip
|
| 203 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 204 |
+
|
| 205 |
+
# 2. Define call parameters
|
| 206 |
+
if prompt is not None and isinstance(prompt, str):
|
| 207 |
+
batch_size = 1
|
| 208 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 209 |
+
batch_size = len(prompt)
|
| 210 |
+
else:
|
| 211 |
+
batch_size = prompt_embeds.shape[0]
|
| 212 |
+
|
| 213 |
+
device = self._execution_device
|
| 214 |
+
|
| 215 |
+
# 3. Encode input prompt
|
| 216 |
+
text_encoder_lora_scale = (
|
| 217 |
+
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
|
| 218 |
+
)
|
| 219 |
+
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
|
| 220 |
+
prompt,
|
| 221 |
+
device,
|
| 222 |
+
num_videos_per_prompt,
|
| 223 |
+
self.do_classifier_free_guidance,
|
| 224 |
+
negative_prompt,
|
| 225 |
+
prompt_embeds=prompt_embeds,
|
| 226 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 227 |
+
lora_scale=text_encoder_lora_scale,
|
| 228 |
+
clip_skip=self.clip_skip,
|
| 229 |
+
)
|
| 230 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 231 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 232 |
+
# to avoid doing two forward passes
|
| 233 |
+
if self.do_classifier_free_guidance:
|
| 234 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, negative_prompt_embeds, prompt_embeds])
|
| 235 |
+
|
| 236 |
+
if ip_adapter_image is not None:
|
| 237 |
+
image_embeds = self.prepare_ip_adapter_image_embeds(
|
| 238 |
+
ip_adapter_image, device, batch_size * num_videos_per_prompt
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
# 4. Prepare timesteps
|
| 242 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 243 |
+
timesteps = self.scheduler.timesteps
|
| 244 |
+
self._num_timesteps = len(timesteps)
|
| 245 |
+
|
| 246 |
+
# 5. Prepare latent variables
|
| 247 |
+
num_channels_latents = self.unet.config.in_channels
|
| 248 |
+
latents = self.prepare_latents(
|
| 249 |
+
batch_size * num_videos_per_prompt,
|
| 250 |
+
num_channels_latents,
|
| 251 |
+
num_frames,
|
| 252 |
+
height,
|
| 253 |
+
width,
|
| 254 |
+
prompt_embeds.dtype,
|
| 255 |
+
device,
|
| 256 |
+
generator,
|
| 257 |
+
latents,
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 261 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 262 |
+
|
| 263 |
+
# 7. Add image embeds for IP-Adapter
|
| 264 |
+
added_cond_kwargs = {"image_embeds": image_embeds} if ip_adapter_image is not None else None
|
| 265 |
+
|
| 266 |
+
# 8. Denoising loop
|
| 267 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 268 |
+
denoise_args = {
|
| 269 |
+
"timesteps": timesteps,
|
| 270 |
+
"num_inference_steps": num_inference_steps,
|
| 271 |
+
"do_classifier_free_guidance": self.do_classifier_free_guidance,
|
| 272 |
+
"guidance_scale": guidance_scale,
|
| 273 |
+
"cloth_guidance_scale": guidance_scale,
|
| 274 |
+
"num_warmup_steps": num_warmup_steps,
|
| 275 |
+
"prompt_embeds": prompt_embeds,
|
| 276 |
+
"negative_prompt_embeds": negative_prompt_embeds,
|
| 277 |
+
"latents": latents,
|
| 278 |
+
"cross_attention_kwargs": self.cross_attention_kwargs,
|
| 279 |
+
"added_cond_kwargs": added_cond_kwargs,
|
| 280 |
+
"extra_step_kwargs": extra_step_kwargs,
|
| 281 |
+
"callback": callback,
|
| 282 |
+
"callback_steps": callback_steps,
|
| 283 |
+
"callback_on_step_end": callback_on_step_end,
|
| 284 |
+
"callback_on_step_end_tensor_inputs": callback_on_step_end_tensor_inputs,
|
| 285 |
+
}
|
| 286 |
+
|
| 287 |
+
if self.free_init_enabled:
|
| 288 |
+
latents = self._free_init_loop(
|
| 289 |
+
height=height,
|
| 290 |
+
width=width,
|
| 291 |
+
num_frames=num_frames,
|
| 292 |
+
num_channels_latents=num_channels_latents,
|
| 293 |
+
batch_size=batch_size,
|
| 294 |
+
num_videos_per_prompt=num_videos_per_prompt,
|
| 295 |
+
denoise_args=denoise_args,
|
| 296 |
+
device=device,
|
| 297 |
+
)
|
| 298 |
+
else:
|
| 299 |
+
latents = self._denoise_loop(**denoise_args)
|
| 300 |
+
|
| 301 |
+
video = self._retrieve_video_frames(latents, output_type, return_dict)
|
| 302 |
+
|
| 303 |
+
# 9. Offload all models
|
| 304 |
+
self.maybe_free_model_hooks()
|
| 305 |
+
|
| 306 |
+
return video
|
pipelines/OmsDiffusionControlNetPipeline.py
ADDED
|
@@ -0,0 +1,437 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from diffusers.pipelines.controlnet.pipeline_controlnet import *
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class OmsDiffusionControlNetPipeline(StableDiffusionControlNetPipeline):
|
| 6 |
+
@torch.no_grad()
|
| 7 |
+
def __call__(
|
| 8 |
+
self,
|
| 9 |
+
prompt: Union[str, List[str]] = None,
|
| 10 |
+
image: PipelineImageInput = None,
|
| 11 |
+
height: Optional[int] = None,
|
| 12 |
+
width: Optional[int] = None,
|
| 13 |
+
num_inference_steps: int = 50,
|
| 14 |
+
timesteps: List[int] = None,
|
| 15 |
+
guidance_scale: float = 7.5,
|
| 16 |
+
cloth_guidance_scale: float = 2.5,
|
| 17 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 18 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 19 |
+
eta: float = 0.0,
|
| 20 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 21 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 22 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 23 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 24 |
+
ip_adapter_image: Optional[PipelineImageInput] = None,
|
| 25 |
+
output_type: Optional[str] = "pil",
|
| 26 |
+
return_dict: bool = True,
|
| 27 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 28 |
+
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
|
| 29 |
+
guess_mode: bool = False,
|
| 30 |
+
control_guidance_start: Union[float, List[float]] = 0.0,
|
| 31 |
+
control_guidance_end: Union[float, List[float]] = 1.0,
|
| 32 |
+
clip_skip: Optional[int] = None,
|
| 33 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 34 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 35 |
+
**kwargs,
|
| 36 |
+
):
|
| 37 |
+
r"""
|
| 38 |
+
The call function to the pipeline for generation.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 42 |
+
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
|
| 43 |
+
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
| 44 |
+
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
| 45 |
+
The ControlNet input condition to provide guidance to the `unet` for generation. If the type is
|
| 46 |
+
specified as `torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can also be
|
| 47 |
+
accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If height
|
| 48 |
+
and/or width are passed, `image` is resized accordingly. If multiple ControlNets are specified in
|
| 49 |
+
`init`, images must be passed as a list such that each element of the list can be correctly batched for
|
| 50 |
+
input to a single ControlNet. When `prompt` is a list, and if a list of images is passed for a single ControlNet,
|
| 51 |
+
each will be paired with each prompt in the `prompt` list. This also applies to multiple ControlNets,
|
| 52 |
+
where a list of image lists can be passed to batch for each prompt and each ControlNet.
|
| 53 |
+
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 54 |
+
The height in pixels of the generated image.
|
| 55 |
+
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 56 |
+
The width in pixels of the generated image.
|
| 57 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 58 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 59 |
+
expense of slower inference.
|
| 60 |
+
timesteps (`List[int]`, *optional*):
|
| 61 |
+
Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
|
| 62 |
+
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
|
| 63 |
+
passed will be used. Must be in descending order.
|
| 64 |
+
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 65 |
+
A higher guidance scale value encourages the model to generate images closely linked to the text
|
| 66 |
+
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
|
| 67 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 68 |
+
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
|
| 69 |
+
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
|
| 70 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 71 |
+
The number of images to generate per prompt.
|
| 72 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 73 |
+
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
|
| 74 |
+
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
|
| 75 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 76 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 77 |
+
generation deterministic.
|
| 78 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 79 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
|
| 80 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 81 |
+
tensor is generated by sampling using the supplied random `generator`.
|
| 82 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 83 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
|
| 84 |
+
provided, text embeddings are generated from the `prompt` input argument.
|
| 85 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 86 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
|
| 87 |
+
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
|
| 88 |
+
ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
|
| 89 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 90 |
+
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
|
| 91 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 92 |
+
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 93 |
+
plain tuple.
|
| 94 |
+
callback (`Callable`, *optional*):
|
| 95 |
+
A function that calls every `callback_steps` steps during inference. The function is called with the
|
| 96 |
+
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
|
| 97 |
+
callback_steps (`int`, *optional*, defaults to 1):
|
| 98 |
+
The frequency at which the `callback` function is called. If not specified, the callback is called at
|
| 99 |
+
every step.
|
| 100 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 101 |
+
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
|
| 102 |
+
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 103 |
+
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
|
| 104 |
+
The outputs of the ControlNet are multiplied by `controlnet_conditioning_scale` before they are added
|
| 105 |
+
to the residual in the original `unet`. If multiple ControlNets are specified in `init`, you can set
|
| 106 |
+
the corresponding scale as a list.
|
| 107 |
+
guess_mode (`bool`, *optional*, defaults to `False`):
|
| 108 |
+
The ControlNet encoder tries to recognize the content of the input image even if you remove all
|
| 109 |
+
prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
|
| 110 |
+
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
|
| 111 |
+
The percentage of total steps at which the ControlNet starts applying.
|
| 112 |
+
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
|
| 113 |
+
The percentage of total steps at which the ControlNet stops applying.
|
| 114 |
+
clip_skip (`int`, *optional*):
|
| 115 |
+
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
| 116 |
+
the output of the pre-final layer will be used for computing the prompt embeddings.
|
| 117 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 118 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 119 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 120 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 121 |
+
`callback_on_step_end_tensor_inputs`.
|
| 122 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 123 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 124 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 125 |
+
`._callback_tensor_inputs` attribute of your pipeine class.
|
| 126 |
+
|
| 127 |
+
Examples:
|
| 128 |
+
|
| 129 |
+
Returns:
|
| 130 |
+
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
| 131 |
+
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
|
| 132 |
+
otherwise a `tuple` is returned where the first element is a list with the generated images and the
|
| 133 |
+
second element is a list of `bool`s indicating whether the corresponding generated image contains
|
| 134 |
+
"not-safe-for-work" (nsfw) content.
|
| 135 |
+
"""
|
| 136 |
+
|
| 137 |
+
callback = kwargs.pop("callback", None)
|
| 138 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 139 |
+
|
| 140 |
+
if callback is not None:
|
| 141 |
+
deprecate(
|
| 142 |
+
"callback",
|
| 143 |
+
"1.0.0",
|
| 144 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 145 |
+
)
|
| 146 |
+
if callback_steps is not None:
|
| 147 |
+
deprecate(
|
| 148 |
+
"callback_steps",
|
| 149 |
+
"1.0.0",
|
| 150 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
|
| 154 |
+
|
| 155 |
+
# align format for control guidance
|
| 156 |
+
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
|
| 157 |
+
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
|
| 158 |
+
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
|
| 159 |
+
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
|
| 160 |
+
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
|
| 161 |
+
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
|
| 162 |
+
control_guidance_start, control_guidance_end = (
|
| 163 |
+
mult * [control_guidance_start],
|
| 164 |
+
mult * [control_guidance_end],
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# 1. Check inputs. Raise error if not correct
|
| 168 |
+
self.check_inputs(
|
| 169 |
+
prompt,
|
| 170 |
+
image,
|
| 171 |
+
callback_steps,
|
| 172 |
+
negative_prompt,
|
| 173 |
+
prompt_embeds,
|
| 174 |
+
negative_prompt_embeds,
|
| 175 |
+
controlnet_conditioning_scale,
|
| 176 |
+
control_guidance_start,
|
| 177 |
+
control_guidance_end,
|
| 178 |
+
callback_on_step_end_tensor_inputs,
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
self._guidance_scale = guidance_scale
|
| 182 |
+
self._clip_skip = clip_skip
|
| 183 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 184 |
+
|
| 185 |
+
# 2. Define call parameters
|
| 186 |
+
if prompt is not None and isinstance(prompt, str):
|
| 187 |
+
batch_size = 1
|
| 188 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 189 |
+
batch_size = len(prompt)
|
| 190 |
+
else:
|
| 191 |
+
batch_size = prompt_embeds.shape[0]
|
| 192 |
+
|
| 193 |
+
device = self._execution_device
|
| 194 |
+
|
| 195 |
+
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
|
| 196 |
+
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
|
| 197 |
+
|
| 198 |
+
global_pool_conditions = (
|
| 199 |
+
controlnet.config.global_pool_conditions
|
| 200 |
+
if isinstance(controlnet, ControlNetModel)
|
| 201 |
+
else controlnet.nets[0].config.global_pool_conditions
|
| 202 |
+
)
|
| 203 |
+
guess_mode = guess_mode or global_pool_conditions
|
| 204 |
+
|
| 205 |
+
# 3. Encode input prompt
|
| 206 |
+
text_encoder_lora_scale = (
|
| 207 |
+
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
|
| 208 |
+
)
|
| 209 |
+
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
|
| 210 |
+
prompt,
|
| 211 |
+
device,
|
| 212 |
+
num_images_per_prompt,
|
| 213 |
+
self.do_classifier_free_guidance,
|
| 214 |
+
negative_prompt,
|
| 215 |
+
prompt_embeds=prompt_embeds,
|
| 216 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 217 |
+
lora_scale=text_encoder_lora_scale,
|
| 218 |
+
clip_skip=self.clip_skip,
|
| 219 |
+
)
|
| 220 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 221 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 222 |
+
# to avoid doing two forward passes
|
| 223 |
+
if self.do_classifier_free_guidance:
|
| 224 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, negative_prompt_embeds, prompt_embeds])
|
| 225 |
+
|
| 226 |
+
if ip_adapter_image is not None:
|
| 227 |
+
image_embeds = self.prepare_ip_adapter_image_embeds(
|
| 228 |
+
ip_adapter_image, device, batch_size * num_images_per_prompt
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
# 4. Prepare image
|
| 232 |
+
if isinstance(controlnet, ControlNetModel):
|
| 233 |
+
image = self.prepare_image(
|
| 234 |
+
image=image,
|
| 235 |
+
width=width,
|
| 236 |
+
height=height,
|
| 237 |
+
batch_size=batch_size * num_images_per_prompt,
|
| 238 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 239 |
+
device=device,
|
| 240 |
+
dtype=controlnet.dtype,
|
| 241 |
+
do_classifier_free_guidance=self.do_classifier_free_guidance,
|
| 242 |
+
guess_mode=guess_mode,
|
| 243 |
+
)
|
| 244 |
+
if self.do_classifier_free_guidance and not guess_mode:
|
| 245 |
+
image = image.chunk(2)[0]
|
| 246 |
+
image = torch.cat([image]*3)
|
| 247 |
+
height, width = image.shape[-2:]
|
| 248 |
+
elif isinstance(controlnet, MultiControlNetModel):
|
| 249 |
+
images = []
|
| 250 |
+
|
| 251 |
+
# Nested lists as ControlNet condition
|
| 252 |
+
if isinstance(image[0], list):
|
| 253 |
+
# Transpose the nested image list
|
| 254 |
+
image = [list(t) for t in zip(*image)]
|
| 255 |
+
|
| 256 |
+
for image_ in image:
|
| 257 |
+
image_ = self.prepare_image(
|
| 258 |
+
image=image_,
|
| 259 |
+
width=width,
|
| 260 |
+
height=height,
|
| 261 |
+
batch_size=batch_size * num_images_per_prompt,
|
| 262 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 263 |
+
device=device,
|
| 264 |
+
dtype=controlnet.dtype,
|
| 265 |
+
do_classifier_free_guidance=self.do_classifier_free_guidance,
|
| 266 |
+
guess_mode=guess_mode,
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
images.append(image_)
|
| 270 |
+
|
| 271 |
+
image = images
|
| 272 |
+
height, width = image[0].shape[-2:]
|
| 273 |
+
else:
|
| 274 |
+
assert False
|
| 275 |
+
|
| 276 |
+
# 5. Prepare timesteps
|
| 277 |
+
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
|
| 278 |
+
self._num_timesteps = len(timesteps)
|
| 279 |
+
|
| 280 |
+
# 6. Prepare latent variables
|
| 281 |
+
num_channels_latents = self.unet.config.in_channels
|
| 282 |
+
latents = self.prepare_latents(
|
| 283 |
+
batch_size * num_images_per_prompt,
|
| 284 |
+
num_channels_latents,
|
| 285 |
+
height,
|
| 286 |
+
width,
|
| 287 |
+
prompt_embeds.dtype,
|
| 288 |
+
device,
|
| 289 |
+
generator,
|
| 290 |
+
latents,
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
# 6.5 Optionally get Guidance Scale Embedding
|
| 294 |
+
timestep_cond = None
|
| 295 |
+
if self.unet.config.time_cond_proj_dim is not None:
|
| 296 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
|
| 297 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 298 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 299 |
+
).to(device=device, dtype=latents.dtype)
|
| 300 |
+
|
| 301 |
+
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 302 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 303 |
+
|
| 304 |
+
# 7.1 Add image embeds for IP-Adapter
|
| 305 |
+
added_cond_kwargs = {"image_embeds": image_embeds} if ip_adapter_image is not None else None
|
| 306 |
+
|
| 307 |
+
# 7.2 Create tensor stating which controlnets to keep
|
| 308 |
+
controlnet_keep = []
|
| 309 |
+
for i in range(len(timesteps)):
|
| 310 |
+
keeps = [
|
| 311 |
+
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
|
| 312 |
+
for s, e in zip(control_guidance_start, control_guidance_end)
|
| 313 |
+
]
|
| 314 |
+
controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
|
| 315 |
+
|
| 316 |
+
# 8. Denoising loop
|
| 317 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 318 |
+
is_unet_compiled = is_compiled_module(self.unet)
|
| 319 |
+
is_controlnet_compiled = is_compiled_module(self.controlnet)
|
| 320 |
+
is_torch_higher_equal_2_1 = is_torch_version(">=", "2.1")
|
| 321 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 322 |
+
for i, t in enumerate(timesteps):
|
| 323 |
+
# Relevant thread:
|
| 324 |
+
# https://dev-discuss.pytorch.org/t/cudagraphs-in-pytorch-2-0/1428
|
| 325 |
+
if (is_unet_compiled and is_controlnet_compiled) and is_torch_higher_equal_2_1:
|
| 326 |
+
torch._inductor.cudagraph_mark_step_begin()
|
| 327 |
+
# expand the latents if we are doing classifier free guidance
|
| 328 |
+
latent_model_input = torch.cat([latents] * 3) if self.do_classifier_free_guidance else latents
|
| 329 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 330 |
+
|
| 331 |
+
# controlnet(s) inference
|
| 332 |
+
if guess_mode and self.do_classifier_free_guidance:
