|
--- |
|
license: cc-by-nc-4.0 |
|
language: |
|
- en |
|
--- |
|
|
|
Trained with compute from [Backyard.ai](https://backyard.ai/) | Thanks to them and @dynafire for helping me out. |
|
|
|
--- |
|
|
|
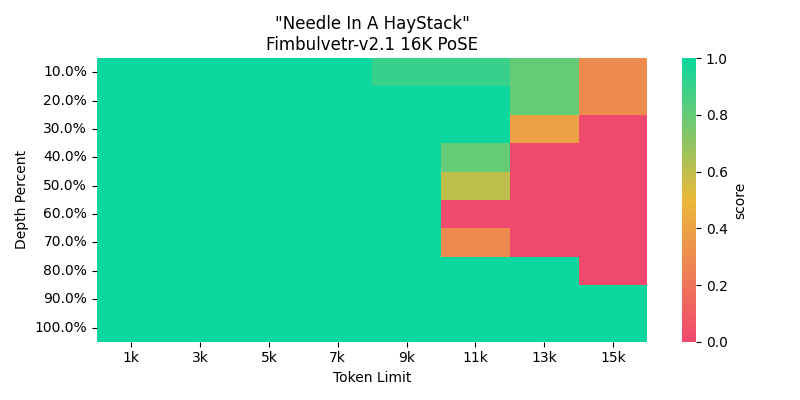
Fimbulvetr-v2 but extended to 16K with PoSE. A sane context value would be ~12K before it degrades. |
|
|
|
Note: |
|
<br> \- I left Rope Theta at 10K for this train, instead of expanding it like with Stheno 3.3. Solar did not play well with extended theta, grad norm / loss values went parabolic or plunged from 10000+ down. Unreliable pretty much, unlike Stheno 3.3's training run. |
|
|
|
--- |
|
|
|
Notes: |
|
<br> \- I noticed people having bad issues with quants. Be it GGUF or others, at 8 bit or less. Kind of a weird issue? I had little to no issues during testing unquanted. |
|
<br> \- Slightly different results from base Fimbulvetr-v2, but during my tests they are similar enough. The vibes are still there. |
|
<br> \- Formatting issues happen rarely. Sometimes. A reroll / regenerate fixes it from tests. |
|
<br> \- I get consistent and reliable answers at ~11K context fine. |
|
<br> \- Still coherent at up to 16K though! Just works not that well. |
|
|
|
I recommend sticking up to 12K context, but loading the model at 16K for inference. It has a really accurate context up to 10K from multiple different extended long context tests. 16K works fine for roleplays, but not for more detailed tasks. |
|
|
|
 |
|
|
|
Red Needle in Haystack testing results for this specific one are usually due to weird result artifacts, like the model answering part of the key, or commenting extra. Basically, they got the result, but it's incomplete or there's additional stuff taken. |
|
Something like `' 3211'` or `'3211 and'` instead of `'321142'`. Weird. Hence why its coherent and semi-reliable for roleplays at 16K context. |
