
Sana
Collection
⚡️Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer
•
17 items
•
Updated
•
56
![]()








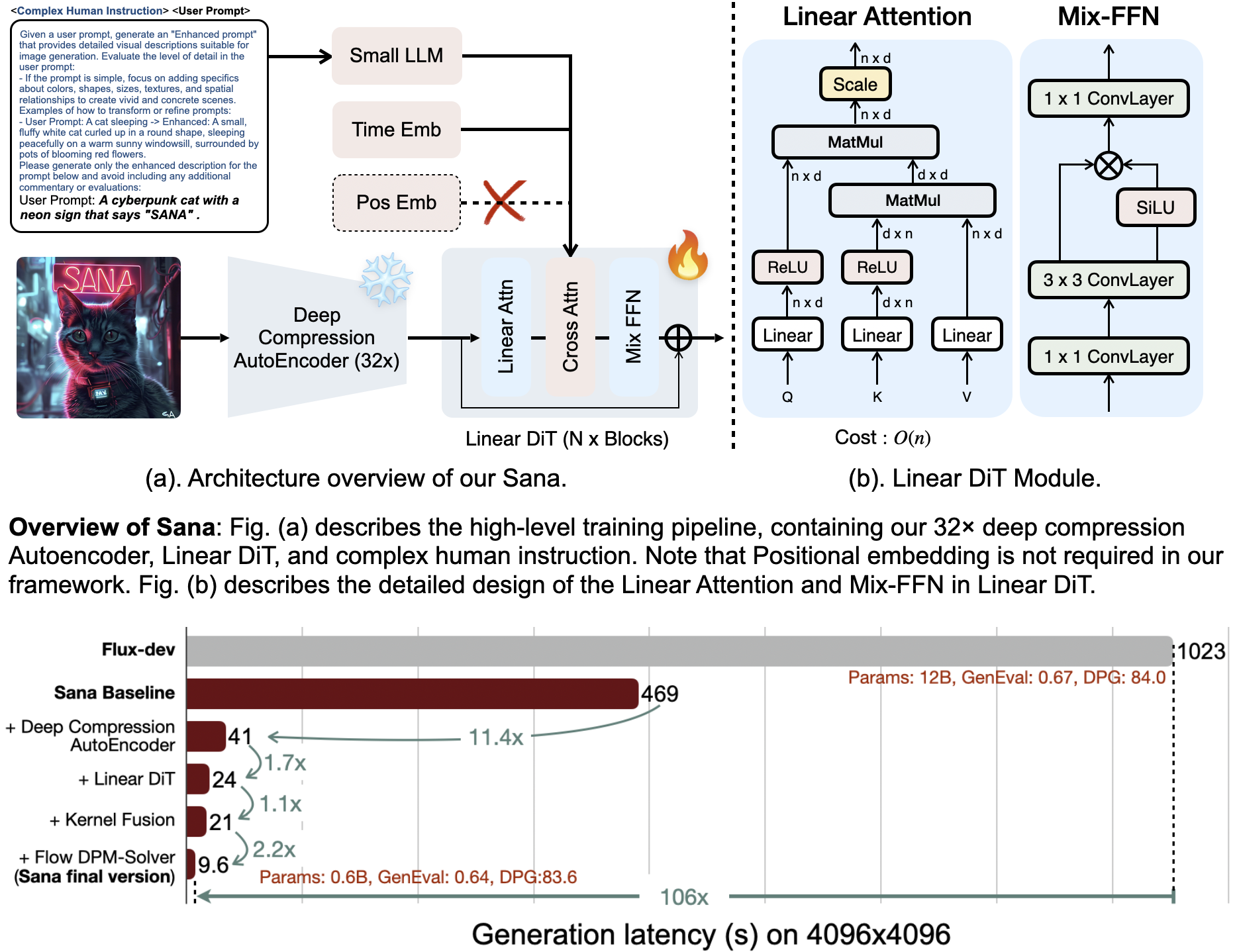
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU.
Source code is available at https://github.com/NVlabs/Sana.
For research purposes, we recommend our generative-models Github repository (https://github.com/NVlabs/Sana),
which is more suitable for both training and inference and for which most advanced diffusion sampler like Flow-DPM-Solver is integrated.
MIT Han-Lab provides free Sana inference.
The model is intended for research purposes only. Possible research areas and tasks include
Generation of artworks and use in design and other artistic processes.
Applications in educational or creative tools.
Research on generative models.
Safe deployment of models which have the potential to generate harmful content.
Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Unable to build the model tree, the base model loops to the model itself. Learn more.