|
| 333 |
+
# Infer ControlNet only for the conditional batch.
|
| 334 |
+
control_model_input = latents
|
| 335 |
+
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
|
| 336 |
+
controlnet_prompt_embeds = prompt_embeds.chunk(3)[1]
|
| 337 |
+
else:
|
| 338 |
+
control_model_input = latent_model_input
|
| 339 |
+
controlnet_prompt_embeds = prompt_embeds
|
| 340 |
+
|
| 341 |
+
if isinstance(controlnet_keep[i], list):
|
| 342 |
+
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
|
| 343 |
+
else:
|
| 344 |
+
controlnet_cond_scale = controlnet_conditioning_scale
|
| 345 |
+
if isinstance(controlnet_cond_scale, list):
|
| 346 |
+
controlnet_cond_scale = controlnet_cond_scale[0]
|
| 347 |
+
cond_scale = controlnet_cond_scale * controlnet_keep[i]
|
| 348 |
+
|
| 349 |
+
down_block_res_samples, mid_block_res_sample = self.controlnet(
|
| 350 |
+
control_model_input,
|
| 351 |
+
t,
|
| 352 |
+
encoder_hidden_states=controlnet_prompt_embeds,
|
| 353 |
+
controlnet_cond=image,
|
| 354 |
+
conditioning_scale=cond_scale,
|
| 355 |
+
guess_mode=guess_mode,
|
| 356 |
+
return_dict=False,
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
if guess_mode and self.do_classifier_free_guidance:
|
| 360 |
+
# Infered ControlNet only for the conditional batch.
|
| 361 |
+
# To apply the output of ControlNet to both the unconditional and conditional batches,
|
| 362 |
+
# add 0 to the unconditional batch to keep it unchanged.
|
| 363 |
+
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
|
| 364 |
+
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
|
| 365 |
+
|
| 366 |
+
# predict the noise residual
|
| 367 |
+
noise_pred = self.unet(
|
| 368 |
+
latent_model_input,
|
| 369 |
+
t,
|
| 370 |
+
encoder_hidden_states=prompt_embeds,
|
| 371 |
+
timestep_cond=timestep_cond,
|
| 372 |
+
cross_attention_kwargs=self.cross_attention_kwargs,
|
| 373 |
+
down_block_additional_residuals=down_block_res_samples,
|
| 374 |
+
mid_block_additional_residual=mid_block_res_sample,
|
| 375 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 376 |
+
return_dict=False,
|
| 377 |
+
)[0]
|
| 378 |
+
|
| 379 |
+
# perform guidance
|
| 380 |
+
if self.do_classifier_free_guidance:
|
| 381 |
+
noise_pred_uncond, noise_pred_cloth, noise_pred_text = noise_pred.chunk(3)
|
| 382 |
+
noise_pred = (
|
| 383 |
+
noise_pred_uncond
|
| 384 |
+
+ guidance_scale * (noise_pred_text - noise_pred_cloth)
|
| 385 |
+
+ cloth_guidance_scale * (noise_pred_cloth - noise_pred_uncond)
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 389 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 390 |
+
|
| 391 |
+
if callback_on_step_end is not None:
|
| 392 |
+
callback_kwargs = {}
|
| 393 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 394 |
+
callback_kwargs[k] = locals()[k]
|
| 395 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 396 |
+
|
| 397 |
+
latents = callback_outputs.pop("latents", latents)
|
| 398 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 399 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 400 |
+
|
| 401 |
+
# call the callback, if provided
|
| 402 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 403 |
+
progress_bar.update()
|
| 404 |
+
if callback is not None and i % callback_steps == 0:
|
| 405 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 406 |
+
callback(step_idx, t, latents)
|
| 407 |
+
|
| 408 |
+
# If we do sequential model offloading, let's offload unet and controlnet
|
| 409 |
+
# manually for max memory savings
|
| 410 |
+
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
| 411 |
+
self.unet.to("cpu")
|
| 412 |
+
self.controlnet.to("cpu")
|
| 413 |
+
torch.cuda.empty_cache()
|
| 414 |
+
|
| 415 |
+
if not output_type == "latent":
|
| 416 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False, generator=generator)[
|
| 417 |
+
0
|
| 418 |
+
]
|
| 419 |
+
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
| 420 |
+
else:
|
| 421 |
+
image = latents
|
| 422 |
+
has_nsfw_concept = None
|
| 423 |
+
|
| 424 |
+
if has_nsfw_concept is None:
|
| 425 |
+
do_denormalize = [True] * image.shape[0]
|
| 426 |
+
else:
|
| 427 |
+
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
|
| 428 |
+
|
| 429 |
+
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
|
| 430 |
+
|
| 431 |
+
# Offload all models
|
| 432 |
+
self.maybe_free_model_hooks()
|
| 433 |
+
|
| 434 |
+
if not return_dict:
|
| 435 |
+
return (image, has_nsfw_concept)
|
| 436 |
+
|
| 437 |
+
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
pipelines/OmsDiffusionInpaintPipeline.py
ADDED
|
@@ -0,0 +1,502 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pdb
|
| 2 |
+
|
| 3 |
+
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint import *
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class OmsDiffusionInpaintPipeline(StableDiffusionInpaintPipeline):
|
| 7 |
+
|
| 8 |
+
@torch.no_grad()
|
| 9 |
+
def __call__(
|
| 10 |
+
self,
|
| 11 |
+
prompt: Union[str, List[str]] = None,
|
| 12 |
+
image: PipelineImageInput = None,
|
| 13 |
+
mask_image: PipelineImageInput = None,
|
| 14 |
+
masked_image_latents: torch.FloatTensor = None,
|
| 15 |
+
height: Optional[int] = None,
|
| 16 |
+
width: Optional[int] = None,
|
| 17 |
+
padding_mask_crop: Optional[int] = None,
|
| 18 |
+
strength: float = 1.0,
|
| 19 |
+
num_inference_steps: int = 50,
|
| 20 |
+
timesteps: List[int] = None,
|
| 21 |
+
guidance_scale: float = 0.,
|
| 22 |
+
cloth_guidance_scale: float = 2.5,
|
| 23 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 24 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 25 |
+
eta: float = 0.0,
|
| 26 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 27 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 28 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 29 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 30 |
+
ip_adapter_image: Optional[PipelineImageInput] = None,
|
| 31 |
+
output_type: Optional[str] = "pil",
|
| 32 |
+
return_dict: bool = True,
|
| 33 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 34 |
+
clip_skip: int = None,
|
| 35 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 36 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 37 |
+
**kwargs,
|
| 38 |
+
):
|
| 39 |
+
r"""
|
| 40 |
+
The call function to the pipeline for generation.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 44 |
+
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
|
| 45 |
+
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
|
| 46 |
+
`Image`, numpy array or tensor representing an image batch to be inpainted (which parts of the image to
|
| 47 |
+
be masked out with `mask_image` and repainted according to `prompt`). For both numpy array and pytorch
|
| 48 |
+
tensor, the expected value range is between `[0, 1]` If it's a tensor or a list or tensors, the
|
| 49 |
+
expected shape should be `(B, C, H, W)` or `(C, H, W)`. If it is a numpy array or a list of arrays, the
|
| 50 |
+
expected shape should be `(B, H, W, C)` or `(H, W, C)` It can also accept image latents as `image`, but
|
| 51 |
+
if passing latents directly it is not encoded again.
