

base_model: mistralai/Mistral-7B-v0.1
license: apache-2.0
Introduction
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
Benchmarking
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
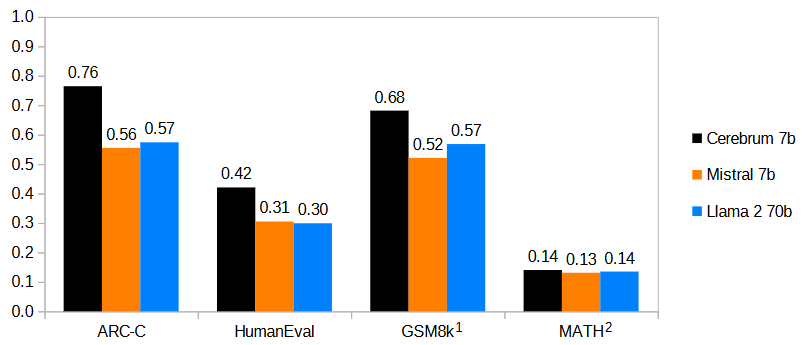
 Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
Usage
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
User: Are you conscious?
AI:
This prompt is also available as a chat template. Here is how you could use it:
messages = [
{'role': 'user', 'content': 'What is chain of thought prompting?'},
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
]
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
with torch.no_grad():
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty.