
VISTA
Collection
Video Augmentation for Synthetic Video Instruction-following Data Generation
•
6 items
•
Updated
This repo contains model checkpoints for VISTA-Mantis. VISTA is a video spatiotemporal augmentation method that generates long-duration and high-resolution video instruction-following data to enhance the video understanding capabilities of video LMMs.
🌐 Homepage | 📖 arXiv | 💻 GitHub | 🤗 VISTA-400K | 🤗 Models | 🤗 HRVideoBench
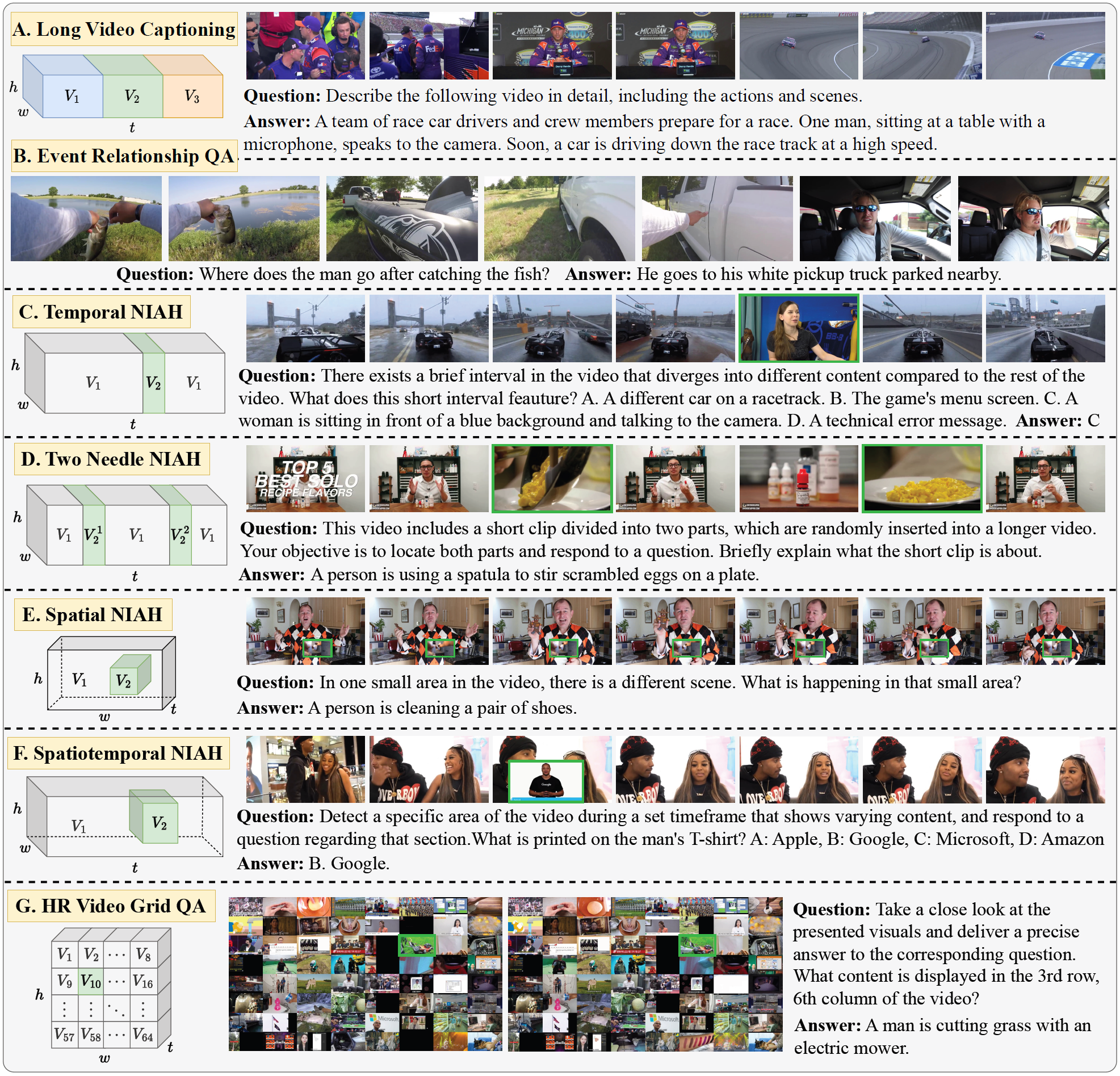
VISTA leverages insights from image and video classification data augmentation techniques such as CutMix, MixUp and VideoMix, which demonstrate that training on synthetic data created by overlaying or mixing multiple images or videos results in more robust classifiers. Similarly, our method spatially and temporally combines videos to create (artificial) augmented video samples with longer durations and higher resolutions, followed by synthesizing instruction data based on these new videos. Our data synthesis pipeline utilizes existing public video-caption datasets, making it fully open-sourced and scalable. This allows us to construct VISTA-400K, a high-quality video instruction-following dataset aimed at improving the long and high-resolution video understanding capabilities of video LMMs.
If you find our paper useful, please cite us with
@misc{ren2024vistaenhancinglongdurationhighresolution,
title={VISTA: Enhancing Long-Duration and High-Resolution Video Understanding by Video Spatiotemporal Augmentation},
author={Weiming Ren and Huan Yang and Jie Min and Cong Wei and Wenhu Chen},
year={2024},
eprint={2412.00927},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.00927},
}