
Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
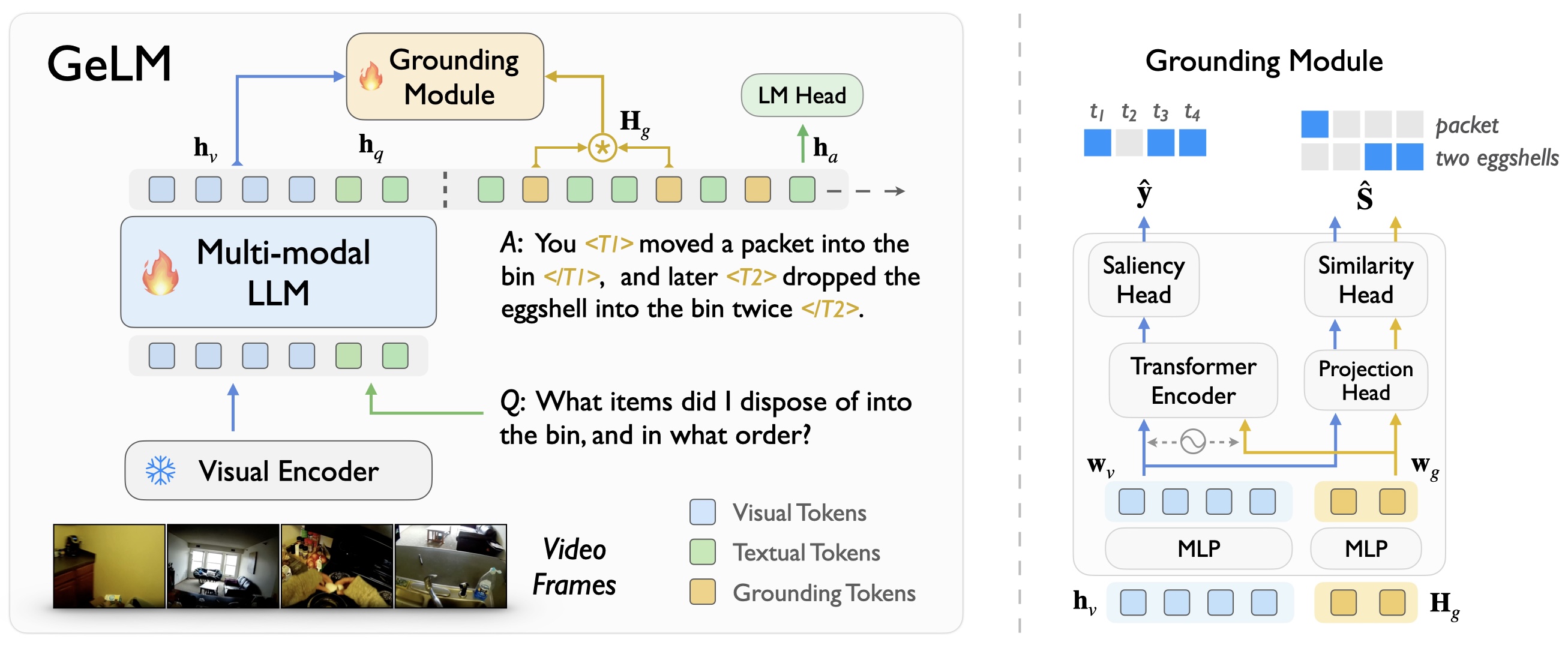
GeLM Model
We propose a novel architecture, termed as GeLM for MH-VidQA, to leverage the world knowledge reasoning capabilities of multi-modal large language models (LLMs), while incorporating a grounding module to retrieve temporal evidence in the video with flexible grounding tokens.
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.