

backbone:
- diffusion
domain:
- multi-modal
frameworks:
- pytorch
license: cc-by-nc-nd-4.0
metrics:
- realism
- video-video similarity
studios:
- damo/Video-to-Video
tags:
- video2video generation
- diffusion model
- 视频到视频
- 视频超分辨率
- 视频生成视频
- 生成
tasks:
- video-to-video
widgets:
- examples:
- inputs:
- data: A panda eating bamboo on a rock.
name: text
- data: XXX/test.mpt
name: video_path
name: 2
title: 示例1
inferencespec:
cpu: 4
gpu: 1
gpu_memory: 28000
memory: 32000
inputs:
- name: text, video_path
title: 输入英文prompt, 视频路径
type: str, str
validator:
max_words: 75, /
task: video-to-video
Video-to-Video
MS-Vid2Vid-XL旨在提升视频生成的时空连续性和分辨率,其作为I2VGen-XL的第二阶段以生成720P的视频,同时还可以用于文生视频、高清视频转换等任务。其训练数据包含了精选的海量的高清视频、图像数据(最短边>=720),可以将低分辨率的视频提升到更高分辨率(1280 * 720),且其可以处理几乎任意分辨率的视频(建议16:9的宽视频)。
MS-Vid2Vid-XL aims to improve the spatiotemporal continuity and resolution of video generation. It serves as the second stage of I2VGen-XL to generate 720P videos, and can also be used for various tasks such as text-to-video synthesis and high-quality video transfer. The training data includes a large collection of high-definition videos and images (with the shortest side >=720), allowing for the enhancement of low-resolution videos to higher resolutions (1280 * 720). It can handle videos of almost any resolution (preferably 16:9 aspect ratio).
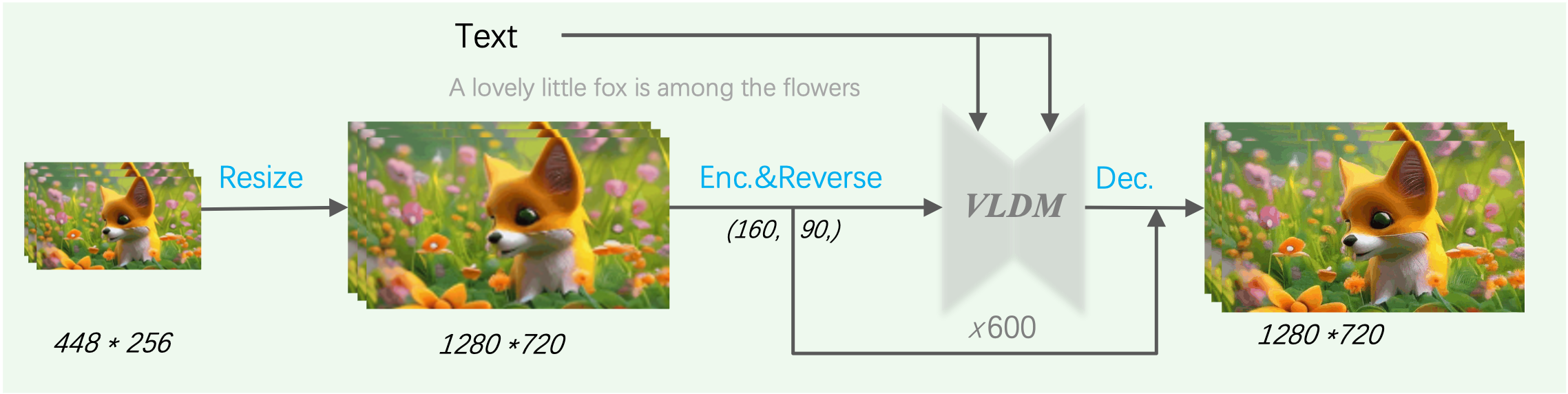
Fig.1 MS-Vid2Vid-XL
体验地址(Project experience address): https://modelscope.cn/studios/damo/I2VGen-XL-Demo/summary
模型介绍 (Introduction)
MS-Vid2Vid-XL和I2VGen-XL第一阶段相同,都是基于隐空间的视频扩散模型(VLDM),且其共享相同结构的时空UNet(ST-UNet),其设计细节延续我们自研VideoComposer,具体可以参考其技术报告。
MS-Vid2Vid-XL and the first stage of I2VGen-XL share the same underlying video latent diffusion model (VLDM). They both utilize a spatiotemporal UNet (ST-UNet) with the same structure, which is designed based on our in-house VideoComposer. For more specific details, please refer to its technical report.
代码范例 (Code example)
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
# VID_PATH: your video path
# TEXT : your text description
pipe = pipeline(task="video-to-video", model='damo/Video-to-Video')
p_input = {
'video_path': VID_PATH,
'text': TEXT
}
output_video_path = pipe(p_input, output_video='./output.mp4')[OutputKeys.OUTPUT_VIDEO]
模型局限 (Limitation)
本MS-Vid2Vid-XL可能存在如下可能局限性:
- 目标距离较远时可能会存在一定的模糊,该问题可以通过输入文本来解决或缓解;
- 计算时耗大,因为需要生成720P的视频,隐空间的尺寸为(160 * 90),单个视频计算时长>2分钟
- 目前仅支持英文,因为训练数据的原因目前仅支持英文输入
This MS-Vid2Vid-XL may have the following limitations:
- There may be some blurriness when the target is far away. This issue can be addressed by providing input text.
- Computation time is high due to the need to generate 720P videos. The latent space size is (160 * 90), and the computation time for a single video is more than 2 minutes.
- Currently, it only supports English. This is due to the training data, which is limited to English inputs at the moment.
相关论文以及引用信息 (Reference)
@article{videocomposer2023,
title={VideoComposer: Compositional Video Synthesis with Motion Controllability},
author={Wang, Xiang* and Yuan, Hangjie* and Zhang, Shiwei* and Chen, Dayou* and Wang, Jiuniu and Zhang, Yingya and Shen, Yujun and Zhao, Deli and Zhou, Jingren},
journal={arXiv preprint arXiv:2306.02018},
year={2023}
}
@inproceedings{videofusion2023,
title={VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation},
author={Luo, Zhengxiong and Chen, Dayou and Zhang, Yingya and Huang, Yan and Wang, Liang and Shen, Yujun and Zhao, Deli and Zhou, Jingren and Tan, Tieniu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
使用协议 (License Agreement)
我们的代码和模型权重仅可用于个人/学术研究,暂不支持商用。
Our code and model weights are only available for personal/academic research use and are currently not supported for commercial use.