

Duplicate from xingyaoww/CodeActAgent-Mistral-7b-v0.1
Browse filesCo-authored-by: Xingyao Wang <xingyaoww@users.noreply.huggingface.co>
- .gitattributes +35 -0
- README.md +75 -0
- added_tokens.json +4 -0
- config.json +24 -0
- generation_config.json +6 -0
- model.safetensors +3 -0
- special_tokens_map.json +26 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +59 -0
.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- xingyaoww/code-act
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
tags:
|
| 9 |
+
- llm-agent
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
<h1 align="center"> Executable Code Actions Elicit Better LLM Agents </h1>
|
| 13 |
+
|
| 14 |
+
<p align="center">
|
| 15 |
+
<a href="https://github.com/xingyaoww/code-act">💻 Code</a>
|
| 16 |
+
•
|
| 17 |
+
<a href="https://arxiv.org/abs/2402.01030">📃 Paper</a>
|
| 18 |
+
•
|
| 19 |
+
<a href="https://huggingface.co/datasets/xingyaoww/code-act" >🤗 Data (CodeActInstruct)</a>
|
| 20 |
+
•
|
| 21 |
+
<a href="https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1" >🤗 Model (CodeActAgent-Mistral-7b-v0.1)</a>
|
| 22 |
+
•
|
| 23 |
+
<a href="https://chat.xwang.dev/">🤖 Chat with CodeActAgent!</a>
|
| 24 |
+
</p>
|
| 25 |
+
|
| 26 |
+
We propose to use executable Python **code** to consolidate LLM agents’ **act**ions into a unified action space (**CodeAct**).
|
| 27 |
+
Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations (e.g., code execution results) through multi-turn interactions.
