
MERaLiON-SpeechEncoder-v1
The MERaLiON-SpeechEncoder is a speech foundation model designed to support a wide range of downstream speech applications, like speech recognition, intent classification and speaker identification, among others. This version was trained on 200,000 hours of predominantly English data including 10,000 hours of Singapore-based speech, to cater to the speech processing needs in Singapore and beyond. Gradual support for other languages, starting with major Southeast Asian ones are planned for subsequent releases.
- Developed by: I2R, A*STAR
- Model type: Speech Encoder
- Language(s): Primarily English (Global & Singapore)
- License: MERaLiON Public License
For details on background, pre-training, tuning experiments and evaluation, please refer to our technical report.
Acknowledgement
This research is supported by the National Research Foundation, Singapore and Infocomm Media Development Authority, Singapore under its National Large Language Models Funding Initiative.
Model Description
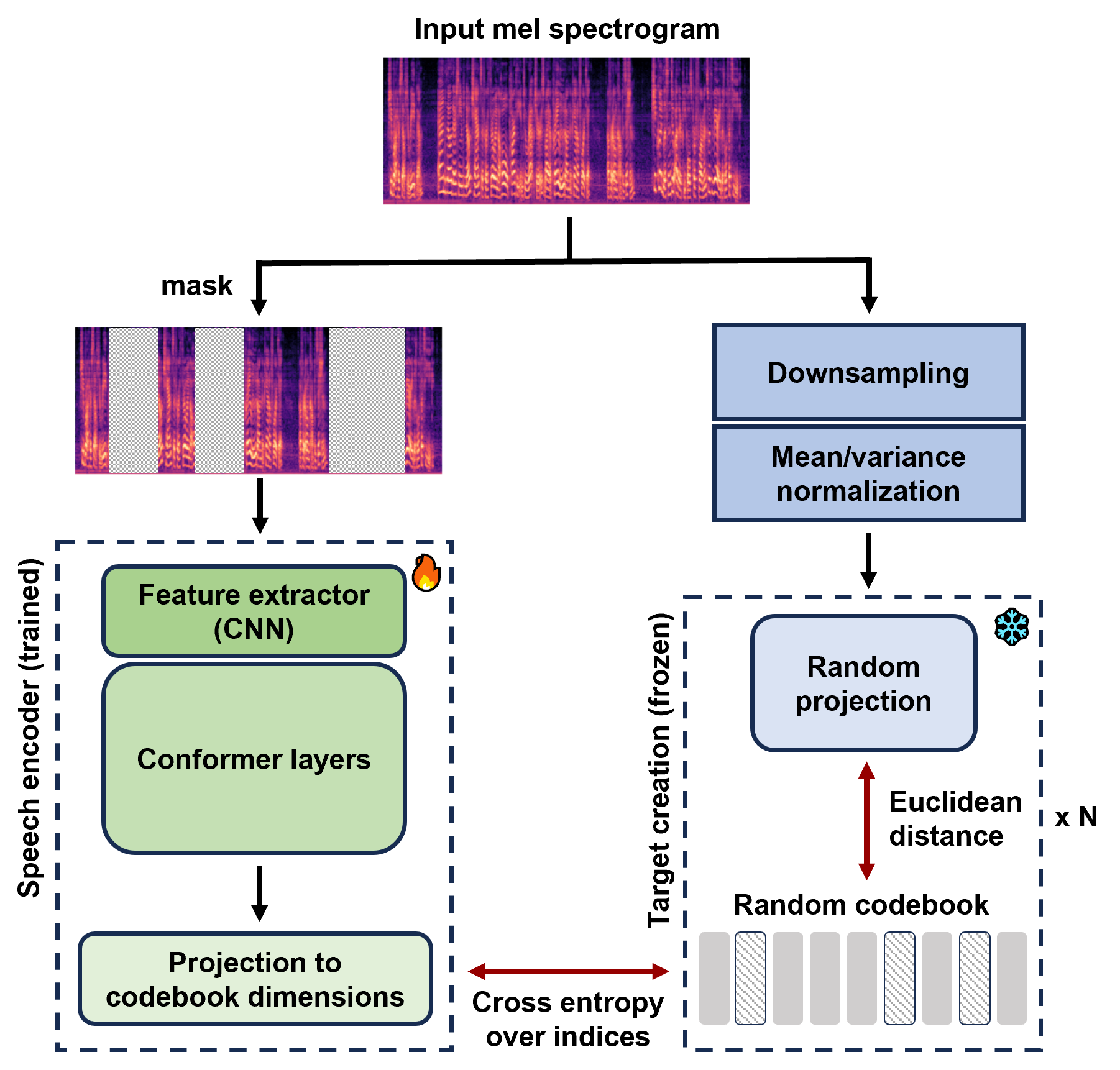
MERaLiON-SpeechEncoder was pre-trained from scratch with a self-supervised learning approach using a BERT-based speech pre-training with random-projection quantizer (BEST-RQ) objective. Analogous to BERT's mask language modelling criterion for text, this entails predicting the correct discrete label from a codebook, over the masked frames of an input speech signal. MERaLiON-SpeechEncoder-v1 contains approximately 630M parameters.
The model takes in speech as input in the form of mel-spectrograms and returns compressed latent features which can then be passed to a task-specific downstream model, relevant to the user's application. Note that the model provided here is the base foundation model itself and the user has to fine-tune the model with task-specific data for a complete inference pipeline. We provide some examples below to get one started.
