
File size: 17,959 Bytes
c0c7665 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 |
---
license: bigcode-openrail-m
library_name: transformers
tags:
- code
- GGUF
base_model: bigcode/starcoder2-15b
datasets:
- bigcode/self-oss-instruct-sc2-exec-filter-50k
pipeline_tag: text-generation
model-index:
- name: starcoder2-15b-instruct-v0.1
results:
- task:
type: text-generation
dataset:
name: LiveCodeBench (code generation)
type: livecodebench-codegeneration
metrics:
- type: pass@1
value: 20.4
verified: false
- task:
type: text-generation
dataset:
name: LiveCodeBench (self repair)
type: livecodebench-selfrepair
metrics:
- type: pass@1
value: 20.9
verified: false
- task:
type: text-generation
dataset:
name: LiveCodeBench (test output prediction)
type: livecodebench-testoutputprediction
metrics:
- type: pass@1
value: 29.8
verified: false
- task:
type: text-generation
dataset:
name: LiveCodeBench (code execution)
type: livecodebench-codeexecution
metrics:
- type: pass@1
value: 28.1
verified: false
- task:
type: text-generation
dataset:
name: HumanEval
type: humaneval
metrics:
- type: pass@1
value: 72.6
verified: false
- task:
type: text-generation
dataset:
name: HumanEval+
type: humanevalplus
metrics:
- type: pass@1
value: 63.4
verified: false
- task:
type: text-generation
dataset:
name: MBPP
type: mbpp
metrics:
- type: pass@1
value: 75.2
verified: false
- task:
type: text-generation
dataset:
name: MBPP+
type: mbppplus
metrics:
- type: pass@1
value: 61.2
verified: false
- task:
type: text-generation
dataset:
name: DS-1000
type: ds-1000
metrics:
- type: pass@1
value: 40.6
verified: false
quantized_by: andrijdavid
---
# starcoder2-15b-instruct-v0.1-GGUF
- Original model: [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
<!-- README_GGUF.md-about-gguf end -->
<!-- compatibility_gguf start -->