|
| 28 |
+
|
| 29 |
+
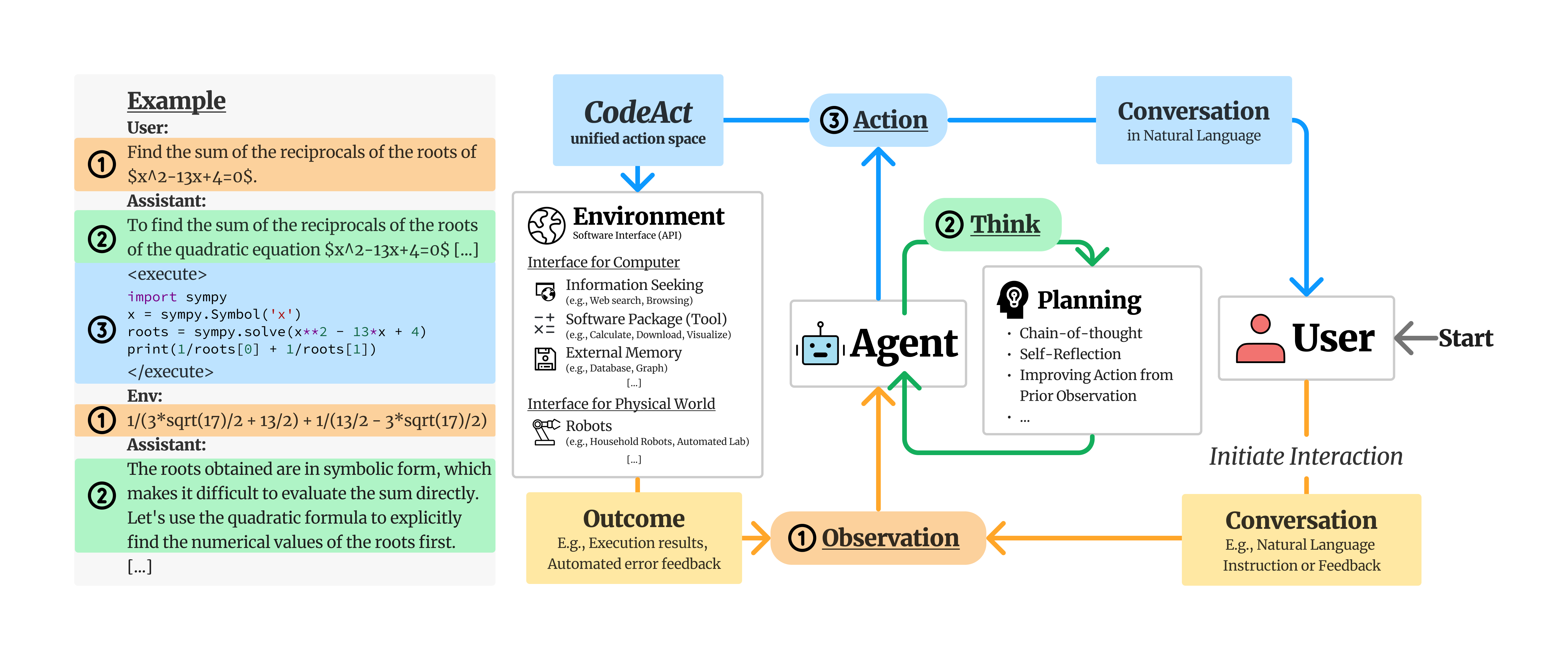
|
| 30 |
+
|
| 31 |
+
## Why CodeAct?
|
| 32 |
+
|
| 33 |
+
Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark [M<sup>3</sup>ToolEval](docs/EVALUATION.md) shows that CodeAct outperforms widely used alternatives like Text and JSON (up to 20% higher success rate). Please check our paper for more detailed analysis!
|
| 34 |
+
|
| 35 |
+
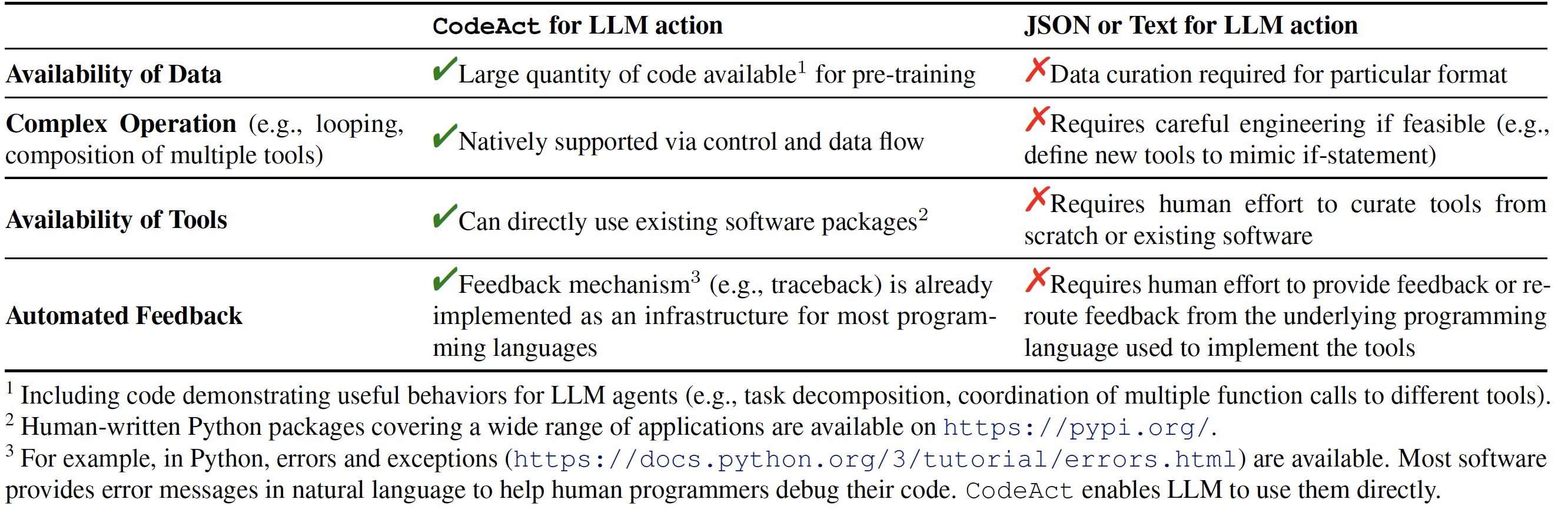
|
| 36 |
+
*Comparison between CodeAct and Text / JSON as action.*
|
| 37 |
+
|
| 38 |
+
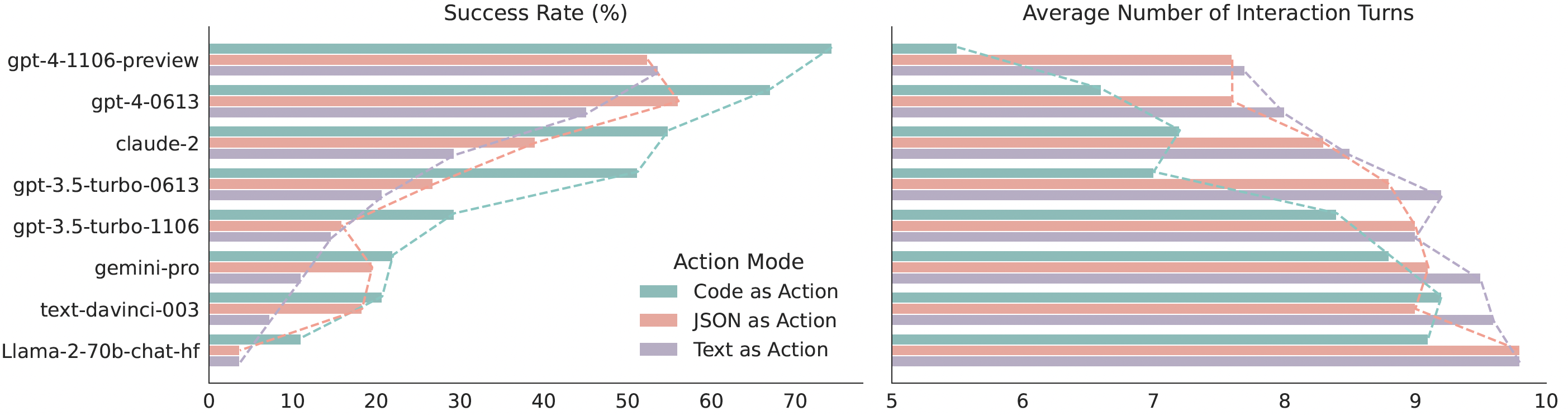
|
| 39 |
+
*Quantitative results comparing CodeAct and {Text, JSON} on M<sup>3</sup>ToolEval.*
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## 📁 CodeActInstruct
|
| 44 |
+
|
| 45 |
+
We collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. Dataset is release at [huggingface dataset 🤗](https://huggingface.co/datasets/xingyaoww/code-act). Please refer to the paper and [this section](#-data-generation-optional) for details of data collection.
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
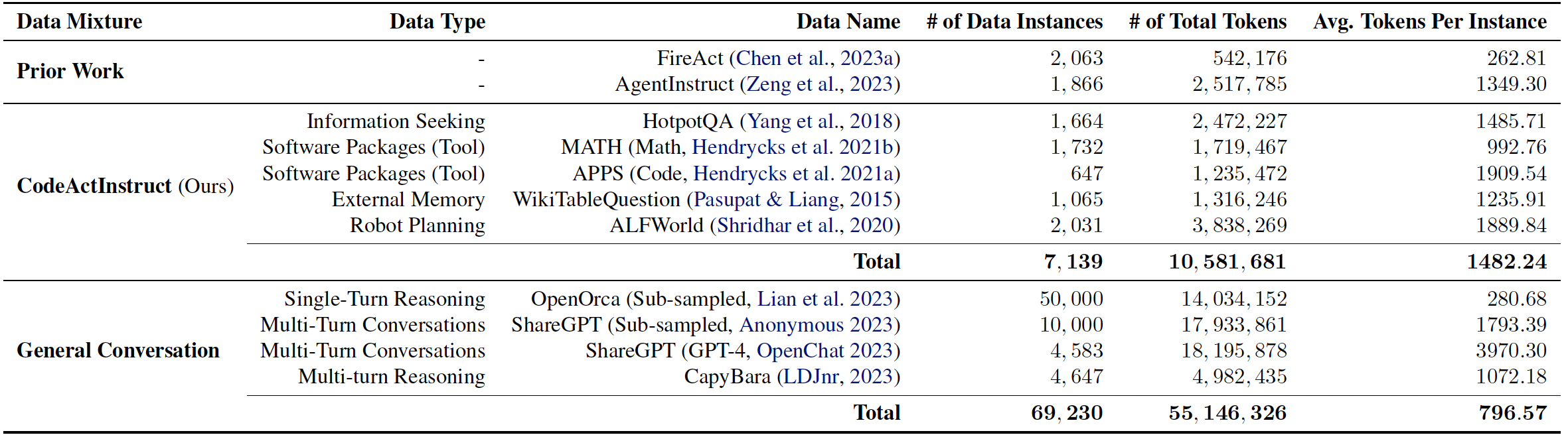
|
| 49 |
+
*Dataset Statistics. Token statistics are computed using Llama-2 tokenizer.*
|
| 50 |
+
|
| 51 |
+
## 🪄 CodeActAgent
|
| 52 |
+
|
| 53 |
+
Trained on **CodeActInstruct** and general conversaions, **CodeActAgent** excels at out-of-domain agent tasks compared to open-source models of the same size, while not sacrificing generic performance (e.g., knowledge, dialog). We release two variants of CodeActAgent:
|
| 54 |
+