|
| 52 |
+
mask_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
|
| 53 |
+
`Image`, numpy array or tensor representing an image batch to mask `image`. White pixels in the mask
|
| 54 |
+
are repainted while black pixels are preserved. If `mask_image` is a PIL image, it is converted to a
|
| 55 |
+
single channel (luminance) before use. If it's a numpy array or pytorch tensor, it should contain one
|
| 56 |
+
color channel (L) instead of 3, so the expected shape for pytorch tensor would be `(B, 1, H, W)`, `(B,
|
| 57 |
+
H, W)`, `(1, H, W)`, `(H, W)`. And for numpy array would be for `(B, H, W, 1)`, `(B, H, W)`, `(H, W,
|
| 58 |
+
1)`, or `(H, W)`.
|
| 59 |
+
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 60 |
+
The height in pixels of the generated image.
|
| 61 |
+
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 62 |
+
The width in pixels of the generated image.
|
| 63 |
+
padding_mask_crop (`int`, *optional*, defaults to `None`):
|
| 64 |
+
The size of margin in the crop to be applied to the image and masking. If `None`, no crop is applied to image and mask_image. If
|
| 65 |
+
`padding_mask_crop` is not `None`, it will first find a rectangular region with the same aspect ration of the image and
|
| 66 |
+
contains all masked area, and then expand that area based on `padding_mask_crop`. The image and mask_image will then be cropped based on
|
| 67 |
+
the expanded area before resizing to the original image size for inpainting. This is useful when the masked area is small while the image is large
|
| 68 |
+
and contain information inreleant for inpainging, such as background.
|
| 69 |
+
strength (`float`, *optional*, defaults to 1.0):
|
| 70 |
+
Indicates extent to transform the reference `image`. Must be between 0 and 1. `image` is used as a
|
| 71 |
+
starting point and more noise is added the higher the `strength`. The number of denoising steps depends
|
| 72 |
+
on the amount of noise initially added. When `strength` is 1, added noise is maximum and the denoising
|
| 73 |
+
process runs for the full number of iterations specified in `num_inference_steps`. A value of 1
|
| 74 |
+
essentially ignores `image`.
|
| 75 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 76 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 77 |
+
expense of slower inference. This parameter is modulated by `strength`.
|
| 78 |
+
timesteps (`List[int]`, *optional*):
|
| 79 |
+
Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
|
| 80 |
+
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
|
| 81 |
+
passed will be used. Must be in descending order.
|
| 82 |
+
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 83 |
+
A higher guidance scale value encourages the model to generate images closely linked to the text
|
| 84 |
+
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
|
| 85 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 86 |
+
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
|
| 87 |
+
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
|
| 88 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 89 |
+
The number of images to generate per prompt.
|
| 90 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 91 |
+
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
|
| 92 |
+
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
|
| 93 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 94 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 95 |
+
generation deterministic.
|
| 96 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 97 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
|
| 98 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 99 |
+
tensor is generated by sampling using the supplied random `generator`.
|
| 100 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 101 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
|
| 102 |
+
provided, text embeddings are generated from the `prompt` input argument.
|
| 103 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 104 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
|
| 105 |
+
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
|
| 106 |
+
ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
|
| 107 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 108 |
+
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
|
| 109 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 110 |
+
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 111 |
+
plain tuple.
|
| 112 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 113 |
+
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
|
| 114 |
+
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 115 |
+
clip_skip (`int`, *optional*):
|
| 116 |
+
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
| 117 |
+
the output of the pre-final layer will be used for computing the prompt embeddings.
|
| 118 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 119 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 120 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 121 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 122 |
+
`callback_on_step_end_tensor_inputs`.
|
| 123 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 124 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 125 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 126 |
+
`._callback_tensor_inputs` attribute of your pipeline class.
|
| 127 |
+
Examples:
|
| 128 |
+
|
| 129 |
+
```py
|
| 130 |
+
>>> import PIL
|
| 131 |
+
>>> import requests
|
| 132 |
+
>>> import torch
|
| 133 |
+
>>> from io import BytesIO
|
| 134 |
+
|
| 135 |
+
>>> from diffusers import StableDiffusionInpaintPipeline
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
>>> def download_image(url):
|
| 139 |
+
... response = requests.get(url)
|
| 140 |
+
... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
| 144 |
+
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
| 145 |
+
|
| 146 |
+
>>> init_image = download_image(img_url).resize((512, 512))
|
| 147 |
+
>>> mask_image = download_image(mask_url).resize((512, 512))
|
| 148 |
+
|
| 149 |
+
>>> pipe = StableDiffusionInpaintPipeline.from_pretrained(
|
| 150 |
+
... "runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16
|
| 151 |
+
... )
|
| 152 |
+
>>> pipe = pipe.to("cuda")
|
| 153 |
+
|
| 154 |
+
>>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
|
| 155 |
+
>>> image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
Returns:
|
| 159 |
+
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
| 160 |
+
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
|
| 161 |
+
otherwise a `tuple` is returned where the first element is a list with the generated images and the
|
| 162 |
+
second element is a list of `bool`s indicating whether the corresponding generated image contains
|
| 163 |
+
"not-safe-for-work" (nsfw) content.
|
| 164 |
+
"""
|
| 165 |
+
|
| 166 |
+
callback = kwargs.pop("callback", None)
|
| 167 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 168 |
+
|
| 169 |
+
if callback is not None:
|
| 170 |
+
deprecate(
|
| 171 |
+
"callback",
|
| 172 |
+
"1.0.0",
|
| 173 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
|
| 174 |
+
)
|
| 175 |
+
if callback_steps is not None:
|
| 176 |
+
deprecate(
|
| 177 |
+
"callback_steps",
|
| 178 |
+
"1.0.0",
|
| 179 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider use `callback_on_step_end`",
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
# 0. Default height and width to unet
|
| 183 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 184 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 185 |
+
|
| 186 |
+
# 1. Check inputs
|
| 187 |
+
self.check_inputs(
|
| 188 |
+
prompt,
|
| 189 |
+
image,
|
| 190 |
+
mask_image,
|
| 191 |
+
height,
|
| 192 |
+
width,
|
| 193 |
+
strength,
|
| 194 |
+
callback_steps,
|
| 195 |
+
output_type,
|
| 196 |
+
negative_prompt,
|
| 197 |
+
prompt_embeds,
|
| 198 |
+
negative_prompt_embeds,
|
| 199 |
+
callback_on_step_end_tensor_inputs,
|
| 200 |
+
padding_mask_crop,
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
self._guidance_scale = 0.
|
| 204 |
+
self.cloth_classifier_free_guidance = cloth_guidance_scale > 1.
