|
--- |
|
license: mit |
|
datasets: |
|
- wikimedia/wikipedia |
|
language: |
|
- ka |
|
- en |
|
pipeline_tag: text-generation |
|
--- |
|
|
|
# GPT-2Geo: Georgian Language Model 🇬🇪 |
|
|
|
> ⚠️ This GPT-2Geo model is not fully trained due to hardware constraints. It has been trained on a subset of 2000 samples for 20 epochs. The model's capabilities and performance are indicative within these limitations. Future iterations may benefit from extended training on more extensive datasets. Please be mindful of these training constraints when utilizing the model. |
|
|
|
## Overview |
|
|
|
GPT-2Geo is a powerful language model tailored for the Georgian language, built upon OpenAI's GPT-2 architecture. This model is designed for various natural language processing tasks, including text generation and understanding. [Github (training script)](https://github.com/Kuduxaaa/gpt2-geo) |
|
|
|
## Features |
|
|
|
- **Georgian Language Model:** Specifically trained to understand and generate text in the Georgian language. |
|
- **GPT-2 Architecture:** Built upon OpenAI's GPT-2, providing a versatile and efficient language model. |
|
- **Easy Integration:** Seamless integration with the Hugging Face Transformers library. |
|
|
|
## Training Information |
|
|
|
### Environment: |
|
- **GPU:** Nvidia T4 (15GB) |
|
- **Model Memory Requirement:** Minimum 13.5GB |
|
|
|
### Training Configuration: |
|
- **Number of Epochs:** 20 |
|
- **Time Consumed:** 49 minutes |
|
|
|
 |
|
|
|
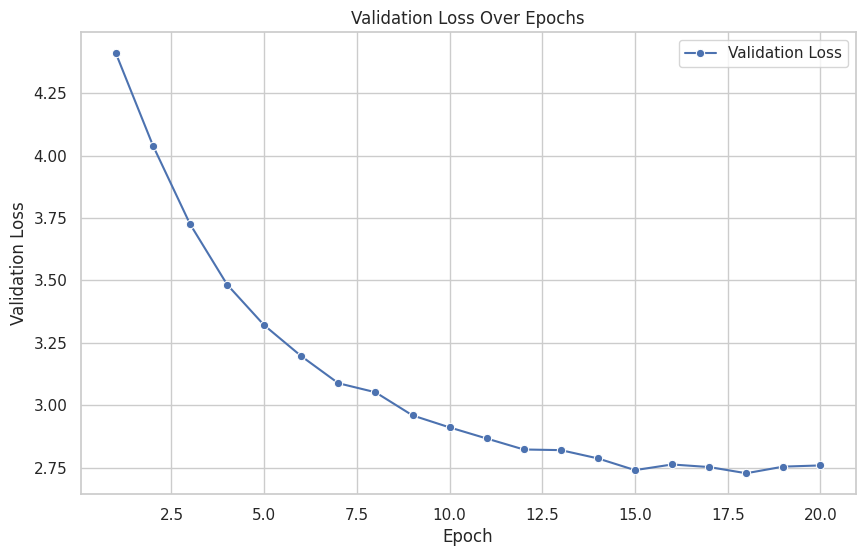
### Training Progress: |
|
The GPT-2Geo model underwent training in a high-performance environment utilizing the **Nvidia T4 GPU** with **15GB** of dedicated memory. This powerful hardware met the minimum model memory requirement of **13.5GB**, ensuring optimal performance during the training process. |
|
|
|
The training configuration included **20 epochs**, allowing the model to iteratively learn from the dataset. The entire training procedure was completed in a time-efficient manner, consuming approximately **49 minutes**. |
|
|
|
For detailed insights into the model's performance, refer to the training logs, which capture key metrics such as validation loss over epochs. This information provides users with a comprehensive understanding of the training environment, configuration, and progress. |
|
|
|
Ensure that your GPU environment is correctly configured to harness the full potential of the available hardware during the training phase. **Before start training process it needs to preprocess text data and it will added in future** |
|
|
|
## Example Usage |
|
|
|
```python |
|
import torch |
|
|
|
from transformers import GPT2LMHeadModel, GPT2Config, ElectraTokenizerFast |
|
|
|
model_name = 'Kuduxaaa/gpt2-geo' |
|
model = GPT2LMHeadModel.from_pretrained(model_name) |
|
tokenizer = ElectraTokenizerFast.from_pretrained(model_name) |
|
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') |
|
model.to(device) |
|
|
|
prompt = 'ქართულ მითოლოგიაში ' |
|
|
|
input_ids = tokenizer.encode(prompt, return_tensors='pt').to(device) |
|
output = model.generate( |
|
input_ids, |
|
max_length = 100, |
|
num_beams = 5, |
|
no_repeat_ngram_size = 2, |
|
top_k = 50, |
|
top_p = 0.95, |
|
temperature = 0.7 |
|
) |
|
|
|
result = tokenizer.decode(output[0], skip_special_tokens=True) |
|
print(result) |
|
# ქართულ მითოლოგიაში, მითების პერსონაჟები და. მითები დაკავშირებული მითური წარმოშობას, რომელიც წარმოიშვა მითი გარემოც, რომ ამ პერიოდში და სხვა სხვა. აგრეთვე მითიდან წარმოადგენს მითებთან ერთად, როგორც საშუალებები, საფუძვლად წარმოების წარსულში. ლიტერატურა წარმომავლობებს მით |
|
|
|
``` |
|
|
|
## Acknowledgments |
|
|
|
This project is made possible by the contributions of Nika Kudukashvili and the open-source community. Special thanks to OpenAI for the GPT-2 architecture and `jnz/electra-ka` for georgian tokenizer. |