- **CodeActAgent-Mistral-7b-v0.1** (recommended, [model link](https://huggingface.co/xingyaoww/CodeActAgent-Mistral-7b-v0.1)): using Mistral-7b-v0.1 as the base model with 32k context window.
|
| 55 |
+
- **CodeActAgent-Llama-7b** ([model link](https://huggingface.co/xingyaoww/CodeActAgent-Llama-2-7b)): using Llama-2-7b as the base model with 4k context window.
|
| 56 |
+
|
| 57 |
+
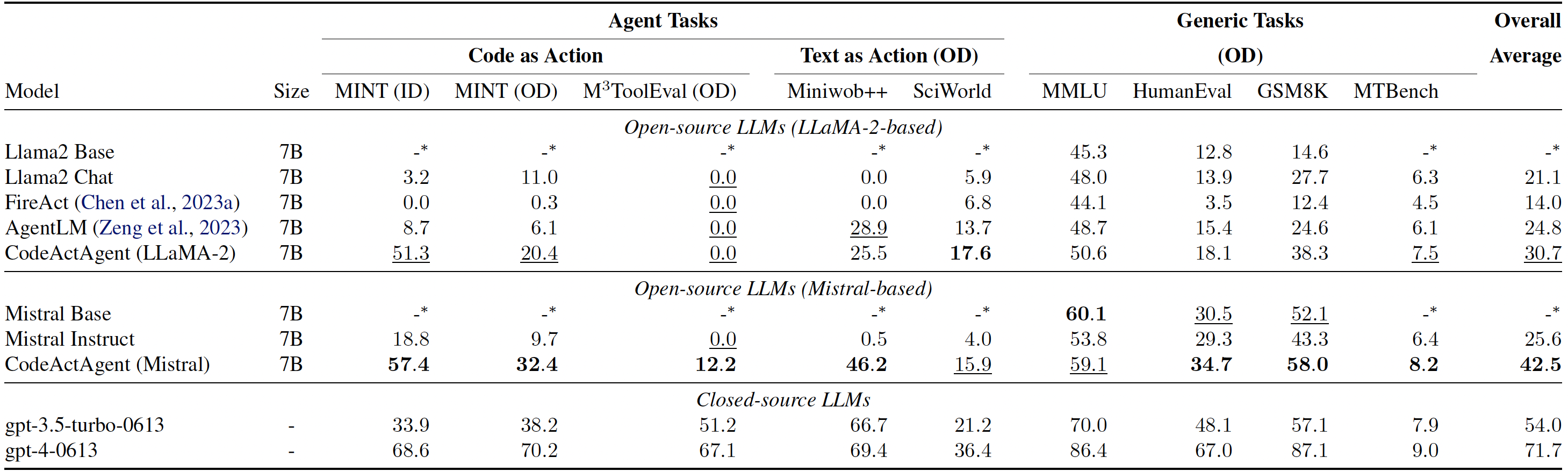
|
| 58 |
+
*Evaluation results for CodeActAgent. ID and OD stand for in-domain and out-of-domain evaluation correspondingly. Overall averaged performance normalizes the MT-Bench score to be consistent with other tasks and excludes in-domain tasks for fair comparison.*
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
Please check out [our paper](TODO) and [code](https://github.com/xingyaoww/code-act) for more details about data collection, model training, and evaluation.