|
| 205 |
+
self._clip_skip = clip_skip
|
| 206 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 207 |
+
self._interrupt = False
|
| 208 |
+
|
| 209 |
+
# 2. Define call parameters
|
| 210 |
+
if prompt is not None and isinstance(prompt, str):
|
| 211 |
+
batch_size = 1
|
| 212 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 213 |
+
batch_size = len(prompt)
|
| 214 |
+
else:
|
| 215 |
+
batch_size = prompt_embeds.shape[0]
|
| 216 |
+
|
| 217 |
+
device = self._execution_device
|
| 218 |
+
|
| 219 |
+
# 3. Encode input prompt
|
| 220 |
+
text_encoder_lora_scale = (
|
| 221 |
+
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
| 222 |
+
)
|
| 223 |
+
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
|
| 224 |
+
prompt,
|
| 225 |
+
device,
|
| 226 |
+
num_images_per_prompt,
|
| 227 |
+
self.do_classifier_free_guidance,
|
| 228 |
+
negative_prompt,
|
| 229 |
+
prompt_embeds=prompt_embeds,
|
| 230 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 231 |
+
lora_scale=text_encoder_lora_scale,
|
| 232 |
+
clip_skip=self.clip_skip,
|
| 233 |
+
)
|
| 234 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 235 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 236 |
+
# to avoid doing two forward passes
|
| 237 |
+
if self.cloth_classifier_free_guidance:
|
| 238 |
+
prompt_embeds = torch.cat([prompt_embeds, prompt_embeds])
|
| 239 |
+
|
| 240 |
+
if ip_adapter_image is not None:
|
| 241 |
+
image_embeds = self.prepare_ip_adapter_image_embeds(
|
| 242 |
+
ip_adapter_image, device, batch_size * num_images_per_prompt
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
# 4. set timesteps
|
| 246 |
+
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
|
| 247 |
+
timesteps, num_inference_steps = self.get_timesteps(
|
| 248 |
+
num_inference_steps=num_inference_steps, strength=strength, device=device
|
| 249 |
+
)
|
| 250 |
+
# check that number of inference steps is not < 1 - as this doesn't make sense
|
| 251 |
+
if num_inference_steps < 1:
|
| 252 |
+
raise ValueError(
|
| 253 |
+
f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
|
| 254 |
+
f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
|
| 255 |
+
)
|
| 256 |
+
# at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
|
| 257 |
+
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
|
| 258 |
+
# create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
|
| 259 |
+
is_strength_max = strength == 1.0
|
| 260 |
+
|
| 261 |
+
# 5. Preprocess mask and image
|
| 262 |
+
|
| 263 |
+
if padding_mask_crop is not None:
|
| 264 |
+
crops_coords = self.mask_processor.get_crop_region(mask_image, width, height, pad=padding_mask_crop)
|
| 265 |
+
resize_mode = "fill"
|
| 266 |
+
else:
|
| 267 |
+
crops_coords = None
|
| 268 |
+
resize_mode = "default"
|
| 269 |
+
|
| 270 |
+
original_image = image
|
| 271 |
+
init_image = self.image_processor.preprocess(
|
| 272 |
+
image, height=height, width=width, crops_coords=crops_coords, resize_mode=resize_mode
|
| 273 |
+
)
|
| 274 |
+
init_image = init_image.to(dtype=torch.float32)
|
| 275 |
+
|
| 276 |
+
# 6. Prepare latent variables
|
| 277 |
+
num_channels_latents = self.vae.config.latent_channels
|
| 278 |
+
num_channels_unet = self.unet.config.in_channels
|
| 279 |
+
return_image_latents = num_channels_unet == 4
|
| 280 |
+
|
| 281 |
+
latents_outputs = self.prepare_latents(
|
| 282 |
+
batch_size * num_images_per_prompt,
|
| 283 |
+
num_channels_latents,
|
| 284 |
+
height,
|
| 285 |
+
width,
|
| 286 |
+
prompt_embeds.dtype,
|
| 287 |
+
device,
|
| 288 |
+
generator,
|
| 289 |
+
latents,
|
| 290 |
+
image=init_image,
|
| 291 |
+
timestep=latent_timestep,
|
| 292 |
+
is_strength_max=is_strength_max,
|
| 293 |
+
return_noise=True,
|
| 294 |
+
return_image_latents=return_image_latents,
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
if return_image_latents:
|
| 298 |
+
latents, noise, image_latents = latents_outputs
|
| 299 |
+
else:
|
| 300 |
+
latents, noise = latents_outputs
|
| 301 |
+
|
| 302 |
+
# 7. Prepare mask latent variables
|
| 303 |
+
mask_condition = self.mask_processor.preprocess(
|
| 304 |
+
mask_image, height=height, width=width, resize_mode=resize_mode, crops_coords=crops_coords
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
if masked_image_latents is None:
|
| 308 |
+
masked_image = init_image * (mask_condition < 0.5)
|
| 309 |
+
else:
|
| 310 |
+
masked_image = masked_image_latents
|
| 311 |
+
|
| 312 |
+
mask, masked_image_latents = self.prepare_mask_latents(
|
| 313 |
+
mask_condition,
|
| 314 |
+
masked_image,
|
| 315 |
+
batch_size * num_images_per_prompt,
|
| 316 |
+
height,
|
| 317 |
+
width,
|
| 318 |
+
prompt_embeds.dtype,
|
| 319 |
+
device,
|
| 320 |
+
generator,
|
| 321 |
+
self.cloth_classifier_free_guidance,
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
# 8. Check that sizes of mask, masked image and latents match
|
| 325 |
+
if num_channels_unet == 9:
|
| 326 |
+
# default case for runwayml/stable-diffusion-inpainting
|
| 327 |
+
num_channels_mask = mask.shape[1]
|
| 328 |
+
num_channels_masked_image = masked_image_latents.shape[1]
|
| 329 |
+
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
|
| 330 |
+
raise ValueError(
|
| 331 |
+
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
|
| 332 |
+
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
|
| 333 |
+
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
|
| 334 |
+
f" = {num_channels_latents + num_channels_masked_image + num_channels_mask}. Please verify the config of"
|
| 335 |
+
" `pipeline.unet` or your `mask_image` or `image` input."
|
| 336 |
+
)
|
| 337 |
+
elif num_channels_unet != 4:
|
| 338 |
+
raise ValueError(
|
| 339 |
+
f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
|
| 340 |
+
)
|
| 341 |
+
|
| 342 |
+
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 343 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 344 |
+
|
| 345 |
+
# 9.1 Add image embeds for IP-Adapter
|
| 346 |
+
added_cond_kwargs = {"image_embeds": image_embeds} if ip_adapter_image is not None else None
|
| 347 |
+
|
| 348 |
+
# 9.2 Optionally get Guidance Scale Embedding
|
| 349 |
+
timestep_cond = None
|
| 350 |
+
if self.unet.config.time_cond_proj_dim is not None:
|
| 351 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
|
| 352 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 353 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 354 |
+
).to(device=device, dtype=latents.dtype)
|
| 355 |
+
|
| 356 |
+
# 10. Denoising loop
|
| 357 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 358 |
+
self._num_timesteps = len(timesteps)
|
| 359 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 360 |
+
for i, t in enumerate(timesteps):
|
| 361 |
+
if self.interrupt:
|
| 362 |
+
continue
|
| 363 |
+
|
| 364 |
+
# expand the latents if we are doing classifier free guidance
|
| 365 |
+
latent_model_input = torch.cat([latents] * 2) if self.cloth_classifier_free_guidance else latents
|
| 366 |
+
|
| 367 |
+
# concat latents, mask, masked_image_latents in the channel dimension
|
| 368 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 369 |
+
|
| 370 |
+
if num_channels_unet == 9:
|
| 371 |
+
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
|
| 372 |
+
|
| 373 |
+
# predict the noise residual
|
| 374 |
+
noise_pred = self.unet(
|
| 375 |
+
latent_model_input,
|
| 376 |
+
t,
|
| 377 |
+
encoder_hidden_states=prompt_embeds,
|
| 378 |
+
timestep_cond=timestep_cond,
|
| 379 |
+
cross_attention_kwargs=self.cross_attention_kwargs,
|
| 380 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 381 |
+
return_dict=False,
|
| 382 |
+
)[0]
|
| 383 |
+
|
| 384 |
+
# perform guidance
|
| 385 |
+
if self.cloth_classifier_free_guidance:
|
| 386 |
+
noise_pred_uncond, noise_pred_cloth = noise_pred.chunk(2)
|
| 387 |
+
noise_pred = noise_pred_uncond + cloth_guidance_scale * (noise_pred_cloth - noise_pred_uncond)
|
| 388 |
+
|
| 389 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 390 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 391 |
+
if num_channels_unet == 4:
|
| 392 |
+
init_latents_proper = image_latents
|
| 393 |
+
if self.cloth_classifier_free_guidance:
|
| 394 |
+
init_mask, _ = mask.chunk(2)
|
| 395 |
+
else:
|
| 396 |
+
init_mask = mask
|
| 397 |
+
|
| 398 |
+
if i < len(timesteps) - 1:
|
| 399 |
+
noise_timestep = timesteps[i + 1]
|
| 400 |
+
init_latents_proper = self.scheduler.add_noise(
|
| 401 |
+
init_latents_proper, noise, torch.tensor([noise_timestep])
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
latents = (1 - init_mask) * init_latents_proper + init_mask * latents
|
| 405 |
+
|
| 406 |
+
if callback_on_step_end is not None:
|
| 407 |
+
callback_kwargs = {}
|
| 408 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 409 |
+
callback_kwargs[k] = locals()[k]
|
| 410 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 411 |
+
|
| 412 |
+
latents = callback_outputs.pop("latents", latents)
|
| 413 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 414 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 415 |
+
mask = callback_outputs.pop("mask", mask)
|
| 416 |
+
masked_image_latents = callback_outputs.pop("masked_image_latents", masked_image_latents)
|
| 417 |
+
|
| 418 |
+
# call the callback, if provided
|
| 419 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 420 |
+
progress_bar.update()
|
| 421 |
+
if callback is not None and i % callback_steps == 0:
|
| 422 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 423 |
+
callback(step_idx, t, latents)