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00009.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install huggingface_hub[hf_transfer]
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00009.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 8192` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Q4_0/Q4_0-00001-of-00009.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00009.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: starcoder2-15b-instruct-v0.1
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation

## Model Summary
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
- **Authors:**
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
[Federico Cassano](https://federico.codes/),
[Jiawei Liu](https://jw-liu.xyz),
[Yifeng Ding](https://yifeng-ding.com),
[Naman Jain](https://naman-ntc.github.io),
[Harm de Vries](https://www.harmdevries.com),
[Leandro von Werra](https://twitter.com/lvwerra),
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
[Lingming Zhang](https://lingming.cs.illinois.edu).

## Use
### Intended use
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
```python
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
```
Here is the expected output:
``````
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
``````
### Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
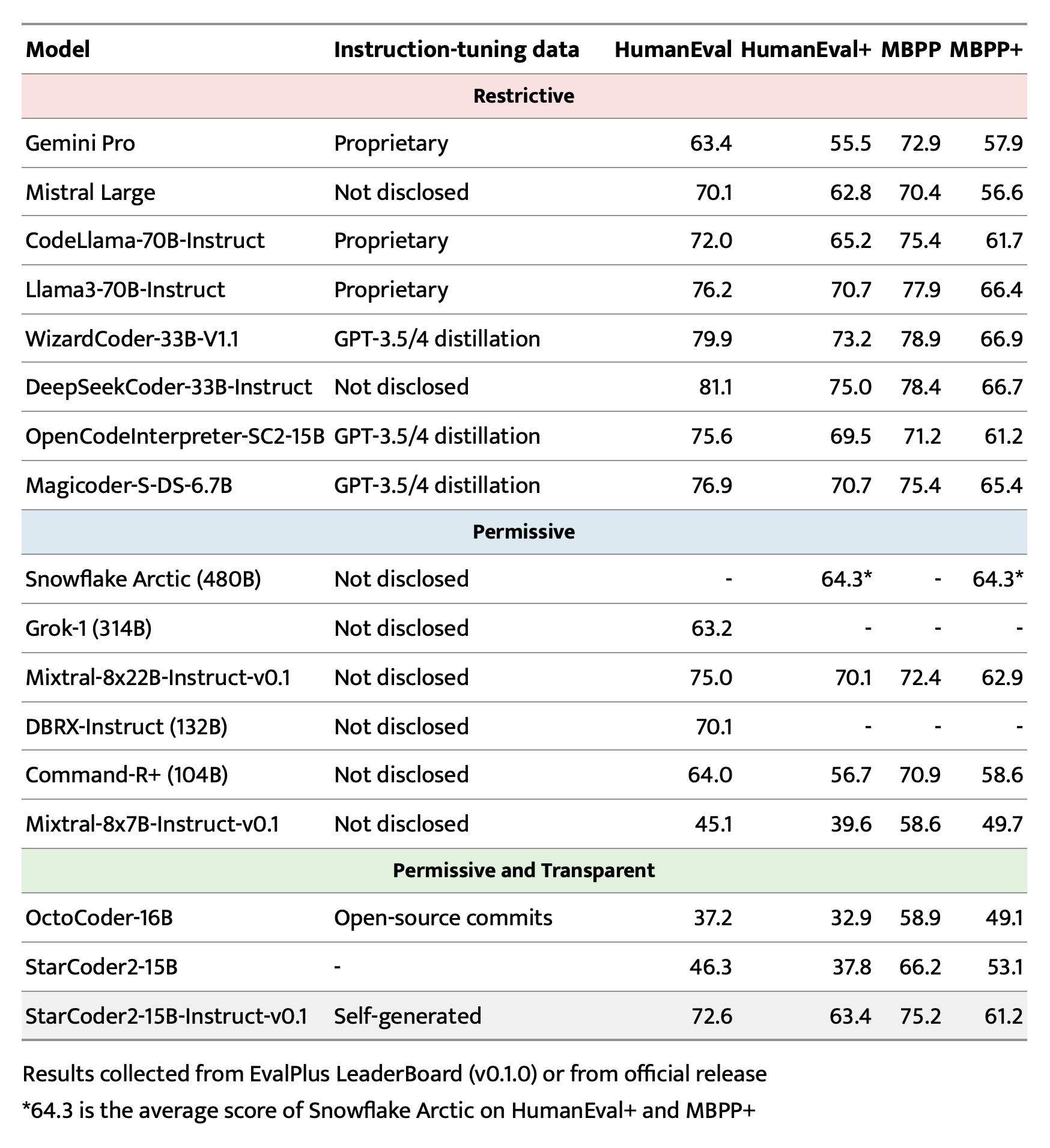
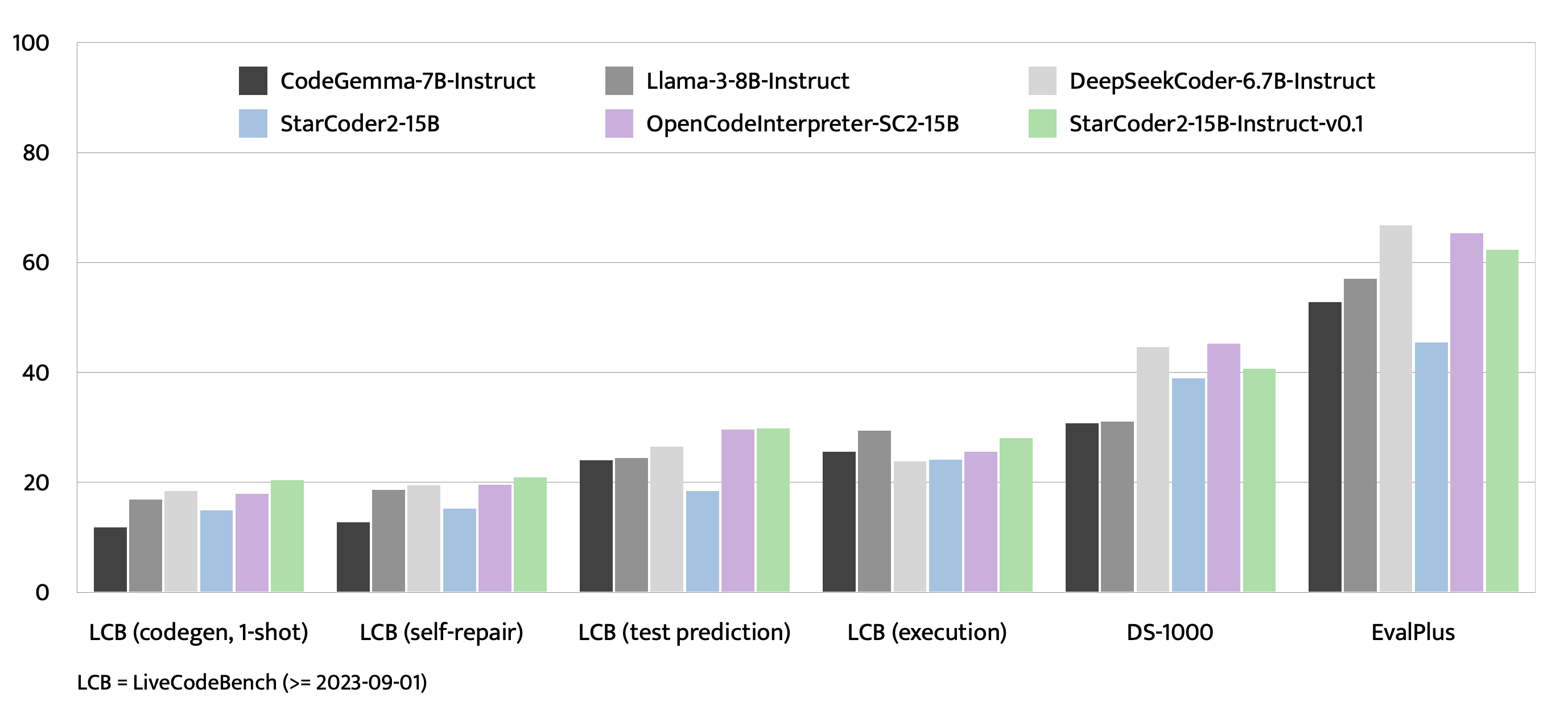
## Training Details
### Hyperparameters
- **Optimizer:** Adafactor
- **Learning rate:** 1e-5
- **Epoch:** 4
- **Batch size:** 64
- **Warmup ratio:** 0.05
- **Scheduler:** Linear
- **Sequence length:** 1280
- **Dropout**: Not applied
### Hardware
1 x NVIDIA A100 80GB
## Resources
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
<!-- original-model-card end -->
|