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
## 📚 Citation
|
| 65 |
+
|
| 66 |
+
```bibtex
|
| 67 |
+
@misc{wang2024executable,
|
| 68 |
+
title={Executable Code Actions Elicit Better LLM Agents},
|
| 69 |
+
author={Xingyao Wang and Yangyi Chen and Lifan Yuan and Yizhe Zhang and Yunzhu Li and Hao Peng and Heng Ji},
|
| 70 |
+
year={2024},
|
| 71 |
+
eprint={2402.01030},
|
| 72 |
+
archivePrefix={arXiv},
|
| 73 |
+
primaryClass={cs.CL}
|
| 74 |
+
}
|
| 75 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|im_end|>": 32001,
|
| 3 |
+
"<|im_start|>": 32000
|
| 4 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"MistralForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"bos_token_id": 1,
|
| 6 |
+
"eos_token_id": 2,
|
| 7 |
+
"hidden_act": "silu",
|
| 8 |
+
"hidden_size": 4096,
|
| 9 |
+
"initializer_range": 0.02,
|
| 10 |
+
"intermediate_size": 14336,
|
| 11 |
+
"max_position_embeddings": 32768,
|
| 12 |
+
"model_type": "mistral",
|
| 13 |
+
"num_attention_heads": 32,
|
| 14 |
+
"num_hidden_layers": 32,
|
| 15 |
+
"num_key_value_heads": 8,
|
| 16 |
+
"rms_norm_eps": 1e-05,
|
| 17 |
+
"rope_theta": 10000.0,
|
| 18 |
+
"sliding_window": 4096,
|
| 19 |
+
"tie_word_embeddings": false,
|
| 20 |
+
"torch_dtype": "bfloat16",
|
| 21 |
+
"transformers_version": "4.35.0",
|
| 22 |
+
"use_cache": true,
|
| 23 |
+
"vocab_size": 32002
|
| 24 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.35.0"
|
| 6 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:391754235e6c6b41619e87ae24a960f0900f73a9f117837e89d90bc0d9b950d1
|
| 3 |
+
size 14483530992
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_end|>"
|
| 4 |
+
],
|
| 5 |
+
"bos_token": {
|
| 6 |
+
"content": "<s>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"eos_token": {
|
| 13 |
+
"content": "</s>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false
|
| 18 |
+
},
|
| 19 |
+
"unk_token": {
|
| 20 |
+
"content": "<unk>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false
|
| 25 |
+
}
|
| 26 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<unk>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"32000": {
|
| 28 |
+
"content": "<|im_start|>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"32001": {
|
| 36 |
+
"content": "<|im_end|>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"additional_special_tokens": [
|
| 45 |
+
"<|im_end|>"
|
| 46 |
+
],
|
| 47 |
+
"bos_token": "<s>",
|
| 48 |
+
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 49 |
+
"clean_up_tokenization_spaces": false,
|
| 50 |
+
"eos_token": "</s>",
|
| 51 |
+
"legacy": true,
|
| 52 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 53 |
+
"pad_token": null,
|
| 54 |
+
"sp_model_kwargs": {},
|
| 55 |
+
"spaces_between_special_tokens": false,
|
| 56 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 57 |
+
"unk_token": "<unk>",
|
| 58 |
+
"use_default_system_prompt": false
|
| 59 |
+
}
|