|
| 424 |
+
|
| 425 |
+
if not output_type == "latent":
|
| 426 |
+
condition_kwargs = {}
|
| 427 |
+
if isinstance(self.vae, AsymmetricAutoencoderKL):
|
| 428 |
+
init_image = init_image.to(device=device, dtype=masked_image_latents.dtype)
|
| 429 |
+
init_image_condition = init_image.clone()
|
| 430 |
+
init_image = self._encode_vae_image(init_image, generator=generator)
|
| 431 |
+
mask_condition = mask_condition.to(device=device, dtype=masked_image_latents.dtype)
|
| 432 |
+
condition_kwargs = {"image": init_image_condition, "mask": mask_condition}
|
| 433 |
+
image = self.vae.decode(
|
| 434 |
+
latents / self.vae.config.scaling_factor, return_dict=False, generator=generator, **condition_kwargs
|
| 435 |
+
)[0]
|
| 436 |
+
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
| 437 |
+
else:
|
| 438 |
+
image = latents
|
| 439 |
+
has_nsfw_concept = None
|
| 440 |
+
|
| 441 |
+
if has_nsfw_concept is None:
|
| 442 |
+
do_denormalize = [True] * image.shape[0]
|
| 443 |
+
else:
|
| 444 |
+
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
|
| 445 |
+
|
| 446 |
+
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
|
| 447 |
+
|
| 448 |
+
if padding_mask_crop is not None:
|
| 449 |
+
image = [self.image_processor.apply_overlay(mask_image, original_image, i, crops_coords) for i in image]
|
| 450 |
+
|
| 451 |
+
# Offload all models
|
| 452 |
+
self.maybe_free_model_hooks()
|
| 453 |
+
|
| 454 |
+
if not return_dict:
|
| 455 |
+
return (image, has_nsfw_concept)
|
| 456 |
+
|
| 457 |
+
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
| 458 |
+
|
| 459 |
+
def prepare_mask_latents(
|
| 460 |
+
self, mask, masked_image, batch_size, height, width, dtype, device, generator, cloth_classifier_free_guidance
|
| 461 |
+
):
|
| 462 |
+
# resize the mask to latents shape as we concatenate the mask to the latents
|
| 463 |
+
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
|
| 464 |
+
# and half precision
|
| 465 |
+
mask = torch.nn.functional.interpolate(
|
| 466 |
+
mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
|
| 467 |
+
)
|
| 468 |
+
mask = mask.to(device=device, dtype=dtype)
|
| 469 |
+
|
| 470 |
+
masked_image = masked_image.to(device=device, dtype=dtype)
|
| 471 |
+
|
| 472 |
+
if masked_image.shape[1] == 4:
|
| 473 |
+
masked_image_latents = masked_image
|
| 474 |
+
else:
|
| 475 |
+
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
|
| 476 |
+
|
| 477 |
+
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
| 478 |
+
if mask.shape[0] < batch_size:
|
| 479 |
+
if not batch_size % mask.shape[0] == 0:
|
| 480 |
+
raise ValueError(
|
| 481 |
+
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
| 482 |
+
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
| 483 |
+
" of masks that you pass is divisible by the total requested batch size."
|
| 484 |
+
)
|
| 485 |
+
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
| 486 |
+
if masked_image_latents.shape[0] < batch_size:
|
| 487 |
+
if not batch_size % masked_image_latents.shape[0] == 0:
|
| 488 |
+
raise ValueError(
|
| 489 |
+
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
| 490 |
+
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
| 491 |
+
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
| 492 |
+
)
|
| 493 |
+
masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
|
| 494 |
+
|
| 495 |
+
mask = torch.cat([mask] * 2) if cloth_classifier_free_guidance else mask
|
| 496 |
+
masked_image_latents = (
|
| 497 |
+
torch.cat([masked_image_latents] * 2) if cloth_classifier_free_guidance else masked_image_latents
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
# aligning device to prevent device errors when concating it with the latent model input
|
| 501 |
+
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
|
| 502 |
+
return mask, masked_image_latents
|
pipelines/OmsDiffusionPipeline.py
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import *
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class OmsDiffusionPipeline(StableDiffusionPipeline):
|
| 5 |
+
@torch.no_grad()
|
| 6 |
+
def __call__(
|
| 7 |
+
self,
|
| 8 |
+
prompt: Union[str, List[str]] = None,
|
| 9 |
+
height: Optional[int] = None,
|
| 10 |
+
width: Optional[int] = None,
|
| 11 |
+
num_inference_steps: int = 50,
|
| 12 |
+
timesteps: List[int] = None,
|
| 13 |
+
guidance_scale: float = 5.,
|
| 14 |
+
cloth_guidance_scale: float = 2.5,
|
| 15 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 16 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 17 |
+
eta: float = 0.0,
|
| 18 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 19 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 20 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 21 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 22 |
+
ip_adapter_image: Optional[PipelineImageInput] = None,
|
| 23 |
+
output_type: Optional[str] = "pil",
|
| 24 |
+
return_dict: bool = True,
|
| 25 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 26 |
+
guidance_rescale: float = 0.0,
|
| 27 |
+
clip_skip: Optional[int] = None,
|
| 28 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 29 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 30 |
+
**kwargs,
|
| 31 |
+
):
|
| 32 |
+
r"""
|
| 33 |
+
The call function to the pipeline for generation.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 37 |
+
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
|
| 38 |
+
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 39 |
+
The height in pixels of the generated image.
|
| 40 |
+
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 41 |
+
The width in pixels of the generated image.
|
| 42 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 43 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 44 |
+
expense of slower inference.
|
| 45 |
+
timesteps (`List[int]`, *optional*):
|
| 46 |
+
Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
|
| 47 |
+
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
|
| 48 |
+
passed will be used. Must be in descending order.
|
| 49 |
+
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 50 |
+
A higher guidance scale value encourages the model to generate images closely linked to the text
|
| 51 |
+
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
|
| 52 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 53 |
+
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
|
| 54 |
+
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
|
| 55 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 56 |
+
The number of images to generate per prompt.
|
| 57 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 58 |
+
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
|
| 59 |
+
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
|
| 60 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 61 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 62 |
+
generation deterministic.
|
| 63 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 64 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
|
| 65 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 66 |
+
tensor is generated by sampling using the supplied random `generator`.
|
| 67 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 68 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
|
| 69 |
+
provided, text embeddings are generated from the `prompt` input argument.
|
| 70 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 71 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
|
| 72 |
+
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
|
| 73 |
+
ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
|
| 74 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 75 |
+
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
|
| 76 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 77 |
+
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 78 |
+
plain tuple.
|
| 79 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 80 |
+
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
|
| 81 |
+
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 82 |
+
guidance_rescale (`float`, *optional*, defaults to 0.0):
|
| 83 |
+
Guidance rescale factor from [Common Diffusion Noise Schedules and Sample Steps are
|
| 84 |
+
Flawed](https://arxiv.org/pdf/2305.08891.pdf). Guidance rescale factor should fix overexposure when
|
| 85 |
+
using zero terminal SNR.
|
| 86 |
+
clip_skip (`int`, *optional*):
|
| 87 |
+
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
| 88 |
+
the output of the pre-final layer will be used for computing the prompt embeddings.
|
| 89 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 90 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 91 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 92 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 93 |
+
`callback_on_step_end_tensor_inputs`.
|
| 94 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 95 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 96 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 97 |
+
`._callback_tensor_inputs` attribute of your pipeline class.
|
| 98 |
+
|
| 99 |
+
Examples:
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
| 103 |
+
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
|
| 104 |
+
otherwise a `tuple` is returned where the first element is a list with the generated images and the
|
| 105 |
+
second element is a list of `bool`s indicating whether the corresponding generated image contains
|
| 106 |
+
"not-safe-for-work" (nsfw) content.
