---
license: apache-2.0
datasets:
- shareAI/ShareGPT-Chinese-English-90k
language:
- zh
- en
pipeline_tag: text-generation
---

Aurora: Activating chinese chat capability for Mistral-8x7B sparse Mixture-of-Experts through Instruction-Tuning
1.
2.
## Overview
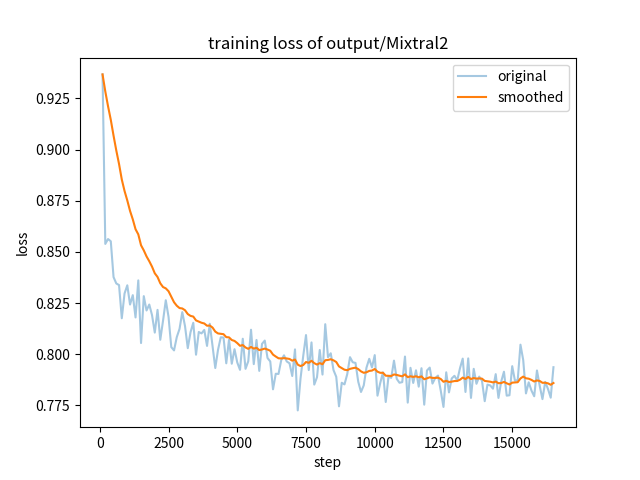
Existing research has demonstrated that refining large language models (LLMs) through the utilization of machine-generated instruction-following data empowers these models to exhibit impressive zero-shot capabilities for novel tasks, without requiring human-authored instructions. In this paper, we systematically investigate, preprocess, and integrate three Chinese instruction-following datasets with the aim of enhancing the Chinese conversational capabilities of Mixtral-8x7B sparse Mixture-of-Experts model. Through instruction fine-tuning on this carefully processed dataset, we successfully construct the Mixtral-8x7B sparse Mixture-of-Experts model named "Aurora." To assess the performance of Aurora, we utilize three widely recognized benchmark tests: C-Eval, MMLU, and CMMLU. Empirical studies validate the effectiveness of instruction fine-tuning applied to Mixtral-8x7B sparse Mixture-of-Experts model. This work is pioneering in the execution of instruction fine-tuning on a sparse expert-mixed model, marking a significant breakthrough in enhancing the capabilities of this model architecture.
## Citation
If you find our work helpful, feel free to give us a cite.
```latex
@misc{wang2023auroraactivating,
title={Aurora:Activating Chinese chat capability for Mixtral-8x7B sparse Mixture-of-Experts through Instruction-Tuning},
author={Rongsheng Wang and Haoming Chen and Ruizhe Zhou and Yaofei Duan and Kunyan Cai and Han Ma and Jiaxi Cui and Jian Li and Patrick Cheong-Iao Pang and Yapeng Wang and Tao Tan},
year={2023},
eprint={2312.14557},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```