
Mantis
Collection
Mantis model family optimized for multi-image reasoning with interleaved text/image format
•
11 items
•
Updated
•
9
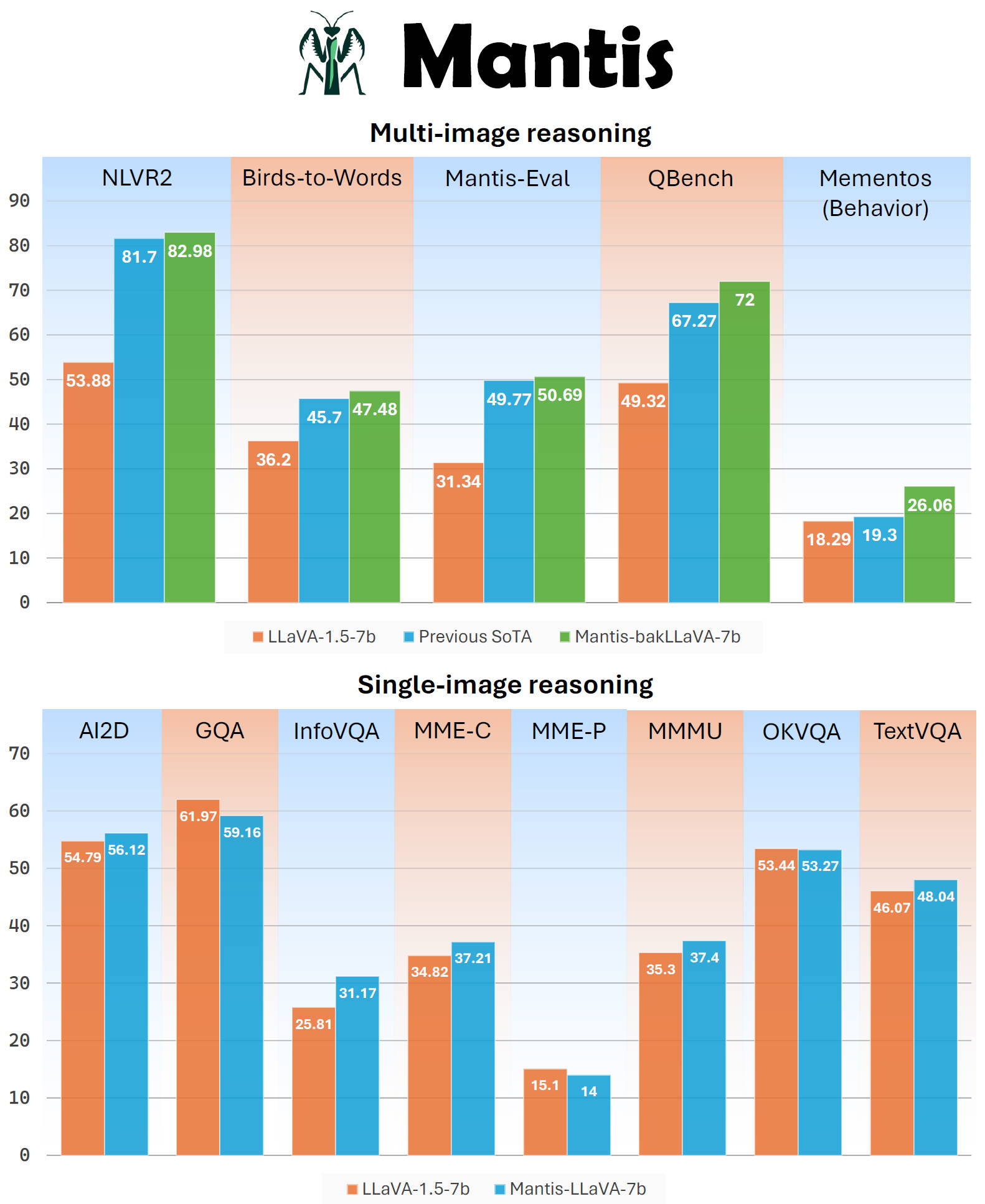
Mantis is a multimodal conversational AI model that can chat with users about images and text. It's optimized for multi-image reasoning, where interleaved text and images can be used to generate responses.
Note that this is an older version of Mantis, please refer to our newest version at mantis-Siglip-llama3. The newer version improves significantly over both multi-image and single-image tasks.
Mantis is trained on the newly curated dataset Mantis-Instruct, a large-scale multi-image QA dataset that covers various multi-image reasoning tasks.
You can install Mantis's GitHub codes as a Python package
pip install git+https://github.com/TIGER-AI-Lab/Mantis.git
then run inference with codes here: examples/run_mantis.py
from mantis.models.mllava import chat_mllava
from PIL import Image
import torch
image1 = "image1.jpg"
image2 = "image2.jpg"
images = [Image.open(image1), Image.open(image2)]
# load processor and model
from mantis.models.mllava import MLlavaProcessor, LlavaForConditionalGeneration
processor = MLlavaProcessor.from_pretrained("TIGER-Lab/Mantis-bakllava-7b")
model = LlavaForConditionalGeneration.from_pretrained("TIGER-Lab/Mantis-bakllava-7b", device_map="auto", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2")
# chat
text = "<image> <image> What's the difference between these two images? Please describe as much as you can."
response, history = chat_mllava(text, images, model, processor)
print("USER: ", text)
print("ASSISTANT: ", response)
# The image on the right has a larger number of wallets displayed compared to the image on the left. The wallets in the right image are arranged in a grid pattern, while the wallets in the left image are displayed in a more scattered manner. The wallets in the right image have various colors, including red, purple, and brown, while the wallets in the left image are primarily brown.
text = "How many items are there in image 1 and image 2 respectively?"
response, history = chat_mllava(text, images, model, processor, history=history)
print("USER: ", text)
print("ASSISTANT: ", response)
# There are two items in image 1 and four items in image 2.
Or, you can run the model without relying on the mantis codes, using pure hugging face transformers. See examples/run_mantis_hf.py for details.
Training codes will be released soon.
Base model
llava-hf/llava-1.5-7b-hf