|
| 107 |
+
"""
|
| 108 |
+
|
| 109 |
+
callback = kwargs.pop("callback", None)
|
| 110 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 111 |
+
|
| 112 |
+
if callback is not None:
|
| 113 |
+
deprecate(
|
| 114 |
+
"callback",
|
| 115 |
+
"1.0.0",
|
| 116 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 117 |
+
)
|
| 118 |
+
if callback_steps is not None:
|
| 119 |
+
deprecate(
|
| 120 |
+
"callback_steps",
|
| 121 |
+
"1.0.0",
|
| 122 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
# 0. Default height and width to unet
|
| 126 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 127 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 128 |
+
# to deal with lora scaling and other possible forward hooks
|
| 129 |
+
|
| 130 |
+
# 1. Check inputs. Raise error if not correct
|
| 131 |
+
self.check_inputs(
|
| 132 |
+
prompt,
|
| 133 |
+
height,
|
| 134 |
+
width,
|
| 135 |
+
callback_steps,
|
| 136 |
+
negative_prompt,
|
| 137 |
+
prompt_embeds,
|
| 138 |
+
negative_prompt_embeds,
|
| 139 |
+
callback_on_step_end_tensor_inputs,
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
self._guidance_scale = guidance_scale
|
| 143 |
+
self._guidance_rescale = guidance_rescale
|
| 144 |
+
self._clip_skip = clip_skip
|
| 145 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 146 |
+
self._interrupt = False
|
| 147 |
+
|
| 148 |
+
# 2. Define call parameters
|
| 149 |
+
if prompt is not None and isinstance(prompt, str):
|
| 150 |
+
batch_size = 1
|
| 151 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 152 |
+
batch_size = len(prompt)
|
| 153 |
+
else:
|
| 154 |
+
batch_size = prompt_embeds.shape[0]
|
| 155 |
+
|
| 156 |
+
device = self._execution_device
|
| 157 |
+
|
| 158 |
+
# 3. Encode input prompt
|
| 159 |
+
lora_scale = (
|
| 160 |
+
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
|
| 164 |
+
prompt,
|
| 165 |
+
device,
|
| 166 |
+
num_images_per_prompt,
|
| 167 |
+
self.do_classifier_free_guidance,
|
| 168 |
+
negative_prompt,
|
| 169 |
+
prompt_embeds=prompt_embeds,
|
| 170 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 171 |
+
lora_scale=lora_scale,
|
| 172 |
+
clip_skip=self.clip_skip,
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 176 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 177 |
+
# to avoid doing two forward passes
|
| 178 |
+
if self.do_classifier_free_guidance:
|
| 179 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, negative_prompt_embeds, prompt_embeds])
|
| 180 |
+
|
| 181 |
+
if ip_adapter_image is not None:
|
| 182 |
+
image_embeds = self.prepare_ip_adapter_image_embeds(
|
| 183 |
+
ip_adapter_image, device, batch_size * num_images_per_prompt
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
# 4. Prepare timesteps
|
| 187 |
+
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
|
| 188 |
+
|
| 189 |
+
# 5. Prepare latent variables
|
| 190 |
+
num_channels_latents = self.unet.config.in_channels
|
| 191 |
+
latents = self.prepare_latents(
|
| 192 |
+
batch_size * num_images_per_prompt,
|
| 193 |
+
num_channels_latents,
|
| 194 |
+
height,
|
| 195 |
+
width,
|
| 196 |
+
prompt_embeds.dtype,
|
| 197 |
+
device,
|
| 198 |
+
generator,
|
| 199 |
+
latents,
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 203 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 204 |
+
|
| 205 |
+
# 6.1 Add image embeds for IP-Adapter
|
| 206 |
+
added_cond_kwargs = {"image_embeds": image_embeds} if ip_adapter_image is not None else None
|
| 207 |
+
|
| 208 |
+
# 6.2 Optionally get Guidance Scale Embedding
|
| 209 |
+
timestep_cond = None
|
| 210 |
+
if self.unet.config.time_cond_proj_dim is not None:
|
| 211 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
|
| 212 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 213 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 214 |
+
).to(device=device, dtype=latents.dtype)
|
| 215 |
+
|
| 216 |
+
# 7. Denoising loop
|
| 217 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 218 |
+
self._num_timesteps = len(timesteps)
|
| 219 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 220 |
+
for i, t in enumerate(timesteps):
|
| 221 |
+
if self.interrupt:
|
| 222 |
+
continue
|
| 223 |
+
|
| 224 |
+
# expand the latents if we are doing classifier free guidance
|
| 225 |
+
latent_model_input = torch.cat([latents] * 3) if self.do_classifier_free_guidance else latents
|
| 226 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 227 |
+
|
| 228 |
+
# predict the noise residual
|
| 229 |
+
noise_pred = self.unet(
|
| 230 |
+
latent_model_input,
|
| 231 |
+
t,
|
| 232 |
+
encoder_hidden_states=prompt_embeds,
|
| 233 |
+
timestep_cond=timestep_cond,
|
| 234 |
+
cross_attention_kwargs=self.cross_attention_kwargs,
|
| 235 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 236 |
+
return_dict=False,
|
| 237 |
+
)[0]
|
| 238 |
+
|
| 239 |
+
# perform guidance
|
| 240 |
+
if self.do_classifier_free_guidance:
|
| 241 |
+
noise_pred_uncond, noise_pred_cloth, noise_pred_text = noise_pred.chunk(3)
|
| 242 |
+
noise_pred = (
|
| 243 |
+
noise_pred_uncond
|
| 244 |
+
+ guidance_scale * (noise_pred_text - noise_pred_cloth)
|
| 245 |
+
+ cloth_guidance_scale * (noise_pred_cloth - noise_pred_uncond)
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
if self.do_classifier_free_guidance and self.guidance_rescale > 0.0:
|
| 249 |
+
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
|
| 250 |
+
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=self.guidance_rescale)
|
| 251 |
+
|
| 252 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 253 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 254 |
+
|
| 255 |
+
if callback_on_step_end is not None:
|
| 256 |
+
callback_kwargs = {}
|
| 257 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 258 |
+
callback_kwargs[k] = locals()[k]
|
| 259 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 260 |
+
|
| 261 |
+
latents = callback_outputs.pop("latents", latents)
|
| 262 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 263 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 264 |
+
|
| 265 |
+
# call the callback, if provided
|
| 266 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 267 |
+
progress_bar.update()
|
| 268 |
+
if callback is not None and i % callback_steps == 0:
|
| 269 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 270 |
+
callback(step_idx, t, latents)
|
| 271 |
+
|
| 272 |
+
if not output_type == "latent":
|
| 273 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False, generator=generator)[
|
| 274 |
+
0
|
| 275 |
+
]
|
| 276 |
+
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
| 277 |
+
else:
|
| 278 |
+
image = latents
|
| 279 |
+
has_nsfw_concept = None
|
| 280 |
+
|
| 281 |
+
if has_nsfw_concept is None:
|
| 282 |
+
do_denormalize = [True] * image.shape[0]
|
| 283 |
+
else:
|
| 284 |
+
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
|
| 285 |
+
|
| 286 |
+
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
|
| 287 |
+
|
| 288 |
+
# Offload all models
|
| 289 |
+
self.maybe_free_model_hooks()
|
| 290 |
+
|
| 291 |
+
if not return_dict:
|
| 292 |
+
return (image, has_nsfw_concept)
|
| 293 |
+
|
| 294 |
+
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
pipelines/__pycache__/OmsDiffusionPipeline.cpython-310.pyc
ADDED
|
Binary file (10.9 kB). View file
|
|
|
run.log
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
nohup: ignoring input
|
| 2 |
+
|
utils/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (2.59 kB). View file
|
|
|
utils/resampler.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
|
| 2 |
+
# and https://github.com/lucidrains/imagen-pytorch/blob/main/imagen_pytorch/imagen_pytorch.py
|
| 3 |
+
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
from einops.layers.torch import Rearrange
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# FFN
|
| 13 |
+
def FeedForward(dim, mult=4):
|
| 14 |
+
inner_dim = int(dim * mult)
|
| 15 |
+
return nn.Sequential(
|
| 16 |
+
nn.LayerNorm(dim),
|
| 17 |
+
nn.Linear(dim, inner_dim, bias=False),
|
| 18 |
+
nn.GELU(),
|
| 19 |
+
nn.Linear(inner_dim, dim, bias=False),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def reshape_tensor(x, heads):
