
language:
- ru
T-lite-0.1
🚨 T-lite is designed for further fine-tuning and is not intended as a ready-to-use conversational assistant. Users are advised to exercise caution and are responsible for any additional training and oversight required to ensure the model's responses meet acceptable ethical and safety standards. The responsibility for incorporating this model into industrial or commercial solutions lies entirely with those who choose to deploy it.
Description
T-lite is a continual pretraining model designed specifically for the Russian language, enabling the creation of large language model applications in Russian. This model aims to improve the quality of Russian text generation and provide domain-specific and cultural knowledge relevant to the Russian context.
Model Training Details
🏛️ Architecture and Configuration
T-lite is a decoder language model with:
- pre-normalization via RMSNorm
- SwiGLU activation function
- rotary positional embeddings (RoPE)
- grouped query attention (GQA)
T-lite was trained in bf16.
⚙️ Hyperparameters
We employed the Decoupled AdamW optimizer with β1 = 0.9, β2 = 0.95, and eps = 1.0e-8. The learning rate was set to 1.0e-5 with a constant schedule and a warmup period of 10 steps during stage 1, and a cosine schedule during stage 2. Weight decay was applied at a rate of 1.0e-6, and gradient clipping was performed with a maximum norm of 1.0. The maximum sequence length was set to 8192. Each batch contained approximately 6 million tokens.
🏋🏽 Hardware Configuration & Performance
Training was conducted on 96 A100 GPUs with 80GB memory each, using Fully Sharded Data Parallel (FSDP) with full shard/hybrid shard strategies. The setup achieved a throughput of 3000 tokens/sec/GPU, with 100B tokens being processed in approximately 4 days. We achieved a 0.59 Model FLOPs Utilization (MFU).
📚 Data
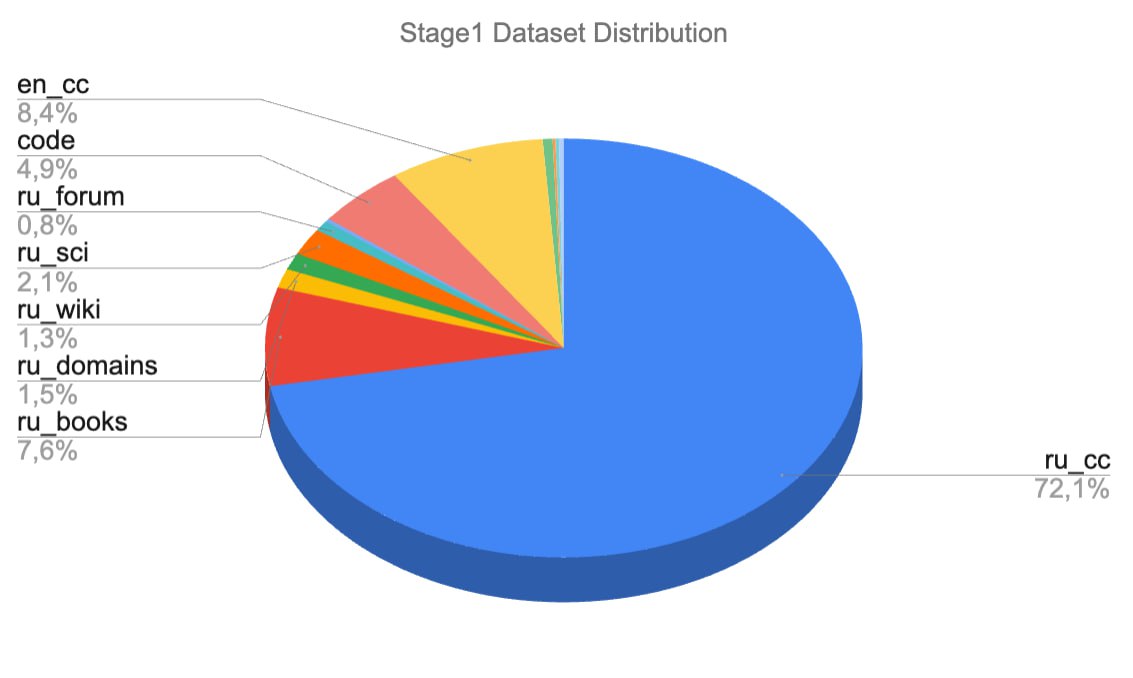
Stage 1
Massive continual pre-training
- 300B tokens * 0.3 epoch
- Proportion of data in Russian is 85%, as a trade-off between language adoptation and English language performance
- Styles and topics in Common Crawl (CC) data were downsampled
- Domains in book datasets were balanced
- Proportion of code data was increased
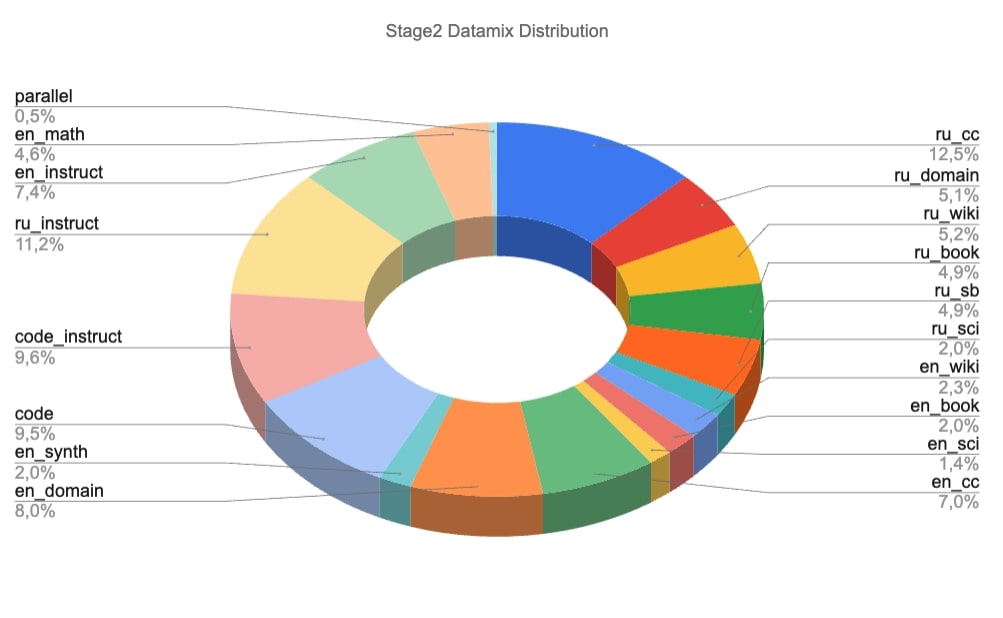
Stage 2
Focuses on refining the quality of the dataset
- 20B tokens * 3 epochs
- Includes instructional sets of smaller volume
- Advertisements and news were aggressively downsampled
- Instructions and articles were upsampled
- Educational content was balanced
📊 Benchmarks
🇷🇺 Russian
MERA benchmark results
| Task name | Metric | N shot | Llama-3-8b | T-lite-0.1 |
|---|---|---|---|---|
| Total score | 0.445 | 0.492 | ||
| BPS | Accuracy | 2-shot | 0.459 | 0.358 |
| CheGeKa | F1 / EM | 4-shot | 0.04/0 | 0.118/0.06 |
