

Add Model Card
Browse files- README.md +102 -5
- assets/result.png +0 -0
README.md
CHANGED
|
@@ -11,6 +11,47 @@ tags:
|
|
| 11 |
arxiv: 2412.17743
|
| 12 |
model-index:
|
| 13 |
- name: YuLan-Mini-Instruct
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
---
|
| 15 |
|
| 16 |
# Important Notice: This is the **post-training version** of YuLan-Mini.
|
|
@@ -183,11 +224,16 @@ We utilize the metrics outlined in following table, where higher scores are cons
|
|
| 183 |
| | MMLU<sub> (5 shot)</sub> |
|
| 184 |
| | TruthfulQA<sub>(0 shot)</sub> |
|
| 185 |
| **Reasoning** | ARC<sub>(0 shot)</sub> |
|
|
|
|
| 186 |
| **Math** | MATH<sub>(0 shot, CoT)</sub> |
|
| 187 |
| | GSM8K<sub>(8 shot)</sub> |
|
| 188 |
| | GSM8K<sub>(0 shot, CoT)</sub> |
|
| 189 |
-
| **Code** | HumanEval<sub>(pass@
|
|
|
|
|
|
|
| 190 |
| | HumanEval+<sub>(pass@10)</sub> |
|
|
|
|
|
|
|
| 191 |
| | MBPP<sub>(pass@10)</sub> |
|
| 192 |
| | MBPP+<sub>(pass@10)</sub> |
|
| 193 |
|
|
@@ -216,13 +262,18 @@ We evaluate code generation capabilities across four established benchmarks: Hum
|
|
| 216 |
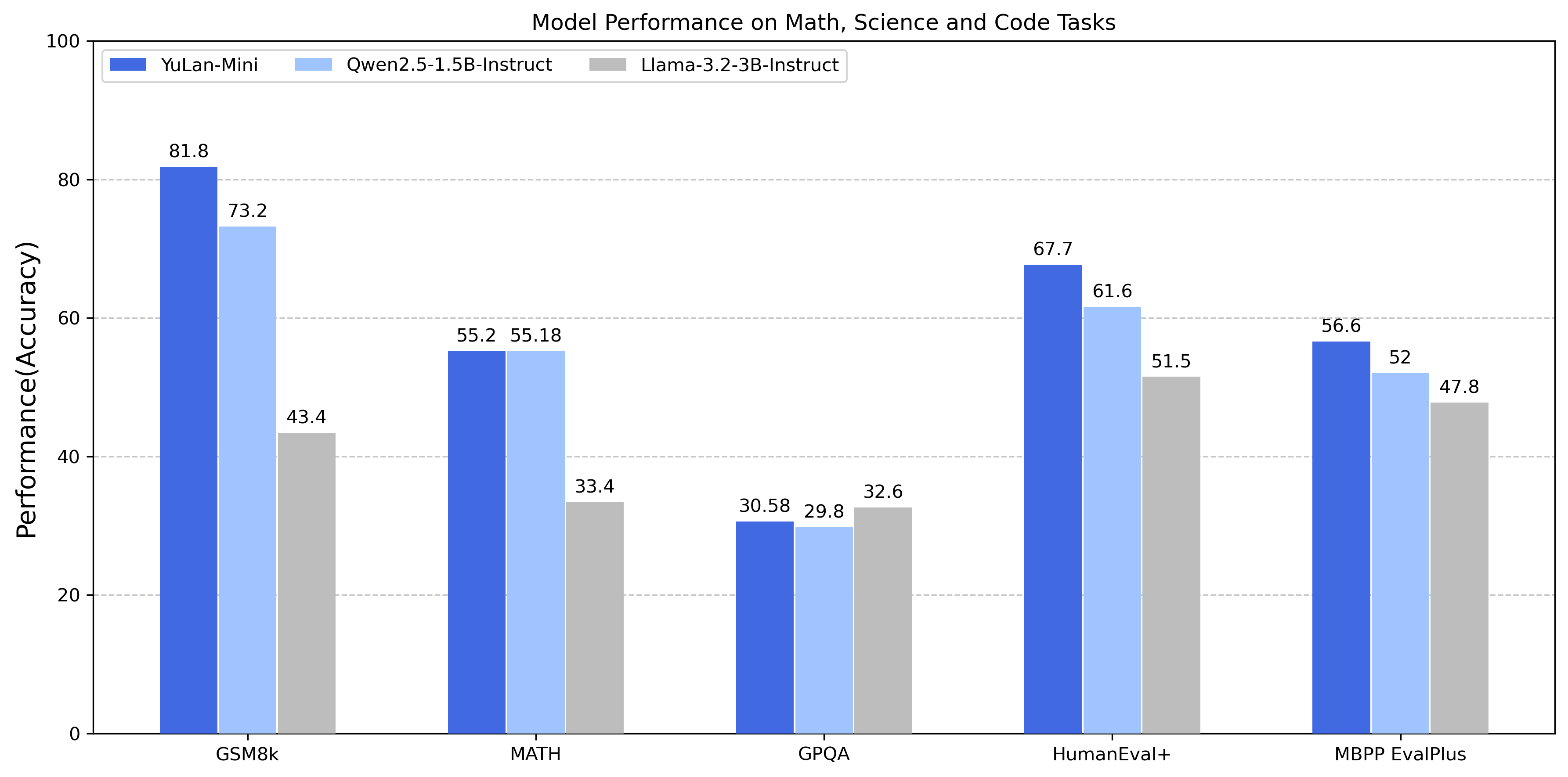
| MMLU<sub> (5 shot)</sub> | 52.7 | 63.4 | **66.5** |
|
| 217 |
| TruthfulQA<sub>(0 shot)</sub> | 50.1 | 49.7 | **58.8** |
|
| 218 |
| ARC<sub>(0 shot)</sub> | 51.8 | **78.6** | 47.8 |
|
| 219 |
-
|
|
|
|
|
| 220 |
| GSM8K<sub>(8 shot)</sub> | **81.8** | 43.4 | 73.2 |
|
| 221 |
-
| GSM8K<sub>(0 shot, CoT)</sub> | **71.
|
|
|
|
|
|
|
| 222 |
| HumanEval<sub>(pass@10)</sub> | **86.6** | 78.7 | 84.1 |
|
| 223 |
-
| HumanEval+<sub>(pass@10)</sub> | **80.5** | 72 | 78.0 |
|
|
|
|
|
|
|
| 224 |
| MBPP<sub>(pass@10)</sub> | 85.7 | 80.4 | **88.1** |
|
| 225 |
-
| MBPP+<sub>(pass@10)</sub> | 75.4 | 71.2 | 77.5 |
|
| 226 |
|
| 227 |
|
| 228 |
## 7. Conclusion, Limitation, and Future Work
|
|
@@ -231,6 +282,46 @@ We evaluate code generation capabilities across four established benchmarks: Hum
|
|
| 231 |
|
| 232 |
We propose YuLan-Mini-Instruct, a powerful small-scale language model with 2.4 billion parameters with complete post-training process with SFT, DPO and PPO strategies. Although YuLan-Mini-Instruct demonstrates limitations on knowledge-intensive benchmarks such as MMLU, our experimental results indicate that it exhibit competitive performance in several general-purpose tasks. We anticipate that our empirical contributions will contribute to the development of more robust and generalizable LLMs. Future research directions will focus on enhancing dataset diversity and comprehensiveness through expanded training data collection to improve reasoning capabilities.
|
| 233 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 234 |
|
| 235 |
## Contributors
|
| 236 |
|
|
@@ -238,6 +329,12 @@ We propose YuLan-Mini-Instruct, a powerful small-scale language model with 2.4 b
|
|
| 238 |
|
| 239 |
Authors are listed in alphabetical order: Fei Bai, Zhipeng Chen, Yanzipeng Gao, Yukai Gu, Yiwen Hu, Yihong Liu, Yingqian Min, Ruiyang Ren, Huatong Song, Shuang Sun, Ji-Rong Wen, Chenghao Wu, Xin Zhao, Kun Zhou, Yutao Zhu
|
| 240 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 241 |
## Reference
|
| 242 |
|
| 243 |
Please kindly cite our reports if they are helpful for your research.