Capabilities
We have evaluated the MERaLiON-SpeechEncoder extensively on several speech recognition datasets, and fine-tuned the model on ten different tasks encompassing the SUPERB benchmark: automatic speech recognition (ASR), automatic phoneme recognition (PR), keyword spotting (KS), query by example spoken term detection (QbE), intent classification (IC), slot filling (SF), speaker identification (SID), automatic speaker verification (ASV), speaker diarization (SD), and emotion recognition (ER). Our evaluation demonstrates improvements to spontaneous and Singapore speech benchmarks for speech recognition, while remaining competitive to other state-of-the-art speech encoders such as WavLM and HuBERT across SUPERB tasks.
This version of the MERaLiON-SpeechEncoder is specifically tailored for English, both global and Singapore-specific, including Singlish. Although the encoder was trained on a portion of multilingual data, this has not been substantially evaluated.
We provide a code snippet below for the direct usage of retrieving latent features from the model, followed by an example of how to set up the model for ASR fine-tuning. Speech input should be sampled at 16kHz.
Get Features
import torch
from datasets import load_dataset
from transformers import AutoModel, AutoFeatureExtractor
repo_id = 'MERaLiON/MERaLiON-SpeechEncoder-v1'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# load model and feature extractor
model = AutoModel.from_pretrained(
repo_id,
trust_remote_code=True,
)
model = model.to(device)
feature_extractor = AutoFeatureExtractor.from_pretrained(
repo_id,
trust_remote_code=True
)
# prepare data
data = load_dataset("distil-whisper/librispeech_long", "clean",
split="validation")
def batch_collater(data):
tensors = []
for idx, sample in enumerate(data):
tensors.append(sample['audio']['array'])
return tensors
audio_array = batch_collater(data)
inputs = feature_extractor(audio_array, sampling_rate=16_000,
return_attention_mask=True,
return_tensors='pt', do_normalize=False)
input_values = inputs['input_values']
input_lengths = torch.sum(inputs['attention_mask'], dim=-1)
input_values, input_lengths = input_values.to(device), input_lengths.to(device)
# model inference to obtain features
with torch.no_grad():
model.eval()
output = model(input_values=input_values,
input_lengths=input_lengths,
output_hidden_states=True)
Downstream Use
import torch
import json
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoFeatureExtractor, Wav2Vec2CTCTokenizer
repo_id = 'MERaLiON/MERaLiON-SpeechEncoder-v1'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# prepare data
def pre_processing(batch):
batch["text"] = batch["text"].lower()
return batch
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
librispeech100h_train = load_dataset("openslr/librispeech_asr", split="train.clean.100")
librispeech100h_test = load_dataset("openslr/librispeech_asr", split="validation.clean")
librispeech100h_train = librispeech100h_train.remove_columns(
['file', 'speaker_id', 'chapter_id', 'id'])
librispeech100h_test = librispeech100h_test.remove_columns(
['file', 'speaker_id', 'chapter_id', 'id'])
librispeech100h_train = librispeech100h_train.map(pre_processing)
librispeech100h_test = librispeech100h_test.map(pre_processing)
vocab_train = librispeech100h_train.map(extract_all_chars, batched=True,
batch_size=-1, keep_in_memory=True,
remove_columns=librispeech100h_train.column_names)
vocab_test = librispeech100h_test.map(extract_all_chars, batched=True,
batch_size=-1, keep_in_memory=True,
remove_columns=librispeech100h_test.column_names)
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
with open('ls_vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
# load model, feature extractor and tokenizer
feature_extractor = AutoFeatureExtractor.from_pretrained(
repo_id,
trust_remote_code = True,
)
tokenizer = Wav2Vec2CTCTokenizer("./ls_vocab.json",
unk_token="[UNK]", pad_token="[PAD]",
word_delimiter_token="|")
model = AutoModelForCTC.from_pretrained(
repo_id,
trust_remote_code=True,
vocab_size=len(vocab_dict),
feat_proj_dropout=0.1,
activation_dropout=0.1,
hidden_dropout=0.1,
conformer_conv_dropout=0.1,
ctc_loss_reduction="mean",
pad_token_id=tokenizer.pad_token_id,
attention_dropout=0.1,
)
model = model.to(device)
Please refer to this blog for further ASR fine-tuning recipe with Huggingface Trainer. Alternatively, the Huggingface model can be loaded to any other frameworks such as Pytorch or ESPnet for custom fine-tuning loops.
Technical Specifications
Training Data
MERaLiON-SpeechEncoder has been trained on a diverse set of unsupervised speech data, primarily in English. Our collection is curated from various publicly available datasets and covers a wide range of conditions, encompassing factors such as domain, style, speaker, gender, and accent. The combined dataset comprises around 170,000 hours of English, including 10,000 hours of Singapore-based English that incorporates code-switching; plus 30,000 additional hours of multilingual speech from 113 languages, totalling 200,000 hours. Consult our technical report for the full breakdown.
Training Procedure and Compute
MERaLiON-SpeechEncoder was trained in two phases, initially on a 60,000 hours subset of data, before continued pre-trainining on the full 200,000 hours dataset using this prior checkpoint as initialisation. The initial model was trained on the ASPIRE 2A Supercomputer Cluster provided by the National Supercomputing Centre (NSCC) for 325K steps on 12 Nvidia A100 40GB GPUs. The full pre-training run was carried out on the LUMI Supercomputer Cluster with 128 AMD MI250x GPUs for a further 382K steps taking about 25 days of active GPU time.
Citation
If you find our work useful, please cite our technical report:
@misc{huzaifah2024speechfoundationmodelsingapore,
title={MERaLiON-SpeechEncoder: Towards a Speech Foundation Model for Singapore and Beyond},
author={{MERaLiON Team}},
year={2024},
eprint={2412.11538},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.11538},
}
- Downloads last month
- 29