| LCS | Accuracy | 2-shot | 0.146 | 0.14 |
| MathLogicQA | Accuracy | 5-shot | 0.365 | 0.37 |
| MultiQ | F1-score / EM | 0-shot | 0.106/0.027 | 0.383/0.29 |
| PARus | Accuracy | 0-shot | 0.72 | 0.858 |
| RCB | Avg F1 / Accuracy | 0-shot | 0.42/0.434 | 0.511/0.416 |
| ruHumanEval | pass@k | 0-shot | 0.017/0.085/0.171 | 0.023/0.113/0.226 |
| ruMMLU | Accuracy | 5-shot | 0.693 | 0.759 |
| ruModAr | EM | 0-shot | 0.708 | 0.667 |
| ruMultiAr | EM | 5-shot | 0.259 | 0.269 |
| ruOpenBookQA | Avg F1 / Accuracy | 5-shot | 0.745/0.744 | 0.783/0.782 |
| ruTiE | Accuracy | 0-shot | 0.553 | 0.681 |
| ruWorldTree | Avg F1 / Accuracy | 5-shot | 0.838/0.839 | 0.88/0.88 |
| RWSD | Accuracy | 0-shot | 0.504 | 0.585 |
| SimpleAr | EM | 5-shot | 0.954 | 0.955 |
| USE | Grade Norm | 0-shot | 0.023 | 0.05 |
The evluation was performed using https://github.com/ai-forever/MERA/tree/main
🇬🇧 English
It's consistent that after the model was adapted for the Russian language, performance on English benchmarks declined.
| Benchmark | N shot | Llama-3-8b | T-lite-0.1 |
|---|---|---|---|
| ARC-challenge | 0-shot | 0.518 | 0.489 |
| ARC-easy | 0-shot | 0.789 | 0.787 |
| MMLU | 0-shot | 0.62 | 0.6 |
| Natural Questions | 0-shot | 0.162 | 0.222 |
| TriviaQA | 0-shot | 0.63 | 0.539 |
The evluation was performed using https://github.com/EleutherAI/lm-evaluation-harness.
👨💻 Examples of usage
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
torch.manual_seed(42)
tokenizer = AutoTokenizer.from_pretrained("t-bank-ai/T-lite-0.1")
model = AutoModelForCausalLM.from_pretrained("t-bank-ai/T-lite-0.1", device_map="auto")
input_text = "Машинное обучение нужно для"
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**input_ids, max_new_tokens=256)
print(tokenizer.decode(outputs[0]))
Output:
Машинное обучение нужно для того, чтобы автоматизировать процесс принятия решений. Вместо того, чтобы человеку нужно было вручную просматривать и анализировать данные, алгоритмы машинного обучения могут автоматически выявлять закономерности и делать прогнозы на основе этих данных. Это может быть особенно полезно в таких областях, как финансы, где объем данных огромен, а решения должны приниматься быстро.
Вот несколько примеров того, как машинное обучение используется в финансах:
1. Обнаружение мошенничества: алгоритмы машинного обучения могут анализировать закономерности в транзакциях и выявлять подозрительные действия, которые могут указывать на мошенничество.
2. Управление рисками: Машинное обучение может помочь финансовым учреждениям выявлять и оценивать риски, связанные с различными инвестициями или кредитами.
3. Обработка данных на естественном языке: Машинное обучение может использоваться для анализа финансовых новостей и других текстовых данных, чтобы выявить тенденции