|
|
|
|
| 11 |
arxiv: 2412.17743
|
| 12 |
model-index:
|
| 13 |
- name: YuLan-Mini-Instruct
|
| 14 |
+
results:
|
| 15 |
+
- task:
|
| 16 |
+
type: text-generation
|
| 17 |
+
dataset:
|
| 18 |
+
type: openai_humaneval
|
| 19 |
+
name: HumanEval
|
| 20 |
+
metrics:
|
| 21 |
+
- name: pass@10
|
| 22 |
+
type: pass@10
|
| 23 |
+
value: 0.866
|
| 24 |
+
verified: false
|
| 25 |
+
- task:
|
| 26 |
+
type: text-generation
|
| 27 |
+
dataset:
|
| 28 |
+
type: mbpp
|
| 29 |
+
name: MBPP
|
| 30 |
+
metrics:
|
| 31 |
+
- name: pass@10
|
| 32 |
+
type: pass@10
|
| 33 |
+
value: 0.857
|
| 34 |
+
verified: false
|
| 35 |
+
- task:
|
| 36 |
+
type: text-generation
|
| 37 |
+
dataset:
|
| 38 |
+
type: math
|
| 39 |
+
name: MATH
|
| 40 |
+
metrics:
|
| 41 |
+
- name: maj@1
|
| 42 |
+
type: maj@1
|
| 43 |
+
value: 0.552
|
| 44 |
+
verified: false
|
| 45 |
+
- task:
|
| 46 |
+
type: text-generation
|
| 47 |
+
dataset:
|
| 48 |
+
type: gsm8k
|
| 49 |
+
name: GSM8K
|
| 50 |
+
metrics:
|
| 51 |
+
- name: maj@1
|
| 52 |
+
type: maj@1
|
| 53 |
+
value: 0.717
|
| 54 |
+
verified: false
|
| 55 |
---
|
| 56 |
|
| 57 |
# Important Notice: This is the **post-training version** of YuLan-Mini.
|
|
|
|
| 224 |
| | MMLU<sub> (5 shot)</sub> |
|
| 225 |
| | TruthfulQA<sub>(0 shot)</sub> |
|
| 226 |
| **Reasoning** | ARC<sub>(0 shot)</sub> |
|
| 227 |
+
| | GPQA<sub>(5 shot)</sub> |
|
| 228 |
| **Math** | MATH<sub>(0 shot, CoT)</sub> |
|
| 229 |
| | GSM8K<sub>(8 shot)</sub> |
|
| 230 |
| | GSM8K<sub>(0 shot, CoT)</sub> |
|
| 231 |
+
| **Code** | HumanEval<sub>(pass@1)</sub> |
|
| 232 |
+
| | HumanEval+<sub>(pass@1)</sub> |
|
| 233 |
+
| | HumanEval<sub>(pass@10)</sub> |
|
| 234 |
| | HumanEval+<sub>(pass@10)</sub> |
|
| 235 |
+
| | MBPP<sub>(pass@1)</sub> |
|
| 236 |
+
| | MBPP+<sub>(pass@1)</sub> |
|
| 237 |
| | MBPP<sub>(pass@10)</sub> |
|
| 238 |
| | MBPP+<sub>(pass@10)</sub> |
|
| 239 |
|
|
|
|
| 262 |
| MMLU<sub> (5 shot)</sub> | 52.7 | 63.4 | **66.5** |
|
| 263 |
| TruthfulQA<sub>(0 shot)</sub> | 50.1 | 49.7 | **58.8** |
|
| 264 |
| ARC<sub>(0 shot)</sub> | 51.8 | **78.6** | 47.8 |
|
| 265 |
+
| GPQA<sub>(5 shot)</sub> | 30.1 | **32.6** | 29.8 |
|
| 266 |
+
| MATH<sub>(0 shot, CoT)</sub> | **55.2** | 48.0 | **55.2** |
|
| 267 |
| GSM8K<sub>(8 shot)</sub> | **81.8** | 43.4 | 73.2 |
|
| 268 |
+
| GSM8K<sub>(0 shot, CoT)</sub> | **71.7** | 66.0 | 69.4 |
|
| 269 |
+
| HumanEval<sub>(pass@1)</sub> | **67.7** | 51.5 | 61.6 |
|
| 270 |
+
| HumanEval+<sub>(pass@1)</sub> | **61.6** | 45.2 | 47.0 |
|
| 271 |
| HumanEval<sub>(pass@10)</sub> | **86.6** | 78.7 | 84.1 |
|
| 272 |
+
| HumanEval+<sub>(pass@10)</sub> | **80.5** | 72.0 | 78.0 |
|
| 273 |
+
| MBPP<sub>(pass@1)</sub> | **66.7** | 57.4 | 63.2 |
|
| 274 |
+
| MBPP+<sub>(pass@1)</sub> | **56.6** | 47.8 | 52.0 |
|
| 275 |
| MBPP<sub>(pass@10)</sub> | 85.7 | 80.4 | **88.1** |
|
| 276 |
+
| MBPP+<sub>(pass@10)</sub> | 75.4 | 71.2 | **77.5** |
|
| 277 |
|
| 278 |
|
| 279 |
## 7. Conclusion, Limitation, and Future Work
|
|
|
|
| 282 |
|
| 283 |
We propose YuLan-Mini-Instruct, a powerful small-scale language model with 2.4 billion parameters with complete post-training process with SFT, DPO and PPO strategies. Although YuLan-Mini-Instruct demonstrates limitations on knowledge-intensive benchmarks such as MMLU, our experimental results indicate that it exhibit competitive performance in several general-purpose tasks. We anticipate that our empirical contributions will contribute to the development of more robust and generalizable LLMs. Future research directions will focus on enhancing dataset diversity and comprehensiveness through expanded training data collection to improve reasoning capabilities.
