
qiruichen1206@gmail.com
commited on
Commit
•
595112c
1
Parent(s):
87f9654
Update README.md
Browse files- README.md +10 -1
- RTL-GeLM-7B/tokenizer.model +0 -0
- assets/architecture_v3.jpeg +0 -0
README.md
CHANGED
|
@@ -3,4 +3,13 @@ datasets:
|
|
| 3 |
- SurplusDeficit/MultiHop-EgoQA
|
| 4 |
---
|
| 5 |
|
| 6 |
-
# Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
- SurplusDeficit/MultiHop-EgoQA
|
| 4 |
---
|
| 5 |
|
| 6 |
+
# Grounded Multi-Hop VideoQA in Long-Form Egocentric Videos
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
## GeLM Model
|
| 10 |
+
|
| 11 |
+
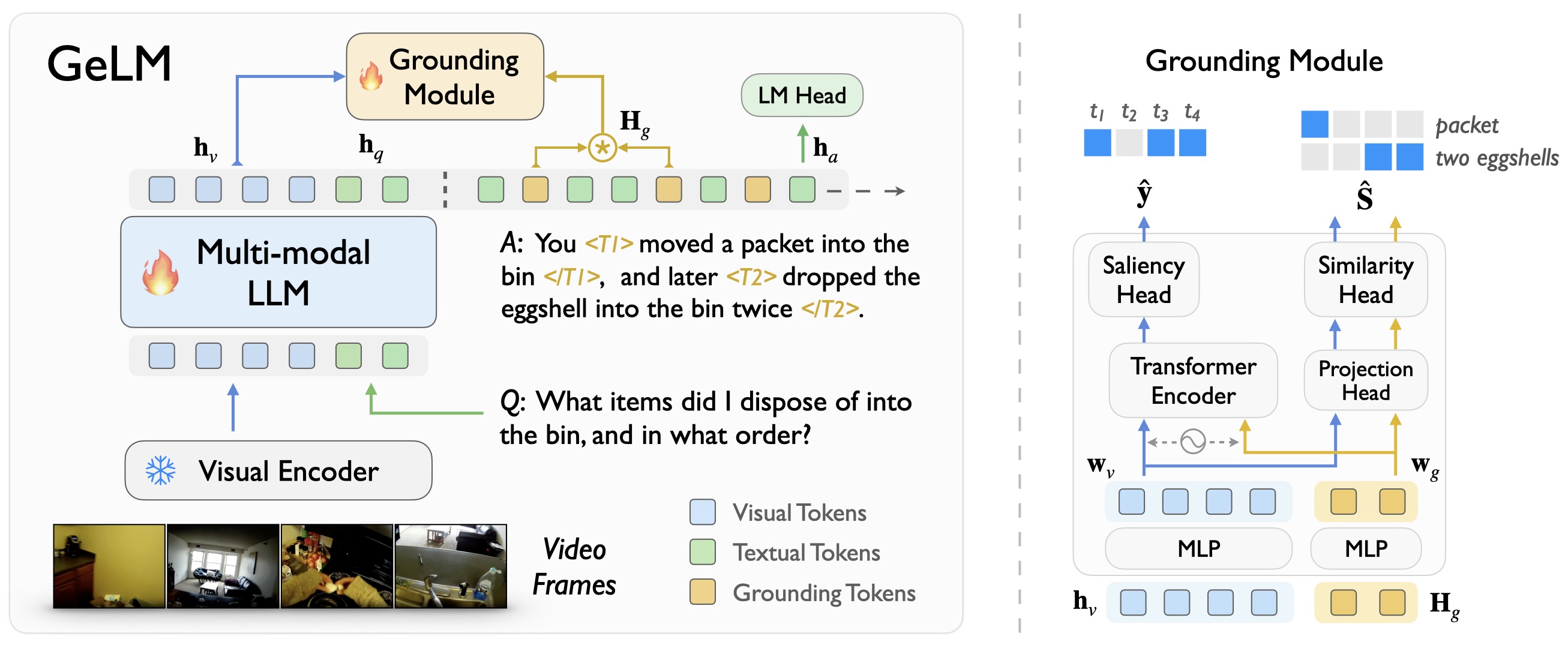
We propose a novel architecture, termed as <b><u>GeLM</u></b> for *MH-VidQA*, to leverage the world knowledge reasoning capabilities of multi-modal large language models (LLMs), while incorporating a grounding module to retrieve temporal evidence in the video with flexible grounding tokens.
|
| 12 |
+
|
| 13 |
+
<div align="center">
|
| 14 |
+
<img src="./assets/architecture_v3.jpeg" style="width: 80%;">
|
| 15 |
+
</div>
|
RTL-GeLM-7B/tokenizer.model
CHANGED
|
Binary files a/RTL-GeLM-7B/tokenizer.model and b/RTL-GeLM-7B/tokenizer.model differ
|
|
|
assets/architecture_v3.jpeg
ADDED
|