
MedQSum
TL;DR
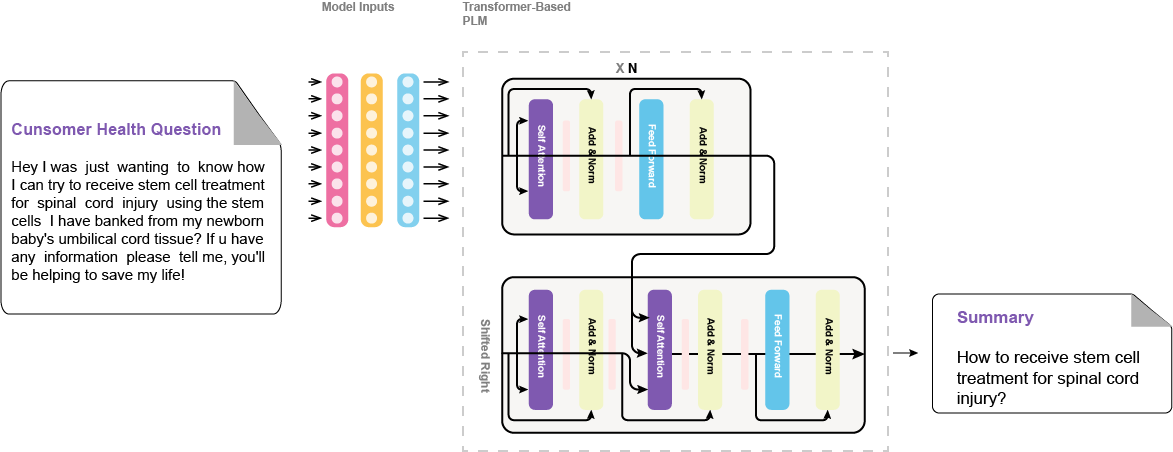
medqsum-bart-large-xsum-meqsum is the best fine-tuned model in the paper Enhancing Large Language Models' Utility for Medical Question-Answering: A Patient Health Question Summarization Approach, which introduces a solution to get the most out of LLMs, when answering health-related questions. We address the challenge of crafting accurate prompts by summarizing consumer health questions (CHQs) to generate clear and concise medical questions. Our approach involves fine-tuning Transformer-based models, including Flan-T5 in resource-constrained environments and three medical question summarization datasets.
Hyperparameters
{
"dataset_name": "MeQSum",
"learning_rate": 3e-05,
"model_name_or_path": "facebook/bart-large-xsum",
"num_train_epochs": 4,
"per_device_eval_batch_size": 4,
"per_device_train_batch_size": 4,
"predict_with_generate": true,
}
Usage
from transformers import pipeline
summarizer = pipeline("summarization", model="NouRed/medqsum-bart-large-xsum-meqsum")
chq = '''SUBJECT: high inner eye pressure above 21 possible glaucoma
MESSAGE: have seen inner eye pressure increase as I have begin taking
Rizatriptan. I understand the med narrows blood vessels. Can this med.
cause or effect the closed or wide angle issues with the eyelense/glacoma.
'''
summarizer(chq)
Results
| key | value |
|---|---|
| eval_rouge1 | 54.32 |
| eval_rouge2 | 38.08 |
| eval_rougeL | 51.98 |
| eval_rougeLsum | 51.99 |
Cite This
@INPROCEEDINGS{10373720,
author={Zekaoui, Nour Eddine and Yousfi, Siham and Mikram, Mounia and Rhanoui, Maryem},
booktitle={2023 14th International Conference on Intelligent Systems: Theories and Applications (SITA)},
title={Enhancing Large Language Models’ Utility for Medical Question-Answering: A Patient Health Question Summarization Approach},
year={2023},
volume={},
number={},
pages={1-8},
doi={10.1109/SITA60746.2023.10373720}}
- Downloads last month
- 48
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
Dataset used to train NouRed/medqsum-bart-large-xsum-meqsum
Space using NouRed/medqsum-bart-large-xsum-meqsum 1
Evaluation results
- Validation ROGUE-1 on Dataset for medical question summarizationself-reported54.320
- Validation ROGUE-2 on Dataset for medical question summarizationself-reported38.080
- Validation ROGUE-L on Dataset for medical question summarizationself-reported51.980
- Validation ROGUE-L-SUM on Dataset for medical question summarizationself-reported51.990