|
| 284 |
|
| 285 |
+
## Quick Start 💻
|
| 286 |
+
|
| 287 |
+
Below is a simple example for inference using Huggingface:
|
| 288 |
+
|
| 289 |
+
**Huggingface Inference Example**
|
| 290 |
+
```python
|
| 291 |
+
import torch
|
| 292 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM
|
| 293 |
+
|
| 294 |
+
# Load model and tokenizer
|
| 295 |
+
tokenizer = AutoTokenizer.from_pretrained("yulan-team/YuLan-Mini-Instruct")
|
| 296 |
+
model = AutoModelForCausalLM.from_pretrained("yulan-team/YuLan-Mini-Instruct", torch_dtype=torch.bfloat16)
|
| 297 |
+
|
| 298 |
+
# Input text
|
| 299 |
+
chat = [
|
| 300 |
+
{"role": "system", "content": "You are YuLan-Mini, created by RUC AI Box. You are a helpful assistant."},
|
| 301 |
+
{"role": "user", "content": "What is Renmin University of China?"}
|
| 302 |
+
]
|
| 303 |
+
formatted_chat = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
|
| 304 |
+
inputs = tokenizer(formatted_chat, return_tensors="pt", add_special_tokens=False)
|
| 305 |
+
|
| 306 |
+
# Completion
|
| 307 |
+
output = model.generate(inputs["input_ids"], max_new_tokens=100, temperature=0.5)
|
| 308 |
+
print(tokenizer.decode(output[0][inputs['input_ids'].size(1):], skip_special_tokens=True))
|
| 309 |
+
```
|
| 310 |
+
|
| 311 |
+
**vLLM Serve Example**
|
| 312 |
+
```bash
|
| 313 |
+
vllm serve yulan-team/YuLan-Mini-Instruct --dtype bfloat16
|
| 314 |
+
```
|
| 315 |
+
|
| 316 |
+
**SGLang Serve Example**
|
| 317 |
+
```bash
|
| 318 |
+
python -m sglang.launch_server --model-path yulan-team/YuLan-Mini-Instruct --port 30000 --host 0.0.0.0
|
| 319 |
+
```
|
| 320 |
+
|
| 321 |
+
**Ollama**
|
| 322 |
+
```bash
|
| 323 |
+
ollama run hf.co/mradermacher/YuLan-Mini-Instruct-GGUF:IQ4_XS
|
| 324 |
+
```
|
| 325 |
|
| 326 |
## Contributors
|
| 327 |
|
|
|
|
| 329 |
|
| 330 |
Authors are listed in alphabetical order: Fei Bai, Zhipeng Chen, Yanzipeng Gao, Yukai Gu, Yiwen Hu, Yihong Liu, Yingqian Min, Ruiyang Ren, Huatong Song, Shuang Sun, Ji-Rong Wen, Chenghao Wu, Xin Zhao, Kun Zhou, Yutao Zhu
|
| 331 |
|
| 332 |
+
## License
|
| 333 |
+
|
| 334 |
+
- The code in this repository, the model weights, and optimizer states are released under the [MIT License](./LICENSE).
|
| 335 |
+
- Policies regarding the use of model weights, intermediate optimizer states, and training data will be announced in future updates.
|
| 336 |
+
- Limitations: Despite our efforts to mitigate safety concerns and encourage the generation of ethical and lawful text, the probabilistic nature of language models may still lead to unexpected outputs. For instance, responses might contain bias, discrimination, or other harmful content. Please refrain from disseminating such content. We are not liable for any consequences arising from the spread of harmful information.
|
| 337 |
+
|
| 338 |
## Reference
|
| 339 |
|
| 340 |
Please kindly cite our reports if they are helpful for your research.
|
assets/result.png
CHANGED
|

|