|
| 24 |
+
bs, length, width = x.shape
|
| 25 |
+
# (bs, length, width) --> (bs, length, n_heads, dim_per_head)
|
| 26 |
+
x = x.view(bs, length, heads, -1)
|
| 27 |
+
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
|
| 28 |
+
x = x.transpose(1, 2)
|
| 29 |
+
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
|
| 30 |
+
x = x.reshape(bs, heads, length, -1)
|
| 31 |
+
return x
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class PerceiverAttention(nn.Module):
|
| 35 |
+
def __init__(self, *, dim, dim_head=64, heads=8):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.scale = dim_head**-0.5
|
| 38 |
+
self.dim_head = dim_head
|
| 39 |
+
self.heads = heads
|
| 40 |
+
inner_dim = dim_head * heads
|
| 41 |
+
|
| 42 |
+
self.norm1 = nn.LayerNorm(dim)
|
| 43 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 44 |
+
|
| 45 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 46 |
+
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
| 47 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 48 |
+
|
| 49 |
+
def forward(self, x, latents):
|
| 50 |
+
"""
|
| 51 |
+
Args:
|
| 52 |
+
x (torch.Tensor): image features
|
| 53 |
+
shape (b, n1, D)
|
| 54 |
+
latent (torch.Tensor): latent features
|
| 55 |
+
shape (b, n2, D)
|
| 56 |
+
"""
|
| 57 |
+
x = self.norm1(x)
|
| 58 |
+
latents = self.norm2(latents)
|
| 59 |
+
|
| 60 |
+
b, l, _ = latents.shape
|
| 61 |
+
|
| 62 |
+
q = self.to_q(latents)
|
| 63 |
+
kv_input = torch.cat((x, latents), dim=-2)
|
| 64 |
+
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
| 65 |
+
|
| 66 |
+
q = reshape_tensor(q, self.heads)
|
| 67 |
+
k = reshape_tensor(k, self.heads)
|
| 68 |
+
v = reshape_tensor(v, self.heads)
|
| 69 |
+
|
| 70 |
+
# attention
|
| 71 |
+
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
|
| 72 |
+
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
|
| 73 |
+
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
| 74 |
+
out = weight @ v
|
| 75 |
+
|
| 76 |
+
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
|
| 77 |
+
|
| 78 |
+
return self.to_out(out)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class Resampler(nn.Module):
|
| 82 |
+
def __init__(
|
| 83 |
+
self,
|
| 84 |
+
dim=1024,
|
| 85 |
+
depth=8,
|
| 86 |
+
dim_head=64,
|
| 87 |
+
heads=16,
|
| 88 |
+
num_queries=8,
|
| 89 |
+
embedding_dim=768,
|
| 90 |
+
output_dim=1024,
|
| 91 |
+
ff_mult=4,
|
| 92 |
+
max_seq_len: int = 257, # CLIP tokens + CLS token
|
| 93 |
+
apply_pos_emb: bool = False,
|
| 94 |
+
num_latents_mean_pooled: int = 0, # number of latents derived from mean pooled representation of the sequence
|
| 95 |
+
):
|
| 96 |
+
super().__init__()
|
| 97 |
+
self.pos_emb = nn.Embedding(max_seq_len, embedding_dim) if apply_pos_emb else None
|
| 98 |
+
|
| 99 |
+
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
|
| 100 |
+
|
| 101 |
+
self.proj_in = nn.Linear(embedding_dim, dim)
|
| 102 |
+
|
| 103 |
+
self.proj_out = nn.Linear(dim, output_dim)
|
| 104 |
+
self.norm_out = nn.LayerNorm(output_dim)
|
| 105 |
+
|
| 106 |
+
self.to_latents_from_mean_pooled_seq = (
|
| 107 |
+
nn.Sequential(
|
| 108 |
+
nn.LayerNorm(dim),
|
| 109 |
+
nn.Linear(dim, dim * num_latents_mean_pooled),
|
| 110 |
+
Rearrange("b (n d) -> b n d", n=num_latents_mean_pooled),
|
| 111 |
+
)
|
| 112 |
+
if num_latents_mean_pooled > 0
|
| 113 |
+
else None
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
self.layers = nn.ModuleList([])
|
| 117 |
+
for _ in range(depth):
|
| 118 |
+
self.layers.append(
|
| 119 |
+
nn.ModuleList(
|
| 120 |
+
[
|
| 121 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 122 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 123 |
+
]
|
| 124 |
+
)
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
def forward(self, x):
|
| 128 |
+
if self.pos_emb is not None:
|
| 129 |
+
n, device = x.shape[1], x.device
|
| 130 |
+
pos_emb = self.pos_emb(torch.arange(n, device=device))
|
| 131 |
+
x = x + pos_emb
|
| 132 |
+
|
| 133 |
+
latents = self.latents.repeat(x.size(0), 1, 1)
|
| 134 |
+
|
| 135 |
+
x = self.proj_in(x)
|
| 136 |
+
|
| 137 |
+
if self.to_latents_from_mean_pooled_seq:
|
| 138 |
+
meanpooled_seq = masked_mean(x, dim=1, mask=torch.ones(x.shape[:2], device=x.device, dtype=torch.bool))
|
| 139 |
+
meanpooled_latents = self.to_latents_from_mean_pooled_seq(meanpooled_seq)
|
| 140 |
+
latents = torch.cat((meanpooled_latents, latents), dim=-2)
|
| 141 |
+
|
| 142 |
+
for attn, ff in self.layers:
|
| 143 |
+
latents = attn(x, latents) + latents
|
| 144 |
+
latents = ff(latents) + latents
|
| 145 |
+
|
| 146 |
+
latents = self.proj_out(latents)
|
| 147 |
+
return self.norm_out(latents)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def masked_mean(t, *, dim, mask=None):
|
| 151 |
+
if mask is None:
|
| 152 |
+
return t.mean(dim=dim)
|
| 153 |
+
|
| 154 |
+
denom = mask.sum(dim=dim, keepdim=True)
|
| 155 |
+
mask = rearrange(mask, "b n -> b n 1")
|
| 156 |
+
masked_t = t.masked_fill(~mask, 0.0)
|
| 157 |
+
|
| 158 |
+
return masked_t.sum(dim=dim) / denom.clamp(min=1e-5)
|
utils/utils.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn.functional as F
|
| 2 |
+
import numpy as np
|
| 3 |
+
import PIL
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def is_torch2_available():
|
| 8 |
+
return hasattr(F, "scaled_dot_product_attention")
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def prepare_image(image, height, width):
|
| 12 |
+
if image is None:
|
| 13 |
+
raise ValueError("`image` input cannot be undefined.")
|
| 14 |
+
|
| 15 |
+
if isinstance(image, torch.Tensor):
|
| 16 |
+
# Batch single image
|
| 17 |
+
if image.ndim == 3:
|
| 18 |
+
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
|
| 19 |
+
image = image.unsqueeze(0)
|
| 20 |
+
|
| 21 |
+
# Check image is in [-1, 1]
|
| 22 |
+
if image.min() < -1 or image.max() > 1:
|
| 23 |
+
raise ValueError("Image should be in [-1, 1] range")
|
| 24 |
+
|
| 25 |
+
# Image as float32
|
| 26 |
+
image = image.to(dtype=torch.float32)
|
| 27 |
+
else:
|
| 28 |
+
# preprocess image
|
| 29 |
+
if isinstance(image, (PIL.Image.Image, np.ndarray)):
|
| 30 |
+
image = [image]
|
| 31 |
+
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
|
| 32 |
+
# resize all images w.r.t passed height an width
|
| 33 |
+
image = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in image]
|
| 34 |
+
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
| 35 |
+
image = np.concatenate(image, axis=0)
|
| 36 |
+
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
| 37 |
+
image = np.concatenate([i[None, :] for i in image], axis=0)
|
| 38 |
+
|
| 39 |
+
image = image.transpose(0, 3, 1, 2)
|
| 40 |
+
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
| 41 |
+
|
| 42 |
+
return image
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def prepare_mask(image, height, width):
|
| 46 |
+
if image is None:
|
| 47 |
+
raise ValueError("`image` input cannot be undefined.")
|
| 48 |
+
|
| 49 |
+
if isinstance(image, torch.Tensor):
|
| 50 |
+
# Batch single image
|
| 51 |
+
if image.ndim == 3:
|
| 52 |
+
assert image.shape[0] == 1, "Image outside a batch should be of shape (3, H, W)"
|
| 53 |
+
image = image.unsqueeze(0)
|
| 54 |
+
image = image.to(dtype=torch.float32)
|
| 55 |
+
else:
|
| 56 |
+
# preprocess image
|
| 57 |
+
if isinstance(image, (PIL.Image.Image, np.ndarray)):
|
| 58 |
+
image = [image]
|
| 59 |
+
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
|
| 60 |
+
# resize all images w.r.t passed height an width
|
| 61 |
+
image = [i.resize((width, height), resample=PIL.Image.NEAREST) for i in image]
|
| 62 |
+
image = [np.array(i.convert("L"))[..., None] for i in image]
|
| 63 |
+
image = np.stack(image, axis=0)
|
| 64 |
+
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
| 65 |
+
image = np.stack([i[..., None] for i in image], axis=0)
|
| 66 |
+
|
| 67 |
+
image = image.transpose(0, 3, 1, 2)
|
| 68 |
+
image = torch.from_numpy(image).to(dtype=torch.float32) / 255.
|
| 69 |
+
image[image > 0.5] = 1
|
| 70 |
+
image[image <= 0.5] = 0
|
| 71 |
+
|
| 72 |
+
return image
|
valid_cloth/t1.png
ADDED

|
valid_cloth/t2.jpg
ADDED

|
valid_cloth/t3.jpg
ADDED

|
valid_cloth/t4.jpg
ADDED

|